Non-Intrusive Load Monitoring via Deep Learning Based User Model and Appliance Group Model


Abstract
1. Introduction
1.1. Feature Sets for NILM
1.2. Algorithms for NILM
1.3. Influencing Factors of NILM
1.4. Contributions
2. NILM Problem Formulation
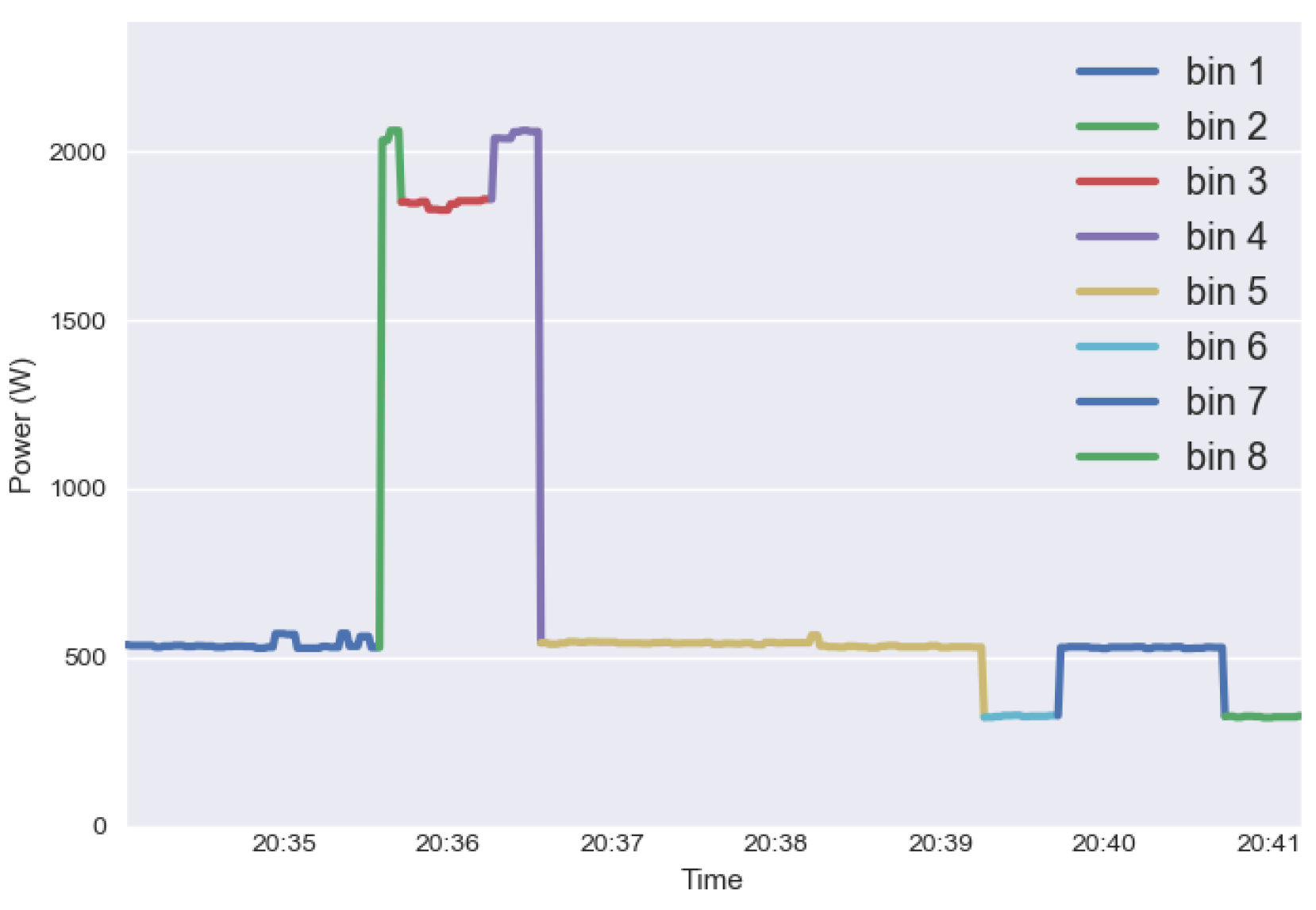
2.1. Condensed Representation
2.2. Super-State
2.3. Electricity Consumption Estimation
3. Methodology
3.1. Deep User Modeling
3.1.1. Temporal Information Embedding
3.1.2. Appliance Usage Behaviors Embedding
3.1.3. Embeddings Incorporation and Inference
3.1.4. Prepare Samples for Training
| Algorithm 1 Preparing Inputs & Targets for Training |
| Input: |
| in (3), in (1) |
| idx=0, step=1, break_flag=False |
| =[], =[] |
| while True do |
| end_idx=idx+ |
| if end_idx then |
| end_idx=T |
| break_flag=True |
| end if |
| //appending element to , |
| =+ |
| , |
| =+ |
| idx=idx+step |
| if break_flag then |
| break |
| end if |
| end while |
| return , |
3.2. Deep Appliance Group Modeling
3.3. Data Augmentation
3.4. Models Fusion
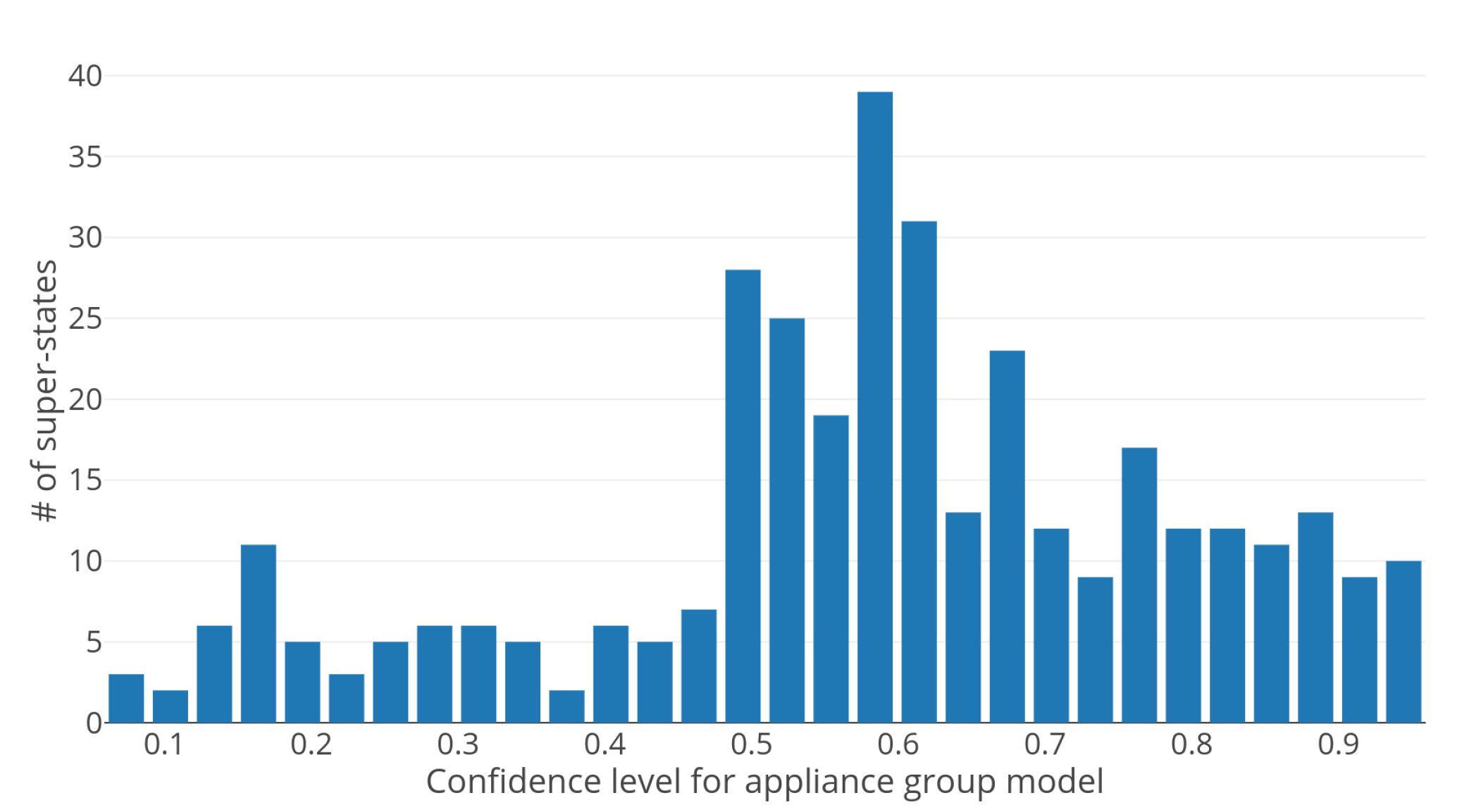
3.4.1. Voting for _s
3.4.2. Overview of Inference Process
4. Case Study
4.1. Data Pre-Processing
4.2. Metrics
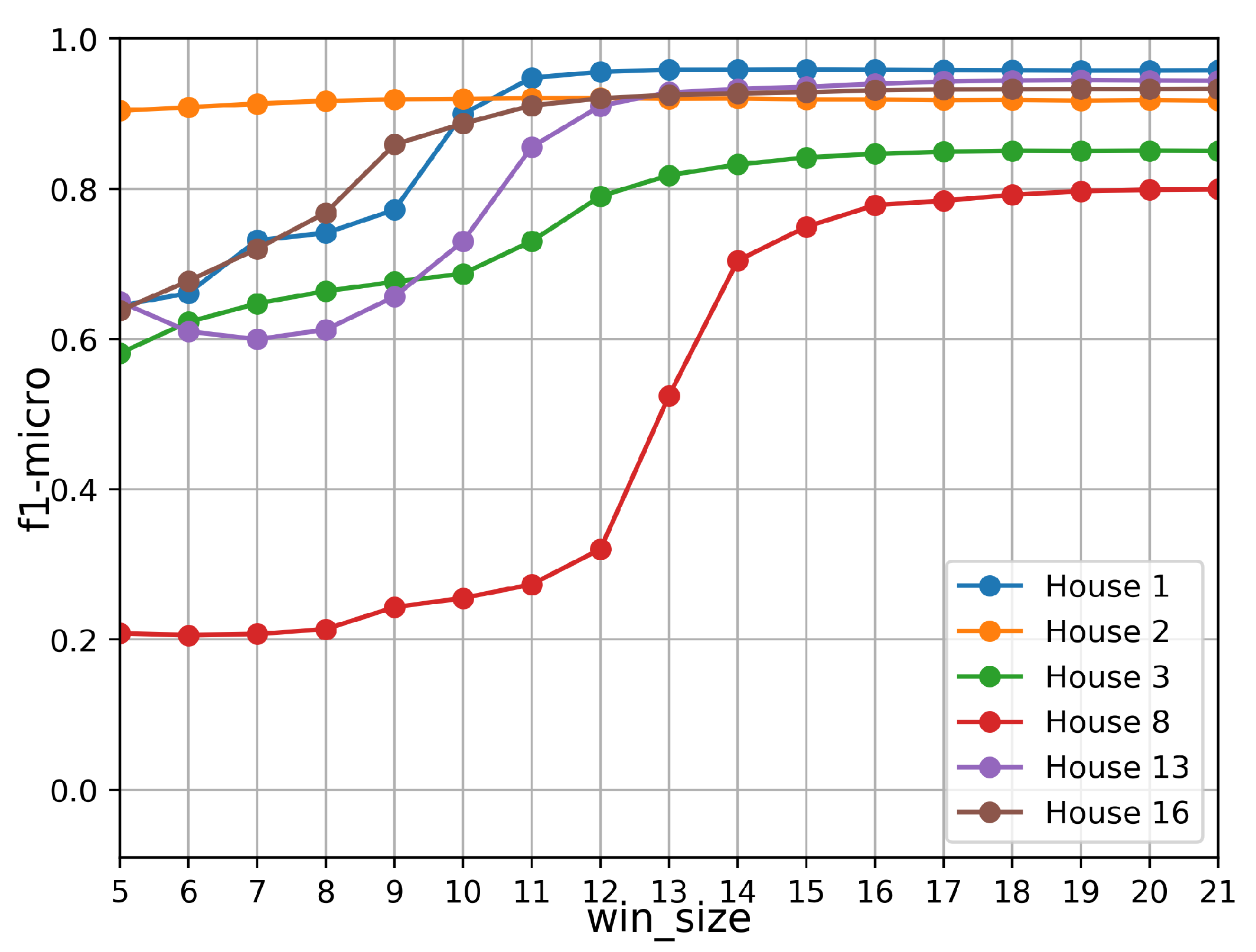
4.3. Hyper-Parameters and Performance of Sub-Models
4.3.1. Appliance Group Model
4.3.2. User Model
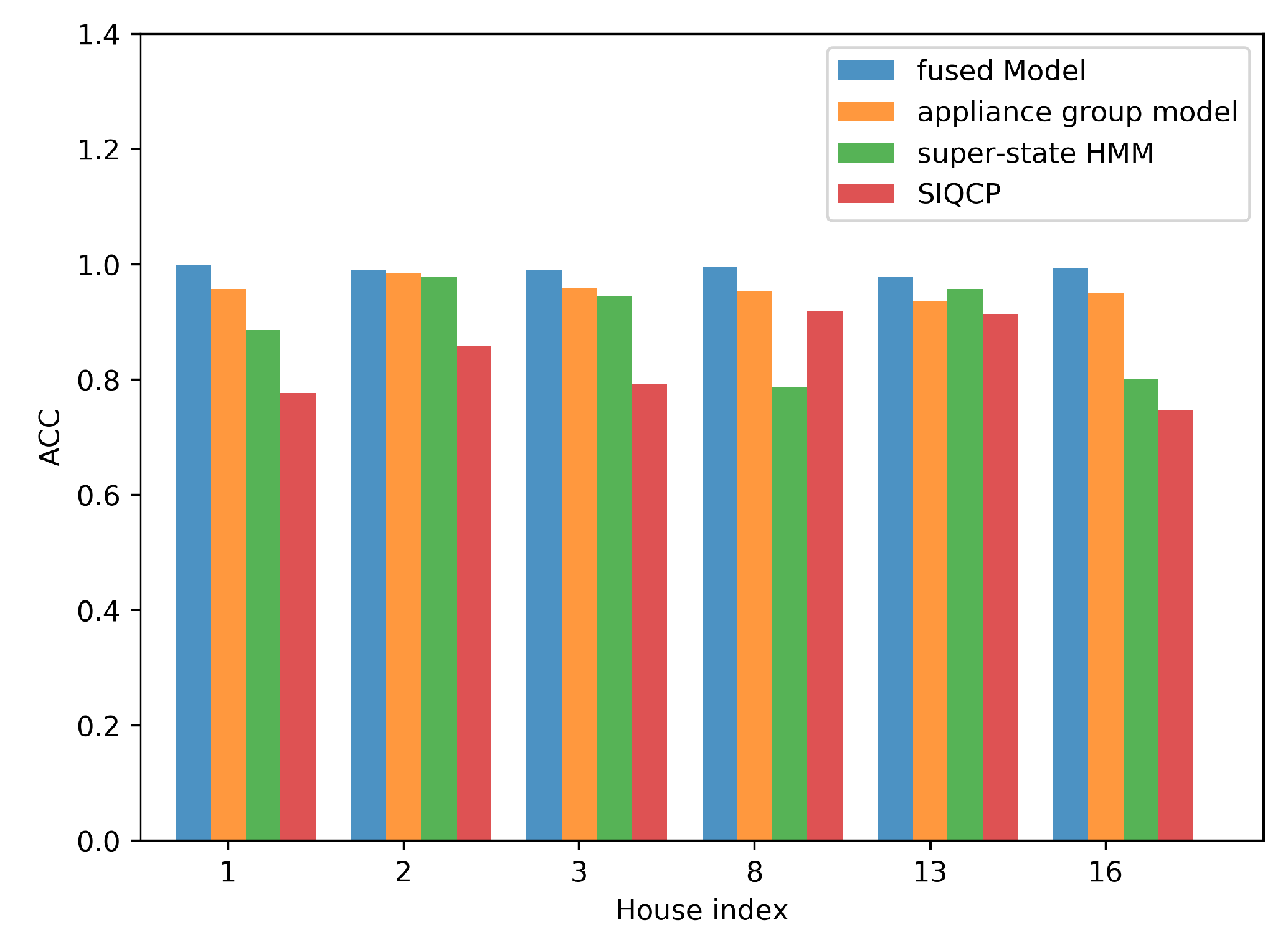
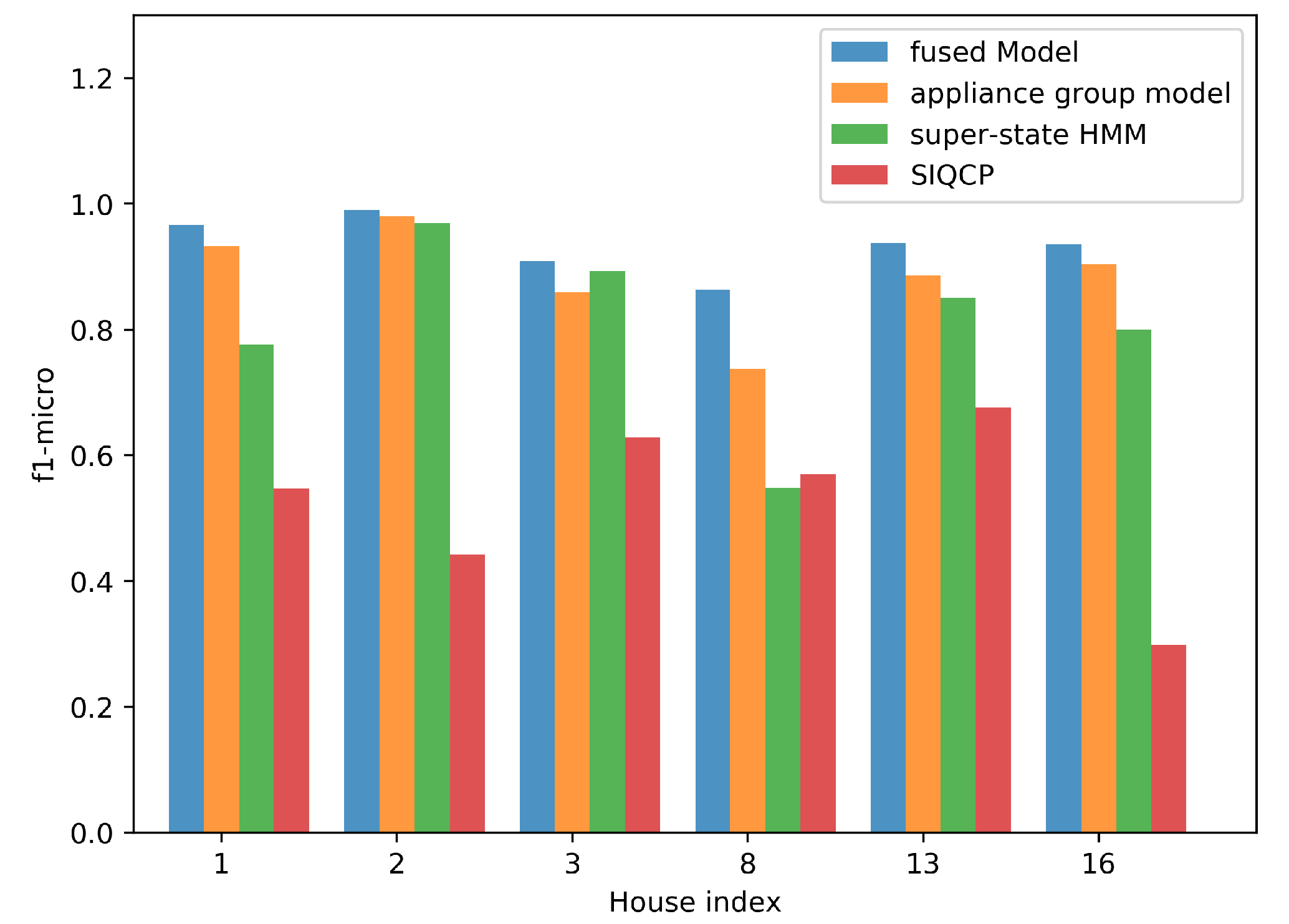
