
Advanced Discretisation and Visualisation Methods for Performance Profiling of Wind Turbines


Abstract
:1. Introduction
2. Related Work
2.1. Discretisation of Temporal Data
2.2. Discretisation Approaches for Wind Data
2.3. Visual Analytics
2.4. Non-Negative Matrix Factorisation Approaches
2.5. Wind Turbine Performance Profiling
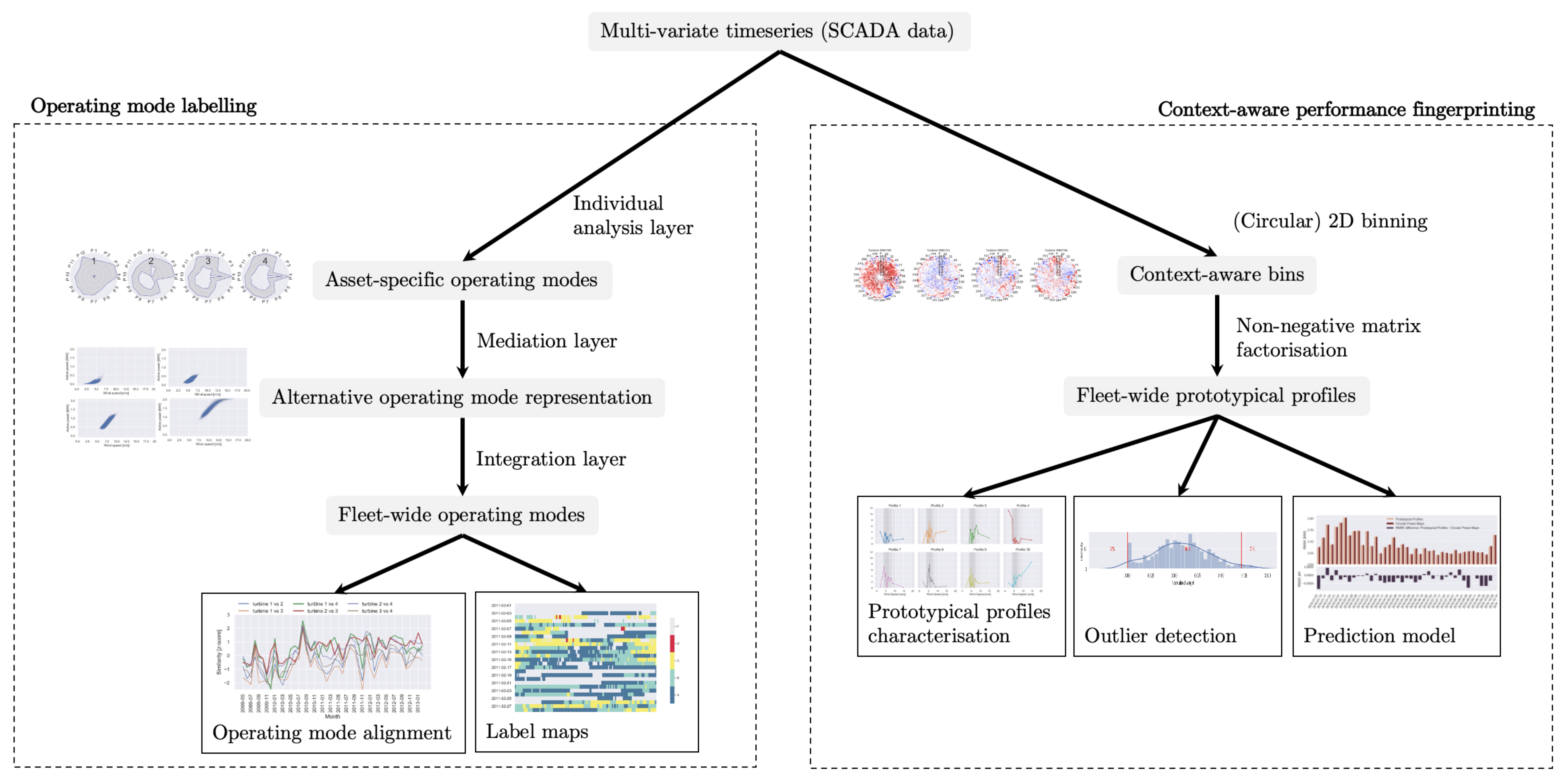
3. Materials and Methods
3.1. Data
3.2. Operating Mode Labelling
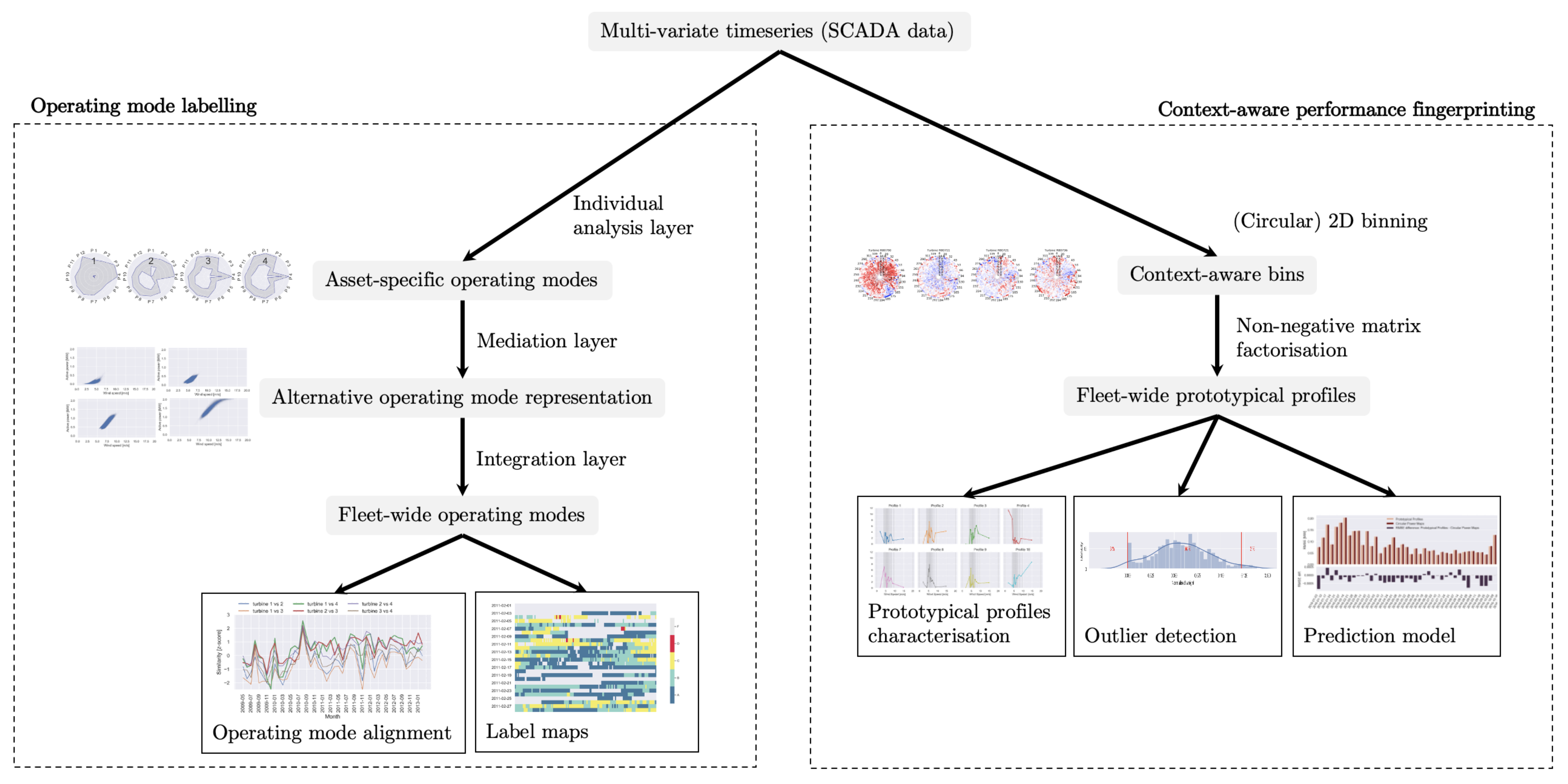
3.2.1. Layered Integration Approach
- (i)
- Individual analysis layer: Apply an individual data analysis per source (wind turbine), solely based on a subset (view) of relevant (e.g., endogenous) parameters.
- (ii)
- Mediation layer: Represent the results from the previous layer by use of an alternative subset of parameters (e.g., exogenous), allowing a comparison of results across data sources (fleet).
- (iii)
