
Evaluation Model of Operation State Based on Deep Learning for Smart Meter

Abstract
:1. Introduction
- RNN is applied for time series prediction of power consumption. Note that RNN outperformed other time-series prediction models [19]. The RNN cell contains the internal state in which information can be stored, making it ideal for time series prediction tasks. The grid-search method is adopted to address the HPO.
- TL is applied for building prediction model of significant number of meters. TL is added to the prediction model construction, and the hyperparameters of the trained model are set as the training starting point of the next prediction model, which greatly reduce the workload of building prediction.
- Flexible threshold setting and abnormal accumulator are added in abnormal judgment, which prevent the false positives caused by man-made or natural factors.
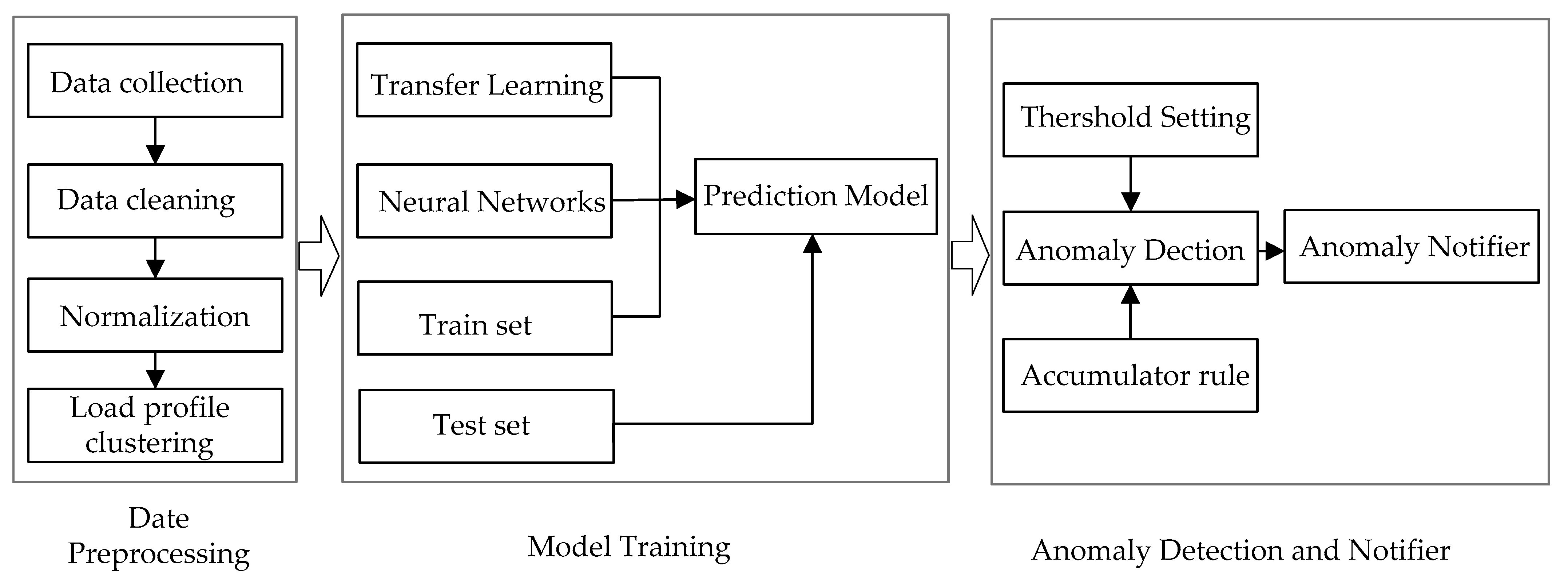
2. Data Preprocessing and Analysis
2.1. Data Cleaning
2.2. Normalization
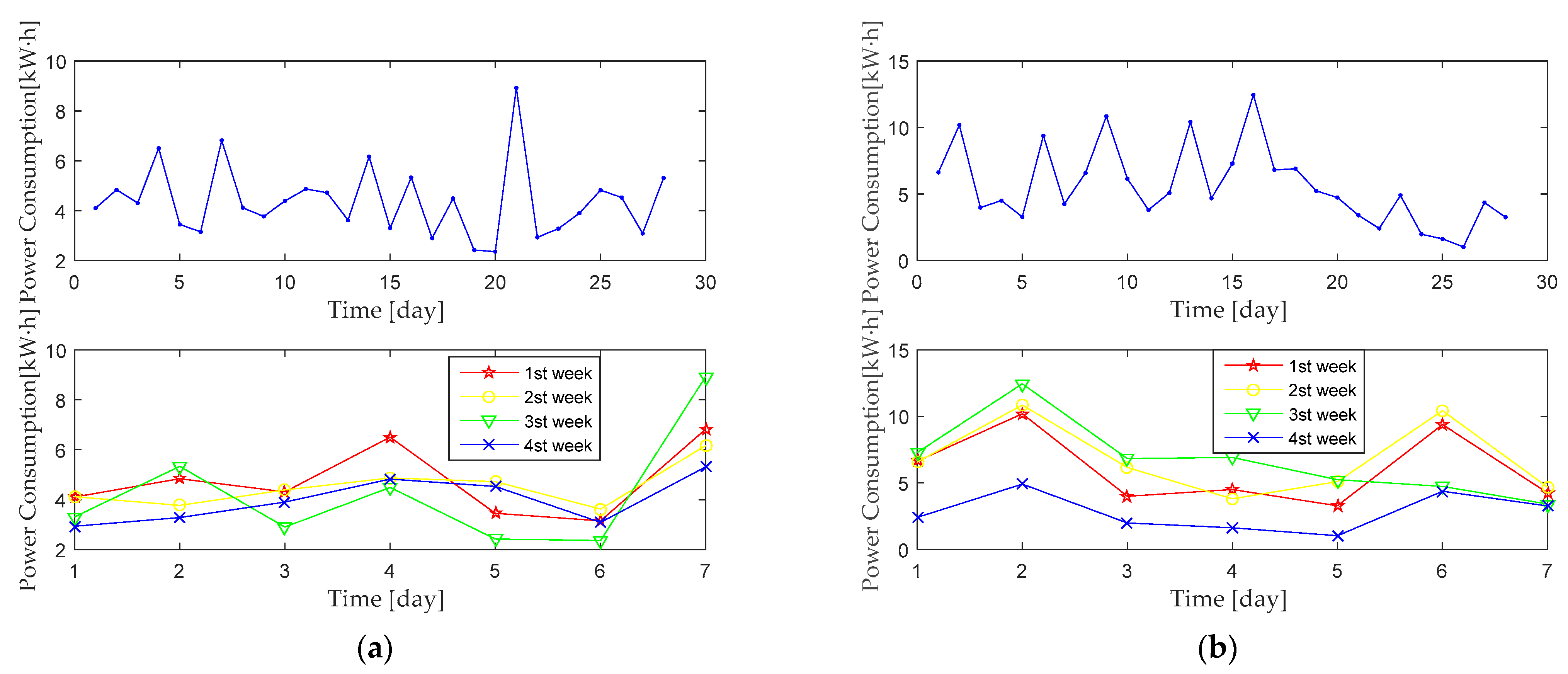
2.3. Electricity Curve Analysis
3. Cluster-Based Chain Transfer Learning
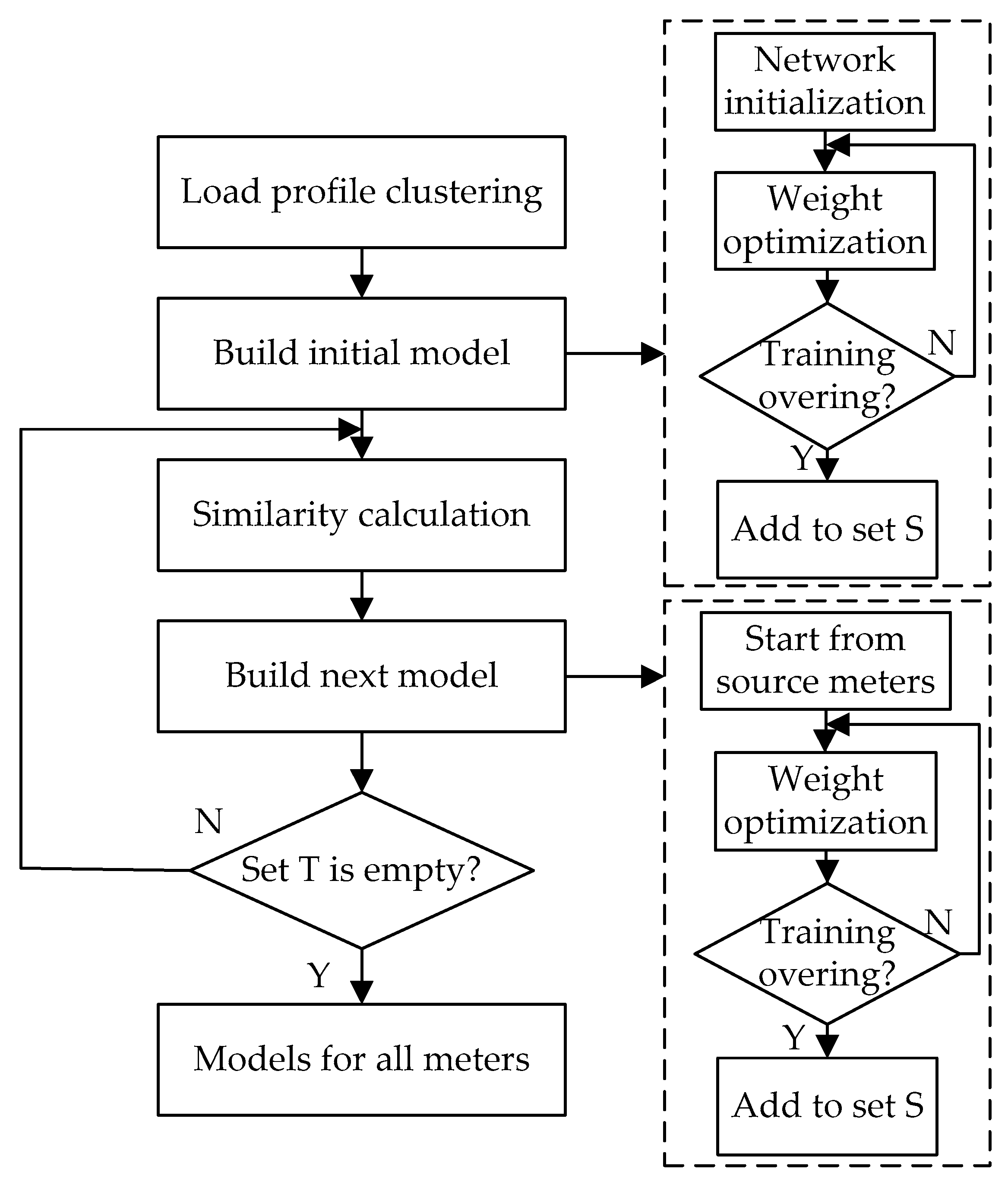
3.1. Load Profile Clustering
3.2. Transfer Learning
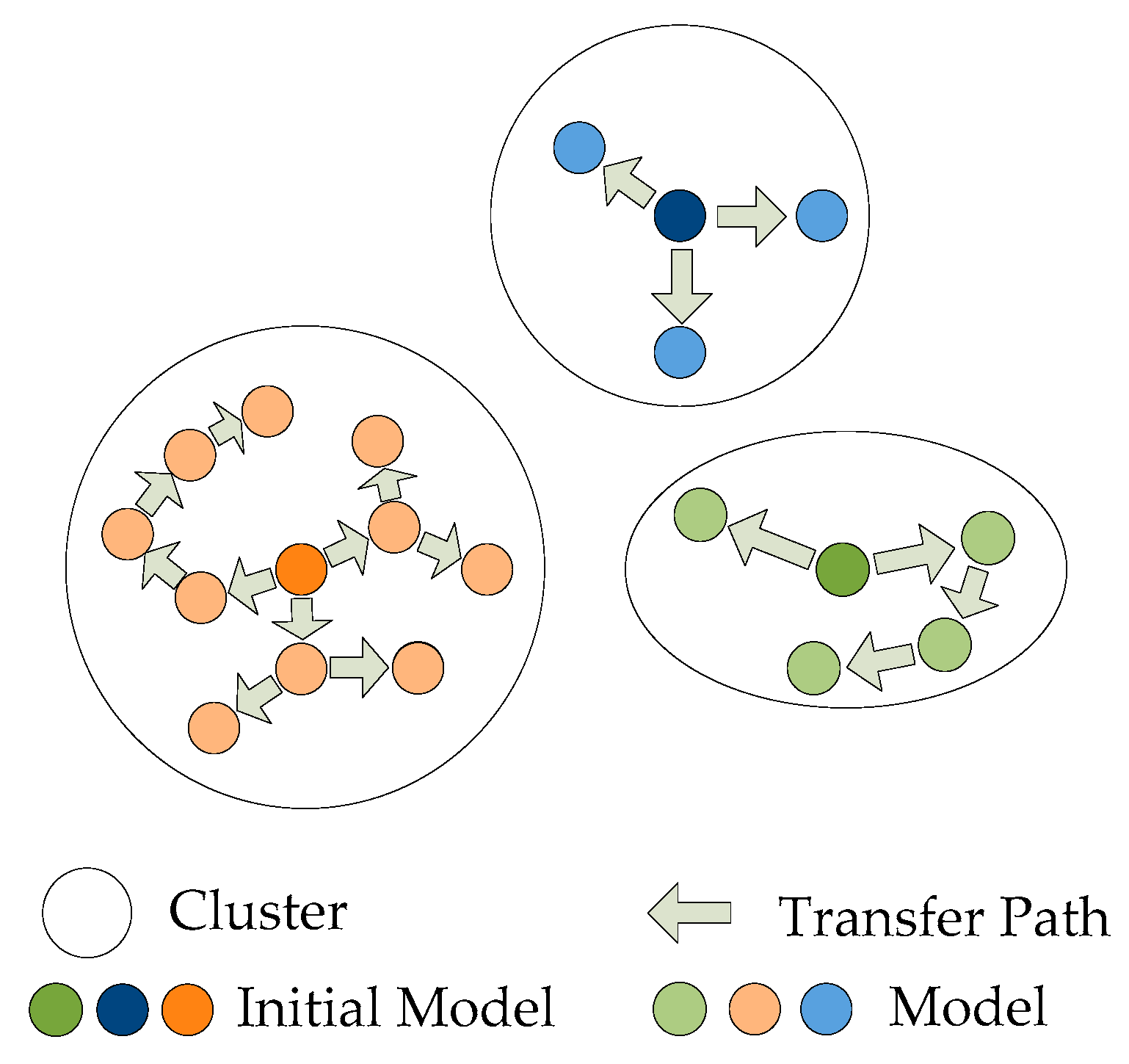
- Within each cluster, it is divided into source set S and target set T. TL starts with similarity calculation which gives similarities between each pair of meters within the cluster. Assume that meter p is the core of cluster and it was selected to build the initial prediction model mp. The meter that has the maximum similarity to the initial meter p is selected as the TL target.
