
Cost Efficient GPU Cluster Management for Training and Inference of Deep Learning



Abstract
:1. Introduction
- To the best of our knowledge, this paper is the first work that conducts electricity price-aware allocation for both the DL training and inference jobs on the GPU-based cluster. Corresponding to the variation of the grid market price, our proposed approach automatically derives the cost optimal DL job allocation given workloads of user requests.
- The statistical power and performance models used in our formulation can be applied to general GPU-based clusters consist of heterogeneous GPU devices. At the cost of negligible estimation error, our approach efficiently estimates the GPU device power usage and the running DL job performance without the entire profiling of various GPU architectures.
- In order to reduce the energy consumption of idle GPU computing nodes, we exploit the dynamic right-sizing (DRS) method that temporarily turns the nodes having no DL jobs off. When the workloads of user requests are low, we can achieve the maximum cost efficiency via the DRS method.
- Through the sophisticated mixed integer nonlinear problem (MINLP) formulation, our approach easily finds the optimal solution considering all the aspects presented above.
- We exploit real trace data of GPU computing nodes and the grid market price, so as to establish the practical simulation experimental environments.
2. Main
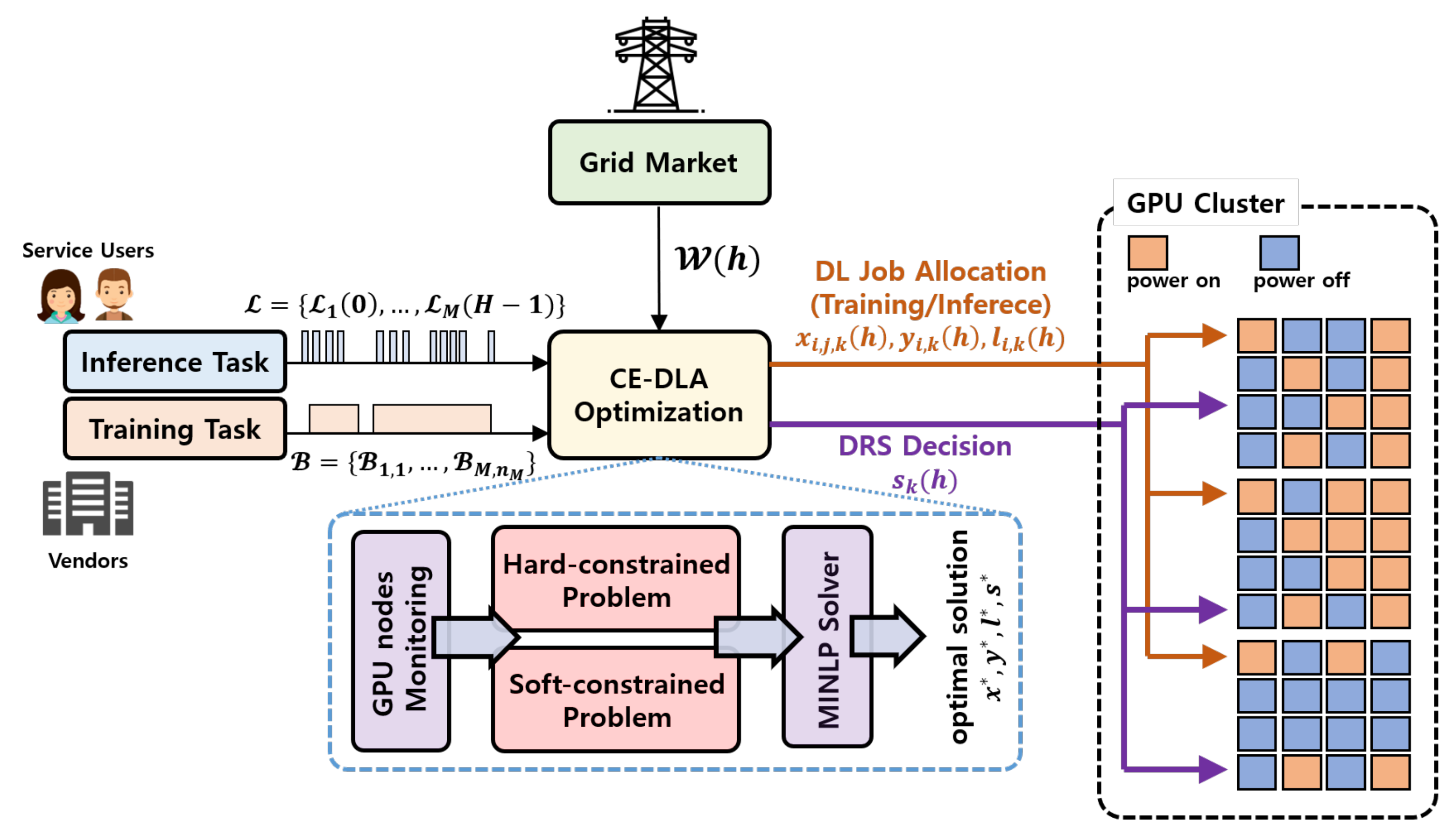
2.1. Proposed System Structure
- Step 1: The system begins to calculate the allocation decisions x and for the DL training and inference jobs, respectively.
