
Prediction of Carbon Dioxide Emissions in China Using Shallow Learning with Cross Validation

Abstract
1. Introduction
2. Literature Review
2.1. Studies on CO2 Emission Predictions
2.2. Studies on the Factors Influencing CO2 Emissions
2.3. Studies on Using ML for CO2 Emissions
3. Data and Methodology
3.1. Data Collection
3.2. Methodology
3.2.1. Modeling Time Series for Supervised Learning
3.2.2. Support Vector Regression (SVR)
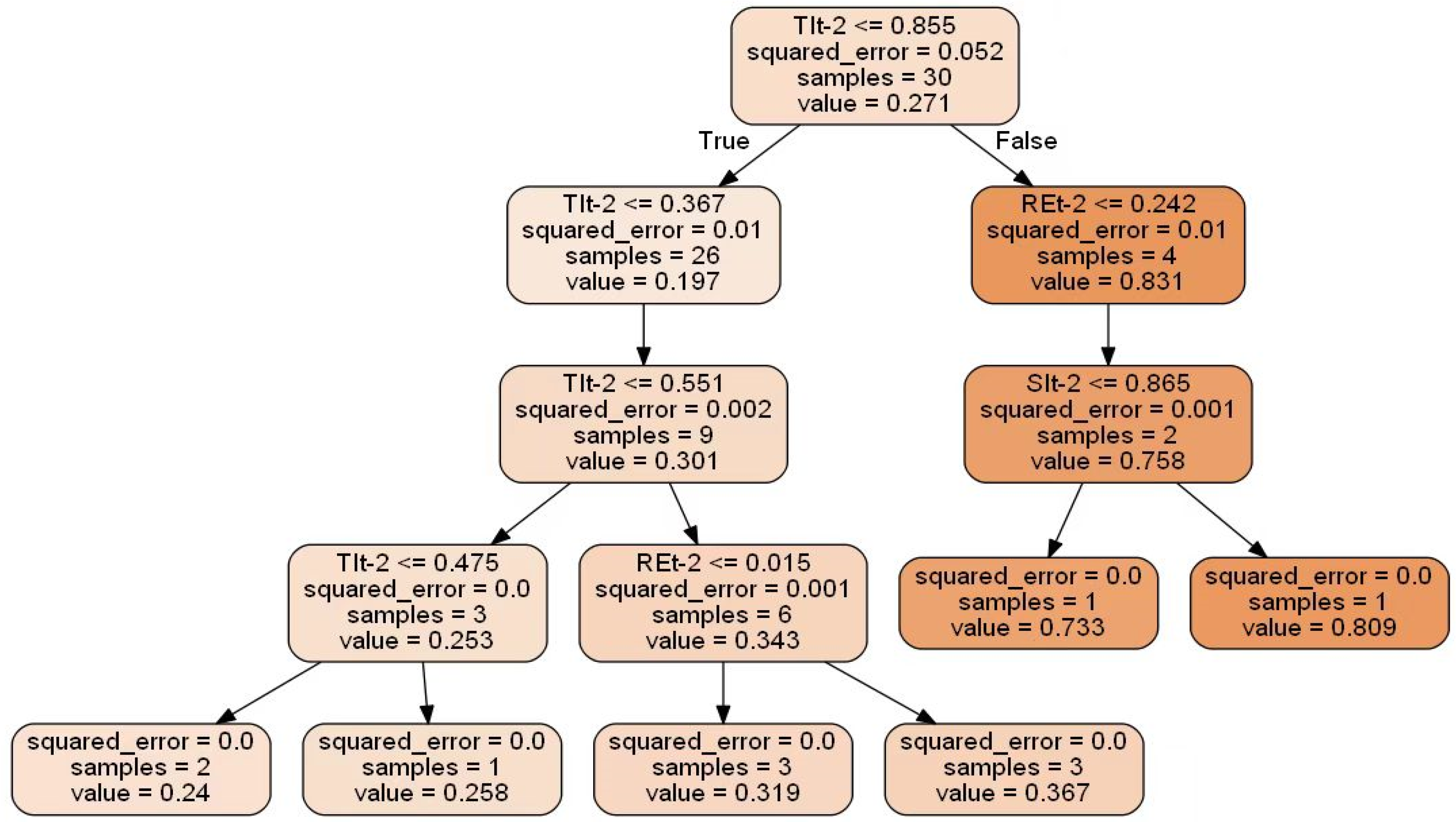
3.2.3. Least Absolute Shrinkage and Selection Operator (LASSO) and Ridge
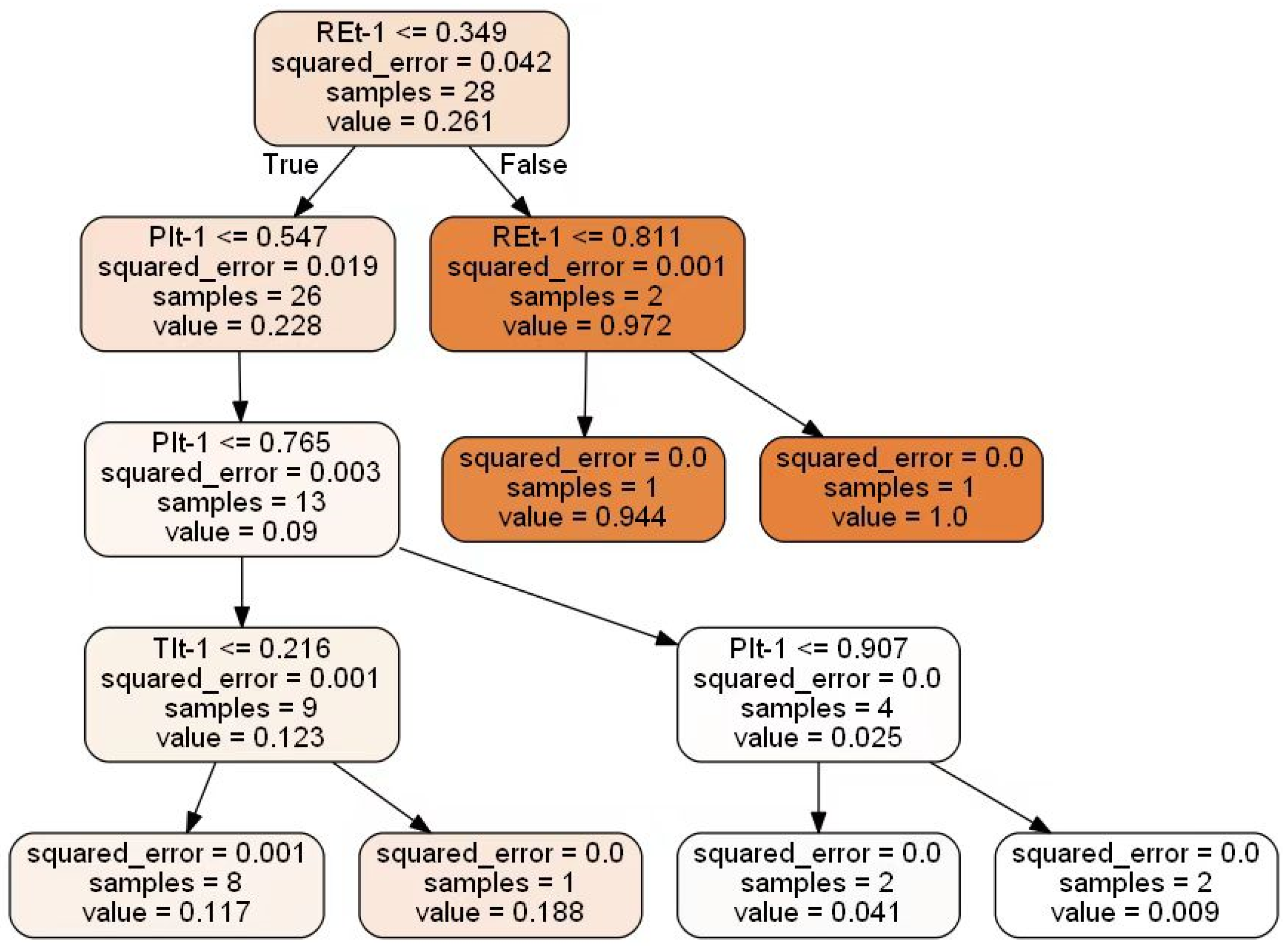
3.2.4. Random Forest (RF)
- (1)
- The samples in the children had equal target values.
