1. Introduction
Solar energy is considered as a major source for future renewable energy [
1]. As the dependence on renewable energy increases, more attention to solar energy is paid. Solar radiation data are the main ingredient of optimum design and operations of solar power systems [
2]. It is necessary to ensure the stability of the energy supplied by solar stations. Therefore, accurate prediction of the amount of solar radiation at a specific location is critical from an operational perspective. For parties such as governments, enterprises, and energy operators, solar radiation prediction is a key for optimal strategic plans, particularly when hybridized with different energy sources. However, such an objective is associated with practical difficulties. Particularly, the potential of solar energy is limited by inaccuracy of solar radiation levels prediction when compared with certain alternative resources. In order to handle this problem, several prediction models have been proposed in the literature to predict solar radiation, including numerical weather prediction (NWP) and artificial intelligence models, e.g., [
3,
4,
5,
6,
7,
8]. However, the large number of parameters associated with the prediction process, including weather and topography variables, significantly affects the underlying prediction models. Therefore, it is crucial to obtain a good representative set of these parameters, or features as termed in machine learning, to improve the predictor performance as well as reducing the computational cost of the real-time prediction systems.
NWP models can provide forecasts of solar radiation several days ahead along with other weather parameters, such as temperature, air pressure, relative humidity, or wind speed [
9]. Such information can be useful for optimizing solar plant operating strategies. These models rely on atmospheric reanalysis to obtain initial and boundary conditions for the model run before it is realistically downscaled to a finer physical resolution using few physical equations. An NWP model that downscales reanalysis data is called a mesoscale model. As mesoscale models run within a smaller area compared with global-scale models, they include additional details. Therefore, these models can provide forecasts of solar irradiance with a high temporal spatial resolution over a wide area but with high levels of computing power. The Weather Research and Forecasting (WRF) model [
10] is the most commonly-used mesoscale model, and it has been extensively applied and assessed. In this paper, a nonhydrostatic WRF v3.7.1 model has been applied to simulate dust storm events over Saudi Arabia to evaluate the reliability of global horizontal irradiance (GHI) forecasts.
Regarding artificial intelligence (AI) models, A large number of AI models for predicting solar radiation or solar power have been proposed. For example, AI models have been applied to predict solar radiation using fuzzy logic sets and systems [
11,
12], neuro-fuzzy systems [
13], neural networks [
14,
15,
16], machine/deep learning [
17,
18,
19,
20,
21,
22,
23,
24], and LSTM [
25,
26,
27,
28,
29]. There are some other regression tools that are based on statistical models linear and non-linear regression, specially for seasonally-repeated patterns, e.g., Prophet [
30,
31]. Automated Time Series Models in Python (AtsPy) [
32] provides a software package to compare the forecasting performance of about ten other regression algorithms along with Prophet.
Abdel-Nasser et al. [
33] developed an LSTM-based method for solar irradiance forecasting. They used LSTM models with an aggregation function based on Choquet integral. Combining Choquet integral with LSTM aimed at achieving more accurate predictions due to the memory units and the recurrent architecture which can model the temporal changes in solar irradiance. The interaction between aggregated inputs are modeled by the Choquet integral through a fuzzy measure.
Almaraashi [
34] applied fuzzy logic systems that are designed and optimized using fuzzy c-means clustering (FCM) and simulated annealing (SA) algorithms to forecast global horizontal irradiance (GHI) in eight stations in Saudi Arabia. In addition, Almaraashi predicted daily solar radiation in the same eight stations in Saudi Arabia using multi-layer neural networks (NNs). This was done after applying four-feature selection methods to discover the most important variables [
35]. The used four-feature selection methods are the Relief algorithm, Random-Frog algorithm, Monte Carlo Uninformative Variable Elimination algorithm (MCUVE), and Laplacian Score algorithm (LS). A hybrid model presented by Voyant et al. [
36] applied the NWP model combined with a hybrid auto-regressive moving average (ARMA) and neural networks to forecast hourly global radiation for five locations in the Mediterranean area.
Boubaker et al. [
37] have investigated one-day prediction of GHI using various DNN models at Hail city, Saudi Arabia. They used six different DNN models: LSTM, BiLSTM, GRU, Bi-GRU, onde dimensional CNN, and other hybrid configurations such as CNN-LSTM and CNN-BiLSTM. The used DNN models depend only on historical daily values of GHI. However, These models did not take into consideration crucial weather parameters that may affect GHI, e.g., air temperature, humidity, wind speed, wind direction, and atmospheric pressure.
The intuitive parameter selection by experts when predicting solar radiation can result in different sets of possible input parameters in which some might appear to be redundant or irrelevant. In addition, the manual selection of the most relevant features for this problem is affected by the large dimensionality of the input feature space. Given such a case, the automatic dimension reduction of the input feature space can be a valuable solution.
