
The Software Cache Optimization-Based Method for Decreasing Energy Consumption of Computational Clusters



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
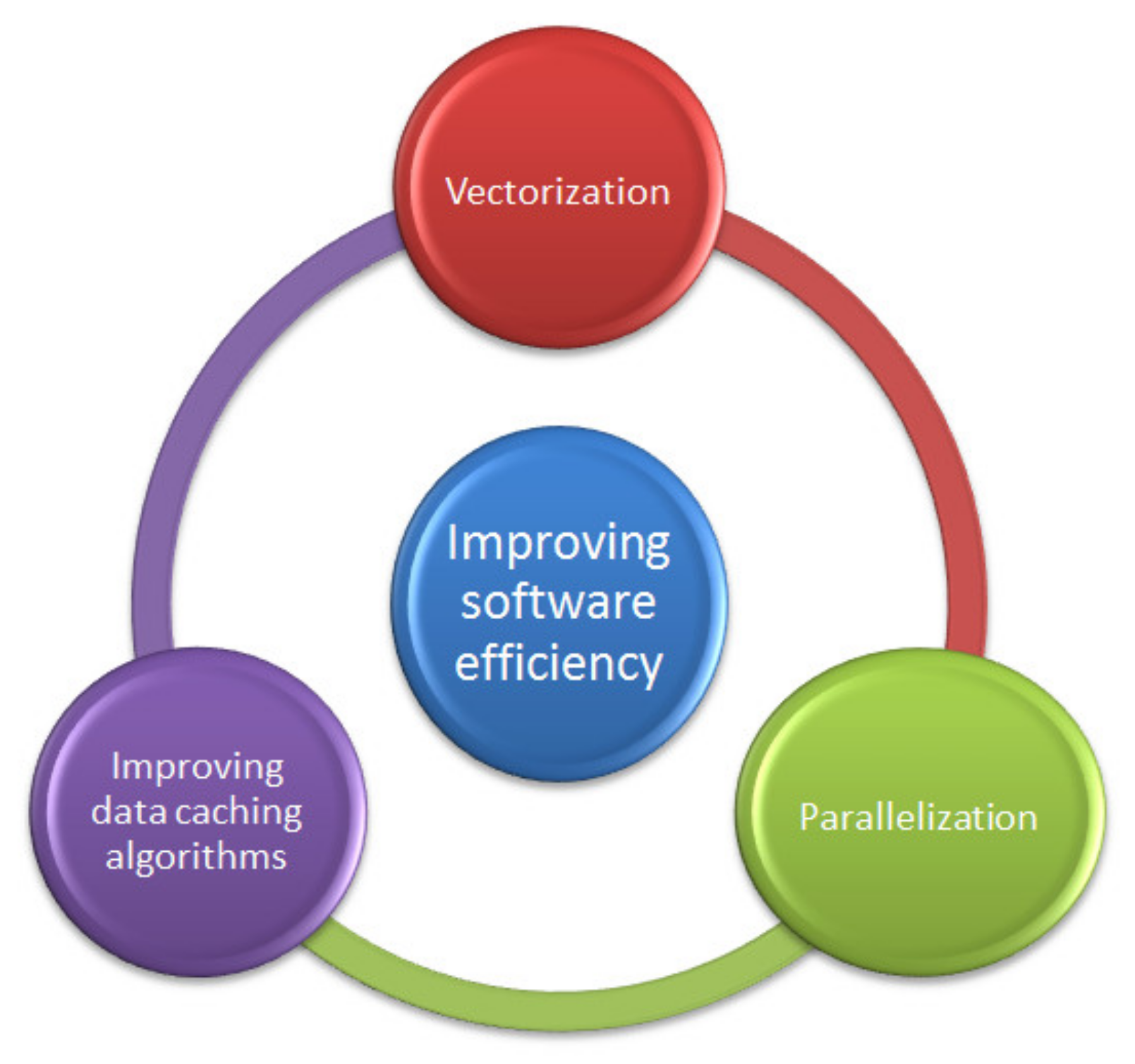
1. Introduction
- -
- -
- -
- related to the energy consumption measurement, the evaluation of software energy efficiency [26];
- -
2. Basic Transformation
- 1:
- Y = v(1)
- 2:
- W = −2 v(1)/[v(1)]T v(1)
- 3:
- for j = 2 to r
- 4:
- z = −2(I + WYT) v(j)/[v(j)]T v(j)
- 5:
- W = [W z]
- 6:
- Y = [Y v(j)]
- 7:
- end
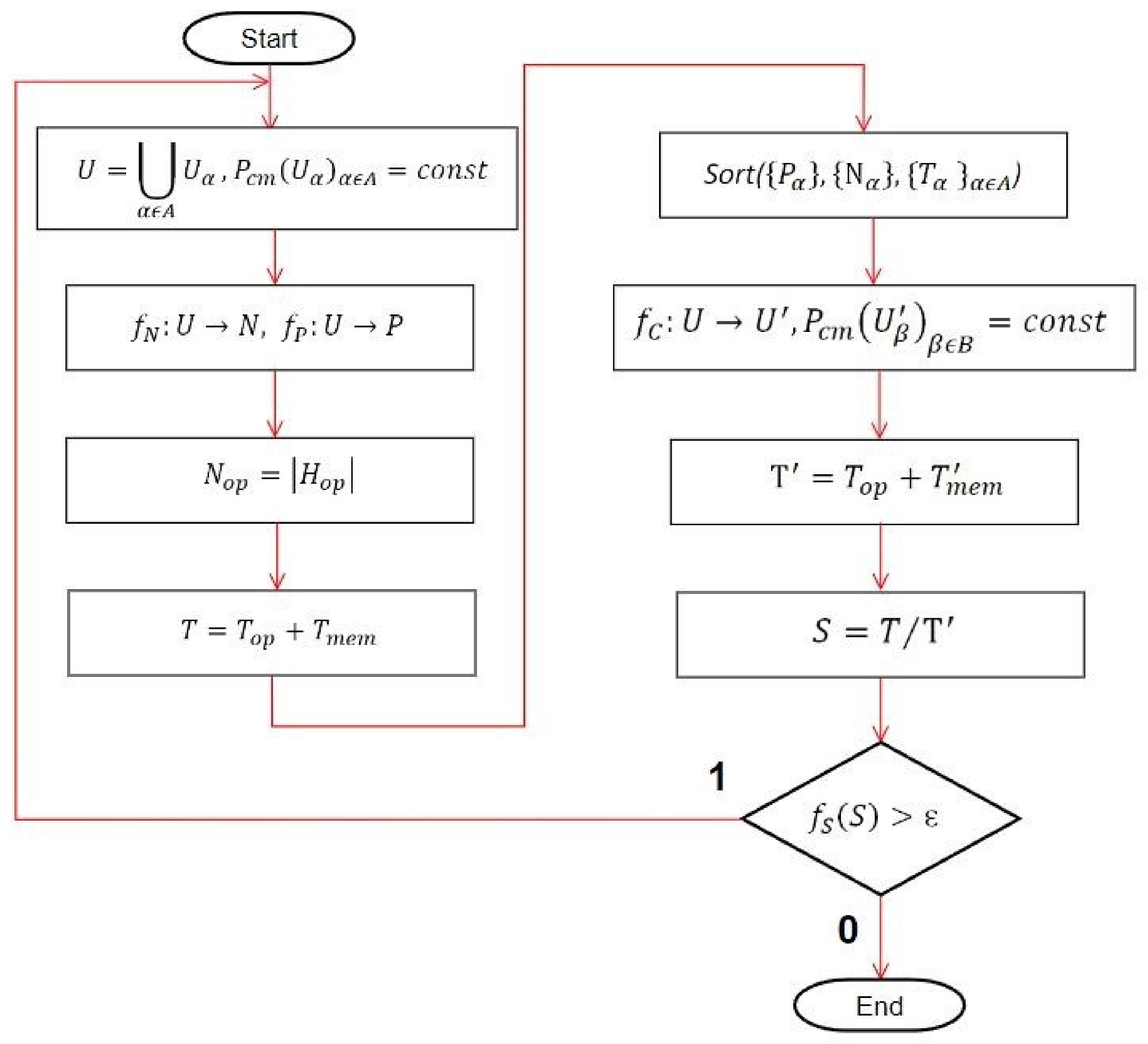
3. Software Cache Optimization-Based Methodology
- -
- the set of memory access operations is divided into disjoint subsets according to the method of accessing memory that affects the cache miss probability; subsets of operations with equal cache miss probability values Pcm are obtained;
- -
- the number of element {Nα}αɛA s and the cache miss probability {Pα}αɛA are determined for each of the obtained subsets;
- -
- the number of arithmetic and logical operations in general for the entire algorithm Nop is determined;
- -
- the expression is formed that evaluates the software running time T.
- -
- analyzing the obtained subsets of memory access operations and the corresponding values of the cache miss probability {Pα}αɛA, the number of operations {Nα}αɛA and the execution time {Tα}αɛA of all subset operations, the search for algorithm sections that negatively affect the data caching process efficiency is carried out;
- -
- an attempt is made to correct the original algorithm, the result is a new division of the memory access operations set into subsets with other characteristics {U’β}βɛB; permutation optimization and other approaches can be used to correct the algorithm;
- -
- software running time T’ with the modified algorithm is estimated;
- -
- resulting speedup value S is calculated.
