
Virtual State Feedback Reference Tuning and Value Iteration Reinforcement Learning for Unknown Observable Systems Control



Abstract
1. Introduction
- A new state representation for systems with unknown dynamics. A virtual state is constructed from historical input/output data samples, under observability assumptions.
- An original Virtual State Feedback Reference Tuning (VSFRT) neural controller tuning based on the new state representation. Stability certification is analyzed.
- Performance comparison of VSFRT and AI-VIRL data-driven neural controllers for LRMO tracking.
- Analysis of the transfer learning suitability for the VSFRT controller to provide initial admissible controllers for the iterative AI-VIRL process.
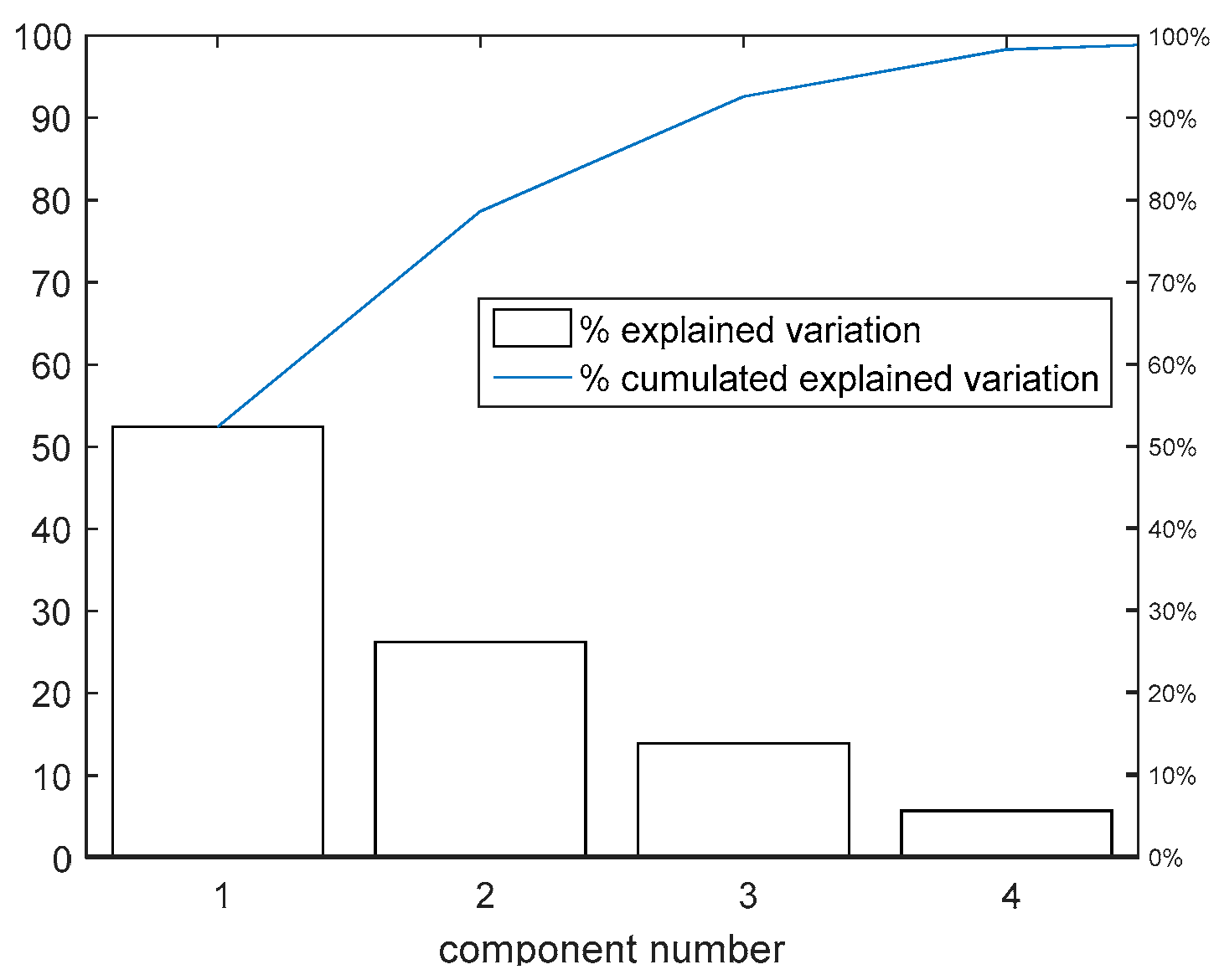
- Analyze the impact of the state representation dimensionality reduction upon the learning performance using unsupervised machine learning tools such as principal component analysis (PCA) and autoencoders (AE).
2. The LRMO Tracking Problem
3. LRM Output Tracking Problem Solution
3.1. Recapitulating VRFT for Error-Feedback IO Control
3.2. VSFRT—The Virtual State Feedback-Based VRFT Solution for the LRM Output Tracking
- The IO database is first collected, then is built. Both and are computed.
- A C-NN is parameterized by properly selecting a NN architecture type together with its training details. called the maximum number of training times is set along with the index j = 1 counting the number of trainings.
- The NN weights vector is initialized (e.g., randomly).
- The C-NN is trained with input patterns and output patterns . This is equivalent to minimizing (5) w.r.t. .
- If , set and repeat from the 3rd Step, otherwise finish the algorithm.
3.3. The AI-VIRL Solution for the LRM Output Tracking
- Select C-NN and Q-NN architectures and training settings. Initialize , , termination threshold , maximum number of iterations and iteration index j = 1. Prepare the transition samples database .
- Train the Q-NN with inputs and target outputs . This is equivalent to solving (10).
- Train the C-NN with inputs and target outputs . This is equivalent to solving (11).
- If and (with some threshold ), make and go to Step 2, else terminate the algorithm.
