Method for Clustering Daily Load Curve Based on SVD-KICIC



Abstract
1. Introduction
2. Basic Principles
2.1. Theory of Singular Value Decomposition
2.2. Weighting K-Means Algorithm in Combination with the Intra-Class and Inter-Class Distance
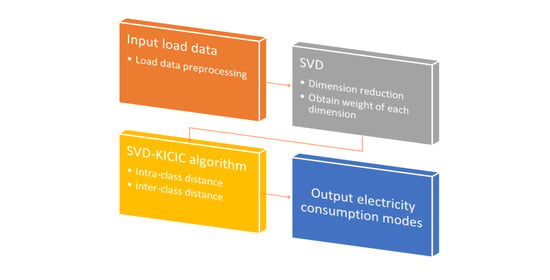
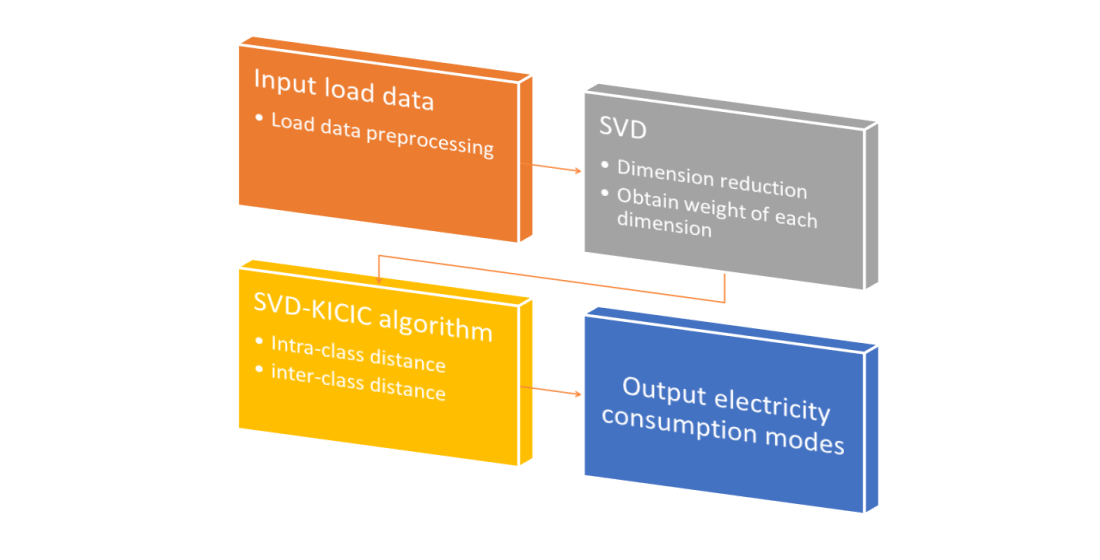
3. SVD-KICIC Algorithm
3.1. Data Preprocessing
3.1.1. Identification and Correction of Abnormal or Missing Data
3.1.2. Load Curve Normalization
3.2. SVD-KICIC and Its Implementation
3.2.1. Improving the Target Function
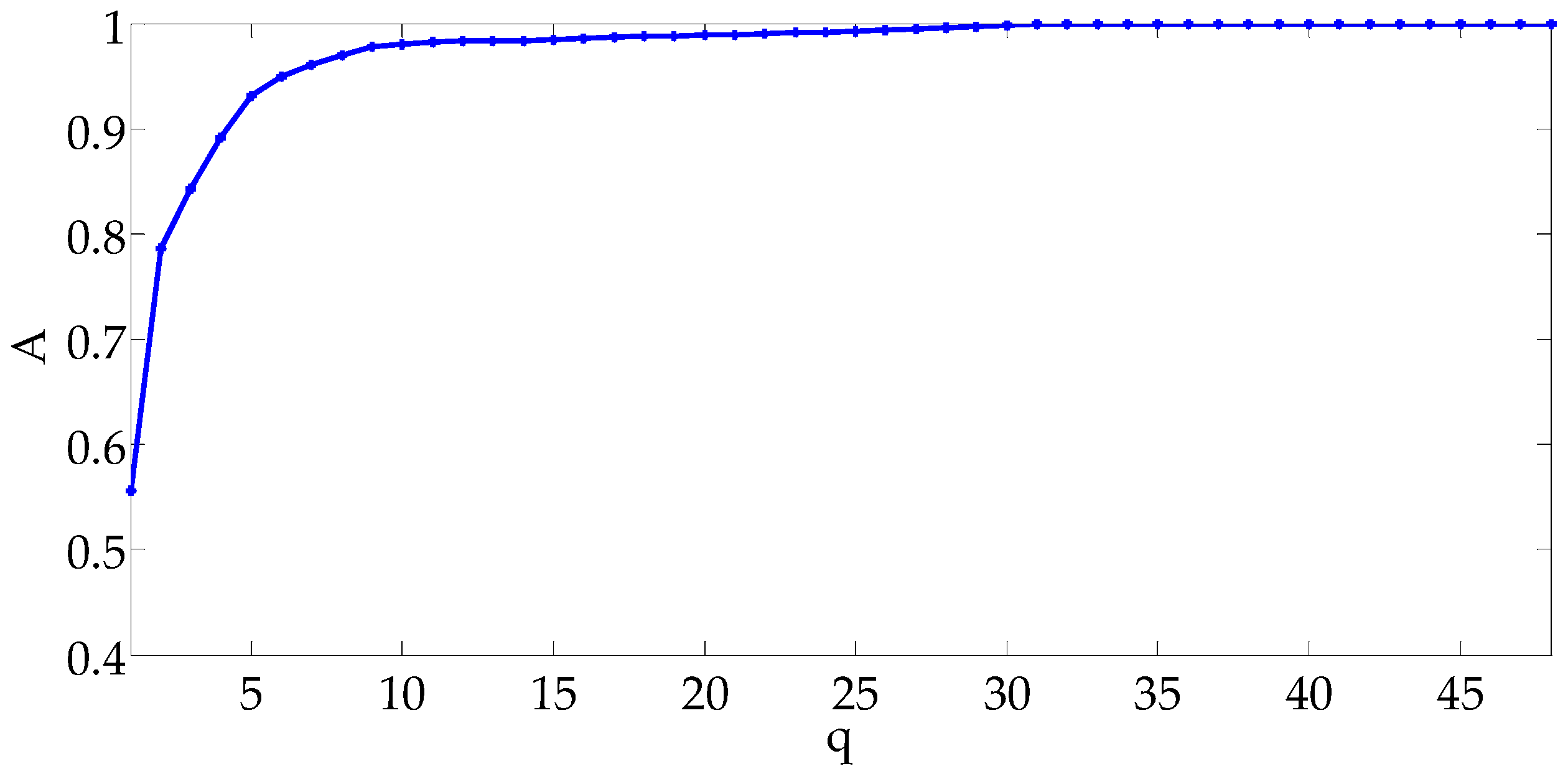
3.2.2. Determination of the Dimensionality of the Characteristic Information Matrix
3.2.3. Solving the Assignment Matrix
3.2.4. Solving the Clustering Center Matrix
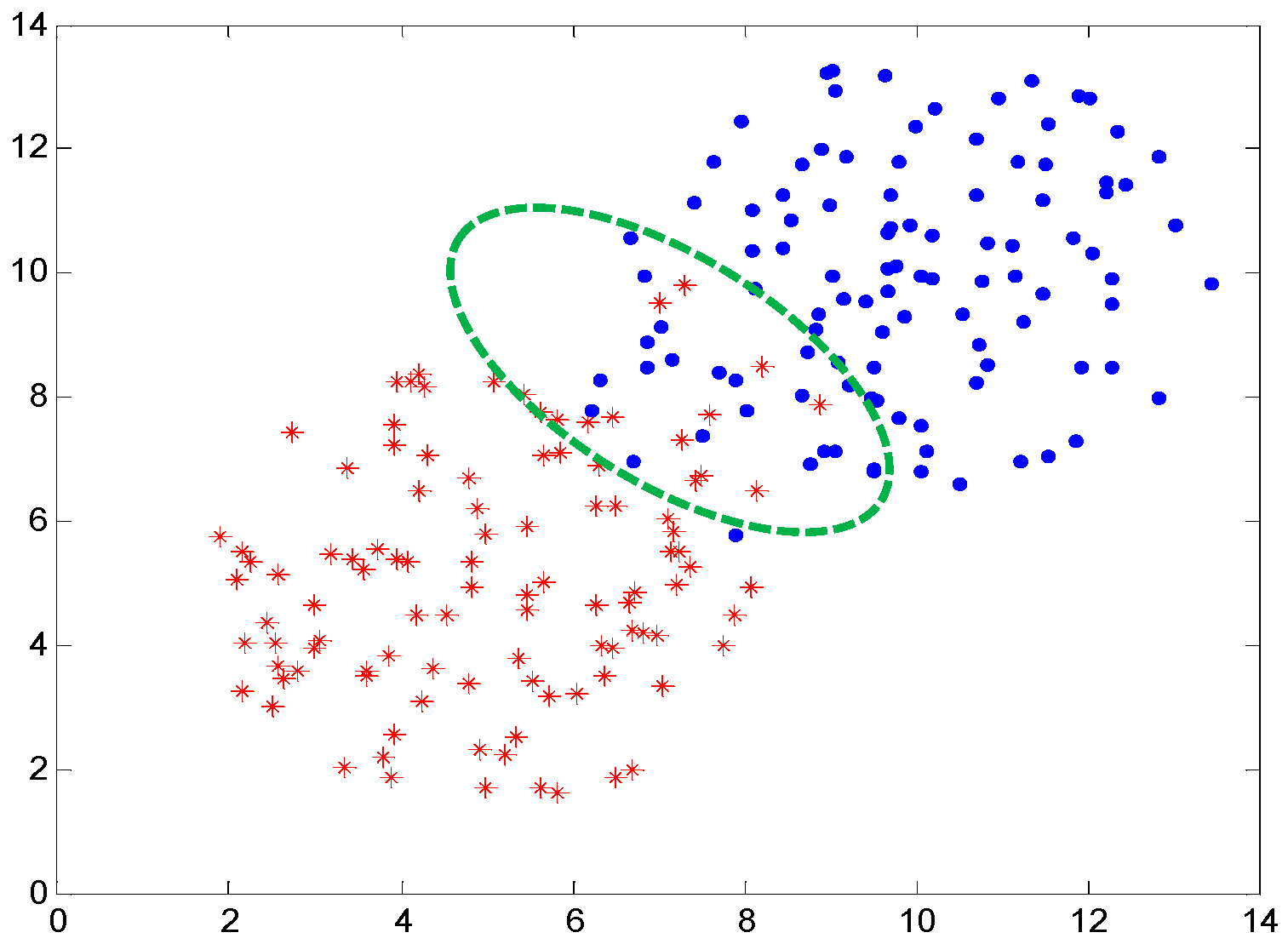
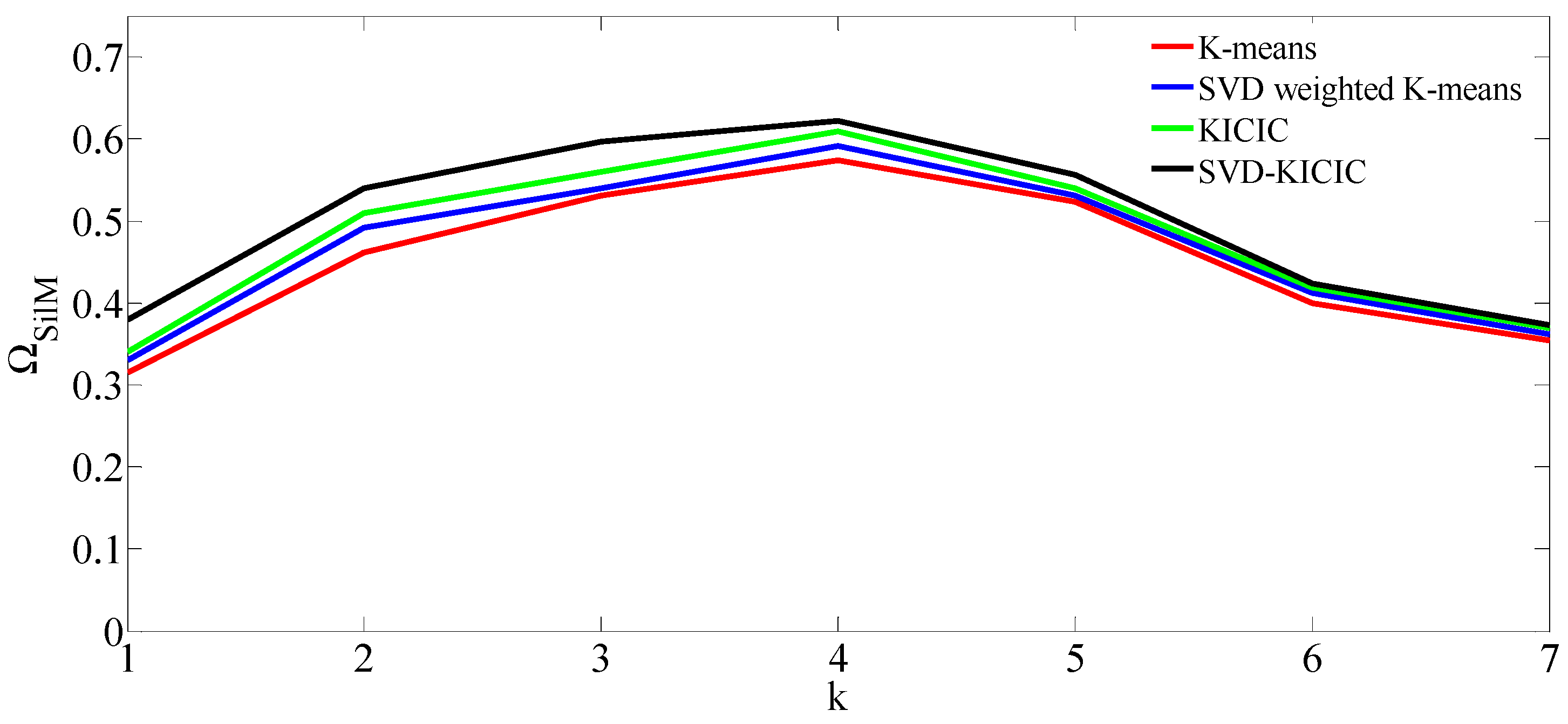
3.3. Clustering Effectiveness Indicator