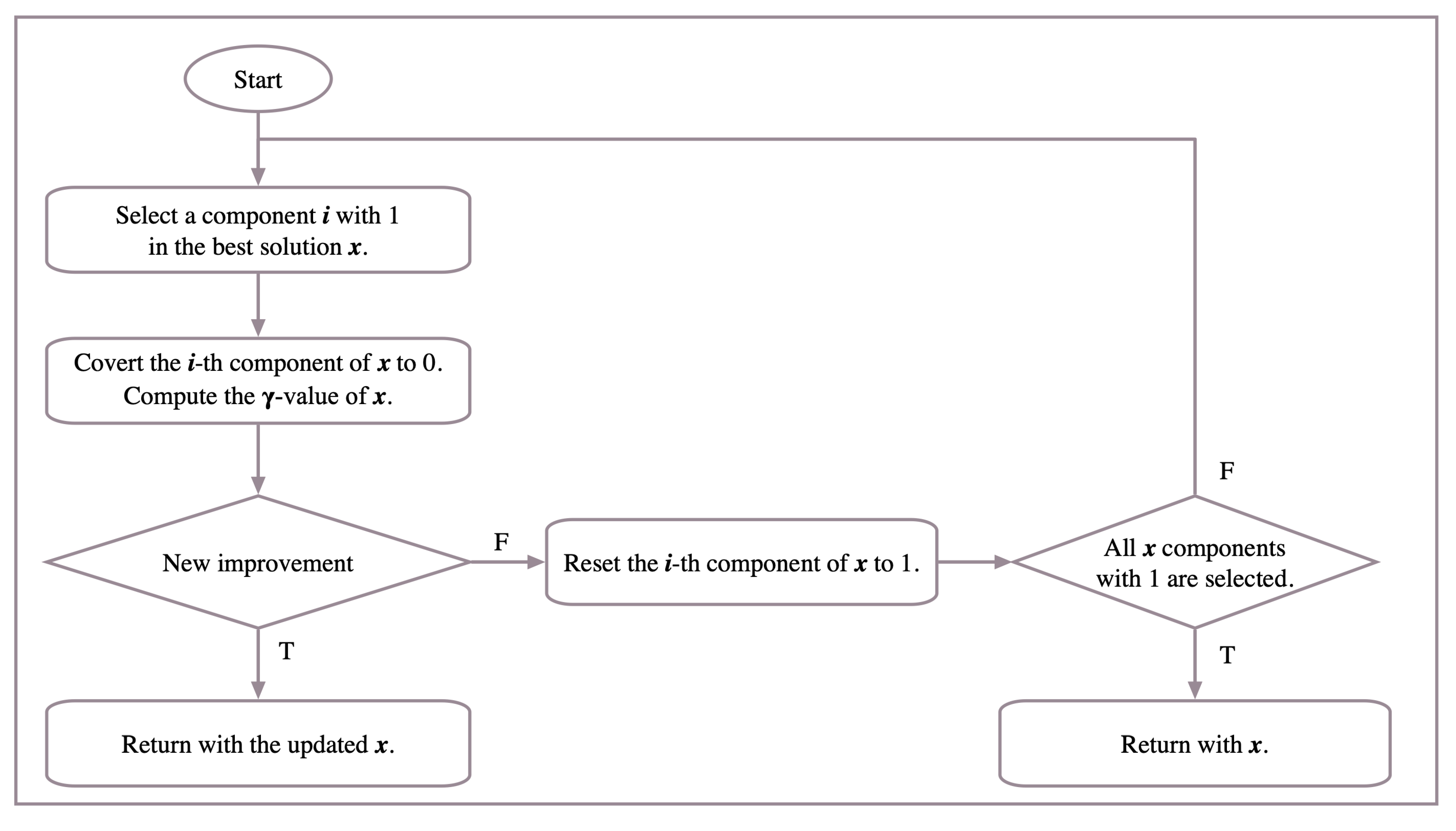
Solar energy prediction needs large amounts of data, which require a large number of measuring devices and equipment. Moreover, the calculations of weather data needed for the solar energy prediction process are often computationally expensive. Therefore, one of the most important motivations for this research is to reduce the data reading and calculation processes required for solar energy prediction and to reduce the cost of this process. This helps to expand prediction operations in a broader and more comprehensive way, even beyond the scope of traditional measurement stations. Another major motivation for this paper is to use the power of smart and hybrid systems in predicting short-term solar energy levels. Therefore, in this paper, a modified version of the tabu search attribute reduction (TSAR) [
38] is presented as a feature selection method along with different prediction models for the estimation of solar radiation levels. The main modifications of that method are adding more local search and extending some other search operations. Consequently, various classification and regression models are designed to predict solar radiation based on reduced features. Moreover, other hybrid predictive models are formulated in order to utilize the outputs of the WRF numerical model as learning elements to increase prediction accuracy. In addition to the proposed prediction models, the impact of the attribute reduction mechanism on different classification and regression models is investigated.
3. Experimental Setup and Evaluation
Available observed historical data are exploited in order to measure the performance of the reduction in the input feature space. In particular, the impact of dimension reduction on the solar radiation estimation process is investigated. This investigation is conducted by measuring weather data variables, such as temperature, wind speed, humidity and direct normal irradiance, as well as other environmental data.
Table 1 enumerates the attributes used for evaluation purposes. Evaluation of the proposed system is performed by setting the GHI for the current day as the objective output.
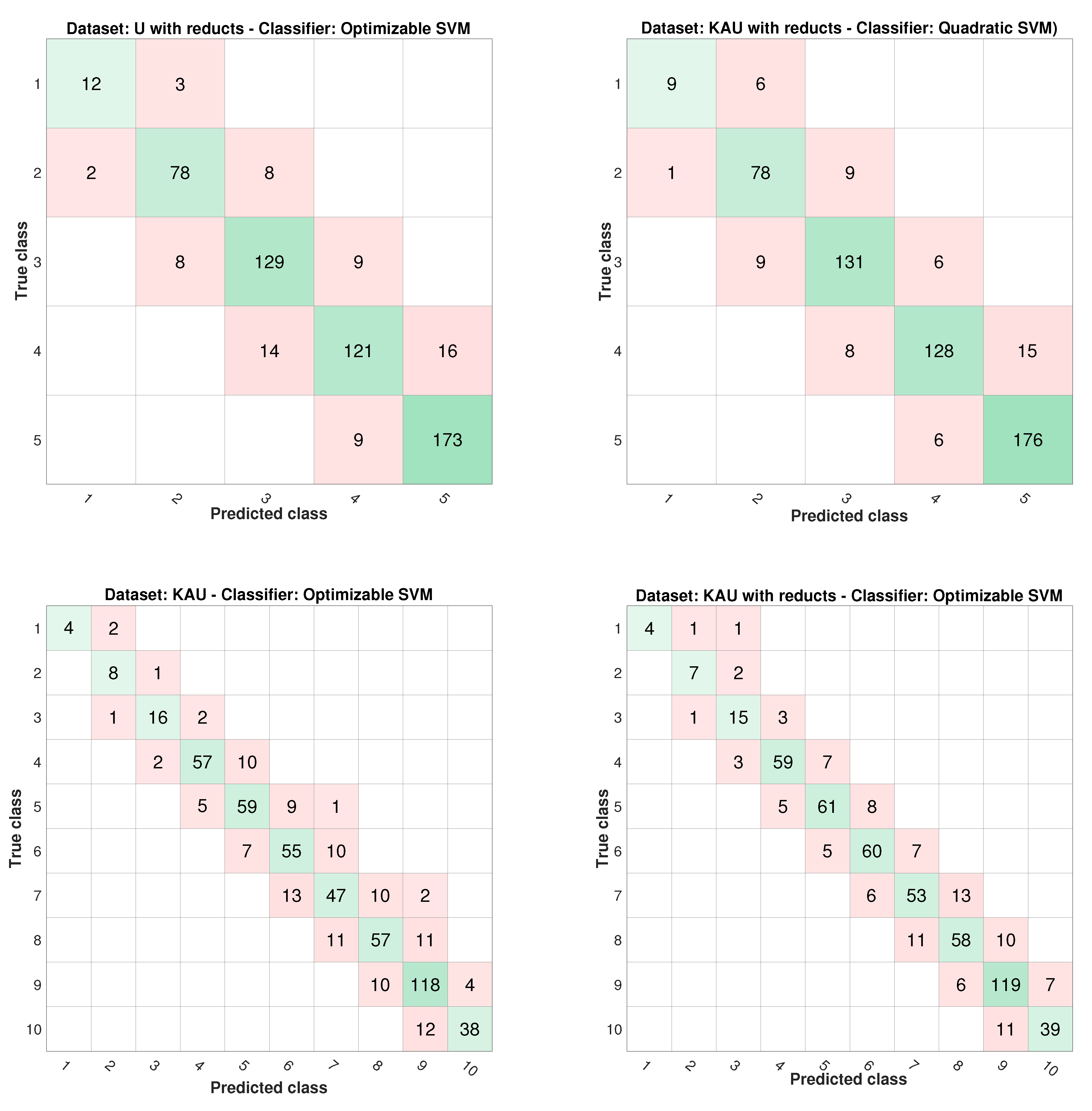
An experiment to evaluate the discrete energy class prediction with and without feature selection is designed. For compliance with typical classification frameworks, the GHI measurements are descretized into a finite number of levels. The range of the recorded GHI expands between 0 and 9000. Two discrete sets are generated. The first set is called 5-class, which comprises five levels of GHI values. Each level contains approximately 2000 values of GHI. Similarly, the other set, 10-class, contains ten different classes representing ten discrete GHI levels of approximately 1000 for each one.
