1. Introduction
One approach to mitigating the impacts of air pollution on human health, and impacts of greenhouse gases (GHGs) on climate, is to reduce the growth of vehicle fuel consumption by improving fuel economy [
1,
2,
3,
4,
5,
6]. Since fuel economy is a good indicator of GHG emissions it has become an important metric to assess trends and allow comparisons in GHG emissions between different vehicles as well as between vehicle fleets from different world regions. It is also a key indicator by which vehicle manufacturers assess compliance with GHG emission targets. As such, making reliable assessments of fuel economy for in-use vehicle fleets is an important policy tool for helping to target emission reduction policy [
6].
Globally, governments have developed and implemented fuel economy policy and standards that specifically target fuel consumption to reduce GHGs. Such policies and standards, have been implemented in four of the largest vehicle markets: USA, China, EU, and Japan [
1,
6,
7,
8]. Policies and standards in other major global markets (Australia, Brazil, India, Mexico and South Korea) tend to harmonize with these larger markets [
6]. Typically, these vehicle manufacturers declare fuel economy for new vehicles determined by chassis dynamometer testing of representative vehicles under laboratory conditions [
8,
9]. However, there is usually a discrepancy between laboratory tests and on-road values as laboratory conditions cannot reflect real-world driving conditions during a vehicle’s lifetime [
6,
8,
9,
10,
11,
12,
13]. Furthermore, the underestimation of actual fuel economy in laboratory type-approval testing directly affects achievable GHGs reductions [
14]. Measuring on-road fuel economy has been undertaken using portable emission measuring monitoring systems (PEMS), but this is expensive and time consuming as measurements are only provided for a single vehicle over a short time period [
9]. Therefore, real-world fuel efficiency emission data are often lacking, especially in developing countries [
10,
15].
Estimating fleet fuel economy of in-use vehicles is difficult as it varies with a number of other factors such as: the number of vehicles, fleet composition, vehicle characteristics, vehicle activities, fuel type and quality, congestion, driving style, road type, inspection and maintenance and degradation [
16,
17]. Prior studies have noted the importance of determining in-use fleet fuel economy especially with vehicles with accumulated mileage over 500,000 km [
18,
19]. USA and European environmental agencies factor in deterioration rates for vehicles under this mileage, but engines now last over 800,000 km before requiring the first rebuild of the engine [
19]. These very high mileages are typical in vehicle fleets in Africa, and the costliness of studies and limited resources are even more of a hindrance when determining in-use fuel economy. Where these data are available, they can be used to estimate current GHG emissions, establish baseline emissions and explore future emission scenarios for a changing vehicle fleet. As such, knowledge of current emissions is crucial to the development and implementation of emission reduction policy measures which are currently lacking in Africa [
20]. In addition, lack of vehicle activity data in formulating Intended Nationally Determined Contribution (INDC) for the transport sector [
21], as set out by United Nations Framework Convention on Climate Change mitigation [
22], has been identified by national governments in Africa as a major challenge in determining priorities in transport mitigation options.
To estimate in-use fuel economy of a vehicle fleet in a typical sub-Saharan African (SSA) city such as Nairobi, one needs data to describe the fleet composition, characteristics and activity for in-use vehicles. Moreover, these data need to include the total number of vehicles disaggregated by vehicle type, fuel type, age, emission technology and annual mileage (i.e., vehicle kilometres travelled (VKT) per year [
23,
24,
25]. These data may be found in vehicle registries but these are often incomplete, inaccurate, inconsistent and outdated in developing countries [
7,
9,
10]. Often national vehicle registries do not portray actual vehicle distribution on city roads, for example, vehicles registered in Nairobi may be in circulation elsewhere [
26]. A particular challenge arises from the growing use of informal transport in SSA such as the use of
matatus [
27,
28,
29],
bodabodas [
30,
31] and
tuktuks [
32]. These vehicles tend to be unregistered (making it difficult to use standard fleet inventory methods to capture their contribution to urban traffic) as well as being old, poorly maintained and overloaded during use, all factors that will increase tail-pipe emissions resulting in enhanced air pollution [
32,
33]. Therefore, in SSA the high composition of such vehicle fleets may be a source of uncertainties [
34]. Thus, developing methodologies that can capture this unique but important component of the vehicle fleet in SSA cities is crucial for the development of representative assessments of the contribution of the transport sector to the atmospheric pollution burden. To address these data shortages, traffic video and parking lot surveys are often conducted and these data used as input for traffic models [
23,
24,
25,
34,
35]. These types of survey however, face various challenges, for example, in determining VKT, type of vehicle, age and emission technologies on the vehicle [
35,
36,
37]. To overcome some of these challenges, previous studies in Nairobi, have made certain assumptions which no longer hold, such as, the belief that licence plate data may serve as a proxy for the age and mileage of the vehicle [
37].
Mathematical models for predicting fuel economy have been developed using vehicle physical characteristics such as engine size, maximum vehicle power, vehicle torque, vehicle weight, wheelbase and cross-sectional area [
38,
39,
40]. The development of one such model required a large detailed historical dataset of new light duty vehicles, n = 6246, with highway fuel economy data and corresponding vehicle characteristics [
39]. In that study, the fuel economy was assumed to be as declared by the manufacturers as per corporate average fuel economy (CAFÉ) standards. This level of quality and quantity of data is rarely available, especially for developing countries [
41]. Furthermore, the fuel economy declared for new vehicles is extremely unlikely to be transferable to the majority of the in-use, often old and second-hand, vehicle fleet in developing countries [
42].
