Short-Term Direct Probability Prediction Model of Wind Power Based on Improved Natural Gradient Boosting

Abstract

1. Introduction
2. Establish Model
2.1. Data Preprocessing
- Normalize the time series of each variable. Taking the kth of n meteorological variables as the comparison sequence (t) and the wind power sequence as the reference sequence (t), the absolute sequence (t) is calculated showing the difference between the two sequences by Equation (1), where k∈(1, n).
- Calculate the correlation coefficientwhere Min (·) and Max (·) means the minimum and maximum value of the sequence.
- Solve the degree of associationwhere Tn is the sequence length.
- Set the threshold and select the variables whose is over the threshold as a new data set.
2.2. Improved NGBoost
2.3. Blending Fusion
- Original data set segmentation
- 2.
- Model fusion
3. Evaluation Indicators
- 1.
- Forecast area coverage
- 2.
- Proportion of average width of prediction interval
- 3.
- Overall score
4. Verification and Analysis
4.1. Calculation Example and Model Parameter Description
4.2. Results Analysis
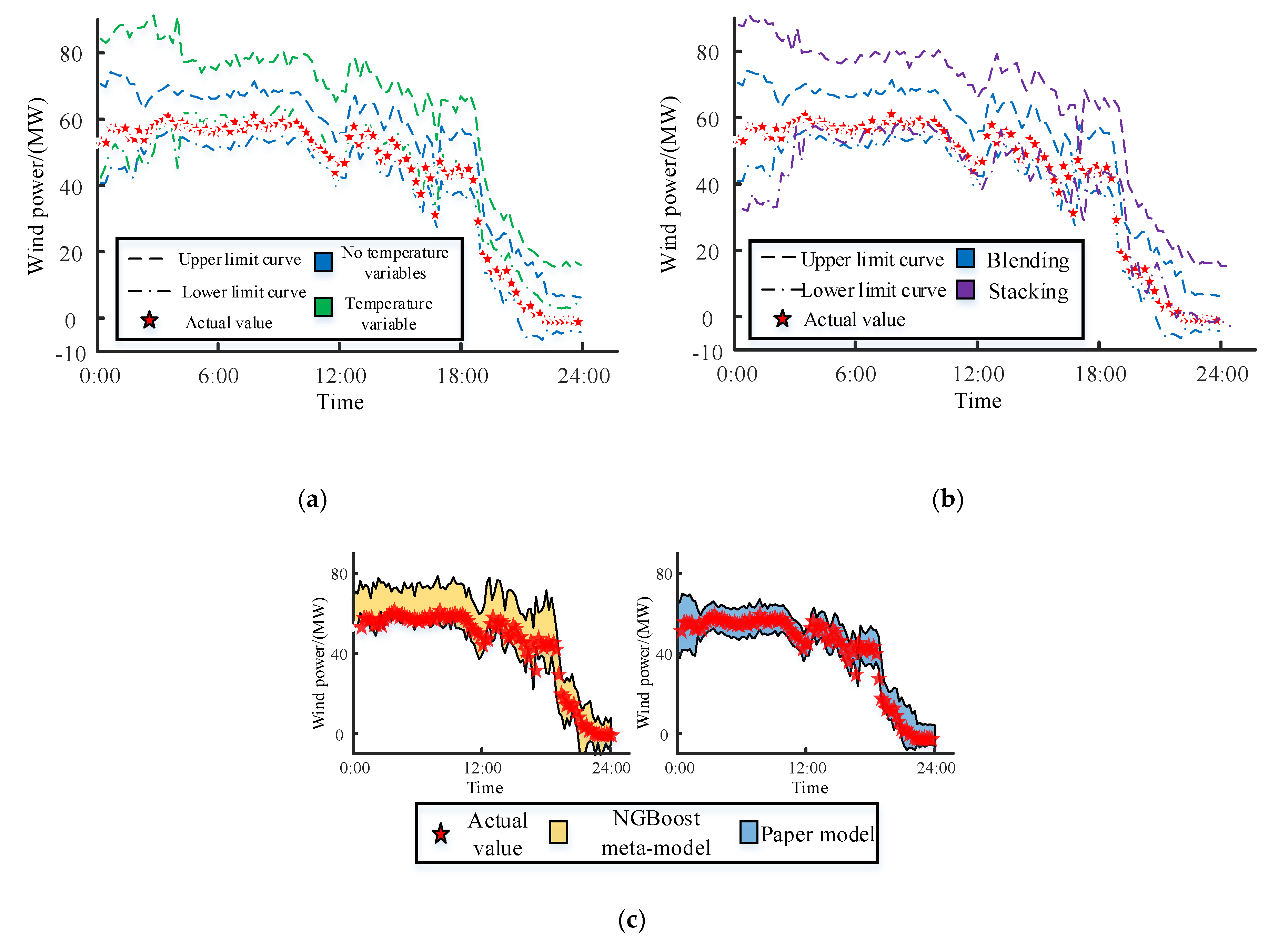
4.2.1. Effectiveness Analysis of Model Improvements
4.2.2. Comparative Analysis with Other Models
5. Conclusions
- (1)
- Considering actual engineering conditions, there are many outliers in the initial data set from SCADA in real wind farms which will cause final prediction errors. With the help of the box plot and gray correlation analysis proposed in this paper, the initial data set can be effectively preprocessed so that the model has a higher generalization and robustness.
