
Implementation of Thermal Event Image Processing Algorithms on NVIDIA Tegra Jetson TX2 Embedded System-on-a-Chip


Abstract
1. Introduction
1.1. Image Plasma Diagnostics
1.2. General-Purpose Computing on Graphics Processing Unit
- 600 MB/s for a 16-bit IR image with resolution 2000 × 1500 at 100 Hz
- 12 GB/s for an 8-bit visible image with resolution 4000 × 3000 at 1 kHz
2. Development and Evaluation System Setup
2.1. NVIDIA Tegra System-on-a-Chip
2.2. Computer Vision Software
2.3. Wendelstein 7-X Experimental Data
3. Algorithms Implementation
3.1. Scene Model Pre-Processing
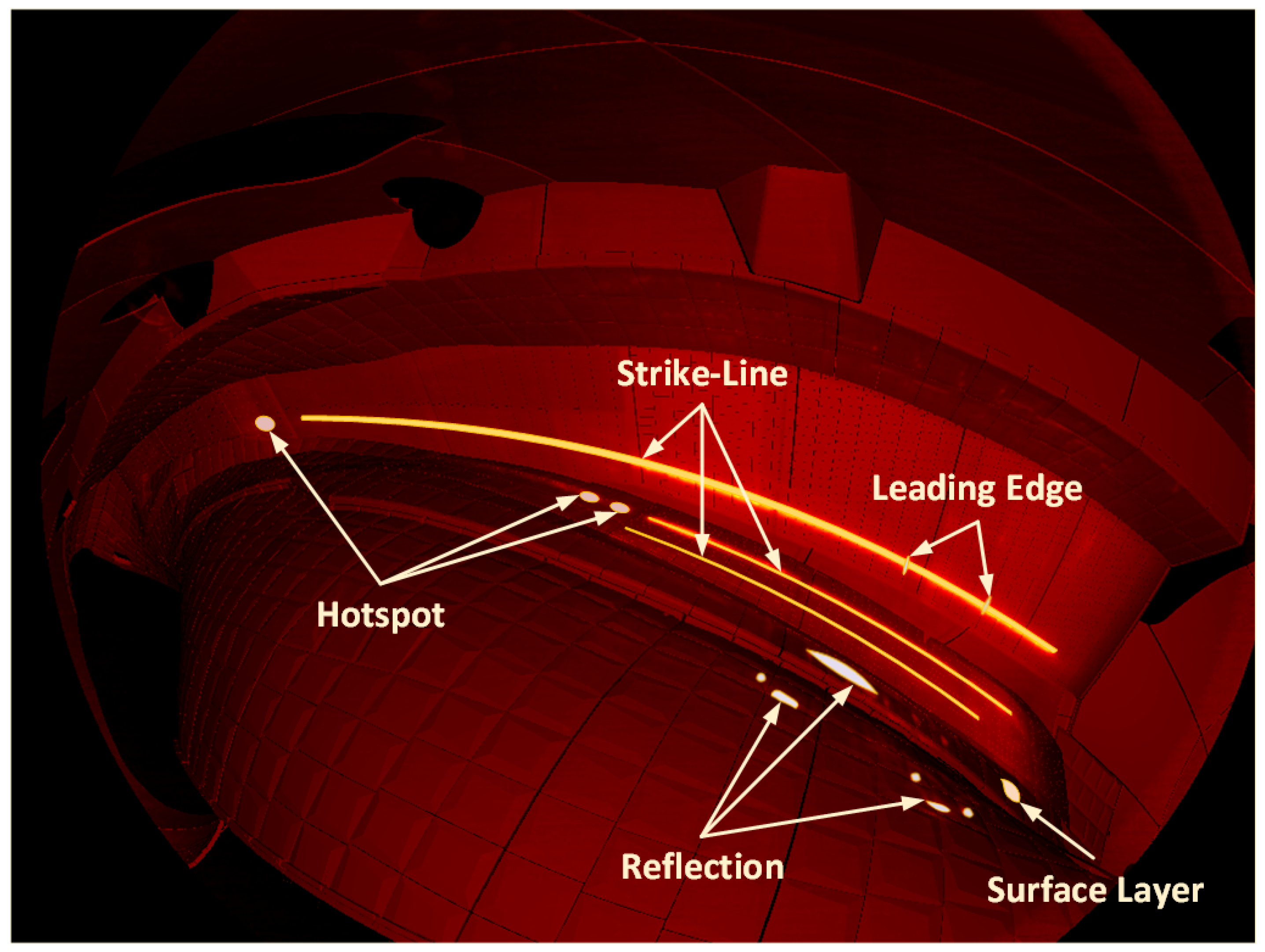
3.2. Overload Hotspots Detection Procedure
