1. Introduction
The stability of electrical grids depends on the balance between electricity generation and electricity demand. In conventional power systems, such a balance is achieved through demand-driven electricity production. Nowadays, however, due to a gradual shift from fossil-based power generation to renewable energy sources, the grid topologies are becoming more decentralized and the flow of power is becoming more bidirectional [
1]. That means that consumers may function as both producers and consumers at the same time; they are often referred to as prosumers [
2]. The volatile and fluctuating nature of renewable energy sources poses a significant challenge as far as design strategies and control of electric power grids are concerned. In order to balance the supply and demand in such fluctuating power grids, various smart grid approaches have been proposed. A key idea they implement is to regulate the consumers’ demand [
3], usually referred to as the demand response strategy [
4,
5].
The changes in the consumption of electricity (in comparison with normal patterns of consumption) by customers in reaction to the changes in the price of electricity are referred to as demand response. There are two general approaches to defining the electricity price and to communicating it to consumers. A conventional approach—using costly information and communication technology infrastructure [
6] is based on extensive communication between producers and consumers [
7,
8], raising questions, however, of cybersecurity and privacy protection [
9,
10]. In contrast, an alternative and novel approach referred to as decentral smart grid control (henceforward DSGC) [
11] avoids massive communication between prosumers by binding the electricity price to the grid frequency which can be easily measured by means of cheap equipment by particular prosumers. During power excess, the frequency increases, whereas in times of underproduction, it decreases [
12]. In that way, DSGC introduces real-time pricing allowing prosumers to easily control their momentary demand on the basis of the grid frequency. For DSGC systems to be successfully applied, they must be able to maintain grid stability for rapid changes in electricity prices and for different levels of reaction times and price sensitivity of particular grid participants [
13,
14].
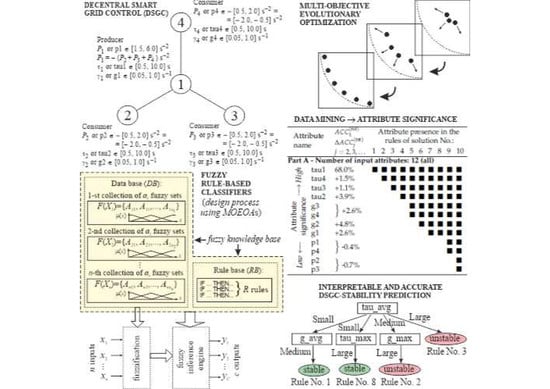
Data mining approaches are well suited for decision support in management, control, and stability analysis of power systems including also decentralized smart grids. That is due to the availability of big amounts of simulated data on various aspects of the power systems operation; see, e.g., [
15,
16,
17,
18]. Many data mining methods have been used in the considered research field—see the next section for a brief review. However, their significant shortcoming is usually their non-transparent, black-box, and accuracy-only-oriented nature. It means that they do not provide any deeper (or any) explanations and justifications of the decisions made. As well, they do not provide any insight into mechanisms governing a given system. A similar remark has been formulated in the most recently published work [
19]: "Various machine-learning and data-mining algorithms have been applied to the decentralized management and control of microgrids... Transparency is typically not the priority for most machine learning algorithms" (a quote from [
19]). The present work is our attempt to address the smart-grid-stability prediction problem in an effective way by providing a solution coming from the knowledge-based data-mining field and characterized by both high interpretability and transparency and high accuracy.
The main goal and contribution of this work is the application of our knowledge-based data-mining technique, i.e., fuzzy rule-based classifiers (FRBCs) with a genetically optimized interpretability-accuracy trade-off (see, e.g., [
20,
21,
22,
23] for details) to transparent and accurate prediction of DSGC stability. In particular, we aim at uncovering the hierarchy of influence of particular input attributes upon the DSGC stability. Moreover, we will also analyze the effect of possible “overlapping” of some input attributes over the other ones from the DSGC-stability perspective. In our approach to designing FRBCs from data, measures of FRBCs’ interpretability and accuracy are treated as separate performance indices and optimization objectives. Due to their complementary/contradictory nature, we employ multi-objective evolutionary optimization algorithms (MOEOAs) in the process of the FRBCs’ structure and parameter optimization which is also equivalent to the FRBC’s interpretability-accuracy trade-off optimization (related work is reviewed in [
24] and—for the case of single-objective optimization of the system—in [
25,
26]).
The remaining parts of the paper are organized as follows: We start with a review of related work regarding applications of data mining techniques to various aspects of electricity grid and microgrid operations. Next, the recently published
Electrical Grid Stability Simulated Data Set available at the UCI Database Repository (
https://archive.ics.uci.edu/ml) and its input-aggregate-based concise version proposed in [
14] are characterized. Both data sets are used in our experiments. Then, main building blocks of our FRBCs are presented. Next, the FRBCs’ learning and optimization process is outlined. Two MOEOAs are independently used and compared; namely, the well-known strength Pareto evolutionary algorithm 2 (SPEA2) [
27] and our generalization of SPEA2, referred to as SPEA3 [
28,
29,
30]. In turn, the previously outlined main goal of the paper, including the application of our approach to the DSGC-stability prediction using two aforementioned simulated data sets and a comparative analysis with as many as 39 alternative approaches, is presented and discussed.
2. Related Work
Various data-mining and machine-learning models and algorithms have been applied to security, stability prediction/monitoring, management, and control of electricity grids and microgrids. An approach using an artificial neural network (ANN for short) for generating security boundaries and their visualization to transmission system operators within a power system in California is presented in [
15]. The resulting security boundaries are visualized in the form of the so-called nomograms (the total number of simulations performed is equal to 1792). Extreme learning machines (ELMs for short)—a special class of ANNs—are used in [
31] to improve the online learning speed and parameter tuning of the real-time transient-stability assessment model for earlier detection of the risk of blackouts. ANNs are also used to construct new monitoring methods for smart power grids. Such a method and a virtual test evaluating its performance are presented in [
32]. A multilayer ANN with four hidden layers trained using a deep reinforcement learning algorithm is applied to a smart grid optimization task in [
33]. In turn, a contextual anomaly detection ANN-based approach for cyber-physical security in smart grids is presented in [
34]. The simulation experiments show that the contextual anomaly detection performs over 55% better than the point anomaly detection.