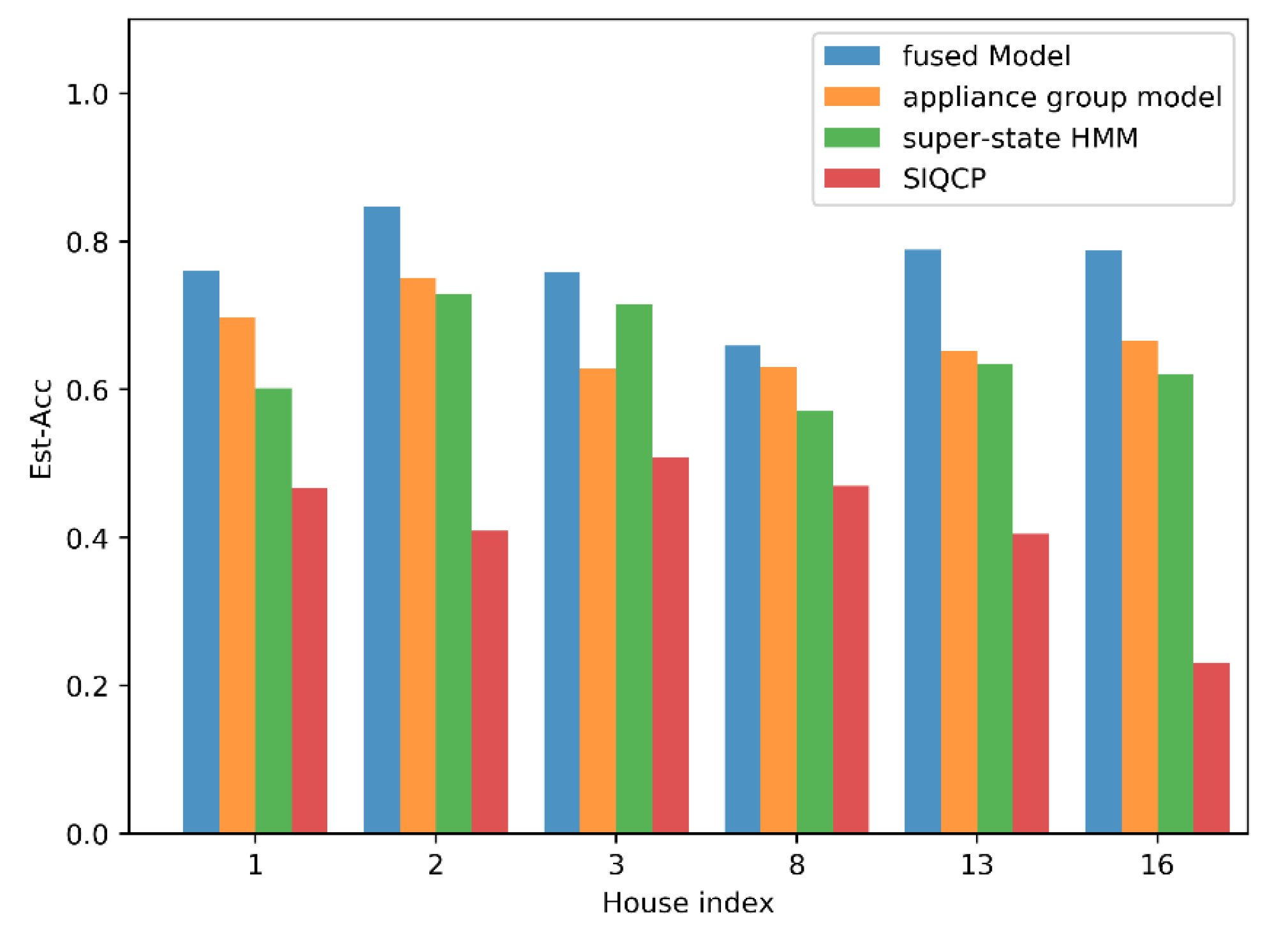
4.4. Performance of the Fused Model
4.4.1. Time Analysis
4.4.2. Performance Evaluation
4.5. Testing with Different Proportions of Training Set
4.6. Testing Continuous Varying Appliances
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Hosseini, S.S.; Agbossou, K.; Kelouwani, S.; Cardenas, A. Non-intrusive load monitoring through home energy management systems: A comprehensive review. Renew. Sustain. Energy Rev. 2017, 79, 1266–1274. [Google Scholar] [CrossRef]
- Zhai, S.; Wang, Z.; Yan, X.; He, G. Appliance Flexibility Analysis Considering User Behavior in Home Energy Management System Using Smart Plugs. IEEE Trans. Ind. Electron. 2019, 66, 1391–1401. [Google Scholar] [CrossRef]
- Makonin, S.; Popowich, F.; Bajić, I.V.; Gill, B.; Bartram, L. Exploiting hmm sparsity to perform online real-time nonintrusive load monitoring. IEEE Trans. Smart Grid 2016, 7, 2575–2585. [Google Scholar] [CrossRef]
- Singhal, V.; Maggu, J.; Majumdar, A. Simultaneous Detection of Multiple Appliances from Smart-meter Measurements via Multi-Label Consistent Deep Dictionary Learning and Deep Transform Learning. IEEE Trans. Smart Grid 2018, 10, 2969–2978. [Google Scholar] [CrossRef]
