1. Introduction
Wind and solar photovoltaic power plants are now the cheapest options for electricity generation in most parts of the world [
1], paving the way for the extensive decarbonization [
2,
3,
4] of the power sector and the economy. However, in the case of wind energy, the accurate assessment of the wind resource at a prospective wind farm site continues to be key to successful development and competitive pricing. While traditional modeling approaches [
5,
6] for wind project development [
7] are often sufficiently accurate in flat or mildly rolling landscapes, wind power predictions in complex terrain are considerably more challenging [
6,
8,
9,
10,
11]. A 5% mean error in predicted wind speed can be the threshold for the approval or rejection of a wind project. Although traditional modeling approaches based on linearized flow solvers are nowadays often complemented with Reynolds-averaged Navier–Stokes (RANS) flow models and sometimes even large-eddy simulations (LES), the benefit is not always clear. Well-tuned linearized flow models, complemented by expert knowledge, may often yield similar or better results compared to advanced computational fluid dynamics (CFD) models.
In an attempt to evaluate and compare the performance of numerical wind flow models, different validation studies have been reported in the literature. Flow modeling approaches include assessments using wind industry-standard linearized flow models such as the one included in the Wind Atlas Analysis and Application Program (WAsP) [
5], and more complex CFD approaches, e.g., RANS and LES. Beaucage et al. [
6] performed a validation study over different terrain features, where the linearized flow model in WAsP and the Meteodyn CFD model were compared. In contrast to what is normally assumed, the results of WAsP were similar or better than those of the CFD model, with an overall root mean squared error (RMSE) of 0.62 m/s (corresponding to an 8.0% error) for WAsP and 0.76 m/s (9.4%) for Meteodyn. Another comparative analysis was performed between the linearized WAsP model and the RANS-model also available within the WAsP suite (WAsP CFD) at a complex site in Brazil [
8]. In this study, it was pointed out that the WAsP CFD model did not present a clear advantage over the linearized version. The authors conjectured that thermal effects not considered by either model highly contributed to the uncertainty of both results. Other studies have suggested the capacity of CFD models to outperform linear models [
9,
10,
11]; Hristov et al. [
11] suggested improvements of about 8% when predicting the annual energy production (AEP).
More recently, statistical learning methods have made their appearance in wind resource assessment. Such methods have the potential for taking advantage of a larger amount of input data than conventional approaches. In such data-based methods, the learning process commonly relies on terrain and meteorological features to estimate the target variable. This provides greater flexibility for considering micro-climatic effects that are generally not accounted for by flow models. Examples of machine learning methods include ensembles of regression trees [
12], support vector regression (SVR) [
13] and neural networks (NN) [
14].
The combination of physics-based and data-based methods may be a natural solution to the problem of accurate wind resource estimations in a complex terrain. Such hybrid approaches take advantage of each method’s strengths to increase robustness and predictive performance. However, for wind resource assessment, these methods are less popular. According to a literature review, only Tang et al. [
15] appear to have used a method that combines flow (CFD) simulations with a data-driven technique for assimilating multiple on-site measurements in complex terrain, in addition to a more traditional inverse-distance weighting (IDW) method [
16].
Here, we address the continuing challenges of accurate wind resource estimation in complex terrains by designing a method which taps into the capabilities of modern wind resource modeling suites such as WAsP or WindSim, but simultaneously provides the capability of accounting for micro-climatic effects, which are generally not properly addressed in flow models. The proposed new method is based on a conceptually simple machine learning approach, the k-nearest neighbors (
k-NN) method (see, e.g., [
17]). To the best of our knowledge, this approach has not been used before. The basic idea was to take advantage of the
similarity between different locations at a prospective wind farm site in terms of a set of classifiers or
features (
Section 2.1). Ideally, it should be possible to determine such features with the terrain information alone (elevation and roughness) and possibly wind resource information from one reference location, very much like in conventional flow models. It will be argued below that all feature parameters required for this work can actually be determined with flow models such as WAsP or WindSim alone, although an improved prediction can be obtained in the case of power density estimates if the wind rose at one reference location is known. The new
k-NN method can then be used in complete analogy to a conventional flow model to predict the wind resource at an arbitrary location for the purpose of turbine yield calculation or wind mapping. It should be noted that while the new method essentially uses the same input information as a conventional flow model, it provides larger flexibility, since it is not restricted by the deterministic relationships between a target and a reference location, which necessarily only consider the properties of the fluid model but not the micro-climate.
In order to build a reference case against which the new method can be compared, flow simulations based on both the linearized model within the WAsP suite (
Section 2.6) and the RANS-CFD model (WindSim) (
Section 2.7) were conducted first and the results were analyzed by cross-validation. The setup of both models was explored in a detailed manner, ensuring that the models were optimally configured and not artificially underperforming. This included the fine-tuning for atmospheric stability (in the case of WAsP), the use of both standard and high-resolution roughness maps, the exploration of a detailed forest model (in the case of WindSim), and the study of two different turbulence closure models (in the case of WindSim).
A number of different implementations were studied for the
k-NN approach (
Section 2.4). The basic approach consists of directly using the observed wind speed or power density at the available met tower locations, with the exception of the target location used for validation in each turn. Alternatively, the local wind climates can be first transferred to the target location, and the
k-NN can then be applied to the transferred climates; this is what we call the
hybrid approach below. Given that the hybrid method is a statistically independent implementation, the linear combination of both methods, i.e., an
ensemble, bears the potential of providing more accurate predictions and was implemented as well.
2. Methods and Data
2.1. The k-NN Method Applied to Wind Resource Modeling: The General Concept
The general idea of the
k-NN approach is to determine similarity between different locations, using a certain number
of
features as variables in a generalized coordinate space. Each site can then be represented as a point in this
-dimensional space, and its distance from any other site can be determined by an appropriate norm. Here, the L2-norm
was used throughout, prior to the standardization of each feature variable
x through
. Feature candidates include strictly terrain-related variables, such as the terrain complexity parameter RIX [
18], speedup and (geometric) distance between sites; variables related to local atmospheric conditions, such as temperature and turbulence intensity; and mixed variables such as the vertical wind shear, which depend on both terrain-dependent flow and atmospheric stability.
The key assumption of the
k-NN method is that the variable of interest, e.g., the wind speed
at time step
, can be predicted from the values of its
k nearest neighbors in the
-dimensional feature space, either by a simple or a weighted average:
where
is the target site and
is the set of nearest neighbors identified by the algorithm. The weights
were taken either as constant (uniform weighting) or as
(inverse distance weighting, IDW), where
is the distance between features (=
. It should be noted that the number
k of nearest neighbors can be dynamically determined at each time step by the algorithm, allowing to account for time-dependent features.
