Optimal Scheduling of Microgrid Based on Deep Deterministic Policy Gradient and Transfer Learning



Abstract
1. Introduction
2. Microgrid System Model and Optimization Model
2.1. Component Model
2.2. Objective Function
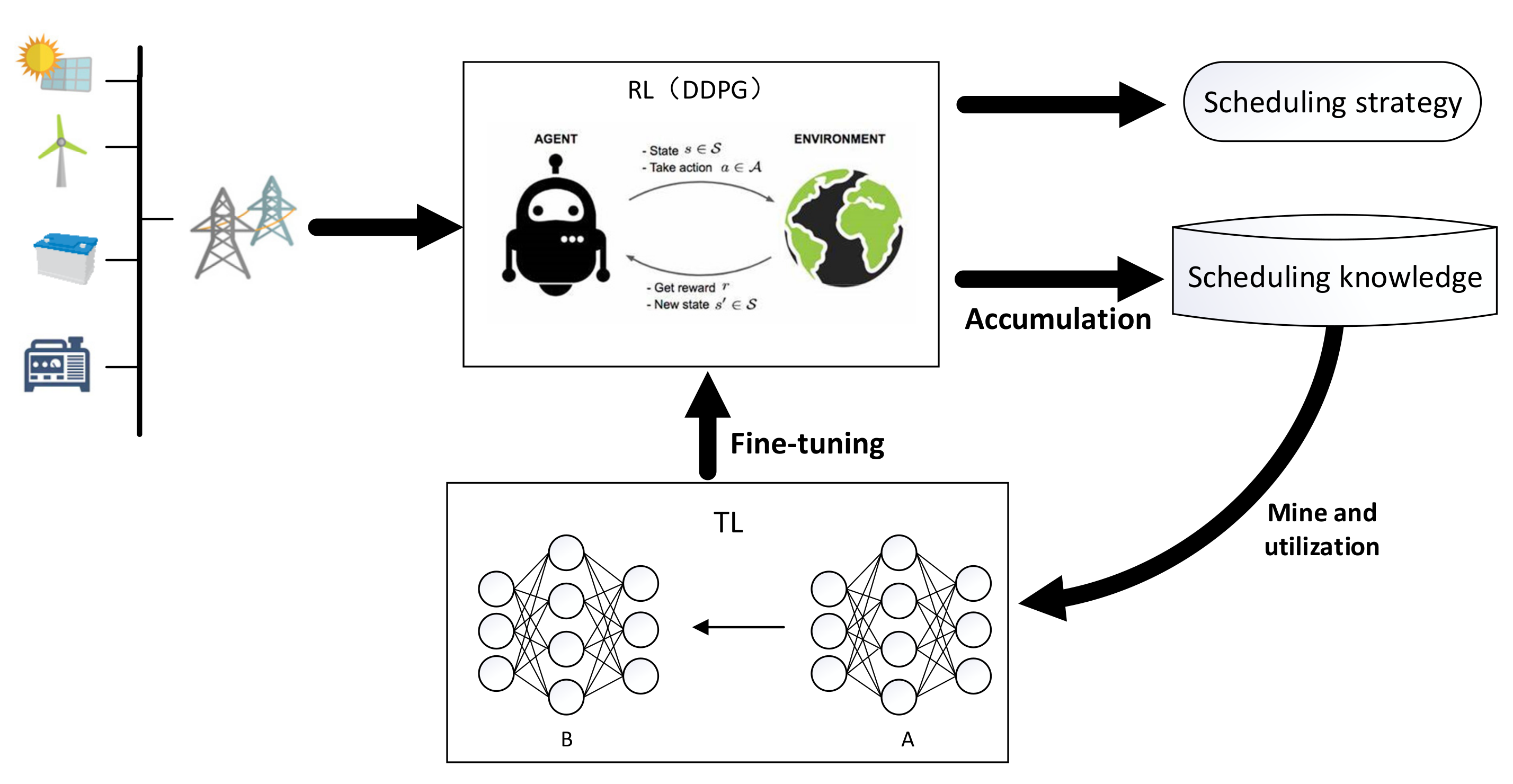
