

ECViST: Mine Intelligent Monitoring Based on Edge Computing and Vision Swin Transformer-YOLOv5


Abstract
1. Introduction
- We present a coarse model using edge-cloud collaborative architecture and update it to realize the continuous improvement of the detection model.
- We propose a target detection model based on a Vision Swin Transformer-YOLOv5 algorithm and improve the model for edge device deployment at the mining workface.
- We highlight the effectiveness of our approach by combining it with the latest developed video backbones and achieve significant improvements over the state-of-the-art results on the dataset.
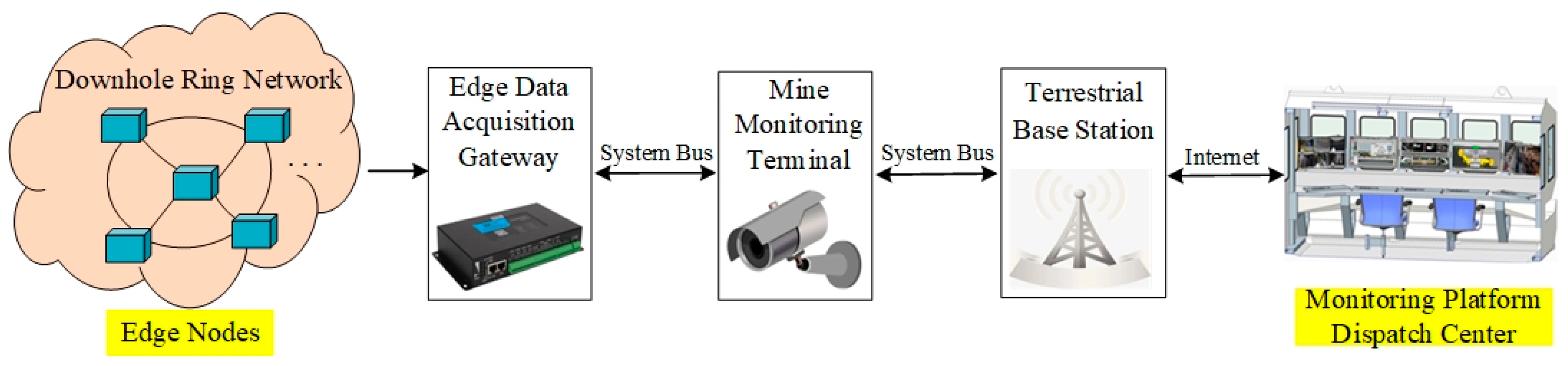
2. Overall Architecture
2.1. Implementation Details
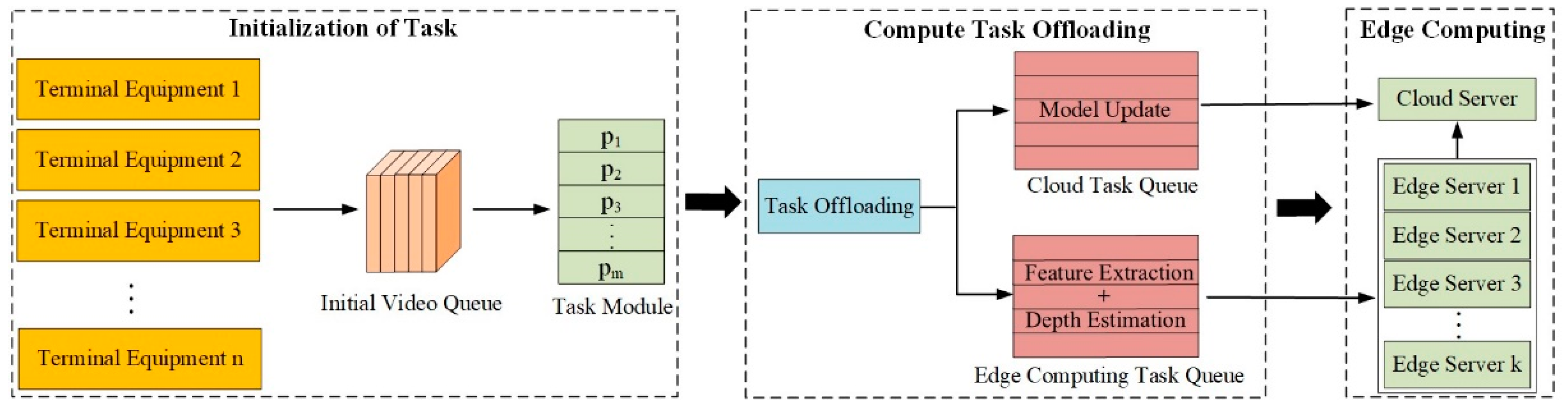
2.2. Edge Computing Based on Task Offloading
- (1)
- Video sequence initialization, dividing the video processing task into modules;
- (2)
- Video processing task offload, feature extraction, depth estimation and model update based on each target image in the video sequence, video processing task offload to cloud computing task queue and edge computing task queue;
- (3)
- Edge computing, which uploads the feature and scale value data completed by the module task processing to the edge server and cloud server and performs edge computing.
