3.1. Data
Domain literature suggest chronological index parameters, lagged variables, and data relating to seasonality as strong potential model inputs [
15]. Additionally, exogenous variables such as generation capacity, load profiles, and ambient weather conditions have already been identified as suitable variables to explain electricity price dynamics [
16,
17]. The impact of external variables on the Irish day-ahead I-SEM spot prices are comprehensively investigated here by examining their correlations using the Pearson Correlation Coefficient (PCC). Variables tested include air temperature, wind speed, wind direction [
18], oil prices (
https://github.com/datasets/oil-prices [
1], accessed on 1 May 2021), and natural gas prices (
https://www.eia.gov/dnav/ng/hist/rngwhhdD.htm [
2], accessed on 1 May 2021). The effects of wind speed are particularly pertinent due to the increasing proliferation of renewable energy generation. From 2010 to 2020, wind penetration has increased incrementally from 1.39 to 4.3 MW [
19]. Today, wind generation accounts for approximately 36% of Ireland’s electricity demand [
20]. The effect of the penetration of wind energy is highly dynamic as it adversely affects the stability of load frequency control (LFC) systems [
21] but dampens the volatility of electricity prices [
22].
This research also reviewed metrological parameters pertaining to principal geographical locations in Ireland along with daily oil and natural gas prices across the EU. Natural gas prices, as well as the wind speed, ambient temperature, and precipitation in all selected counties yielded favorable PCC values—c.f.
Table 2. Feature engineering is an experimental process in Machine Learning (ML) that involves creating new artificial features using the existing raw data streams. Engineered features induce novelty and are proved to have a significant impact on performance of ML models [
23].
As well as examining the suitability of Gradient Boosting algorithms in the domain of Irish electricity price forecasts, this research explores the application of elementary mathematical transformations and combinations thereof, including sum, mean, square, logarithm, and square root of the aforementioned independent variables to generate new predictor variables. Applying feature importance and ranking accordance to the Pearson’s score achieved, an excerpt of the results attained is presented in
Table 3. Similar to the rolling window technique, it can be observed that the application of the expanding window mean method [
24] on historical spot prices yielded the leading PCC value.
3.3. Evaluation
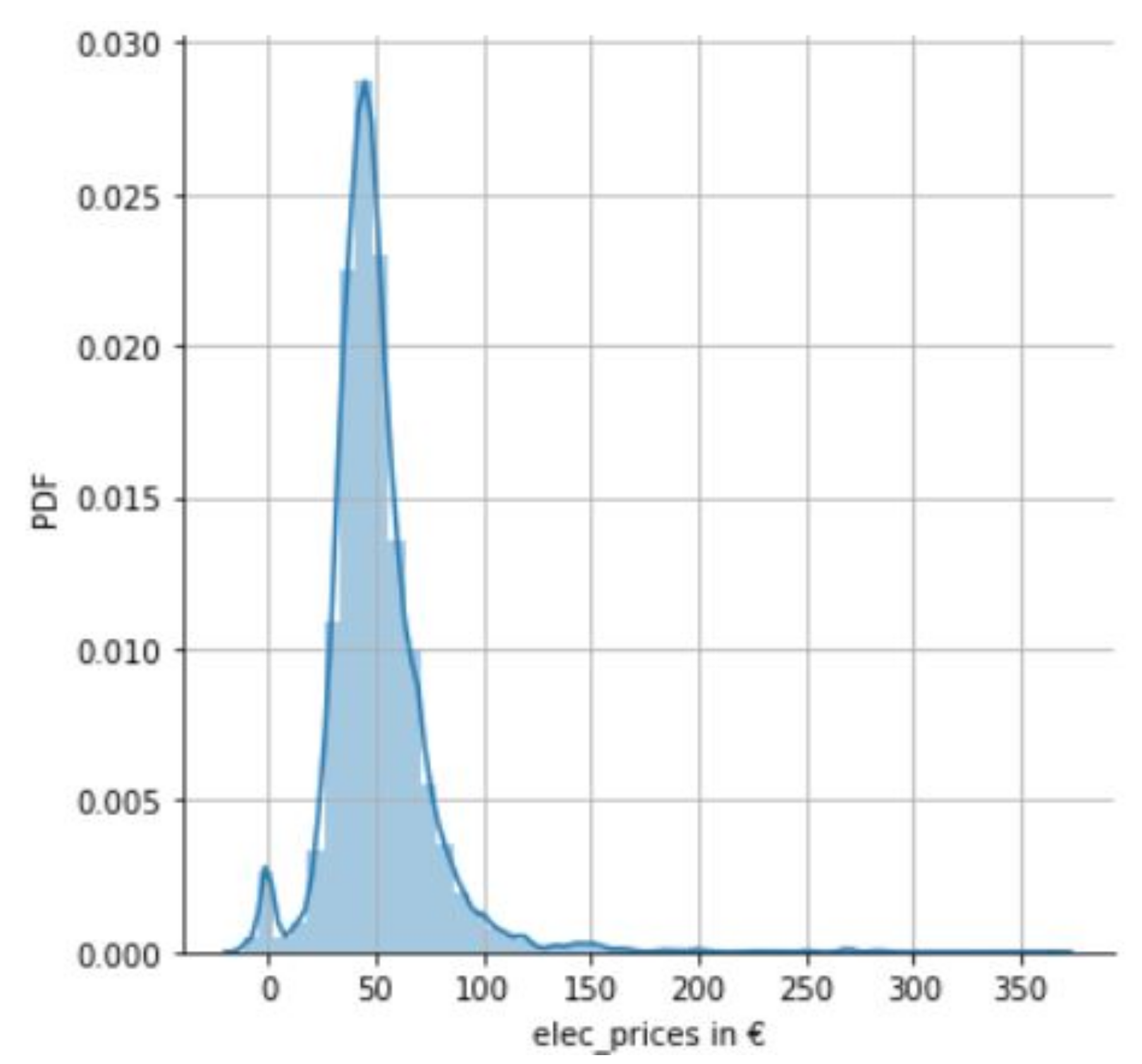
To demonstrate the volatility of the dataset, a univariate analysis of the electricity prices was performed for the evaluation period of interest, 1 January–12 December 2019. This saw min/max values of-EUR 11.86 and EUR 365, respectively.
