1. Introduction
The vapor compression refrigeration cycle is an essential system that has been widely used in residential, commercial, and industrial sections, including refrigerators, refrigeration air conditioning, freezers, and air conditioning systems. Different types of refrigeration systems are used depending on the application. In the commercial sector, the multiplex direct expansion system is used for refrigeration systems in supermarkets. These systems typically use compressors and air-cooled condensers with axial blowers (working together) for the heat rejection process [
1]. The main components or elements of these systems are compressors (C), evaporators (E), condensers and thermo-expansion valves (TEV). The evaporative condensers can be used in these systems, reducing condensing temperature and optimizing energy consumption [
2]. Another feature of vapor compression is its ability to gain low evaporating temperatures. This action can be done while keeping a large cooling capacity per unit of power input to the system [
3]. As mentioned, in addition to refrigerators, the VCRS is used in air conditioning systems which are available in several types having different refrigerants depending on their purposes [
4]. According to research performed on a refrigeration system by Frenkel and Khvatskin, when a fault occurs in a machinery’s single unit or item, a harmful effect on the whole system will not be caused because of the system’s nature. However, the system’s cooling capacity will be reduced. However, when a component such as a compressor or the axial condenser blower fails, both partial system failure and complete system failure can occur. The components and subsystems of the refrigeration systems have arbitrary finite-state numbers, which means that due to various performance rates, the system may have different corresponding states. Hence, the refrigeration system is a Multi-State System (MSS). MSS models have been analysed and studied by researchers [
2,
5].
Since the components and subsystems in refrigeration systems have arbitrary finite-state numbers and could vary from perfect functioning to complete failure, the whole system is considered a multi-state one [
1]. In these types of systems, the availability percentage of each unit has an impact on the whole system’s performance rate. Thus, having different numbers of the available units leads to various levels of task performance [
2].
The reliability and optimization analysis and studies require mathematical formulations for the vapor compression refrigeration cycle. The term reliability has its origin in the failure analysis of electronic equipment for military use during the 1950s in the United States. Based on the literature, the system or product’s reliability is defined as the probability of performing the intended function for that system or product during a specific time horizon. This performance should be in normal operating conditions [
6,
7].
This research also applies the Failure Mode and Effects Analysis (FMEA) to identify different failure modes of the VCRS and their effects on the whole system. FMEA is used along with Criticality Analysis (CA) by researchers, highlighting the single-point failures requiring corrective action. FMEA can be applied to provide a ranking for the Failure Modes (FMs) of products and components, from the ones presenting the highest risk to those that present the lowest risk for the system [
8]. FMEA also assists the development of test methods and enhances the troubleshooting techniques. Therefore, a foundation for qualitative reliability, maintainability, safety, and logistics analyses can be provided by applying the combination of FMEA and CA, known as FMECA [
9].
A cooling system can be elaborated as a heat engine working in reverse, technically referred to as a reverse Carnot engine. In other words, it is the transfer of energy from a cold reservoir to a hot one. In the primary form of vapor refrigeration compression system, there are four major components: evaporator, compressor, condenser, and expansion valve. External energy (power) is supplied to the compressor, and heat is added to the system in the evaporator, whereas in the condenser, heat rejection occurs from the system. Heat rejection and heat addition are dissimilar to different refrigerants, which cause a change in energy efficiency for the systems. Exergy losses in various components of the system are not the same. The Schematic diagram of a typical vapor compression refrigeration cycle is shown in
Figure 1, including its main components (evaporator, compressor, condenser and expansion valve). To take the heat from the external environment, the evaporator is used. The mechanical compressor, which consumes a considerable amount of energy, performs the suction process of evaporated vapors to compress and expel them at a higher pressure and temperature. The vapor refrigerant condenses in the condenser by transferring heat to the outdoor environment. Finally, through the expansion valve, the liquid refrigerant returns to the evaporator having a lower pressure for the cycle’s repetition [
10].
Various research works and studies have been performed to evaluate different types of refrigeration systems. This section presents the vital relevant publications and research works. According to the recent literature, energy analysis and reliability analysis were mainly studied to evaluate such a system’s performance. The authors have thoroughly reviewed recent and relevant publications and presented them here.
