1. Introduction
Agriculture, fisheries, and animal husbandry are the main contributors to the development of the global economy. The increase in temperature caused by carbon dioxide emissions has a huge impact on them. Because global warming has led to reduced fishery production and threatened food security, this will affect the development of the global economy and the environment for human survival [
1]. Global warming has aggravated the frequency of river drought and caused serious damage to the ecosystem [
2]. In summary, carbon dioxide emissions have had an important impact on the human living environment, natural ecosystems, and the development of the global economy. Therefore, we should reduce carbon emissions as our urgent problem.
To reduce carbon emissions worldwide, the international community has adopted carbon dioxide emissions trading rights as an important economic measure to deal with global warming, which is very important for the global promotion of carbon emissions reduction. The European Union Emissions Trading Scheme (EU ETS) is an important mechanism to deal with carbon emissions. The EU ETS is the first, largest, and most prominent carbon emission regulatory system in European countries. The EU Emissions Trading Program has established European Union Permits (EUAs), and emitters have a certain number of EU permits, and emitters can freely trade EUAs. In this way, emission reduction targets can be achieved at the lowest cost, especially it is very effective in reducing industrial carbon emissions [
3]. EU ETS has an important impact on the performance of enterprises. The performance of enterprises with free carbon emission allowances is significantly better than that of enterprises without free carbon emission allowances [
4]. At the same time, EU ETS is also a good benchmark for China. China is becoming the world’s largest carbon emitter. Since 2011, China has launched carbon trading pilot projects in 8 provinces and cities including Beijing, Tianjin, Shanghai, Chongqing, Hubei, Guangdong, Shenzhen, and Fujian. At present, China’s carbon market is making every effort to promote the construction of the carbon market, and it is expected that a unified national carbon market will be formed around 2020 [
5]. According to this plan, China will have about 3 billion tons of carbon emissions trading. This scale will exceed the EU.
There are currently three main carbon price predictions. The first is a quantitative statistical model. The second is a neural network model. The third is a hybrid model.
The first is the quantitative statistical model. They are autoregressive integral moving average (ARIMA) model [
6], Generalized Auto Regressive Conditional Heteroskedasticity (GARCH) model [
7], and ARIMA-GARCH model [
8]. However, due to the high complexity and nonlinearity of carbon prices, the prediction results of statistical models are often not ideal. With the development of neural networks and deep learning, the second is the neural network model prediction. The backpropagation neural network (BP) model [
9], the least square support vector machine method (LSSVM) model [
10], and the artificial neural network (MLP) model [
11] are the other models.
Because carbon prices are complex and very unstable, a single model cannot fully capture them. However, with the popularization and application of digital signal technology, digital signal decomposition technology has also been applied to the field of carbon price prediction. The third type is the neural network hybrid model [
12]. Zhu compared the model combining empirical mode decomposition (EMD) and genetic algorithm optimization (GA) artificial neural network (ANN) with the GA-ANN model and proved the effectiveness of EMD decomposition [
13]. Li et al. proposed an EMD-GARCH model [
14]. Zhu et al. used EMD and particle swarm optimization (PSO) optimized LSSVM model to predict carbon prices [
15]. Sun et al. used an extreme learning machine (ELM) optimized by EMD and PSO to predict carbon prices [
16]. Sun et al. used variational modal decomposition (VMD) and Spike Neural Network (SNN) models to predict carbon prices [
17]. Zhu et al. proposed VMD, model reconstruction (MR), and optimal combination forecasting model (CFM) combined model to predict carbon prices [
18]. Liu et al. proposed that EMD can reduce the nonlinearity and complexity of carbon price time series, but there is still room for improvement [
19]. In terms of wind speed prediction, compared with the primary decomposition prediction model, the performance of the secondary decomposition prediction model is better [
20,
21,
22]. Secondary decomposition is also used for carbon price prediction. Sun et al. proposed an EMD-VMD model to predict carbon prices, which verified that the EMD-VMD model is more effective than the EMD model [
23,
24].
In addition to considering the time series of carbon prices, carbon price prediction also needs to consider influencing factors. Byun et al. verified that carbon prices are also related to Brent crude oil, coal, natural gas, and electricity [
25]. Zhao et al. verified that coal is the best factor for carbon price prediction [
26]. Dutta used the Crude Oil Volatility Index (OVX) to study the impact of oil market uncertainty on emission price fluctuations [
27]. Sun et al. used a one-time decomposition algorithm combined with influencing factor models to predict carbon prices [
28,
29].