3. Method
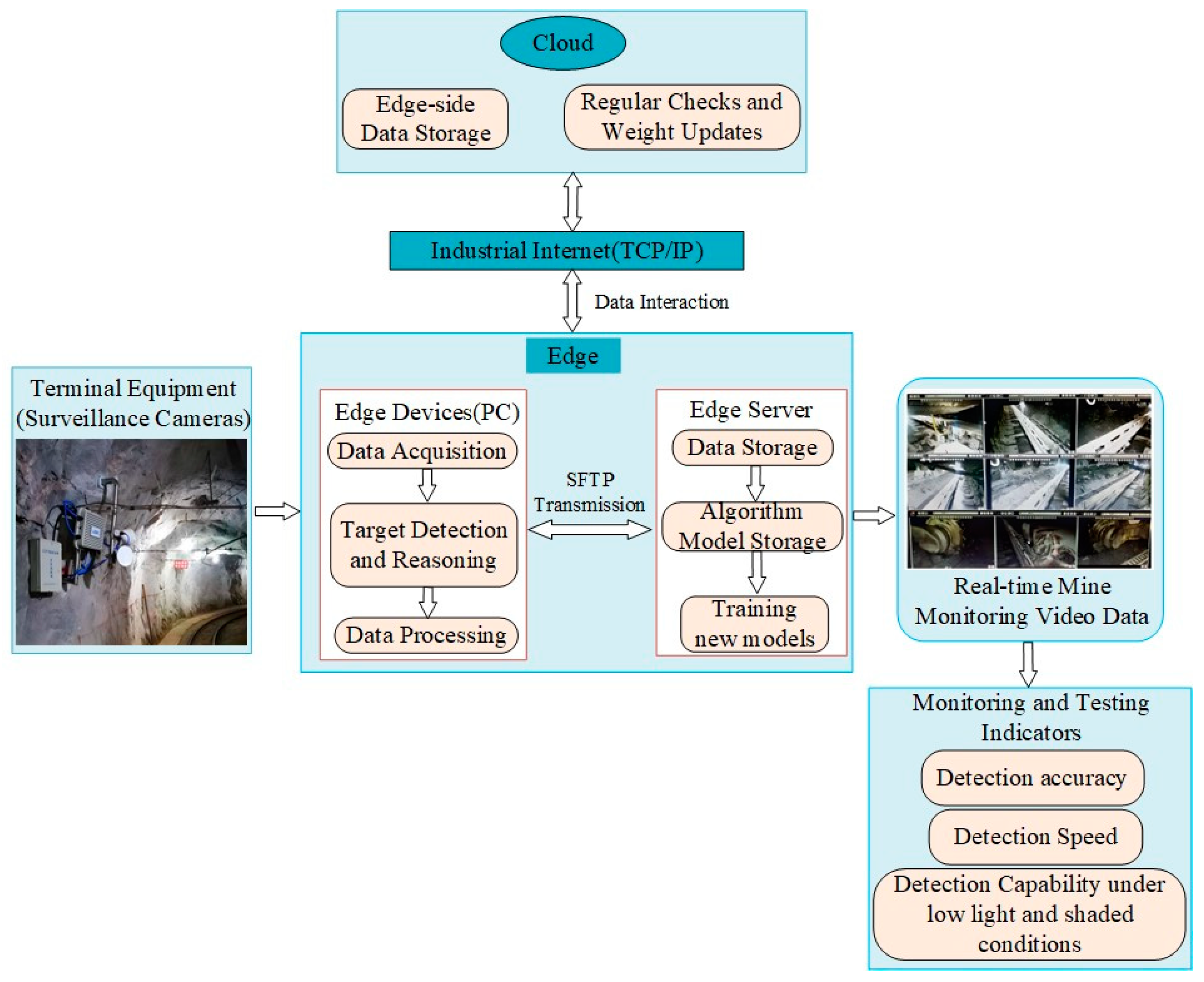
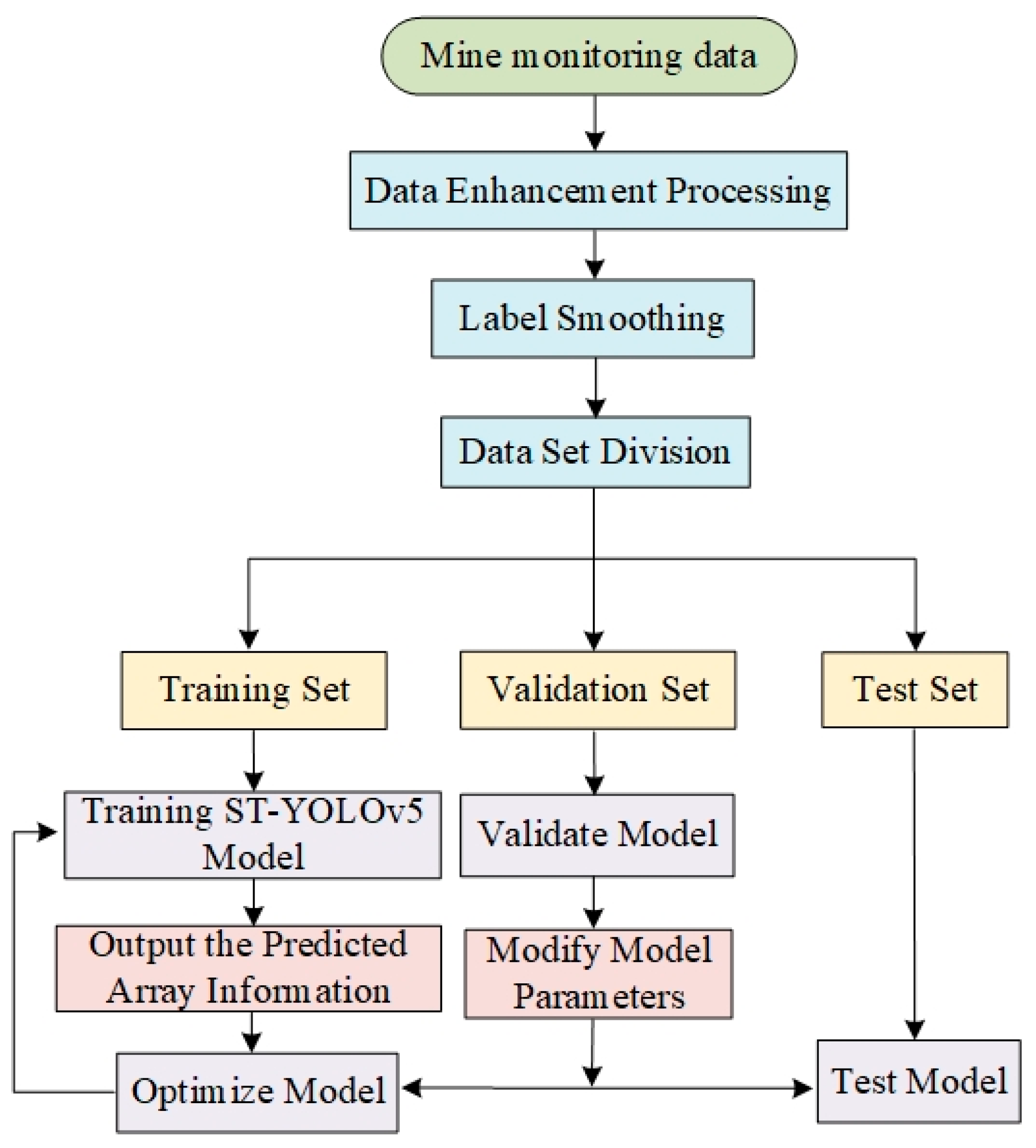
3.1. Mine Intelligent Monitoring Model
3.2. Data Input
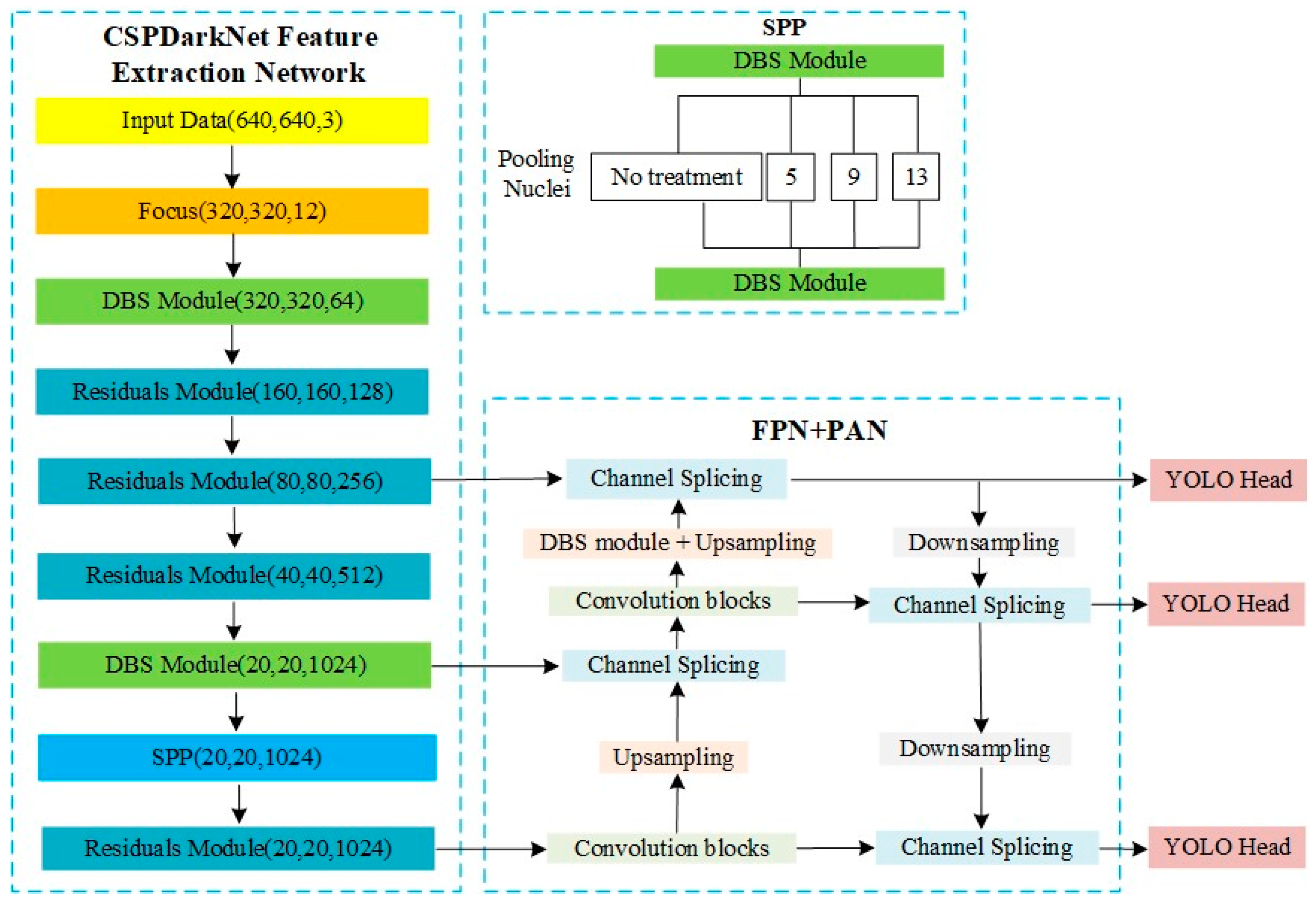
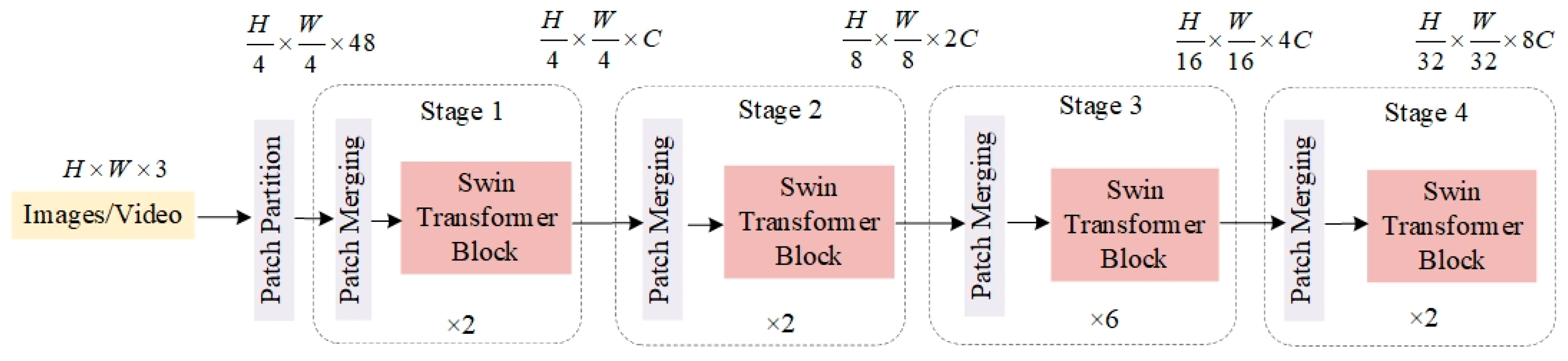
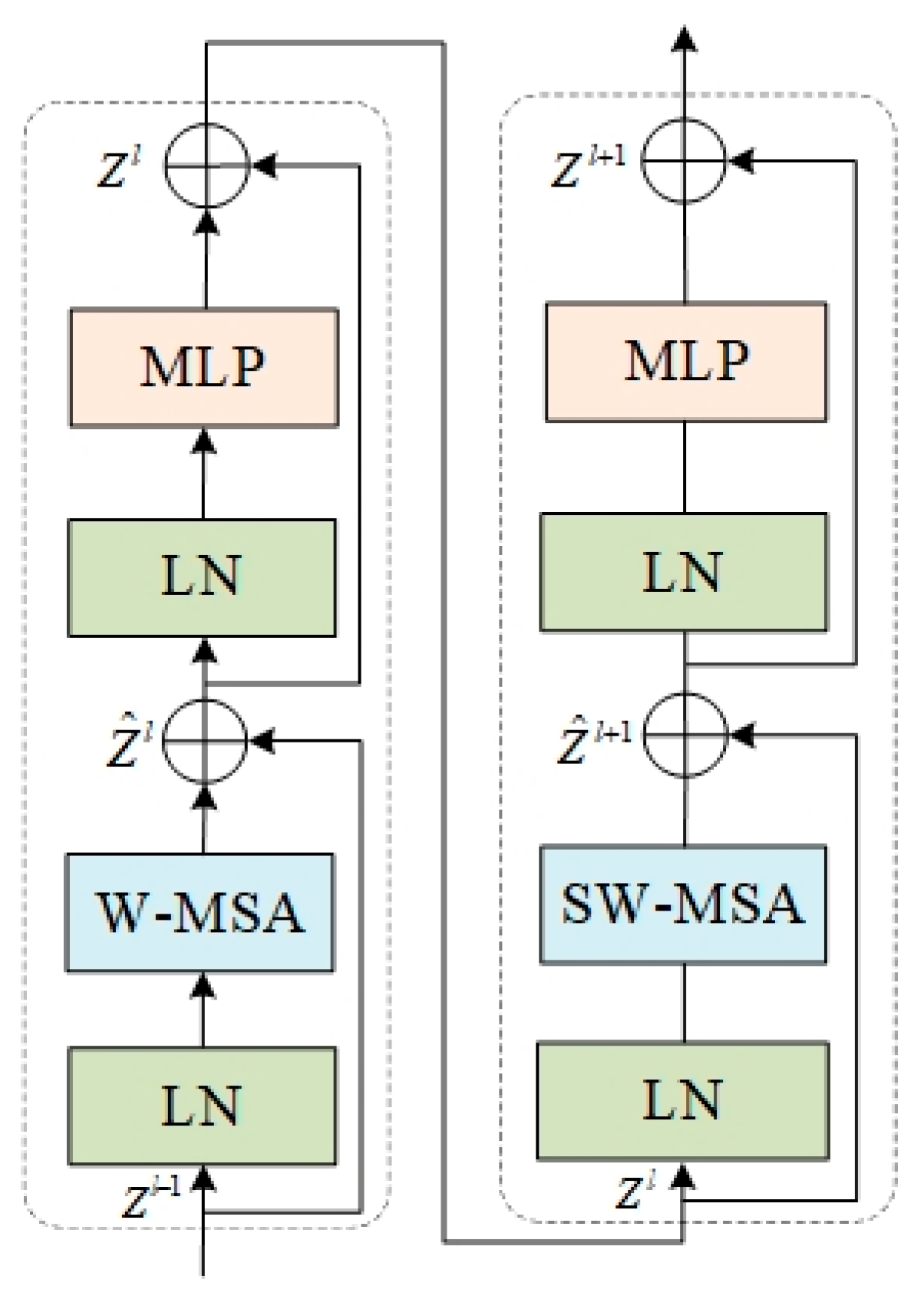
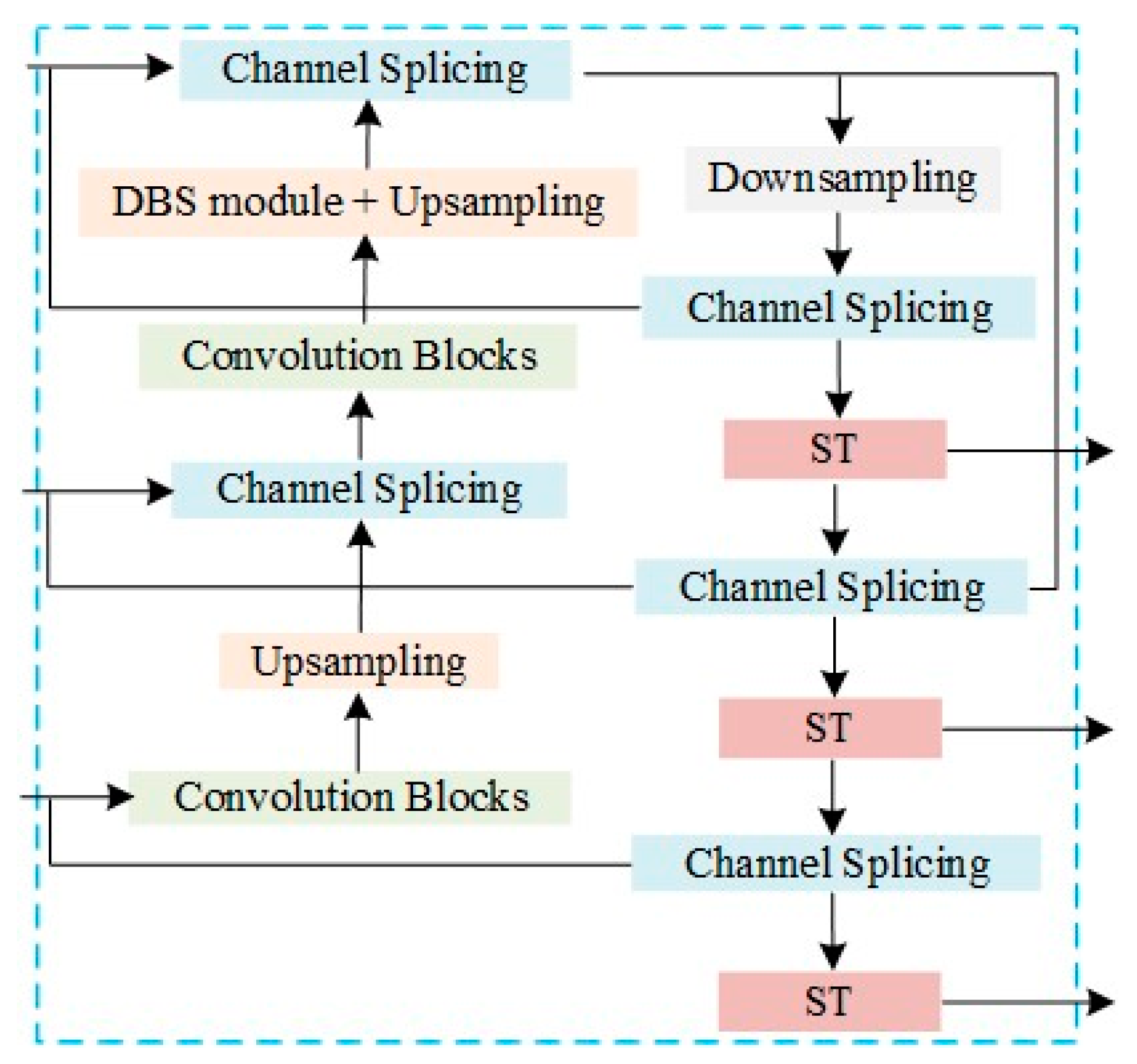
3.3. Backbone Improvements
3.4. Training Prediction
4. Experiments
4.1. Data Acquisition
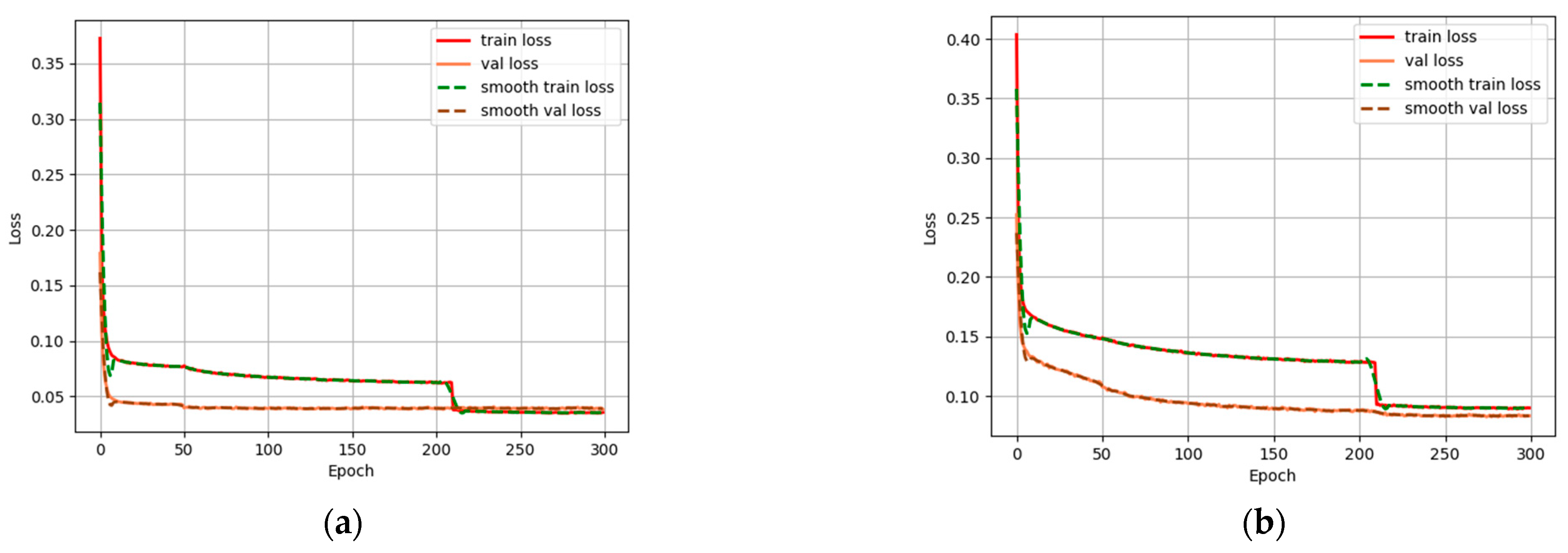
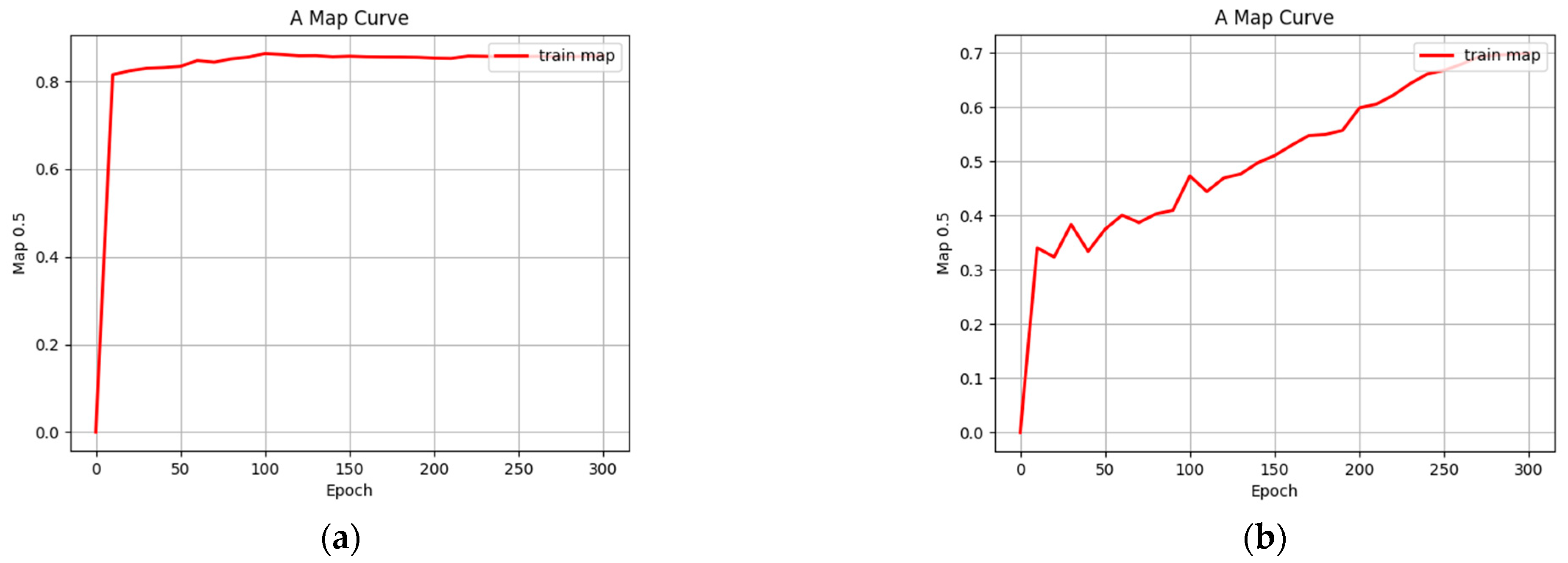
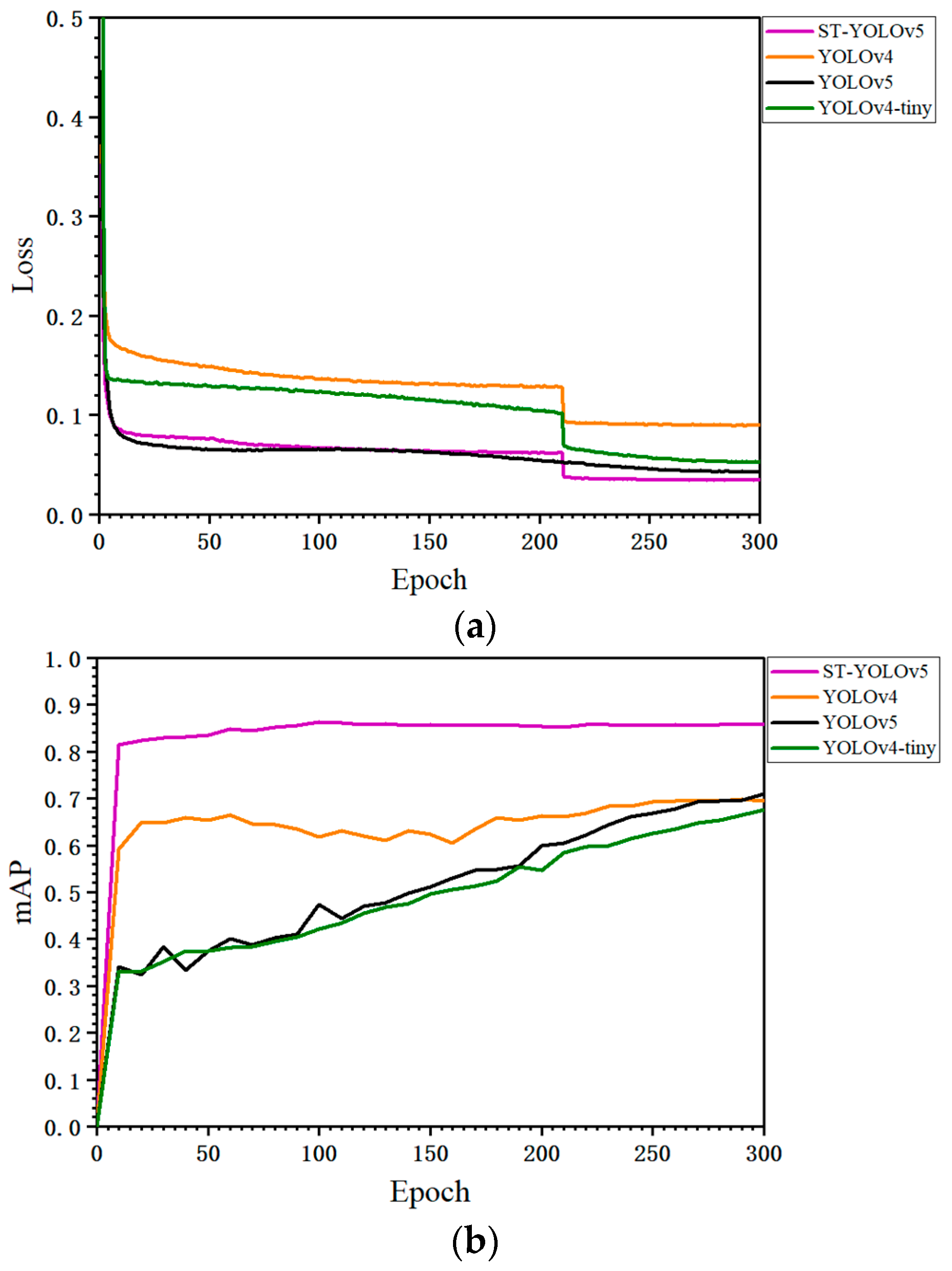
4.2. Testing and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, X.; Li, B.; Liu, Z.P. Underground video pedestrian detection method. J. Mine Autom. 2020, 46, 54–58. [Google Scholar] [CrossRef]
- Xu, Z.; Li, J.; Zhang, M. A Surveillance Video Real-Time Analysis System Based on Edge-Cloud and FL-YOLO Cooperation in Coal Mine. IEEE Access 2021, 9, 68482–68497. [Google Scholar] [CrossRef]
