1. Introduction
Since the start of the energy crisis, energy-saving problems have risen in popularity among the general public [
1]. According to the study reported in [
2], the global energy problem is driven by global population increase, rising demand, and continuous reliance on fossil fuels for production. Moreover, global energy consumption influences greenhouse gas emissions and, thus, climate change [
3]. As a result of this situation, several governments have acted and set CO
2 emission reduction objectives. For instance, China, one of the world’s major consumers of fossil fuels and major CO
2 emitter [
2], promised to reach peak CO
2 emissions and carbon neutrality by 2030 and 2060, respectively [
4]. Likewise, the European Union (EU) made a significant effort to combat global warming by implementing a variety of strategic policies [
5,
6].
The building sector is a prominent energy consumer and greenhouse gas emitter. For instance, it accounts for 27.5% of the overall final energy use in EU [
5]. Therefore, there is a pressing need to halt the rising trend in building energy consumption. Energy management through adequate saving energy mechanisms has been the focus in recent years as a key strategy for conserving energy [
1].
Home energy management systems (HEMS) are an efficient way to minimize energy consumption in a home while preserving occupant comfort [
7,
8]. The development of an effective HEMS system requires the implementation of a process to identify and monitor the principal loads in the household [
9], thus allowing the HEMS to efficiently control the operation of (some) electric devices [
10]. It also enables consumers to have a better awareness of their electricity usage patterns, potentially leading to more energy-conscious behavior and decreasing operating and electrical costs for grid operators and end users [
11].
One of the techniques for monitoring appliances is to install measuring devices or sensors for each load of interest. This is known as intrusive load monitoring (ILM) in the literature and can properly estimate the operating condition of devices [
12,
13,
14]. However, some disadvantages limit its practical application, such as the difficulties of deploying and configuring many sensors, its high cost, and its intrusive nature, which raises privacy and security concerns [
15]. Non-intrusive load monitoring (NILM), on the other hand, aims to estimate the energy consumption of individual devices from a single meter that monitors the aggregated demand across many appliances [
10]. It is one of the most effective energy disaggregation approaches since it enables users to disaggregate the power consumption of specific appliances in the household while maintaining user privacy and using smart meters that are already installed at the house entrance [
15].
George Hart pioneered the use of NILM in [
16,
17]. He presented NILM as a monitoring system for appliances in an electrical circuit that turns ON and OFF independently. He showed that devices generate unique power consumption signatures. Therefore, the NILM techniques enable the recognition of these signatures from the total aggregated power consumption.
NILM algorithms are often classified into event-based algorithms [
16,
17,
18,
19] that relate signal state changes to device state changes and eventless algorithms that estimate a global system state using statistical and machine learning approaches [
20]. Event-based approaches seek to detect and classify ON/OFF events of electrical devices. In Hart’s approach, the ON/OFF events were used to detect the operation of specific appliances using the aggregated active and reactive powers. However, the technique struggled to identify certain types of appliances (multistate appliances, continuously variable consumer appliances, and permanent consumer devices).
Subsequently, several other techniques have been explored to solve the problem of energy disaggregation. Initially, researchers were drawn to the approaches of hidden Markov models (HMM) and their extensions [
21,
22,
23,
24,
25,
26,
27]. However, as the number of target appliances increases, the complexity of HMM models and their extensions grow exponentially. Furthermore, difficulties with generalization and scalability were noted for these approaches, as well as a large sensitivity to current inference techniques for state estimation to local optima, thus limiting their applicability in the real world [
13].
To tackle this NILM challenge, researchers have lately resorted to machine learning methods. Indeed, both supervised and unsupervised approaches have been explored to address the challenge of NILM. Support vector machines demonstrated good performance in [
28,
29,
30,
31]. K-nearest neighbors were explored in [
32,
33], decision tree in [
34,
35], k-means clustering in [
36], and graph signal processing in [
37,
38]. More recently, deep learning approaches have prompted an upsurge in NILM research. The studies reported in [
39,
40] were among the first to use deep learning-based NILM. In [
40], three deep learning models (long short-term memory, convolutional neural network, and autoencoders) were compared. The models were trained using a six-second low frequency sampling rate using only the active power as the input feature. They obtained better performance than the factorial HMM and combinatorial optimization state of the art models. In [
41], the authors presented a bidirectional long short-term memory model based on a low frequency sampling rate. They combined several electrical features to create a multi-feature input. The model was evaluated on low frequency data from the public datasets UKDALE and ECO. An approach based on deep convolutional networks was proposed in [
42]. They classified the states of devices using a feature space enriched by the introduction of a temporal pooling module. The authors tested their model using the UKDALE low frequency dataset and demonstrated good generalization properties. In [
43], a hybrid deep learning architecture based on a convex hull data selection approach using low frequency power data for NILM was proposed. They selected the most informative vertices of the real convex hull using a random approximation algorithm, incorporating them in the training data. They showed that the proposed framework is effective and performs well compared to existing approaches.
However, deep learning approaches require a large amount of training data to achieve satisfactory results [
44]. This poses a major challenge for NILM algorithms due to the scarcity of high-quality datasets, both in terms of duration and label quality [
10,
45,
46]. Additionally, such methods gain greatly from a large number of trainable parameters, which requires a processing capacity that is neither inexpensive nor cheaply accessible in most circumstances [
44]. A comprehensive literature review of NILM approaches, beyond the scope of this paper, can be found in [
15].
The application of NILM techniques depends strongly on the sampling rate, which refers to the frequency at which the meter measures the data. The sampling rate defines the type of information that can be obtained from the electrical signals [
47]. There are two basic approaches for collecting data [
13,
14,
15]: low frequency sampling rate (1 Hz or less) and high frequency sampling rate (in the range of kHz).
The high sampling frequencies enable the use of fine-grained characteristics such as harmonics [
48], voltage-current (V-I) trajectory [
49], and wavelet coefficients [
50,
51] from steady-state and transient. Although these methods may lead to good results in terms of device identification accuracy, high sampling frequency data have the drawbacks of being both difficult to transfer and store and very expensive in terms of software and hardware specificity [
14]. Moreover, the current smart meter infrastructure, which typically allows for low sampling rates of the range of a few seconds, is not generally compatible with high frequency data collection and, therefore, specific equipment is required [
52,
53].
Conversely, low frequency methods are the ideal option in NILM applications since they enable the use of commonly used smart meter resources without requiring extra hardware. In principle, low-frequency data-based approaches perform load disaggregation by identifying the combination of states that substantially reduce the uncertainty margin [
53]. However, the complexity and computational time of these methods may significantly increase with the number of appliances. Additionally, NILM algorithms must fulfill a variety of criteria, including good precision in recognizing device usage and accurately estimating their power consumption, using low complex models and low-cost equipment [
15,
41].