Vehicle fuel economy and consumption are terms that are often used interchangeably in the literature [
5,
6,
8,
14,
39,
43,
44,
45,
46]. Within this study, fuel economy will refer to volume of fuel consumed per distance (L/100km) and fuel consumption will refer to volume of fuel consumed over time (L/day). Kenya does not have fuel economy standards [
21]. A previous study estimated Kenyan fuel economy to be near equivalent to European and Japanese standards lagged by 8 years [
47]. In that study an assumption was made in the absence for in-use vehicle activity data for the Kenyan fuel economy fleet to be equivalent to European fleets of the same year of manufacture; in addition, the study only covered light-duty newly registered vehicles.
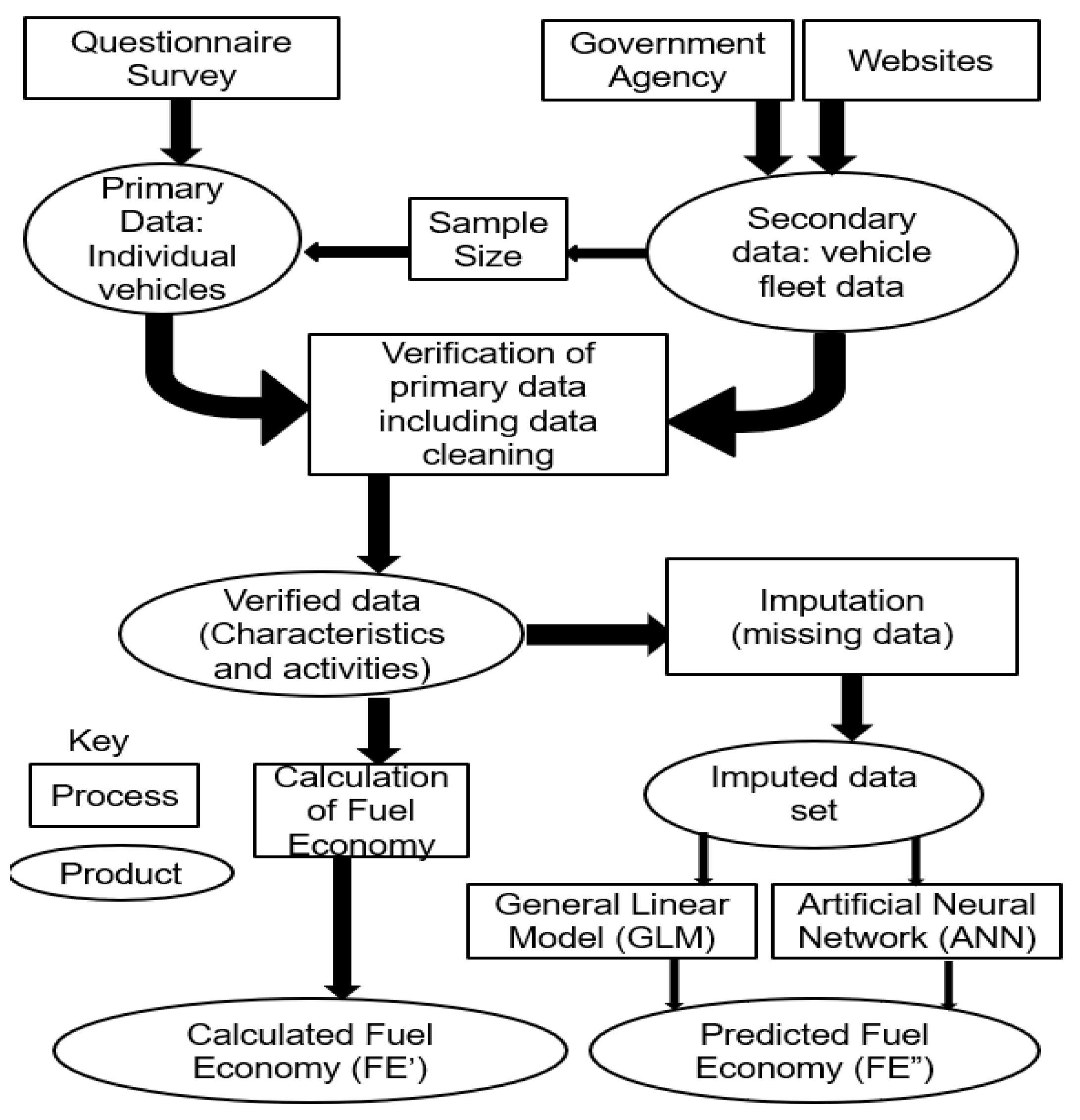
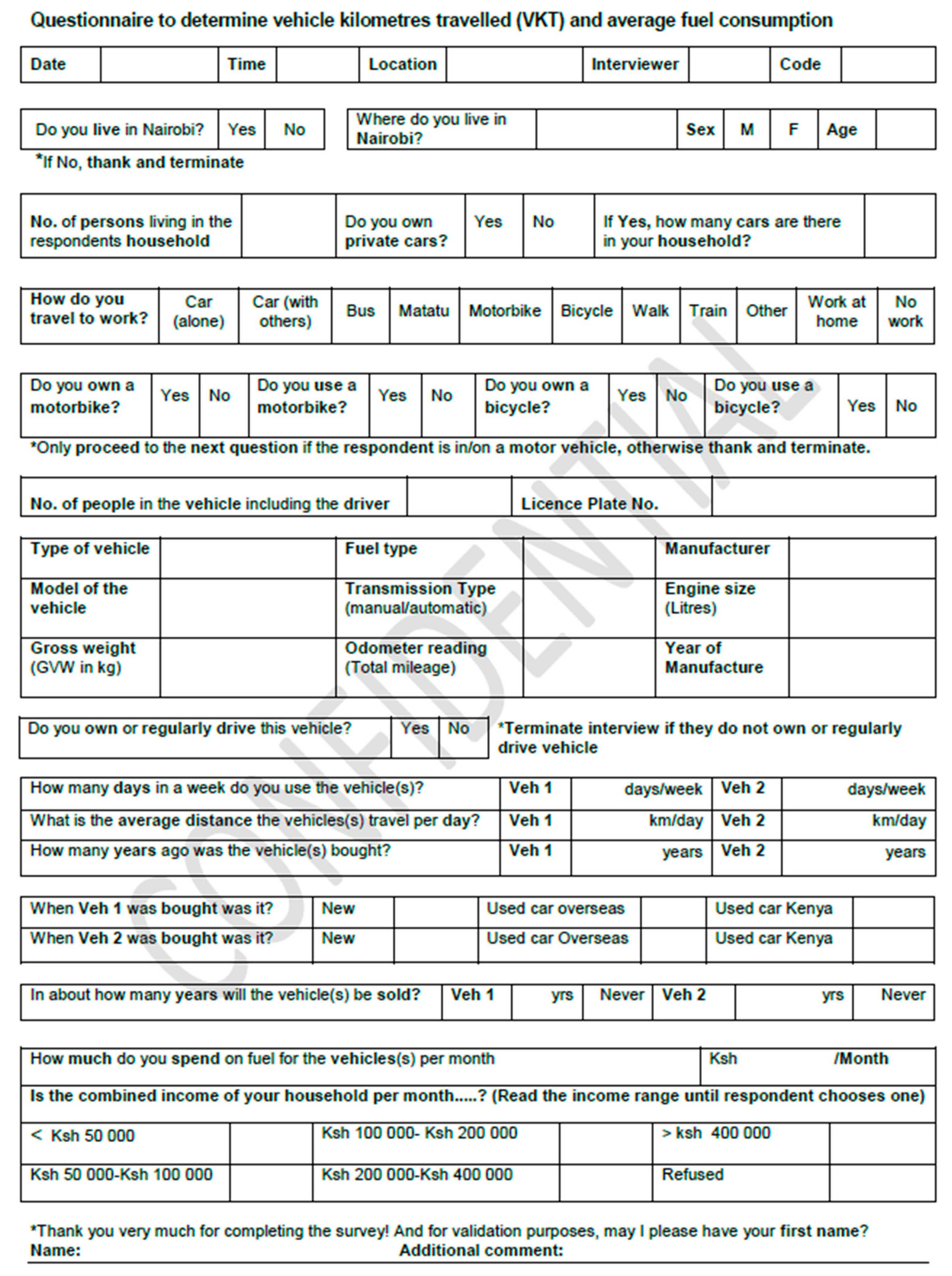