- Integration layer: Leverage the previous results from all sources in order to derive explicit links between the different views.
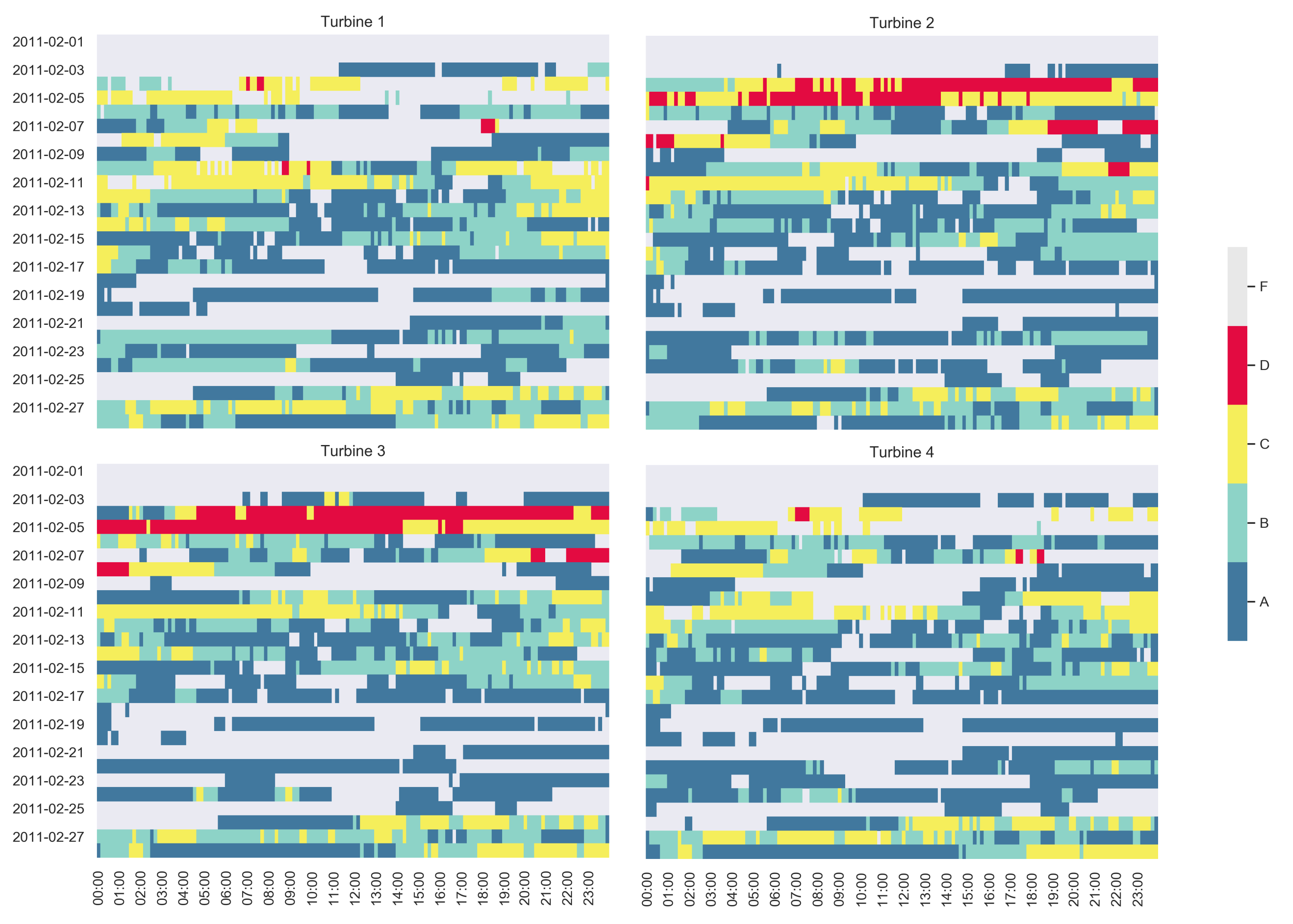
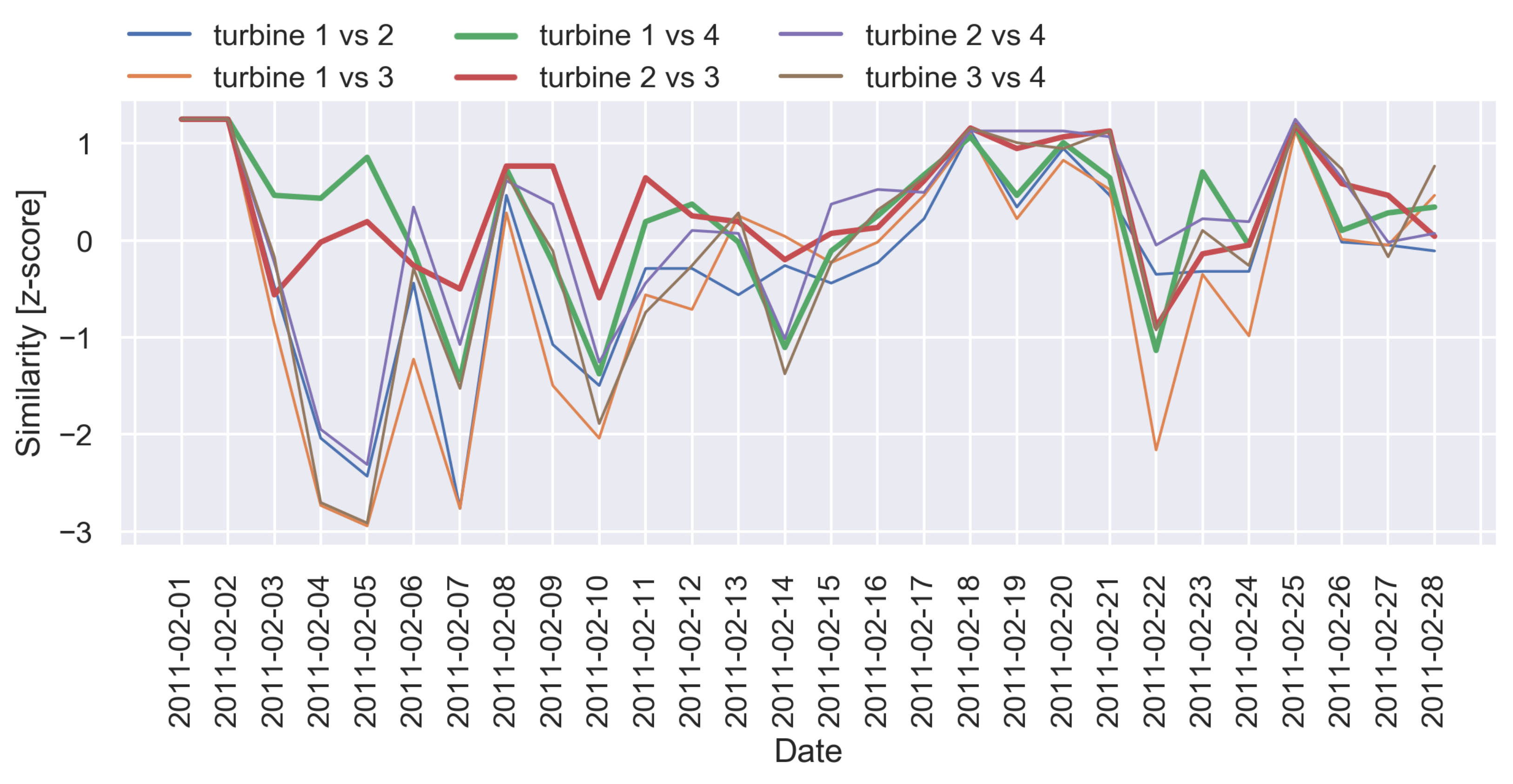
3.2.2. Sequence Alignment
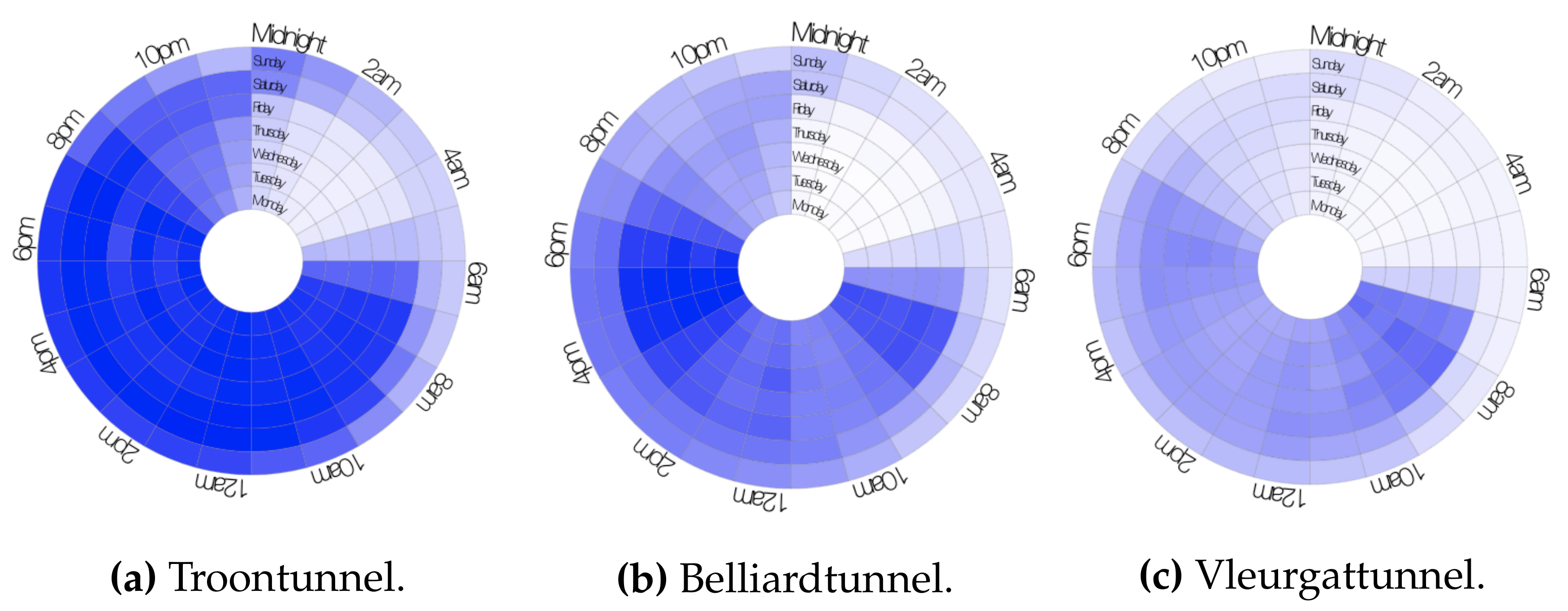
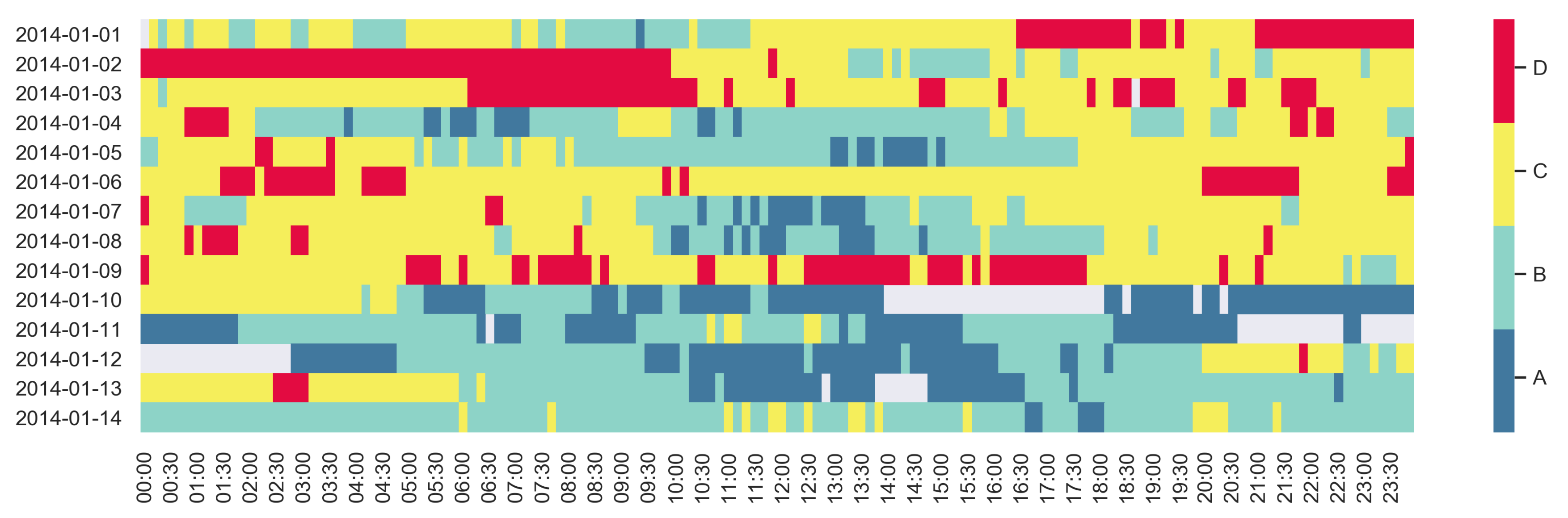
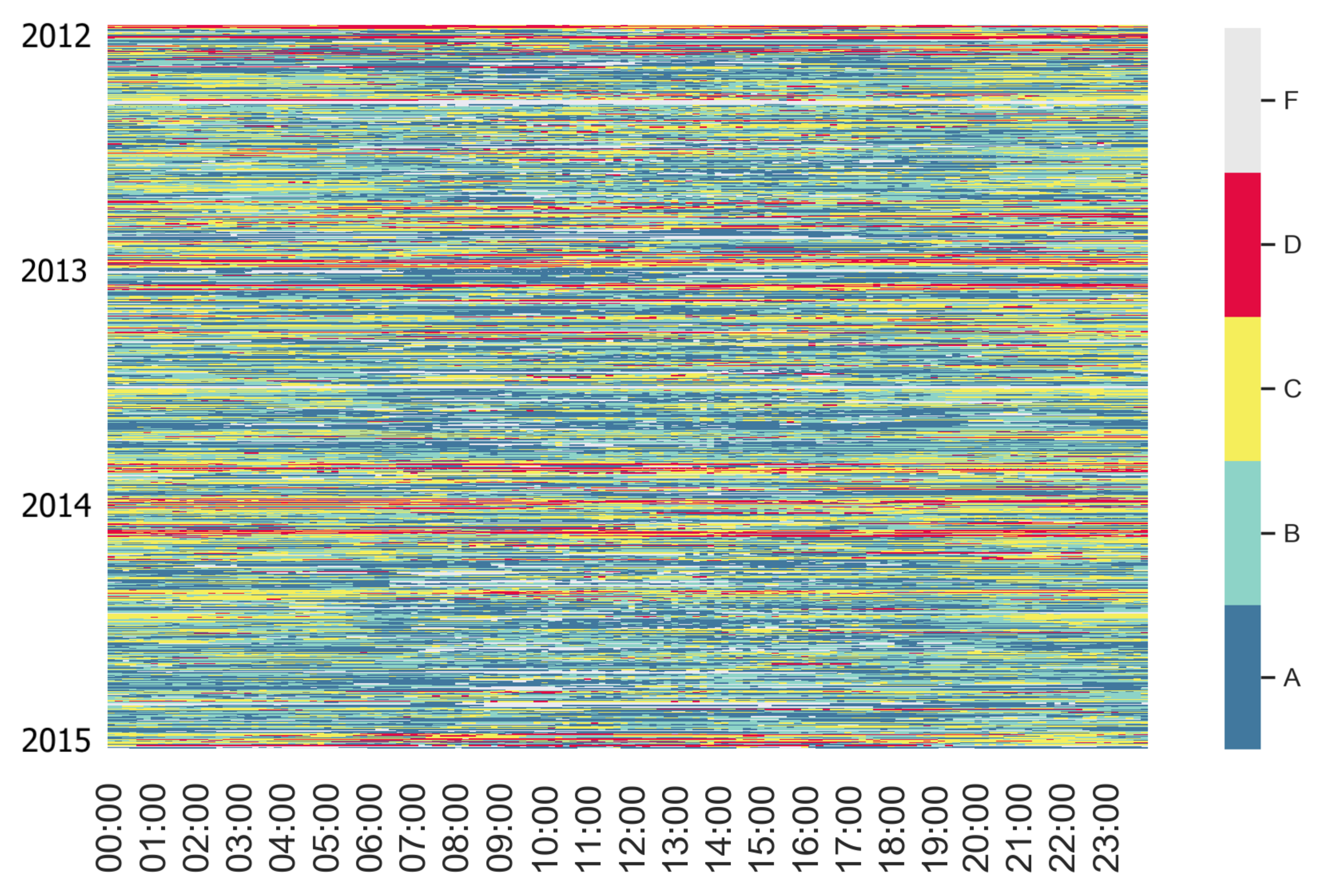
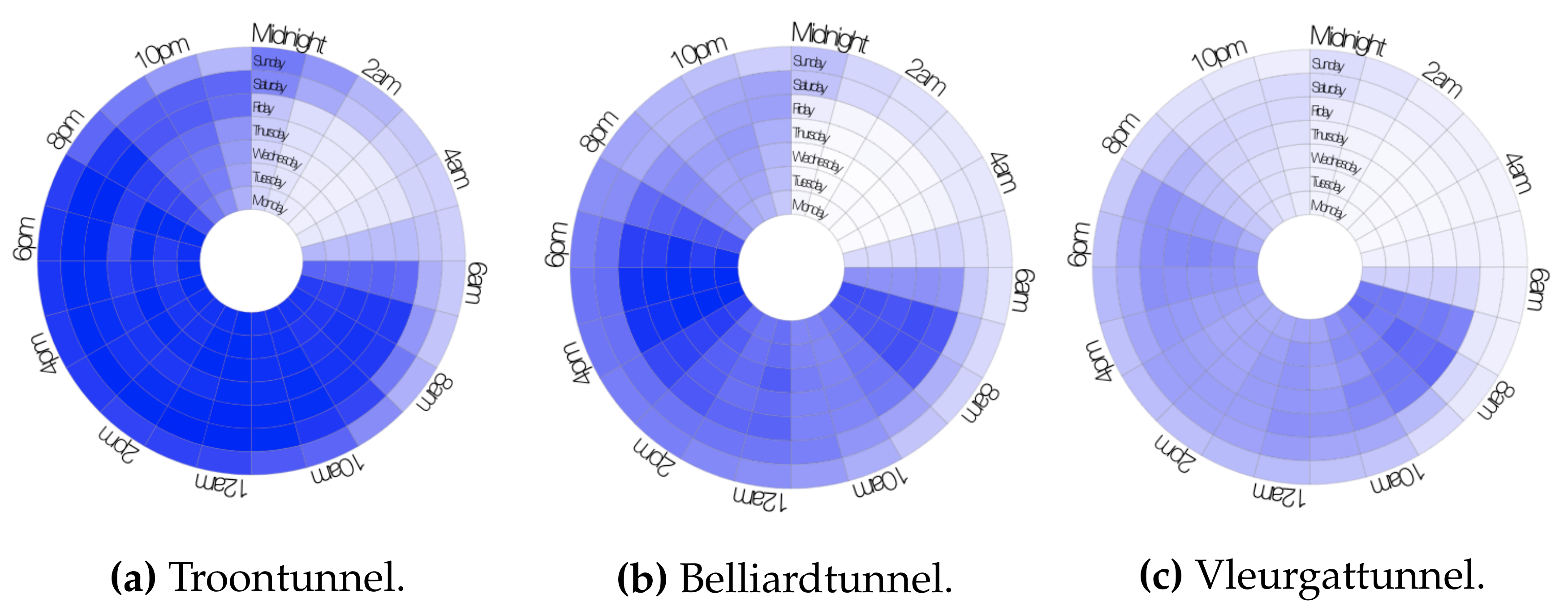
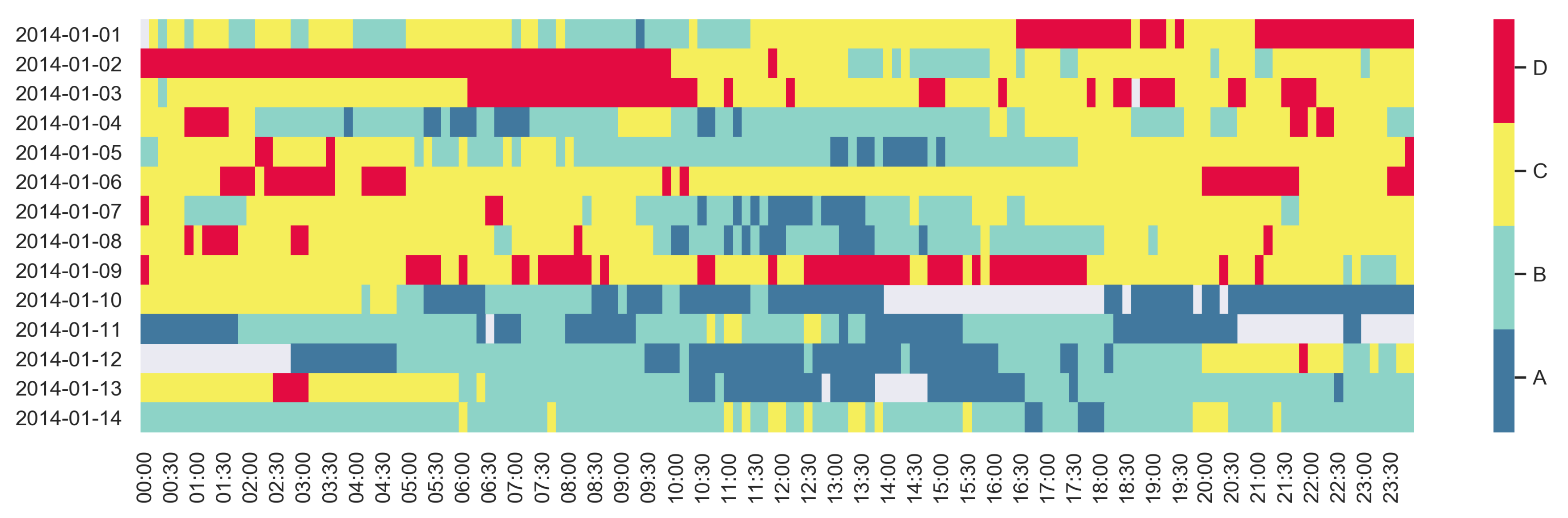
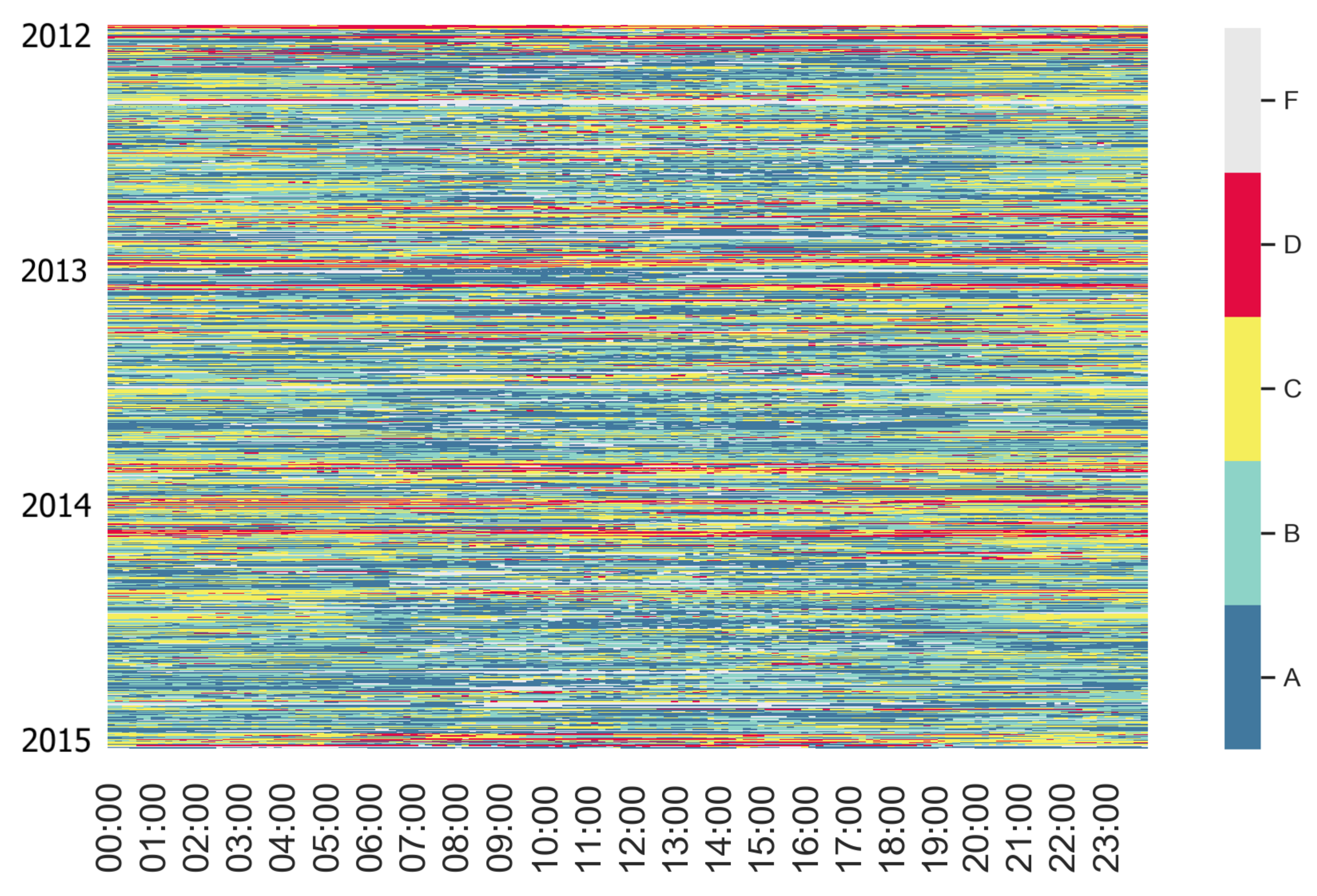
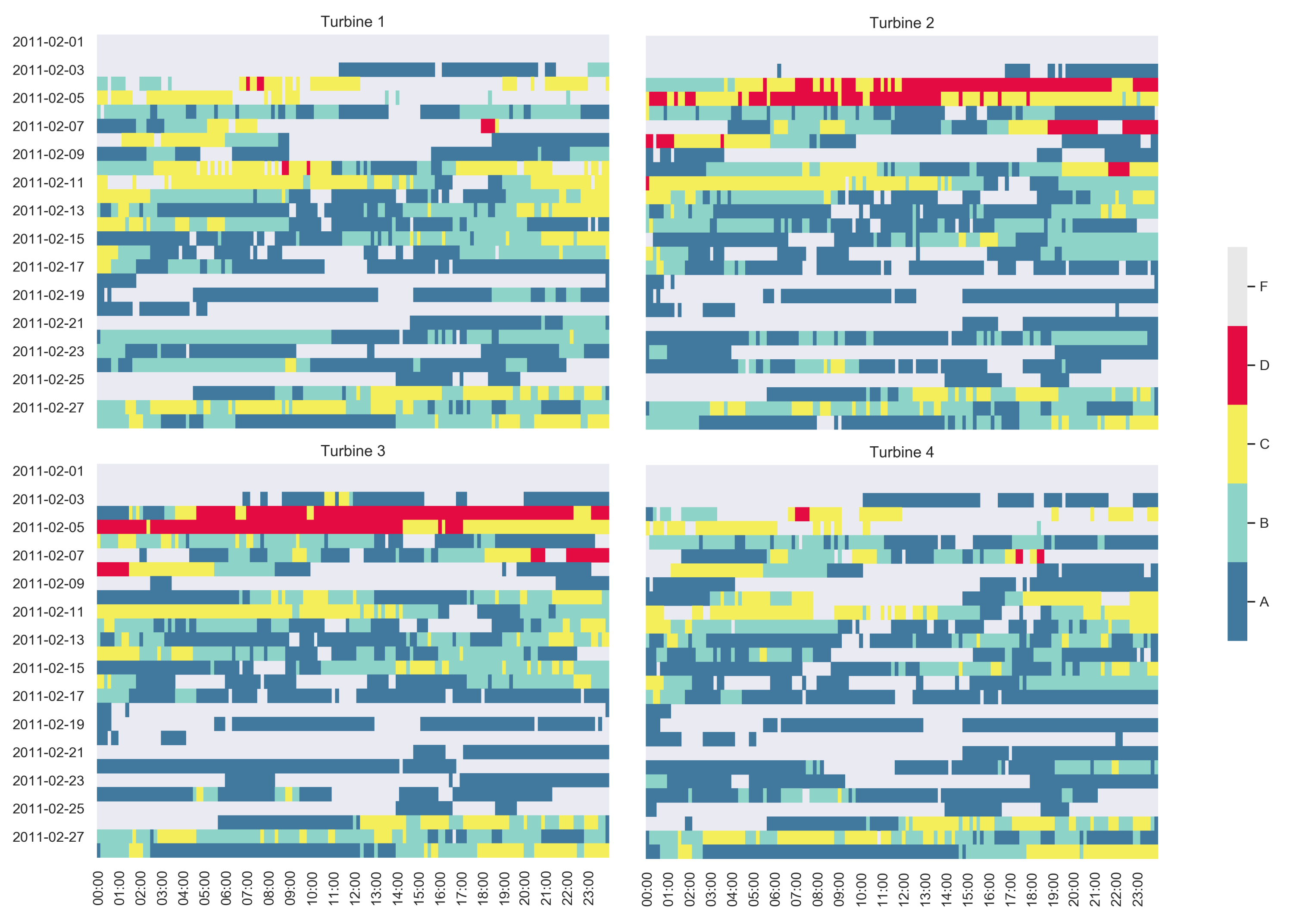
3.2.3. Label Maps
3.3. Context-Aware Performance Fingerprinting
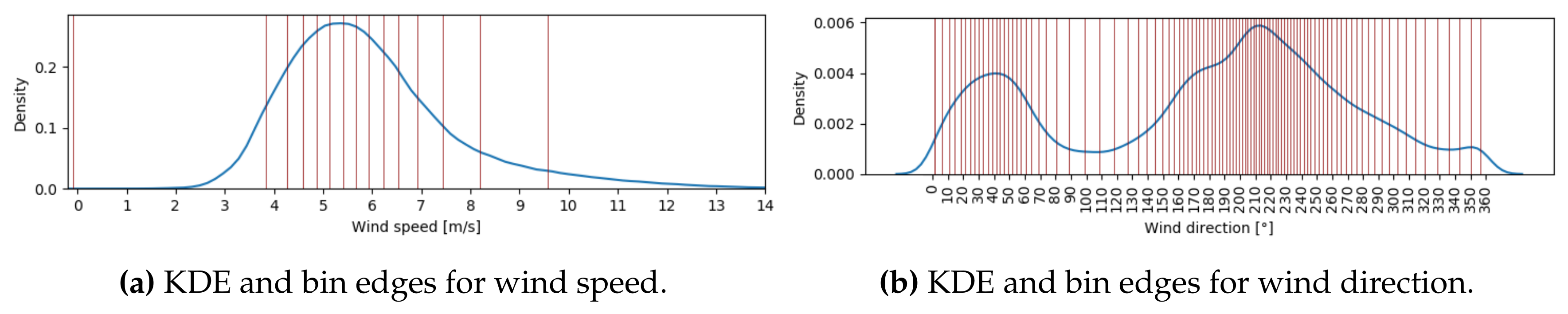
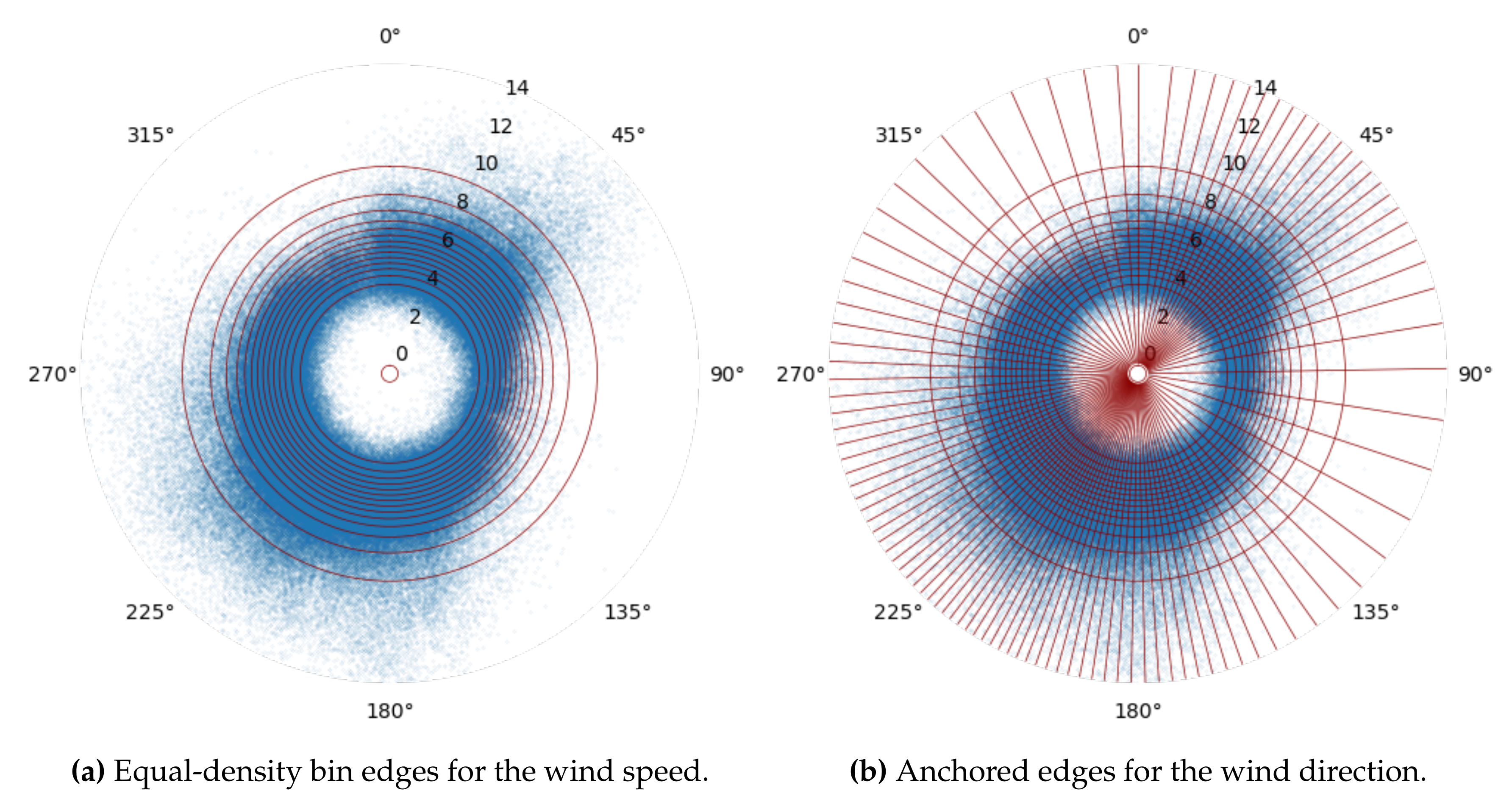
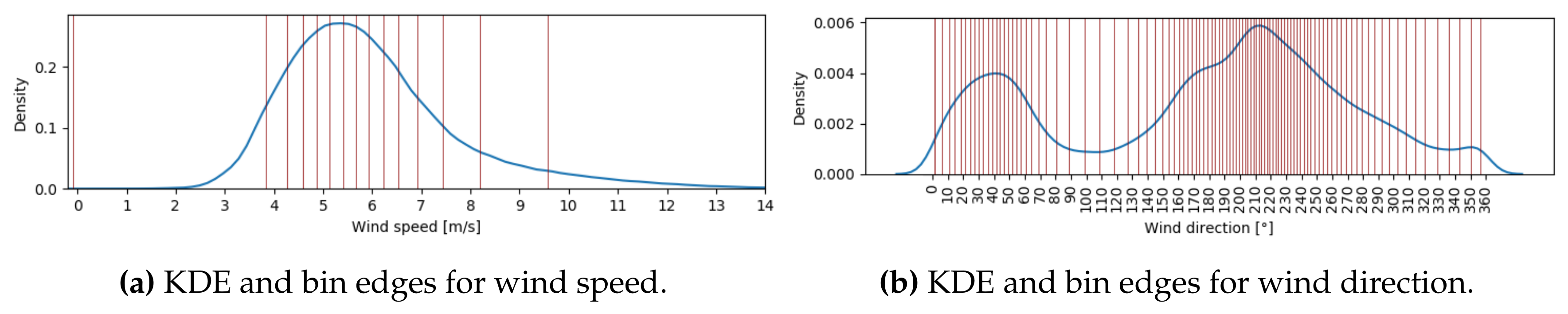
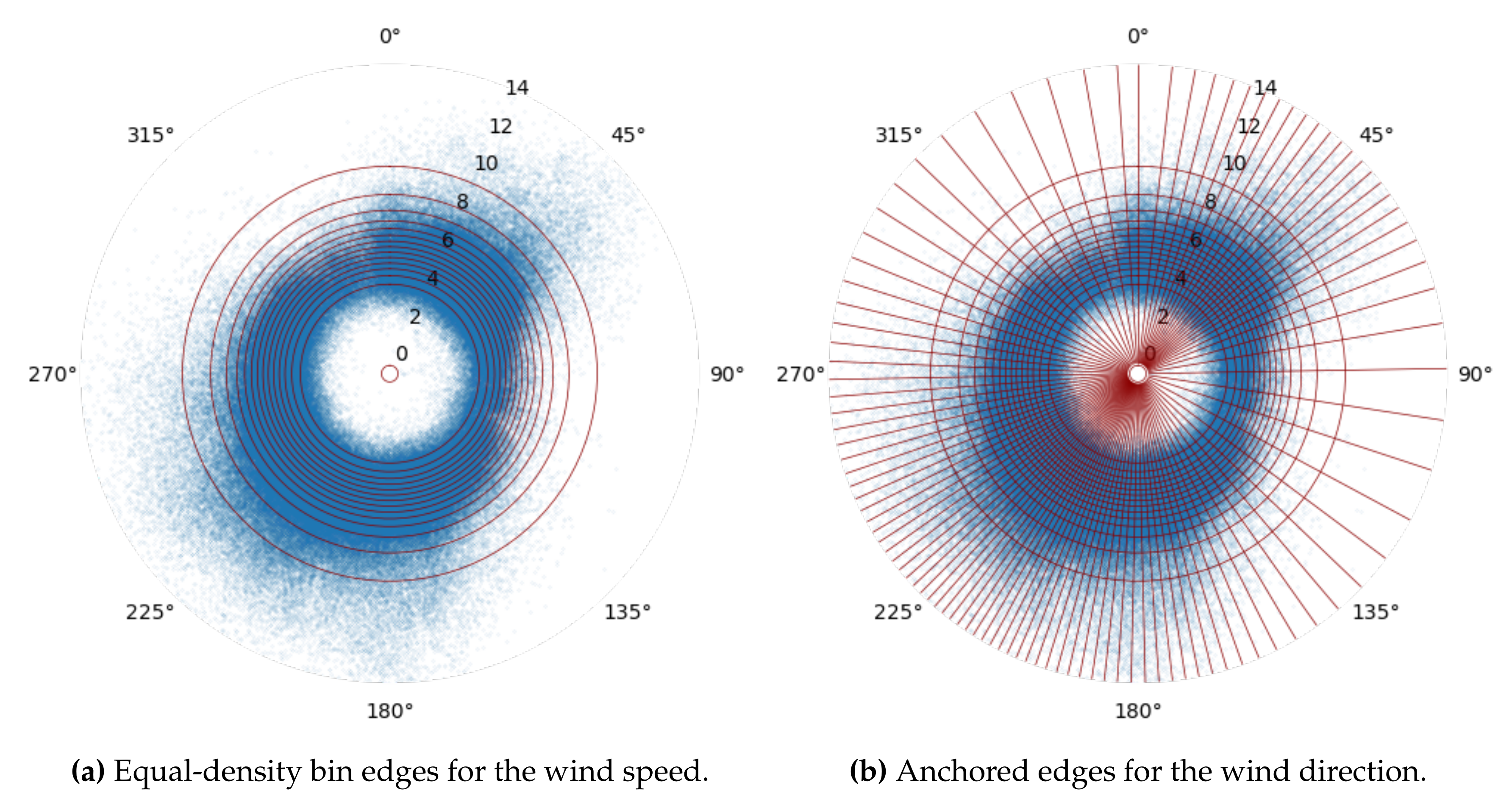
3.3.1. Circular Binning
- (i)
- Anchored-edge binning: All the data points in the polar coordinate system are partitioned into K equal-density (in terms of number of data points contained) sectors along the angular coordinate (see Figure 5a). This approach treats the wind direction parameter in the same way for each wind speed circle. However, note that the above approach does not guarantee perfectly equal-density bins or non-zero bins.
- (ii)
- Equal-density binning: All the data points in each concentric circle l () are partitioned into K equal-density (in terms of number of data points contained) sectors along the angular coordinate (see Figure 5b). This approach treats the wind direction parameter differently for each wind speed circle and generates true equal-density bins.
- (i)
- the first bin is positioned in a concentric circle that is closer to the pole than the concentric cycle in which the second bin is positioned;
- (ii)
- the two bins are positioned in the same concentric cycle, but the second bin is situated clock-wise after the first one when considering the polar axis as the starting position.