- Shi, W.S.; Zhang, X.Z.; Yifan, W.; Qinyang, Z. Edge Computing: State-of-the-Art and Future Directions. J. Comput. Res. Dev. 2019, 56, 69–89. [Google Scholar]
- Zhang, F.; Xu, Z.; Chen, W.; Zhang, Z.; Zhong, H.; Luan, J.; Li, C. An Image Compression Method for Video Surveillance System in Underground Mines Based on Residual Networks and Discrete Wavelet Transform. Electronics 2019, 8, 1559. [Google Scholar] [CrossRef]
- Tan, Z.L.; Wu, Q.; Xiao, Y.X. Research on information visualization of smart mine. J. Mine Autom. 2020, 46, 26–31. [Google Scholar] [CrossRef]
- Zhang, F.; Ge, S.R. Construction method and evolution mechanism of mine digital twins. J. China Coal Soc. 2022, 1, 1–13. [Google Scholar] [CrossRef]
- Qu, S.J.; Wu, F.S.; He, Y. Research on edge computing mode in coal mine safety monitoring and control system. Coal Sci. Technol. 2022, 1, 1–8. [Google Scholar]
- Wang, H.; He, M.; Zhang, Z.; Zhu, J. Determination of the constant mi in the Hoek-Brown criterion of rock based on drilling parameters. Int. J. Min. Sci. Technol. 2022, 32, 747–759. [Google Scholar] [CrossRef]
- Xu, Y.J.; Li, C. Light-weight Object Detection Network Optimized Based on YOLO Family. Comput. Sci. 2021, 48, 265–269. [Google Scholar]
- Li, T.; Wang, H.; Li, G.; Liu, S.; Tang, L. SwinF: Swin Transformer with feature fusion in target detection. J. Physics Conf. Ser. 2022, 2284, 012027. [Google Scholar] [CrossRef]
- He, M.; Zhou, J.; Li, P.; Yang, B.; Wang, H.; Wang, J. Novel approach to predicting the spatial distribution of the hydraulic conductivity of a rock mass using convolutional neural networks. Q. J. Eng. Geol. Hydrogeol. 2022, 1, 17–25. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; Volume 17, pp. 1833–1844. [Google Scholar] [CrossRef]