3.4. The Neural Transfer Learning Capacity
4. First Validation Case Study
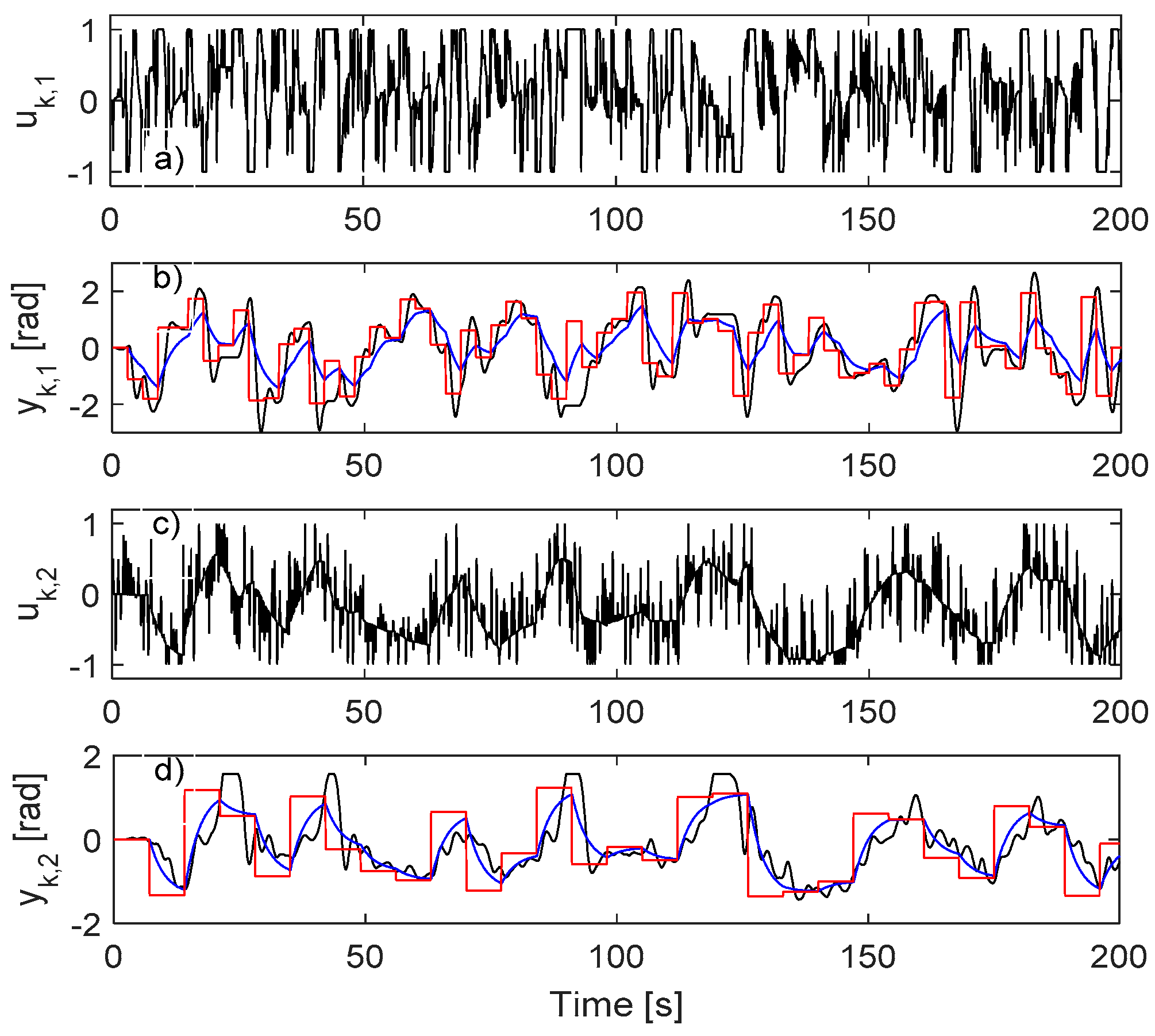
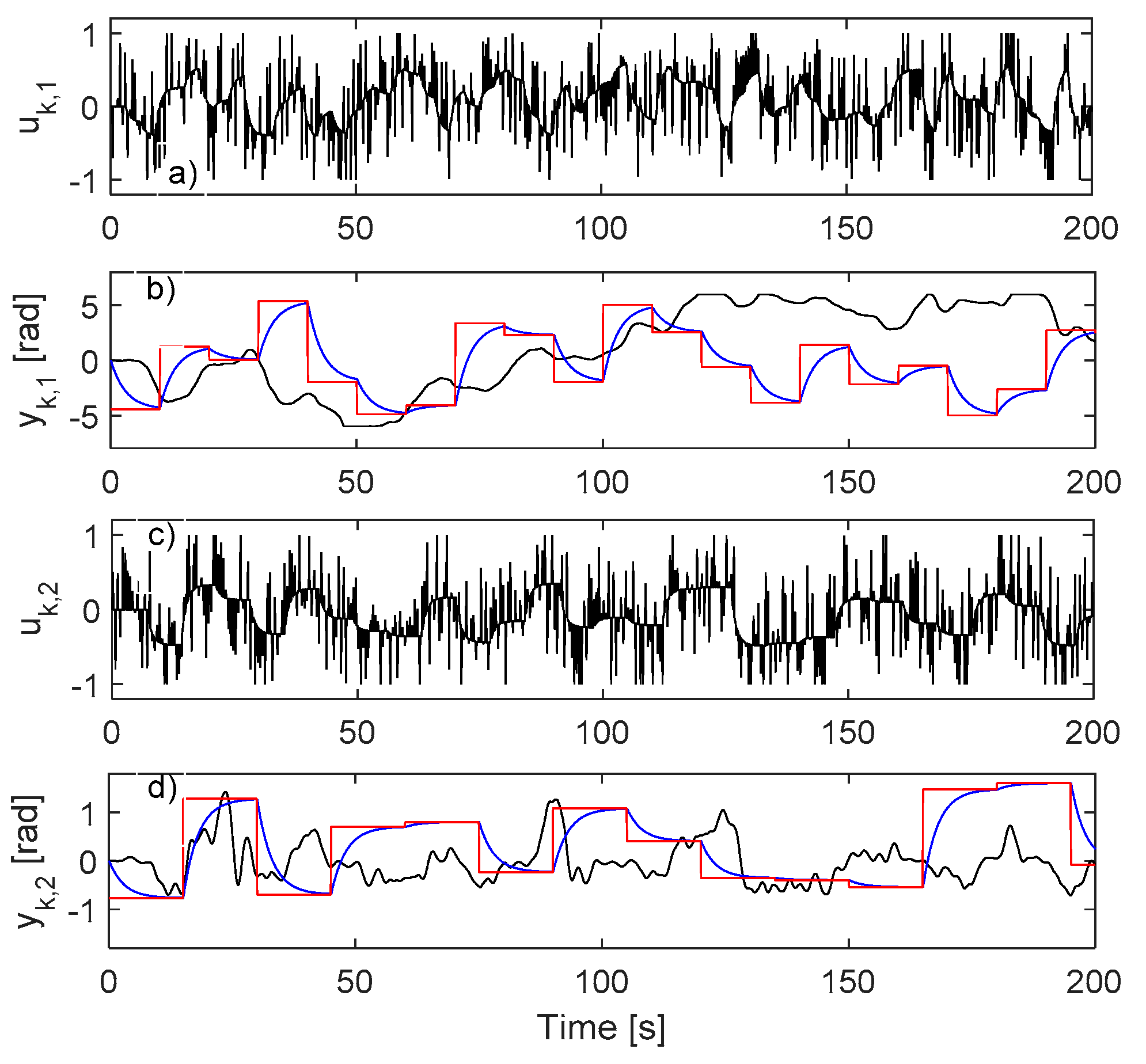
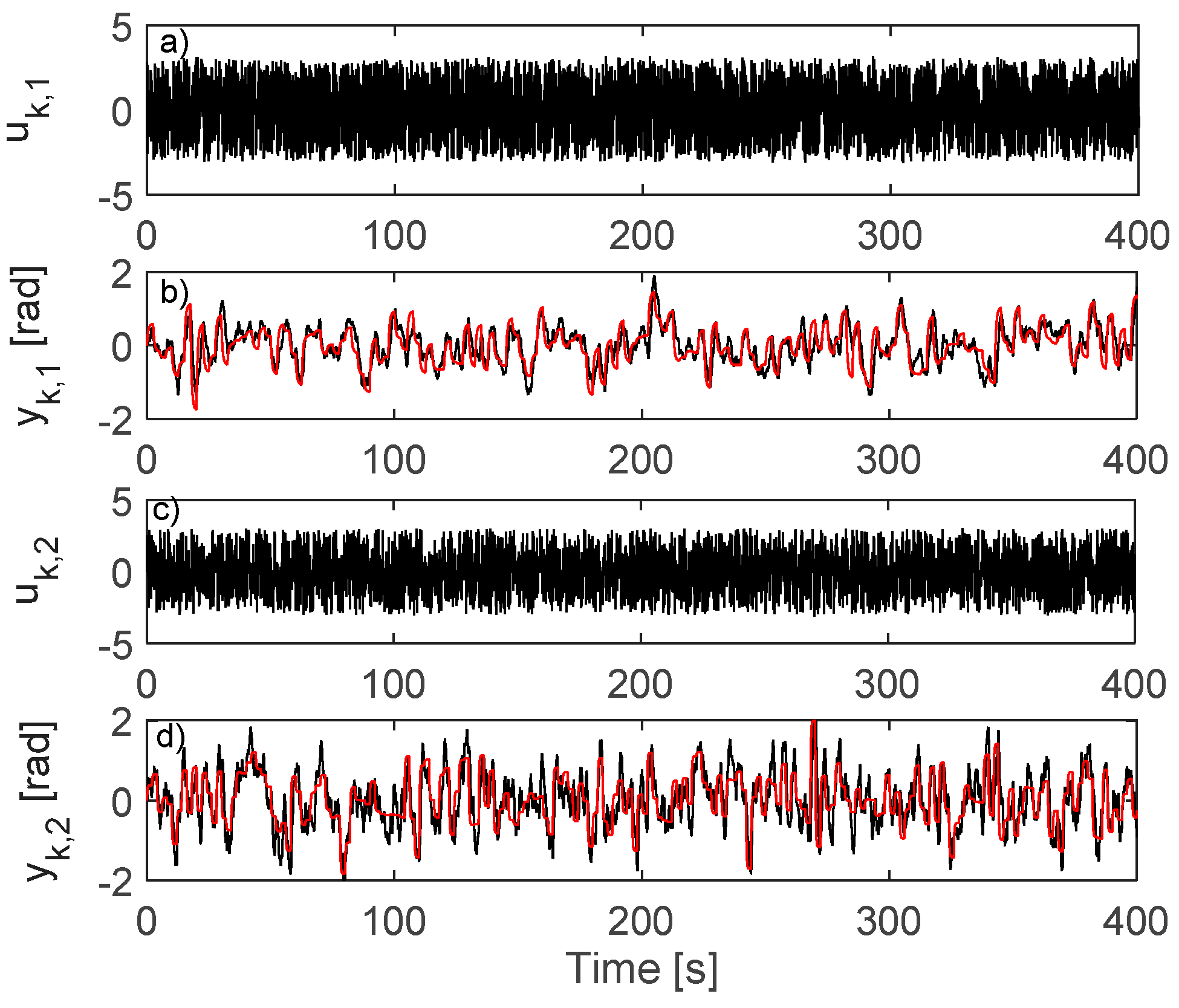
4.1. IO Data Collected in Closed-Loop
4.2. Learning the VSFRT Controller from Closed-Loop IO Data
4.3. Learning the AI-VIRL Controller from Closed-Loop IO Data
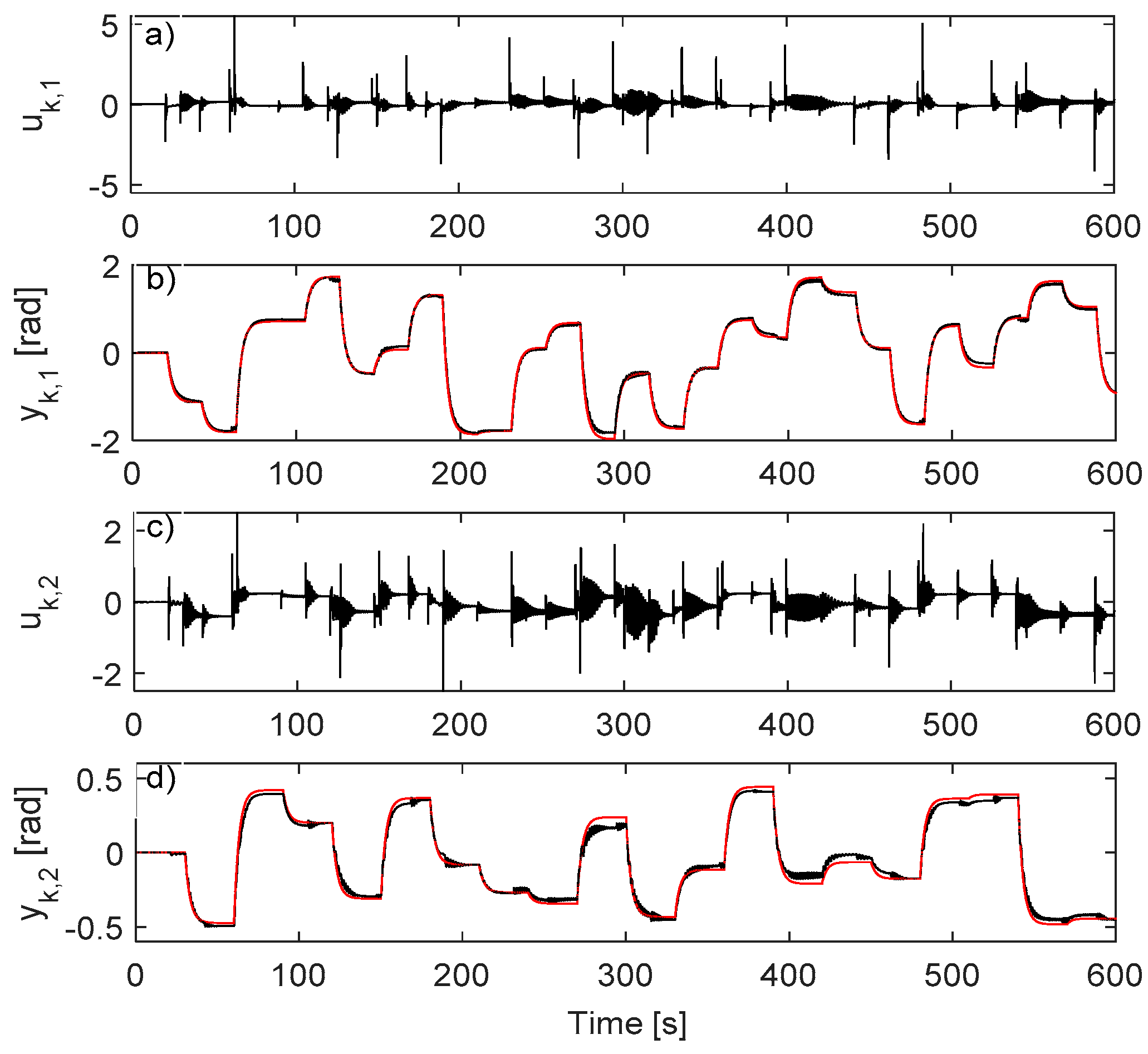
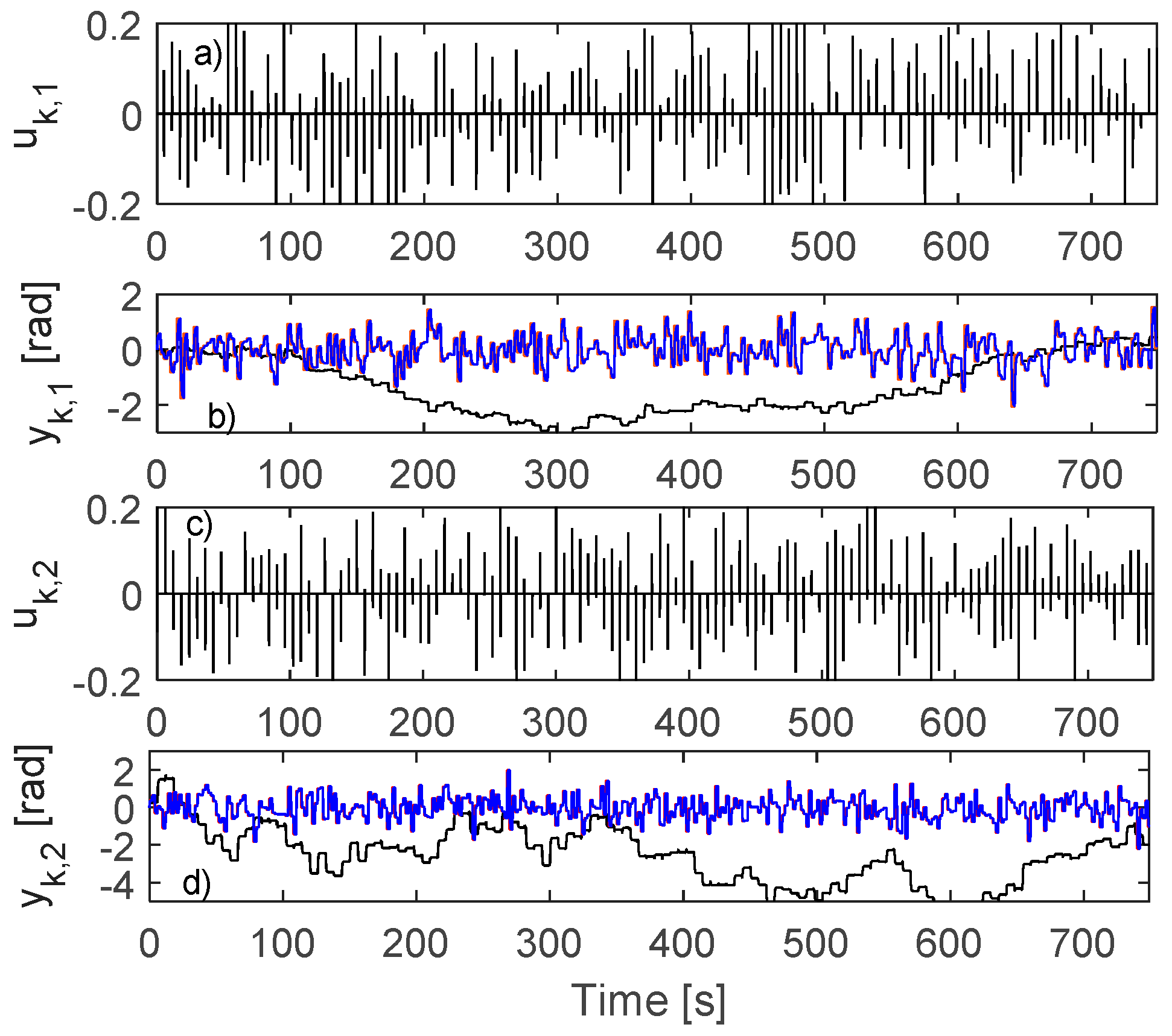
4.4. Learning VSFRT and AI-VIRL Control Using IO Data Collected in Open-Loop
4.5. Testing the Transfer Learning Advantage
4.6. VSFRT and AI-VIRL Performance under State Dimensionality Reduction with PCA and Autoencoders
5. Second Validation Case Study
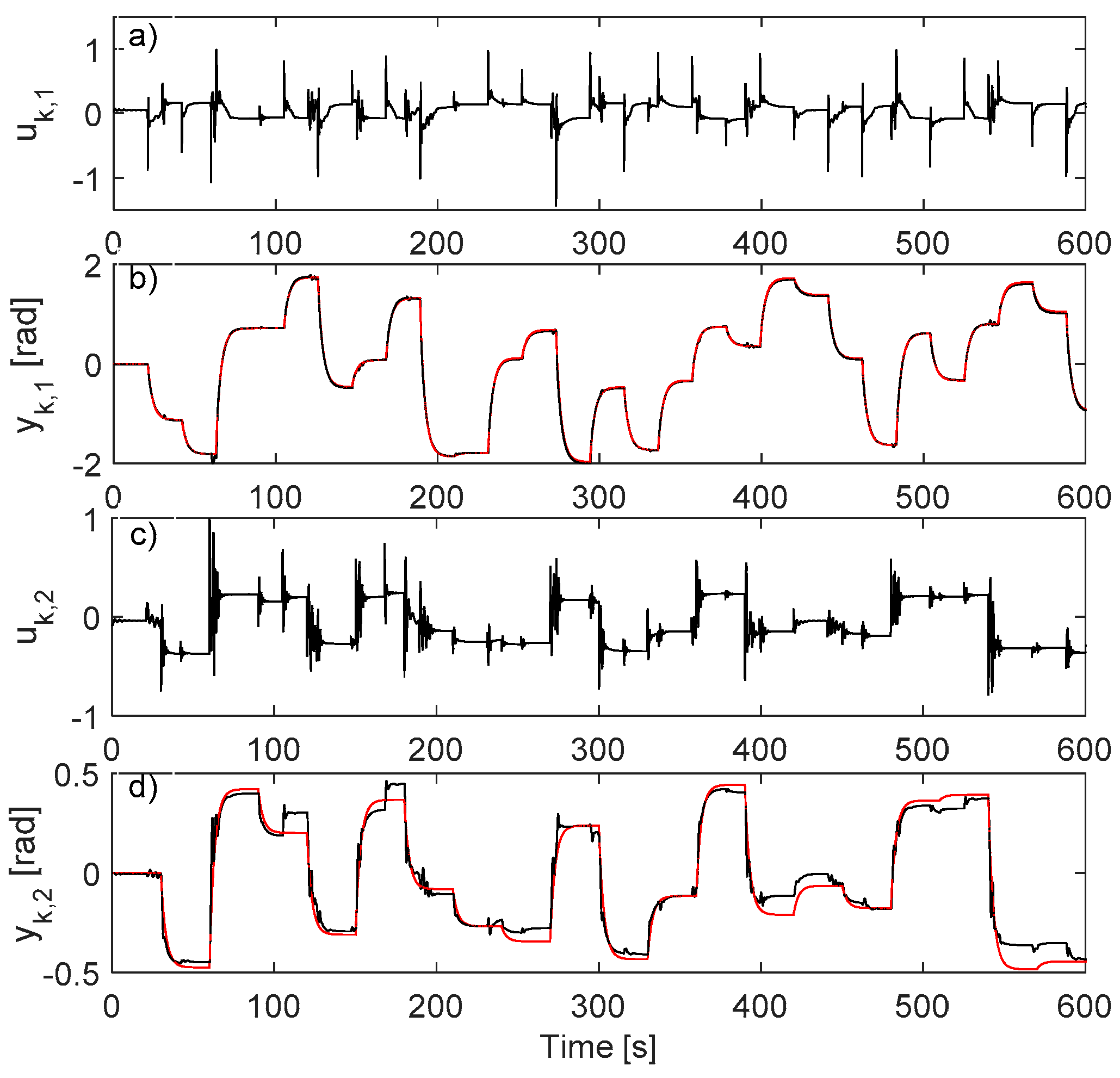
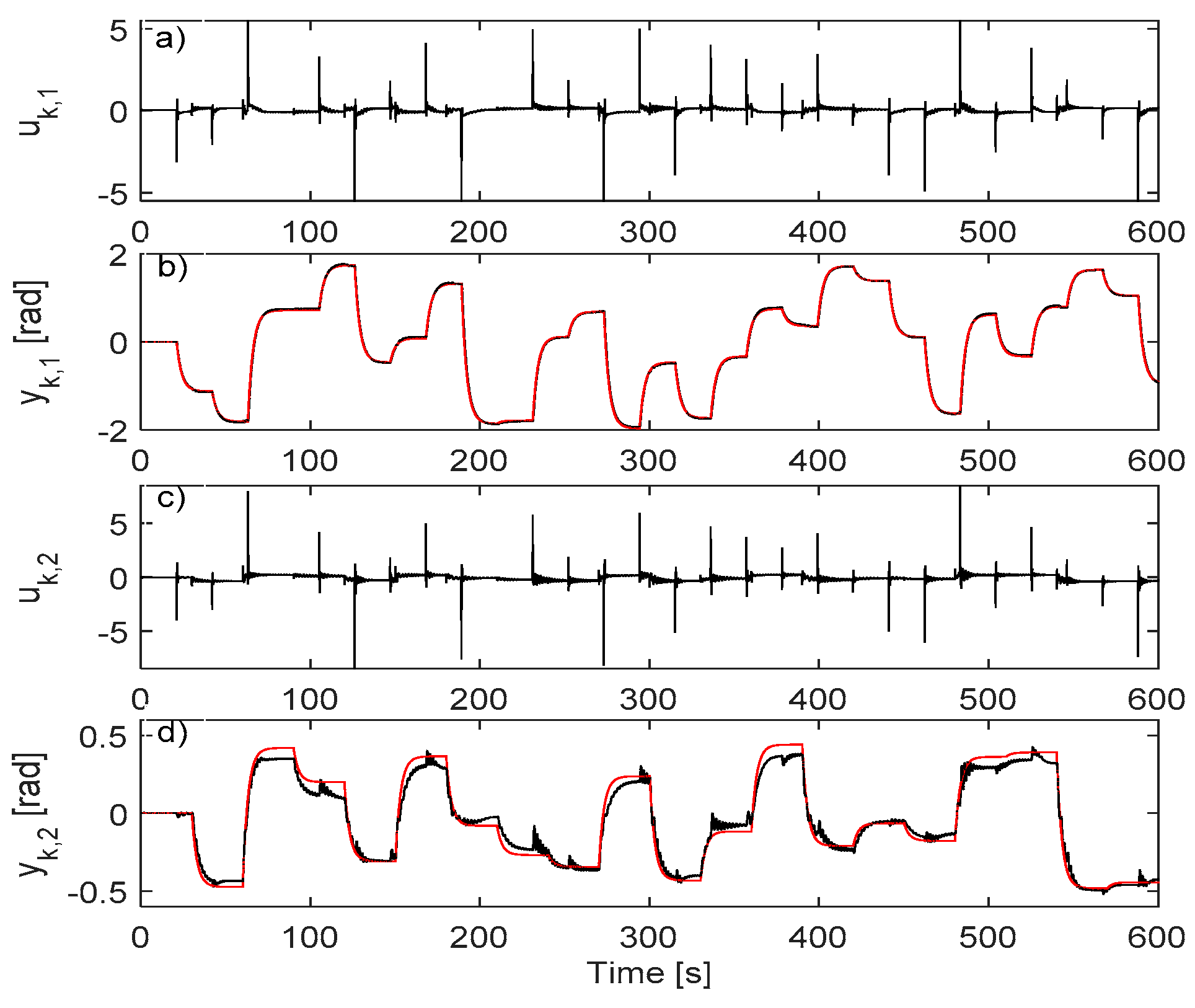
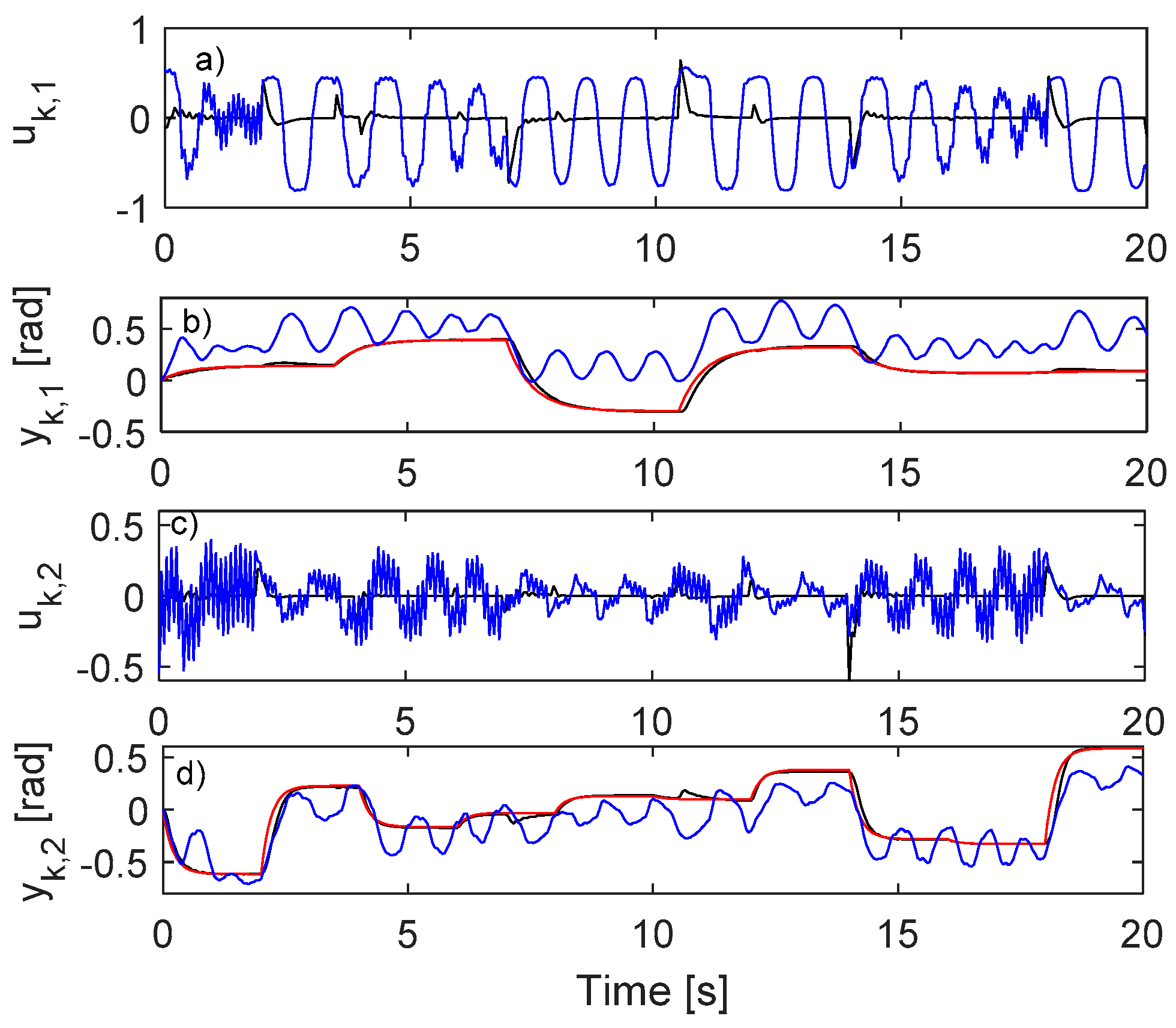
5.1. IO Data Collection in Closed-Loop
5.2. Learning the VSFRT Controller from Closed-Loop IO Data
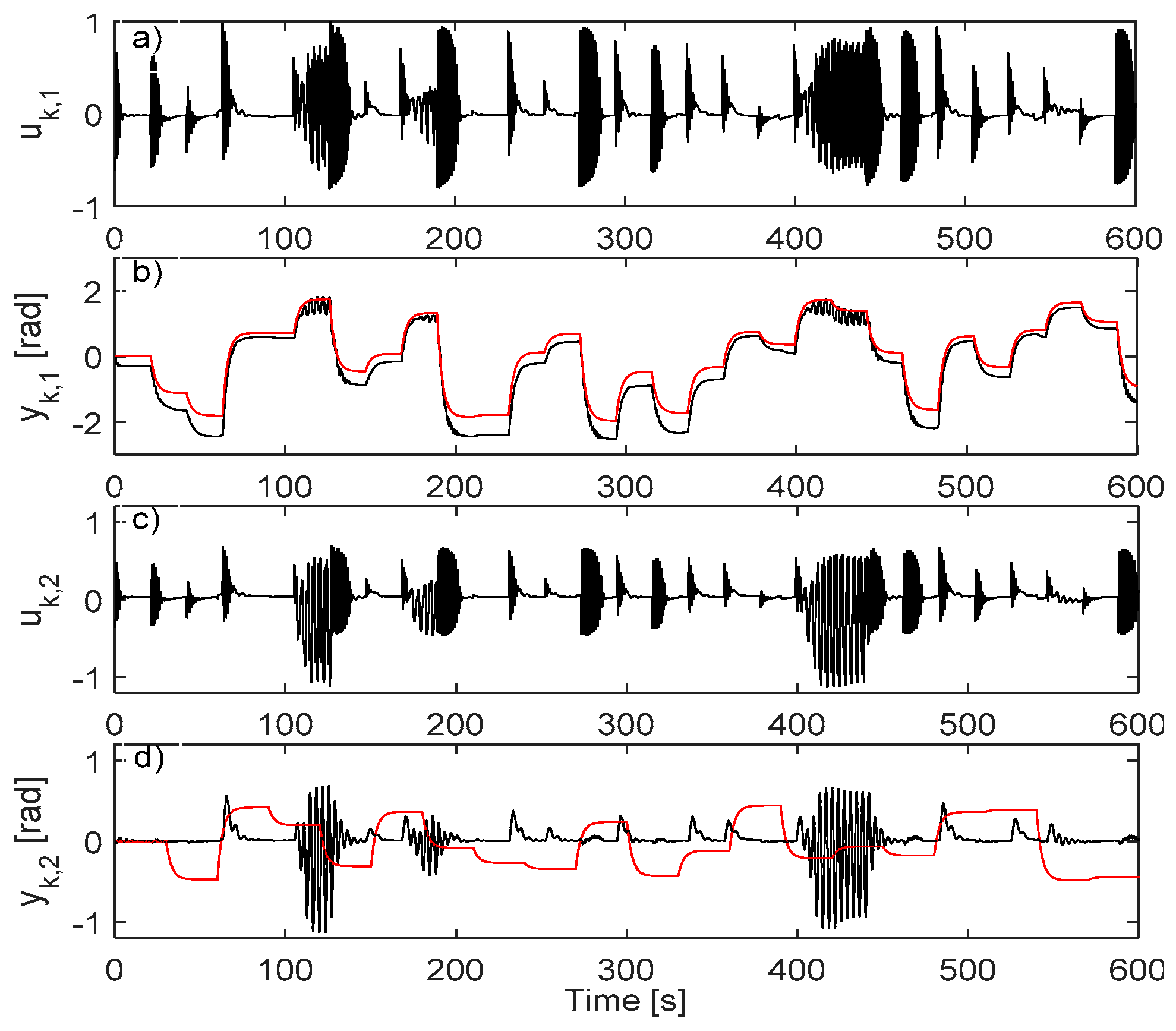
5.3. Learning the AI-VIRL Controller from Closed-Loop IO Data
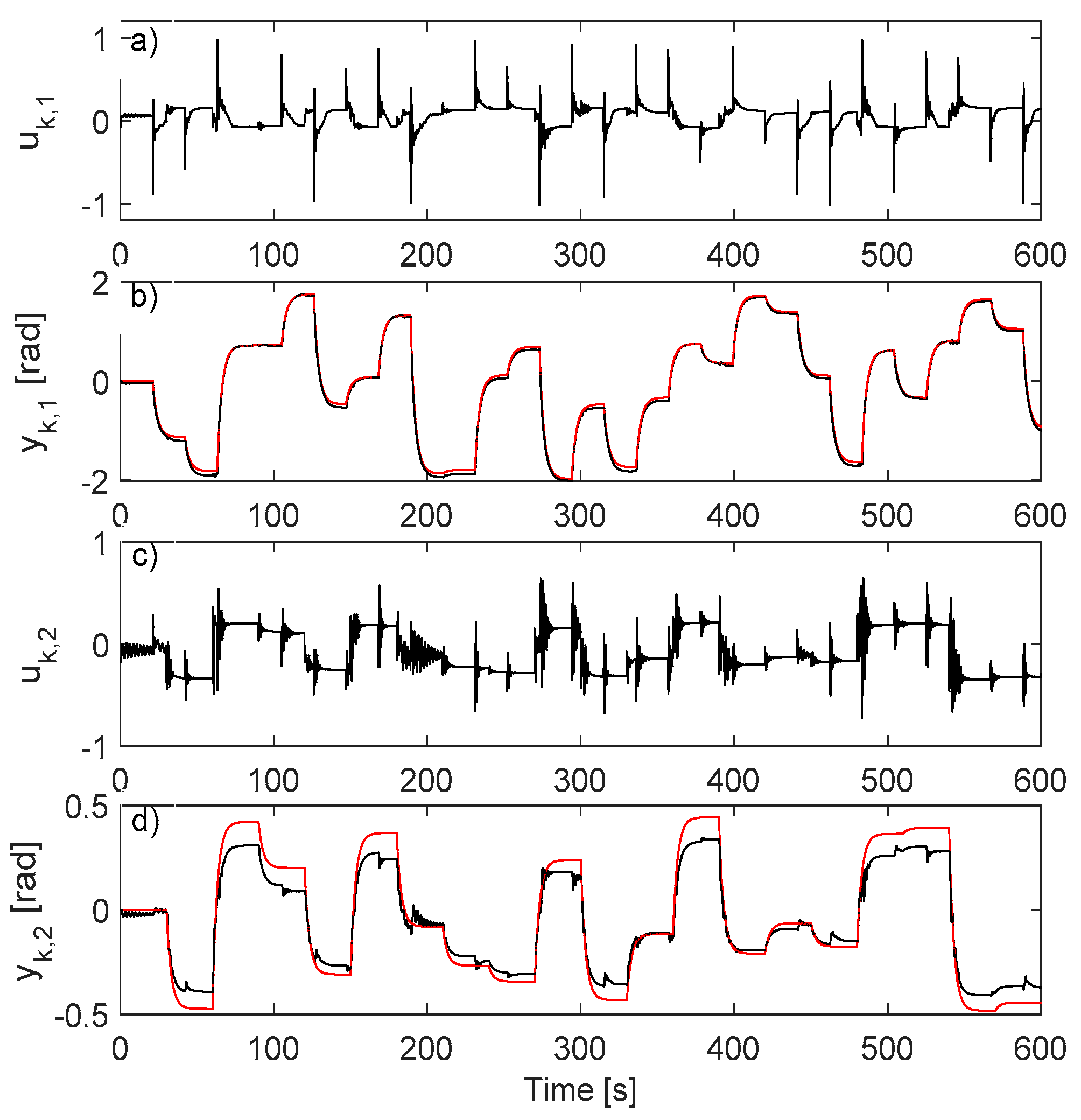
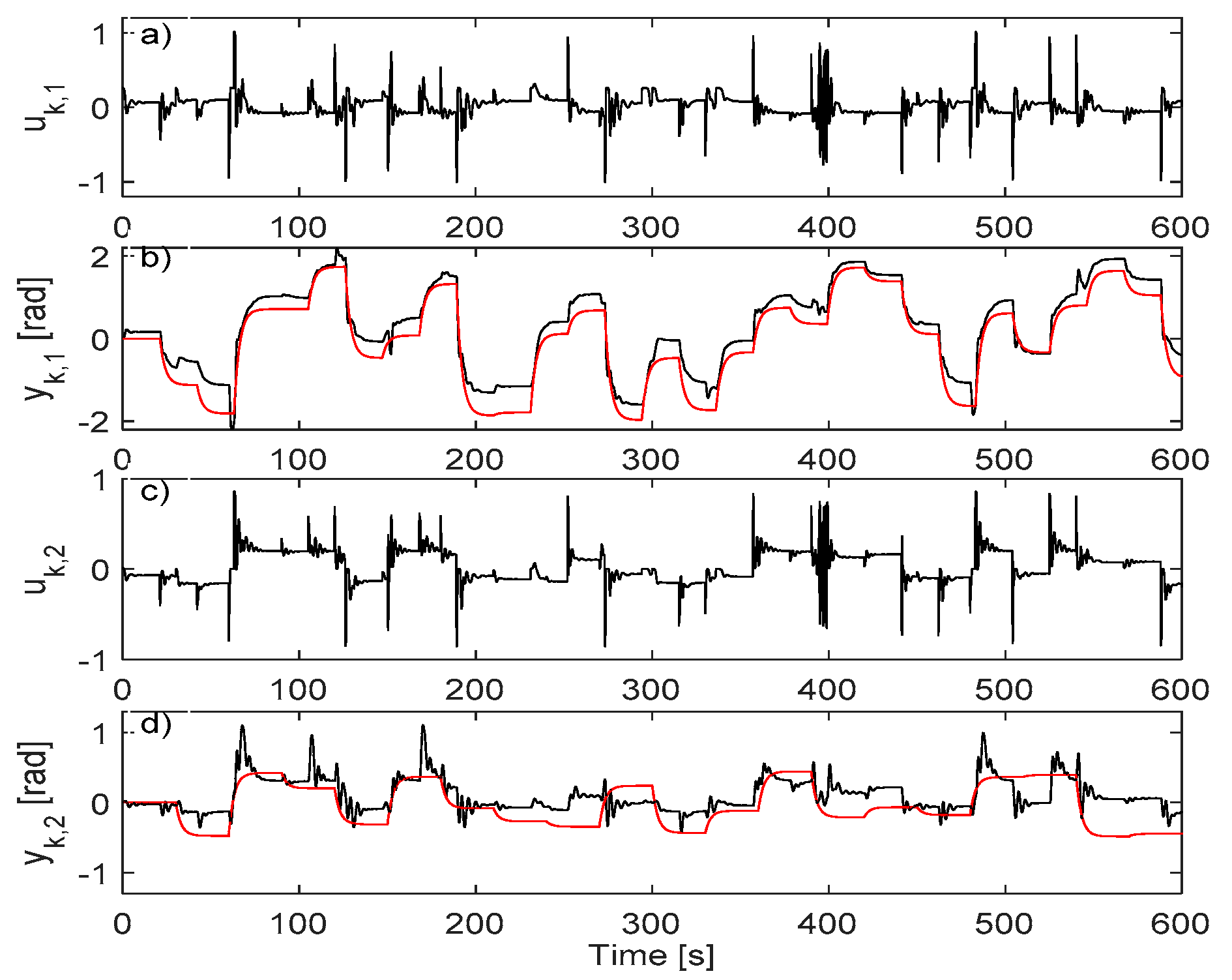
5.4. Learning VSFRT and AI-VIRL Control Based on IO Data Collected in Open-Loop
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Fu, H.; Chen, X.; Wang, W.; Wu, M. MRAC for unknown discrete-time nonlinear systems based on supervised neural dynamic programming. Neurocomputing 2020, 384, 130–141. [Google Scholar] [CrossRef]
- Wang, W.; Chen, X.; Fu, H.; Wu, M. Data-driven adaptive dynamic programming for partially observable nonzero-sum games via Q-learning method. Int. J. Syst. Sci. 2019, 50, 1338–1352. [Google Scholar] [CrossRef]
- Perrusquia, A.; Yu, W. Neural H2 control using continuous-time reinforcement learning. IEEE Trans. Cybern. 2020, 1–10. [Google Scholar] [CrossRef]
- Sardarmehni, T.; Heydari, A. Sub-optimal switching in anti-lock brake systems using approximate dynamic programming. IET Control Theory Appl. 2019, 13, 1413–1424. [Google Scholar] [CrossRef]