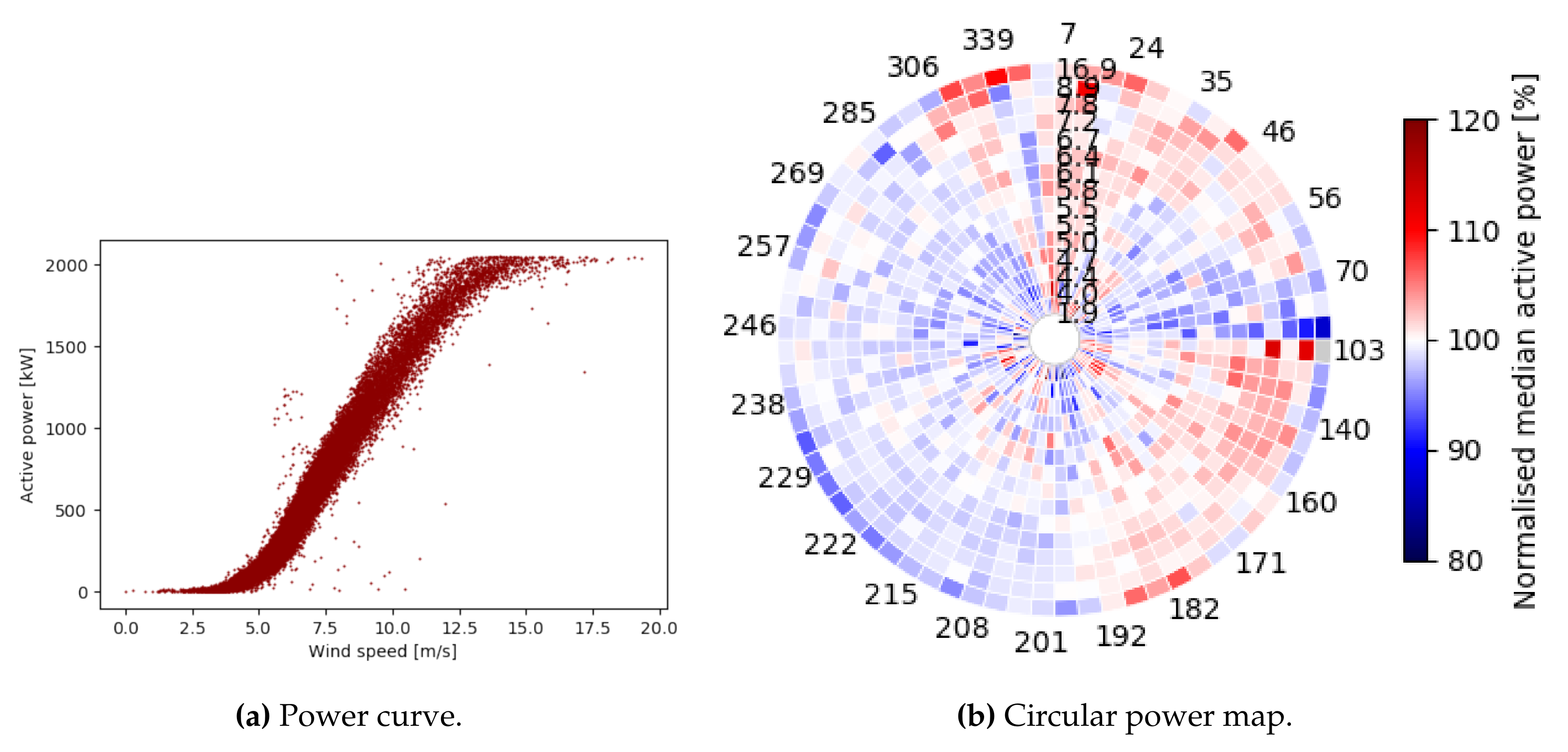
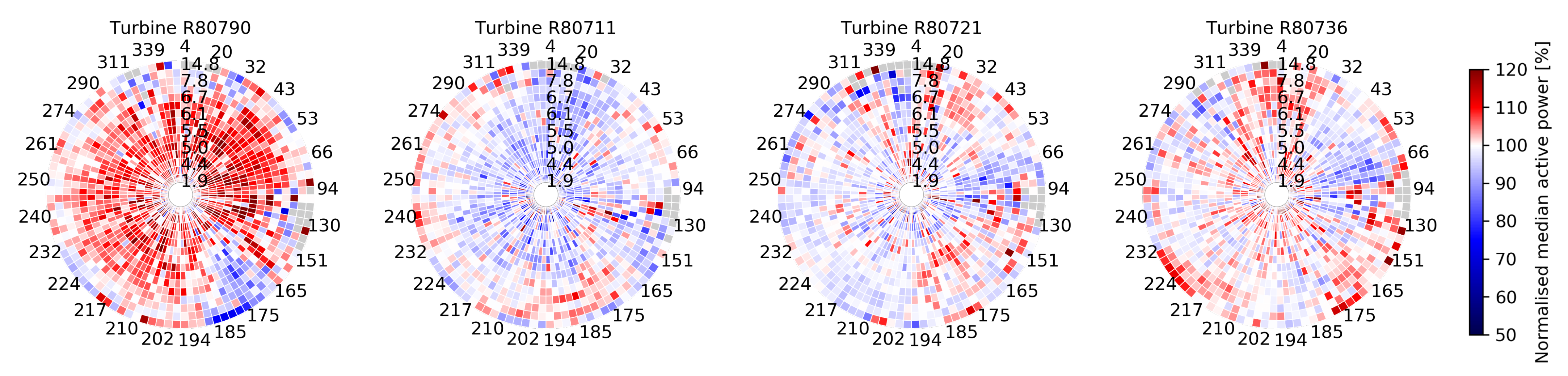
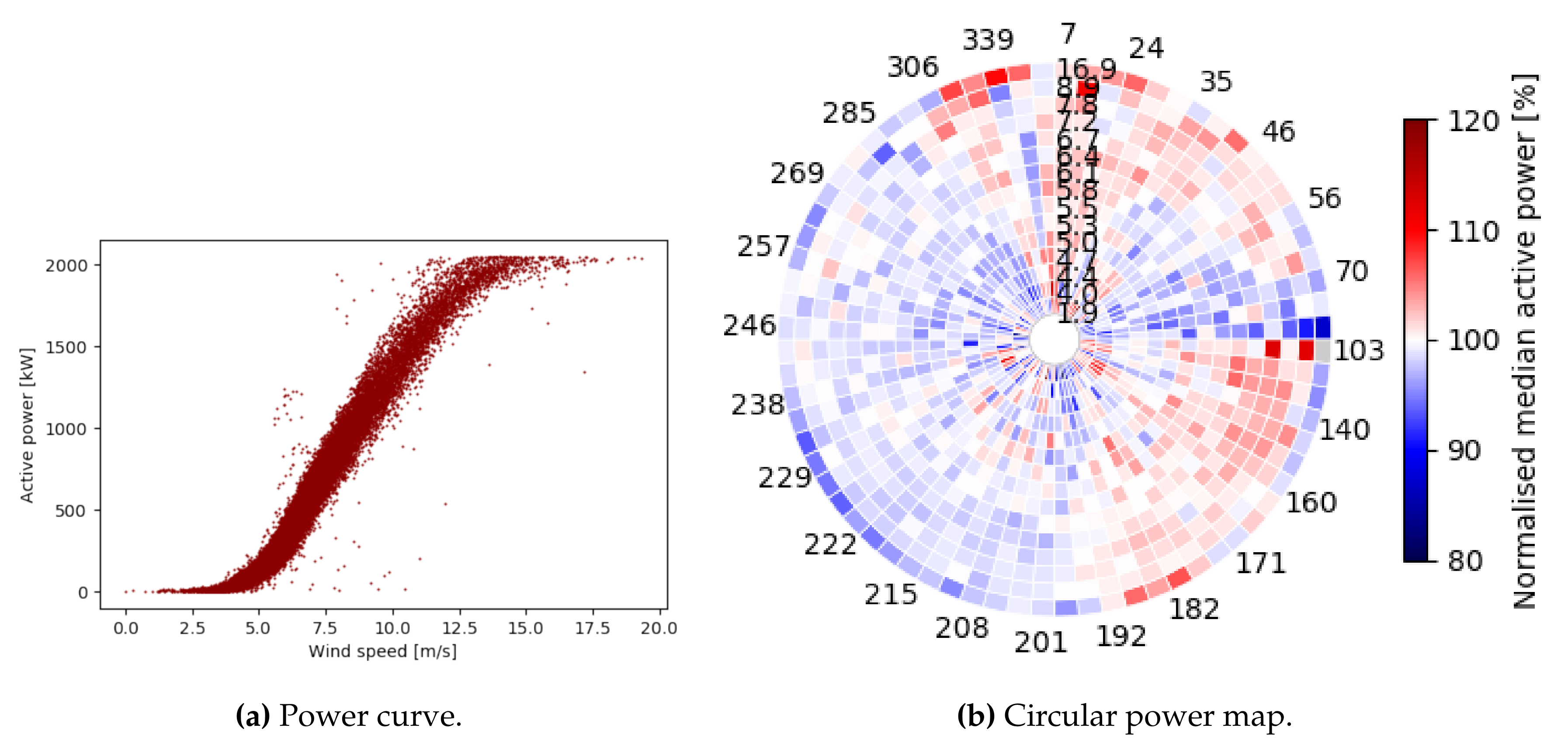
3.3.2. Circular Power Maps
3.3.3. Non-Negative Matrix Factorisation
3.3.4. Prototypical Fleet Profiling
4. Results
4.1. Operating Mode Labelling
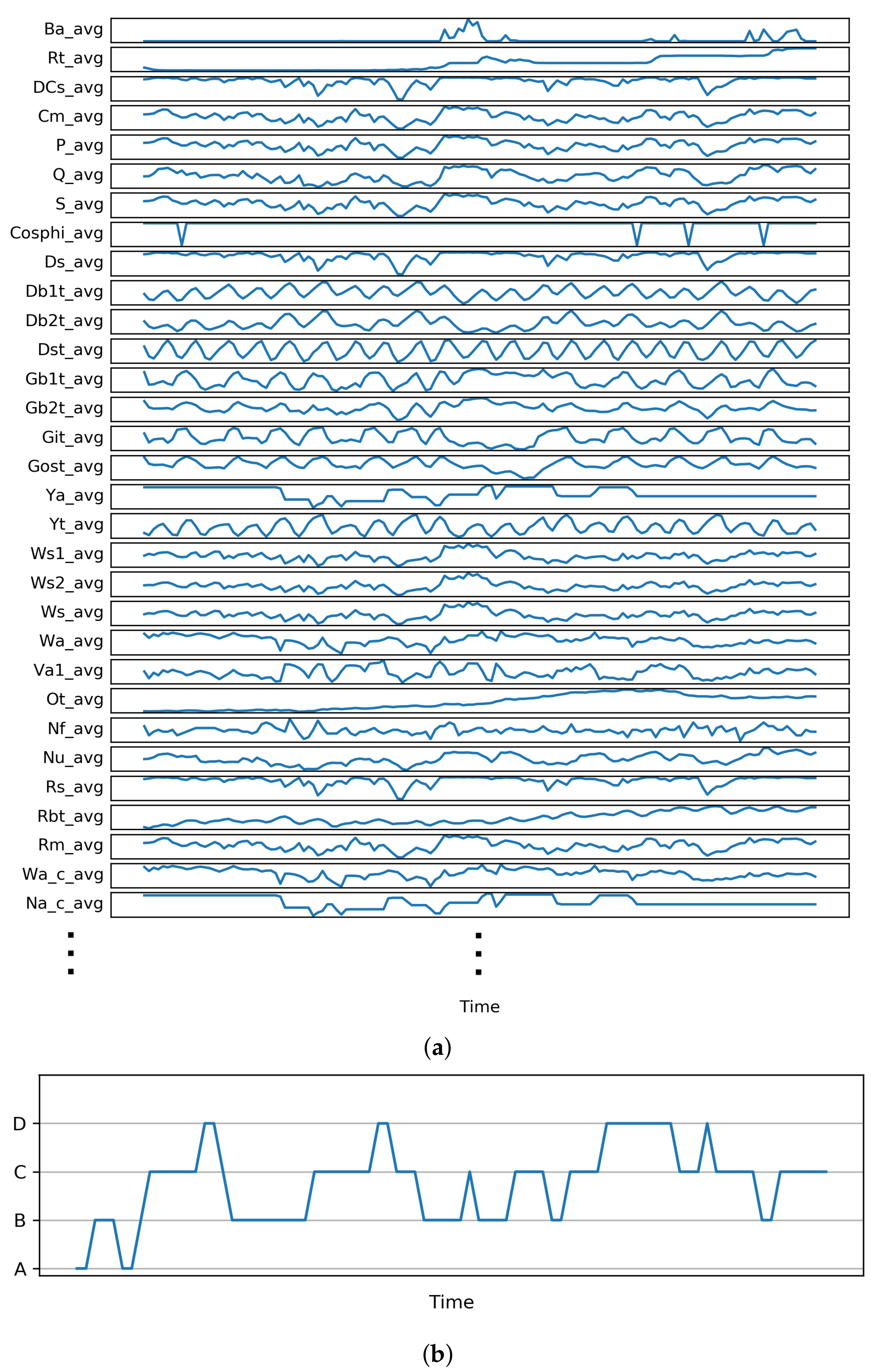
4.1.1. Data Preparation
- (i)
- Eliminate correlated parameters: The values of some of the parameters are highly correlated due to several reasons:
- (i)
- The same phenomenon is monitored with multiple sensors, e.g., for reliability, each wind turbine is equipped with two identical anemometers on its nacelle, both measuring the wind speed.
- (ii)
- Parameters are derived from other parameters, e.g., the average wind speed is constructed by combining the two nacelle anemometer values.
- (iii)
- Some parameters have strong internal dependencies, e.g., generator speed and generator converter speed.
To prevent over-fitting, only a single parameter is selected to represent each set of highly correlated parameters in the experimental data set. - (ii)
- Remove noise: Considering that we are performing research on real-world data, it is expected that the data set will contain a significant amount of noise, e.g., extreme values and outliers. Several different filters based on the active power are applied in order to discard data points with atypical active power values (with respect to the values of the input parameters). To avoid masking source-specific fluctuations, this is applied on each wind turbine separately. In addition, parameters with too many missing values are completely removed from the experimental data set. For more details, see [6].
- (iii)
- Standardise: The values of some of the selected parameters have very different ranges (e.g., nacelle temperature varies between and C, while the generator speed has values between 0 and 1800 rpm), and have a different nature (e.g., angular versus linear). This results in parameter values that are hard to compare. For this reason, the sine and cosine transformation is used to convert angular parameters into two linear values. In the case of the wind direction parameter, we scale the outcome of the trigonometric functions by multiplying them with the wind speed. By doing this, the information on both wind speed and wind direction is captured into the two newly created parameters. In addition, min–max normalisation [37] is applied along the time dimension over the period selected for analysis, per wind turbine. Thanks to this, the parameter ranges are scaled relatively within the same wind turbine between 0 and 1.
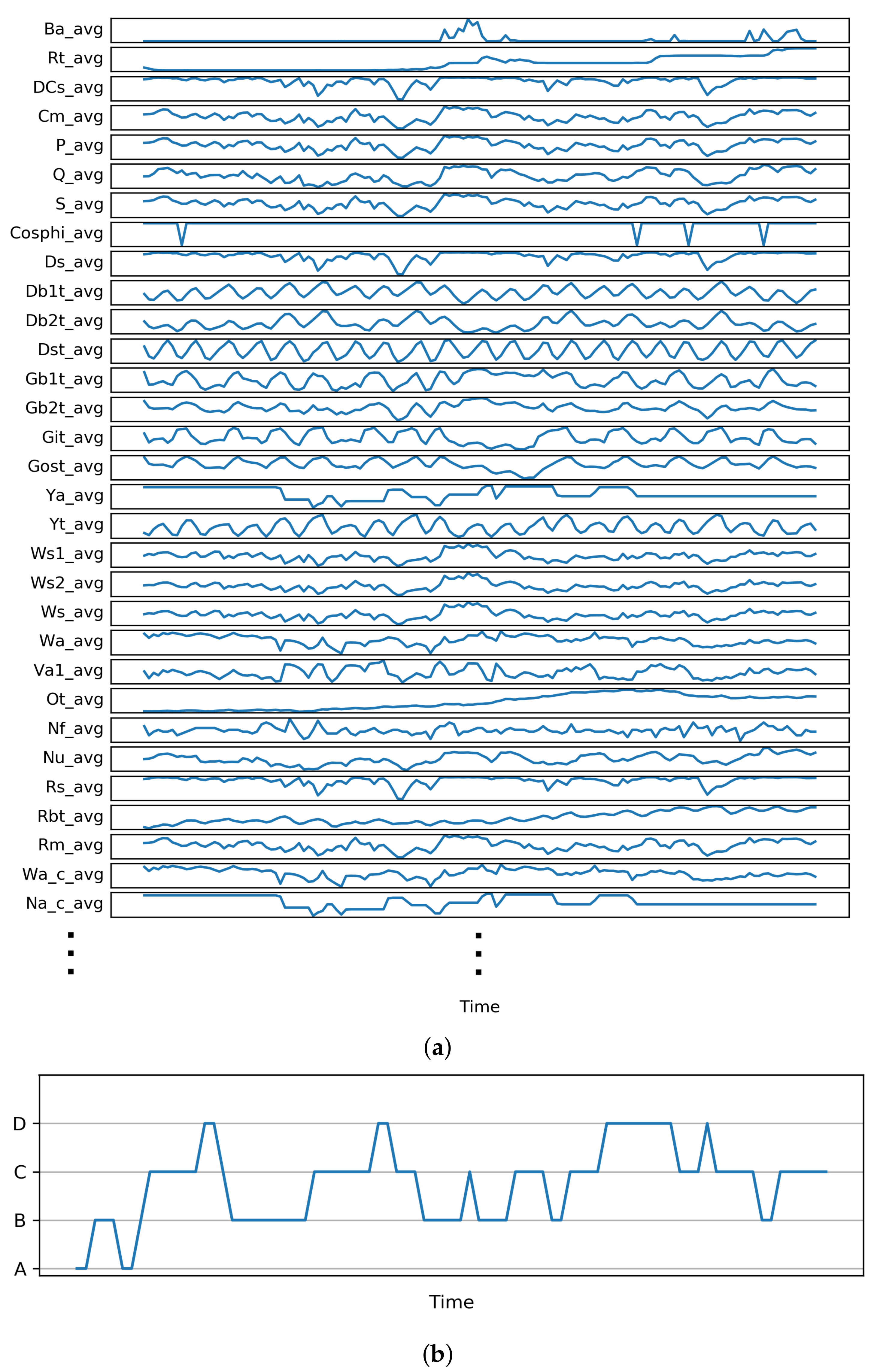
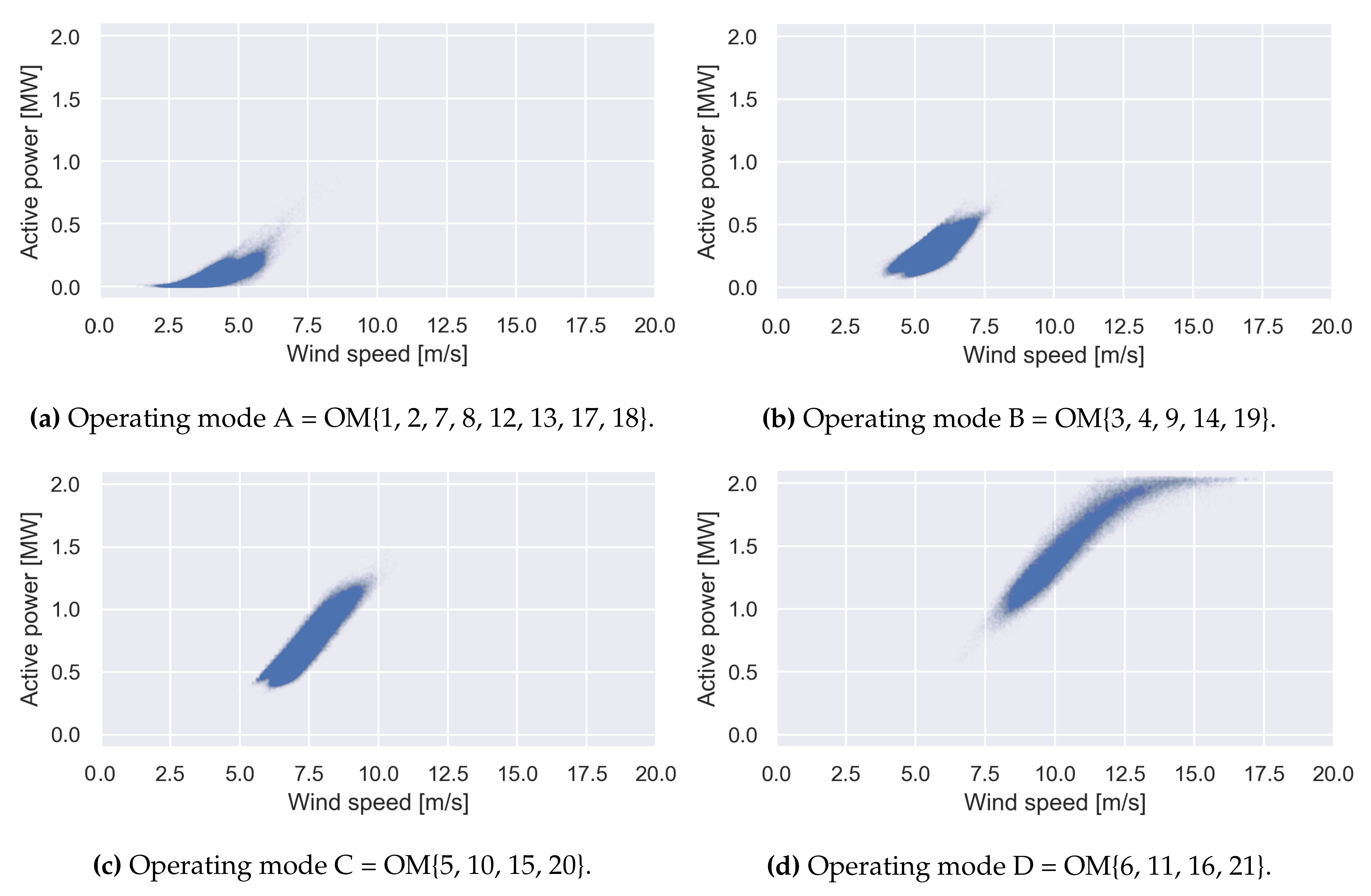
4.1.2. Deriving Operating Modes
- OM A. Pre-startup: The wind is relatively low (e.g., wind gust). The turbine blades can start moving but the wind speed is not sufficient to significantly produce energy.
