
Advanced Ensemble Methods Using Machine Learning and Deep Learning for One-Day-Ahead Forecasts of Electric Energy Production in Wind Farms




Abstract
:
1. Introduction
- analysing the usefulness of various explanatory data;
- utilizing machine learning;
- preparing forecasts with single, team and hybrid methods;
- analysing the influence of point distribution of Numerical Weather Prediction (NWP) models at large wind farms;
- conducting comparative analysis of forecast quality for various wind farms.
1.1. Related Works
1.2. Objective and Contribution
- Perform extensive statistical analysis of time series of energy generated in two wind farms and perform statistical analysis of potential exogenous explanatory variables;
- Perform very extensive analysis of sensitivity of explanatory variables;
- Verify the accuracy of forecasts conducted by single methods, hybrid methods, and ensemble methods (13 methods in total);
- Develop and verify an original ensemble method, called “Ensemble Averaging Without Extremes” and conduct an original selection of combinations of predictors for ensemble methods;
- Identify the most efficient forecasting methods from among tested methods for data from both wind farms.
- This research addresses forecasting for large wind farms. Although this topic frequently appears in literature, this research has its unique values. First of all, an extensive data analysis was performed, including the time series itself, additional data, and two different NWP model parameters (81 inputs in total). Secondly, 13 forecasting methods for two wind farms were tested and compared.