In summary, the neural network hybrid forecasting model is a trend. Influencing factors are very important for carbon price prediction. EMD-VMD is a good decomposition method. Since the ELM model randomly sets the hidden layer parameters and brings about the problem of poor stability, the kernel function mapping replaces the random mapping of the hidden layer, avoiding this problem and improving the robustness of the model. Kernel Extreme Learning Machine (KELM) is a good neural network model. However, KELM also has the problem of the influence of kernel parameter settings [
30]. This paper uses the latest sparrow search algorithm (SSA) to optimize the kernel parameters of KELM and obtain the optimal model. Finally, this paper proposes the EMD-VMD-SSA-KELM model. This model may have three main contributions. The first is that there is few literature on carbon price prediction models based on the secondary decomposition algorithm (Enriched models in this area). The second is that there are still gaps in the literature on the carbon price prediction model based on the combination of the secondary decomposition algorithm and multiple influencing factors. This model fills the gap in this area. The third document about KELM’s carbon price prediction model is relatively small. This paper proposed the latest SSA-KLEM model to predict carbon prices, which enriches the models in this area.
Introduce the rest of this article. The second part is the methods and models, including EMD, VMD, KELM, SSA, and the EMD-VMD-SSA-KELM model framework proposed in this paper. The third part is the collection of data including carbon price, structural influencing factors, and nonstructural influencing factors (the primary and secondary decomposition of carbon prices). The fourth part is model input and parameter setting. The fifth part is the prediction result and error analysis. The sixth part is the additional forecast, and the seventh part is the conclusion.
2. Method
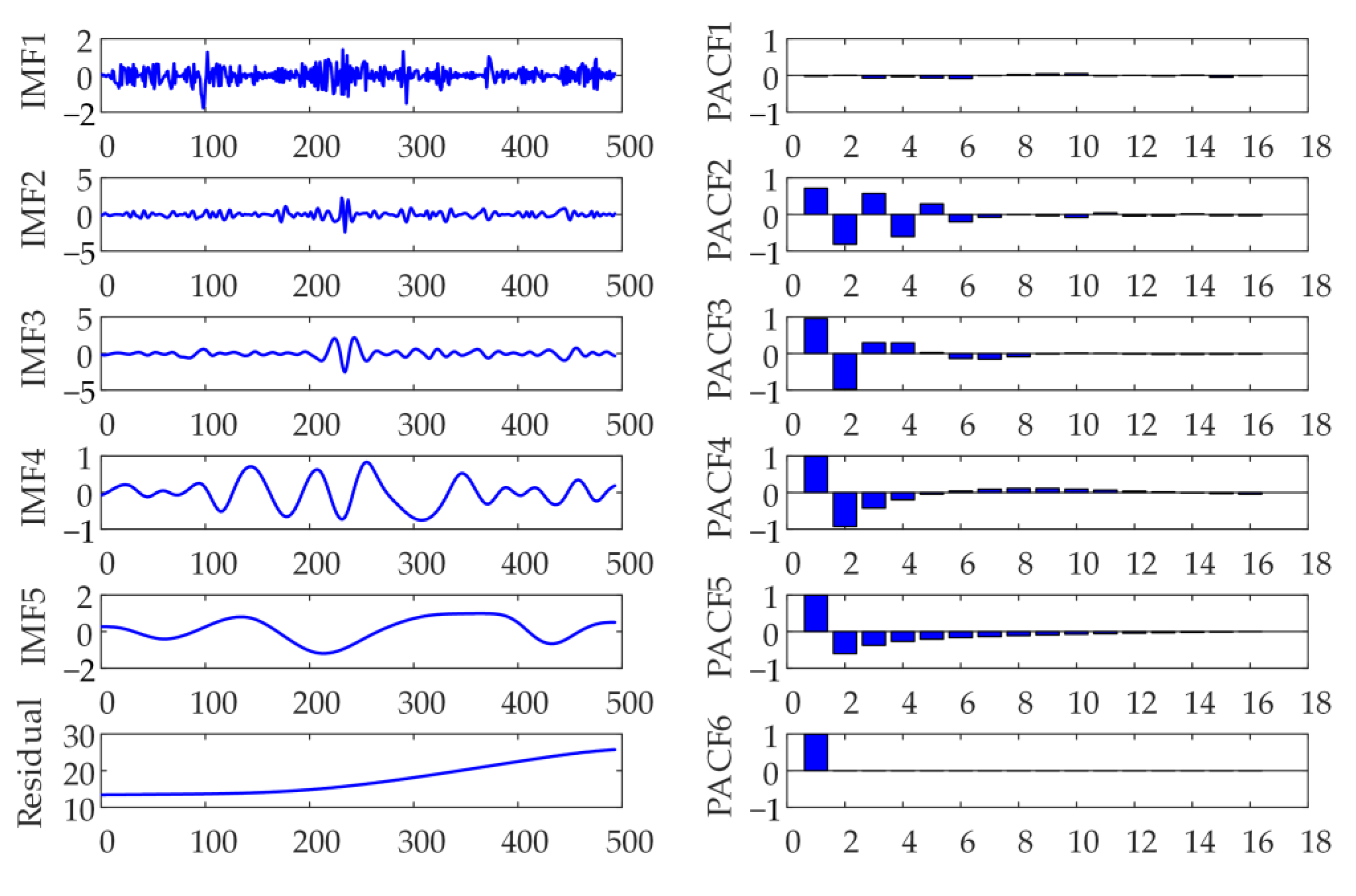
2.1. Empirical Mode Decomposition
EMD is a signal decomposition algorithm [
31]. EMD decomposition is to decompose a signal
into Intrinsic Mode Functions (IMFs) and a residual. The following prerequisites must be met by every IMF: in the whole data, the amount of local extreme points and zero points must be the same or at most one difference. At any point in the data, the sum value of the upper envelope and the lower envelope must be zero.