- (2)
- The number of samples of nodes reached the threshold.
- (3)
- The tree reached its maximum depth.
3.2.5. Gradient Boosting Decision Tree (GBDT)
- (1)
- For the sample i = 1, 2, …, m, calculate the negative gradient using Formula (10):
- (2)
- For the leaf region , calculate the best fit value using Formula (11):
- (3)
- The stronger learner is determined using Formula (12):
3.2.6. K-Fold Cross Validation (CV) and Grid Search
4. Results and Discussion
4.1. Exploratory Data Analysis (EDA)
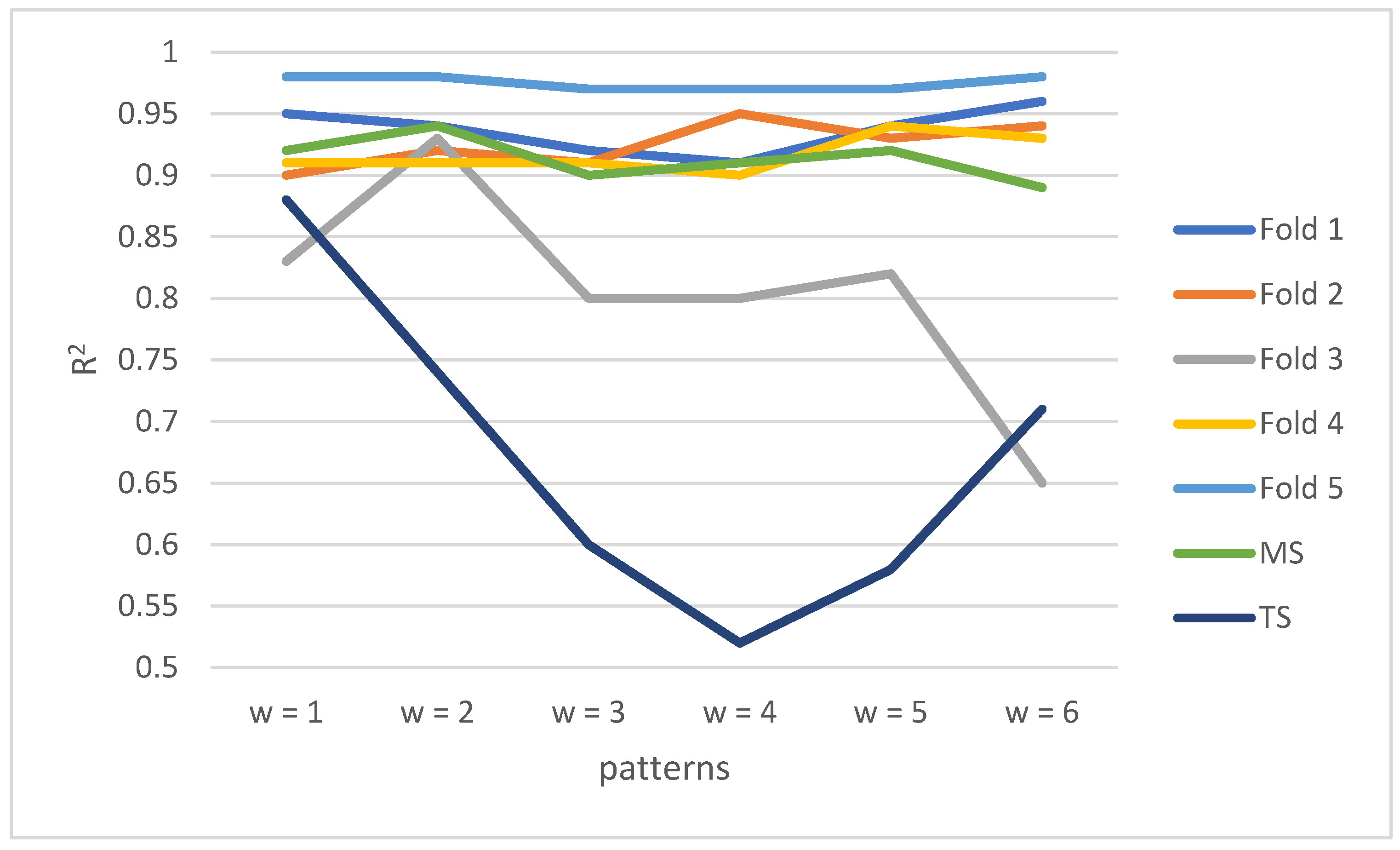
4.2. Cross Validation of Random Forest
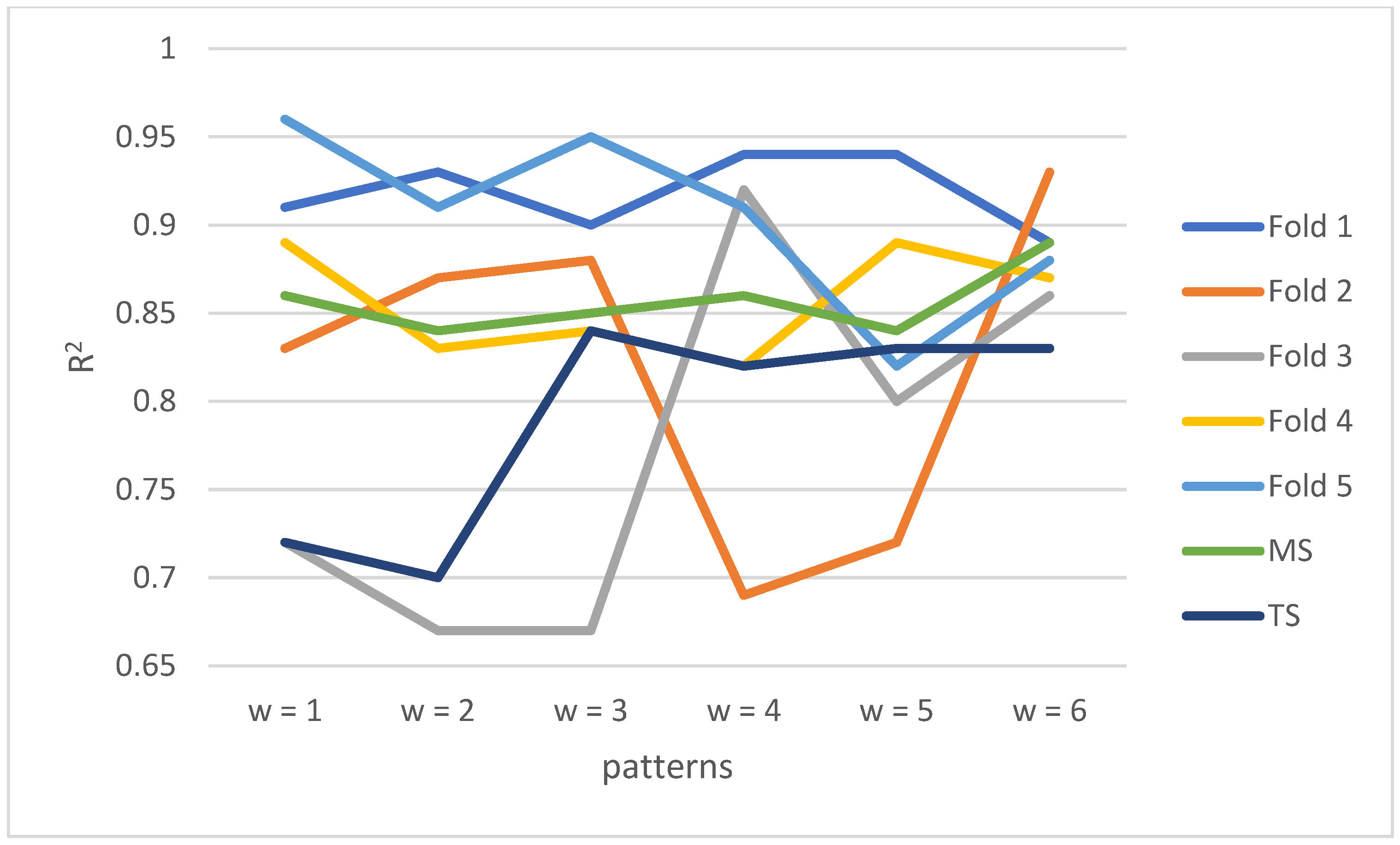
4.3. Cross Validation of LASSO
4.4. Model Selection
4.5. Future Carbon Dioxide Emissions
4.6. Feature Importance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Inergovernmental Panel on Climate Change (IPCC). Contribution of Working Group III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Shukla, P.R., Skea, J., Slade, R., Al Khourdajie, A., van Diemen, R., McCollum, D., Pathak, M., Some, S., Vyas, P., Fradera, R., et al., Eds.; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Song, M.; Zhu, S.; Wang, J.; Zhao, J. Share green growth: Regional evaluation of green output performance in China. Int. J. Prod. Econ. 2020, 219, 152–163. [Google Scholar] [CrossRef]
- Wang, W.W.; Zhang, M.; Zhou, M. Using LMDI method to analyze transport sector CO2 emissions in China. Energy 2011, 36, 5909–5915. [Google Scholar] [CrossRef]
- Jing, Q.; Bai, H.; Luo, W.; Cai, B.; Xu, H. A top-bottom method for city-scale energy-related CO2 emissions estimation: A case study of 41 Chinese cities. J. Clean. Prod. 2018, 202, 444–455. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Z.; Wu, X.; Nie, X. Can a carbon trading system promote the transformation of a low-carbon economy under the framework of the porter hypothesis?—Empirical analysis based on the PSM-DID method. Energy Policy 2019, 129, 930–938. [Google Scholar] [CrossRef]