- (2)
- The related concepts of direct calculation by natural gradients are extremely complicated, which is not conducive to popularization and applications in actual engineering. Based on the amount of Fisher information, calculating natural gradients through ordinary gradients is liable to simplify the metamodel calculation process and promote the model applicated in practical engineering.
- (3)
- Blending fusion is more suitable for solving probabilistic prediction problems effectively strengthening the learning effect of the metamodel without causing excessive model redundancy.
Author Contributions
Funding
Conflicts of Interest
Appendix A

Appendix B

Appendix C

References
- Huo, Y.; Jiang, P.; Zhu, Y.; Feng, S.; Wu, X. Optimal real-time scheduling of wind integrated power system presented with storage and wind forecast uncertainties. Energies 2015, 8, 1080–1100. [Google Scholar] [CrossRef]
- Zuluaga, C.D.; Álvarez, M.A.; Giraldo, E. Short-term wind speed prediction based on robust Kalman filtering: An experimental comparison. Appl. Energy 2015, 156, 321–330. [Google Scholar] [CrossRef]
- Neeraj, B.; Andrés, F.; Daniel, V.; Kulat, K. A novel and alternative approach for direct and indirect wind-power prediction methods. Energies 2018, 11, 2923. [Google Scholar]
- Costa, A.; Crespo, A.; Navarro, J.; Lizcano, G.; Madsen, H.; Feitosa, E. A review on the young history of the wind power short-term prediction. Renew. Sustain. Energy Rev. 2008, 12, 1725–1744. [Google Scholar] [CrossRef]
- Xie, L.; Gu, Y.; Zhu, X. Short-term patio-temporal wind power forecast in robust look-ahead power system dispatch. IEEE Trans. Smart Grid 2013, 5, 511–520. [Google Scholar] [CrossRef]
- Buhan, S.; Özkazanç, Y.; Çadırcı, I. Wind pattern recognition and reference wind mast data correlations with NWP for improved wind-electric power forecasts. IEEE Trans. Ind. Inform. 2016, 12, 991–1004. [Google Scholar] [CrossRef]
- Wei, W.; Zhang, Y.; Wu, G. Ultra-short-term/short-term wind power continuous prediction based on fuzzy clustering analysis. IEEE PES Innov. Smart Grid Technol. 2012, 7, 6. [Google Scholar] [CrossRef]
- Sharma, K.C.; Jain, P.; Bhakar, R. Wind power scenario generation and reduction in stochastic programming framework. Electr. Power Compon. Syst. 2013, 41, 271–285. [Google Scholar] [CrossRef]
- Ambach, D.; Croonenbroeck, C. A selection of time series models for short- to medium-term wind power forecasting. J. Wind Eng. Ind. Aerodyn. 2015, 136, 201–210. [Google Scholar]
- Zhu, Q.; Chen, J.; Zhu, L.; Duan, X.; Liu, Y. Wind Speed Prediction with Spatio-temporal Correlation: A Deep Learning Approach. Energies 2018, 11, 705. [Google Scholar] [CrossRef]
- Zheng, L.; Hu, W.; Min, Y. Raw wind data preprocessing: A data-mining approach. IEEE Trans. Sustain. Energy 2015, 6, 11–19. [Google Scholar] [CrossRef]
- Khodayar, M.; Wang, J. Spatio-temporal graph deep neural network for short-term wind speed forecasting. IEEE Trans. Sustain. Energy 2019, 10, 670. [Google Scholar] [CrossRef]
- Foley, A.M.; Leahy, P.G.; Marvuglia, A. Current methods and advances in forecasting of wind power generation. Renew. Energy 2012, 37, 1–8. [Google Scholar] [CrossRef]
