1. Introduction
Over the past 20 years, the world’s growing energy demand has led to a growing interest in energy efficiency in the residential, services, and public building sectors. The energy consumption of buildings (ECB) is a big challenge in most European countries since buildings consume a large amount of energy, especially sustainability buildings in energy sectors (e.g., public buildings) [
1]. In Europe, in 2019, the transport sector accounted for 37% of total final energy consumption in the EU Member States, followed by the households (32%), industry (42%), and services (23%) sectors. Additionally, over the past years, the efficiency of appliances and equipment has increased substantially [
2]. Therefore, European countries, notably Portugal, strive to enhance the energy efficiency in buildings while maintaining sufficient levels of thermal comfort and energy consumption, aiming at sustaining their economic and social levels [
3]. The energy sector seeks to control energy consumption in general by analyzing available data sources and by studying different dimensions taken from analyzing data sources, such as natural gas and electricity usage data, residential building characteristics and the energy performance of building data, cooling, and heating systems data, or climate and weather forecast data, just to name a few [
4]. Public authorities also seek to guide citizen behavior to more efficient uses of energy, adopting structured approaches based on scientific grounds through legal measures, economic subsidies, or best practice dissemination initiatives [
5].
Energy consumption in the building stock of different sectors, namely, residential, public services, or industrial, is a relevant research topic, as mentioned. The literature has relied on traditional statistical methods to classify and predict energy consumption, which has led to inaccurate results. The lack of control over energy consumption in many different building sectors has led to significant monetary losses for many countries. Energy stakeholders worldwide seek to find different solutions to reduce energy consumption and improve its efficiency by influencing building occupants’ behavior in those various sectors [
6]. Such stakeholders are also looking to find intelligent computing solutions for classifying and forecasting energy consumption with a reasonable degree of accuracy, taking into account the critical factors that affect such consumption.
Notably, in Portugal, the energy sector is particularly interested in finding the fundamental factors that affect the ECB, being residential or service buildings, given that there is a noticeable increase in residential energy intensity in the last three years [
5,
6].
Current research in the field is actively struggling to find intelligent models capable of classifying energy consumption levels (e.g., low, medium, high levels) [
7], based on actual factors that affect energy consumption in residential or service buildings. Such models are also able to predict energy consumption in future periods [
8]. Such intelligent models could help stakeholders in the energy sector (decision makers, citizens in general) to (1) determine the actual factors that affect energy consumption [
9]; (2) classify and predict energy consumption in residential or service buildings [
10], (3) improve energy efficiency in such buildings [
11]; (4) influence positively building occupant behavior in the same context [
12], and (5) change energy suppliers in an informed way [
13].
In the literature, we can find several systematic surveys published on this topic, presenting relevant research. Our literature analysis detected 11 such review manuscripts published between 2019 and 2021. Runge & Bourdeau presented manuscripts on using machine learning to predict buildings’ energy consumption [
14,
15]. Qolomany and Djenouri showed how smart buildings deal with machine learning methods and big data [
16,
17]. Vázquez-Canteli and Mason presented a new approach to improve building control by using machine learning techniques and reinforcement learning [
18,
19]. Guyot presented a model to improve energy applications in the different building sectors by using artificial neural networks [
20]. Amasyali and Mosavi showed how machine learning techniques can be applied for predicting energy consumption in various buildings [
21,
22]. Perera presented review studies in energy system applications by using reinforcement learning [
23]. However, those review studies only concentrated on a single specific factor that influences the energy consumption of buildings (e.g., building control, electricity, and natural gas), or on a specific application (e.g., occupant behavior, load forecasting), or were restricted to the use of a specific intelligent computing technique (e.g., artificial neural networks and reinforcement learning), to classify and predict the energy consumption of buildings. There are also many recent studies [
24,
25,
26,
27,
28] that provide novel intelligent methods and can help stakeholders in the field of energy to improve energy efficiency. Most of these literature studies lack the identification of critical factors that affect the ECB. In addition, several studies rely on finding methods used in classifying and predicting energy consumption, by means of traditional statistical or manual methods.
To address these gaps, our study used a text-mining tool to find common terms to cover the largest possible number of factors that influence the ECB to address these gaps. In addition, the tool automatically and accurately found the most adopted intelligent methods. Moreover, bibliometric analysis was used to find the relationships between factors and applications related to the energy consumption of buildings and intelligent computing techniques.
This paper provides a systematic literature review on the topic of intelligent computing methods applied to the ECB. The paper adopts the PRISMA methodology [
29], a simple text mining approach, and a bibliometric map analysis (with Vosviewer) [
30]. This last method was used to provide an initial identification of the most used terms in the energy and intelligent computing domains, which helped the subsequent step of the manuscript analysis. The paper surveys machine learning and other methods appropriate for clustering and classification of ECB (e.g., low, medium, and high consumption). Additionally, it reviews intelligent computing methods for predicting such energy consumption. Moreover, it analyzes various literature contributions, combining more than one method, to achieve such goals. Finally, it analyzes and discusses the most promising intelligent computing models for the classification and prediction of ECB. In addition, this paper helps researchers to identify fertile areas for further research work in the area.
The main objectives of this paper are to identify the critical factors that influence the energy consumption of buildings, identify the most used intelligence computing techniques, predict, and classify energy consumption in those buildings and finally, identify the performance metrics that have been adopted in the literature in such cases.
As mentioned, our study aims to provide a state-of-the-art review of current research efforts in classifying and forecasting the energy consumption of buildings. We start by introducing the reader to specific topics concerning our research objectives and employed methods. Particularly, our survey addresses the following research questions, aiming to identify the adoption techniques that have been applied in the overall domain of energy consumption of buildings:
RQ1: What kinds of metrics, data sources, and critical factors, have been adopted in prior studies of profiling the ECB?
RQ2: Which machine learning techniques provide the best performance in clustering and classification of ECB?
RQ3: Which machine learning techniques provide the best performance in predicting the ECB?
RQ4: Which machine learning techniques provide the best performance in both classification and prediction of ECB?
RQ5: What performance metrics have been adopted in the literature in the classification or prediction of ECB?
The paper is organized as follows.
Section 2 presents our adopted methodologies, including the systematic literature strategy with inclusion and exclusion criteria for manuscripts, the text mining method, and the research questions. In
Section 3, we present, analyze, and discuss our results, encompassing the detailed analysis of text mining procedures, bibliometric map analysis with Vosviewer, and the analysis of representative manuscripts per topic.
Section 4 presents our study limitations. Finally, in
Section 5, we discuss the results, identify several research gaps, draw conclusions, and suggest lines for further work.
2. Methods
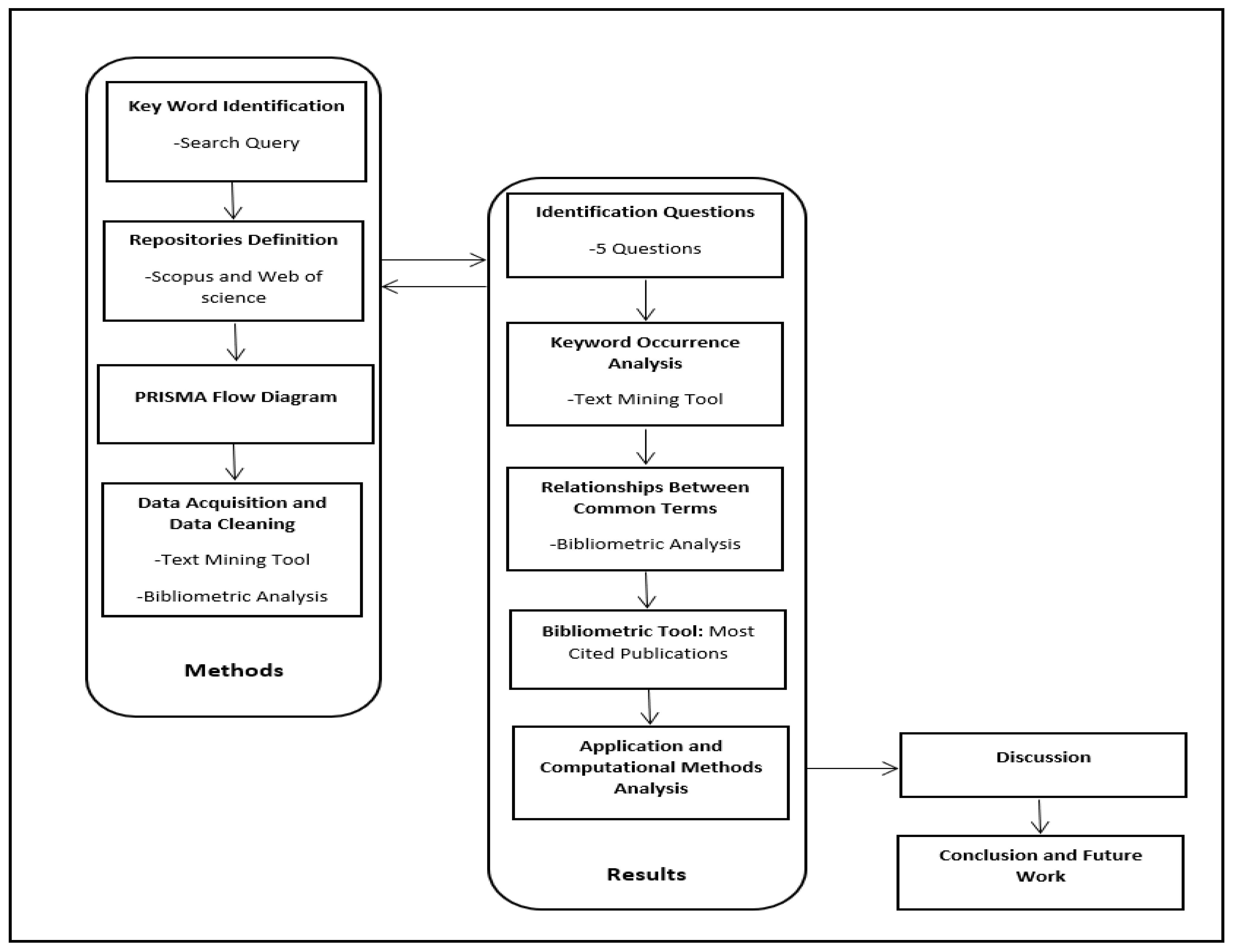
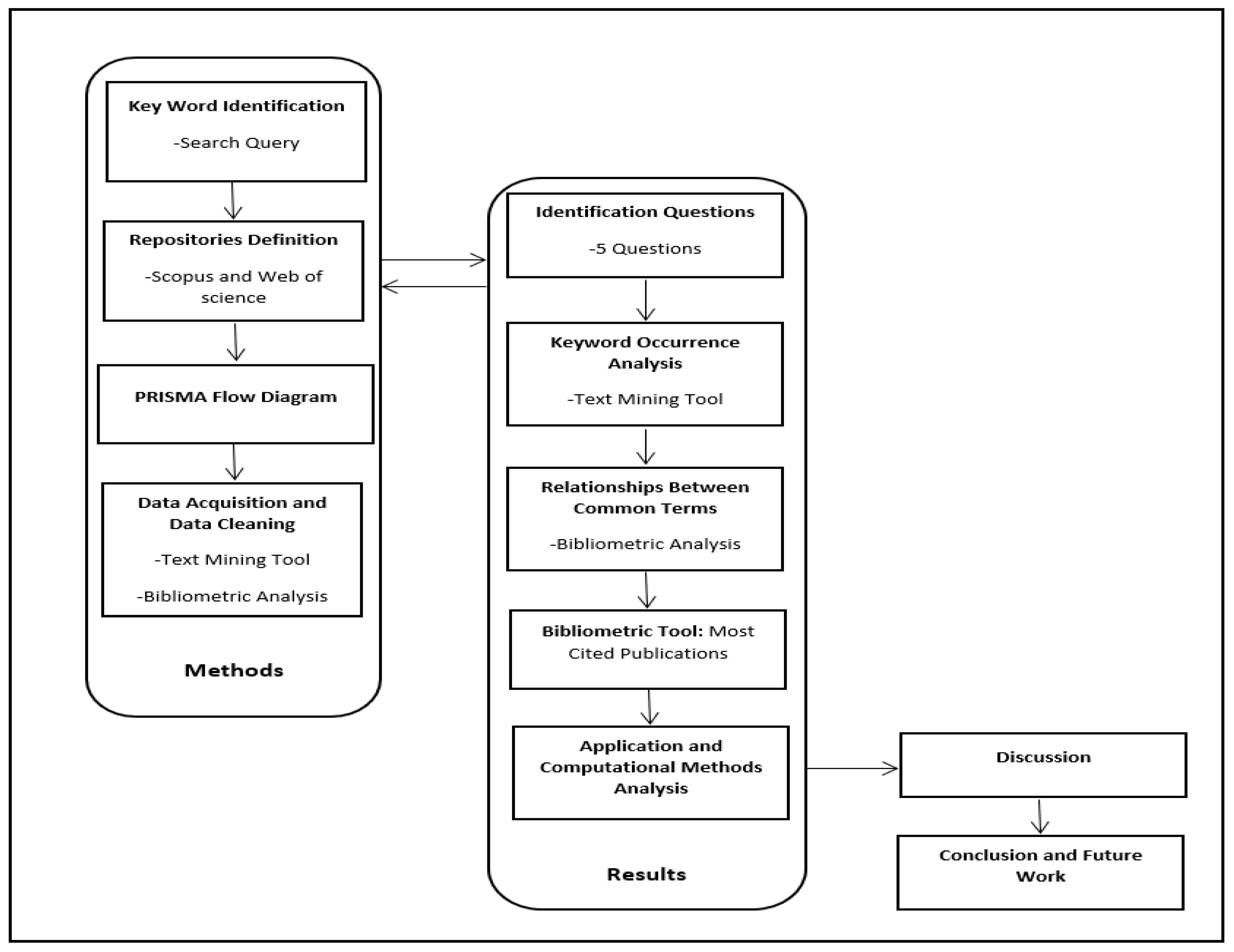
The methodology of this literature survey is divided into two main parts: in the first part, we present a standard method to find and select published manuscripts. In the second part, we describe our survey results through the text mining and bibliometric analysis, as shown in
Figure 1.
