Once the sample dataset for the training is available, the functionality of the stage consists of the execution of the intelligent classification algorithm. Therefore, the tests are oriented towards the selection of the classification technique and the configuration of its parameters to obtain the best possible classification.
3.3.1. Selection of the Intelligent Classification Technique
In
Section 2.3, three techniques are considered for the implementation of this stage. These techniques are artificial neural networks, support vector machines, and random forests. The one with the best performance for solving the problem of the classification of users into fraudulent and non-fraudulent is selected. An experiment is executed to compare the three techniques, where the evaluation of their performance is carried out by the most commonly used method to evaluate classification algorithms, which is known as the K-fold cross-validation [
28].
To describe it briefly, K-fold cross-validation divides the total set of training data into K equal (or roughly equal) groups. K-1 groups are used to train the algorithm, the remaining group is used for testing, the algorithm is executed, and the results are recorded (performance). Next, K-1 groups are used once more to train the algorithm a second time, and the remaining group is reserved for testing. In this second run, the group that is first used for testing must be part of the K-1 used for the training, with a different group used for testing. The process is repeated until the K groups are used for testing, i.e., the technique is executed a total of K times. The overall performance of the classification algorithm is the average of the performances that are obtained for each of the K testing groups.
3.3.2. Experiment to Select the Classification Technique
The number of periods (months) for training the detector is six (November 2017 to April 2018). The set of examples that results from examining these periods consist of 4640 users. This amount is considerably smaller than the 92,794 total users of the system. However, this is explained because the sample base is constructed from the variables of macrometers (non-fraudulent users) and inspection results (fraudulent users).
The electricity company of the region carries out between 20,000 and 30,000 monthly customer inspections. This number is the total for the entire Caribbean region. It is reasonable to assume that the number of monthly inspections carried out for users belonging to the Barranquilla delegation is well below the total number presented. Besides, the total number of users of the system is the product of a series of filters. Therefore, of all inspections carried out in Barranquilla, those that encounter valid users of the system are even smaller. All of the above explains the reason why only 4640 users are obtained after reviewing the six periods for the training of the detector.
One of the conditions for the correct training of a classification algorithm is to guarantee the homogeneity of the training base, that is, to have an equal number of examples of each class. This is done so the algorithm can perform a good generalization since highly unbalanced training sets (with an appreciable difference between the number of examples for each class) tend to present bias in learning towards classes with more examples.
From the above, it is possible to infer that of the 4640 training examples, 2320 are fraudulent users and the remaining 2320 are non-fraudulent. On average, 750 users are provided monthly to feed the bank of examples of training: approximately 375 of each class (fraudulent and non-fraudulent).
The experiment performed for the comparison of the three techniques is K-fold cross-validation with a K of 10, which is executed three times (one time for each technique). The complete base of 4640 users is used for the experiment, which means that 10 groups of 464 users are obtained for cross-validation, with each round using 9 for training (4176 users) and 1 for validation (464 users).
The network topology, number of neurons of the hidden layer, and the training algorithm are fixed for the configuration of the neural network. The topology is a two-layer feed-forward; the number of neurons is obtained by the expression presented in Equation (4), and the training algorithm corresponds to the best performance (in classification problems) with longer training time. The parameter varied is the number of times training the network, that is to say, the same network is trained several times to find the one with the best results. To configure the SVM, the Kernel function is fixed, using the most common Kernel for classification problems. Gamma coefficient and cost are varied. To configure the random forest, the parameter varied is the number of trees.
A set of tests is performed to determine the values of the parameters of each technique that make it possible to obtain suitable results for the training dataset.
Table 5 compiles the values of the fixed and variable parameters of each technique.
Table 6 compiles the K-fold cross-validation with
K of 10 results for the three techniques, which show the training and testing performances for each one of the 10 rounds. The performance represents the success rate (percentage of hits) of each technique, i.e., in what percentage of the times it indicates as
fraudulent a fraudulent user and as
non-fraudulent a non-fraudulent user.
