1. Introduction
The reinforcement learning (RL) paradigm has seen significant recent development in terms of both artificial intelligence (AI) and in control systems as the two main paths leading the research, with some of the most popularized achievements belonging to the former area. However, recent progress has seen hybridization of ideas from the two fields. The promise of data-driven RL is its ability to learn complex decision policies (controllers) under uncertain, unknown (model-free), high-dimensional environments. While the AI approach largely deals with scalability issues, learning efficiency in terms of data volume and speed, and complex environments, some other features are also well-established, such as, e.g., using neural networks (NNs) (plain feedforward, convolutional or LSTM-like recurrent ones) as function approximators, both for the value function and for the policy function, which is the golden standard. The AI approach presents many contributions, such as parallel exploration using multiple environments to enrich exploration diversity, or sparse or dense reward-shaping in various environments under hierarchical learning problem formulation [
1,
2], and value function overestimation biasing the learning in random environments, which is dealt with by multiple value function approximators, different update frequencies of the critic and policy networks, target policy smoothing, etc., in DDPG, TD3 and SAC versions [
3,
4,
5], to name a few.
But it should be of no surprise that most of these RL achievements in AI have been tested under simulation environments, like video games (DQN Atari for example) and other simulated mechatronics, and not in real world test rigs. In the context of real-world control problems other issues prevail, such as: stability and learning convergence meet the learning efficiency in terms of data volume, and mechanical constraints and real-time implementation requirements being leveraged by efficient function approximators. This is the reason why classical control theory has addressed RL control from somewhat different perspectives than AI. In addition, real-world control problems have often and traditionally been considered as low-dimensional compared to AI problems.
Some of the earliest works in RL, also known as approximate (adaptive) dynamic programming, have been established by seminal works of [
6,
7,
8]. RL for control uses two main algorithms, namely Policy Iteration (PoIt) and Value Iteration (VI), and their in-between, Generalized PoIt [
7]. In the context of these two popular RL algorithms, the implementation flavors have witnessed offline and online variants, batch- and sample-by-sample adaptive-wise, model-based and model-free, and their combinations. Out of the two algorithms, VI-RL has been arguably considered as the most attractive, since it spans the “unknown dynamics” control case, and its initial controller and value function approximators bear random initialization, which is natural when unknown system dynamics are assumed from start. A significant effort was dedicated to ensuring learning convergence and stability, more generally under generic function approximators, such as NNs.
Much of the learnability in RL relies on the Markovian assumption about the controlled system, together with its full state availability. Although different state representations have been proposed in AI, involving virtual states (called state aliases) built from present and past system’s input-output (I/O) data samples, it has not benefited from a well-established theoretical foundation [
9]. However, for RL in control systems, the system observability and controllability are well-founded concepts from a historical perspective [
10,
11].
Among the vast practical control problems approached by RL under classical control analysis approach [
12,
13,
14,
15,
16,
17] and under AI-based analysis approach [
18,
19,
20,
21], the output reference model (ORM) tracking has attracted a lot of research attention [
12,
22,
23,
24]. This control problem tries learning a state-feedback controller to make the controlled system output behave similarly to the ORM’s output, under the same reference input excitation signal. The practical implications of ORM tracking are even more appealing when linear ORMs are used, as indirect feedback linearization is ensured, i.e., a nonlinear system coupled with a nonlinear controller to make the closed-loop control system (CLS) match a linear ORM. Such control problem can be posed as an optimal control problem and has been solved, e.g., by VI-RL and Virtual State-Feedback Reference Tuning (VSFRT) control learning approaches [
24]. This linear ORM tracking has proven itself as the building block for more advanced hierarchical control architectures [
25,
26] aimed at generalizing learned optimal tracking behavior to new unseen trajectories, therefore endowing control systems with extrapolation reasoning similar to intelligent beings. Such goals have been tackled by primitive-based learning frameworks [
25,
26,
27,
28,
29,
30].
Learning LORM tracking control from system I/O data samples with unknown dynamics based on a virtual state representation is a data-driven research approach motivated by the need to solve the control performance degradation occurring due to the mismatch between the true, complex system and its identified, simplified and uncertain model. This is considered a nuisance with the model-based control paradigm. In this context, this work’s contribution is threefold:
- (a)
a novel convergence analysis of the model-free VI-RL (MFVI-RL) algorithm is proposed. The iterative convergence of the cost function towards the optimal cost and the convergence of the iterative controller towards the optimal controller are proven, as updated by VI steps;
- (b)
an original validation on a visual servo tracking system comprising of an inexpensive and modern hardware processing platform (Arduino) combined with the software platform MATLAB. The visual tracking control validation uses the new state representation comprising of present and past I/O data samples;
- (c)
the proposed MFVI-RL (implemented with NN approximator for the Q-value function and with linear controller parameterization) is compared with:
- (1)
a model-based control strategy aiming at the same objective, namely a two-degree-of-freedom (2DOF) controller for ORM tracking; and
- (2)
with a competitive VSFRT linearly parameterized controller also sharing the same learning control objective and the same underlying virtual state representation.
The learning process for MFVI-RL and VSFRT utilizes a form of pseudo-state-feedback control where, in fact, I/O data is used only for reconstructing the virtual state.
The paper is organized as next presented.
Section 2 deals with VI-RL convergence under general assumptions.
Section 3 integrates several subsections, such as: the visual servo system hardware and software description, followed by the LORM tracking problem formulation, subsequently solved by 2DOF control, by VI-RL algorithm and by VSFRT algorithm. All three are presented in detail. Performance comparisons reveal the learned control performance and offer the achieved results’ interpretation.
2. The VI-RL Convergence Analysis for ORM Tracking Systems
The VI-RL convergence analysis is first performed in terms of the original “V” cost function, for ORM tracking systems for which particular penalty functions are sought. The result is then straightforwardly extended to the case of extended “Q” cost function, which characterizes the subsequent MFVI-RL implementation where the controlled system is assumed with unknown dynamics. Furthermore, the derivations are based on a state-space model, however this will be relaxed later on since a new state-space representation is reconstructed from I/O system data samples, using the virtual state transformation concept. Which implies that from any I/O nonlinear unknown dynamics system model which is assumed to be observable, we could arrive at a state-space model, with unknown dynamics a but measurable state. This will be clearly illustrated in the validation case study. For now, let the nonlinear unknown state-space system be
defined in discrete-time, comprising of a transition function equation and an output equation, respectively. The system state is
, the system’s input is
, and the measured (and controlled) output is denoted as
. The functions
are assumed as unknown on their definition domains and also continuously differentiable.
The cost function to be minimized is the summed penalties over an infinite horizon, which reduces to the control problem
where
is the penalty function which is dependent only on
, and has the property that
,
. The penalty function has the value
only when
, with
some goal (or target) state.