The decomposition principle of EMD is as below:
Step 1: find out all the local maximum and minimum points in the signal, and then combine each extreme point to construct the upper envelope and lower envelope by the curve fitting method, so that the original signal is Enveloped by the upper and lower envelopes.
Step 2: the mean curve can be constructed from the upper and lower envelope lines, and then the original signal is subtracted from the mean curve, so the obtained is the IMF.
Step 3: since the IMF obtained in the first and second steps usually does not meet the two conditions of the IMF, the first and second steps must be repeated until the
(screening threshold, generally 0.2~0.3) is less than the threshold. It stops when the limit is reached so that the first
that meets the condition is the first IMF. How to find
:
Repeat the first, second, and third steps until meets the preset conditions.
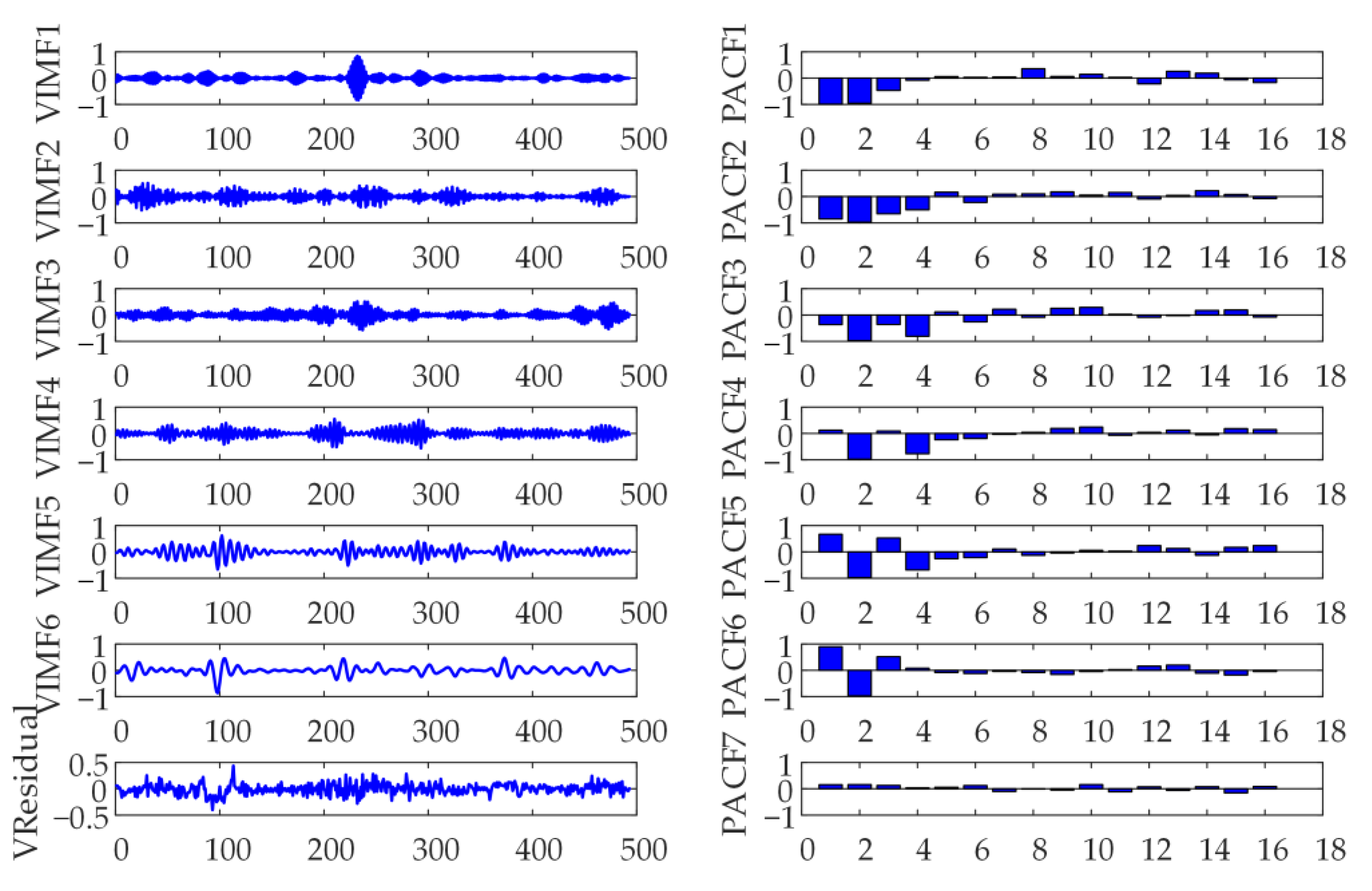
2.2. Variational Mode Decomposition
VMD is an adaptive, completely non-recursive modal change and signal processing method [
32]. This technique has the advantage of being able to determine the number of modal decompositions. It can achieve the best center frequency and limited bandwidth, can achieve the effective separation of the IMF, signal frequency domain division, and then obtain the effective decomposition component of a given signal. First, construct the variational problem. Assuming that the original signal
is decomposed into
components, each modal component must have a center frequency and a limited bandwidth, and the sum of the estimated bandwidth of each model is the smallest. The sum of all modal components is equivalent to the original signal as a constraint condition. The corresponding constraint variational expression is
In the Formula (3): is the number of decomposed modes, correspond to the K-th component and its central frequency, and is the Dirac fir tree. * is the convolution operator.