For a supermarket refrigeration system, the reliability analysis and calculation have been performed by applying the combined stochastic process and universal generating function methods. Reliability measures for different performance levels are considered for the system’s structure in the decision-making process, and the availability, output performance and performance deficiency are achieved [
1].
Concerning FMEA, various studies suggest different grouping and classifications of FMs for a system. To obtain the weights of risk factors, a consensus-based model is proposed within the FMEA framework. The objective of the research conducted by Hengjie Zhang et al. [
8] was to classify the FMs according to a possibilistic fuzzy approach using linguistic information collected. In addition, they also presented a consensus rule-based optimization approach to minimize the adjustment distance in the consensus-reaching process. This minimization approach assists FMEA members in improving their consensus level. This optimization aims to reach the predefined consensus level among all FMEA members. Finally, the consensual FM risk classes were achieved [
8]. A case study was implemented into an active Scanned Proton Beam (SPB) which is used in radiation therapy. The results of their research present the benefits of applying a Possibilistic Hesitant Fuzzy Linguistic Term Sets (PHFLTSs) approach. Since the FMEA members express their uncertain assessments, the PHFLTS has convenience and flexibility for handling hesitancy and uncertainty in practical contexts [
8].
Another study presented an FMEA model based on Personalized Individual Semantics (PIS) [
12]. By applying PIS along with the Linguistic Distribution Assessment Matrices (LDAMs), they used feedback and opinions collected from different FMEA experts to define the failure modes and risk factors. They proposed an incomplete Additive Preference Relations (APRs) which was used for incorporating the experts’ opinions about FMs. In addition, a two-stage optimization method is presented and applied. In first stage, they obtained the complete APRs and identified the PISs. In the second stage, a minimum-based optimization model has been used for consistency improvement which generates a complete APR with an acceptable consistency level. Another optimization model was formulated for minimizing the deviation between the APR and the numerical assessment matrix which is obtained from the corresponding LDAM. Finally, the researchers have ranked the FMs according to their corresponding risk factors. By implementing a case study and performing a detailed comparison analysis, the authors tested the validity of their proposed PIS-based linguistic FMEA model. The results of their study assist risk managers in identifying critical FMs to improve the system’s reliability and safety [
12]. Another study used a Comparative Linguistic Expression Preference Relations (CLEPRs) tool for PISs assessment. This method is helpful in representing uncertain opinions of decision makers in Group Decision Making (GDM). The optimization model formulated and used by the authors assists in assessing individual semantics in CLEPRs and it is used to obtain PNSs of linguistic terms associated with FMEA members [
13].
For Heating, Ventilation, and Air Conditioning (HVAC) systems in buildings, a data-driven fault detection and diagnosis (FDD) model has been proposed and applied in research work. This model is implemented for the Air Handling Units (AHUs) to enable reliable maintenance by considering undefined states. Based on the study’s results, their model could identify undefined and defined data with high performance. Therefore, the results of their research reached the objective of facilitating the maintenance management of AHUs in HVAC systems [
14]. Scholars have also studied the large-scale industrial vapor-compression refrigeration systems to conduct an experimental dynamic performance analysis. This refrigeration system was a conventional industrial type included in a discrete cooling system, which was a cold storage facility warehouse. The energy, exergy, and exergoeconomic aspects were obtained by implementing a real-time data monitoring system for achieving future energy planning. According to the study’s results, future work towards energy management and further profit-making can be done [
15].
The exergy analysis can be applied to different VCRSs based on their applications. Hence, various potential research topics are discovered by scholars. They have reviewed studies in various countries or societies in this field to highlight the importance of exergy analysis in VCRSs. Based on the findings, exergy depends on evaporating temperature, condensing temperature, sub-cooling and compressor pressure and the environmental temperature [
4].
Another critical literature review has been performed for compact and miniature mechanical VCRSs regarding their fundamentals, design, and application aspects [
3]. Their publication has highlighted the thermodynamic and thermal factors for the cooling cycle. The researchers have also reviewed recent advancements of the cooling cycle components such as the compressor, heat exchangers and the expansion device. They have also presented the main issues related to different cycle designs and recent works on new technologies. Various VCRS electronics and personal cooling devices have been compared in their comprehensive review concerning technical information and application [
3].