- Ma, X.; Wang, C.; Dong, B.; Gu, G.; Chen, R.; Li, Y.; Zou, H.; Zhang, W.; Li, Q. Carbon emissions from energy consumption in China: Its measurement and driving factors. Sci. Total Environ. 2019, 648, 1411–1420. [Google Scholar] [CrossRef]
- Wang, M.; Feng, C. Using an extended logarithmic mean Divisia index approach to assess the roles of economic factors on industrial CO2 emissions of China. Energy Econ. 2018, 76, 101–114. [Google Scholar] [CrossRef]
- Abokyi, E.; Appiah-Konadu, P.; Tangato, K.F.; Abokyi, F. Electricity consumption and carbon dioxide emissions: The role of trade openness and manufacturing sub-sector output in Ghana. Energy Clim. Chang. 2021, 2, 100026. [Google Scholar] [CrossRef]
- Hou, J.; Hou, P. Polarization of CO2 emissions in China’s electricity sector: Production versus consumption perspectives. J. Clean. Prod. 2018, 178, 384–397. [Google Scholar] [CrossRef]
- Lin, B.; Tan, R. Sustainable development of China’s energy intensive industries: From the aspect of carbon dioxide emissions reduction. Renew. Sustain. Energy Rev. 2017, 77, 386–394. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, F. Hybrid input-output analysis for life-cycle energy consumption and carbon emissions of China’s building sector. Build. Environ. 2016, 104, 188–197. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, B. Research on the life-cycle CO2 emission of China’s construction sector. Energy Build. 2016, 112, 244–255. [Google Scholar] [CrossRef]
- Du, Z.; Lin, B. Changes in automobile energy consumption during urbanization: Evidence from 279 cities in China. Energy Policy 2019, 132, 309–317. [Google Scholar] [CrossRef]
- Zhao, M.; Sun, T. Dynamic spatial spillover effect of new energy vehicle industry policies on carbon emission of transportation sector in China. Energy Policy 2022, 165, 112991. [Google Scholar] [CrossRef]
- Guan, D.; Hubacek, K.; Weber, C.L.; Peters, G.P.; Reiner, D.M. The drivers of Chinese CO2 emissions from 1980 to 2030. Glob. Environ. Chang. 2008, 18, 626–634. [Google Scholar] [CrossRef]