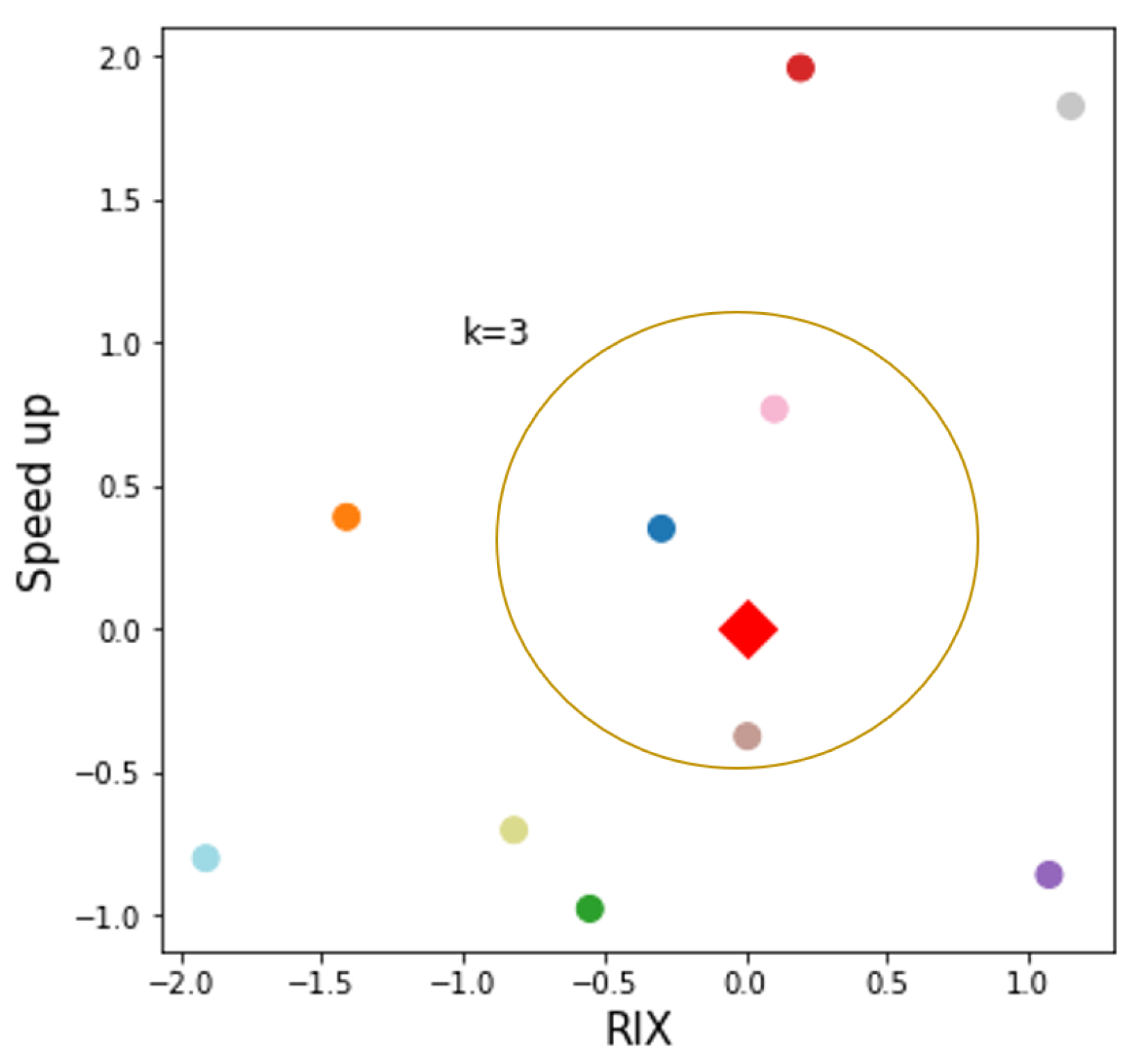
The
k-NN procedure is illustrated in
Figure 1 for the case of two features, which in this case are the RIX number and the speedup. The differences in RIX between the predictor and the predicted site (delta-RIX) can be used to correct results obtained with the linearized flow model in WAsP for complex terrain analysis [
5]. Here, RIX is used as one of the potential features determining similarity. In
Figure 1, the target site is shown is a diamond-shaped location in the RIX-speedup plane, together with a number of potential predictor sites. Note that both features may be taken as constant or time dependent; in the more general case of time-dependent features,
Figure 1 shows a snapshot of a set of locations at a given time step
. The methodology can also be extended to include the
time as an additional feature.
2.2. Hyperparameter Estimation in k-NN Models
In a
k-NN regression, the number of nearest neighbors in feature space
k is a
hyperparameter that determines the accuracy of the model. The other hyperparameter used in this work is the type of weighting
(uniform or inverse-distance weighting); see Equation (
1). Both hyperparameters are evaluated systematically in a process called
parameter tuning, which determines the optimal value of
k so that prediction errors are minimized. The standard methodology is based on splitting the data set into a training and a testing set, in such a way that the training set allows to estimate the optimal
value (usually by cross-validation to avoid over-fitting). Then, the selected
value is evaluated on the testing set (unseen data) to obtain an unbiased estimation of the model’s performance. In the present work, this approach was used for reference purposes (see below), however, the main contribution of this work to the
k-NN methodology is the estimation of the optimal hyperparameters without the target location, while still using the full observational period, thereby avoiding seasonality biases; a detailed description can be found in
Section 2.4. The two conceptually different approaches used in the work for hyperparameter estimation can then be described as follows:
In the first approach, the complete annual set of wind measurements was used to obtain the
minimizing the prediction errors for each site. In a first step (termed method kNN0 in
Section 2.4), data from all locations, including the target site, were used for that purpose. This step provides a fit to the data, not a prediction. It does, however, allow creating prior knowledge of the best hyperparameters possible for the reference sites. An estimation of the optimal hyperparameters
without using data from the target site, required for wind resource estimation at a location without measured data, is then conducted in a separate step, as described in
Section 2.2.1.
The second approach consists of the implementation of a nested cross-validation method, similar to the standard procedure of splitting the data set into a training and evaluation set. As opposed to the standard procedure, however, biases are avoided by using training periods of variable lengths, while maintaining validation and testing periods at constant lengths; as can be seen in
Section 2.2.2.