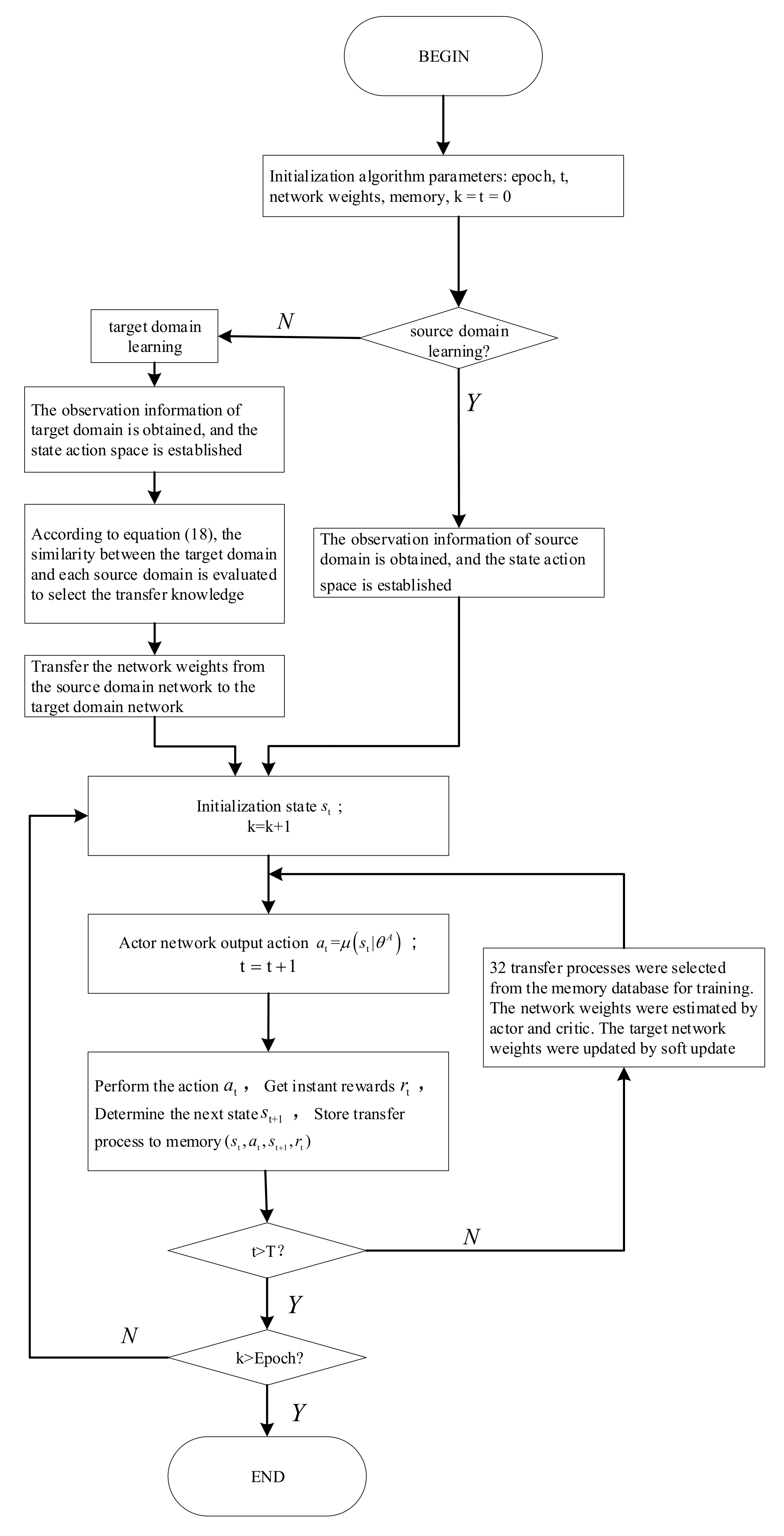
3. Optimal Scheduling Method Based on Deep Deterministic Policy Gradient and Transfer Learning
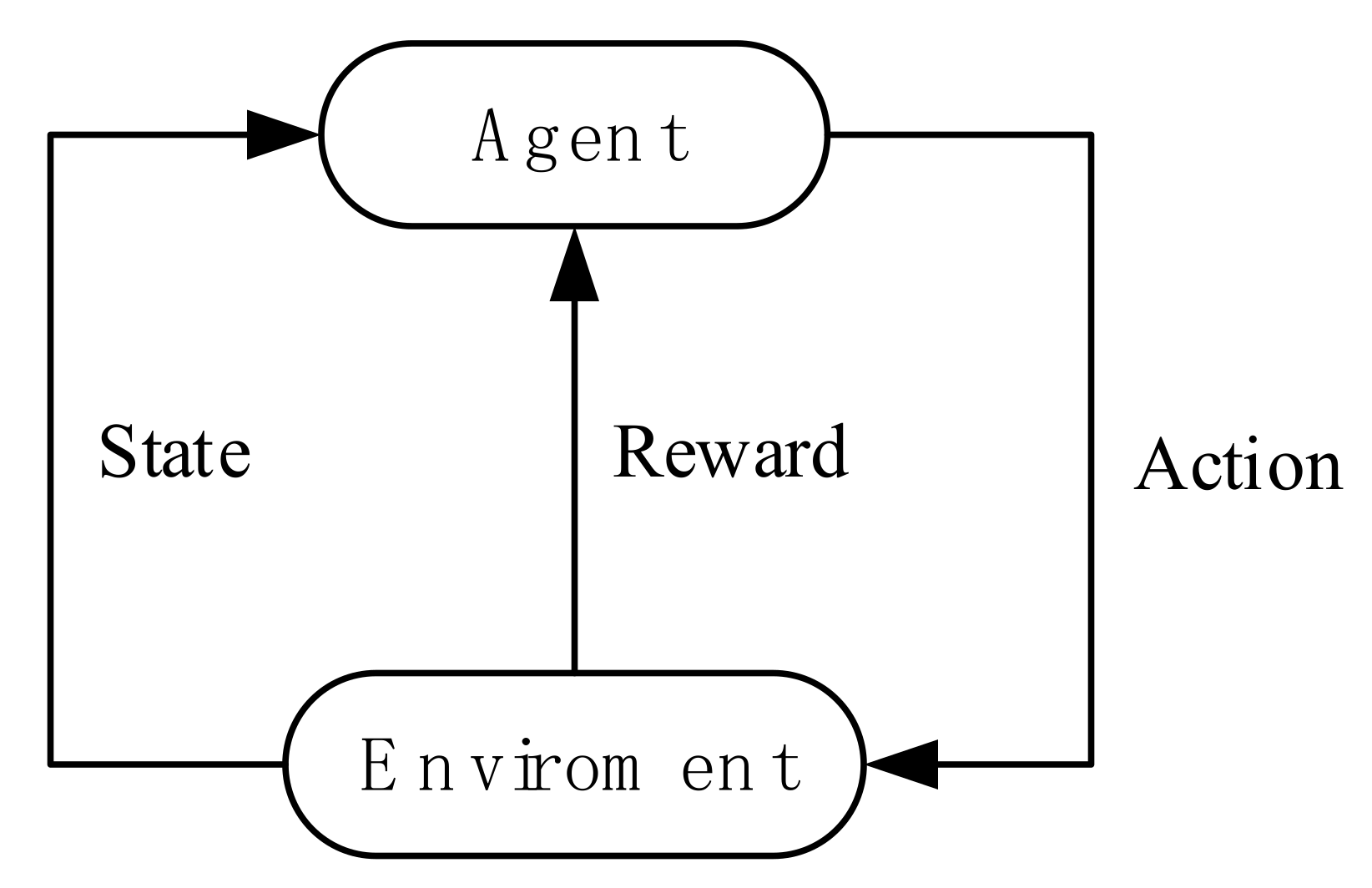
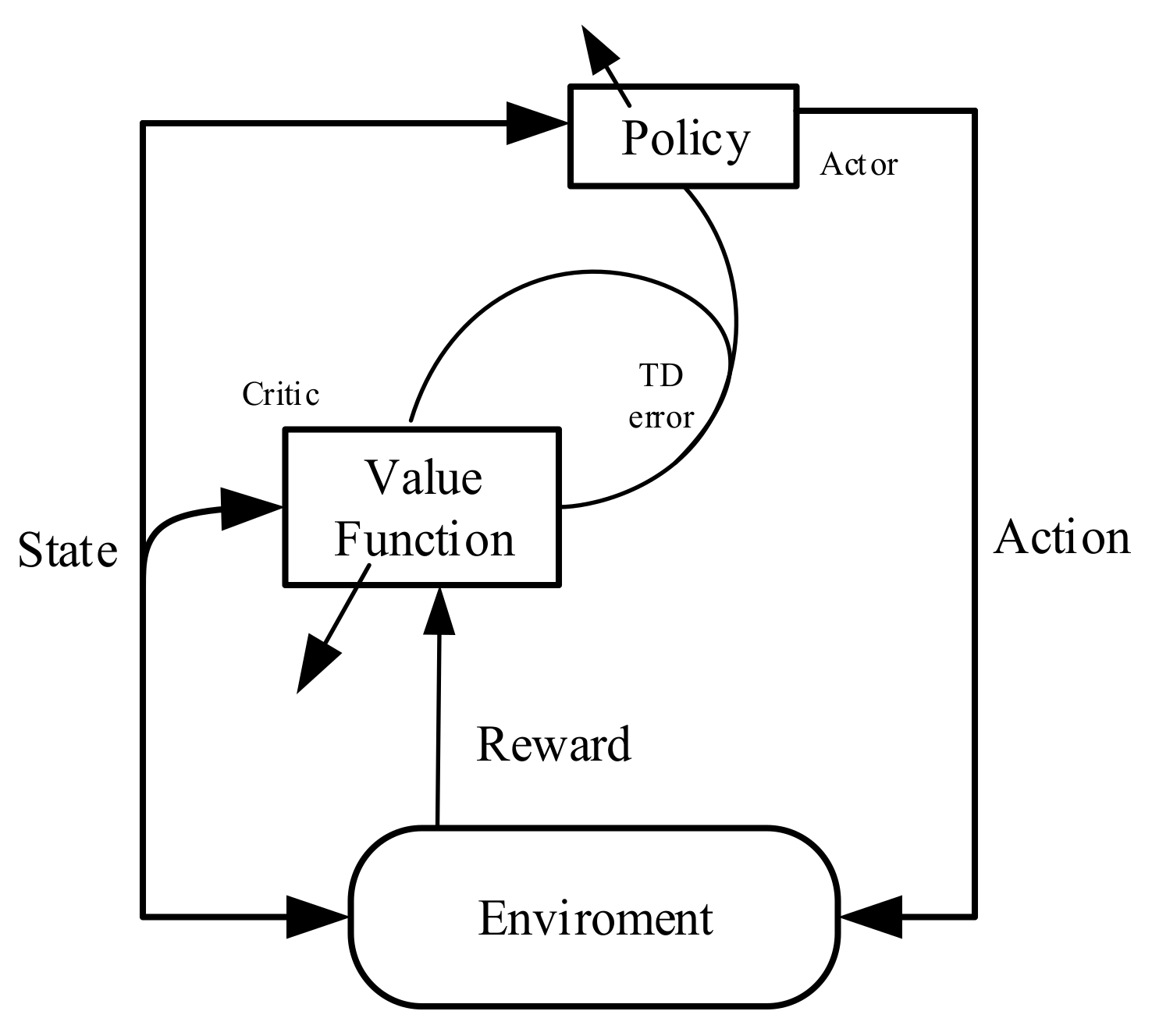
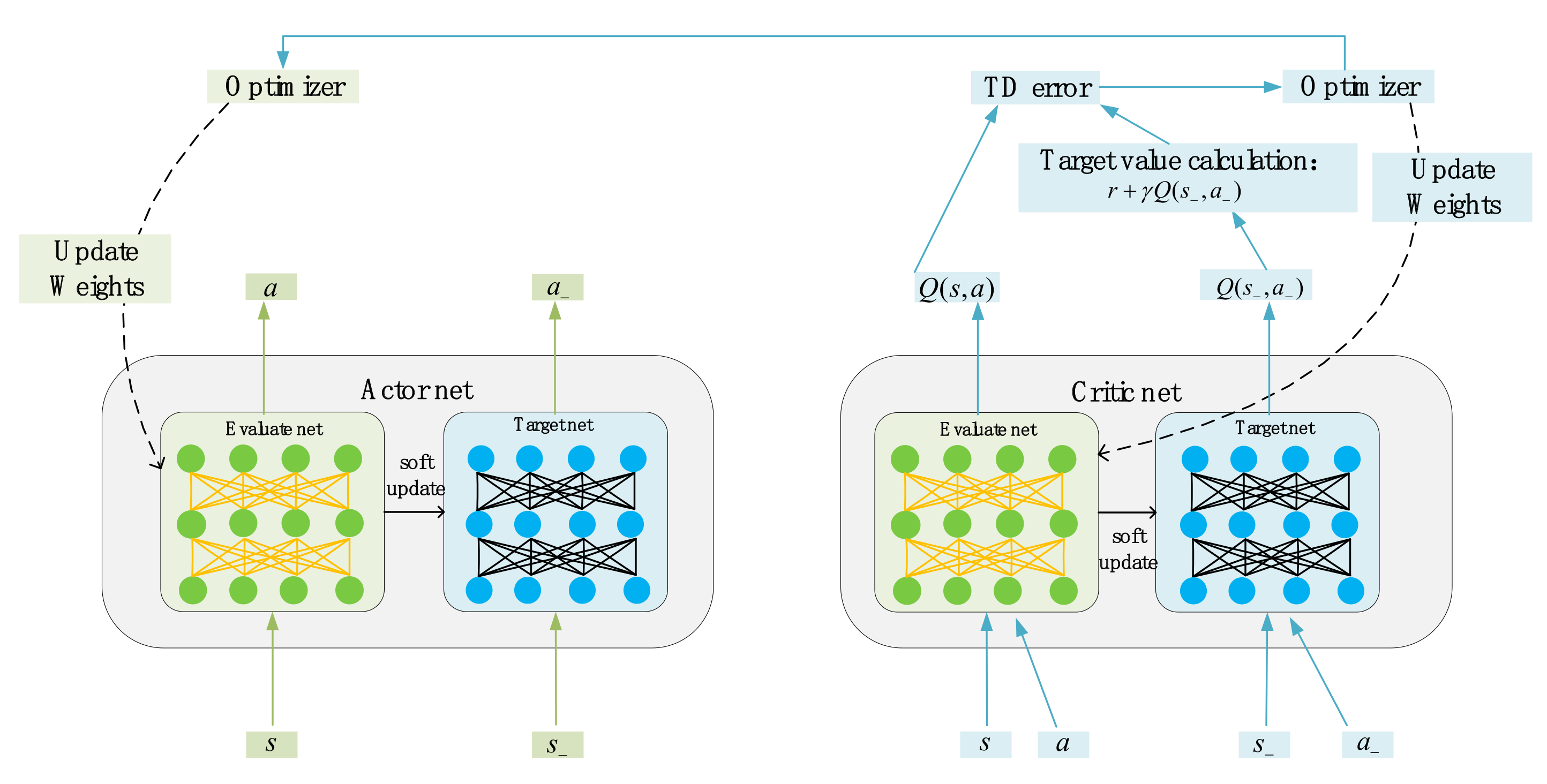
3.1. DDPG
3.2. Knowledge Transfer
3.2.1. TL
3.2.2. Knowledge Transfer Rules
- (1)
- According to the characteristics of the source domain, an appropriate similarity evaluation function is selected to evaluate the characteristic correlation between the source domain and the target domain.