- The existing model mp, which is trained by the power consumption data, is regarded as the starting point for training next prediction model mq. Initial model mp is trained by the target model dataset dq to build the next model mq. During the transferred process, the structure and hyperparameters of initial model remain the same. The weights for each model changed only in this situation that trained by its own dataset.
- The result of the training with the transferred model is the new source model mq. The new built source model mq, which is available for TL, was added to the source set S. For mp, mq, and mk of the model that has already been built, the electrical data is attributed to the set S. For the electrical history data that does not have a model in the process, the data is attributed to set T.
- Next, the direction of the chain transfer is determined by calculating the similarity between set S and set T. Figure 4 shows the direction of chain transfer learning. The chain Transfer process ends with an empty set T, where all users have a well-trained evaluation model.
4. Evaluation Model
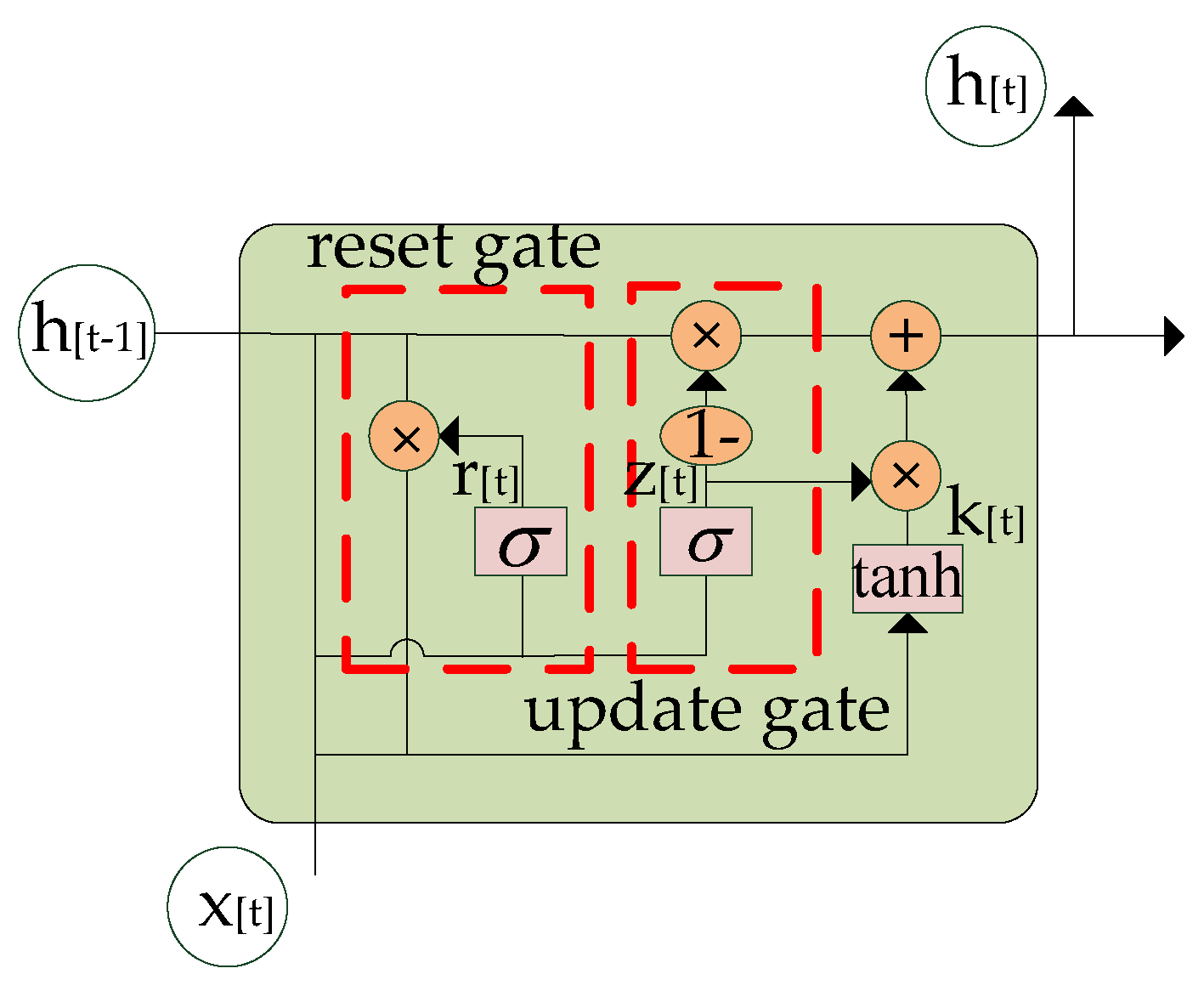
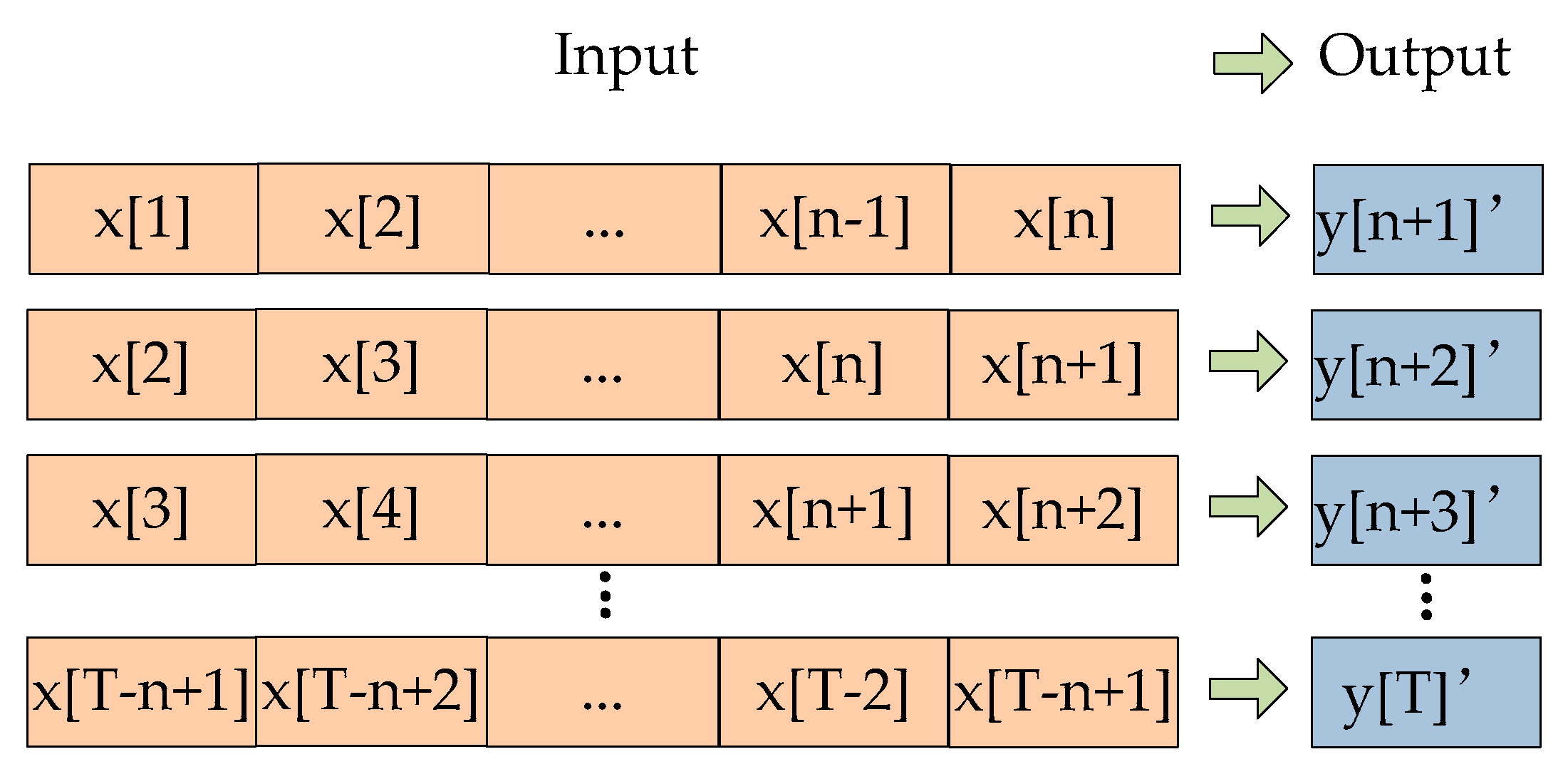
4.1. Prediction Model
4.2. Anomaly Detection Model
