
Support Vector Quantile Regression for the Post-Processing of Meso-Scale Ensemble Prediction System Data in the Kanto Region: Solar Power Forecast Reducing Overestimation


Abstract
:1. Introduction
- Balance responsible parties (BRPs) submit supply/demand plan to the system operator (SO) and work towards meeting the same amount of the plan through the use of the intra-day market;
- The SO is ultimately responsible for the imbalance of the BRPs after the gate close (GC), and procures power from the balance service providers (BSPs) for adjustment before the day before the GC in order to deal with it;
- BSPs activate their regulating power upon receiving orders from the SO when imbalance occurs in the actual section.
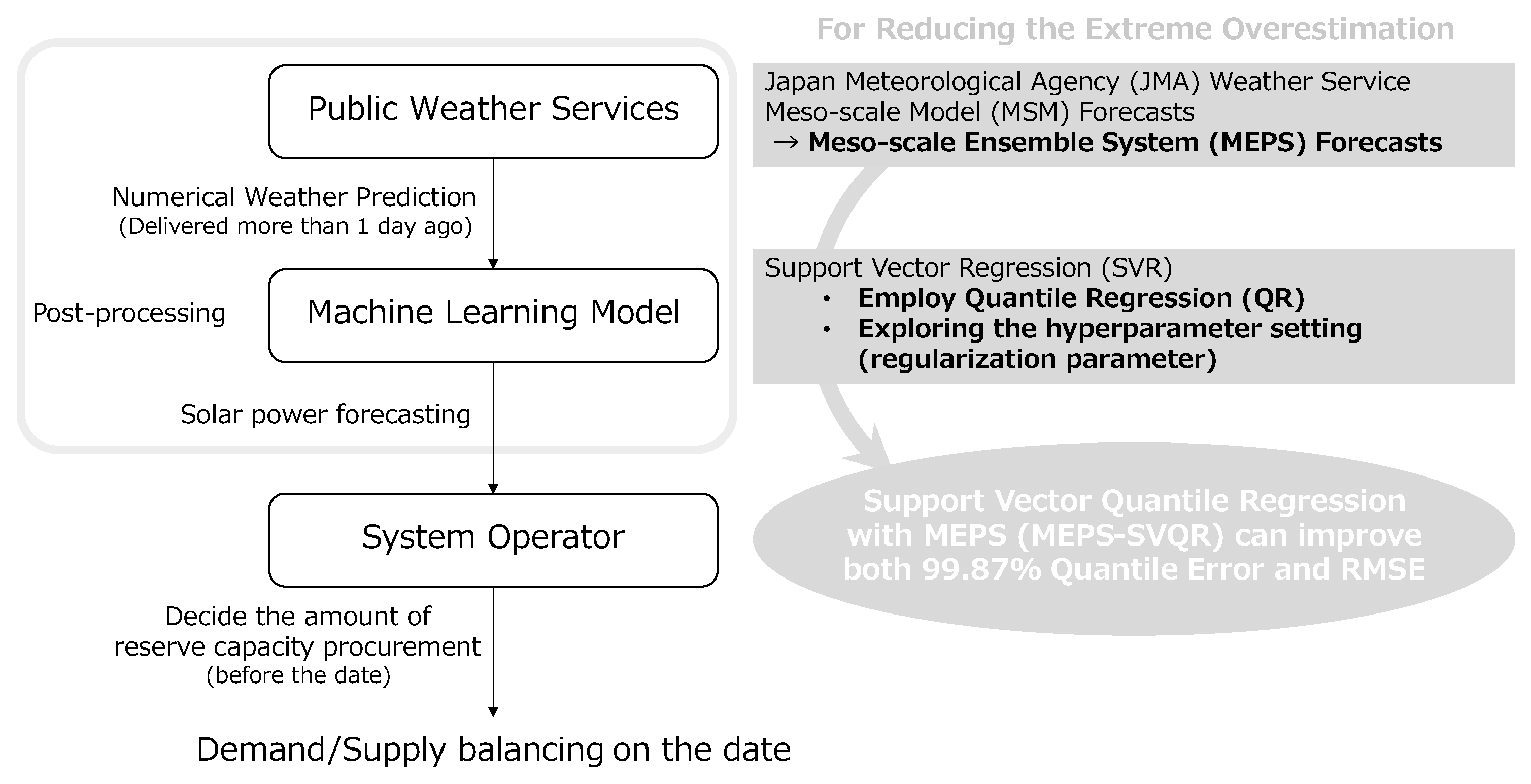
- Adoption of the method for the machine learning model that enables to reduce the overestimation risk;
- Upgrading the NWP data used as explanatory variables;
- Adjustment of hyperparameters.