- Development of an original method, called “Ensemble Averaging Without Extremes”. Predictions by this method have yielded the lowest SS metric (Skill Score) and nMAE error among the tested methods; the original “Additional Expert Correction” method yielded additional improvement of forecasts.
- Construction of a number of different models, data scenarios and parameters resulted in testing more than 400 forecasting models. This makes this research one of the most extensive studies on the topic. The conclusions drawn from this research can be generalized, at least for Central Europe.
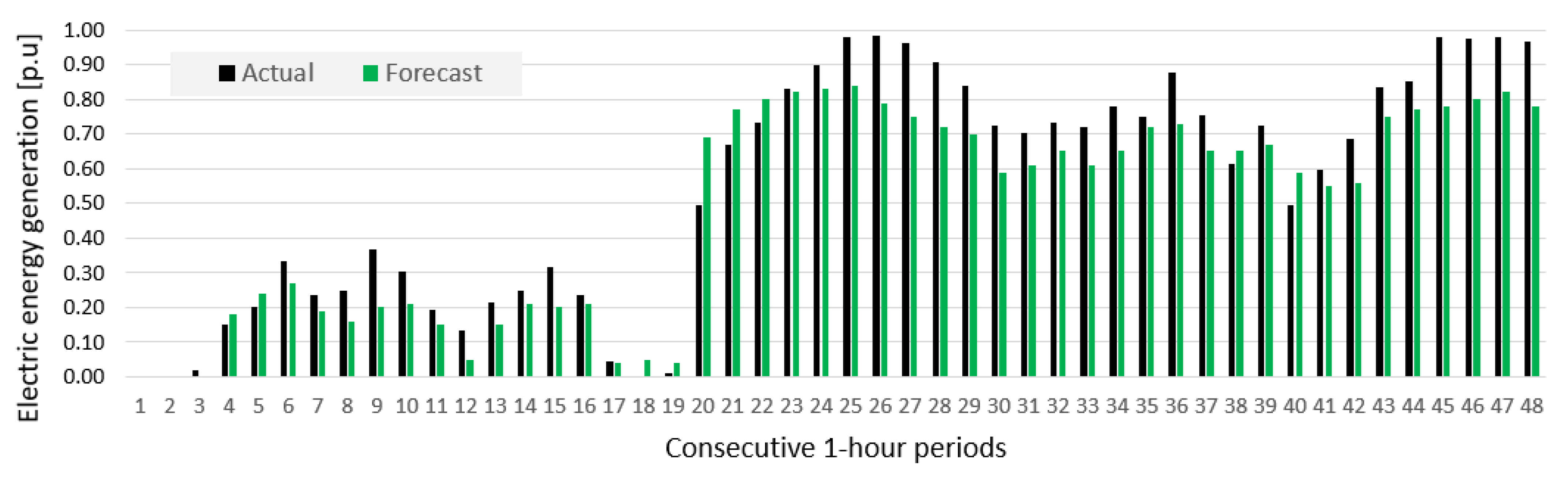
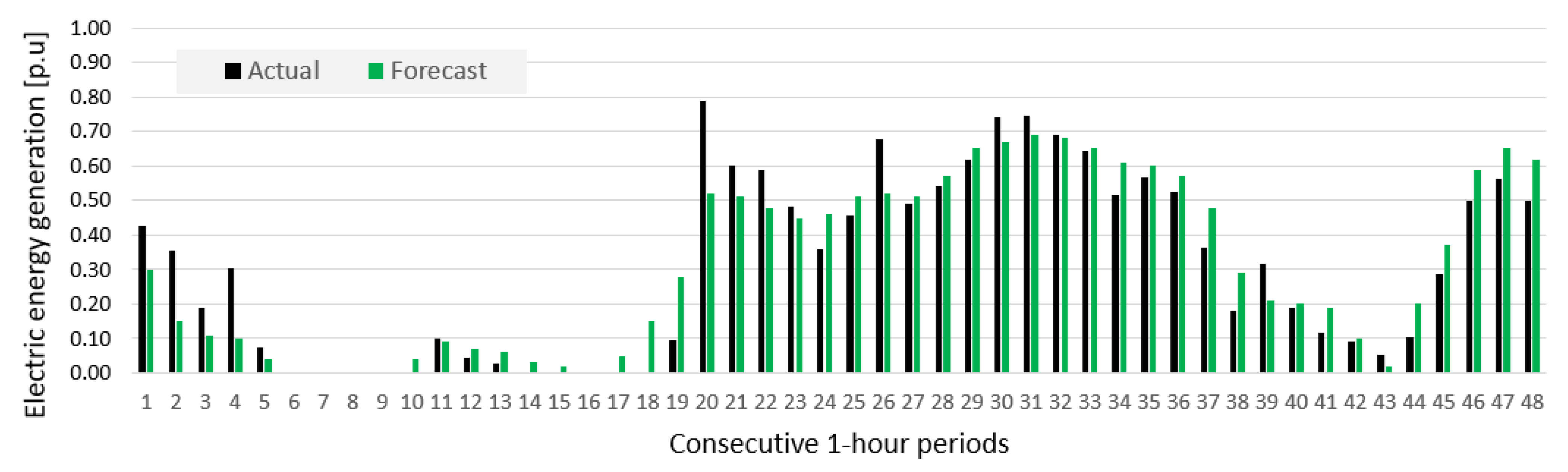
2. Data
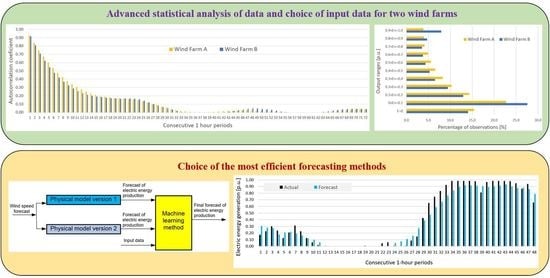
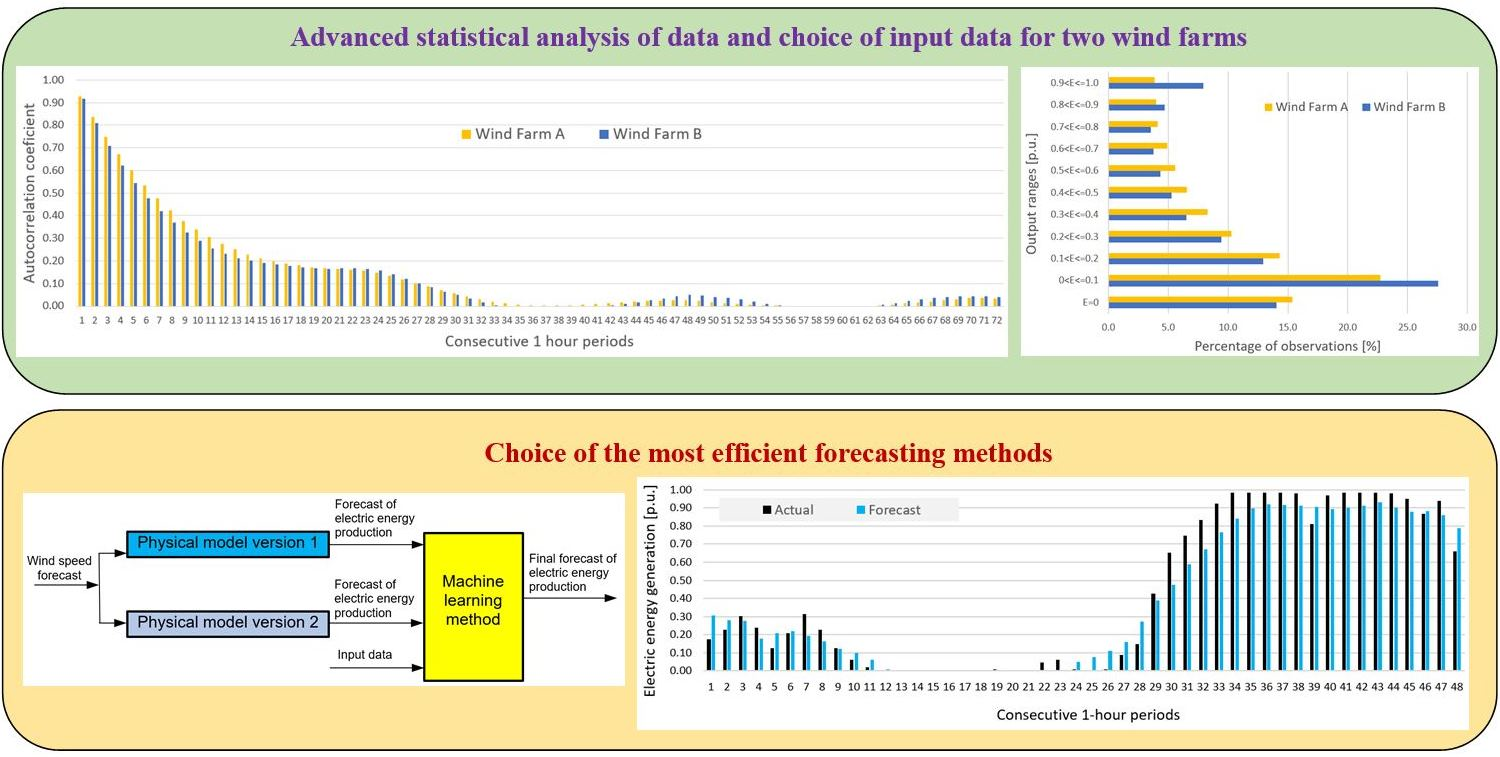
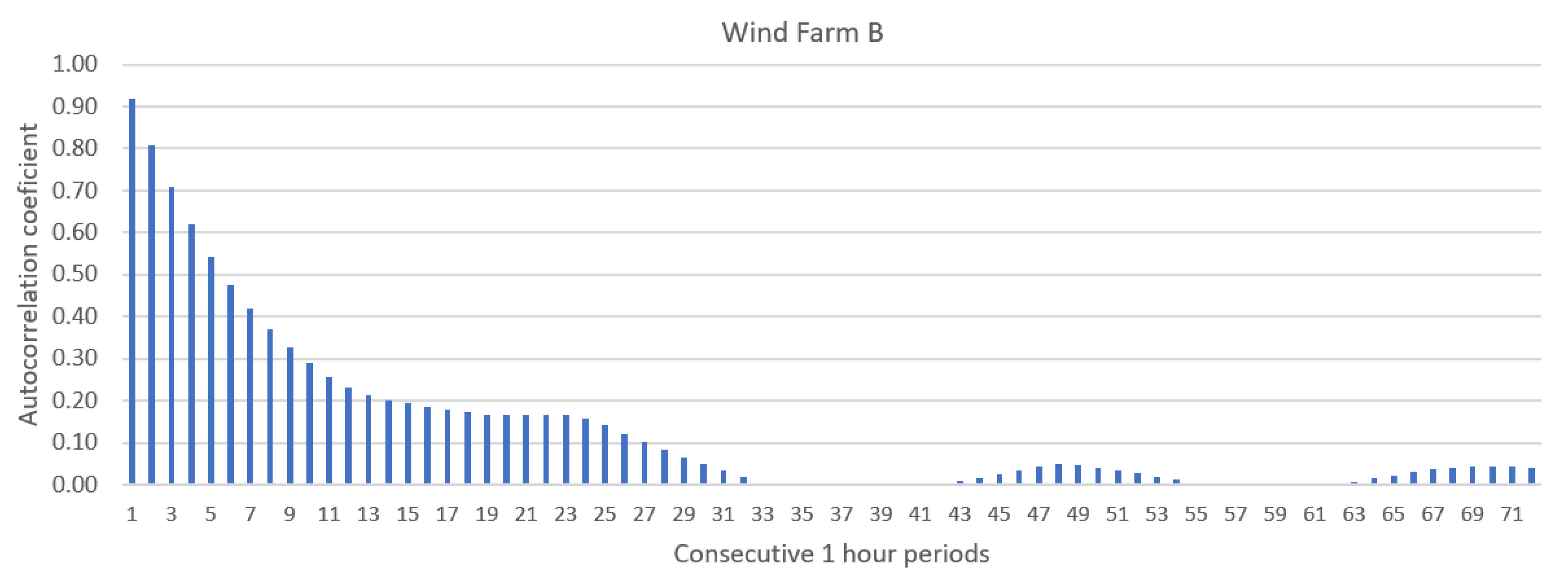
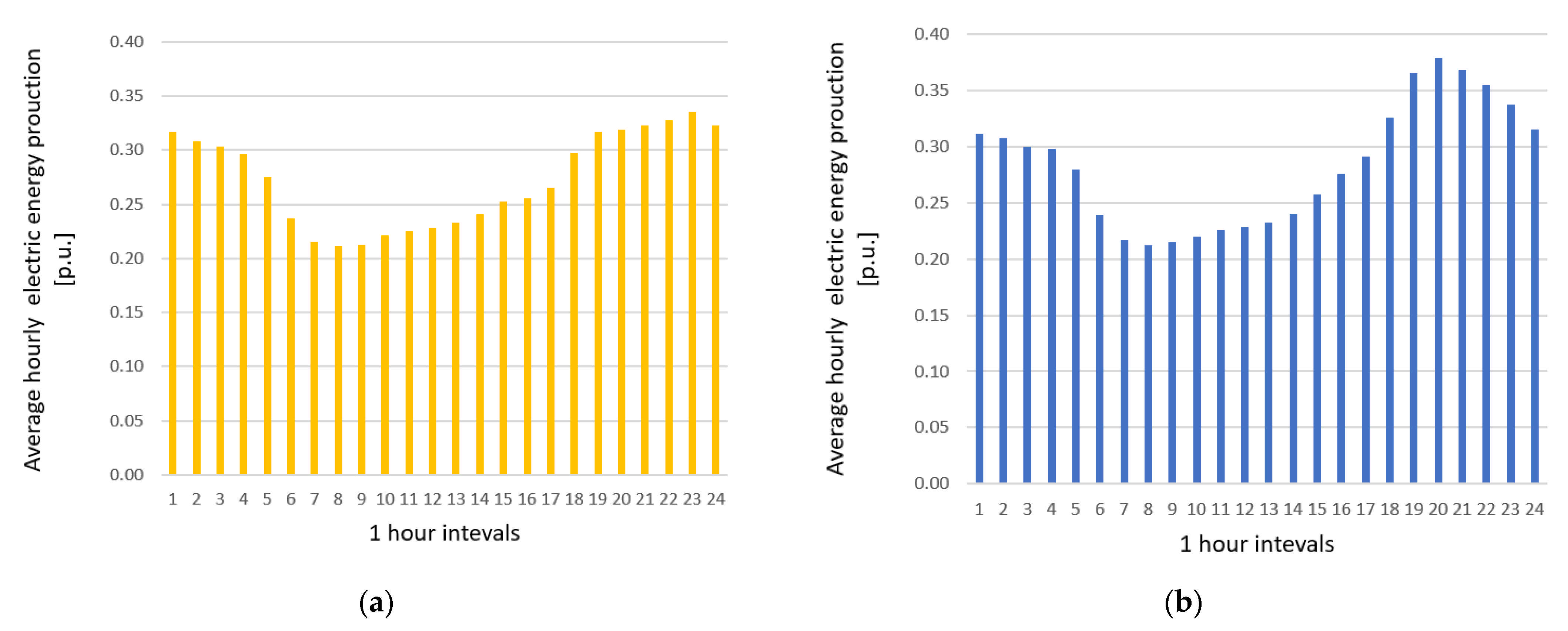
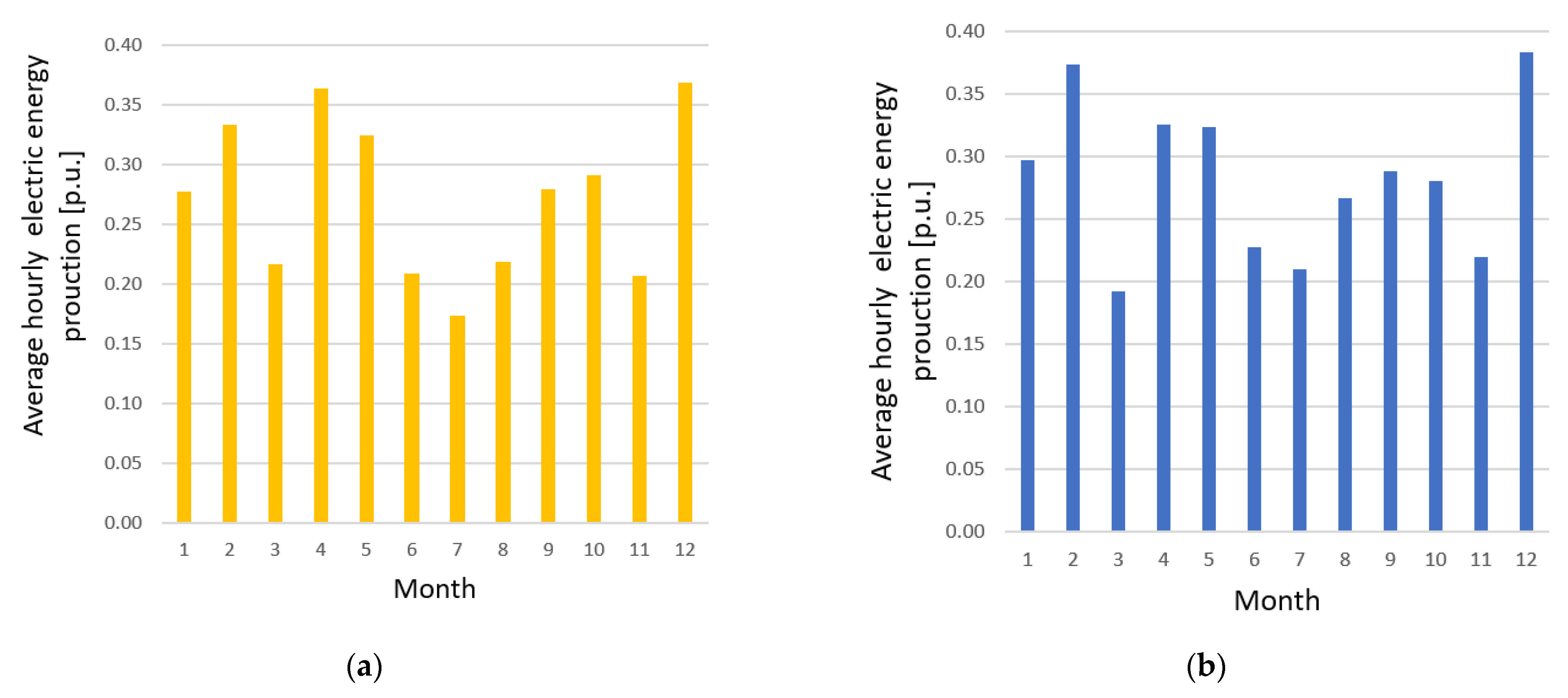
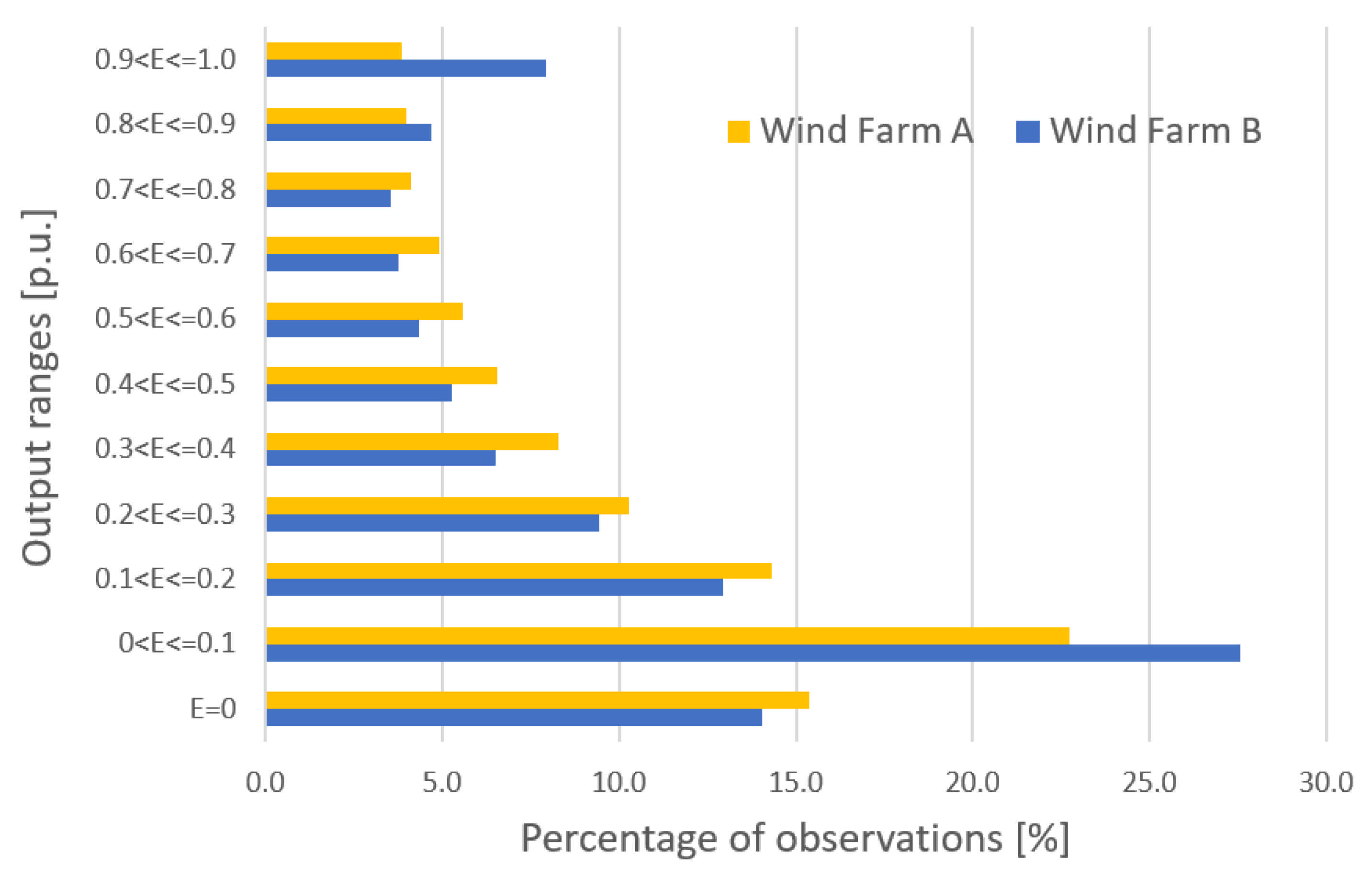
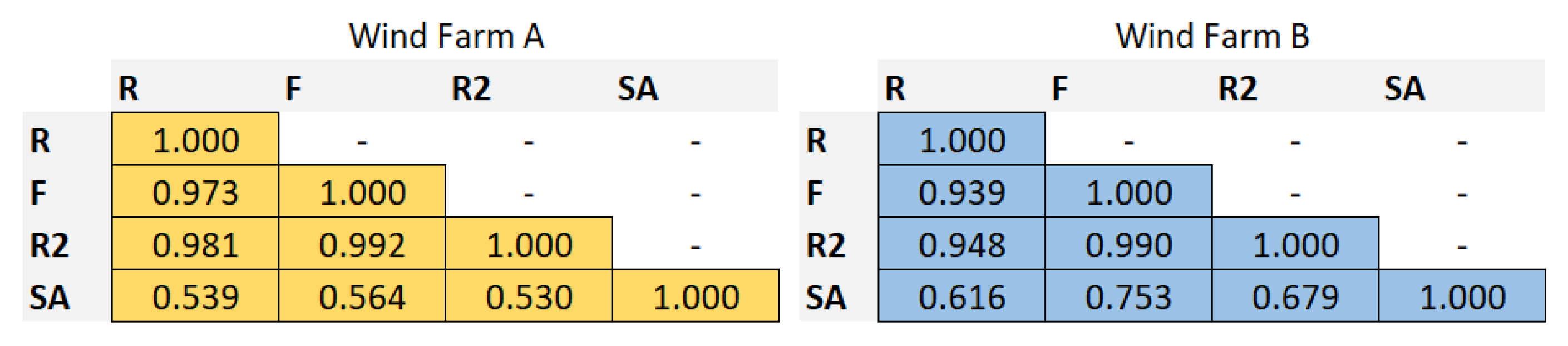
2.1. Statistical Analysis
- Wind farm generation time series (forecasted variable);
- Weather forecasts for wind farms location.
- Data include wind speed forecasts instead of actual, recorded values;
- Wind speed forecasts are momentary values for a given hour and actual wind speed usually changes during a 1 h period;
- Data come from very large wind farms with turbines scattered across vast territory with varying orography. For single wind turbines, data would probably be much more concentrated.