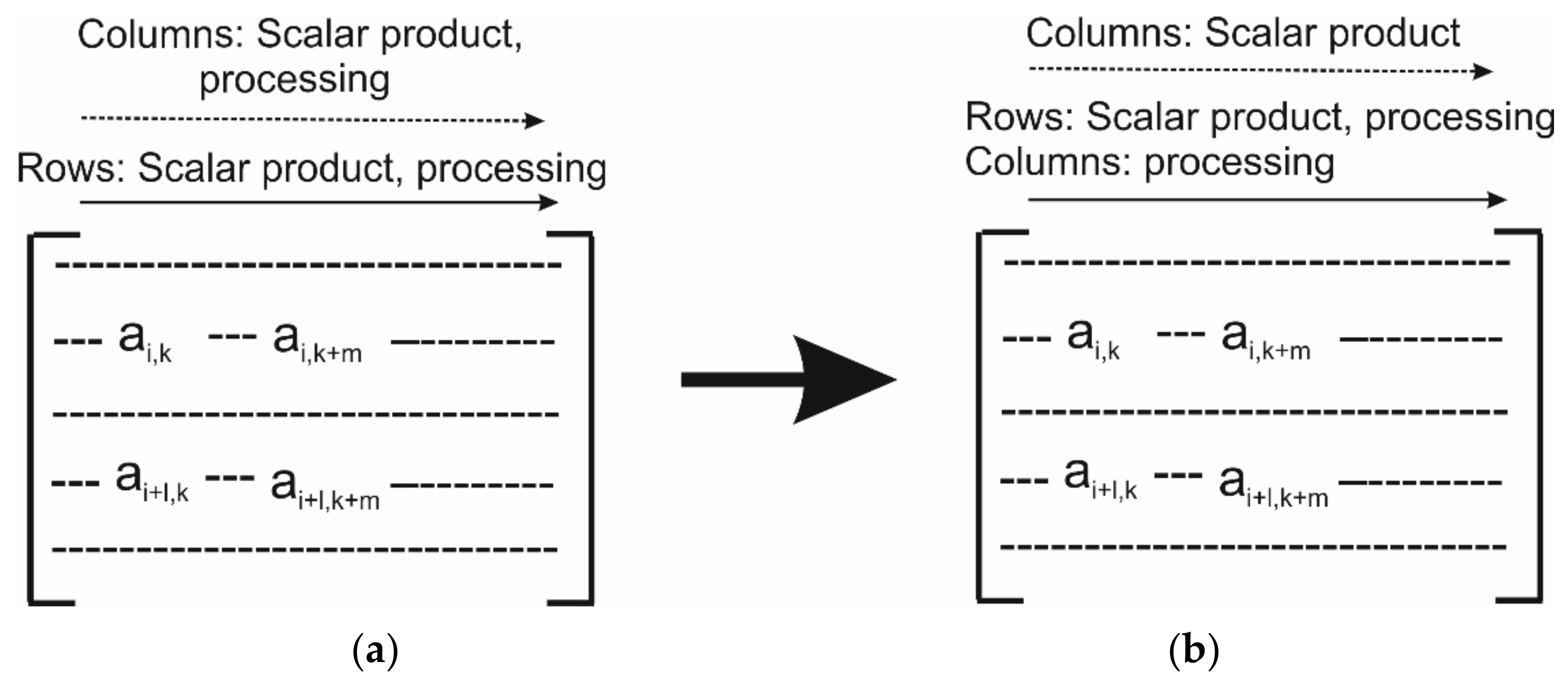
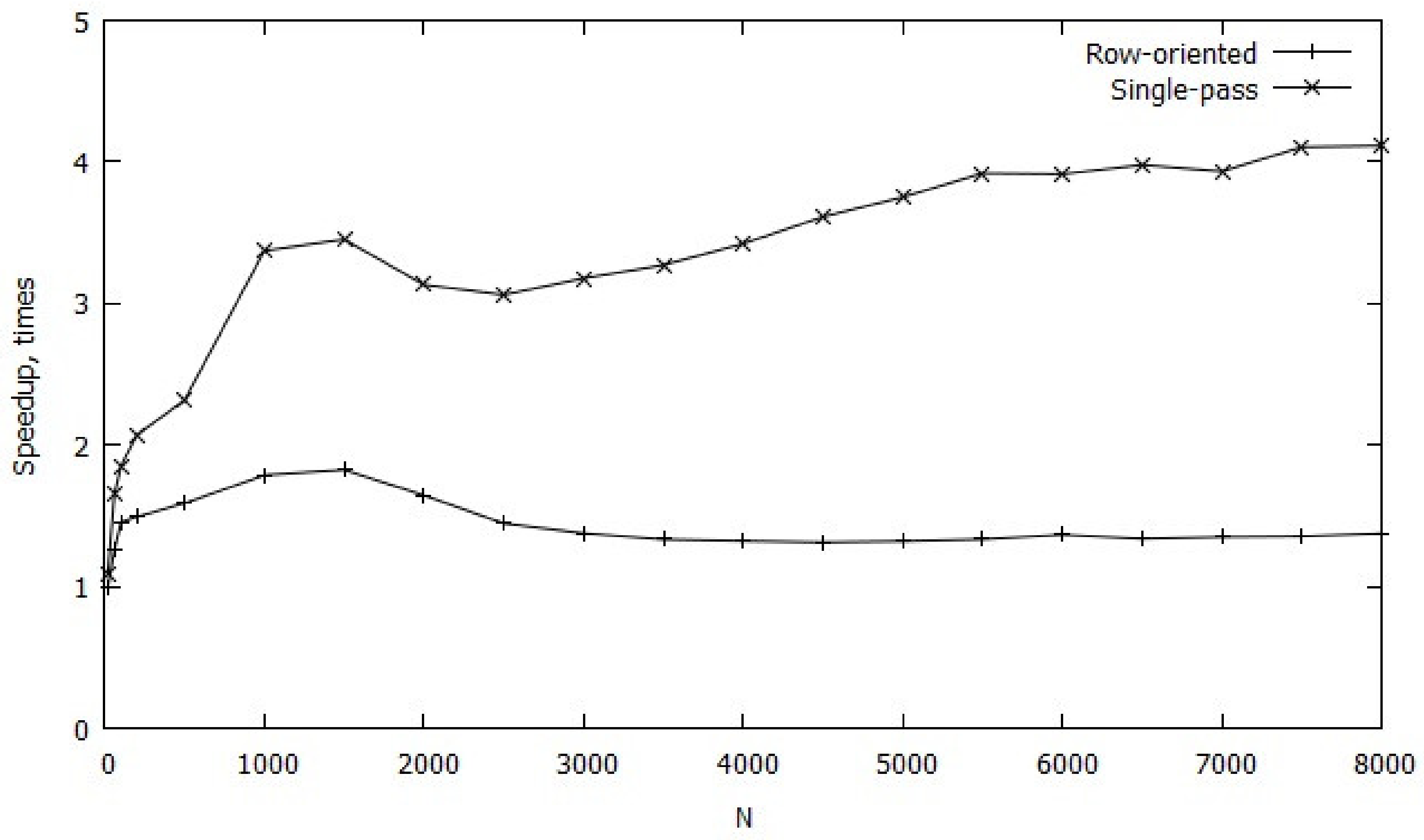
3.1. Row-Oriented Householder Reflection
3.2. Single-Pass Householder Reflection
- 1:
- Hessenberg (A, N)
- 2:
- for s = 1 to N − 2 do
- 3:
- (g, uS) = Householder(As, s);
- 4:
- SPH(A, N, s, g, uS)
- 5:
- end for
- 6:
- end Hessenberg
- 1:
- SPH(A, N, s, g, uS)
- 2:
- for r = 1 to (s−1) do
- 3:
- vrs = g A[r, s + 1:N] uS[s + 1:N]
- 4:
- A[r, s + 1:N] -= vrs uST[s + 1:N]
- 5:
- vsT[s:N] = g uST[s + 1:N] A[s + 1:N, s:N]
- 6:
- for r = s to N do
- 7:
- A[r, s:N] -= uS[r] vsT[s:N]
- 8:
- vrs = g A[r, s + 1:N] uS[s + 1:N]
- 9:
- A[r, s + 1:N] -= vrs uST[s + 1:N]
- 10:
- end SPH
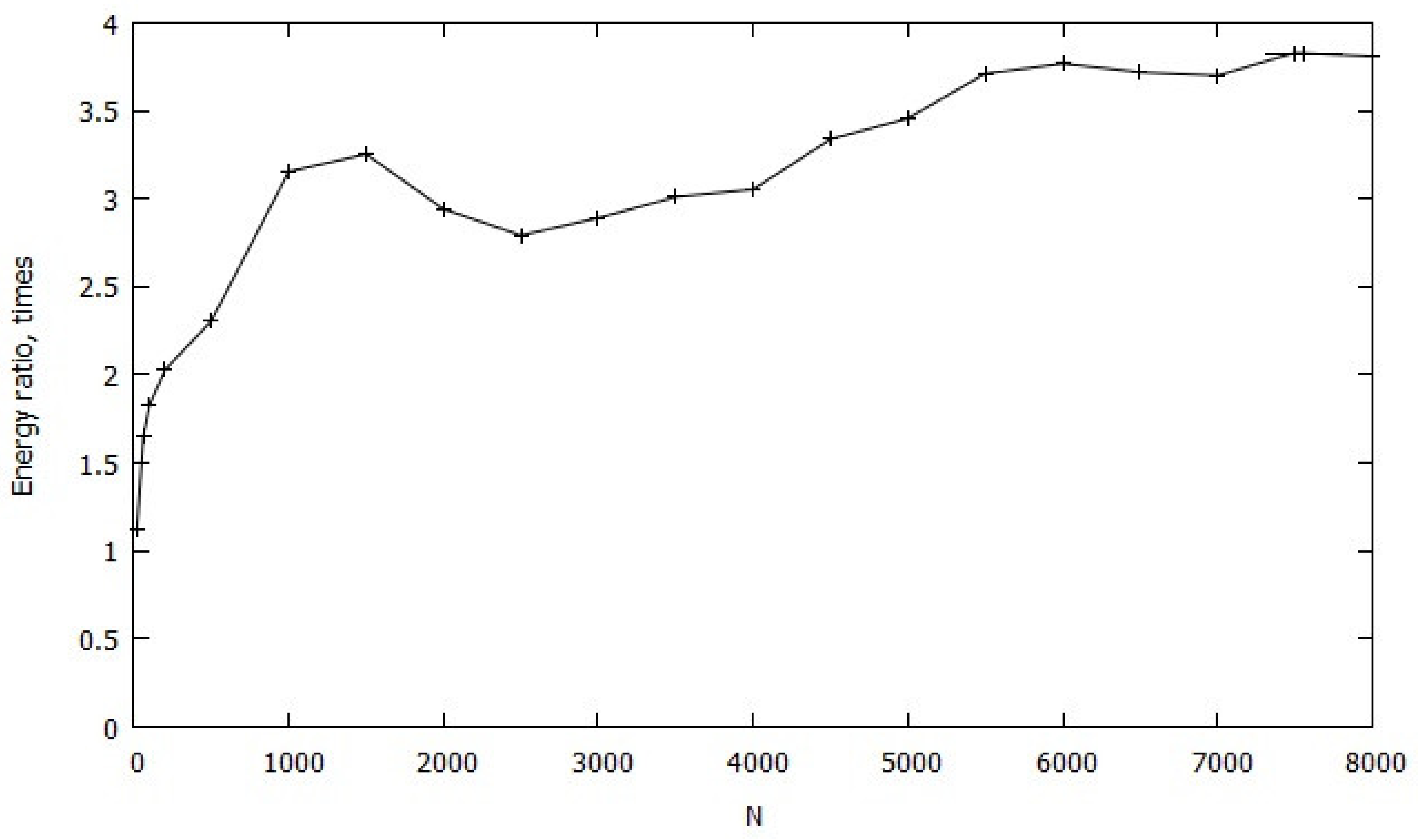
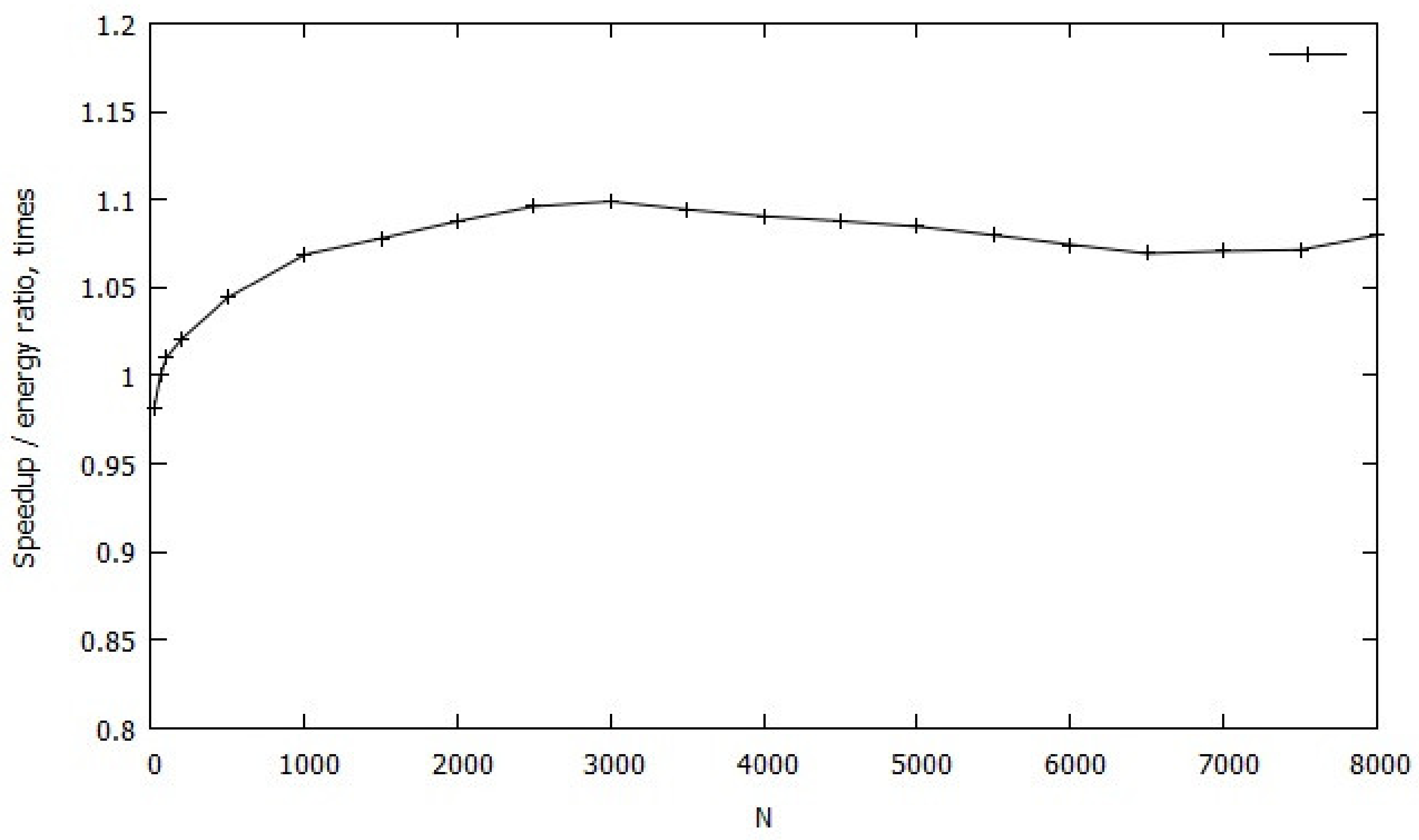
4. Results and Discussions
- PKG—the power consumed by the socket as a whole (Package);
- DRAM—the power consumed by DRAM;
- PKG Idle—the power consumed by the socket in «idle» mode;
- DRAM Idle—the power consumed by DRAM in «idle» mode.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fallis, E.; Spachos, P. Power Consumption and Throughput of Wireless Communication Technologies for Smartphones. In Proceedings of the 2018 Global Information Infrastructure and Networking Symposium (GIIS), Thessaloniki, Greece, 23–25 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lutui, P.R.; Cusack, B.; Maeakafa, G. Energy efficiency for IoT devices in home environments. In Proceedings of the 2018 IEEE International Conference on Environmental Engineering (EE), Milan, Italy, 12–14 March 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Schill, A.; Globa, L.; Stepurin, O.; Gvozdetska, N.; Prokopets, V. Power Consumption and Performance Balance (PCPB) scheduling algorithm for computer cluster. In Proceedings of the 2017 International Conference on Information and Telecommunication Technologies and Radio Electronics (UkrMiCo), Odessa, UKraine, 11–15 September 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Rahmati, A.; Qian, A.; Zhong, L. Understanding human-battery interaction on mobile phones. In Proceedings of the 9th International Conference on Human Computer Interaction with Mobile Devices and Services, Singapore, 9–12 September 2007. [Google Scholar]
