
FAIR Metadata Standards for Low Carbon Energy Research—A Review of Practices and How to Advance

 ,
,  , , , ,
, , , ,  ,
,  ,
,  , , ,
, , ,  , ,
, ,  , , , , , , , and add
Show full author list
, , , , , , , and add
Show full author list
Abstract

1. Introduction
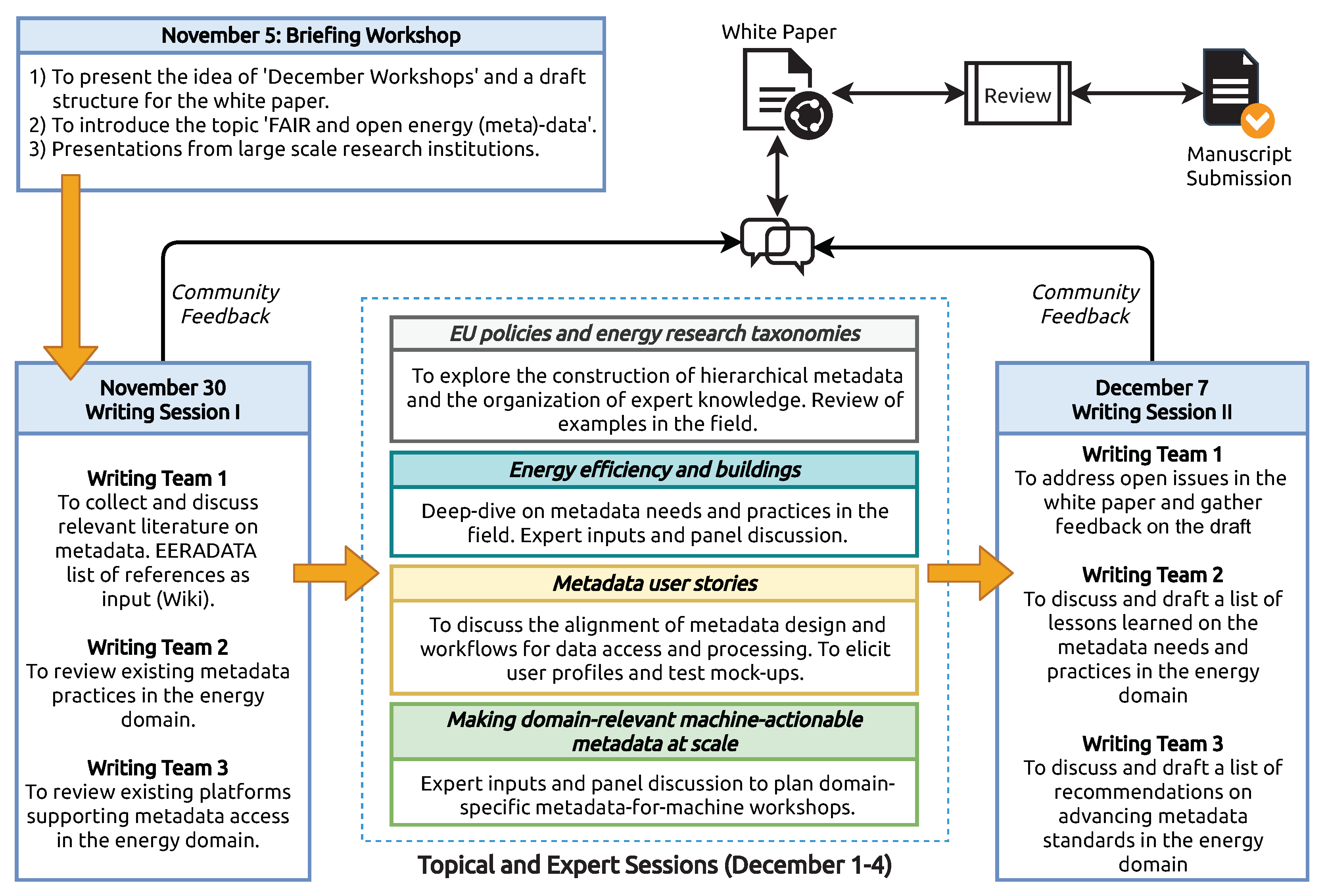
2. Method to Enable Community-Wide Reflection on Metadata
3. Discussion of Results
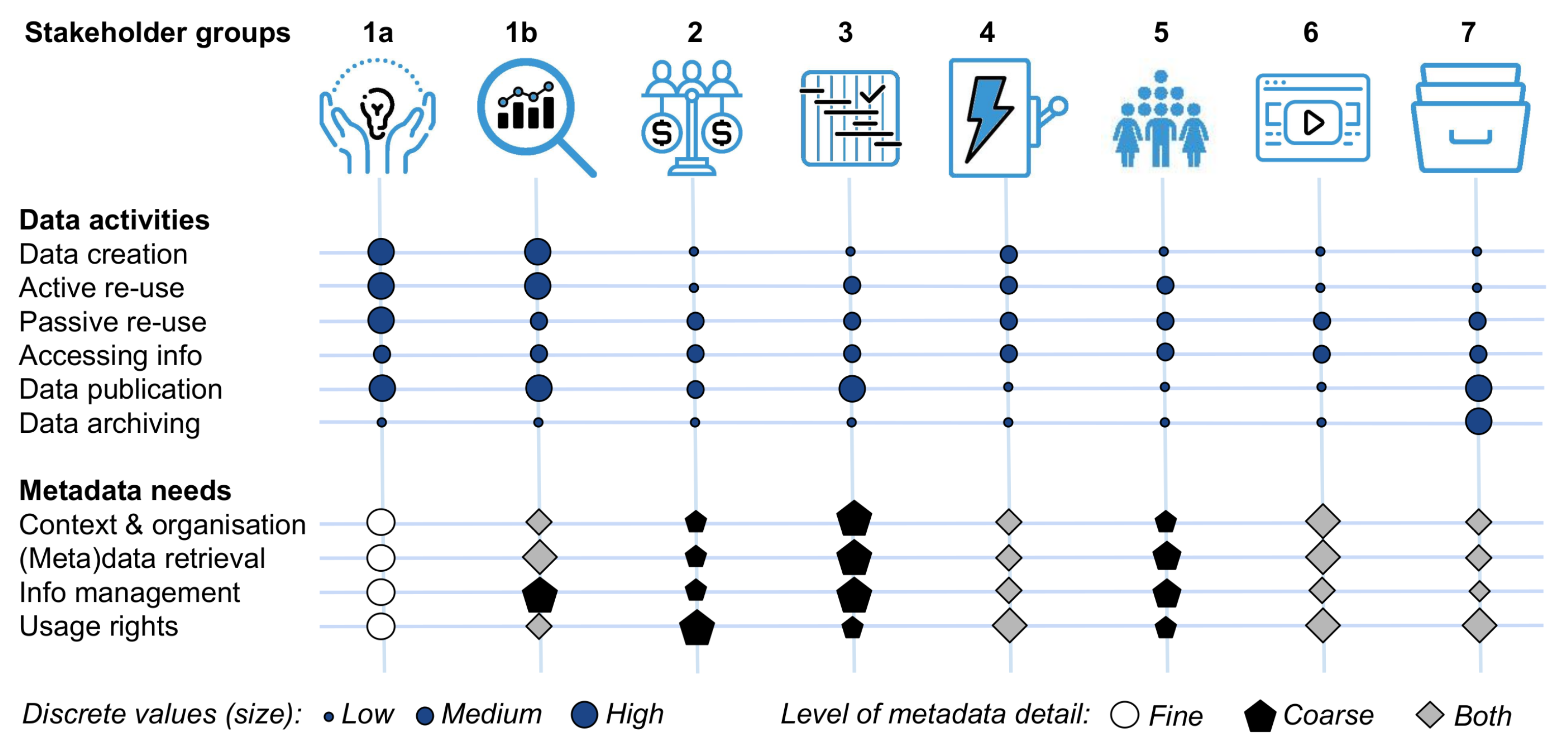
3.1. Needs and Gaps for Users of Low Carbon Energy (meta)Data
3.1.1. Users of Low Carbon Energy (meta)Data and Their Needs
- Researchers—(a) Energy domain experts create data from scratch, re-use existing data to curate, aggregate, analyze, and publish data. They come from various disciplines. As re-users of data, they need support from metadata in searching and finding data. They require context information with high granularity and rich provenance to assess data quality and relevance, precise information on usage rights, and intellectual property rights (IPR) requirements. (b) Interdisciplinary scientists inform themselves on (other) expert knowledge, re-use data, aggregate and analyze data, and publish data. They require context information for searching and finding data. They need information on the context of data and provenance (mostly on aggregated levels) and precise information on usage rights and IPR. Shared and open data fall within the interest of this group.
- Science funders of energy R&D activities inform themselves of the results of funded research and projects. They need to monitor, adjust, and plan funding policies and principles to better direct R&D investments and to ensure the impact of policy measures [8,9,10]. Evaluation agencies are a key mediator in this regard as they compile existing (meta)data and develop evaluation tools. Another important objective of funders is to unlock the potential of added value by exploring knowledge generated by research, exploiting and expanding its use [11]. Therefore, funding agencies also require the Data Management Plan (DMP) to track data’s provenance and future maintenance. Typically, this application is at a high level of aggregation, and information should be easy to understand and disseminate. Last but not least, a pivotal interest is that the funding agency be acknowledged in the metadata.