- OM B. Post-startup: The wind strength is sufficient to start producing energy.
- OM C. Linear mode: Any increase in wind speed results in a linear increase in energy production.
- OM D. High production: There is an optimal wind flow, resulting in high active power.

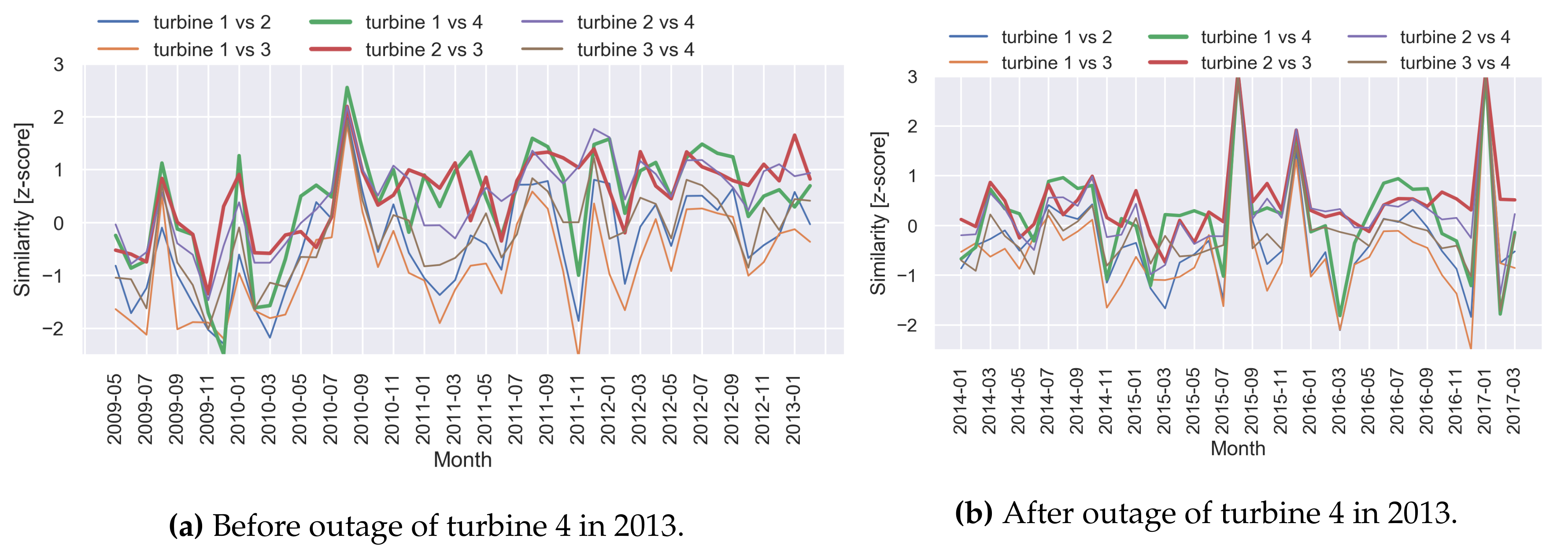
4.1.3. Operating Mode Alignment
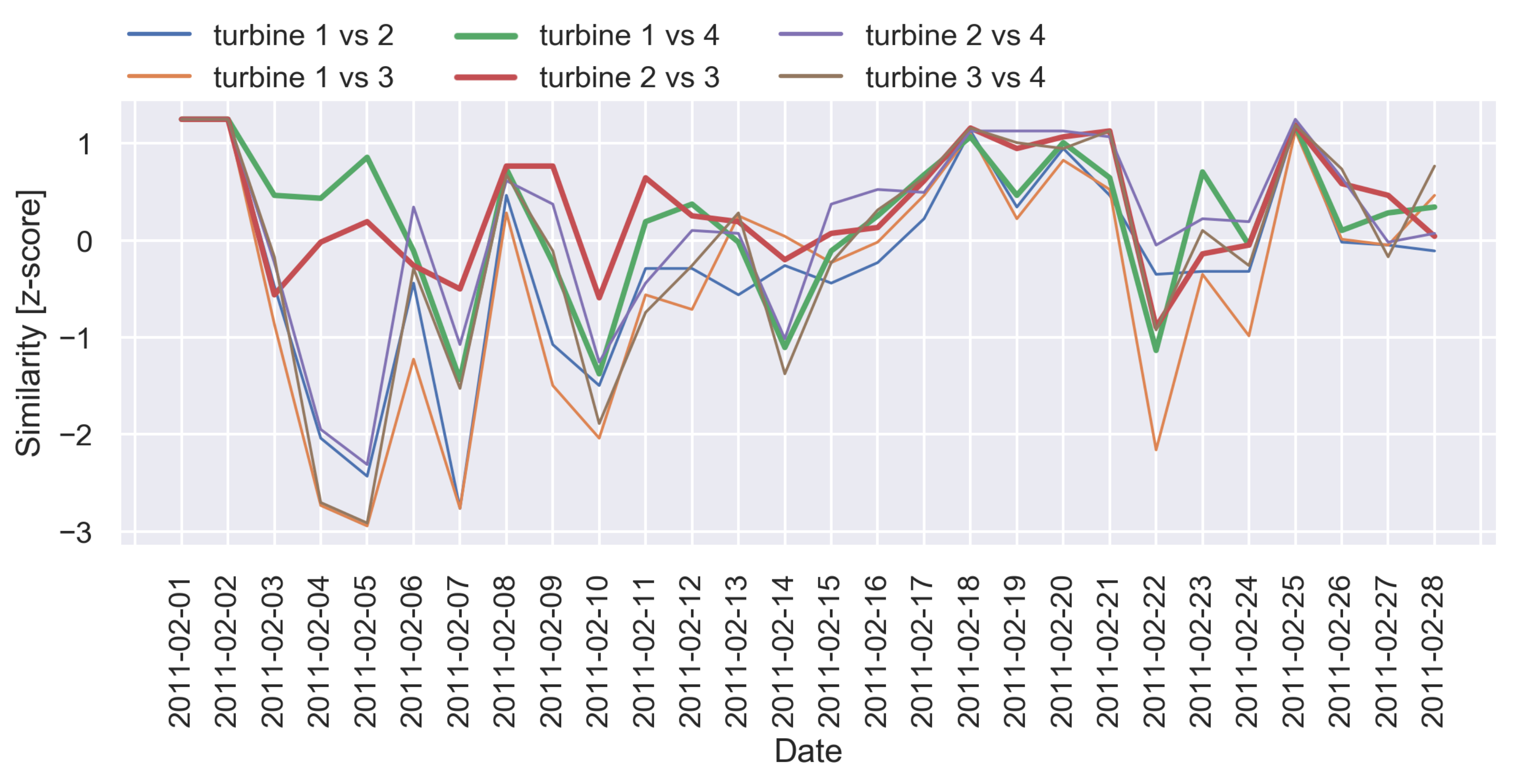
4.1.4. Temporal Behaviour Characterisation through Label Maps
4.2. Context-Aware Performance Fingerprinting
4.3. Data Preparation
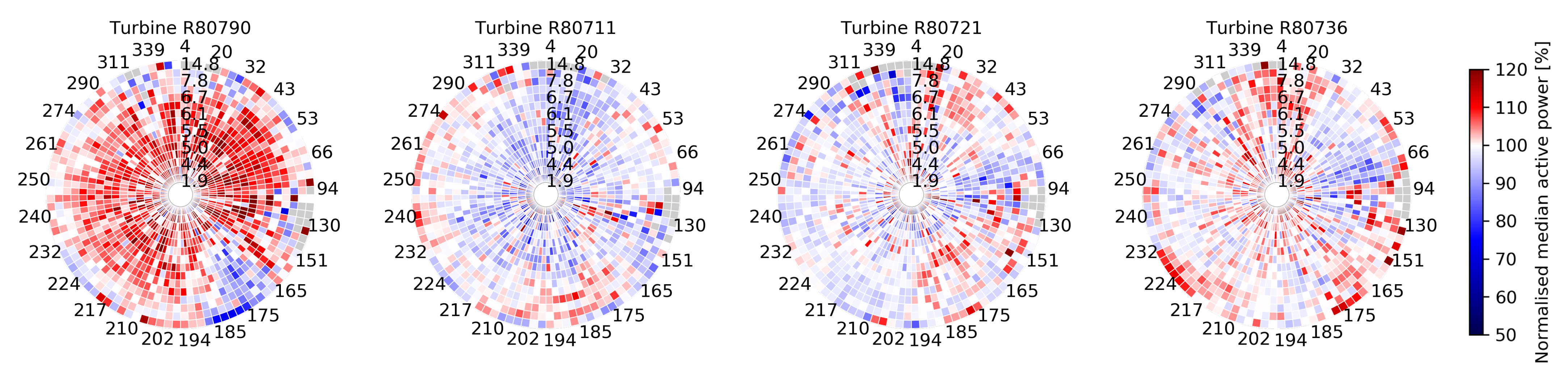
4.3.1. Context-Aware Fingerprinting via Circular Power Maps
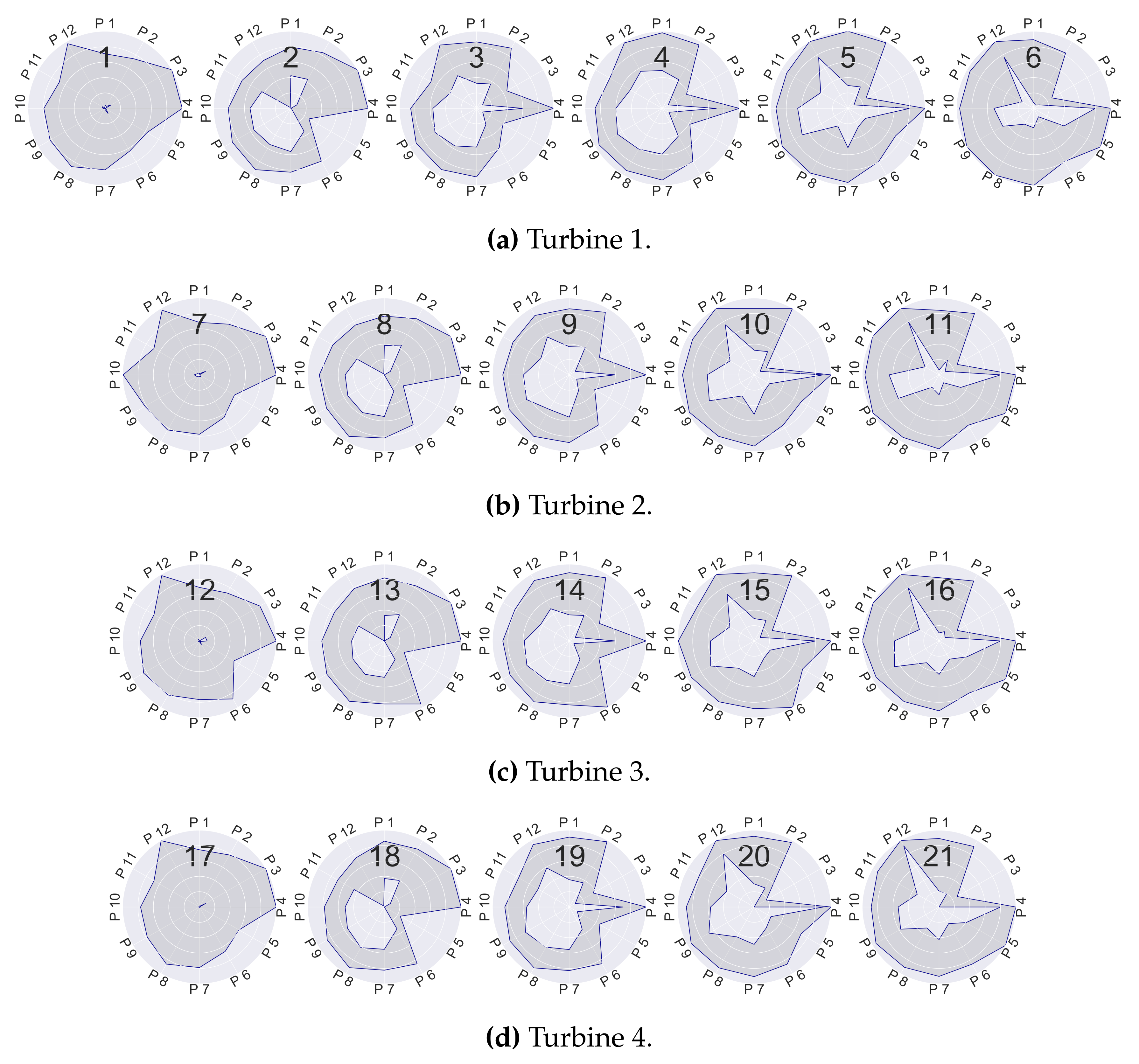
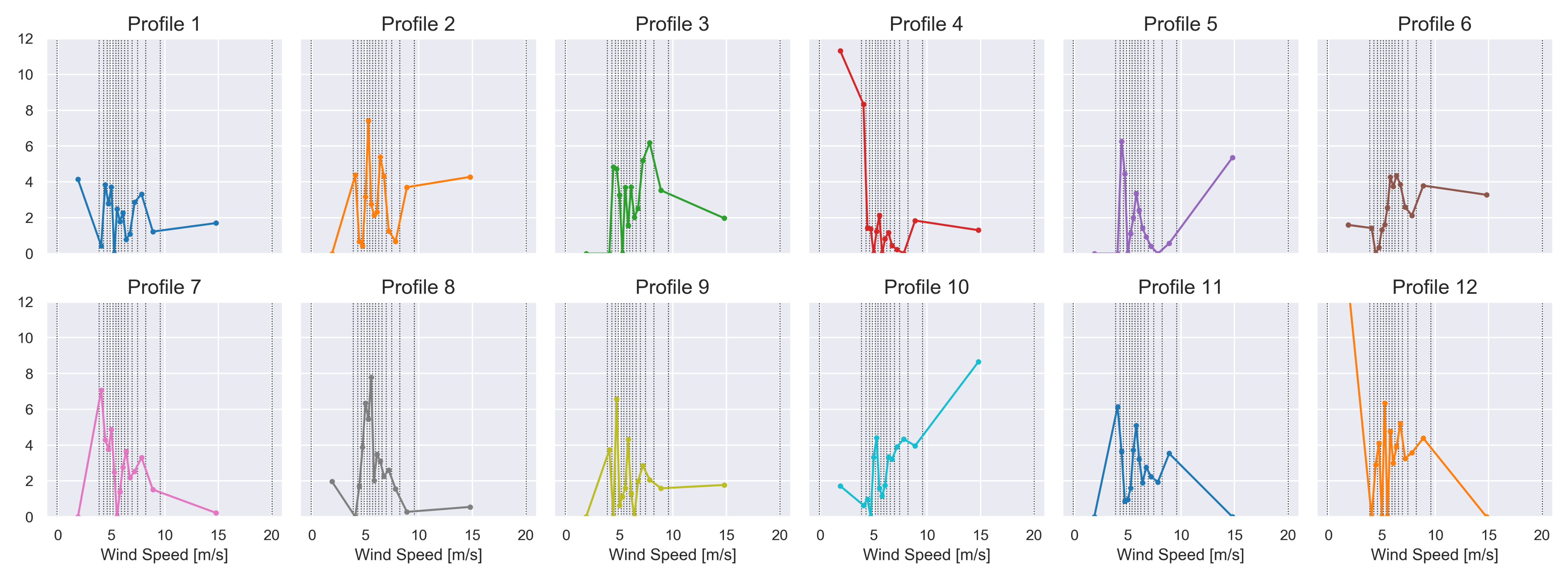
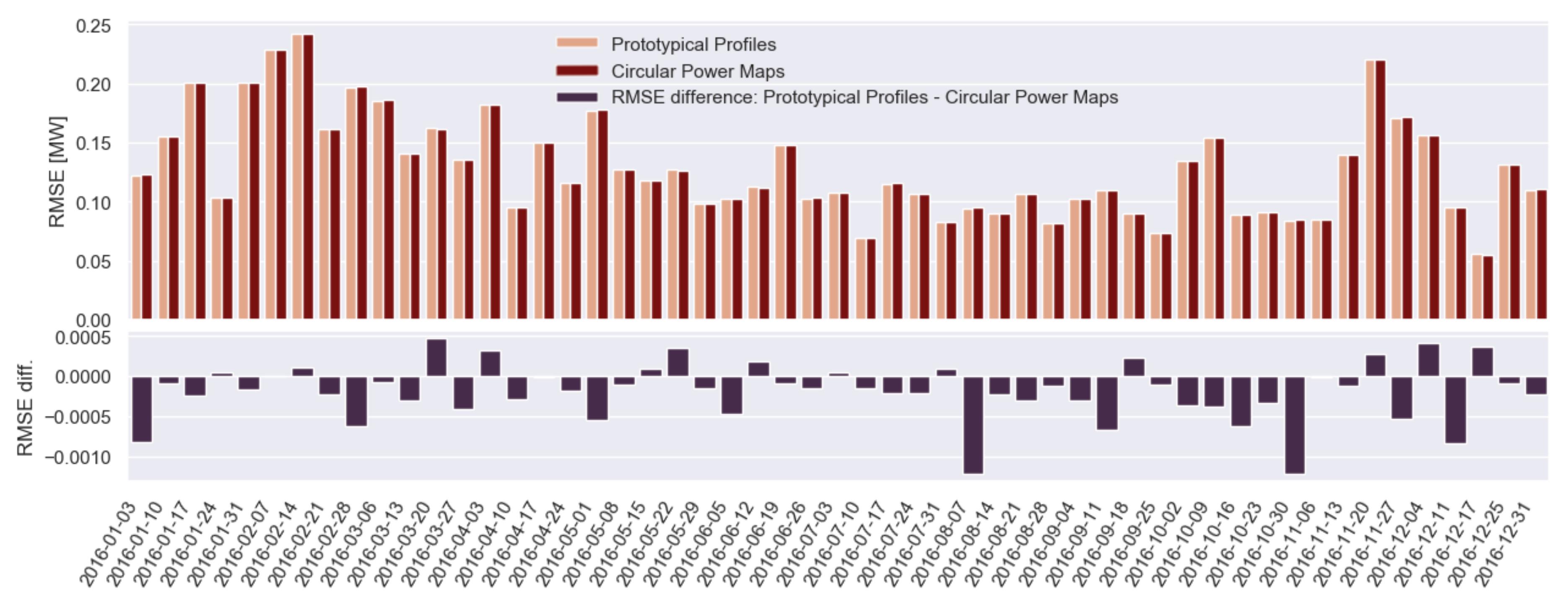
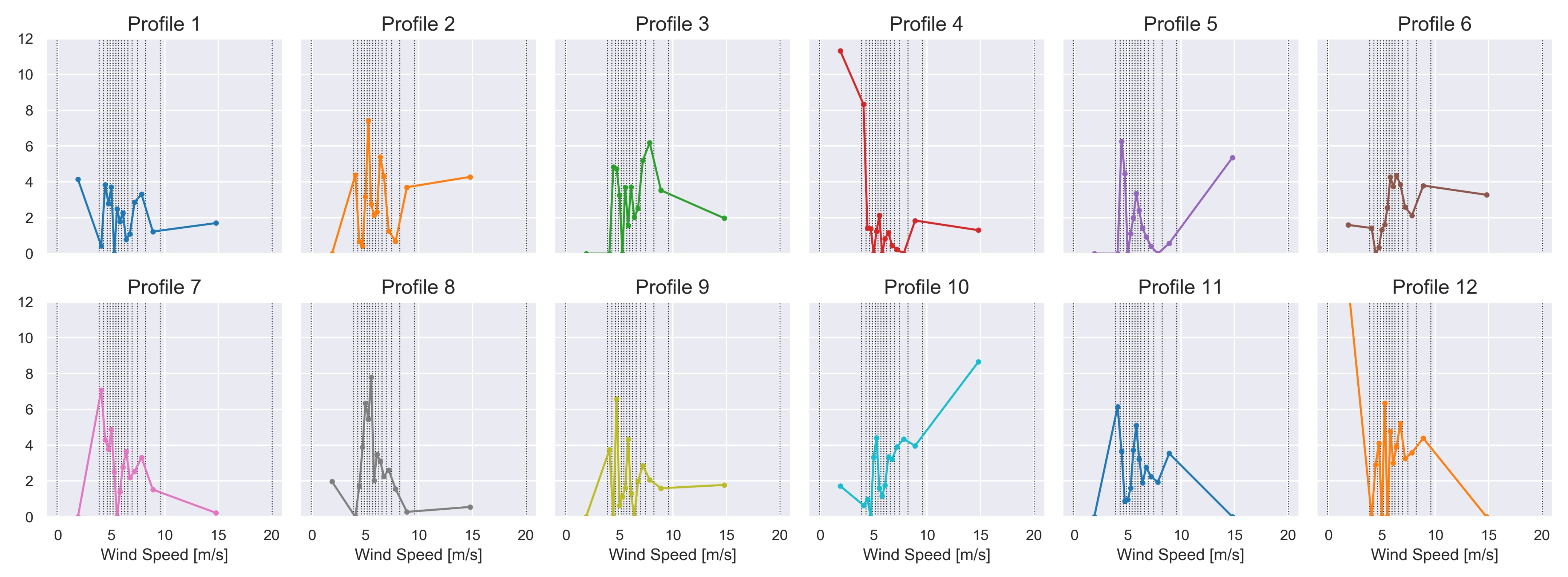
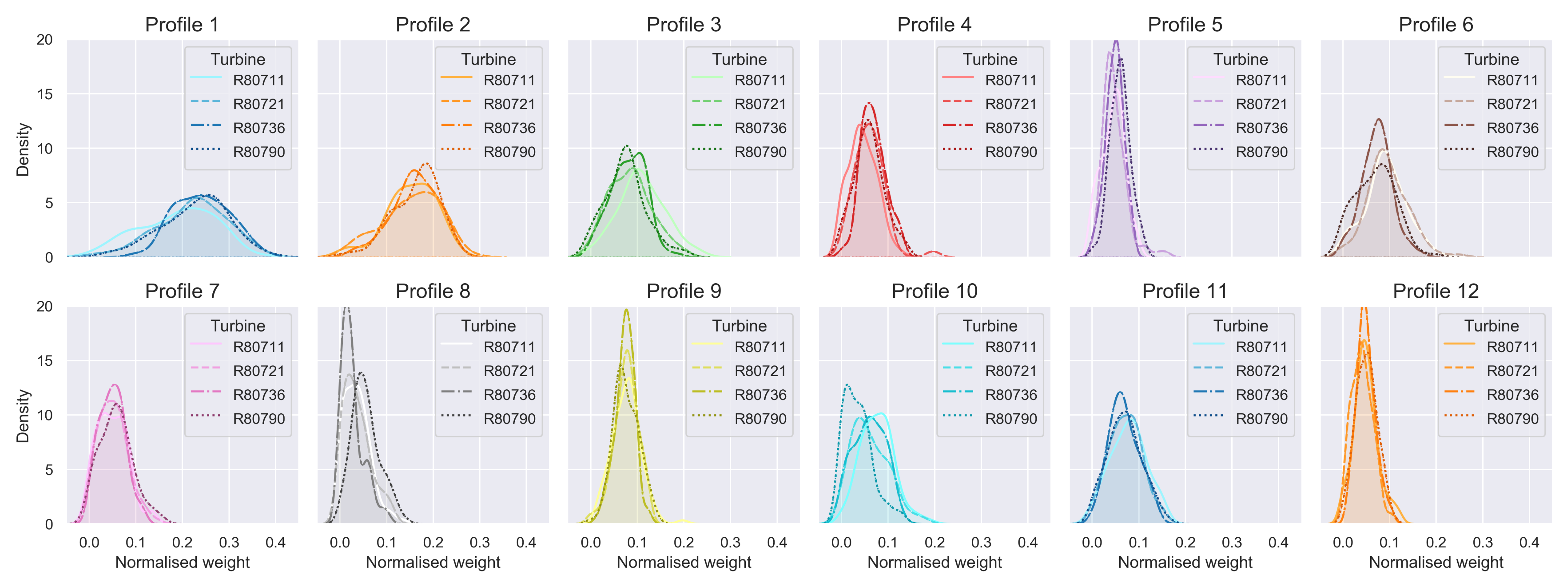
4.3.2. Fleet-Wide Prototypical Profiles
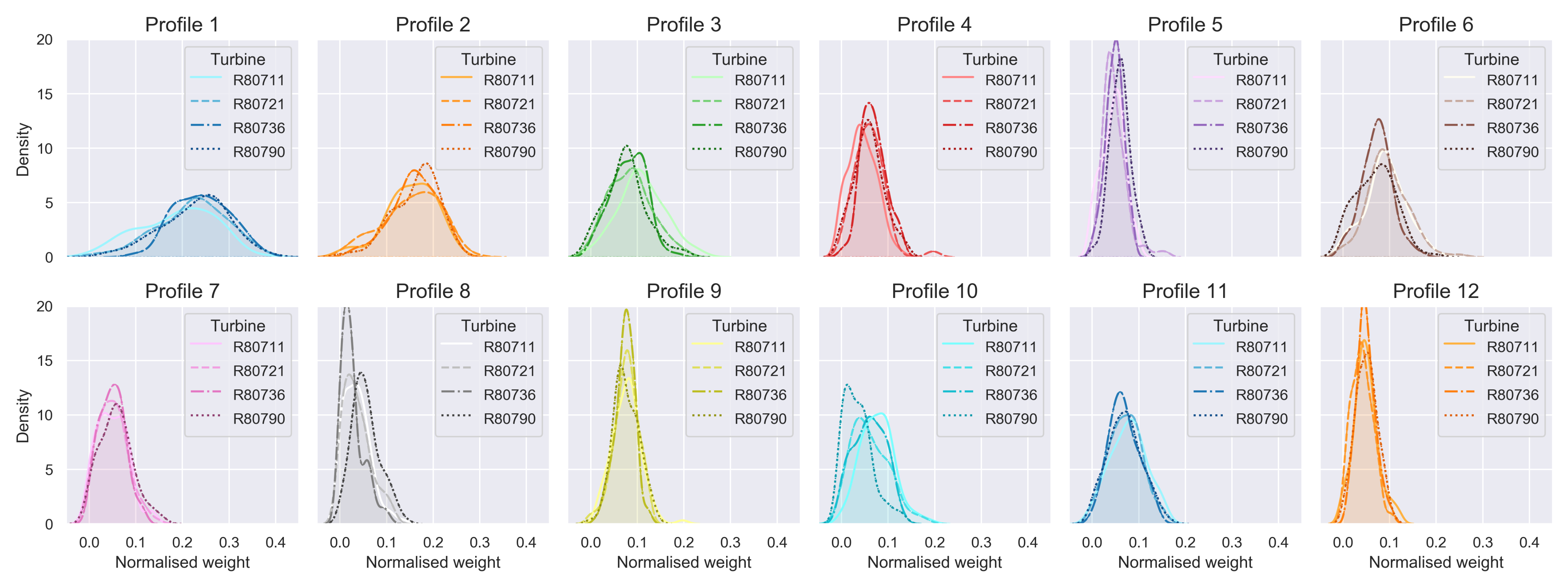
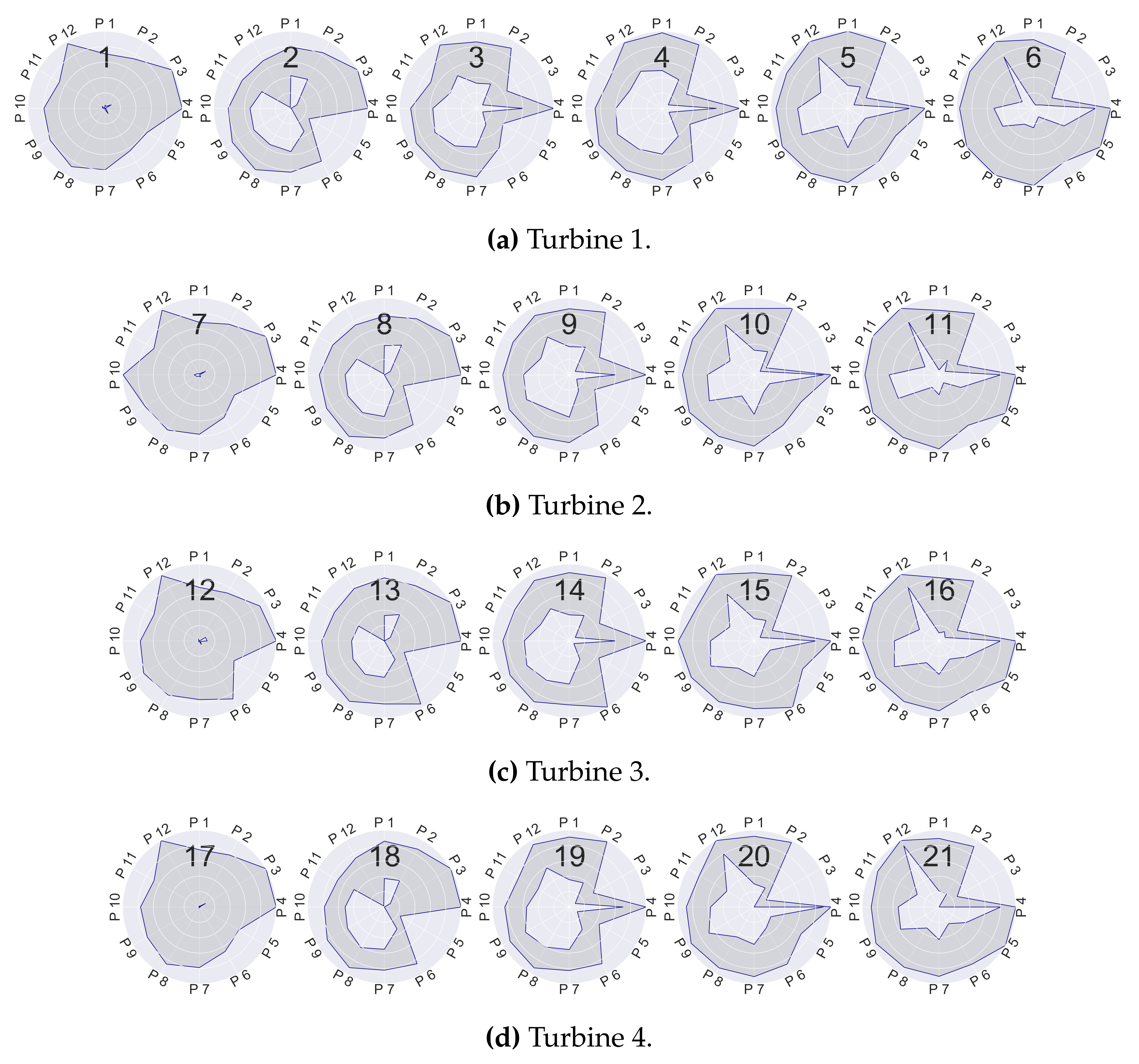
Characterisation of Prototypical Profiles ()
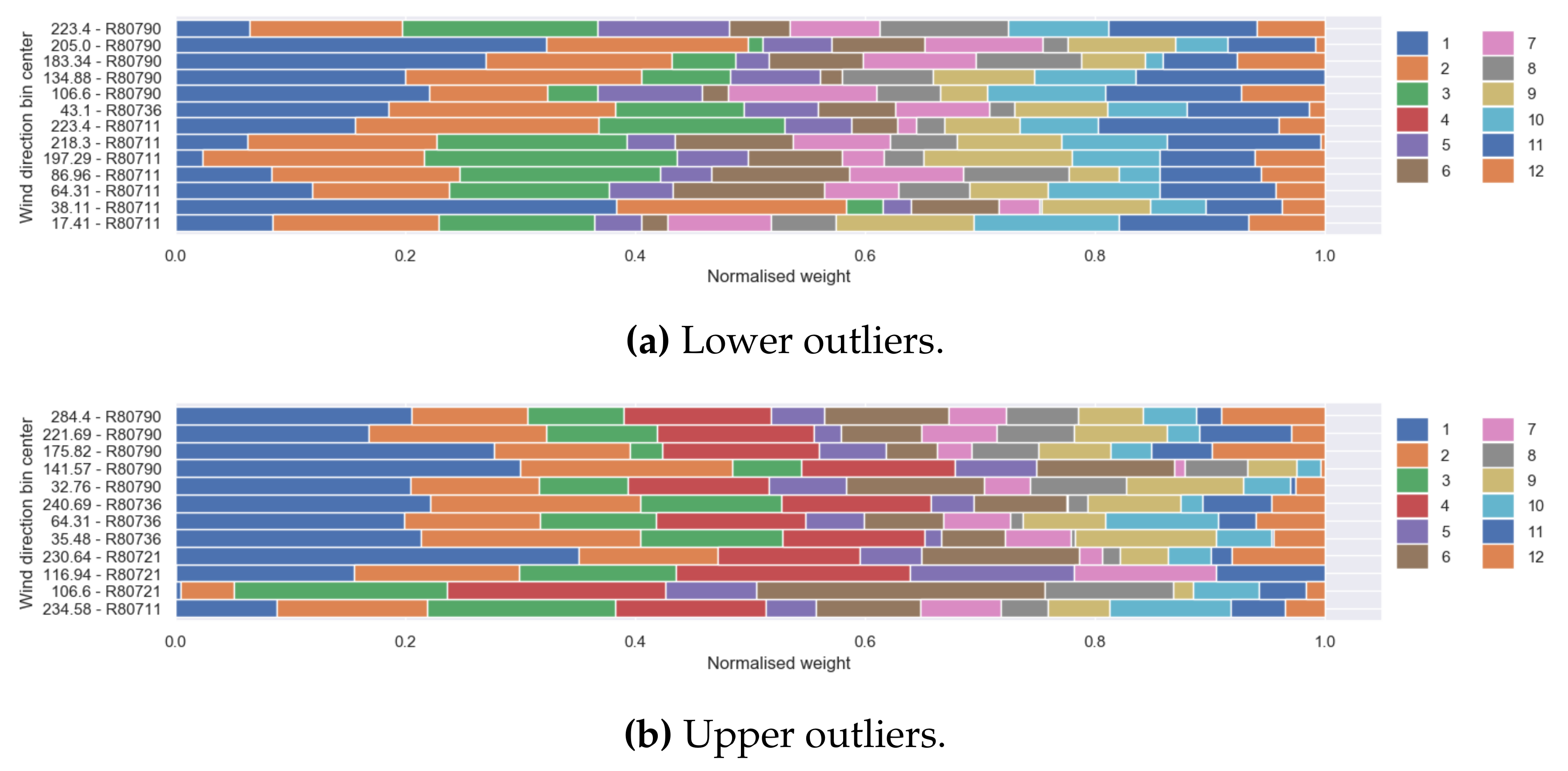
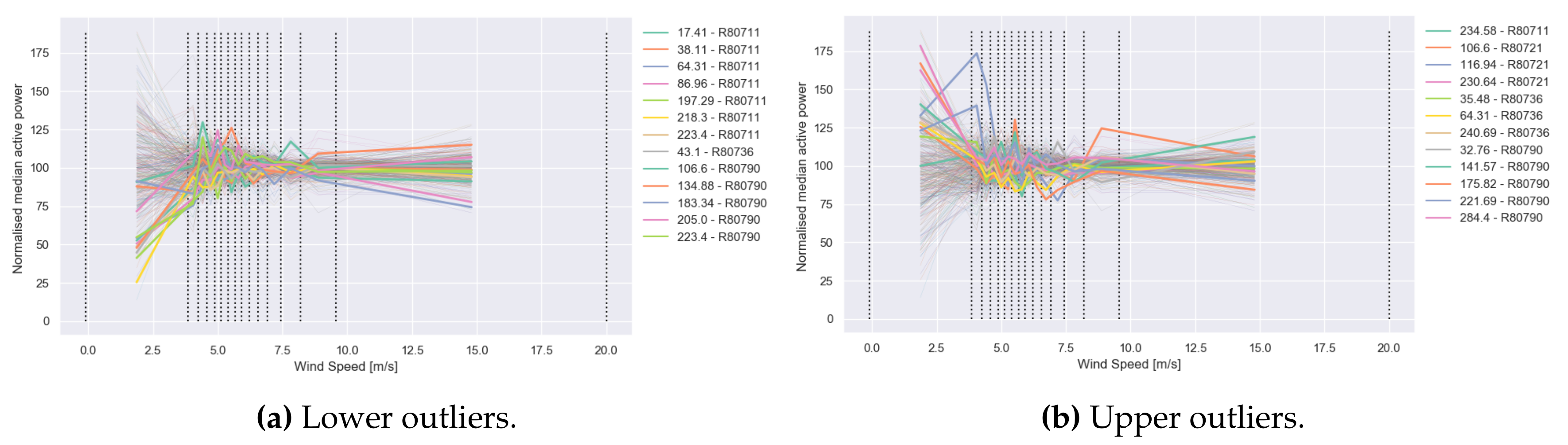
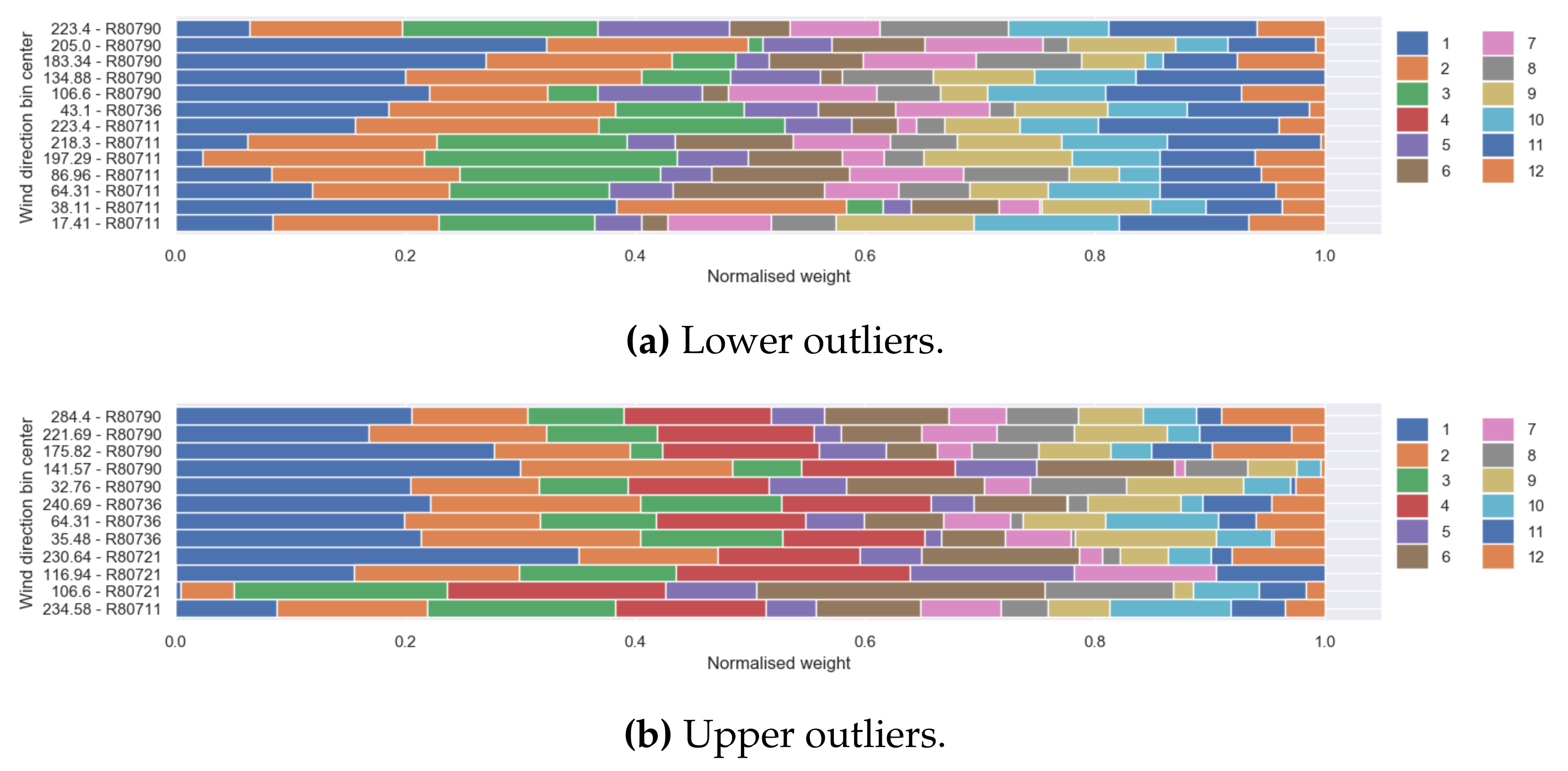
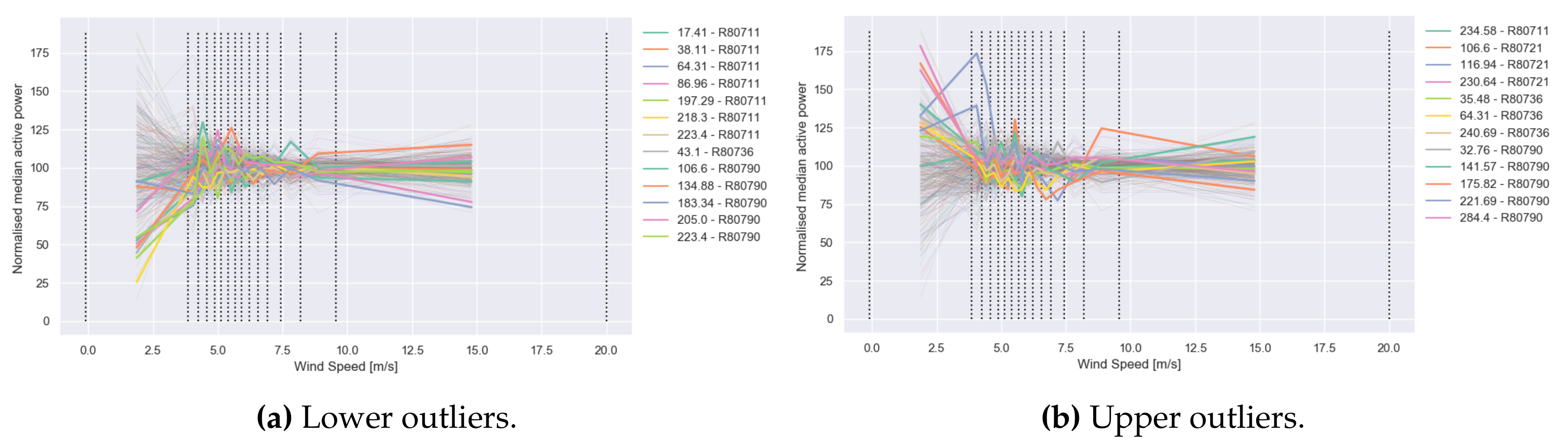
Outlier Detection Based on Weight Matrix ()
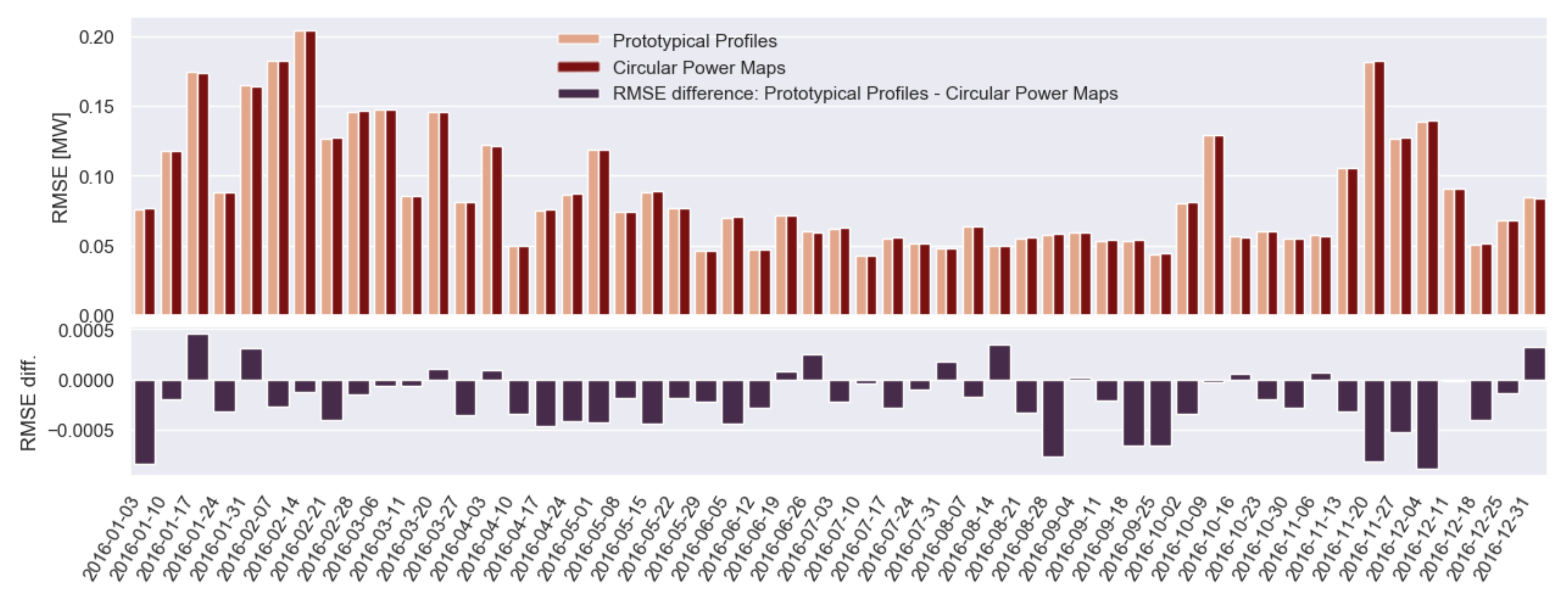
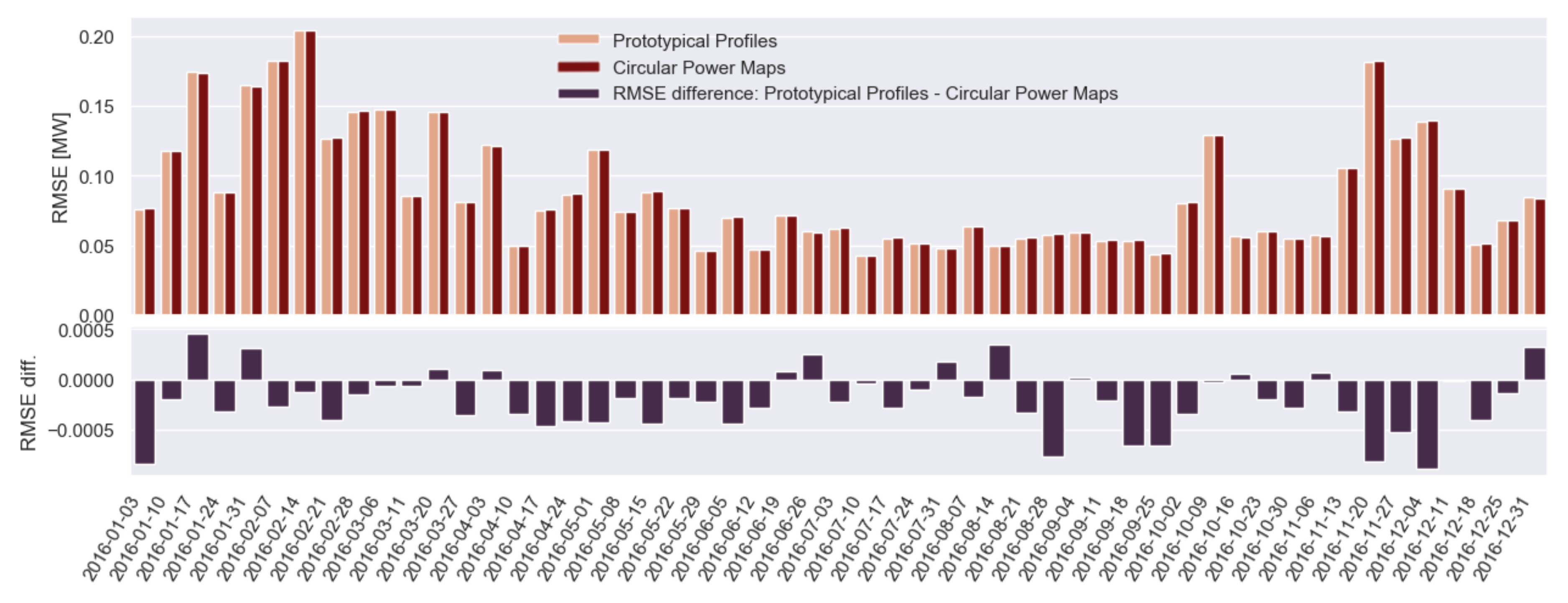
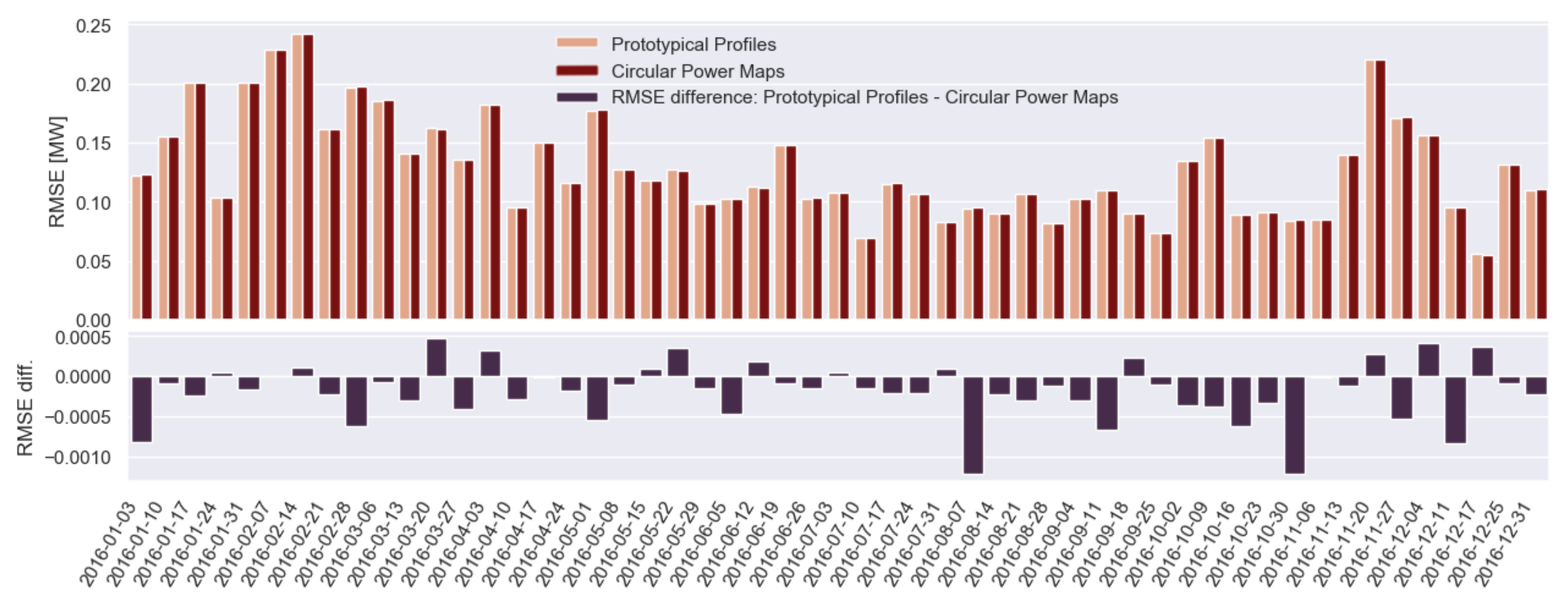
Prediction of Active Power Based on Prototypical Profiles
5. Discussion
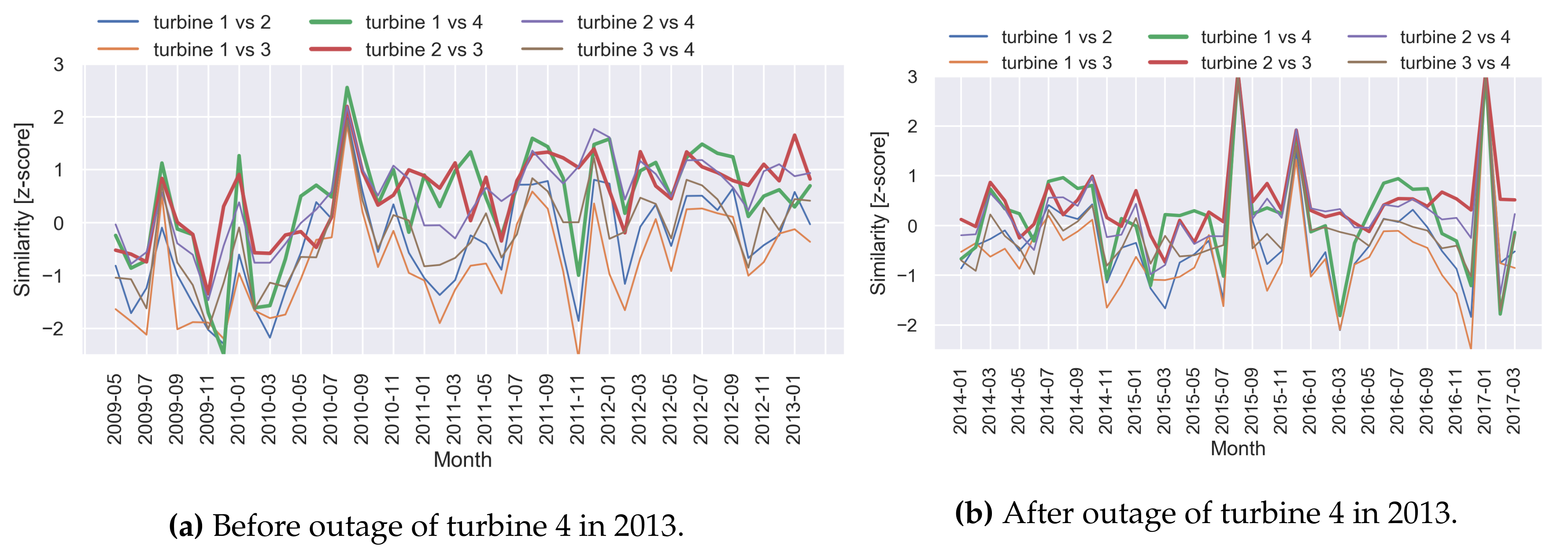
5.1. Visual Inspection for Detecting Trends
5.2. Continuous Anomaly Detection
5.3. Production Forecasting