Then, by solving Equation (3) and introducing Lagrange multiplication operator
, the constrained variational problem is transformed into an unconstrained variational problem, and the augmented Lagrange expression is obtained.
In Formula (4):
is the secondary penalty factor, and its function is to reduce the interference of Gaussian noise. Using the Alternating Direction Multiplier (ADMM) iterative algorithm combined with Parseval, Fourier equidistant transformation, optimize the modal components and center frequency, and search for the saddle point of the augmented Lagrange function, alternately optimize
and
after iteration. These formulas are as follows.
In the formula: is the noise tolerance, which satisfies the fidelity requirement of signal decomposition, , , correspond to ,, and Fourier transforms of , respectively.
The main iteration requirements of VMD are as follows:
- 1:
Initialize and the maximum number of iterations N, .
- 2:
Use Formulas (5) and (6) to update and .
- 3:
Use Formula (7) to update .
- 4:
Accuracy convergence judgment basis , if not satisfied , return to the second step, otherwise complete the iteration and output the final and .
2.3. Sparrow Search Algorithm
SSA is a new swarm intelligence optimization algorithm [
33]. Its bionic principles are as follows:
The sparrow foraging process can be abstracted as a discoverer–adder model, and a reconnaissance early warning mechanism is added. The discoverer itself is highly adaptable and has a wide search range, guiding the population to search and forage. To obtain better fitness, the joiner follows the discoverer for food. At the same time, to increase their predation rate, some joiners will monitor the discoverer to fight for food or forage around them. When the entire population faces the threat of predators or realizes the danger, it will immediately carry out anti-predation behavior.
In SSA, the solution to the optimization problem is obtained by simulating the foraging process of sparrows. Assuming that there are sparrows in a D-dimensional search space, the position of the i-th sparrow in the D-dimensional search space is where , represents the position of the i-th sparrow in the d-th dimension.
Discoverers generally account for 10% to 20% of the population. The position update formula is as follows:
In Formula (8): t represents the current number of iterations. represents the maximum number of iterations. is a uniform random number between . is a random digit that submits to a standard normal distribution. represents a size of 1xd, with all elements matrix of 1. is the warning value. is a safe value. When , the population does not find the presence of predators or other dangers, the search environment is safe, and the discoverer can search extensively to guide the population to obtain higher fitness. When , the sparrows are detected and the predators are found. The danger signal was immediately released, and the population immediately performed anti-predation behavior, adjusted the search strategy, and quickly moved closer to the safe area.
Except for the discoverer, the remaining sparrows are all joiners and update their positions according to the following formula:
In the Formula (9): is the worst position of the sparrow in the d dimension at the t-th iteration of the population. represents the optimal position of the sparrow in the d dimension at the (t+1)-th iteration of the population position. When , it indicates that the i-th joiner has no food, is hungry, and has low adaptability. To obtain higher energy, he needs to fly to other places for food. When , the i-th joiner will randomly find a location near the current optimal position for foraging.
Sparrows for reconnaissance and early warning generally account for 10% to 20% of the population. The location is updated as follows:
In the Formula (10): is the step control parameter, which is a random digit subject to . is a random number between , indicating the direction of the sparrow’s movement, which is also a step Long control parameter, e is a minimal constant to avoid the situation where the denominator is 0. represents the fitness value of the i-th sparrow, and are the optimal and worst fitness values of the current sparrow population, respectively. When , it makes known that the sparrow is at the margin of the whole population and is easily attacked by predators. When , it indicates that the sparrow is in the center of the whole population because it is aware of the threat of predators to avoid being attacked by predators and get close to other sparrows in time to adjust the search strategy.