Therefore, there is the need to have an NILM technique available that, besides delivering very good results both in terms of operation detection and energy estimation, does not require specific acquisition systems, the existence of large amount of design data, and expensive processing power to design the classification and estimation models. To address these challenges, this paper proposes an NILM framework based on a low-frequency sampling rate, allowing the use of low-cost meters and employing low-complexity shallow neural network models. The following are the key contributions of this paper:
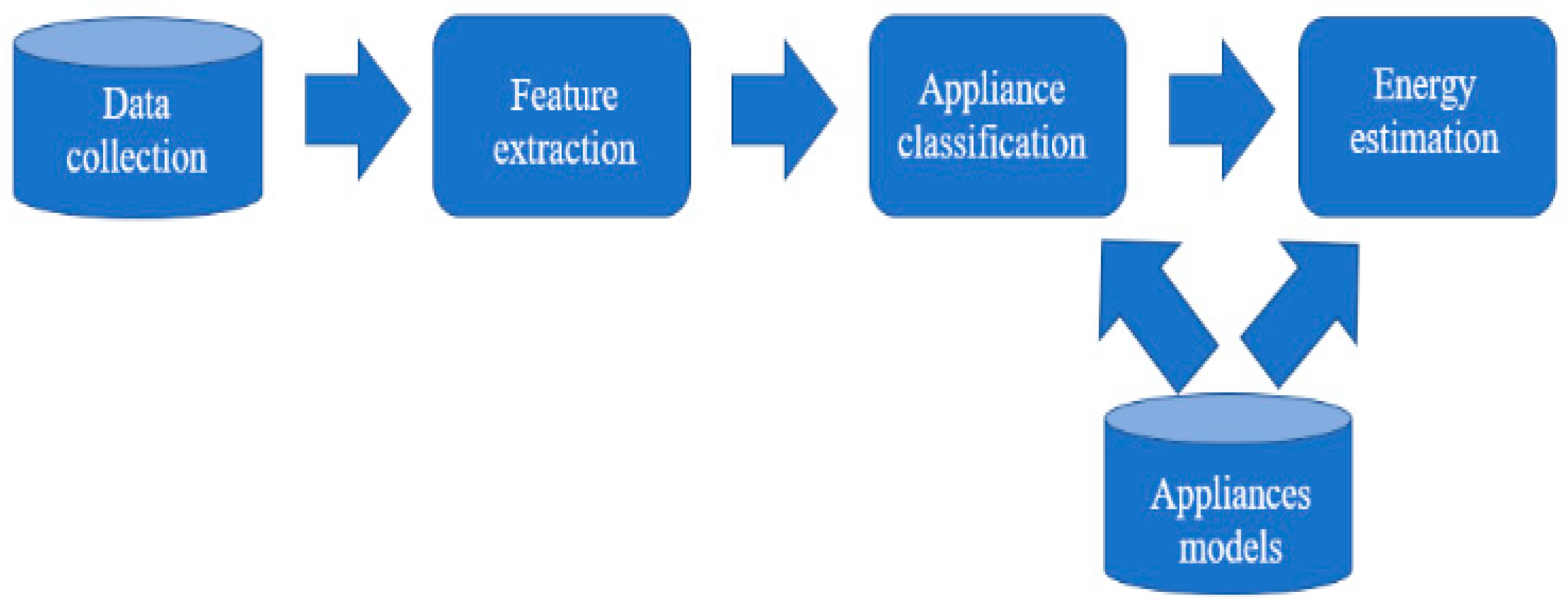
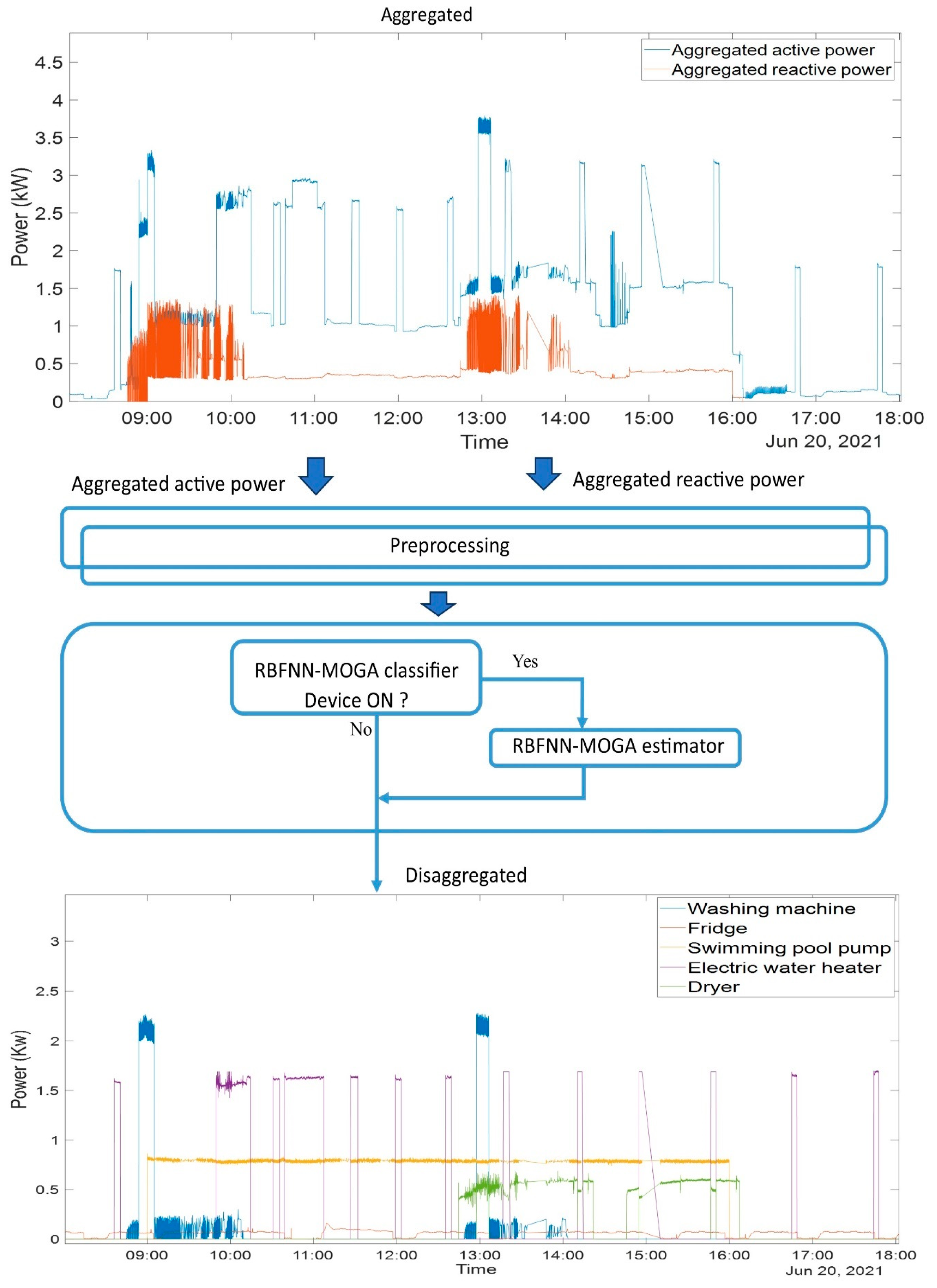
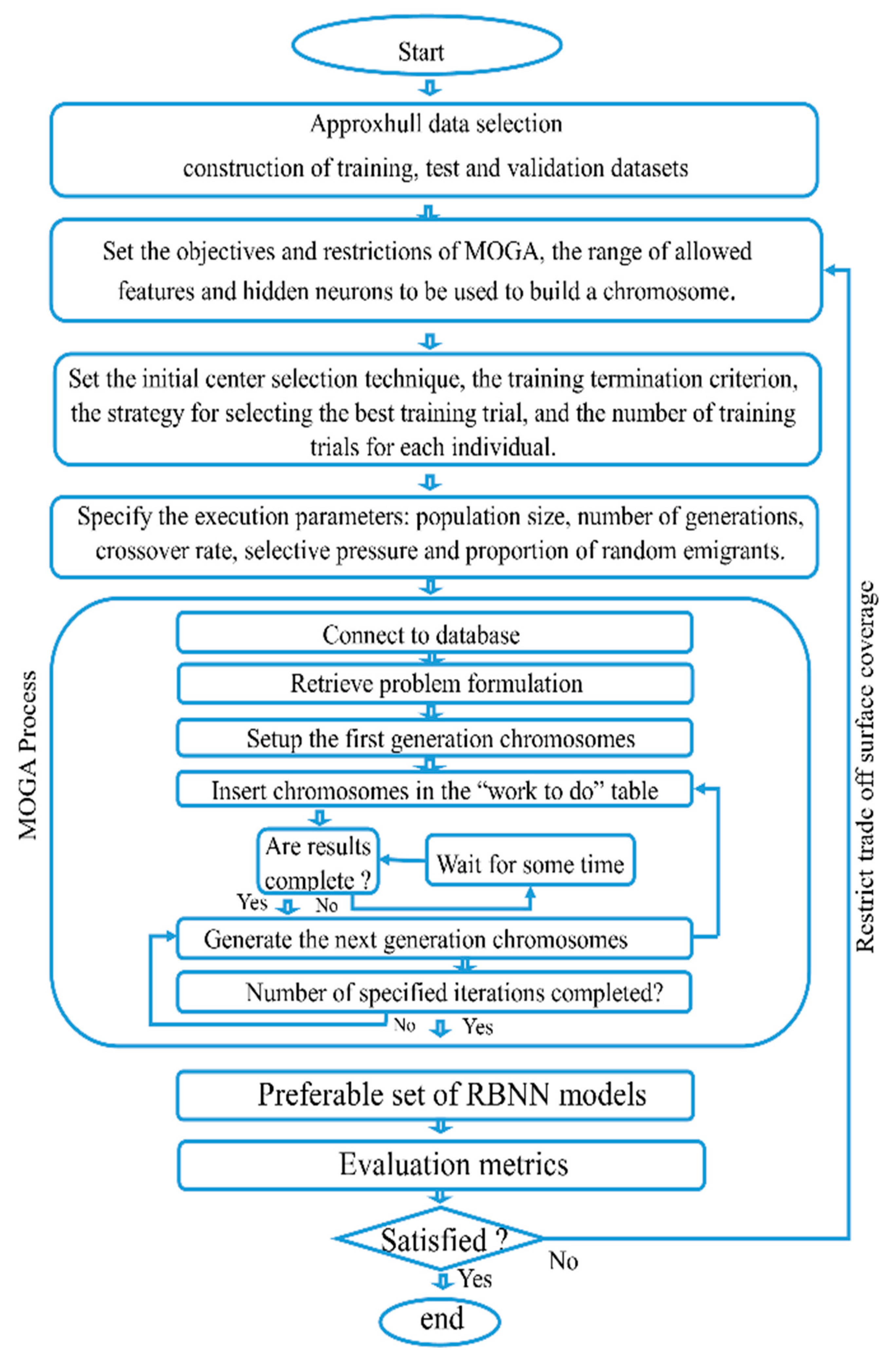
A low-complexity NILM framework based on a radial basis function neural network designed by a multi-objective genetic algorithm (MOGA) with data selected by an approximate convex hull algorithm was proposed. The framework includes residential house data gathered in a real-life situation, feature extraction, appliance classification, and energy estimation.
A comparative analysis of several computational intelligence’s classifiers for non-intrusive load monitoring using the same data, including support vector machine, k-nearest neighbors, decision trees, long short-term memory, and convolutional neural network, was performed.