Observation 1. In the case of linear quadratic control, the penalty function is commonly with respect to regulation of the system state towards zero. Here, and are positive definite penalty matrices on the state energy and on the control input energy, respectively. It is known that the missing input energy penalization (for ) renders the linear optimal control unfeasible. In the case of ORM tracking systems where the time-varying goal state is the result of a reference model dynamic system, it is possible to define a penalty function independent on the control input energy, e.g., as in . This would eventually lead to a feasible optimal control solution. We preserve notation even if there is no explicit dependence on since this will prove to be useful when acknowledging the role of the control input in transiting from one state to another one .
Let
and
be the optimal cost and the optimal controller. In the following,
and
will imply the same operation under the constraint that
. Starting with an initial controller
and V-function
, for all possible combinations of
,
is solved as follows:
Having the policy determined, the c.f. update renders
Then, for the iterative VI algorithm the following steps are alternated at each j-th iteration:
S1. Update the controller
S2. Update the V-function
Assumption 1.
We assume that the system is fully state controllable. This means that any state can be accessed from any other initial state in a finite number of time steps.
Assumption 2.
We assume all the states from the process have been uniformly visited, and each possible action was tried for each possible state. This is equivalent to a complete fully state exploration, that reveals all the process dynamics.
Definition 1.
The transition distance is defined as the number of minimum state transitions from to using a succession of commands .
Definition 2.
We define a controller to be admissible with respect to (2), if it stabilizes the system (1) from state to the goal state , with finite.
Lemma 1.
The command selection operation performed at each jth VI-RL iteration consists of selecting the minimum value of the series rendered by the nextsuccessive state transitions penalties Proof.
Having
and the controller update
, the c.f. and controller update for
j = 1 are
This step consists of finding the command that transitions from the current state to the next state (), rendering the minimal value for .
For iteration
, the c.f. and the controller update are
Since
can be written as a sum of penalties, this operation can be expressed as the selection of the two-state transitions with minimum cost. This step finds the optimal command in the first step of the
two-stage state transitions series, depicted as
Then, the c.f. update at iteration
is
Following the reasoning, for any given iteration
j, the cost function update is
The controller improvement step is then
This step consists of finding the optimal command
in the first step of the
j-stage state transitions series
which concludes the proof. □
Lemma 2.
For each iteration, the cost function of the goal stateis, and the controllermaintains the system in state. Consequently, the c.f. of any stateis.
Proof.
Since the initial cost function for any state
is
, the controller update for any state
at
is
The VI-update for the state
at iteration
is
and for any state
is
The controller update
selects for the state
the command
that takes the system to the state
.
Assuming by induction that
, the controller updates as
Since for any , and , the VI update will be , meaning that the operation will select for state the command that maintains the system to the state .
The c.f. update renders
proving thus that
Also, accordingly to Lemma 1, the cost function
of any
can be written as
Since , this proves that □
Lemma 3.
All c.f.that have its series of penalties ending in the goal stateare finite, as.
Proof.
A necessary condition for convergent series is that the sequence of its elements must converge to zero. Having the sequence of the penalties
, it is required that
as
. Since only the state
has penalty
, it follows that the sequence must converge to
. With this result, it follows that the finite c.f. can be written as
This proves that all c.f. that have its penalties sequence ending on state are finite and remain constant as . □
Theorem 1.
Letbe the c.f. of a statewithdefined on the set. Then,converges onto a limitif, whenever, it follows that. Moreover, as,and.
Proof.
Let , . We first show that is convergent for with .
Having the controller update for
the c.f. and controller update for
are
For all the states
with
, the optimal command
u that transitions to
will be selected. So, the c.f. of all states
with
at iteration
, can be written as
At any at iteration
, the c.f. and controller update are
Since according to Lemma 1 , the selected command after the controller update (5) will be the one that transitions the system to .
Assuming that
, after the controller update (5), the command
u =
that transitions to
will be selected. The c.f. relative to iteration
is going to be
It can be seen that for all states with , for any , , meaning that . This follows since at each iteration , the improved controller u = transitions to .
Assuming that is convergent for all states with , it is next proven that is convergent for all states with .
Having the controller update as (5) at iteration , it is assumed for states with that there exists a command u that transitions the system to a state with that has the c.f. finite. According to Lemma 2, the operator has to choose between different series of elements, where the one associated with state that has the transition distance , will therefore be selected instead of any other state with , since it represents the minimum penalty series. As , the operator will also select the command u that transitions to the state that has , since according to Lemma 2, its c.f. will remain constant and therefore finite.
Showing that from , for a state with , proves that the sequence of optimal commands that bring the system to the goal state will be selected as . Updating using (5), will find the controller that bring the system to the goal state using optimal commands, meaning that the found controller is the optimal controller . Since the optimal controller can be derived only from the optimal c.f., this means that , from . This completes the proof. □
The VI convergence proved in Theorem 1 is based on the true V-function parameterization, and hence can be used only for systems for which the c.f. is known and for table-based VI implementations with finite states and actions. For continuous-time nonlinear processes as in (1), a broad range of function approximators need to be used for the V-function and for the controller . Employing these approximations in the VI operations, some approximation error is added at each iteration, enforcing thus the V-function and the controller to be suboptimal. It is next proved that the VI learning scheme also converges under approximation errors.
Having the c.f. approximation error function and starting with an initial V-function , the controller and c.f update are represented as
Equations (32) and (33) show that the approximate V-function and controller follow the real ones with a small approximation deviation As long as the true V-function parameterization is unknown, the residuals , making the approximated VI (AVI) updates (32), (33) differ from (3), (4). Even if the obtained controller is suboptimal, it must be admissible to make the system reach the goal state . To prove the existence of an approximation error upper bound at each iteration such that the controller ) will be admissible for each state , with the c.f. constant and finite in the original VI-update, the following definition must be given.
Definition 3.
We defineas the set that contains all the statesfor which the controller) is admissible. Additionally, the complement setrepresents the set of all statesfor which the controller) is not admissible.
Theorem 2.
For the c.f.at iteration,that under any commandwill transition the system to a state, the c.f. approximation error of the state, denoted as, respects the following condition
in order to make the controller
) admissible. Additionally, as
Proof.
Let
,
,
,
. The controller update is
According to Lemma 1, for the state
with
, the optimal command maintains the system to the same state
. Since
, this command will be selected by the minimization operation, making thus
. The c.f. and the controller update at
are
According to Theorem 1, for
with
the optimal command transitions the system to the goal state
. Also, for the state
, the command that maintains the system to the goal state
needs to be selected. If the c.f. approximation error
has its value, such that the cost of transitioning to
from any state
with
will be lower than any cost associated with
with
, namely
then the
operator will not be motivated to choose the command that transits the system to another state rather than the goal state
. By selecting the command
for the state
,
. Having done so, the c.f. and controller update for
are
For all states
with
, the optimal command selected at this iteration by controller update (32) is the one that transitions the system to a state
with
. For all states
with
, an admissible command can transition the system to the goal state
or to any
. Then, the approximation error
for
must have the value such that
making thus
At any iteration
, we assume that for some states
with
there exists a command that transitions to
,
. The selected command
by controller update (35) for state
needs to transition the system to any state
with
, in order to make
. Also, for any state
with
the selected command
can transition to any state
, to make
. The approximation error
for
must then hold the following inequality
making
. □
Theorem 2 shows that by bounding the approximation error such that the selected command will transition to a state , although the obtained controller is suboptimal, it will be restricted to be admissible, thus stabilizing the system asymptotically. This does not guarantee that and will remain constant for all iterations , but it will ensure that their distance to the original V-function and the original controller , will be dependent on the performance of the selected function approximators.