- Planners and decision-makers (incl. energy market regulators, security coordinators, policy-makers) inform themselves on expert knowledge. They may reuse data, analyze some data, and publish aggregated data and decisions. This involves a middle to high level of aggregation, information on the context of data, and provenance. An important aspect is the metadata information on aggregated data. While this group has an interest in open data policies, they are also obliged to protect private data pertaining to citizens.
- Energy and other industries (incl. technical and operational planners and decision-makers, energy market operators). They inform themselves on expert knowledge and re-use and analyze some data on all aggregation levels. They require information on the context and provenance of data. Important is metadata information on aggregated data. To assess the commercialization potential, legally secure information on usage rights and IPR are needed.
- General public. The group informs itself to adjust behavior and practices (e.g., energy consumption behavior, voting in elections, engagement as prosumers, activists or citizen-scientists). They may re-use data to tell others and pose questions leading to research activities. A high level of aggregation is needed to make data easy to understand and navigate.
- Data scientists (incl. data engineers, software and algorithm developers). This group codes, tests, and validates software with existing data. Specifically, data engineers (who may be domain specific or agnostic) are key builders of (meta)data pipelines and back-end solutions. Data scientists may re-use (meta)data to design scientific workflows considering interoperability with other tools and demonstrate applications. They need concise metadata to integrate data sources within the software tool, machine-actionable open file formats, agreed standards, terminologies, and interoperability protocols. Being in legally-compliant control of private data is of particular interest for this user group.
- Publishers, librarians, and data curators publish, store, and archive research data. They may re-use data to link them to metrics such as access statistics and to cross-reference. They need metadata regarding ownership/authorship of results or the size of the data and information such as keywords to provide searchability in their publications and archives.
