1. Introduction
Load forecasting is a significant component of distribution-system planning and operation [
1]. By means of predictive models, the pattern of the demand is being investigated, and some electrical generators are assigned to meet this demand at subtransmission and distribution networks, so any large deviation in the forecasting could cause technical and economical problems [
2]. Furthermore, in deregulated power system marketing, all the bidding strategies from both the energy producer and the customer are directly dependent on the forecast demand [
2]. Frequently, there is a delay between awareness of an increase in load demand and the occurrence of that increase. This time allows electrical engineers to perform the task of planning and forecasting to meet the expected demand increase. A load forecast is required in order to determine when an increase on load will occur so that suitable actions can be taken.
The required forecast horizon determines the type of forecasting, whether it is long, medium, or short term. In short-term forecasting, the time span is intended to be 1 h ahead up to 1 week, including daily forecasting (24 h). Many operation activities are done in this short period, such as generator dispatching, unit commitment, voltage regulating, real-time pricing in the energy market, and more. As such, accurate short-term load forecasting methods require data that are mainly associated with the time dimension: historical load, historical weather conditions, predicted weather conditions, and the nature of the day and the season are examples of the required data for the short-term electric load forecast. The following are the generalized important factors for proper load forecast studies [
3]:
Historical load data in megawatts (MW) and megavolt amperes (MAVR).
Weather conditions (temperature, dew point, pressure, sky cover, visibility, wind speed, etc.).
Economic indicators (energy prices, local industrial production, housing starts, etc.).
Time factor (time of the year, the day of the week, and hour of the day).
Customers’ classes (residential, commercial, industrial, hospitals, etc.).
Time factors and weather conditions besides the historical load demand should be handled carefully in electric load forecast studies. The time factor takes into account different scales, such as the months in a year, days in a week, and hours in a day. Also, an index can be utilized in load forecasting studies that distinguish between weekdays and weekends. The second important factor in short-term power demand forecast is how the weather conditions affect the behavior of the load. Various weather variables are considered by different utilities and research engineers to capture the effect of weather conditions (temperature, wind, humidity) on electric load forecast. Utilities widely utilize two factors to capture these effects: the first factor is related to temperature and humidity indices and is usually utilized in summer to capture the effect of heat and humidity on electric consumption. Other indices that are related to wind speed, temperature, and rate of ice falling are utilized in winter. Customers’ classes play an essential role as well in order to define the pattern of the forecast load. Each individual dataset should be inspected manually. However, when there are large datasets to analyze, manually cleaning each data file individually will require substantial time and effort, and automated examination may be the best alternative, using some well-established statistically based methods.
A variety of methods, such as naïve approaches, simple regression analysis, time-series analysis, and methods based on soft computing, have been deployed for short electric load forecast [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23]. Short-term load forecasting was presented using multiple linear regression incorporating polynomial terms in [
4]. Papalexopoulos et al. [
5] proposed a linear regression model incorporating heating and cooling functions, as well as binary variables. SA short-term load forecast is presented in reference [
6] using the application of nonparametric regression inspired by the probability distribution function for the load and some affecting variables. Song et al. [
7] employed a fuzzy regression analysis for short-term demand prediction that encompassed the effect of holidays on the predictive model. Load forecasting was employed by Heinemann et al. [
8] using regression analysis, taking into account two components of loads: temperature-sensitive load and non-temperature-sensitive load. An adaptive short-term forecasting of hourly loads using multivariate regression was applied in [
11]. Krogh et al. [
12] combined regression with autoregression integrated moving average to provide an online load prediction. Artificial neural network (ANN) is used to forecast the electric demand in [
13,
14]: the only data involved in the model are temperature and load data. Short-term load forecasting is implemented utilizing cascaded learning methods parallel with load and temperature records [
15], and this method is called cascaded artificial neural networks (CANNs). A fuzzy neural network is proposed for the short-term load forecast [
16,
17]. Chen et al. [
18] used a non-fully connected ANN for short-term forecasting in order to minimize the training time. In [
19], load pattern based on both weekdays and weekends was modeled. Active selection for training data, k-nearest neighbors, and pilot simulation are incorporated with ANN to forecast the short-term demand [
20]. Ho et al. [
21] designed a multilayer neural network with an adaptive learning algorithm for short-term load forecast. The authors in [
22] used the decision tree ID3 to forecast the load in the long term, while the authors in [
23] applied expert systems besides the ID3 decision tree to forecast the short-term demand.
To the best of our knowledge, this is the only work to compare two machine based learning techniques (ANN and DT) with a regression model. In addition, there is a lack in the literature of utilizing decision tree-based machine learning in short-term load forecasting, so this work focuses on that as well. Many published papers in the literature have not used statistical tests (parametric/nonparametric); hence, results cannot be verified without using statistical tests [
24]. Therefore, this paper applies statistical tests in order to verify the results and examine whether the predictive model that has been used produces results that are statistically different or not.
This paper is organized into four sections: (1) introduction in
Section 1, (2)
Section 2 shows the datasets and methodology, which include the proposed approach, brief information of datasets for the experimental demonstration, data preparation and correlation analysis; methods for load forecasting (such as DNN, ANN, DT implementation), and model performance criteria, and (3)
Section 3 presents the results and discussion for three different type of forecasting (per hour, per day, and per week), and (4) the conclusion is presented in
Section 4.
2. Datasets and Methodology
The proposed approach is shown in
Figure 1, which is a combination of 7 basic steps. These steps are: (1) online/offline dataset collection, (2) data preprocessing, (3) feature extraction, (4) most relevant feature selection, (5) AI model development, (6) forecast value extraction, and (7) result comparison. The collected dataset may be online or offline, which is selected as per the user’s application. After collecting the dataset, data preprocessing is performed to eliminate the spikes and fill missing values, if any. Generally, spikes and missing values in the dataset occur due to several issues/reasons, such as unwanted weather conditions and/or instrumental/operational/technical and human error. After preprocessing the dataset, feature extraction is performed, which includes several possible combinations of features, such as statistical features (mean, SD, variance, kurtosis, etc.), time-domain features, frequency-domain features, and time-frequency-domain features. Feature selection is performed to select the most relevant input variables/features that affect the performance of the AI/machine learning model for forecasting. Thereafter, forecasting model development is performed, which may include different types of models, such as linear time-series model (AR, MA, ARMA, ARIMA, ARFIMA, SARIMA, etc.), nonlinear time-series model (ARCH, GARCH, EGARCH, TAR, NAR, NMA, etc.), and AI/ML-based model (ANN, SVM, ELM, PSO, GA, ACO, decision tree, etc.). After the model development, training and testing are performed to validate the model performance, and finally obtained results are compared to obtain the best model for future forecasting applications. For more detail regarding demonstration of step-step-wise procedure of implementation of feature extraction and selection, the reader may refer [
25,
26,
27,
28,
29,
30,
31] and [
25,
26,
27,
32,
33,
34], respectively.