- Zakarya, M.; Gillam, L. Energy efficient computing, clusters, grids and clouds: A taxonomy and survey. In Sustainable Computing: Informatics & Systems; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Zakarya, M. Energy, performance and cost efficient datacenters: A survey. In Renewable and Sustainable Energy Reviews; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Iyer, S.G.; Dipakumar Pawar, A. GPU and CPU Accelerated Mining of Cryptocurrencies and their Financial Analysis. In Proceedings of the 2018 2nd International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 30–31 August 2018; pp. 599–604. [Google Scholar] [CrossRef]
- Pereira, R.; Couto, M.; Ribeiro, F.; Rua, R.; Cunha, J.; Fernandes, J.P.; Saraiva, J. Energy Efficiency across Programming Languages. In Proceedings of the SLE’17, Vancouver, BC, Canada, 23–24 October 2017; 12p. [Google Scholar] [CrossRef]
- Pandey, N.; Verma, O.P.; Kumar, A. A framework for usage pattern–based power optimization and battery lifetime prediction in smartphones. Pers. Ubiquit. Comput. 2022, 26, 821–836. [Google Scholar] [CrossRef]
- Yang, R.; Song, J.; Huang, B.; Li, W.; Qi, G. An Energy-Efficient Step-Counting Algorithm for Smartphones. Comput. J. 2020, 65, 689–700. [Google Scholar] [CrossRef]
- Oliveira, W.; Oliveira, R.; Castor, F. A study on the energy consumption of Android app development approaches. In Proceedings of the 14th International Conference on Mining Software Repositories, Buenos Aires, Argentina, 20–21 May 2017; pp. 42–52. [Google Scholar]
- Li, D.; Halfond, W.G.J. An investigation into energy-saving programming practices for Android smartphone app development. In Proceedings of the 3rd International Workshop on Green and Sustainable Software, Hyderabad, India, 1 June 2014. [Google Scholar]
- Sahin, C.; Cayci, F.; Gutierrez, I.L.M.; Clause, J.; Kiamilev, F.; Pollock, L.; Winbladh, K. Initial explorations on design pattern energy usage. In Proceedings of the 4th International Workshop on Green and Sustainable Software, Zurich, Switzerland, 3 June 2012; pp. 55–61. [Google Scholar]
- Chen, Y.-J.; Hsu, C.-H.; Li, K.-C.; Chang, H.-Y.; Wang, S.-T. Power Consumption Optimization of MPI Programs on Multi-core Clusters. In Scalable Information Systems; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, INFOSCALE 2009; Mueller, P., Cao, J.N., Wang, C.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 18. [Google Scholar] [CrossRef]
- Görtz, M.D.; Kühn, R.; Zietek, O.; Bernhard, R.; Bulinski, M.; Duman, D.; Freisen, B.; Jentsch, U.; Klöppner, T.; Popovic, D.; et al. Energy Efficiency of a Low Power Hardware Cluster for High Performance Computing. In INFORMATIK 2017; Eibl, M., Gaedke, M., Eds.; Gesellschaft für Informatik: Bonn, Germany, 2017; pp. S2537–S2548. [Google Scholar] [CrossRef]
