
A Photovoltaic System Fault Identification Method Based on Improved Deep Residual Shrinkage Networks


Abstract
:1. Introduction
- (1)
- Only the I-V curve is chosen as the input of the fault diagnosis network, which reduces the dependence of the diagnosis network on environmental characteristics.
- (2)
- The structure of the DRSN was improved by adding long short term memory (LSTM) branches, so as to explore the dynamic time waveform change rule in the I-V curve.
- (3)
- The traditional ReLU activation function was replaced by the Mish function, which improved the convergence speed and generalization performance of the model.
- (4)
- The algorithm has been trained and tested on Raspberry Pi to detect its application capability on edge computing terminals.
2. Methodology
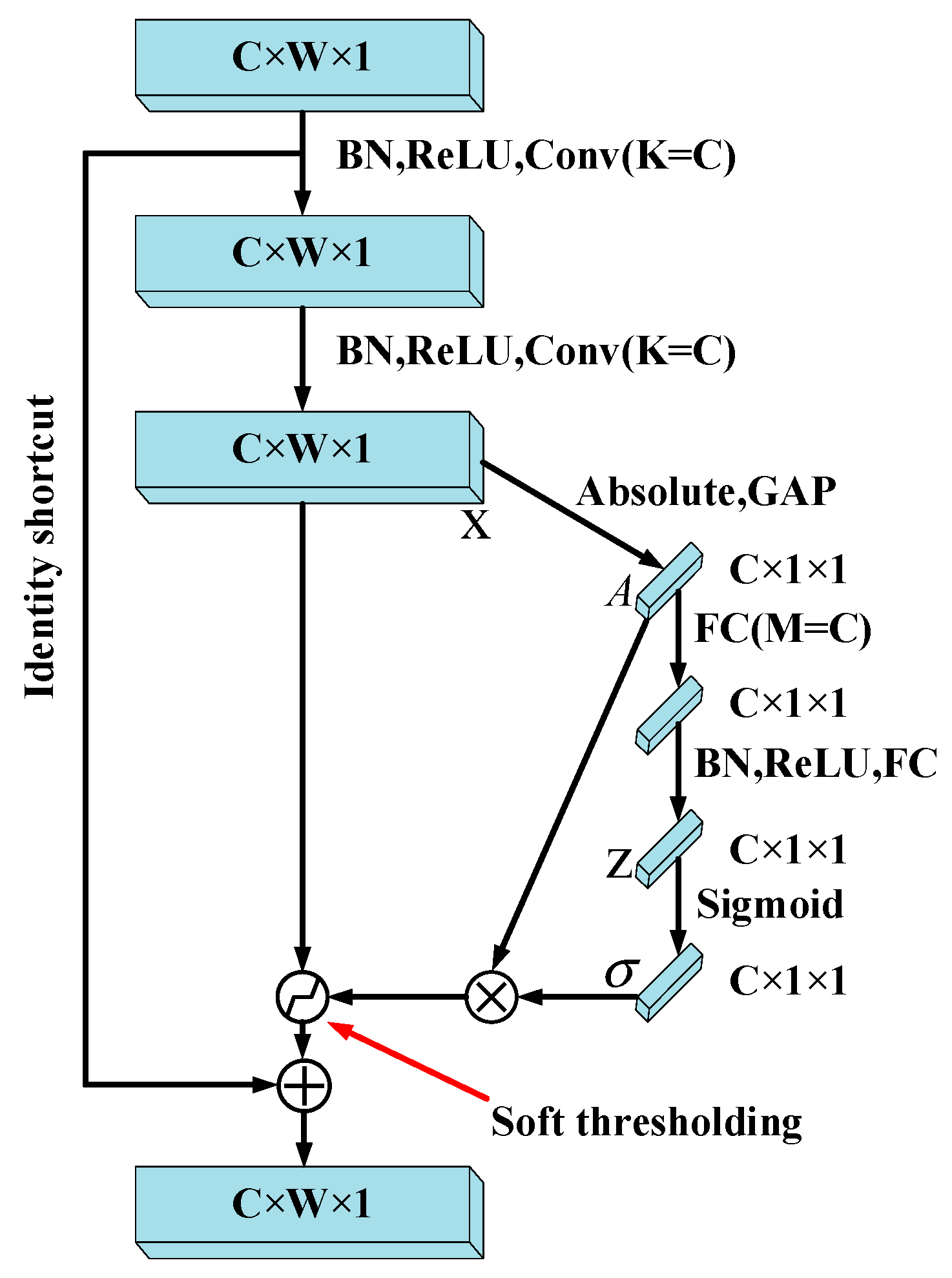
2.1. Deep Residual Shrinkage Network
2.2. Improved Deep Residual Shrinkage Network
2.3. Process of PV Fault Diagnosis
- (1)
- Solar system analyzer is used to collect the I-V curves of the PV array.