2.1. Brief Information on Datasets for the Experimental Demonstration
Short-load forecasting mainly depends on the weather conditions and the previous historical data for the demand. Three datasets have been used in this paper. The first dataset, which is related to the historical recorded power demand, is obtained from Independent Electricity System Operator (IESO) [
35]. These demand readings represent the power demand in Ontario province in Canada. The second dataset is related to the weather conditions which was obtained from Canadian Climate Data—Environment Canada [
36]. Enormous recorded data, including temperature, dew-point temperature, humidity, and others, are obtained in dataset 2. The third dataset was acquired from Independent Electricity System Operator as well [
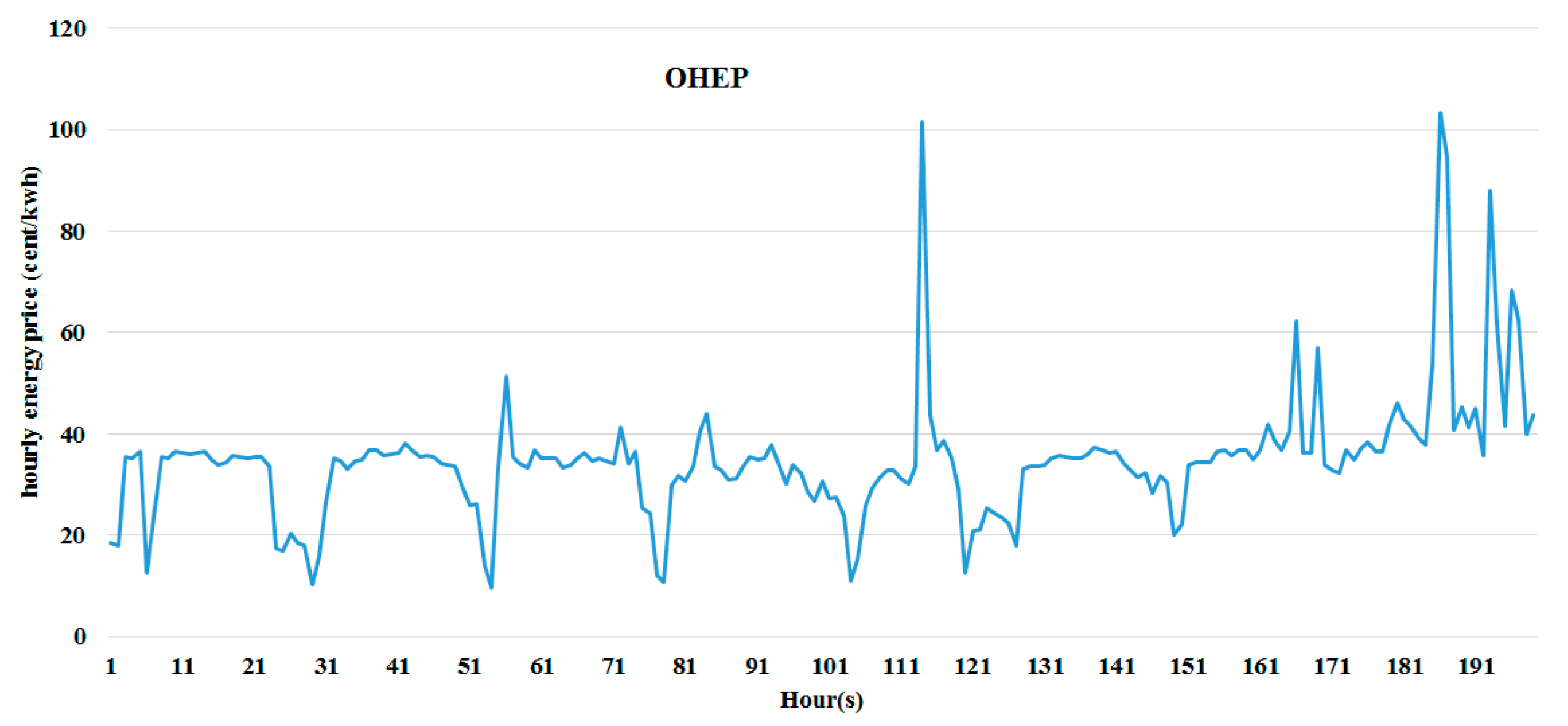
35], and it contains the hourly Ontario energy prices (HOEP). Energy prices play a key role in influencing the load patterns [
37]. Since the dataset for the demand is quite large, a random sample containing 200 hourly readings from dataset 1 is generated. Then, the other variables in the remaining datasets are mapped into this hourly sample. To illustrate, if hour 50 is selected randomly from dataset 1, then all the predictors’ variables in each dataset in hour 50 will be selected and mapped to this hour to represent the first reading in the new dataset and so on. As such, the new dataset that will be used in the analysis contains 200 readings randomly selected to be unbiased. This sample was selected randomly using PHStat package [