Our systematic literature survey presents an evaluation of the scientific community contributions to the topic of energy consumption of buildings by using a rigorous and auditable methodology based on the PRISMA approach.
The PRISMA method is composed of five phases, as follows:
Identification of relevant manuscripts of the domain or domains.
Screening of titles, abstracts, papers, excluding papers without experimental evidence and position papers.
Eligibility analysis.
Full text screening.
Final papers to be analyzed in detail.
We also adopted a text mining method and bibliometric map analysis. The bibliometric map is used to find the relationships between common in energy and machine learning domains terms [
31], and text mining is used to find the more relevant terms about the energy and machine learning domains. To this end, we followed three phases, evaluating the following quantities:
By following PRISMA, this section is structured in the following way: (1) paper search strategy, (2) text mining approach and bibliometric map analysis, (3) inclusion and exclusion criteria, and (4) final paper selection.
2.1. Search Strategy
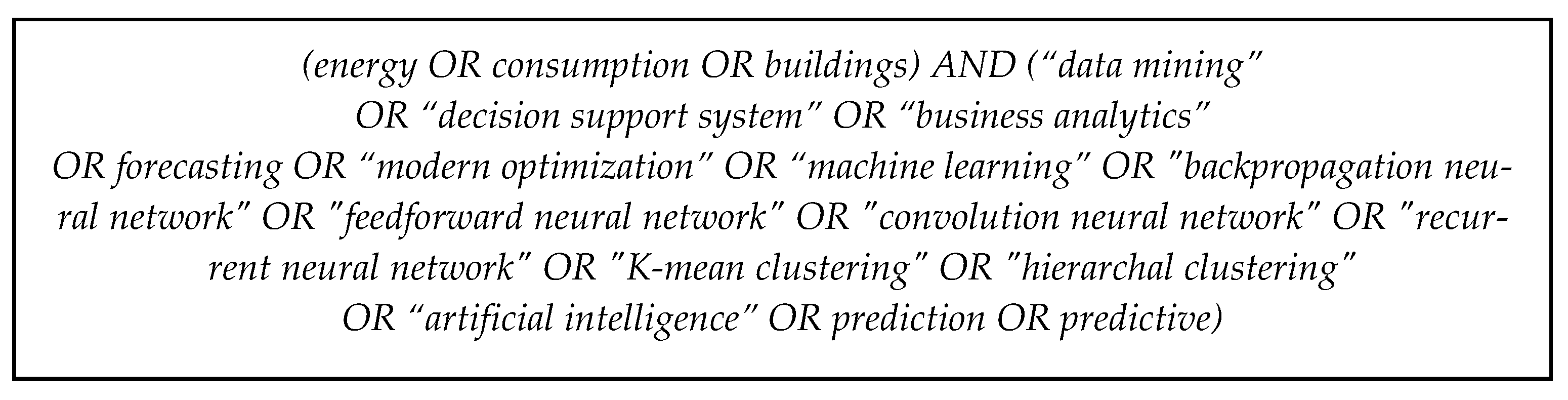
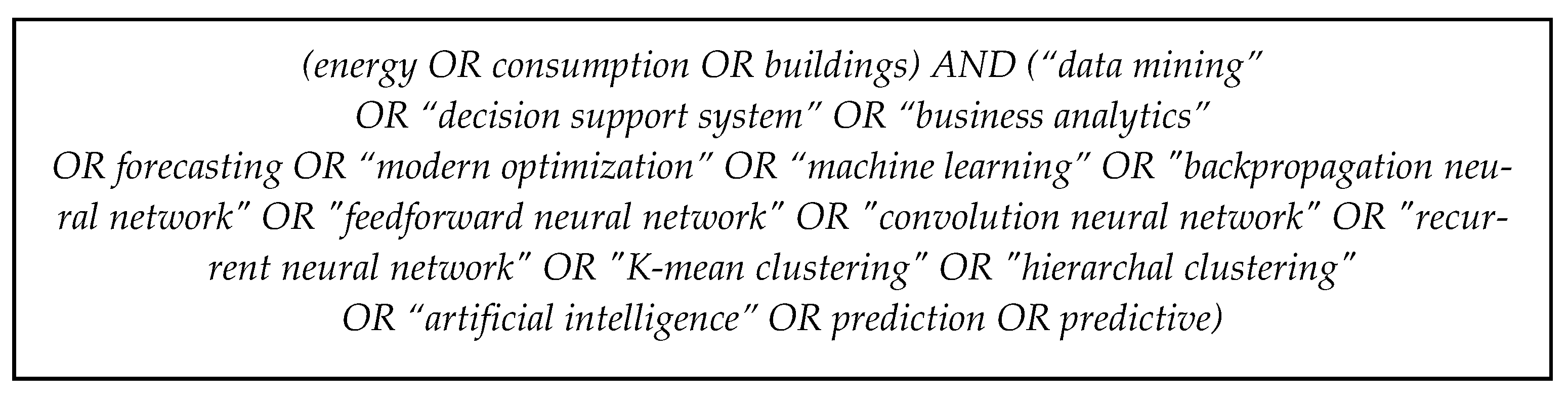
A literature survey generally recommends searching several available journal and conference paper repositories in order to determine if similar work has already been performed, aiding in locating potentially relevant studies. In this study, we searched the following electronic paper repositories: (1) IEEE Xplore, (2) Science Direct, (3) Springer, (4) Scopus, (5) Web of Science and reviewed the following types of manuscripts: technical reports, scientific conference papers, and scientific journal papers. The search query was created to match the search string only in the head of the manuscripts. We used alternative keywords, logically connected by ‘OR’ or ‘AND’ statements. The resulting search string utilized in the mentioned electronic repositories is depicted in
Figure 2.
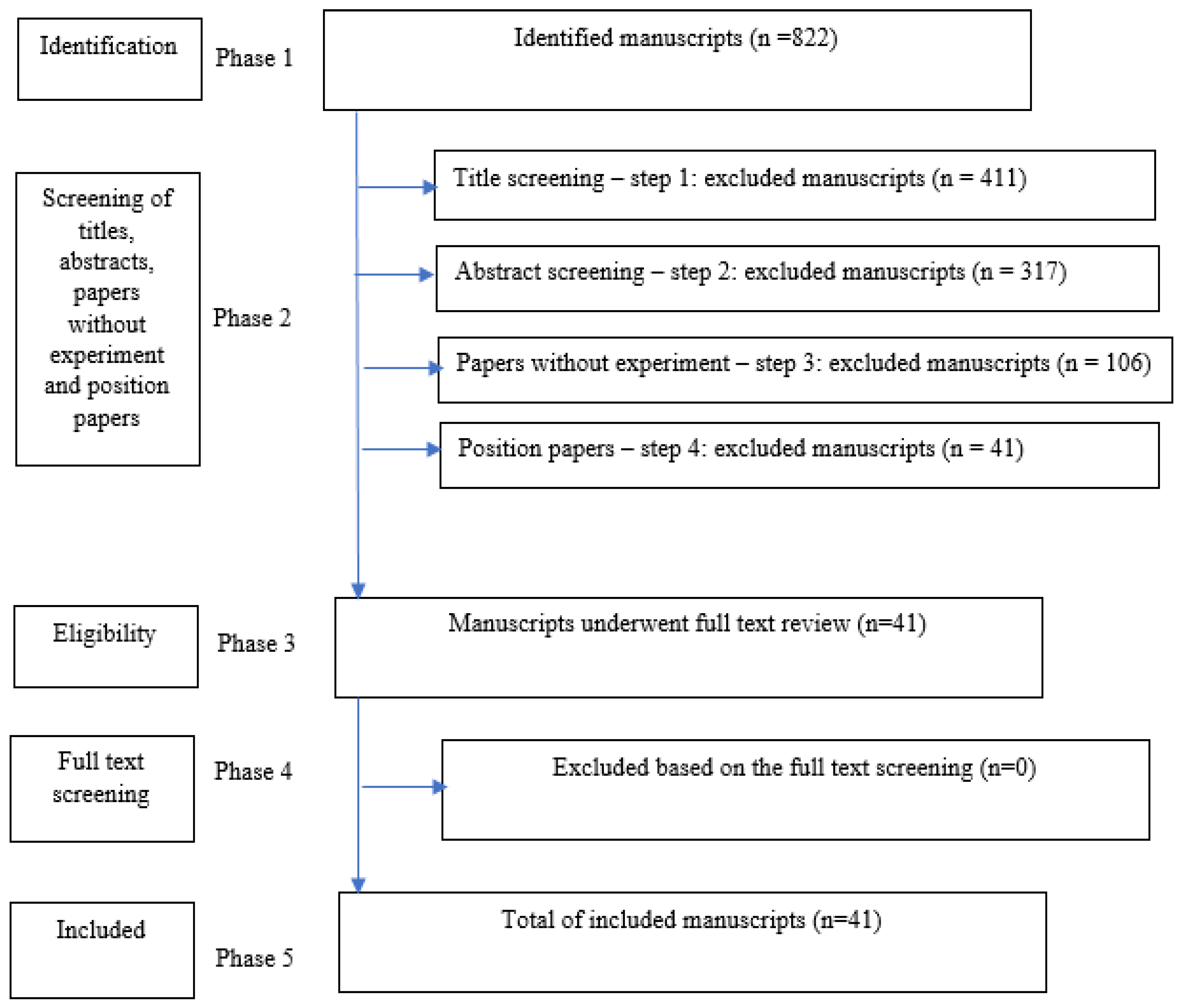
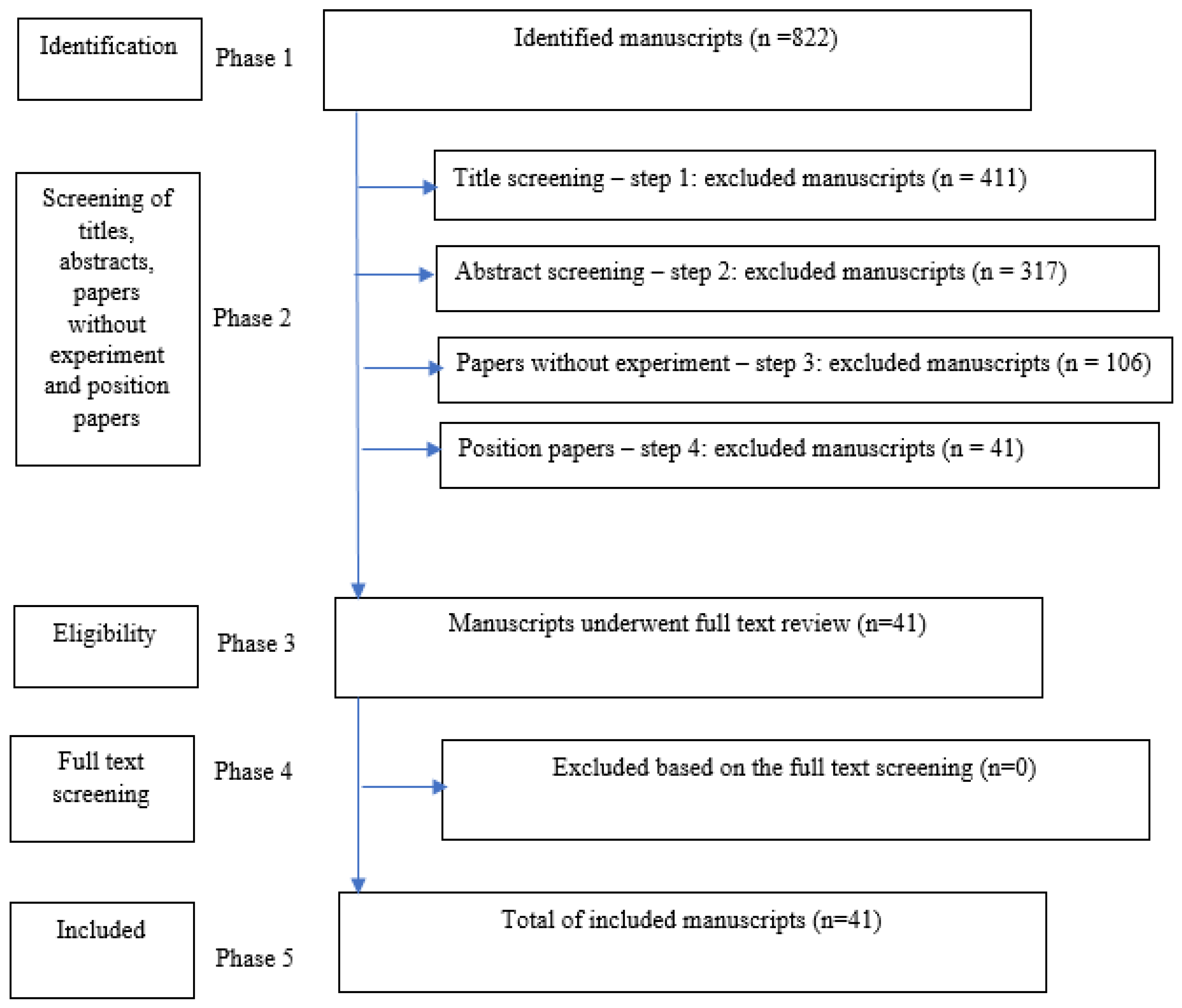
Figure 3 depicts the PRISMA flow chart, illustrating the 5 phases used when filtering the manuscript set. n is the resulting number of papers at the end of each Phase or Step.