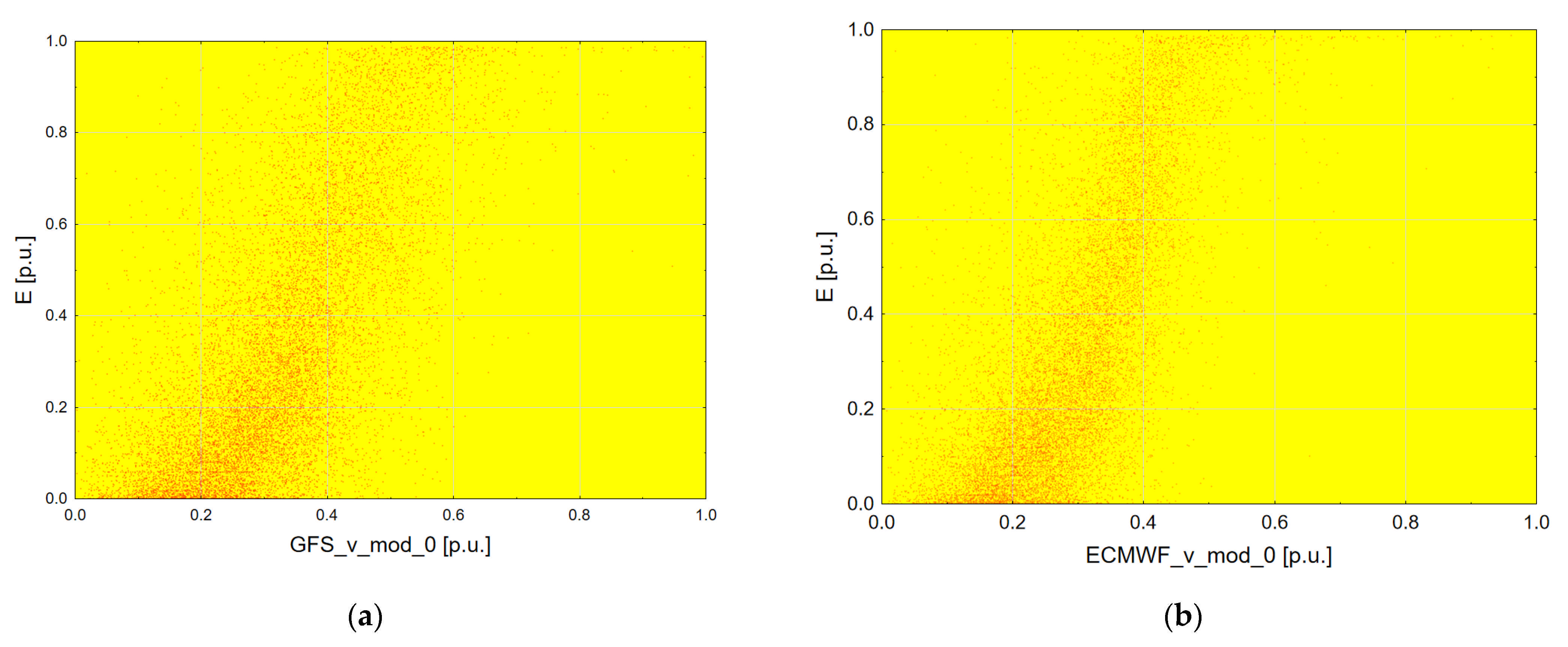
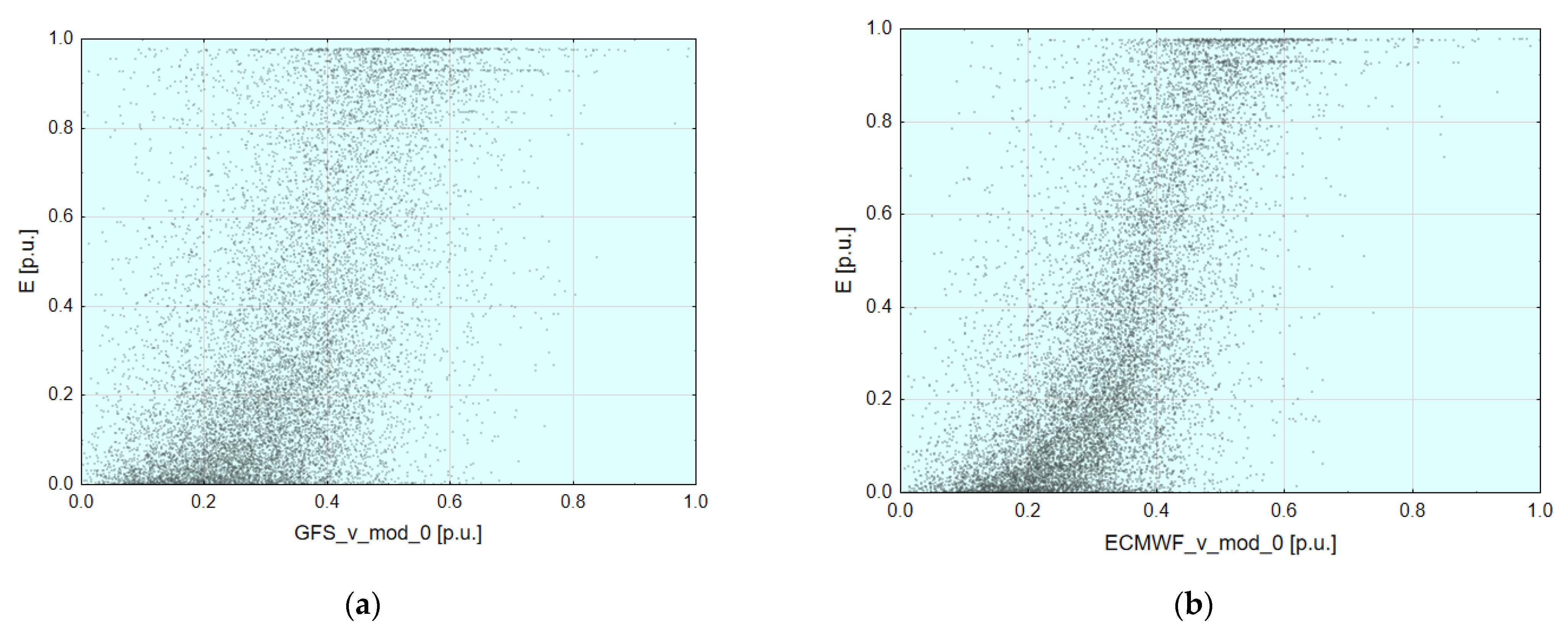
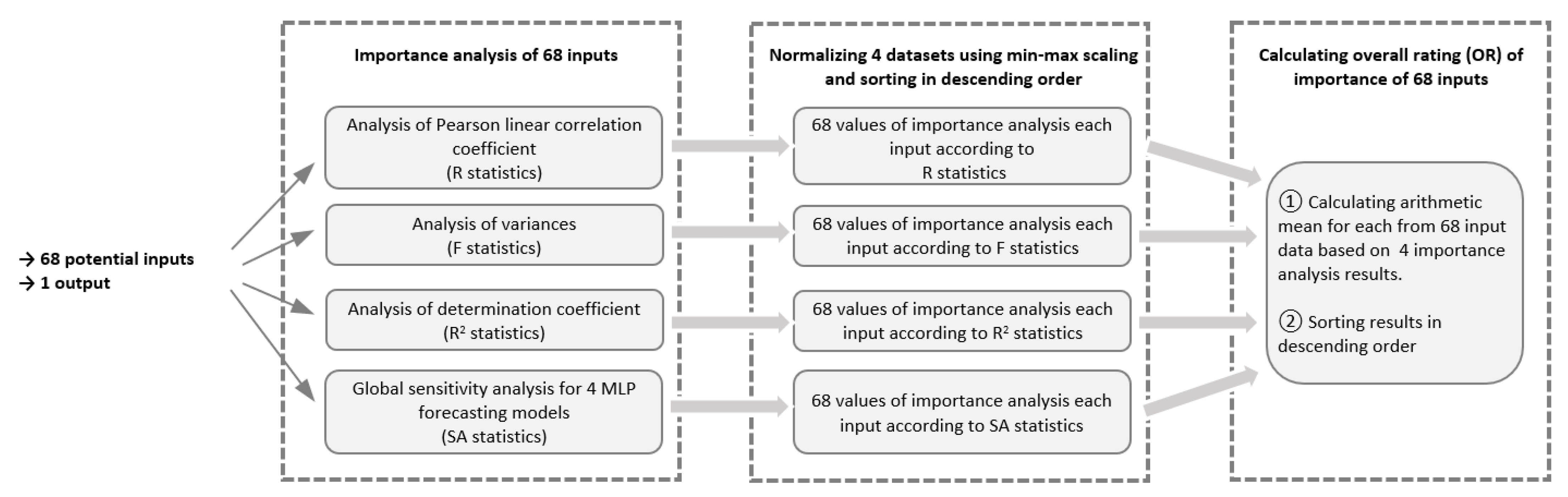
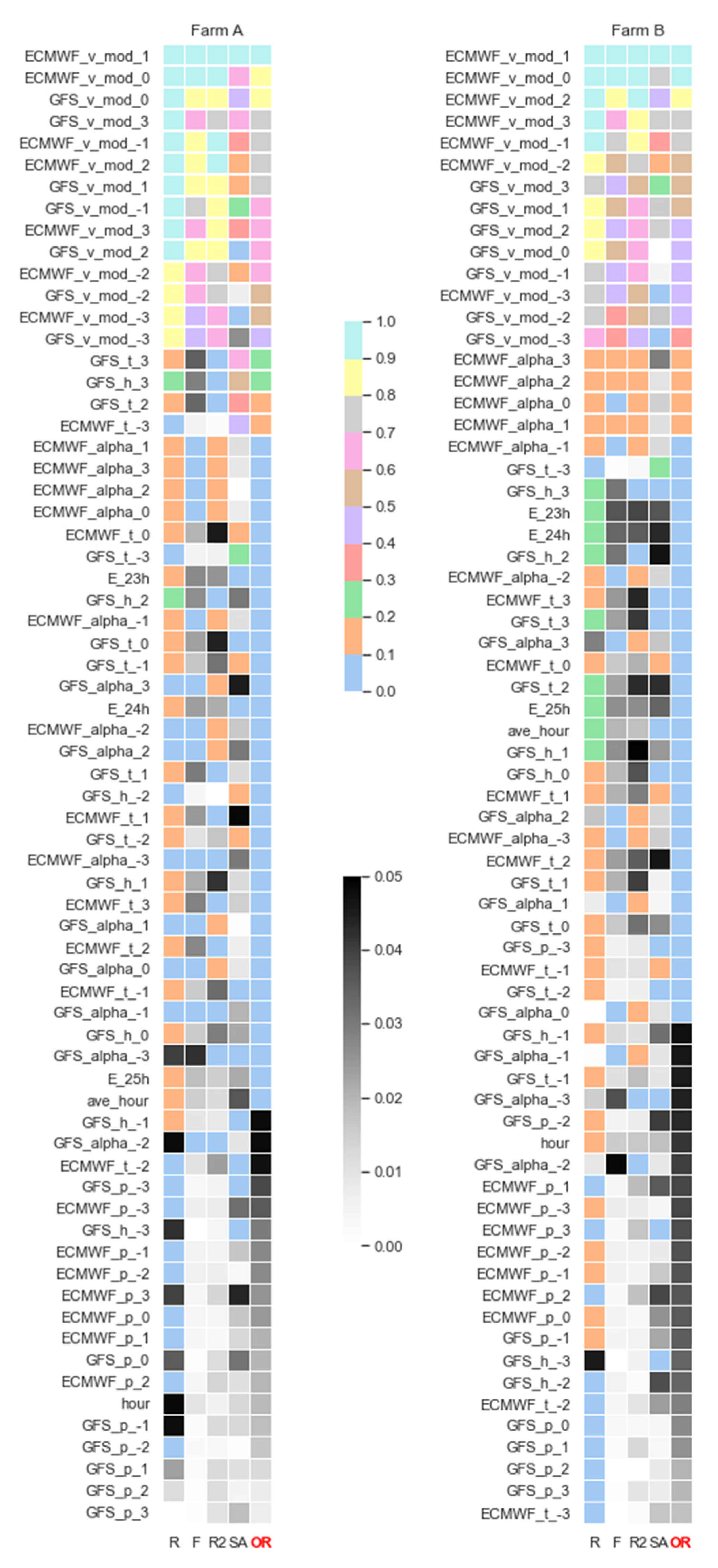
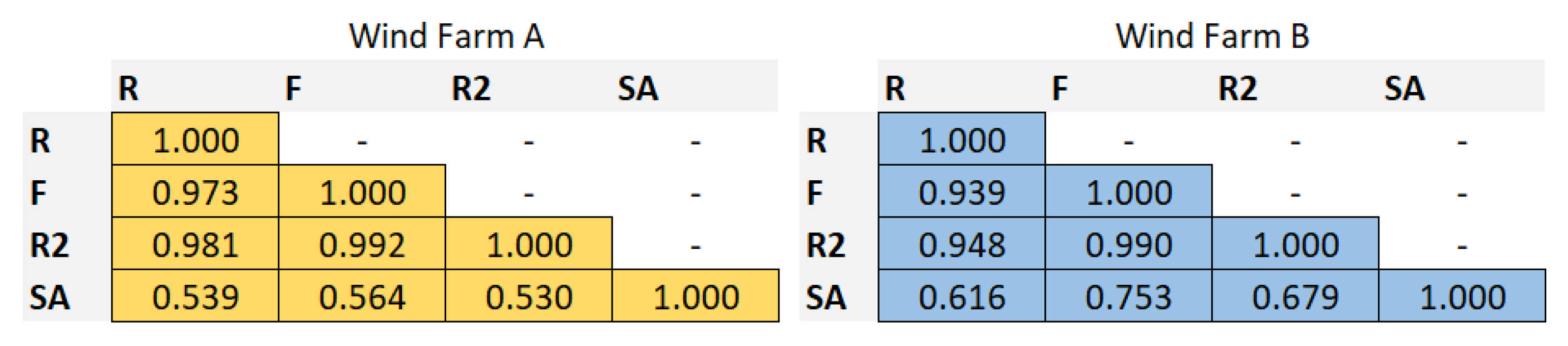
2.2. Analysis of Importance of Available Basic Input Data for Forecasting Methods
2.3. Analysis of Importance of Additional Input Data Created
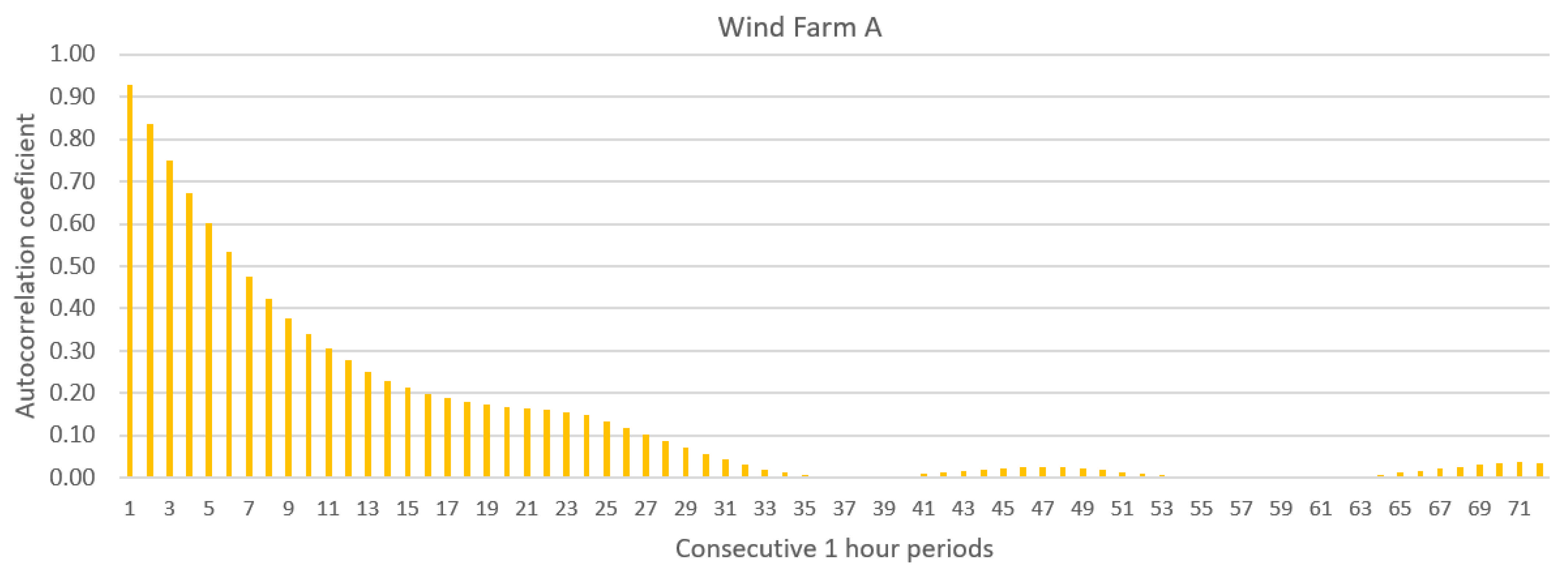
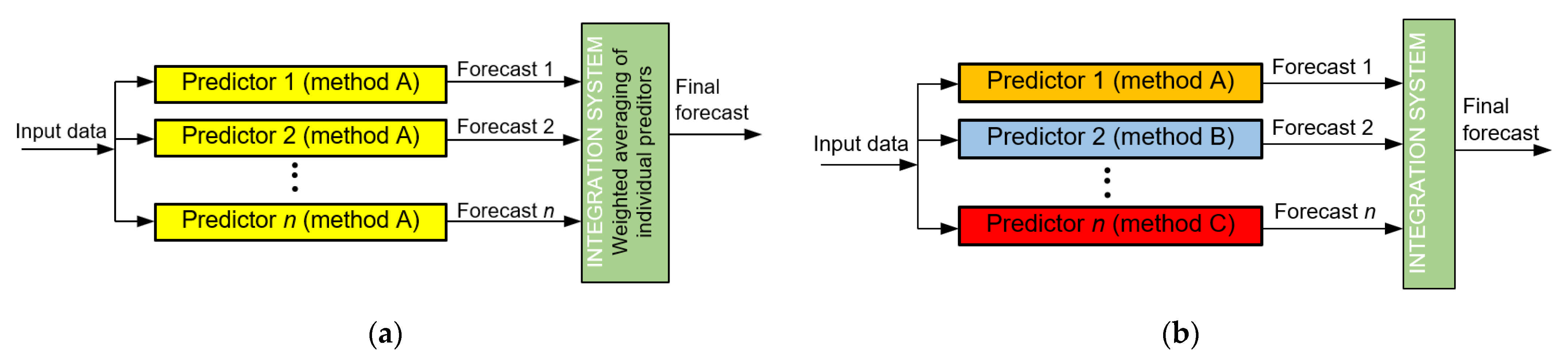
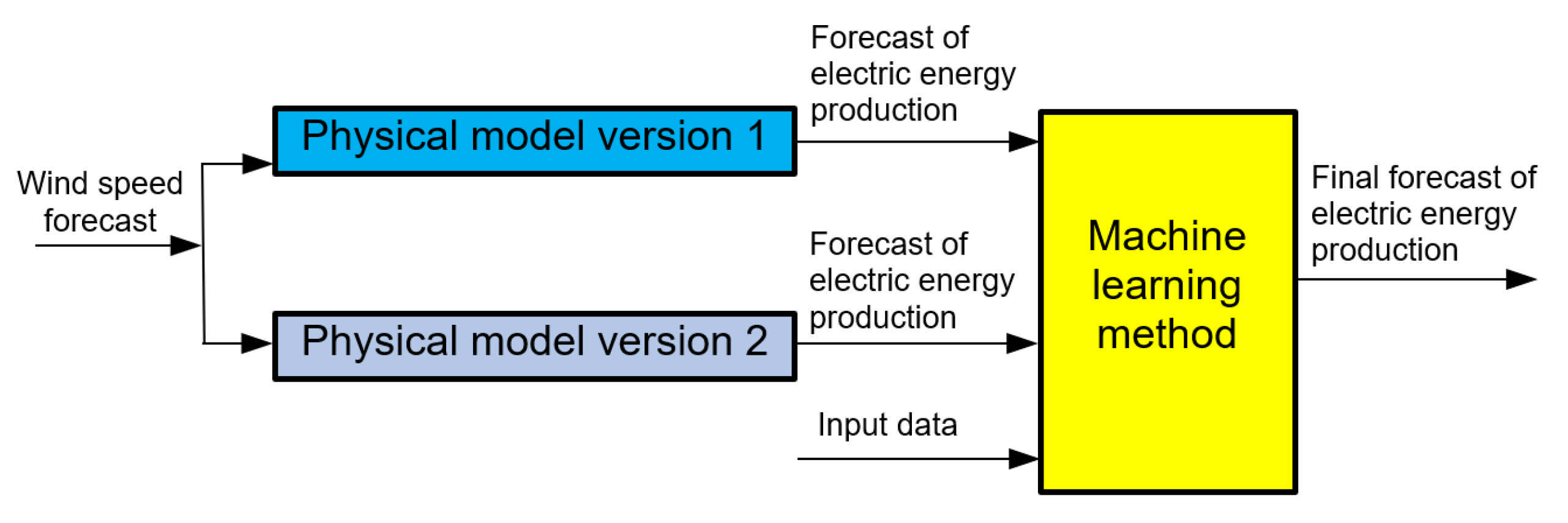
3. Forecasting Methods
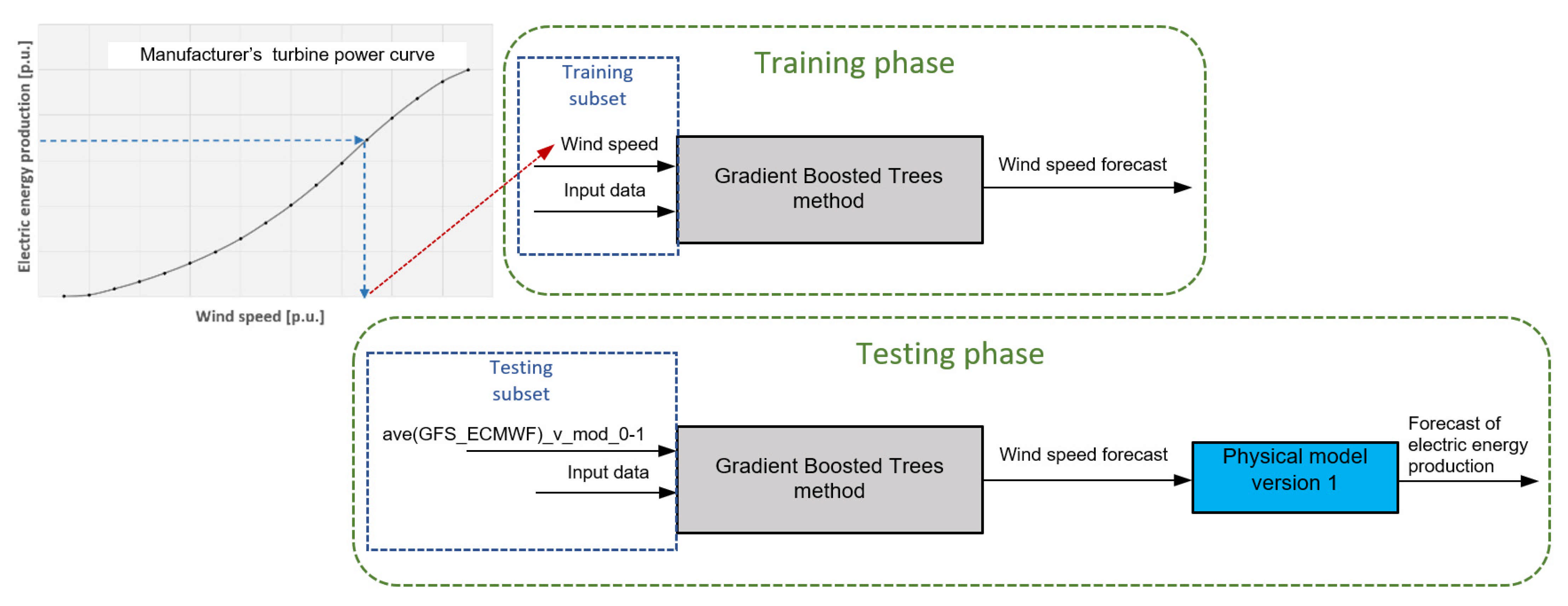
- Physical model version 1. The polynomial of degree 3 is estimated based on turbine power curve data from the manufacturer’s catalogue (turbine power for wind speeds with 1 m/s steps). For input data below and above cut-in for each turbine, the forecast is equal to zero. The input data depend on variant (ave(GFS_ECMWF)_v_mod_0-1, ave_ECMWF_v_mod_0-1 or ave_GFS_v_mod_0-1).