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DBSCAN | Density-based spatial clustering of applications with noise |
| DNA | Deoxyribonucleic acid |
| DTW | Dynamic time warping |
| EFD | Equal frequency discretisation |
| EWD | Equal width discretisation |
| FDIC | Frequency dynamic interval class |
| KDE | Kernel density estimation |
| NMF | Non-negative matrix factorisation |
| OM | Operating mode |
| PAA | Piecewise aggregate approximation |
| PCA | Principal component analysis |
| PLSA | Probabilistic latent semantic analysis |
| RMSE | Root mean square error |
| RNA | Ribonucleic acid |
| SAX | Symbolic aggregate approximation |
| SCADA | Supervisory control and data acquisition |
| SVD | Singular value decomposition |
| SW | Smith–Waterman |
References
- Uluyol, O.; Parthasarathy, G.; Foslien, W.; Kim, K. Power curve analytic for wind turbine performance monitoring and prognostics. In Proceedings of the Annual Conference of the PHM Society, Montreal, QC, Canada, 25–29 September 2011; Volume 3. [Google Scholar]
- Cooney, C.; Byrne, R.; Lyons, W.; O’Rourke, F. Performance characterisation of a commercial-scale wind turbine operating in an urban environment, using real data. Energy Sustain. Dev. 2017, 36, 44–54. [Google Scholar] [CrossRef]
- Vanderwende, B.J.; Lundquist, J.K. The modification of wind turbine performance by statistically distinct atmospheric regimes. Environ. Res. Lett. 2012, 7, 034035. [Google Scholar] [CrossRef]