In phase 1, we applied the search string to all electronic repositories looking for papers published between 2013 and 2019, which resulted in 822 publications. Phase 2 followed a 5-step approach. In step 1, we excluded manuscripts based on titles (e.g., energy consumption on industry buildings, transport, and services), which narrowed the set to 411 publications. In step 2, we excluded manuscripts based on abstracts screening, which resulted in 317 publications. In the following step 3, we excluded manuscripts reporting research without experiments, resulting in 106 publications. Subsequently, in step 4 of phase 2, we excluded position manuscripts which gave us the final figure of 41 publications. In phase 3, manuscripts underwent a full-text reading and review, which led to no exclusions (result of phase 4).
As a result of our paper selection approach, the final list included 41 manuscripts (phase 5), which are analyzed in detail in this paper. These were further divided into the following four categories, as shown in
Table 1,
Table 2,
Table 3 and
Table 4:
Energy consumption of buildings (S1–S10).
Classification of ECB (S11–S20).
Prediction of ECB (S21–S33).
Combination of classification and prediction of ECB (S34–S41).
2.2. Text Mining for the Literature
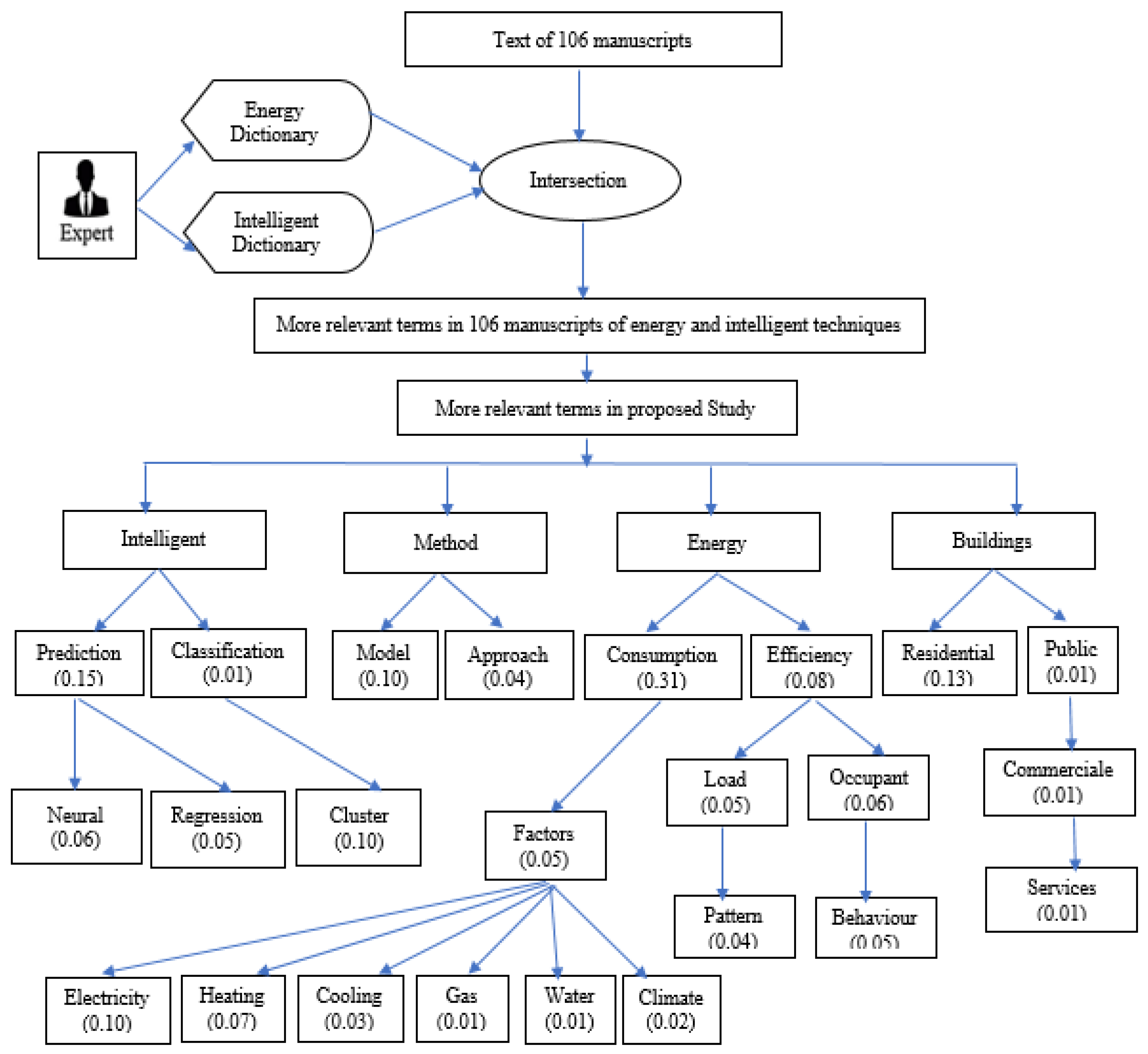
As mentioned, by adopting the PRISMA method, our paper analyzed 822 manuscripts published between 2013 and 2020. These manuscripts were filtered out to 106 studies based on title, abstract, and manuscripts without experiments. Since 106 manuscripts is a large number for a manual analysis, we describe in this section a text mining approach, aiming at discovering relevant terms in both intelligent computing models and energy consumption fields, that we performed in a stage prior to the full-text review of the retained 41 papers of this survey. Text mining was therefore adopted to allow the creation of structured information to improve the subsequent analysis of such manuscripts. To be effective, this type of technique requires the prior definition of a dictionary that includes not only common terms of the domain but also terms associated with concepts related to our research topic: intelligent computing models and the energy consumption of buildings. This approach is more comprehensive if we compare it with standard text mining techniques that randomly search, group, and count words. Thus, the authors created two dictionaries, one for “intelligent computing models” and another for “energy consumption of buildings,” each of them including a preliminary list of expressions consisting of one or more words.
It should be noted that all three authors are experienced in the topics of the paper, particularly computer science and machine learning (first, second, third authors) and energy (third author). The manuscripts were analyzed in terms of title, abstract, and keywords to verify the dictionaries. Given the large number of manuscripts available for our analysis, a reasonable number of randomly selected articles were chosen to validate the dictionary. Such dictionaries are shown in
Table 5 and
Table 6. It should be borne in mind that the terms “energy” and “intelligence” are not mentioned in the dictionaries since they are too broad. Terms like “industrial building” are also not included in our dictionaries whenever they represent a topic outside the scope of our research, like this example.
During our analysis, we understood that it could be possible that some dictionary terms might not be available in title + abstract + keywords of our surveyed manuscripts since many terms could be expressed several times throughout an article, and these might be more relevant than the ones mentioned only in the abstract. Thus, the entire text was considered for an analysis of the collected literature, especially in the areas of intelligent computing models and energy consumption of buildings. The reference section was removed of all manuscripts during the analysis.
The second part of our terminology analysis adopted a bibliometric map to find critical relationships between factors and intelligent computing methods. Such a bibliometric map helps stakeholders to find the most used factors and methods and their relationships.
For these, we computed a quantity, referred to as “The Important Terms”—TITs (of a given word) Elgendy and Wu [
70,
71] that represents the importance of each word in the corpus, of the form:
where: review = words in our studied corpus; £ = a common word, such as “consumption” or “cluster”.
