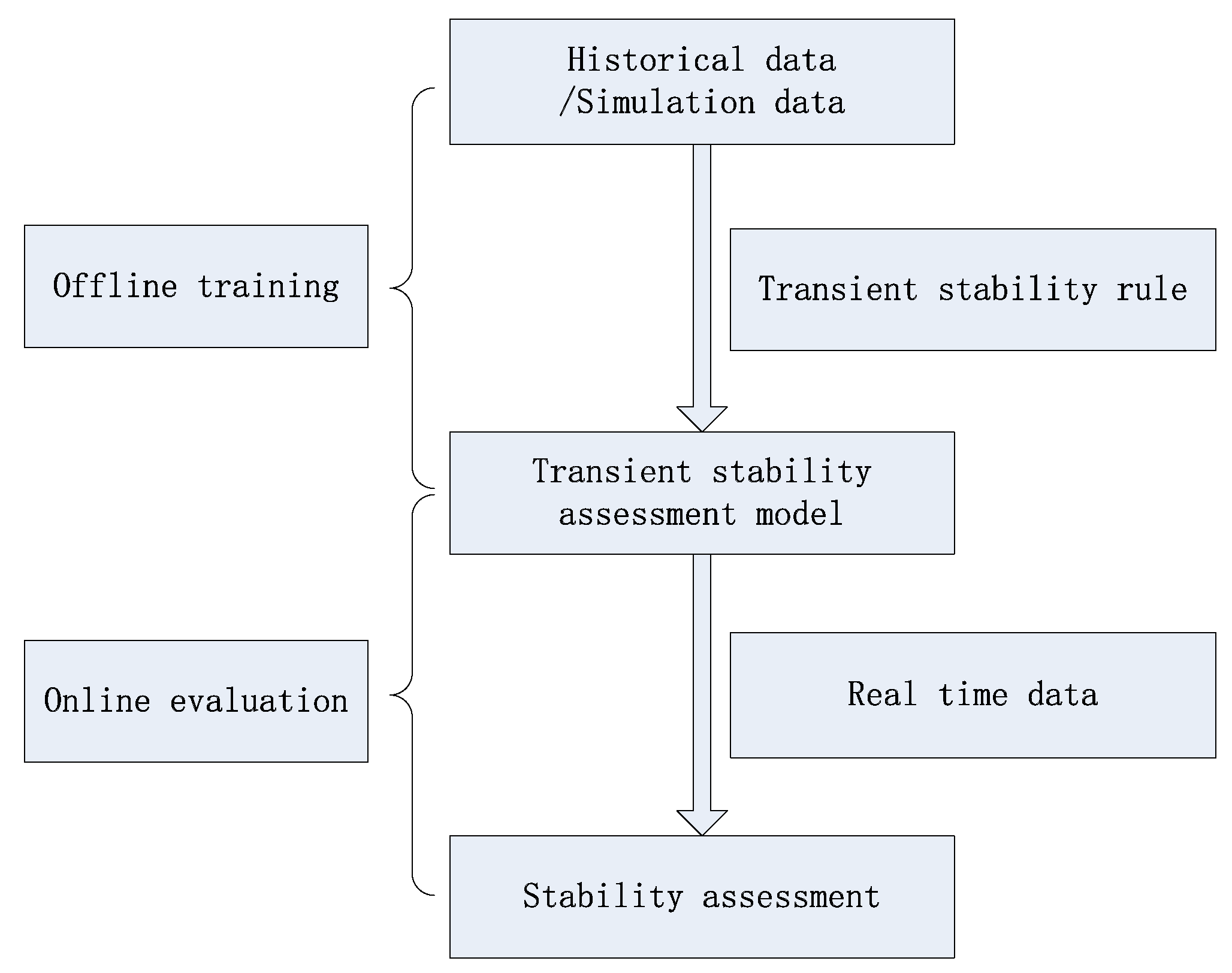
4.1. Experimental Results and Analysis
According to
Section 2.2, we select
and
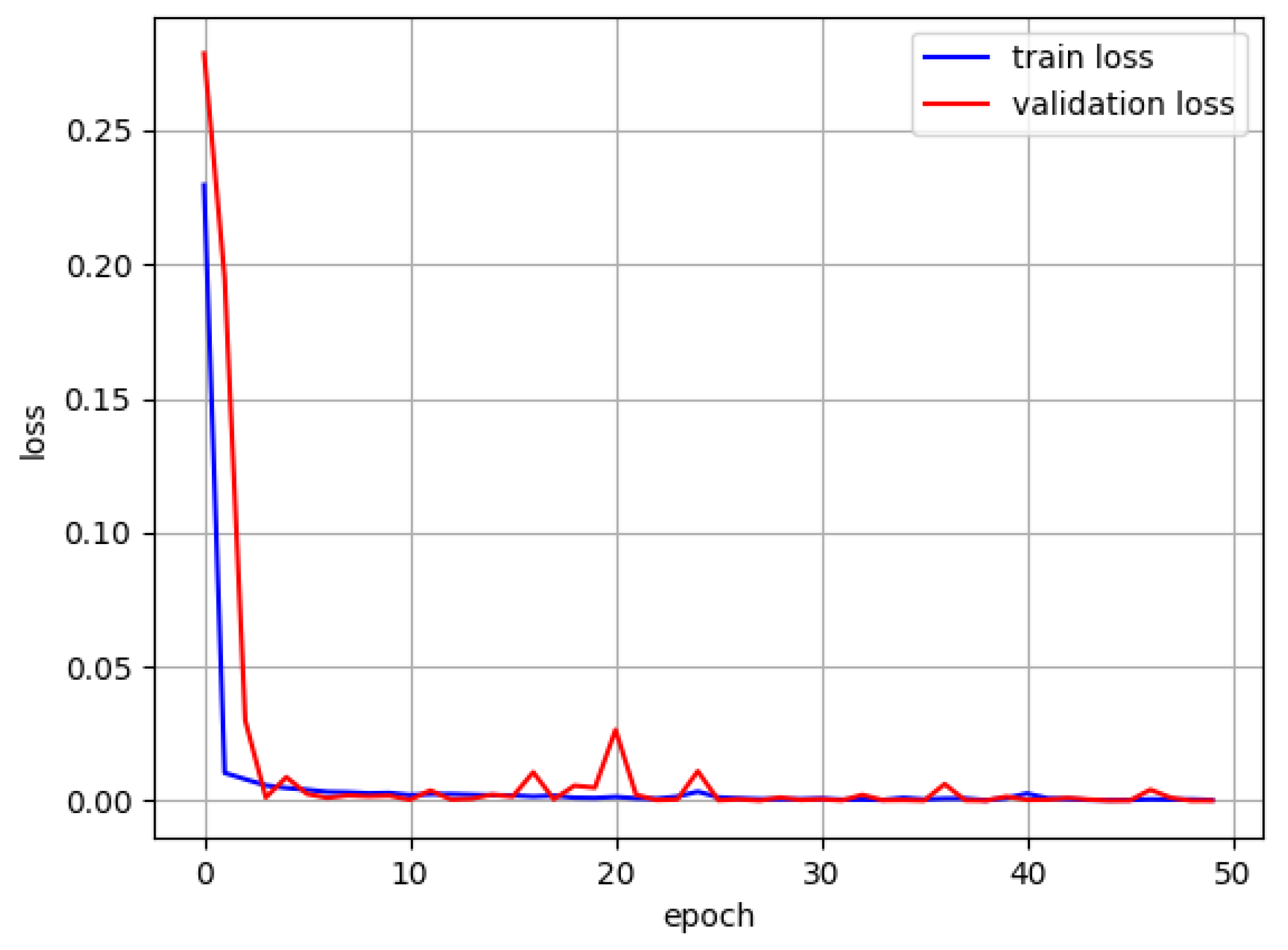
. The loss value curve of the experimental results is shown in
Figure 4.