Regarding maintenance management, research works have been performed for processing plants. To evaluate the technical and economic feasibility of a condition-based maintenance task, an HVAC system in a pharmaceutical laboratory was selected as the case study. The corrective, time-based and condition-based maintenance strategies were chosen and investigated to obtain the most efficient economic strategy. Their research has also implemented a reliability continuous monitoring system to evaluate its cost-effectiveness [
16]. The scholars have provided valuable results for facility service and process plant managers.
Moreover, researchers have recently focused on the environmental impacts of widely used refrigerants applied in air conditioning and refrigeration systems regarding international agreements. The development of such refrigerants has also been considered and studied. Considering the leakage of these systems, equivalent CO
2 emission value has been calculated and analyzed based on the leakage rate and initial charge number of different refrigerants. Different air conditioning and refrigeration systems have been included in this research in terms of their types and sizes [
10].
Identifying failures for VCRS is of particular importance due to the critical role of this system in HVAC systems. In this sense, the main motivation for this research is to enhance the reliability and performance of VCRS improving the HVAC system. Hence, the primary objective of this research is to evaluate the reliability of components as well as whole system to identify pathways to reduce the failure and increase the whole system’s reliability. The system considered for this study is used to provide and supply cooling load for an office building. The analysis is based on a failure database, which presents the failure modes and time-to-failure reports in reciprocating and retaliating systems provided by maintenance management companies and derived from the literature and relevant studies.
In this paper, some basic information about the concept of the vapor compression system is given, and the system’s operations are explained.
In the first part of this work, by collecting data and using relevant references, a reliability analysis was performed on this system to determine the relevant parameters for each random variable (a component in the system). Then, the corresponding reliability parameters and functions are calculated. The second part represents the Reliability Block Diagram (RBD) for the VCRS, which defines and illustrates the components, units, and subsystems established in the whole system. Then, the reliability parameters such as the Mean Time to Failure (MTTF), median value, and the standard deviation, calculated for the whole system are obtained. Using these data, an optimization model based on the Genetic Algorithm (GA) method has been created by the MATLAB software to optimize the system’s reliability. Finally, the impact of modifying the system’s configuration on its reliability improvement is highlighted, and a comparison between the basic system and the optimized system in terms of system reliability is presented.
3. Results
In this section, a concise and precise description of the calculations and results according to the case study are presented, and interpretations of the conclusions of this research are also drawn.
The first part of this section provides calculations for statistical reliability parameters of each component, the subsystems, and the whole system. Then, in the second part, the reliability functions of the components, subsystems and the whole system are calculated and obtained. Finally, in the third part, details regarding optimizing the system’s reliability are shown. The optimized values for each component and the comparison between the original system and the optimum one are also included in the third part of this section.
3.1. Statistical Parameters for Each Component
The statistical parameters of system components, including MTTF, the median time to failure and standard deviation, are calculated by taking the failure density function parameters into account and following the distribution formulas.
3.1.1. Reliability Function
As explained previously, the distribution parameters were obtained from different references and indexed in
Table 1. Then, failure and reliability function depending on the time for each component would be achieved, which are listed in
Table 2.
3.1.2. Mean Time to Failure (MTTF)
This parameter is the length of time a device or other product is expected to last in operation. MTTF is one of many ways to evaluate the reliability of pieces of hardware or other technology.
In some references, a Mean Time Between Failure (MTBF) is calculated. It is computed as the average time between failure occurrences of components, which is applicable to all types of systems. On the contrary, MTTF is generally used for replaceable or non-repairable components or devices in a system and is used in calculation of components failure rates [
25,
26].
MTTF represents how long a product can reasonably be expected to perform in the field considering specific testing. However, it should be noted that MTTF metrics provided by companies for specific products or components may not have been obtained by running one unit continuously until failure. This metric could be alternatively achieved by running many units, even thousands of units, for a specific number of hours [
27]. The MTTF could be calculated by taking the integration of the reliability function between 0 and infinity. These calculations have been conducted for each component in the case study’s system and are listed in
Table 3.