38]. Because the model is about to forecast the load for a short period of time, the hourly power demand is selected to be the dependent variable (model’s output), while the other variables shown in
Table 1 are independent variables (model’s inputs). All the variables are numeric. It is worth mentioning that the predictor PW (previous week load for the same time) implicitly includes whether this hour in weekdays or weekends. Therefore, it gave an advantage for the model to transfer the categorical predictors into numeric predictors, making the model easy to implement. Moreover, dataset characteristic is shown in
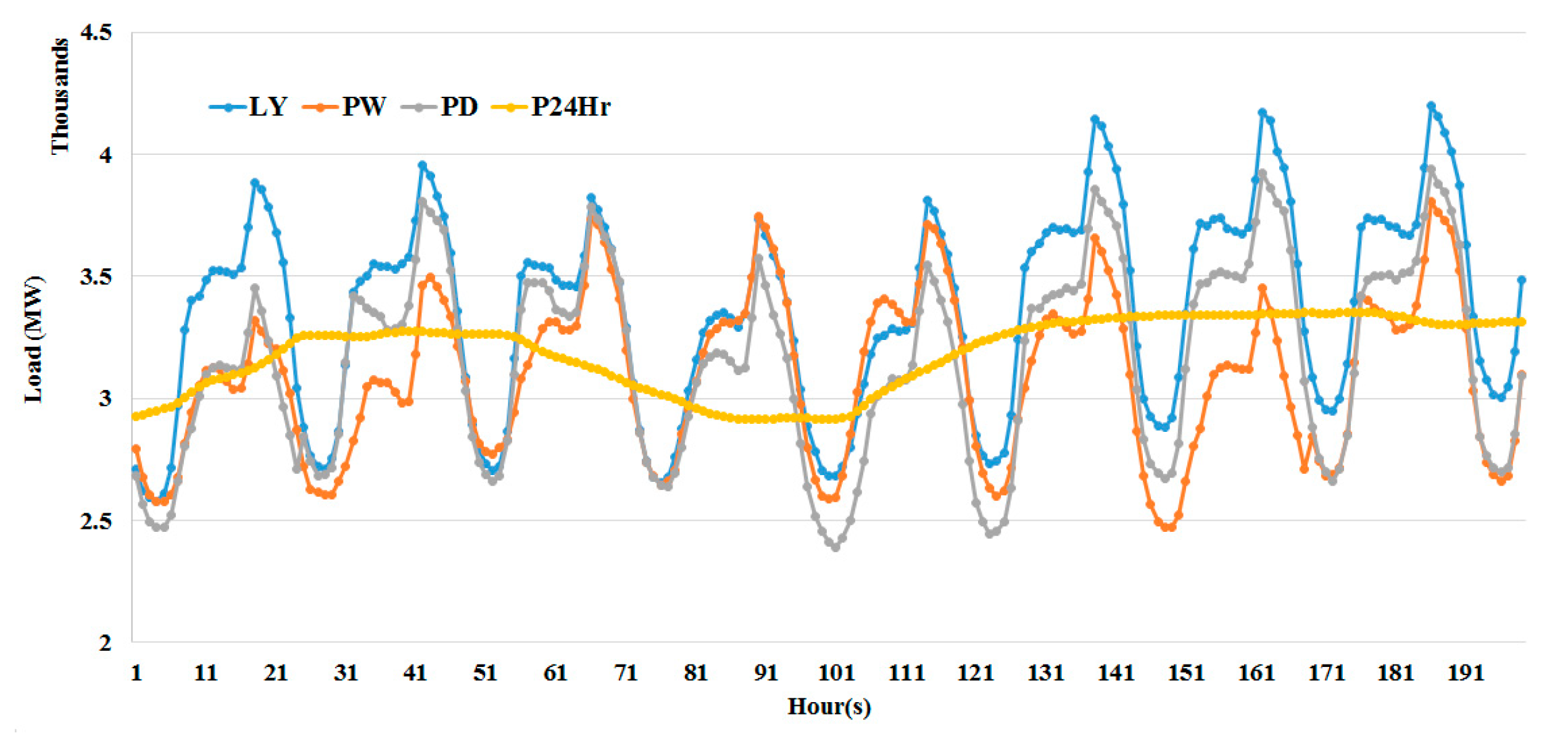
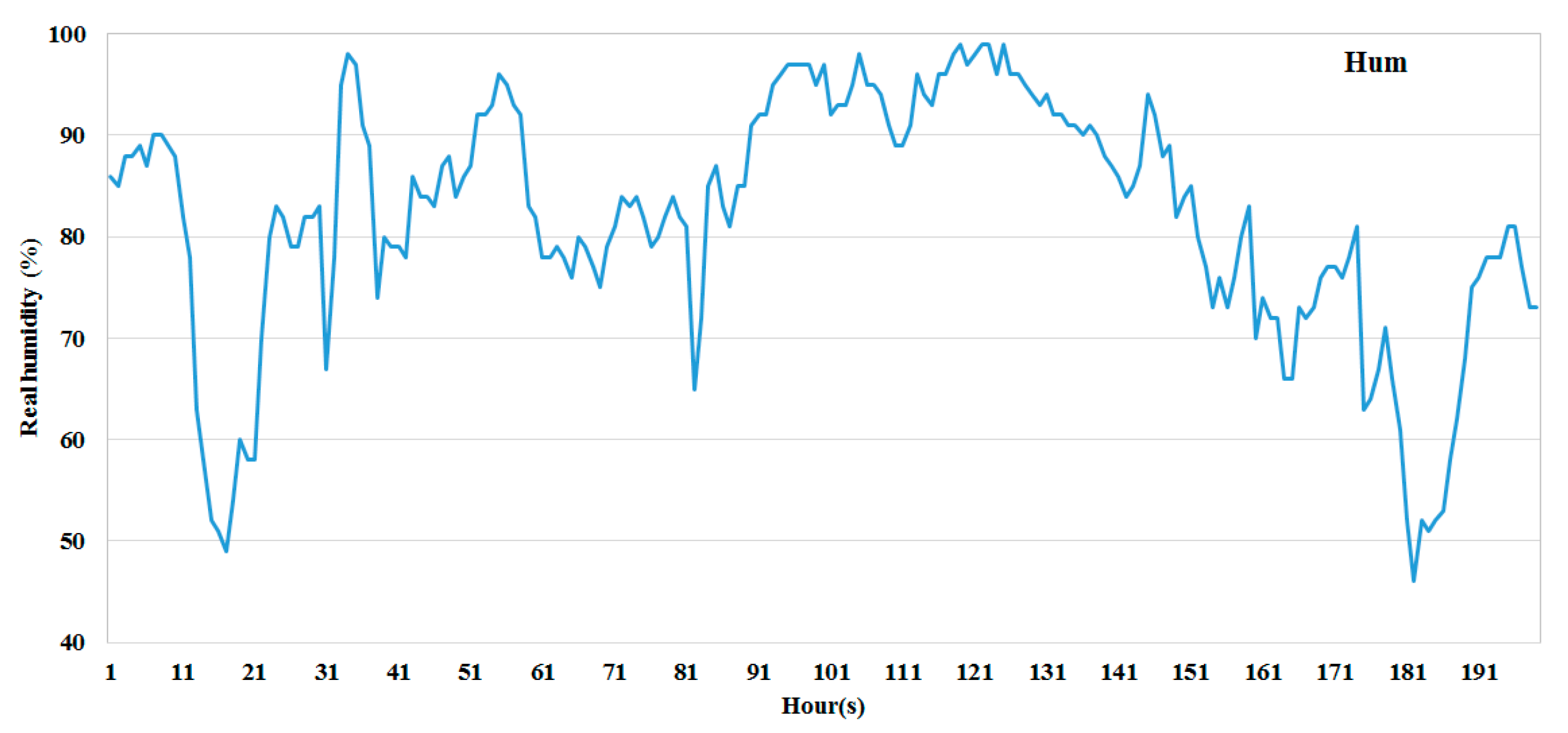
Table 2 and are represented graphically in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7.
Data Preparation and Correlation Analysis
The data preparation procedure for the predictive models is common in most steps, especially in the preparation stage. The independent variables and dependent variables should be clearly distinguished. All data in this work are numeric. Then, the outliers are tested before applying any machine learning-based methods. Dixion’s Q test [
39] is applied in order to identify the outliers in the dataset. In Dixion’ Q test, it is assumed that all data values come from the same normal population. The alternative hypothesis is that the smallest or largest values are outlier at a 5% significance level.