2.2.1. Hyperparameter Estimation with the Full Data Set
The parameter estimation for the full observational period is based on the following four algorithms. Algorithm 1 estimates the wind speed at each time step i using multiple combinations of features and a maximum of k neighbors. The uniformly weighted k-NN average and the inverse-distance weighted k-NN prediction were used to estimate the wind speed. The mean percentage error MPE was used as the main error metric.
Algorithm 2 was used to determine the best hyperparameter
k and its associated regression type
c, either uniform or inverse-distance weighted. Those best
ks were selected for each site and for each set of features based on their MPE values. A ranking of the best set of features for the study site was determined by
cardinality (i.e., the number of features in a set) based on the average of the MPE of all sites. Here, the four highest-ranking sets of features (i.e., the four best indicators of similarity) are reported in all cases.
| Algorithm 1k-NN regression with subset and number of neighbors selection |
Let X be the matrix of predictors and y be the vector of target values Let be the vector of query predictors Let be the set of all possible combination of features Let K be the maximum number of neighbors to consider Let for eachdo for to K do for to N do ▹ Variable D stores the L2 norm between query site and each predictor site for each instance i. Let be an empty set for to k do ← ▹ The set N stores the nearest neighbors to the query site for each instance i. end for ← ← end for ← ▹ The MPE variable stores the percentage error for each set of features and number of neighbors k ← end for end for ← return
|
| Algorithm 2 Selection of the optimal k and best predictors for cardinality 2 to |
Let X be the matrix of predictors and y be the vector of target values Let be the vector of query predictors Let be the set of all possible combination of features Let K be the maximum number of neighbors to consider Let be the set of sites that will be predicted for eachdo Algorithm 1 () end for return for eachdo for each do ← ▹ Selection of optimal hyperparameter for each site and set of features indexed by end for end for Let be an empty set for to do ← ▹ Selection of features that minimize the average MPE of all sites per cardinality end for return
|
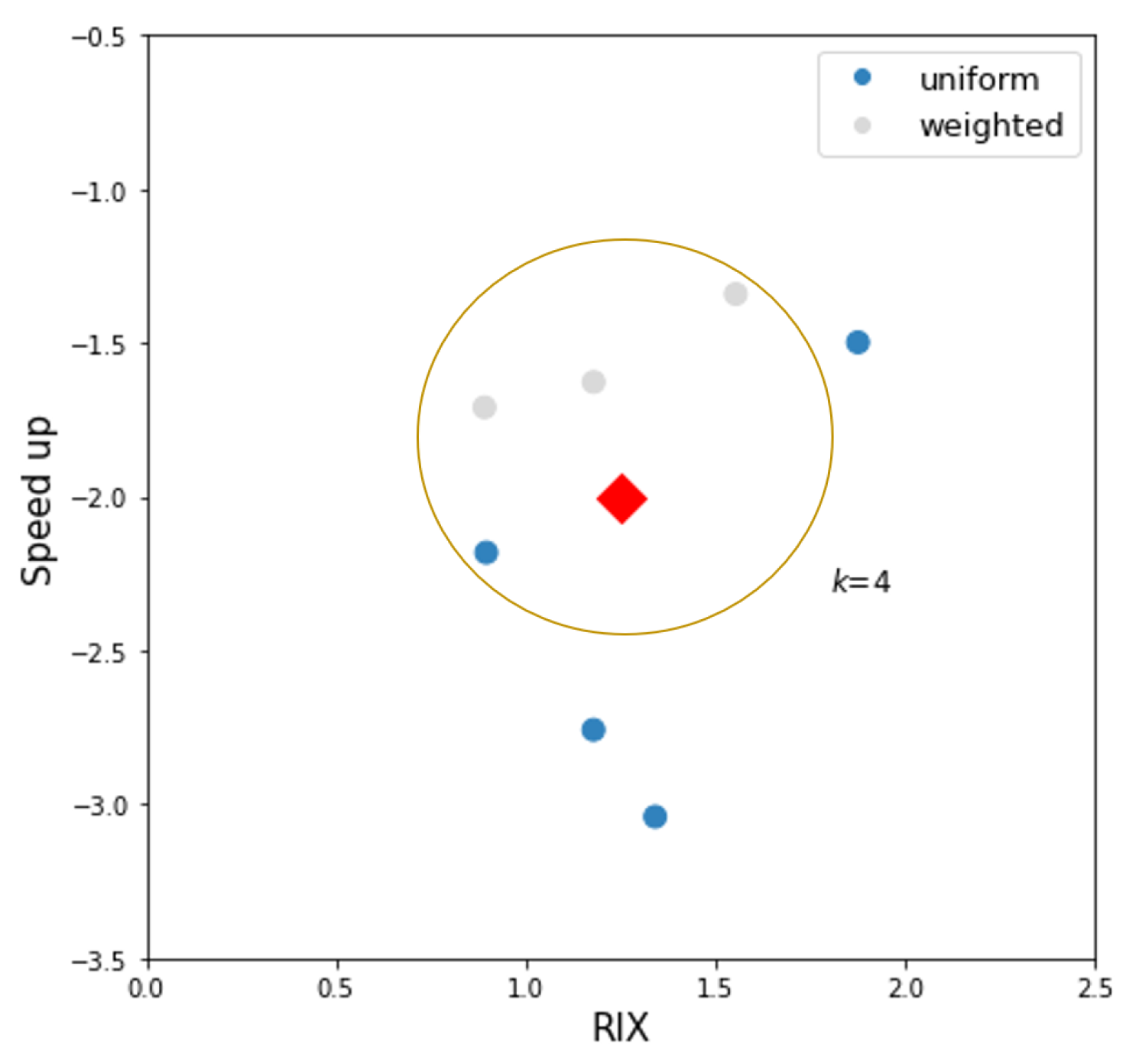
As mentioned previously, the optimal hyperparameters (
and
) determined by Algorithm 2 (also referred to as method kNN0, as can be seen in
Section 2.4) were determined using the wind measurements of all sites and are therefore not suitable for the estimation of the wind resource at a target location without on-site measurements. To overcome this limitation, the kNNa method (
Section 2.4) was designed to estimate the hyperparameters of an arbitrary target site using the optimal hyperparameters of neighboring reference sites, where the estimation is based on the similarity between sites. An illustration of this approach is given in
Figure 2. A
k-NN classifier was used to predict the two target variables
and
at the target site by the majority or weighted majority class of its
k nearest neighbors. This procedure was conducted using Algorithm 3, where an in-depth exploration of the parameters was performed using multiple combinations of features and a number of neighbors in the classifier. Each combination of parameters is called a different classifier. Given that hyperparameters in the present study are not time-dependent, all the features used to estimate
and
must be constant in time. Therefore, a mean value was calculated for time-dependent variables.