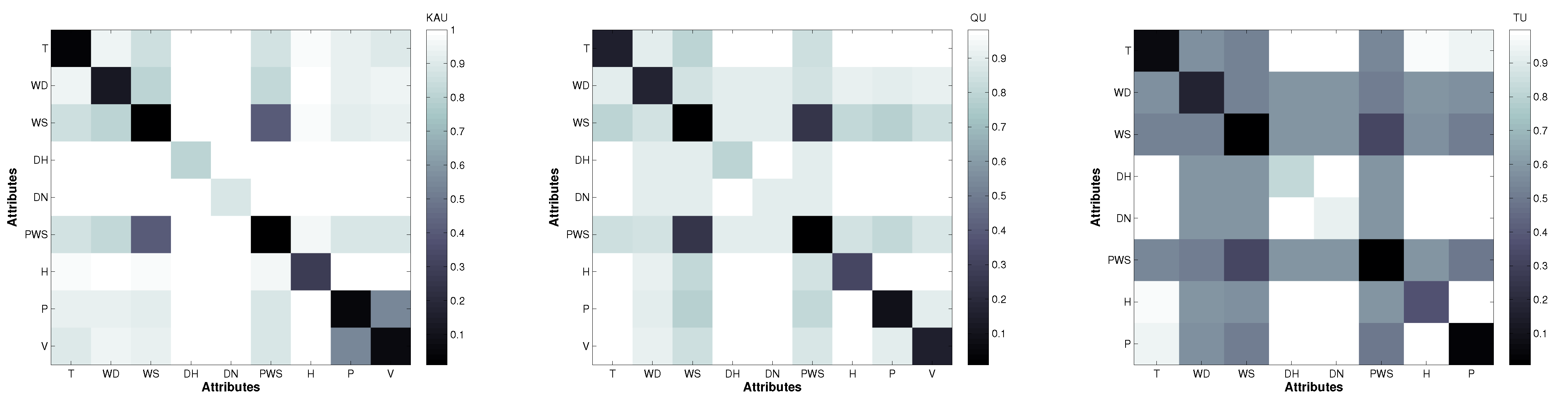
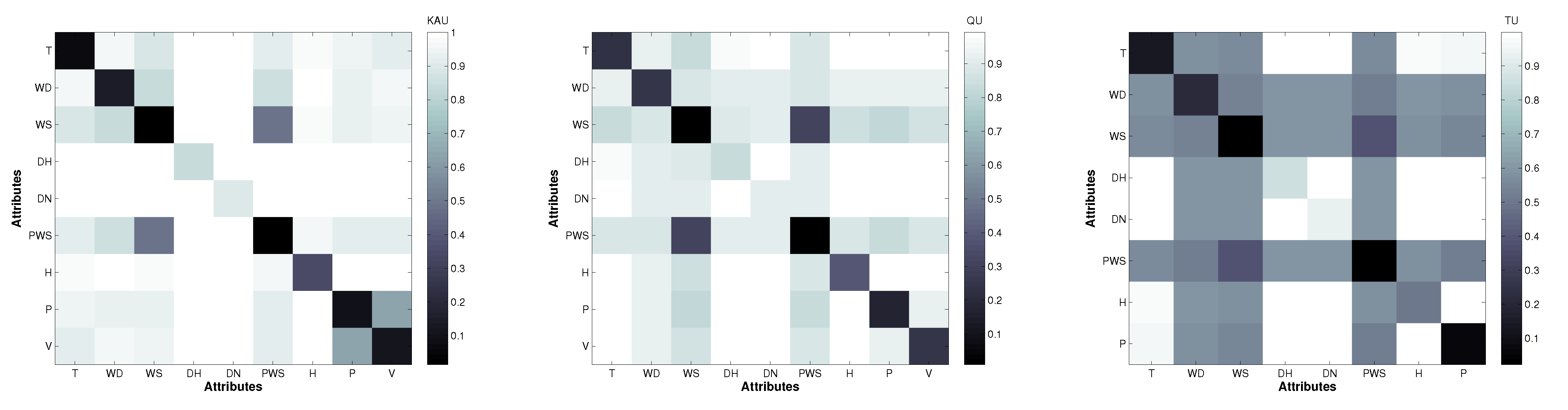
In order to measure the candidate reduction of the input feature space, three data sets, which were collected at distant stations distributed around Saudi Arabia, are used. As shown in
Table 2, the locations of these stations exhibit diverse climatic conditions. The diversity of these cities in terms of locations and topographies has supported the choice of these cities for our experimentation. Furthermore, the research nature of the installed stations in these cities makes it easy to obtain the necessary solar data. King Abdullah City for Atomic and Renewable Energy (KACARE) has installed and monitors these stations under the Renewable Resource Monitoring and Mapping (RRMM) Program [
53,
54]. The main weather measurement that is used for evaluation is the GHI. The data sets are collected for three Saudi cities on a daily basis from mid-2013 to the end of 2014. Comprehensive evaluation is performed using these data sets. However, because of technical issues with some of these recently-installed KACARE stations, two important readings are missing during this period: visibility and sky cover parameters. This is apart from the obvious uncertainty associated with all other measurements. Therefore, to overcome this issue, another source to obtain the visibility variable data—the Presidency of Meteorology and Environment stations is used. As depicted in
Table 1, only two cities out of the used three have the visibility parameter recorded.