- Step 2: For DL training jobs, the system maps the partial epochs of the jobs to the multiple time slots of GPU computing nodes. Each DL training job requires the feed-forward and back-propagation computations. In the feed-forward computation, user input data is sequentially passed over the DNN model weight parameters, and the output is derived from the last layer in the DNN model. After that, in the back-propagation computation, the model gradients are derived layer by layer based on the loss function value. After the calculation of all the gradients is done based on the chain-rule, the DNN model parameters are updated. The system iteratively conducts these procedures for all the pre-defined epochs.
- Step 3: For DL inference jobs, the system carries out the load-balancing for the input workloads on the available GPU computing nodes. In contrast to DL training jobs, each DL inference job requires only the feed-forward computation. Therefore, the DL inference jobs can be handled immediately. The system takes the DL inference jobs as the base workloads, and allocates them into the time slots right after they arrived.
- Step 4: If DL training jobs are deferrable, the system tries to halt-and-resume the assigned training jobs with considering the variation of the electricity price, as long as the deadline is not violated.
- Step 5: The system derives the DRS decision s for the GPU computing nodes in the cluster. The system turns idle nodes that have no running jobs off until it needs to deploy more available time slots for workload increasing. The system circumspectly conducts the turning-on/turning-off for nodes because the power state transition requires the non-negligible overheads [28].
2.2. Proposed System Model
2.2.1. Training and Inference Job Model
2.2.2. Performance Model
2.2.3. Power Consumption Model
2.2.4. Energy Consumption Model
2.2.5. State Transition Cost Model
2.2.6. Constraints
2.2.7. Hard Constrained Problem Formulation
2.2.8. Soft Constrained Problem Formulation
2.2.9. Job Allocation Algorithm
| Algorithm 1 DL Job Allocation based on the CE-DLA approach |
| INPUT: parameters , , , , H request set of DL training jobs request set of DL inference jobs weight values , , , OUTPUT: optimal solution (, , , )
|
3. Experiments
3.1. Experimental Setup
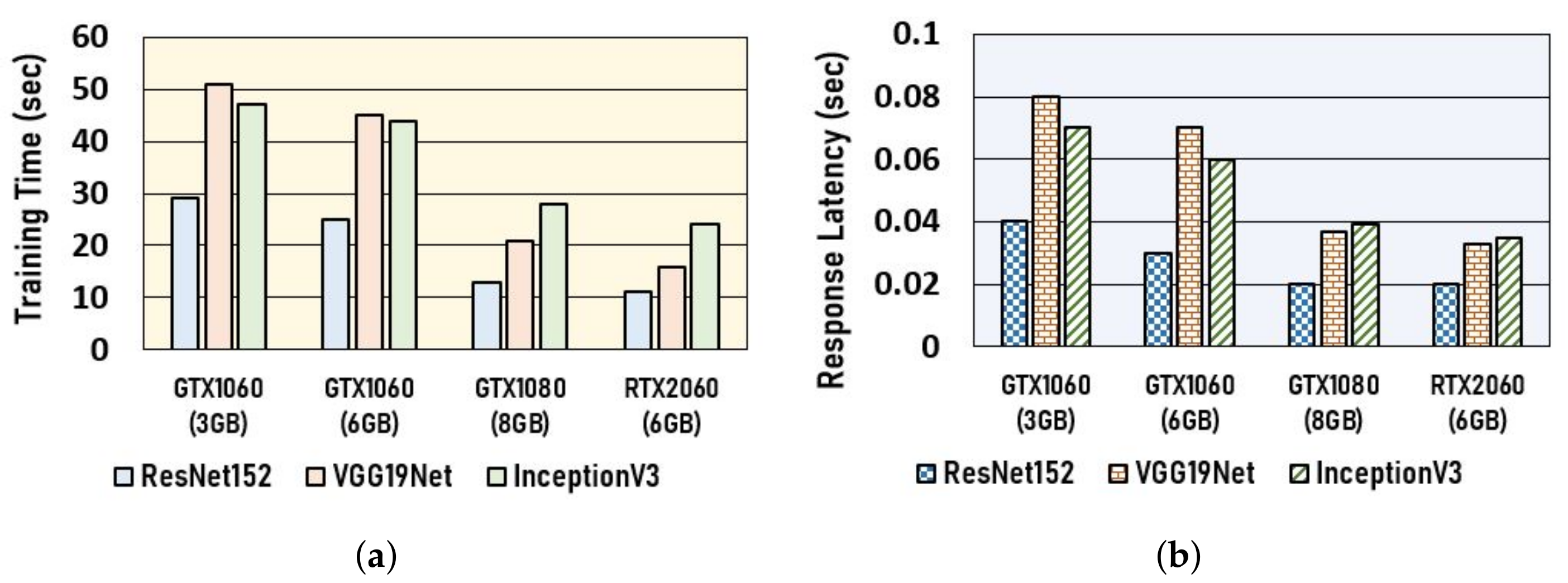
3.1.1. Deep Learning Job Setup
3.1.2. GPU Computing Node Setup
3.1.3. Simulation Testbed Setup
3.1.4. Evaluation Metric