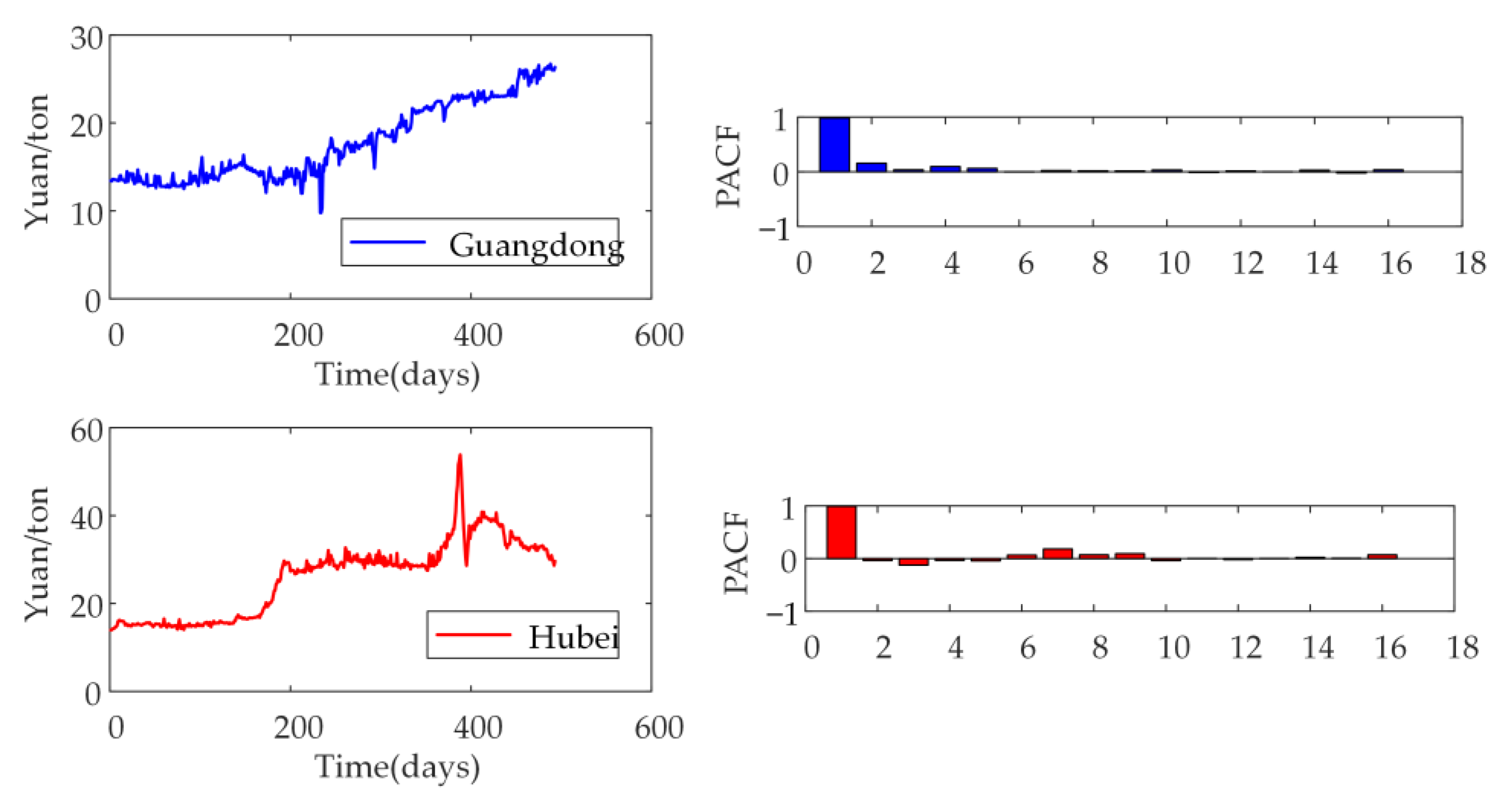
2.4. Partial Autocorrelation Function
The relationship between time series and their lags is given. Based on the lag order, the input and output variables of the neural network are determined. Given the time series
with
representing the autoregressive equation of
and
order regression coefficients, the k order autoregressive model is expressed as
2.5. Maximum Correlation Minimum Redundancy Algorithm
mRMR is to find the most relevant feature in the original feature set, but the least correlation with each other, and to use mutual information to express the correlation [
34]. The mutual information between the two variables
and
is:
The Sub-Formulas , are frequency functions, and are joint frequency functions.
Based on mutual information, the core expression of the algorithm is
In the formula, Formula (13) represents the maximum correlation, Formula (14) represents the minimum redundancy. is the feature subset. n shows the number of features. shows the mutual information between the feature and the target feature. represents the target feature. represents the mutual information between the features.