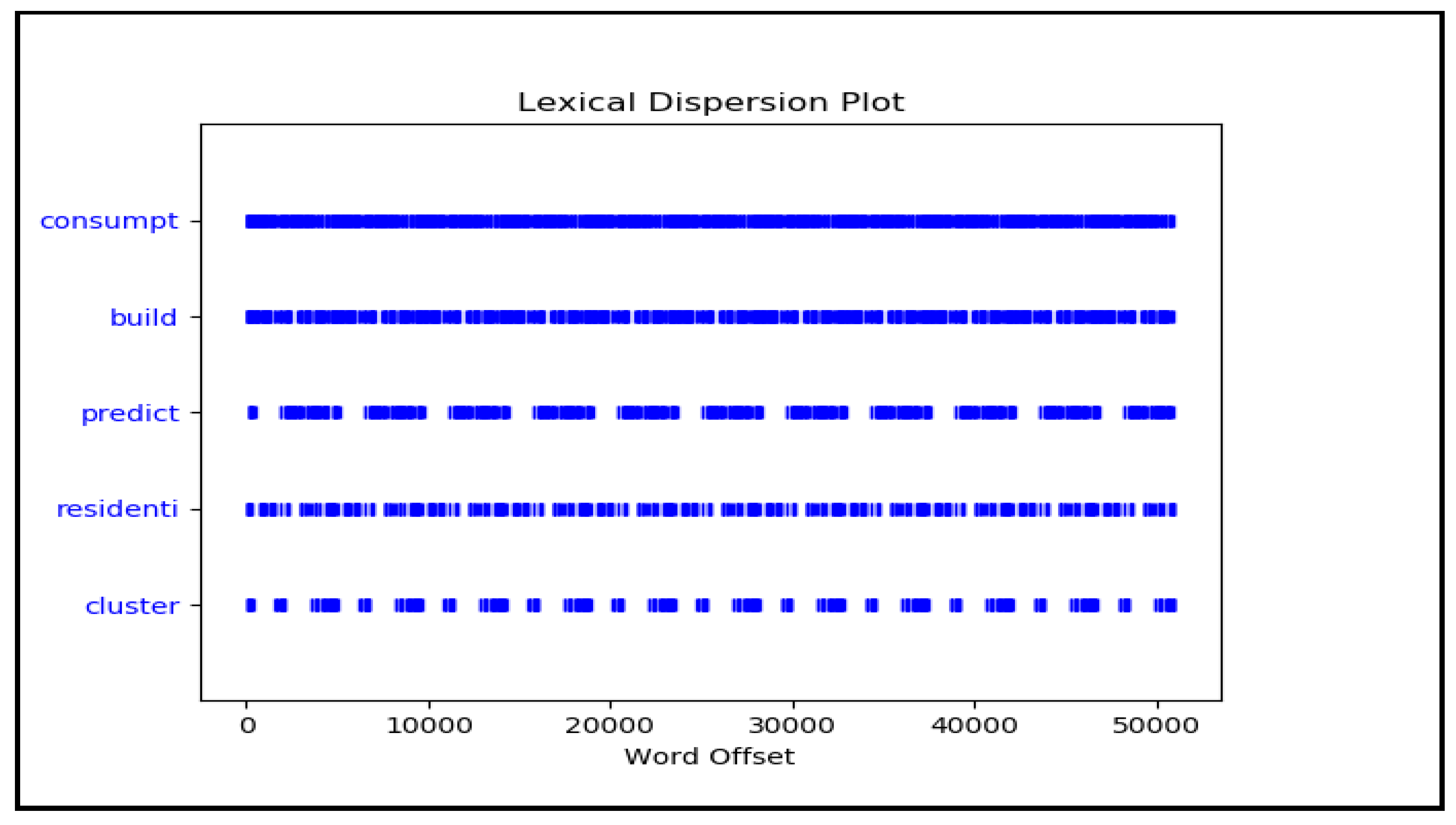
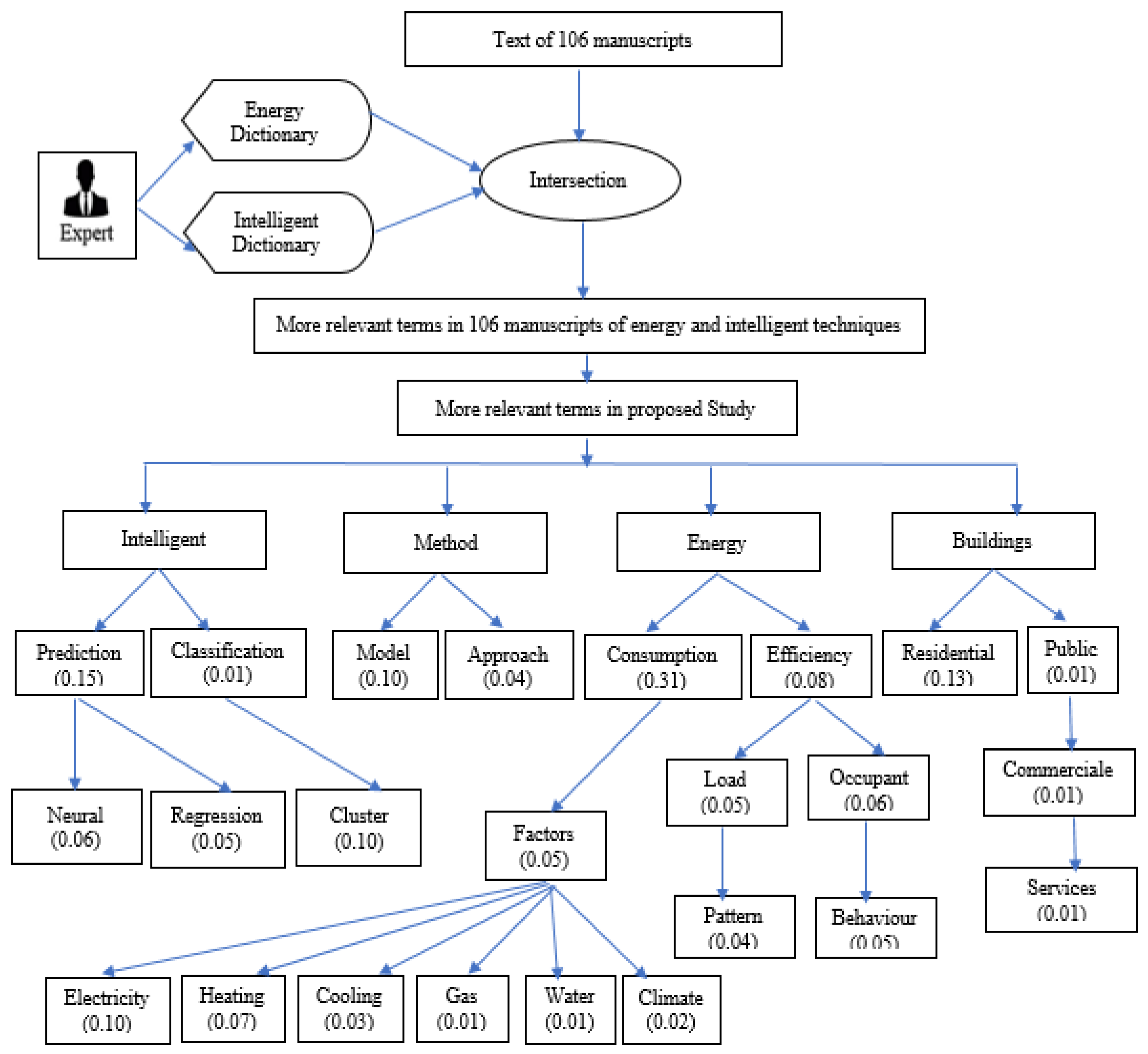
As an example, if we have review count (“consumption”) = 1881 words, and review = 6000 words, then TITs = 0.31. We assume that if (TITs) > 0.05, the word represents a highly relevant term in the corpus. We supposed 0.05 as a percentile to exclude less relevant values. This number is the nearest number to a high relevant term (consumption (0.31)). Thus, the terms “consumption (TITs = 0.31),” “residential (TITs = 0.13),” “prediction (TITs = 0.06),” and “cluster (TITs = 0.10)” represent the most relevant terms. By contrast, the terms “classification (TITs = 0.01),” “water (TITs = 0.01),” “commercial (TITs = 0.01),” and “services (TITs = 0.01),” represent those which are less relevant.
By looking at the results obtained from text mining, we can notice a close relationship between the most important terms found and all the manuscripts in our study. To ascertain this, we computed the following quantity PR (Paper Relationship) [
72,
73]:
where:
PCCT = number of papers that contain common terms;
MRW = all manuscripts in related work.
2.3. Inclusion and Exclusion Criteria
All the manuscripts analyzed in our paper were selected based on the following inclusion criteria and specific criteria excluded manuscripts from our analysis, as shown in
Table 7.
2.4. Study Selection and Data Extraction
Using the above inclusion and exclusion criteria, our paper repository search returned several papers that were analyzed and read in-depth. We especially focused our attention in finding a scientific research gap. To aid the process, we created a data extraction form, which enabled us to collect relevant information from the selected primary papers in order to address our proposed research questions.
4. Discussion