For multiple linear regression, stepwise regression is applied first in order to consider only the predictors that are statistically significant at 95% confidence. Descriptive analysis should be obtained, especially the coefficient of skewness (CS) and coefficient of kurtosis (CK). When CS is ranging between −0.5 and 0.5, this indicates that the data are relatively symmetric. The conditions of applying multiple linear regression should be tested before applying MLR, as stated previously. It has been found that the conditions to apply the MLR model, such as the normality of variables’ distribution and the linear relationship between the output variable and the predictors, are not met, so we used MLR with logarithmic transformation. Lastly, cross-validation with leave-one-out (LOO) was used in the model development. For machine learning methods, the models were trained and tested using the LOO technique. It is important to state that in machine learning techniques, all predictors were considered as inputs. This is because a predictor that was not considered significant in the regression model might be significant in machine learning-based models.
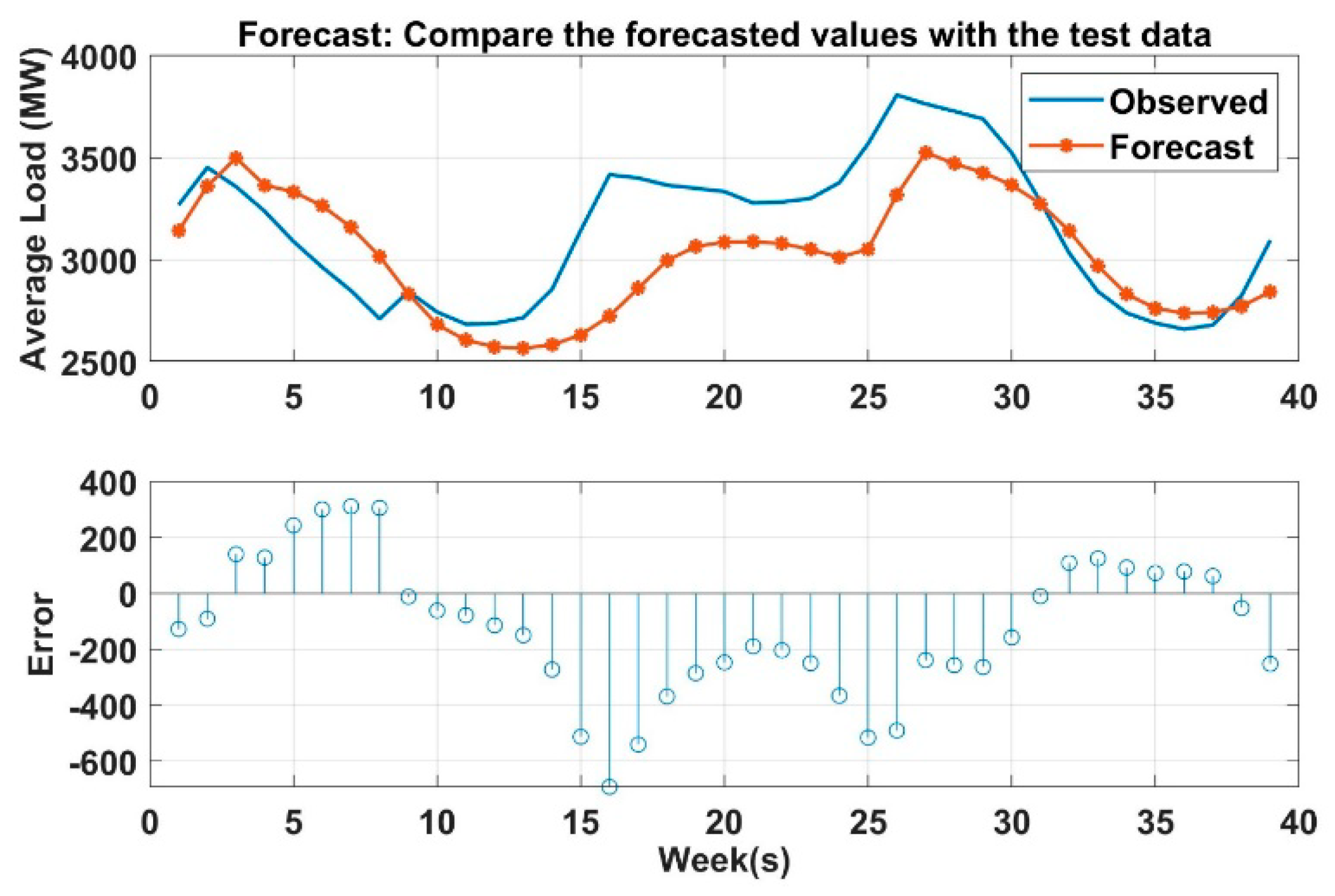
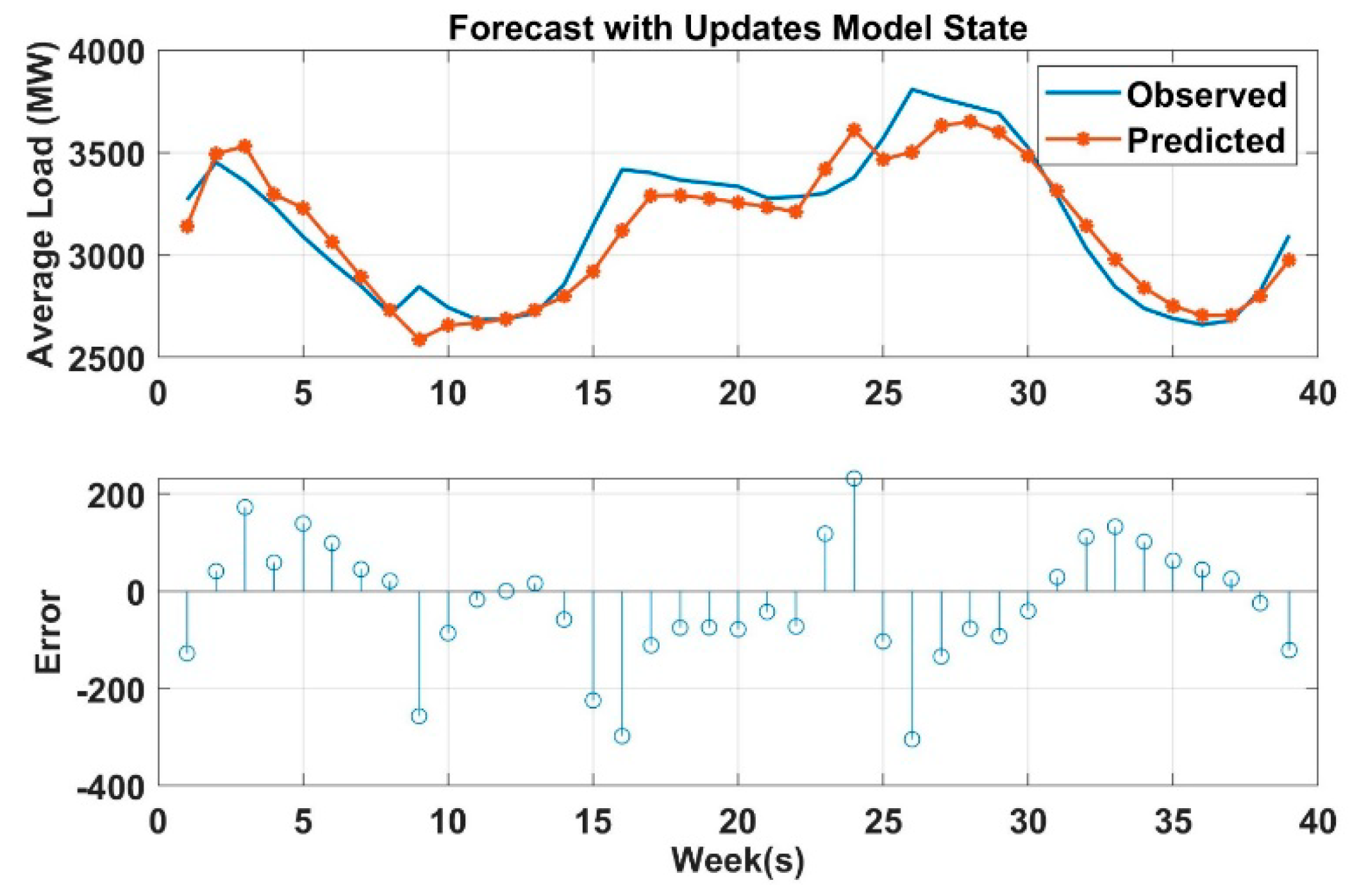
It is worth mentioning that the three models were trained/tested using the same datasets with LOO validation. This is to ensure that the comparison among these three models is fair and unbiased.
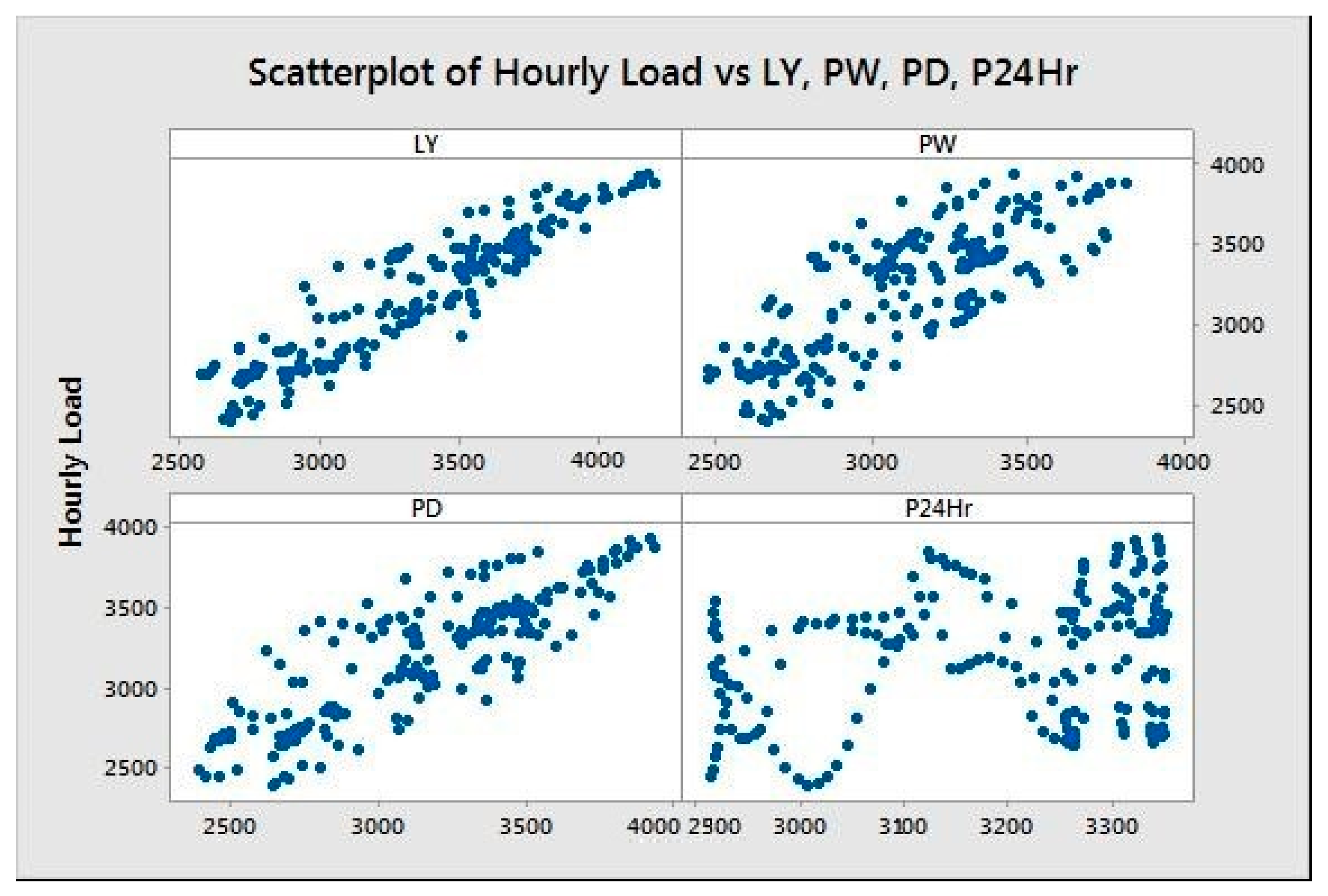
Figure 8 shows the relationships between the hourly load and the independent variables LY, PW, PD, and P24Hr.