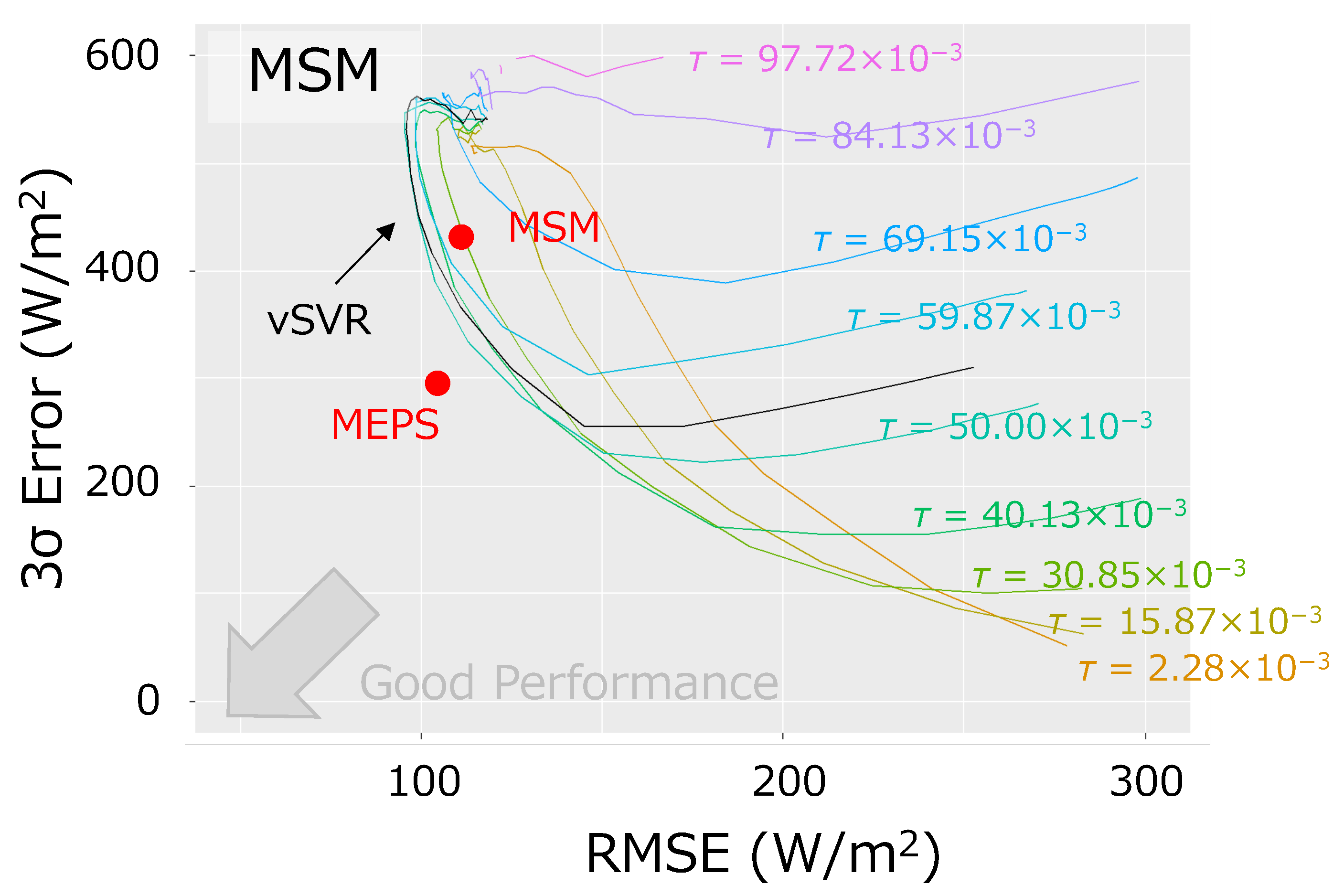
- When the penalty of the regularization term is varied, there tends to be a trade-off between the RMSE of SVR and the 3 error;
- SVR can be used as a post-processing of MEPS data to improve the original data on both metrics;
- Comparing SVQR with the MSM data (MSM-SVQR), SVQR with MEPS data (MEPS-SVQR) is more effective in the 3 error reduction due to quantile regression, and tuning can build a better model for the two metrics.