- (2)
- Adopt the open-circuit voltage and short-circuit current at the STC of the array to standardization the voltage and current data, and reconstruct the standardized voltage and current into an n × 2 matrix as the input of the diagnostic model.
- (3)
- The samples are randomly divided into three categories by proportion including training set, validation set, and test set.
- (4)
- Input the training set samples into the improved DRSN model. The model adaptively learns the characteristics of the training set samples and uses the validation set samples to adjust the network weights until the accuracy of the model validation set converges.
- (5)
- Input the test-set samples into the trained model to evaluate the fault diagnosis performance of this model.
3. Experimental Verification
3.1. Introduction to the Experimental Platform
3.2. Selection of Hyper-Parameters
3.3. Feature Visualization
3.4. Analysis of Model Training and Test Results
3.5. Influence of Different Irradiance
3.6. Verification in a Multi-String System
3.7. Analysis of Anti-Interference Ability
4. Comparison and Discussion
4.1. Performance Evaluation of Improved DRSN
4.2. Comparison and Analysis of Different Methods
5. Edge Diagnosis of PV Faults
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| PV | photovoltaic |
| DRSN | deep residual shrinkage networks |
| CNN | convolutional neural network |
| LSTM | long short term memory |
| STC | G = 1000 W/m2, T = 25 °C |
| SC | short-circuit |
| CS | channel-shared thresholds |
| CW | channel-wise thresholds |
| RNN | recurrent neural network |
| DNN | Deep neural network |
| t-SNE | t-distributed stochastic neighbor embedding |
| TP | the true positive category |
| FN | the false negative category |
| FP | the false positive category |
| TN | the true negative category |
| SNR | signal-to-noise ratio |
| ResNet | deep residual network |
| PS-BO | partial-shading with bypass-diode on |
| PS-BR | partial-shading with bypass-diode reversed |
| Aa | abnormal aging |
| Voc | open circuit voltage of the PV array |
| Isc | short circuit current of the PV array |
| Vm | maximum power point voltage of the PV array |
| Im | maximum power point current of the PV array |
| Pm | maximum power of the PV array |
| SENet | Squeeze and excitation network |
| RSBU-CW | residual shrinkage building unit with channel-wise thresholds |
| feature map | |
| X | feature map |
| coefficient | |
| threshold value | |
| the feature at the n-th neuron | |
| n-th scaling parameter | |
| the threshold for the n-th channel of the feature map | |
| FF | PV module fill factor |
| Roc | the slope of open-circuit point |
References
- Wang, Z.; Yang, G. Static operational impacts of residential solar PV plants on the medium voltage distribution grids—a case study based on the danish island bornholm. Energies 2019, 12, 1458. [Google Scholar] [CrossRef] [Green Version]
- Agoua, X.G.; Girard, R.; Kariniotakis, G. Photovoltaic power forecasting: Assessment of the impact of multiple sources of spatio-temporal data on forecast accuracy. Energies 2021, 14, 1432. [Google Scholar] [CrossRef]
- Renewables 2021 Global Status Report. Available online: https://www.ren21.net/reports/global-status-report/ (accessed on 15 December 2021).