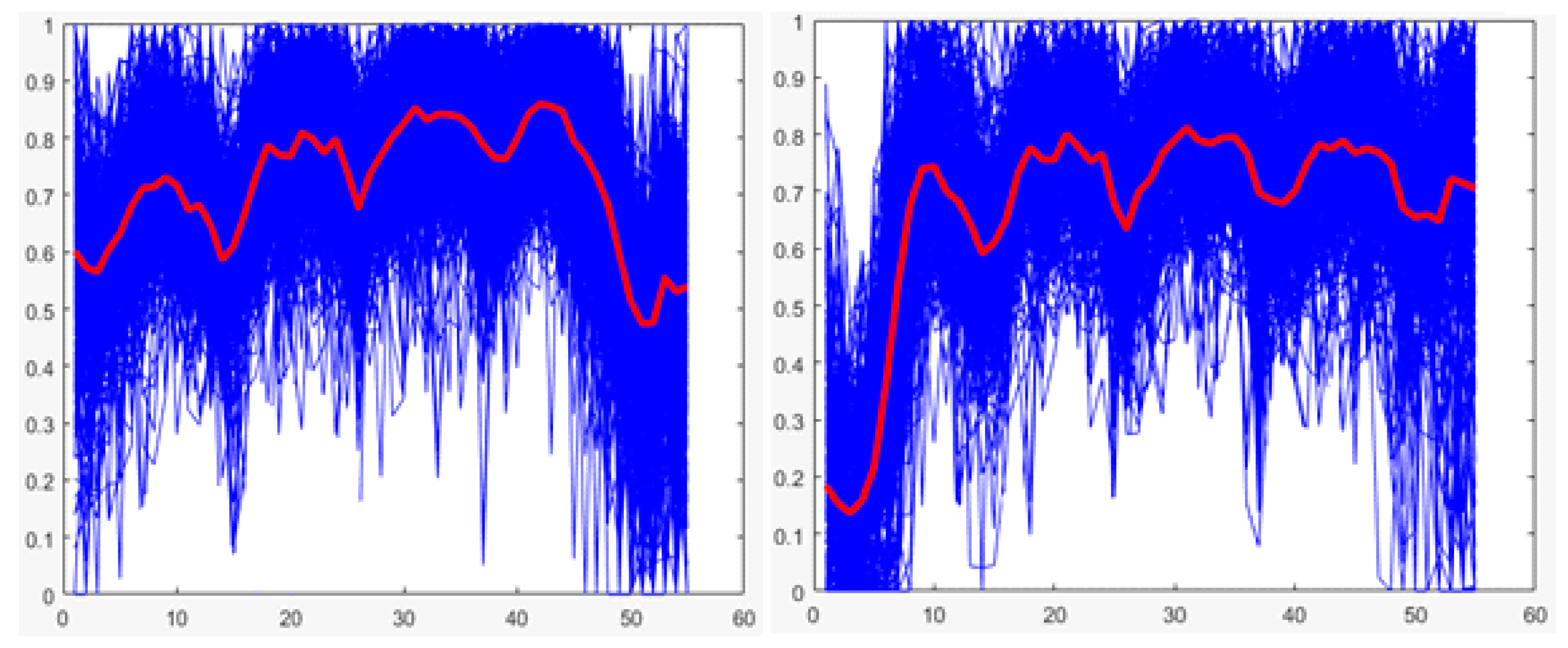
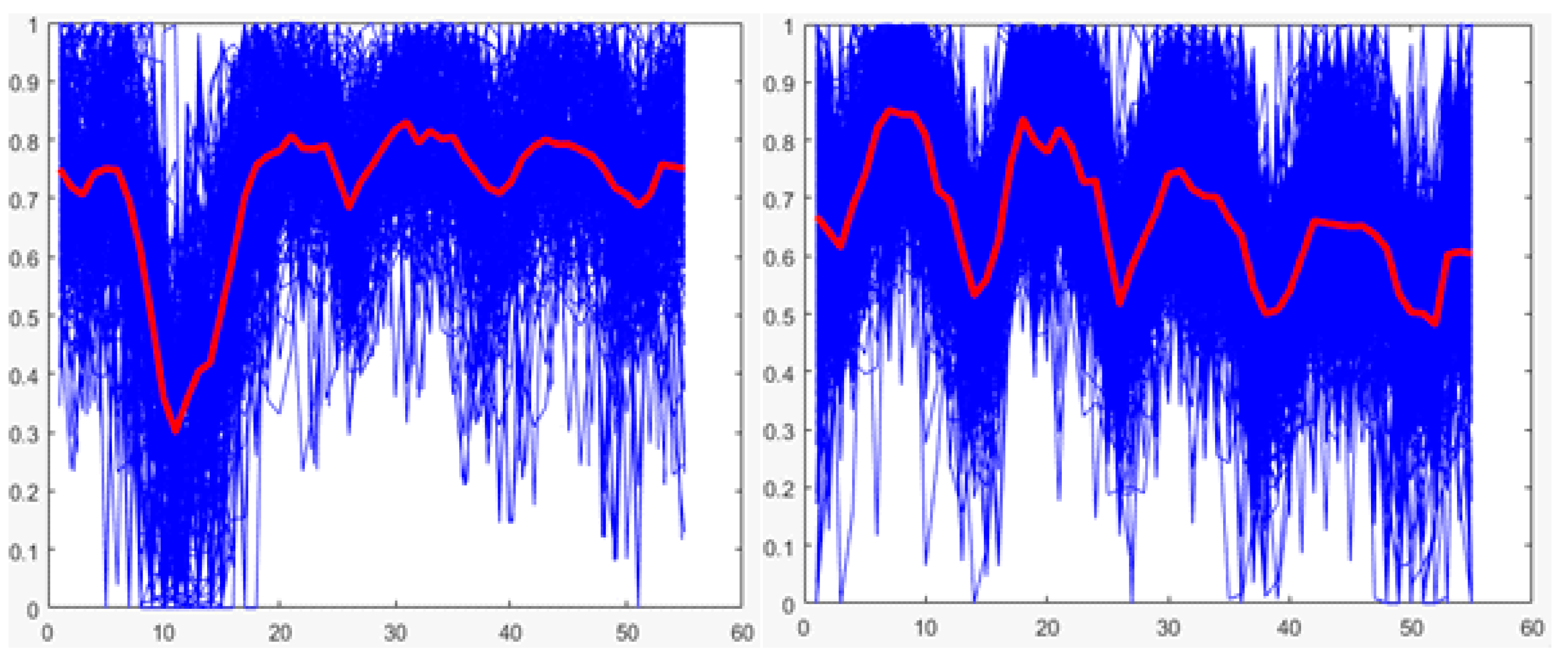
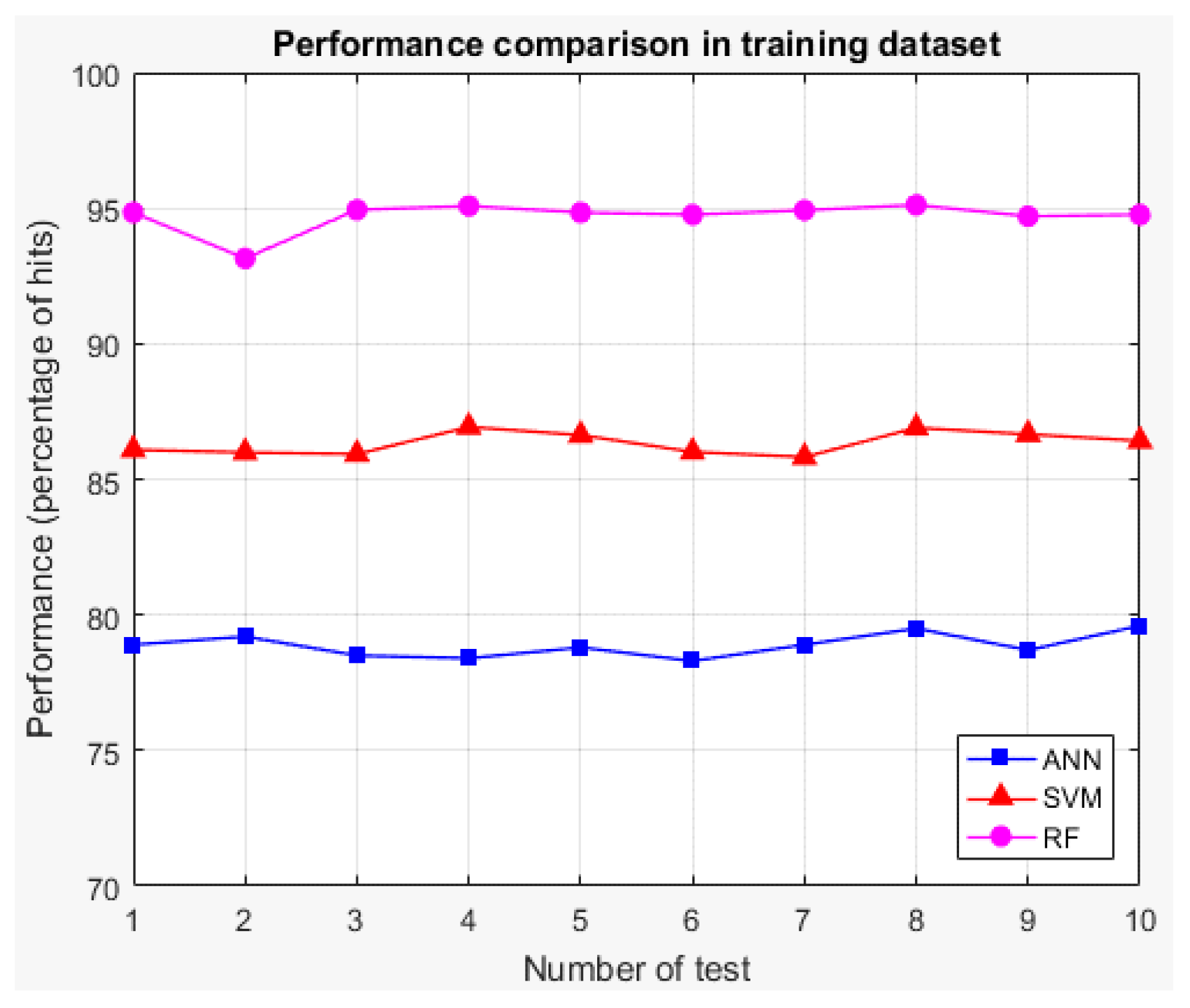
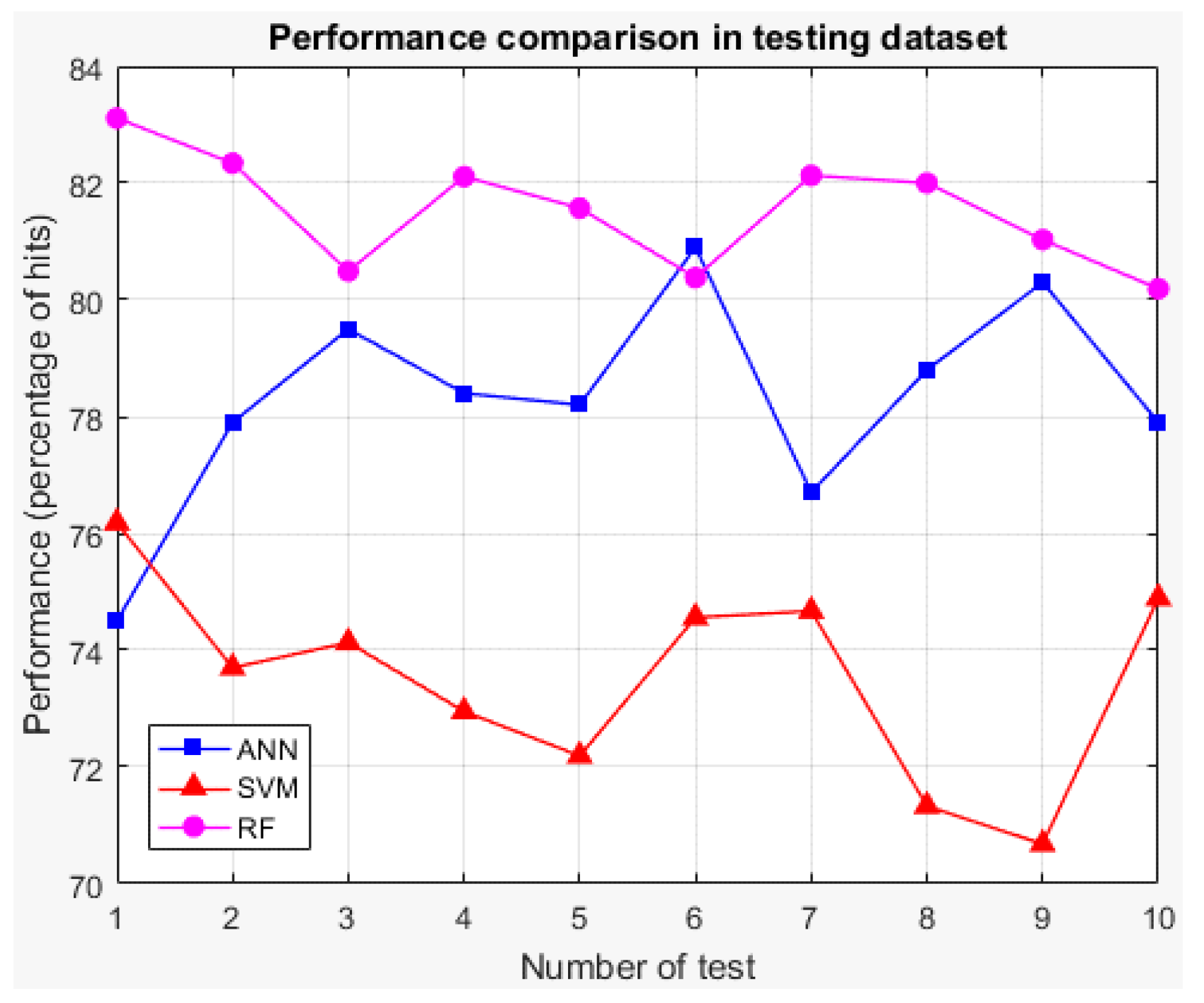
The values below in bold indicate the technique with the highest average performance for each case (training and testing), which shows that for both cases, the random forest is the technique with the best average performance. Therefore, it is the technique selected for the implementation of the classifier of stage 3. Additionally, for both