| Algorithm 3k-NN classification with subset and number of neighbors selection |
Let be the matrix of mean predictor values for all sites Let and be the vector of optimal parameters for k and c for all sites Let be the vector of mean predictor values at query location Let be the set of all possible combinations of features Let be the maximum number of neighboring sites for eachdo for to do for each do Let be an empty set for to j do ← end for Let be the set of unique denoted as ▹ The subset of unique values of is given by ←, ▹ saves the votes for each class from neighborhood ← ▹ The majority class is the predicted number of neighbors , estimated with the classifier and number of neighbors j ←, ← Let be a set of two labels ←, ▹ saves the votes for each class from neighborhood ← ▹ The majority class is the predicted type of regression , estimated with the classifier and number of neighbors j ←, ← end for end for end for ← ← return
|
To determine which of the
k-NN classifiers evaluated in Algorithm 3 had the best performance, wind speed predictions were conducted using the predicted hyperparameters
and
. The classifier minimizing the average error of the reference sites (leaving out the target site) was selected. Each site at its turn was assumed to be a target site, therefore
(number of sites) average errors were calculated; the classifier that repeated the most in those performance rankings was then selected. A pseudocode description of the method described is shown in Algorithm 4.
| Algorithm 4k-NN regression to estimate using estimated hyperparameters |
Let X be the matrix of predictors and y be the vector of target values Let be the vector of query predictors Let be the set of all possible combinations of features Let be the set of best predictors for eachdo ▹ The k-NN regression uses the set of selected features () by Algorithm 2, and indexed by for each do for each do ▹ The hyperparameters and predicted by the k-NN classifiers are indexed by r for to N do Let be an empty set for to do ← end for if then ← else ← end if end for ← ▹ The variable stores the errors using features , at a given with the estimated and end for ← ▹ Selection of the classifier that belongs to the index r that minimizes the avg. error leaving one site out end for Let be the set of unique denoted as ←, ▹ saves the votes for each classifier ← ▹ saves the classifier that repeat the most for each set of features end for return
|
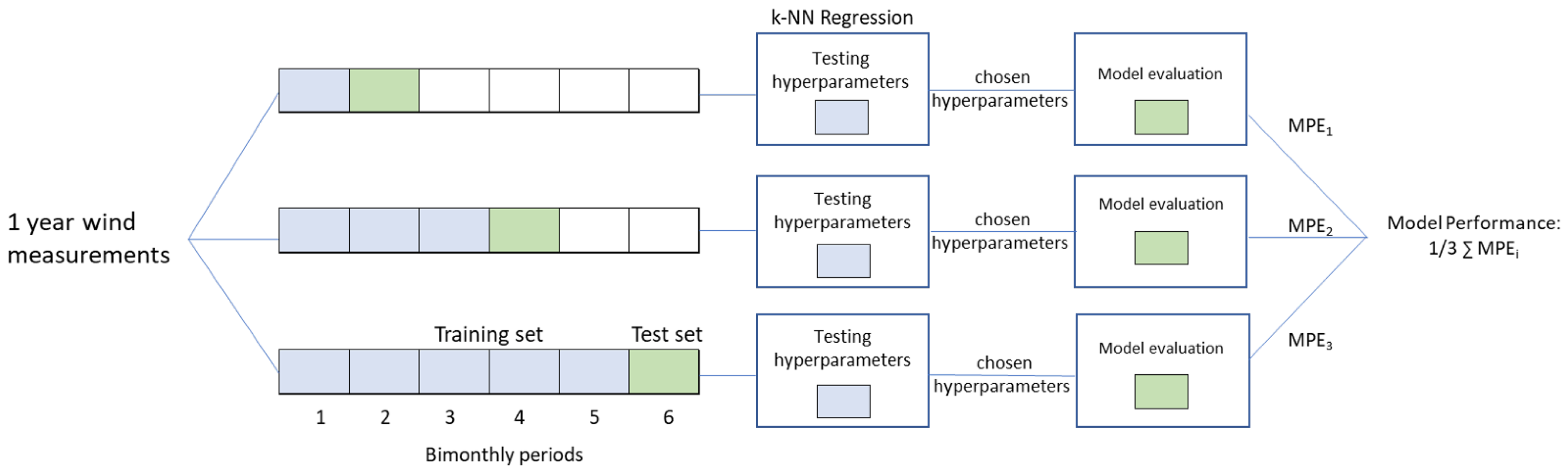
2.2.2. Hyperparameter Selection and Testing through Nested Cross-Validation
As described above, often
k-NN methods deals with time series data, which portray different characteristics when analyzed within different periods. For hyperparameter tuning and providing an unbiased validation of a given method for modeling or predicting a variable (such as wind speed), cross-validation is commonly carried out. In the present work, the nested cross-validation approach illustrated in
Figure 3 was implemented. With such an approach, the testing period (green square in
Figure 3) appears chronologically after the training period (blue squares). The training data are used to systematically evaluate the number of neighbors and type of regression, and the setup that minimizes the MPE is selected and used in the testing set to provide an unbiased measure of the model prediction error. By repeating this process with multiple testing sets, a better estimate of model performance is obtained. In this work, the data set was split into five nested subsets, using the setup shown in
Table 1. The testing period was constant in all runs (2 months). As mentioned before, this implementation was conducted for reference purposes only.