The feasibility of the approach was also validated using the public AMPds (Almanac of Minutely Power datasets) dataset, and a comparative study with other approaches was conducted.
The proposed NILM framework was used to disaggregate one month of consumption of a case study house, identifying that 60% of the total consumption is related to schedulable devices, thus enabling a further degree of flexibility to HEMS.
The rest of the paper is structured as follows:
Section 2 introduces the problem statement, the methods used, the data acquisition system, and the accuracy metrics employed. The obtained results are presented in
Section 3, and their discussion is in
Section 4.
Section 5 concludes the paper.
4. Discussion
By analyzing the results presented in
Table 7,
Table 9,
Table 10,
Table 11,
Table 13, and
Table 15, we observed that all the models explored can detect the operating states of the different devices with good performance. To illustrate the effectiveness of the proposed method, the
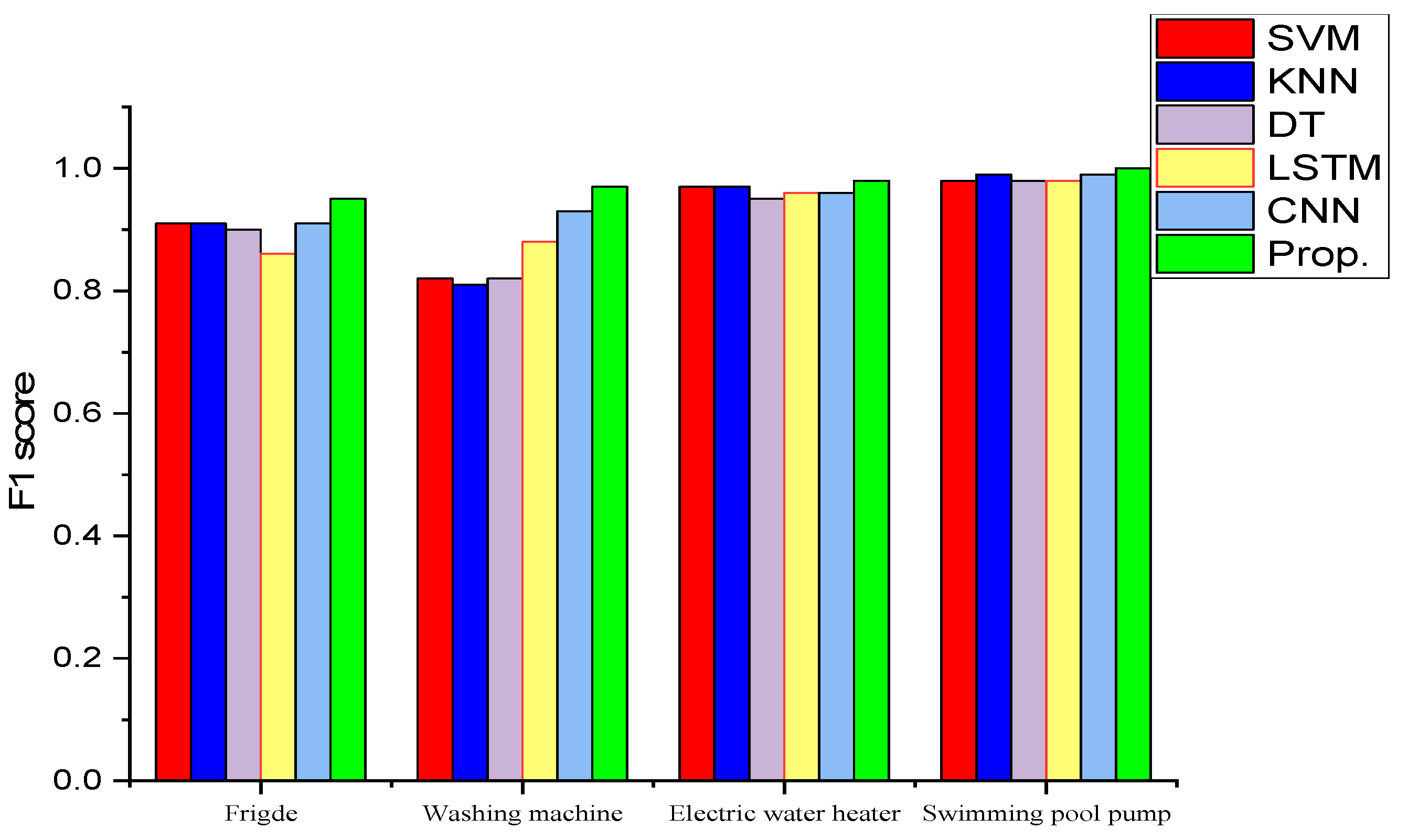
F1-score value achieved with the proposed method was compared with the other state-of-the-art classification methods.