This section discusses two important topics: our research questions and some research gaps that we could identify.
4.1. Research Question Discussion
Our systematic review aimed to answer five basic questions targeting the application of intelligent techniques in the field of energy consumption in different building sectors.
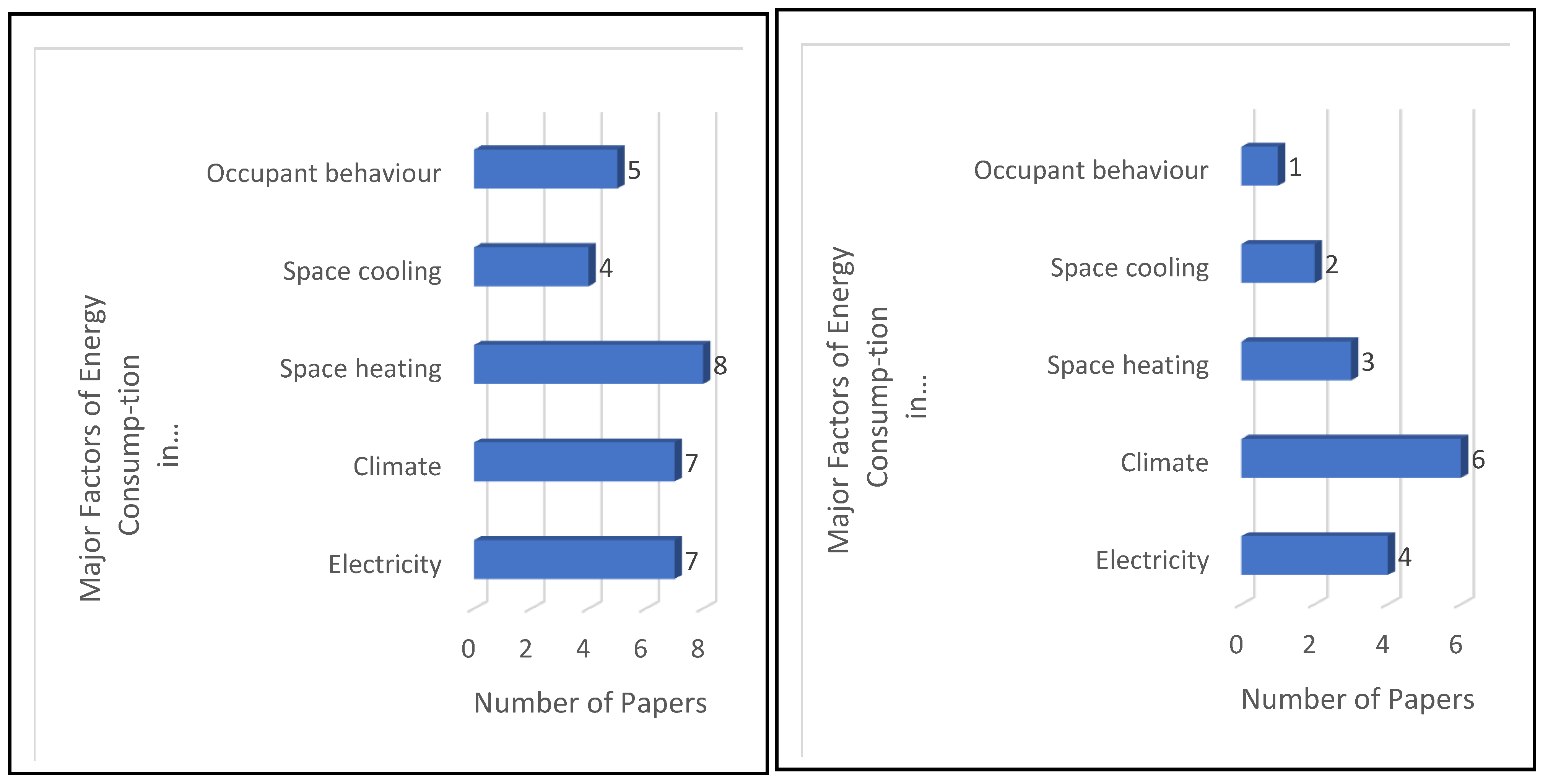
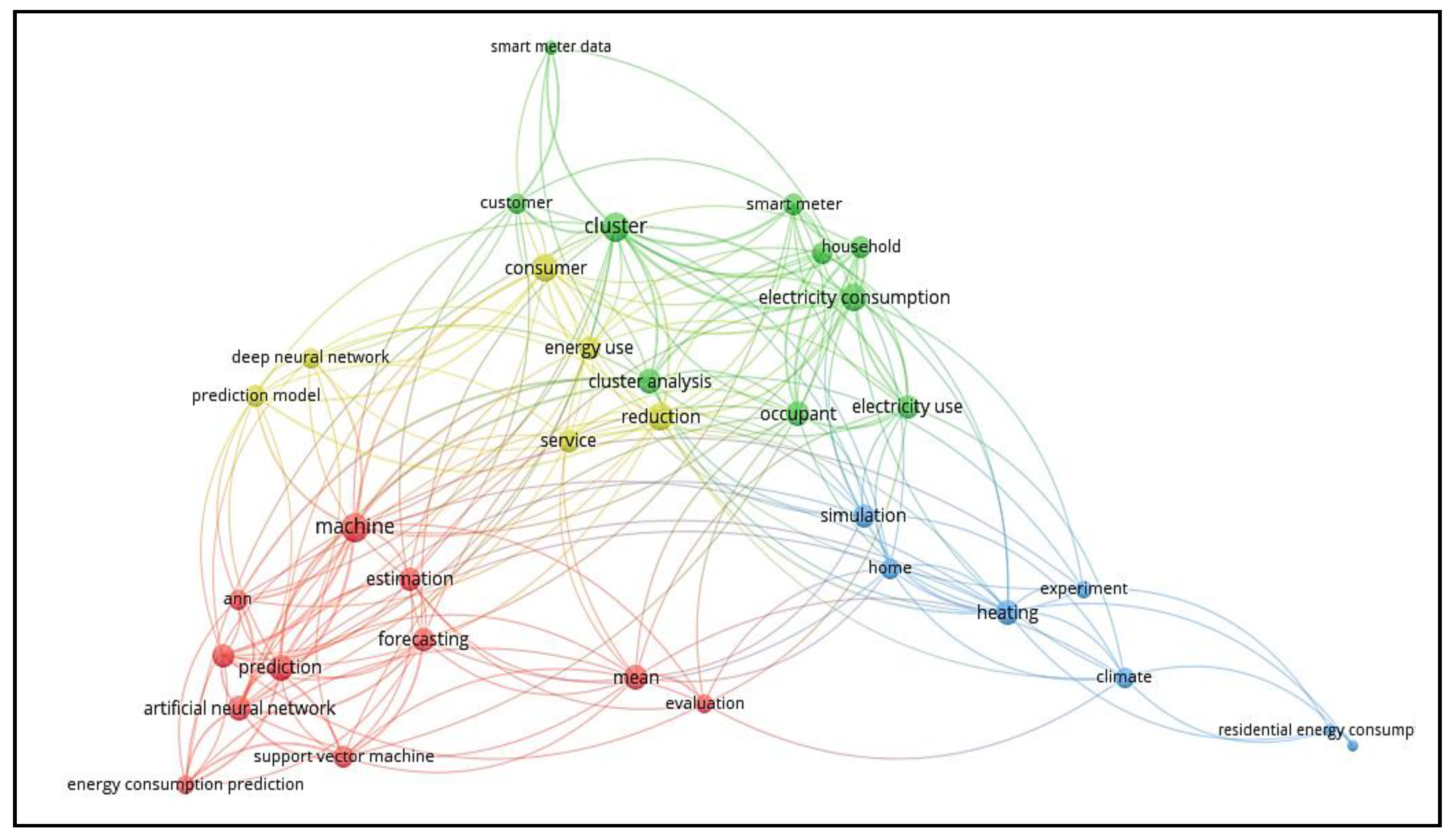
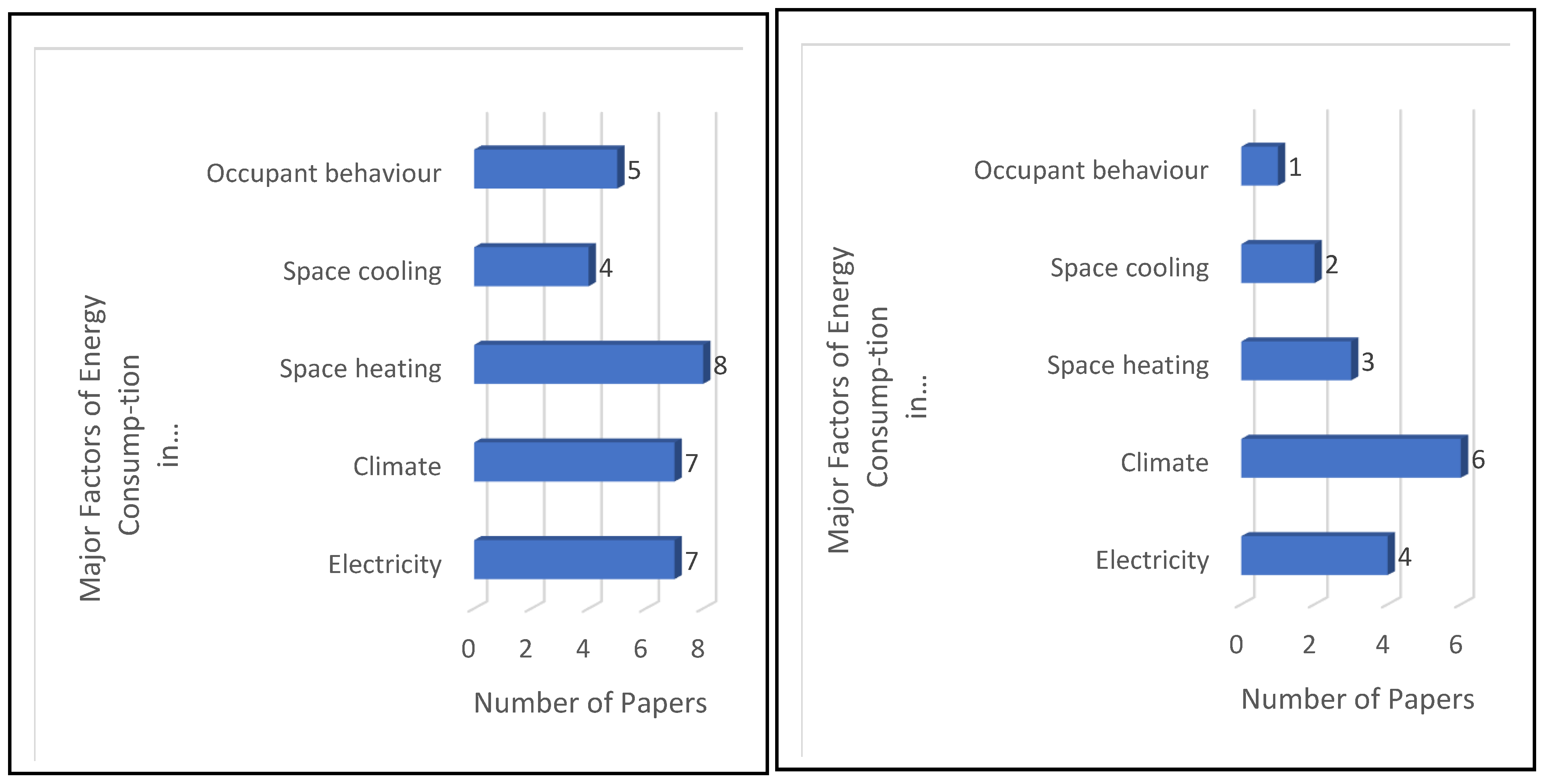
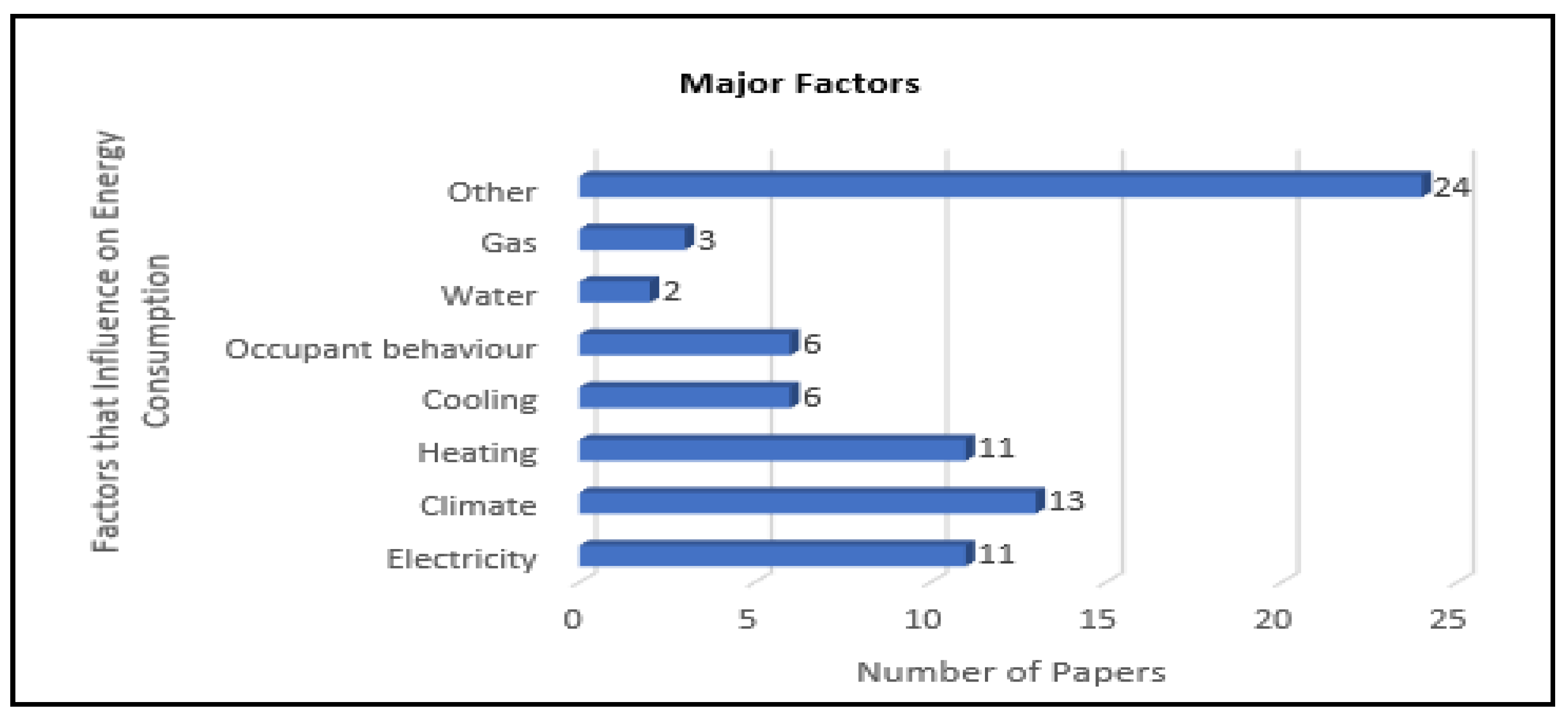
Focusing on our RQ1, we can highlight the main results obtained with our detailed analysis. In fact, the terms “electricity,” “heating,” and “climate” seem to be the most relevant when studying the energy consumption of buildings. We also observed a similarity between such results, based on a 41-paper analysis, and the text mining results, which took into consideration 106 papers. In our text mining approach, we calculated TITs for the terms “electricity” and “heating,” giving 0.1 and 0.07, respectively, thus showing their high relevancy. Nonetheless, there is a noticeable difference regarding the analysis of the term “climate.” From our detailed analysis of 41 papers, we found “climate” to be relevant. However, from our text mining results, the TITs value for “climate,” was 0.02, thus, showing that the “climate factor” has a lower relevance. Finally, we observed that “other factors” (“others” in
Figure 12), including “socio-economic,” “geospatial,” and “building characteristics,” along with “electricity,” “heating,” “cooling,” “occupant behavior,” “gas,” and “climate” are relevant when tackling energy consumption of buildings, as shown in
Figure 13. In the bibliometric map, we observed that there is a great relationship between “Residential Energy Consumption” with “Electricity Consumption,” “Heating,” and “Climate” (see in
Figure 7).
