
Power and Performance Evaluation of Memory-Intensive Applications †


Abstract
1. Introduction
2. Related Work
3. Notations of Server Energy Efficiency Evaluation
- (1)
- Utilization. In the target load column of specpower results in Table 2, which assume benchmark to delete all hardware components concertedly, there are 10 utilization levels, ranging from 10% to 100%.
- (2)
- Peak utilization. We refer to 100% utilization as peak utilization.
- (3)
- Energy efficiency (EE). It is defined as the performance to power ratio with unit of ssj_ops per watt. The formula is as follows:In Table 2, the energy efficiency values are the last column named “performance to power ratio” and we abbreviate energy efficiency as EE. However, for memory systems, we use bandwidth per watt (BpW) to measure memory energy efficiency (MEE):
- (4)
- Server overall energy efficiency. The server’s overall performance to power ratio, that is, the ratio of the sum of ssj_ops to the sum of 10 utilization levels (from 10% to 100%) and the sum of active idle power (∑ssj_ops/∑power). In addition, the server overall energy efficiency is also used as its SPECpower score. For example, in Table 2, the overall energy efficiency of the server (total score) is 5316.
- (5)
- Peak energy efficiency. It is defined as the highest energy efficiency of a server among all utilization levels. For example, in Table 2, the server peak energy efficiency is 6619 (at 70% utilization).
- (6)
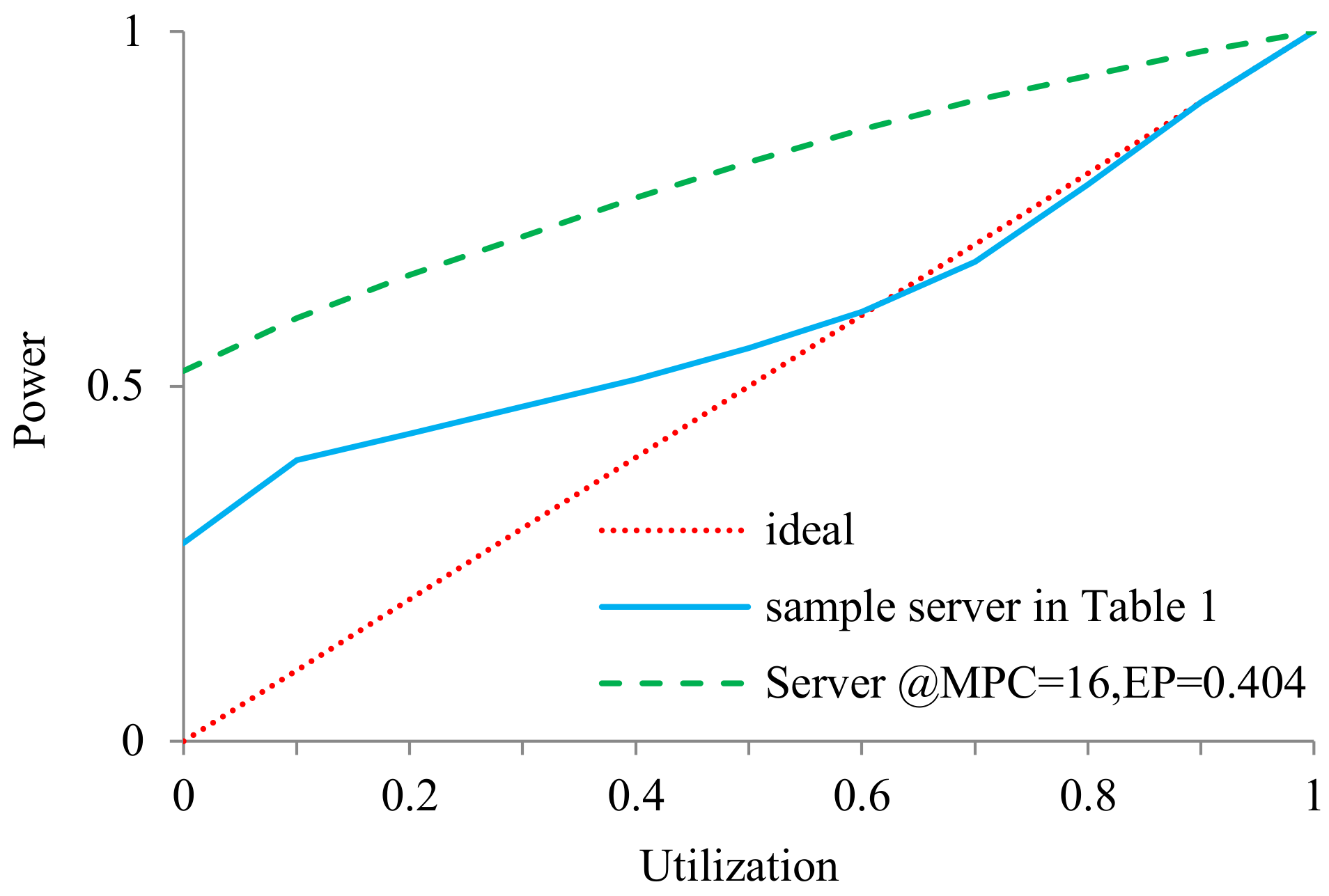
- Energy Proportionality (EP). In this paper, we use the energy proportionality (EP) metric proposed in [64]. Taking the server in Table 2 as an example, we can draw its normalized utilization–power curve in Figure 