- Martinez-Piazuelo, J.; Ochoa, D.E.; Quijano, N.; Giraldo, L.F. A multi-critic reinforcement learning method: An application to multi-tank water systems. IEEE Access 2020, 8, 173227–173238. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Yu, R.; Xing, Z. H∞ tracking control of discrete-time system with delays via data-based adaptive dynamic programming. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 4078–4085. [Google Scholar] [CrossRef]
- Na, J.; Lv, Y.; Zhang, K.; Zhao, J. Adaptive identifier-critic-based optimal tracking control for nonlinear systems with experimental validation. IEEE Trans. Syst. Man. Cybern. Syst. 2020, 1–14. [Google Scholar] [CrossRef]
- Li, J.; Ding, J.; Chai, T.; Lewis, F.L.; Jagannathan, S. Adaptive interleaved reinforcement learning: Robust stability of affine nonlinear systems with unknown uncertainty. IEEE Trans. Neural. Netw. Learn. Syst. 2020, 1–11. [Google Scholar] [CrossRef]
- Buşoniu, L.; de Bruin, T.; Tolić, D.; Kober, J.; Palunko, I. Reinforcement learning for control: Performance, stability, and deep approximators. Annu. Rev. Control 2018, 46, 8–28. [Google Scholar] [CrossRef]
- Treesatayapun, C. Knowledge-based reinforcement learning controller with fuzzy-rule network: Experimental validation. Neural Comput. Appl. 2020, 32, 9761–9775. [Google Scholar] [CrossRef]
- Huang, M.; Liu, C.; He, X.; Ma, L.; Lu, Z.; Su, H. Reinforcement learning-based control for nonlinear discrete-time systems with unknown control directions and control constraints. Neurocomputing 2020, 402, 50–65. [Google Scholar] [CrossRef]
- Chen, C.; Sun, W.; Zhao, G.; Peng, Y. Reinforcement Q-Learning incorporated with internal model method for output feedback tracking control of unknown linear systems. IEEE Access 2020, 8, 134456–134467. [Google Scholar] [CrossRef]
- De Bruin, T.; Kober, J.; Tuyls, K.; Babuska, R. Integrating state representation learning into deep reinforcement learning. IEEE Robot. Autom. Lett. 2018, 3, 1394–1401. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vamvoudakis, K.G. Reinforcement learning for partially observable dynamic processes: Adaptive Dynamic Programming using measured output data. IEEE Trans. Syst. Man. Cybern. B Cybern. 2011, 41, 14–25. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, D. Data-based controllability and observability analysis of linear discrete-time systems. IEEE Trans. Neural Netw. 2011, 22, 2388–2392. [Google Scholar] [CrossRef]