3.2. Competitors
3.3. Evaluation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gawande, N.A.; Daily, J.A.; Siegel, C.; Tallent, N.R.; Vishnu, A. Scaling deep learning workloads: Nvidia dgx-1/pascal and intel knights landing. Future Gener. Comput. Syst. 2020, 108, 1162–1172. [Google Scholar] [CrossRef]
- NVIDIA. Available online: https://www.nvidia.com/en-us/ (accessed on 6 December 2021).
- Gu, C.; Li, Z.; Huang, H.; Jia, X. Energy efficient scheduling of servers with multi-sleep modes for cloud data center. IEEE Trans. Cloud Comput. 2018, 8, 833–846. [Google Scholar] [CrossRef]
- Kang, D.K.; Ha, Y.G.; Peng, L.; Youn, C.H. Cooperative Distributed GPU Power Capping for Deep Learning Clusters. IEEE Trans. Ind. Electron. 2021. [Google Scholar] [CrossRef]
- Ghamkhari, M.; Wierman, A.; Mohsenian-Rad, H. Energy portfolio optimization of data centers. IEEE Trans. Cloud Comput. 2016, 8, 1898–1910. [Google Scholar] [CrossRef]
- Kwon, S. Ensuring renewable energy utilization with quality of service guarantee for energy-efficient data center operations. Appl. Energy 2020, 276, 115424. [Google Scholar] [CrossRef]
- Han, Z.; Tan, H.; Wang, R.; Chen, G.; Li, Y.; Lau, F.C.M. Energy-efficient dynamic virtual machine management in data centers. IEEE/ACM Trans. Netw. 2019, 27, 344–360. [Google Scholar] [CrossRef]
- Hu, Q.; Sun, P.; Yan, S.; Wen, Y.; Zhang, T. Characterization and Prediction of Deep Learning Workloads in Large-Scale GPU Datacenters. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), St. Louis, MO, USA, 16–18 November 2021; pp. 1–15. [Google Scholar]
- Wang, Y.; Karimi, M.; Xiang, Y.; Kim, H. Balancing Energy Efficiency and Real-Time Performance in GPU scheduling. In Proceedings of the 2021 IEEE Real-Time Systems Symposium (RTSS), Virtual Event, 7–10 December 2021; pp. 110–122. [Google Scholar]
- Mei, X.; Chu, X.; Liu, H.; Leung, Y.W.; Li, Z. Energy efficient real-time task scheduling on CPU-GPU hybrid clusters. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Guan, H.; Yao, J.; Qi, Z.; Wang, R. Energy-efficient SLA guarantees for virtualized GPU in cloud gaming. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 2434–2443. [Google Scholar] [CrossRef]
- Zou, P.; Ang, L.P.; Barker, K.; Ge, R. Indicator-Directed Dynamic Power Management for Iterative Workloads on GPU-Accelerated Systems. In Proceedings of the 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 11–14 May 2020; pp. 559–568. [Google Scholar]