1. The solid line in Figure 1 is the EP curve of the server in Table 2, the dotted line is the ideal energy proportionality server and the dashed line is our tested and untuned server with 16 GB of memory per core running the SPECpower benchmark. Based on this, we can compute the EP of a real server by the following formula [64]:
4. Experiment Results on Typical Memory-Intensive Workloads
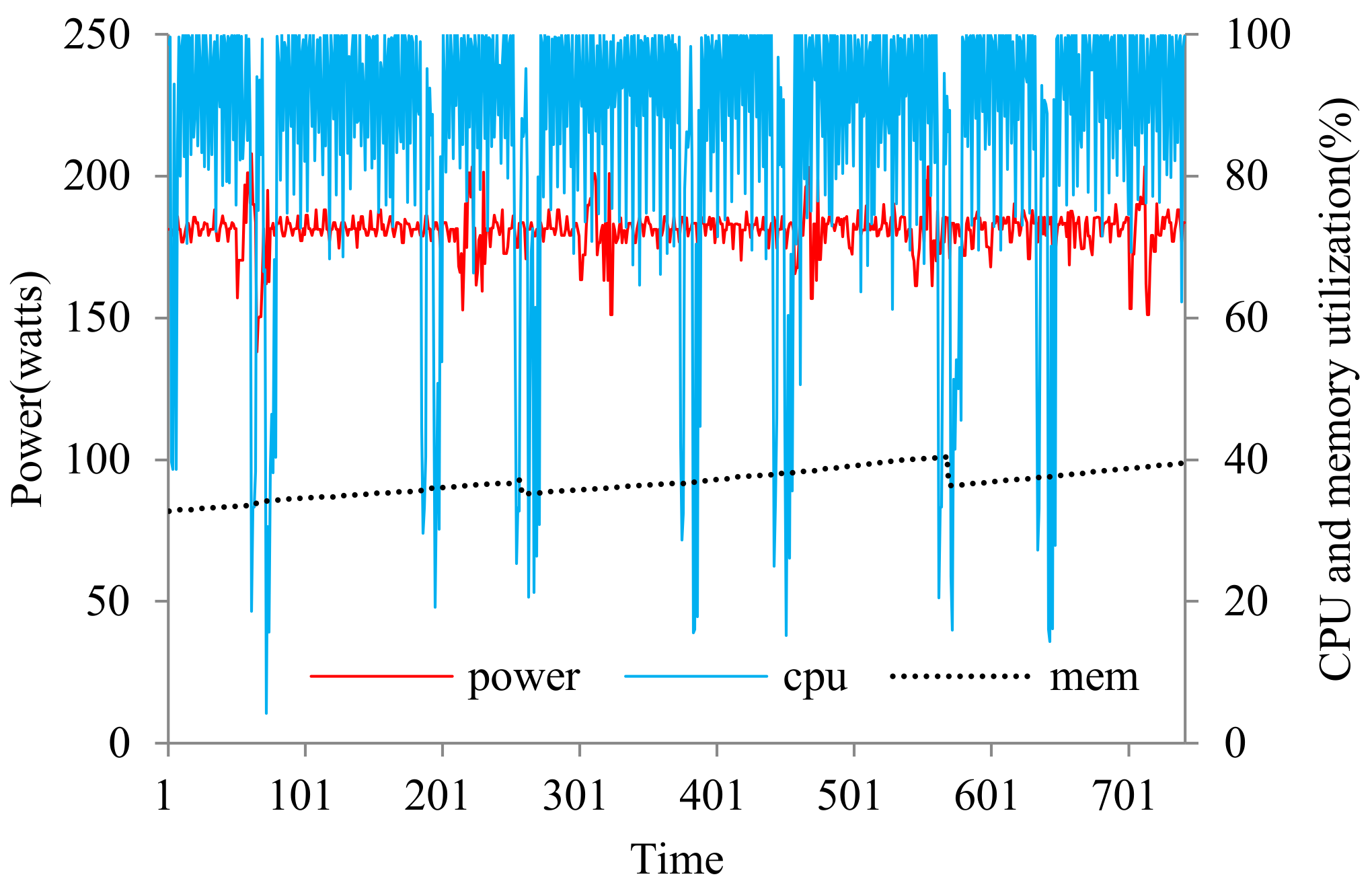
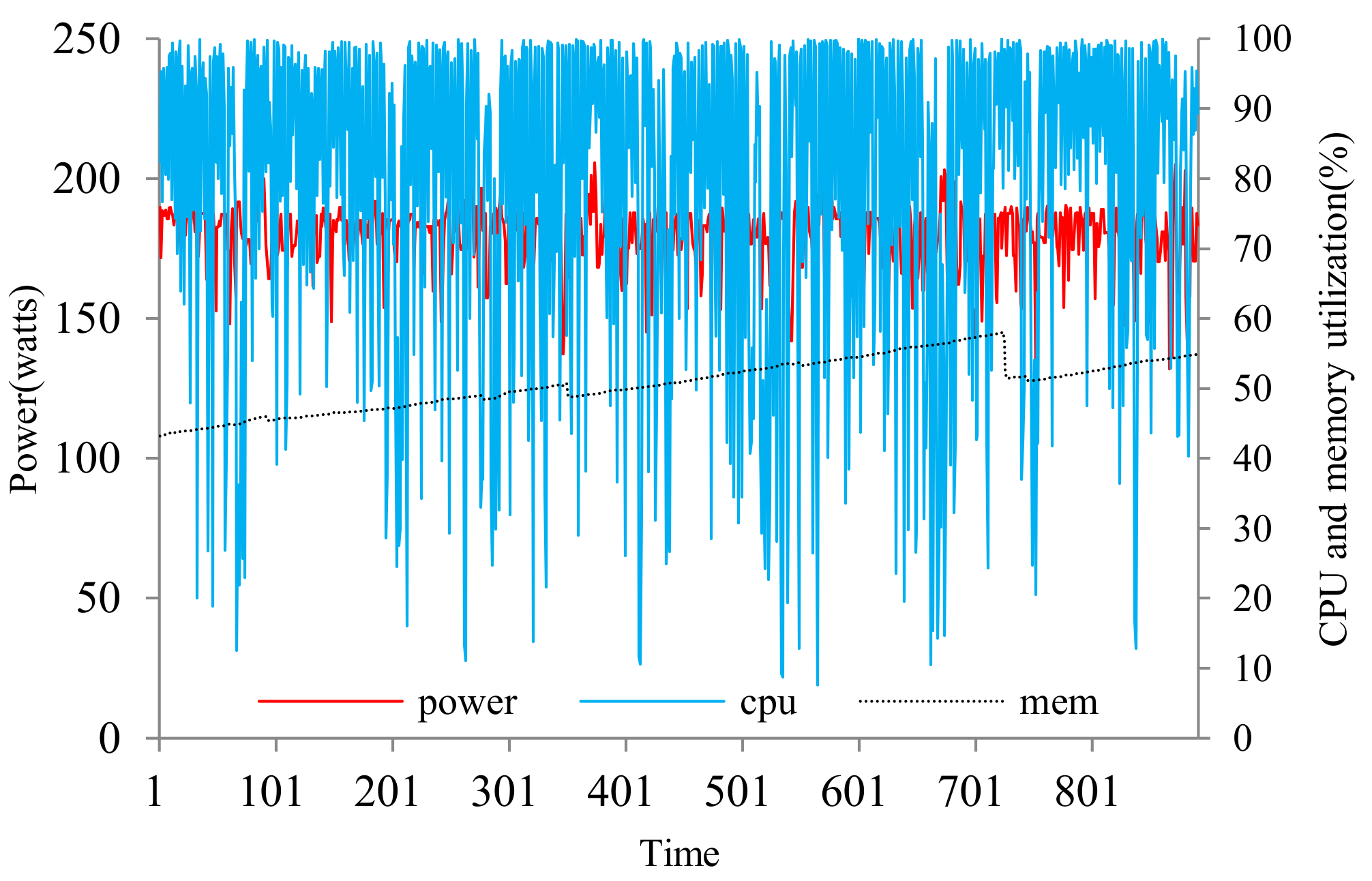
4.1. Experiment Setup
4.2. Results of STREAM Workload
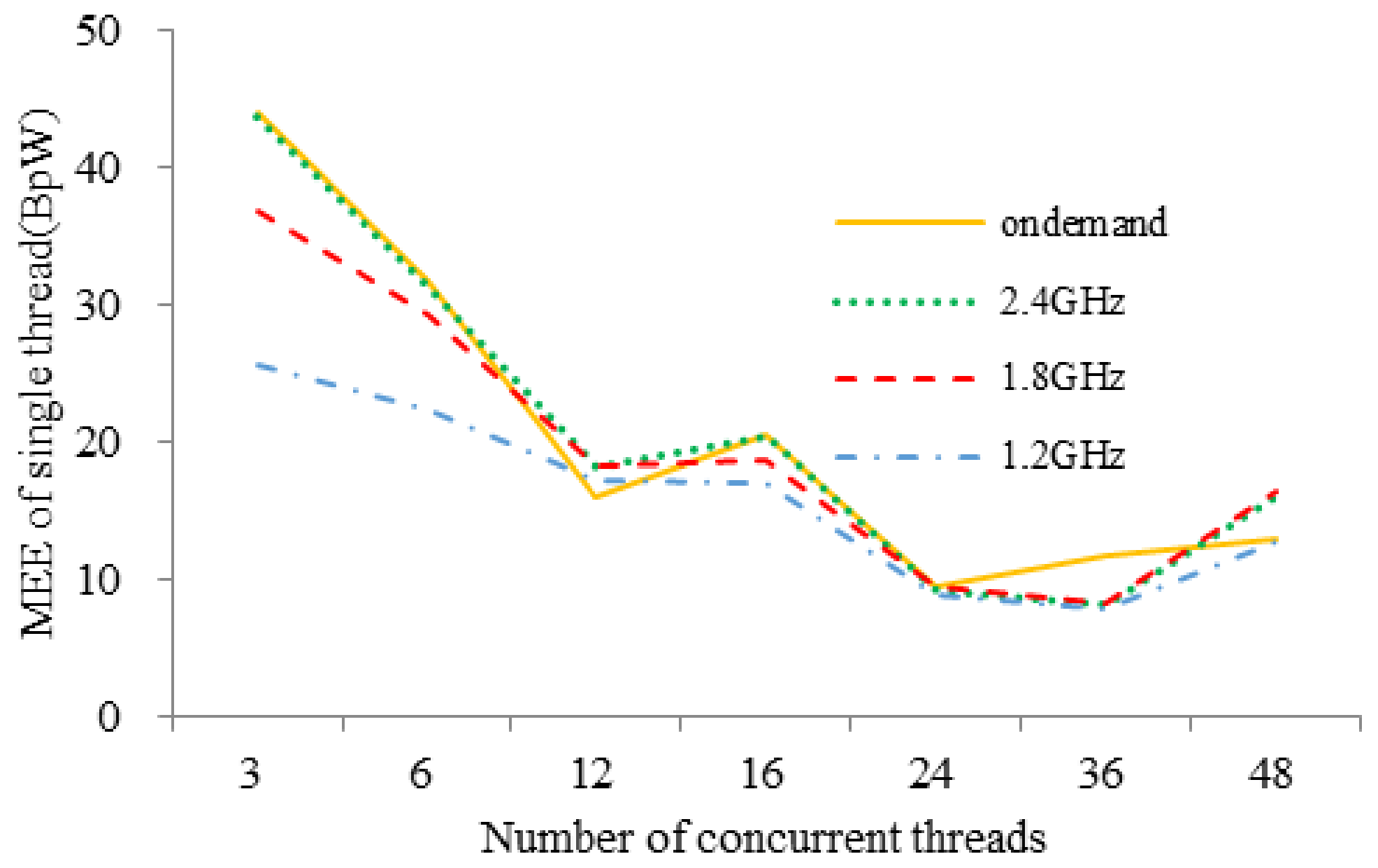
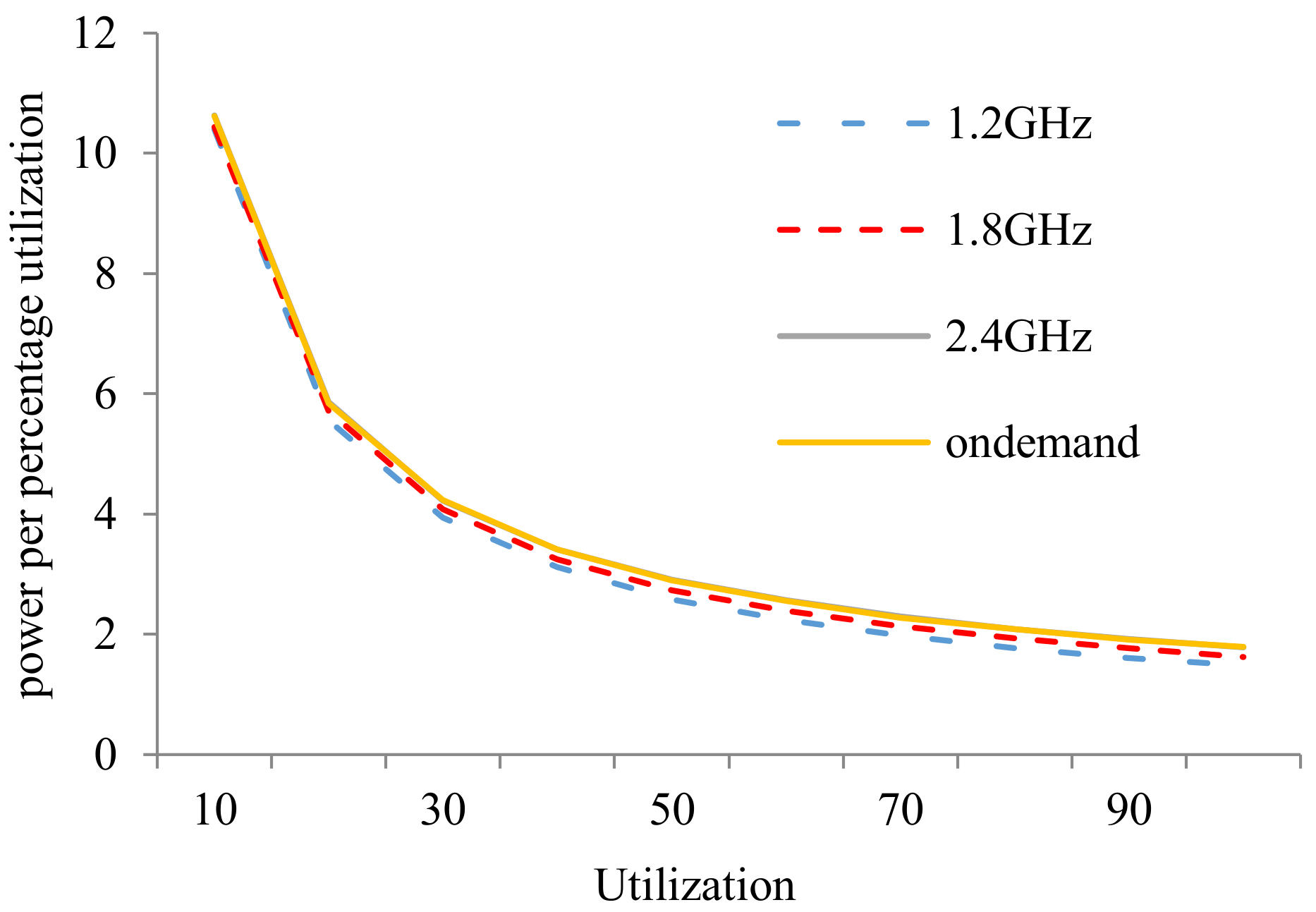
- (1)
- When the number of concurrent threads is 36, the power consumption and CPU utilization are the highest at the CPU frequencies of 1.2 GHz, 1.8 GHz, 2.4 GHz, and on-demand governor. Generally, power consumption grows with the CPU frequencies.