2.3. Feature Selection for k-NN Methods
A number of features were considered for their use with k-NN-based methods. A basic requirement for all candidates was the possibility of calculating their values for each location of interest from geographic information alone, in a completely analogous way in which flow modeling tools such as WAsP or WindSim construct wind maps for a site or region of interest. The following feature candidates were found to be suitable candidates:
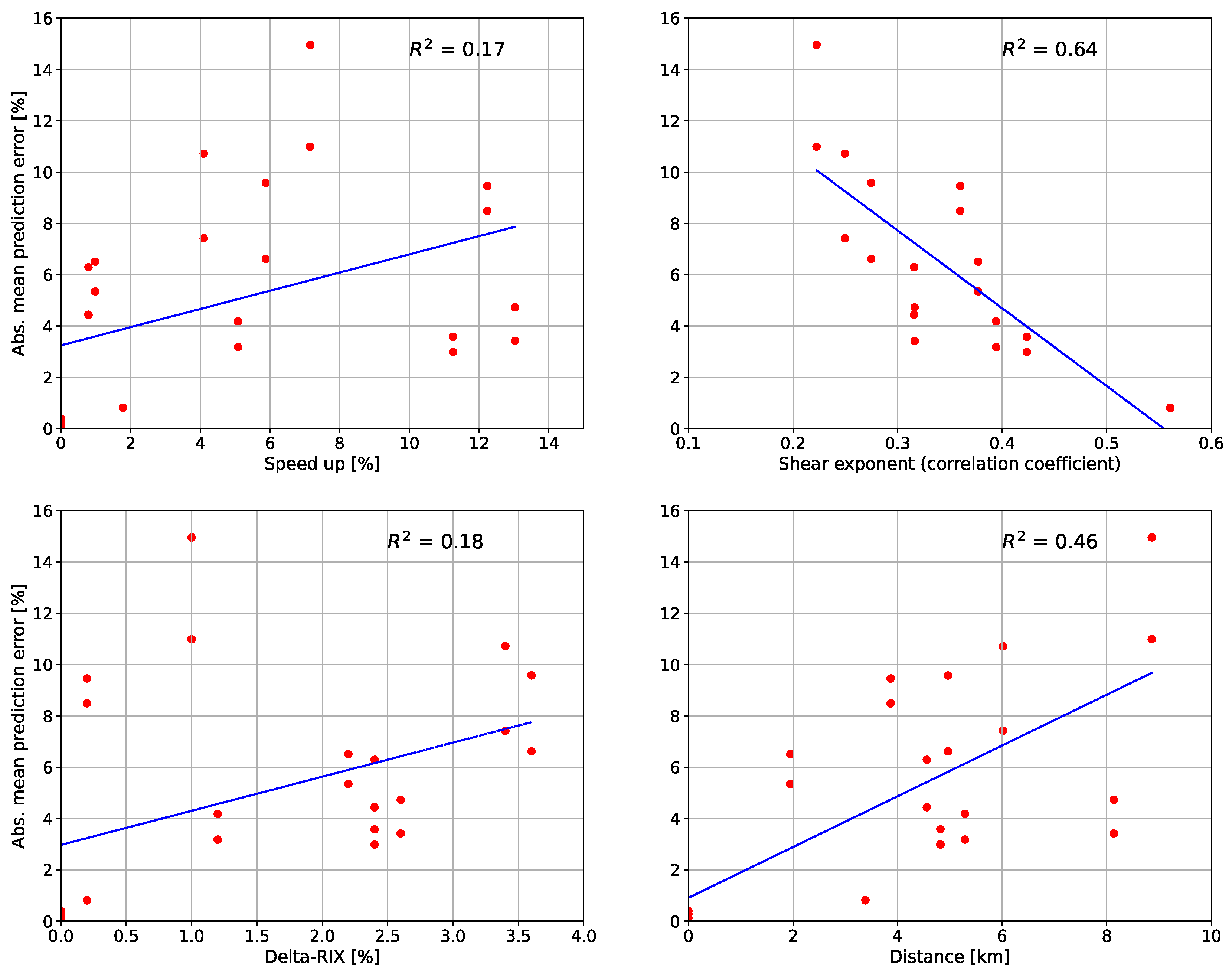
The terrain ruggedness index RIX. Although the
RIX correction procedure [
18] did not provide a significant improvement of the WAsP flow modeling results for the site, a weak correlation between the WAsP flow modeling error for the wind speed indicated a possible suitability of the RIX index as a similarity feature.
The orography-induced speedup (e.g., relative increase in wind speed due the terrain slope). A modest correlation between the prediction error and the difference between the WAsP-calculated topography-induced speedups was found (
Figure 4), indicating that the speedup is a possible similarity measure candidate.
The distance between measurement locations (met towers). As shown in
Figure 4, the distance between locations bears a similar impact on the flow modeling results as the difference between speedup values.
The vertical wind shear. The wind shear was found to have a significant (negative) correlation with the prediction error, and was therefore expected to be among the important predictor variables of the
k-NN method. Note that the degree of correlation between the flow modeling error and the feature candidates shown in
Figure 4 does not have any impact on the
k-NN methodology, beyond the decision of including or not a given candidate feature in the list of
k-NN predictors. The
k-NN method determines the optimal set of predictors in an automated fashion, as described above.
The following additional feature parameters were used for the assessment of power density:
The Weibull scale and shape parameters. Determining Weibull parameters requires on-site measurements (or simulated winds from atmospheric models) for at last one location. Using such a reference location, a transferred wind rose (the latter understood as the set of angular wind speed histograms) can be constructed using a wind flow modeling tool. Since local flow conditions are different for different wind directions, the average transferred wind rose will generally have different Weibull parameters.
The -value, or coefficient of determination, of the Weibull fit. The transfer of wind roses may not only change the Weibull parameters, but may also distort the underlying histogram, resulting in varying degrees of goodness of fit.
-related parameters can be constructed for their use as similarity features; additionally, a modified weighting scheme (similarly to the one proposed in [
19]) was explored as well, where the
-value was used to build a confidence level matrix as part of a generalized inverse-distance averaging scheme.
2.4. Setup of the k-NN Simulations
The current work consists of the following sequence of assessments:
- (1)
KNN0. All available wind speed data for the full one-year period (see
Section 2.5) were used to perform a
k-NN regression for each of the five towers as target site. The optimal hyperparameters
and
were calculated from the full regression. Algorithms 1 and 2 were used for this purpose. This is a baseline case, constructed for reference purposes.
- (2)
KNNa. In order to conduct an independent test of the methodology, the optimal hyperparameters were estimated from all towers, excluding the target tower itself. The corresponding procedure is described in Algorithm 3.
- (3)
KNNb. Instead of using the measured wind speed information directly as a predictor for a given target site, an alternative method consists of using the WAsP predictions for the target site, prepared with each of the predictor sites. The same set of features and feature combinations as before were used in this step.
- (4)
KNNc. Since methods KNNa (driven exclusively with observed wind speed data) and KNNb (working on WAsP-processed observational data) represent independent assessments, an ensemble version was performed, where methods KNNa and KNNb were combined linearly.
- (5)
KNNd. For an independent validation of the
k-NN approach, an additional method was implemented, where optimal hyperparameters were determined and validated in the nested approach described in
Section 2.2.2.