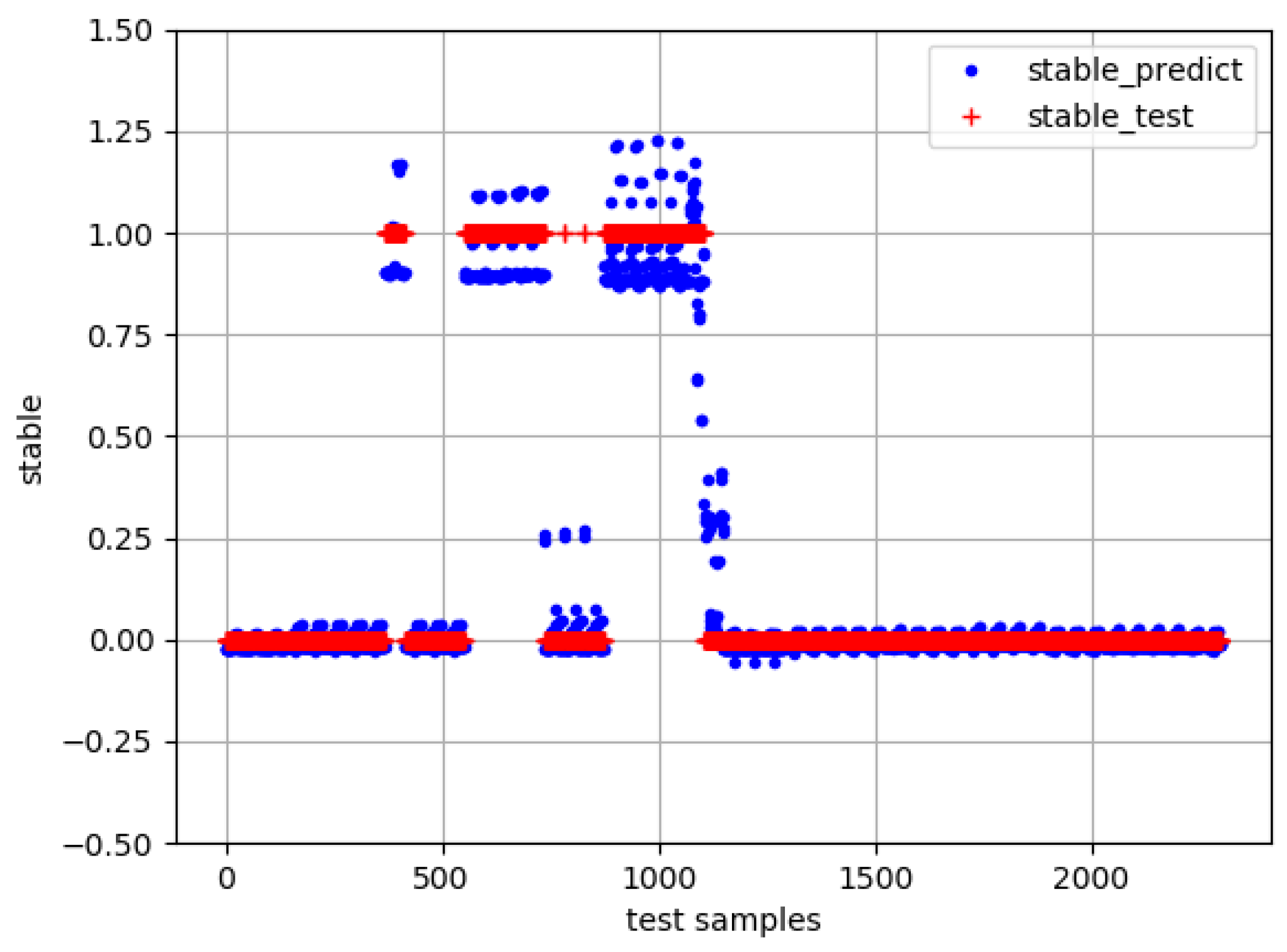
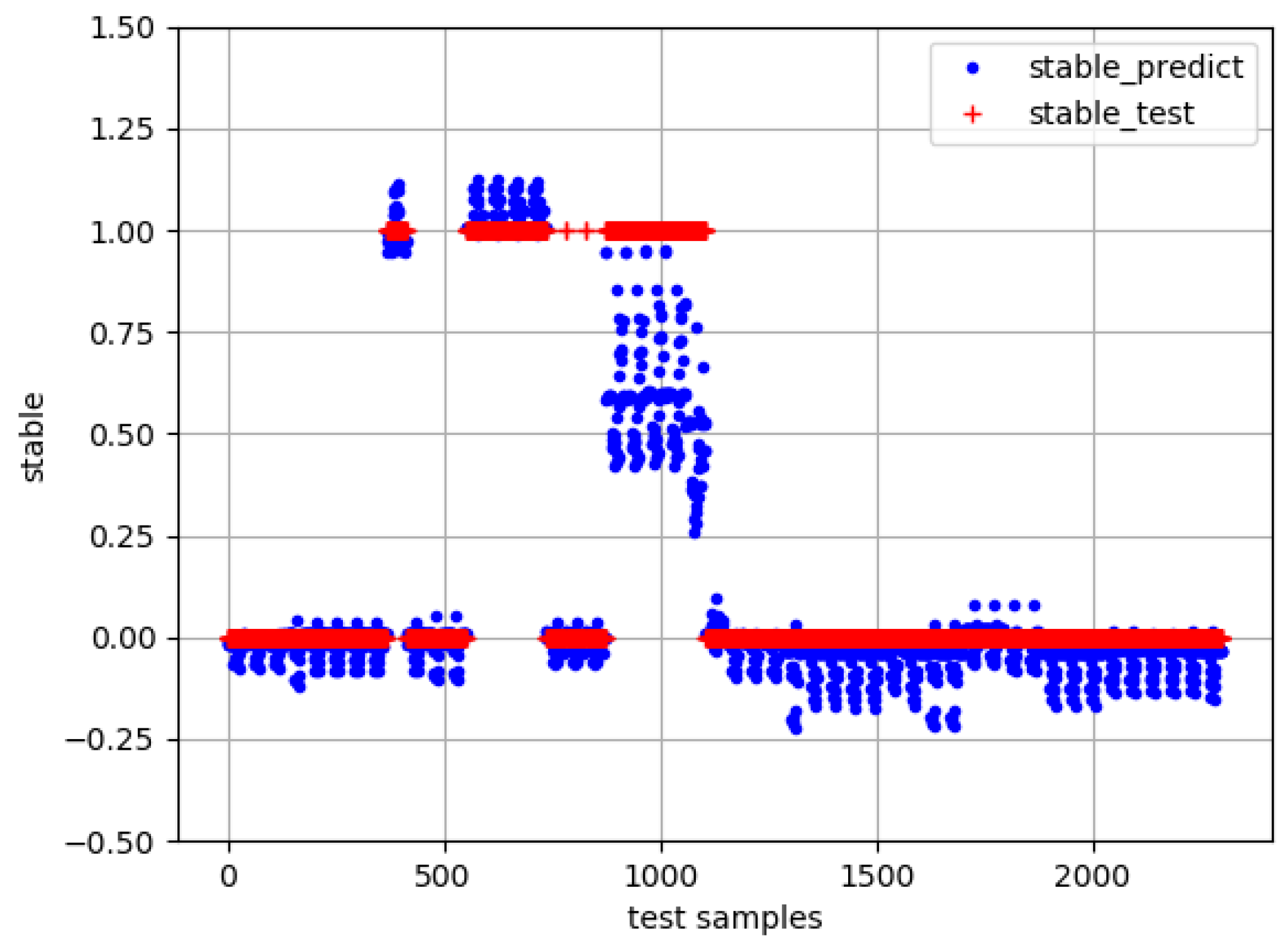
The results of the stability prediction on the test set are shown in
Figure 5. Taking
as the dividing line, the value that is greater than
is classified as “1”, which is considered as stable. The value that is less than
is classified as “0”, which is considered as unstable. The accuracy is
.