- Wagner, R.; Antoniou, I.; Pedersen, S.M.; Courtney, M.S.; Jørgensen, H.E. The influence of the wind speed profile on wind turbine performance measurements. Wind Energy 2009, 12, 348–362. [Google Scholar] [CrossRef]
- Byrne, R.; Astolfi, D.; Castellani, F.; Hewitt, N.J. A study of wind turbine performance decline with age through operation data analysis. Energies 2020, 13, 2086. [Google Scholar] [CrossRef] [Green Version]
- Dhont, M.; Tsiporkova, E.; Boeva, V. Layered Integration Approach for Multi-view Analysis of Temporal Data. In Proceedings of the International Workshop on Advanced Analytics and Learning on Temporal Data, Ghent, Belgium, 18 September 2020; Springer: Berlin, Germany, 2020; pp. 138–154. [Google Scholar]
- Dhont, M.; Tsiporkova, E.; Tourwé, T.; González-Deleito, N. Visual Analytics for Extracting Trends from Spatio-temporal Data. In Proceedings of the International Workshop on Advanced Analytics and Learning on Temporal Data, Ghent, Belgium, 18 September 2020; Springer: Berlin, Germany, 2020; pp. 122–137. [Google Scholar]
- Lkhagva, B.; Suzuki, Y.; Kawagoe, K. Extended SAX: Extension of symbolic aggregate approximation for financial time series data representation. DEWS2006 4A-i8. 2006, Volume 7. Available online: https://www.researchgate.net/profile/Yu-Suzuki-2/publication/229046404_Extended_SAX_extension_of_symbolic_aggregate_approximation_for_financial_time_series_data_representation/links/570b819d08ae8883a1ffa123/Extended-SAX-extension-of-symbolic-aggregate-approximation-for-financial-time-series-data-representation.pdf (accessed on 18 September 2021).