- Pereira, R.; Carção, T.; Couto, M.; Cunha, J.; Fernandes, J.P.; Saraiva, J. Helping programmers improve the energy efficiency of source code. In Proceedings of the 39th International Conference on Software Engineering—Companion, ICSE-C, Buenos Aires, Argentina, 20–28 May 2017. [Google Scholar]
- Chowdhury, S.A.; Hindle, A. Greenoracle: Estimating software energy consumption with energy measurement corpora. In Proceedings of the 13th International Conference on Mining Software Repositories, MSR, Austin, TX, USA, 14–15 May 2016; pp. 49–60. [Google Scholar]
- Sahin, C.; Pollock, L.; Clause, J. How do code refactorings affect energy usage? In Proceedings of the 8th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Torino, Italy, 18–19 September 2014; p. 36. [Google Scholar]
- Hao, S.; Li, D.; Halfond, W.G.J.; Govindan, R. Estimating mobile application energy consumption using program analysis. In Proceedings of the 2013 International Conference on Software Engineering, ICSE ’13, San Francisco, CA, USA, 18–26 May 2013; pp. 92–101. [Google Scholar]
- Couto, M.; Borba, P.; Cunha, J.; Fernandes, J.P.; Pereira, R.; Saraiva, J. Products go green: Worst-case energy consumption in software product lines. In Proceedings of the 21st International Systems and Software Product Line Conference, SPLC, Sevilla, Spain, 25–29 September 2017; Volume A, pp. 84–93. [Google Scholar]
- Pereira, R.; Couto, M.; Saraiva, J.; Cunha, J.; Fernandes, J.P. The influence of the Java collection framework on overall energy consumption. In Proceedings of the 5th International Workshop on Green and Sustainable Software, Austin, TX, USA, 14–22 May 2016; pp. 15–21. [Google Scholar]
- Yuki, T.; Rajopadhye, S. Folklore confirmed: Compiling for speed = compiling for energy. In Languages and Compilers for Parallel Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 169–184. [Google Scholar]
- Pinto, G.; Castor, F.; Liu, Y.D. Understanding energy behaviors of thread management constructs. In Proceedings of the 2014 ACM International Conference on Object Oriented Programming Systems Languages & Applications, Portland, OR, USA, 20–24 October 2014; pp. 345–360. [Google Scholar]
- Trefethen, A.E.; Thiyagalingam, J. Energy-aware software: Challenges, opportunities and strategies. J. Comput. Sci. 2013, 4, 444–449. [Google Scholar] [CrossRef]