- Physical model version 2. The polynomial of degree 3 is estimated based on the scatter plot between electric energy production and wind speed forecasts (ave(GFS_ECMWF)_v_mod_0-1). For input data below and above cut-in for each turbine, the forecast value is equal to zero. The input data are ave(GFS_ECMWF)_v_mod_0-1.
- time series of the residues from forecasts should be most distant from each other (small R values);
- the smallest nMAE errors on the validation subset.
4. Evaluation Criteria
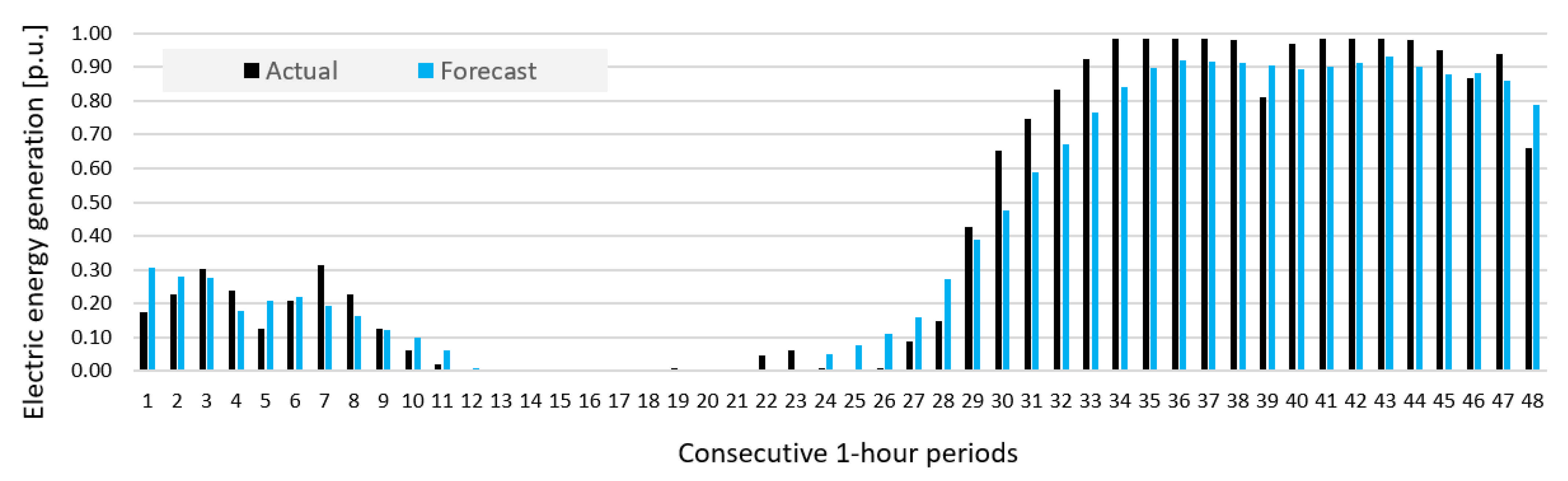
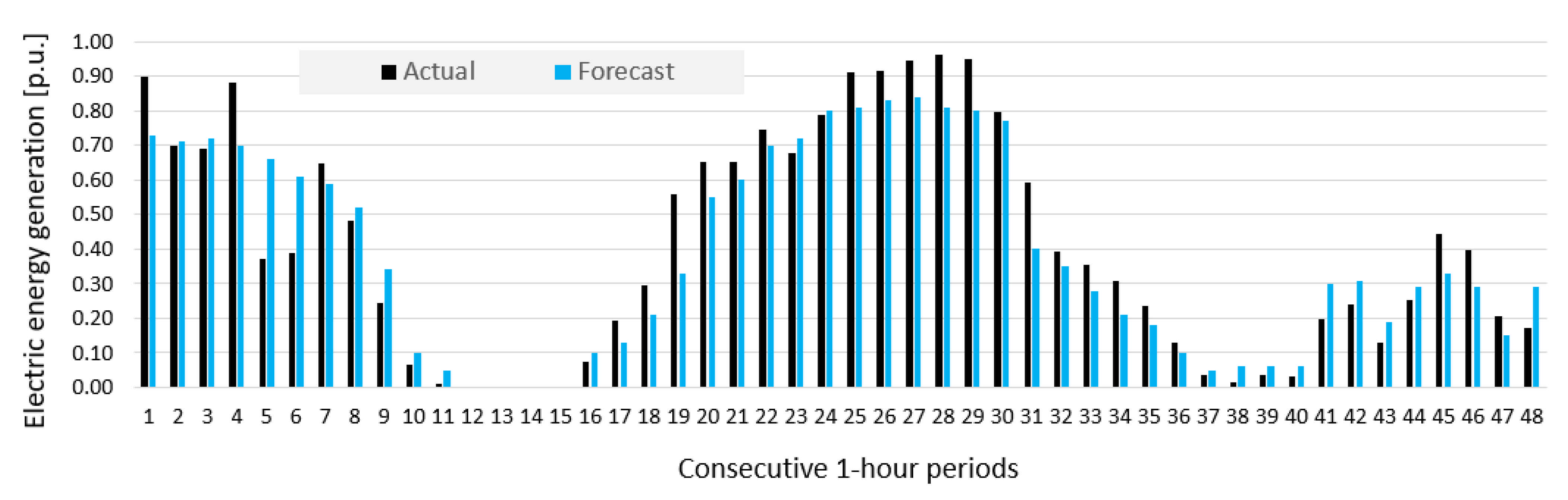
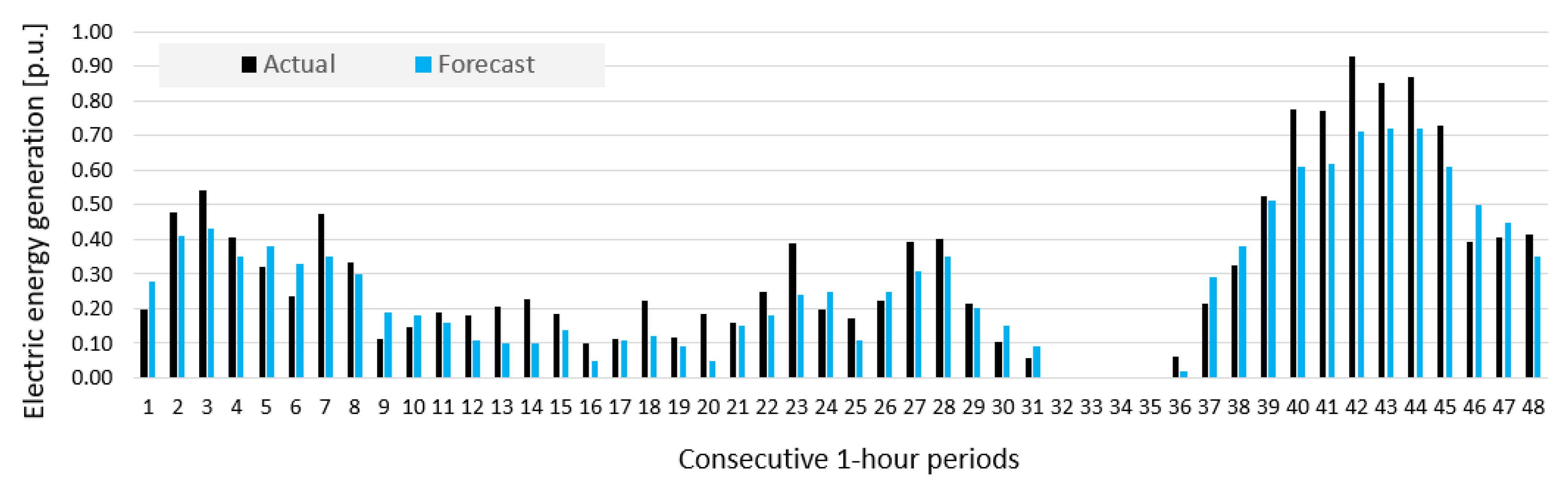
5. Results and Discussion
- Are the accuracies of two designed physical models different from each other?