- Singh, S.; Majumdar, A. Deep Sparse Coding for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2018, 9, 4669–4678. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Ma, J.; Hill, D.; Zhao, J.; Luo, F. An Extensible Approach for Non-Intrusive Load Disaggregation with Smart Meter Data. IEEE Trans. Smart Grid 2017, 9, 3362–3372. [Google Scholar] [CrossRef]
- Welikala, S.; Dinesh, C.; Ekanayake, M.P.B.; Godaliyadda, R.I.; Ekanayake, J. Incorporating Appliance Usage Patterns for Non-Intrusive Load Monitoring and Load Forecasting. IEEE Trans. Smart Grid 2017, 10, 448–461. [Google Scholar] [CrossRef]
- Liu, Y.; Geng, G.; Gao, S.; Xu, W. Non-Intrusive Energy Use Monitoring for a Group of Electrical Appliances. IEEE Trans. Smart Grid 2016, 9, 3801–3810. [Google Scholar] [CrossRef]
- Iwayemi, A.; Zhou, C. SARAA: Semi-supervised learning for automated residential appliance annotation. IEEE Trans. Smart Grid 2017, 8, 779–786. [Google Scholar] [CrossRef]
- Houidi, S.; Fourer, D.; Auger, F. On the Use of Concentrated Time–Frequency Representations as Input to a Deep Convolutional Neural Network: Application to Non Intrusive Load Monitoring. Entropy 2020, 22, 911. [Google Scholar] [CrossRef]
- Jazizadeh, F.; Becerik-Gerber, B.; Berges, M.; Soibelman, L. An unsupervised hierarchical clustering based heuristic algorithm for facilitated training of electricity consumption disaggregation systems. Adv. Eng. Inform. 2014, 28, 311–326. [Google Scholar] [CrossRef]