- Ni, Z.; He, H.; Zhong, X. Experimental studies on data-driven heuristic dynamic programming for POMDP. Front. Intell. Control. Inf. Process. 2014, 83–105. [Google Scholar]
- Ruelens, F.; Claessens, B.J.; Vandael, S.; De Schutter, B.; Babuska, R.; Belmans, R. Residential demand response of thermostatically controlled loads using batch reinforcement learning. IEEE Trans. Smart Grid 2017, 8, 2149–2159. [Google Scholar] [CrossRef]
- Campi, M.C.; Lecchini, A.; Savaresi, S.M. Virtual reference feedback tuning: A direct method for the design of feedback controllers. Automatica 2002, 38, 1337–1346. [Google Scholar] [CrossRef]
- Formentin, S.; Savaresi, S.M.; Del Re, L. Non-iterative direct data-driven controller tuning for multivariable systems: Theory and application. IET Control Theory Appl. 2012, 6, 1250. [Google Scholar] [CrossRef]
- Campestrini, L.; Eckhard, D.; Gevers, M.; Bazanella, A.S. Virtual Reference Feedback Tuning for non-minimum phase plants. Automatica 2011, 47, 1778–1784. [Google Scholar] [CrossRef]
- Eckhard, D.; Campestrini, L.; Christ Boeira, E. Virtual disturbance feedback tuning. IFAC J. Syst. Control 2018, 3, 23–29. [Google Scholar] [CrossRef]
- Campi, M.C.; Savaresi, S.M. Direct nonlinear control design: The Virtual Reference Feedback Tuning (VRFT) approach. IEEE Trans. Automat. Contr. 2006, 51, 14–27. [Google Scholar] [CrossRef]
- Esparza, A.; Sala, A.; Albertos, P. Neural networks in virtual reference tuning. Eng. Appl. Artif. Intell. 2011, 24, 983–995. [Google Scholar] [CrossRef]
- Yan, P.; Liu, D.; Wang, D.; Ma, H. Data-driven controller design for general MIMO nonlinear systems via virtual reference feedback tuning and neural networks. Neurocomputing 2016, 171, 815–825. [Google Scholar] [CrossRef]
- Radac, M.-B.; Precup, R.-E. Data-driven model-free slip control of anti-lock braking systems using reinforcement Q-learning. Neurocomputing 2018, 275, 317–329. [Google Scholar] [CrossRef]
- Radac, M.-B.; Precup, R.-E. Data-driven model-free tracking reinforcement learning control with VRFT-based adaptive actor-critic. Appl. Sci. 2019, 9, 1807. [Google Scholar] [CrossRef]
