
Borderline SMOTE Algorithm and Feature Selection-Based Network Anomalies Detection Strategy


 and
and
Abstract
:1. Introduction
2. Literature Review
- (1)
- There are too many features in the dataset. For example, [22] optimized the parameter and weight selection of support vector machine based on a genetic algorithm and combined with feature selection, which improved the intrusion detection rate and reduced the training time of the SVM (support vector machine). However, the dataset used, KDD Cup 99, only had 41 features, while CIC-IDS2017 had 78 features.
- (2)
- Unbalanced dataset: For example, in [21], an unbalanced dataset is used, resulting in a poor detection effect for a few classes.
- (3)
- Binary classification problem and multi-classification problem: at present, most studies are focused on abnormal binary classification problems [23,24]; that is, each classifier can only detect one attack mode; and there is little research on the multi-classification of network attacks based on the CIC-IDS dataset [25]. Not only is this a waste of computing resources, it is also hard to identify different types of attacks.
3. Findings
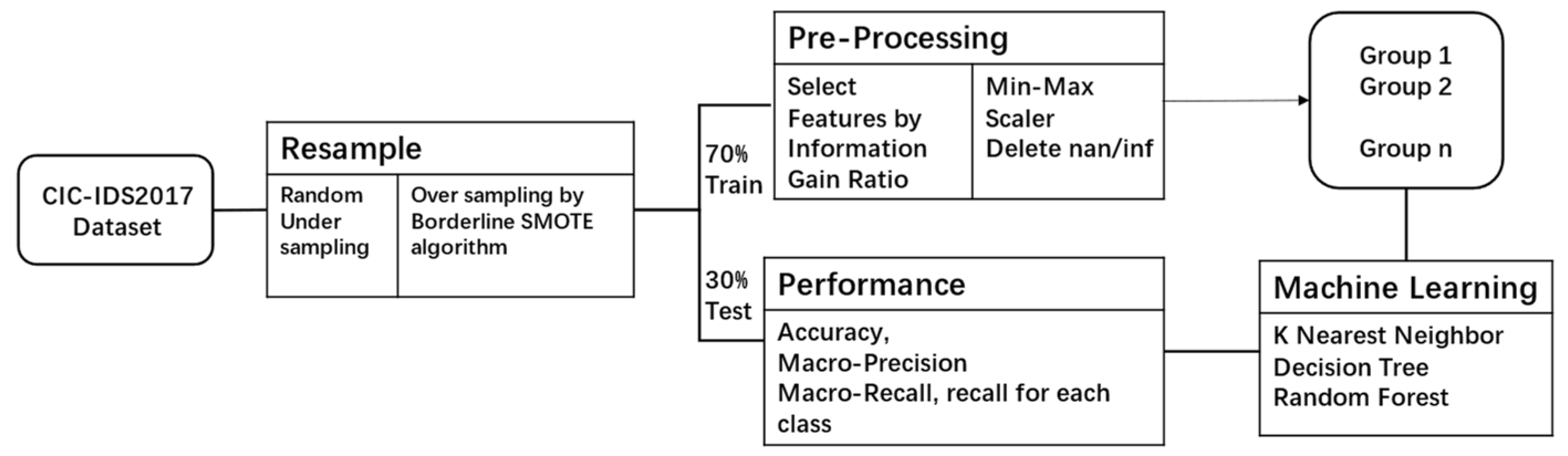
3.1. Dataset
3.2. Borderline SMOTE
- (1)
- For every sample in a few classes , compute the nearest m samples from the entire dataset. The number of other categories in the most recent samples m is denoted by .
- (2)
- Classify the samples :
- (3)
- After the marking, use the SMOTE algorithm to expand the Danger samples. Select in the Danger dataset samples, compute k-nearest neighbor samples of the same kind . New samples are randomly synthesized according to the following formulawhere is a random number between 0 and 1.