- (2)
- When threads increase, the perceived bandwidth of triad computation in a single STREAM thread decreases at first and reaches its lowest at 36 threads. Then it bounces a little at 48 threads because of the contention and starvation of execution threads.
- (3)
- The perceived bandwidth increases while the bandwidth growth rate decreases as CPU frequency increases. Moreover, the bandwidth of different CPU frequency is almost the same at 24 threads, which is because the server has 12 physical cores and 24 execution threads in total.
- (4)
- Both the memory energy efficiency and its change rate decreases as the number of concurrent threads increases. It can also be inferred that frequency scaling cannot improve memory energy efficiency a lot in a highly contented condition.
4.3. Results of NAMD Workload
4.4. Results of CloudSuite Workload
5. Characterizing Energy Efficiency of Memory Systems
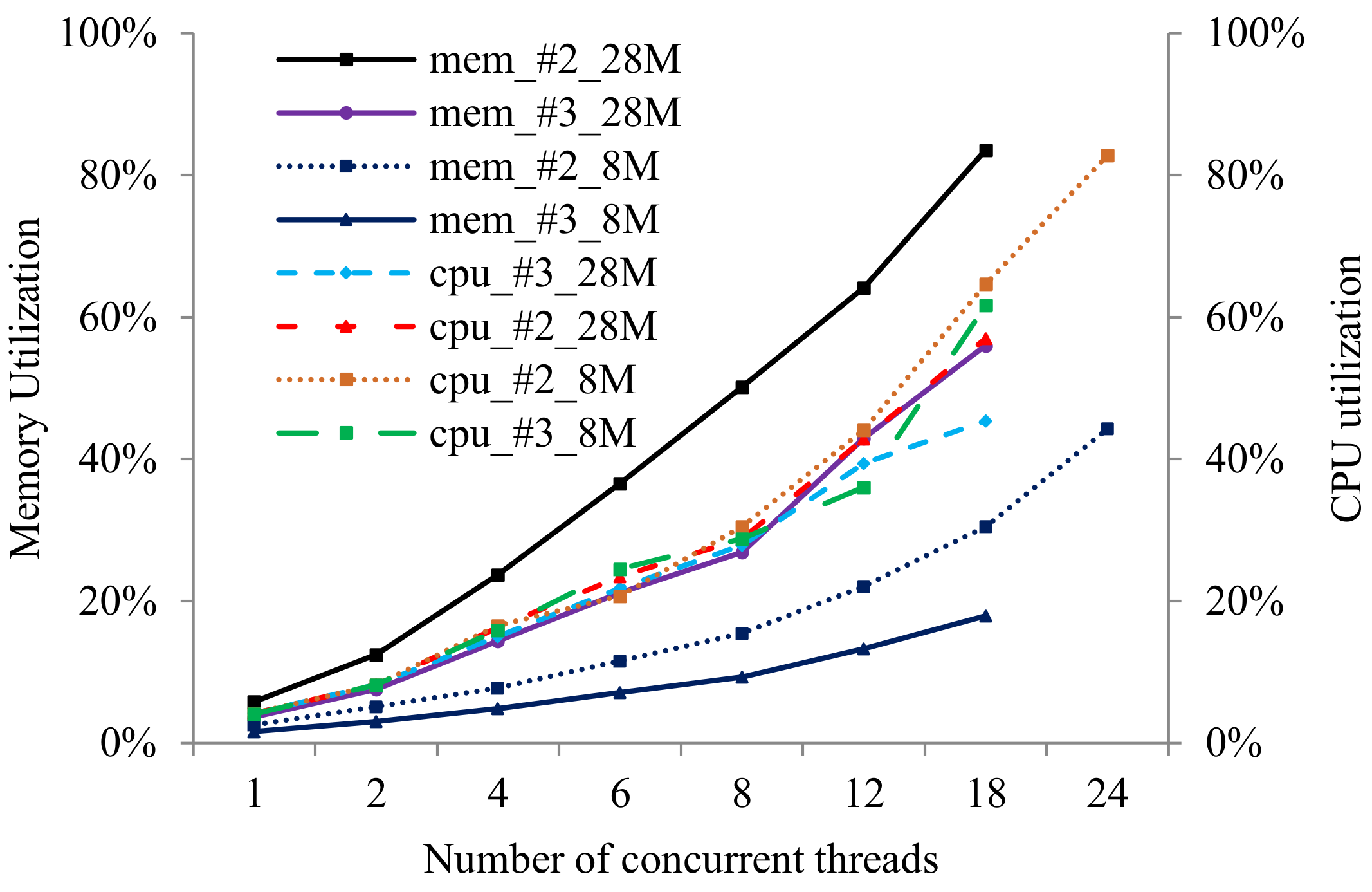
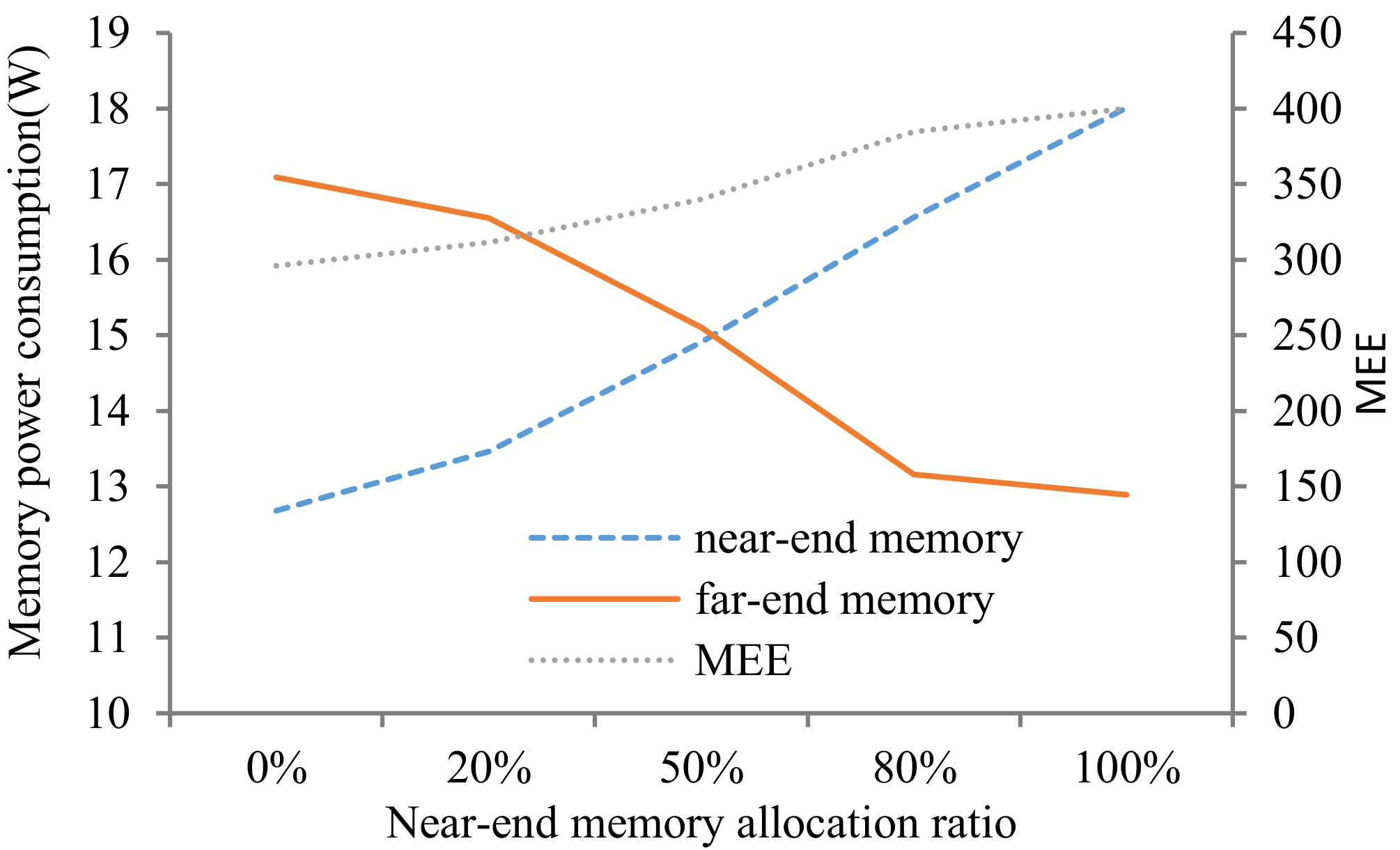
5.1. Economies of Scale in Memory Utilization
5.2. SMP and NUMA Energy Efficiency Comparison
5.3. Insights on Energy Efficiency of Memory-Intensive Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Reed, D.A.; Dongarra, J. Exascale Computing and Big Data. Commun. ACM 2015, 58, 56–68. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Ahn, J.; Hong, S.; Yoo, S.; Mutlu, O.; Choi, K. A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing. In Proceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA’15), Portland, OR, USA, 13–17 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 105–117. [Google Scholar]
- Hirzel, M.; Soulé, R.; Schneider, S.; Gedik, B.; Grimm, R. A Catalog of Stream Processing Optimizations. ACM Comput. Surv. 2014, 46, 1–34. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, G.; Ooi, B.C.; Tan, K.-L.; Zhang, M. In-Memory Big Data Management and Processing: A Survey. IEEE Trans. Knowl. Data Eng. 2015, 27, 1920–1948. [Google Scholar] [CrossRef]
- Jiang, C.; Han, G.; Lin, J.; Jia, G.; Shi, W.; Wan, J. Characteristics of co-allocated online services and batch jobs in internet data centers: A case study from alibaba cloud. IEEE Access 2019, 7, 22495–22508. [Google Scholar] [CrossRef]
- Jiang, C.; Qiu, Y.; Shi, W.; Ge, Z.; Wang, J.; Chen, S.; Cerin, C.; Ren, Z.; Xu, G.; Lin, J. Characterizing co-located workloads in alibaba cloud datacenters. IEEE Trans. Cloud Comput. 2020, 1. [Google Scholar] [CrossRef]
- Hamdioui, S.; Xie, L.; Anh, A.N.H.; Taouil, M.; Bertels, K.; Corporaal, H.; Jiao, H.; Catthoor, F.; Wouters, D.; Eike, L.; et al. Memrisor Based Computation-in-Memory Architecture for Data-Intensive Applications. In Proceedings of the 2015 Design, Automation & Test. In Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; IEEE Conference Publications: New Jersey, NJ, USA, 2015; pp. 1718–1725. [Google Scholar]
- Nair, R.; Antao, S.F.; Bertolli, C.; Bose, P.; Brunheroto, J.R.; Chen, T.; Cher, C.-Y.; Costa, C.H.A.; Doi, J.; Evangelinos, C.; et al. Active Memory Cube: A Processing-in-Memory Architecture for Exascale Systems. IBM J. Res. Dev. 2015, 59, 17:1–17:14. [Google Scholar] [CrossRef][Green Version]
- Pugsley, S.H.; Jestes, J.; Balasubramonian, R.; Srinivasan, V.; Buyuktosunoglu, A.; Davis, A.; Li, F. Comparing Implementations of Near-Data Computing with in-Memory MapReduce Workloads. IEEE Micro 2014, 34, 44–52. [Google Scholar] [CrossRef]
- Tanabe, N.; Nuttapon, B.; Nakajo, H.; Ogawa, Y.; Kogou, J.; Takata, M.; Joe, K. A Memory Accelerator with Gather Functions for Bandwidth-Bound Irregular Applications. In Proceedings of the First Workshop on Irregular Applications: Architectures and Algorithm (IAAA’11), Seattle, WA, USA, 13 November 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 35–42. [Google Scholar]
- Pawlowski, J.T. Hybrid Memory Cube (HMC). In Proceedings of the 2011 IEEE Hot Chips 23 Symposium (HCS), Stanford, CA, USA, 17–19 August 2011; pp. 1–24. [Google Scholar]
- Wang, Y.; Yu, H. An Ultralow-Power Memory-Based Big-Data Computing Platform by Nonvolatile Domain-Wall Nanowire Devices. In Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED), Beijing, China, 4–6 September 2013; pp. 329–334. [Google Scholar]
- Weis, C.; Loi, I.; Benini, L.; Wehn, N. An Energy Efficient DRAM Subsystem for 3D Integrated SoCs. In Proceedings of the 2012 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 12–16 March 2012; pp. 1138–1141. [Google Scholar]