4.2.1. K-Sigma
4.2.2. Confidence Interval
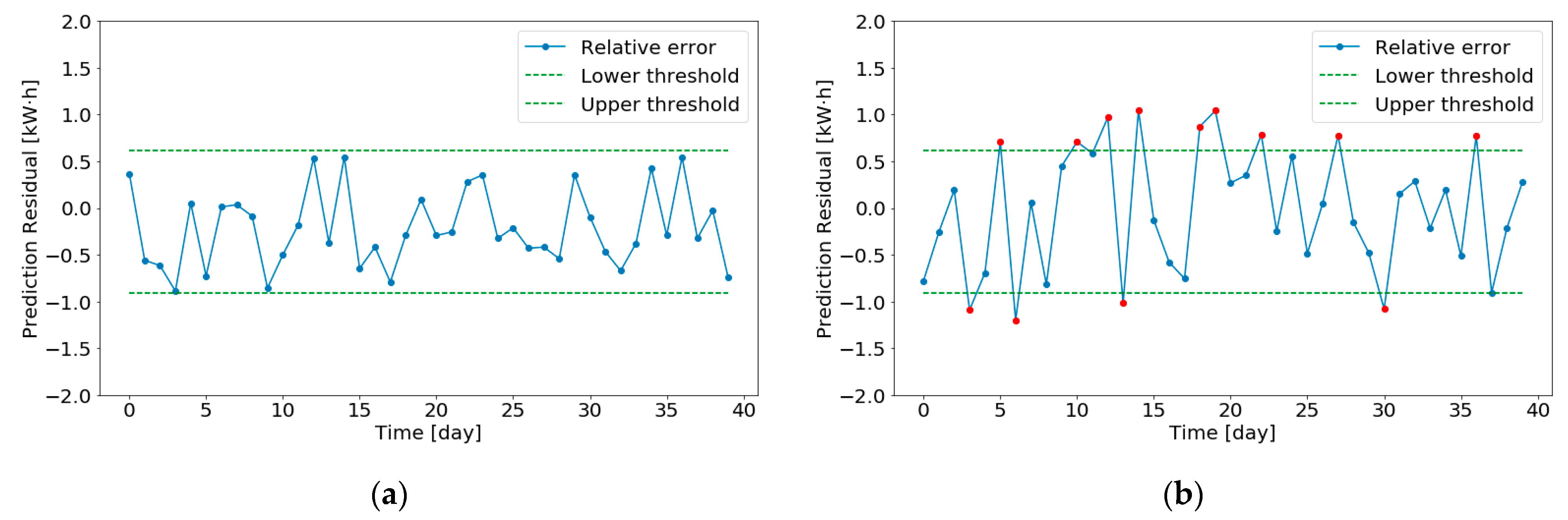
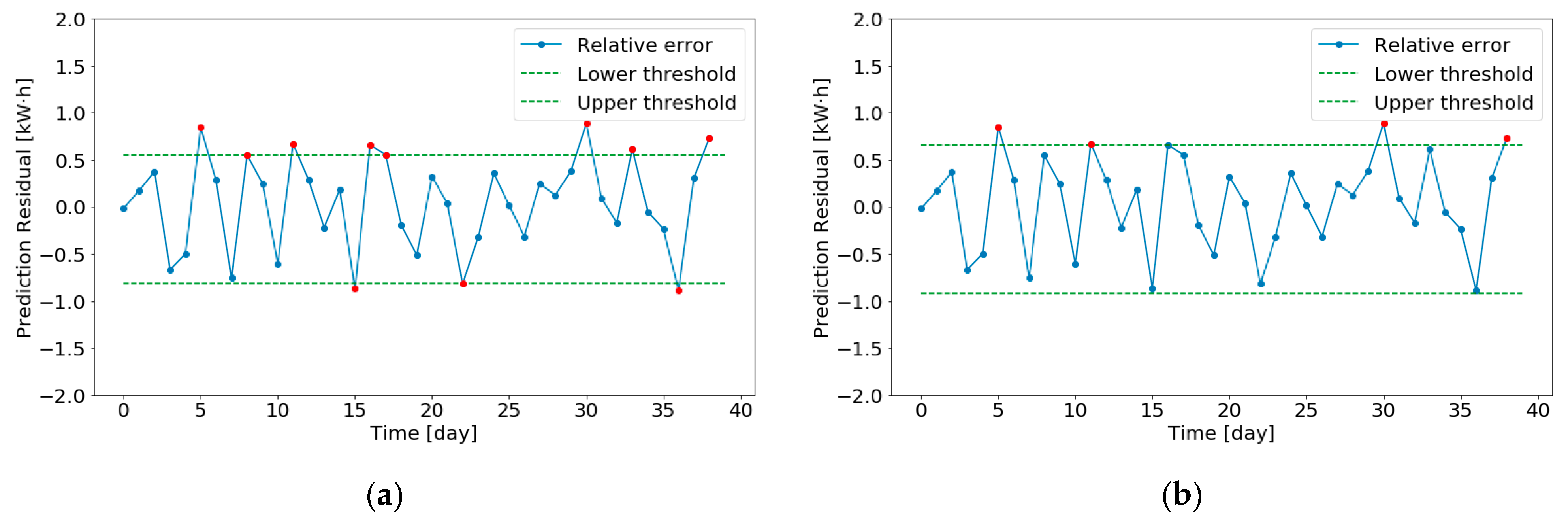
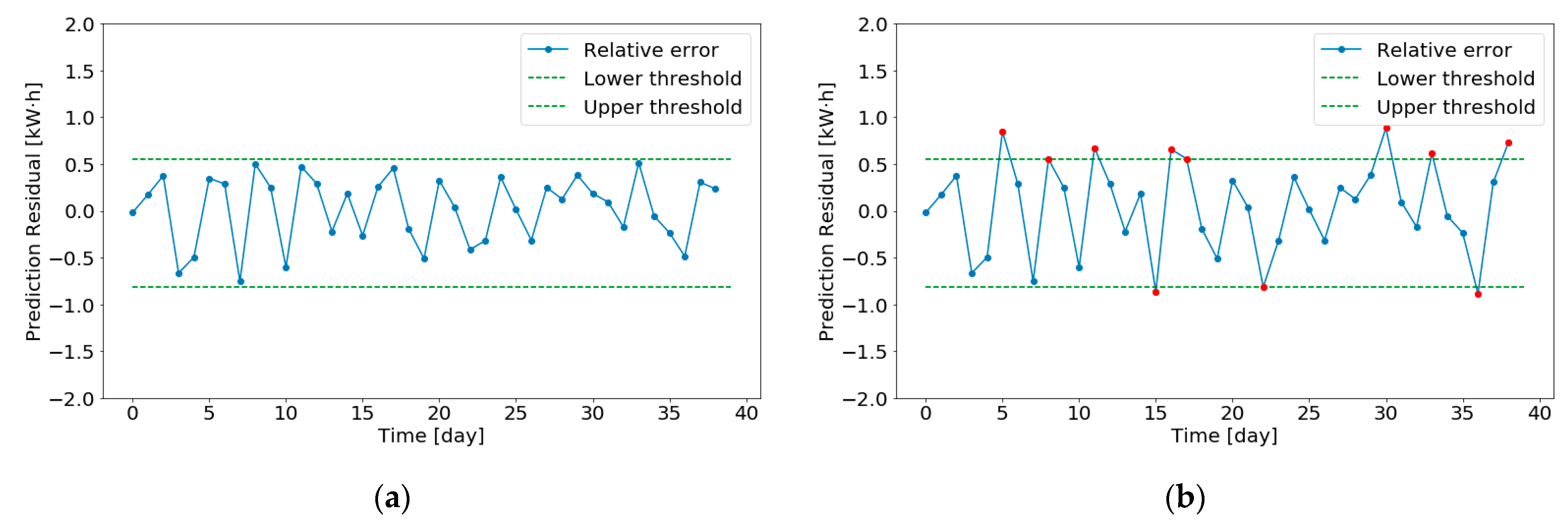
4.2.3. Abnormal Judgment
- Abnormal detection requires reliability and effective identification when the operation state of meters changes.
- Abnormal detection needs to be robust, an abnormality caused by short-term power mutation or non-human causes during the operation of power system cannot be judged as abnormal.
5. Evaluation
5.1. EX1
- (1)
- The prediction accuracy of GRU is higher overall than that of LSTM, and the model training time of GRU is shorter.