- (2)
- For the target domain, according to the similarity evaluation function, the similarity between the target domain and the number of N source domains is calculated. The higher the value, the higher the similarity between the target domain and the source domain, which means that source domain knowledge is more instructive to target domain learning.
- (3)
- Selecting the source domain with the highest similarity for knowledge transfer.
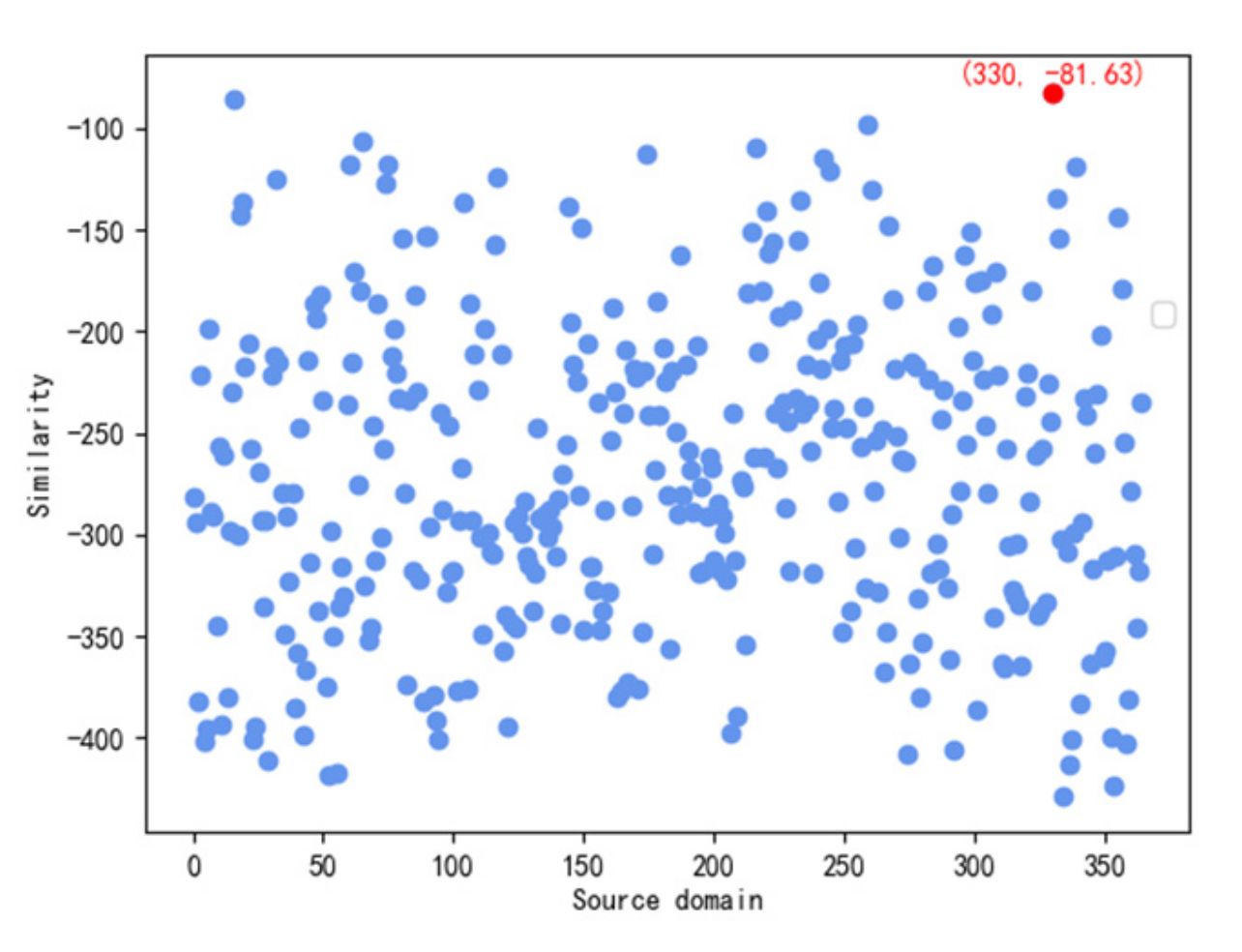
3.2.3. Similarity Evaluation Function
3.3. State-Action Space and Reward Function
3.3.1. State-Action Space
3.3.2. Reward Function
3.4. Algorithm Flow
4. Simulation Verification and Analysis
4.1. Simulation
- (1)
- DDQN, the power of the battery, and the diesel generator are discretized to 13 and 5 fixed actions respectively, so the action space is set as .