For the model-free implementation of the VI-RL algorithm, subsequently called MFVI-RL, the V-function is extended to the so-called Q-function that has both the state and the command at time
as its arguments. The Q-function update for an arbitrary command
in state
is
The control update step at current iteration is represented by
It results from Theorem 1 that and that the right-hand side of Equation (29) embeds in fact the VI-RL update of the V-function, via the operation . This means that and are paired. It follows that . This result also implies that . Using function approximators for both the Q-function and the controller, namely and , the c.f. approximation error , must respect the condition , in order to make the controller admissible for states that under any command will transition the system to a state .
The MFVI-RL using Q-functions is shown convergent to the optimal control which must also be stabilizing in order to render a finite cost function. At this point, the problem formulation is sufficiently general, it will be made particular for the output reference model tracking in the case study.
The next section presents in detail the case study of a visual servo system built for output reference model tracking purpose. Tracking control is learned with MFVI-RL but also with competitive methods used for comparisons: a model-based 2DOF controller and a model-free VSFRT controller.
3. Visual Output Reference Model Tracking Control Design
3.1. The Visual Tracking Servo System Description
Building a hardware system from scratch assumes a well-structured plan, in which the desired behavior must be established from the system. Several components were used in the project, which will be presented below [
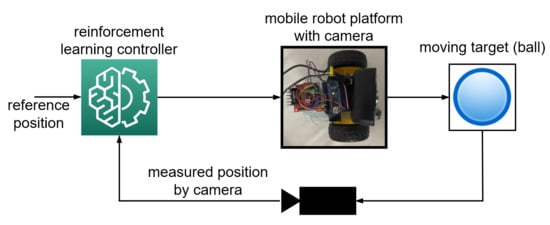
31]: Arduino Nano, webcam, double H-bridge L298n, a micro actuated DC motor (ADCM) with reduction, two side wheels, an independent wheel with a supporting role, acrylic chassis, breadboard, power cord, webcam connection cable to PC, Arduino connection cable to the PC, and a power adapter.
The resulting hardware assembly has a chassis represented by an acrylic plate, having three wheels, two of which are the side ones, the left one being connected to the ADCM so that the assembly can perform rotational (yaw) movements, in order to track a fixed or mobile visual target seen through the webcam [
31]. The third wheel is placed in the rear of the chassis; its free motion has solely the role of facilitating the whole assembly yaw motion. On top of the acrylic board and in front of the assembly, the webcam captures images to send back to the PC. The Arduino board was placed in the breadboard, from here making the connection with the ADCM being used, through the H-bridge. The assembly can be observed in
Figure 1.
Sending commands from the MATLAB environment running on the PC to the ADCM, is handled via Arduino using an USB cable. Arduino sends the commands to the motor driver, which powers the ADCM. The L298n motor driver operates in this project with a single motor. It is powered by a 7.5 V input voltage from a power adapter connected to the outlet that has an output voltage of 7.5 V. Part of this voltage is used to power the ADCM. The ADCM selection was made by connecting the D5 pin to one of the two “Enable” ports of the L298n. Thus, the rotating direction is controlled by the input pins I1 and I2 of the driver, receiving logical voltage level from pins D11 and D12 of Arduino. Depending on the state of these two pins (set or reset), the ADCM spin direction is set. For pin D11 having logical value 1 (5 V) and pin D12 having the value 0 (0 V), the motor will spin clockwise and when D11 has the value 0 and D12 the value 1, the ADCM will spin in counterclockwise direction. In each specific direction, the ADCM’s angular speed is set by a PWM signal generated with Arduino, whose duty cycle value is set in MATLAB and transmitted from the PC. The ADCM is a carbon-brushed motor from Pololu, 6 V, reduction ration 1000:1, with 33 revolutions per minute at no load, drawing a nominal current of 0.1 amps. Due to the high reduction factor, it is ideal for fine low angular speed control.
However, the micro reduction ADCM used is not built for precise position control (as demanded by a video servo tracking system), while a dedicated one is costlier. The ADCM has a variable dead-zone (DZ) around about 0.156 V (per each rotational direction) which is time-varying due to the multiple magnetic and thermal effects that occur after longer time usage. A logical solution is to compensate the DZ, but due to the mentioned phenomena, the DZ thresholds are impossible to compensate exactly. However, an approximate compensation is actually performed, allowing acceptable positioning visual tracking accuracy [
31].
In practice, there are certain video tracking platforms involving advanced image processing and features detections techniques, combined with advanced localization techniques of complex motion dynamics, such as unmanned aerial vehicles (UAVs), as done, e.g., in [
32]. In work [
32] the focus is to ensure tracking reliability under complex practical conditions, including huge scale variation, occlusion and long-term task. Other visual tracking solutions were proposed in [
33,
34,
35]. Such a tracking approach relies on low level controllers which could be designed based on the proposed learning strategies carried out in this work. The main advantage of our platform is its cost efficiency and flexibility, allowing for affordable educational and research activities.
Further on, at the software level, color-based identification of the moving target object (in this project, a blue ball) was performed in MATLAB. The implementation of the object identification process involved several steps. A general position control goal is to track the desired object (blue ball) to keep its position in the image center.
After setting up the desired image capture settings such as resolution (
) and the RGB (red, green and blue) image color type, to be able to process it, the next step is to extract the RGB components. Three 2D matrices are extracted using the commands (in MATLAB code style):
r = img (:,:, 1); g = img (:,:, 2); b = img (:,:, 3) where
img is the captured image object. To emphasize the tracked object whose blue color is known inside the image, a single 2D matrix is obtained having each pixel intensity level denoted “
blueComponent” calculated with (matrix element-wise operation) [
31]
The next step is to set some threshold values in order to identify the regions inside the image that are considered “sufficiently blue”, to include the object to be identified. This is ensured by the
bwareafilt function which extracts objects from an image depending on their size or their area. For the detection of unique objects, an analysis of the connected components is performed, in which case each blue region is assigned a unique ID. We ensure that the largest blue object inside the scene is the ball. The image center coordinates being easily calculated as
where
are the image width and height, with respect to the top-left corner. Identifying the center of gravity (CoG) of the identified ball object is the next action. The MATLAB function
logical first converts numeric values into logical values for the final 2D image. The calculation of the center of gravity of the target object was performed by the
regionprops function which measures the properties of a specific region of an image. The function returns the measurements for the property set of each connected component (object) in the binary image. The function can be used for both contiguous or adjacent regions and for discontinuous regions. Regarding these types, we can say about the adjacent regions that they are also called objects, connected components or blobs. The object’s CoG specific coordinates (
,)
, locates its position within the image. The system’s controlled output is defined as
. In sample-based measurement in discrete-time, it will denote
.