3.3. Information Gain Ratio
3.4. Metric Performance
4. Discussion
4.1. Data Preprocess
4.1.1. Data Resampling
4.1.2. Data Preprocessing and Feature Selection
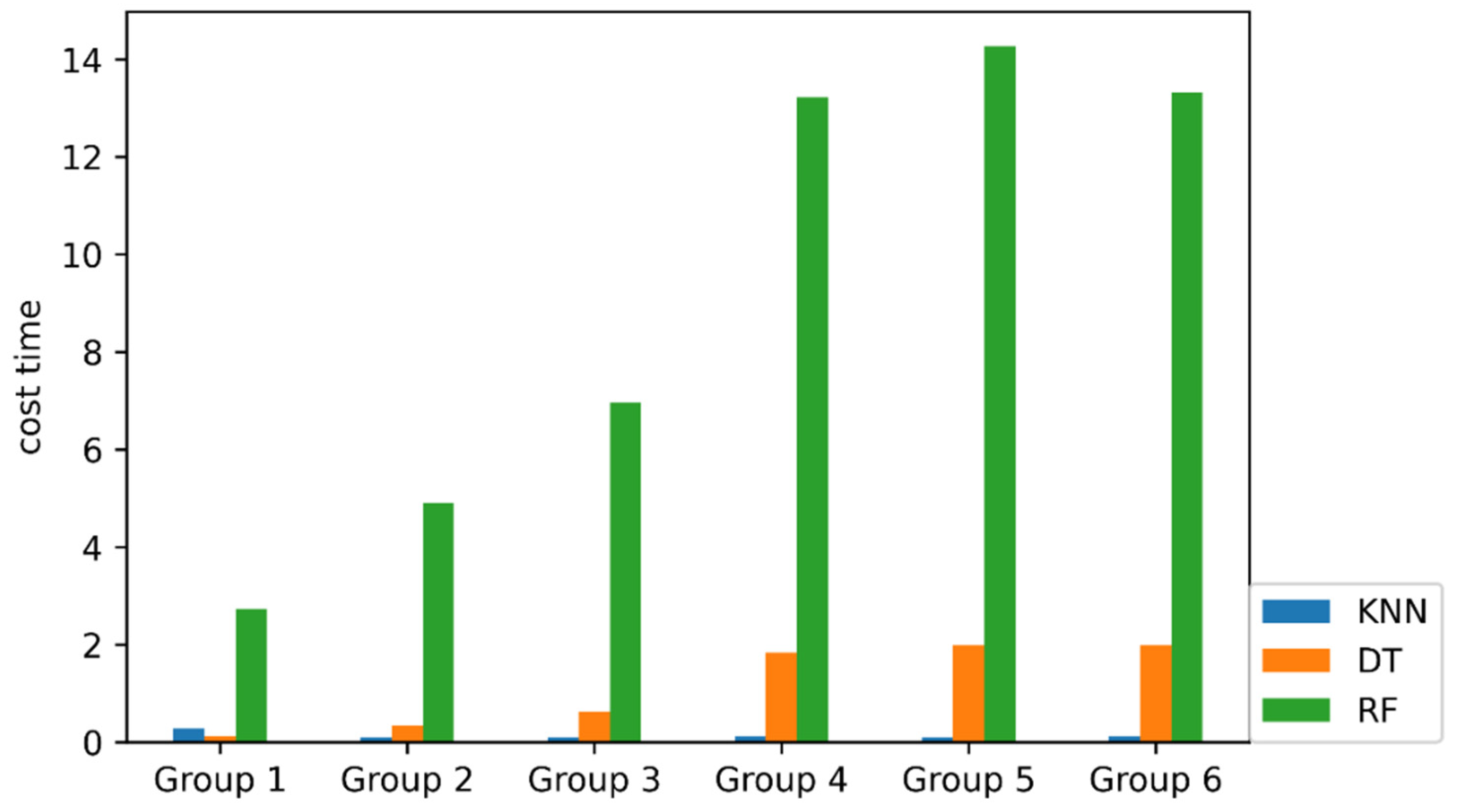
4.2. Evaluation of Models
4.2.1. Model construction and Training Phase
4.2.2. Evaluation of Models
5. Conclusions
6. Future Work and Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, C.; Cardenas, D.J.S.; Hahn, A.; Liu, C. Intrusion Detection for Cybersecurity of Smart Meters. IEEE Trans. Smart Grid 2021, 12, 612–622. [Google Scholar] [CrossRef]
- Sun, C.; Hahn, A.; Liu, C. Cyber security of a power grid: State-of-the-art. Int. J. Electr. Power Energy Syst. 2018, 99, 45–56. [Google Scholar] [CrossRef]
- Liang, G.; Weller, S.R.; Zhao, J.; Luo, F.; Dong, Z.Y. The 2015 Ukraine Blackout: Implications for False Data Injection Attacks. IEEE Trans. Power Syst. 2017, 32, 3317–3318. [Google Scholar] [CrossRef]
- Sun, Q.; Li, H.; Ma, Z.; Wang, C.; Campillo, J.; Zhang, Q.; Wallin, F.; Guo, J. A Comprehensive Review of Smart Energy Meters in Intelligent Energy Networks. IEEE Internet Things J. 2015, 3, 464–479. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, S.; Zomaya, A.Y. The Hierarchical Smart Home Cyberattack Detection Considering Power Overloading and Frequency Disturbance. IEEE Trans. Ind. Inform. 2016, 12, 1973–1983. [Google Scholar] [CrossRef]
- Sgouras, K.I.; Kyriakidis, A.N.; Labridis, D.P. Short-term risk assessment of botnet attacks on advanced metering infrastructure. IET Cyber-Phys. Syst. Theory Appl. 2017, 2, 143–151. [Google Scholar] [CrossRef]
- Alfakeeh, A.S.; Khan, S.; Al-Bayatti, A.H. A Multi-User, Single-Authentication Protocol for Smart Grid Architectures. Sensors 2020, 20, 1581. [Google Scholar] [CrossRef] [Green Version]
- Abbasinezhad-Mood, D.; Ostad-Sharif, A.; Nikooghadam, M.; Mazinani, S.M. A Secure and Efficient Key Establishment Scheme for Communications of Smart Meters and Service Providers in Smart Grid. IEEE Trans. Ind. Inform. 2019, 16, 1495–1502. [Google Scholar] [CrossRef]
- Fouda, M.M.; Fadlullah, Z.M.; Kato, N.; Lu, R.; Shen, X.S. A Lightweight Message Authentication Scheme for Smart Grid Communications. IEEE Trans. Smart Grid 2011, 2, 675–685. [Google Scholar] [CrossRef] [Green Version]