- Radac, M.-B.; Precup, R.-E.; Petriu, E.M. Model-free primitive-based iterative learning control approach to trajectory tracking of MIMO systems with experimental validation. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2925–2938. [Google Scholar] [CrossRef] [PubMed]
- Chi, R.; Hou, Z.; Jin, S.; Huang, B. An improved data-driven point-to-point ILC using additional on-line control inputs with experimental verification. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 687–696. [Google Scholar] [CrossRef]
- Chi, R.; Zhang, H.; Huang, B.; Hou, Z. Quantitative data-driven adaptive iterative learning control: From trajectory tracking to point-to-point tracking. IEEE Trans. Cybern. 2020, 1–15. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, D. Convergence analysis of saturated iterative learning control systems with locally Lipschitz nonlinearities. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4025–4035. [Google Scholar] [CrossRef]
- Li, X.; Chen, S.-L.; Teo, C.S.; Tan, K.K. Data-based tuning of reduced-order inverse model in both disturbance observer and feedforward with application to tray indexing. IEEE Trans. Ind. Electron. 2017, 64, 5492–5501. [Google Scholar] [CrossRef]
- Madadi, E.; Soffker, D. Model-free control of unknown nonlinear systems using an iterative learning concept: Theoretical development and experimental validation. Nonlinear Dyn. 2018, 94, 1151–1163. [Google Scholar] [CrossRef]
- Shi, J.; Xu, J.; Sun, J.; Yang, Y. Iterative Learning Control for time-varying systems subject to variable pass lengths: Application to robot manipulators. IEEE Trans. Ind. Electron. 2019, 67, 8629–8637. [Google Scholar] [CrossRef]
- Wu, B.; Gupta, J.K.; Kochenderfer, M. Model primitives for hierarchical lifelong reinforcement learning. Auton. Agent Multi Agent Syst. 2020, 34, 28. [Google Scholar] [CrossRef]
- Li, J.; Li, Z.; Li, X.; Feng, Y.; Hu, Y.; Xu, B. Skill learning strategy based on dynamic motion primitives for human-robot cooperative manipulation. IEEE Trans. Cogn. Dev. Syst. 2020, 1. [Google Scholar] [CrossRef]
- Kim, Y.L.; Ahn, K.H.; Song, J.B. Reinforcement learning based on movement primitives for contact tasks. Robot. Comput. Integr. Manuf. 2020, 62, 101863. [Google Scholar] [CrossRef]