- Sun, X.; Chavali, R.V.K.; Alam, M.A. Real-time monitoring and diagnosis of photovoltaic system degradation only using maximum power point-the Suns-Vmp method. Prog. Photovolt. Res. Appl. 2019, 27, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Fadhel, S.; Delpha, C.; Diallo, D.; Bahri, I.; Migan, A.; Trabelsi, M.; Mimouni, M.F. PV shading fault detection and classification based on I-V curve using principal component analysis: Application to isolated PV system. Sol. Energy 2019, 179, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Dhimish, M.; Holmes, V.; Mehrdadi, B.; Dales, M. The impact of cracks on photovoltaic power performance. J. Sci. 2017, 2, 199–209. [Google Scholar] [CrossRef]
- Abderrezek, M.; Fathi, M. Experimental study of the dust effect on photovoltaic panels’ energy yield. Sol. Energy 2017, 142, 308–320. [Google Scholar] [CrossRef]
- Zhao, Y.; de Palma, J.-F.; Mosesian, J.; Lyons, R.; Lehman, B. Line-line fault analysis and protection challenges in solar photovoltaic arrays. IEEE Trans. Ind. Electron. 2013, 60, 3784–3795. [Google Scholar] [CrossRef]
- Alam, M.K.; Khan, F.; Johnson, J.; Flicker, J. A comprehensive review of catastrophic faults in PV arrays: Types, detection, and mitigation techniques. IEEE J. Photovolt. 2015, 5, 982–997. [Google Scholar] [CrossRef]
- Otamendi, U.; Martinez, I.; Quartulli, M.; Olaizola, I.G.; Viles, E.; Cambarau, W. Segmentation of cell-level anomalies in electroluminescence images of photovoltaic modules. Sol. Energy 2021, 220, 914–926. [Google Scholar] [CrossRef]
- Parikh, H.; Buratti, Y.; Spataru, S.V.; Villebro, F.; Dos Reis Benatto, G.A.; Poulsen, P.B.; Wendlandt, S.; Kerekes, T.; Sera, D.; Hameiri, Z. Solar cell cracks and finger failure detection using statistical parameters of electroluminescence images and machine learning. Appl. Sci. 2020, 10, 8834. [Google Scholar] [CrossRef]
- Cubukcu, M.; Akanalci, A. Real-time inspection and determination methods of faults on photovoltaic power systems by thermal imaging in Turkey. Renew. Energy 2020, 147, 1231–1238. [Google Scholar] [CrossRef]
- Ali, M.U.; Khan, H.F.; Masud, M.; Kallu, K.D.; Zafar, A. A machine learning framework to identify the hotspot in photovoltaic module using infrared thermography. Sol. Energy 2020, 208, 643–651. [Google Scholar] [CrossRef]
- Tsanakas, J.A.; Ha, L.D.; Shakarchi, F.A. Advanced inspection of photovoltaic installations by aerial triangulation and terrestrial georeferencing of thermal/visual imagery. Renew. Energy 2017, 102, 224–233. [Google Scholar] [CrossRef]
- Hashemi, B.; Taheri, S.; Cretu, A.M.; Pouresmaeil, E. Systematic photovoltaic system power losses calculation and modeling using computational intelligence techniques. Appl. Energy 2021, 284, 116396. [Google Scholar] [CrossRef]
- Xie, X.; Meng, F.; Luo, X.; Cai, S.; Ma, X.; Na, Z.; Ma, D.; Shan, Y.; Ge, L.; Liu, Y. Fault diagnosis and detection based on efficiency loss test of photovoltaic power station. In Proceedings of the 2020 6th International Conference on Energy Materials and Environment Engineering, Tianjin, China, 24–26 April 2020. [Google Scholar]