- Javed, Y.; Felemban, M.; Shawly, T.; Kobes, J.; Ghafoor, A. A Partition-Driven Integrated Security Architecture for Cyberphysical Systems. Computer 2020, 53, 47–56. [Google Scholar] [CrossRef] [Green Version]
- Korba, A.A.; Tamani, N.; Ghamri-Doudane, Y.; Karabadji, N.E.I. Anomaly-based framework for detecting power overloading cyberattacks in smart grid AMI. Comput. Secur. 2020, 96, 101896. [Google Scholar] [CrossRef]
- Kurt, M.N.; Yılmaz, Y.; Wang, X. Real-Time Nonparametric Anomaly Detection in High-Dimensional Settings. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2463–2479. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vasudeo, S.H.; Patil, P.; Kumar, R.V. IMMIX-intrusion detection and prevention system. In Proceedings of the 2015 International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (ICSTM), Avadi, India, 6–8 May 2015. [Google Scholar]
- Ripan, R.C.; Islam, M.M.; Alqahtani, H.; Sarker, I.H. Effectively predicting cyber-attacks through isolation forest learning-based outlier detection. Secur. Priv. 2022, 5, e212. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.J. Semi-Supervised Spatiotemporal Deep Learning for Intrusions Detection in IoT Networks. IEEE Internet Things J. 2021, 8, 12251–12265. [Google Scholar] [CrossRef]
- Raman, M.R.G.; Somu, N.; Jagarapu, S.; Manghnani, T.; Selvam, T.; Krithivasan, K.; Sriram, V.S.S. An efficient intrusion detection technique based on support vector machine and improved binary gravitational search algorithm. Artif. Intell. Rev. 2020, 53, 3255–3286. [Google Scholar] [CrossRef]
- Zhang, J.; Pan, L.; Han, Q.; Chen, C.; Wen, S.; Xiang, Y. Deep Learning Based Attack Detection for Cyber-Physical System Cybersecurity: A Survey. IEEE CAA J. Autom. Sin. 2022, 9, 377–391. [Google Scholar] [CrossRef]
- Wu, Y.; Nie, L.; Wang, S.; Ning, Z.; Li, S. Intelligent Intrusion Detection for Internet of Things Security: A Deep Convolutional Generative Adversarial Network-enabled Approach. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Ahmad, I.; Basheri, M.; Iqbal, M.J.; Rahim, A. Performance Comparison of Support Vector Machine, Random Forest, and Extreme Learning Machine for Intrusion Detection. IEEE Access 2018, 6, 33789–33795. [Google Scholar] [CrossRef]