- (2)
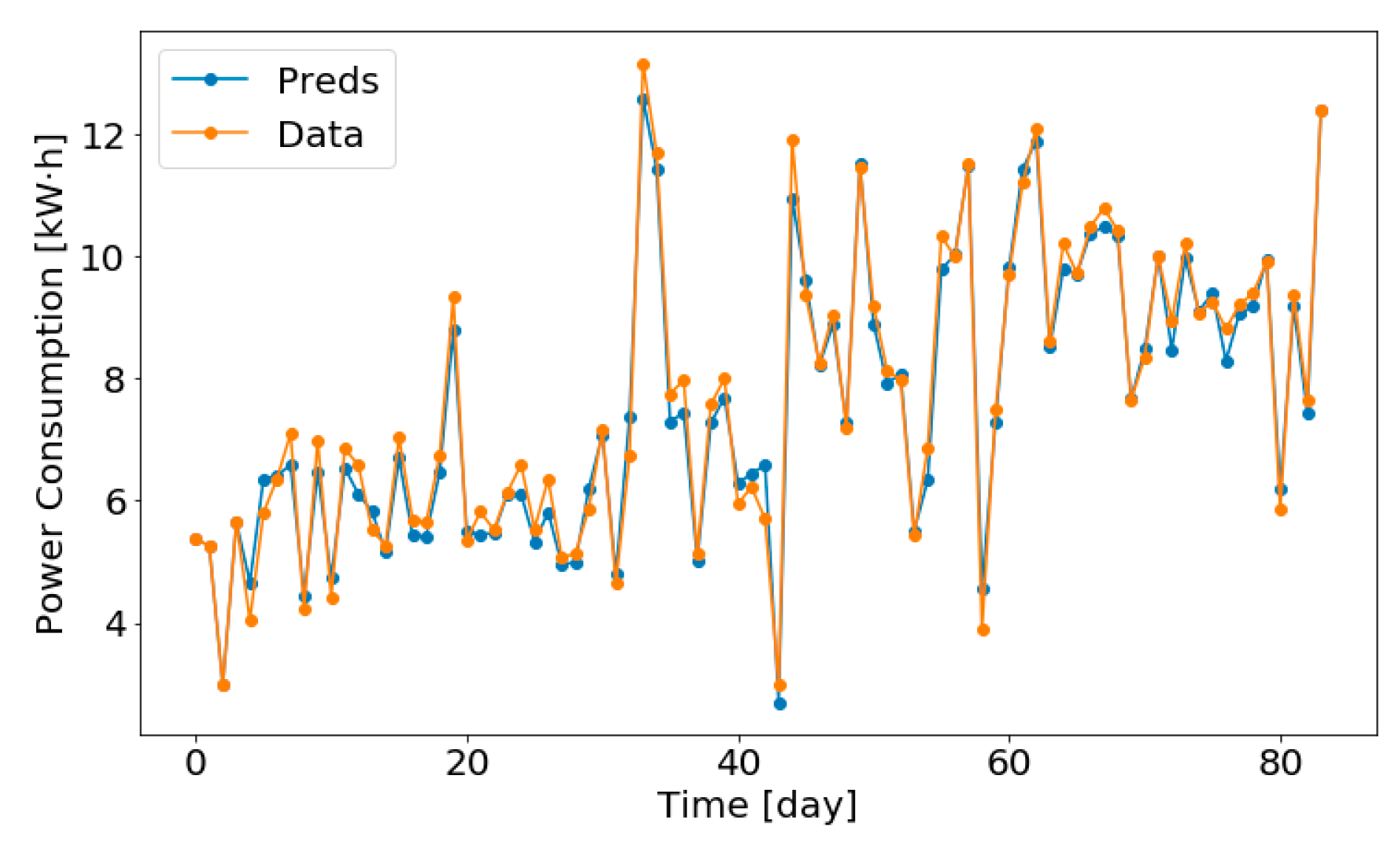
- Through the comparison of MSE, RMSE, MAE, and other indicators in the process of predicting the power consumption, the prediction effect of GRU and 14-day sliding window is the best, and the prediction effect is shown in Figure 8.
- (3)
- The size of the sliding window affects the training time of the model, and the training time of the model increases with the expansion of the window.
5.2. EX2
5.3. EX3
- (1)
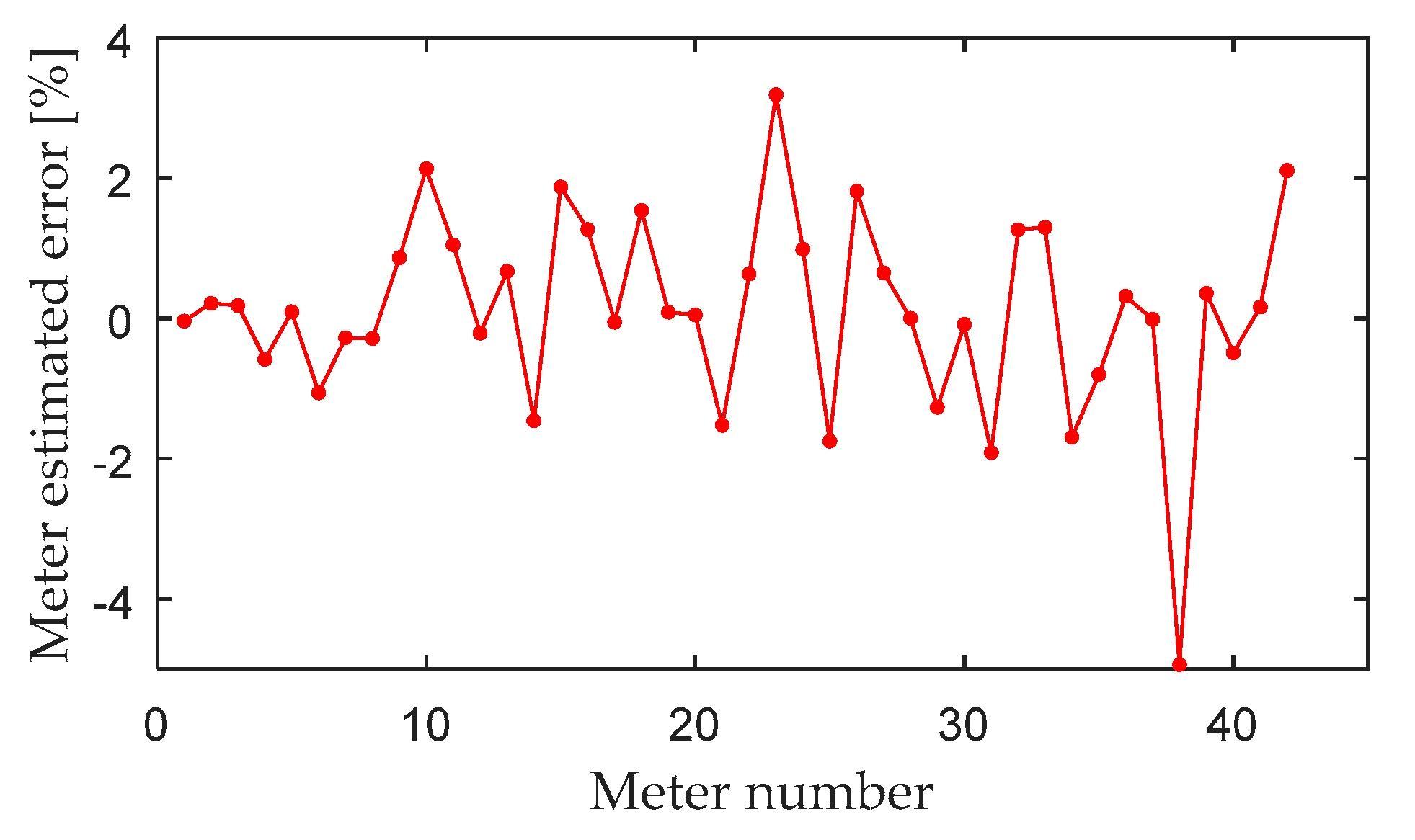
- When the cluster-based error estimation matrix of smart meter is constructed, the measurement result is the average operation error of the whole measurement cycle. The historical data will affect the recent state of smart meters. The error estimation of smart meter has no timeliness.