2. Enhancement of the Numerical Weather Prediction
2.1. Post-Processing Approach Based on Machine Learning
2.2. Stochastic Approach Based on Ensemble Prediction System
3. Data Description
3.1. Forecasts of Meso-Ensemble Prediction System
3.2. Surface Observation Data
3.3. Performance of the Numerical Weather Prediction
4. Methodology
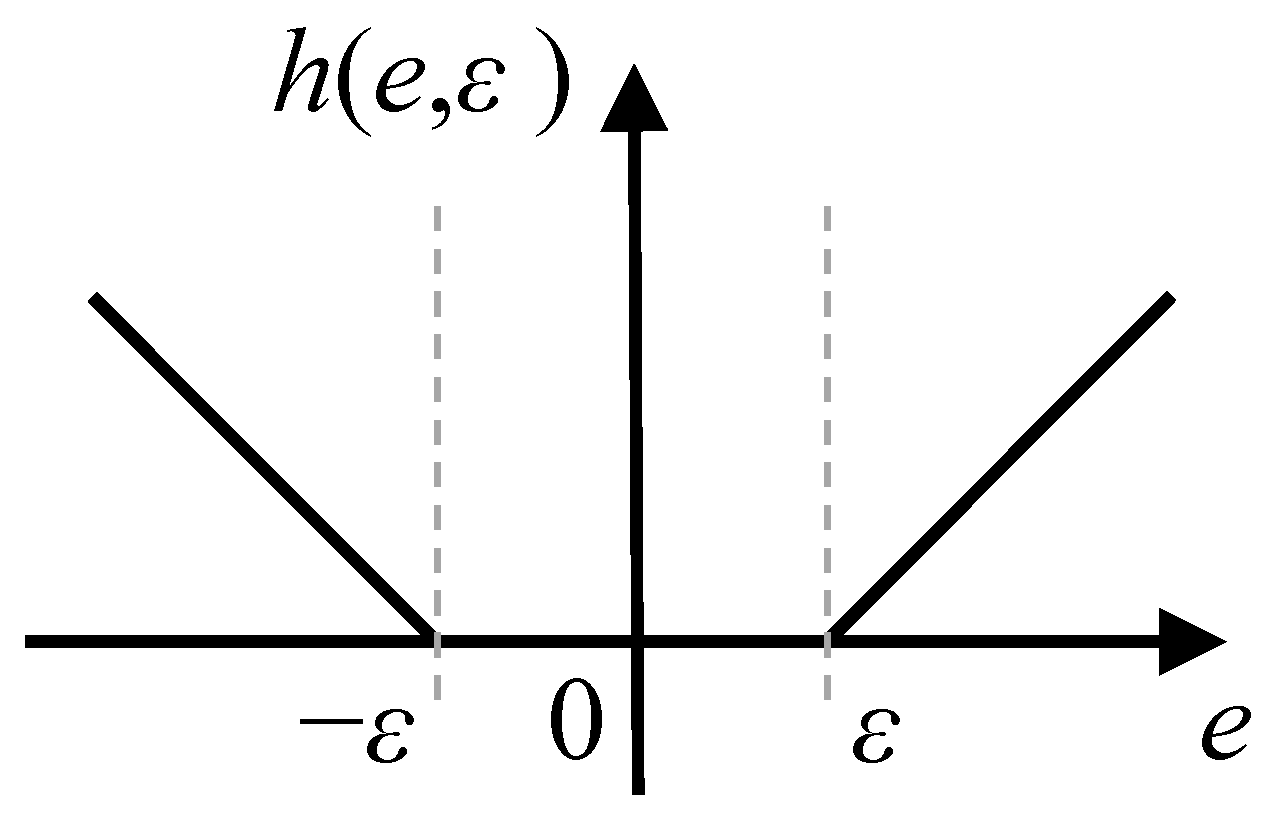
4.1. Support Vector Regression
4.2. Quantile Regression
4.3. Metrics of Error
4.4. Cross-Validation
5. Prediction Model
6. Results and Discussion
7. Conclusions
- Use of the QR method to SVR for reducing the risk of forecast errors;
- Increasing the degrees of freedom of the model by adopting MEPS prediction as an explanatory variable;
- Changing the parameters of the regularization parameter C and the pinball-loss function.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- IEA. Renewables 2020; IEA: Paris, France, 2020; Available online: https://www.iea.org/reports/renewables-2020 (accessed on 14 January 2022).