- Is it better to use one or two NWP models with wind speed forecasts for physical models?
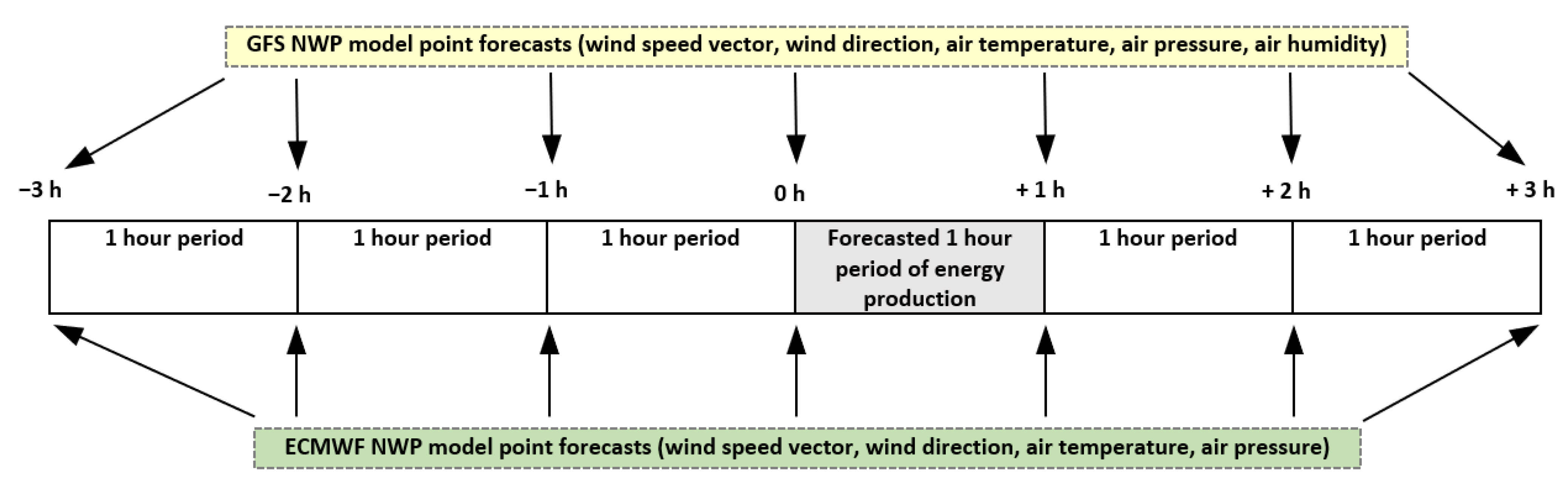
- Is it better to use NWP point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3 (original contribution) as input data instead of the typically used lags 0, 1?
- Is it better to use one or two NWP models as input data source?
- Which method group yields the lowest prediction errors (recommended methods) and does the Ensemble Averaging Without Extremes original method developed by us belong to the recommended methods?
- Does the original proposition developed by us—additional input variables (see Table 3)—reduce the prediction error?
- Does the original proposition developed by us—additional expert correction—reduce the prediction error?
- Original method called “Ensemble Averaging Without Extremes” is the best for both wind farms (SS metric and nMAE error);
- For “Ensemble Averaging Without Extremes”, the best fitted solution was to use an ensemble of 5 methods, while a 3-method ensemble was the best for “Weighted Averaging As an Integrator of Ensemble”;
- Our original method “Additional Expert Correction” resulted in lower nMAE than for predictions without correction. For “Ensemble Averaging Without Extremes”, nMAE decreased by 0.42% for Wind Farm A and 0.92% for Wind Farm B;
- Hybrid methods have worse accuracy measures of nMAE and nRMSE than ensemble methods for both wind farms;
- Deep neural network LSTM is the best single method, MLP is the second best;
- Original hybrid “Physical Model Version 1 With Input Data As Wind Speed Forecast from Gradient-Boosted Trees Method” turned out to be of less advantage than ensemble methods;
- For most methods, using additional input data (numbers: 1A, 2A, 3A) reduced nMAE in comparison with using basic input data only (numbers: 1–68). KNNR was an exception as it yielded the lowest nMAE with a highly reduced number of input data variables;
- Values of nMBE were very low for the analysed methods, which means there was no systematic error in predictions. The lowest nMBE for both wind farms was achieved with the RF Method;
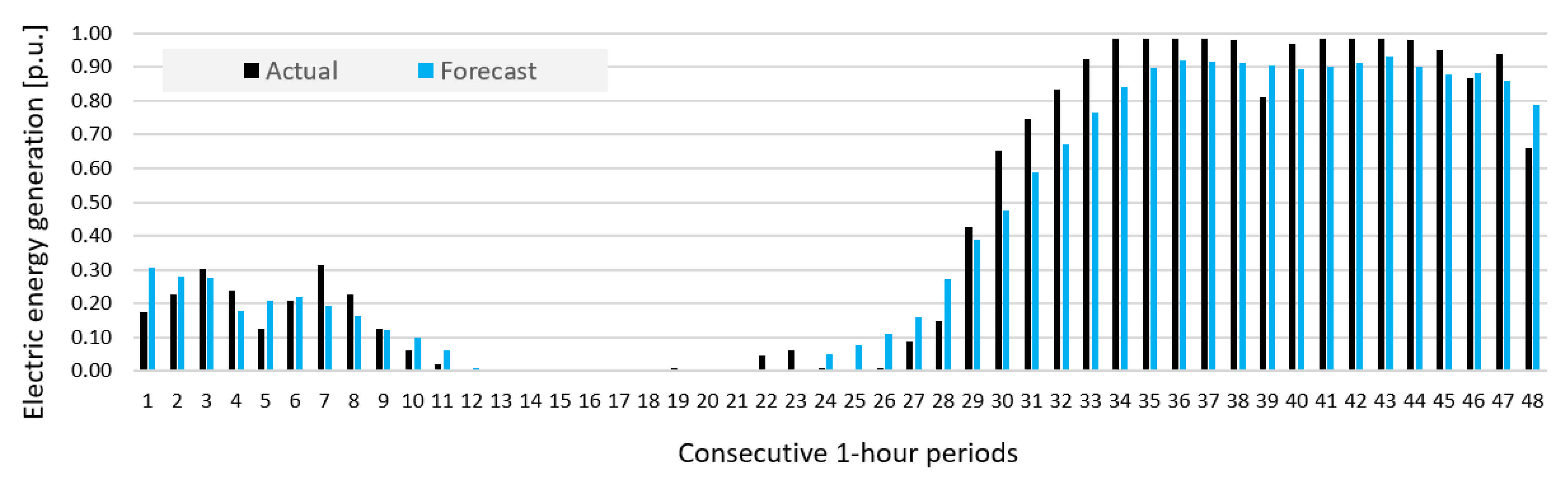
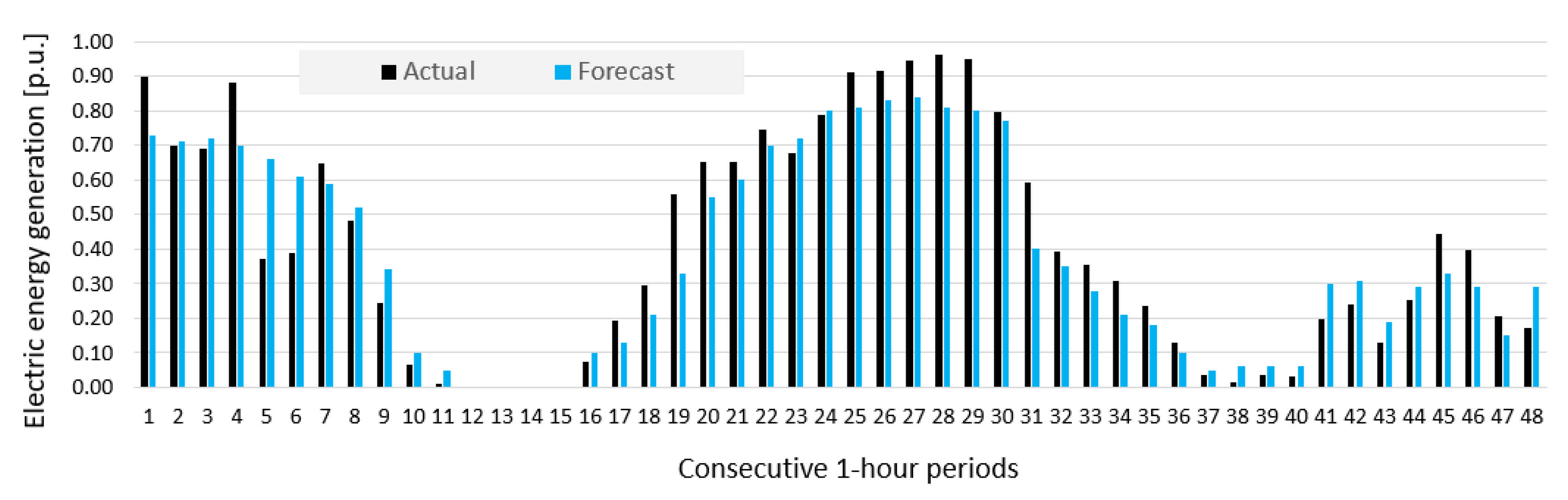
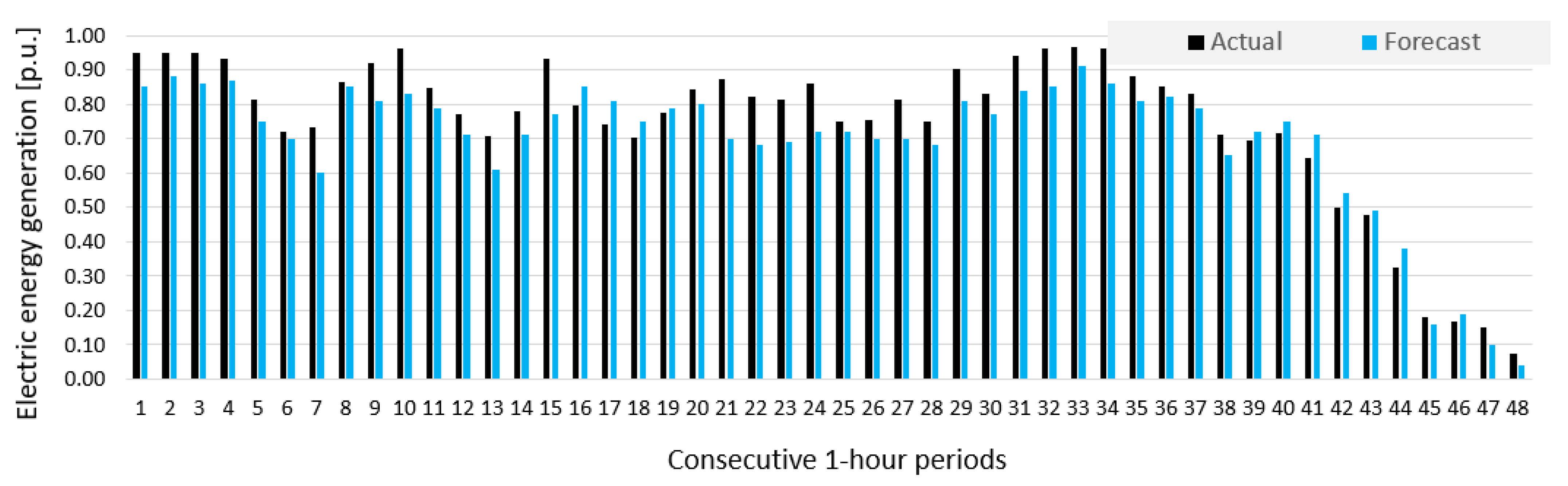
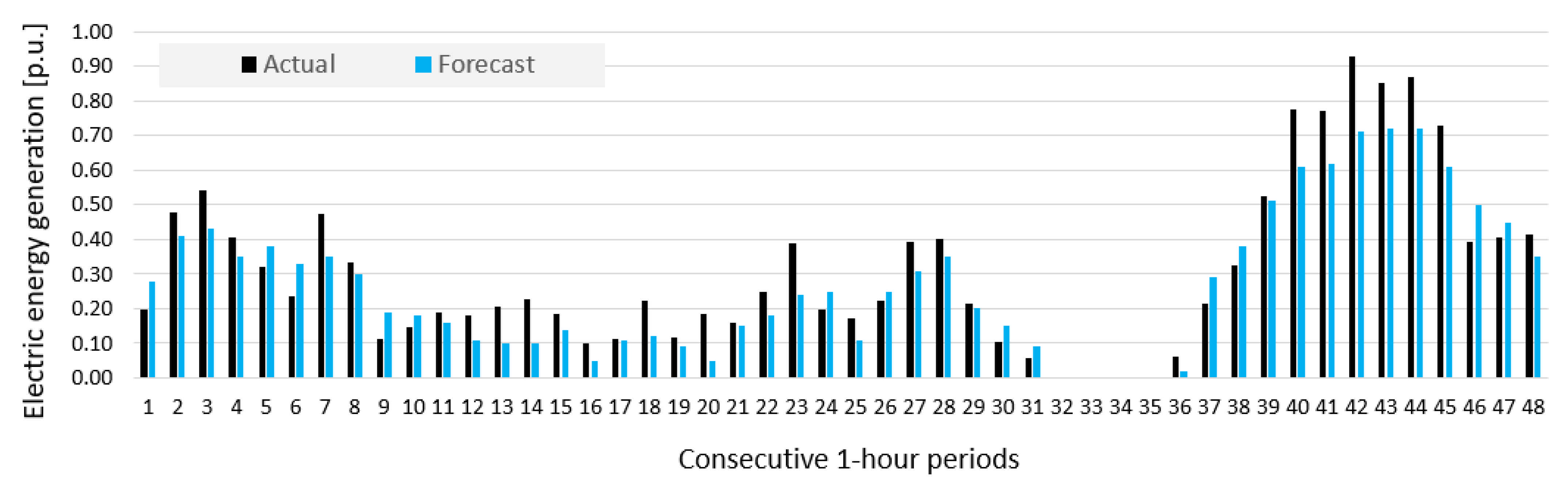
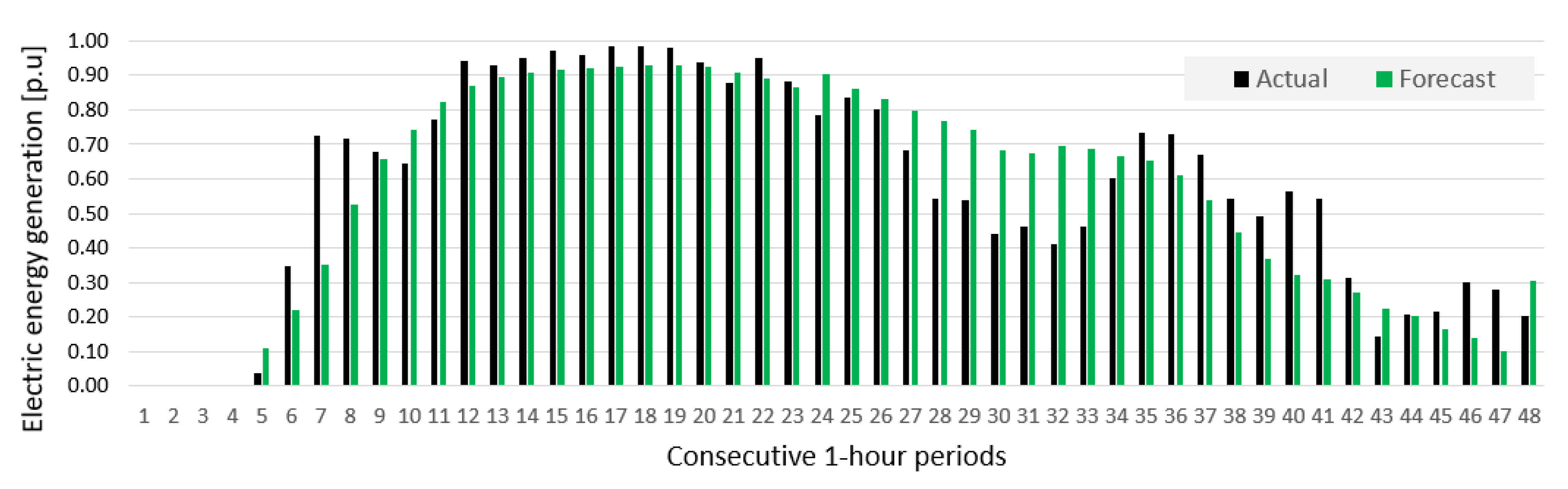
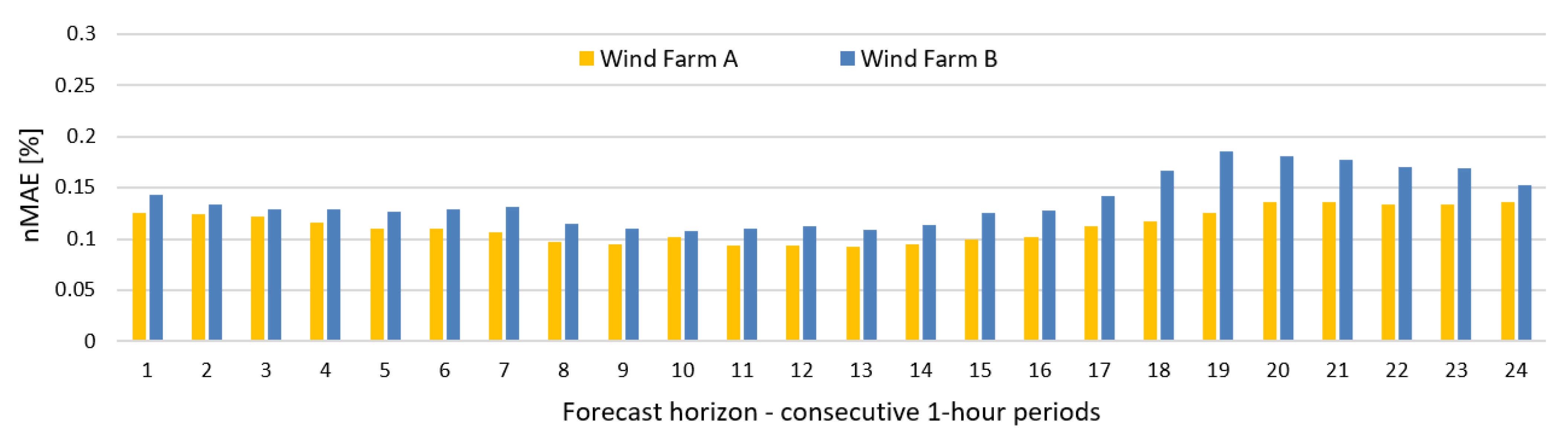
- Prediction errors for Wind Farm B were bigger than for Wind Farm A, which was indicated by results of sensitivity analysis of potential input variables (see Figure 10).
6. Conclusions
- Does prediction accuracy depend on using forecasts from more than one spot of a medium-sized wind farm and how the accuracy of forecasts will be affected by other factors, i.e., data with higher time resolution, e.g., 15 min, using real measurements of weather as input data?
- Can measurements and weather predictions be used to create a weather-error sensitive switching regime for models of ensembles?
- Is it possible to reduce the level of high random component in predictions?
- Will the proposed, original method of “Ensemble Averaging Without Extremes” be equally good for different types of RES predictions (e.g., photovoltaic systems and hydropower system)?
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACF | Autocorrelation function |
| ANN | Artificial Neural Network |
| BFGS | Broyden–Fletcher–Goldfarb–Shanno algorithm |
| BPNN | Back Propagation Neural Network |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| ECMWF | European Center for the Medium-Range Weather Forecast |
| ELM | Extreme Learning Machine |
| ENN | Elman Neural Network |
| ESN | Echo State Network |
| F | Fisher test |
| GBT | Gradient-Boosted Trees |
| GFS | Global Forest System |
| GRU | Gated Recurrent Unit |
| HRES | High-resolution atmospheric model |
| IEC | International Electrotechnical Commission |
| KNNR | K-Nearest Neighbours Regression |
| LSTM | Long short-term memory |
| ML | Machine Learning |
| MLP | Multi-Layer Perceptron |
| NARX | Nonlinear Autoregressive Exogenous Model |
| nMAE | normalized Mean Absolute Error |
| nMBE | normalized Mean Bias Error |
| NWP | Numerical Weather Prediction |
| PSO | Particle Swarm Optimization |
| p.u. | Per unit |
| R | Pearson linear correlation coefficient |
| R2 | Determination coefficient |
| RES | Renewable Energy Sources |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| nRMSE | normalized Root Mean Square Error |
| SA | Sensitivity analysis |
| SS | Skill Score |
| SVR | Support Vector Regression |
| SVM | Support Vector Machine |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Code | Description of Method, the Name and the Range of Values of Hyperparameters Tuning and Selected Values |
|---|---|
| LSTM | The number of hidden layers: 1–2, selected: 2, the number of neurons in hidden layer: 4–50, selected: 35–20, the activation function in hidden layer: ReLU/sigmoid/tanh, selected hyperbolic tangent, the activation function in output layer: linear, learning algorithms ADAM, RMSprop, selected optimizer: ADAM, lr = 0.001, decay = 1 × 10−5, epochs: 1500, patience: 100, batch size: 128; shuffle: True. Dropout after each hidden layer: 0/0.2, selected dropout: 0.2 |
| SVR | Regression SVM: Type-1, Type 2, selected: Type-1, kernel type: Gaussian (RBF), the width parameter σ: 0.147, the regularization constant C, range: 1–20 (step 1), selected: 2, the tolerance ε, range: 0.01–1 (step 0.01), selected: 0.05. |
| PHYS(v1&v2)→KNNR | Distance metrics: Euclidean, Manhattan, Minkowski, selected: Euclidean, the number of nearest neighbours k, range: 1–50, selected: 4. |
| MLP | The number of neurons in hidden layer: 10–80, selected 30, learning algorithm: BFGS, the activation function in hidden layer: linear, hyperbolic tangent, selected: hyperbolic tangent, the activation function in output layer: linear. |
| GBT | Considered max depth: 2/4/6/10, selected depth: 6; trees number: 100/200/400, selected number: 100; learning rate: 0.1/0.01/0.001, selected: 0.1 |
| RF | The number of predictors chosen at random: 30, 35, 40, 45, 50, 55, 60, selected 35 number of decision trees: 1–500, selected: 385. Stop parameters: maximum number of levels in each decision tree: 5, 10, 20, selected 10, minimum number of data points placed in a node before the node is split: 100, 200, 300, selected 200, min number of data points allowed in a leaf node: 10, maximum number of nodes: 100. |
References
- Liu, H.; Chen, C.; Lv, X.; Wu, X.; Liu, M. Deterministic wind energy forecasting: A review of intelligent predictors and auxiliary methods. Energy Convers. Manag. 2019, 195, 328–345. [Google Scholar] [CrossRef]
- Yildiz, C.; Acikgoz, H.; Korkmaz, D.; Budak, U. An improved residual-based convolutional neural network for very short-term wind power forecasting. Energy Convers. Manag. 2021, 228, 113731. [Google Scholar] [CrossRef]
- Duan, J.; Wang, P.; Ma, W.; Tian, X.; Fang, S.; Cheng, Y.; Chang, Y.; Liu, H. Short-term wind power forecasting using the hybrid model of improved variational mode decomposition and Correntropy Long Short-term memory neural network. Energy 2021, 214, 118980. [Google Scholar] [CrossRef]
- Abedinia, O.; Lotfi, M.; Bagheri, M.; Sobhani, B.; Shafiekhah, M.; Catalao, J.P.S. Improved EMD-Based Complex Prediction Model for Wind Power Forecasting. IEEE Trans. Sustain. Energy 2020, 11, 2790–2802. [Google Scholar] [CrossRef]