- Poncela, M.; Poncela, P.; Perán, J.R. Automatic tuning of Kalman filters by maximum likelihood methods for wind energy forecasting. Appl. Energy 2013, 108, 349–362. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, P.; Zhang, C. Wind energy prediction with LS-SVM based on Lorenz perturbation. J. Eng. 2017, 13, 1724. [Google Scholar] [CrossRef]
- Villacorta, C.; Cardoso, A.; Lima, C.G. Forecasting natural gas consumption using ARIMA models and artificial neural networks. IEEE Latin Am. Trans. 2016, 14, 2233. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, J.; Shi, D.; Zhu, L.; Bai, X.; Duan, X.; Liu, Y. Learning Temporal and Spatial Correlations Jointly: A Unified Framework for Wind Speed Prediction. IEEE Trans. Sustain. Energy 2020, 11, 509–523. [Google Scholar] [CrossRef]
- Yang, X.; Ma, X.; Kang, N. Probability interval prediction of wind power based on kde method with rough sets and weighted markov Chain. IEEE Access 2018, 6, 51556. [Google Scholar] [CrossRef]
- Yu, R.; Liu, Z.; Li, X.; Lu, W.; Ma, D.; Yu, M.; Wang, J.; Li, B. Scene learning: Deep convolutional networks for wind power prediction by embedding turbines into grid space. Appl. Energy 2019, 238, 249–257. [Google Scholar] [CrossRef]
- Yan, J.; Zhang, H.; Liu, Y.; Han, S.; Li, L. Uncertainty estimation for wind energy conversion by probabilistic wind turbine power curve modeling. Appl. Energy 2019, 239, 1356. [Google Scholar] [CrossRef]
- Wan, C.; Xu, Z.; Pinson, P.; Dong, Z.Y.; Wong, K.P. Probabilistic forecasting of wind power generation using extreme learning machine. IEEE Trans. Power Syst. 2014, 29, 1033–1044. [Google Scholar] [CrossRef]
- Naik, J.; Bisoi, R.; Dash, P.K. Prediction interval forecasting of wind speed and wind power using modes decomposition based low rank multi-kernel ridge regression. Renew. Energy 2018, 129, 357. [Google Scholar] [CrossRef]
- Cui, M.; Krishnan, V.; Hodge, B.M.; Zhang, J. A copula-based conditional probabilistic forecast model for wind power ramps. IEEE Trans. Smart Grid 2018, 1, 13. [Google Scholar] [CrossRef]
- Malvoni, M.; De Giorgi, M.G.; Congedo, P.M. Forecasting of PV Power Generation using weather input data-preprocessing techniques. Energy Procedia 2017, 126, 651. [Google Scholar] [CrossRef]
- Zhang, G.Y.; Wu, Y.G.; Wong, K.P. An advanced approach for construction of optimal wind power prediction intervals. IEEE Trans. Power Syst. 2015, 30, 2706. [Google Scholar] [CrossRef]
- Kou, P.; Liang, D.L.; Gao, F. Probabilistic wind power forecasting with online model selection and warped gaussian process. Energy Convers. Manag. 2014, 84, 649. [Google Scholar] [CrossRef]
- Hu, M.Y.; Hu, Z.J.; Qian, M.L. Research on wind power prediction method based on improved AdaBoost. RT and KELM. Power Grid Technol. 2017, 41, 536. [Google Scholar]
- He, D.; Wu, M. Probe into application of Ada-BP neural network improved algorithm in electric power load forecasting. Shanxi Electr. Power 2012, 40, 21–28. [Google Scholar]
- Liu, W.; Zhang, R.F.; Peng, D.G. Load forecasting of distribution network based on k-adaboost data mining. Zhejiang Electr. Power 2019, 38, 104. [Google Scholar]
- Tan, J.; Deng, C.H.; Yang, W. Ultra-short-term photovoltaic power forecasting in microgrid based on adaboost clustering. Autom. Electr. Power Syst. 2017, 41, 33. [Google Scholar]