It is shown in
Table 2 that the false negative value is 6, i.e., six samples are actually stable. However, the prediction result is unstable. In order to maintain the stable operation of EI, it is acceptable to consider appropriate over-warning in real scenarios. While the false positive value is 0, i.e., the actual unstable sample is correctly predicted, which meets our requirements. In this paper, the threshold of accuracy is set to be 99%. The calculation is available with a precision of 1, a recall of 98.7%, and an f1-score of 99.4%.
The evaluation of stability prediction at this stage is to prepare for the decision optimization of subsequent reactive power compensation. In order to know in advance whether the EI would return to a stable state in the future, the characteristic time period is expected to be reduced. The data from the first 100 cycles would be intercepted, and the aforementioned CNN is still used for training. The accuracy is 2252/2300, which also meets the expected requirements.
The results of stability prediction are specifically analyzed in
Table 3. Through calculating, the precision, the recall and the f1-score are 91.2%, 99.4% and 95.1%, respectively. The accuracy does not meet the requirement.
Although the precision of the prediction has achieved 97.9%, such rate is still relatively low and does not meet the requirement. Therefore, the structure of CNN is determined to be optimized. The parameters in the CNN is set to be fixed. The size of the convolution kernel is selected as
. The depth of the network is adjusted by changing the number of convolution layers. The number of feature extractions is altered by changing the number of convolution kernels per layer, which makes the extraction effect much better. After twenty experiments are conducted, the average value of the training results of different CNN structures with different parameters is obtained. The results are shown in
Table 4.
It can be seen from
Table 4 that as the number of convolution kernels increases, the time for calculation increases substantially. The effect of increasing the number of the convolution layer on the calculation time is not obvious. The setting of the number of convolution layers and convolution kernels affects the prediction results. After twenty experiments are implemented, when the 6-layer convolution is set, and the number of convolution kernels per convolution layer is 64, the duration of calculation becomes shorter, and the accuracy is higher. The false positive value is smaller. More than half of the false positive values in the experimental results are all 0, which implies that the samples that are actually unstable are successfully predicted to be unstable. In this sense, the goal of stability prediction in this paper has been achieved. Thus, the model of CNN is selected. The results of the stability prediction on the test set are shown in
Figure 6. The accuracy is 2236/2300, which meets the expected target.
The analysis of the stability prediction results is shown in
Table 5. The false negative value is 64, i.e., 64 samples are actually stable. However, the prediction result is unstable, which is acceptable in the real engineering scenario. The false positive value is 0, i.e., the actual unstable samples are not predicted to be stable, which meets the expected requirements. Compared with the result before optimization, although the false negative value has increased, such value is reduced to be 0. In real-world applications, a false negative is acceptable, and a false positive is unacceptable. Therefore, the optimized results appear to meet the expected requirements. Through computation, the precision, the recall and the f1-score are 1, 86.3% and 92.7%, respectively.
The output of existing research on stability prediction is mainly based on the analysis of single node data. Differently, this study selects the data of each node of the whole network as input data. Meanwhile, the data format is different. In order to verify the feasibility and effectiveness of the study as a comparative experiment, the SVM algorithm [
16] is used for training. The false negative value is 141, i.e., 141 samples are stable. However, the prediction result is unstable, which is acceptable. The false positive value is 25, i.e., 25 samples are unstable but these samples are predicted to be stable. In real engineering practice, important information about voltage instability would be missed in such results. The future unstable states are difficult to be predicted accurately. Therefore, it is difficult to make a judgement, which is unacceptable. The obtained precision, the recall and the f1-score are 92.9%, 69.9% and 79.7%, respectively, which are much lower than the result obtained by our algorithm.
In summary, when data for each node in the whole grid system is used as high-dimensional input feature data within a certain characteristic time period, feature extraction can be better performed by deep learning CNN than by the conventional machine learning algorithm. A satisfactory fitting effect is obtained, and the application result in transient voltage stability judgment of EI achieves the expected target. Based on the mainstream power simulation software, a data batch processing toolkit has been developed, which improves the efficiency of data processing.