- IEA. Renewables 2021; IEA: Paris, France, 2021; Available online: https://www.iea.org/reports/renewables-2021 (accessed on 14 January 2022).
- ENTSO-E. ENTSO-E Balancing Report 2020. Available online: https://eepublicdownloads.entsoe.eu/clean-documents/Publications/Market%20Committee%20publications/ENTSO-E_Balancing_Report_2020.pdf (accessed on 14 January 2022).
- Van der Veen, R.A.C. Designing Multinational Electricity Balancing Markets. Ph.D. Thesis, Technische Universiteit Delft, Delft, The Netherlands, 2012. [Google Scholar]
- Poplavskaya, K.; Lago, J.; De Vries, L. Effect of market design on strategic bidding behavior: Model-based analysis of European electricity balancing markets. Appl. Energy 2020, 270, 115130. [Google Scholar] [CrossRef]
- Commission Regulation (EU) 2017/1485 of 2 August 2017 Establishing a Guideline on Electricity Transmission System Operation. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32017R1485 (accessed on 14 January 2022).
- Elia Transmission Belgium SA/NV, 30 September 2020, Methodology for the Dimensioning of the aFRR Needs. Available online: https://www.elia.be/-/media/project/elia/elia-site/public-consultations/2020/20200930_finalreport_en.pdf (accessed on 14 January 2022).
- Knorr, K.; Dreher, A.; Böttger, D. Common dimensioning of frequency restoration reserve capacities for european load-frequency control blocks: An advanced dynamic probabilistic approach. Electr. Power Syst. Res. 2019, 170, 358–363. [Google Scholar] [CrossRef]
- Li, B.; Zhang, J. A review on the integration of probabilistic solar forecasting in power systems. Sol. Energy 2020, 210, 68–86. [Google Scholar] [CrossRef]
- METI. Cost of Securing Regulating Power to Cope with Errors in Renewable Energy Forecasts; METI: Tokyo, Japan, 2020; Available online: https://www.meti.go.jp/shingikai/enecho/denryoku_gas/saisei_kano/pdf/022_03_00.pdf (accessed on 14 January 2022).
- IEA. Japan 2021; IEA: Paris, France, 2021; Available online: https://www.iea.org/reports/japan-2021 (accessed on 14 January 2022).
- Frías-Paredes, L.; Mallor, F.; León, T.; Gastxoxn-Romeo, M. Introducing the Temporal Distortion Index to perform a bidimensional analysis of renewable energy forecast. Energy 2016, 94, 180–194. [Google Scholar] [CrossRef]
- Vallance, L.; Charbonnier, B.; Paul, N.; Dubost, S.; Blanc, P. Towards a standardized procedure to assess solar forecast accuracy: A new ramp and time alignment metric. Sol. Energy 2017, 150, 408–422. [Google Scholar] [CrossRef]
- Izidio, D.M.; de Mattos Neto, P.S.; Barbosa, L.; de Oliveira, J.F.; Marinho, M.H.D.N.; Rissi, G.F. Evolutionary Hybrid System for Energy Consumption Forecasting for Smart Meters. Energies 2021, 14, 1794. [Google Scholar] [CrossRef]
- Koenker, R.; Hallock, K.F. Quantile regression. J. Econ. Perspect. 2001, 15, 143–156. [Google Scholar] [CrossRef]
- Lauret, P.; David, M.; Pedro, H.T. Probabilistic solar forecasting using quantile regression models. Energies 2017, 10, 1591. [Google Scholar] [CrossRef]
- Almeida, M.P.; Perpinan, O.; Narvarte, L. PV power forecast using a nonparametric PV model. Sol. Energy 2015, 115, 354–368. [Google Scholar] [CrossRef] [Green Version]
- Verbois, H.; Rusydi, A.; Thiery, A. Probabilistic forecasting of day-ahead solar irradiance using quantile gradient boosting. Sol. Energy 2018, 173, 313–327. [Google Scholar] [CrossRef]
- Fernandez-Jimenez, L.A.; Terreros-Olarte, S.; Mendoza-Villena, M.; Garcia-Garrido, E.; Zorzano-Alba, E.; Lara-Santillan, P.M.; Zorzano-Santamaria, P.J.; Falces, A. Day-ahead probabilistic photovoltaic power forecasting models based on quantile regression neural networks. In Proceedings of the 2017 European Conference on Electrical Engineering and Computer Science (EECS), Bern, Switzerland, 17–19 November 2017; pp. 289–294. [Google Scholar]
- Yu, Y.; Wang, M.; Yan, F.; Yang, M.; Yang, J. Improved convolutional neural network-based quantile regression for regional photovoltaic generation probabilistic forecast. IET Renew. Power Gener. 2020, 14, 2712–2719. [Google Scholar] [CrossRef]