- (2)
- DDPG, the action space is set as , action .
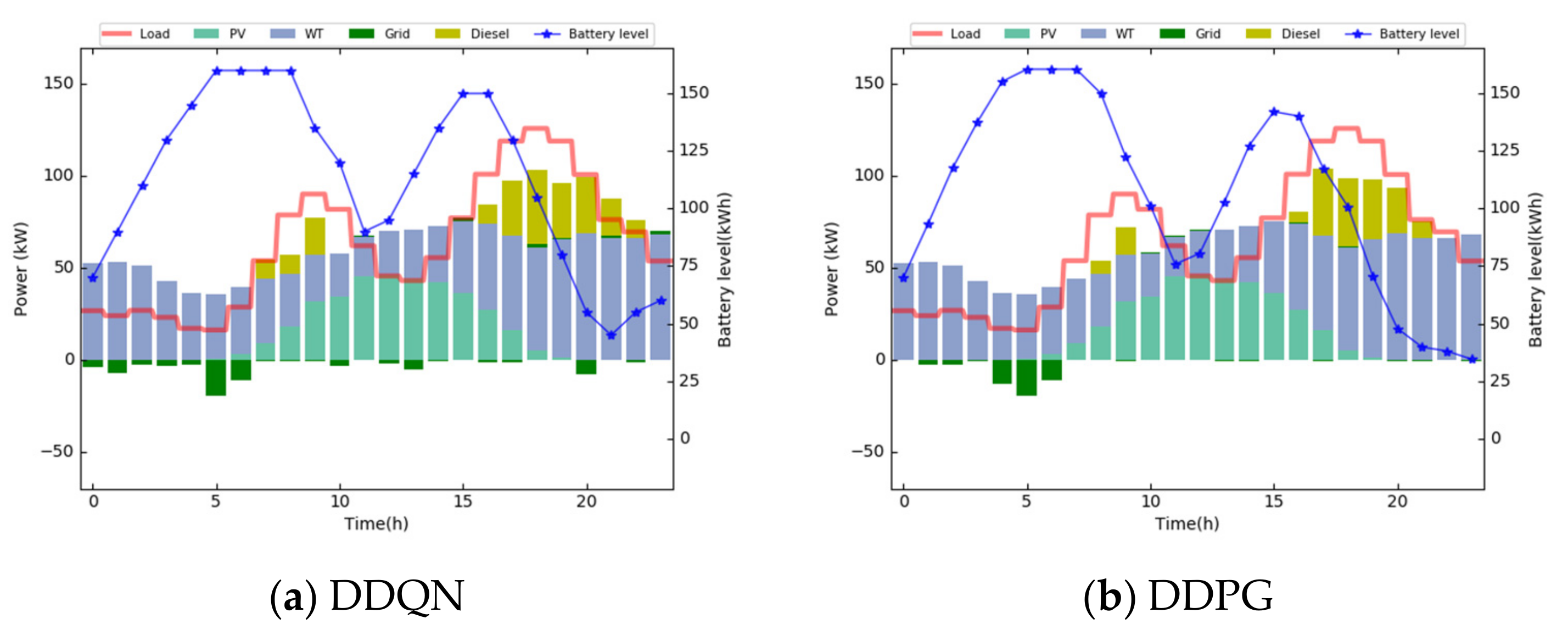
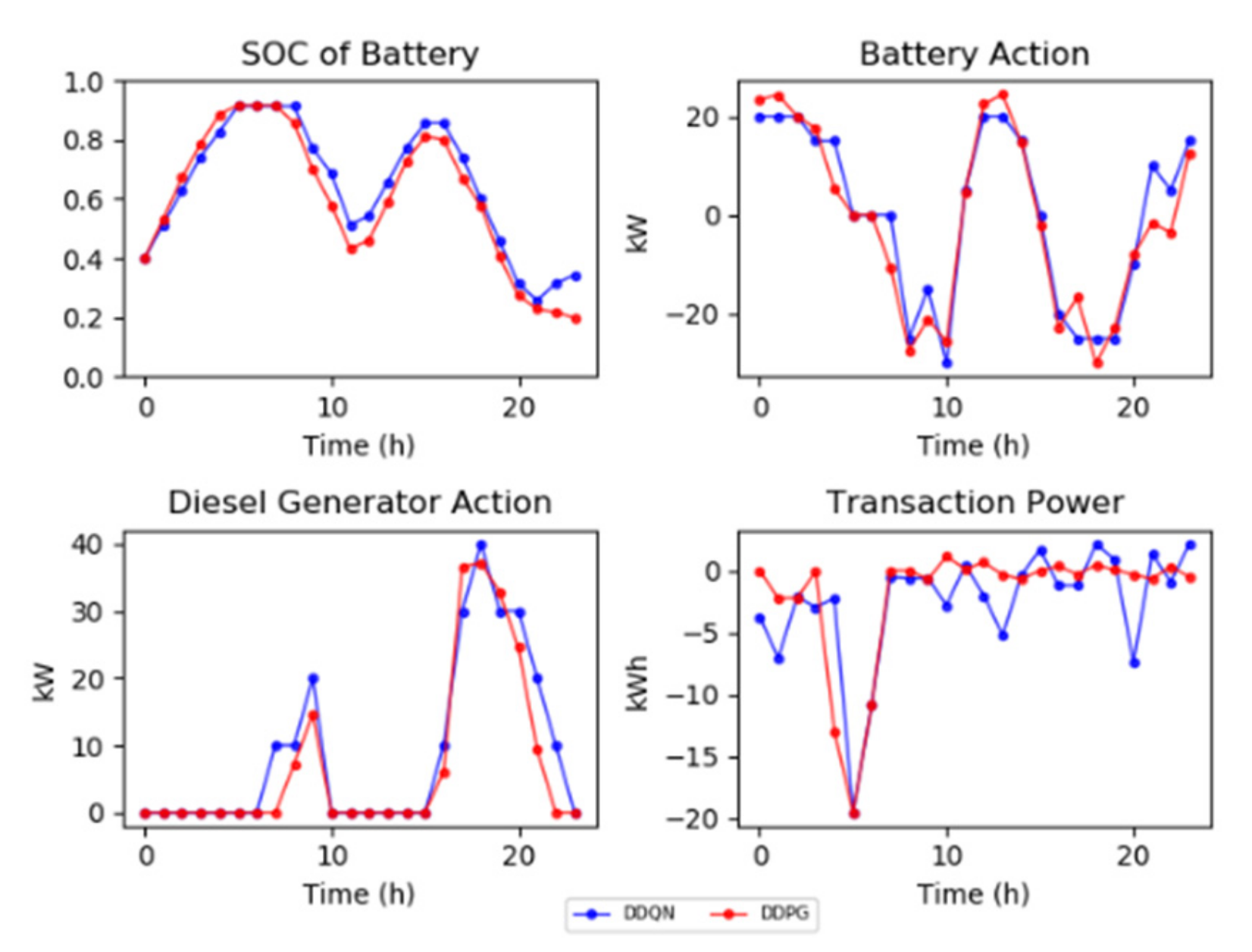
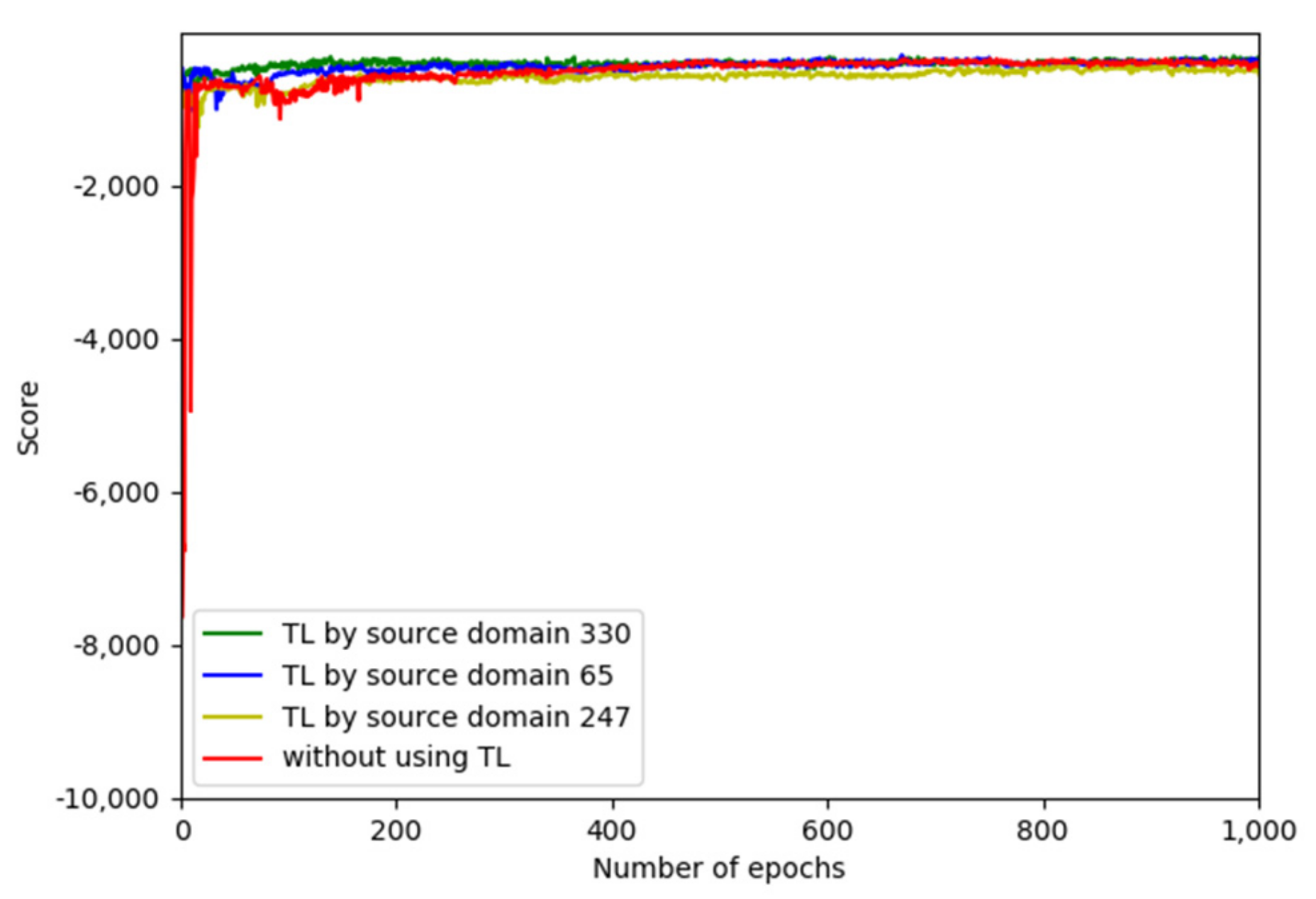
4.2. Source Domain Learning
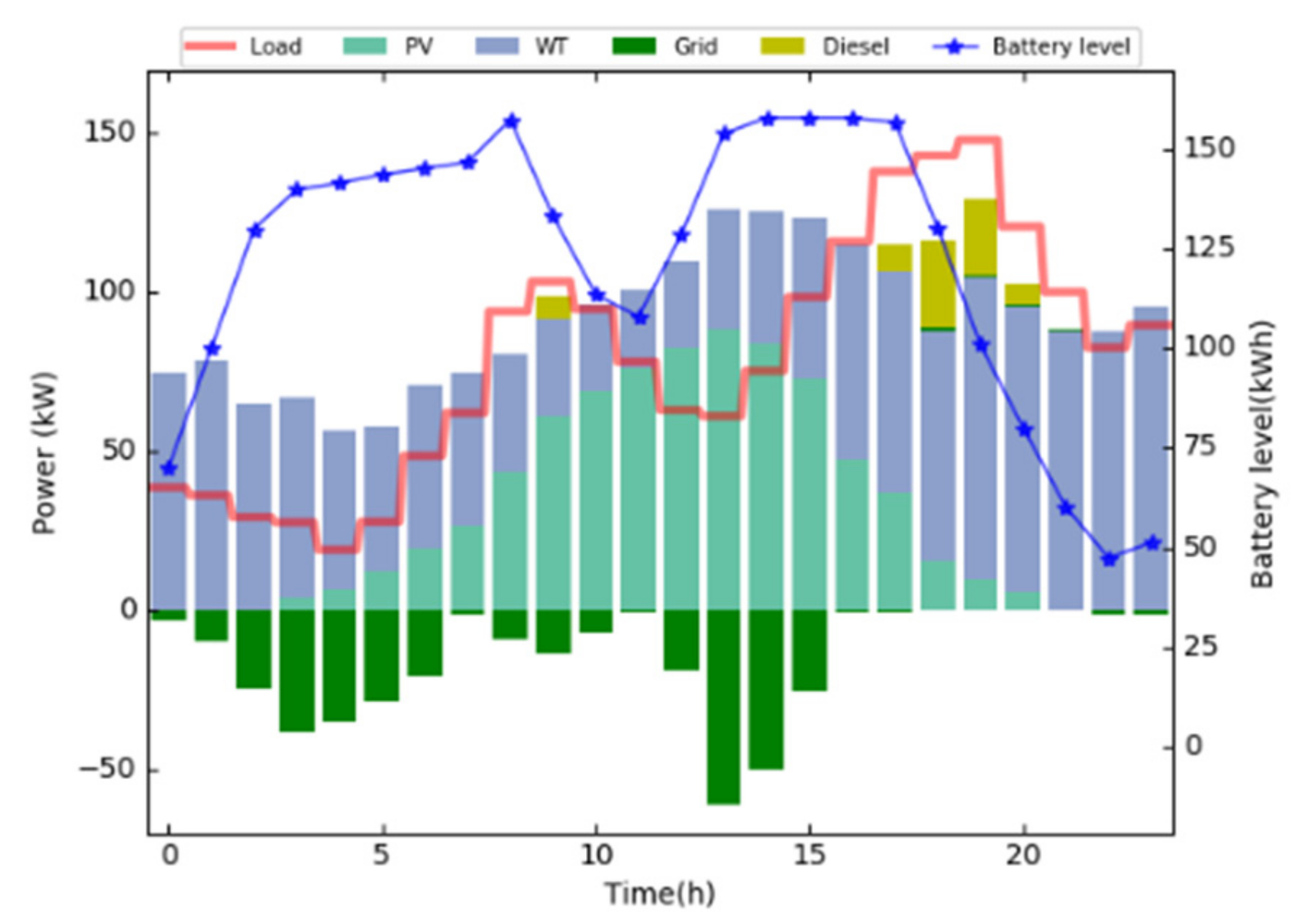
4.3. Target Domain Learning
5. Conclusions
- (1)
- This paper provides an optimal scheduling strategy for microgrid with complex and changeable operation mode flexibility and efficiency through the effective accumulation of scheduling knowledge and the utilization of scheduling knowledge through knowledge transfer.
- (2)
- The DDPG model is introduced into RL, and the action space of traditional RL is extended from discrete space to continuous space.
- (3)
- A microgrid optimal scheduling TL algorithm based on the actual supply and demand similarity is proposed and the effective utilization of scheduling knowledge achieved the transfer of scheduling knowledge.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| RL | Reinforcement Learning |
| TL | Transfer Learning |
| DPG | Deterministic Policy Gradient |
| DDQN | Double Deep Q Network |
| DDPG | Deep Deterministic Policy Gradient |
| RELU | Rectified Linear Unit |
| diesel | Diesel Generator |
| , T | Time indices |
| , PV | Photovoltaic (PV) indices |
| , WT | Wind turbine (WT) indices |
| Parameters | |
| Number of source domains | |
| Efficiency of PV | |
| Total area of PV | |
| Maximum climbing power of diesel generator | |
| Power generated by WT | |
| Total rated power of WT | |
| Cut-in speed of WT | |
| Rated speed of WT | |
| Cut-off speed of WT | |
| Capacity of battery | |
| Efficiency of battery in discharge state | |
| Efficiency of battery in charge state | |
| Maximum charge power of battery | |
| Maximum discharge power of battery | |
| Minimum of battery | |
| Maximum of battery | |
| Electricity buy price of microgrid from main grid | |
| Electricity sell price of microgrid to main grid | |
| Network loss conversion coefficient | |
| Cost factors of diesel generator | |
| Decision variables | |
| Power generated by PV | |
| The load demand | |
| Transaction power between microgrid and main network | |
| Power generated by WT | |