4.2. Simulation Example of Reactive Power Decision Optimization
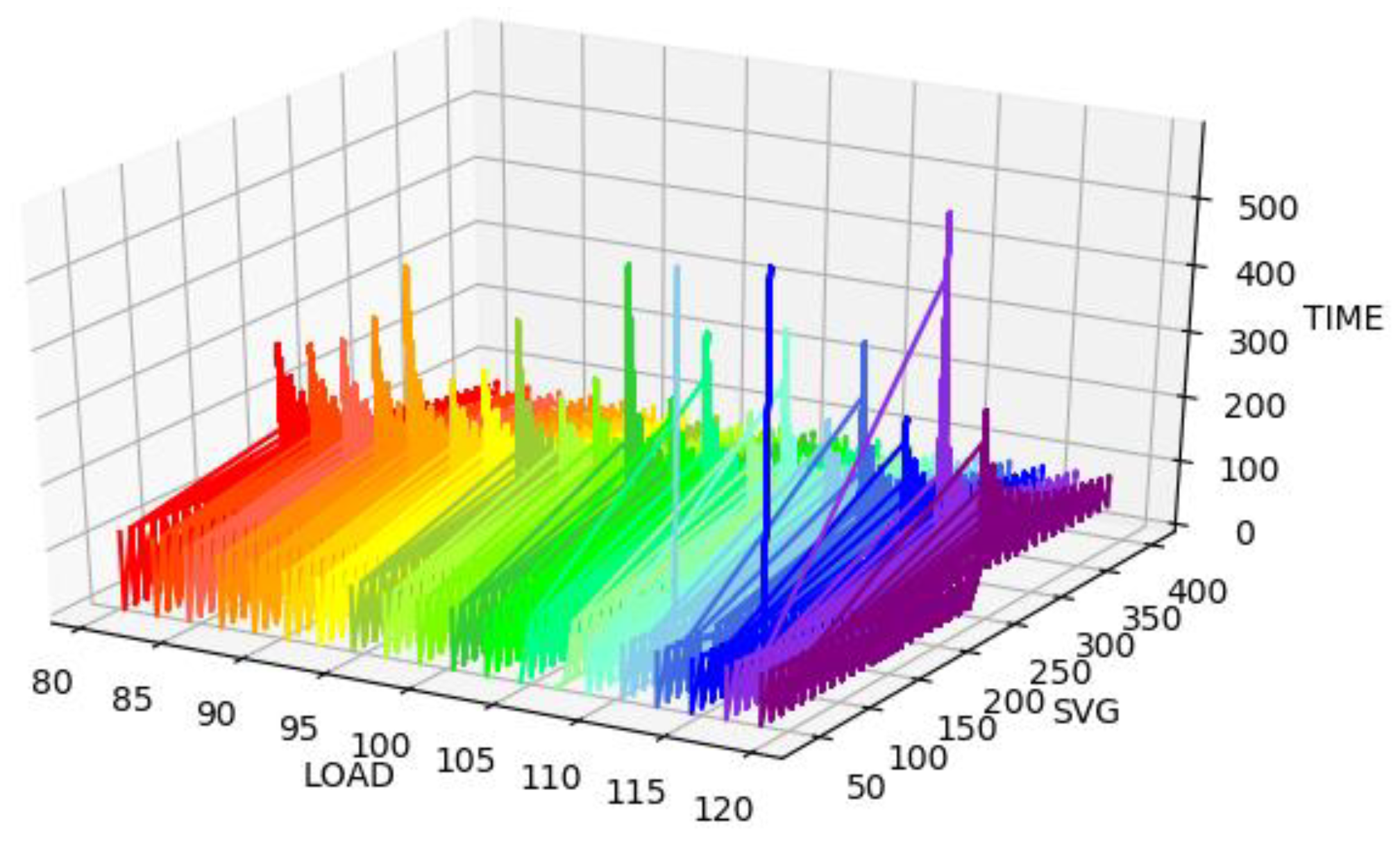
BPA is used to simulate different short-circuit faults. Since only the load model and load rate can be changed in BPA, the real-time load value cannot be collected. The system recovery time (cycle) corresponding to different load rates and the total SVG compensation is shown in
Figure 7.
It can be seen that under the same load rate, as the amount of SVG compensation increases, the system fluctuates from an unstable state to a stable state, and the time of returning to the stable state decreases gradually.
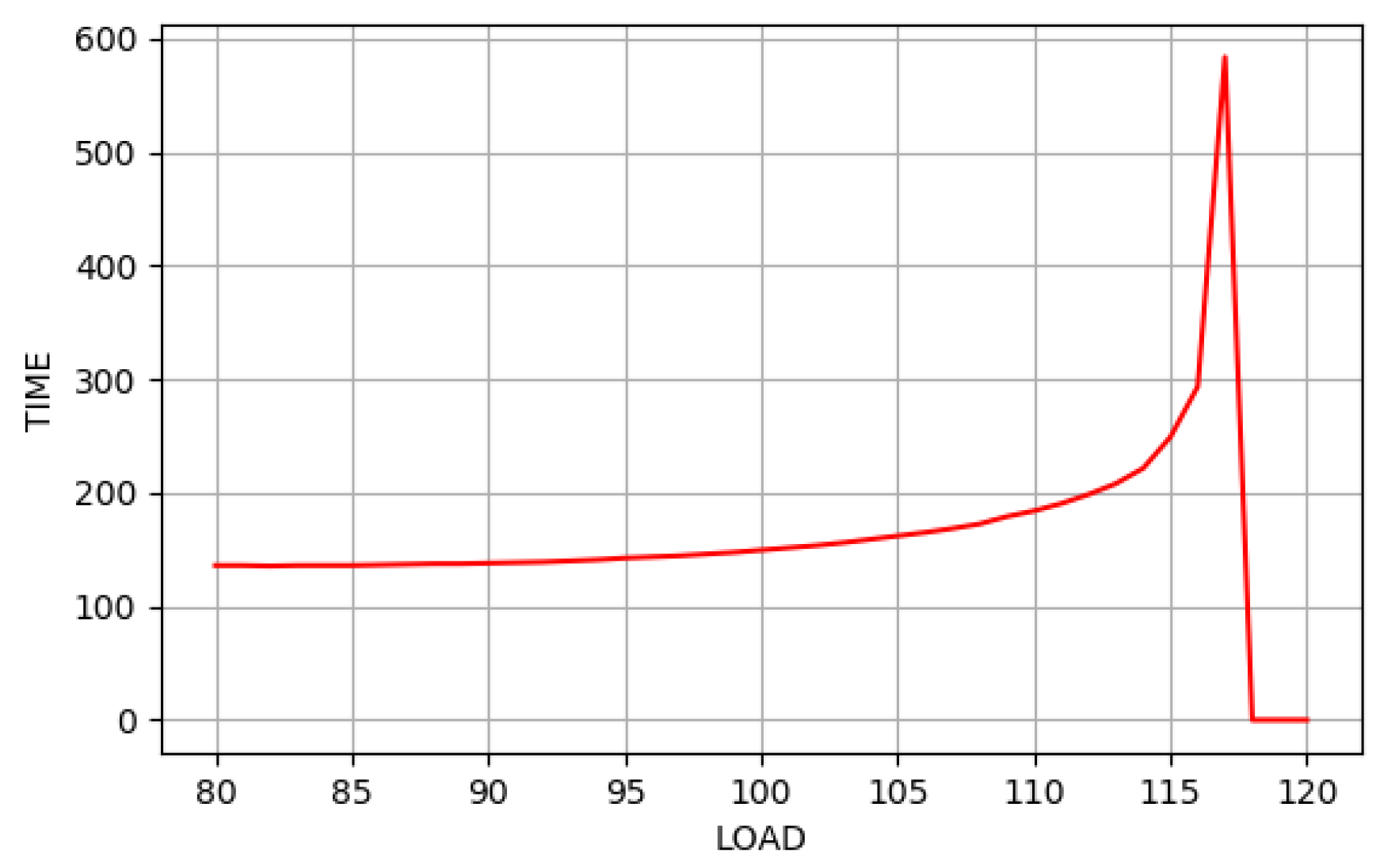
One set of SVG compensation was extracted. The load rate-time of returning to stable state (cycle) curve is drawn under the same SVG compensation. As is shown in
Figure 8, with the increase in the load rate, the time of returning to a stable state increases gradually after the same SVG compensation is obtained until stability cannot be restored. In
Figure 6, the system instability is represented by the time of returning to a stable state of
.