Figure 2 illustrates a Probability Density Function (PDF) of electricity prices for the same period, which indicates a higher than usual mean of circa EUR 50, as discussed earlier in the paper.
From the best features determined, detailed in part in
Section 3.1, the Taguchi method, a process/product optimization method that is based on planning, conducting, and evaluating results of matrix experiments [
29], was then employed to test the impact of each of the selected features and their impact on GBM, XGBM, and LGBM model performance for multi-step ahead prediction.
The tuned GBM based models were then evaluated on test sets comprising various permutations of the advocated input data streams. Combinations included the amalgamation of engineered and time-based features—an extract of the leading results of which are presented in
Table 4. From this table, it is observed that a logarithm of the average wind speed as a feature had a significant impact on a model’s performance, deriving the lowest MAE score of 10.045. It was noted that including the logarithm of natural gas prices resulted in a weakened input matrix, producing one of the highest MAE values, 11.073.
To build on the results in
Table 4, derived from following Taguchi’s method of experiments in assessing the various feature variables individually, the next effort explored an adjusted input matrix considering the top five features that augmented model performance. Statistical results from this, for two test periods, are presented in
Table 5 and
Table 6, respectively.
In
Table 5, which considers available 2019 calendar data for 1 January to 12 December, the minimum MAE score of 10.36 is achieved by the XGBM model. Additionally, observing the benchmark period, 30 September 2018 to 12 December 2019,
Table 6 again elects the XGBM model as the algorithm of choice—achieving a MAE score of 10.021 over 30 runs.
Finally, this research analyzed the performance of GBM based models that gave consideration to all observed feature data. These results are displayed in
Table 7 and
Table 8, respectively, for the two test periods.
Looking at the 2019 test period,
Table 7 presents the XGBM model as having the lowest MAE score of 10.15. Then, observing the benchmark period used by O’Leary et al. [
6], i.e., 30 September 2018 to 12 December 2019,
Table 8 again endorses the XGBM model as the algorithm of choice—achieving a MAE score of 9.93 over 30 runs.
For the purpose of scientific rigor and transparency in this domain, i.e., the Irish market, the outlined experimental methodology was also performed on 2020 data. These results should facilitate benchmarking outcomes on multiple contextual levels. Furthermore, as an additional feature, Brent crude and West Texas Intermediate (WTI) oil prices from the US Energy Information Administration with a correlation score of 0.16 was included. Results from the consideration of all conventional time series and engineered features are registered in
Table 9.
Additionally, included in
Table 9 are the results of additional experiments to evaluate the efficacy of outlier preprocessing. Two means of outlier preprocessing were tested, i.e., outlier removal and outlier imputation. Outliers were first identified as being outside of a set threshold. This threshold was assumed to be four standard deviations from the mean. Outliers were then either capped at the outlier threshold or removed entirely from the training data. Outliers occurring in the test data were left unaltered.
It can be seen that the LGBM algorithm now presents itself as model of choice—yielding a single digit degree of error of 9.58 for the MAE. While outlier removal resulted in a slightly worse MAE score, outlier capping did consistently improve model performance.
From the experiments conducted in the research of this paper, it can be noted that there are some minor shortcomings of this methodology. Firstly, using different feature set and preprocessing combinations requires the reinitialization and retraining of models. This is a time-consuming process and is compounded multiplicatively by the forecast horizon size, i.e., by a factor of 24. Furthermore, the simulation time is also increased by a factor of 30 as experiments are repeated to achieve stable model rankings and scores.





{kind=link}
{kind=link}