- Wu, F.; Li, T.; Wu, Z.; Wu, S.; Xiao, C. Research on Network Intrusion Detection Technology Based on Machine Learning. Int. J. Wirel. Inf. Netw. 2021, 28, 262–275. [Google Scholar] [CrossRef]
- Stiawan, D.; Idris, M.Y.B.; Bamhdi, A.M.; Budiarto, R. CICIDS-2017 Dataset Feature Analysis with Information Gain for Anomaly Detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar]
- Tao, P.; Sun, Z.; Sun, Z. An Improved Intrusion Detection Algorithm Based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Aziz, A.S.A.; Hanafi, S.E.; Hassanien, A.E. Comparison of classification techniques applied for network intrusion detection and classification. J. Appl. Log. 2017, 24, 9–118. [Google Scholar] [CrossRef]
- Zhou, T.L.; Xiahou, K.S.; Zhang, L.L.; Wu, Q.H. Multi-agent-based hierarchical detection and mitigation of cyber attacks in power systems. Int. J. Electr. Power Energy Syst. 2021, 125, 106516. [Google Scholar] [CrossRef]
- Aksu, D.; Aydin, M.A. MGA-IDS: Optimal feature subset selection for anomaly detection framework on in-vehicle networks-CAN bus based on genetic algorithm and intrusion detection approach. Comput. Secur. 2022, 118, 102717. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Madeira, Portugal, 22–24 January 2018. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Binary Classification | ||||
| Confusion Matrix | Predicted Label | ||||
| Positive | Negative | ||||
| Actual Label | Positive | TP | FN | ||
| Negative | FP | TN | |||
| Accuracy | |||||
| Recall/True Positive Rate | |||||
| Multi Class Classification | |||||
| Confusion Matrix | Predicted Label | ||||
| Class-1 | …… | Class-n | |||
| Actual Label | Class-1 | ||||
| …… | |||||
| Class-n | |||||
| Accuracy | |||||
| Recall/True Positive Rate | |||||
| Class | CIC-IDS Dataset | Resampled Dataset | Training Dataset | Testing Dataset |
|---|---|---|---|---|
| BENIGN | 2,271,320 | 20,000 | 13,973 | 6027 |
| DoS Hulk | 230,124 | 20,000 | 13,962 | 6038 |
| PortScan | 158,804 | 20,000 | 13,994 | 6006 |
| DDoS | 128,025 | 20,000 | 14,161 | 5839 |
| DoS GoldenEye | 10,293 | 10,293 | 7221 | 3072 |