3.1.2. Gaps for Users of Energy (meta)Data
3.2. Advancing Metadata Practices—Practical Explorations
3.2.1. Human Perspective on Metadata Navigation
3.2.2. Machine Perspective on Metadata Navigation
3.2.3. Advancing Metadata Practices—Technical Aspects
- Richness relates to the extent and completeness of metadata, supporting the usefulness of metadata. For example, only 12 identifiers for administrative data is used in the repository ‘figshare’, whereas 100 identifiers are requested for the ‘dataverse’.
- Consensus concerns the level of agreement in the community and through the institutional backup. For example, a consortium working on the concept has a more extensive backup than an individual, supporting metadata’s credibility. Alternatively, a community may have formally approved a practice, or the practice may even have been adopted by standard-setting institutions such as CODATA. The continuous curation further increases consensus.
- Accessibility and transparency concern the ease of using metadata for different stakeholders. This criterion supports usefulness and findability, answering the following questions: Does metadata support the empowerment of many users, e.g., by providing information on varying levels of granularity? How good is the quality of data documentation? Are open standards supported? Specifically for machines: Are persistent and unique identifiers used? Are they retrievable by standard search engines?
- Linked metadata supports compatibility and interoperability between data. This criterion concerns how well metadata is interlinked, structured, and grounded, allowing navigation at different levels.
- Functional implementation should be up to standard, supporting authorization and authentication. Recommended are the ubiquitous use of persistent identifiers, a high degree of modularity, and the inclusion of licensing information. JSON-LD and XML-RDF are recommended metadata formats.
4. Conclusions
4.1. Lessons Learned
- Reaching agreements on common standards requires a synthesis of established terminologies, vocabularies, and data formats to create rich and linked, but still comprehensible, metadata that caters to the needs of all stakeholder groups. Metadata concepts to track the domain- and user-specific workflows are still under development. Practices on licensing and access control are uncommon. While the functional implementation should adhere to emerging solutions found in the ICT community (e.g., the widespread use of persistent identifiers, semantic web technology), they need to tie with established practices in the energy domain and match existing IT competencies.
- Limited functionality of supporting tools and infrastructure. If an energy research team aims at tackling the problem of interoperability and machine-actionability of their (meta)data, very limited or unspecific top-down support is available. For example, one of the main projects of the European Cloud—EUDAT Collaborative Data Infrastructure—offers support for integrated data services. However, none of the seven core communities covers low carbon energy research, and none of the use cases of the European Open Science Cloud includes best practice examples from the field. (Compare with the information about the core communities at https://eudat.eu/news/eudat-keeps-engaging-communities-all-you-need-to-know-on-the-eudat-data-pilots, (accessed on 1 September 2021)). At the same time guidance is needed to address the lack of resources and skills. In consequence, the reluctance to commit to engage with new data curation technologies appears well founded.
- Durable solutions for the energy domain and beyond. Since the context of data is given by the current domain knowledge, metadata is inevitably dynamic in nature. Therefore, metadata needs to be updated to align with the current state of knowledge. Moreover, the relevance and appropriateness of data descriptions has to be regularly verified. No practices are established yet to enable dynamic and machine-supported updating.
- Data curation literacy across user groups. The lack of FAIR data curation skills is an issue for all stakeholders of (low carbon) energy data. Indeed, the level of competence ranges from IT-enthusiasts to technology skeptics. Also, little experience exists to map specialist-terminology with non-specialist terminology to facilitate the broad reuse of (meta)data.
- Organizing a community approach. For advancing (meta)data practices, a framework able to address and involve all stakeholders is needed. A suitable framework should have a high visibility in the community to ensure legitimacy and to promote the uptake of standards. The challenge is that the implementation of such a framework is beyond the possibilities of a few funded projects, because it requires a long-term and consistent commitment.
- A challenge to fund data curation activities. Data curation as well as skill building is resource-intensive for individual researchers and institutions alike, but available funding is clearly not matching the needs.
- Lack of acknowledgement for data curators. Data curation is not acknowledged in the same way as data processing and analysis. Despite its relevance, this task is largely seen as inferior. Even more, contributions by data curators are generally less visible (including suitable journals to publish on the matter).
4.2. Recommendations
- Augment and synthesize existing metadata practices in the energy domain. The starting point to reach agreements on common standards is the identification, extension, and integration of existing approaches. This includes the search for best practices in other domains. In this way, domain-specific attempts can be matched with emerging solutions. At the same time, researchers are picked up where they are, and their contributions utilized. With this white paper, we invite interested researchers and existing initiatives in the field to organize a joint conference with the Open Energy Modelling Community, the Wind Energy Community, and the EERAdata project, among others.
- Establish platforms that gather and document domain-specific metadata practices. The recommendation is to build a knowledge base with supporting tools, guidelines, best practices, FAIR implementation choices, and links to (meta)data repositories. The hub should be anchored in a number of widely frequented energy community websites. The platform should also offer contacts to domain experts and other FAIR data curators (e.g., linking energy-related working groups of top-down initiatives). This promotes the use of general metadata standards such as Dublin Core and also supports a energy-specific implementation of FAIR (meta)data principles that aligns with the general trends. The FAIR Implementation Profiles [86] can serve as an inspiration.
- Build a FAIR energy data network and foster long-term commitment. A starting point is to utilize existing international and EU-level networks in the field. The idea is to link up with periodic conferences and workshops, which are mainstream meeting places for the energy community already. Established international umbrella organizations that target the wide range of energy data stakeholders from researchers to policy-makers, industries, funders, publishers, and so forth, appear as a good choice. One candidate is the European Energy Research Alliance (EERA), working at the interface of European policy-making, national governments, the research community and industry. Members of EERA engage in a broad range of research and cross-cutting activities facilitated in 18 Joint Programs. In particular, the recently established transversal program ‘Digitalization of Energy’ may serve as a suitable means to kick-off community activities.