- Bharadwaj, S.; Das, S.; Eckert, Y.; Oskin, M.; Krishna, T. DUB: Dynamic underclocking and bypassing in nocs for heterogeneous GPU workloads. In Proceedings of the 2021 15th IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Virtual Event, 14–15 October 2021; pp. 49–54. [Google Scholar]
- Kandiah, V.; Peverelle, S.; Khairy, M.; Pan, J.; Manjunath, A.; Rogers, T.G.; Aamodt, T.M.; Hardavellas, N. AccelWattch: A Power Modeling Framework for Modern GPUs. In Proceedings of the 54th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 18–22 October 2021; pp. 738–753. [Google Scholar]
- Ran, Y.; Hu, H.; Zhou, X.; Wen, Y. Deepee: Joint optimization of job scheduling and cooling control for data center energy efficiency using deep reinforcement learning. In Proceedings of the IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; pp. 645–655. [Google Scholar]
- Gao, J. Machine Learning Applications for Data Center Optimization (Google, 2014). Available online: https://research.google/pubs/pub42542/ (accessed on 6 December 2021).
- Wang, B.; Liu, F.; Lin, W. Energy-efficient VM scheduling based on deep reinforcement learning. Elsevier Future Gener. Comput. Syst. 2021, 125, 616–628. [Google Scholar] [CrossRef]
- Chi, C.; Ji, K.; Song, P.; Marahatta, A.; Zhang, S.; Zhang, F.; Qiu, D.; Liu, Z. Cooperatively Improving Data Center Energy Efficiency Based on Multi-Agent Deep Reinforcement Learning. Energies 2021, 14, 2071. [Google Scholar] [CrossRef]
- Wu, S.; Li, G.; Chen, F.; Shi, L. Training and inference with integers in deep neural networks. arXiv 2018, arXiv:1802.04680. [Google Scholar]
- Chaudhary, S.; Ramjee, R.; Sivathanu, M.; Kwatra, N.; Viswanatha, S. Balancing efficiency and fairness in heterogeneous GPU clusters for deep learning. In Proceedings of the Fifteenth European Conference on Computer Systems (EuroSys), Heraklion, Crete, Greece, 27–30 April 2020; pp. 1–16. [Google Scholar]
- Wu, W.; Wang, W.; Fang, X.; Junzhou, L.; Vasilakos, A.V. Electricity price-aware consolidation algorithms for time-sensitive vm services in cloud systems. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the Ninth International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Microsoft Computation Network Toolkit (CNTK). Available online: https://github.com/Microsoft/CNTK (accessed on 6 December 2021).
- Federal Energy Regulatory Commission (FERC). Available online: https://www.ferc.gov/ (accessed on 6 December 2021).