Another important criterion which is considered in the reliability analysis is the Mean Residual Lifetime (MRL) of a component or asset. This parameter is calculated in different studies to find the expected lifetime of a component after its current age. It is usually studied to obtain an optimal burn-in time for a component or asset [
28]. MRL is calculated depending on the component’s failure distribution. In the exponential distribution, due to the memory-less property, MRL is constant and is equal to the MTTF which is 1/λ. Hence, since it is assumed that most of the components used in this research follow an exponential failure distribution, the MRL has not been calculated separately.
3.1.3. Median Time to Failure
This parameter is obtained and used to evaluate the time of reaching the reliability or unreliability of the component to 50%. The median time of components for the case study’s system are indexed below in
Table 4.
3.1.4. Standard Deviation
The Standard Deviation (SD), also represented by the Greek letter sigma σ or the Latin letter s), is a statistical measure for quantifying the variation’s amount or dispersion of a set of data values. For measuring the data’s dispersion in a given dataset about the mean, SD has been widely used in the literature and by researchers [
29].
A low standard deviation is defined when the data points tend to be close to the mean (also called the expected value) of the set. On the other hand, we have a high standard deviation when the data points are spread out over a broader range of values [
30]. In this research, the SD has been calculated for all the components, and the results are presented in
Table 5.
3.2. Reliability Parameters & Functions for the Subsystems and the Whole System
3.2.1. Reliability of the Components
In this section, according to the reliability equations previously shown for each component in
Table 2, the reliability of each component has been calculated for three different times (3000, 20,000 and 35,000 h) and is illustrated below in
Table 6.
In addition, the mean and median time to failure parameters of the air filter and the AHU, which are considered a subsystem in unit A, are presented in
Table 7.
For more comprehensive evaluation and for understanding the change of reliability function for components during their lifetime, the graphical method is more appropriate. Thus, the reliability curve of some of the most critical components is shown in
Figure 3.
It could be seen in
Figure 3 that after 5000 h from the beginning of the unit’s operation, the reliability of some components, such as the cooling tower and compressor will dramatically decrease. On the other hand, according to the same diagram, redundant parts are available in several sections of the system.
The impact of using redundant components for the air filter and the AHU will now be evaluated. First, having three air filters in the parallel configuration instead of one has been assumed and evaluated.
Figure 4 illustrates how the system’s reliability differs while adding two additional filters before the AHU.
Reliability of one air filter having two additional filters compared to an induvial one after 20,000 and 35,000 h of operation will be 21% and 39% higher, respectively.
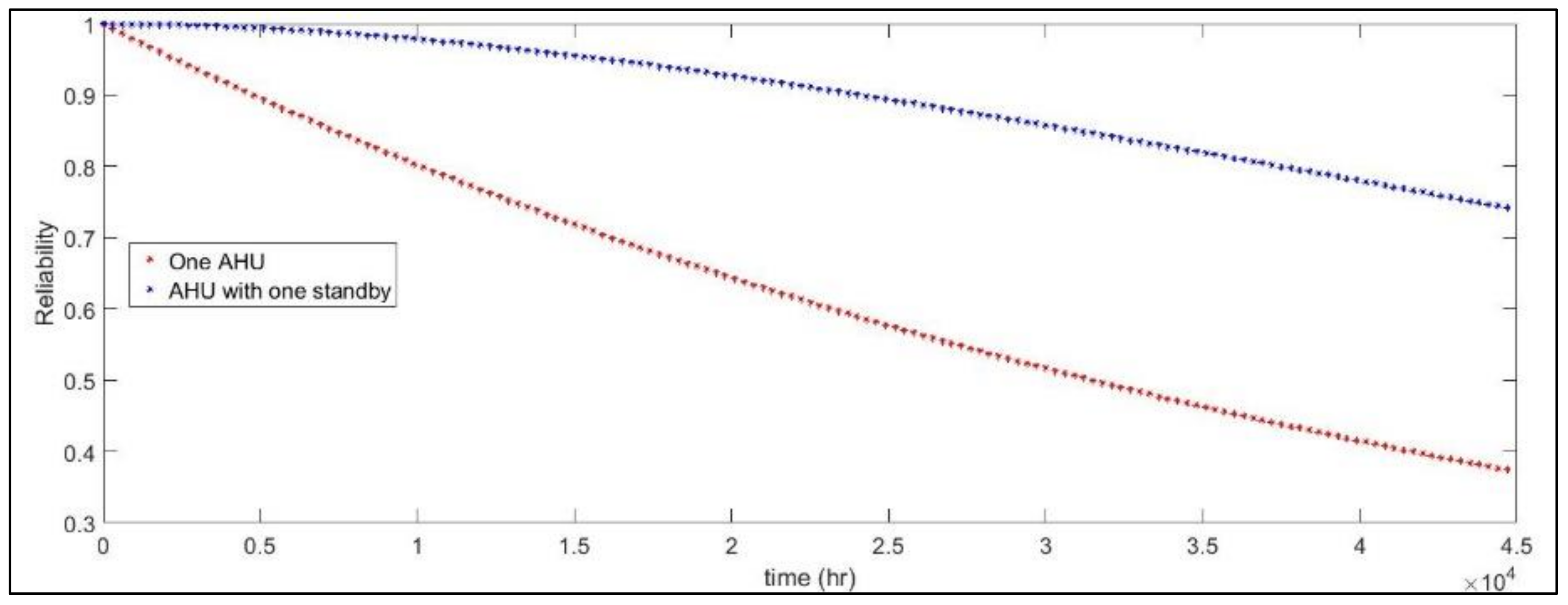
Regarding the AHU, an extra unit is considered a standby state with perfect switching.
Figure 5 shows the variation trend in the case of an individual AHU compared to having an additional standby unit.