2.2. Methods for Load Forecasting
Short-load forecast mainly depends on the weather conditions and the previous historical data for the demand. Three datasets have been used in this paper. The first dataset, which is related to the historical recorded power demand, is obtained from Independent Electricity System Operator (IESO) [
35].
2.2.1. Deep Neural Network (DNN)
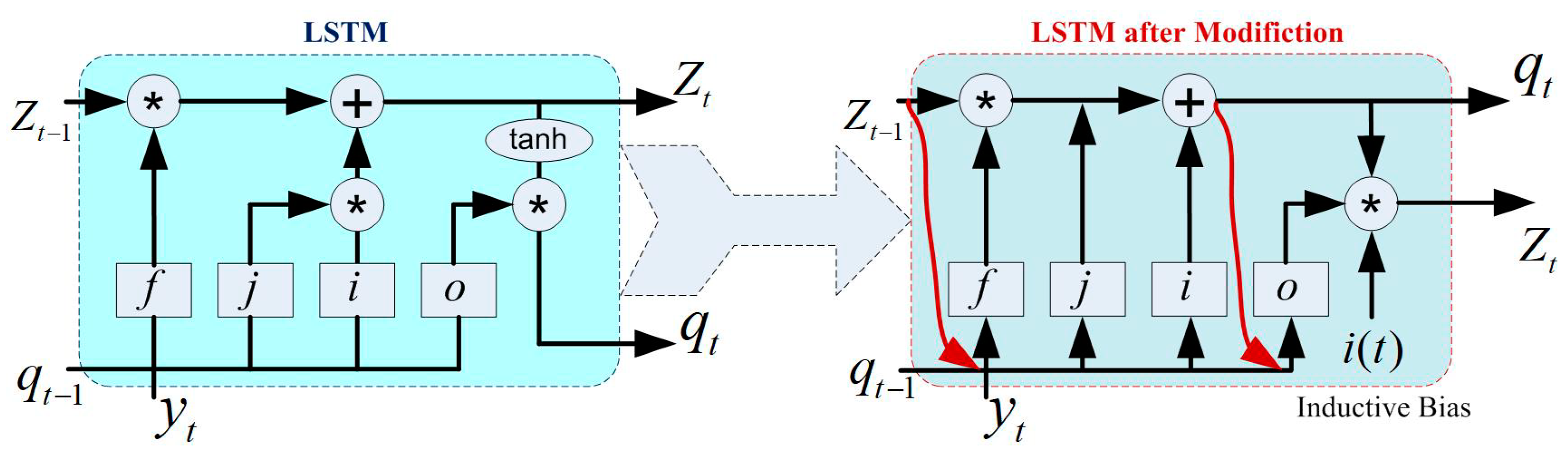
In the DNN, CNN is a type of ANN, which is the most implemented technique. But CNN is limited to the flow of parameter sharing and sequence data. After that, RNN is introduced to overcome these problems. At the same time, RNN has limited memory to store the operation of each stage and suffers from gradient problems [
25,
26,
27], such as vanishing or exploding, etc. To resolve these problems, an advanced version of RNN was formulated, LSTM, in 1997 [
32]. LSTM also works based on the sequential structure of 4 states. In this study, a modified LSTM is developed, which may adapt inductive bias to compensate the missing cases. The modified LSTM, along with standard LSTM architecture, is presented in
Figure 9. The reader may refer to [
25] for mathematical implementation for more detail. The implementation of DNN based time-series forecasting includes the following steps: (1) load the dataset, (2) formulation of training and testing data file, (3) standardize both training and testing dataset for a better fit from the diverging, (4) define the DNN network architecture (i.e., hidden unit, layers, learning option, threshold, learning rate, search method, number of epochs, etc.), (5) train the DNN model (using function trainNetwork), (6) forecast future time steps (using the function of predictAndUpdateState), and (7) update the DNN network state with observed values. For more detail regarding LSTM implementation, the reader may refer to [
25,
26,
27,
32].
2.2.2. Artificial Neural Network (ANN)
An artificial neural network is a machine learning type that uses the biological neural network as an inspiration for study [
28,
40]. The critical point of using ANN is estimating a mathematical function that relies on a huge amount of data with undescribed behavior. It consists of a fair number of interconnected neurons that capture the input parameters and direct them into a learning algorithm to compute the output values. A multilayer perceptron (MLP) is a feed-forward operation mechanism and is the most commonly used model among ANN models [
33,
40]. The primary function of an MLP model is to assign a group number of inputs to suitable output nodes. From its name, MLP has many layers that are fully interconnected in directed graphical representation. An activation function is required to operate all nodes, excluding the input node, this function being mostly a nonlinear function, and some cases have a linear activation function. It is essential to mention that the back-propagation technique, one of the supervised learning algorithms, can be used to train the network in multilayer perceptron ANN.
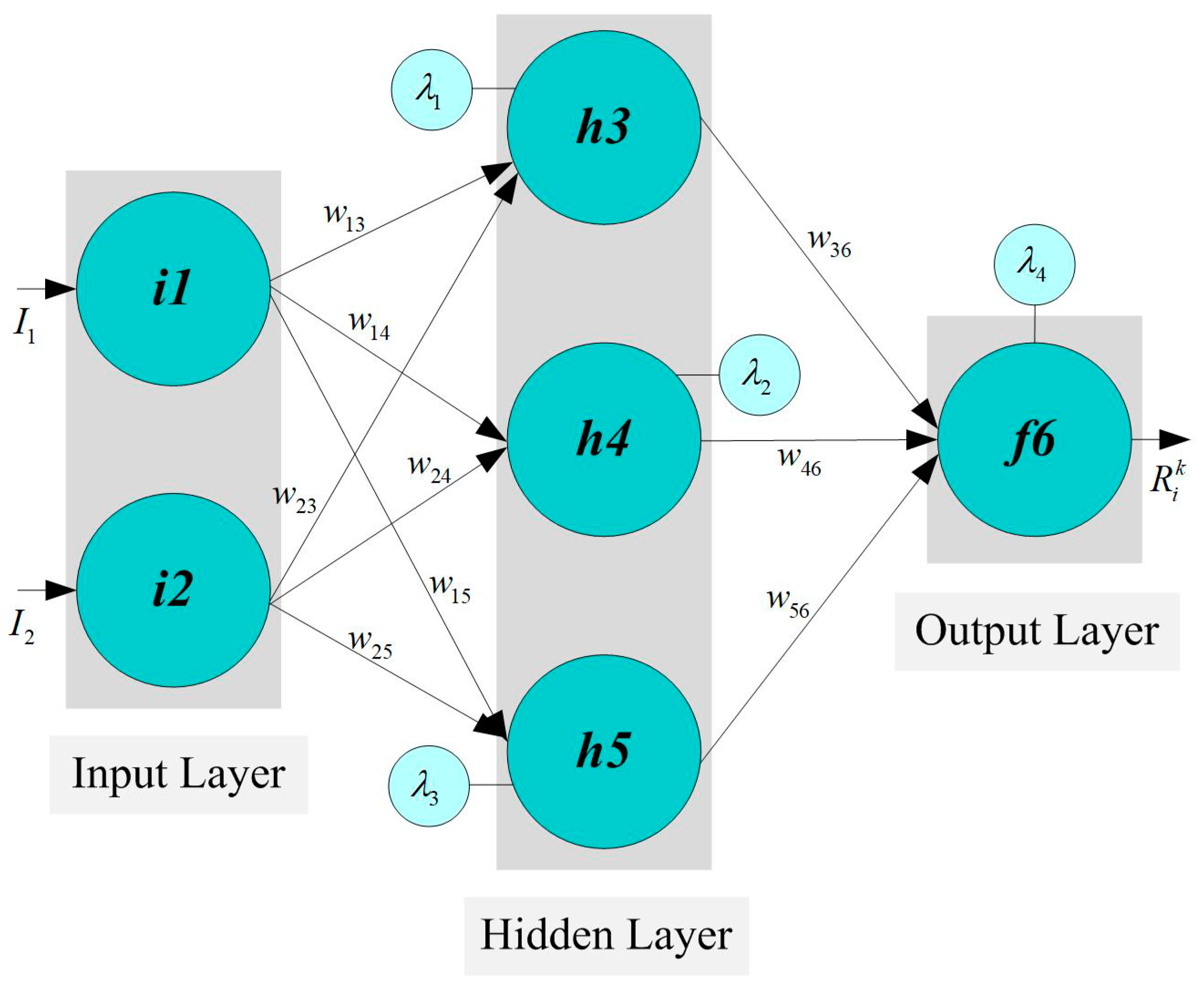
Generally, N layers indicate that there are N non-input layers of processing units and N layers of weights since the input layer is excluded as stated before.