- Tabatabaei, S.M.; Dick, S.; Xu, W. Toward non-intrusive load monitoring via multi-label classification. IEEE Trans. Smart Grid 2017, 8, 26–40. [Google Scholar] [CrossRef]
- Liang, J.; Ng, S.K.; Kendall, G.; Cheng, J.W. Load signature study Part 1 Basic concept, structure, and methodology. IEEE Trans. Power Deliv. 2010, 25, 551–560. [Google Scholar] [CrossRef]
- Mengistu, M.A.; Girmay, A.A.; Camarda, C.; Acquaviva, A.; Patti, E. A Cloud-based On-line Disaggregation Algorithm for Home Appliance Loads. IEEE Trans. Smart Grid 2018, 10, 3430–3439. [Google Scholar] [CrossRef]
- Cominola, A.; Giuliani, M.; Piga, D.; Castelletti, A.; Rizzoli, A.E. A hybrid signature-based iterative disaggregation algorithm for non-intrusive load monitoring. Appl. Energy 2017, 185, 331–344. [Google Scholar] [CrossRef]
- Parson, O.; Ghosh, S.; Weal, M.J.; Rogers, A. Non-Intrusive Load Monitoring Using Prior Models of General Appliance Types. In Proceedings of the Twenty-Sixth Conference on Artificial Intelligence (AAAI-12), Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Guo, Z.; Wang, Z.J.; Kashani, A. Home appliance load modeling from aggregated smart meter data. IEEE Trans. Power Syst. 2015, 30, 254–262. [Google Scholar] [CrossRef]
- Aquino, A.L.L.; Ramos, H.S.; Frery, A.C.; Viana, L.P.; Cavalcante, T.S.G.; Rosso, O.A. Characterization of electric load with Information Theory quantifiers. Phys. A Stat. Mech. Its Appl. 2017, 465, 277–284. [Google Scholar] [CrossRef]