- (2)
- The evaluation model of smart meters evaluates meters in real-time. The abnormal state of smart meter can be identified quickly, sensitively, and reliably when the characteristics of power consumption data change combined with abnormal judgment.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, X.; Xue, Y. Smart Grids: A Cyber–Physical Systems Perspective. Proc. IEEE 2016, 104, 1–13. [Google Scholar] [CrossRef]
- Saputro, N.; Akkaya, K. Investigation of Smart Meter Data Reporting Strategies for Optimized Performance in Smart Grid AMI Networks. IEEE Internet Things 2017, 4, 894–904. [Google Scholar] [CrossRef]
- Ekanayake, J.B.; Jenkins, N.; Liyanage, K.; Wu, J.; Yokoyama, A. Smart Grid: Technology and Applications; Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Alahakoon, D.; Yu, X. Smart Electricity Meter Data Intelligence for Future Energy Systems: A Survey. IEEE Trans. Ind. Inform. 2016, 12, 425–436. [Google Scholar] [CrossRef]
- Xiaojuan, P.; Lei, W.; Zhengsen, J.; Xuewei, W.; Hongtao, H.; Lijuan, L. Evaluation of digital energy meter error by Monte Carlo method. In Proceedings of the 2016 Conference on Precision Electromagnetic Measurements (CPEM 2016), Ottawa, ON, Canada, 10–15 July 2016; pp. 1–2. [Google Scholar]
- Zhang, Z.; Gong, H.; Li, C.; Wang, Z.; Xiang, X. Research on estimating method for the smart electric energy meter’s error based on parameter degradation model. IOP Conf. Ser. Mater. Sci. Eng. 2018, 366, 012065. [Google Scholar] [CrossRef]
- Fangxing, L.; Qing, H.; Shiyan, H.; Lei, W.; Zhengsen, J. Estimation of Smart Meters Errors Using Meter Reading Data. In Proceedings of the 2018 Conference on Precision Electromagnetic Measurements (CPEM 2018), Paris, France, 8–13 July 2018; pp. 1–2. [Google Scholar]
- Liu, F.; Liang, C.; He, Q. A Data-Based Approach for Smart Meter Online Calibration. Acta IMEKO 2020, 9, 32. [Google Scholar] [CrossRef]
- Kong, X.; Ma, Y.; Zhao, X.; Li, Y.; Teng, Y. A Recursive Least Squares Method with Double-Parameter for Online Estimation of Electric Meter Errors. Energies 2019, 12, 805. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.Y.; Hwang, Y.M.; Sun, Y.G.; Sim, I.; Kim, D.I.; Wang, X. Detection for Non-Technical Loss by Smart Energy Theft With Intermediate Monitor Meter in Smart Grid. IEEE Access 2019, 7, 129043–129053. [Google Scholar] [CrossRef]
- Ying, C.Y.; Jie, D.; Feng, Z.; Ji, X.; Xiao, Y.H. Application of variable weight fuzzy analytic hierarchy process in evaluation of electric energy meter. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017; pp. 1985–1989. [Google Scholar]
- Berhane Araya, D. Collective Contextual Anomaly Detection for Building Energy Consumption. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 511–518. [Google Scholar]
- Yaffee, R.A.; McGee, M. An Introduction to Time Series Analysis and Forecasting: With Applications of SAS® and SPSS®; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Tian, Y.; Sehovac, L.; Grolinger, K. Similarity-Based Chained Transfer Learning for Energy Forecasting With Big Data. IEEE Access 2019, 7, 139895–139908. [Google Scholar] [CrossRef]
- Cui, W.; Wang, H. Anomaly detection and visualization of school electricity consumption data. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 606–611. [Google Scholar]
- Liu, M.; Liu, D.; Sun, G.; Zhao, Y.; Wang, D.; Liu, F.; Fang, X.; He, Q.; Xu, D. Deep Learning Detection of Inaccurate Smart Electricity Meters: A Case Study. IEEE Ind. Electron. Mag. 2020, 14, 79–90. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, Y.; Niu, X.; Dai, H.-N.; Zhou, Y. Wide and deep convolutional neural networks for electricity-theft detection to secure smart grids. IEEE Trans. Ind. Inform. 2017, 14, 1606–1615. [Google Scholar] [CrossRef]
- Amarbayasgalan, T.; Pham, V.H.; Theera-Umpon, N.; Ryu, K.H. Unsupervised anomaly detection approach for time-Series in multi-domains using deep reconstruction error. Symmetry 2020, 12, 1251. [Google Scholar] [CrossRef]
- Sehovac, L.; Nesen, C.; Grolinger, K. Forecasting building energy consumption with deep learning: A sequence to sequence approach. In Proceedings of the 2019 IEEE International Congress on Internet of Things (ICIOT), Milan, Italy, 8–13 July 2019; pp. 108–116. [Google Scholar]
- Kou, Z.; Fang, Y. An Improved Residual Network for Electricity Power Meter Error Estimation. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1959024. [Google Scholar] [CrossRef]
- Kim, T.-Y.; Cho, S.-B. Web traffic anomaly detection using C-LSTM neural networks. Expert Syst. Appl. 2018, 106, 66–76. [Google Scholar] [CrossRef]
- Neshat, M.; Nezhad, M.M.; Abbasnejad, E.; Mirjalili, S.; Tjernberg, L.B.; Astiaso Garcia, D.; Alexander, B.; Wagner, M. A deep learning-based evolutionary model for short-term wind speed forecasting: A case study of the Lillgrund offshore wind farm. Energy Convers. Manag. 2021, 236, 114002. [Google Scholar] [CrossRef]
- Wang, J.Q.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- Duan, J.; Zuo, H.; Bai, Y.; Duan, J.; Chang, M.; Chen, B. Short-term wind speed forecasting using recurrent neural networks with error correction. Energy 2021, 217, 119397. [Google Scholar] [CrossRef]