Support vector machines (SVMs for short) and ANNs supported by some feature selection methods are applied in [
17] to the analysis of the transient stability of a large-scale Brazilian power system (the data are generated in 1242 simulation runs). SVMs and random forests (RFs for short) are used in [
35] to detect smart grid devices compromised by cyber attacks. The proposed framework in different evaluation scenarios yields high accuracy (91% on average) which confirms its effectiveness at overcoming the compromised smart grid devices problem. Core vector machines (CVMs for short)—faster and big-data-oriented extensions of SVMs—are used in [
36] for an online transient stability assessment of a power system by mapping that problem as a two-class classification task. An online approach makes it attractive to be used in real time applications. Genetic-algorithm-based SVMs (GA-SVMs for short) are used (and compared with conventional SVMs and ANNs) in [
37] for an online voltage-stability monitoring and prediction. Their effectiveness is demonstrated by applying them to the New England 39-bus system and to the real Indian Northern Region Power Grid system.
Decision trees (DTs for short) are used (and compared with ANNs and SVMs) in [
18] for prediction of the transient instability of a large-scale Iranian national grid following the test on a small 9-bus system. DTs are also used in [
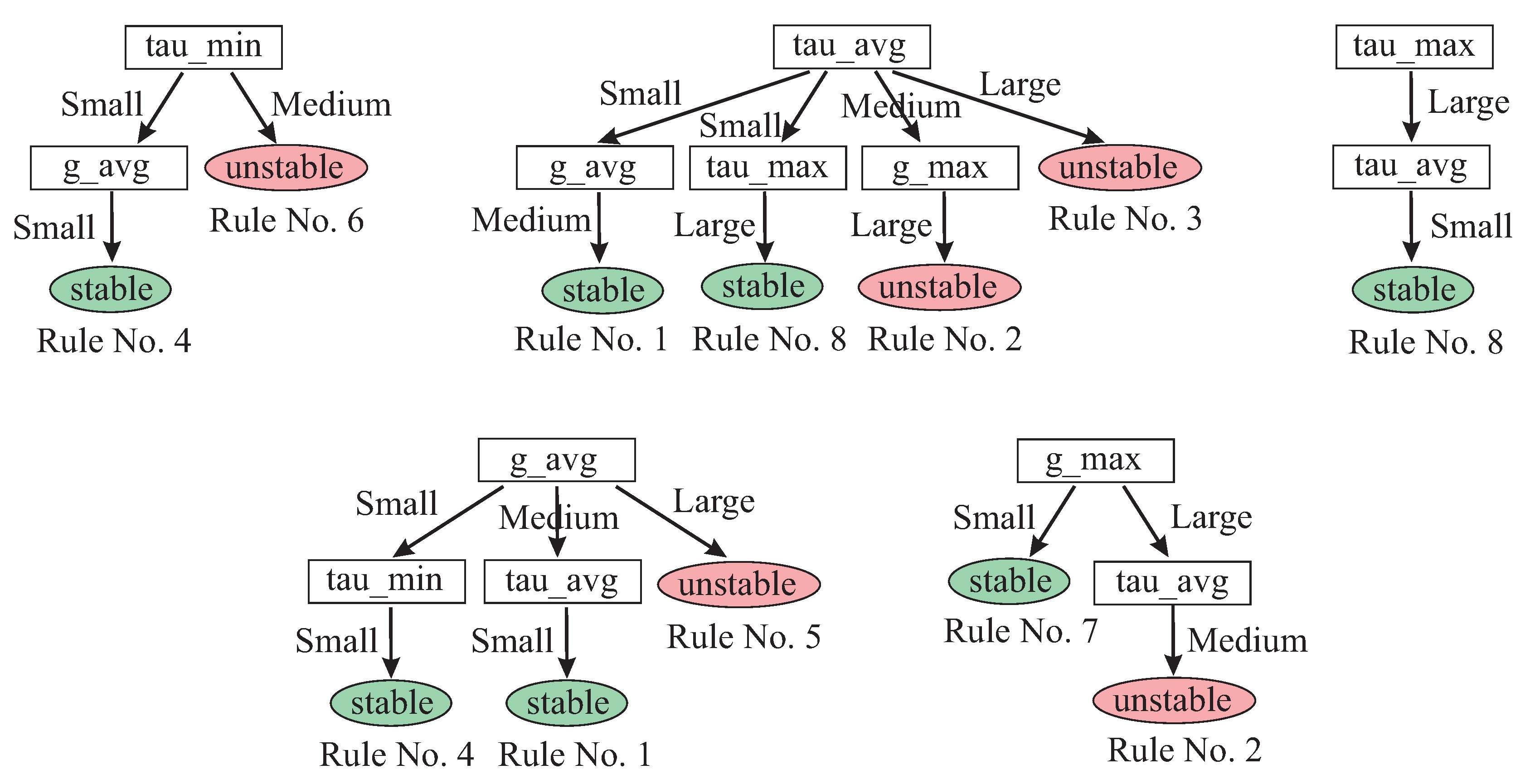
14] to classify the DSGC stability conditions based on the response of heterogeneous consumers to provide some insight into the relationship between the input space parameters and the grid stability.
As far as other selected data-mining techniques are concerned, the so-called active learning solution is applied in [
38] to the voltage-stability prediction problem. The active learning approach interacts with the online prediction and offline training process to enhance the well-known data-mining methods (DTs, ANNs, SVMs, RFs, and radial basis function networks). In turn, modeling a non-linear security boundary by (i) using features formed as monomials of the original input up to a certain level and (ii) using kernel ridge regression to solve the problem of a large number of features is proposed in [
16]. The potential of the proposed method is demonstrated by simulating the aforementioned New England 39-bus system and a larger power system with 470 buses. Next, the study [
39] presents a cooperative multi-agent approach for solving the complex problems of energy management in a stand-alone solar microgrid using fuzzy logic systems and a reinforcement learning method referred to as fuzzy Q-learning. Moreover, the study [
19] applies an optimized data-matching algorithm referred to as transparent open box learning network to the DSGC stability prediction. This study demonstrates the importance of compound feature selection in the considered stability prediction problem. The overwhelming majority of the above-listed studies presents the accuracy-oriented approaches. The transparency is not their priority and they usually do not provide an insight into the considered systems.