Again, adding an AHU in the standby state will increase the reliability compared to the situation with only one stand-alone AHU. The reliability increase is 45% and 77% after 20,000 and 35,000 h of operation, respectively.
3.2.2. Reliability of the Subsystems and Whole System
Unit A consists of compressor, evaporator, condenser, pump, piping, cooling tower, expansion valve, AHU (in standby mode) and air filter (with parallel configuration) which makes the main subsystem of the whole system. Based on the research’s assumption, unit A provides 500 kW and to supply 1000 kW required cooling load, three units the same as unit A are used to supply this demanded load. Taking the reliability of each component into consideration, the equivalent reliability of unit A would be obtained as below:
The reliability curve of unit A is shown in
Figure 6A–D. This curve trend comes with an exponential curve due to multiplying several exponential equations and a linear equation. To assess the most effective components in reducing the reliability of unit A, a parametric study on each component was carried out in this research, and the results of this study are provided in this section.
For this purpose, the time of 20,000 h is fixed, and a range of variation is determined for the component’s reliability. Hence, the influence of the component’s reliability changes on the reliability of unit A could be observed and evaluated. The reliability of unit A at 20,000 h before performing the parametric study was 0.2005.
Four critical components of unit A have been selected in this study and their failure parameters (hazard rates for the evaporator, AHU, cooling tower and for the compressor) varied in the range of 20% higher and 20% lower of the primary value. The time of 20,000 h is fixed and only one failure parameter of a particular component is considered as the variable. Then, the reliability of unit A is calculated based on the variation of that component’s reliability.
In fact, this sensitivity analysis determines how the failure parameter can affect the component’s reliability and, in sequence, illustrates the influence of the reliability of that component on the reliability of unit A. In the case of the compressor, it is observed that the increase in has a lower effect on the compressor’s reliability than its reduction. In general, a 40% fluctuation of can change unit A reliability by 7%.
For the AHU, the impact is not as significant as the compressor, while 40% fluctuation of the compressor’s hazard rate can influence its reliability by 5% and will make a 1.1% change for unit A’s reliability. Evaporator and condenser with the same failure rates have a lower impact on unit A’s reliability since a 40% change in their hazard rates will only create a 1.7% variation in their reliability and a 0.4% change in unit A. Finally, 40% fluctuation of the cooling tower’s hazard rate will affect its reliability and unit A’s reliability by 13% and 4.5%, respectively.
Now, according to the equation below, we consider the whole system with three units of A in 2-out-of-3 configuration having a control system in series.
It is expected that the whole system would experience higher reliability compared to unit A’s reliability because of the 2-out-of-3 arrangement. However, since the reliability of the control system shall be in the series state with other parts of the system, it could compromise the whole system reliability.