To complete the system overview in the proposed design, we denote the PC command sent from the MATLAB environment to the ADCM as the duty cycle factor
. Regardless of the DZ size, this
is sent to the ADCM by adding an offset value for each direction of rotation corresponding to the DZ threshold values. The position reference input
sets the desired distance of the object center to the image center. In most applications,
means that the assembly (the camera in particular) should rotate in order to keep the tracked object in the center. Normally, both
are measured in pixels, leading to a magnitude of hundreds of pixels, depending on the image size. A normalized value of
is being used by dividing its pixel value with 1000. Therefore, normalized reference inputs
are used as well. The system is capable of consistently processing the frames in native resolution and all the subsequent controller calculations, for a sample period of
. This sample period was established after many statistical evaluations, by timing all the image transfer, visual processing tasks and control law evaluations [
31]. Timer objects were used for software implementation convenience, to properly run the recurrent control tasks.
3.2. The Visual Servo Tracking in Model Reference Control Setting
The controlled system is formally described by the discrete-time I/O equation (with
the sample index)
with system control input
inside the known domain
, system output
in known domain
, unknown integer orders
, and unknown dynamic nonlinear continuous differentiable map
. System (47) is assumed to be observable and controllable; these are common data-driven assumptions extracted from working interaction with the system, from technical specifications or from literature survey. Lemma 1 in [
36] allows for a virtual state space construct equivalent model of (47) defined as
where
, more specifically with
,
, where
has the role of a nonlinear observability index similar to the one in linear systems theory. Here,
is defined as the minimal value for which the true state of (48) is recoverable from I/O data samples
. When the order of (48) is unknown, so is
In practice, one starts with an initial value and searches for the one which achieves the best control when using the virtual state
for feedback. Some remarkable features are synthesized in the following observations.
Observation 2. Systems (47) and (48) have the same input and output, hence from I/O perspective their control is the same. The means to achieve control may be different, however the intention is to attempt state feedback control on the virtual system (48) and feed it as input to the true system (47). System (48) is fully state-observable, with measurable states and with partially known dynamics where domain is completely known since it is built on known domains .
Observation 3. Time delays in (47) can also lead to a fully observable description (48) by proper definition of additional states. If present, the (assumed constant) time delays should be known and easily measured from the historical I/O response data.
The visual tracking problem in model reference control intends to find a control law which makes the output
in (47) match (or track) the output of a linear output reference model (LORM) best described in its discrete-time state space form as
where
is the LORM state,
is the reference input in known domain
and
is the LORM output within a known domain. Note that (49) is a state space realization of a more compact linear pulse transfer function (PTF)
which relates
, among all infinite realizations’ triplet
. Here,
is the unit time step advance operator (
). Selection of
is not arbitrary. Under classical model reference control guidelines, it should account for true system dynamics (47) and its bandwidth, and it should include the true system’s time delay and nonminimum-phase dynamic if it is the case.
The ORM control problem is formally expressed as in
where the explicit dependence of
on
has been captured. The intention is to find an explicit closed-loop control law
with
some regressor state dependent on the control design approach. For example, if
, the control renders
which is a recurrence equation accommodating many control architectures (PI/PID, etc.). However, other selections of
are possible, as illustrated in the following sections. Essentially, when driven by the same
, we should ideally get
, i.e., the system’s output (also the closed-loop system (CLS) output) equals the ORM output. The class of ORM tracking control problems belong to the “dense rewards” settings, as opposed to the “sparse rewards” case which is found in many AI-related environments, whereas in classical control, the problem is known as a model reference control.
Differently from the model reference adaptive control (MRAC) but nevertheless sharing the same overall goal of output reference tracking, the control solution to (50) should be a stationary, non-adaptive controller. Formulation of the penalty function may impact the resulted control performance significantly. For example, non-quadratic Lyapunov functions serving the role of penalty functions in adaptive control have been proposed in MRAC [
37,
38]. Based on
Observation 1, herein we employ quadratic penalties since we preserve interpretation parallelism with the linear quadratic controller case. A quadratic penalty combined with a linear system renders an infinite-horizon cost that is quadratic convex with respect to the state, which facilitates the existence and uniqueness of a global minimum, but also its analytic derivation. Such desirable properties are expected also with smooth nonlinear systems, to some extent at least.
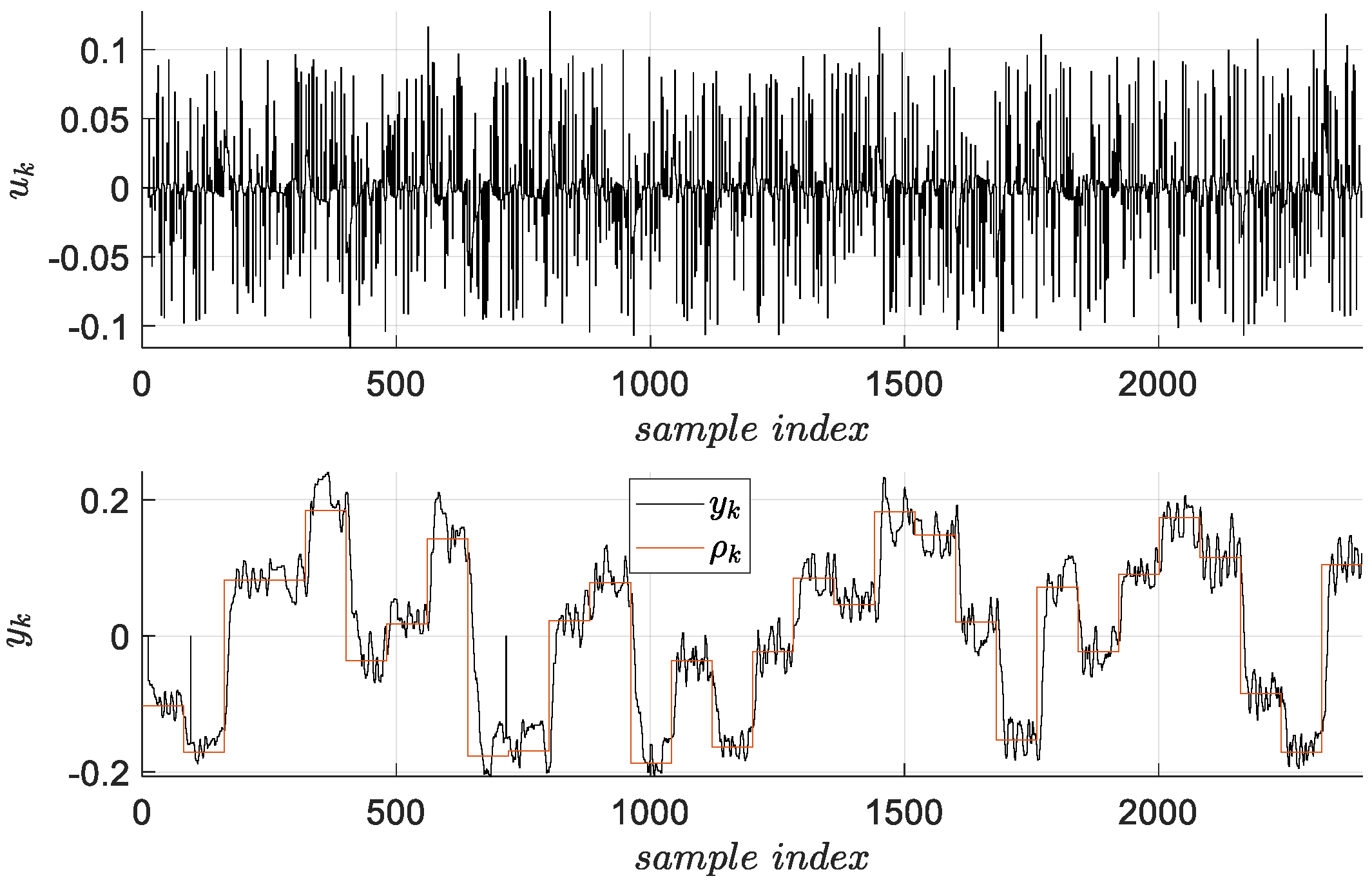
3.3. Closed-Loop Input-Output Data Collection
The simplest standardized controller, namely the proportional (P)-type one will be used to stabilize the positioning process and to further collect I/O data for finally learning more advanced ORM tracking control. Its transfer function is
, where
is the transfer coefficient. As shown in [
31], this type of controller is recommended in the case of simple driven processes with a single large time constant, with or without an integral component. In this case, the servo positioning has an integral component. The P controller’s law in discrete-time (with transfer function
)
is used with
established following experimental tests to give satisfactory tracking performance. Here,
is the reference input to the control system. The tracking scenario implies a sequence of successive piecewise constant reference input values
(each value is kept constant for 10 s) with the amplitude uniformly randomly distributed in
. Additive noise on
is applied for enhancing exploration (also understood as persistent excitation) with the following settings: the command
receives an additive noise with uniform random amplitude in
, every three samples.