- Camci, E.; Kayacan, E. Learning motion primitives for planning swift maneuvers of quadrotor. Auton. Robots 2019, 43, 1733–1745. [Google Scholar] [CrossRef]
- Yang, C.; Chen, C.; He, W.; Cui, R.; Li, Z. Robot learning system based on adaptive neural control and dynamic movement primitives. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 777–787. [Google Scholar] [CrossRef] [PubMed]
- Huang, R.; Cheng, H.; Qiu, J.; Zhang, J. Learning physical human-robot interaction with coupled cooperative primitives for a lower exoskeleton. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1566–1574. [Google Scholar] [CrossRef]
- Liu, H.; Li, J.; Ge, S. Research on hierarchical control and optimisation learning method of multi-energy microgrid considering multi-agent game. IET Smart Grid 2020, 3, 479–489. [Google Scholar] [CrossRef]
- Van, N.D.; Sualeh, M.; Kim, D.; Kim, G.-W. A hierarchical control system for autonomous driving towards urban challenges. Appl. Sci. 2020, 10, 3543. [Google Scholar] [CrossRef]
- Jiang, W.; Yang, C.; Liu, Z.; Liang, M.; Li, P.; Zhou, G. A hierarchical control structure for distributed energy storage system in DC micro-grid. IEEE Access 2019, 7, 128787–128795. [Google Scholar] [CrossRef]
- Merel, J.; Botvinick, M.; Wayne, G. Hierarchical motor control in mammals and machines. Nat. Commun. 2019, 10, 5489. [Google Scholar] [CrossRef]
- Radac, M.-B.; Lala, T. Robust control of unknown observable nonlinear systems solved as a zero-sum game. IEEE Access 2020, 8, 214153–214165. [Google Scholar] [CrossRef]
- Alagoz, B.-B.; Tepljakov, A.; Petlenkov, E.; Yeroglu, C. Multi-loop model reference proportional integral derivative controls: Design and performance evaluations. Algorithms 2020, 13, 38. [Google Scholar] [CrossRef]
- Radac, M.-B.; Precup, R.-E. Data-driven MIMO model-free reference tracking control with nonlinear state-feedback and fractional order controllers. Appl. Soft Comput. 2018, 73, 992–1003. [Google Scholar] [CrossRef]
- Two Rotor Aerodynamical System, User’s Manual; Inteco Ltd.: Krakow, Poland, 2007.