Figure 10 is an example of multiple-layer MLP. The relationships between these layers is described in the following equations:
where
f is the activation function, w is the weighting factor,
z is the number of neurons in the hidden layer, and
t is the total number of inputs in the first layer.
The nonlinear activation functions in MLP provide flexibility to the model in order to capture the variations in action potentials of biological neurons. The activation function should be normalized and able to be mathematically differentiated. There are two main activation functions widely used in the field of ANN. These functions are hyperbolic tangent and logistic function, and both are S-curve functions (sigmoid function). Hyperbolic tangent ranges −1 to 1, while logistic function ranges 0 to 1. Each node is connected to another node in the next layer with weighting factor, and these factors as summed using the following formula:
Training neural network models in power-demand forecasting could be done offline or online. Neural network offline training depends on the input–output set, which is prepared to learn the neural network, and the use of neural network with data outside the training range may cause false results. The use of online training makes the network adapt itself to change in the dynamics of the system. The data collected for online training could contain bad data due to sensor errors. The network will respond to the bad data and produce an output that endangers the operation of the whole system, and this is the main factor that limits the use of neural network to online application in practice. In this paper, ANN is used as an offline application to predict the next 24 h loads and the next-week hourly loads.
2.2.3. Decision Tree (DT)
Decision tree is an effective algorithm in machine learning inspired by identifying a certain pattern to data in order to sort or predict events such that the goal is to optimally construct the decision tree with minimum generalization error [
22,
29]. In fact, decision tree is a pattern classification for trained subsets or objects in which the values of the properties of these objects are tested [
22]. Decision tree structure starts from the first or initial node and ends up at the downstream nodes. The property of every node in the decision tree is evaluated using gain-below methodology. The procedures of decision tree can be summarized in the following steps:
- A-
Initial node is selected and assigned to a discretional attribute value A.
- B-
The border value of A is determined and the partition entropy aroused by value A is calculated; after that, the minimum one will be selected.
- C-
For all attributes, gain below will be calculated and the attribute that has highest gain will be considered. The selected attribute will be the sort basis for the tree and the decision tree will be expanded at this particular node.
- D-
The procedures above will be repeated until two main points are reached:
- 1-
Every node has only one node left and this node is called leaf node where there is no more expansion.
- 2-
The gain factor reaches the stopping criterion where there is no more sorting process.
Decision tree inducers can be classified into two types or conceptual phases [
29]:
- 1-
Growing and pruning phase like C4.5 [
34], CART [
28], and M5 [
29].
- 2-
Growing phase like ID3 [
31].
M5 algorithm, which is used in this work, was constructed by Quinlan in 1992 for inducing trees of regression models [
34]. It works initially by constricting a tree using induction. In order to reduce the intra-subset variation for the class values under each branch, a splitting methodology is utilized. Then, a back-pruning technique from the leaves is performed. Lastly, a smoothing step is applied to avoid the discontinuities among the subtrees. For more detail regarding DT implementation, the reader may refer to [
22,
28,
29,
31,
34,
37].
2.3. Model Performance Criteria
Several performance criteria have been proposed in the literature to evaluate the performance of predictive models. Mean magnitude relative error (MMRE), which is the average of residual error by the actual value, is a very popular performance criterion, but it was criticized, because it is biased and caters to models that underestimate [
41]. For this purpose, the coefficient of determination R
2 and mean absolute residual MAR are used as evaluation criteria. Moreover, the time that each model takes for training is also considered. When R
2 gets closer to 1 and MAR gets closer to the zero, the accuracy of the model is very high. MAR depends on the unit of the predicted value. For instant, if the unit of the predicted value in megawatts (106 watts), it is reasonable to have some kilowatts as an error.
R
2 (the coefficient of determination) is a number (equal or below 1) that describes how well the data fit the regression model. It varies from 1 (when the regression line passes through all the data) to 0 (when there is no correlation—poor correlation). Mean absolute residual is measuring how far the predicted values are to the actual values. Clearly, the model is accurate when MAR is getting lower.
where
is the actual value,
the estimated value,
the average value of
and
n the total number of observations.