The ORM continuous-time transfer function is selected as
where
sets the response speed and
sets the magnitude overshoot. This transfer function was discretized by using the zero-order hold method with the sampling period
, to render:
For
, a state-space controllable canonical form transform is
which will be used to generate the input-state-output data for the ORM. Meanwhile, a different reference input
which excites the ORM was also selected as a sequence of successive piecewise constant values where each value is kept constant for 15 s and the amplitude is uniformly randomly distributed in
. The switching periods of the reference inputs
was not a negligible problem, their values trade-off exploration and lengthy collection time [
31]. The I/O data samples contained within the trajectory
will be subjected to various control design approaches. A number of 2400 samples for 300 s of collection were obtained, as in
Figure 2.
3.4. The Visual Servo System Identification
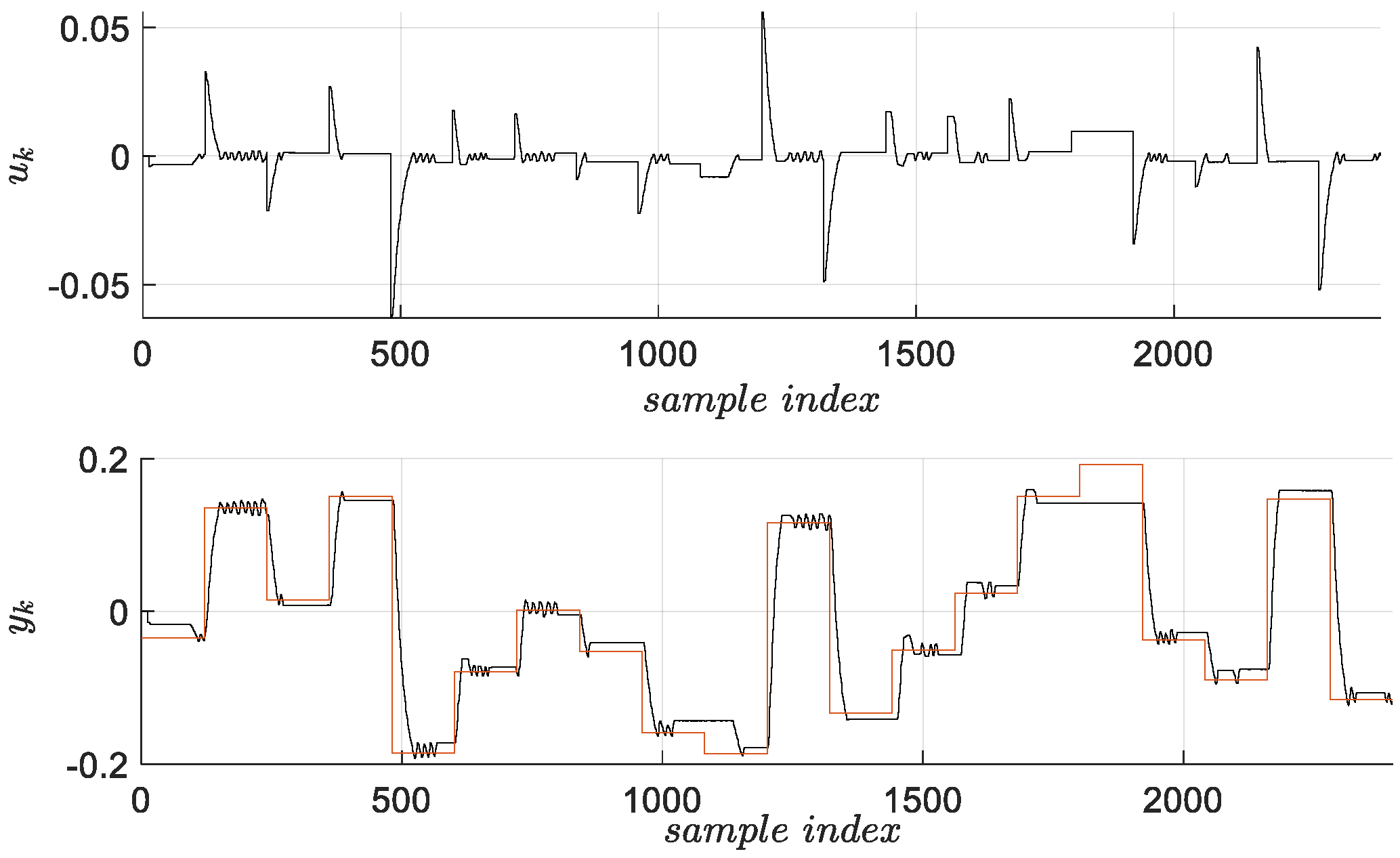
In order to apply a model-based control design dedicated to ORM tracking, a pulse transfer function of the visual servo system must be identified. Since the system has an integral component, the identification is indirectly performed, by firstly identifying the closed-loop pulse transfer function
, based on closed-loop data from
Figure 2 [
31]. A set of validation data for the same dynamics is generated, as in
Figure 3.