Figure 8 presents a comparative histogram of the different methods implemented.
For fridge, the best F1 score of 95% was achieved by the proposed technique, while LSTM achieved the worst F1 score of 86%. The other models classified the fridge with a similar F1 score of 91% for SVM, KNN, and CNN and 90% for DT.
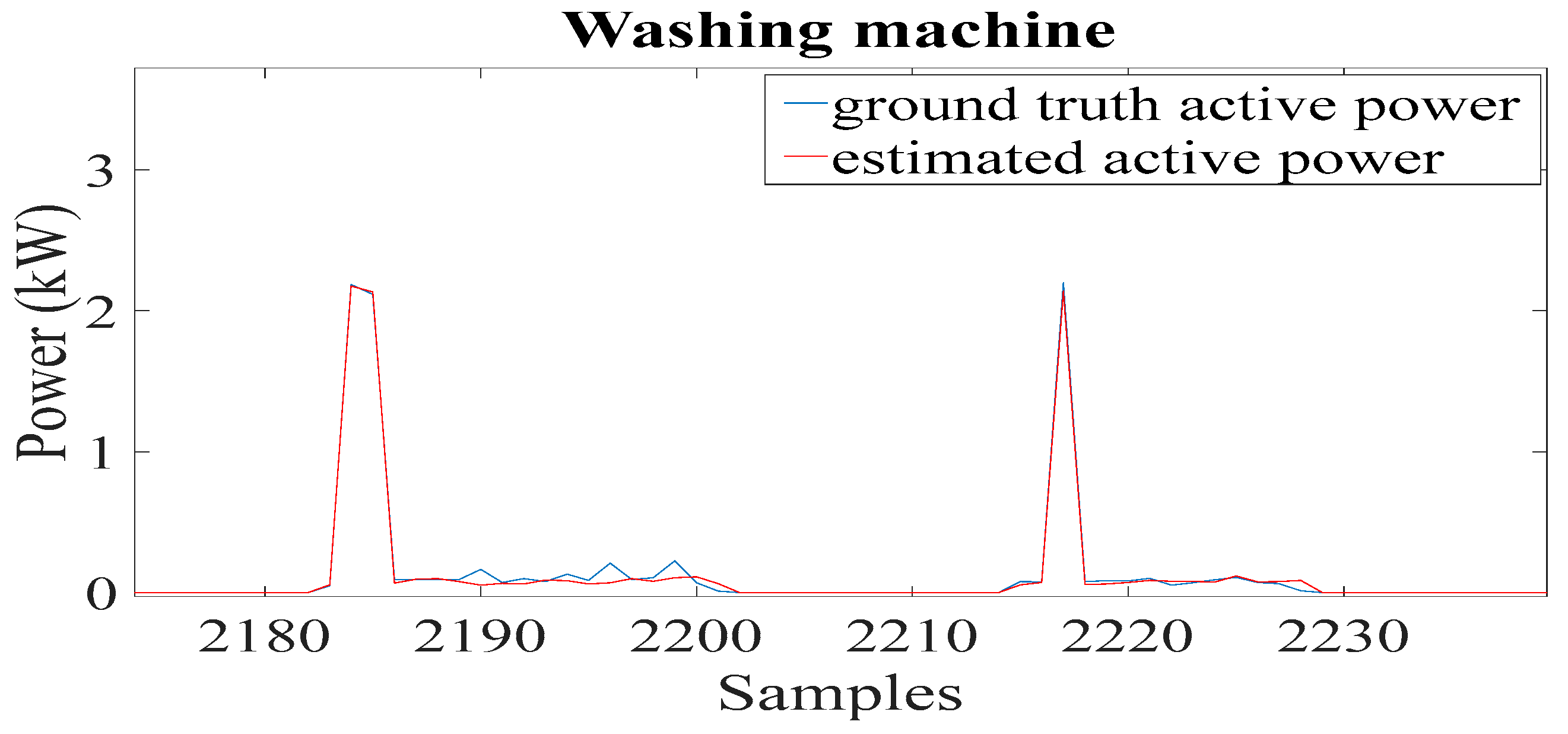
For washing machine, the proposed model obtained the best F1 score of 97%, while the SVM and decision tree models obtained similar F1 scores of 82%. Similarly, the two deep learning models obtained slightly better results than the SVM and decision tree models, with the CNN obtaining an F1 score of 93% and the LSTM an F1 score of 88%. The KNN model achieved the worst F1 score of 81%.