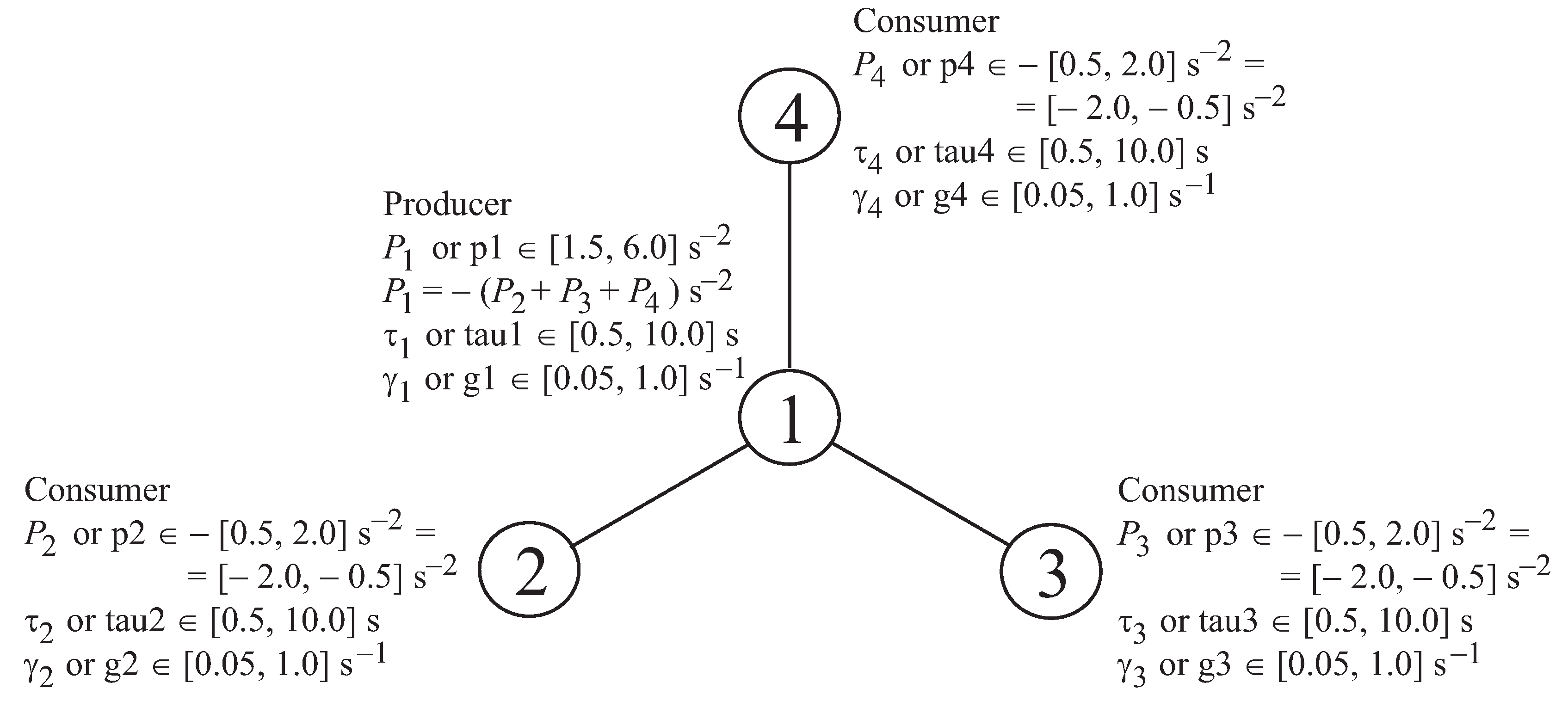
3. Electrical Grid Stability Simulated Data Set and Its Input-Aggregate-Based Version for Stability Prediction of a Four-Node Star System Implementing the DSGC Concept
As already mentioned in the Introduction of this paper, the
Electrical Grid Stability Simulated Data Set available since November 2018 at the UCI Database Repository (
https://archive.ics.uci.edu/ml) is the first set used in our experiments. This data set is the outcome of a simulation experiment using a two-part mathematical model of a four-node star grid implementing the DSGC concept. The first part of the model describes the physical dynamics of electric power generation and its connection with consumption loads. The second part is an economic structure which binds the electricity price to the grid frequency (see [
11,
13,
14,
19] for details). In the simulation experiment, three key input variables of the model were selected (each allowed to vary independently) for each of the four grid participants. These key input variables include: (i)
,
(referred to as p1, ..., p4 in the simulated data set) describing the mechanical power produced (for
) or consumed (for
); (ii)
,
(referred to as tau1, ..., tau4 in the simulated data set) describing reaction time of each grid participant to an electricity price change; and (iii)
,
(referred to as g1, ..., g4 in the simulated data set) which is a coefficient proportional to price elasticity for each grid participant.
Figure 1 illustrates the structure of the DSGC system considered in the simulation experiment and the feasible solution space values (boundary conditions) for all the previously listed key input variables. Except for
(
as shown in
Figure 1), they all are sampled as uniform distributions throughout their respective feasible spaces to initialize and launch the simulations (10000 simulation runs were performed). Several other input variables of the two-part mathematical model of the DSGC system are kept unchanged during the simulation process. They include: (i) the averaging time
T required to measure the price signal (
), (ii) the coupling strength
K proportional to line capacity (
), and (iii) the damping constant
(
). The model’s output variable (referred to as stab in the simulated data set), i.e., the stability metric (ranging from −0.0808 to +0.1094), is quantified such that a negative value of that metric indicates that the grid is stable, whereas a positive value indicates that the grid is unstable. In the simulated data set the stab-variable is accompanied by a stabf label of the grid stability—a categorical attribute taking values from a two-element set: “stable” for stab < 0 and “unstable” for stab > 0. The details regarding the simulation experiment are presented in [
14].