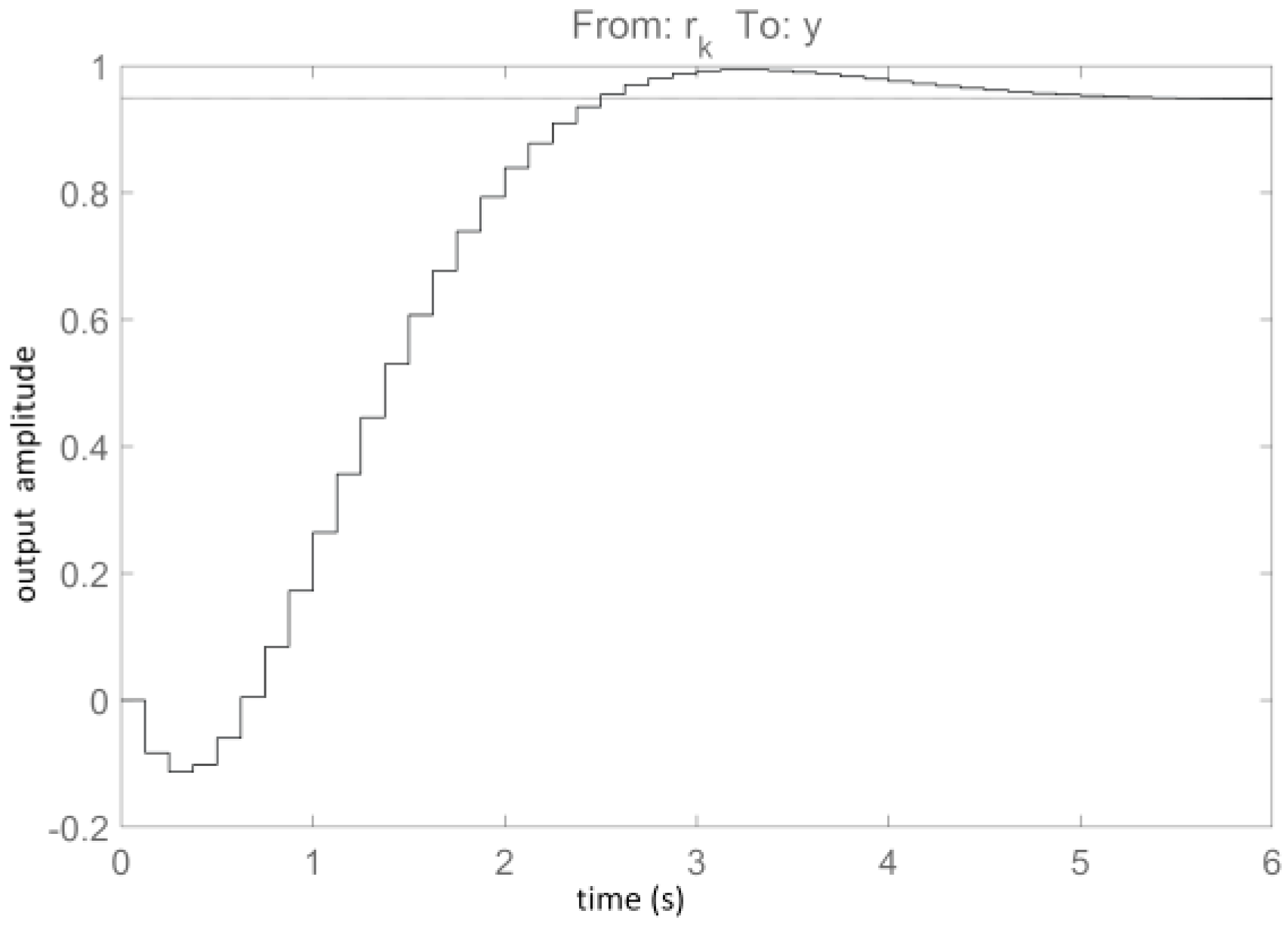
A second-order output-error (OE) recurrent model for the closed-loop visual servo system transfer function is selected, being identified as (and whose step response is shown in
Figure 4) [
31]
The closed-loop transfer function allows for identifying the I/O visual servo system model as [
31]
whose step response is shown in the
Figure 5. Note that the identified
has a non-minimum-phase character which is not observed in the true system, this non-minimum-phase is a result of the imperfect DZ compensation. Additionally, the model
appears as a first-order lag with a large time constant, although its true dynamics must contain an integrator. However, the incipient step response phase (first 20 s) overlaps with that of an integral-type system. Finally, the indirectly identified
can be used for model-based control design.
3.5. The 2DOF Model-Based Control Design
The 2DOF (also known as RST) control design procedure is next described, for the case with the same imposed dynamics in terms of setpoint tracking and disturbance rejection. Assume that
can be written in the form
which is validated for the identified model since
(the operator
measures the polynomial degree) in our case. With the ORM transfer function (53), in the case of the 2DOF controller without stable zero compensation (
has a non-minimum-phase zero) and with integral component in the controller to ensure zero steady-state tracking error and steady-state disturbance rejection simultaneously, we first define the polynomials as factors for
:
The denominator
from the imposed
will actually set the step-response character of the closed-loop system. An artificial, maximal degree polynomial
is constructed as
such that it will simultaneously fulfil a set of conditions set out in [
39], namely
and
After factoring
the polynomial
results
.
The polynomials
,
and
are imperative in the 2DOF controller design. Firstly, it must be ensured that
[
39] where
in our case. Then,
must be monic (leading coefficient is 1) and since
must have an integral component, based on
, we must further explicit
. Due to the degree condition
, we must write
. Then,
fulfils the degree condition, while the observer polynomial
is selected to ensure minimal degree fulfilment of the polynomial equation [
39]
equivalent to
The above polynomial equation was solved as a compatible determined system of linear equations in the unknown coefficients of
:
The solution to (61) will produce
of the form
. Finally,
renders the transfer function description of the 2DOF controller as [
31]
which in its recurrent filter form writes as
Using this scheme, we validated the 2DOF controller with the identified system model
in closed-loop with unit reference input step response, in
Figure 6.