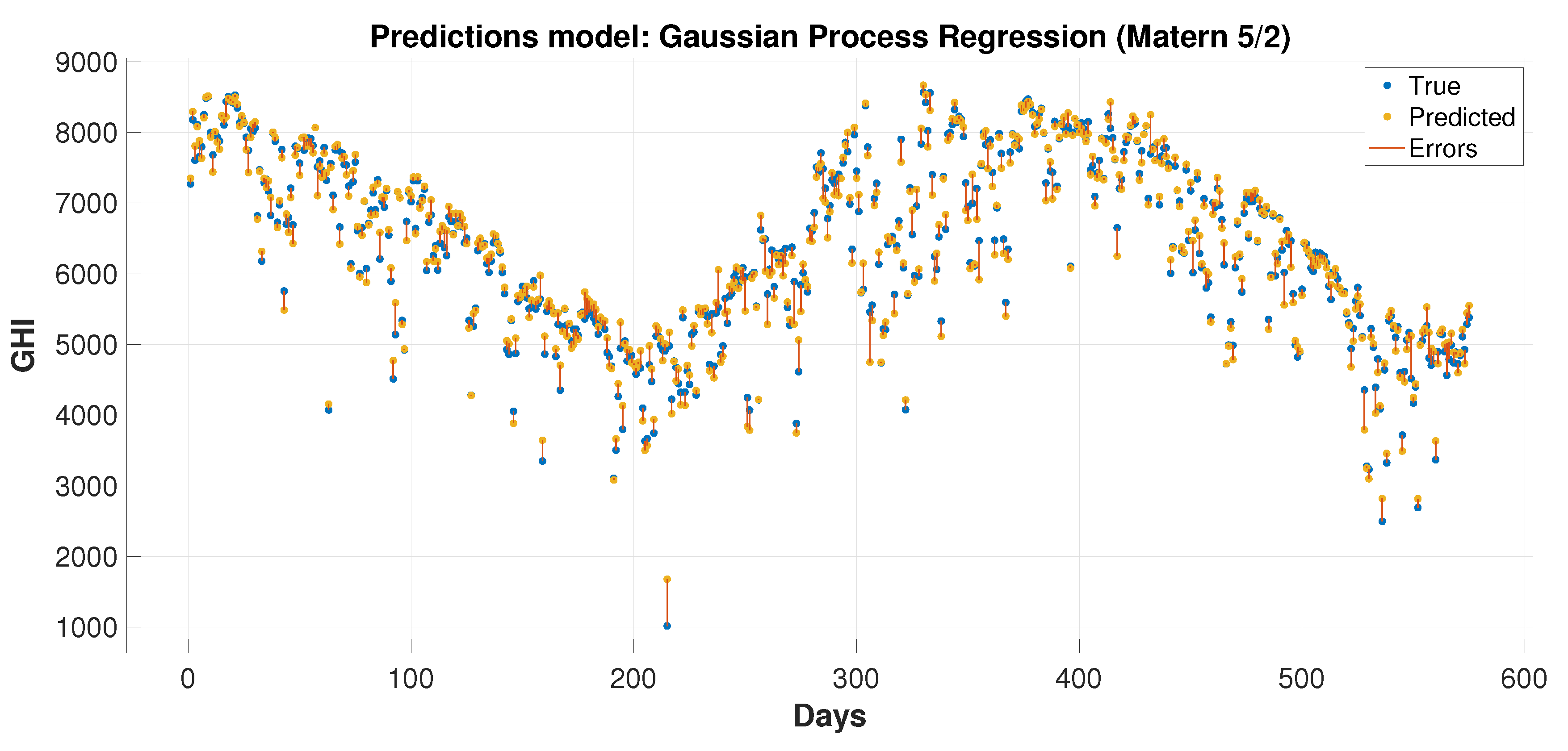
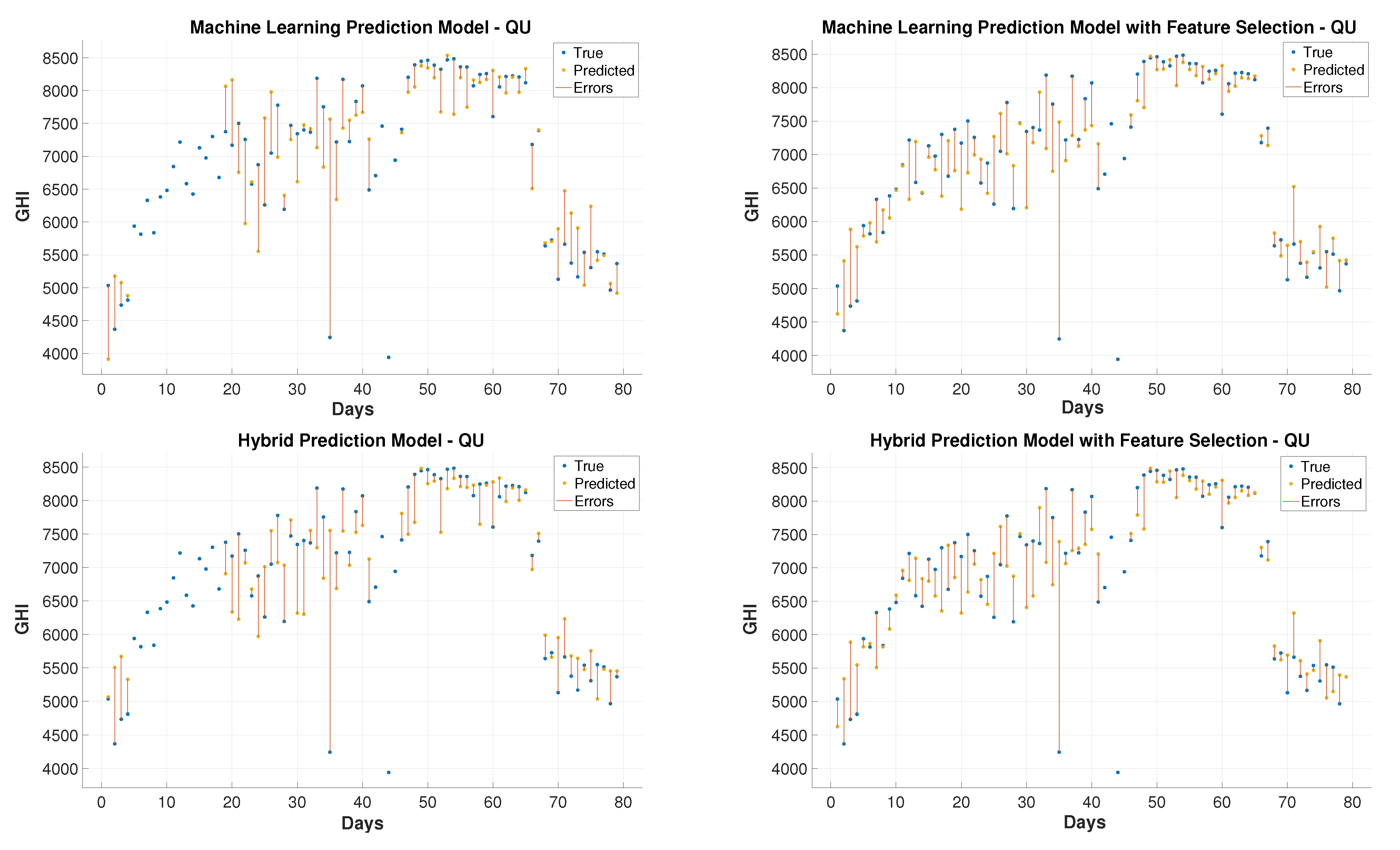
In order to evaluate the GHI prediction performance of the proposed hybrid learning model, which is used for regression in this case, other data sets were selected to cover four different levels of challenge: clear, cloudy, dusty, and dusty-cloudy [
8].