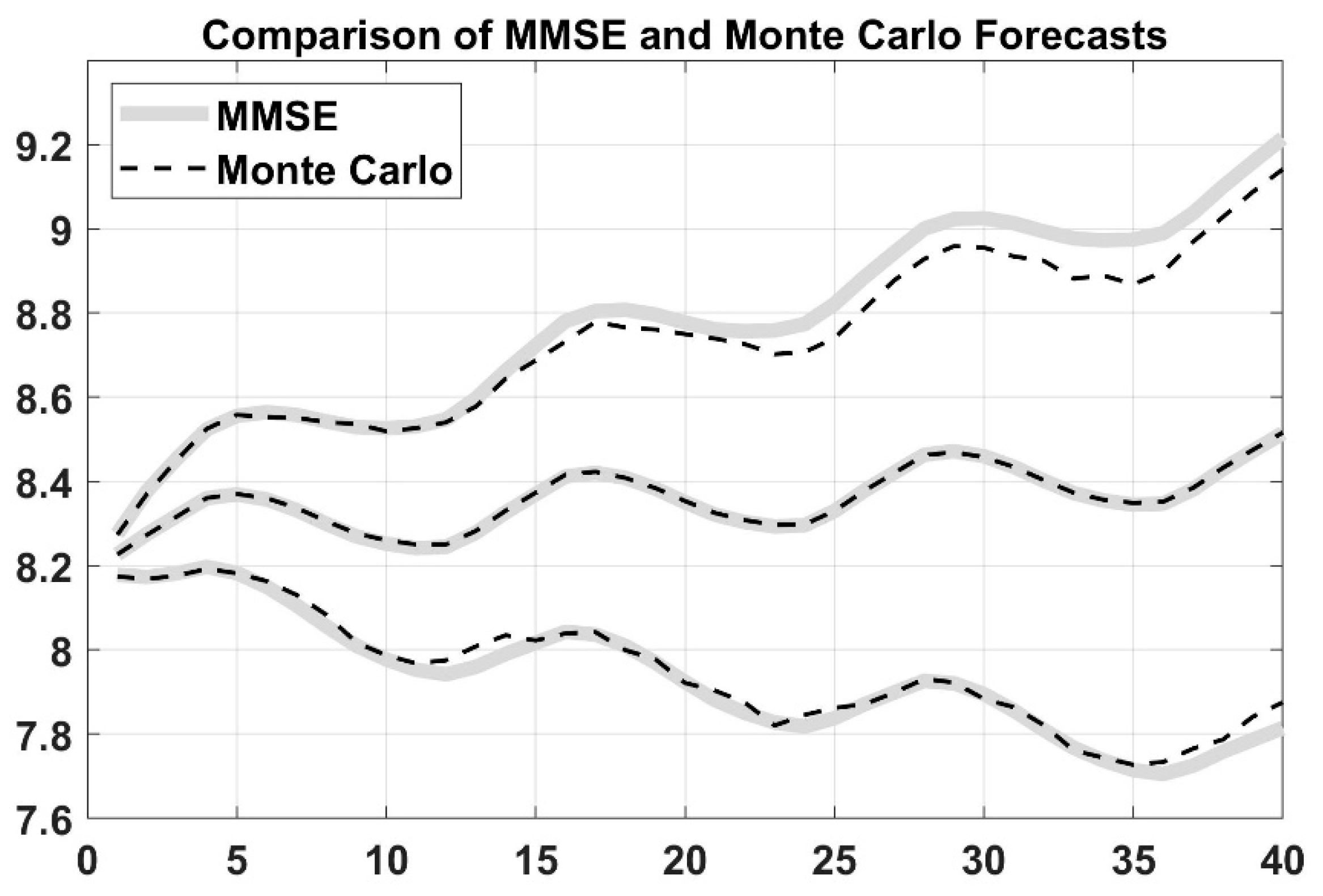
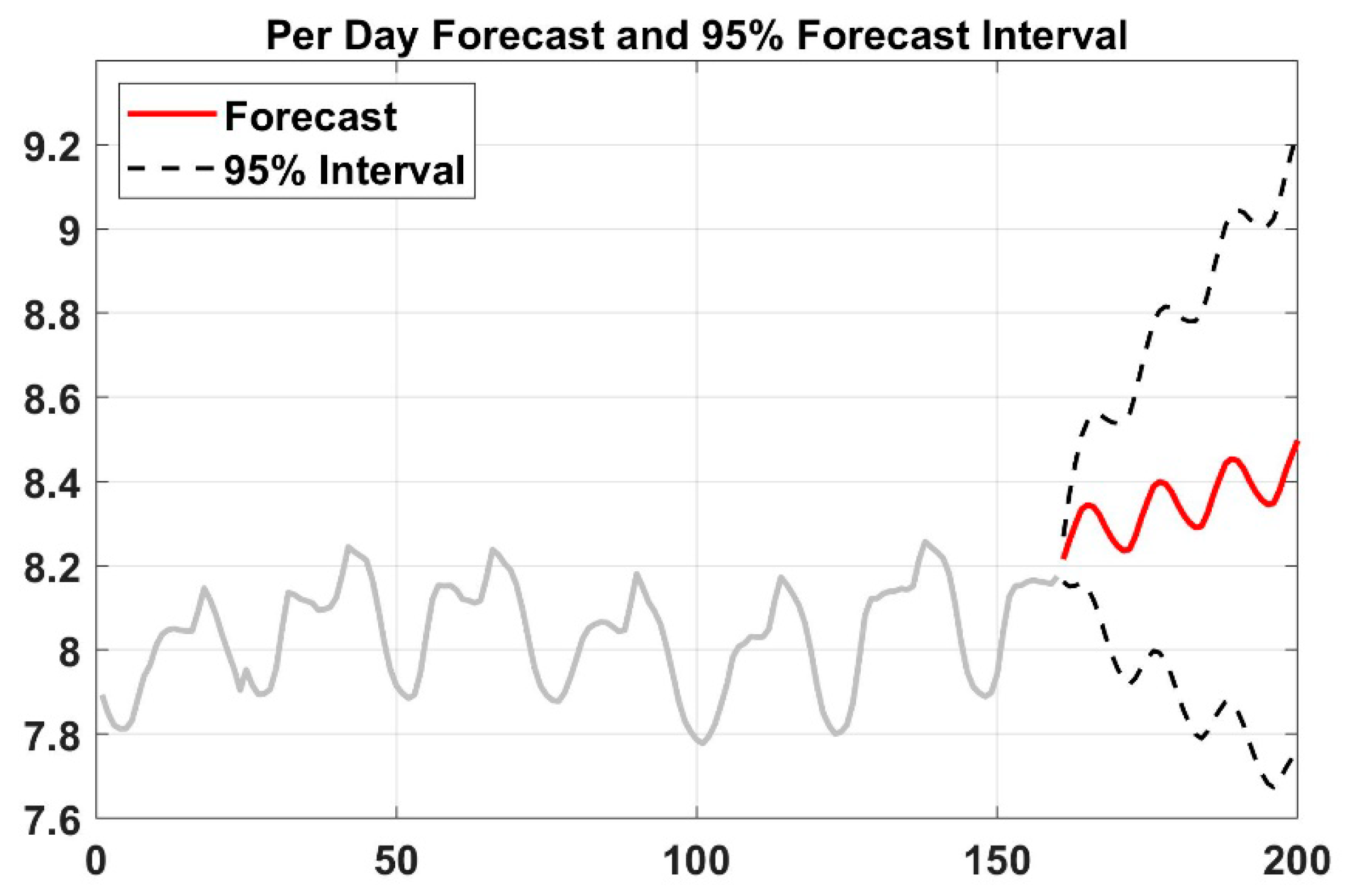
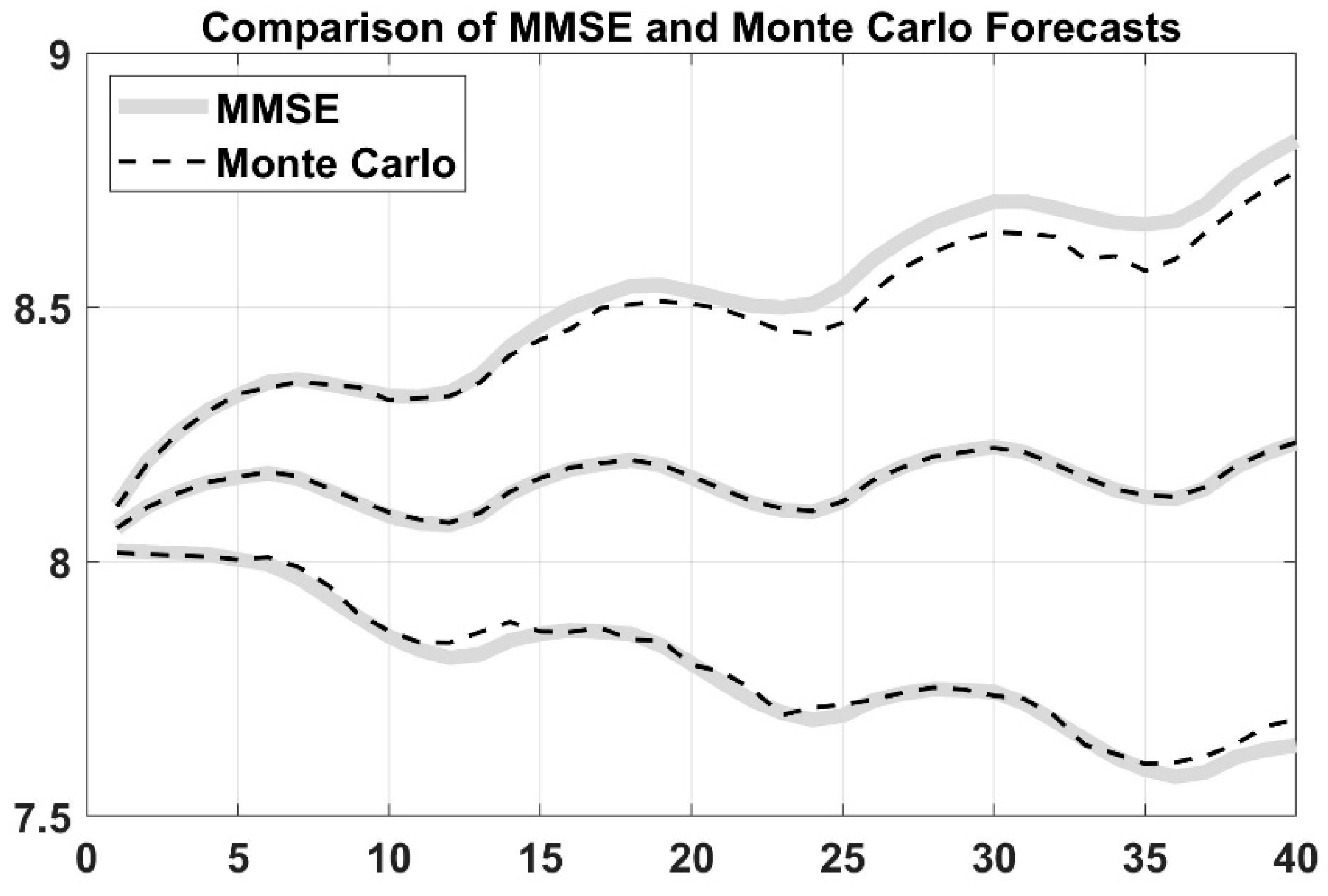
To examine whether these three models are statistically different or not, statistical tests (i.e., ARIMA and Monte Carlo method) are implemented. It is checked first if the conditions, such as the distribution of data and the value of variance for using parametric tests, are satisfied. If the results from the tests reveal that these conditions were not satisfied, then author used the nonparametric Kruskal–Wallis test to compare the different models.