- Hajkazemi, M.H.; Chorney, M.; Jabbarvand Behrouz, R.; Khavari Tavana, M.; Homayoun, H. Adaptive Bandwidth Management for Performance-Temperature Trade-Offs in Heterogeneous HMC + DDRx Memory. In Proceedings of the 25th Edition on Great Lakes Symposium on VLSI (GLSVLSI’15), Pittsburgh, PA, USA, 20–22 May 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 391–396. [Google Scholar]
- Goswami, N.; Cao, B.; Li, T. Power-Performance Co-Optimization of Throughput Core Architecture Using Resistive Memory. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 342–353. [Google Scholar]
- Sharad, M.; Fan, D.; Roy, K. Ultra Low Power Associative Computing with Spin Neurons and Resistive Crossbar Memory. In Proceedings of the 50th Annual Design Automation Conference (DAC’13), Austin, TX, USA, 29 May–7 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Imani, M.; Mercati, P.; Rosing, T. ReMAM: Low Energy Resistive Multi-Stage Associative Memory for Energy Efficient Computing. In Proceedings of the 2016 17th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 15–16 March 2016; pp. 101–106. [Google Scholar]
- Ahn, J.; Yoo, S.; Choi, K. Low-Power Hybrid Memory Cubes with Link Power Management and Two-Level Prefetching. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2016, 24, 453–464. [Google Scholar] [CrossRef]
- Islam, N.S.; Wasi-ur-Rahman, M.; Lu, X.; Shankar, D.; Panda, D.K. Performance Characterization and Acceleration of In-Memory File Systems for Hadoop and Spark Applications on HPC Clusters. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; IEEE: Santa Clara, CA, USA, 2015; pp. 243–252. [Google Scholar]
- Paraskevas, K.; Attwood, A.; Luján, M.; Goodacre, J. Scaling the Capacity of Memory Systems; Evolution and Key Approaches. In Proceedings of the International Symposium on Memory Systems (MEMSYS’19), Washington, DC, USA, 30 September–3 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 235–249. [Google Scholar]
- Jiang, C.; Wang, Y.; Ou, D.; Luo, B.; Shi, W. Energy Proportional Servers: Where Are We in 2016? In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; IEEE: Atlanta, GA, USA, 2017; pp. 1649–1660. [Google Scholar]
- Qiu, Y.; Jiang, C.; Wang, Y.; Ou, D.; Li, Y.; Wan, J. Energy Aware virtual machine scheduling in data centers. Energies 2019, 12, 646. [Google Scholar] [CrossRef]
- SPECpower_ssj®. 2008. Available online: https://www.spec.org/power_ssj2008/ (accessed on 1 May 2021).
- Jiang, C.; Fan, T.; Gao, H.; Shi, W.; Liu, L.; Cérin, C.; Wan, J. Energy aware edge computing: A survey. Comput. Commun. 2020, 151, 556–580. [Google Scholar] [CrossRef]
- Jiang, C.; Wang, Y.; Ou, D.; Qiu, Y.; Li, Y.; Wan, J.; Luo, B.; Shi, W.; Cerin, C. EASE: Energy efficiency and proportionality aware virtual machine scheduling. In Proceedings of the 2018 30th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Lyon, France, 24–27 September 2018; pp. 65–68. [Google Scholar]
- Islam, M.; Scrbak, M.; Kavi, K.M.; Ignatowski, M.; Jayasena, N. Improving Node-Level MapReduce Performance Using Processing-in-Memory Technologies. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 425–437. [Google Scholar]
- Pattnaik, A.; Tang, X.; Jog, A.; Kayiran, O.; Mishra, A.K.; Kandemir, M.T.; Mutlu, O.; Das, C.R. Scheduling Techniques for GPU Architectures with Processing-in-Memory Capabilities. In Proceedings of the 2016 International Conference on Parallel Architectures and Compilation (PACT’16), Haifa, Israel, 11–15 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 31–44. [Google Scholar]
- Li, S.; Reddy, D.; Jacob, B. A Performance & Power Comparison of Modern High-Speed DRAM Architectures. In Proceedings of the International Symposium on Memory Systems (MEMSYS ’18), Alexandria, VA, USA, 1–4 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 341–353. [Google Scholar]
- Asghari-Moghaddam, H.; Son, Y.H.; Ahn, J.H.; Kim, N.S. Chameleon: Versatile and Practical near-DRAM Acceleration Architecture for Large Memory Systems. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–13. [Google Scholar]
- Zhang, D.; Jayasena, N.; Lyashevsky, A.; Greathouse, J.L.; Xu, L.; Ignatowski, M. TOP-PIM: Throughput-Oriented Programmable Processing in Memory. In Proceedings of the 23rd International Symposium on High-Performance Parallel and Distributed Computing (HPDC’14), Vancouver, BC, Canada, 23–27 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 85–98. [Google Scholar]