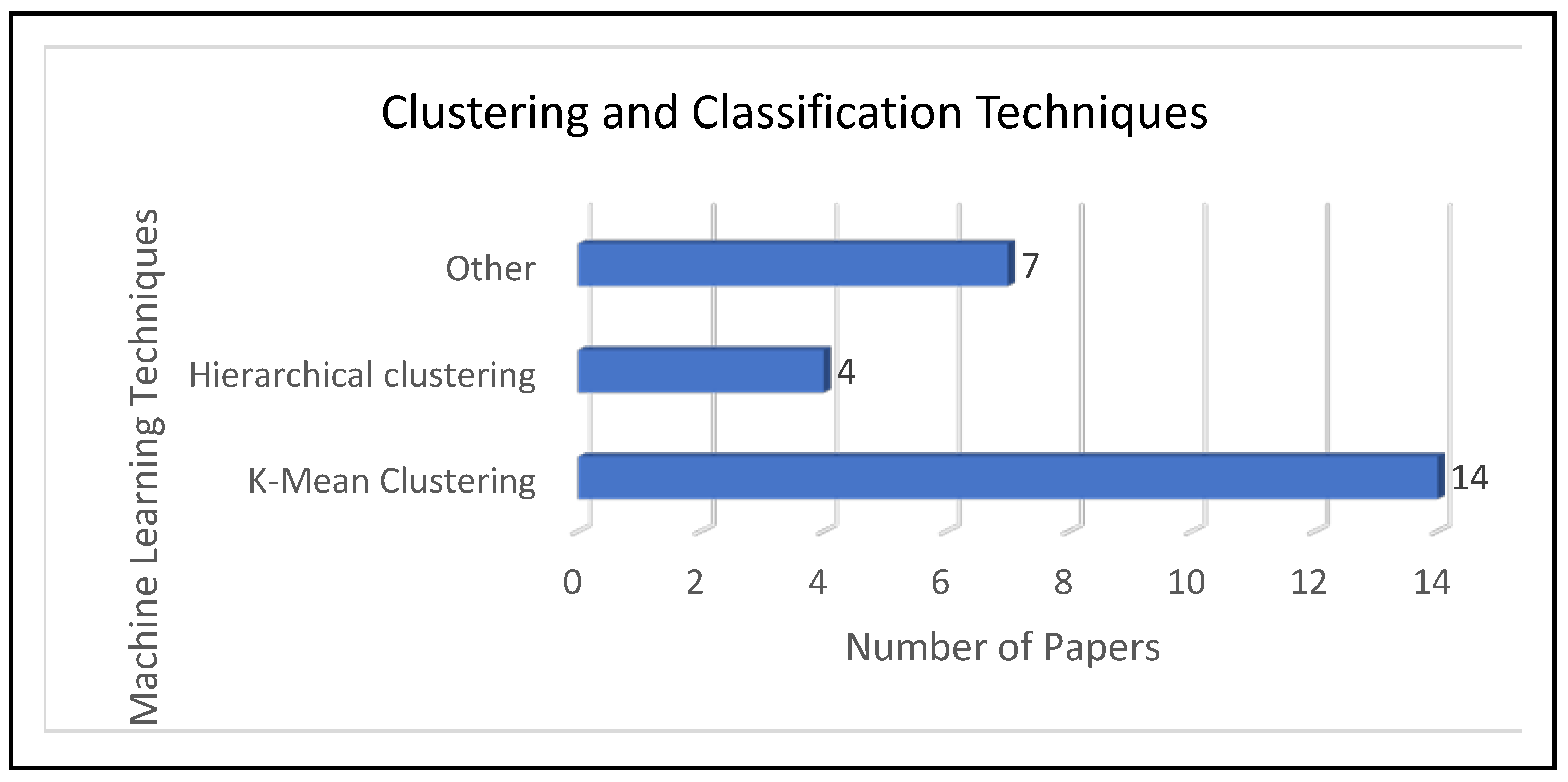
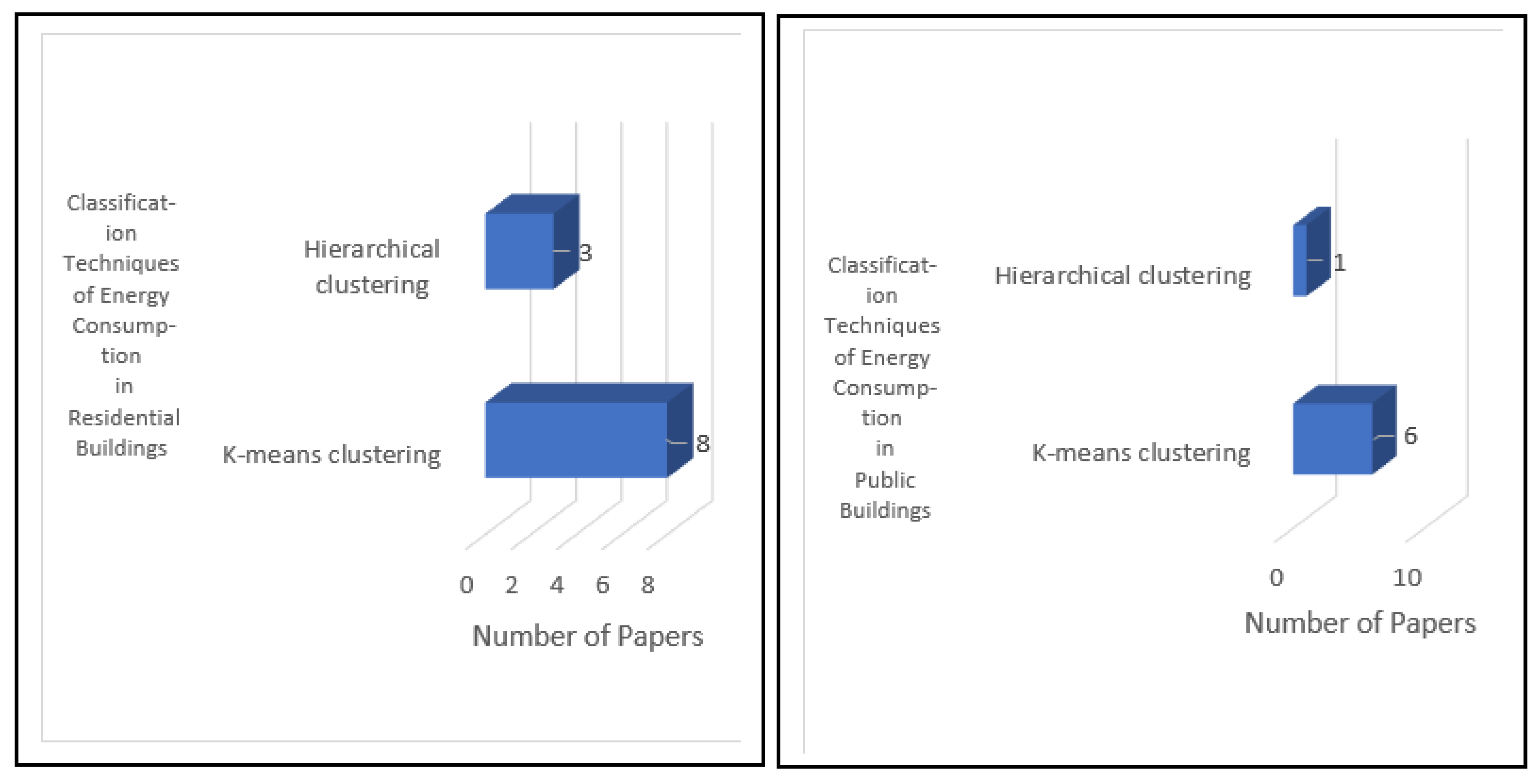
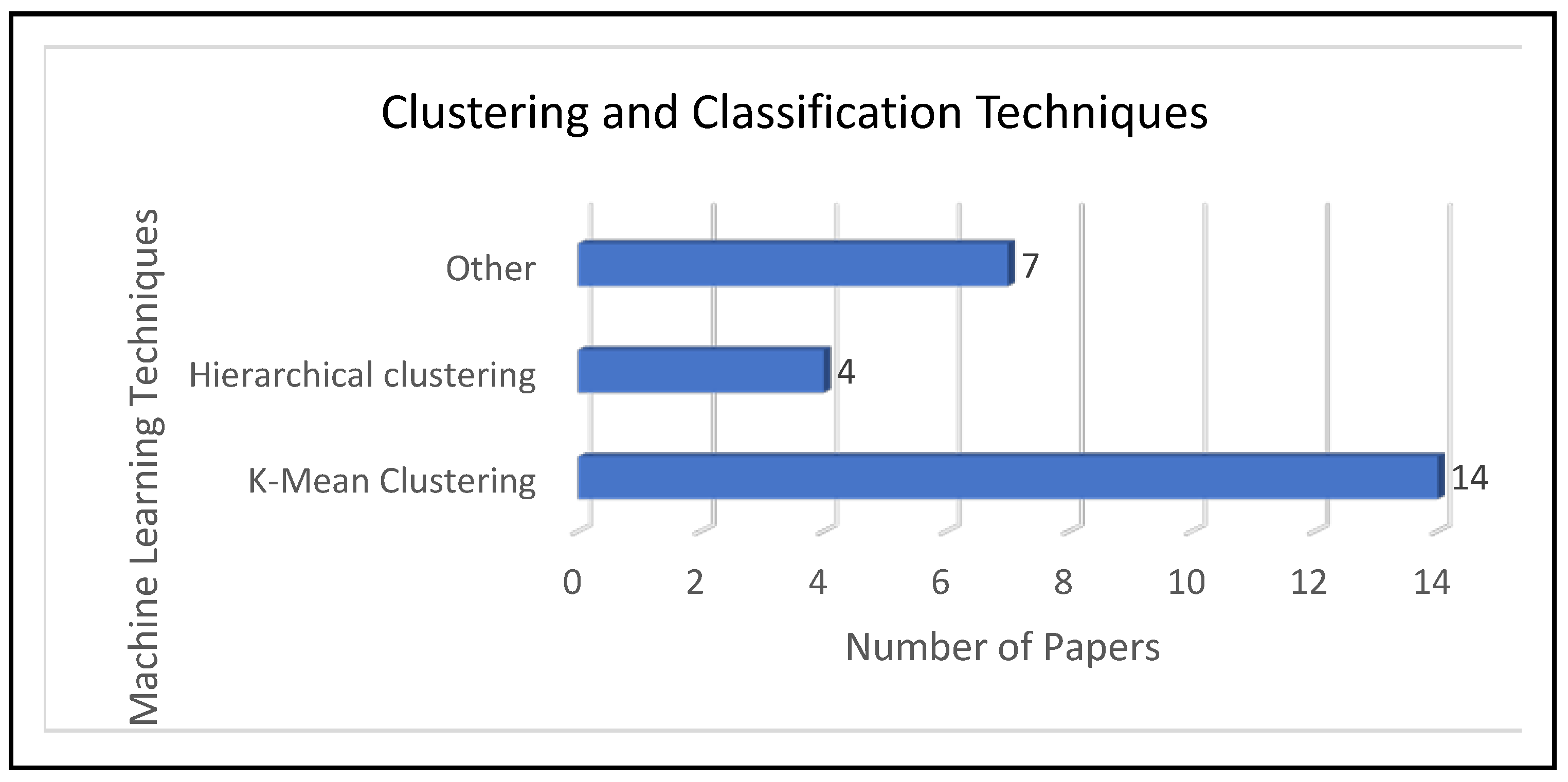
Regarding RQ2, and by examining papers S11 to S20 and S34 to S41, we can conclude that the term “cluster” is important when applying machine learning techniques to the ECB. We observed a relationship between this result and the conclusions drawn from text mining. In fact, TITs for the “cluster” term was 0.1, which shows that this term is highly relevant. However, in our graph of
Figure 14, the “cluster” term is further divided into two terms, which are “K-means clustering” and “hierarchical clustering.” By analyzing the mentioned papers, “K-means clustering” was used 3.5 times more than “hierarchical clustering,” as shown in
Figure 13. In the bibliometric map, we observed that there is a significant relationship between “Cluster” with “Electricity Consumption,” “Energy consumption prediction,” and “Residential Energy Consumption” (see in
Figure 7).