4. Analysis of Examples
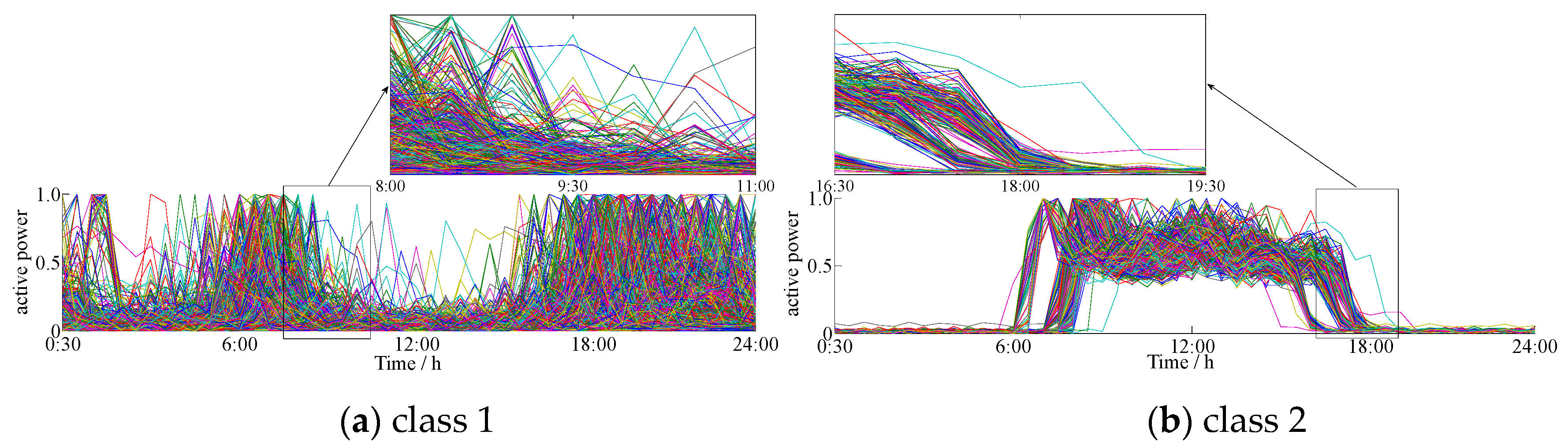
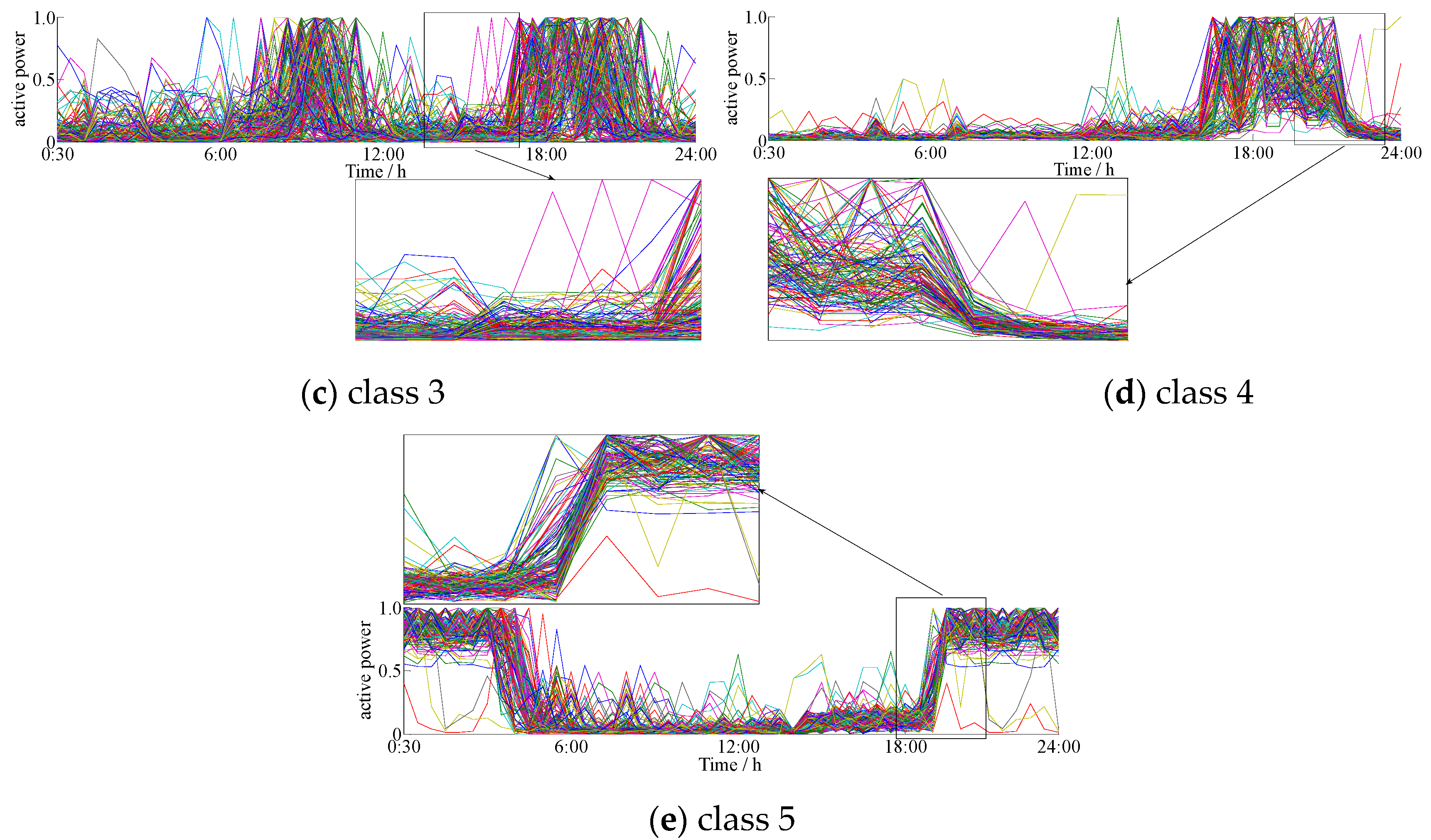
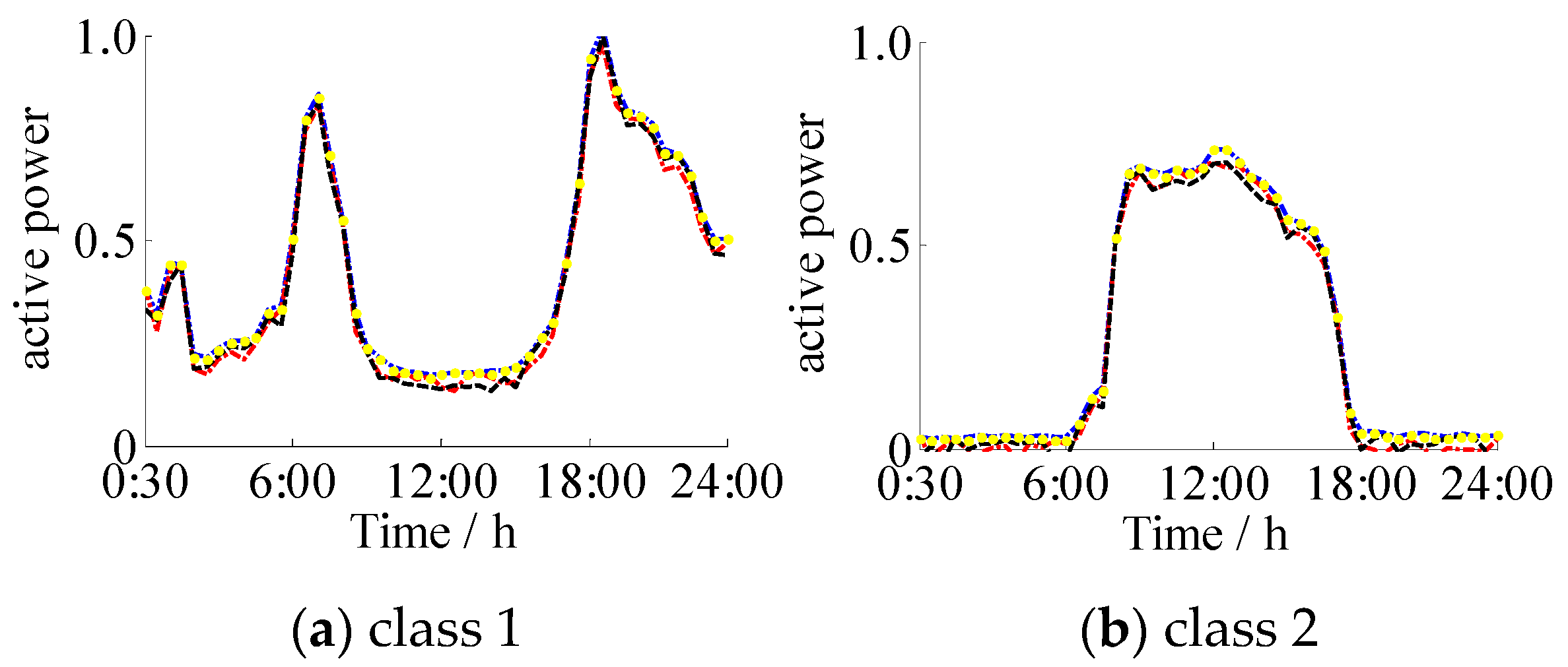
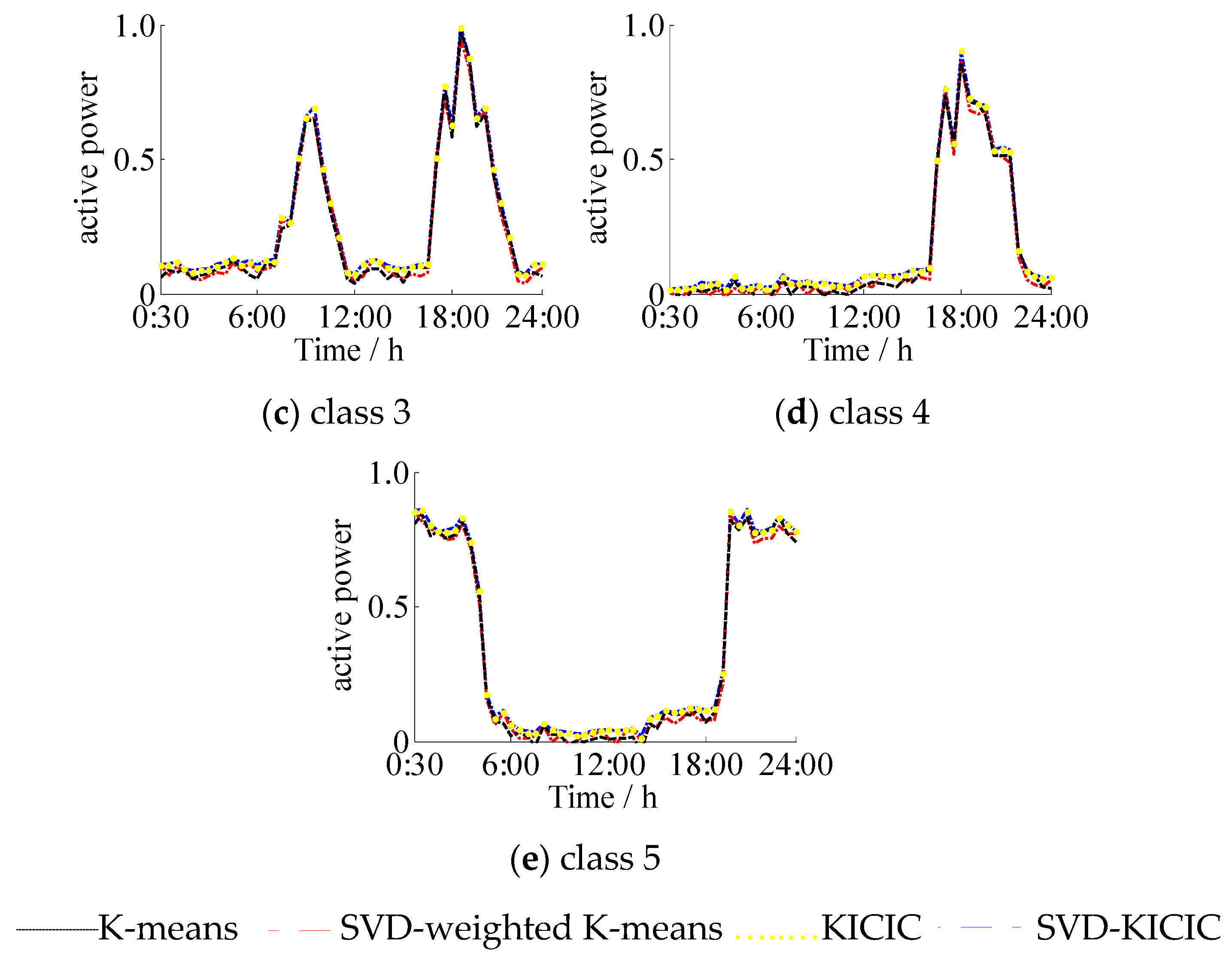
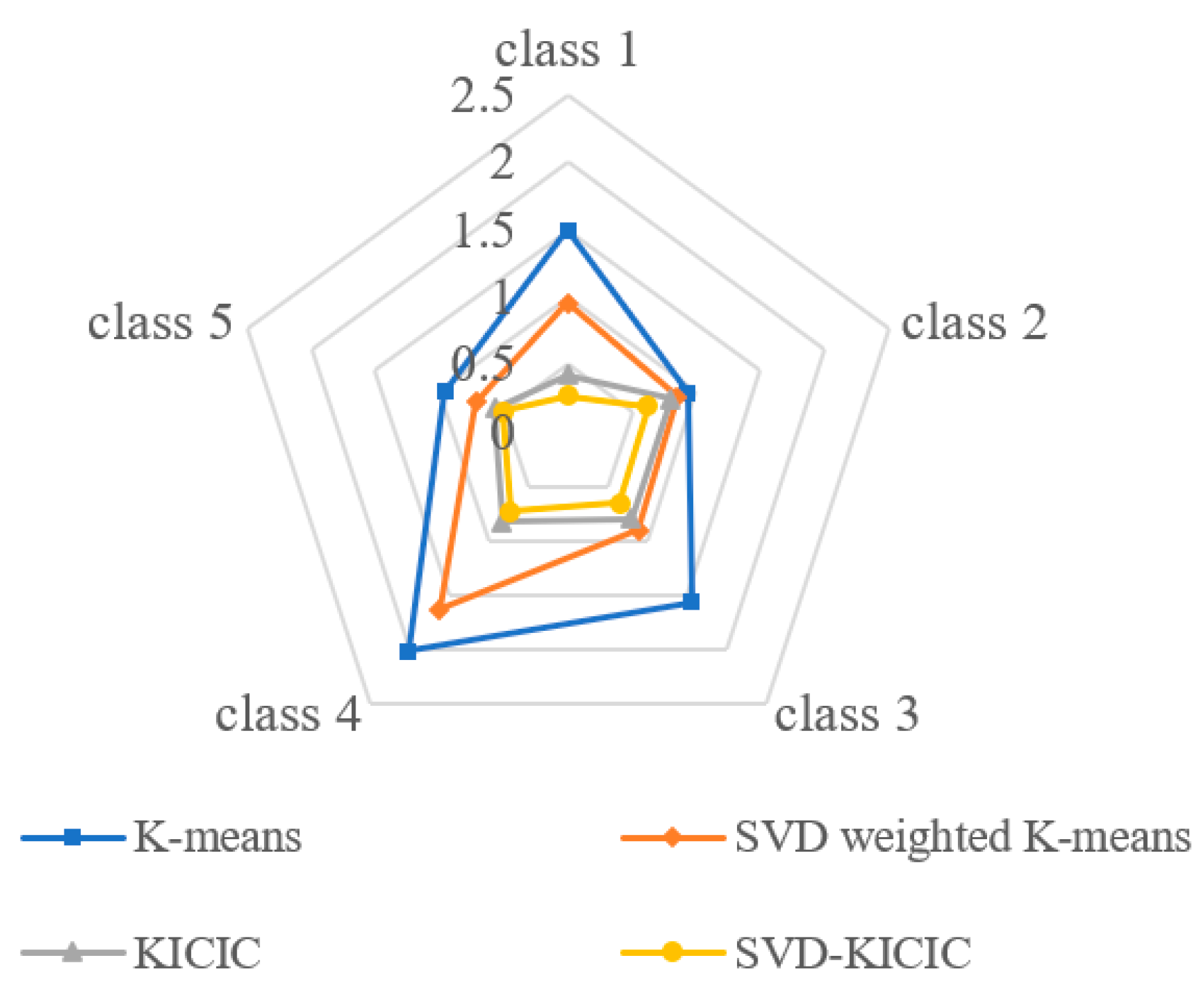
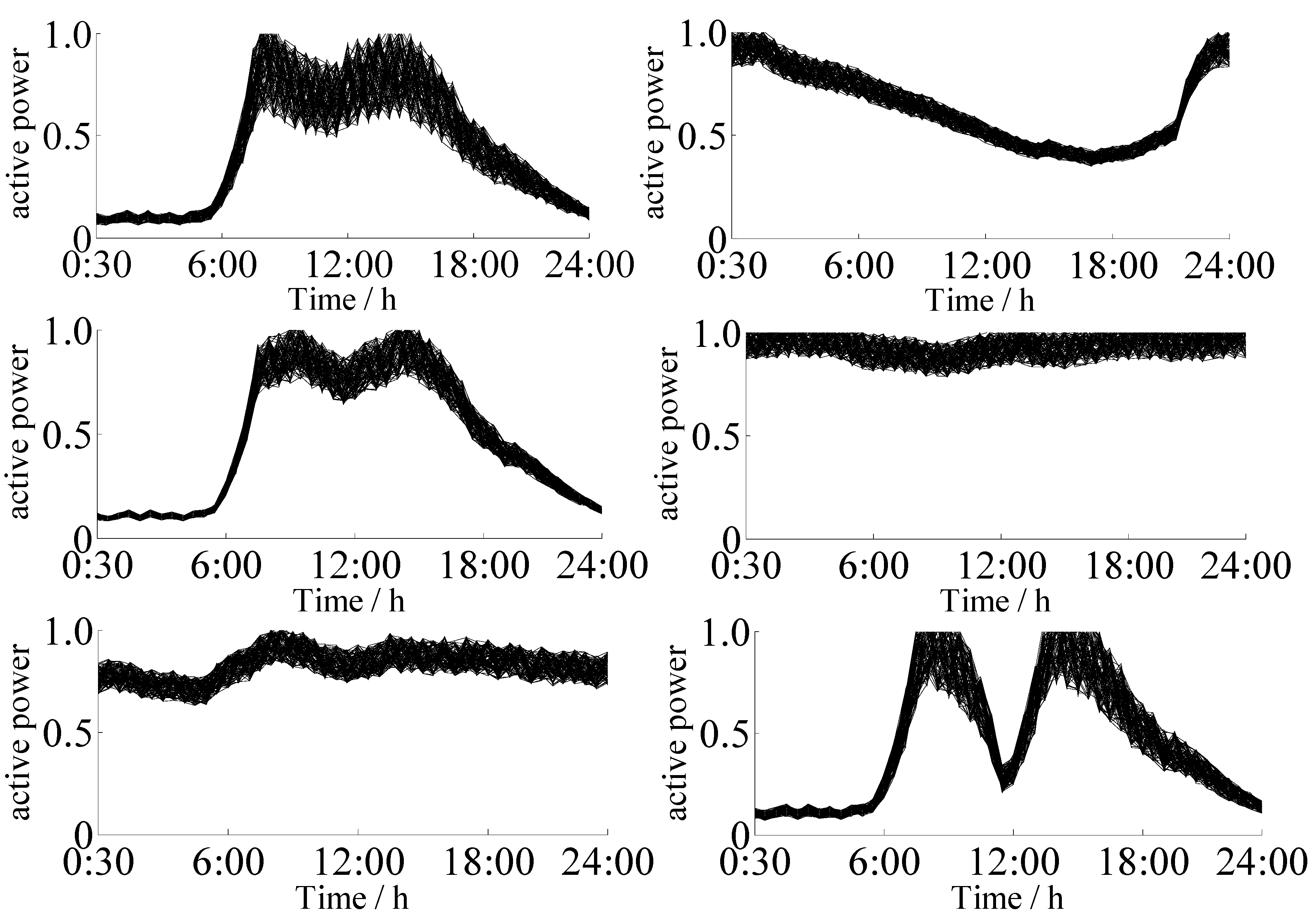
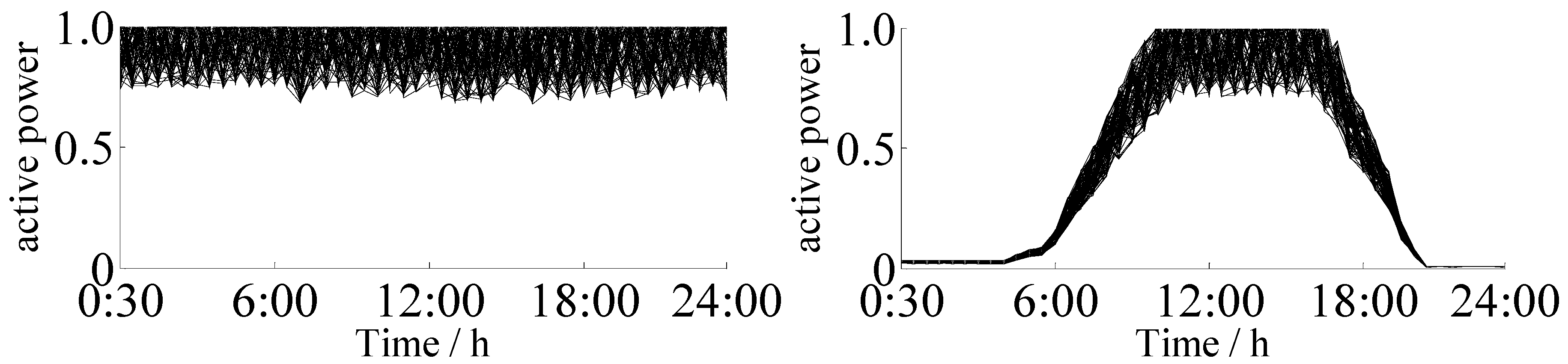
4.1. Clustering of Actual Daily Load Curves
4.2. Simulation Examples
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lu, S.; Fang, H.; Wei, Y. Distributed Clustering Algorithm for Energy Efficiency and Load-Balance in Large-Scale Multi-Agent Systems. J. Syst. Complex. 2018, 31, 234–243. [Google Scholar] [CrossRef]
- Xu, X.; Chen, W.; Sun, Y. Over-sampling algorithm for imbalanced data classification. J. Syst. Eng. Electron. 2019, 30, 1182–1191. [Google Scholar] [CrossRef]