Tracking with Cluster Correspondence
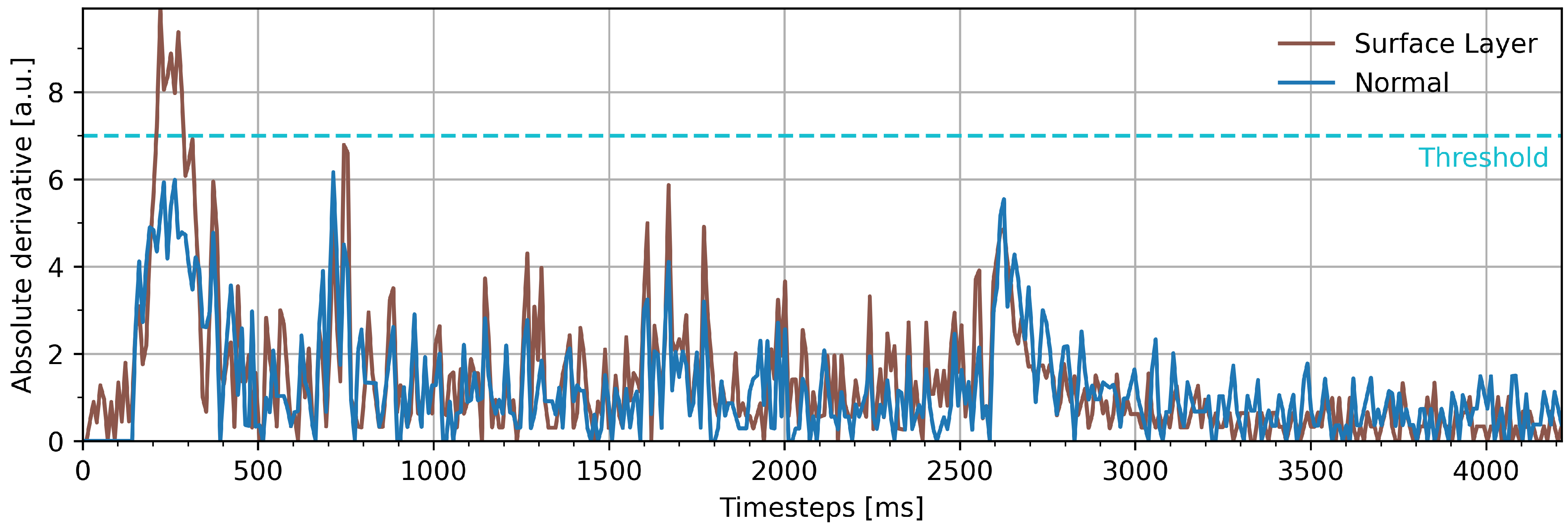
3.3. Surface Layers Detection
4. Results
5. Discussion
- Shared memory minimises global memory accesses for threads in the same block. An image is chunked into 2D thread blocks that have assigned shared memory of the block size with additional zero-padded borders. Each thread loads the corresponding pixel value from the global memory to the shared memory. Edge threads fill the zero-padding, and if the padded value belongs to the image, it is replaced with the underlying pixel value (see Figure 14) [33].
- Branchless exchange sorts two values with a single instruction [32].