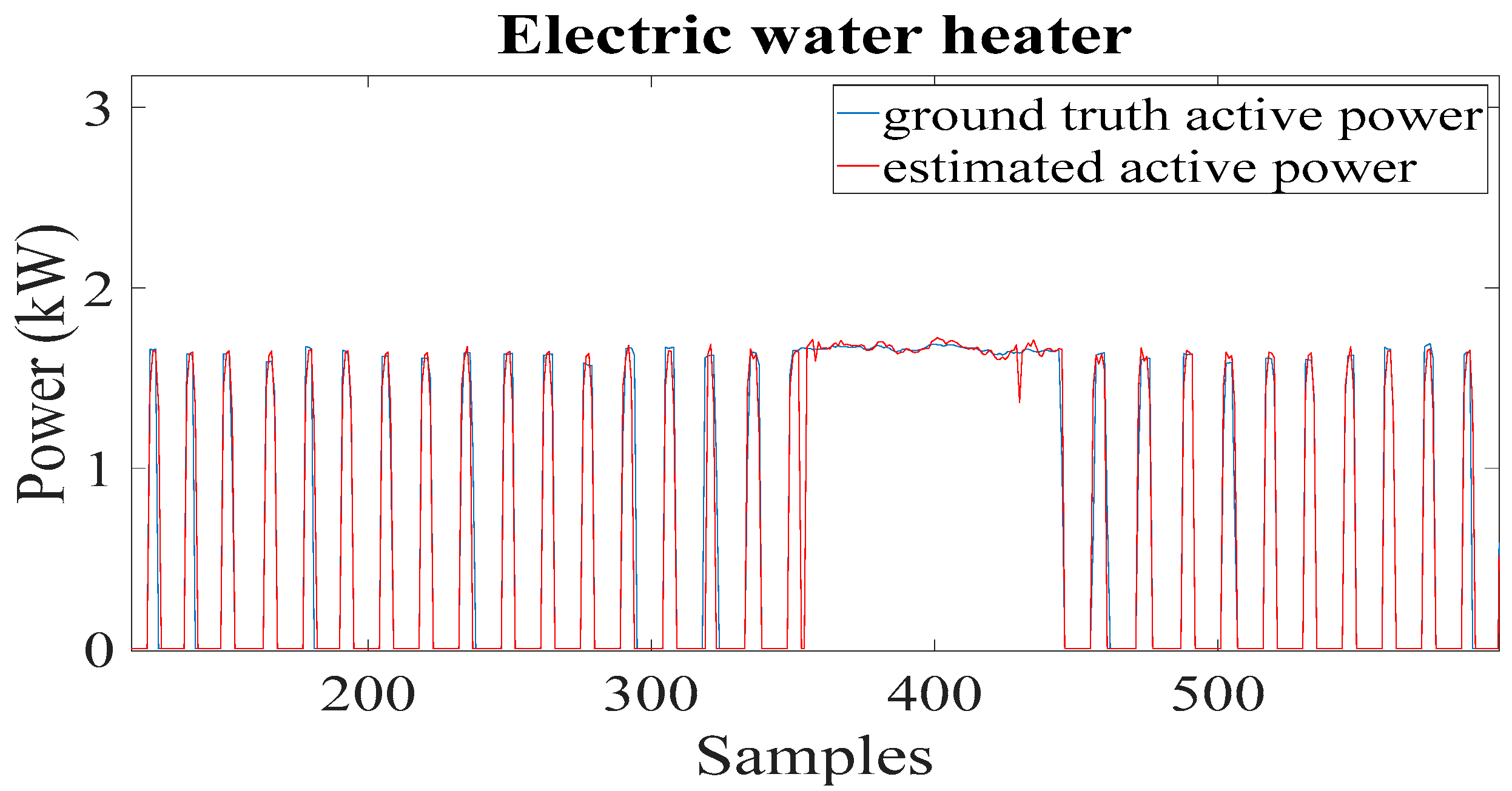
For the electric water heater, the proposed approach obtained an F1 score of 98% slightly higher than the F1 score of 97% obtained by the SVM and KNN models. The LSTM and CNN models had a comparable F1 score of 96%, and the decision tree model had the lowest F1 score of 95%.
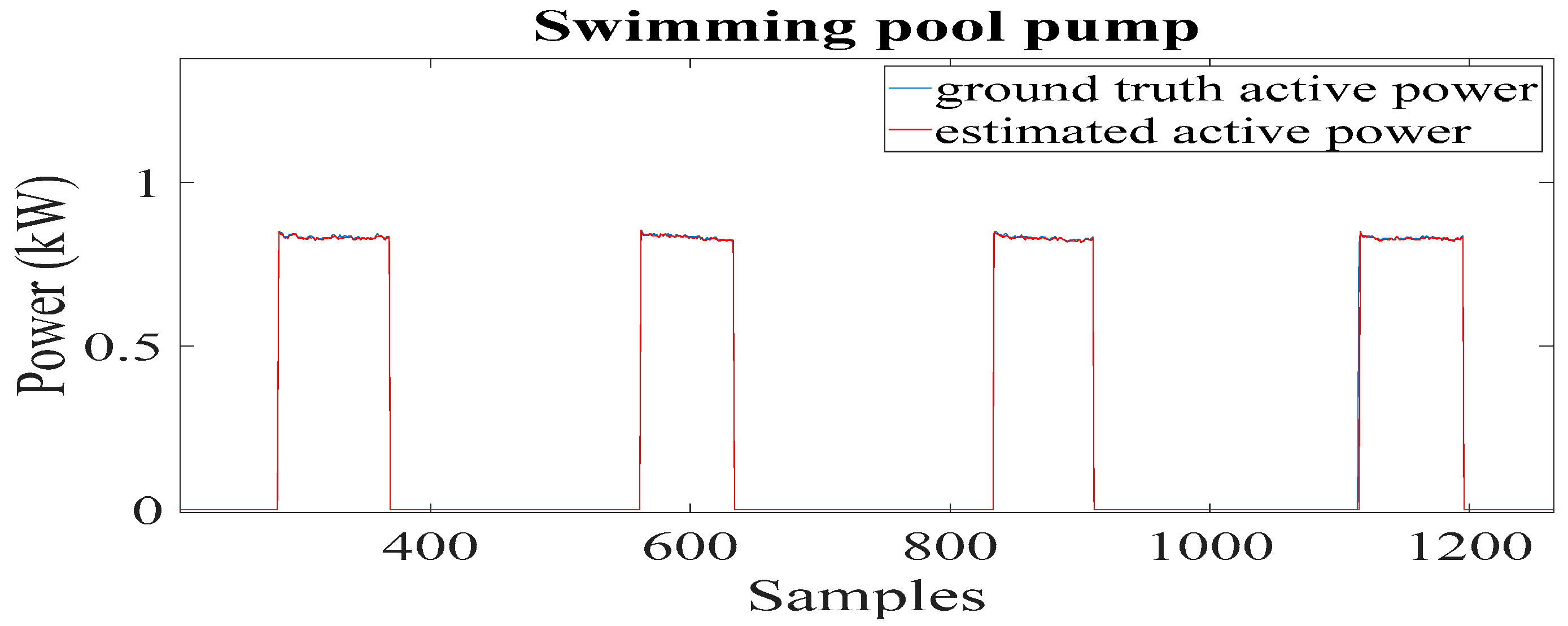
All the models performed well in the classification of the swimming pool pump, with an F1 score of more than 98% for the models SVM, KNN, decision tree, CNN, and LSTM and 100% for the proposed model. As can be seen, the best performances were obtained for high consumption devices, while most of the algorithms seemed to have more difficulties correctly detecting the washing machine and fridge activations. This is due to the complex architecture of these multi-state appliances, for which detection is a little more challenging for some models, resulting in a large number of false positives. Overall, it can be seen that the proposed framework achieved the best performance in terms of F1 score.
The performance of the six methods presented earlier was qualitatively comparable, as the same data were used for each one of the techniques. This is typically not the case when comparing the performance of state-of-the-art approaches found in the literature, as the data used and the context of these works are different. However, for the sake of illustration, a comparison with state-of-the-art approaches was conducted. It is also worth mentioning that the work reported in [
43] used the same data as the case study described here but with different sampling periods (1 s in [
43] and 1 min here). The washing machine and fridge are two popular multi-state devices for evaluating state-of-the-art NILM approaches, and they were used here.
Table 16 compares the proposed NILM framework to some state-of-the-art NILM approaches for the washing machine. The fridge’s performance in comparison with state-of-the-art approaches is presented in
Table 17. In both tables, the column labeled S(s) denotes the sampling time in seconds.
According to the analysis of the comparison results presented in
Table 16 and
Table 17, the proposed framework designed by MOGA performed better than the NILM method presented in [
43] in terms of estimation accuracy for the fridge (96% versus 88% in [
43]). The mean absolute error of the washing machine was reduced by 32% using the MOGA framework compared to the work presented in [
43]. It should be noted that the proposed models designed by MOGA and the approach presented in [
43] outperformed the other state-of-the-art methods referenced in
Table 16 and
Table 17.
Since the design of a radial basis function neural network by MOGA does not require too much training data (around 8212 samples to 24,493 samples) when using a sampling interval of one minute, while achieving a similar or better performance than approaches using more training data [
43] (around 1.3 million samples to 1.4 million samples), it is worth noting that resampling the data sampling rate from 1 s to 1 min did not affect the performance of the MOGA framework and significantly reduced the amount of data to be processed.