A numerical example is given in the following study where site
A and site
B represent for two cities. The load model is set as follows: (1) 30% constant resistance load, 40% constant current load and 30% constant power load at site
A; and (2) 70% motor and 30% constant impedance with a load rate of 115% at site
B. The short-circuit fault of single-circuit three-phase is set on buses with different voltage grades. Eight faults are considered in this example, including fault 1 (high-voltage level bus fault of 220 kV between site
A and site
B), fault 2 and fault 3 (220 kV high voltage grade bus fault on site
B, i.e., the grid location studied in the experiment), as well as fault 4 to fault 8 (low voltage bus fault of 110 kV and 66 kV on site
B).The fault clearing time is taken as 5 cycles, i.e., 0.1 s. Five SVGs are set at two 220 kV high voltage grade substations (
substation and
substation) and three 110 kV voltage grade substations (
substation,
substation and
substation), respectively. The compensation values of five SVGs, which are intervals of the action in the proposed algorithm, are set as follows: [20 Mvar, 80 Mvar], [50 Mvar, 80 Mvar], [60 Mvar, 80 Mvar], [50 Mvar, 80 Mvar] and [50 Mvar, 80 Mvar]. In the proposed algorithm, the action space is discretized, and the discretized step is 10 Mvar. By this means, 1344 discrete actions are obtained. These actions are numbered from 1 to 1344. These actions are further converted into
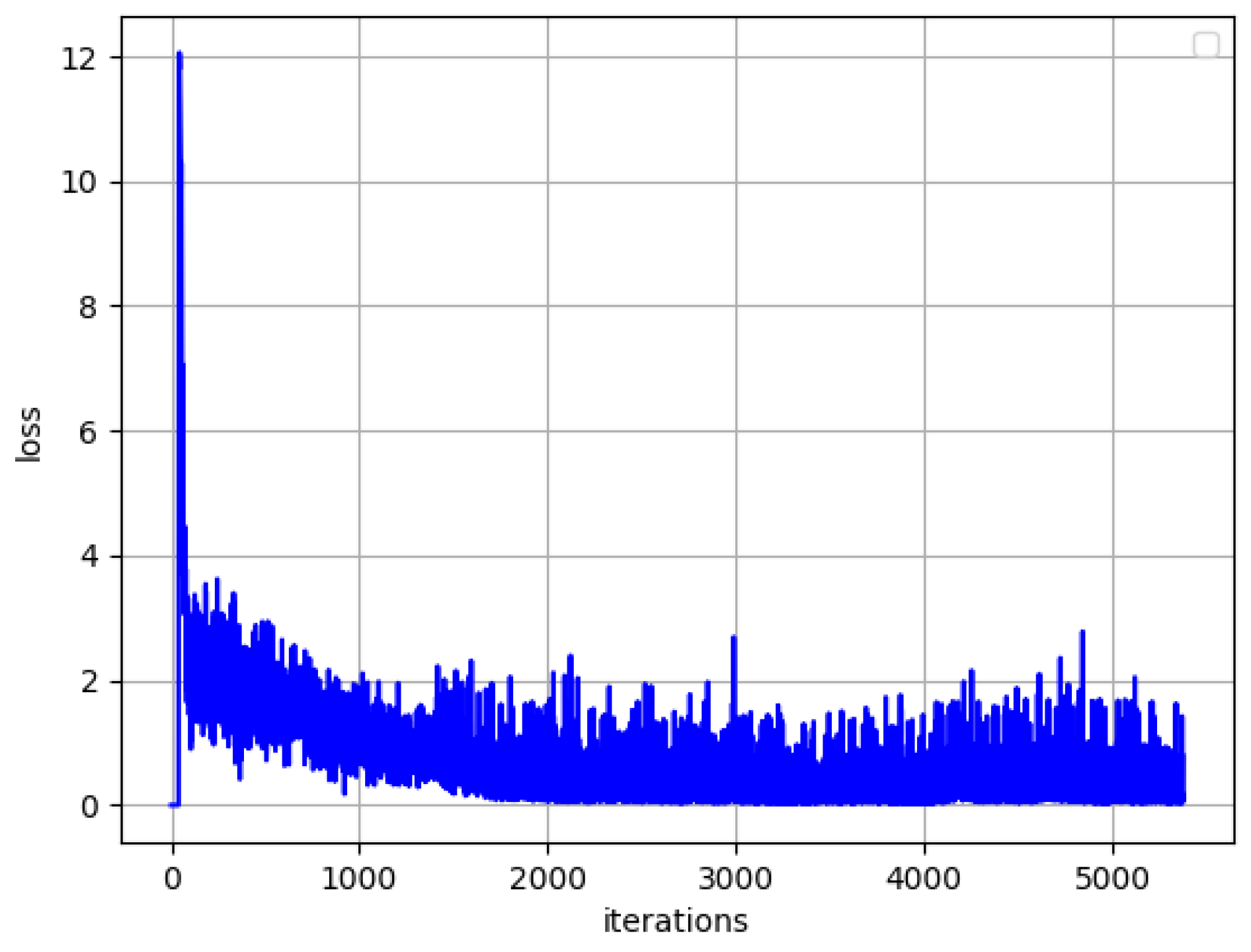
form. The network is trained by CNN. The loss value is shown in
Figure 9.
The optimization results based on deep reinforcement learning are shown in
Table 6. The compensations value of each action in
Table 5 for five SVGs are listed in
Table 7. These two tables can be understood as follows. Taking the number in the first row of
Table 6 as an example, when the network training times are 5000, the output action numbers of fault 1 to fault 8 are 34. According to the second line of
Table 7, action 34 compensates for five SVGs with 20 Mvar, 50 Mvar, 80 Mvar, 50 Mvar and 60 Mvar, respectively.
Fault 1, fault 2 and fault 3 are in the high voltage bus. Thus, reactive compensation should be increased. It can be seen that at the initial stage of training, the differences from fault 1 to fault 3 and from fault 4 to fault 8 are not successfully identified. Similar action outputs with high compensation are given. However, the decision of reactive compensation for different grades could be given by increasing the training times. The difference can be seen in the results of later training.