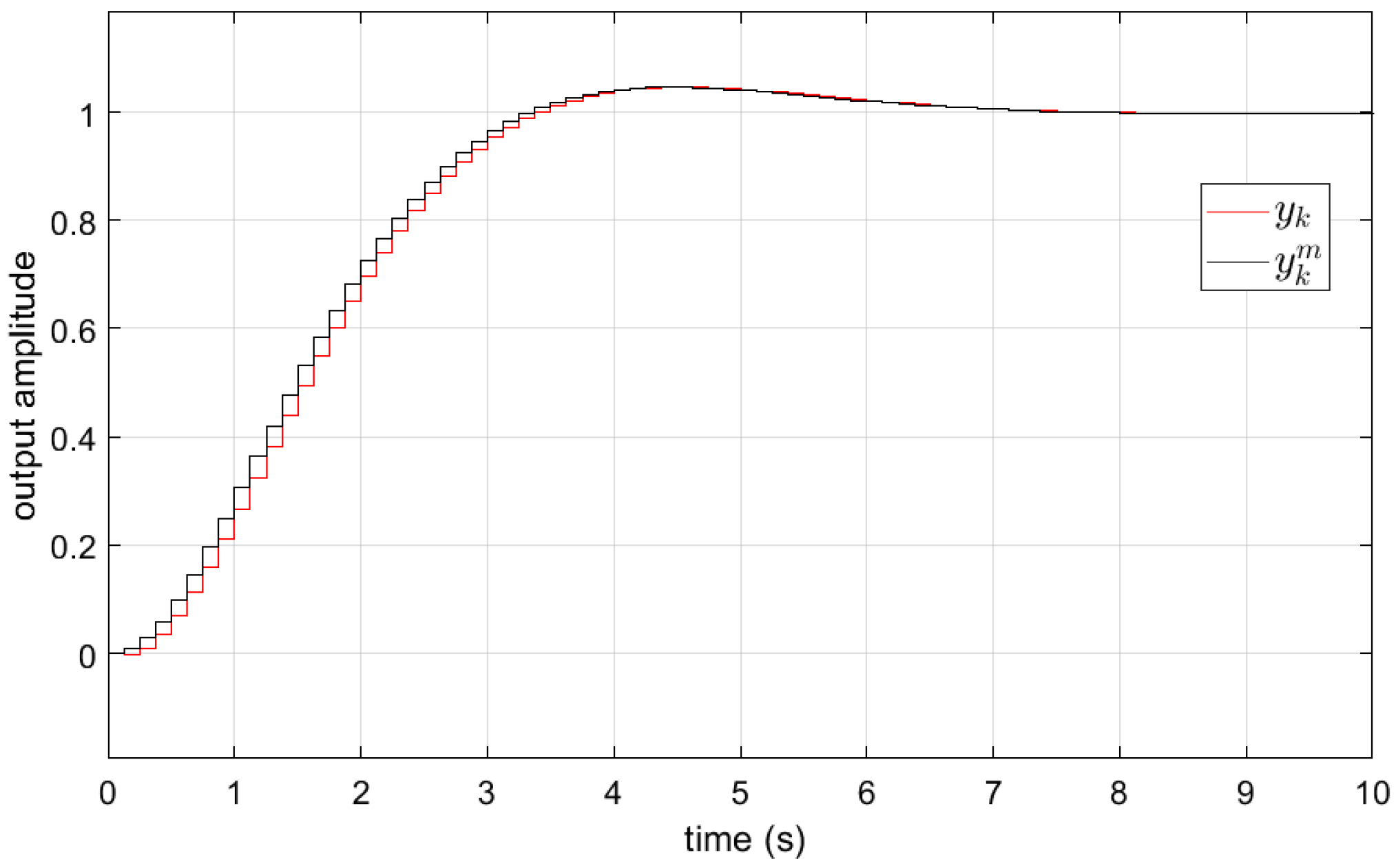
The experimental validation of the designed 2DOF controller used with the true visual servo system is depicted in
Figure 7 below, on a test scenario.
3.6. The MFVI-RL Control for ORM Tracking
MFVI-RL requires some Markovian assumptions about the controlled system, hence the controlled extended system will be
where
is some generic nonlinear map which is partially unknown, (
is partially unknown) over the extended state, and
. The domain
of
is known, as the domains
are known. In addition,
is the reference input generative model which is user-defined. Many types of practical reference inputs comply with this generative model equation (e.g., piece-wise constant model
).
MFVI-RL is able to learn the ORM tracking control solution for the system (64) without complete knowledge of . The extended states-space system representation (64) can perfectly replace the dynamics (47) in the problem definition (50). Note that in (50) depends on components of ( is the first component from the vector while ). In its off-policy offline version (more popularly known as Q-learning), MFVI-RL starts with a dataset of transition samples (known as tuples or as experiences) of the form for a number of elements.
MFVI-RL relies on the estimate of a “Q-function” which is an extension of the original cost function . We notice that whenever the discount factor and the penalty term is defined, like in which explicitly captures the ORM tracking goal. Using the Bellman equation to which we associate the controller , the Q-function is defined as .
To cope with infinitely dense state and control input domains, it is common to parameterize both the Q-function and the controller with (deep) neural networks (NNs). In the following, the MFVI-RL steps with a generic NN approximator for the Q-function (which is expressed as with being the NN weights) and a linear controller defined by where , are presented in Algorithm 1.
| Algorithm 1. The MFVI-RL Algorithm 1 for ORM tracking |
Choose a reference model with dynamic , under the rules and in terms of specifications which are representative for model reference control. Build a state space realization (49) from . Run data collection experiments on system (47) to obtain a dataset of I/O samples . In the same time-frame or in a simulated process afterwards, generate using a prescribed generative reference input model and the state-space (49). Make sure the domains and are correlated in amplitude. The collection of both and must be sufficiently exploratory i.e., the variables should cover all combinations of their values inside their respective domains. This is usually achieved for long enough trajectories. However, good coverage of the state-action space in a shorter time is achievable in various ways: straightforward procedures include adding noise and avoiding already visited combinations by recording the tracks. Select the observability index . Data-driven construct the virtual trajectory which defines the virtual state-space system (49). Couple this trajectory with to construct transition samples from (64). Select an initial parameterization for the NN modeling the Q-function, let this be denoted as where lumps all the NN tunable weights at iteration . Select as the initial controller parameter, it need not be stabilizing for MFVI-RL algorithm (e.g., random initial value is feasible). At current iteration , prepare the Q-function NN input patterns as and the target output patterns as , for all . Train the NN using the I/O patterns, based on architecture-dependent training settings. It is equivalent to solving which is the well-known MSSE cost. For each in the dataset, find . For a bounded infinite domain e.g., , this minimization will be approximately done by enumerating a finite set of equidistant values for e.g., . Although apparently exhaustive and not as accurate as a gradient based search scheme, this minimization can be efficiently implemented even for multivariable systems where the dimension of is acceptable (up to three). Build the overdetermined system of linear equations
and solve it by ordinary linear least-squares as where . Another possible gradient-based search solution for finding is to train the cascaded network w.r.t. , over all inputs , with the target values set to zero. If the number of maximal MFVI-RL algorithm iterations was reached, or there is no improvement in the control parameter (), exit the algorithm; otherwise increment and go to step 5.
|
For the MFVI-RL practical implementation of learning visual servo tracking, the Q-function is a deep neural network of feedforward type, with two hidden layers having 100 and 50 rectified linear unit (ReLU) activation function, respectively. A single neuron in the output with linear activation predicts the Q-value of a state-action input. Training settings include: 90%–10% training-validation data splitting with random shuffling; early stopping after 10 consecutive increases of the MSSE cost on the validation data; and maximum 500 epochs with a scaled conjugated gradient descent backprop algorithm. The entire training data is used as one batch in each epoch, therefore the “replay buffer” consists of all the transition samples in the experience replay mechanism. This can be considered a deep reinforcement learning approach belonging to the supervised machine learning field.
Starting with the I/O data collection from the closed-loop system under the P-type controller and with the ORM input-state-output data collected offline, the trajectory
has 2400 samples out of which only 2369 obey the piecewise-constant generative reference input model
. A total number of 100 iterations lead to the MFVI-RL controller matrix
for the controller modeled as
, shown performing in
Figure 7. We stress that the linear controller structure complies very well with the 2DOF controller structure (and with the subsequent VSFRT controller structure), in an attempt to investigate and check the best achievable framework-dependent control performance.