- Lin, M.; Wierman, A.; Andrew, L.L.; Thereska, E. Dynamic right-sizing for power-proportional data centers. IEEE/ACM Trans. Netw. 2013, 21, 1378–1391. [Google Scholar] [CrossRef]
- Wu, C.J.; Brooks, D.; Chen, K.; Chen, D.; Choudhury, S.; Dukhan, M.; Hazelwood, K.; Isaac, E.; Jia, Y.; Jia, B.; et al. Machine learning at facebook: Understanding inference at the edge. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, USA, 16–20 February 2019; pp. 331–344. [Google Scholar]
- Carrera, D.; Steinder, M.; Whalley, I.; Torres, J.; Ayguade, E. Autonomic placement of mixed batch and transactional workloads. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 219–231. [Google Scholar] [CrossRef]
- Abe, Y.; Sasaki, H.; Kato, S.; Inoue, K.; Edahiro, M.; Peres, M. Power and performance characterization and modeling of GPU-accelerated systems. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium (IPDPS), Phoenix, AZ, USA, 19–23 May 2014; pp. 113–122. [Google Scholar]
- Cheng, D.; Zhou, X.; Ding, Z.; Wang, Y.; Ji, M. Heterogeneity aware workload management in distributed sustainable datacenters. IEEE Trans. Parallel Distrib. Syst. 2018, 30, 375–387. [Google Scholar] [CrossRef]
- Yao, J.; Liu, X.; Gu, Z.; Wang, X.; Li, J. Online adaptive utilization control for real-time embedded multiprocessor systems. J. Syst. Archit. 2018, 56, 463–473. [Google Scholar] [CrossRef]
- Horvath, T.; Skadron, K. Multi-mode energy management for multi-tier server clusters. In Proceedings of the 2008 International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, ON, Canada, 25–29 October 2008; pp. 270–279. [Google Scholar]
- Belotti, P.; Kirches, C.; Leyffer, S.; Linderoth, J.; Luedtke, J.; Mahajan, A. Mixed-integer nonlinear optimization. Acta Numer. 2013, 22, 1–131. [Google Scholar] [CrossRef] [Green Version]
- GUROBI Optimization. Available online: https://www.gurobi.com/ (accessed on 6 December 2021).
- ANACONDA. Available online: https://www.anaconda.com/ (accessed on 6 December 2021).
- NVIDIA System Management Interface (NVIDIA-SMI). Available online: https://developer.nvidia.com/nvidia-system-management-interface (accessed on 6 December 2021).
- Zhou, L.; Chou, C.H.; Bhuyan, L.N.; Ramakrishnan, K.K.; Wong, D. Joint server and network energy saving in data centers for latency-sensitive applications. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018; pp. 700–709. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| set of DL training jobs | |
| individual j-th DL training job of i-th DNN model | |
| arrived time slot index of | |
| total count of epochs required to be trained in | |
| deadline index for | |
| set of DL inference jobs | |
| number of DL inference jobs of i-th DNN model arrived | |
| at time slot h | |
| response latency bound for i-th DNN model | |
| duration for a single time slot | |
| training completion time per an epoch | |
| response latency | |
| arrival rate of partial workloads | |
| power consumption for DL training jobs | |
| power consumption for DL inference jobs | |
| statistical model coefficients | |
| energy consumption of k-th GPU computing node | |
| electricity price by grid market at time slot h | |
| switching cost | |
| additional penalty cost for soft-constrained problem | |
| decision variable for DL training job allocation | |
| decision variable for DL inference job distribution | |
| decision variable for partial workloads in | |
| distributed to k-th GPU computing node | |
| decision variable for DRS method |
| CE-DLA | EPRONS | PA-MBT | |
|---|---|---|---|
| USD 0–20 | 0.59 | 0.31 | 0.28 |
| USD 20–30 | 0.40 | 0.63 | 0.59 |
| USD 30–50 | 0.01 | 0.09 | 0.13 |
| Soft-Constrained | Hard-Constrained | PA-MBT | |
|---|---|---|---|
| 280, 1700 | 3 jobs (1%) | 9 jobs (3.2%) | 9 jobs (3.2%) |
| 400, 2500 | 45 jobs (11.2%) | 98 jobs (24.5%) | 97 jobs (24.2%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, D.-K.; Lee, K.-B.; Kim, Y.-C. Cost Efficient GPU Cluster Management for Training and Inference of Deep Learning. Energies 2022, 15, 474. https://doi.org/10.3390/en15020474
Kang D-K, Lee K-B, Kim Y-C. Cost Efficient GPU Cluster Management for Training and Inference of Deep Learning. Energies. 2022; 15(2):474. https://doi.org/10.3390/en15020474
Chicago/Turabian StyleKang, Dong-Ki, Ki-Beom Lee, and Young-Chon Kim. 2022. "Cost Efficient GPU Cluster Management for Training and Inference of Deep Learning" Energies 15, no. 2: 474. https://doi.org/10.3390/en15020474
APA StyleKang, D.-K., Lee, K.-B., & Kim, Y.-C. (2022). Cost Efficient GPU Cluster Management for Training and Inference of Deep Learning. Energies, 15(2), 474. https://doi.org/10.3390/en15020474