- Qiang, C.; Xiuli, W.; Weizhou, W. Stagger peak electricity price for heavy energy-consuming enterprises considering improvement of wind power accommodation. Power Syst. Technol. 2015, 39, 946–952. [Google Scholar]
- Lin, R.; Wu, B.; Su, Y. An Adaptive Weighted Pearson Similarity Measurement Method for Load Curve Clustering. Energies 2018, 11, 2466. [Google Scholar] [CrossRef]
- Zhang, T.; Gu, M. Overview of Electricity Customer Load Pattern Extraction Technology and Its Application. Power Syst. Technol. 2016, 40, 804–811. [Google Scholar]
- Bu, F.; Chen, J.; Zhang, Q.; Tian, S.; Ding, J. A controllable and refined recognition method for load patterns based on two-layer iterative clustering analysis. Power Syst. Technol. 2018, 42, 903–913. [Google Scholar]
- Kim, N.; Park, S.; Lee, J.; Choi, J.K. Load Profile Extraction by Mean-Shift Clustering with Sample Pearson Correlation Coefficient Distance. Energies 2018, 11, 2397. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among clustering techniques for electricity customer classification. IEEE Trans. Power Syst. 2006, 21, 933–940. [Google Scholar] [CrossRef]
- Koivisto, M.; Heine, P.; Mellin, I.; Lehtonen, M. Clustering of connection point and load modeling in distribution systems. IEEE Trans. Power Syst. 2013, 28, 1255–1265. [Google Scholar] [CrossRef]
- Zhang, M.; Li, L.; Yang, X.; Sun, G.; Cai, Y. A Load Classification Method Based on Gaussian Mixture Model Clustering and Multi-dimensional Scaling Analysis. Power Syst. Technol. 2019. [Google Scholar] [CrossRef]
- Bin, Z.; Chijie, Z.; Jun, H.; Shuiming, C.H.; Mingming, Z.H.; Ke, W.; Rong, Z. Ensemble clustering algorithm combined with dimension reduction techniques for power load profiles. Proc. CSEE 2015, 35, 3741–3749. [Google Scholar]