- Fan, J.-L.; Da, Y.-B.; Wan, S.-L.; Zhang, M.; Cao, Z.; Wang, Y.; Zhang, X. Determinants of carbon emissions in ‘Belt and Road initiative’ countries: A production technology perspective. Appl. Energy 2019, 239, 268–279. [Google Scholar] [CrossRef]
- Net, X. Statement by H.E. Xi Jinping President of the People’s Republic of China At the General Debate of the 75th Session of The United Nations General Assembly. Available online: https://baijiahao.baidu.com/s?id=1678546728556033497&wfr=spider&for=pc (accessed on 25 June 2022).
- Xiong, P.P.; Xiao, L.S.; Liu, Y.C.; Yang, Z.; Zhou, Y.F.; Cao, S.R. Forecasting carbon emissions using a multi-variable GM (1,N) model based on linear time-varying parameters. J. Intell. Fuzzy Syst. 2021, 41, 6137–6148. [Google Scholar] [CrossRef]
- Ye, L.; Yang, D.L.; Dang, Y.G.; Wang, J.J. An enhanced multivariable dynamic time-delay discrete grey forecasting model for predicting China’s carbon emissions. Energy 2022, 249, 123681. [Google Scholar] [CrossRef]
- Zhang, F.; Deng, X.Z.; Xie, L.; Xu, N. China’s energy-related carbon emissions projections for the shared socioeconomic pathways. Resour. Conserv. Recycl. 2021, 168, 105456. [Google Scholar] [CrossRef]
- Li, B.; Han, S.W.; Wang, Y.F.; Li, J.Y.; Wang, Y. Feasibility assessment of the carbon emissions peak in China’s construction industry: Factor decomposition and peak forecast. Sci. Total Environ. 2020, 706, 135716. [Google Scholar] [CrossRef]
- Zheng, J.L.; Mi, Z.F.; Coffman, D.; Milcheva, S.; Shan, Y.L.; Guan, D.B.; Wang, S.Y. Regional development and carbon emissions in China. Energy Econ. 2019, 81, 25–36. [Google Scholar] [CrossRef]
- Dong, B.Y.; Ma, X.J.; Zhang, Z.L.; Zhang, H.B.; Chen, R.M.; Song, Y.Q.; Shen, M.C.; Xiang, R.B. Carbon emissions, the industrial structure and economic growth: Evidence from heterogeneous industries in China. Environ. Pollut. 2020, 262, 114322. [Google Scholar] [CrossRef] [PubMed]