- Develop a multi-year work program actively engaging low carbon energy data stakeholders to (1) estimate the resources needed to implement and sustain FAIR data activities from the perspective of user groups, (2) coordinate the development of community practices and consensus on standards, (3) organize workshops to advance unresolved issues (incl. the open/closed data spectrum, incentive problem of data curation, business opportunities, data protection and GDPR, data licensing, and so forth), and (4) promote the building of FAIR data competences and skills.
- Advocate for broadening funding programs and encourage industry funding. The lack of funding for FAIR data activities is a major barrier to advance community practices, build the necessary skills, and increase awareness for the need for data curation. It is important to actively approach funders to motivate the funding of on-the-job training and the development of new university education on energy data stewardship for instance. The industry should also be targeted, and public-private partnerships seem a way forward in this respect.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kahn, R.; Wilensky, R. A Framework for Distributed Digital Object Services. Available online: http://www.cnri.reston.va.us/k-w.html (accessed on 1 December 2020).
- Georgescu-Roegen, N. The Entropy Law and the Economic Process; Harvard University Press: Cambridge, MA, USA, 1971. [Google Scholar]
- Wilkinson, M.; Dumontier, M.; Aalbersberg, I.; Appleton, G.; Axton, M.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; Bouwman, J.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- European Union. Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the re-use of public sector information—PE/28/2019/REV/1. Off. J. Eur. Union 2019, L 172, 56–83.
- Schwanitz, V.J.; Wierling, A.; Paier, M.; Biresselioglu, M.E.; Celino, M.; Bałazińska, M.; Fernandez Vanoni, M.L. Towards a FAIR and Open Data Ecosystem in the Low-Carbon Energy Research Community (eeradata), Project Funded by the European Union’s Horizon 2020 Programme. Available online: https://www.eeradata.eu/ (accessed on 17 February 2021).
- Transversal Joint Program ‘Digitalization for Energy’ of the European Energy Research Alliance (EERA). Available online: https://www.eera-set.eu/component/projects/projects.html?id=183 (accessed on 17 February 2021).
- Gregg, W.J.; Erdmann, C.; Paglione, L.A.D.; Schneider, J.; Dean, C. A literature review of scholarly communications metadata. Res. Ideas Outcomes 2019, 5, e38698. [Google Scholar]
- Lane, J.; Bertuzzi, S. Measuring the Results of Science Investments. Science 2011, 331, 678–680. [Google Scholar] [CrossRef] [PubMed]
- Bloch, C.; Sørensen, M.P.; Graversen, E.K.; Schneider, J.W.; Kalpazidou, E.; Aagaard, S.K.; Mejlgaard, N. Developing a methodology to assess the impact of research grant funding: A mixed methods approach. Eval. Prog. Plan. 2014, 43, 105–117. [Google Scholar]
- Álvarez-Bornstein, B.; Bordonsa, M. Is funding related to higher research impact? Exploring its relationship and the mediating role of collaboration in several disciplines. J. Inform. 2021, 15, 101102. [Google Scholar]
- O’Kane, C.; Zhang, J.A.; Cunningham, J.A.; Dooley, L. Value capture mechanisms in publicly funded research. Ind. Market. Manag. 2020, 90, 400–416. [Google Scholar]
- Haynes, D. Metadata for Information Management and Retrieval: Understanding Metadata and Its Use, 2nd ed.; Facet Publishing: London, UK, 2018. [Google Scholar]
- Rumble, J.; Broome, J.; Hodson, S. Building an International Consensus on Multi-Disciplinary Metadata Standards: A CODATA Case History in Nanotechnology. Data Sci. J. 2019, 18, 1–11. [Google Scholar]
- Schauppenlehner, T.; Muhar, A. Theoretical Availability versus Practical Accessibility: The Critical Role of Metadata Management in Open Data Portals. Sustainability 2018, 10, 545. [Google Scholar]
- McQuilton, P.; Batista, D.; Beyan, O.; Granell, R. Helping the Consumers and Producers of Standards, Repositories and Policies to Enable FAIR Data. Data Intell. 2020, 2, 151–157. [Google Scholar] [CrossRef]
- Guo, S.; Yan, D.; Hu, S.; An, J. Global comparison of building energy use data within the context of climate change. Energy Build. 2020, 226, 110362. [Google Scholar] [CrossRef]
- Kopackova, H.; Michalek, K.; Cejna, K. Accessibility and findability of local e-government websites in the Czech Republic. Univ. Access Informat. Soc. 2009, 9, 51–61. [Google Scholar] [CrossRef]
- Hirth, L.; Mühlenpfordt, J.; Bulkeley, M. The ENTSO-E Transparency Platform—A review of Europe’s most ambitious electricity data platform. Appl. Energy 2018, 225, 1054–1067. [Google Scholar] [CrossRef]
- Francis, D.J.; Das, A.K. Open Data Resources for Clean Energy and Water Sectors in India. J. Libr. Inform. Technol. 2019, 39, 300–307. [Google Scholar] [CrossRef][Green Version]
- Holmegaard, E.; Johansen, A.; Kjærgaard, M.B. Towards a metadata discovery, maintenance and validation process to support applications that improve the energy performance of buildings. In Proceedings of the IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, Australia, 14–18 March 2016; pp. 1–6. [Google Scholar]
- Oakleaf, J.; Kennedy, C.; Baruch-Mordo, S.; Gerber, J.; West, P.; Johnson, J.; Kiesecker, J. Mapping global development potential for renewable energy, fossil fuels, mining and agriculture sectors. Sci. Data 2019, 6, 101. [Google Scholar] [CrossRef] [PubMed]
- Mishra, S.; Glaws, A.; Cutler, D.; Frank, S.; Azam, M.; Mohammadi, F.; Venne, J.S. Unified architecture for data-driven metadata tagging of building automation systems. Autom. Constr. 2020, 120, 103411. [Google Scholar] [CrossRef]
- Fahrenkrog, G.; Polt, W.; Rojo, R.; Tubke, A.; Zinocker, K. RTD Evaluation Toolbox. Assessing the Socio-Economic Impact of RTD Policies, Prepared by Joanneum Research and the Institute for Prospective Technological Studies (JRC-EC), IPTS, Seville, 2002. Available online: https://publications.jrc.ec.europa.eu/repository/handle/JRC23461 (accessed on 10 September 2021).