It should be noted that MOGA is a time complex process. Although it runs on a computer cluster, the training of models with data sampled at 1 min takes several hours. As the complexity of MOGA is linear with the number of samples, the use of the same time period, sampled at one second, would translate the execution time to several days. In practice, MOGA cannot cope with this large number of samples, which would have the consequence of reducing the design data, diminishing in this way the number of events that could be used in the design process.
4.1. Test on AMPD Public Dataset
The proposed framework was also evaluated using the public dataset AMPD [
82] (Almanac of Minutely Power datasets). It records a Canadian household’s water, natural gas, and electricity consumption data for two years, including electrical features such as voltage, current, active, and reactive power, collected at one-minute intervals. The data from 1 April 2012 to 30 April 2012 were considered. The models were trained using the same configuration as the proposed framework. Two appliances (fridge and clothes dryer) were considered in the experiment. The results of the test performed in the validation dataset in terms of energy estimation and device classification are presented in
Table 18.
From the results in
Table 18, it can be seen that the fridge and the clothes dryer were detected with a high
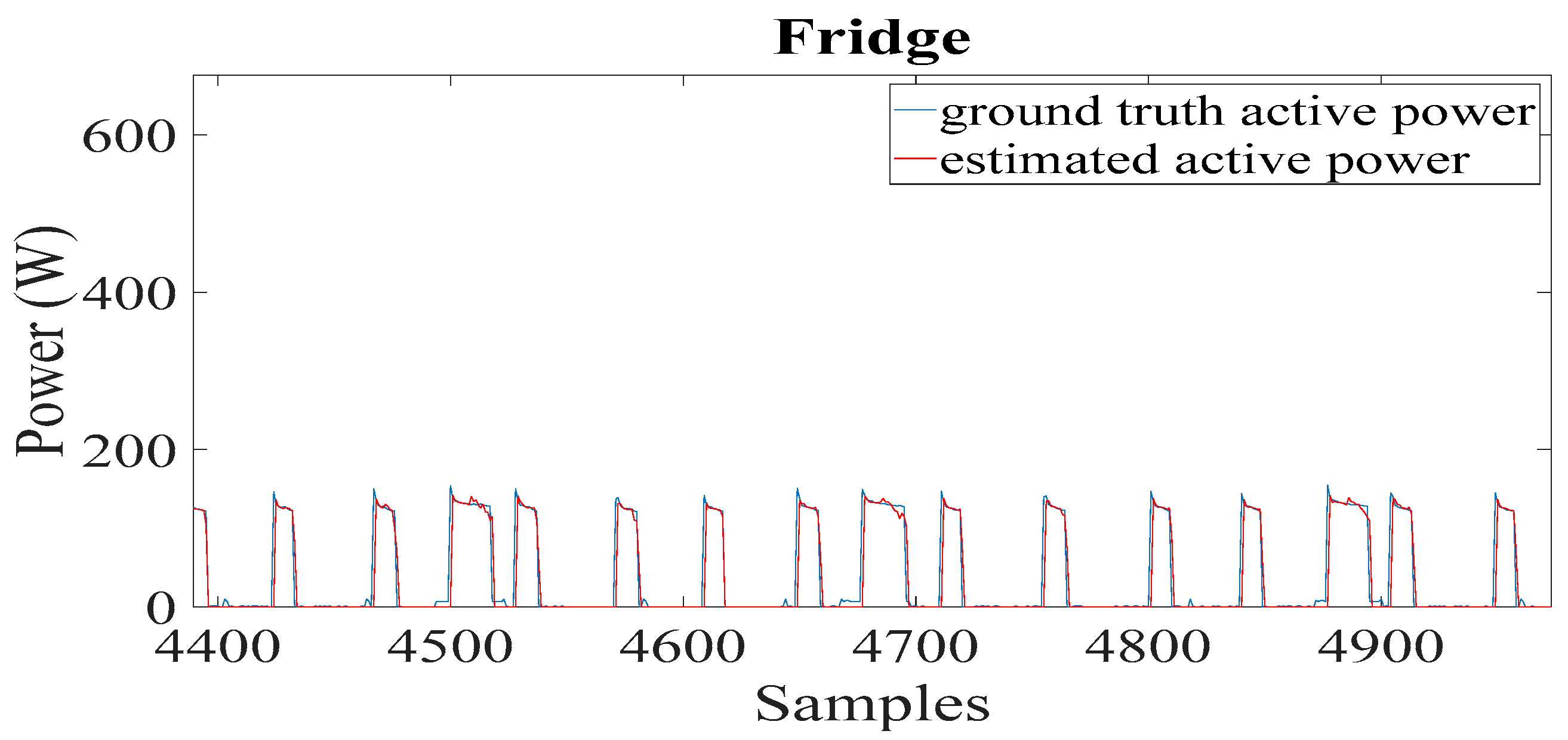
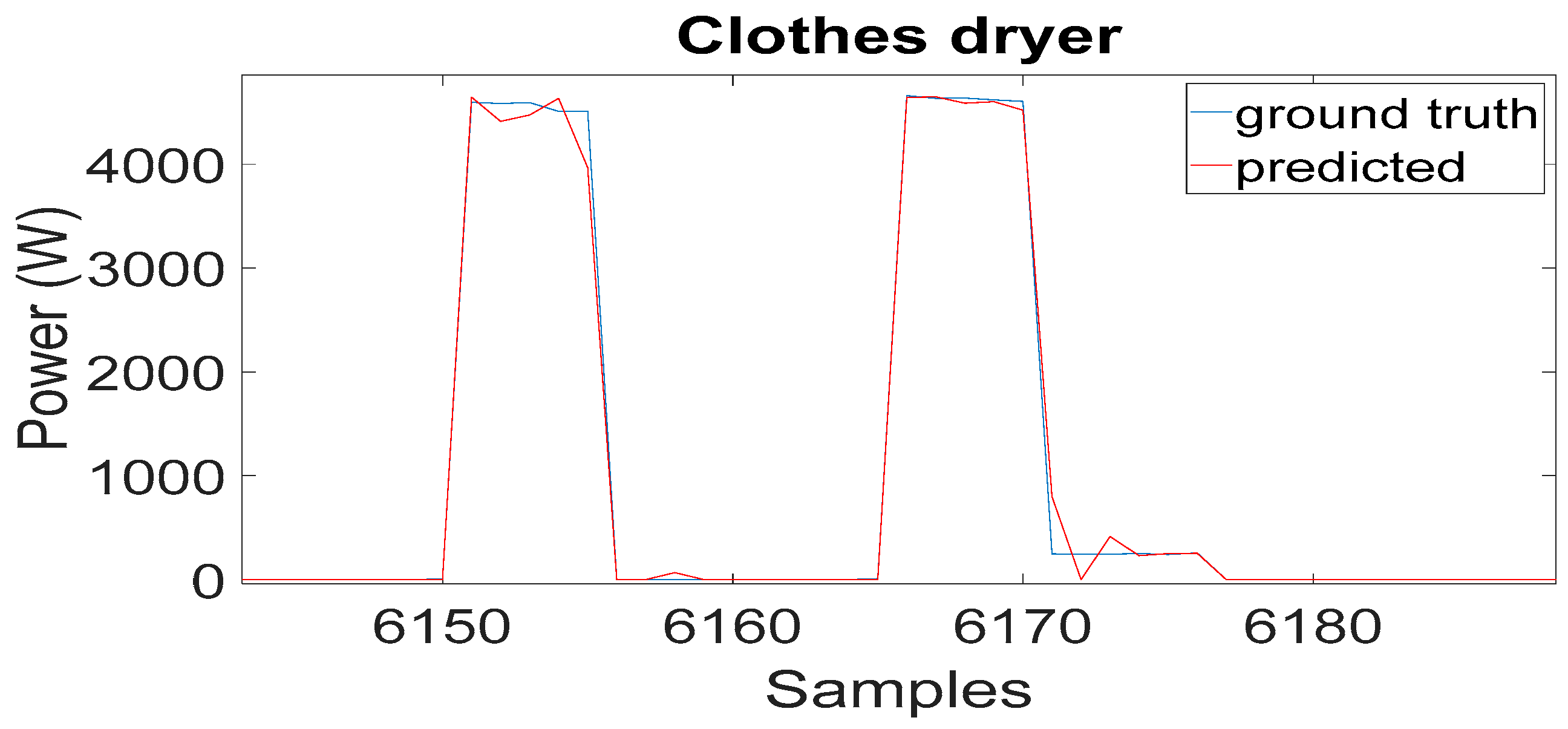
F1 score of 0.92 and 0.99, respectively. Regarding the energy estimation, the fridge was estimated with an accuracy of more than 90%, while the clothes dryer was estimated with an accuracy of 94%.