- Ye, C.; Hao, W.; Junyi, S. Application of singular value decomposition algorithm to dimension-reduced clustering analysis of daily load profiles. Autom. Electr. Power Syst. 2018, 42, 105–111. [Google Scholar]
- Liu, S.; Li, L.; Wu, H.; Sun, W.; Fu, X.; Ye, C.; Huang, M. Cluster analysis of daily load profiles using load pattern indexes to reduce dimensions. Power Syst. Technol. 2016, 40, 797–803. [Google Scholar]
- Deng, Z.; Choi, K.S.; Chung, F.L.; Wang, S. Enhanced soft subspace clustering integrating within-cluster and between-cluster information. Pattern Recognit. 2010, 43, 767–781. [Google Scholar] [CrossRef]
- Huang, X.; Wang, C.; Xiong, L.; Zeng, H. A Weighting k-Means Clustering Approach by Integrating Intra-cluster and Inter-cluster Distances. Chin. J. Comput. 2019, 42, 2836–2848. [Google Scholar]
- Golub, G.; Loan, C. Matrix Computation; Johns Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Zhang, J.; Xiong, G.; Meng, K. An improved probabilistic load flow simulation method considering correlated stochastic variables. Int. J. Electr. Power Energy Syst. 2019, 111, 260–268. [Google Scholar] [CrossRef]
- Bezdek, J.C. A convergence theorem for the fuzzy ISODATA clustering algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 1980, 1, 1–8. [Google Scholar] [CrossRef]
- Selim, S.Z.; Ismail, M.A. K-means-type algorithms: A generalized convergence theorem and characterization of local optimality. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 81–87. [Google Scholar] [CrossRef]
- Al-Otaibi, R.; Jin, N.; Wilcox, T.; Flach, T. Feature Construction and Calibration for Clustering Daily Load Curves from Smart-Meter Data. IEEE Trans. Ind. Inf. 2016, 12, 645–654. [Google Scholar] [CrossRef]
- Li, Z.; Yuan, W.; Ren, C.; Huang, C.; Dong, X. Approximate computing method based on cross-layer dynamic precision scaling for the k-means. J. Xidian Univ. 2020, 47, 1–8. [Google Scholar]