- Xi, S.L.; Babarinsa, O.; Athanassoulis, M.; Idreos, S. Beyond the Wall: Near-Data Processing for Databases. In Proceedings of the 11th International Workshop on Data Management on New Hardware (DaMoN’15), Melbourne, Australia, 31 May–4 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–10. [Google Scholar]
- Keeton, K. Memory-Driven Computing. In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST), Santa Clara, CA, USA, 27 February–2 March 2017; USENIX Association: Santa Clara, CA, USA, 2017. [Google Scholar]
- Imani, M.; Gupta, S.; Rosing, T. Digital-Based Processing in-Memory: A Highly-Parallel Accelerator for Data Intensive Applications. In Proceedings of the International Symposium on Memory Systems (MEMSYS’19), Washington DC, USA, 30 September 2019—3 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 38–40. [Google Scholar]
- Azarkhish, E.; Pfister, C.; Rossi, D.; Loi, I.; Benini, L. Logic-Base Interconnect Design for near Memory Computing in the Smart Memory Cube. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2017, 25, 210–223. [Google Scholar] [CrossRef]
- Sura, Z.; Jacob, A.; Chen, T.; Rosenburg, B.; Sallenave, O.; Bertolli, C.; Antao, S.; Brunheroto, J.; Park, Y.; O’Brien, K.; et al. Data Access Optimization in a Processing-in-Memory System. In Proceedings of the 12th ACM International Conference on Computing Frontiers (CF ’15), Ischia, Italy, 18–21 May 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–8. [Google Scholar]
- Yun, H.; Mancuso, R.; Wu, Z.-P.; Pellizzoni, R. PALLOC: DRAM Bank-Aware Memory Allocator for Performance Isolation on Multicore Platforms. In Proceedings of the 2014 IEEE 19th Real-Time and Embedded Technology and Applications Symposium (RTAS), Berlin, Germany, 15–17 April 2014; pp. 155–166. [Google Scholar]
- Ahmed, A.; Skadron, K. Hopscotch: A Micro-Benchmark Suite for Memory Performance Evaluation. In Proceedings of the International Symposium on Memory Systems (MEMSYS’19), Washington, DC, USA, 30 September–3 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 167–172. [Google Scholar]
- Patil, O.; Ionkov, L.; Lee, J.; Mueller, F.; Lang, M. Performance Characterization of a DRAM-NVM Hybrid Memory Architecture for HPC Applications Using Intel Optane DC Persistent Memory Modules. In Proceedings of the International Symposium on Memory Systems (MEMSYS’19), Washington, DC, USA, 30 September–3 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 288–303. [Google Scholar]
- Chishti, Z.; Akin, B. Memory System Characterization of Deep Learning Workloads. In Proceedings of the International Symposium on Memory Systems (MEMSYS’19), Washington, DC, USA, 30 September–3 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 497–505. [Google Scholar]
- Liu, J.; Zhao, H.; Ogleari, M.A.; Li, D.; Zhao, J. Processing-in-Memory for Energy-Efficient Neural Network Training: A Heterogeneous Approach. In Proceedings of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Fukuoka, Japan, 20–24 October 2018; pp. 655–668. [Google Scholar]
- Dasari, D.; Nelis, V.; Akesson, B. A Framework for Memory Contention Analysis in Multi-Core Platforms. Real-Time Syst. 2016, 52, 272–322. [Google Scholar] [CrossRef]
- Kim, Y.; Han, D.; Mutlu, O.; Harchol-Balter, M. ATLAS: A Scalable and High-Performance Scheduling Algorithm for Multiple Memory Controllers. In Proceedings of the HPCA—16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar]
- Muralidhara, S.P.; Subramanian, L.; Mutlu, O.; Kandemir, M.; Moscibroda, T. Reducing Memory Interference in Multicore Systems via Application-Aware Memory Channel Partitioning. In Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-44), Porto Alegre, Brazil, 3–7 December 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 374–385. [Google Scholar]
- Mutlu, O.; Moscibroda, T. Stall-Time Fair Memory Access Scheduling for Chip Multiprocessors. In Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO 2007), Chicago, IL, USA, 1–5 December 2007; pp. 146–160. [Google Scholar]
- Mutlu, O.; Moscibroda, T. Parallelism-Aware Batch Scheduling: Enhancing Both Performance and Fairness of Shared DRAM Systems. In Proceedings of the 2008 International Symposium on Computer Architecture, Beijing, China, 21–25 June 2008; pp. 63–74. [Google Scholar]
- Kim, H.; de Niz, D.; Andersson, B.; Klein, M.; Mutlu, O.; Rajkumar, R. Bounding Memory Interference Delay in COTS-Based Multi-Core Systems. In Proceedings of the 2014 IEEE 19th Real-Time and Embedded Technology and Applications Symposium (RTAS), Berlin, Germany, 15–17 April 2014; pp. 145–154. [Google Scholar]