Generally, through the wig integration Formulas (13) and (14), the final maximum correlation and minimum redundancy judgment conditions are obtained:
2.6. Extreme Learning Machine with Kernel
KELM is an extension of ELM by Huang et al. [
35]. The kernel function mapping is used to replace the random mapping of the hidden layer, which avoids the problem of poor stability caused by randomly given hidden layer parameters by ELM, and improves the robustness of the model. Because of its fast calculation speed and strong generalization ability, KELM’s basic principles are as follows:
Assuming that the number of hidden layer nodes is L, the hidden layer output function is
, the hidden layer output weight
, training sample set
the ELM model can be shown as:
The goal of ELM is to minimize the training error and the output weight
of the hidden layer. Based on the principle of minimum structural risk, a quadratic programming problem is constructed as follows:
In the formula, C is the penalty factor; is the i-th error variable.
Introducing the Lagrange multiplier
, the quadratic programming problem of Equation (17) is transformed into:
According to the KKT condition, the derivatives of
, and
are obtained, respectively. Finally, get the output weight of the ELM model:
In the Formula (19): is the hidden layer matrix, is the target value matrix, is the identity matrix.
To improve the prediction accuracy and stability of the model, the kernel matrix is introduced to replace the hidden layer matrix
of ELM, and the training samples are mapped to high-dimensional space through the kernel function. Define the kernel matrix as
, and the elements
, construct the KELM model as follows:
In the Formula (20),
usually chooses radial basis kernel function and linear kernel function, and the expressions are shown in Formulas (22) and (23):
In the Formula (22),
is the width parameter of the kernel function.
Although the introduction of the kernel function increases the stability of the prediction model, and affect the two important parameters of the KELM prediction accuracy during the training process. If is too small, a larger training error will occur, and if is too large, overfitting will occur. Moreover, affects the generalization performance of the model.
2.7. The Proposed Model
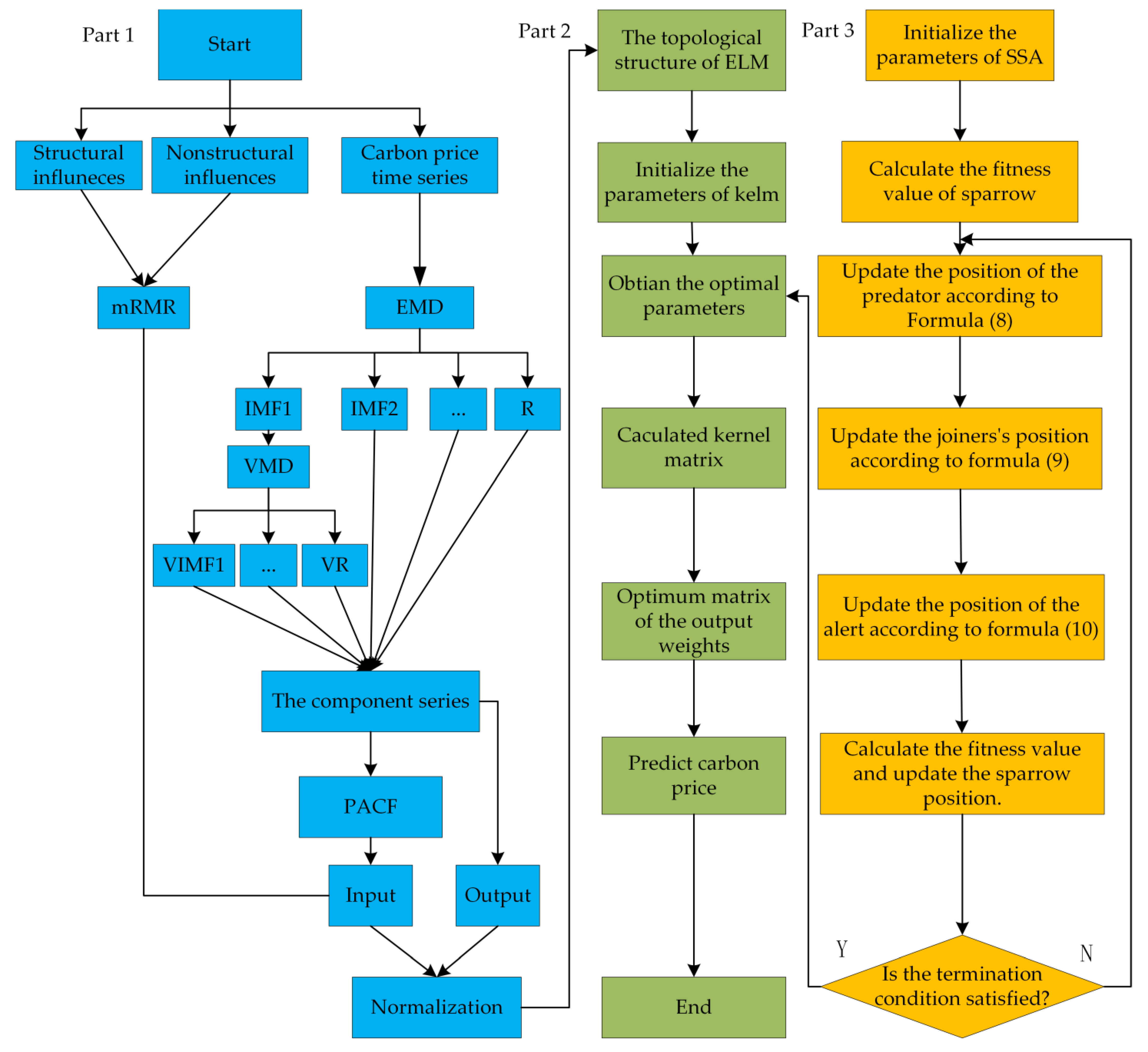
This structural model is based on a new carbon price prediction model proposed by data preprocessing technology, structural influencing factors, nonstructural influencing factors, feature selection technology, sparrow search algorithm, and secondary decomposition algorithm.