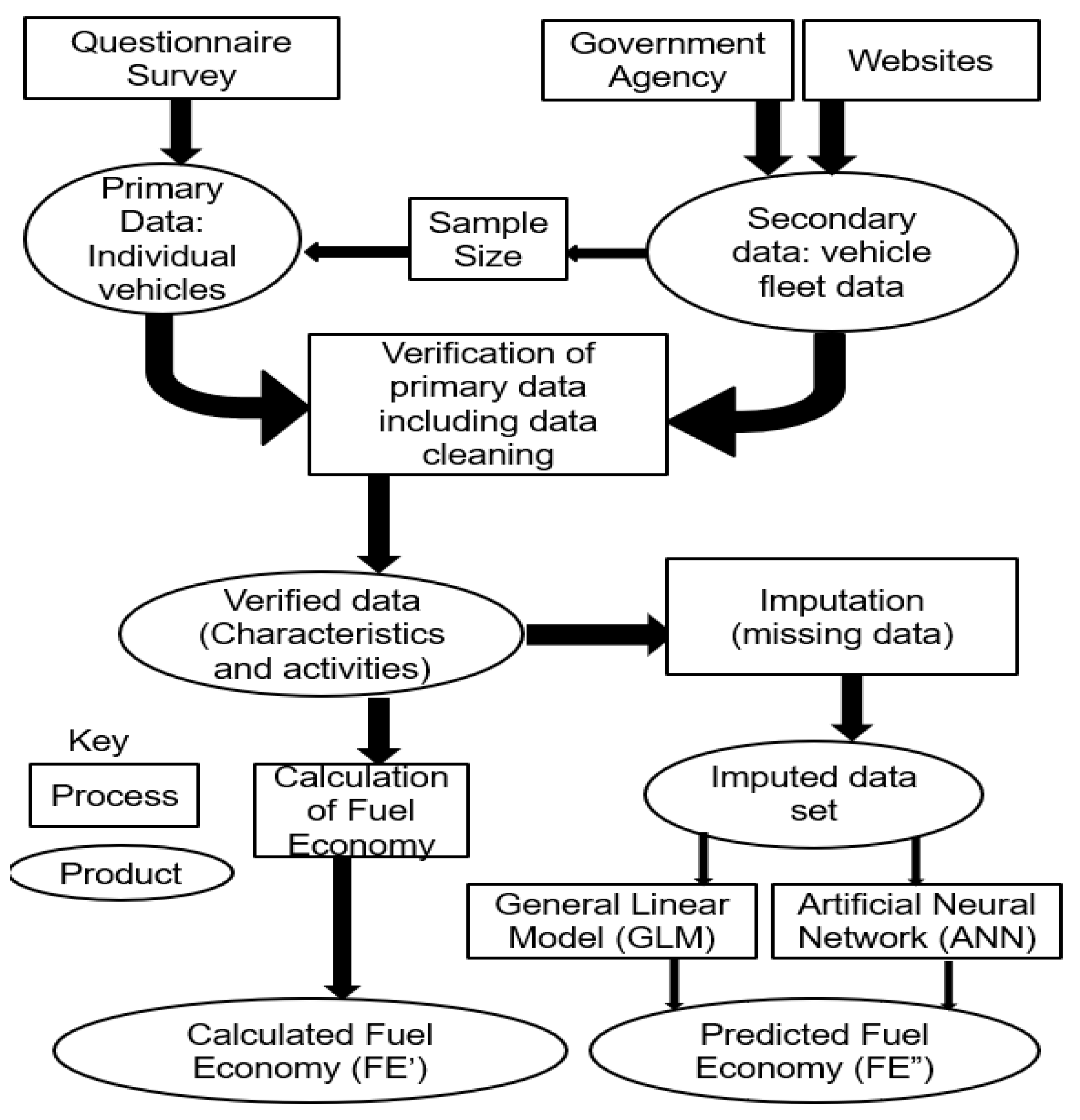
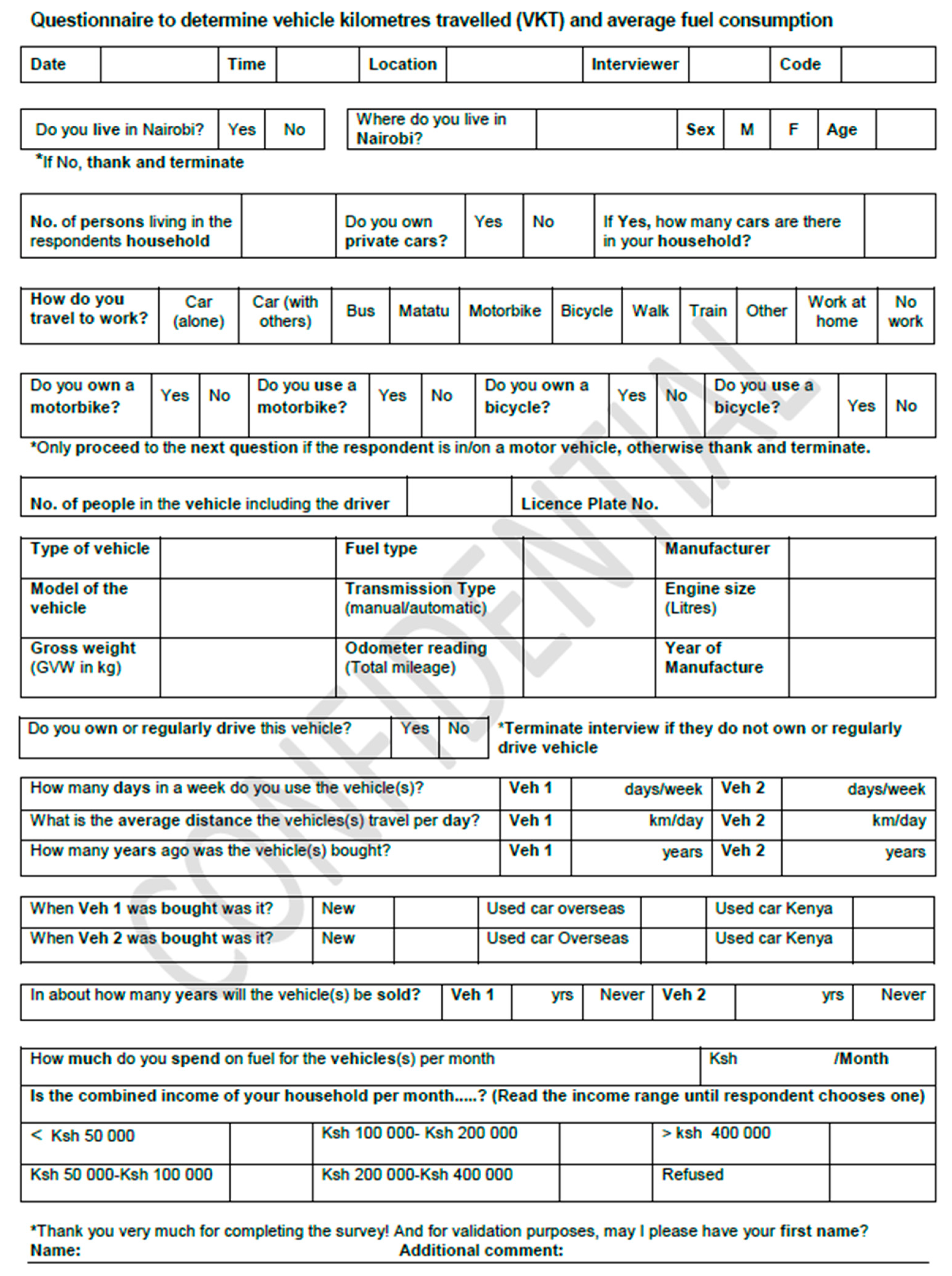
The overall objective of this paper is to develop a vehicle fleet questionnaire survey and associated procedure whose applicability is demonstrated for Nairobi Metropolitan Region (NMR), Kenya, allowing for the collection of primary data that includes characteristics such as engine size, weight of vehicle, mileage, money spend on fuel, transmission, age of vehicle, fuel type and vehicle utility. These primary data (mileage and the money spend on fuel) are used to calculate fuel economy. We also use a statistical method, multiple imputation, to deal with missing data [
48], a common problem with surveys. To the authors’ knowledge, this approach for dealing with missing data has not previously been applied in vehicle survey data. The secondary data, obtained from existing literature, are used to determine the total number and composition of vehicles as well as to verify primary data describing vehicle characteristics. These verified primary data, when used in conjunction with secondary data, gives a baseline of real-world vehicle characteristics and activity for in-use vehicles. Further, this paper demonstrates how to use previously applied methodologies to build mathematical models to predict fuel economy; here we use and compare generalized linear models (GLM) and artificial neural networks (ANNs) [
39,
49]. These methods have the potential to be rapidly deployed in other SSA cities and regions which suffer from similar data limitations and resources and importantly can capture the variability in the vehicle activity and emission data that exists both in the formal and informal vehicle fleets.