- Kim, H.; Marwah, M.; Arlitt, M.; Lyon, G.; Han, J. Unsupervised disaggregation of low frequency power measurements. In Proceedings of the 2011 SIAM International Conference on Data Mining; SIAM: Philadelphia, PA, USA, 2011; pp. 747–758. [Google Scholar]
- Jiang, L.; Luo, S.; Li, J. An Approach of Household Power Appliance Monitoring Based on Machine Learning. In Proceedings of the 2012 Fifth International Conference on Intelligent Computation Technology and Automation, Zhangjiajie, China, 12–14 January 2012; pp. 577–580. [Google Scholar] [CrossRef]
- Kelly, J.; Knottenbelt, W. Neural nilm: Deep neural networks applied to energy disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Korea, 4–5 November 2015; pp. 55–64. [Google Scholar]
- Nguyen, M.; Alshareef, S.; Gilani, A.; Morsi, W.G. A novel feature extraction and classification algorithm based on power components using single-point monitoring for NILM. In Proceedings of the 2015 IEEE 28th Canadian Conference on Electrical and Computer Engineering (CCECE), Halifax, NS, Canada, 3–6 May 2015; pp. 37–40. [Google Scholar]
- Kolter, J.Z.; Jaakkola, T. Approximate inference in additive factorial hmms with application to energy disaggregation. In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, La Palma, Canary Islands, Spain, 21–23 April 2012; pp. 1472–1482. [Google Scholar]