- Memarzadeh, G.; Keynia, F. A new short-term wind speed forecasting method based on fine-tuned LSTM neural network and optimal input sets. Energy Convers. Manag. 2020, 213, 112824. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, S.; Yu, X.; Zhang, L.; Wang, Q. A Novel Deep Learning Approach for Wind Power Forecasting Based on WD-LSTM Model. Energies 2020, 13, 4964. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Ma, P. Wind power forecasting based on singular spectrum analysis and a new hybrid Laguerre neural network. Appl. Energy 2020, 259, 114139. [Google Scholar] [CrossRef]
- Sun, Z.; Zhao, S.; Zhang, J. Short-Term Wind Power Forecasting on Multiple Scales Using VMD Decomposition, K-Means Clustering and LSTM Principal Computing. IEEE Access 2019, 7, 166917–166929. [Google Scholar] [CrossRef]
- Piotrowski, P.; Kopyt, M.; Baczyński, D.; Robak, S.; Gulczyński, T. Hybrid and Ensemble Methods of Two Days Ahead Forecasts of Electric Energy Production in a Small Wind Turbine. Energies 2021, 14, 1225. [Google Scholar] [CrossRef]
- Sun, M.; Feng, C.; Zhang, J. Multi-distribution ensemble probabilistic wind power forecasting. Renew. Energy 2020, 148, 135–149. [Google Scholar] [CrossRef]
- Chen, C.; Liu, H. Medium-term wind power forecasting based on multi-resolution multi-learner ensemble and adaptive model selection. Energy Convers. Manag. 2020, 206, 112492. [Google Scholar] [CrossRef]
- Du, P. Ensemble Machine Learning-Based Wind Forecasting to Combine NWP Output With Data From Weather Station. IEEE Sustain. Energy 2019, 10, 2133–2141. [Google Scholar] [CrossRef]
- Chen, J.; Zhu, Q.; Li, H.; Lin, Z.; Shi, D.; Li, Y.; Duan, X.; Liu, Y. Learning Heterogeneous Features Jointly: A Deep End-to-End Framework for Multi-Step Short-Term Wind Power Prediction. IEEE Trans. Sustain. Energy 2020, 11, 1761–1772. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Mehmood, A.; Raja, M.A.Z. A novel wavenets long short term memory paradigm for wind power prediction. Appl. Energy 2020, 269, 115098. [Google Scholar] [CrossRef]
- Su, H.-Y.; Huang, C.-R. Enhanced Wind Generation Forecast Using Robust Ensemble Learning. IEEE Trans. Smart Grid 12.1 2021, 2, 912–915. [Google Scholar] [CrossRef]
- Saini, V.K.; Kumar, R.; Mathur, A.; Saxena, A. Short term forecasting based on hourly wind speed data using deep learning algorithms. In Proceedings of the 2020 3rd International Conference on Emerging Technologies in Computer Engineering: Machine Learning and Internet of Things (ICETCE), Jaipur, India, 7–8 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ahmadi, A.; Nabipour, M.; Mohammadi-Ivatloo, B.; Amani, A.M.; Rho, S.; Piran, M.J. Long-Term Wind Power Forecasting Using Tree-Based Learning Algorithms. IEEE Access 2020, 8, 151511–151522. [Google Scholar] [CrossRef]
- Kisvari, A.; Lin, Z.; Liu, X. Wind power forecasting A data-driven method along with gated recurrent neural network. Renew. Energy 2021, 163, 1895–1909. [Google Scholar] [CrossRef]
- Ouyang, T.; Huang, H.; He, Y.; Tang, Z. Chaotic wind power time series prediction via switching data-driven modes. Renew. Energy 2020, 145, 270–281. [Google Scholar] [CrossRef]
- Li, L.L.; Zhao, X.; Tseng, M.L.; Tan, R.R. Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm. J. Clean. Prod. 2020, 242, 118447. [Google Scholar] [CrossRef]
- Wang, X.; Li, P.; Yang, J. Short-term Wind Power Forecasting Based on Two-stage Attention Mechanism. IET Renew. Power Gener. 2019, 14, 297–304. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Jiang, M.; Yuan, Y. Prediction interval of wind power using parameter optimized Beta distribution based LSTM model. Appl. Soft Comput. 2019, 82, 105550. [Google Scholar] [CrossRef]
- Niu, Z.; Yu, Z.; Tang, W.; Wu, Q.; Reformat, M. Wind power forecasting using attention-based gated recurrent unit network. Energy 2020, 196, 117081. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Lv, S.X. Forecasting energy consumption and wind power generation using deep echo state network. Renew. Energy 2020, 154, 598–613. [Google Scholar] [CrossRef]
- Yu, R.; Liu, Z.; Li, X.; Lu, W.; Ma, D.; Yu, M.; Wang, J.; Li, B. Scene learning: Deep convolutional networks for wind power prediction by embedding turbines into grid space. Appl. Energy 2019, 238, 249–257. [Google Scholar] [CrossRef] [Green Version]
- Hu, T.; Wu, W.; Guo, Q.; Sun, H.; Shi, L.; Shen, X. Very short-term spatial and temporal wind power forecasting A deep learning approach. CSEE J. Power Energy Syst. 2020, 6, 434–443. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Zhang, Y.; Huang, C.; Wang, L. Short-Term Wind Speed Forecasting Based on Information of Neighboring Wind Farms. IEEE Access 2020, 8, 16760–16770. [Google Scholar] [CrossRef]
- Yin, H.; Ou, Z.; Huang, S.; Meng, A. A cascaded deep learning wind power prediction approach based on a two-layer of mode decomposition. Energy 2019, 189, 116316. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, X. Wind power forecasting of an offshore wind turbine based on high-frequency SCADA data and deep learning neural network. Energy 2020, 201, 117693. [Google Scholar] [CrossRef]
- Medina, S.V.; Ajenjo, U.P. Performance Improvement of Artificial Neural Network Model in Short-term Forecasting of Wind Farm Power Output. J. Mod. Power Syst. Clean Energy 2020, 8, 484–490. [Google Scholar] [CrossRef]
- Tang, B.; Chen, Y.; Chen, Q.; Su, M. Research on Short-Term Wind Power Forecasting by Data Mining on Historical Wind Resource. Appl. Sci. 2020, 10, 1295. [Google Scholar] [CrossRef] [Green Version]
- Piotrowski, P.; Baczyński, D.; Kopyt, M.; Szafranek, K.; Helt, P.; Gulczyński, T. Analysis of forecasted meteorological data (NWP) for efficient spatial forecasting of wind power generation. Electric Power Systems Research 2019, 175, 105891. [Google Scholar] [CrossRef]
- De Mattos Neto, P.S.G.; de Oliveira, J.F.L.; de O. Santos Júnior, D.S.; Siqueira, H.V.; Marinho, M.H.N.; Madeiro, F. An adaptive hybrid system using deep learning for wind speed forecasting. Inf. Sci. 2021, 581, 495–514. [Google Scholar] [CrossRef]
- Atmospheric Model high resolution 10-day forecast (Set I—HRES). Available online: https://www.ecmwf.int/en/forecasts/datasets/set-i (accessed on 15 January 2021).
- NCEP Products Inventory. Available online: https://www.nco.ncep.noaa.gov/pmb/products/gfs/ (accessed on 15 January 2021).
- Available online: https://mapy.meteo.pl (accessed on 15 January 2021).
- Dudek, G.; Pełka, P. Forecasting monthly electricity demand using k nearest neighbor method. Przegląd Elektrotechniczny 2017, 93, 62–65. [Google Scholar]
- Dudek, G. Multilayer Perceptron for Short-Term Load Forecasting: From Global to Local Approach. Neural Comput. App. 2019, 32, 3695–3707. [Google Scholar] [CrossRef] [Green Version]
- Osowski, S.; Siwek, K. Local dynamic integration of ensemble in prediction of time series. Bull. Pol. Ac. Tech. 2019, 67, 517–525. [Google Scholar]
- Piotrowski, A.P.; Napiorkowski, J.J.; Piotrowska, A.E. Impact of deep learning-based dropout on shallow neural networks applied to stream temperature modelling. Earth-Sci. Rev. 2020, 201, 103076. [Google Scholar] [CrossRef]