- Liu, Y.; Liu, Y.; Xu, L. High-performance back propagation neural network algorithm for mass load data classification. Autom. Electr. Power Syst. 2018, 42, 131–140. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Best k | DBI | Running Time/s | |
|---|---|---|---|---|
| K-means | 5 | 0.574 | 1.283 | 61.32 |
| SVD-weighted K-means | 5 | 0.591 | 1.206 | 24.71 |
| KICIC | 5 | 0.609 | 1.127 | 45.83 |
| SVD-KICIC | 5 | 0.622 | 1.007 | 19.35 |
| r/% | SVD-KICIC | K-means | ||||
|---|---|---|---|---|---|---|
| Best k | Acc/% | Best k | Acc/% | |||
| 5 | 8 | 0.9516 | 100 | 8 | 0.9516 | 100 |
| 10 | 8 | 0.9233 | 100 | 8 | 0.9233 | 100 |
| 15 | 8 | 0.9085 | 100 | 8 | 0.8536 | 94.30 |
| 20 | 8 | 0.8860 | 100 | 8 | 0.8033 | 91.16 |
| 25 | 8 | 0.8649 | 100 | 7 | 0.7294 | 89.56 |
| 30 | 8 | 0.8327 | 99.85 | 7 | 0.6697 | 88.34 |
| 35 | 7 | 0.7638 | 90.63 | 7 | 0.6185 | 80.16 |
| 40 | 7 | 0.6079 | 78.41 | 6 | 0.5839 | 69.83 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, J.; Yao, G.; Xu, X.; Wei, K. Method for Clustering Daily Load Curve Based on SVD-KICIC. Energies 2020, 13, 4476. https://doi.org/10.3390/en13174476
Zhang Y, Zhang J, Yao G, Xu X, Wei K. Method for Clustering Daily Load Curve Based on SVD-KICIC. Energies. 2020; 13(17):4476. https://doi.org/10.3390/en13174476
Chicago/Turabian StyleZhang, Yikun, Jing Zhang, Gang Yao, Xiao Xu, and Kewen Wei. 2020. "Method for Clustering Daily Load Curve Based on SVD-KICIC" Energies 13, no. 17: 4476. https://doi.org/10.3390/en13174476
APA StyleZhang, Y., Zhang, J., Yao, G., Xu, X., & Wei, K. (2020). Method for Clustering Daily Load Curve Based on SVD-KICIC. Energies, 13(17), 4476. https://doi.org/10.3390/en13174476