- Dhimish, M.; Badran, G. Photovoltaic hot-spots fault detection algorithm using fuzzy systems. IEEE Trans. Device Mater. Reliab. 2019, 19, 671–679. [Google Scholar] [CrossRef] [Green Version]
- Kuo, C.L.; Chen, J.L.; Chen, S.J.; Kao, C.C.; Yau, H.T.; Lin, C.H. Photovoltaic energy conversion system fault detection using fractional-order color relation classifier in microdistribution systems. IEEE Trans. Smart Grid 2017, 8, 1163–1172. [Google Scholar] [CrossRef]
- Miao, W.; Lam, K.H.; Pong, P.W.T. A string-current behavior and current sensing based technique for line-line fault detection in photovoltaic systems. IEEE Trans. Magn. 2017, 57, 1–6. [Google Scholar] [CrossRef]
- Lu, X.; Lin, P.; Cheng, S.; Lin, Y.; Chen, Z.; Wu, L.; Zheng, Q. Fault diagnosis for photovoltaic array based on convolutional neural network and electrical time series graph. Energy Conv. Manag. 2019, 196, 950–965. [Google Scholar] [CrossRef]
- Huang, J.M.; Wai, R.J.; Gao, W. Newly-designed fault diagnostic method for solar photovoltaic generation system based on IV-curve measurement. IEEE Access 2019, 7, 70919–70932. [Google Scholar] [CrossRef]
- Gao, W.; Wai, R.J. A novel fault identification method for photovoltaic array via convolutional neural network and residual gated recurrent unit. IEEE Access 2020, 8, 159493–159510. [Google Scholar] [CrossRef]
- Chine, W.; Mellit, A.; Lughi, V.; Malek, A.; Sulligoi, G.; Pavan, A.M. A novel fault diagnosis technique for photovoltaic systems based on artificial neural networks. Renew. Energy 2016, 90, 501–512. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Y.; Wu, L.; Cheng, S.; Lin, P. Deep residual network based fault detection and diagnosis of photovoltaic arrays using current-voltage curves and ambient conditions. Energy Conv. Manag. 2019, 198, 111793. [Google Scholar] [CrossRef]
- Aziz, F.; Haq, A.U.; Ahmad, S.; Mahmoud, Y.; Jalal, M.; Ali, U. A novel convolutional neural network based approach for fault classification in photovoltaic arrays. IEEE Access 2020, 8, 41889–41904. [Google Scholar] [CrossRef]
- Chen, S.Q.; Yang, G.J.; Gao, W.; Guo, M.F. Photovoltaic fault diagnosis via semisupervised ladder network with string voltage and current measures. IEEE J. Photovolt. 2021, 11, 219–231. [Google Scholar] [CrossRef]
- Yang, J.; Gao, T.; Jiang, S.; Li, S.; Tang, Q. Fault diagnosis of rotating machinery based on one-dimensional deep residual shrinkage network with a wide convolution layer. Shock Vib. 2020, 2020, 8880960. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2020, 16, 4681–4690. [Google Scholar] [CrossRef]
- Chen, G.; Lu, J.; Yang, M.; Zhou, J. Learning recurrent 3D attention for video-based person re-identification. IEEE Trans. Image Process. 2020, 29, 6963–6976. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S.X. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, J.; Wang, L.; Wen, D.; Gao, K.Z. Signal-to-noise ratio improvement of MAMR on CoX/Pt media. IEEE Trans. Magn. 2015, 51, 11–14. [Google Scholar] [CrossRef]
- Zaki, S.A.; Zhu, H.L.; Al Fakih, M.; Sayed, A.R.; Yao, J. Deep-learning-based method for faults classification of PV system. IET Renew. Power Gen. 2021, 15, 193–205. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pm | Vm | Im | Voc | Isc |
|---|---|---|---|---|