- Parol, M.; Piotrowski, P.; Kapler, M.; Piotrowski, M. Forecasting of 10-Second Power Demand of Highly Variable Loads for Microgrid Operation Control. Energies 2021, 14, 1290. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd ed.; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2019. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning. Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Zhao, Y.; Ye, L.; Li, Z.; Song, X.; Lang, Y.; Su, J. A novel bidirectional mechanism based on time series model for wind power forecasting. Appl. Energy 2016, 177, 793–803. [Google Scholar] [CrossRef]
- Shahram, H.; Xiaolei, L.; Zi, L.; Saeid, L. A Critical Review of Wind Power Forecasting Methods—Past, Present and Future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- Barcons, J.; Avila, M.; Folch, A. Diurnal cycle RANS simulations applied to wind resource assessment. Wind Energy 2019, 22, 269–282. [Google Scholar] [CrossRef] [Green Version]

















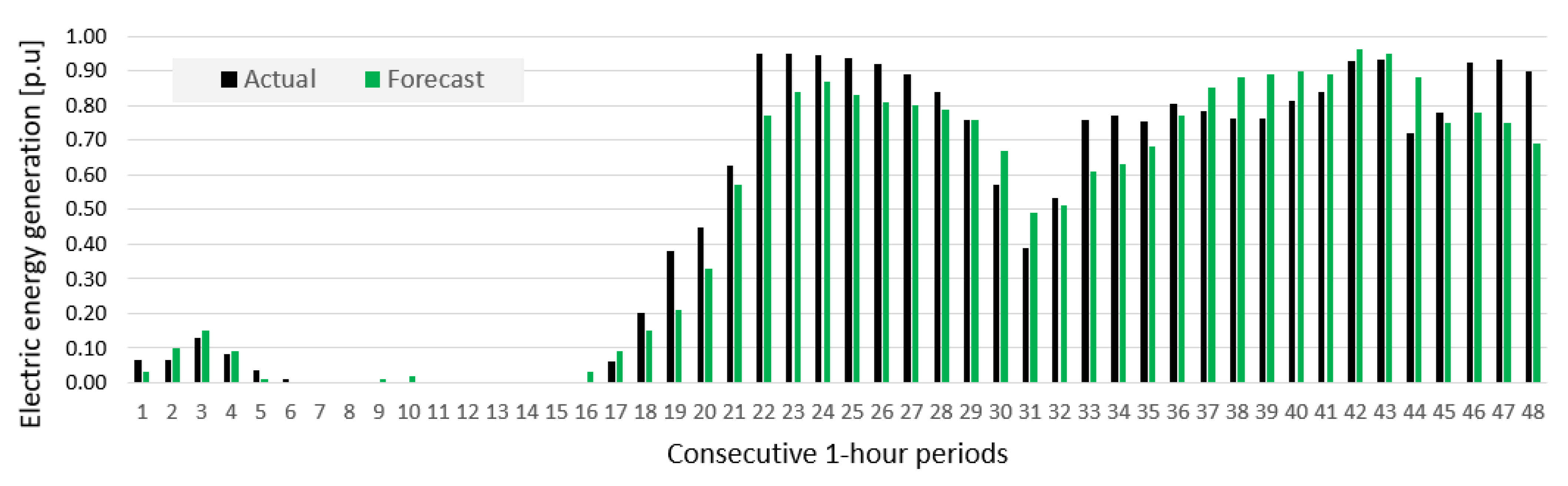


| Descriptive Statistics | Wind Farm A | Wind Farm B |
|---|---|---|
| Mean | 0.278 [p.u.] | 0.288 [p.u.] |
| Standard deviation | 0.284 [p.u.] | 0.315 [p.u.] |
| Minimum | 0.000 [p.u.] | 0.000 [p.u.] |
| Maximum | 0.990 [p.u.] | 0.980 [p.u.] |
| Coefficient of variation | 102.277% | 109.164% |
| The 10th percentile | 0.000 [p.u.] | 0.000 [p.u.] |
| The 25th percentile (lower quartile) | 0.025 [p.u.] | 0.018 [p.u.] |
| The 50th percentile (median) | 0.181 [p.u.] | 0.163 [p.u.] |
| The 75th (upper quartile) | 0.459 [p.u.] | 0.483 [p.u.] |
| The 90 percentile | 0.742 [p.u.] | 0.861 [p.u.] |
| Variance | 0.080 | 0.099 |
| Skewness | 0.906 | 0.941 |
| Kurtosis | −0.320 | −0.468 |
| Input Data Numbers | Input Data Code/Codes | Description of Input Data (Three Categories) |
|---|---|---|
| Category I. Markers of variability of wind farm’s daily energy production | ||
| 1 | hour | Numbers from 0 to 23 refer to the time of the forecast, where 0 refers to power generation from 23:00 to 00:00 |
| 2 | ave_hour | Arithmetic mean of power generation for the given hour of the day (24 values) |
| Category II. Lagged variables of hourly energy generation forecasted time series | ||
| 3–5 | E-23 h, E-24 h, E-25 h | Energy generation lagged by 23/24/25 h from currently considered timestamp |
| Category III. NWP forecasts | ||
| 6–12 | GFS_t_−3, GFS_t_−2,…, GFS_t_3 | Seven values of air temperature point forecasts from GFS NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 13–19 | ECMWF_t_−3, ECMWF_t_−2,…, ECMWF_t_3 | Seven values of air temperature point forecasts from ECMWF NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 20–26 | GFS_p_−3, GFS _p_−2,…, GFS _p_3 | Seven values of atmospheric pressure point forecasts from GFS NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 27–33 | ECMWF_p_−3, ECMWF_p_−2,…, ECMWF_p_3 | Seven values of atmospheric pressure point forecasts from ECMWF NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 34–40 | GFS_h_−3, GFS_h_−2,…, GFS_h_3 | Seven values of air humidity point forecasts from GFS NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 41–47 | GFS_alpha_−3, GFS_alpha_−2,…, GFS_alpha_3 | Seven values of wind direction (0 degree at N, 90 at E) point forecasts from GFS NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 48–55 | ECMWF_alpha_−3, ECMWF_alpha_−2,…, ECMWF_alpha_3 | Seven values of wind direction (0 degree at N, 90 at E) point forecasts from ECMWF NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 55–61 | GFS_v_mod_−3, GFS_v_mod_−2,…, GFS_v_mod_3 | Seven values of wind speed (modulus calculated from NS and WE components) point forecasts from GFS NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| 62–68 | ECMWF_v_mod_−3, ECMWF_v_mod_−2,…, ECMWF_v_mod_3 | Seven values of wind speed (modulus calculated from NS and WE components) point forecasts from ECMWF NWP model for respective hourly lags −3, −2, −1, 0, +1 1, +2, +3 h |
| Input Data Numbers | Input Data Code(s) | Description of Additional Input Data |
|---|---|---|
| 1A | ave(GFS_ECMWF)_v_mod_0-1 | Arithmetic mean of averaged wind speed point forecasts for hourly lags 0 h and +1 1 h from ECMWF NWP and GFS NWP models |
| 2A | ave_ECMWF_v_mod_0-1 | Arithmetic mean of wind speed point forecasts for hourly lags 0 h and +1 1 h from ECMWF NWP model |
| 3A | ave_GFS_v_mod_0-1 | Arithmetic mean of forecasts of wind speed point for hourly lags 0 h and +1 1 h from GFS NWP model |
| 4A–7A | differ(GFS_ECMWF)_v_mod_−2_−1 differ(GFS_ECMWF)_v_mod_−1_0 differ(GFS_ECMWF)_v_mod_0_1 differ(GFS_ECMWF)_v_mod_1_2 | Percentage difference between averaged wind speed point forecasts for respective pair of hourly lags −2, −1, 0, +1 1, +2 h from ECMWF NWP and GFS NWP models |
| 8A–11A | differ(GFS_ECMWF)_p_−2_−1 differ(GFS_ECMWF)_p_−1_0 differ(GFS_ECMWF)_p_0_1 differ(GFS_ECMWF)_p_1_2 | Percentage difference between averaged atmospheric pressure point forecasts for respective pair of hourly lags −2, −1, 0, +1 1, +2 h from ECMWF NWP and GFS NWP models |
| 12A | E_from_producer_turbine_power_curve | Forecast of electric energy production calculated based on producer turbine power curve estimated as a polynomial of degree 3, with ave(GFS_ECMWF)_v_mod_0-1 as input data. For input data below and above the cut-in for turbine, the forecast value is equal to zero |
| 13A | E_from_power_curve(scatter_plot) | Forecast electric energy production calculated based on estimated polynomial of degree 3 as turbine power curve with ave(GFS_ECMWF)_v_mod_0-1 as input data. The estimation of power curve was executed based on the scatter plot between electric energy production and wind speed forecasts. For input data below and above the cut-in for turbine, the forecast value is equal to zero |
| Name of Method | Method Code | Category | Complexity |
|---|---|---|---|
| Persistence | PERSISTENCE | Linear/ non-parametric | Single |
| Physical model version 1 | PHYS_v1 | Non-linear/ parametric | Single |
| Physical model version 2 | PHYS_v2 | Non-linear/ parametric | Single |
| K-Nearest Neighbours Regression | KNNR | Non-linear/ non-parametric | Single |
| Type MLP artificial neural network | MLP | Non-linear/ parametric | Single |
| Support Vector Regression | SVR | Non-linear/ non-parametric | Single |
| Deep neural network type LSTM | LSTM | Non-linear/ parametric | Single |
| Random Forest Regression | RF | Non-linear/ non-parametric | Ensemble (one type of model) |
| Gradient-Boosted Trees for regression | GBT | Non-linear/ non-parametric | Ensemble (one type of model) |
| Ensemble Averaging Without Extremes | INT_OUT_EXT [p1 *,…, pn] | Non-linear/ non-parametric | Ensemble (different types of models including hybrid models) |
| Weighted Averaging as an Integrator of Ensemble based on nMAE and R | INT_AVE [p1 *,…, pn] | Non-linear/ non-parametric | Ensemble (different types of models including hybrid models) |
| Machine learning method with additional input data from two physical models | PHYS(v1&v2)→ML | Non-linear/ parametric | Hybrid |
| Physical model version 1 with input data as wind speed forecast from Gradient-Boosted Trees method | GBT→PHYS_v1 | Non-linear/ parametric | Hybrid |
| Method Code | Input Data Codes | nMAE [%] | nRMSE | nMBE |
|---|---|---|---|---|
| PHYS_v1 | ave(GFS_ECMWF)_v_mod_0-1 | 12.3288 | 0.1813 | 0.0349 |
| PHYS_v2 | ave(GFS_ECMWF)_v_mod_0-1 | 12.3700 | 0.1709 | 0.0025 |
| PHYS_v1 | ave_ECMWF_v_mod_0-1 | 13.2318 | 0.1920 | 0.0663 |