- Lima, L.G.; Melfe, G.; Soares-Neto, F.; Lieuthier, P.; Fernandes, J.P.; Castor, F. Haskell in green land: Analyzing the energy behavior of a purely functional language. In Proceedings of the 23rd IEEE International Conference on Software Analysis, Evolution, and Reengineering, SANER, Suita, Japan, 14–18 March 2016; pp. 517–528. [Google Scholar]
- Abdulsalam, S.; Zong, Z.; Gu, Q.; Qiu, M. Using the greenup, powerup, and speedup metrics to evaluate software energy efficiency. In Proceedings of the 6th International Green and Sustainable Computing Conference, IGCC, Las Vegas, NV, USA, 14–16 December 2015; pp. 1–8. [Google Scholar]
- Ortega, J.M. Introduction to Parallel and Vector Solution of Linear Systems; Plenum Press: New York, NY, USA, 1988; p. 305. ISBN 0-306-42862-8. [Google Scholar]
- Demmel, J.W. Applied Numerical Linear Algebra; SIAM: Philadelphia, PA, USA, 1997; p. 430. [Google Scholar]
- Salam, A.; Kahla, H.B. An upper J-Hessenberg reduction of a matrix through symplectic Householder transformations. Comput. Math. Appl. 2019, 78, 178–190. [Google Scholar] [CrossRef]
- Bujanovic, Z.; Karlsson, L.; Kressner, D. A householder-based algorithm for Hessenberg-triangular reduction. SIAM J. Matrix Anal. Appl. 2018, 39, 1270–1294. [Google Scholar] [CrossRef]
- Bogoya, J.M.; Grudsky, S.M.; Malysheva, I.S. Extreme individual eigenvalues for a class of large hessenberg toeplitz matrices. Oper. Theory Adv. Appl. 2018, 271, 119–143. [Google Scholar]
- Kabir, K.; Haidar, A.; Tomov, S.; Dongarra, J. Performance analysis and design of a hessenberg reduction using stabilized blocked elementary transformations for new architectures. Simul. Ser. 2015, 47, 135–142. [Google Scholar]
- Tomov, S.; Nath, R.; Dongarra, J. Accelerating the reduction to upper hessenberg, tridiagonal, and bidiagonal forms through hybrid GPU-based computing. Parallel Comput. 2010, 36, 645–654. [Google Scholar] [CrossRef]
- Buttari, A.; Langou, J.; Kurzak, J.; Dongarra, J. Parallel tiled QR factorization for multicore architectures. Concurr. Comput. Pract. Exp. 2008, 20, 1573–1590. [Google Scholar] [CrossRef]
- Merchant, F.; Vatwani, T.; Chattopadhyay, A.; Nandy, S.K.; Narayan, R. Efficient realization of householder transform through algorithm-architecture co-design for acceleration of QR Factorization. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1707–1720. [Google Scholar] [CrossRef]