| FTP-Patator | 7935 | 7935 | 5589 | 2346 |
| SSH-Patator | 5897 | 5897 | 4130 | 1767 |
| DoS slowloris | 5796 | 5796 | 4046 | 1750 |
| DoS Slowhttptest | 5499 | 5499 | 3829 | 1670 |
| Bot | 1956 | 5000 | 3447 | 1553 |
| Web Attack Brute Force | 1507 | 5000 | 3470 | 1530 |
| Web Attack XSS | 652 | 5000 | 3472 | 1528 |
| Infiltration | 36 | 0 | 0 | 0 |
| Web Attack Sql Injection | 21 | 0 | 0 | 0 |
| Heartbleed | 11 | 0 | 0 | 0 |
| Total | 2,827,876 | 145,420 | 87,847 | 37,573 |
| No. | ID | Feature Names | IGR |
|---|---|---|---|
| 1 | 69 | min_seg_size_forward | 0.642905 |
| 2 | 67 | Init_Win_bytes_backward | 0.568649 |
| 3 | 66 | Init_Win_bytes_forward | 0.534474 |
| 4 | 11 | Bwd Packet Length Min | 0.500375 |
| 5 | 5 | Total Length of Bwd Packets | 0.479726 |
| 6 | 65 | Subflow Bwd Bytes | 0.479726 |
| 7 | 35 | Bwd Header Length | 0.477581 |
| 8 | 34 | Fwd Header Length | 0.46183 |
| 9 | 55 | Fwd Header Length.1 | 0.46183 |
| 10 | 30 | Fwd PSH Flags | 0.460098 |
| 11 | 44 | SYN Flag Count | 0.460098 |
| 12 | 39 | Max Packet Length | 0.444258 |
| 13 | 12 | Bwd Packet Length Mean | 0.439078 |
| 14 | 54 | Avg Bwd Segment Size | 0.439078 |
| 15 | 10 | Bwd Packet Length Max | 0.426576 |
| 16 | 43 | FIN Flag Count | 0.420984 |
| 17 | 3 | Total Backward Packets | 0.41914 |
| 18 | 64 | Subflow Bwd Packets | 0.41914 |
| 19 | 48 | URG Flag Count | 0.412948 |
| 20 | 0 | Destination Port | 0.411226 |
| 21 | 2 | Total Fwd Packets | 0.404084 |
| 22 | 62 | Subflow Fwd Packets | 0.404084 |
| 23 | 68 | act_data_pkt_fwd | 0.399244 |
| 24 | 38 | Min Packet Length | 0.395738 |
| 25 | 7 | Fwd Packet Length Min | 0.392421 |
| 26 | 6 | Fwd Packet Length Max | 0.382406 |
| 27 | 4 | Total Length of Fwd Packets | 0.356587 |
| 28 | 63 | Subflow Fwd Bytes | 0.356587 |
| 29 | 46 | PSH Flag Count | 0.34864 |
| 30 | 51 | Down/Up Ratio | 0.346817 |
| 31 | 13 | Bwd Packet Length Std | 0.344646 |
| 32 | 52 | Average Packet Size | 0.338569 |
| 33 | 40 | Packet Length Mean | 0.335255 |
| 34 | 8 | Fwd Packet Length Mean | 0.320388 |
| 35 | 53 | Avg Fwd Segment Size | 0.320388 |
| 36 | 75 | Idle Std | 0.317702 |
| 37 | 42 | Packet Length Variance | 0.299398 |
| 38 | 41 | Packet Length Std | 0.297963 |