cases, graphs showing the performances of the techniques for each round of K-fold cross-validation are presented (See
Figure 22 and
Figure 23).
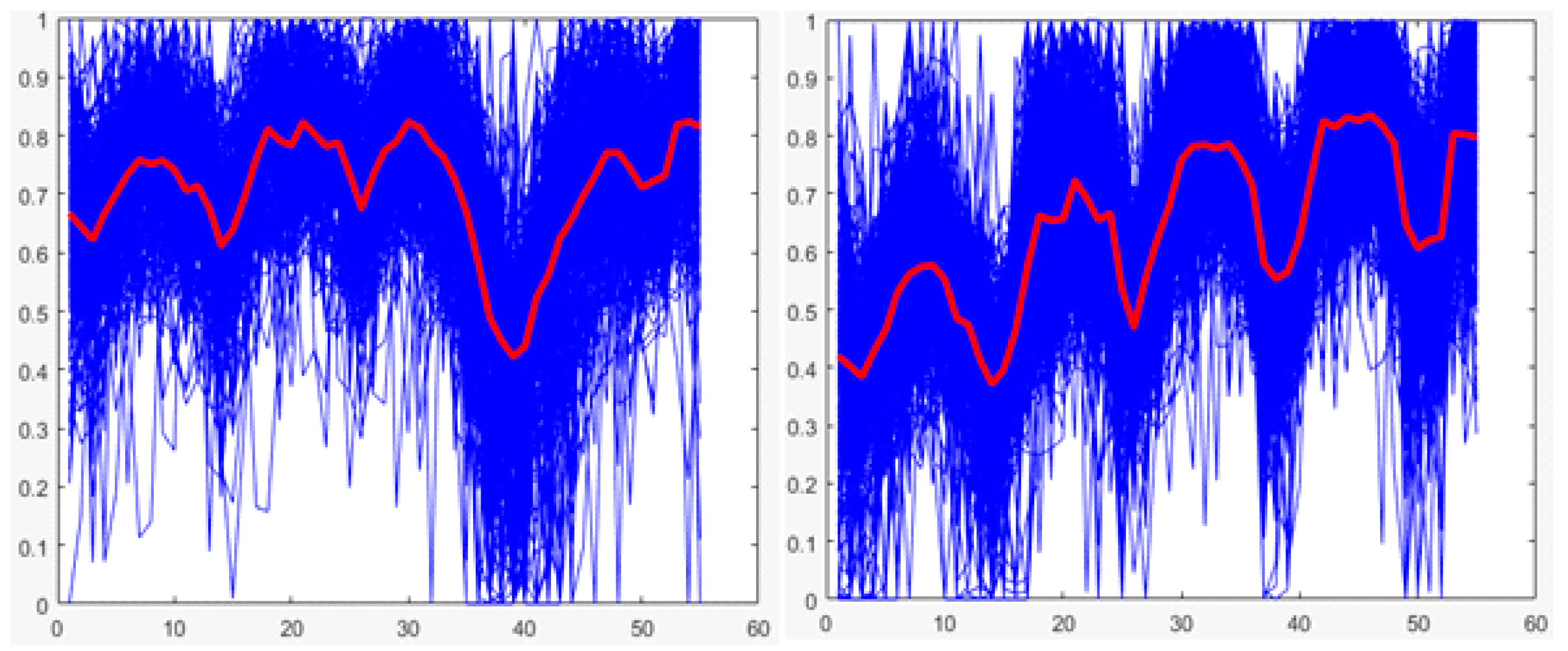
Once random forests are selected as the technique to be used, it is necessary to find the values of the parameters of the random forest that made it possible to obtain the best performance of the classification. As mentioned previously, for this technique, the only parameter that can be varied is the number of trees of the model. Therefore, an experiment based on K-fold cross-validation is performed once more to determine the number of trees that could obtain the best performance.
K-fold cross-validation is used with K of 5; the decrease in the value of K is justified in the low variability of the output of the technique (see
Figure 22 and
Figure 23). The total training base (4640 users) is used to carry out the experiment. This means that five groups of 928 users each are obtained for cross-validation, using four in each round for training (3712 users) and one for validation (928 users). The number of trees to test ranged from 10 to 100 in steps of 10.
A total of 10 K-fold cross-validations are performed with K of 5 since for each value of the number of trees, it is necessary to obtain the general performance of the technique.
Figure 24 compiles the average performance results for each number of trees in training and testing cases.
From the presented results, the value of 60 is selected for the parameter of the number of trees of the model. The best average performance of the training is the model of 90 trees, with 95.7%; the model of 60 trees has the second-best average performance in the training, with 95.6%. However, in the testing scenario, the 90-tree model has the lowest average performance, with 81.36%, while the 60-tree model has the highest average performance, with 82.87%. Because of the small difference in the training case and the big difference in the testing, the 60-tree model performs best.