- Qu, S.J.; Wu, F.S. Study on Environmental Safety Monitoring and Early Warning Method of Intelligent Working Face for Coal Mines. Safety in Coal Mines. 2020, 51(08), 132–135. [Google Scholar] [CrossRef]
- Wang, L.; Wu, C.K.; Wenhui, F. A Survey of Edge Computing Resource Allocation and Task Scheduling Optimization. J. Syst. Simul. 2021, 33, 509–520. [Google Scholar] [CrossRef]
- Zhou, H.; Wan, W.G. Task scheduling strategy of edge computing system. Electr. Meas. Technol. 2020, 43, 99–103. [Google Scholar] [CrossRef]
- Zhu, X.J.; Zhang, H. Research on task allocation of edge computing in intelligent coal mine. J. Mine Autom. 2021, 47, 32–39. [Google Scholar] [CrossRef]
- Fang, L.; Ge, C.; Zu, G.; Wang, X.; Ding, W.; Xiao, C.; Zhao, L. A Mobile Edge Computing Architecture for Safety in Mining Industry. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Leicester, UK, 19–23 August 2019; Volume 25, pp. 1494–1498. [Google Scholar] [CrossRef]
- Sun, L.; Li, Z.; Lv, J.; Wang, C.; Wang, Y.; Chen, L.; He, D. Edge computing task scheduling strategy based on load balancing. MATEC Web Conf. 2020, 309, 03025. [Google Scholar] [CrossRef][Green Version]
- Hu, J.P.; Li, Z.; Huang, H.Q.; Hong, T.S.; Jiang, S.; Zeng, J.Y. Citrus psyllid detection based on improved YOLOv4-Tiny model. OLOv4-Tiny. Nongye Gongcheng Xuebao Trans. Chin. Soc. Agric. Eng. 2021, 37, 197–203. [Google Scholar] [CrossRef]
- Ye, M.L.; Zhou, H.Y.; Wang, F. Forest fire detection algorithm based on an improved Swin Transformer. J. Cent. South Univers. For. Technol. 2022, 42, 101–110. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 816–832. [Google Scholar] [CrossRef]