| 39 | 9 | Fwd Packet Length Std | 0.291304 |
| 40 | 76 | Idle Max | 0.254416 |
| 41 | 23 | Fwd IAT Max | 0.254233 |
| 42 | 74 | Idle Mean | 0.252443 |
| 43 | 20 | Fwd IAT Total | 0.251187 |
| 44 | 21 | Fwd IAT Mean | 0.24798 |
| 45 | 22 | Fwd IAT Std | 0.234591 |
| 46 | 77 | Idle Min | 0.233341 |
| 47 | 17 | Flow IAT Std | 0.231187 |
| 48 | 25 | Bwd IAT Total | 0.219028 |
| 49 | 18 | Flow IAT Max | 0.218065 |
| 50 | 24 | Fwd IAT Min | 0.215989 |
| 51 | 47 | ACK Flag Count | 0.21487 |
| 52 | 14 | Flow Bytes/s | 0.212526 |
| 53 | 28 | Bwd IAT Max | 0.212366 |
| 54 | 26 | Bwd IAT Mean | 0.21108 |
| 55 | 29 | Bwd IAT Min | 0.20972 |
| 56 | 37 | Bwd Packets/s | 0.208757 |
| 57 | 16 | Flow IAT Mean | 0.208709 |
| 58 | 71 | Active Std | 0.206242 |
| 59 | 15 | Flow Packets/s | 0.203749 |
| 60 | 36 | Fwd Packets/s | 0.203416 |
| 61 | 1 | Flow Duration | 0.20025 |
| 62 | 27 | Bwd IAT Std | 0.20008 |
| 63 | 70 | Active Mean | 0.196345 |
| 64 | 72 | Active Max | 0.196185 |
| 65 | 73 | Active Min | 0.193686 |
| 66 | 45 | RST Flag Count | 0.177221 |
| 67 | 50 | ECE Flag Count | 0.177221 |
| 68 | 32 | Fwd URG Flags | 0.16054 |
| 69 | 49 | CWE Flag Count | 0.16054 |
| 70 | 19 | Flow IAT Min | 0.153983 |
| 71 | 31 | Bwd PSH Flags | 0 |
| 72 | 33 | Bwd URG Flags | 0 |
| 73 | 56 | Fwd Avg Bytes/Bulk | 0 |
| 74 | 57 | Fwd Avg Packets/Bulk | 0 |
| 75 | 58 | Fwd Avg Bulk Rate | 0 |
| 76 | 59 | Bwd Avg Bytes/Bulk | 0 |
| 77 | 60 | Bwd Avg Packets/Bulk | 0 |
| 78 | 61 | Bwd Avg Bulk Rate | 0 |
| Group | Criterion | Number of Selected Feature | Selected Feature |
|---|---|---|---|
| Group 1 | >0.5 | 4 | 69, 67, 66, 11 |
| Group 2 | >0.4 | 22 | 69, 67, 66, 11, 5, 65, 35, 55, 34, 30, 44, 39, 12, 54, 10, 43, 64, 3, 48, 0, 62, 2 |
| Group 3 | >0.3 | 36 | 69, 67, 66, 11, 5, 65, 35, 55, 34, 30, 44, 39, 12, 54, 10, 43, 64, 3, 48, 0, 62, 2 68, 38, 7, 6, 4, 63, 46, 51, 13, 52, 40, 53, 8, 75 |
| Group 4 | >0.2 | 62 | 69, 67, 66, 11, 5, 65, 35, 55, 34, 30, 44, 39, 12, 54, 10, 43, 64, 3, 48, 0, 62, 2 68, 38, 7, 6, 4, 63, 46, 51, 13, 52, 40, 53, 8, 75, 42, 41, 9, 76, 23, 74, 20, 21, 22, 77, 17, 25, 18, 24, 47, 14, 28, 26, 29, 37, 16, 71, 15, 36, 1, 27 |