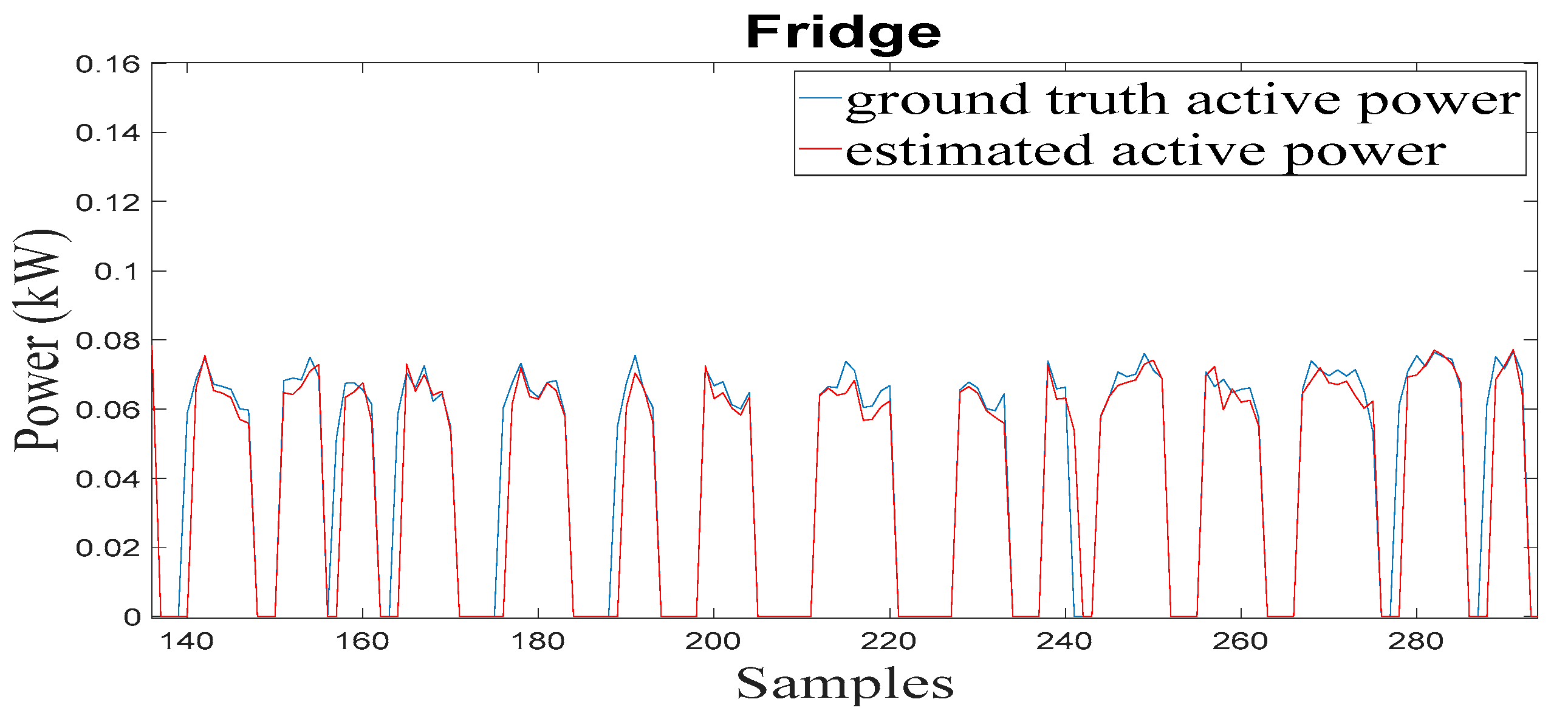
Examples of disaggregation outputs, in terms of active power for the fridge, are presented in
Figure 9.
Figure 10 shows the example of disaggregation outputs for the clothes dryer.
There is a reasonably consistent agreement between the measured and estimated active power, as shown in
Figure 9 and
Figure 10.
The results obtained with this dataset were also compared to the work proposed in [
53,
83]. In both works, two weeks of data were used. In [
83], the authors proposed a modified cross-entropy algorithm (MCE) based on a combinatorial optimization method to classify the load states. The approach consisted of searching for the best combination of states by iteratively updating the device’s operation probability to generate a load decomposition while considering the constraint of the penalty function. In [
53], the authors suggested an approach based on the probability of time-segmented states. They used an affinity propagation clustering approach to extract the load power patterns, which were then used to count the probabilities of time-segmented states. After generating a range of appliance state matrices using probabilities, the function selects the most suitable matrix as the result of the appliance state detection.
Table 19 compares the results of the two appliances (fridge and clothes dryer) in terms of state identification (F1) with the references [
53,
83].
As illustrated in
Table 19 for the fridge, the
F1 score achieved by the proposed framework (92%) is comparable to the
F1 score obtained by the Ref. [
53], while the MCE [
83] approach had the lowest score of 88%. For the clothes dryer, the proposed framework performed the best
F1 score of 99%, while the Ref. [
53] and MCE methods had the lowest scores of 23% and 29%, respectively. We concluded from these results that the proposed framework allowed us to achieve very satisfactory results.
4.2. Energy Consumption Estimation in the Case Study House
The procedure used to identify the four appliances discussed in
Section 4 was extended to other devices in the case study house that consume the most electricity. One month of data was considered in the model design. The results generated by the data selection algorithm and the size of the datasets for each device for classification and estimation are presented in
Table 20 and
Table 21, respectively.
After one run of MOGA, the non-dominated sets were generated. The size of the non-dominated sets for the classification models and energy estimation models are shown in
Table 22 for each device.
Suitable models with good performance and low complexity were analyzed in the non-dominated sets. Two models (a classification and an estimation model) were selected for each device.
Table 23 shows the results of the device state classification using the selected models in terms of model complexity, number of neurons in the hidden layer, number of features, recall, precision, and
F1 score. The results in terms of device energy estimation using the selected models are shown in
Table 24.