- He, Y.; Yan, Y.; Xu, Q. Wind and solar power probability density prediction via fuzzy information granulation and support vector quantile regression. Int. J. Electr. Power Energy Syst. 2019, 113, 515–527. [Google Scholar] [CrossRef]
- Takamatsu, T.; Ohtake, H.; Oozeki, T. Global Horizontal Irradiance Forecast at Kanto Region in Japan by Qunatile Regression of Support Vector Machine. In Proceedings of the 2021 IEEE 48th Photovoltaic Specialists Conference (PVSC), Fort Lauderdale, FL, USA, 20–25 June 2021; pp. 2646–2647. [Google Scholar]
- Lorenz, E.N. Deterministic nonperiodic flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef] [Green Version]
- Aybar-Ruiz, A.; Jiménez-Fernández, S.; Cornejo-Bueno, L.; Casanova-Mateo, C.; Sanz-Justo, J.; Salvador-González, P.; Salcedo-Sanz, S. A novel grouping genetic algorithm–extreme learning machine approach for global solar radiation prediction from numerical weather models inputs. Sol. Energy 2016, 132, 129–142. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Jiménez-Fernández, S.; Aybar-Ruíz, A.; Casanova-Mateo, C.; Sanz-Justo, J.; García-Herrera, R. A CRO-species optimization scheme for robust global solar radiation statistical downscaling. Renew. Energy 2017, 111, 63–76. [Google Scholar] [CrossRef]
- Eseye, A.T.; Zhang, J.; Zheng, D. Short-term photovoltaic solar power forecasting using a hybrid Wavelet-PSO-SVM model based on SCADA and Meteorological information. Renew. Energy 2018, 118, 357–367. [Google Scholar] [CrossRef]
- Ma, Y.; Lv, Q.; Zhang, R.; Zhang, Y.; Zhu, H.; Yin, W. Short-term photovoltaic power forecasting method based on irradiance correction and error forecasting. Energy Rep. 2021, 7, 5495–5509. [Google Scholar] [CrossRef]
- Yang, B.; Zhu, T.; Cao, P.; Guo, Z.; Zeng, C.; Li, D.; Chen, Y.; Ye, H.; Shao, R.; Shu, H.; et al. Classification and summarization of solar irradiance and power forecasting methods: A thorough review. CSEE J. Power Energy Syst. 2021, 1–19. Available online: https://ieeexplore.ieee.org/document/9535400 (accessed on 10 December 2021). [CrossRef]
- Guermoui, M.; Melgani, F.; Gairaa, K.; Mekhalfi, M.L. A comprehensive review of hybrid models for solar radiation forecasting. J. Clean. Prod. 2020, 258, 120357. [Google Scholar] [CrossRef]
- IRENA. Innovation Landscape Brief: Advanced Forecasting of Variable Renewable Power Generation; International Renewable Energy Agency: Abu Dhabi, United Arab Emirates, 2020. [Google Scholar]
- Browning, K.A.; Collier, C. Nowcasting of precipitation systems. Rev. Geophys. 1989, 27, 345–370. [Google Scholar] [CrossRef]
- Diagne, M.; David, M.; Lauret, P.; Boland, J.; Schmutz, N. Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renew. Sustain. Energy Rev. 2013, 27, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Haupt, S.E.; Chapman, W.; Adams, S.V.; Kirkwood, C.; Hosking, J.S.; Robinson, N.H.; Lerch, S.; Subramanian, A.C. Towards implementing artificial intelligence post-processing in weather and climate: Proposed actions from the Oxford 2019 workshop. Philos. Trans. R. Soc. A 2021, 379, 20200091. [Google Scholar] [CrossRef] [PubMed]
- Lauret, P.; Diagne, H.M.; David, M. A neural network post-processing approach to improving NWP solar radiation forecasts. Energy Procedia 2014, 57, 1044–1052. [Google Scholar] [CrossRef]
- Gari da Silva Fonseca, J., Jr.; Uno, F.; Ohtake, H.; Oozeki, T.; Ogimoto, K. Enhancements in Day-Ahead Forecasts of Solar Irradiation with Machine Learning: A Novel Analysis with the Japanese Mesoscale Model. J. Appl. Meteorol. Climatol. 2020, 59, 1011–1028. [Google Scholar] [CrossRef]
- Lazorthes, B. A gradient boosting approach for the short term prediction of solarenergy production. In Proceedings of the (AMS 2013–2014 Solar Energy Prediction Contest) 12th Conference on Artificial and Computational Intelligence and Its Applications to the Environmental Sciences, Atlanta, GA, USA, 2–6 February 2014; Available online: https://ams.confex.com/ams/94Annual/webprogram/Session3537 (accessed on 14 January 2022).