3.7. The VSFRT Learning Control Design for ORM Tracking
The VSFRT feedback control concept is briefly detailed in this section. Since it relies on state information for feedback, it uses again a state-space model, this time it is the model (48), together with a different rationale for computing offline the virtual reference input. It generalizes over the classical nonlinear virtual reference feedback tuning (VRFT) concept [
40,
41,
42,
43,
44,
45,
46,
47] in the sense that the control law is not explicitly depending on the output feedback error as in
but rather in the form
or, more generally, depending on the lumped regressor
hence resulting in the law
Starting from a dataset of I/O samples
collected from the system (47), VSFRT computes the virtual trajectory
of (48) first. The virtual reference is afterwards computed as
. From this, the virtual lumped regressor builds the dataset of states as
. The VSRFT principle solves (50) indirectly by solving a controller identification problem posed as [
48]
which specifies that the controller fed with
and parameterized by
should output
obtained in the first place in the collection phase. A remarkable observation is that
in VSFRT does not contain the ORM state
as in the MFVI-RL case, since it is viewed as an unnecessary redundancy [
24]. Hence, the ORM state-space model is useless, except for its I/O model
. VSFRT does not require the Markovian assumption about the system state-space model, hence it does not require a reference input generative model because the VRFT principle is different about getting
. The VSFRT steps are next described in Algorithm 2 for the case of a linear control
where
(notice the resemblance with MFVI-RL control, except for the ORM states). In the linear controller case,
.
| Algorithm 2. The VSFRT Algorithm 2 for ORM tracking |
Choose a reference model dynamic under the rules and in terms of specifications which are representative for model reference control. Run data collection experiments on system (47) to obtain a dataset of I/O samples . Here, should be persistently exciting to make capture all of the system’s dynamics. This is a sort of exploration condition, as in MFVI-RL. The excitation condition is usually ensured by (additive) exploratory noise, whether in an open- or in closed-loop. Select the observability index . Data-driven build the virtual trajectory which defines the virtual state-space system (48). Compute the virtual reference input as . Here, a series of aspects are of interest. commonly has a low-pass behavior, making as a high-pass filter. If is noisy, low-pass prefiltering is strongly advised, which could be done, for instance, as a zero-phase filtering. This filtering is not the same as the classical VRFT pre-filter as it is not applied on the entire regressor vector but only on . Further, even if is non-causal, it can be implemented offline. Build the regressor vector . Form the overdetermined system of linear equations
and solve it by ordinary linear least-squares as where . This, in fact, solves the controller identification (66) over the controller parameter .
|
Commonly, nonlinear controllers modeled as NNs have also been employed in many settings [
24,
48,
49,
50,
51,
52,
53,
54]. Most of these deal with tracking applications extensively [
55,
56,
57,
58,
59,
60,
61,
62]. In the case of mildly nonlinear systems, linear state-feedback controllers, such as the proposed one, have proven functional. In fact, using the input patterns
and the output patterns
, one can train any approximator for the controller using appropriate methods by minimizing the cost function (66), which is the popular MSSE cost. Several intercoupled aspects of how can VSFRT serve for transfer learning to the MFVI-RL controller have been thoroughly investigated in [
24], where other aspects, such as using principal component analysis and autoencoders for dimensionality reduction of the state, have been tested as well. Depending on the VSFRT NN controller complexity, it can be framed within the deep learning type of applications.
For our practical implementation on the visual servo tracking, the same dataset of I/O data was used for VSFRT control design; namely, there were 2400 samples of trajectory
. There is no need for a specific generative reference input model, hence all samples were used. Before computing the virtual reference
, the output was prefiltered through the low-pass filter
. The reason is that there exists some high-frequency content in
due to the imperfect DZ compensation in the collection experiment with the P-type controller. Different from the classical VRFT setting, the role of the prefilter here is not to make the controller identification cost function match the ORM tracking cost function, but to merely minimize the DZ’s negative influence. Solving (66) with (67) renders
and the resulted VSFRT controller is
, performing in
Figure 7.
3.8. Testing the Controllers and Measuring the Resulted Tracking Control Performance
For a fair evaluation of the ORM tracking control, the index
was measured, where the mean value is defined
for
samples. This fit score metric is more practical and correlates well with the cost
in (50). It also represents the percentage expression of the
Pearson coefficient of determination used in statistics. The ORM tracking performance for the visual servo system is shown in
Figure 7, in terms of mean response and 95% confidence intervals obtained after five runs with each of the 2DOF, MFVI-RL and VSFRT controllers. The actual values of
are rendered in
Table 1 below.
From a testing viewpoint, we do not move the blue ball target manually since this behavior is hardly reproducible. Instead, we change the reference setpoint distance of the image center with respect to the detected blue ball as a sequence of piecewise constant steps. This piecewise constant variation of the reference is then filtered through the linear ORM. This ORM’s output should be tracked accordingly with all tested controllers (An illustration of the test scenario with the MFVI-RL controller is to be found in the movie that can be accessed and viewed at the following address
https://drive.google.com/file/d/1VI8mbi7GOyaOE4ceIxJyaEPvRVBqTQPP/view?usp=sharing (accessed on 7 November 2021)).
A linear controller parameterization was used in this case study, to verify and discriminate the control capability of MFVI-RL and VSFRT, compared to the model-based 2DOF controller. As seen from the results recorded in
Table 1, the MFVI-RL controller achieves the best statistical result, even better than the 2DOF model-based controller, which supports the conclusion that model-free design can in fact surpass the model-based design which relies on approximate identified system models. The inferiority of VSFRT with respect to both the baseline 2DOF controller and MFVI-RL controller, observed in
Table 1, indicates that the I/O data exploration issues is the main responsible factor. This conclusion is supported by the fact that VSFRT has been shown to be superior to MVFI-RL when applied to other systems, such as aerodynamic or robotic ones [
24]. In fact, VSFRT was able to learn better control with fewer transition samples and with less exploration. This observation confirms that the exploration issue in data-driven control is still an open problem and efforts are needed to define exploration quality indexes. These indexes must be accounted for and balance the overall responses to the big questions of data-driven control, such as what is the tradeoff between the controller complexity and parameterization vs. the control goal vs. the optimal data volume and exploration quality?
On the application level, all three compared controllers are limited in the achievable linear ORM tracking performance. The reason lies with the visual servo system actuation quality from the ADCM: it has a time-varying dead zone whose thresholds in each rotation direction change with longer runs, owing to electromagnetic effects. A perfect compensation is therefore impossible to achieve without an adaptive mechanism. The used ADCM is certainly not suitable for quality positioning systems. Under these adversarial settings, the learned control for the visual servo system ORM tracking is deemed satisfactory and it achieved the desired quality level. With better actuators, the tracking performance is certainly expected to increase. In conclusion, such video servo systems are widely usable in real world applications, such as surveillance cameras, motion tracking, etc.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}