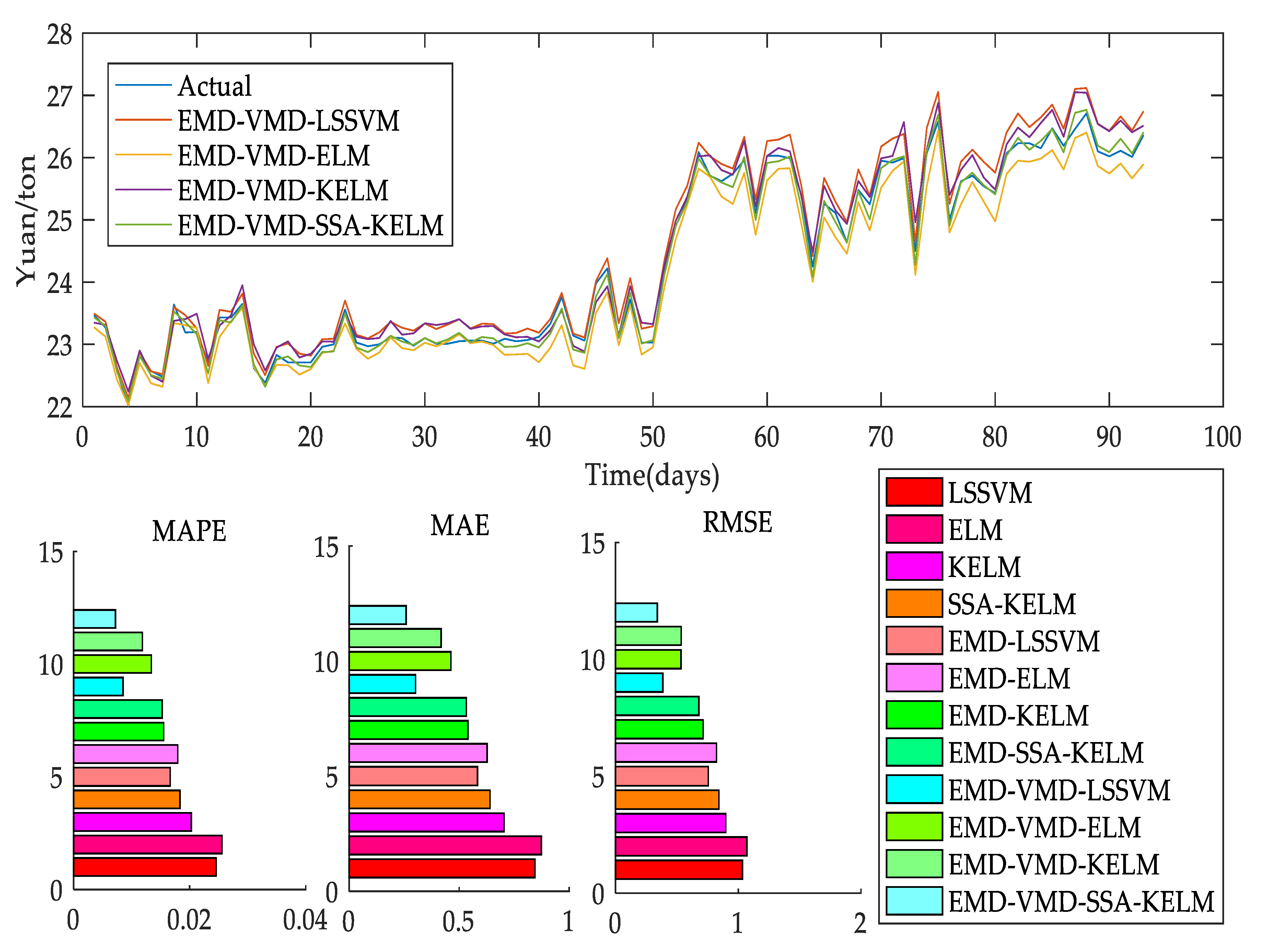
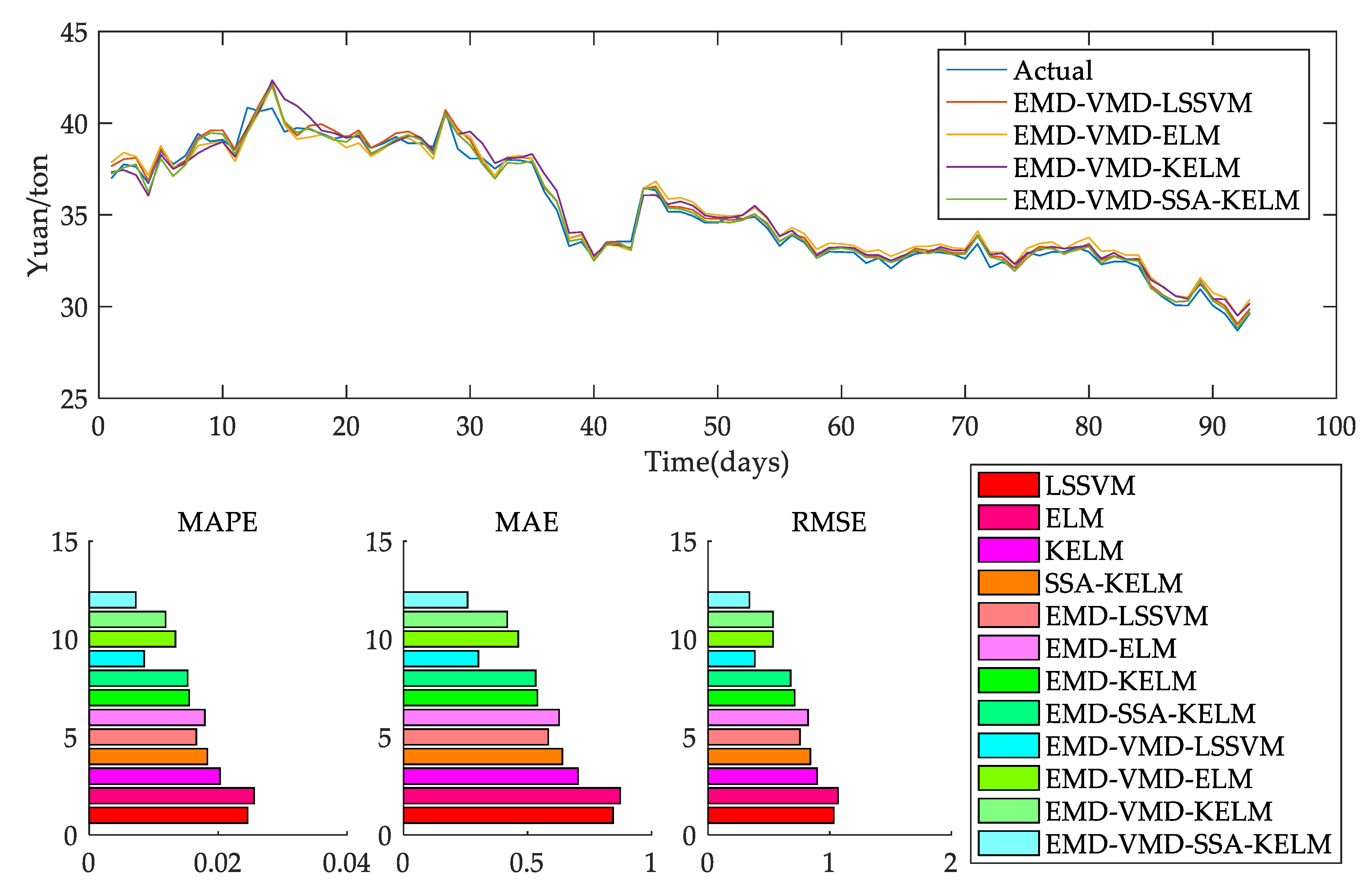
Figure 1 shows the flow chart of the EMD-VMD-SSA-KLEM model.
- (1)
Part 1 is the flow chart of carbon price prediction. EMD is used to decompose the initial carbon price to obtain a decomposed IMF. Then, use variational modal decomposition to decompose IMF1 to get the VIMF of secondary decomposition. VIMF is the inherent mode function generated by VMD decomposition of IMF1.This is the output of the model.
- (2)
Partial autocorrelation function (PACF) is used to select the features of the decomposed components, and then as part of the input of the model. Considering the structural and nonstructural factors, mRMR is used to reduce the dimension of the influencing factors, and the best feature of the influencing input is selected as the other part of the input of the model.
- (3)
Part 2 is the flow chart of the KELM model. Part 3 is the SSA flow chart. Since in the KELM algorithm, system performance is mainly affected by the selection of γ and C, cross-validation is generally used for parameter confirmation. To avoid the influence caused by parameter selection, on this basis, the searchability of the sparrow search algorithm is combined with the fast-learning ability of KELM, and the γ and C of the model are optimized and evolved to obtain the optimal SSA-KELM prediction model.
- (4)
Establish undecomposed models, EMD models, EMD-VMD models, and other multiple models as
Figure 2 to verify the superiority of the EMD-VMD-SSA-KELM model.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}