- Zhu, H.; Erez, M. Dirigent: Enforcing QoS for Latency-Critical Tasks on Shared Multicore Systems. In Proceedings of the Twenty-First International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS’16), Atlanta, GA, USA, 2–6 April 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 33–47. [Google Scholar]
- Jeong, M.K.; Erez, M.; Sudanthi, C.; Paver, N. A QoS-aware memory controller for dynamically balancing GPU and CPU bandwidth use in an MPSoC. In Proceedings of the 49th Annual Design Automation Conference (DAC), San Francisco, CA, USA, 3–7 June 2012; pp. 850–855. [Google Scholar]
- Yu, J.; Nane, R.; Ashraf, I.; Taouil, M.; Hamdioui, S.; Corporaal, H.; Bertels, K. Skeleton-Based Synthesis Flow for Computation-in-Memory Architectures. IEEE Trans. Emerg. Top. Comput. 2020, 8, 545–558. [Google Scholar] [CrossRef]
- Li, H.; Ghodsi, A.; Zaharia, M.; Shenker, S.; Stoica, I. Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks. In Proceedings of the ACM Symposium on Cloud Computing (SOCC’14), Seattle, WA, USA, 3–5 November 2014; ACM: New York, NY, USA, 2014; pp. 1–15. [Google Scholar]
- Zhao, D.; Zhang, Z.; Zhou, X.; Li, T.; Wang, K.; Kimpe, D.; Carns, P.; Ross, R.; Raicu, I. FusionFS: Toward Supporting Data-Intensive Scientific Applications on Extreme-Scale High-Performance Computing Systems. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014; pp. 61–70. [Google Scholar]
- Jiang, D.; Chen, G.; Ooi, B.C.; Tan, K.-L.; Wu, S. EpiC: An Extensible and Scalable System for Processing Big Data. Proc. VLDB Endow. 2014, 7, 541–552. [Google Scholar] [CrossRef]
- Imani, M.; Gupta, S.; Kim, Y.; Zhou, M.; Rosing, T. DigitalPIM: Digital-Based Processing in-Memory for Big Data Acceleration. In Proceedings of the 2019 on Great Lakes Symposium on VLSI (GLSVLSI’19), Tysons Corner, VA, USA, 9–11 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 429–434. [Google Scholar]
- Zhang, C.; Meng, T.; Sun, G. PM3: Power Modeling and Power Management for Processing-in-Memory. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 558–570. [Google Scholar]
- Tan, K.-L.; Cai, Q.; Ooi, B.C.; Wong, W.-F.; Yao, C.; Zhang, H. In-Memory Databases: Challenges and Opportunities from Software and Hardware Perspectives. SIGMOD Rec. 2015, 44, 35–40. [Google Scholar] [CrossRef]
- Makrani, H.M.; Sayadi, H.; Dinakarra, S.M.P.; Rafatirad, S.; Homayoun, H. A Comprehensive Memory Analysis of Data Intensive Workloads on Server Class Architecture. In Proceedings of the International Symposium on Memory Systems (MEMSYS’18), Alexandria, VA, USA, 1–4 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 19–30. [Google Scholar]
- Wang, H.; Singh, R.; Schulte, M.J.; Kim, N.S. Memory Scheduling towards High-Throughput Cooperative Heterogeneous Computing. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation (PACT’14), Edmonton, AB, Canada, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 331–342. [Google Scholar]
- Jiang, C.; Wang, Y.; Ou, D.; Li, Y.; Zhang, J.; Wan, J.; Luo, B.; Shi, W. Energy Efficiency Comparison of Hypervisors. Sustain. Comput. Inform. Syst. 2019, 22, 311–321. [Google Scholar] [CrossRef]
- Yun, H.; Yao, G.; Pellizzoni, R.; Caccamo, M.; Sha, L. MemGuard: Memory Bandwidth Reservation System for Efficient Performance Isolation in Multi-Core Platforms. In Proceedings of the 2013 IEEE 19th Real-Time and Embedded Technology and Applications Symposium (RTAS), Philadelphia, PA, USA, 9–11 April 2013; pp. 55–64. [Google Scholar]
- Zhang, D.P.; Jayasena, N.; Lyashevsky, A.; Greathouse, J.; Meswani, M.; Nutter, M.; Ignatowski, M. A New Perspective on Processing-in-Memory Architecture Design. In Proceedings of the ACM SIGPLAN Workshop on Memory Systems Performance and Correctness (MSPC’13), Seattle, WA, USA, 16–19 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1–3. [Google Scholar]
- Lee, S.; Kim, N.S.; Kim, D. Exploiting OS-Level Memory Offlining for DRAM Power Management. IEEE Comput. Arch. Lett. 2019, 18, 141–144. [Google Scholar] [CrossRef]
- Gray, L.D.; Kumar, A.; Li, H.H. Workload Characterization of the SPECpower_ssj2008 Benchmark. In Performance Evaluation: Metrics, Models and Benchmarks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 262–282. [Google Scholar]
- Ryckbosch, F.; Polfliet, S.; Eeckhout, L. Trends in Server Energy Proportionality. Comput. Long Beach Calif. 2011, 44, 69–72. [Google Scholar] [CrossRef]
- Memory Bandwidth: Stream Benchmark Performance Results. Available online: https://www.cs.virginia.edu/stream/ (accessed on 1 May 2021).