| Power generated by diesel | |
| Change Power of battery | |
| The state of charge | |
| Univariate variable of , , , , | |
| Difference power between renewable energy output and load demand at each time in the target domain | |
| Difference power between renewable energy output and load demand at each time in m source domain, | |
| The similarity between target domain and source domain | |
| Wind speed | |
| Solar radiation intensity | |
References
- IEEE Power Engineering Society Winter Meeting. In IEEE Power Engineering Review, Volume PER-4; IEEE: New York, NY, USA, 1984; p. 18. [CrossRef]
- Zhang, J.; Fan, L.; Zhang, Y.; Yao, G.; Yu, P.; Xiong, G.; Meng, K.; Chen, X.; Dong, Z. A Probabilistic Assessment Method for Voltage Stability Considering Large Scale Correlated Stochastic Variables. IEEE Access 2020, 8, 5407–5415. [Google Scholar] [CrossRef]
- Dai, C.; Chen, W.; Zhu, Y.; Zhang, X. Seeker Optimization Algorithm for Optimal Reactive Power Dispatch. IEEE Trans. Power Syst. 2009, 24, 1218–1231. [Google Scholar]
- Fumin, Z.; Zijing, Y.; Zhankai, L.; Shengxue, T.; Chenyang, M.; Han, J. Energy Management of Microgrid Cluster Based on Genetic-tabu Search Algorithmy. High Volt. Eng. 2018, 44, 2323–2330. [Google Scholar]
- Ge, S.; Sun, H.; Liu, H.; Zhang, Q. Power Supply Capability Evaluation of Active Distribution Network Considering Reliability and Post-fault Load Response. Autom. Electr. Power Syst. 2019, 43, 77–84. [Google Scholar]
- Zhuang, F.-Z.; Luo, P.; He, Q.; Shi, Z. Survey on Transfer Learning Research. J. Softw. 2015, 26, 26–39. [Google Scholar]
- Xiaoshun, Z.H.A.N.G.; Tao, Y.U. Knowledge Transfer Based Q-learning Algorithm for Optimal Dispatch of Multi-energy System. Autom. Electr. Power Syst. 2017, 41, 18–25. [Google Scholar]
- Zhang, X.; Yu, T.; Yang, B.; Zheng, L.; Huang, L. Approximate ideal multi-objective solution Q(λ) learning for optimal carbon-energy combined-flow in multi-energy power systems. Energy Convers. Manag. 2015, 106, 543–556. [Google Scholar] [CrossRef]
- Xiaoshun, Z.H.A.N.G.; Tao, Y.U. Optimization Algorithm of Reinforcement Learning Based Knowledge Transfer Bacteria Foraging for Risk Dispatch. Autom. Electr. Power Syst. 2017, 41, 69–77. [Google Scholar]