- Morrison, R. Energy system modeling: Public transparency, scientific reproducibility, and open development. Energy Strategy Rev. 2018, 20, 49–63. [Google Scholar] [CrossRef]
- Martin, S.; Foulonneau, M.; Turki, S.; Ihadjadene, M. Risk Analysis to Overcome Barriers to Open Data. Electron. J. e-Gov. 2013, 11, 324–388. [Google Scholar]
- Pfenninger, S.; DeCarolis, J.; Hirth, L.; Quoilin, S.; Staffell, I. The importance of open data and software: Is energy research lagging behind? Energy Policy 2017, 107, 211–215. [Google Scholar] [CrossRef]
- Benndorf, G.A.; Wystrcil, D.; Réhault, N. Energy performance optimization in buildings: A review on semantic interoperability, fault detection, and predictive control. Appl. Phys. Rev. 2018, 5, 041501. [Google Scholar] [CrossRef]
- Li, S.; Yang, J.; Fang, J.; Liu, Z.; Zhang, H. Electricity scheduling optimisation based on energy cloud for residential microgrids. IET Renew. Power Gener. 2019, 13, 1105–1114. [Google Scholar] [CrossRef]
- Vikhorev, K.; Greenough, R.; Brown, N. An advanced energy management framework to promote energy awareness. J. Clean. Prod. 2013, 43, 103–112. [Google Scholar] [CrossRef]
- Fahey, R.A.; Hino, A. COVID-19, digital privacy, and the social limits on data-focused public health responses. Int. J. Inf. Manag. 2020, 55, 102181. [Google Scholar] [CrossRef]
- Hallinan, D.; Friedewald, M.; Mc Carthy, P. Citizens’ perceptions of data protection and privacy in EU. Comput. Law Secur. Rev. 2012, 28, 263–272. [Google Scholar] [CrossRef]
- Brunnschweiler, C.; Edjekumhene, I.; Lujala, P. Does information matter? Transparency and demand for accountability in Ghana’s natural resource revenue management. Ecol. Econ. 2020, 181, 106903. [Google Scholar] [CrossRef]
- Cantadora, I.; Cortés-Cediel, M.E.; Fernández, M. Exploiting Open Data to analyze discussion and controversy in online citizen participation. Inf. Process. Manag. 2020, 57, 102301. [Google Scholar] [CrossRef]
- Veliz, C.; Grunewald, P. Protecting data privacy is key to a smart energy future. Nat. Energy 2018, 3, 702–704. [Google Scholar] [CrossRef]
- Gendron, J.; Killian, D. Data citizens: Rights and responsibilities in a data republic. In Data Democracy—At the Nexus of Artificial Intelligence, Software Development and Knowledge Engineering; Batarseh, F.A., Yang, R., Eds.; Academic Press: London, UK, 2020; pp. 9–28. [Google Scholar]
- Anhalt-Depies, C.; Stenglein, J.L.; Zuckerberg, B.; Townsend, P.A.; Rissman, A.R. Tradeoffs and tools for data quality, privacy, transparency, and trust in citizen science. Biol. Conserv. 2019, 238, 108195. [Google Scholar] [CrossRef]
- Lhoste, E.F. Can do-it-yourself laboratories open up the science, technology, and innovation research system to civil society? Technol. Forecast. Soc. Chang. 2020, 161, 120226. [Google Scholar] [CrossRef]
- Dunnett, S.; Sorichetta, A.; Taylor, G.; Eigenbrod, F. Harmonised global datasets of wind and solar farm locations and power. Sci. Data 2020, 7, 130. [Google Scholar] [CrossRef]
- The State of AI and Machine Learning 2017. Available online: https://appen.com/resources/whitepapers/ (accessed on 3 February 2021).
- The State of AI and Machine Learning 2018. Available online: https://appen.com/resources/whitepapers/ (accessed on 3 February 2021).
- Ntoutsi, N.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in Data-driven AI Systems—An Introductory Survey. arXiv 2020, arXiv:2001.09762. [Google Scholar]
- Bascones, M.; Staniforth, A. What is all this fuss about? Is wrong metadata really bad for libraries and their end-users? Insights 2018, 31, 41. [Google Scholar] [CrossRef]
- Studer, R.; Benjamins, R.; Fensel, D. Knowledge engineering: Principles and methods. Data Knowl. Eng. 1998, 25, 161–198. [Google Scholar] [CrossRef]
- Arp, R.; Smith, B.; Spear, A.D. Building Ontologies with Basic Formal Ontology; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Glauer, M.; Booshehri, M.; Emele, L.; Flügel, S.; Förster, H.; Frey, J.; Frey, U.; Hastings, J.; Hofmann, C.; Hoyer-Klick, C.; et al. The Open Energy Ontology ESWC 2021 Conference Resources Track. Available online: https://openreview.net/forum?id=ofZ5BBg2lSe (accessed on 23 December 2020).