| PHYS_v1 | ave_GFS_v_mod_0-1 | 14.5975 | 0.2152 | −0.0063 |
| PERSISTENCE | E-24 h | 28.7790 | 0.3833 | 0.0127 |
| Method Code | Input Data Codes | nMAE [%] | nRMSE | nMBE |
|---|---|---|---|---|
| PHYS_v1 | ave_ECMWF_v_mod_0-1 | 14.6101 | 0.2246 | −0.0173 |
| PHYS_v1 | ave(GFS_ECMWF)_v_mod_0-1 | 15.2718 | 0.2286 | 0.0403 |
| PHYS_v2 | ave(GFS_ECMWF)_v_mod_0-1 | 15.9984 | 0.2196 | −0.0025 |
| PHYS_v1 | ave_GFS_v_mod_0-1 | 19.5102 | 0.2889 | −0.0468 |
| PERSISTENCE | E-24 h | 29.9931 | 0.3886 | −0.0291 |
| Method Code | Input Data Numbers/Description | nMAE [%] | nRMSE | nMBE |
|---|---|---|---|---|
| GBT | 1−68 (68 inputs)/including NWP forecasts from ECMWF and GFS models (point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3) | 11.8518 | 0.1636 | 0.0006 |
| GBT | 1–5, 13–19, 27–33, 48–55, 62–68 (34 inputs)/including NWP forecasts from ECMWF model (point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3) | 12.5388 | 0.1701 | −0.0019 |
| GBT | 1–5, 16–17, 30–31, 51–52, 65–66 (13 inputs)/including NWP forecasts from ECMWF model (point forecasts for hourly lags: 0, 1) | 12.9633 | 0.1760 | −0.0006 |
| GBT | 1–5, 6–12, 20–26, 34–47, 55–61 (40 inputs)/including NWP forecasts from GFS model (point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3) | 13.8295 | 0.1855 | 0.0037 |
| GBT | 1–5, 16–17, 30–31, 51–52, 65–66 (13 inputs)/including NWP forecasts from GFS model (point forecasts for hourly lags: 0, 1) | 14.1665 | 0.1888 | 0.0026 |
| Method Code | Input Data Numbers/Description | nMAE [%] | nRMSE | nMBE |
|---|---|---|---|---|
| GBT | 1–68 (68 inputs)/NWP forecasts from ECMWF and GFS models (point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3) | 14.4555 | 0.2090 | 0.0032 |
| GBT | 1–5, 13–19, 27–33, 48–55, 62–68 (34 inputs)/including NWP forecasts from ECMWF model (point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3) | 14.7389 | 0.2141 | 0.0066 |
| GBT | 1–5, 16–17, 30–31, 51–52, 65–66 (13 inputs)/including NWP forecasts from ECMWF model (point forecasts for hourly lags: 0, 1) | 14.9831 | 0.2161 | 0.0048 |
| GBT | 1–5, 6–12, 20–26, 34–47, 55–61 (40 inputs)/including NWP forecasts from GFS model (point forecasts for hourly lags: −3, 2, −1, 0, 1, 2, 3) | 17.8355 | 0.2397 | −0.0003 |
| GBT | 1–5, 16–17, 30–31, 51–52, 65–66 (13 inputs)/including NWP forecasts from GFS model (point forecasts for hourly lags: 0, 1) | 18.0803 | 0.2446 | −0.0019 |
| Method Code | Input Data Numbers | SS | nMAE [%] | nRMSE | nMBE |
|---|---|---|---|---|---|
| INT_OUT_EXT [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] with additional expert correction | Different, it depends on predictor in ensemble | 0.5925 | 11.3055 | 0.1618 | 0.0146 |
| INT_AVE [GBT, RF, LSTM] with additional expert correction | Different, it depends on predictor in ensemble | 0.5923 | 11.3387 | 0.1615 | 0.0117 |
| INT_OUT_EXT [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] | Different, it depends on predictor in ensemble | 0.5921 | 11.3527 | 0.1615 | 0.0123 |
| INT_AVE [GBT, RF, LSTM] | Different, it depends on predictor in ensemble | 0.5910 | 11.4403 | 0.1612 | 0.0085 |
| INT_AVE [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] with additional expert correction | Different, it depends on predictor in ensemble | 0.5904 | 11.3558 | 0.1627 | 0.0149 |
| INT_AVE [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] | Different, it depends on predictor in ensemble | 0.5898 | 11.4174 | 0.1624 | 0.0124 |
| LSTM | 1–68, 1A, 2A, 3A | 0.5842 | 11.4012 | 0.1669 | 0.0252 |
| GBT | 1–68 | 0.5807 | 11.8518 | 0.1636 | 0.0006 |
| RF | 1–68, 1A, 2A, 3A | 0.5803 | 11.8847 | 0.1635 | −0.0004 |
| PHYS(v1&v2)→GBT | 1–68, 1A–13A | 0.5791 | 11.9190 | 0.1639 | 0.0022 |
| MLP | 1–68, 1A, 2A, 3A | 0.5781 | 11.9211 | 0.1646 | 0.0041 |
| GBT→PHYS_v1 | 1–68, 1A, 2A, 3A | 0.5760 | 11.6604 | 0.1698 | 0.0463 |
| PHYS(v1&v2)→MLP | 1–68, 1A–13A | 0.5694 | 12.1960 | 0.1676 | −0.0026 |
| PHYS_v1 | 1A | 0.5622 | 12.3700 | 0.1709 | 0.0025 |
| PHYS(v1&v2)→LSTM | 1–68, 1A–13A | 0.5534 | 12.2249 | 0.1796 | 0.0134 |
| PHYS(v1&v2)→KNNR | 1A, 2A, 3A, 12A, 13A | 0.5507 | 12.2899 | 0.1807 | 0.0326 |
| PHYS_v1 | 1A | 0.5493 | 12.3288 | 0.1813 | 0.0349 |
| PHYS(v1&v2)→SVR | 2A, 12A, 13A | 0.5432 | 13.1031 | 0.1757 | −0.0202 |
| PERSISTENCE | 4 | 0.0000 | 28.7790 | 0.3833 | 0.0127 |
| Method Code | Input Data Numbers | SS | nMAE [%] | nRMSE | nMBE |
|---|---|---|---|---|---|
| INT_OUT_EXT [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] with additional expert correction | Different, it depends on predictor in ensemble | 0.5096 | 13.7552 | 0.2029 | 0.0108 |
| INT_OUT_EXT [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] | Different, it depends on predictor in ensemble | 0.5091 | 13.8199 | 0.2025 | 0.0075 |
| INT_AVE [GBT, RF, LSTM] with additional expert correction | Different, it depends on predictor in ensemble | 0.5087 | 13.7794 | 0.2033 | 0.0061 |
| INT_AVE [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] with additional expert correction | Different, it depends on predictor in ensemble | 0.5078 | 13.8182 | 0.2035 | 0.0128 |
| INT_AVE [GBT, RF, LSTM] | Different, it depends on predictor in ensemble | 0.5073 | 13.8994 | 0.2028 | 0.0019 |
| INT_AVE [GBT, RF, PHYS(v1&v2)→KNNR, MLP, LSTM] | Different, it depends on predictor in ensemble | 0.5071 | 13.8928 | 0.2031 | 0.0096 |
| RF | 1–68, 1A, 2A, 3A | 0.4977 | 14.4916 | 0.2026 | 0.0000 |
| GBT→PHYS_v1 | 1–68, 1A, 2A, 3A | 0.4944 | 14.6231 | 0.2035 | 0.0053 |
| LSTM | 1–68, 1A, 2A, 3A | 0.4932 | 13.9797 | 0.2127 | 0.0109 |
| GBT | 1–68, 1A, 2A, 3A | 0.4909 | 14.4610 | 0.2083 | −0.0003 |
| MLP | 1–68 | 0.4894 | 14.6654 | 0.2068 | 0.0057 |
| PHYS(v1&v2)→GBT | 1–68, 1A–13A | 0.4838 | 14.8258 | 0.2091 | −0.0015 |
| PHYS(v1&v2)→MLP | 1–68, 1A–13A | 0.4781 | 15.0611 | 0.2105 | −0.0008 |
| PHYS_v1 | 2A | 0.4675 | 14.6101 | 0.2246 | −0.0173 |
| SVR | 1–68 | 0.4617 | 15.9566 | 0.2116 | 0.0143 |
| PHYS(v1&v2)→LSTM | 1–68, 1A, 2A, 3A, 12A, 13A | 0.4574 | 15.2485 | 0.2241 | 0.0111 |
| PHYS(v1&v2)→KNNR | 1A, 2A, 3A, 12A, 13A | 0.4548 | 15.1681 | 0.2272 | 0.0366 |
| PHYS_v2 | 1A | 0.4508 | 15.9984 | 0.2196 | −0.0025 |
| PERSISTENCE | 4 | 0.0000 | 29.9931 | 0.3886 | −0.0291 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piotrowski, P.; Baczyński, D.; Kopyt, M.; Gulczyński, T. Advanced Ensemble Methods Using Machine Learning and Deep Learning for One-Day-Ahead Forecasts of Electric Energy Production in Wind Farms. Energies 2022, 15, 1252. https://doi.org/10.3390/en15041252
Piotrowski P, Baczyński D, Kopyt M, Gulczyński T. Advanced Ensemble Methods Using Machine Learning and Deep Learning for One-Day-Ahead Forecasts of Electric Energy Production in Wind Farms. Energies. 2022; 15(4):1252. https://doi.org/10.3390/en15041252
Chicago/Turabian StylePiotrowski, Paweł, Dariusz Baczyński, Marcin Kopyt, and Tomasz Gulczyński. 2022. "Advanced Ensemble Methods Using Machine Learning and Deep Learning for One-Day-Ahead Forecasts of Electric Energy Production in Wind Farms" Energies 15, no. 4: 1252. https://doi.org/10.3390/en15041252
APA StylePiotrowski, P., Baczyński, D., Kopyt, M., & Gulczyński, T. (2022). Advanced Ensemble Methods Using Machine Learning and Deep Learning for One-Day-Ahead Forecasts of Electric Energy Production in Wind Farms. Energies, 15(4), 1252. https://doi.org/10.3390/en15041252