- Siqin, Z.Y.; Niu, D.X.; Li, M.Y.; Zhen, H.; Yang, X.L. Carbon dioxide emissions, urbanization level, and industrial structure: Empirical evidence from North China. Environ. Sci. Pollut. Res. 2022, 29, 34528–34545. [Google Scholar] [CrossRef] [PubMed]
- Dong, K.Y.; Sun, R.J.; Hochman, G. Do natural gas and renewable energy consumption lead to less CO2 emission? Empirical evidence from a panel of BRICS countries. Energy 2017, 141, 1466–1478. [Google Scholar] [CrossRef]
- Zheng, H.Y.; Song, M.L.; Shen, Z.Y. The evolution of renewable energy and its impact on carbon reduction in China. Energy 2021, 237, 121639. [Google Scholar] [CrossRef]
- Abbasi, K.R.; Shahbaz, M.; Zhang, J.J.; Irfan, M.; Alvarado, R. Analyze the environmental sustainability factors of China: The role of fossil fuel energy and renewable energy. Renew. Energy 2022, 187, 390–402. [Google Scholar] [CrossRef]
- Sun, W.; Ren, C.M. Short-term prediction of carbon emissions based on the EEMD-PSOBP model. Environ. Sci. Pollut. Res. 2021, 28, 56580–56594. [Google Scholar] [CrossRef]
- Shi, M.S. Forecast of China’s carbon emissions under the background of carbon neutrality. Environ. Sci. Pollut. Res. 2022, 29, 43019–43033. [Google Scholar] [CrossRef]
- Zhang, J.X.; Zhang, H.; Wang, R.; Zhang, M.X.; Huang, Y.Z.; Hu, J.H.; Peng, J.Y. Measuring the critical influence factors for predicting carbon dioxide emissions of expanding megacities by XGBoost. Atmosphere 2022, 13, 599. [Google Scholar] [CrossRef]
- Lu, X.Y.; Ota, K.R.; Dong, M.X.; Yu, C.; Jin, H. Predicting transportation carbon emission with urban big data. IEEE Trans. Sustain. Comput. 2017, 2, 333–344. [Google Scholar] [CrossRef]
- Ning, L.Q.; Pei, L.J.; Li, F. Forecast of China’s carbon emissions based on ARIMA method. Discret. Dyn. Nat. Soc. 2021, 2021, 1441942. [Google Scholar] [CrossRef]
- Magazzino, C.; Mele, M.; Schneider, N. A machine learning approach on the relationship among solar and wind energy production, coal consumption, GDP, and CO2 emissions. Renew. Energy 2021, 167, 99–115. [Google Scholar] [CrossRef]