- Ahmed, A.M.; Bakar, A.A.; Hamdan, A.R. Dynamic data discretization technique based on frequency and K-Nearest Neighbour algorithm. In Proceedings of the 2009 2nd Conference on Data Mining and Optimization, Selangor, Malaysia, 27–28 October 2009; IEEE: New York, NY, USA, 2009; pp. 10–14. [Google Scholar]
- Chaudhari, P.; Rana, D.P.; Mehta, R.G.; Mistry, N.J.; Raghuwanshi, M.M. Discretization of temporal data: A survey. arXiv 2014, arXiv:1402.4283. [Google Scholar]
- Liu, J.; Wang, C.; Gao, J.; Han, J. Multi-view clustering via joint nonnegative matrix factorization. In Proceedings of the 2013 SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013; SIAM: Philadelphia, PA, USA, 2013; pp. 252–260. [Google Scholar]
- Bruno, E.; Marchand-Maillet, S. Multiview clustering: A late fusion approach using latent models. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 736–737. [Google Scholar]
- Greene, D.; Cunningham, P. A matrix factorization approach for integrating multiple data views. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bled, Slovenia, 7–11 September 2009; Springer: Berlin, Germany, 2009; pp. 423–438. [Google Scholar]
- Chaudhuri, K.; Kakade, S.M.; Livescu, K.; Sridharan, K. Multi-view clustering via canonical correlation analysis. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 129–136. [Google Scholar]
- Blaschko, M.B.; Lampert, C.H. Correlational spectral clustering. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: New York, NY, USA, 2008; pp. 1–8. [Google Scholar]
- Bickel, S.; Scheffer, T. Multi-View Clustering. In Proceedings of the IEEE International Conference on Data Mining, Brighton, UK, 1 November 2004; IEEE: New York, NY, USA, 2004; Volume 1, pp. 19–26. [Google Scholar]
- Kumar, A.; Rai, P.; Daume, H. Co-regularized multi-view spectral clustering. Adv. Neural Inf. Process. Syst. 2011, 24, 1413–1421. [Google Scholar]
- Murgia, A.; Tsiporkova, E.; Verbeke, M.; Tourwé, T. Context-Aware Performance Benchmarking of a Fleet of Industrial Assets. Arch. Data Sci. Ser. A 2020, 5. [Google Scholar] [CrossRef]
- Archer, C.L.; Mirzaeisefat, S.; Lee, S. Quantifying the sensitivity of wind farm performance to array layout options using large-eddy simulation. Geophys. Res. Lett. 2013, 40, 4963–4970. [Google Scholar] [CrossRef]
- Zhang, B.; Liu, J. Wind turbine clustering algorithm of large offshore wind farms considering wake effects. Math. Probl. Eng. 2019, 2019, 6874693. [Google Scholar] [CrossRef]
- Cao, M.; Shi, D. Equivalence Method for Wind Farm Based on Clustering of Output Power Time Series Data. In Proceedings of the 2020 12th IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 24–26 April 2020; IEEE: New York, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Han, J.; Miao, S.; Li, Y.; Yin, H.; Zhang, D.; Yang, W.; Tu, Q. Improved Equivalent Method for Large-Scale Wind Farms Using Incremental Clustering and Key Parameters Optimization. IEEE Access 2020, 8, 172006–172020. [Google Scholar] [CrossRef]
- Wu, W.; Peng, M. A data mining approach combining k-means clustering with bagging neural network for short-term wind power forecasting. IEEE Internet Things J. 2017, 4, 979–986. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Forer, P.; Harvey, A.S. Activities, ringmaps and geovisualization of large human movement fields. Inf. Vis. 2008, 7, 198–209. [Google Scholar] [CrossRef]
- Vartak, M.; Huang, S.; Siddiqui, T.; Madden, S.; Parameswaran, A. Towards visualization recommendation systems. ACM SIGMOD Record 2017, 45, 34–39. [Google Scholar] [CrossRef]
- Luo, Y.; Qin, X.; Tang, N.; Li, G. DeepEye: Towards automatic data visualization. In Proceedings of the 34th International Conference on Data Engineering, Paris, France, 16–19 April 2018; IEEE: New York, NY, USA, 2018; pp. 101–112. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Lyu, H.; Strohmeier, C.; Menz, G.; Needell, D. COVID-19 Time-series Prediction by Joint Dictionary Learning and Online NMF. arXiv 2020, arXiv:2004.09112. [Google Scholar]
- Iverson, D.L. Inductive System Health Monitoring; NASA: Moffett Field, CA, USA, 2004. [Google Scholar]
- Smith, T. Smith-Waterman Algorithm. Adv. Appl. Math. 1981, 2, 482–489. [Google Scholar] [CrossRef] [Green Version]
- Dickson, M. Non-relativistic quantum mechanics. In Philosophy of Physics; Handbook of the Philosophy of Science; Butterfield, J., Earman, J., Eds.; North-Holland: Amsterdam, The Netherlands, 2007; pp. 275–415. [Google Scholar] [CrossRef] [Green Version]
- Lanzafame, R.; Mauro, S.; Messina, M. HAWT design and performance evaluation: Improving the BEM theory mathematical models. Energy Procedia 2015, 82, 172–179. [Google Scholar] [CrossRef] [Green Version]
- Villanueva, D.; Feijóo, A.E. Reformulation of parameters of the logistic function applied to power curves of wind turbines. Electr. Power Syst. Res. 2016, 137, 51–58. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, Q.; Li, L.; Foley, A.M.; Srinivasan, D. Approaches to wind power curve modeling: A review and discussion. Renew. Sustain. Energy Rev. 2019, 116, 109422. [Google Scholar] [CrossRef]
- Dhillon, I.S.; Sra, S. Generalized Nonnegative Matrix Approximations with Bregman Divergences; NIPS; Citeseer: Pennsylvania, PA, USA, 2005; Volume 18. [Google Scholar]
- Hawkins, D. Clustering scotch whiskies using non-negative matrix factorization. Jt. Newsl. Sect. Phys. Eng. Sci. Qual. Product. Sect. Am. Stat. Assoc. 2006, 14, 11–13. [Google Scholar]
- Li, W.; Liu, Z. A method of SVM with normalization in intrusion detection. Procedia Environ. Sci. 2011, 11, 256–262. [Google Scholar] [CrossRef] [Green Version]
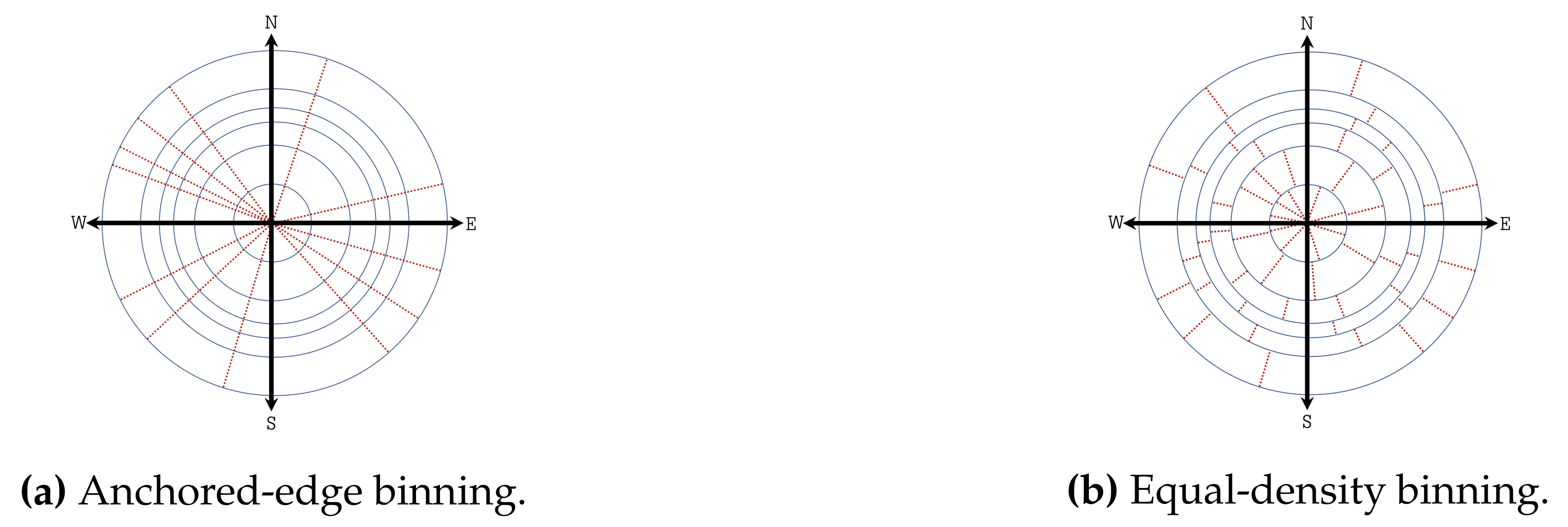


{kind=link}
{kind=link}
{kind=link}
{kind=link}
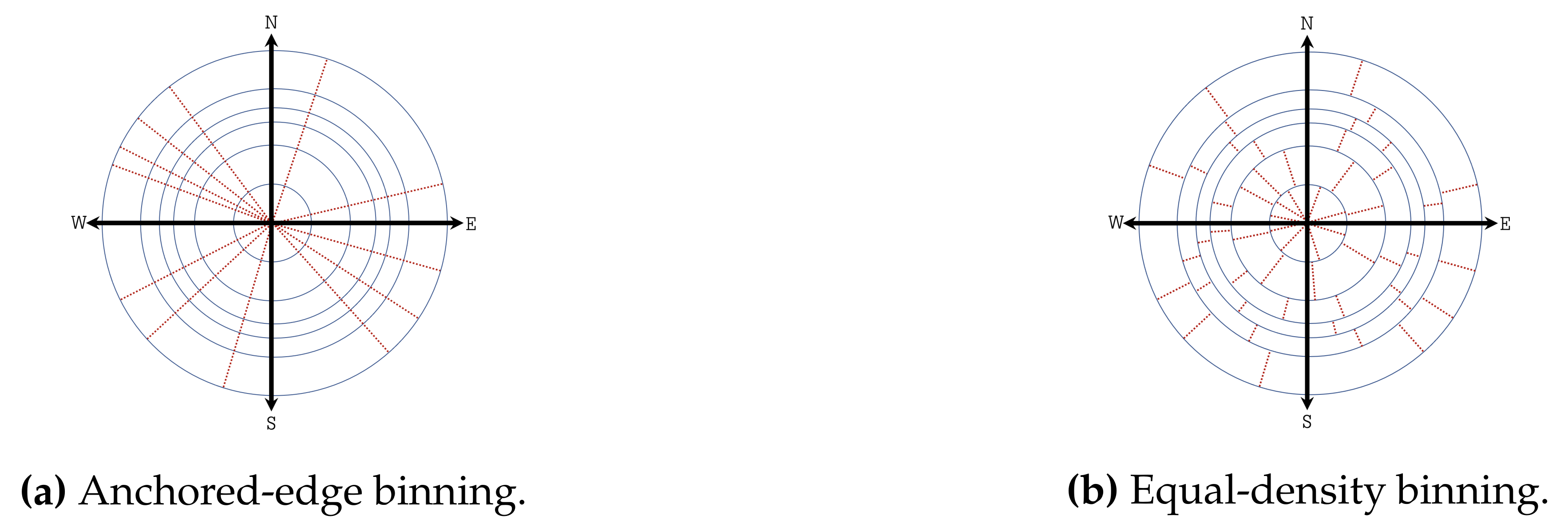{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P 1 | Generator bearing 1 temperature | P 7 | Gearbox oil sump temperature | |
| P 2 | Generator bearing 2 temperature | P 8 | Gearbox inlet temperature | |
| P 3 | Pitch angle (sine) | P 9 | Gearbox bearing 1 temperature | |
| P 4 | Pitch angle (cosine) | P 10 | Gearbox bearing 2 temperature | |
| P 5 | Torque | P 11 | Generator stator temperature | |
| P 6 | Rotor bearing temperature | P 12 | Generator speed |
| (a) Before outage of turbine 4 in 2013. | |||
|---|---|---|---|
| Turbine 1 | Turbine 2 | Turbine 3 | |
| Turbine 2 | −0.81 | ||
| Turbine 3 | −1.56 | 1.06 | |
| Turbine 4 | 0.86 | 0.91 | −0.45 |
| (b) After outage of turbine 4 in 2013. | |||
| Turbine 1 | Turbine 2 | Turbine 3 | |
| Turbine 2 | −0.85 | ||
| Turbine 3 | −1.53 | 1.37 | |
| Turbine 4 | 0.58 | 0.76 | −0.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhont, M.; Tsiporkova, E.; Boeva, V. Advanced Discretisation and Visualisation Methods for Performance Profiling of Wind Turbines. Energies 2021, 14, 6216. https://doi.org/10.3390/en14196216
Dhont M, Tsiporkova E, Boeva V. Advanced Discretisation and Visualisation Methods for Performance Profiling of Wind Turbines. Energies. 2021; 14(19):6216. https://doi.org/10.3390/en14196216
Chicago/Turabian StyleDhont, Michiel, Elena Tsiporkova, and Veselka Boeva. 2021. "Advanced Discretisation and Visualisation Methods for Performance Profiling of Wind Turbines" Energies 14, no. 19: 6216. https://doi.org/10.3390/en14196216
APA StyleDhont, M., Tsiporkova, E., & Boeva, V. (2021). Advanced Discretisation and Visualisation Methods for Performance Profiling of Wind Turbines. Energies, 14(19), 6216. https://doi.org/10.3390/en14196216