Therefore, the characteristics of the
Electrical Grid Stability Simulated Data Set collecting the simulation experiment results and used in our experiments is the following. It contains 10,000 records (instances). Each record is characterized by 12 input attributes—tau1, tau2, tau3, tau4, p1, p2, p3, p4, g1, g2, g3, and g4; and two output attributes—stab and stabf, out of which only the stabf labels are used in our experiments (see
Table 1 for details).
A more concise representation of the above-characterized simulated data set is proposed in [
14]. It is based on aggregates—such as minimum, maximum, and average (mean) values—of input attributes across all grid participants. For instance, for the reaction time
,
, the input aggregates are the following:
,
, and
. In the modified simulated data set, they are referred to as tau_min, tau_avg, and tau_max; analogously—p_min, p_avg, and p_max for
and g_min, g_avg, and g_max for
,
(see
Table 2 for details). The modified data set (referred to as the
Concise Simulated Data Set) is the second set used in our experiments.
4. Methodology: Main Components of the Proposed FRBCs Designed from Data Using MOEOAs
In this section we briefly present the main components of our approach to designing FRBCs from data by means of MOEOAs. They are used to perform FRBCs’ learning and structure-and-parameter optimization, which also results in the optimization of FRBCs’ interpretability-accuracy trade-off (see [
20,
21,
22,
28] for details and discussion). The following components are characterized: learning data set, representation of input attributes and class labels, FRBC knowledge base, objectives of the FRBCs’ evolutionary optimization, original dedicated genetic operators introduced, and MOEOAs used in our experiments. An FRBC with
n input attributes
and an output—a fuzzy set over the set
of
c class labels—is considered. Our approach can process both numerical and categorical attributes. However, in the DSGC-stability prediction problem, only numerical attributes occur. Hence, only numerical attributes will be considered from now on.
Learning data set L: The construction of the proposed FRBC is based on the data set
L which contains
K input–output samples:
where
(× stands for Cartesian product of ordinary sets) represents the collection of input attributes and
represents the corresponding class label (
) for the
k-th data sample,
.
Representation of input attributes and class labels: Each numerical attribute
,
is represented by
fuzzy sets
,
, where
is a family of all fuzzy sets defined in the universe
,
.
represents an
S-type fuzzy set (corresponding to linguistic term “
Small”),
represents an
L-type set (corresponding to linguistic term “
Large”), and
represent
M-type sets (corresponding to linguistic terms “
Medium 1,’ “
Medium 2,’ ... , “
Medium ”). For simplicity,
s denote the corresponding linguistic terms also.
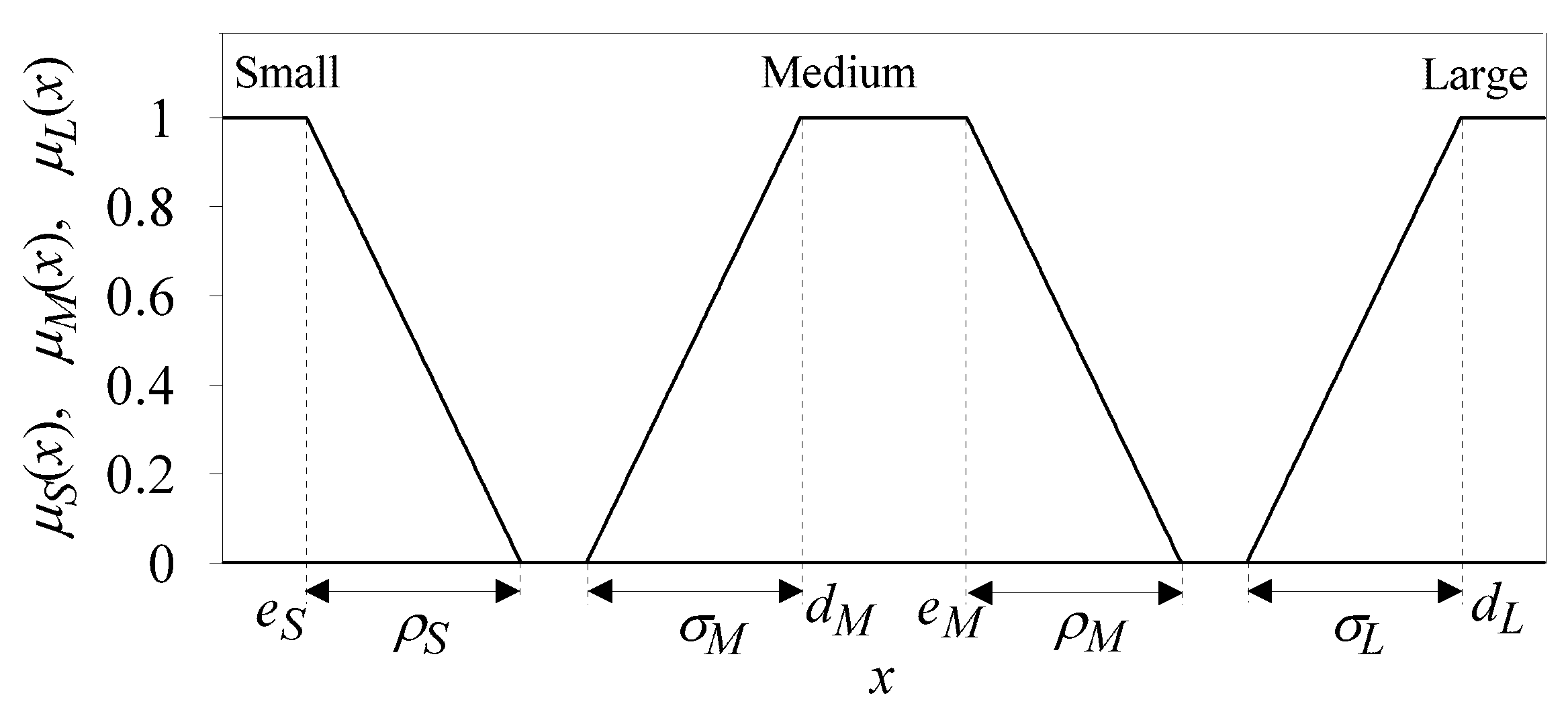
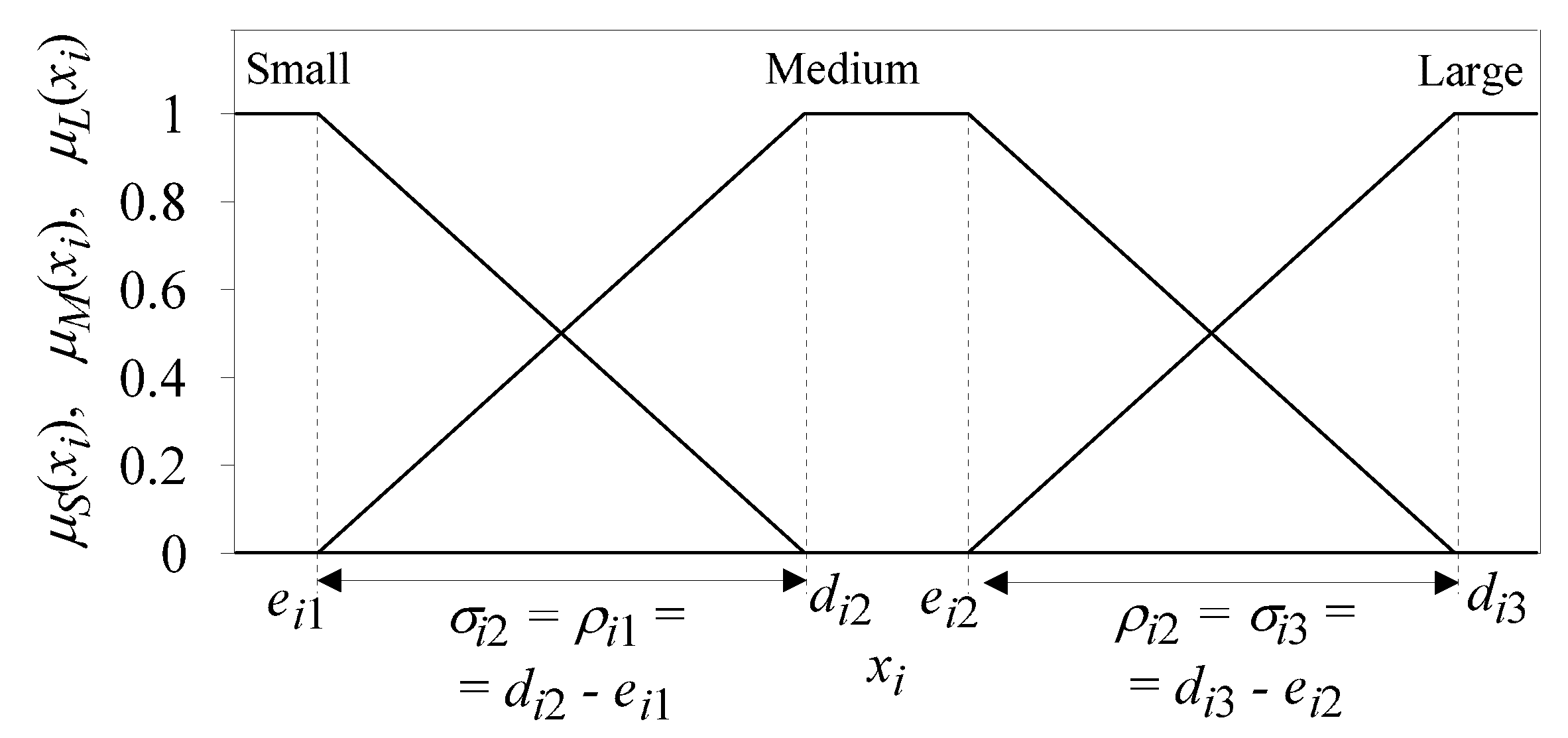
Figure 2 shows trapezoidal membership functions for
S,
M, and