2.5. Validation Data
On-site tall tower meteorological data from the development phase of a commercial wind farm in Mexico were used for model construction and validation. The data are proprietary and are not in the public domain. Each of the five towers at the site (“site B”) was equipped with three pairs of redundant cup anemometers (class I for primary sensors, standard for redundant) placed at 80, 60, and 40 m above ground level. The wind direction was measured at two levels (42 and 78 m). Temperature measurements were taken at 12 and 80 m above ground level. Data were recorded at 10 min intervals; for each variable, the mean, maximum, minimum and standard deviation were recorded. One full year of concurrent information with only minor data gaps was selected to avoid seasonal biases. Initial quality assurance was conducted in a semi-automatic way using Windographer. Overall data recovery after quality assurance was 99.9%. All reported results for the wind speed modeling accuracy in this study refer to the 80 m wind speed.
In order to build a continuous observational period, three reconstruction methods were used: (1) replacement of missing or invalid 80 m data with those from the redundant sensor, prior tower shadow correction when necessary; (2) vertical extrapolation, and (3) principal component analysis (PCA). Vertical extrapolation was used when 40 m and 60 m wind speed data were available. PCA was used to take advantage of concurrent data from other towers where no concurrent wind speed data at the same tower were available.
In order to ascertain that the reconstructed continuous data records for each met tower were statistically indistinguishable from the quality-controlled original data, both a test for the observed () and reconstructed () wind speed distributions, with , and a Kolmogorov–Smirnov test for the cumulative probability density functions ( and , respectively) were conducted. All tower measurements at site B successfully passed both tests, demonstrating that the quality-controlled original data sets and the reconstructed full data sets were statistically indistinguishable.
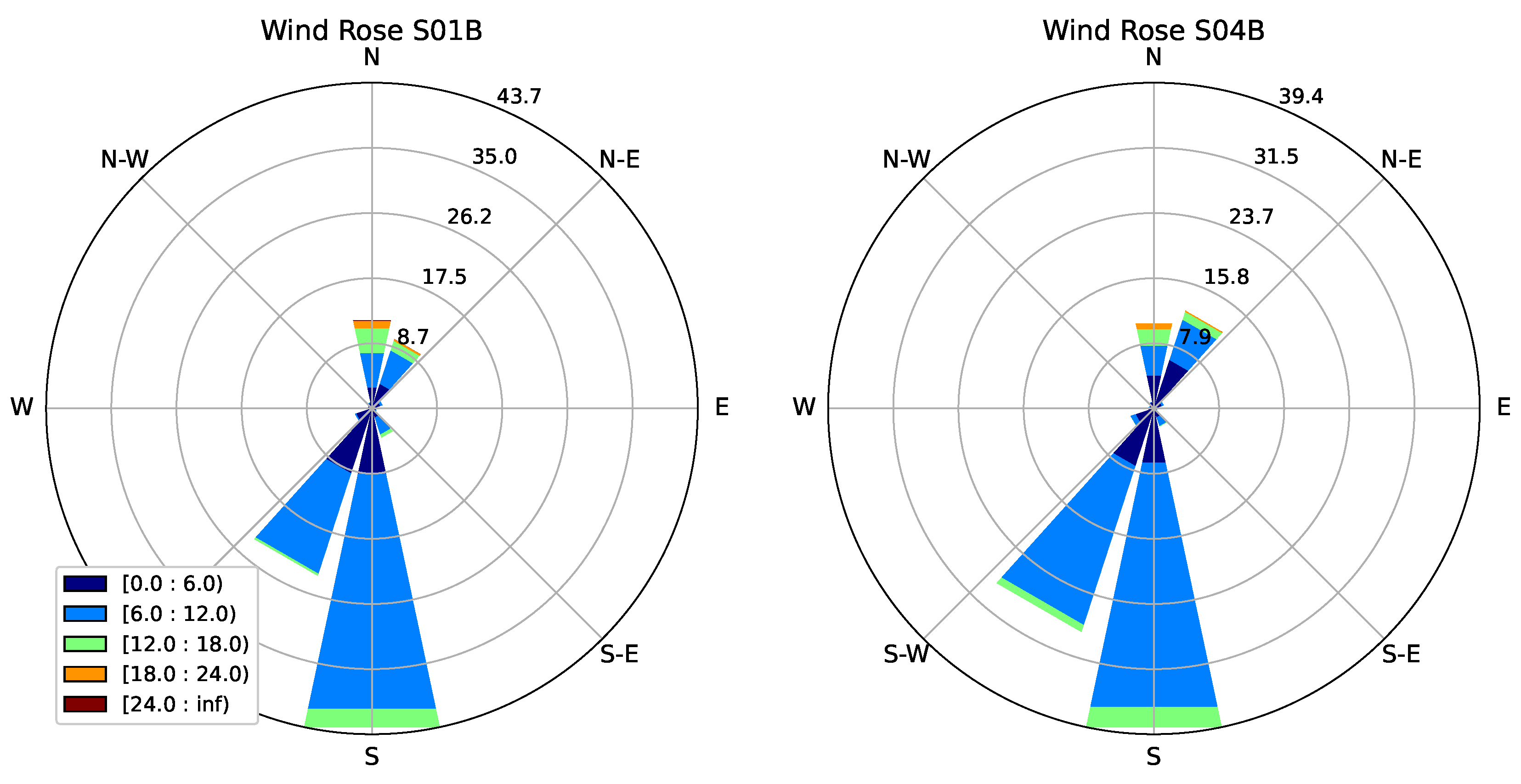
The wind regime at the site is essentially bi-modal, with Southerly winds predominating most of the year, the remainder corresponding to Northerly winds (see
Figure 5). All towers were located at either the Southern or the Northern edge of a plateau structure, with three towers (S01_B, S02_B, SO3_B) being located at the Southern and two (S04_B, S05_B) at the Northern edge. S01_B and S05_B are somewhat more exposed locations, sitting on extruded portions of the plateau, whereas the other towers sit between a steep slope and the flat upper part of the plateau.
2.6. Flow Modeling: WAsP
WAsP [
5] was used for (1) wind flow modeling and cross-prediction of the wind resource at all locations with observational data; and (2) the determination of the feature parameters (
Section 2.4). Orography inputs come from the Shuttle Radar Topography Mission (SRTM) digital elevation data [
20] with a resolution of 1 arcsec (30 m). The SRTM 1 Arc-Second Global version [
21] used was downloaded from the U.S. Geological Survey (USGS) website. The domain extends 10 km beyond the limits of the site of interest in order to create a large enough buffer to avoid boundary effects; contour lines with a spacing of 10 m were used. The GlobeLand30 (GLC30) database [
22] with a resolution of 1 arcsec (30 m) was used to create a roughness map. Using the GLC30 version 2020 database improves the cross-validation results for the wind speed compared to using the WAsP default database (GlobCover-2009 map [
23]); therefore, we use the former roughness data hereafter. A detailed discussion of the impact of potentially more accurate roughness maps and its impact of flow modeling accuracy is not part of the present work.