- Stavropoulos, T.G.; Vrakas, D.; Vlachava, D.; Bassiliades, N. BOnSAI: A smart building ontology for ambient intelligence. In WIMS ’12 Proc. of the 2nd International Conference on Web Intelligence, Mining and Semantics; Burdescu, D.D., Akerkar, R., Bădică, C., Eds.; Association for Computing Machinery: New York, NY, USA, 2012; pp. 1–12. [Google Scholar]
- Lork, C.; Choudhary, V.; Hassan, N.U.; Tushar, W.; Yuen, C.; Ng, B.K.K.; Wang, X.; Liu, X. An Ontology-Based Framework for Building Energy Management with IoT. Electronics 2019, 8, 485. [Google Scholar] [CrossRef]
- Ouhajjou, N.; Loibl, W.; Anjomshoaa, A.; Fenz, S. An Ontology-based Urban Energy Planning Support: Building-Integrated Solar PV. In Architecture, Engineering, and Construction; Mahdavi, A., Martens, B., Scherer, R., Eds.; CRS Press: London, UK, 2014; pp. 543–550. [Google Scholar]
- Shah, N.; Chao, K.M.; Zlamaniec, T.; Matei, A. Ontology for Home Energy Management Domain. In Digital Information and Communication Technology and Its Applications, Proceedings of the International Conference DICTAP 2011; Cherifi, H., Mohamad Zain, J., El-Qawasmeh, E., Eds.; Springer: Cham, Switzerland, 2011; pp. 337–347. [Google Scholar]
- Santos, G.; Pinto, T.; Vale, Z.; Praça, I.; Morais, H. Electricity markets ontology to support MASCEM’s simulations. In Highlights of Practical Applications of Scalable Multi-Agent Systems. The PAAMS Collection: International Workshops of PAAMS 2016; Bajo, J., Ed.; Springer: Cham, Switzerland, 2016; pp. 393–404. [Google Scholar]
- Oppermann, L.; Hinrichs, E.; Schade, U.; Koch, T.; Rettweiler, M.; Ohrem, F.; Plötz, P.; Beier, C.; Prinz, W. EnArgus: Zentrales Informationssystem Energieforschungsförderung. In GI Edition Proceedings Band 246 45. Jahrestagung der Gesellschaft für Informatik—INFORMATIK 2015; Cunningham, D.W., Hofstedt, P., Meer, K., Schmitt, I., Eds.; Gesellschaft für Informatik eV.: Bonn, Germany, 2015; pp. 1717–1730. [Google Scholar]
- Burel, G.; Piccolo, L.G.S.; Alani, H. EnergyUse—A Collective Semantic Platform for Monitoring and Discussing Energy Consumption. In The Semantic Web—ISWC 2016; Groth, P., Simperl, E., Gray, A.J.G., Sabou, M., Krötzsch, M., Lecue, F., Flöck, G.Y., Eds.; Springer: Cham, Switzerland, 2016; pp. 257–272. [Google Scholar]
- Blomqvist, E.; Thollanderb, P.; Keskisärkkä, R. Energy Efficiency Measures as Linked Open Data; IOS Press: Lund, Sweden, 2014. [Google Scholar]
- Cuenca, J.; Larrinaga, F.; Curry, E. A Unified Semantic Ontology for Energy Management Applications. WSP/WOMoCoE@ISWC, 86–97. Data Scientist Report. 2017. Available online: https://visit.figure-eight.com/rs/416-ZBE-142/images/CrowdFlower_DataScienceReport.pdf (accessed on 6 December 2020).
- Boosheri, M.; Emele, L.; Flügel, S.; Förster, H.; Frey, J.; Frey, U.; Glauer, M.; Hastings, J.; Hofmann, C.; Hoyer-Klick, C.; et al. Introducing the Open Energy Ontology: Enhancing data interpretation and interfacing in energy systems analysis. Energy AI 2021, 5, 100074. [Google Scholar] [CrossRef]
- Devanand, A.; Karmakar, G.; Krdzavac, N.; Rigo-Mariani, R.; Foo Eddy, Y.S.F.; Karimi, I.A.; Markus Kraft, M. OntoPowSys: A power system ontology for cross domain interactions in an eco industrial park. Energy AI 2020, 1, 100008. [Google Scholar] [CrossRef]
- Küçük, D.; Küçük, D. OntoWind: An Improved and Extended Wind Energy Ontology. arXiv 2018, arXiv:1803.02808. [Google Scholar]
- Gillani, S.; Laforest, F.; Picard, G. A Generic Ontology for Prosumer-Oriented Smart Grid. In Proceedings of the CEUR Workshop, Aalborg, Denmark, 7–11 July 2014. [Google Scholar]
- ETSI: SmartM2M;Smart Appliances Extension to SAREF; Part 1: Energy Domain, (ETSI TS 103 410-1), 2017. Available online: https://saref.etsi.org/saref4ener/v1.1.2/ (accessed on 30 December 2020).
- Haghgoo, M.; Sychev, I.; Monti, A. SARGON–Smart energy domain ontology. IET Smart Cities 2020, 2, 191–198. [Google Scholar] [CrossRef]
- Lefrançois, M. Planned ETSI SAREF Extensions based on the W3C&OGC SOSA/SSN-compatible SEAS Ontology Patterns. In Proceedings of the Workshop on Semantic Interoperability and Standardization in the IoT, SIS-IoT, Amsterdam, The Netherlands, 20 November 2017. [Google Scholar]
- Madrazo, L.; Sicilia, A.; Gamboa, G. SEMANCO: Semantic tools for carbon reduction in urban planning. In Proceedings of the 9th European Conference Product & Process Modelling, Reykjavik, Island, 25–27 July 2012. [Google Scholar]
- Kott, J.; Kott, M. Generic Ontology of Energy Consumption Households. Energies 2019, 12, 3712. [Google Scholar] [CrossRef]
- Kofler, N.J.; Reinisch, C.; Kastner, W. A semantic representation of energy-related information in future smart homes. Energy Build. 2012, 47, 169–179. [Google Scholar] [CrossRef]
- Sempreviva, A.M.; Vesth, A.; Bak, C.; Verelst, D.R.; Giebel, G.; Danielsen, H.K.; Mikkelsen, L.P.; Andersson, M.; Vasiljevic, N.; Barth, S.; et al. Taxonomy and metadata for wind energy Research and Development. IRPWind Report 2017, Zenodo. Available online: http://doi.org/10.5281/zenodo.1199489 (accessed on 17 February 2021).