- Xie, C.Z.; Wang, J.C.; Xie, X.H. BOA-GBDT photovoltaic output prediction based on fine-grained features. Power Grid Technol. 2020, 44, 689. [Google Scholar]
- Liu, B.; Qin, C.; Ju, P. Short-term bus load forecast based on the fusion of XGBoost and Stacking model. Electr. Power Autom. Equip. 2020, 40, 147. [Google Scholar]
- Tony, D.; Anand, A.; Daisy, Y.D. NGBoost: Natural gradient boosting for probabilistic prediction. arXiv 2019, arXiv:1910.03225. [Google Scholar]
- Zhang, Z.Z.; Zou, J.X.; Zheng, G. Ultra-short-term wind power prediction model based on modified grey model method for power control in wind farm. Wind Energy 2011, 35, 55. [Google Scholar] [CrossRef]
- Han, Q.; Wu, H.; Hu, T.; Chu, F. Short-term wind speed forecasting based on signal decomposing algorithm and hybrid linear/nonlinear models. Energies 2018, 11, 2796. [Google Scholar] [CrossRef]
- Dong, W.; Yang, Q.; Fang, X.L. Multi-step ahead wind power generation prediction based on hybrid machine learning techniques. Energies 2018, 11, 1975. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, N.; Jia, B.; Peng, T. A novel decomposition-optimization model for short-term wind speed forecasting. Energies 2018, 11, 1752. [Google Scholar] [CrossRef]
- Meng, Y.H.; Zhi, J.H.; Jing, P.Y. A novel multi-objective optimal approach for wind power interval prediction. Energies 2017, 10, 419. [Google Scholar]
- Huang, G.B. An insight into extreme learning machines: Random neurons, Random features and kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Yang, X.Y.; Zhang, Y.F.; Ye, T.Z. Probabilistic interval prediction of wind power combination based on Naive Bayes. High Volt. Technol. 2020, 46, 1099. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confidence Level | Method of [33] | Method of This Paper | ||||
|---|---|---|---|---|---|---|
| IF (%) | IP (%) | IC | IF (%) | IP (%) | IC | |
| 80% | 92.71 | 11.31 | 82.80 | 92.71 | 11.34 | 82.77 |
| 90% | 96.88 | 12.11 | 82.14 | 96.88 | 12.07 | 82.17 |
| 95% | 97.92 | 12.97 | 81.43 | 97.92 | 12.95 | 81.45 |
| Confidence Level | Model 1 | Model 2 | Model 3 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| IF (%) | IP (%) | IC | IF (%) | IP (%) | IC | IF (%) | IP (%) | IC | |
| 80% | 93.75 | 7.81 | 86.71 | 43.75 | 32.36 | 31.60 | 81.25 | 38.22 | 55.34 |
| 90% | 97.92 | 8.39 | 90.04 | 67.71 | 41.46 | 44.63 | 85.42 | 48.98 | 52.21 |
| 95% | 98.96 | 9.55 | 89.95 | 72.92 | 49.55 | 44.32 | 88.54 | 58.53 | 49.17 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, Y.; Wu, B. Short-Term Direct Probability Prediction Model of Wind Power Based on Improved Natural Gradient Boosting. Energies 2020, 13, 4629. https://doi.org/10.3390/en13184629
Li Y, Wang Y, Wu B. Short-Term Direct Probability Prediction Model of Wind Power Based on Improved Natural Gradient Boosting. Energies. 2020; 13(18):4629. https://doi.org/10.3390/en13184629
Chicago/Turabian StyleLi, Yonggang, Yue Wang, and Binyuan Wu. 2020. "Short-Term Direct Probability Prediction Model of Wind Power Based on Improved Natural Gradient Boosting" Energies 13, no. 18: 4629. https://doi.org/10.3390/en13184629
APA StyleLi, Y., Wang, Y., & Wu, B. (2020). Short-Term Direct Probability Prediction Model of Wind Power Based on Improved Natural Gradient Boosting. Energies, 13(18), 4629. https://doi.org/10.3390/en13184629