- Chen, Z.; Wu, L.; Fu, Y. Real-time price-based demand response management for residential appliances via stochastic optimization and robust optimization. IEEE Trans. Smart Grid 2012, 3, 1822–1831. [Google Scholar] [CrossRef]
- Liu, H. Appliance Identification Based on Template Matching. In Non-intrusive Load Monitoring; Springer: Berlin/Heidelberg, Germany, 2020; pp. 79–103. [Google Scholar]
- D’Incecco, M.; Squartini, S.; Zhong, M. Transfer learning for non-intrusive load monitoring. IEEE Trans. Smart Grid 2019, 11, 1419–1429. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Secaucus, NJ, USA, 2006. [Google Scholar]
- Li, D.; Bissyandé, T.F.; Kubler, S.; Klein, J.; Le Traon, Y. Profiling household appliance electricity usage with n-gram language modeling. In Proceedings of the 2016 IEEE International Conference on Industrial Technology (ICIT), Taipei, Taiwan, 14–17 March 2016; pp. 604–609. [Google Scholar]
- Murray, D.; Stankovic, L.; Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci. Data 2017, 4, 160122. [Google Scholar] [CrossRef]
- Pipattanasomporn, M.; Kuzlu, M.; Rahman, S.; Teklu, Y. Load profiles of selected major household appliances and their demand response opportunities. IEEE Trans. Smart Grid 2014, 5, 742–750. [Google Scholar] [CrossRef]
- Zhou, C.; Bai, J.; Song, J.; Liu, X.; Zhao, Z.; Chen, X.; Gao, J. ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation. arXiv 2017, arXiv:1711.06632. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 28 October 2020).