- He, J.B.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.-S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Adv. Neural Inf. Process. Syst. 2021, 1, 28–35. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment Name | Role | CPU | GPU | Memory | HardDrive |
|---|---|---|---|---|---|
| Dell Precision 7920 | Cloud | Intel Xeon Silver 4215R | RTX3080 | 64 GB | 1T |
| PC | Edge Side | Intel Core i7 | GTX1080 | 16 GB | 512G |
| Model | mAP/% | FPS/(Frame/s) | Speed/ms |
|---|---|---|---|
| ST-YOLOv5(ours) | 87.8 | 113.56 | 8.55 |
| CBAM-YOLOv4-tiny | 73.1 | 107.55 | 9.96 |
| ECA-YOLOv4-tiny | 72.4 | 115.56 | 9.70 |
| YOLOv5 | 70.4 | 100.28 | 10.29 |
| YOLOv4-tiny | 65.8 | 80.86 | 12.37 |
| Processing Architecture | FPS/(Frame/s) | Time Delay(ms) |
|---|---|---|
| Edge Cloud Collaboration(ours) | 100.58 | 59.68 |
| Cloud | 103.55 | 103.25 |
| Edge | 89.52 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Tian, J.; Wang, J.; Liu, G.; Liu, Y. ECViST: Mine Intelligent Monitoring Based on Edge Computing and Vision Swin Transformer-YOLOv5. Energies 2022, 15, 9015. https://doi.org/10.3390/en15239015
Zhang F, Tian J, Wang J, Liu G, Liu Y. ECViST: Mine Intelligent Monitoring Based on Edge Computing and Vision Swin Transformer-YOLOv5. Energies. 2022; 15(23):9015. https://doi.org/10.3390/en15239015
Chicago/Turabian StyleZhang, Fan, Jiawei Tian, Jianhao Wang, Guanyou Liu, and Ying Liu. 2022. "ECViST: Mine Intelligent Monitoring Based on Edge Computing and Vision Swin Transformer-YOLOv5" Energies 15, no. 23: 9015. https://doi.org/10.3390/en15239015
APA StyleZhang, F., Tian, J., Wang, J., Liu, G., & Liu, Y. (2022). ECViST: Mine Intelligent Monitoring Based on Edge Computing and Vision Swin Transformer-YOLOv5. Energies, 15(23), 9015. https://doi.org/10.3390/en15239015