- Vasiljevic, N.; Sempreviva, A.M. Wind Energy Taxonomy of Topics. Available online: http://data.windenergy.dtu.dk/controlled-terminology/taxonomy-topics/ (accessed on 17 February 2021).
- DTU Wind Energy, Wind Energy Parameters. Available online: http://data.windenergy.dtu.dk/controlled-terminology/wind-energy-parameters/ (accessed on 17 February 2021).
- Collier, D.; Mahon, J. Conceptual ‘Stretching’ Revisited: Adapting Categories in Comparative Analysis. Am. Polit. Sci. Rev. 1993, 87, 845–855. [Google Scholar]
- Sartori, G. Concept Misformation in Comparative Politics. Am. Polit. Sci. Rev. 1970, 64, 1033–1053. [Google Scholar]
- Chen, H.; Luo, X. An automatic literature knowledge graph and reasoning network modeling framework based on ontology and natural language processing. Adv. Eng. Inf. 2019, 42, 100959. [Google Scholar] [CrossRef]
- C2meta. 2021. Continuous Capture of Metadata, University of Michigan. Available online: https://c2metadata.org/ (accessed on 12 January 2021).
- Heckman, J.J. Selection bias. In Encyclopedia of Social Measurement; Kempf-Leonard, K., Ed.; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Thornberg, G.; Oskins, W.M. Misinformation and Bias in Metadata Processing: Matching in Large Databases. Inf. Technol. Libr. 2007, 26, 15–26. [Google Scholar] [CrossRef]
- Murray, D.; Stankovic, L.; Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci. Data 2017, 4, 160122. [Google Scholar]
- Jiang, L.; Xu, L.D.; Cai, H.; Jiang, Z.; Bu, F.; Xu, B. An IoT-oriented data storage framework in cloud computing platform. IEEE Trans. Ind. Inf. 2014, 10, 1443–1451. [Google Scholar]
- Govindarajan, R.; Meikandasivam, S.; Vijayakumar, D. Cloud computing based smart energy monitoring system. Int. J. Sci. Technol. Res. 2019, 8, 886–890. [Google Scholar]
- Giordano, A.; Mastroianni, C.; Sorrentino, N.; Menniti, D.; Pinnarelli, A. An energy community implementation: The unical energy cloud. Electronics 2019, 8, 1517. [Google Scholar]
- Burgio, A.; Giordano, A.; Manno, A.A.; Mastroianni, C.; Menniti, D.; Pinnarelli, A.; Scarcello, L.; Sorrentino, N.; Stillo, M. An IoT Approach for Smart Energy Districts. In Proceedings of the 2017 IEEE 14th International Conference on Networking, Sensing and Control (ICNSC), Calabria, Italy, 16–18 May 2017; pp. 146–151. [Google Scholar]
- Go-Fair Website, Metadata for Machines. Available online: https://www.go-fair.org/how-to-go-fair/metadata-for-machines/ (accessed on 3 December 2020).
- Gonçalves, R.S.; O’Connor, M.J.; Martínez-Romero, M.; Egyedi, A.L.; Willrett, D.; Graybeal, J.; Musen, M.A. The CEDAR Workbench: An Ontology-Assisted Environment for Authoring Metadata that Describe Scientific Experiments. In The Semantic Web—ISWC 2017; d’Amato, C., Fernandez, M., Tamma, V., Lecue, F., Cudré-Mauroux, P., Sequeda, J., Lange, C., Heflin, J., Eds.; Springer: Cham, Switzerland, 2017; pp. 103–110. [Google Scholar]
- Vasiljevic, N. sheet2rdf: Automatic Workflow for Generation of RDF Vocabularies from Google Sheets (Version v0.1). Zenodo. Available online: http://doi.org/10.5281/zenodo.4432136 (accessed on 17 February 2021).
- Vasiljevic, N.; Graybeal, J. excel2rdf: Automatic Workflow for Generation of RDF Vocabularies from Excel Sheets (Version v0.1). Zenodo. Available online: http://doi.org/10.5281/zenodo.4273159 (accessed on 17 February 2021).
- DeiC. 2020. M4M for the Danish e-Infrastructure Cooperation. Available online: https://www.go-fair.org/2020/07/08/m4m-for-the-danish-e-infrastructure-cooperation/ (accessed on 17 February 2021).
- Graybeal, J. Easy FAIR Metadata for Earth Science. Available online: http://bit.ly/fair-metadata (accessed on 17 February 2020).
- Hotmaps Project. Available online: https://gitlab.com/hotmaps/ (accessed on 17 February 2021).
- Magagna, B.; Schultes, E.A.; Pergl, R.; Hettne, K.; Kuhn, T.; Suchánek, M. Reusable FAIR Implementation Profiles as Accelerators of FAIR Convergence. OSF Preprints. Available online: https://doi.org/10.31219/osf.io/2p85g (accessed on 17 February 2021).
- Lammey, R.; Mitchell, D.; Counsell, F. Metadata 2020: A collaborative effort to improve metadata quality in scholarly communications. In Septentrio Conference Series; No 1 (2018): The 13th Munin Conference; Scholarly Publishing: Tromsø, Norway, 2018. [Google Scholar]
- Schneider, J. Metadata 2020: Updates and Plans, Research Data Alliance, Berlin 2018. Available online: https://rd-alliance.org/system/files/documents/RDA_Metadata2020.pdf (accessed on 28 December 2020).