4. Discussion
This study has shown that for cities such as Nairobi, with limited or low-quality data and a large informal transport component (
tuktuk,
matatu,
bodaboda,
Askfortransport); questionnaire survey data can be reliably used to determine fuel economy of an urban fleet. A statistical test, ANOVA, comparing the calculated fuel economies among the various vehicle categories in
Table A1, shows that the mean values for the chosen vehicle categories, even for the informal sector, were statistically significantly different from each other. Thus, the Afritype vehicle categories may be used as the classification for vehicle fleets with a large component of informal fleets with similar profiles.
There was however constraint due to the sample size: the total sample disaggregated to vehicle categories for heavy goods vehicles (HGVs) for example reduced the sample to N = 10 (see
Table 2), affecting the level of confidence of the results in this category. This is because the trucks and lorries are kept out of the city centre and replaced with smaller trucks, hence their sample was much smaller than that for the passenger vehicles.
A distinct methodological limitation was the collinearity detected amongst the predictor variables, for example between weight of the vehicle and engine size. Removing these highly correlated variables from the model did not show improvement in the collinearity. Collinearity is on the one hand a statistical problem, since it reduces the precision with which the regression coefficients of linear models are estimated. On the other hand, this shows that several of these variables could be used as proxies for each other and high correlations help with imputation of missing values (although more complete data would be preferable in any case). This could be explored in future studies to increase the efficiency of which features to collect in surveys. However even with these limitations, we can conclude fuel economy and vehicle activity developed for formal transport in developed countries’ sectors do not map the complexity of the informal sector in developing countries due to differences in vehicle types and utility of the vehicles.
4.1. Comparison across Countries
Major vehicle manufacturers (Japan, USA, EU and China) have fuel economy policies [
6].
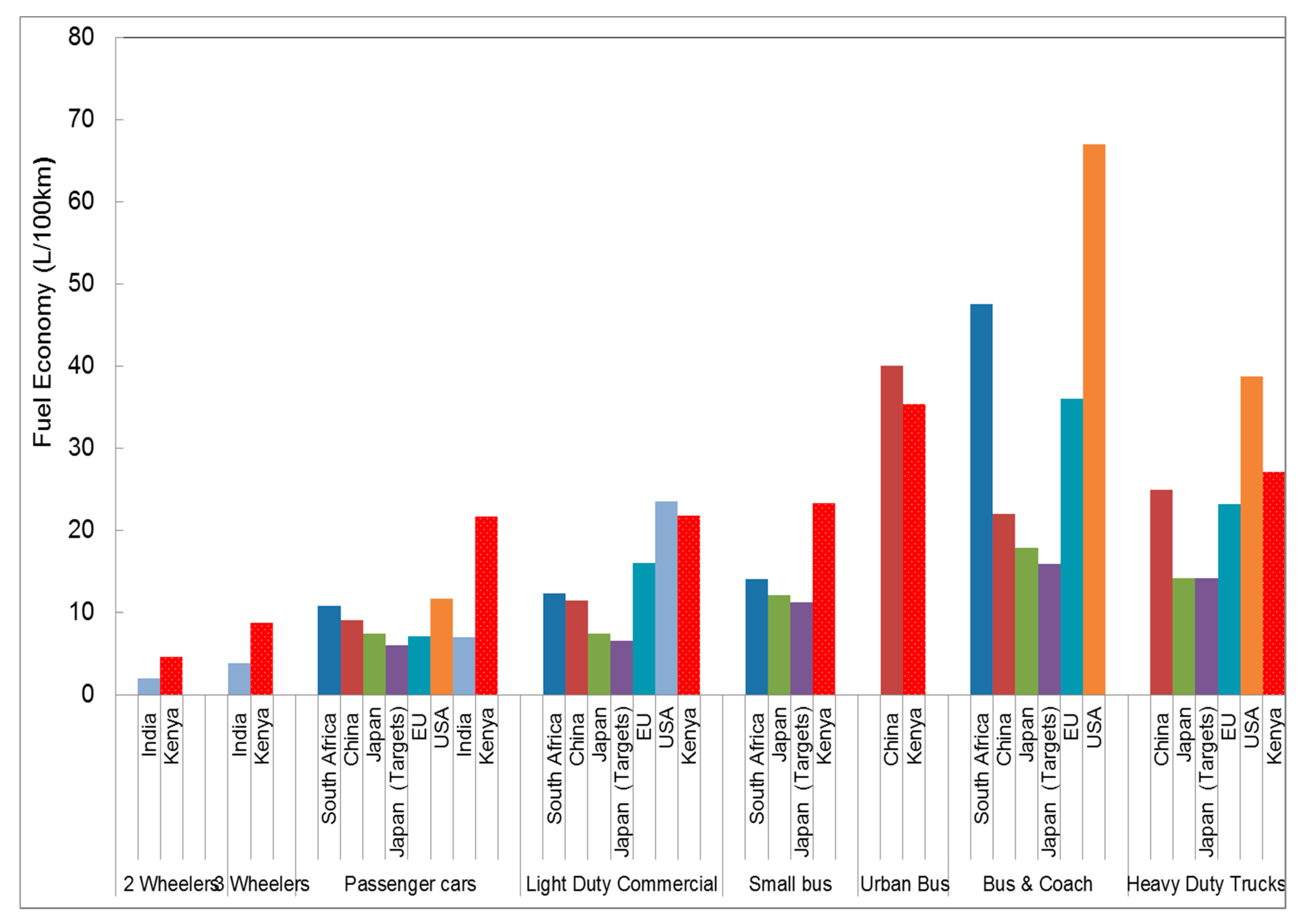
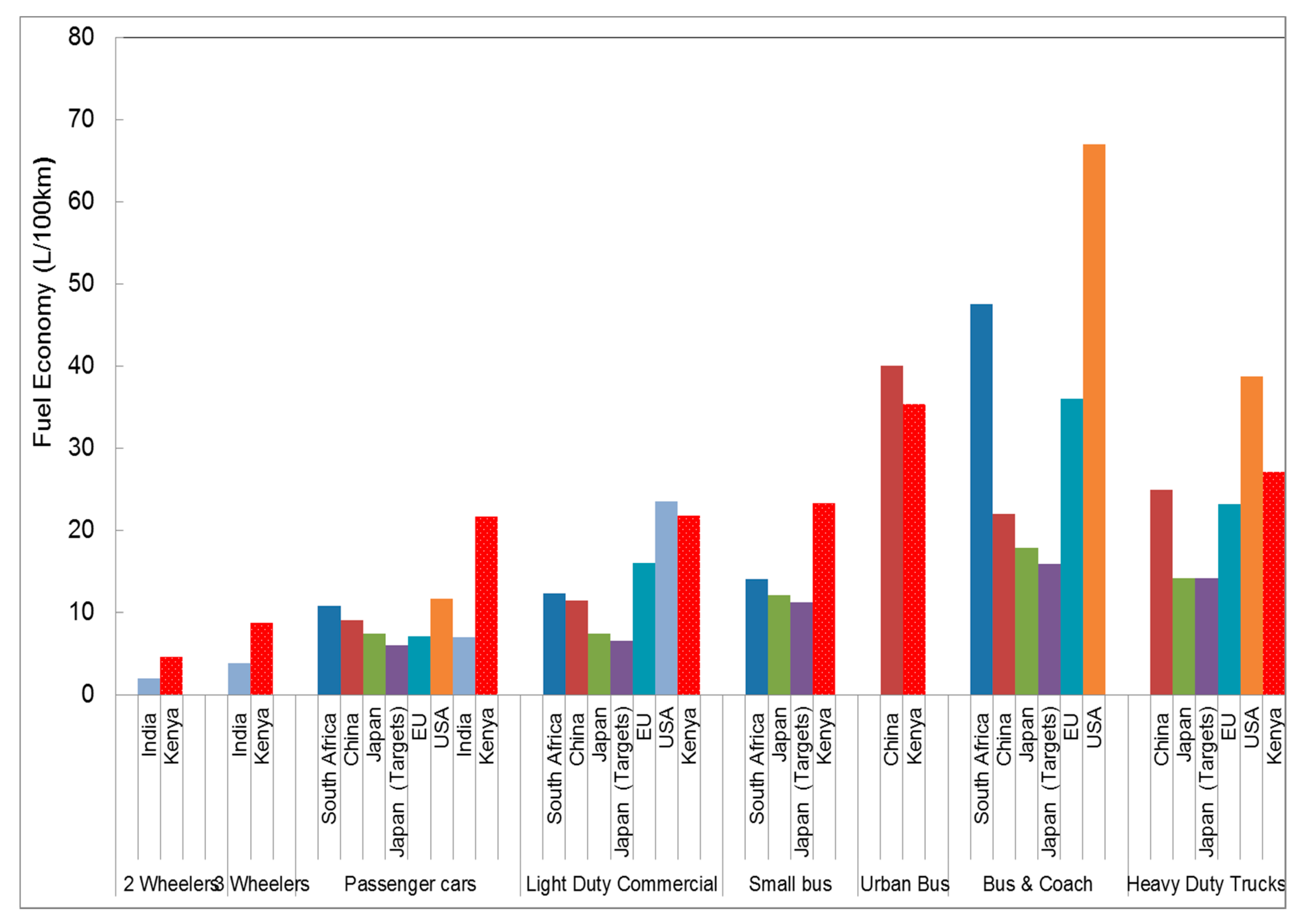
Figure 9 compares the various studies conducted to estimate vehicle fleet fuel economy compared to the current fuel economy values of this study. The Kenyan passenger cars have three times poorer/lower fuel economy compared to the Japanese, EU and Indian fleets and two times lower than the South Africa, Chinese and USA fleets. For the Kenyan light duty commercial vehicles, fuel economy was up to three times poorer compared to the Japanese fleet or targets. Fuel economy of the two-wheelers and three-wheelers of the Kenyan fleet (named
bodaboda and
tuktuk, respectively) were two times poorer than the corresponding Indian fleet. The
matatu 14 seater was determined to be the equivalent to the Japanese small bus (a vehicle designed to carry 11 or more passengers and with GVW up to 3500 kg) and the South African minibus taxi. In this category the Japanese fleet was two times and South Africa fleet was 1.7 times more fuel economic than the
matatu 14 seater.