- Noble, J.H.; Lubasch, M.; Stevens, J.; Jentschura, U.D. Diagonalization of complex symmetric matrices: Generalized Householder reflections, iterative deflation and implicit shifts. Comput. Phys. Commun. 2017, 221, 304–316. [Google Scholar] [CrossRef]
- Getmanskiy, V.; Andreev, A.; Alekseev, S.; Gorobtsov, A.; Egunov, V.; Kharkov, E. Optimization and Parallelization of CAE Software Stress-Strain Solver for Heterogeneous Computing Hardware. In Proceedings of the Creativity in Intelligent Technologies and Data Science. Second Conference, CIT&DS 2017, Volgograd, Russia, 12–14 September 2017; Communications in Computer and Information Science. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Volume 754, pp. 562–674. [Google Scholar]
- Low, T.M.; Igual, F.D.; Smith, T.M.; Quintana-Orti, E.S. Analytical Modeling Is Enough for High-Performance BLIS. ACM Trans. Math. Softw. 2016, 43, 1–18. [Google Scholar] [CrossRef]
- Schreiber, R.; VanLoan, C. A Storage-Efficient WY Representation for Products of Householder Transformations. SIAM J. Sci. Stat. Comput. 1989, 10, 53–57. [Google Scholar] [CrossRef]
- Golub, G.; Van Loan, C. Matrix Computations, 3rd ed.; The Johns Hopkins University Press: Baltimore, MD, USA, 1996; p. 728. [Google Scholar]
- Eljammaly, M.; Karlsson, L.; Kagstrom, B. On the tunability of a new Hessenberg reduction algorithm using parallel cache assignment. In Parallel Processing and Applied Mathematics; Springer: Cham, Switherland, 2018; Volume 10777, pp. 579–589. [Google Scholar]
- Andreev, A.; Doukhnitch, E.; Egunov, V.; Zharikov, D.; Shapovalov, O.; Artuh, S. Evaluation of Hardware Implementations of CORDIC-Like Algorithms in FPGA Using OpenCL Kernels. In Knowledge-Based Software Engineering, Proceedings of 11th Joint Conference, JCKBSE, Volgograd, Russia, 17–20 September 2014; Communications in Computer and Information Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; Volume 466, pp. 228–242. [Google Scholar]
- Egunov, V.A.; Kravets, A.G. Povyshenie effektivnosti programm dlya vychislitel’nyh sistem s ierarhicheskoj strukturoj pamyati [Improving the efficiency of software for computing systems with a hierarchical memory structure]. Mat. Metod. V Tekhnologiyah I Tekhnike 2022, 4, 100–103. [Google Scholar] [CrossRef]