- Busoniu, L.; De Schutter, B.; Babuska, R. Decentralized reinforcement learning control of a robotic manipulator. In Proceedings of the 2006 9th International Conference on Control, Automation, Robotics and Vision, Singapore, 5–8 December 2006. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting | C-NN |
|---|---|
| Architecture | 12-6-2 (12 inputs for , 6 hidden layer neurons and 2 outputs: ) |
| Activation function in hidden layer | tansig |
| Activation function in output layer | linear |
| Initial weights | uniform random numbers in [0;1] |
| Training algorithm | scaled conjugate gradient |
| Maximum number of epochs to train | 100 |
| Validation/training ratio | 10–90% |
| Maximum validation failures | 50 |
| Minimum performance gradient | |
| Training cost function | mean sum of squared errors (MSSE) |
| Trial | VSFRT | AI-VIRL (500 Epochs) | AI-VIRL (100 Epochs) |
|---|---|---|---|
| 1 | 0.0058104 | 0.010102 | 0.0070567 |
| 2 | 0.0054775 | 0.0066765 | 0.017531 |
| 3 | 0.0051332 | 0.0039271 | 0.034047 |
| 4 | 0.0092913 | 0.024098 | 0.01389 |
| 5 | 0.0058103 | 0.0069556 | 0.013097 |
| Average | 0.00630454 | 0.01035184 | 0.03424868 |
| Setting | C-NN | Q-NN |
|---|---|---|
| Architecture | 14-10-2 | 16-30-1 |
| Activation function in hidden layer | tansig | tansig |
| Activation function in output layer | linear | linear |
| Initial weights | uniform random numbers in [0;1] | uniform random numbers in [0;1] |
| Training algorithm | scaled conjugate gradient | scaled conjugate gradient |
| Maximum number of epochs to train | 500 or 100 | 500 |
| Validation/training ratio | 10–90% | 10–90% |
| Maximum validation failures | 50 | 50 |
| Minimum performance gradient | ||
| Training cost function | MSSE | MSSE |
| Trial | VSFRT | AI-VIRL (500 Epochs) | AI-VIRL (100 Epochs) |
|---|---|---|---|
| 1 | 0.0057742 | 1.6159 | 1.0426 |
| 2 | 0.004507 | 0.24 | 0.96942 |
| 3 | 0.0055276 | 1.8268 | 1.0055 |
| 4 | 0.0043692 | 0.63566 | 1.3044 |
| 5 | 0.0049202 | 0.84485 | 0.20267 |
| Average | 0.00501964 | 1.032642 | 0.904918 |
| Setting | C-NN |
|---|---|
| Architecture | 10-6-2 |
| Activation function in hidden layer | tansig |
| Activation function in output layer | linear |
| Initial weights | uniform random numbers in [0;1] |
| Training algorithm | scaled conjugate gradient |