- Torres-Barrán, A.; Alonso, Á.; Dorronsoro, J.R. Regression tree ensembles for wind energy and solar radiation prediction. Neurocomputing 2017, 326, 151–160. [Google Scholar] [CrossRef]
- Gari da Silva Fonseca, J., Jr.; Oozeki, T.; Ohtake, H.; Shimose, K.; Takashima, T.; Ogimoto, K. Analysis of different techniques to set support vector regression to forecast insolation in Tsukuba, Japan. J. Int. Counc. Electr. Eng. 2013, 3, 121–128. [Google Scholar] [CrossRef]
- Gala, Y.; Fernández, Á.; Díaz, J.; Dorronsoro, J.R. Support vector forecasting of solar radiation values. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Salamanca, Spain, 11–13 September 2013; Springer: Berlin/Heidelberg, Germnay, 2013. [Google Scholar]
- Epstein, E.S. Stochastic dynamic prediction. Tellus 1969, 21, 739–759. [Google Scholar] [CrossRef]
- Leith, C.E. Theoretical skill of Monte Carlo forecasts. Mon. Weather Rev. 1974, 102, 409–418. [Google Scholar] [CrossRef] [Green Version]
- Toth, Z.; Kalnay, E. Ensemble forecasting at NMC: The generation of perturbations. Bull. Am. Meteorol. Soc. 1993, 74, 2317–2330. [Google Scholar] [CrossRef] [Green Version]
- Hou, D.; Kalnay, E.; Droegemeier, K.K. Objective verification of the SAMEX’98 ensemble forecasts. Mon. Weather Rev. 2001, 129, 73–91. [Google Scholar] [CrossRef]
- Du, J.; Tracton, M.S. Implementation of a Real-Time Short Range Ensemble Forecasting System at NCEP: An update. In Proceedings of the 9th Conference on Mesoscale Processes, Fort Lauderdale, FL, USA, 29 July–2 August 2001. [Google Scholar]
- Bowler, N.E.; Arribas, A.; Mylne, K.; Robertson, K.B.R.; Beare, S.E. The MOGREPS short-range ensemble prediction system. Q. J. R. Meteorol. Soc. J. Atmos. Sci. Appl. Meteorol. Phys. Oceanogr. 2008, 134, 703–722. [Google Scholar] [CrossRef]
- Erfani, A.; Frenette, R.; Gagnon, N.; Charron, M.; Beauregaurd, S.; Giguère, A.; Parent, A. The New Regional Ensemble Prediction System at 15 km Horizontal Grid Spacing (REPS 2.0.1), Canadian Meteorological Centre Technical Note. Available online: https://collaboration.cmc.ec.gc.ca/cmc/cmoi/product_guide/docs/lib/technote_reps201_20131204_e.pdf (accessed on 14 January 2022).
- Gebhardt, C.; Theis, S.E.; Paulat, M.; Bouallègue, Z.B. Uncertainties in COSMO-DE precipitation forecasts introduced by model perturbations and variation of lateral boundaries. Atmos. Res. 2011, 100, 168–177. [Google Scholar] [CrossRef]
- Ono, K.; Kunii, M.; Honda, Y. The regional model-based Mesoscale Ensemble Prediction System, MEPS, at the Japan Meteorological Agency. Q. J. R. Meteorol. Soc. 2021, 147, 465–484. [Google Scholar] [CrossRef]
- Sperati, S.; Alessandrini, S.; Delle Monache, L. An application of the ECMWF Ensemble Prediction System for short-term solar power forecasting. Sol. Energy 2016, 133, 437–450. [Google Scholar] [CrossRef] [Green Version]
- Rasp, S.; Lerch, S. Neural networks for postprocessing ensemble weather forecasts. Mon. Weather. Rev. 2018, 146, 3885–3900. [Google Scholar] [CrossRef] [Green Version]
- Massidda, L.; Marrocu, M. Quantile regression post-processing of weather forecast for short-term solar power probabilistic forecasting. Energies 2018, 11, 1763. [Google Scholar] [CrossRef] [Green Version]
- Mori, Y.; Wakao, S.; Ohtake, H.; Oozeki, T.; Takamatsu, T.; Nakaegawa, T.; Honda, Y. Fundamental Study on Interval Estimation of Solar Irradiance by Just-In-Time Modeling with MEPS. In Proceedings of the 2020 Annual Conference of Power and Energy Society, Online Meeting, 2–6 August 2020; Available online: https://www.bookpark.ne.jp/cm/ieej/detail/IEEJ-BTB2020176-PDF/ (accessed on 15 December 2021).