- Ahmed, M.; Shuai, C.M.; Ahmed, M. Influencing factors of carbon emissions and their trends in China and India: A machine learning method. Environ. Sci. Pollut. Res. 2022, 29, 48424–48437. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Al Mamlook, R.E.; Jamal, A. A comparative performance of machine learning algorithm to predict electric vehicles energy consumption: A path towards sustainability. Energy Environ. 2021. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hamrani, A.; Akbarzadeh, A.; Madramootoo, C.A. Machine learning for predicting greenhouse gas emissions from agricultural soils. Sci. Total Environ. 2020, 741, 140338. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Zahid, M.; Jamal, A. Prediction of electric vehicle charging duration time using ensemble machine learning algorithm and Shapley additive explanations. Int. J. Energy Res. 2022, 46, 15211–15230. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Yamamoto, T.; Shafiullah, M.; Jamal, A. Grey wolf optimizer-based machine learning algorithm to predict electric vehicle charging duration time. Transp. Lett. Int. J. Transp. Res. 2022. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | MS | TS | MD | MF | NT | |
|---|---|---|---|---|---|---|---|---|---|---|
| Pattern 1 (w = 1) | 0.95 | 0.9 | 0.83 | 0.91 | 0.98 | 0.92 | 0.88 | 4 | 0.6 | 10 |
| Pattern 2 (w = 2) | 0.94 | 0.92 | 0.93 | 0.91 | 0.98 | 0.94 | 0.74 | 4 | 0.7 | 10 |
| Pattern 3 (w = 3) | 0.92 | 0.91 | 0.8 | 0.91 | 0.97 | 0.9 | 0.6 | 5 | 0.7 | 20 |
| Pattern 4 (w = 4) | 0.91 | 0.95 | 0.8 | 0.9 | 0.97 | 0.91 | 0.52 | 5 | 0.6 | 20 |
| Pattern 5 (w = 5) | 0.94 | 0.93 | 0.82 | 0.94 | 0.97 | 0.92 | 0.58 | 3 | 0.6 | 10 |
| Pattern 6 (w = 6) | 0.96 | 0.94 | 0.65 | 0.93 | 0.98 | 0.89 | 0.71 | 5 | 0.8 | 50 |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | MS | TS | Alpha | |
|---|---|---|---|---|---|---|---|---|