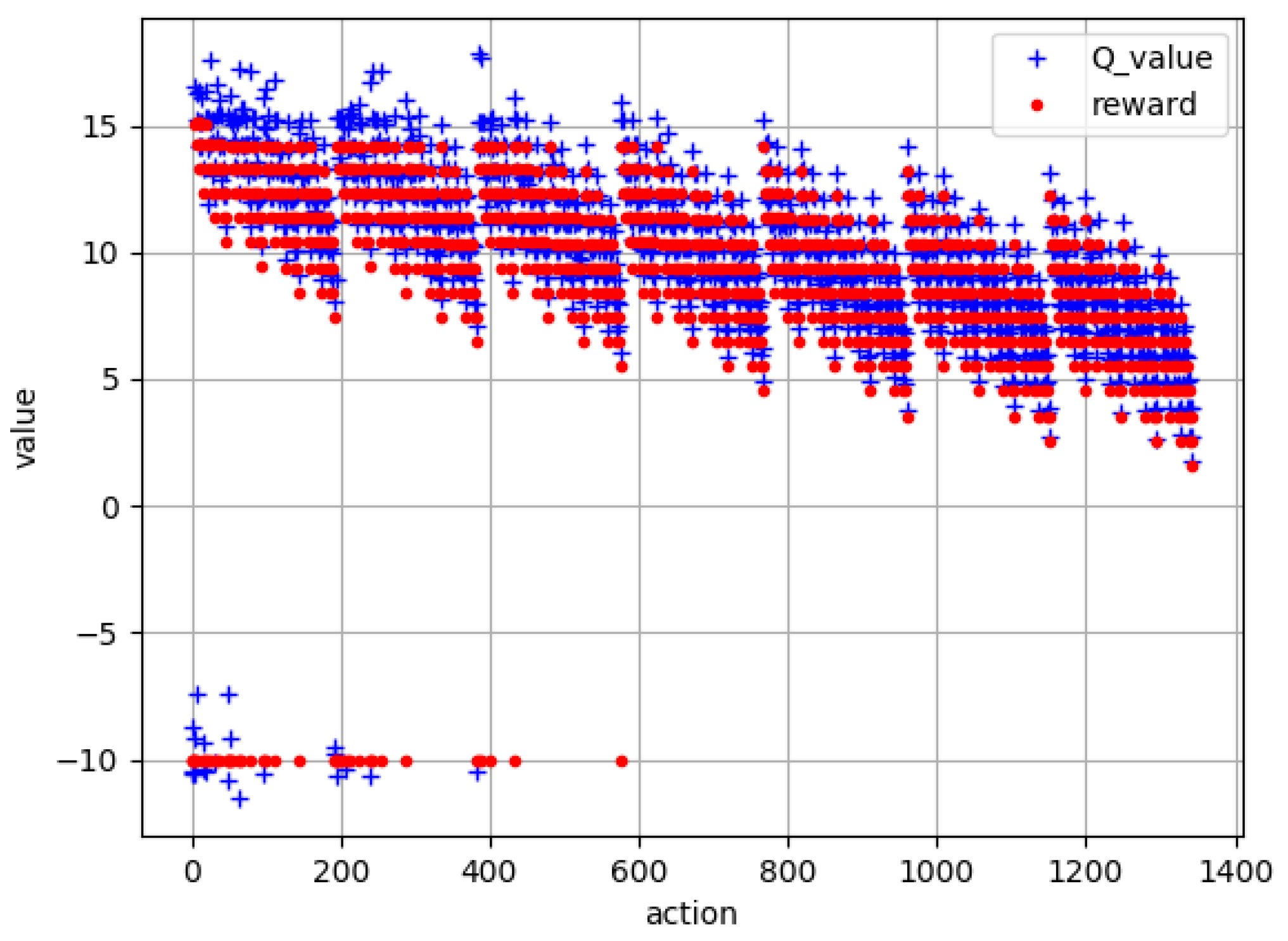
The contrast curve of
value and reward value are shown in
Figure 10. It can be seen that the general trend of the
value is consistent with the general trend of the reward value. As the training time increases, the
value is constantly close to the reward value, which achieves the goal of training.
All buses with high voltage are set to be stable. The total compensation of SVG is the lowest. The decision scheme of the final test is shown in
Table 6.
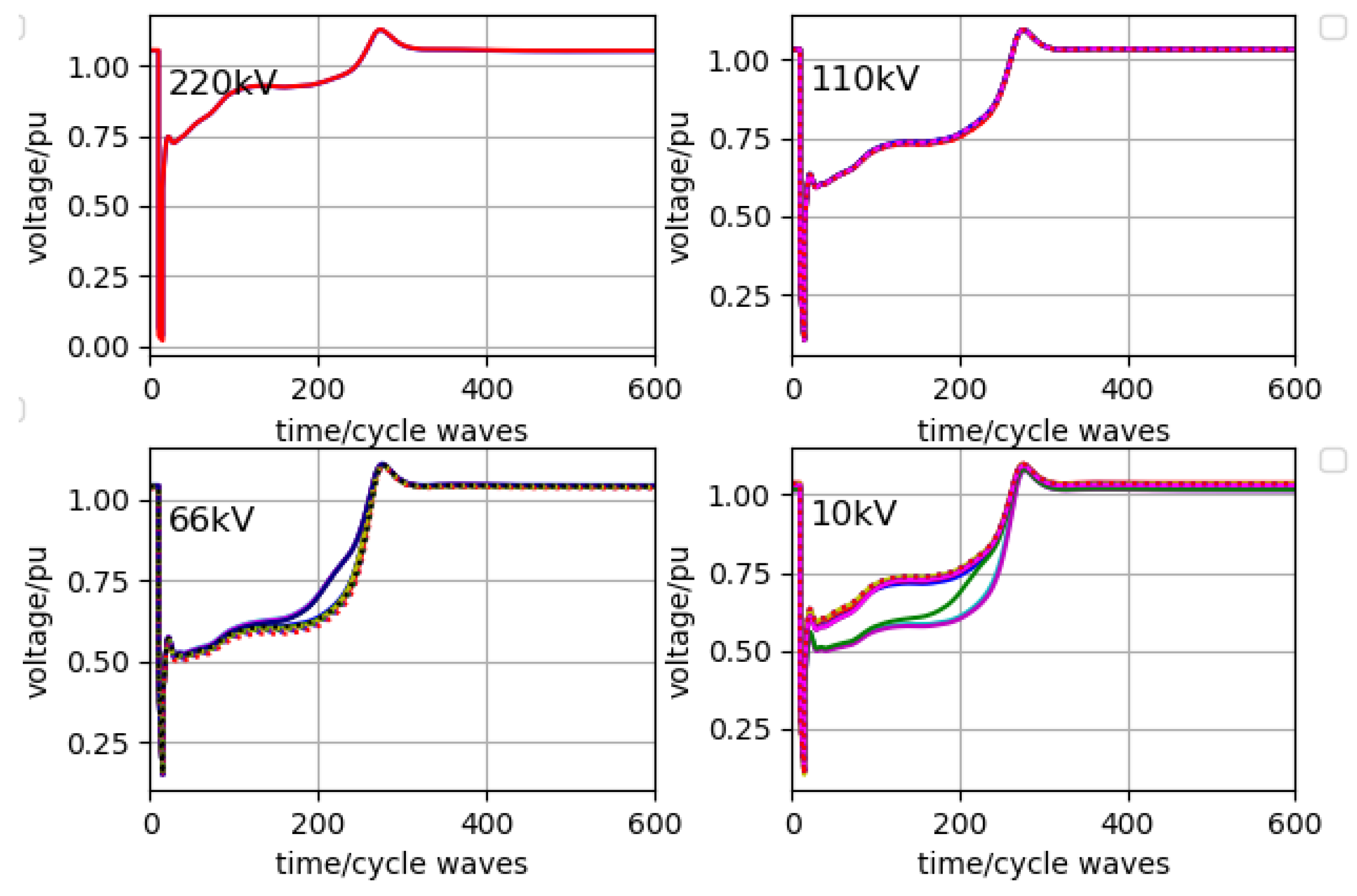
Fault 1 occurs on the highest level of the transmission bus between site
A and site
B. One of the decision schemes obtained by the model is action 19, i.e., five SVGs compensate 20 Mvar, 50 Mvar, 70 Mvar, 50 Mvar