L-type fuzzy sets used in our experiments. In turn, each class label
,
is represented by a fuzzy singleton
with the following membership function:
for
and 0 elsewhere.
FRBC’s knowledge base contains
R genetically optimized fuzzy rules discovered in the learning data set (
1). The form of the
r-th rule,
, is the following (the overall number of rules
R changes as the learning progresses):
Formula
in (
2) represents conditional inclusion of the
-part into a given rule assuming that the (
)-part is fulfilled. In turn,
denotes a switch-parameter which controls the presence/absence of the
i-th input attribute in the
r-th rule,
.
, where is the number of fuzzy sets (and the corresponding linguistic terms) defined for the i-th attribute. For , the i-th attribute is removed from (not active in) that rule, whereas for the component () is included (active) in that rule.
An FRBC’s knowledge base contains two separate modules; i.e., a rule-base-structure module RB and a data-base module DB. We propose a simple, direct, and thus computationally efficient RB representation as follows:
In turn, DB contains tunable and non-tunable parts. The tunable part contains parameters of membership functions of fuzzy sets representing particular numerical input attributes. These parameters—subject to tuning during the FRBCs’ learning and MOEOA-based optimization—include (see
Figure 2):
and
for S-type fuzzy sets;
,
,
, and
for M-type fuzzy sets; and
and
for L-type fuzzy sets. The non-tunable part of DB contains the set of class labels
.
Objectives of the FRBC’s evolutionary optimization: Two separate optimization objectives are considered; i.e., the accuracy and the interpretability of the system. The FRBC’s accuracy measure (subject to maximization) is defined as follows [
20,
21,
22,
40]:
where
is the membership function of fuzzy set
, which is a response of system (
2) for the learning data sample
. In turn,
(equal to 1 for
and to 0 elsewhere) is the membership function of fuzzy singleton
, which is the desired fuzzy-singleton response for that sample (
).
As far as the FRBC’s interpretability is concerned, we use the notion of interpretability in a broader sense, which includes two essential aspects; i.e., the FRBC’s complexity and semantic aspects of the FRBC’s operation. We evaluate the FRBC’s complexity-related interpretability using the following measure (subject to maximization):
where
and
The FRBC’s complexity measure
(
7) takes its values from interval [0, 1], where 0 represents the minimal complexity and 1 the maximal one.
is an average of three sub-measures that evaluate: (i) an average complexity of particular rules
(
8) (
in (
8) denotes the number of active input attributes in the
r-th rule); (ii) the complexity of the whole system in terms of its active inputs
(
8) (
in (
8) denotes the number of active inputs in the whole system); and (iii) the whole-system complexity in terms of its active fuzzy sets
(
8) (
in (
8) denotes the numbers of active fuzzy sets (linguistic terms) in the whole system).