| Group 5 | >0.1 | 70 | 69, 67, 66, 11, 5, 65, 35, 55, 34, 30, 44, 39, 12, 54, 10, 43, 64, 3, 48, 0, 62, 2 68, 38, 7, 6, 4, 63, 46, 51, 13, 52, 40, 53, 8, 75, 42, 41, 9, 76, 23, 74, 20, 21, 22, 77, 17, 25, 18, 24, 47, 14, 28, 26, 29, 37, 16, 71, 15, 36, 1, 27, 70, 72, 73, 45, 50, 32, 49, 19 |
| Group 6 | All | 78 | All Feature |
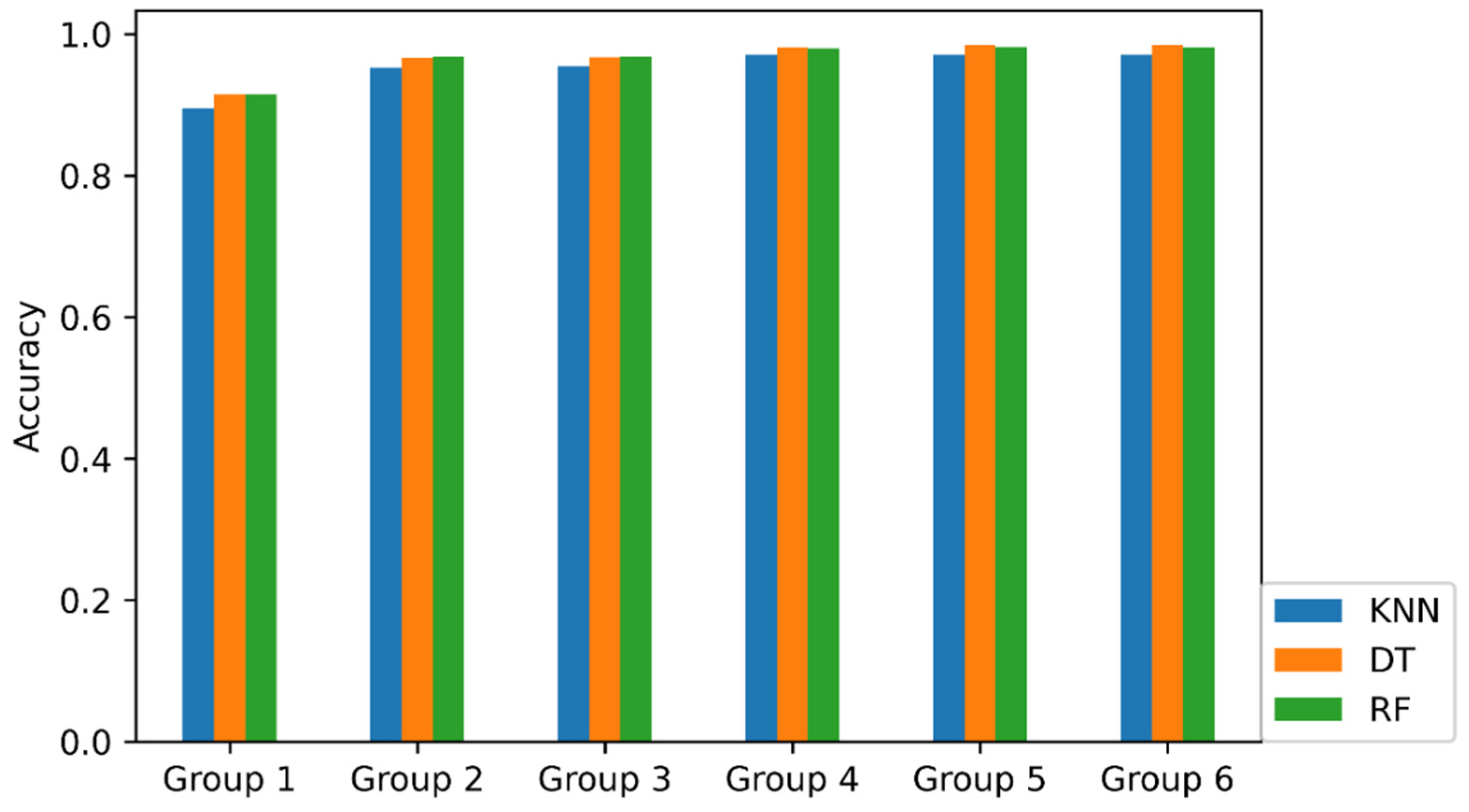
| Group | Method | Accuracy | BENING | Bot | DDoS | DoS Golden Eye | DoS Hulk | DoS Slow http Test |
| 1 (4 features) | KNN | 0.8945 | 0.9497 | 0.9672 | 0.9990 | 0.9993 | 0.9268 | 0.1252 |
| DT | 0.9144 | 0.9537 | 0.9736 | 0.9990 | 0.9993 | 0.9324 | 0.5665 | |
| RF | 0.9146 | 0.9539 | 0.9781 | 0.9990 | 0.9993 | 0.9323 | 0.5665 | |
| 2 (22 features) | KNN | 0.9523 | 0.9617 | 0.9749 | 0.9955 | 0.9980 | 0.9962 | 0.9880 |
| DT | 0.9666 | 0.9910 | 0.9910 | 0.9981 | 0.9990 | 0.9975 | 0.9886 | |
| RF | 0.9672 | 0.9935 | 0.9936 | 0.9986 | 0.9997 | 0.9980 | 0.9868 | |
| 3 (36 features) | KNN | 0.9541 | 0.9740 | 0.9871 | 0.9949 | 0.9987 | 0.9925 | 0.9874 |
| DT | 0.9668 | 0.9910 | 0.9929 | 0.9985 | 0.9993 | 0.9974 | 0.9880 | |
| RF | 0.9672 | 0.9932 | 0.9923 | 0.9986 | 0.9993 | 0.9980 | 0.9886 | |
| 4 (62 features) | KNN | 0.9702 | 0.9655 | 0.9942 | 0.9932 | 0.9987 | 0.9949 | 0.9922 |
| DT | 0.9808 | 0.9939 | 0.9923 | 0.9985 | 0.9980 | 0.9980 | 0.9934 | |
| RF | 0.9802 | 0.9934 | 0.9974 | 0.9986 | 0.9993 | 0.9997 | 0.9916 | |
| 5 (70 features) | KNN | 0.9704 | 0.9647 | 0.9942 | 0.9926 | 0.9987 | 0.9970 | 0.9922 |
| DT | 0.9840 | 0.9952 | 0.9910 | 0.9990 | 0.9990 | 0.9978 | 0.9928 | |
| RF | 0.9818 | 0.9930 | 0.9981 | 0.9983 | 0.9993 | 0.9998 | 0.9922 | |
| 6 (78 features) | KNN | 0.9704 | 0.9647 | 0.9942 | 0.9926 | 0.9987 | 0.9970 | 0.9922 |
| DT | 0.9841 | 0.9952 | 0.9910 | 0.9986 | 0.9987 | 0.9978 | 0.9928 | |
| RF | 0.9814 | 0.9924 | 0.9974 | 0.9985 | 0.9990 | 0.9997 | 0.9916 | |
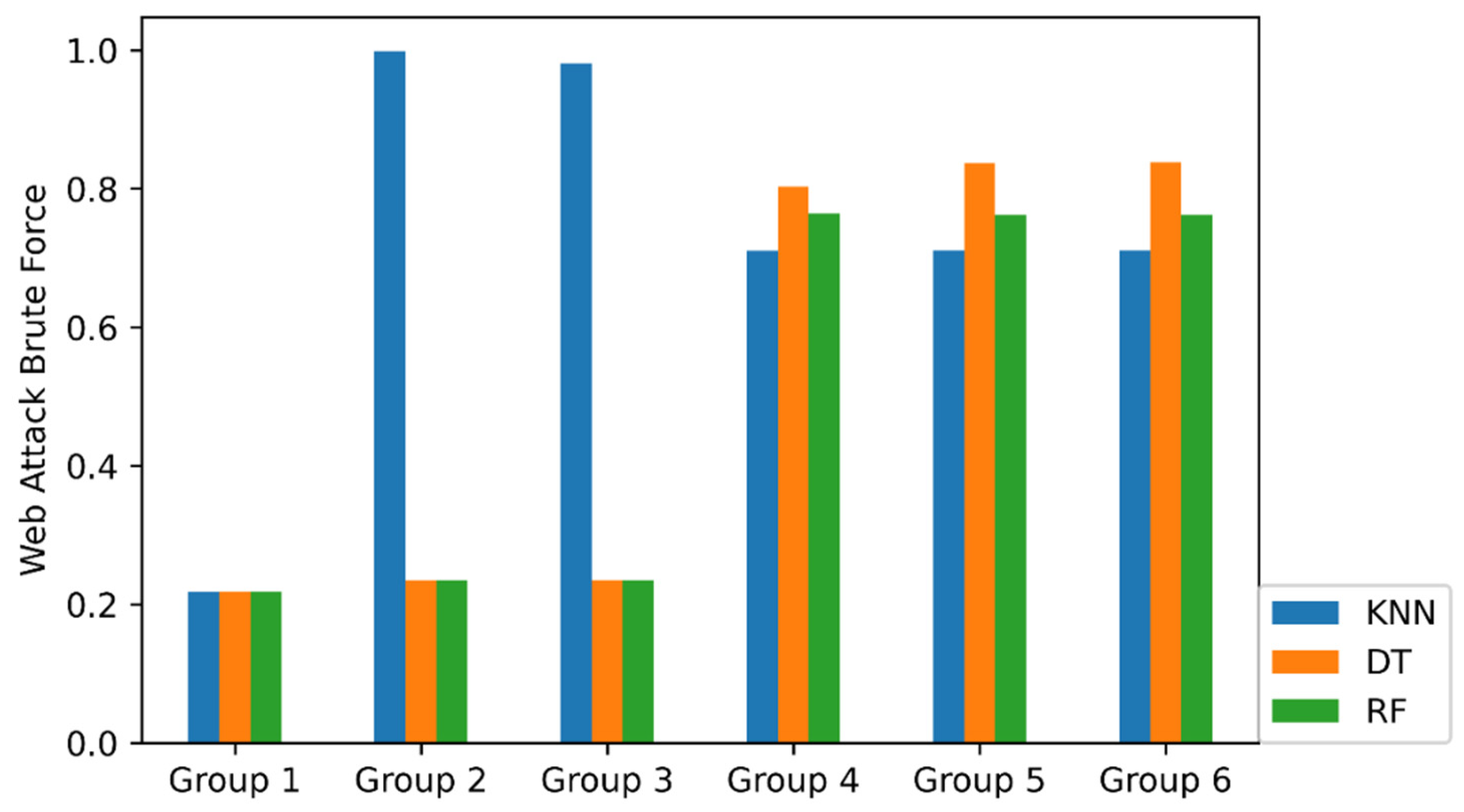
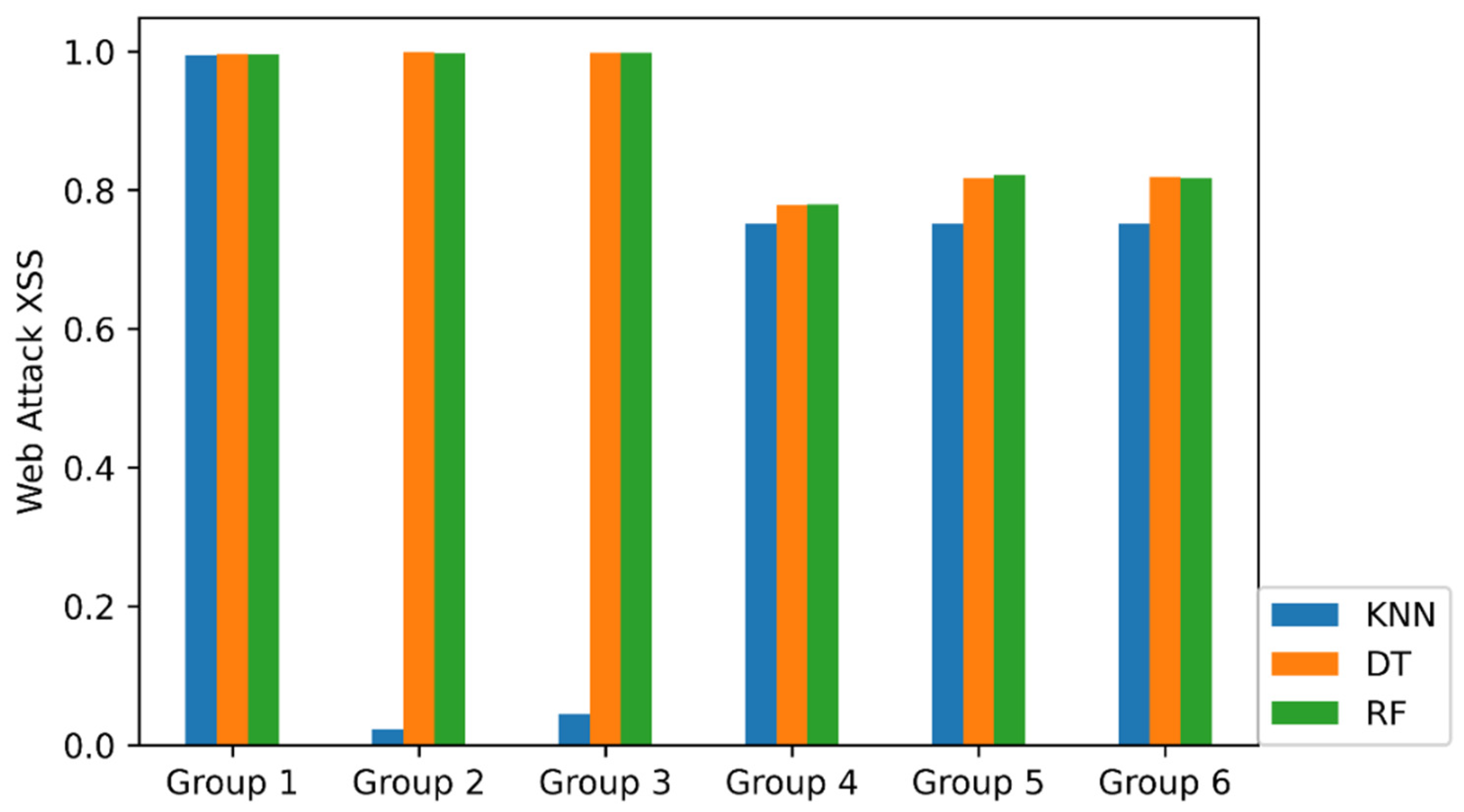
| Group | Method | Micro RECALL | DoS Slow Loris | FTP-Patator | Port Scan | SSH-Patator | Web Attack Brute Force | Web Attack XSS |
| 1 (4 features) | KNN | 0.8234 | 0.9029 | 0.8103 | 0.9953 | 0.9932 | 0.2170 | 0.9948 |
| DT | 0.8548 | 0.6309 | 0.9987 | 0.9953 | 0.9943 | 0.2176 | 0.9961 | |