In the WAsP modeling chain, the observed wind is generalized using predefined heights and roughness lengths, which can be modified. It was observed that a fine tune of these values reduces the error in the predicted wind. Here, the predefined heights were set to 10, 30, 60, 80 and 100 m above ground level and the standard roughness lengths were set to 0.0, 0.05, 0.11, 0.23 and 0.5 m.
In order to account for atmospheric stability, a systematic assessment of the heat flux impact on the vertical wind shear profiles was conducted (not shown). By using the WAsP default configuration, corresponding to a slightly stable condition with a heat flux offset of
W/m
, a good fit with the observed profiles was found at all tower locations. Allowing for heat flux offset variations did not improve the results. Another option in the WAsP software is the geostrophic shear model, which is turned on by default. The geostrophic shear is obtained from coarse reanalysis data, which cannot resolve the slopes in mountainous terrain [
24], and can therefore give unphysically large geostrophic wind shear values. This was also observed for the study site in this work (0.02 m/s/m). The model was therefore turned off in all cases.
An attempt to further improve the results of the cross-validation predictions using the delta-RIX methodology [
18] was performed. However, as mentioned in
Section 2.3, no statistically significant improvement was obtained.
As an additional reference, the WAsP software was run in (RANS) CFD mode; the results were found to be similar to the ones obtained with WindSim, discussed in the next subsection. Unless mentioned otherwise, all WAsP results were obtained with the standard (linear) flow solver.
2.7. Flow Modeling: WindSim
A RANS-based solver, the commercial software package WindSim ([
25]), was used in an attempt to improve cross-predictions, given the terrain complexity of the site. The same topography data (STRM and GLC30) as those in WAsP were used. The WindSim mesh was setup with an initial horizontal resolution of 50 m in the refinement area for convergence and initial performance tests; the resolution in the refinement area used in the final selected configuration was then set to 20 m for a better representation of the terrain at its steep parts. Setup parameters for WindSim include (1) a toggle parameter for including the forest model (on/off); (2) the free parameters of the forest model; (3) the turbulence closure model (
k-
or
k-
); and (4) the type of atmospheric stability. A Taguchi experiment design [
26] was set up in order to assess the different free parameters of the forest model. The assumption of neutral stability was found to produce a good agreement with the observed wind speed profiles; moreover, simulations under stable and unstable conditions lead to convergence problems, so only neutral stability conditions were considered for the final model setup. The use of the
k-
turbulence closure model and the omission of the forest model produce the best results generally, so we use this configuration hereafter. A detailed discussion of the setup, experiment design and results obtained with the WindSim study are beyond the scope of the present work and will be reported elsewhere.
4. Summary and Conclusions
Here, a novel method for the modeling of the wind resource with improved accuracy was proposed and evaluated using on-site data from a site with complex terrain characteristics. As opposed to industry-standard approaches, which mainly rely on flow models, the new method uses a simple and intuitive machine learning algorithm, based on the k-nearest neighbors concept. While being a consolidated method in the literature on advanced statistical modeling and machine learning, to the best knowledge of the authors, no such approach was previously proposed or demonstrated in the field of wind resource assessment.