| Maximum number of epochs to train | 100 |
| Validation/training ratio | 10–90% |
| Maximum validation failures | 50 |
| Minimum performance gradient | |
| Training cost function | MSSE |
| Trial | VSFRT | AI-VIRL (500 Epochs) |
|---|---|---|
| 1 | 0.0043144 | 0.0039152 |
| 2 | 0.0050468 | 0.0051058 |
| 3 | 0.0040801 | 0.0068728 |
| 4 | 0.0044891 | 0.0058930 |
| 5 | 0.0045807 | 0.0055730 |
| Average | 0.0045022 | 0.0054719 |
| Setting | C-NN | Q-NN |
|---|---|---|
| Architecture | 12-6-2 | 14-40-1 |
| Activation function in hidden layer | tansig | tansig |
| Activation function in output layer | linear | linear |
| Initial weights | uniform random numbers in [0;1] | uniform random numbers in [0;1] |
| Training algorithm | scaled conjugate gradient | scaled conjugate gradient |
| Maximum number of epochs to train | 100 | 500 |
| Validation/training ratio | 10–90% | 10–90% |
| Maximum validation failures | 50 | 50 |
| Minimum performance gradient | ||
| Training cost function | MSSE | MSSE |
| Trial | VSFRT | AI-VIRL (100 Epochs) |
|---|---|---|
| 1 | 0.0021623 | 0.127480 |
| 2 | 0.0021440 | 0.273590 |
| 3 | 0.0021695 | 0.865850 |
| 4 | 0.0021951 | 0.202360 |
| 5 | 0.0021497 | 0.175330 |
| Average | 0.0021641 | 0.328922 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radac, M.-B.; Borlea, A.-I. Virtual State Feedback Reference Tuning and Value Iteration Reinforcement Learning for Unknown Observable Systems Control. Energies 2021, 14, 1006. https://doi.org/10.3390/en14041006
Radac M-B, Borlea A-I. Virtual State Feedback Reference Tuning and Value Iteration Reinforcement Learning for Unknown Observable Systems Control. Energies. 2021; 14(4):1006. https://doi.org/10.3390/en14041006
Chicago/Turabian StyleRadac, Mircea-Bogdan, and Anamaria-Ioana Borlea. 2021. "Virtual State Feedback Reference Tuning and Value Iteration Reinforcement Learning for Unknown Observable Systems Control" Energies 14, no. 4: 1006. https://doi.org/10.3390/en14041006
APA StyleRadac, M.-B., & Borlea, A.-I. (2021). Virtual State Feedback Reference Tuning and Value Iteration Reinforcement Learning for Unknown Observable Systems Control. Energies, 14(4), 1006. https://doi.org/10.3390/en14041006