| RF | 0.8552 | 0.6309 | 0.9987 | 0.9953 | 0.9943 | 0.2183 | 0.9954 | |
| 2 (22 features) | KNN | 0.9104 | 0.9943 | 1.0000 | 0.9983 | 0.9972 | 0.9980 | 0.0223 |
| DT | 0.9326 | 0.9954 | 1.0000 | 0.9988 | 1.0000 | 0.2340 | 0.9980 | |
| RF | 0.9330 | 0.9960 | 1.0000 | 0.9992 | 0.9977 | 0.2346 | 0.9980 | |
| 3 (36 features) | KNN | 0.9122 | 0.9926 | 1.0000 | 0.9983 | 0.9960 | 0.9804 | 0.0445 |
| DT | 0.9329 | 0.9954 | 1.0000 | 0.9992 | 1.0000 | 0.2353 | 0.9980 | |
| RF | 0.9330 | 0.9954 | 1.0000 | 0.9992 | 0.9989 | 0.2346 | 0.9980 | |
| 4 (62 features) | KNN | 0.9486 | 0.9920 | 0.9983 | 0.9985 | 0.9943 | 0.7098 | 0.7513 |
| DT | 0.9619 | 0.9920 | 0.9996 | 0.9995 | 1.0000 | 0.8039 | 0.7742 | |
| RF | 0.9600 | 0.9960 | 1.0000 | 0.9997 | 0.9966 | 0.7686 | 0.7795 | |
| 5 (70 features) | KNN | 0.9487 | 0.9920 | 0.9983 | 0.9985 | 0.9943 | 0.7105 | 0.7513 |
| DT | 0.9681 | 0.9931 | 0.9991 | 0.9998 | 1.0000 | 0.8340 | 0.8161 | |
| RF | 0.9637 | 0.9954 | 1.0000 | 0.9995 | 0.9972 | 0.7601 | 0.8318 | |
| 6 (78 features) | KNN | 0.9487 | 0.9920 | 0.9983 | 0.9985 | 0.9943 | 0.7105 | 0.7513 |
| DT | 0.9684 | 0.9931 | 0.9991 | 0.9998 | 1.0000 | 0.8353 | 0.8194 | |
| RF | 0.9631 | 0.9949 | 1.0000 | 0.9995 | 0.9966 | 0.7627 | 0.8246 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Que, H.; Cai, Q.; Zhao, J.; Li, J.; Kong, Z.; Wang, S. Borderline SMOTE Algorithm and Feature Selection-Based Network Anomalies Detection Strategy. Energies 2022, 15, 4751. https://doi.org/10.3390/en15134751
Sun Y, Que H, Cai Q, Zhao J, Li J, Kong Z, Wang S. Borderline SMOTE Algorithm and Feature Selection-Based Network Anomalies Detection Strategy. Energies. 2022; 15(13):4751. https://doi.org/10.3390/en15134751
Chicago/Turabian StyleSun, Yong, Huakun Que, Qianqian Cai, Jingming Zhao, Jingru Li, Zhengmin Kong, and Shuai Wang. 2022. "Borderline SMOTE Algorithm and Feature Selection-Based Network Anomalies Detection Strategy" Energies 15, no. 13: 4751. https://doi.org/10.3390/en15134751
APA StyleSun, Y., Que, H., Cai, Q., Zhao, J., Li, J., Kong, Z., & Wang, S. (2022). Borderline SMOTE Algorithm and Feature Selection-Based Network Anomalies Detection Strategy. Energies, 15(13), 4751. https://doi.org/10.3390/en15134751