- Qu, Z.; Xu, J.; Wang, Z.; Chi, R.; Liu, H. Prediction of electricity generation from a combined cycle power plant based on a stacking ensemble and its hyperparameter optimization with a grid-search method. Energy 2021, 227, 120309. [Google Scholar] [CrossRef]
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 9. [Google Scholar] [CrossRef] [Green Version]
- Ma, H.; Hu, Y.; Shi, H. Fault detection and identification based on the neighborhood standardized local outlier factor method. Ind. Eng. Chem. Res. 2013, 52, 2389–2402. [Google Scholar] [CrossRef]
- Jokar, P.; Arianpoo, N.; Leung, V.C. Electricity theft detection in AMI using customers’ consumption patterns. IEEE Trans. Smart Grid 2015, 7, 216–226. [Google Scholar] [CrossRef]
- Kodinariya, T.; Makwana, P. Review on Determining of Cluster in K-means Clustering. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2013, 1, 90–95. [Google Scholar]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-Means Clustering Method and Elbow Method For Identification of The Best Customer Profile Cluster. IOP Conf. Ser. Mater. Sci. Eng. 2018, 336, 012017. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Cao, X.; Liang, H.; Huang, W.; Chen, Z.; Li, Z. New Interpretations of Normalization Methods in Deep Learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 5875–5882. [Google Scholar]
- Zheng, J.; Xu, C.; Zhang, Z.; Li, X. Electric load forecasting in smart grids using long-short-term-memory based recurrent neural network. In Proceedings of the 2017 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2017; pp. 1–6. [Google Scholar]
- Malekizadeh, M.; Karami, H.; Karimi, M.; Moshari, A.; Sanjari, M. Short-term load forecast using ensemble neuro-fuzzy model. Energy 2020, 196, 117127. [Google Scholar] [CrossRef]
- Zanetti, M.; Jamhour, E.; Pellenz, M.; Penna, M.; Zambenedetti, V.; Chueiri, I. A Tunable Fraud Detection System for Advanced Metering Infrastructure Using Short-Lived Patterns. IEEE Trans. Smart Grid 2019, 10, 830–840. [Google Scholar] [CrossRef]
- Shipmon, D.T.; Gurevitch, J.M.; Piselli, P.M.; Edwards, S.T. Time series anomaly detection; detection of anomalous drops with limited features and sparse examples in noisy highly periodic data. arXiv 2017, arXiv:1708.03665. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GRU | MSE | RMSE | MAE | MAPE | SMAPE | |
|---|---|---|---|---|---|---|
| 3 Day | Mean | 0.29 | 0.54 | 0.42 | 6.06 | 6.08 |
| Min | 0.2 | 0.43 | 0.36 | 5.09 | 5.11 | |
| Max | 0.45 | 0.66 | 0.52 | 7.12 | 7.1 | |
| Std | 0.12 | 0.09 | 0.08 | 1.04 | 1.02 | |
| 7 Day | Mean | 0.28 | 0.52 | 0.39 | 5.81 | 5.72 |
| Min | 0.18 | 0.43 | 0.32 | 4.79 | 4.61 | |
| Max | 0.44 | 0.66 | 0.51 | 6.64 | 7.07 | |
| Std | 0.08 | 0.07 | 0.06 | 0.79 | 0.78 | |
| 14 Day | Mean | 0.22 | 0.47 | 0.32 | 4.55 | 4.51 |
| Min | 0.18 | 0.43 | 0.28 | 4.09 | 4.04 | |
| Max | 0.28 | 0.53 | 0.37 | 5.44 | 5.33 | |
| Std | 0.06 | 0.06 | 0.05 | 0.77 | 0.71 | |
| 20 Day | Mean | 0.56 | 0.73 | 0.5 | 7.58 | 7.15 |
| Min | 0.24 | 0.49 | 0.31 | 4.64 | 4.51 | |
| Max | 0.86 | 0.92 | 0.64 | 9.39 | 8.8 | |
| Std | 0.25 | 0.18 | 0.13 | 2.06 | 1.87 |
| LSTM | MSE | RMSE | MAE | MAPE | SMAPE | |
|---|---|---|---|---|---|---|
| 3 Day | Mean | 0.62 | 0.72 | 0.62 | 7.26 | 7.12 |
| Min | 0.43 | 0.56 | 0.42 | 6.16 | 6.06 | |
| Max | 0.81 | 0.94 | 0.84 | 8.2 | 8.18 | |
| Std | 0.19 | 0.2 | 0.24 | 1.12 | 1.08 | |
| 7 Day | Mean | 0.52 | 0.66 | 0.54 | 6.82 | 5.67 |
| Min | 0.38 | 0.48 | 0.32 | 5.46 | 5.44 | |
| Max | 0.66 | 0.92 | 0.62 | 7.6 | 7.44 | |
| Std | 0.16 | 0.28 | 0.22 | 1.22 | 1.02 | |
| 14 Day | Mean | 0.42 | 0.58 | 0.37 | 5.26 | 5.43 |
| Min | 0.32 | 0.45 | 0.26 | 4.36 | 4.28 | |
| Max | 0.54 | 0.68 | 0.44 | 6.22 | 6.08 | |
| Std | 0.13 | 0.12 | 0.09 | 0.98 | 0.96 | |
| 20 Day | Mean | 0.59 | 0.74 | 0.52 | 7.02 | 6.9 |
| Min | 0.36 | 0.54 | 0.36 | 5.22 | 5.04 | |
| Max | 0.74 | 0.98 | 0.64 | 8.44 | 8.38 | |
| Std | 0.24 | 0.21 | 0.15 | 2.04 | 2.02 |
| Failure Injection | K-Sigma | Confidence Interval |
|---|---|---|
| 3% | abnormal | normal |
| 5% | abnormal | abnormal |
| 7% | abnormal | abnormal |
| 10% | abnormal | abnormal |
| Meter Number | Failure Injection |
|---|---|
| 9 | 3% |
| 13 | 5% |
| 22 | 7% |
| 37 | 10% |
| Meter Number | Failure Injection |
|---|---|
| 9 | abnormal |
| 13 | abnormal |
| 22 | abnormal |
| 37 | abnormal |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Mu, J.; Han, X.; Liang, D.; Wang, X. Evaluation Model of Operation State Based on Deep Learning for Smart Meter. Energies 2021, 14, 4674. https://doi.org/10.3390/en14154674
Zhao Q, Mu J, Han X, Liang D, Wang X. Evaluation Model of Operation State Based on Deep Learning for Smart Meter. Energies. 2021; 14(15):4674. https://doi.org/10.3390/en14154674
Chicago/Turabian StyleZhao, Qingsheng, Juwen Mu, Xiaoqing Han, Dingkang Liang, and Xuping Wang. 2021. "Evaluation Model of Operation State Based on Deep Learning for Smart Meter" Energies 14, no. 15: 4674. https://doi.org/10.3390/en14154674
APA StyleZhao, Q., Mu, J., Han, X., Liang, D., & Wang, X. (2021). Evaluation Model of Operation State Based on Deep Learning for Smart Meter. Energies, 14(15), 4674. https://doi.org/10.3390/en14154674