- Tao, Y.; Bin, Z.; Weiguo, Z.H.E.N. Application and development of reinforcement learning theory in power systems. Power Syst. Prot. Control 2009, 37, 122–128. [Google Scholar]
- Ahamed, T.I.; Rao, P.N.; Sastry, P.S. A reinforcement learning approach to automatic generation control. Electric Power Syst. Res. 2002, 63, 9–26. [Google Scholar] [CrossRef]
- Li, T.; Liu, M. Reduced Reinforcement Learning Method Applied to Multi-objective Coordinated Secondary Voltage Control. Proc. CSEE 2013, 33, 130–139. [Google Scholar]
- Sanseverino, E.R.; Di Silvestre, M.L.; Mineo, L.; Favuzza, S.; Nguyen, N.Q.; Tran, Q.T.T. A multi-agent system reinforcement learning based optimal power flow for islanded microgrids. In Proceedings of the 2016 IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), Florence, Italy, 7–10 June 2016; pp. 1–6. [Google Scholar]
- Zhang, X.; Bao, T.; Yu, T.; Yang, B.; Han, C. Deep transfer Q-learning with virtual leader-follower for supply-demand Stackelberg game of smart grid. Energy 2017, 133, 348–365. [Google Scholar] [CrossRef]
- Jiazhi, Z.E.N.G.; Xiongfei, Z.H.A.O.; Jing, L.I. Game among Multiple Entities in Electricity Market with Liberalization of Power Demand Side Market. Autom. Electr. Power Syst. 2017, 41, 129–136. [Google Scholar]
- Li, S.; Wang, X.P.; Wang, Q.D.; Niu, S.W. Research on intrusion detection based on SMDP reinforcement learning in electric power information network. Electric Power Autom. Equip. 2006, 12, 75–78. [Google Scholar]
- Liu, G.; Han, X.; Wang, S.; Yang, M.; Wang, M. Optimal decision-making in the cooperation of wind power and energy storage based on reinforcement learning algorithm. Power Syst. Technol. 2016, 40, 2729–2736. [Google Scholar]
- Yadong, W.; Chenggang, C.; Shensheng, Q. Research on Energy Storage scheduling Strategy of Microgrid based on Deep reinforcement Learning. Renew. Energy Resour. 2019, 37, 1220–1228. [Google Scholar]
- Zhang, Z.; Qiu, C.; Zhang, D.; Xu, S.; He, X. A Coordinated Control Method for Hybrid Energy Storage System in Microgrid Based on Deep Reinforcement learning algorithm. Power Syst. Technol. 2019, 43, 1914–1921. [Google Scholar]