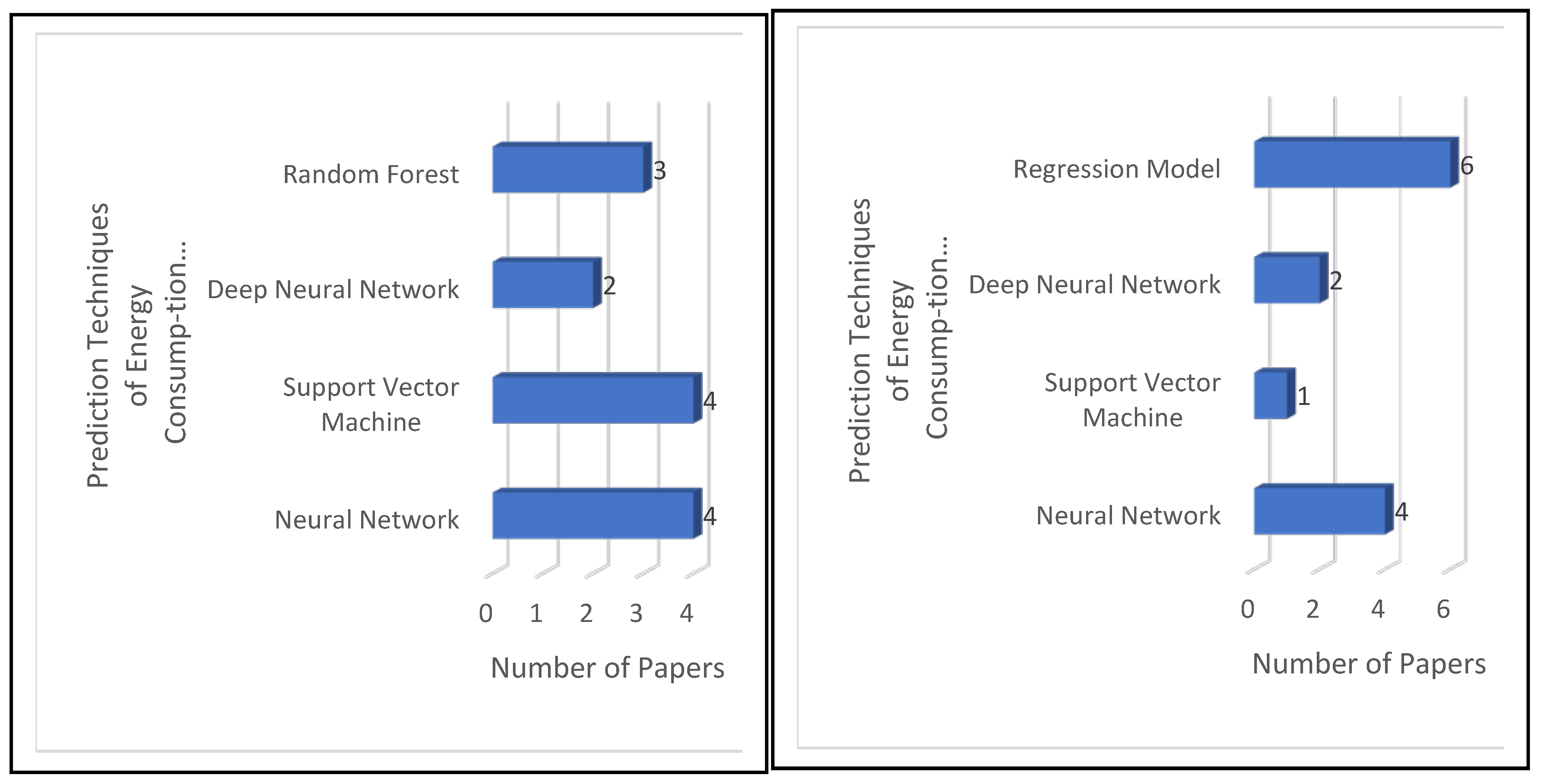
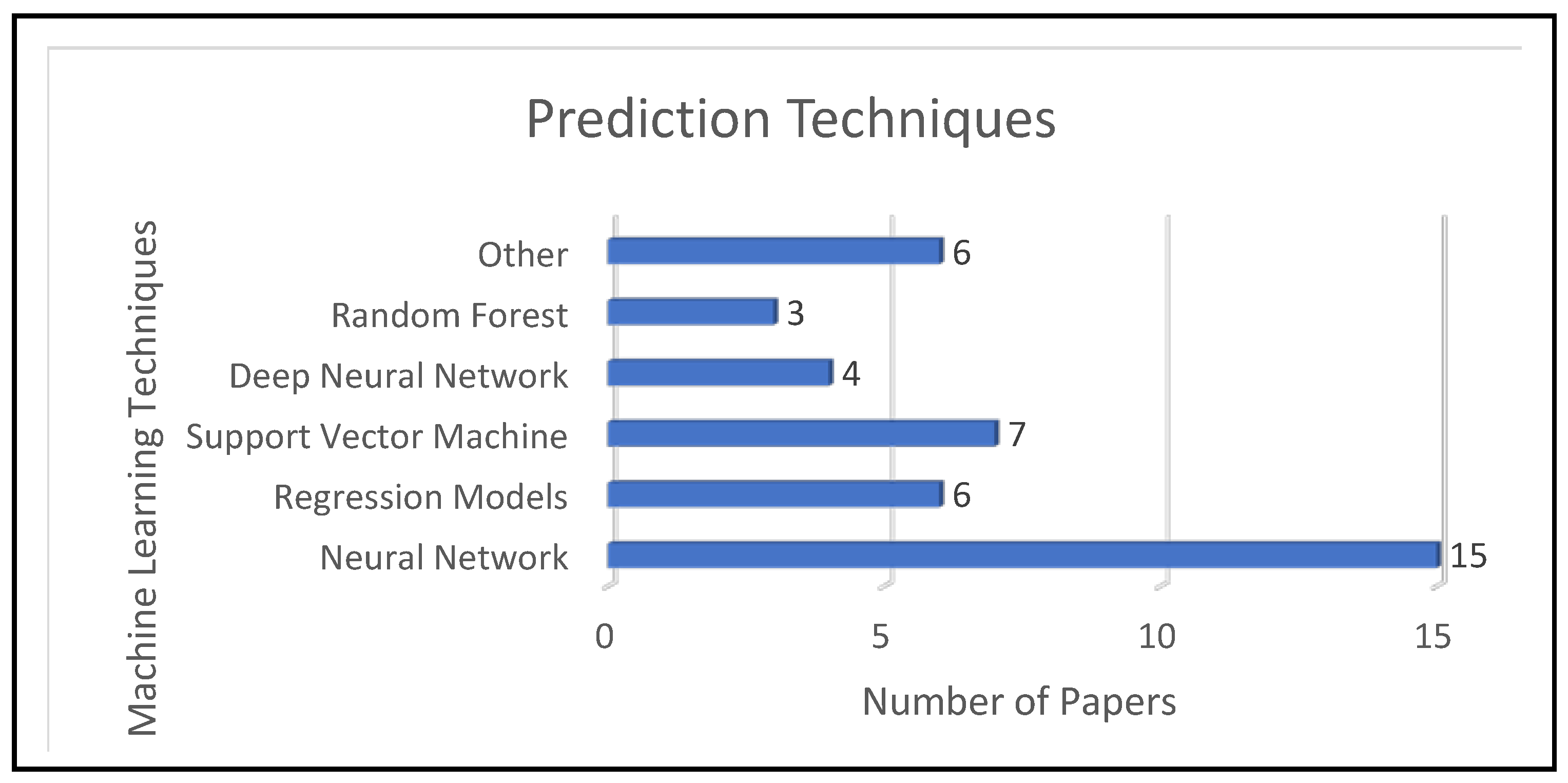
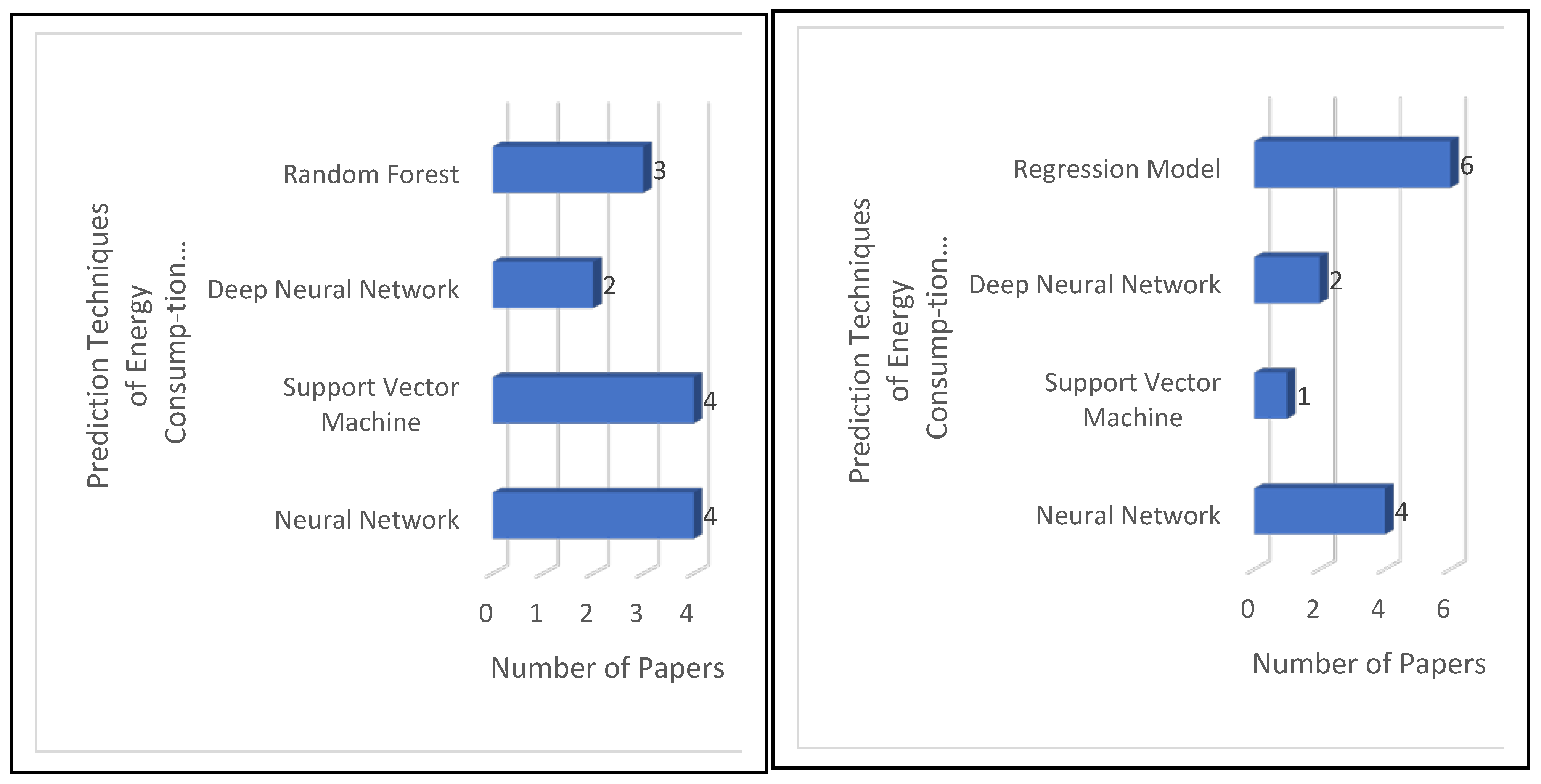
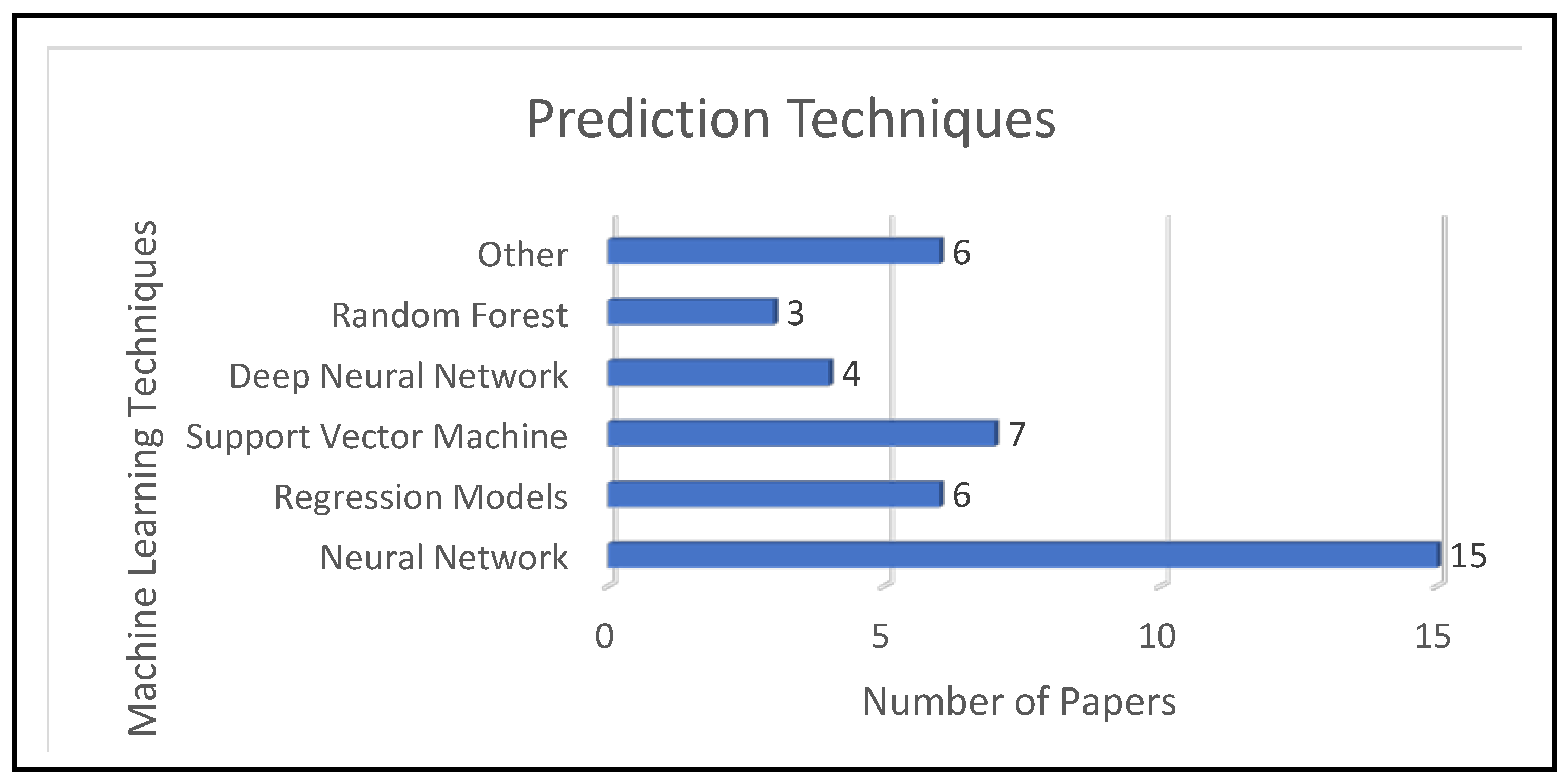
For RQ3, our analysis of papers S21 to S41 showed that the terms “backpropagation,” “feedforward neural network,” and regression models such as “multiple linear regression” and “support vector machine” are the more relevant. Much like our analysis of RQ2, we observed a similarity between such results and the conclusions of text mining. The TITs for terms “neural” and “regression” were 0.06 and 0.05, respectively. Thus, the terms “neural” and “regression” are relevant too. In papers S21 to S41, the neural network technique was used 2.5 times more than regression techniques and 2.143 more times than support vector machines, as shown in
Figure 15. In the bibliometric map, we observed that there is a significant relationship between “Neural Network” and “Deep Neural Network” with “Energy use,” “Energy consumption prediction,” and “Prediction Model.” In addition, there is a relationship between “Support Vector Machine” with “Energy consumption prediction” (see in
Figure 7).