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CAD | Computer-Aided Design |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| CV | Computer Vision |
| DMA | Direct Memory Access |
| DSP | Digital Signal Processor |
| EAST | Experimental Advanced Superconducting Tokamak |
| ELM | Edge Localised Mode |
| FoV | Field of View |
| FPGA | Field-Programmable Gate Array |
| GCC | GNU Compiler Collection |
| GPU | Graphics Processing Unit |
| HDF5 | Hierarchical Data Format version 5 |
| IR | Infrared |
| JET | Joint European Torus |
| L4T | Linux for Tegra |
| LUT | Lookup Table |
| MARFE | Multifaceted Asymmetric Radiation From the Edge |
| NPP | NVIDIA Performance Primitives |
| OP | Operational Phase |
| OS | Operating System |
| PCIe | Peripheral Component Interconnect Express |
| PFC | Plasma Facing Component |
| RAM | Random-Access Memory |
| RoI | Region of Interest |
| SoC | System-on-a-Chip |
| SWNCC | Normalised Cross Correlations (NCC) on a Sliding Time Window |
| TBB | Threading Building Blocks |
| THEODOR | THermal Energy Onto DivertOR |
| W7-X | Wendelstein 7-X |
| WEST | W Environment in Steady-state Tokamak |
References
- Vollmer, M.; Möllmann, K.P. Infrared Thermal Imaging: Fundamentals, Research and Applications; Wiley-VCH: Weinheim, Germany, 2010; ISBN 978-3527407170. [Google Scholar]
- Puig-Sitjes, A.; Jakubowski, M.; Fellinger, J.; Drewelow, P.; Gao, Y.; Niemann, H.; Sunn-Pedersen, T.; König, R.; Naujoks, D.; Winter, A.; et al. Strategy for the real-time detection of thermal events on the plasma facing components of Wendelstein 7-X. In Proceedings of the 31st Symposium on Fusion Technology (SOFT2020), Dubrovnik, Croatia, 20–25 September 2020. [Google Scholar]
- Drenik, A.; Brezinsek, S.; Carvalho, P.; Huber, V.; Osterman, N.; Matthews, G.; Nemec, M. Analysis of the outer divertor hot spot activity in the protection video camera recordings at JET. Fusion Eng. Des. 2019, 139, 115–123. [Google Scholar] [CrossRef]
- Zhang, H.; Xiao, B.; Luo, Z.; Hang, Q.; Yang, J. High-Speed Visible Image Acquisition and Processing System for Plasma Shape and Position Control of EAST Tokamak. IEEE Trans. Plasma Sci. 2018, 46, 1312–1317. [Google Scholar] [CrossRef]
- Makowski, D.; Mielczarek, A.; Perek, P.; Jabłoński, G.; Orlikowski, M.; Sakowicz, B.; Napieralski, A.; Makijarvi, P.; Simrock, S.; Martin, V. High-Performance Image Acquisition and Processing System with MTCA.4. IEEE Trans. Nucl. Sci. 2015, 62, 925–931. [Google Scholar] [CrossRef]
- Pisano, F.; Cannas, B.; Fanni, A.; Sias, G.; Jakubowski, M.W.; Drewelow, P.; Niemann, H.; Sitjes, A.P.; Gao, Y.; Moncada, V.; et al. Tools for Image Analysis and First Wall Protection at W7-X. Fusion Sci. Technol. 2020, 76, 933–941. [Google Scholar] [CrossRef]
- Sitjes, A.P.; Gao, Y.; Jakubowski, M.; Drewelow, P.; Niemann, H.; Ali, A.; Moncada, V.; Pisano, F.; Ngo, T.; Cannas, B.; et al. Observation of thermal events on the plasma facing components of Wendelstein 7-X. J. Instrum. 2019, 14, C11002. [Google Scholar] [CrossRef]
- Sitjes, A.P.; Jakubowski, M.; Ali, A.; Drewelow, P.; Moncada, V.; Pisano, F.; Ngo, T.T.; Cannas, B.; Travere, J.M.; Kocsis, G.; et al. Wendelstein 7-X Near Real-Time Image Diagnostic System for Plasma-Facing Components Protection. Fusion Sci. Technol. 2018, 74, 116–124. [Google Scholar] [CrossRef]
- Pisano, F.; Cannas, B.; Jakubowski, M.W.; Niemann, H.; Puig Sitjes, A.; Wurden, G.A. Towards a new image processing system at Wendelstein 7-X: From spatial calibration to characterization of thermal events. Rev. Sci. Instrum. 2018, 89, 123503. [Google Scholar] [CrossRef] [PubMed]
- Ali, A.; Jakubowski, M.; Greuner, H.; Böswirth, B.; Moncada, V.; Sitjes, A.P.; Neu, R.; Pedersen, T.S. Experimental results of near real-time protection system for plasma facing components in Wendelstein 7-X at GLADIS. Phys. Scr. 2017, T170, 014074. [Google Scholar] [CrossRef]