The FRBC’s semantics-related interpretability is addressed by us by imposing—as optimization constraints—the so-called strong fuzzy partitions (SFPs) [
41] upon domains of particular numerical attributes. SFPs are special class of fuzzy partitions; namely, for any domain value, the sum of the values of all membership functions constituting SFP is equal to 1. It can be shown [
41] that SFPs satisfy the desired demands regarding the semantics-related interpretability. Straightforward implementation of SFP requirements for the case of trapezoidal membership functions can be formulated in the following way (see
Figure 3 for illustration of the SFP-requirements’ implementation for the three-set SFP of
-domain):
and, obviously,
Original, dedicated genetic operators introduced: A population of FRBC’s knowledge bases (each represented by its RB and DB) is processed during the genetic learning process. We developed original crossover and mutation operators for the transformation of the RB population. The crossover operator processes two individuals (i.e., two RBs) containing and fuzzy rules, respectively, by performing one sub-operation randomly selected from the set of five sub-operations referred to as Cro-RB1, Cro-RB2, ..., Cro-RB5. They are defined as follows:
Cro-RB1 (labeled as “exchange of many fuzzy rules”) operates in two stages. First, for the r-th rule in both RBs, , a random-switch condition (equivalent to the random selection of 1 from the set {0, 1}) is checked. Then, the r-th rules from both RBs are exchanged, provided that the random-switch condition is fulfilled. Second, each of the remaining rules of the larger RB is moved to the smaller RB, provided that its random-switch condition is fulfilled.
Cro-RB2 (labeled as “exchange of a single fuzzy rule”) is similar to Cro-RB1 but the Cro-RB1 activities are carried out unconditionally and only once for randomly selected single rule from the larger RB.
Cro-RB3 (labeled as “exchange of many fuzzy sets in many fuzzy rules”) is analogous to the first stage of Cro-RB1. This time, the random-switch condition is run for each input attribute and for the output class label from the corresponding rules coming from both RBs. Fuzzy sets describing a given input attribute or class label in both RBs are exchanged provided that their random-switch conditions are fulfilled.
Cro-RB4 (labeled as “exchange of many fuzzy sets in a single fuzzy rule”) performs the activities of Cro-RB3 unconditionally and only once for a randomly selected single rule from the first RB and its counterpart from the second RB.
Cro-RB5 (labeled as “exchange of a single fuzzy set”) is a special case of Cro-RB4. The activities of Cro-RB4 are performed unconditionally and only once for a randomly selected input attribute or output class label.
The mutation operator for the RB transformation processes a single individual (i.e., a single RB) by performing one sub-operation randomly selected from the set of four sub-operations referred to as Mut-RB1, Mut-RB2, Mut-RB3, Mut-RB4. They are defined as follows:
Mut-RB1 (labeled as “fuzzy rule insertion”) inserts into RB a new fuzzy rule (
2) with randomly selected values of switches
(
,
) and class label
(
).
Mut-RB2 (labeled as “fuzzy rule deletion”) removes a randomly selected fuzzy rule from the RB.
Mut-RB3 (labeled as “change a single fuzzy set”) randomly selects one fuzzy rule from the RB and its one i-th input attribute or output class label j. Next, it randomly selects a new value of its switch or class label j.
Mut-RB4 (labeled as “change of an input in a fuzzy rule”) randomly selects: (i) one fuzzy rule from the RB, (ii) its one active input attribute (i.e., with ), and (iii) its one non-active input attribute (i.e., with ). Then, the first attribute is set to be non-active (i.e., ) and the second attribute—to be active (i.e., ) in that rule.
The crossover and mutation operators for the RB-population transformation are followed by three RB-repairing operators. The first operator removes “empty” fuzzy rules, i.e., the rules with all non-active input attributes (with for ), whereas the second one removes rule duplicates. In turn, the third operator adds—for each class label that is currently not represented in RB—one fuzzy rule with that class label (in order to preserve the principle “at least one fuzzy rule per class in RB”).
DB population transformation is performed by means of separate genetic operators. The crossover operator (processing two individuals; i.e., two DBs), randomly selects one fuzzy set from each DB. New values of
d and
e-parameters, which characterize membership functions of both fuzzy sets (see
Figure 2) are calculated as linear combinations of their old values from both sets; they also must fulfill condition (
10). New values of
and
-parameters are calculated from (
9) using new values of
d and
e-parameters. The mutation operator (processing a single individual, i.e., a single DB) randomly selects one fuzzy set from the DB and one of its two parameters
d and
e (say,
d is selected). Its new value
, where
returns a random number from the assumed interval and
is a range of the domain of the selected set. New values of
and
-parameters are calculated from (
9).