- Zhang, J.; Xiong, G.; Meng, K.; Yu, P.; Yao, G.; Dong, Z. An improved probabilistic load flow simulation method considering correlated stochastic variables. Int. J. Electr. Power Energy Syst. 2019, 111, 260–268. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. Comput. Sci. 2016, 8, A187. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with deep reinforcement learning. In Proceedings of the Workshops at the 26th Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 201–220. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- François-Lavet, V.; Taralla, D.; Ernst, D.; Fonteneau, R. Deep reinforcement learning solutions for energy microgrids management. In European Workshop on Reinforcement Learning (EWRL 2016); University of Liege: Barcelona, Spain, 2016. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Electricity Buys Price (RMB/kWh) | Electricity Sells Price (RMB/kWh) |
|---|---|
| 1.1 | 0.85 |
| Index | DDQN | DDPG |
|---|---|---|
| Operating cost of microgrid (RMB) | 176.26 | 142.75 |
| Diesel generator fuel cost (RMB) | 118.77 | 95.50 |
| Transaction cost (RMB) | 57.49 | 47.25 |
| The microgrid buys electricity from the main grid (kWh) | 8.92 | 3.014 |
| The microgrid sells electricity to the main grid (kWh) | 68.84 | 51.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Zhang, J.; He, Y.; Liu, Y.; Hu, T.; Zhang, H. Optimal Scheduling of Microgrid Based on Deep Deterministic Policy Gradient and Transfer Learning. Energies 2021, 14, 584. https://doi.org/10.3390/en14030584
Fan L, Zhang J, He Y, Liu Y, Hu T, Zhang H. Optimal Scheduling of Microgrid Based on Deep Deterministic Policy Gradient and Transfer Learning. Energies. 2021; 14(3):584. https://doi.org/10.3390/en14030584
Chicago/Turabian StyleFan, Luqin, Jing Zhang, Yu He, Ying Liu, Tao Hu, and Heng Zhang. 2021. "Optimal Scheduling of Microgrid Based on Deep Deterministic Policy Gradient and Transfer Learning" Energies 14, no. 3: 584. https://doi.org/10.3390/en14030584
APA StyleFan, L., Zhang, J., He, Y., Liu, Y., Hu, T., & Zhang, H. (2021). Optimal Scheduling of Microgrid Based on Deep Deterministic Policy Gradient and Transfer Learning. Energies, 14(3), 584. https://doi.org/10.3390/en14030584