- Takamatsu, T.; Ohtake, H.; Oozeki, T.; Nakaegawa, T.; Honda, Y.; Kazumori, M. Regional Solar Irradiance Forecast for Kanto Region by Support Vector Regression Using Forecast of Meso-Ensemble Prediction System. Energies 2020, 14, 3245. [Google Scholar] [CrossRef]
- Japan Meteorological Agency. Numerical Weather Prediction Activities. Available online: https://www.jma.go.jp/jma/en/Activities/nwp.html (accessed on 14 January 2022).
- Japan Meteorological Agency. Surface Observation. Available online: https://www.jma.go.jp/jma/en/Activities/surf/surf.html (accessed on 14 January 2022).
- Japan Meteorological Agency. Observation of Solar Radiation. Available online: https://www.jma-net.go.jp/kousou/obs_third_div/rad/rad_sol-e.html (accessed on 14 January 2022).
- Japan Meteorological Agency. Past Weather Data Download. Available online: http://www.data.jma.go.jp/gmd/risk/obsdl/index.php (accessed on 14 January 2022).
- Müller, K.R.; Smola, A.J.; Rätsch, G.; Schölkopf, B.; Kohlmorgen, J.; Vapnik, V. Predicting time series with support vector machines. In Proceedings of the 7th International Conference, Lausanne, Switzerland, 8–10 October 1997. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Williamson, R.C.; Bartlett, P.L. New support vector algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071). TUWien. R Package Version 1.7-4. 2020. Available online: https://CRAN.R-project.org/package=e1071 (accessed on 14 January 2022).
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Koenker, R. Quantile Regression; Econometric Society Monographs; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Takeuchi, I.; Furuhashi, T. Non-crossing quantile regressions by SVM. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 1, pp. 401–406. [Google Scholar]
- Steinwart, I.; Thomann, P. liquidSVM: A Fast and Versatile SVM Package. arXiv 2017, arXiv:1702.06899. [Google Scholar]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An S4 Package for Kernel Methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.; Alessandrini, S.; Antonanzas, J.; Antonanzas-Torres, F.; Badescu, V.; Beyer, H.G.; Blaga, R.; Boland, J.; Bright, J.M.; Coimbra, C.F.; et al. Verification of deterministic solar forecasts. Sol. Energy 2020, 210, 20–37. [Google Scholar] [CrossRef]
- Wilkinson, M.E. Estimating Probable Maximum Loss with Order Statistics. Casualty Actuarial Society Forum. 1982, pp. 195–209. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.491.3144&rep=rep1&type=pdf (accessed on 15 January 2022).