MOEOAs used in our experiments: The performances of different MOEOAs are usually evaluated and compared in terms of three aspects [
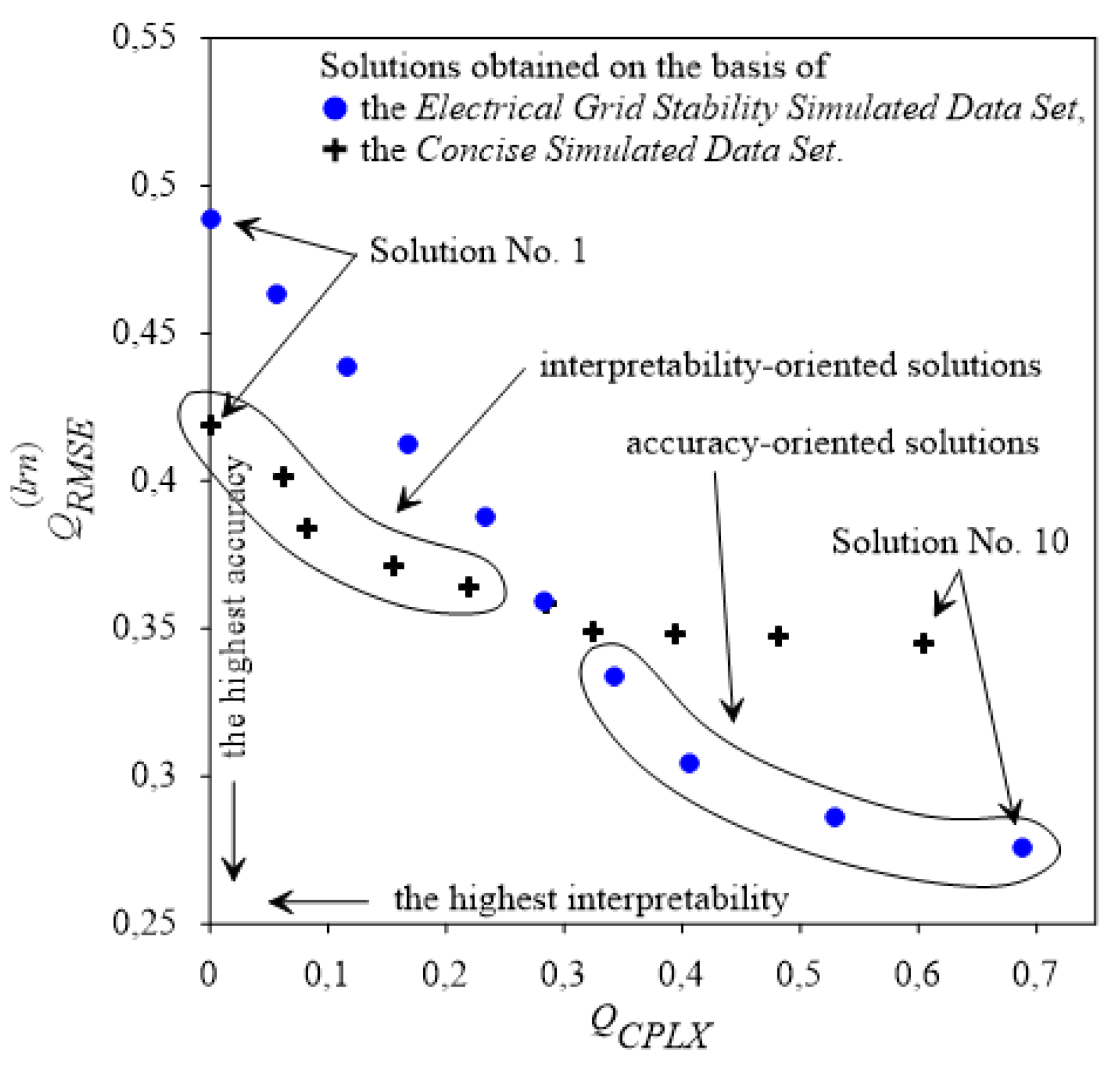
42]. First, the accuracy of generated non-dominated solutions is considered. The accuracy represents the closeness of those solutions to either the Pareto-optimal solutions, or if they are not available, to reference solutions. Second, the spread of the solution set is investigated; i.e., how well these solutions arrive at the extrema of the Pareto-optimal or reference solution sets. The spread is usually represented by the distance between the extreme solutions in the set. Third, the distribution of the solutions in the set, i.e., how evenly distributed they are along the approximation of Pareto-optimal front in the objective space, is considered. A set of solutions which are more accurate and are characterized by a higher spread and a better-balanced distribution outperforms the alternative solution sets.
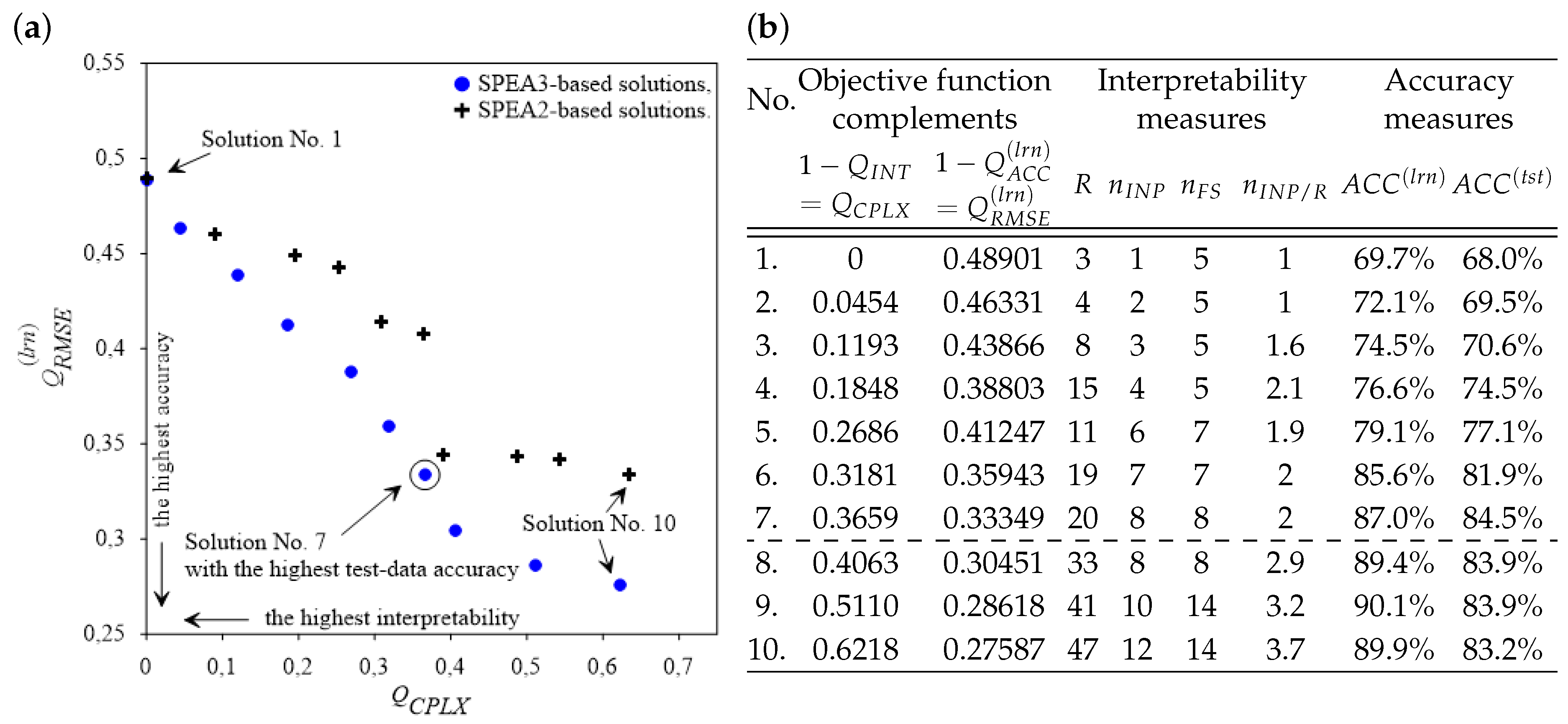
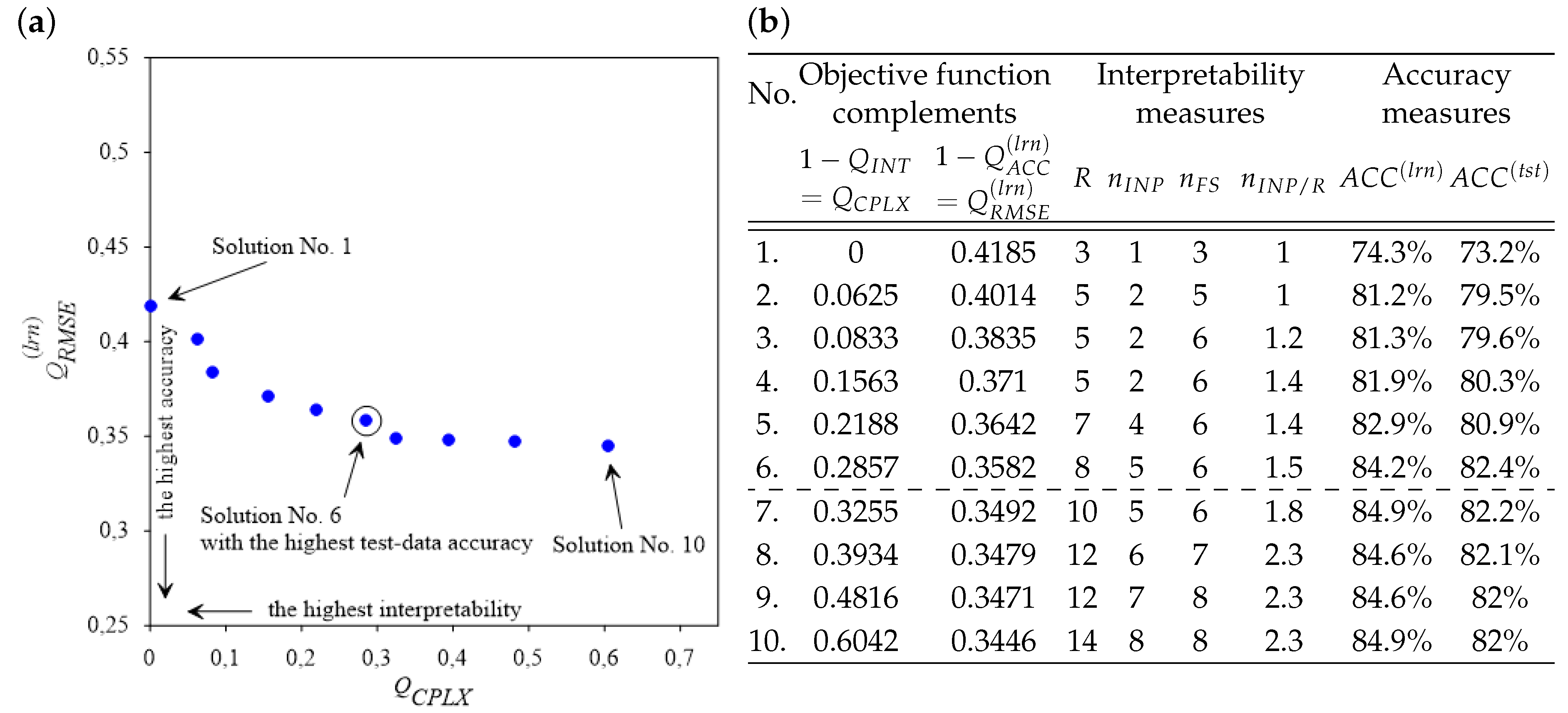
For the purpose of comparison, two MOEOAs are used in experiments reported in this work; i.e., the well-known SPEA2 method and our generalization of SPEA2, referred to as SPEA3. In comparison with SPEA2, the proposed SPEA3 approach generates sets of non-dominated solutions characterized by higher spread and a more even distribution in the objective space. The essence of the proposed SPEA2’s generalization consists of replacing its environmental selection procedure with our original algorithm, which improves both the spread and distribution balance of generated solutions. The environmental selection consists of selecting a representation of the best solutions from all solutions obtained so far and keeping them in an external archive of a fixed size. In SPEA2 all non-dominated solutions from the archive and the current population are copied to the next-generation archive (to fill the archive, the best dominated solutions are copied to it). In the case of overfilling the archive, a truncation procedure is run to reduce the archive size to the predefined level. Thus, only the truncation procedure (if activated) contributes to improving the distribution balance and diversity of the final set of solutions. On the contrary, the proposed environmental selection algorithm implemented in SPEA3 is fully-oriented towards achieving these goals. The archive is iteratively increased by gradual adding of carefully selected non-dominated solutions from the current population (in each subsequent generation, a single solution characterized by possible longest and similar distances to its near neighbors is added). Then, a process of relocation of particular archived solutions aiming at increasing average distances between solutions and their nearest neighbors is carried out. Said relocation is performed by gradual replacement of archived solutions by new solutions selected from the population in such a way as (i) to maximize the distances between extreme solutions (which results in improving the spread of solutions) and (ii) to minimize the distance differences between neighboring solutions (which results in improving the distribution of solutions). Concluding, in our approach, the complementary operations of increasing and reducing the archive aim at obtaining the best available distribution balance and spread of solutions belonging to Pareto-front approximation (see [
28,
29] for detailed presentation and discussion).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}