- Glinsky, B.; Kulikov, I.; Chernykh, I.; Weins, D.; Snytnikov, A.; Nenashev, V.; Andreev, A.; Egunov, V.; Kharkov, E. The Co-design of Astrophysical Code for Massively Parallel Supercomputers. In Proceedings of the Algorithms and Architectures for Parallel Processing, ICA3PP 2016 Collocated Workshops: SCDT, TAPEMS, BigTrust, UCER, DLMCS, Granada, Spain, 14–16 December 2016; Lecture Notes in Computer Science. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 10049, pp. 342–353. [Google Scholar]
- Dominguez, T.; Quintana, A.E.; Orti, E.S. Fast Blocking of Householder Reflectors on Graphics Processors. In Proceedings of the 26th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, PDP, Cambridge, UK, 21–23 March 2018; pp. 385–393. [Google Scholar]
- Egunov, V.A.; Andreev, A.E. Vektorizaciya algoritmov vypolneniya sobstvennogo i singulyarnogo razlozhenij matric s ispol’zovaniem preobrazovaniya Hauskholdera [Vectorization of algorithms for performing proper and singular matrix expansions using the Householder transformation]. Prikaspijskij Zhurnal: Upr. I Vysok. Tekhnologii 2020, 2, 71–85. [Google Scholar]
- Andreev, A.E. Solving of Eigenvalue and Singular Value Problems via Modified Householder Transformations on Shared Memory Parallel Computing Systems. In Supercomputing: RuSCDays, Proceedings of the 5th Russian Supercomputing Days, Moscow, Russia, 23–24 September 2019; Springer: Cham, Switzerland, 2019; Volume 1129, pp. 131–151. [Google Scholar]
- Egunov, V.A. Implementation of QR and LQ decompositions on shared memory parallel computing systems. In Proceedings of the 2nd International Conference on Industrial Engineering, Applications and Manufacturing, ICIEAM, Chelyabinsk, Russia, 19–20 May 2016; p. 5. [Google Scholar] [CrossRef]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kravets, A.G.; Egunov, V. The Software Cache Optimization-Based Method for Decreasing Energy Consumption of Computational Clusters. Energies 2022, 15, 7509. https://doi.org/10.3390/en15207509
Kravets AG, Egunov V. The Software Cache Optimization-Based Method for Decreasing Energy Consumption of Computational Clusters. Energies. 2022; 15(20):7509. https://doi.org/10.3390/en15207509
Chicago/Turabian StyleKravets, Alla G., and Vitaly Egunov. 2022. "The Software Cache Optimization-Based Method for Decreasing Energy Consumption of Computational Clusters" Energies 15, no. 20: 7509. https://doi.org/10.3390/en15207509
APA StyleKravets, A. G., & Egunov, V. (2022). The Software Cache Optimization-Based Method for Decreasing Energy Consumption of Computational Clusters. Energies, 15(20), 7509. https://doi.org/10.3390/en15207509