Table 3 [
8] presents the challenging cases, including 41 dust storms. The solar attributes are collected on those dates and the following days thereby leading to the creation of data sets with 81 records at three stations KAU, QU, and TU. If one day after the storm is recorded in addition to the storm days, it should add up to 82 days rather than 81. There is one day missing because one of the storms lasted for two consecutive days. The prediction performance is done by feeding measurements of preceding days to the regression process in order to predict GHI in these specific 81 days.
These 41 cases reveal a clear seasonality changes in the observed frequency of dust storms during 2014. The highest frequency of events are during the spring and summer (March–August), whereas the lowest number of dust storms events took place in the autumn and winter (September–November). More details are found in [
55].
The simulations of the severe dust storm events over Saudi Arabia are performed using the WRF with the dynamic core of the Advanced Research WRF (ARW). The WRF model provides two-day hourly forecasting for surface solar irradiance for specific cases in 2014. The atmospheric dust aerosol is indirect data that is highly correlated with the solar radiation at the surface. Specifically, an increase in atmospheric aerosol dust will immediately turn into solar irradiance reduction on the surface. Consequently, improving the aerosol forecasting leads to more accurate prediction of surface solar radiation.
For the solar irradiance prediction process, the forceasting data of the National Centers for Environmental Prediction (NCEP), which follows the Global Forecast System (GFS) model [
56], is used. As a preprocessing step, these GFS forecasts are downscaled both spatially and temporally. Four daily samples of NCEP GFS are given at 0 UTC, 6 UTC, 12 UTC, and 18 UTC. The temporal and spatial resolutions are three hours and
, respectively. The forecast accuracy evaluation is performed by comparing the GHI forecasts of WRF with the obtained ground measurements. Land cover and elevation and land cover data were obtained from the digital terrain model of the United States Geological Survey [
57].
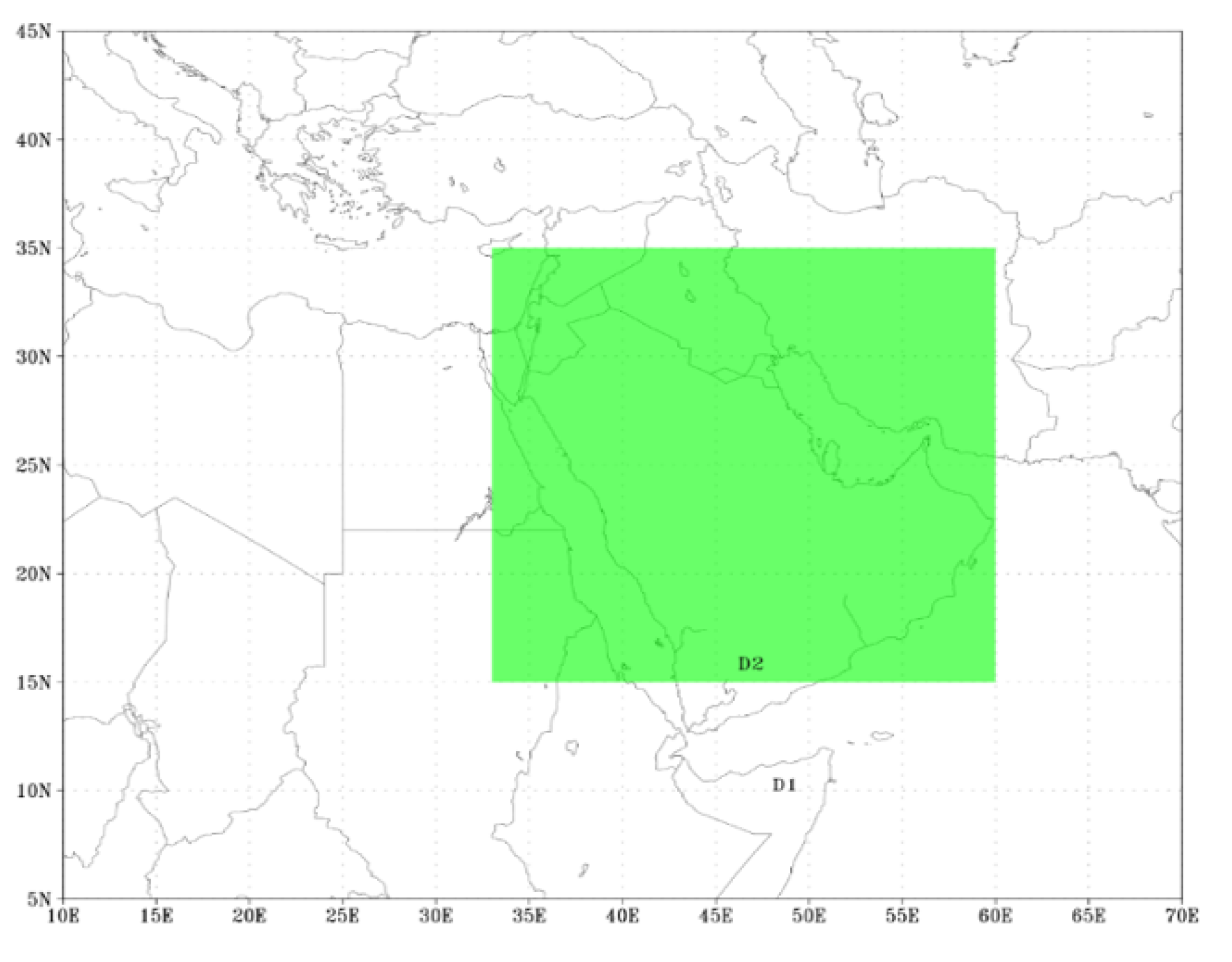
In order to represent different weather conditions, simulations of the aforementioned cases were obtained using non-hydrostatic WRF-ARW mesoscale model (version 3.7.1). These simulations were based on the NCEP GFS. Two nested domains are included in the model configuration, as depicted in
Figure 5. Unevenly spaced vertical levels are used with 27 km and 9 km of grid spacing for the coarser grid of domain 1 and for domains 2 and 45, respectively. In the evaluation procedure, estimates corresponding to domain two grid points that enclose the experimental radiometric stations are used. Two-day with one-hour resolution forecasting simulations were performed on a daily basis. The starting point was ate midnight UTC. The two-way nesting option between domains 1 and 2 was selected to allow the grids to interact in both directions.