In
Figure 7, the diagram compares the reliability profile of the complete system with unit A as well as the system without a redundant unit. For example, in time of 10,000 h, the reliability of unit A, complete system and system without redundancy is 51%, 46%, and 23%, respectively.
3.2.3. MTTF of the Subsystems and the Whole System
To calculate the mean time to failure of unit A, integration unit A’s reliability in the range of 0 to infinity is inevitable. As seen in the equation below, the term under integration is too much complicated and it is solved by numerical methods.
The MTTF of the complete system is also calculated with the same process as unit A although the term under integration becomes more complicated than the preceding one.
3.2.4. Median Time of the Subsystems and the Whole System
Obtaining the median time for unit A (the time of reaching reliability to 50%) due to the complex equation form should be solved by trial and error methods which could be done in MATLAB software. Therefore, this software has been applied in this research for the calculation.
Thus, solving the above equation means that the median time for unit A is 10,323 h. For the complete system, the calculation is conducted similarly by substituting the reliability by 0.5 in the whole system’s reliability function and finding the time.
Hence, the complete system’s median time is 9401 h.
3.3. Optimization
Generally, the optimization term conducts independent variables to a certain point to maximize or minimize dependent variables. Optimization implementation always requires making an algorithm code (such as a genetic algorithm or particle swarm optimization algorithm, etc.) in a programming language (such as FORTRAN, C+, MATLAB, etc.). There would often be particular constraints in each optimization process to limit independent variables. Otherwise, they always tend to go far towards positive or negative infinity.
Before starting the optimization procedure for the current problem, it can be predicted that for maximizing the total system’s reliability, the failure rate of components should lessen. However, we do not have a clear idea in the case of other distributions parameters like Weibull and Rayleigh. With this context, optimization of an independent variable is selected, which considers the distribution parameters to maximize the system’s probability.
As a searching area for the independent variables in this research, we considered 20% higher and 20% lower than their specific value as the threshold in order to perform an algorithm search for the best value among this range while the reliability reaches a peak. A Genetic Algorithm (GA) was coded to carry out this task for this research. Compared to single solution algorithms and methodologies, GA has the ability to process global searching for a population of solutions. It was introduced as a valid optimization method that can adapt and replicate the natural biological evolution process. The process produces fitter solutions which can lead towards obtaining an optimal solution [
31]. Based on a primary guess for the variable in the given range, a couple of outputs from the fitness function are produced.
In the next step, a crossover and mutation process is applied to a certain percentage of variables, and the new population from the fitness function would be created. The new population is merged with previous ones. This cycle would continue to a certain number of trials or generations or can be terminated after a specified computation time to achieve the optimal solution [
31]. Finally, the available population would be sorted, and the highest is found based on the goal, which is a maximization of the problem.
In
Table 8, the optimum variable value for each distribution parameter is shown.
Figure 8 compares the basic system and the optimized one with new distribution parameters over their lifetime.
An increase in reliability percentage between the basic system and the optimized one is given in
Table 9.
Eventually, the MTTF and median time for the optimized system were calculated, and 29% and 32% increases were observed in results compared to the basic system.
4. Discussion
This section discusses the results and provides their interpretation from the perspective of previous studies and of the working hypotheses. The findings of this research and their implications are also included.
In the process of calculating the reliability of some components, because of some limitations in the working conditions and the high cost of such devices, the designers of this system did not consider any redundant devices for these components. This issue may be one of several drawbacks for keep system reliability high over a long period. However, some methods, such as periodical maintenance, could cover this weak point.
Based on the reliability results, applying two additional air filters (three filters in total) for this system could increase the reliability at more operating time. Moreover, adding an extra AHU as a standby state, has the same impact and could improve the reliability significantly compared to the situation having only one AHU. Additionally, some components have shown more criticality in terms of the system’s reliability.
This study determined that improving the reliability of some components, such as the compressor and the cooling tower could improve the reliability of the subsystem (unit A). In contrast, some other components, such as the evaporator and the air handling unit, had little effect on the subsystem reliability.
According to the GA optimization model and regarding the comparison results between the basic and optimized systems, the data illustrate that during the useful lifetime of the system, a significant improvement could happen if there is a chance of modification in the distribution parameters.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}