| w = 1 | 0.91 | 0.83 | 0.72 | 0.89 | 0.96 | 0.86 | 0.72 | 0.0023 |
| w = 2 | 0.93 | 0.87 | 0.67 | 0.83 | 0.91 | 0.84 | 0.7 | 0.0021 |
| w = 3 | 0.9 | 0.88 | 0.67 | 0.84 | 0.95 | 0.85 | 0.84 | 0.00057 |
| w = 4 | 0.94 | 0.69 | 0.92 | 0.82 | 0.91 | 0.86 | 0.82 | 0.00189 |
| w = 5 | 0.94 | 0.72 | 0.8 | 0.89 | 0.82 | 0.84 | 0.83 | 0.00002 |
| w = 6 | 0.89 | 0.93 | 0.86 | 0.87 | 0.88 | 0.89 | 0.83 | 0.003 |
| SVR | Ridge | LASSO | RF | GBDT | RF-LASSO | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | |
| w = 1 | 0.80 | 0.14 | 0.67 | 0.17 | 0.72 | 0.16 | 0.88 | 0.10 | 0.79 | 0.14 | 0.88 | 0.10 |
| w = 2 | 0.67 | 0.17 | 0.56 | 0.20 | 0.70 | 0.16 | 0.74 | 0.15 | 0.37 | 0.24 | 0.74 | 0.15 |
| w = 3 | 0.75 | 0.15 | 0.67 | 0.17 | 0.84 | 0.12 | 0.60 | 0.19 | 0.32 | 0.25 | 0.84 | 0.12 |
| w = 4 | 0.76 | 0.15 | 0.66 | 0.17 | 0.82 | 0.13 | 0.52 | 0.21 | 0.29 | 0.25 | 0.82 | 0.13 |
| w = 5 | 0.79 | 0.14 | 0.69 | 0.17 | 0.83 | 0.12 | 0.58 | 0.2 | 0.35 | 0.24 | 0.83 | 0.12 |
| w = 6 | 0.82 | 0.13 | 0.72 | 0.16 | 0.83 | 0.12 | 0.71 | 0.16 | 0.67 | 0.17 | 0.83 | 0.12 |
| mean | 0.77 | 0.15 | 0.66 | 0.17 | 0.79 | 0.14 | 0.67 | 0.17 | 0.47 | 0.22 | 0.82 | 0.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; Wang, Q.; Tan, T. Prediction of Carbon Dioxide Emissions in China Using Shallow Learning with Cross Validation. Energies 2022, 15, 8642. https://doi.org/10.3390/en15228642
Hou Y, Wang Q, Tan T. Prediction of Carbon Dioxide Emissions in China Using Shallow Learning with Cross Validation. Energies. 2022; 15(22):8642. https://doi.org/10.3390/en15228642
Chicago/Turabian StyleHou, Yali, Qunwei Wang, and Tao Tan. 2022. "Prediction of Carbon Dioxide Emissions in China Using Shallow Learning with Cross Validation" Energies 15, no. 22: 8642. https://doi.org/10.3390/en15228642
APA StyleHou, Y., Wang, Q., & Tan, T. (2022). Prediction of Carbon Dioxide Emissions in China Using Shallow Learning with Cross Validation. Energies, 15(22), 8642. https://doi.org/10.3390/en15228642