In this work, the used a scheme known as Grell convective scheme, which represents an advanced version of the Grell-Devenyi ensemble convection scheme [
58]. The rapid radiative transfer scheme (RRTM) is selected to control parameterization for long-wave radiation [
59]. The RRTM scheme represents the influences of the detailed absorption spectrum, accounting for carbon dioxide, ozone, and water vapor as well as a scheme for short-wave radiation [
60] and PBL scheme [
61] of Yonsei University (YSU).
Specific days of the year, with distinct sky conditions, are selected to analyze the performance of the WRF model. The main objective of such selection is to evaluate the model’s forecasting accuracy under different meteorological conditions. Therefore, the condition of the sky is the main basis of the analysis. In particular, four different daily scenarios are considered: clear sky, cloudy, dusty, and dusty-cloudy. From an operational perspective, it is more practical to forecast on a day-ahead mean basis than an hour-ahead basis.
5. Conclusions
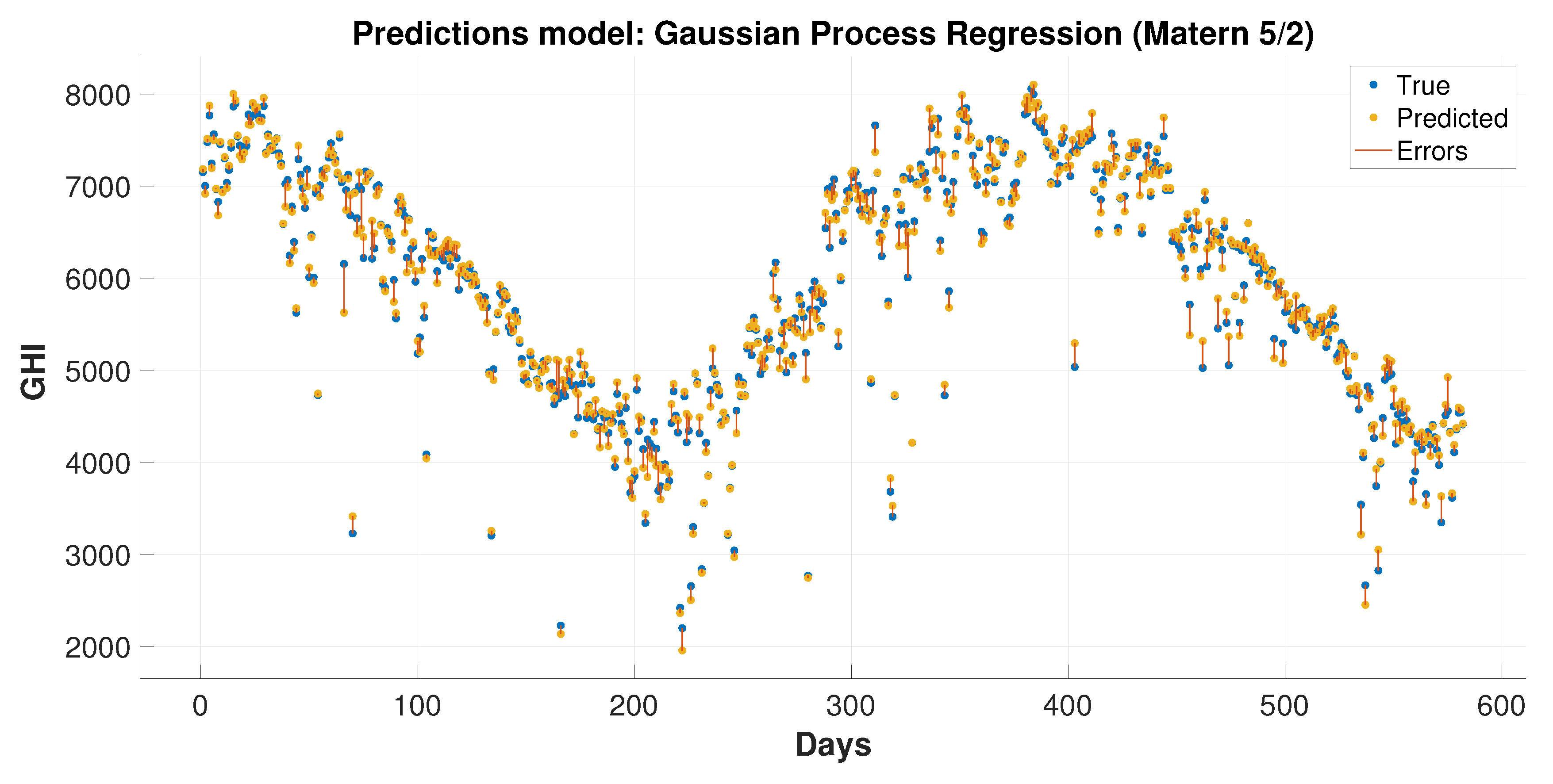
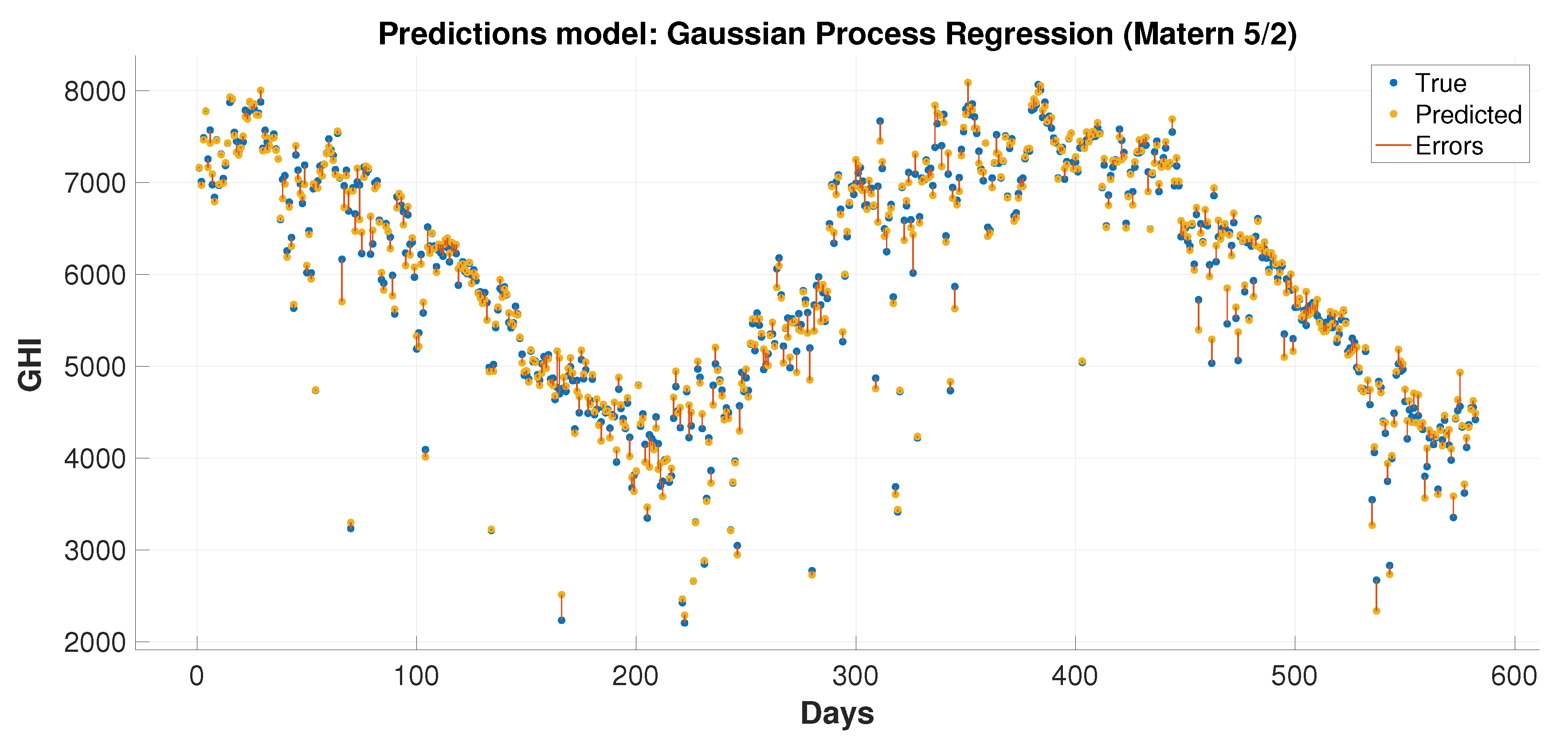
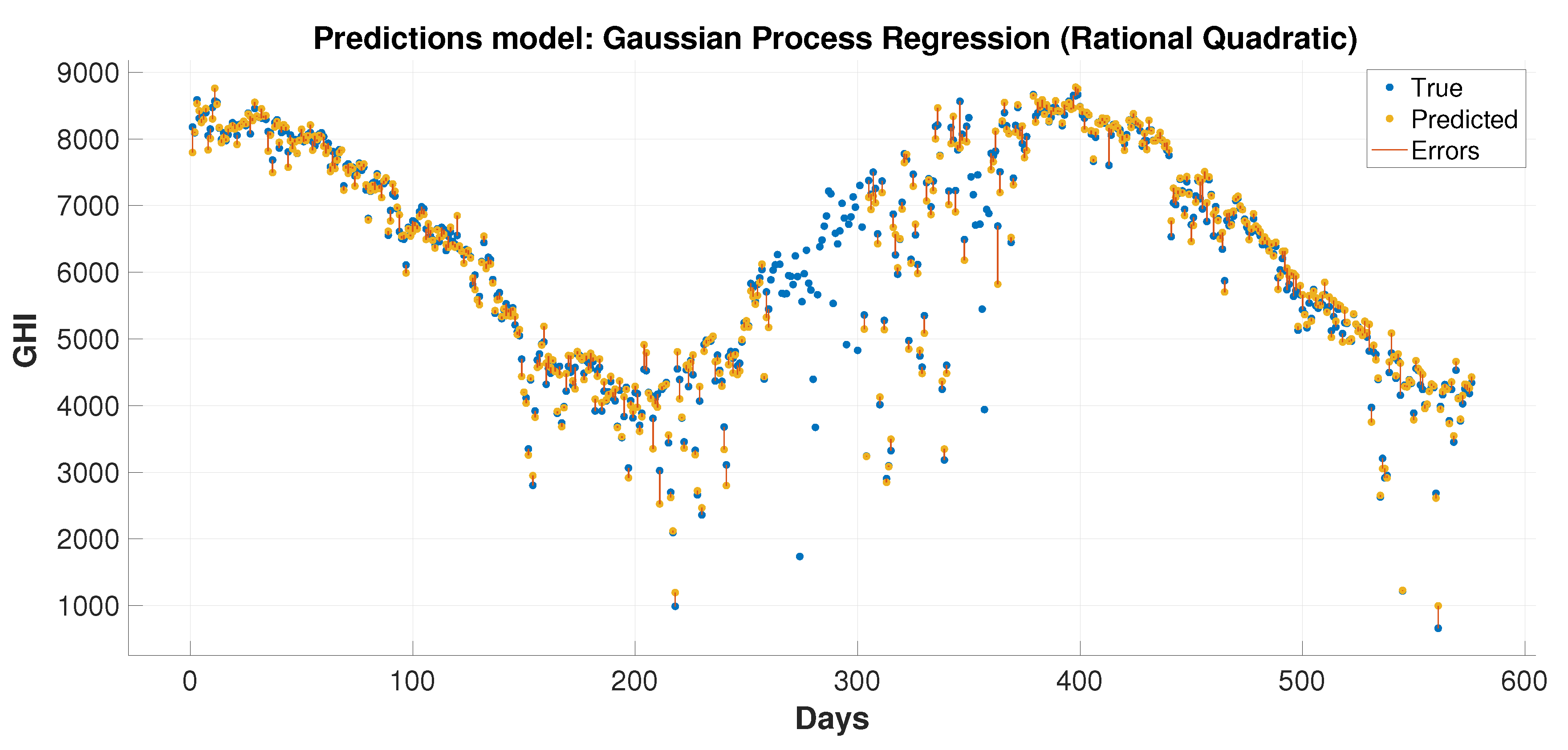
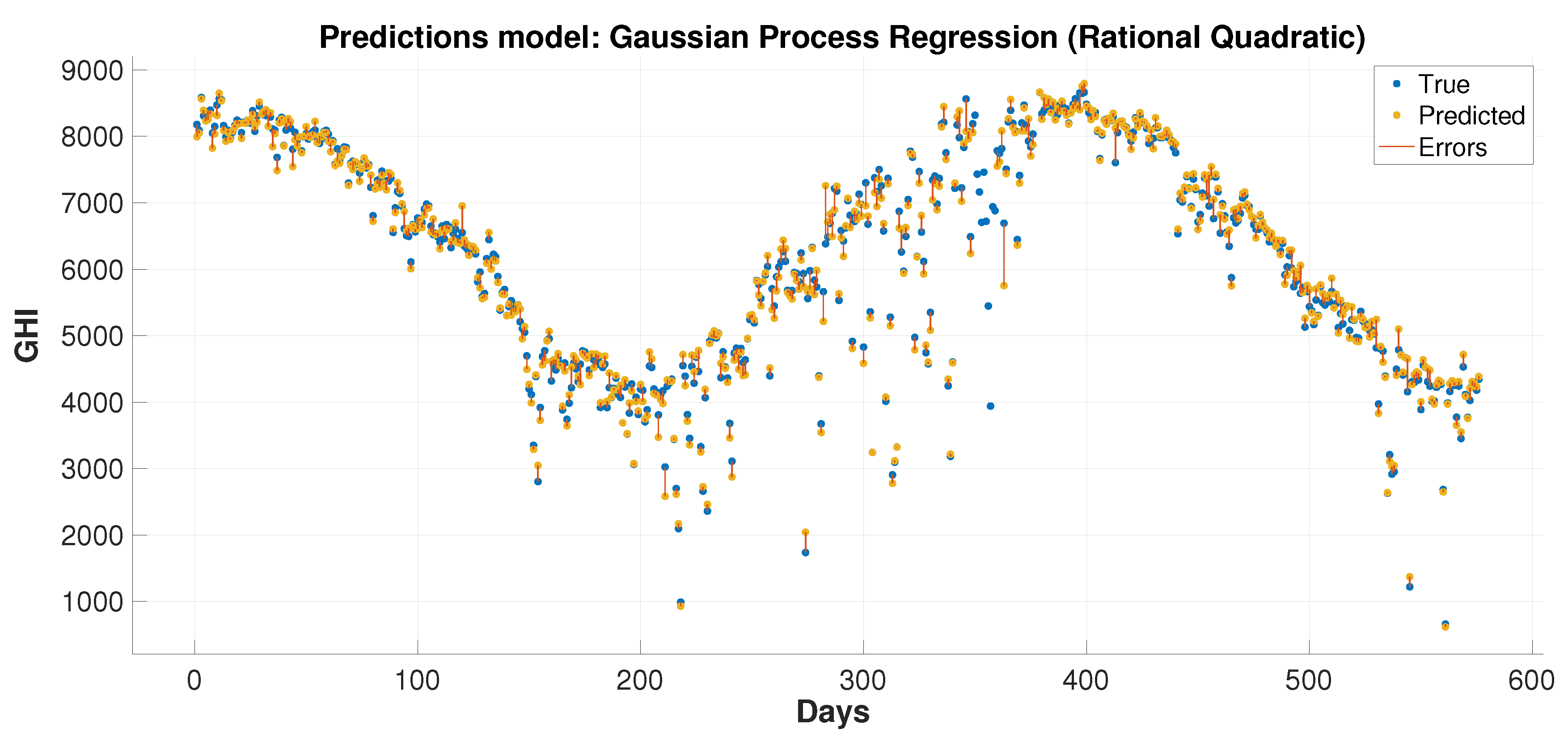