3.3.3. Selection of the Number of Trees
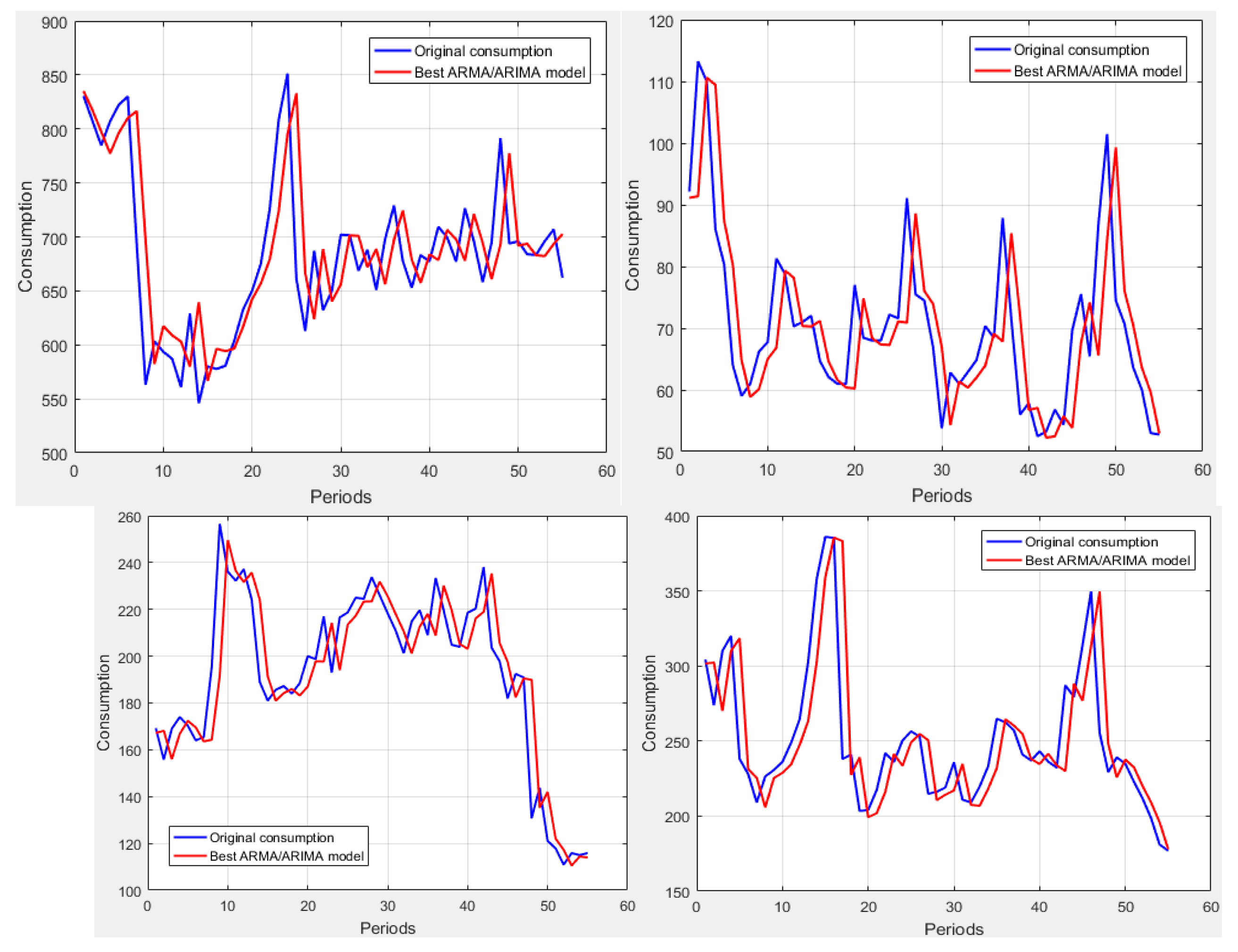
Based on the experiment carried out to select the number of trees, the model of 60 trees is obtained and trained with the training dataset of 4640 users (six periods). Stage 3 and the system validation are performed through the execution of the detector in the three periods reserved for testing (May 2018 to July 2018). The execution of the system is done monthly; therefore, each period is independently tested. The extraction of the users from each test period makes it possible to obtain three sets of data, which are summarized in
Table 7. However, although some of them are not perfectly homogeneous; the difference is minimal and does not have any impact on the execution of the system.
A confusion matrix is used to evaluate the system performance in each testing set (see
Table 8). The three sets (i.e., periods reserved for testing) are not used during training, so they are completely new and unknown to the system. The results of these sets are known and used to compare them with those obtained from the execution of the system.
The performance (percentage of hits) of the classification for the first period is 82.9%. Of the 494 fraudulent users, the detector identified correctly 423, missing 71 users. Of the 513 non-fraudulent users, the detector identified correctly 412, missing 101 users.
The performance (percentage of hits) of the classification for the second period is 82.7%. Of the 453 fraudulent users, the detector identified correctly 386, missing 67 users. Of the 461 non-fraudulent users, the detector identified correctly 370, missing 91 users.
The performance (percentage of hits) of the classification for the third period is 83.1%. Of the 549 fraudulent users, the detector identified correctly 470, missing 79 users. Of the 549 non-fraudulent users, the detector identified correctly 442, missing 107 users.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}