- CloudSuite. Available online: http://cloudsuite.ch/ (accessed on 1 May 2021).
- NAMD—Scalable Molecular Dynamics. Available online: https://www.ks.uiuc.edu/Research/namd/ (accessed on 1 May 2021).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| memory per core(GB/core) | 0.06 | 0.25 | 0.48 | 0.5 | 0.57 | 0.66 | 0.85 | 0.88 | 1.0 | 1.2 | 1.3 | 1.45 | 1.5 | 1.6 | 1.71 | 1.77 | 2.0 |
| count | 1 | 1 | 1 | 2 | 1 | 15 | 1 | 2 | 153 | 3 | 32 | 7 | 68 | 4 | 20 | 13 | 145 |
| memory per core(GB/core) | 2.25 | 2.28 | 2.5 | 2.6 | 2.9 | 3.0 | 3.2 | 3.4 | 3.5 | 4.0 | 4.3 | 5.3 | 6.0 | 6.8 | 8.0 | 10.6 | 16.0 |
| count | 1 | 1 | 1 | 9 | 6 | 37 | 1 | 78 | 1 | 33 | 1 | 4 | 1 | 2 | 7 | 4 | 2 |
| Performance | Power | Performance to Power Ratio | ||
|---|---|---|---|---|
| Target Load | Actual Load | ssj_ops | Average Active Power (W) | |
| 100% | 99.80% | 24,662,648 | 3868 | 6377 |
| 90% | 90.10% | 22,252,836 | 3481 | 6393 |
| 80% | 80.00% | 19,758,684 | 3032 | 6517 |
| 70% | 70.00% | 17,284,975 | 2611 | 6619 |
| 60% | 60.00% | 14,824,481 | 2340 | 6336 |
| 50% | 50.00% | 12,350,615 | 2143 | 5764 |
| 40% | 40.00% | 9,877,126 | 1971 | 5011 |
| 30% | 30.00% | 7,410,001 | 1823 | 4064 |
| 20% | 20.00% | 4,949,964 | 1674 | 2956 |
| 10% | 10.00% | 2,475,968 | 1531 | 1618 |
| Active Idle | 0 | 1080 | 0 | |
| ∑ssj_ops/∑power | 5316 | |||
| No. | Name | Hardware Availability Year | CPU Model | Total Cores | CPU TDP (Watts) | Memory (GB) | DISK |
|---|---|---|---|---|---|---|---|
| #1 | ThinkServer RD640 | 2014 | 2×Intel Xeon E5-2620 #1 | 12 | 80 | 160(16 G×10) DDR4 2133 MHz | 1×SSD 480 GB |
| #2 | ThinkServer RD450 | 2015 | 2×Intel Xeon E5-2620 #2 | 12 | 85 | 192(16 G×12) DDR4 2133 MHz | 1×SSD 480 GB |
| #3 | Fujitsu | 2019 | 2×Intel Xeon 8260 | 40 | 165 | 384(16 G×24) DDR4 2666 MHz | 1×SSD 480 GB |
| Server | Power-Memory | Power-Cpu | Cpu-Memory |
|---|---|---|---|
| #1_8M | 0.936 | 0.958 | 0.995 |
| #1_28M | 0.973 | 0.966 | 0.997 |
| #2_8M | 0.922 | 0.938 | 0.983 |
| #2_28M | 0.671 | 0.750 | 0.944 |
| Power-Memory | Power-Cpu | Memory Utilization | |
|---|---|---|---|
| IM | −0.57 | 0.05 | 0.39 |
| IM_DS | −0.52 | −0.09 | 0.48 |
| Size of STREAM | Memory Power Consumption (W) | MEE |
|---|---|---|
| 16 G | 28.54 | 341.45 |
| 32 G | 28.43 | 342.12 |
| 64 G | 29.85 | 331.52 |
| 128 G | 29.08 | 340.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Ou, D.; Jiang, C.; Qiu, Y.; Yan, L. Power and Performance Evaluation of Memory-Intensive Applications. Energies 2021, 14, 4089. https://doi.org/10.3390/en14144089
Zhang K, Ou D, Jiang C, Qiu Y, Yan L. Power and Performance Evaluation of Memory-Intensive Applications. Energies. 2021; 14(14):4089. https://doi.org/10.3390/en14144089
Chicago/Turabian StyleZhang, Kaiqiang, Dongyang Ou, Congfeng Jiang, Yeliang Qiu, and Longchuan Yan. 2021. "Power and Performance Evaluation of Memory-Intensive Applications" Energies 14, no. 14: 4089. https://doi.org/10.3390/en14144089
APA StyleZhang, K., Ou, D., Jiang, C., Qiu, Y., & Yan, L. (2021). Power and Performance Evaluation of Memory-Intensive Applications. Energies, 14(14), 4089. https://doi.org/10.3390/en14144089