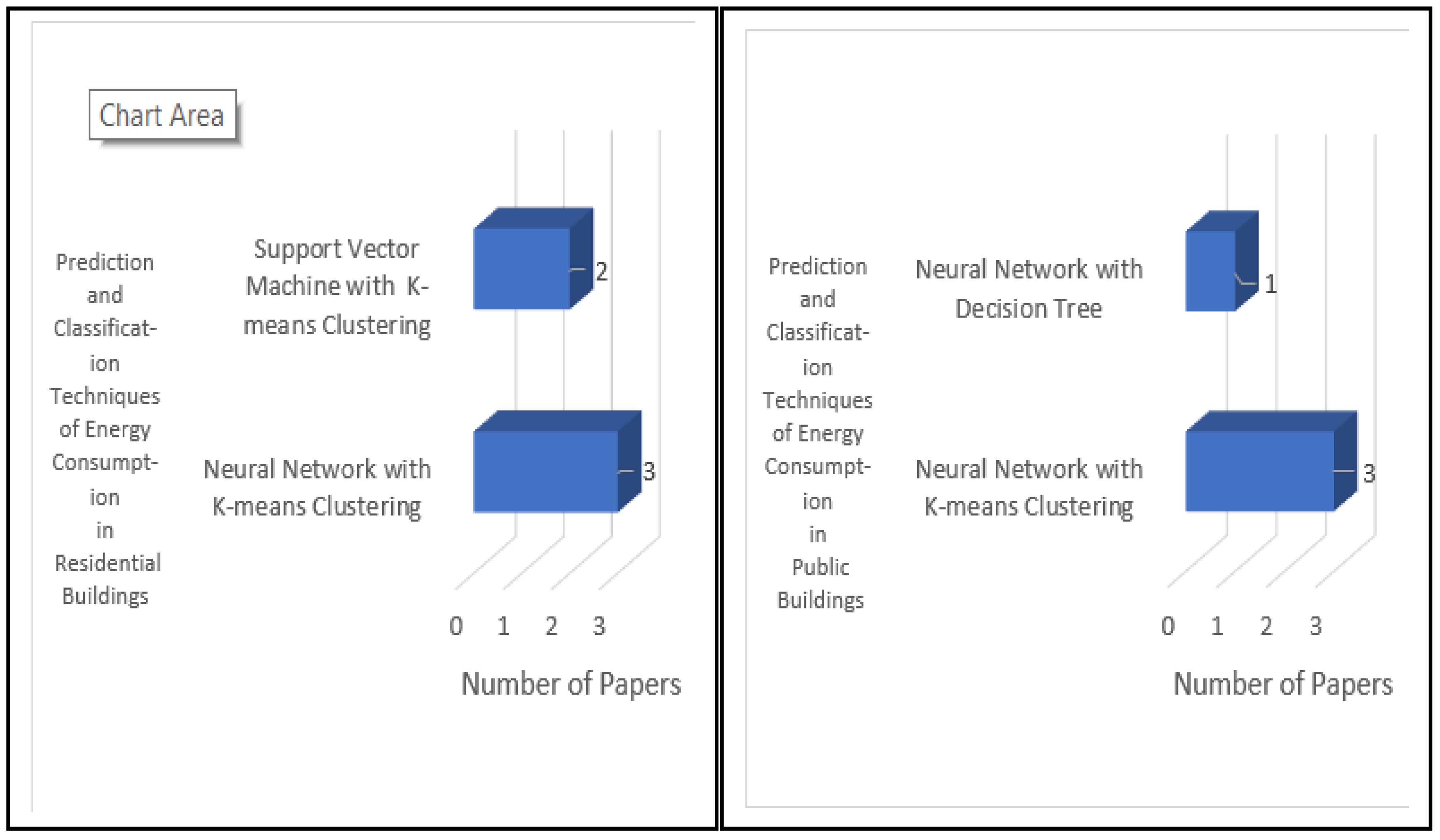
Regarding our RQ4, our analysis of papers S34 to S41 showed that K-means clustering was combined with backpropagation and feedforward neural networks in 75% of such papers (namely, in papers S34, S35, S37, S38, S39, and S41).
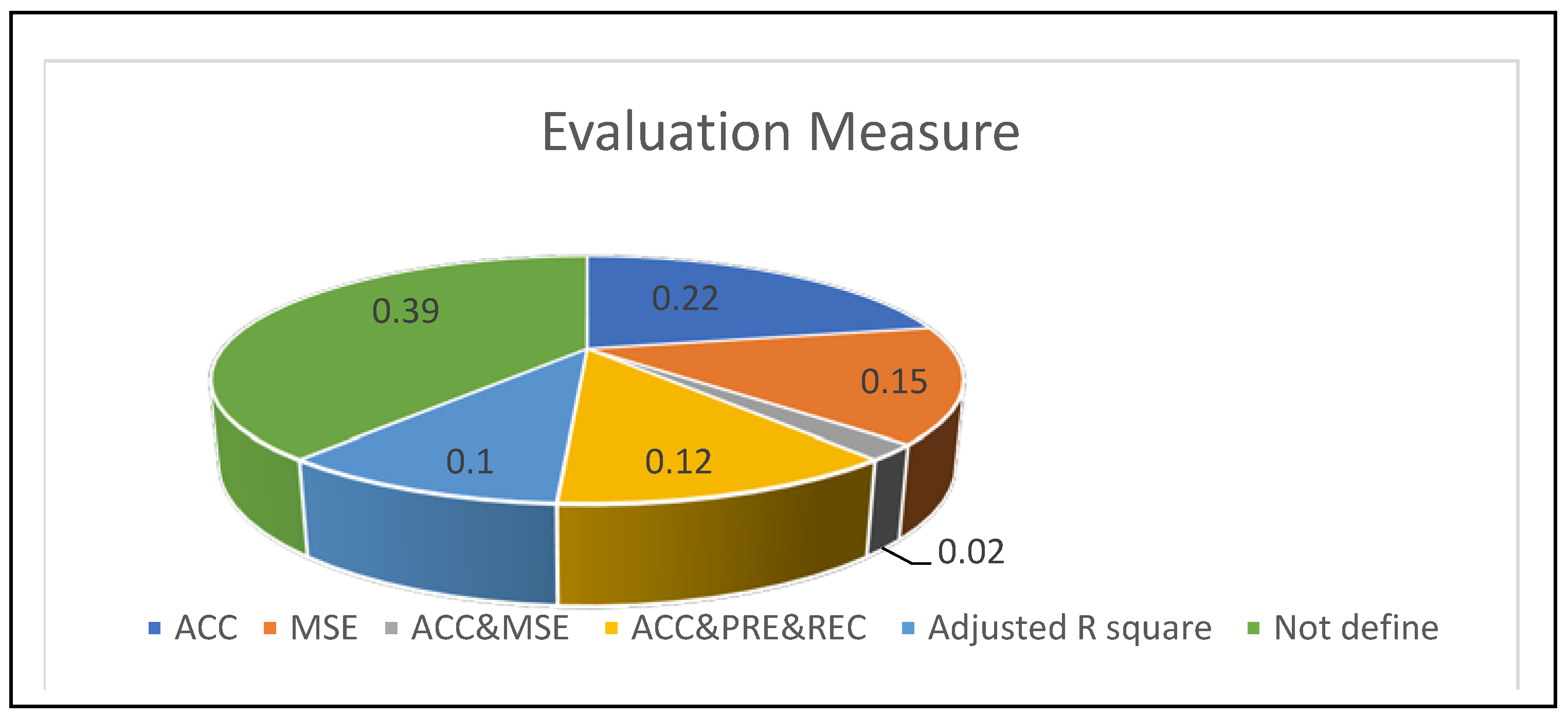
Finally, regarding our RQ5, accuracy scale is one of the most important metrics used to measure the accuracy of the intelligent model used in the field of energy consumption of different buildings (see
Figure 12).
4.2. Research Gap Discussion
By reviewing the studies that were mentioned previously, three main problems were covered in our survey.
Firstly, the lack of an official study to find the main factors used in the field of energy consumption in the different building sectors. Moreover, it is unclear how these factors relate to the different applications in the field of energy. For example, studies S18, S28, S32, and S41 used the electricity factor in the ECB as the only factor in the study. In addition, manuscripts S2, S14, and S22 relied on consumer behavior in residential buildings as the only factor in the study. Our study shows that heating and climate factors directly influence the energy consumption of residential buildings, while electricity and climate factors directly influence energy consumption for public buildings.
Secondly, most of the previous studies (S11, S13, S14, S15, S34, S37, and S40) used K-means clustering and hierarchical clustering to classify the ECB. Our study shows that two main aspects were not covered in previous research: a) there is a direct relationship between “K-means clustering” and “electricity consumption” in public and residential buildings, b) our paper proposes other classification methods such as a self-organizing map, for comparison with other classification models found in our survey, in terms of accuracy.
Thirdly, most of the previous studies used four basic intelligent computing models to predict the ECB: neural networks (S23, S28, S34, S37, and S41), regression (S21, S26, S29, and S30), support vector machines (S32 and S40), and deep learning (S24 and S27). Our study shows that there is a direct relationship between “neural networks,” “support vector machines,” and “prediction of energy consumption in residential buildings.” Additionally, there is a direct relation between “deep learning” and “prediction of energy consumption in public buildings.” Our study proposes the use of recent literature techniques, such as recurrent neural networks, for comparison with the prediction models found in our survey.
Additionally, our research allowed us to identify several research gaps. We found that only a small number of papers (S1 and S6) address specific factors influencing the energy consumption of buildings. For example, some studies (S5, S11, S18, S21, S26, S28, S32, and S41) focused on the electricity factor in general, with no mention of the number of building occupants or the activities carried out by them. Only a few studies (S31, S33, and S38) related to the energy consumption in public buildings. However, stakeholders in public buildings, particularly in Portugal, find this topic relevant and are not only willing to improve the energy efficiency in those buildings but also interested in switching energy suppliers whenever the market conditions favor such change [
13]. The results of this systematic review also displayed a wide gap in the domain of intelligent computing models, particularly regarding the automatic classification and prediction of the ECB, since the number of available machine learning techniques in the state-of-the-art is vast, and we saw from our survey, that some of the most promising techniques are not yet being used to their full potential. In fact, only a few studies (S24, S27, S31, and S39) address the application of the deep neural network model, which is a promising technique for predicting the ECB.
6. Conclusions and Future Work
This paper introduced a systematic literature review on the topic of classifying and predicting the ECB, focusing on finding answers to our five research questions. Text mining procedures were used to find the most used terms in the energy and intelligent computing model domains, and a bibliometric map was used to find the relationships between the most common terms in those domains prior to a more detailed manuscript analysis. By following a PRISMA approach in our survey, we started by identifying 822 manuscripts and ended up analyzing 41. Our survey highlighted the most used intelligent computing models, notably machine learning methods, adopted by the community to classify and forecast the ECB. This study provides contributions in three aspects. The first one considers factors that influence the ECB. The second one provides a systematic survey of classification and prediction techniques used in that context. The last aspect tackles the evaluation criteria used by those techniques.
As mentioned, the study has not covered all manuscripts in 2021, which may contain new intelligent models. The emergence of new intelligent methods may help improve the accuracy of classification models and predict energy consumption for different building sectors.
Thus, there are still opportunities for improvements regarding our topic of research. As a recommendation for future work, there are some other factors that affect energy consumption in buildings (e.g., green roof, building envelope, internal and external factors). These factors may be used in the future for the classification and prediction of energy consumption. Our survey suggests tackling the classification of the ECB by combining clustering and optimization techniques aiming to classify the ECB to levels (low–medium–high). As for predicting the ECB, this study suggests adopting machine learning approaches from the family of deep learning techniques, such as long short-term memory, convolutional neural networks, and deep forest, which are some of the recent trends found in research.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}