and 70 Mvar, respectively. It can be seen that the SVGs are distributed. The compensation value of each SVG is smaller than that of only two SVGs. The desired distributed setting of the reactive power compensation device is achieved. The stability result is shown in
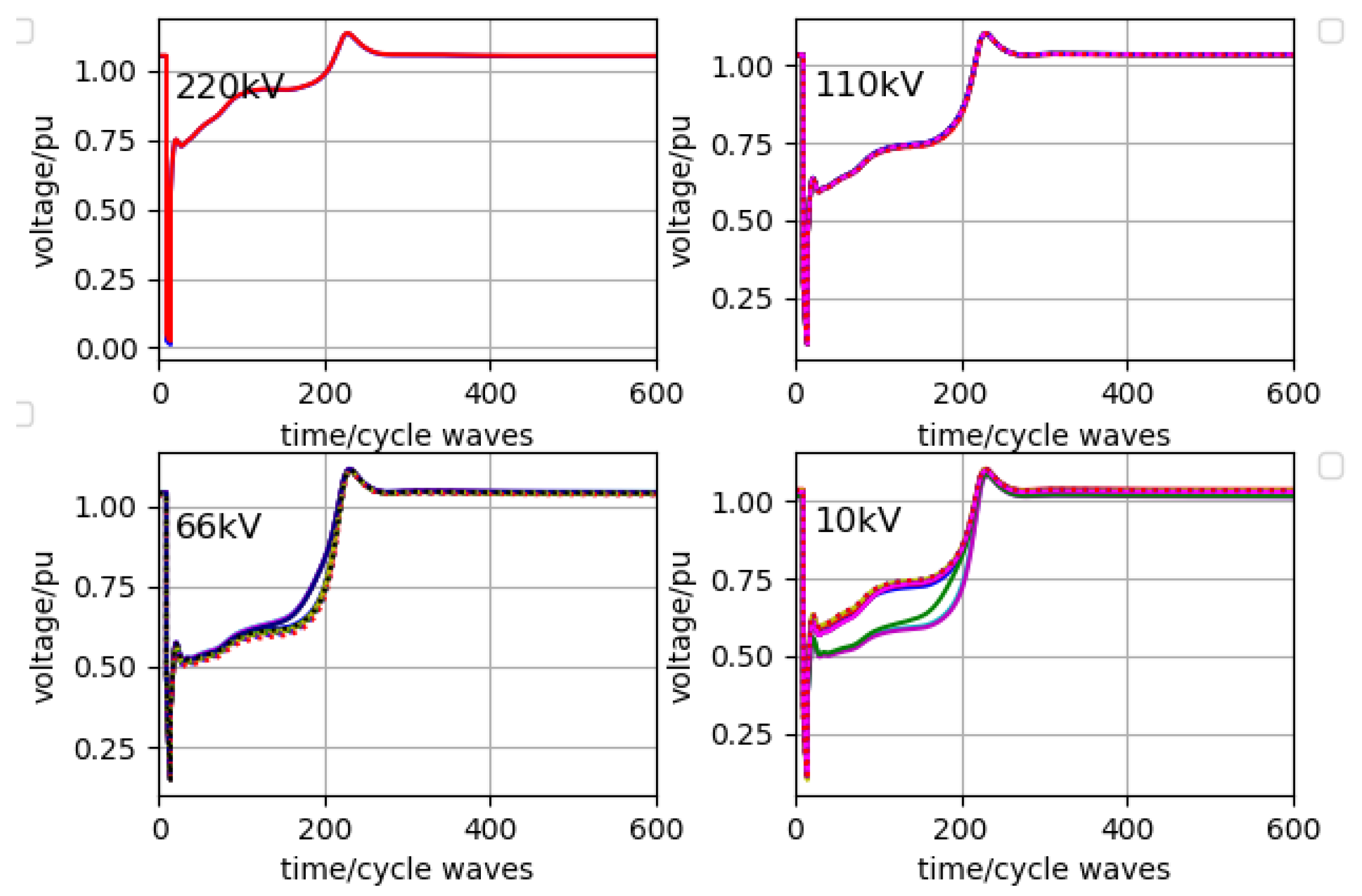
Figure 11. The time of returning to a stable state is about 550 cycles.
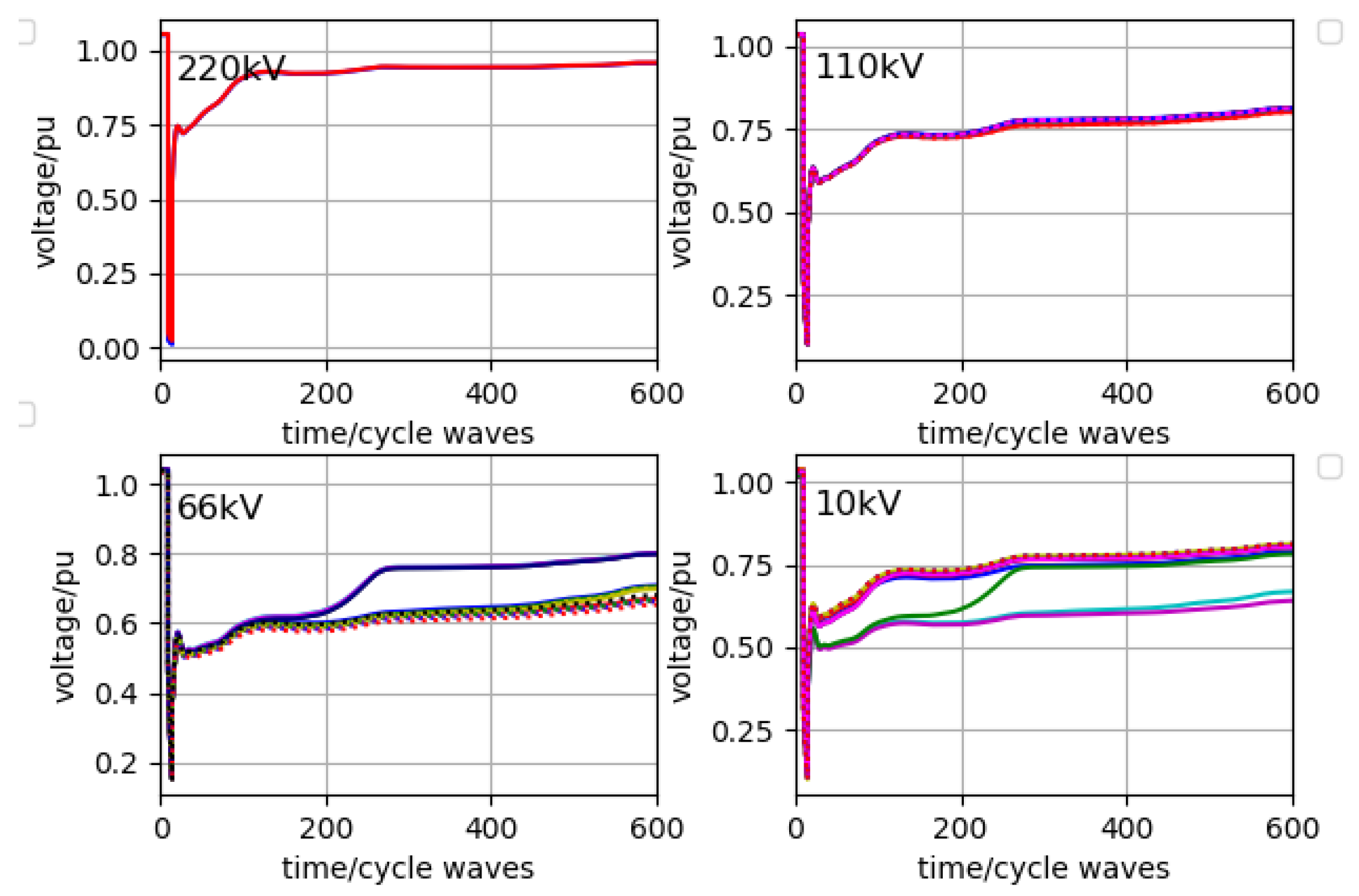
Fault 2 occurs on the high-voltage bus with 220 kV at site
B. One of the decision schemes given by the model is action 34, that is, five SVGs compensate 20 Mvar, 50 Mvar, 80 Mvar, 50 Mvar and 60 Mvar, respectively. The stability result is shown in
Figure 12. The time of returning to a state of stability is about 250 cycles.