- Martin, V.; Moncada, V.; Travere, J. Challenges of video monitoring for phenomenological diagnostics in Present and Future Tokamaks. In Proceedings of the 2011 IEEE/NPSS 24th Symposium on Fusion Engineering, Chicago, IL, USA, 26–30 June 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Martin, V.; Moncada, V.; Travere, J.M.; Loarer, T.; Brémond, F.; Charpiat, G.; Thonnat, M. A Cognitive Vision System for Nuclear Fusion Device Monitoring. In Computer Vision Systems; Crowley, J.L., Draper, B.A., Thonnat, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 163–172. [Google Scholar]
- Pisano, F.; Cannas, B.; Fanni, A.; Sias, G.; Jakubowski, M.W.; Drewelow, P.; Niemann, H.; Sitjes, A.P.; Gao, Y.; Moncada, V.; et al. Tools for Image Analysis and First Wall Protection at W7-X. In Proceedings of the 3rd IAEA Technical Meeting on Fusion Data Processing, Validation and Analysis, Vienna, Austria, 28–31 May 2019. [Google Scholar]
- Ali, A.; Niemann, H.; Jakubowski, M.; Pedersen, T.S.; Neu, R.; Corre, Y.; Drewelow, P.; Sitjes, A.P.; Wurden, G.; Pisano, F.; et al. Initial results from the hotspot detection scheme for protection of plasma facing components in Wendelstein 7-X. Nucl. Mater. Energy 2019, 19, 335–339. [Google Scholar] [CrossRef]
- Herrmann, A.; Junker, W.; Gunther, K.; Bosch, S.; Kaufmann, M.; Neuhauser, J.; Pautasso, G.; Richter, T.; Schneider, R. Energy flux to the ASDEX-Upgrade diverter plates determined by thermography and calorimetry. Plasma Phys. Control. Fusion 1995, 37, 17–29. [Google Scholar] [CrossRef]
- Zoletnik, S.; Biedermann, C.; Cseh, G.; Kocsis, G.; König, R.; Szabolics, T.; Szepesi, T. First results of the multi-purpose real-time processing video camera system on the Wendelstein 7-X stellarator and implications for future devices. Rev. Sci. Instrum. 2018, 89, 013502. [Google Scholar] [CrossRef] [PubMed]
- Winter, A.; Bluhm, T.; Bosch, H.S.; Brandt, K.; Dumke, S.; Grahl, M.; Grün, M.; Holtz, A.; Laqua, H.; Lewerentz, M.; et al. Preparation of W7-X CoDaC for OP2. IEEE Trans. Plasma Sci. 2020, 48, 1779–1782. [Google Scholar] [CrossRef]
- Martin, V.; Esquembri, S.; Awanzino, C.; Nieto, J.; Ruiz, M.; Reichle, R. ITER upper visible/infrared wide angle viewing system: I&C design and prototyping status. Fusion Eng. Des. 2019, 146, 2446–2449. [Google Scholar] [CrossRef]
- Kadziela, M.; Jablonski, B.; Perek, P.; Makowski, D. Evaluation of the ITER Real-Time Framework for Data Acquisition and Processing from Pulsed Gigasample Digitizers. J. Fusion Energy 2020, 39, 261–269. [Google Scholar] [CrossRef]
- Makowski, D.; Mielczarek, A.; Perek, P.; Napieralski, A.; Butkowski, L.; Branlard, J.; Fenner, M.; Schlarb, H.; Yang, B. High-Speed Data Processing Module for LLRF. IEEE Trans. Nucl. Sci. 2015, 62, 1083–1090. [Google Scholar] [CrossRef][Green Version]
- HajiRassouliha, A.; Taberner, A.J.; Nash, M.P.; Nielsen, P.M. Suitability of recent hardware accelerators (DSPs, FPGAs, and GPUs) for computer vision and image processing algorithms. Signal Process. Image Commun. 2018, 68, 101–119. [Google Scholar] [CrossRef]
- NVIDIA Corporation. NVIDIA Jetson TX2 Series System-on-Module Data Sheet. Version 1.8. 2021. Available online: http://developer.nvidia.com/embedded/dlc/jetson-tx2-series-modules-data-sheet (accessed on 7 July 2021).
- NVIDIA Corporation. NVIDIA Jetson TX2 Developer Kit Carrier Board Specification. Version 20200608. 2020. Available online: https://developer.nvidia.com/embedded/dlc/jetson-tx2-developer-kit-carrier-board-spec (accessed on 7 July 2021).
- Makowski, D. Application of PCI express interface in high-performance video systems. In Proceedings of the 2015 22nd International Conference Mixed Design of Integrated Circuits Systems (MIXDES), Torun, Poland, 25–27 June 2015; pp. 141–143. [Google Scholar] [CrossRef]
- Mielczarek, A.; Makowski, D.; Perek, P.; Napieralski, A. Framework for High-Performance Video Acquisition and Processing in MTCA.4 Form Factor. IEEE Trans. Nucl. Sci. 2019, 66, 1144–1150. [Google Scholar] [CrossRef]
- Xilinx Kintex UltraScale+ FPGA NVIDIA Jetson AGX Xavier SOFI Carrier, AMC. 2021. Available online: https://www.vadatech.com/media/AMC565_AMC565_Datasheet.pdf (accessed on 27 May 2021).