4. Conclusions
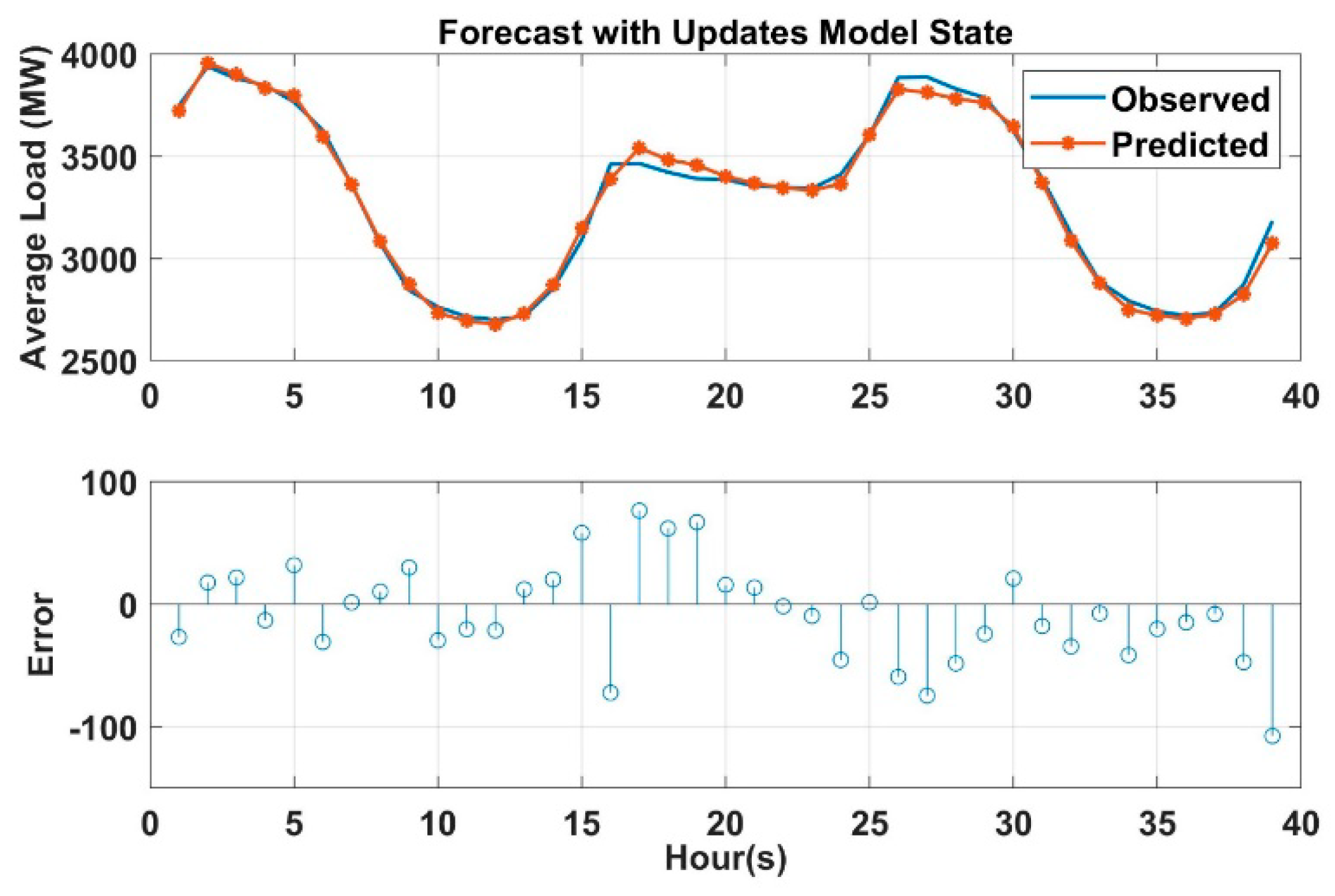
Load forecasting in power system is a very important daily duty in the operation section. Many activities in power system (or in power system planning) used the output from load prediction models as an input to their operation. For an example, LF (based on 1 week to 1 year) is required for maintenance scheduling. Similarly, LF (based on 1 min to 1 week) is required for unit commitment analysis (UCA), economic load dispatch flow analysis (ELD-FA), and automatic generation control and scheduling (AGCS). Therefore, it is very crucial to build an accurate and efficient predictive model to handle the uncertainty caused by load fluctuation. In this paper, three predictive models are created to predict the power load for short term period (i.e., 24 h to one week) to meet the demand and supply equilibrium, which is very helpful to the maintenance scheduling, UCA, ELD-FA, AGCS and PS dynamic analysis. These models prove its effectiveness and accuracy to predict the load. DNN, artificial neural network, and decision tree-based prediction are used in this paper. DNN performance is also validated based on ARIMA and MC method. As shown in the results, LSTM based DNN has the higher coefficient of determination R2 among all models, and it has the lowest mean absolute residual. However, ANN takes more time for building and training the models compared to the others. Decision tree-based prediction algorithm has R2 equals to 0.9 which is lower than ANN. The mean absolute residual of the decision tree model is lower than MLR and higher than ANN. The lowest R2 value compared to the other is for multiple log-linear regression and it also has the higher MAR. However, with respect to the time taken to develop the model, DNN is very fast compared with ANN and DT. Broadly speaking, in the field of large power system, it is acceptable to have a few kilowatts errors in the forecast load since the total load is measured by megawatts or gigawatts, and it can been seen the differences between the MAR are relatively small. After conducting the Kruskal–Wallis nonparametric test, one can conclude that there is statistical significant difference between all the models at 5% level of significance. This work is also validated with stochastic time-series methods such as ARIMA and MC simulation which are very useful in short term prediction as well. This work can be applied to predict the micro-grid operation in power system by forecasting both renewable resources output and the existing demand output and making multiple relationships between the sources and demands. To sum up, machine learning algorithms and regression analysis provide an efficient and fairly accurate estimation for the power system demand.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}