Fault 3 occurs on the high-voltage bus with 220 kV at site B. One of the decision schemes given by the model is action 389, i.e., five SVGs compensate 40 Mvar, 50 Mvar, 60 Mvar, 60 Mvar and 50 Mvar, respectively. The time of returning to a stable state is about 295 cycles.
Fault 4 occurs on the high-voltage bus with 220 kV at site B. One of the decision schemes given by the model is action 34, i.e., five SVGs compensate 20 Mvar, 50 Mvar, 80 Mvar, 50 Mvar and 60 Mvar, respectively. The time of returning to the state of stability is about 50 cycles.
From the above analysis, the difference between the high voltage bus with 220 kV and 110 kV in the initial stage of training is not distinguished by the model. The scheme with the same total compensation amount is selected. Although the requirement of restoring stability can be met, the whole EI is subject to the impact of smaller short-circuit faulting with lower bus voltage level. In the later stage of training, a scheme for fault 4 to fault 8 is given by the model. Five SVGs compensate 30 Mvar, 60 Mvar, 60 Mvar, 50 Mvar and 50 Mvar, respectively. At this point, the total compensation amount is 250 Mvar. Fault 4 is set, and then action 241 is executed. The stability result is shown in
Figure 13. The time of returning to a stable state is about 60 cycles. A better optimal decision scheme can be given by the model though training.
However, in the previous setting of the reward value calculation formula, only the requirement that buses with high voltage grade finally restore stability is considered. The time of returning to a stable state is not considered. Thereby, we can see from
Figure 11 that although the strategy given by the algorithm ultimately achieves system stability, it is time consuming. The stable operation of the grid and the usage of the customer side’s load would also be affected. The calculation of rewards is changed by the choice. The time of returning to the stable state is taken into account. New and different strategies are given by the algorithm in the final experimental results. One of these strategies is action 673, i.e., five SVGs compensate 50 Mvar, 70 Mvar, 60 Mvar, 50 Mvar and 50 Mvar, respectively. Although the total compensation is slightly higher than the previous strategy, it can be seen that the compensation of each SVG is distributed more evenly.
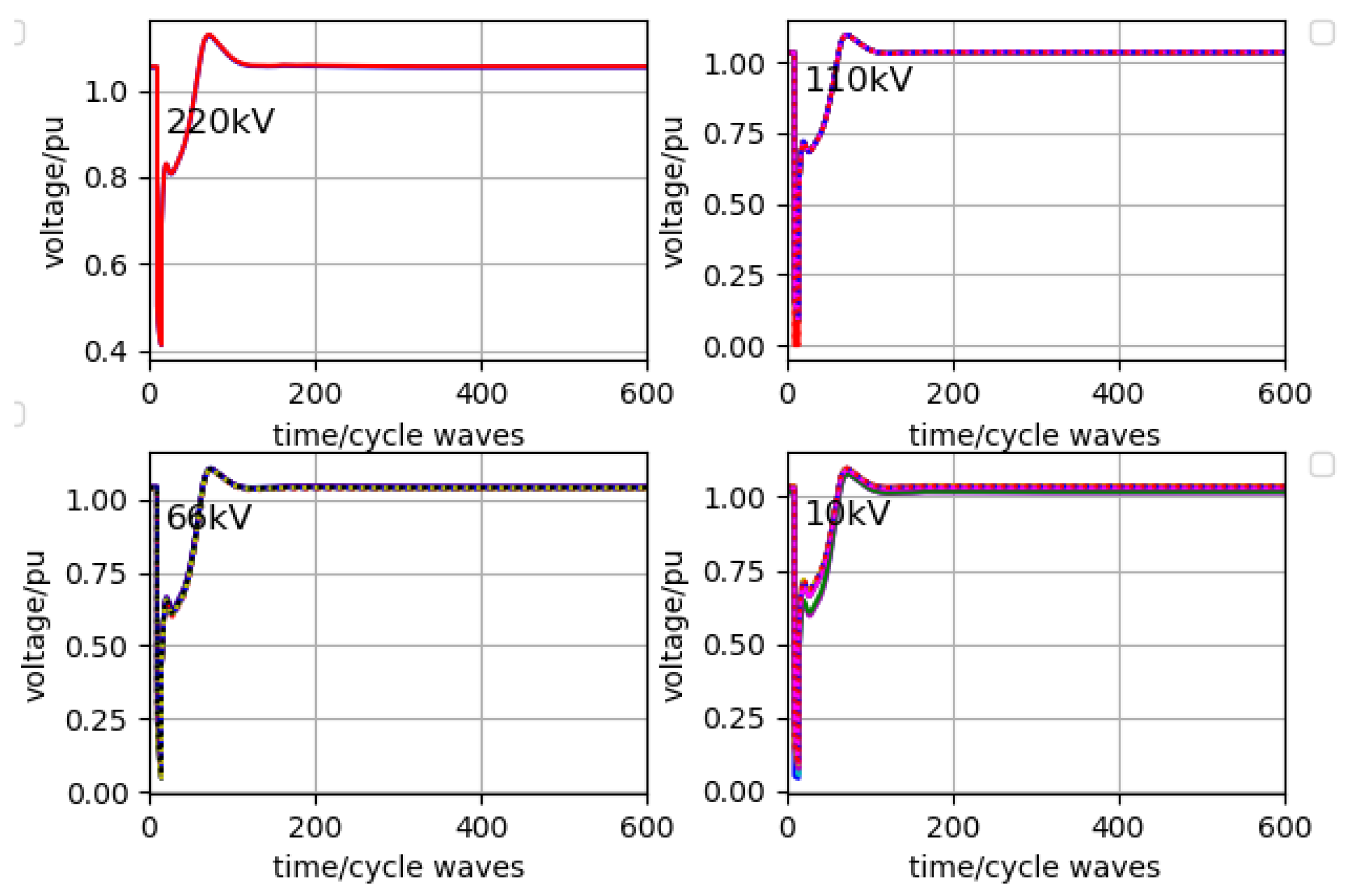
Fault 1 is set, and action 673 is executed. The stable result is shown in
Figure 14. When five SVGs compensate 50 Mvar, 70 Mvar, 60 Mvar, 50 Mvar and 50 Mvar, respectively, the time of returning to a stable state is about 200 cycles.
Based on the comparison of the above experimental results, it can be seen that the strategy proposed by the final algorithm meets the requirement of bus voltage stability. Meanwhile, the SVG presents distributed settings, and the output compensation is distributed uniformly. In addition, the distributed SVG conducts reactive compensation with a shorter timeframe, which greatly improves the efficiency of decision-making compared with conventional manual operations. The distributed SVG obtains stability within 200 cycles, which meets the requirement for secure and stable operation of the EI.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}