- AG A1x/m1d N—Series. 2017. Available online: https://www.gocct.com/wp-content/uploads/Datasheets/AdvancedMC/aga1xm1d_0117.pdf (accessed on 27 May 2021).
- NVIDIA Corporation. CUDA for Tegra. Version 11.3.1. 2021. Available online: https://docs.nvidia.com/cuda/cuda-for-tegra-appnote/ (accessed on 27 May 2021).
- Clemente Bonjour, R. Detection and Classification of Thermal Events in the Wendelstein 7-X. Master’s Thesis, UPC, Escola Tècnica Superior d’Enginyeria de Telecomunicació de Barcelona, Departament de Teoria del Senyal i Comunicacions, Barcelona, Spain, 2020. [Google Scholar]
- Suzuki, S.; Abe, K. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Jakubowski, M.; Drewelow, P.; Fellinger, J.; Puig Sitjes, A.; Wurden, G.; Ali, A.; Biedermann, C.; Cannas, B.; Chauvin, D.; Gamradt, M.; et al. Infrared imaging systems for wall protection in the W7-X stellarator (invited). Rev. Sci. Instrum. 2018, 89, 10E116. [Google Scholar] [CrossRef] [PubMed]
- McGuire, M. A Fast, Small-Radius GPU Median Filter. Published in ShaderX6. 2008. Available online: https://casual-effects.com/research/McGuire2008Median/index.html (accessed on 21 July 2021).
- Malcolm, J. Median Filtering: A Case Study in CUDA Optimization. Presented at GTC Silicon Valley. 2009. Available online: https://on-demand-gtc.gputechconf.com/gtcnew/sessionview.php?sessionName=s09455-median+filtering%3a+a+case+study+in+cuda+optimization (accessed on 21 July 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| GPU | 256-core Pascal @ 1300 MHz (memory shared with RAM) |
| CPU | Arm Cortex-A57 (4 cores) @ 2 GHz + NVIDIA Denver2 (2 cores) @ 2 GHz |
| RAM | 8 GB 128-bit LPDDR4 @ 1866 MHz | 59.7 GB/s |
| PCIe | Gen 2 |
| Power | 7.5 W/15 W |
| Measurements [ms] | ||||||||
|---|---|---|---|---|---|---|---|---|
| Implementation | Overload Hotspots Detection | Surface Layers Detection | ||||||
| Avg. | Std. Dev. | Min. | Max. | Avg. | Std. Dev. | Min. | Max. | |
| CPU | 8.04 | 0.067 | 7.86 | 8.12 | 14.04 | 0.149 | 13.88 | 14.42 |
| GPU | 4.52 | 0.046 | 4.44 | 4.63 | 3.67 | 0.037 | 3.63 | 3.78 |
| Speed-up | ×1.78 | ×3.83 | ||||||
| Algorithm | Achieved Occupancy | Multiprocessor Activity |
|---|---|---|
| Overload Hotspots Detection | 0.93 | |
| Surface Layers Detection | 0.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jabłoński, B.; Makowski, D.; Perek, P. Implementation of Thermal Event Image Processing Algorithms on NVIDIA Tegra Jetson TX2 Embedded System-on-a-Chip. Energies 2021, 14, 4416. https://doi.org/10.3390/en14154416
Jabłoński B, Makowski D, Perek P. Implementation of Thermal Event Image Processing Algorithms on NVIDIA Tegra Jetson TX2 Embedded System-on-a-Chip. Energies. 2021; 14(15):4416. https://doi.org/10.3390/en14154416
Chicago/Turabian StyleJabłoński, Bartłomiej, Dariusz Makowski, and Piotr Perek. 2021. "Implementation of Thermal Event Image Processing Algorithms on NVIDIA Tegra Jetson TX2 Embedded System-on-a-Chip" Energies 14, no. 15: 4416. https://doi.org/10.3390/en14154416
APA StyleJabłoński, B., Makowski, D., & Perek, P. (2021). Implementation of Thermal Event Image Processing Algorithms on NVIDIA Tegra Jetson TX2 Embedded System-on-a-Chip. Energies, 14(15), 4416. https://doi.org/10.3390/en14154416