The k-NN method in this work was based on the concept of similarity between met tower locations. To assess similarity, the method uses classifiers or features of each location. Features related to the terrain characteristics, flow-related quantities and micro-climate parameters were selected. All location features can be readily obtained with a microscale flow model. All k-NN runs performed in this work use features generated with WAsP. In order to generate a baseline for comparisons, cross-validations between the five tall (80 m) tower locations were conducted with both WAsP (using its linear flow solver) and WindSim (using a RANS implementation). Both software suites were fine-tuned in order to strive for optimal performance.
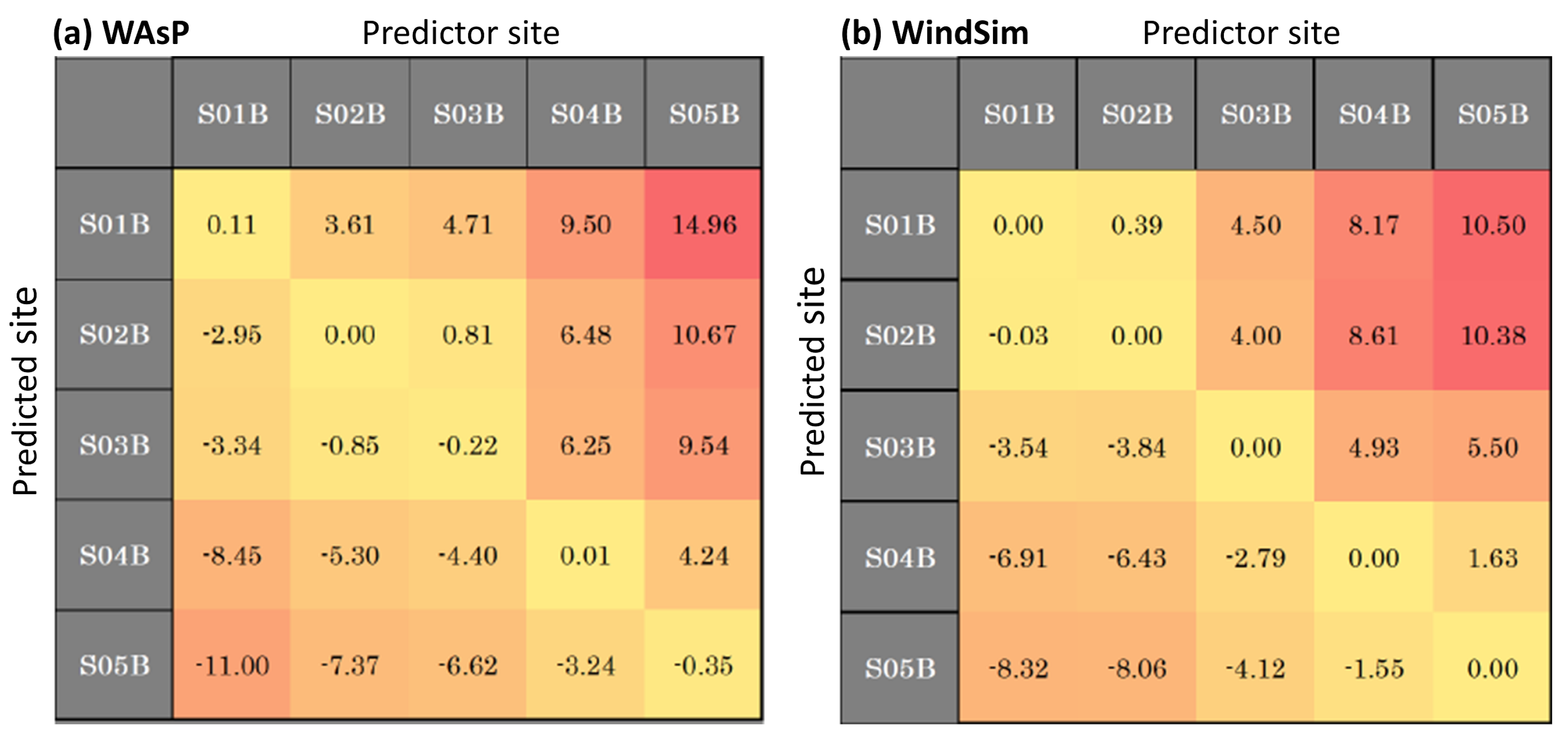
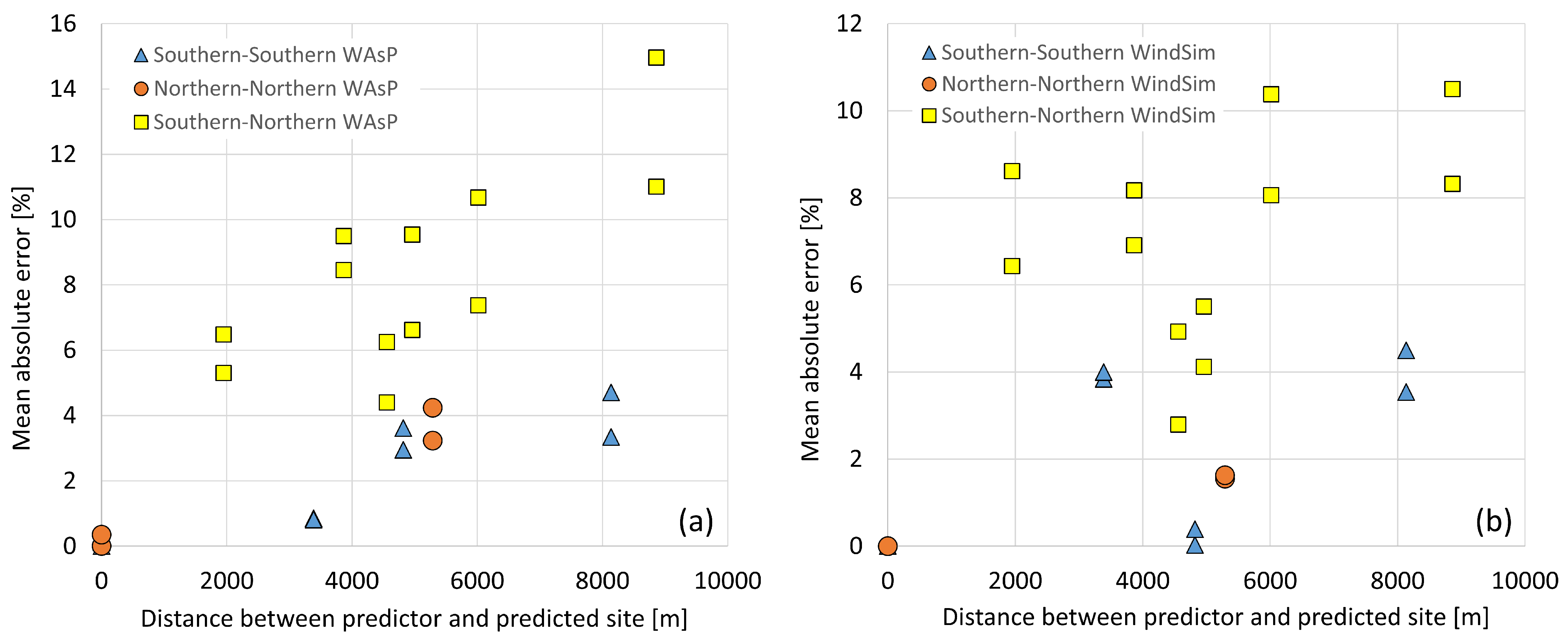
Given that all met towers are located at edge locations, a clear improvement of the RANS-CFD predictions over the linear flow model was expected. Some improvement by the best-tuned RANS model was indeed observed. Both flow models failed, however, to accurately transfer the measured climatologies from the northern edge to the southern edge locations and vice versa with the accuracy required by modern competitive wind farms.
Four conceptually different k-NN approaches were proposed and assessed, with one of the methods (kNNd) being used for reference purposes. The baseline model (kNNa) works directly with the quality-controlled wind speed or power density 10 min time series retrieved from all met towers other than the target location used for validation. The hyperparameters required by the k-NN model were estimated with a novel methodology based on the similarity between locations, which takes advantage of the full observational period. This is somewhat different from a typical machine-learning approach (implemented as method kNNd) and more suitable for the context of this work.
Two other variants of the k-NN concept were implemented as well. In kNNb, the observed wind data were first transferred to the target site using WAsP, and the k-NN method was then applied to those transferred climatologies. This hybrid approach has the advantage of being an independent assessment of the wind resource at the target site, allowing for the construction of an ensemble method (kNNc) by combining the predictions of kNNa and kNNb.
The k-NN concept, in its different implementations, provided significant improvements overflow modeling results. While the average WAsP prediction accuracy was around 5% for the wind speed and 7% for the wind power density, the corresponding figures for k-NN method were only approximately 1.5 and 3%, respectively. It should be noted that from the perspective of a wind resource modeler, the k-NN method works similarly to a flow model such WAsP or WindSim; only terrain-related information and wind time series for different measurement locations are needed.
While providing improved accuracy over wind flow models, the k-NN approach does have some limitations. First, a flow model is needed to determine the feature parameters of each location of interest. Therefore, the k-NN method can be viewed as an add-on to existing wind modeling suites such as WAsP and WindSim, rather than a stand-alone method. However, wind resource modelers typically have access to flow modeling tools, so this is not a practical limitation. Second, the k-NN method needs more than one measurement location, as opposed to WAsP or WindSim. This is, however, not a strong limitation, since nowadays, a number of met towers are routinely installed at prospective wind farm sites, and additional measurement locations can be created dynamically using remote sensing devices such as lidar and sodar. The proposed method was therefore believed to have good prospects for applications in a practical wind resource assessment context.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}