- Farnadi, G.; Tang, J.; De Cock, M.; Moens, M.F. User Profiling through Deep Multimodal Fusion. In Proceedings of the 11th ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018. [Google Scholar]
- Zhang, Y.; Dai, H.; Xu, C.; Feng, J.; Wang, T.; Bian, J.; Wang, B.; Liu, T.Y. Sequential Click Prediction for Sponsored Search with Recurrent Neural Networks. AAAI 2014, 14, 1369–1375. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- 2016. Available online: https://github.com/shi-yan/FreeWill/tree/master/Docs/Diagrams (accessed on 28 October 2020).
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, ICML 2013, Atlanta, GA, USA, 16–21 June 2013; number PART 3. pp. 2347–2355. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: Amethod for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Makonin, S.; Popowich, F. Nonintrusive load monitoring (NILM) performance evaluation. Energy Effic. 2015, 8, 809–814. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Johnson, M.J. REDD: A public data set for energy disaggregation research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 24 August 2011; Volume 25, pp. 59–62. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer 1 | Layer 2 | Layer 3 | Layer 4 | Layer 5 | Layer 6 | Layer 7 |
|---|---|---|---|---|---|---|
| 20 | 40 | 60 | 80 | 71 | 118 | 256 |
| 5 | 10 | × | × | × | × | × |
| 10 | 40 | 200 | 256 | × | × | × |
| Freezer | Dryer | Washer | Computer | Heater | Cooking | TV | Others | |
|---|---|---|---|---|---|---|---|---|
| Fused Model | 0.88 | 0.98 | 0.93 | 0.90 | 0.99 | 0.97 | 0.82 | 0.96 |
| Appliance Group Model | 0.85 | 0.98 | 0.92 | 0.88 | 0.99 | 0.97 | 0.76 | 0.96 |
| Super-state HMM | 0.92 | 0.98 | 0.89 | 0.98 | 0.95 | 0.96 | 0.94 | 0.99 |
| SIQCP | 0.70 | 0.99 | 0.88 | 0.85 | 0.95 | 0.95 | 0.79 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, C.; Lin, G.; Zhai, S.; Ding, Y.; He, G. Non-Intrusive Load Monitoring via Deep Learning Based User Model and Appliance Group Model. Energies 2020, 13, 5629. https://doi.org/10.3390/en13215629
Peng C, Lin G, Zhai S, Ding Y, He G. Non-Intrusive Load Monitoring via Deep Learning Based User Model and Appliance Group Model. Energies. 2020; 13(21):5629. https://doi.org/10.3390/en13215629
Chicago/Turabian StylePeng, Ce, Guoying Lin, Shaopeng Zhai, Yi Ding, and Guangyu He. 2020. "Non-Intrusive Load Monitoring via Deep Learning Based User Model and Appliance Group Model" Energies 13, no. 21: 5629. https://doi.org/10.3390/en13215629
APA StylePeng, C., Lin, G., Zhai, S., Ding, Y., & He, G. (2020). Non-Intrusive Load Monitoring via Deep Learning Based User Model and Appliance Group Model. Energies, 13(21), 5629. https://doi.org/10.3390/en13215629