- Liou, K.N. An Introduction to Atmospheric Radiation, 2nd ed.; Academic Press: London, UK, 2002; Available online: https://www.elsevier.com/books/an-introduction-to-atmospheric-radiation/liou/978-0-12-451451-5 (accessed on 15 January 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
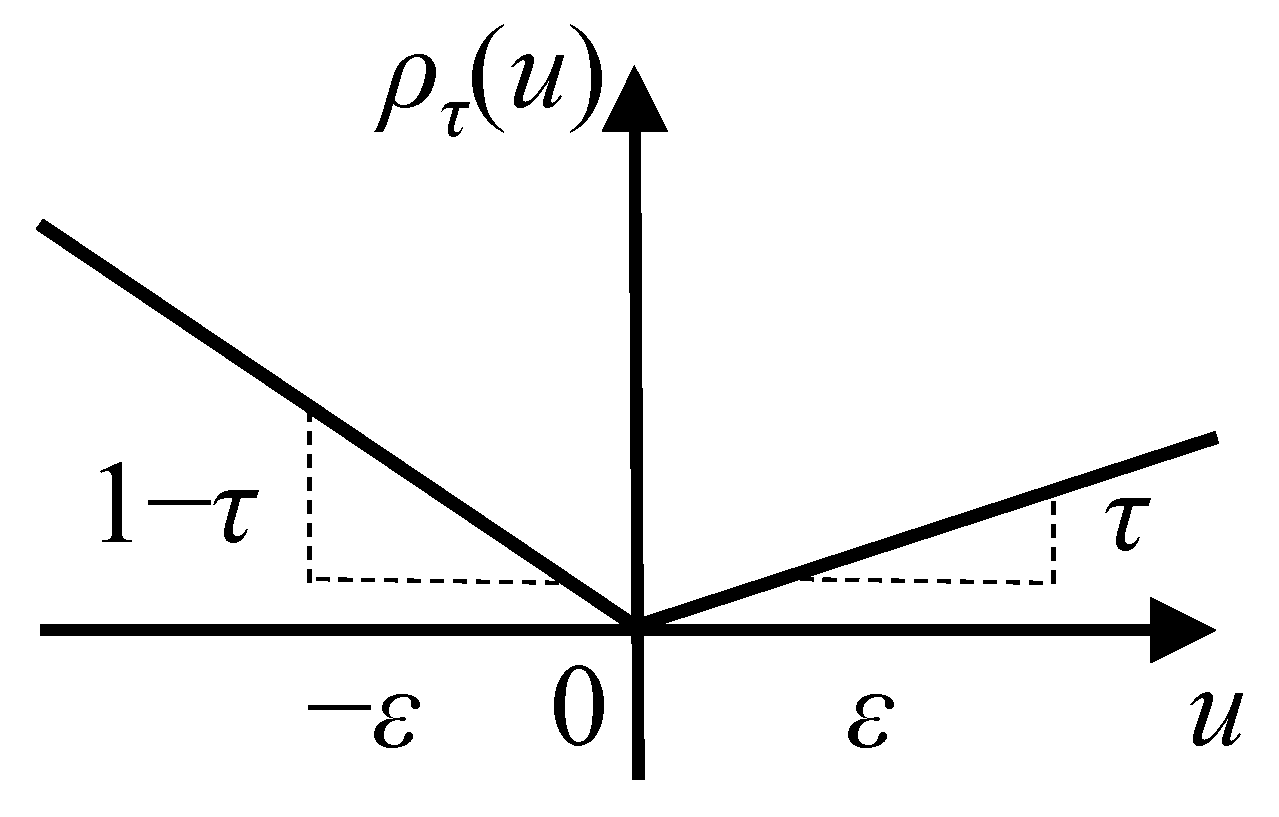{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Symbol | Description | Source |
|---|---|---|---|
| Objective | Surface GHI on Area Average | JMA stations’ data | |
| Explanatory | Extraterrestrial Irradiance | Theoretical form [70] | |
| Temperature | MSM | ||
| Relative Humidity | |||
| High-level Cloud Cover | |||
| Middle-level Cloud Cover | |||
| Low-level Cloud Cover | |||
| Global Horizontal Irradiance | MSM or MEPS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takamatsu, T.; Ohtake, H.; Oozeki, T. Support Vector Quantile Regression for the Post-Processing of Meso-Scale Ensemble Prediction System Data in the Kanto Region: Solar Power Forecast Reducing Overestimation. Energies 2022, 15, 1330. https://doi.org/10.3390/en15041330
Takamatsu T, Ohtake H, Oozeki T. Support Vector Quantile Regression for the Post-Processing of Meso-Scale Ensemble Prediction System Data in the Kanto Region: Solar Power Forecast Reducing Overestimation. Energies. 2022; 15(4):1330. https://doi.org/10.3390/en15041330
Chicago/Turabian StyleTakamatsu, Takahiro, Hideaki Ohtake, and Takashi Oozeki. 2022. "Support Vector Quantile Regression for the Post-Processing of Meso-Scale Ensemble Prediction System Data in the Kanto Region: Solar Power Forecast Reducing Overestimation" Energies 15, no. 4: 1330. https://doi.org/10.3390/en15041330
APA StyleTakamatsu, T., Ohtake, H., & Oozeki, T. (2022). Support Vector Quantile Regression for the Post-Processing of Meso-Scale Ensemble Prediction System Data in the Kanto Region: Solar Power Forecast Reducing Overestimation. Energies, 15(4), 1330. https://doi.org/10.3390/en15041330