Analyzing the classification results presented in
Table 23, we observed an excellent
F1 score of 100% for the air conditioner (AC-4), whereas the lowest
F1 scores were observed in the classification of the burner stove (BS-1: 68%) and the electric air heater (EAH-3: 75%). In the first case, a higher sampling frequency should be used, while in the second case, the device is rarely activated and there is a lack of identifiable data. The other appliances were classified with good
F1 scores ranging from 88% to 98%. The results reported in
Table 24 show that the electric air heater (EAH-2) was estimated with an excellent estimation accuracy (EA) of 99%. The lowest performance was observed in the disaggregation of the oven (73%). This is due to the fact that the oven has several different operating modes, with different consumptions together with a large range of temperatures. The other devices were estimated with good estimation accuracy ranging from 86% to 98%.
Once the models were designed, the energy consumption of certain appliances in the case study house was estimated using these models. The aggregated data from January 2022 were considered in the experiment.
Table 25 shows the results of the disaggregation in terms of appliance energy consumption. Since the aggregated data were measured by the EM340 three-phase smart meter, the distribution of appliance consumption by phase is presented.
Analyzing the disaggregation results reported in
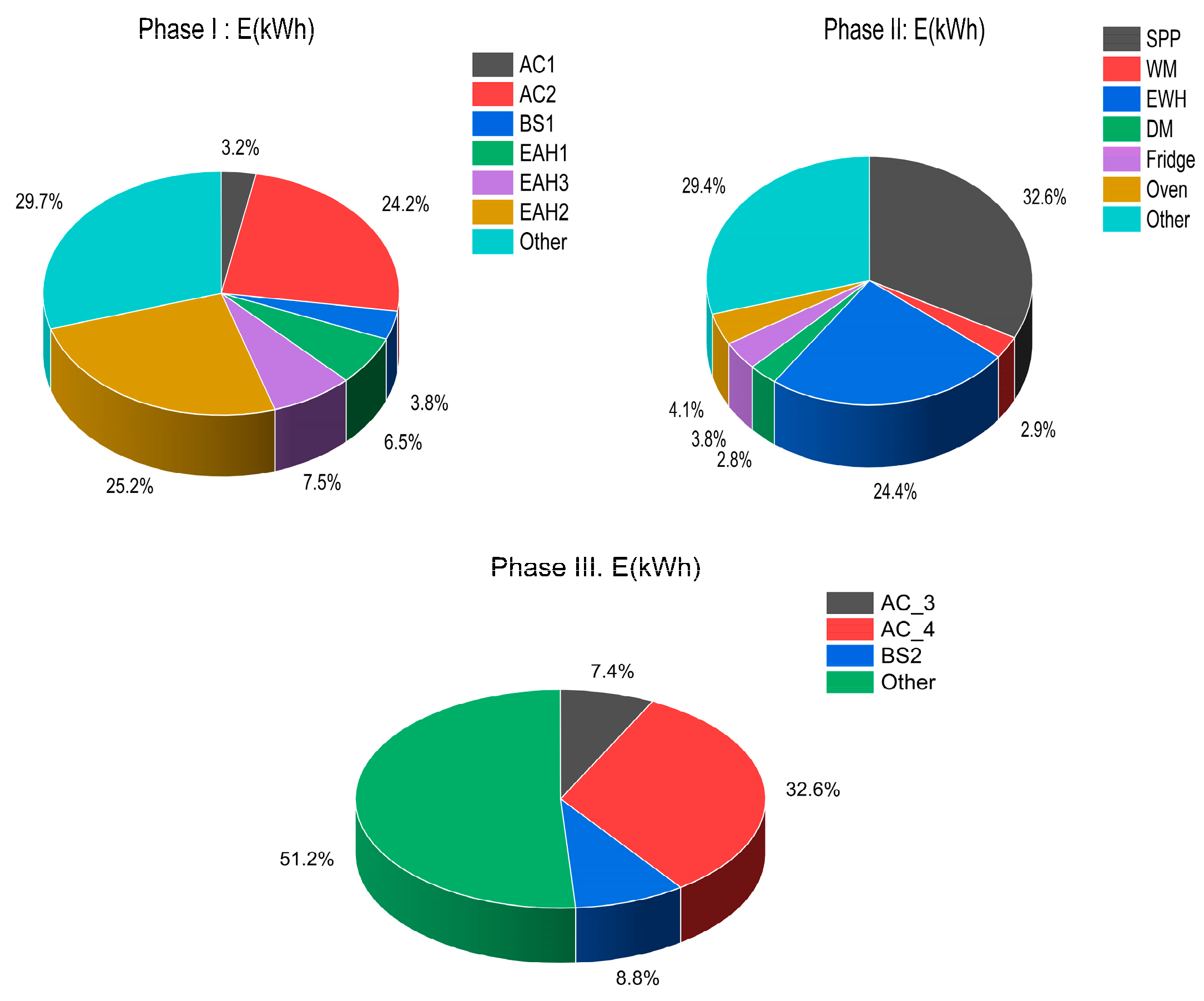
Table 25, it can be seen that the highest energy consumption in the month of January 2022 was assigned to the swimming pool pump (153.14 kWh) followed by the electric water heater (114.54 kWh). The electric air heater (EHA2) and air conditioners (AC2 and AC4) consumed approximately 11.97 kWh, 91.98 kWh, and 71.74 kWh respectively. The consumption of the other appliances was estimated between 4.22 kWh and 28.40 kWh.
Figure 11 presents pie charts summarizing the distribution of electricity consumption in the case study house in the month of January 2022.
The total consumption of the house, during the month of January 2022, was 1070 kWh, divided into 380, 470, and 220 kWh for Phases 1 to 3. The appliances considered in this section account for 66% of the total monthly consumption. Besides being responsible for most of the electric energy consumption in the household, most of these appliances are schedulable, meaning that their operation can be changed without causing much trouble for the occupants. This is the case with HVAC appliances (AC 1-4, EAH 1-3, WM, DM, SPP, and, to a less extent, EWH). These appliances account for 60% of the house’s total consumption, which means that there is considerable flexibility in shaping the house electric profile to meet energy management goals. As the house in question has PV panels and electric storage, the online operation of some of these electric appliances is taken into account in our proposed model-based predictive control of HEMS [
84].
5. Conclusions
In this study, a low complexity NILM framework based on radial basis function neural networks designed by a multi-objective genetic algorithm (MOGA) was proposed for energy disaggregation. Despite reducing the data sampling from one second to one minute to allow for the use of low-cost meters, the reduction of design time, and the employment of low complexity models, the proposed technique presented an excellent ability to disaggregate the usage of devices.
A comparative analysis of other computational intelligence classifiers for non-intrusive load monitoring, using the same data, showed that the proposed framework obtained the best experimental results in terms of appliance identification. The comparison with other state-of-the-art methods, both using different data and common data, highlighted the efficiency of the proposed framework in achieving the best estimation of the energy consumed by each device in the house.
The proposed NILM technique was used to disaggregate one month of consumption of the house, and it was able to identify the operation of appliances accounting for 2/3 of the electric consumption. It allowed us also to recognize that around 60% of the consumption was related to schedulable appliances, therefore allowing an additional flexibility for the HEMS available in the residence.
Future work will be devoted to the question of the transferability of the proposed framework to other houses, as well as its integration in the house HEMS. One additional advantage of using very simple models is that their real time execution is in the order of a few milliseconds in standard computer architectures, which allows an edge implementation.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}