- National Information Standards Organization (NISO). A Framework of Guidelines for Building Good Digital Collections (3rd Edition). 2007. Available online: https://www.niso.org/sites/default/files/2017-08/framework3.pdf (accessed on 17 February 2021).
- Wilkinson, M.D.; Dumontier, M.; Sansone, S.A.; da Silva Santos, L.O.B.; Prieto, M.; Batista, D.; McQuilton, P.; Kuhn, T.; Rocca-Serra, P.; Crosas, M.; et al. Evaluating FAIR maturity through a scalable, automated, community-governed framework. Sci. Data 2019, 6, 174. [Google Scholar] [CrossRef] [PubMed]
- Király, P.A. Metadata Quality Assurance Framework; Gesellschaft für wissenschaftliche Datenverarbeitung mbH Göttingen (GWDG): Göttingen, Germany, 2015. [Google Scholar]
- Stiller, J.; Király, P. Multilinguality of Metadata Measuring the Multilingual Degree of Europeana’s Metadata. In Everything Changes, Everything Stays the Same? Understanding Information Spaces, Proceedings of the 15th International Symposium of Information Science (ISI 2017), Berlin, 13–15 March 2017; Gäde, M., Trkulja, V., Petras, V., Eds.; Werner Hülsbusch Publishing: Glückstadt, Germany, 2017; pp. 164–176. [Google Scholar]
- Bruce, T.R.; Hillmann, D.I. The Continuum of Metadata Quality: Defining, Expressing, Exploiting. In Metadata in Practice; Hillmann, D., Westbrooks, E., Eds.; ALA Editions: Chicago, IL, USA, 2004; pp. 238–256. [Google Scholar]
- Ochoa, X.; Duval, E. Automatic Evaluation of Metadata Quality in Digital Repositories. Int. J. Dig. Libr. 2009, 10, 67–91. [Google Scholar] [CrossRef]
- Kemp, J.; Dean, C.; Chodacki, J. Can Richer Metadata rescue research? Ser. Libr. 2018, 74, 207–211. [Google Scholar] [CrossRef]
- Scott, J. The Metadata Mania. 2011. Available online: http://ascii.textfiles.com/archives/3181 (accessed on 17 February 2021).



{kind=link}
{kind=link}
{kind=link}
| Name | Field of Application | Reference |
|---|---|---|
| BOnSAI | Smart building ontology for ambient intelligence | [46,47] |
| Building Integrated PV | Urban energy planning for building integrated PV | [48] |
| DEHEMS | Energy consumption behavior of households | [49] |
| Electr. Markets Ontology | Supporting agent-based simulations | [50] |
| EnArgus Ontology | Reporting on energy projects | [51] |
| EnergyUse ontology | Collaborative web-based framework | [52] |
| DEFRAM | Energy efficiency measures | [53] |
| OEMA ontology network | Energy management ontology | [54] |
| OEO | Open energy ontology by the energy modeling community | [55] |
| OntoPowSys | Power system ontology for eco industrial parks | [56] |
| OntoWind | Wind Energy Ontology | [57] |
| ProSGV3 | Smart energy consumption | [58] |
| SAREF4ENER | Smart household appliances and flexibility | [59] |
| SARGON | Intelligent energy domain ontology | [60] |
| SEAS Ontology | Generalisation of the Semantic Sensor Ontology | [61] |
| SEMANCO ontology | Low carbon infrastructure urban planning | [62] |
| SUMO | Upper foundation ontology owned by IEEE | [63] |
| ThinkHome | Energy Resources Ontology | [47,64] |
| WETAXTOPICS | Wind Energy Taxonomy of Topics | [65,66] |
| WEP | Wind Energy Parameters | [67] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wierling, A.; Schwanitz, V.J.; Altinci, S.; Bałazińska, M.; Barber, M.J.; Biresselioglu, M.E.; Burger-Scheidlin, C.; Celino, M.; Demir, M.H.; Dennis, R.; et al. FAIR Metadata Standards for Low Carbon Energy Research—A Review of Practices and How to Advance. Energies 2021, 14, 6692. https://doi.org/10.3390/en14206692
Wierling A, Schwanitz VJ, Altinci S, Bałazińska M, Barber MJ, Biresselioglu ME, Burger-Scheidlin C, Celino M, Demir MH, Dennis R, et al. FAIR Metadata Standards for Low Carbon Energy Research—A Review of Practices and How to Advance. Energies. 2021; 14(20):6692. https://doi.org/10.3390/en14206692
Chicago/Turabian StyleWierling, August, Valeria Jana Schwanitz, Sebnem Altinci, Maria Bałazińska, Michael J. Barber, Mehmet Efe Biresselioglu, Christopher Burger-Scheidlin, Massimo Celino, Muhittin Hakan Demir, Richard Dennis, and et al. 2021. "FAIR Metadata Standards for Low Carbon Energy Research—A Review of Practices and How to Advance" Energies 14, no. 20: 6692. https://doi.org/10.3390/en14206692
APA StyleWierling, A., Schwanitz, V. J., Altinci, S., Bałazińska, M., Barber, M. J., Biresselioglu, M. E., Burger-Scheidlin, C., Celino, M., Demir, M. H., Dennis, R., Dintzner, N., el Gammal, A., Fernández-Peruchena, C. M., Gilcrease, W., Gładysz, P., Hoyer-Klick, C., Joshi, K., Kruczek, M., Lacroix, D., ... Vasiljevic, N. (2021). FAIR Metadata Standards for Low Carbon Energy Research—A Review of Practices and How to Advance. Energies, 14(20), 6692. https://doi.org/10.3390/en14206692