This paper presents hybrid machine learning approaches for solar radiation estimation by utilizing numerical methods. The numerical models, particularly the WRF models, are widely used in forecasting weather data. One of the main achievements of this paper is to show the extent to which the use of machine learning models can improve predictions for numerical methods. This has been achieved by building hybrid models through several layers of methodology design. First, a feature selection and dimensionality reduction approach was proposed for parameters associated with solar radiation estimation. The proposed attribute reduction is based on using an adaptive memory programming approach to optimize the input feature space of a solar radiation model. Then, different classification models are used to predict the solar radiation classes. The proposed methodologies are evaluated using a real environmental temporal dataset collected from diverse regions in Saudi Arabia. The feature selection has played an important role in increasing the class prediction rates. The class prediction rates increased, after using feature selection, by values up to depending on the used classifier and the considered test region. Finally, the WRF data were used in the proposed regression models to obtain improved prediction results that are generally better than the predictions of pure machine learning and WRF models. The prediction improvements of the average root mean square error reached up to and in the mean absolute error values up to . The obtained results proved the effectiveness of the proposed hybrid model in improving the prediction of the GHI values. The hybrid models could reduce the root mean square errors by 70.2% and 4.3% than the numerical and machine learning models, respectively, when these models are applied to some dataset. For some reduced feature dataset, the hybrid models could decrease the root mean square errors by 47.3% and 14.4% than the numerical and machine learning models, respectively. For discrete classes, attribute reduction, which combines few low-dependency degree single-reduct attributes with other attributes, results in very good quality solutions. On the other side, attribute reduction did not contribute much to performance improvement. when discretization is used with the input data classes.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}