| 270 W | 31.3 V | 8.63 A | 38.5 V | 9.09 A |
| Fault Type Description | Category Label | Sample Number |
|---|---|---|
| Normal | Class 0 | 200 |
| SC | Class 1 | 200 |
| PS-BR | Class 2 | 200 |
| PS-BO | Class3 | 200 |
| Aa | Class 4 | 200 |
| SC & PS-BO | Class 5 | 200 |
| SC & PS-BR | Class 6 | 200 |
| SC & Aa | Class 7 | 200 |
| PS-BO & Aa | Class 8 | 200 |
| PS-BR & Aa | Class 9 | 200 |
| PS-BR & PS-BO | Class 10 | 200 |
| Layer Type | Kernel Size | No. of Kernel | Stride | Activation | Output |
|---|---|---|---|---|---|
| Input layer | - | - | - | - | 149 × 2 × 1 |
| Conv2D | (3, 3) | 8 | (1, 1) | - | 149 × 2 × 8 |
| Residual | number of RSBU-CW units = 6 out_channels = 8 downsample_strides = 2 | 3 × 1 × 8 | |||
| shrinkage | |||||
| block | |||||
| LSTM | output dimension = 16, dropout coefficient = 0.2 | 16 | |||
| Dense1 | num_neurons = 256 | ReLU | 256 | ||
| Dense2 | num_neurons = 128 | ReLU | 128 | ||
| Dense3 | num_neurons = 64 | ReLU | 64 | ||
| Output layer | 11 | 1 | - | Softmax | 11 |
| Fault Type | Testing Accuracy | |||
|---|---|---|---|---|
| 150–500 W/m2 | 500–800 W/m2 | 800–1000 W/m2 | Total Accuracy | |
| Normal | 90% | 100% | 100% | 97.5% |
| SC | 100% | 100% | 100% | 100% |
| PS-BR | 100% | 100% | 100% | 100% |
| PS-BO | 100% | 100% | 100% | 100% |
| Aa | 50% | 88.9% | 100% | 80% |
| SC & PS-BO | 100% | 100% | 100% | 100% |
| SC & PS-BR | 100% | 100% | 100% | 100% |
| SC & Aa | 100% | 100% | 100% | 100% |
| PS-BO & Aa | 100% | 100% | 100% | 100% |
| PS-BR & Aa | 100% | 95.2% | 100% | 97.5% |
| PS-BR & PS-BO | 100% | 100% | 100% | 100% |
| Total | 93.2% | 98.5% | 100% | 97.73% |
| Fault Type | Normal | SC | PS-BO |
|---|---|---|---|
| Sample number | 21 | 25 | 23 |
| Recall (%) | 100% | 100% | 100% |
| ε (%) | SNR | Proposed Method | CNN | ResNet |
|---|---|---|---|---|
| 0 | - | 97.73% | 88.41% | 93.18% |
| 0.316% | 50 dB | 97.73% | 88.41% | 93.18% |
| 1% | 40 dB | 97.73% | 88.41% | 93.18% |
| 3.162% | 30 dB | 97.73% | 87.05% | 92.05% |
| 10% | 20 dB | 94.09% | 85.00% | 91.36% |
| 31.622% | 10 dB | 92.50% | 77.50% | 87.27% |
| Model | Proposed Method | LSTM | DRSN |
|---|---|---|---|
| Training accuracy | 97.65% | 89.24% | 95.15% |
| Testing accuracy | 97.73% | 87.05% | 96.60% |
| Running time/epoch | 6 s | 5 s | 1 s |
| Test time/sample | 0.0318 s | 0.0102 s | 0.0360 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, F.; Tu, Y.; Gao, W. A Photovoltaic System Fault Identification Method Based on Improved Deep Residual Shrinkage Networks. Energies 2022, 15, 3961. https://doi.org/10.3390/en15113961
Cui F, Tu Y, Gao W. A Photovoltaic System Fault Identification Method Based on Improved Deep Residual Shrinkage Networks. Energies. 2022; 15(11):3961. https://doi.org/10.3390/en15113961
Chicago/Turabian StyleCui, Fengxin, Yanzhao Tu, and Wei Gao. 2022. "A Photovoltaic System Fault Identification Method Based on Improved Deep Residual Shrinkage Networks" Energies 15, no. 11: 3961. https://doi.org/10.3390/en15113961
APA StyleCui, F., Tu, Y., & Gao, W. (2022). A Photovoltaic System Fault Identification Method Based on Improved Deep Residual Shrinkage Networks. Energies, 15(11), 3961. https://doi.org/10.3390/en15113961