In Kenya, 90% all imported and registered light duty vehicles between 2010–2012 were from Japan and Europe [
47]. Japan has very stringent fuel economy standards to meet their 2015 targets [
74], yet when the Kenyan fleet is compared to the Japan in-use vehicle fleet in 2004, overall fleet fuel economy was two to three times worse. The comparison in
Figure 9 is made on the assumption that other studies have similar or smaller confidence intervals. The confidence interval for the Kenyan study (see
Figure 4), ranges from 7–54% with an average of 24%.
The passenger car fuel economy for USA includes light duty trucks [
76], while for other countries light duty trucks were a separate category. This may contribute to the seemingly poor fleet fuel economy for passenger cars in the USA, even when the technology and fuels meet the latest equivalent current European and Japanese standards.
The light duty commercial fleet in-use in Nairobi was typically
AskforTransport vans and trucks, an informal van and truck hire within the city and in residential areas. This category had the second highest age, as “retired” older vehicles are not scrapped but are repurposed. The fuel economy of this category is better than USA fuel economy for the same category, but USA fleet for this category is heavier (weight of this category in USA includes trucks up to 3800 kg, whilst the other fleets are less than 3500 kg) and bigger engines [
6,
76].
Bodabodas and
tuktuks are mainly imported from Asia: India, Indonesia, Thailand, and China, as they are cheaper compared to European imports [
30,
33]. Motorcycles are used as public transport in India and Vietnam as they are in Kenya, but they have twice the average mileage compared to Kenya, 79.7 ± 4.3 km/day [
24,
77]. In Asian cities they have a lower daily mileage because they represent a larger share of the urban vehicle fleet, the reason being that motorcycles are often used in Asian cities to avoid congestion, for instance motorcycles represent 90% of the vehicle fleet in Hanoi [
77]. Kenyan motorcycles were in this study (see
Figure 3) found to be mainly 150 cc engine and 4-stroke engine compared to motorcycles in West Africa that are 50 cc engines and two stroke [
33]. Given the trend in increasing numbers of motorcycles in SSA [
30,
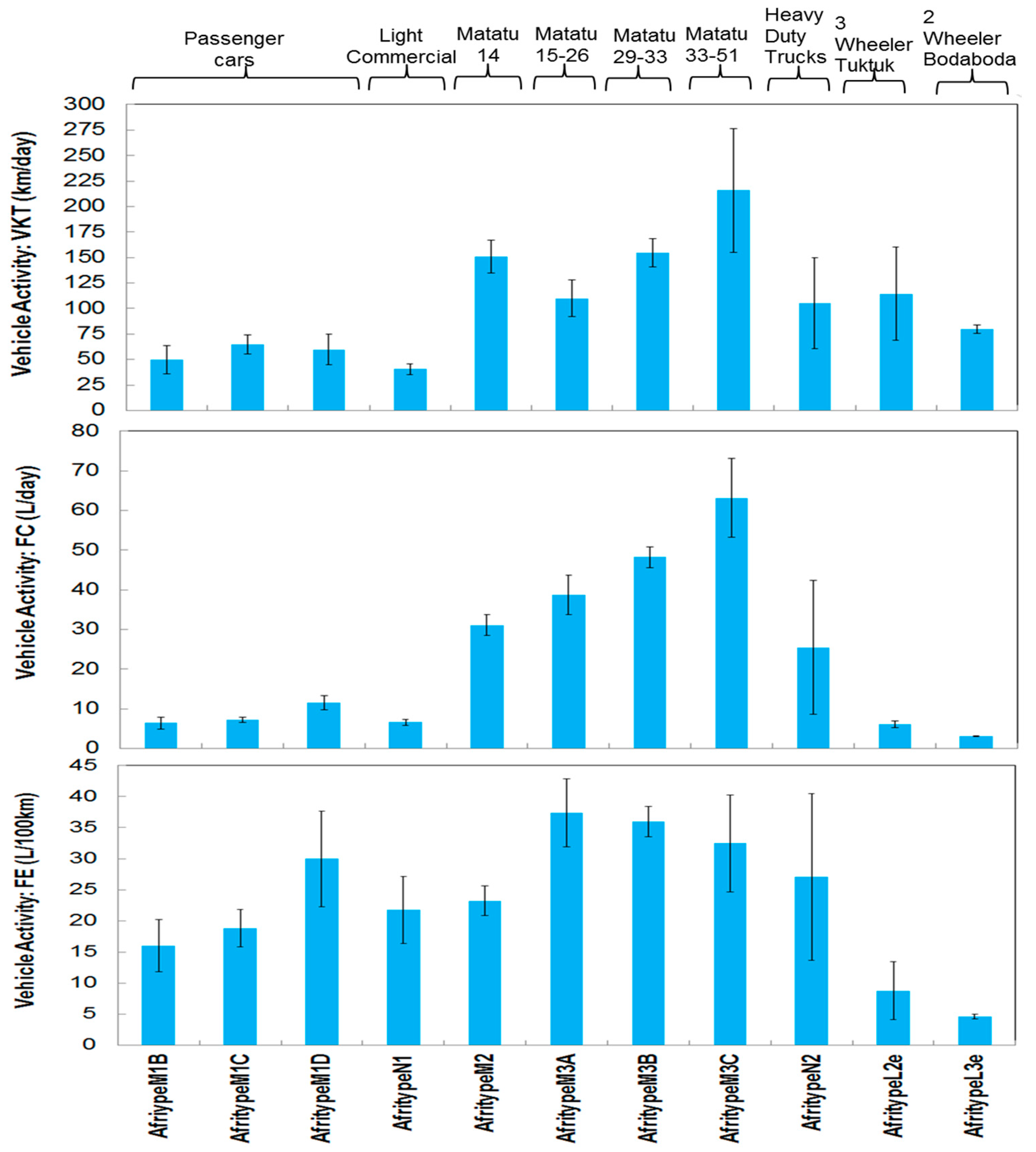
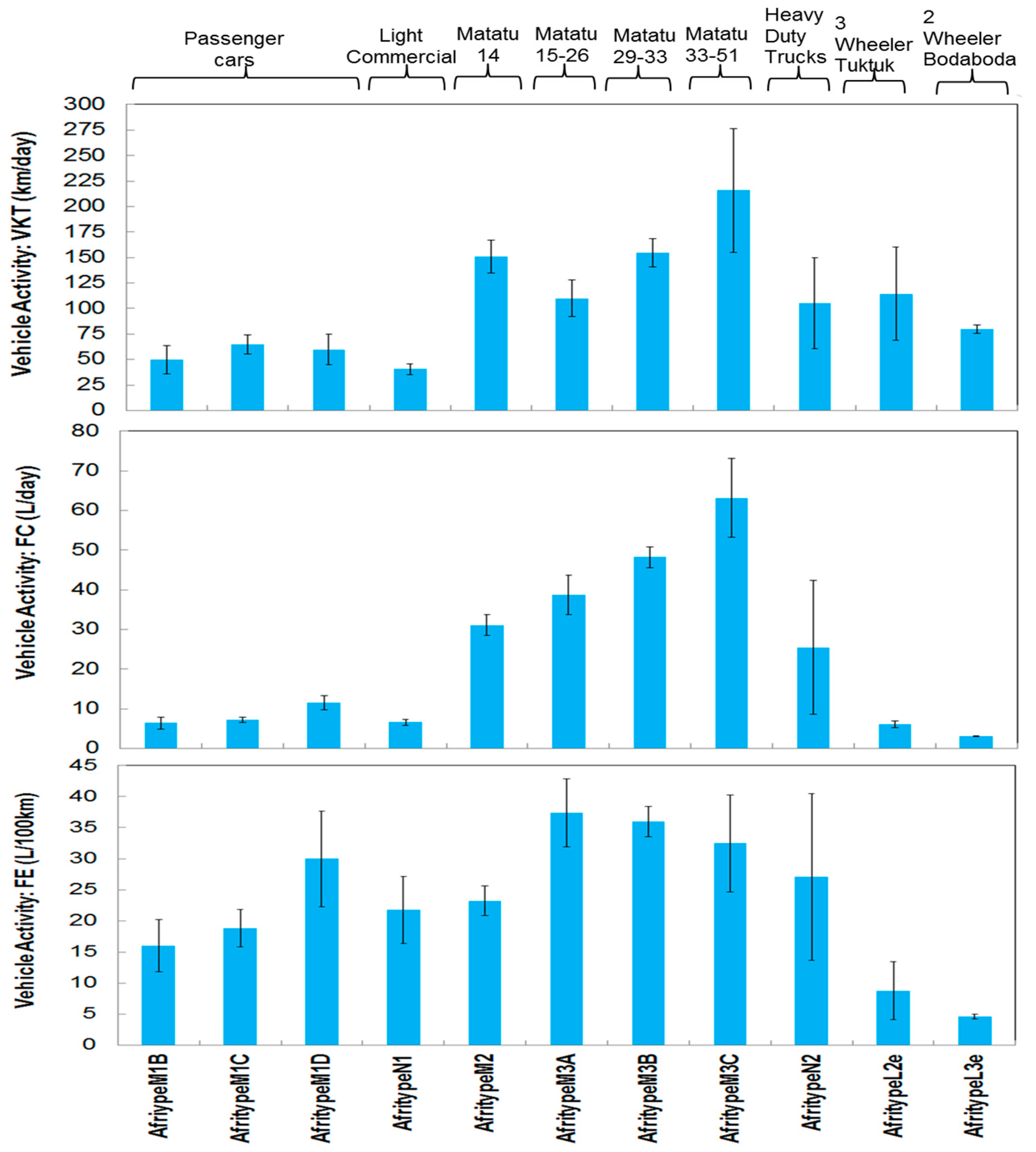
33], the average daily mileage for motorcycles may also decrease. The study also highlighted high intensity vehicle usage, indicated by an average vehicle mileage, VKT, for other vehicle types such as passenger cars (61.04 ± 7.18 km/day), and
matatu 151.55 ± 10.42 km/day.
South Africa has a strong domestic vehicle manufacturing industry and restricts imports of second-hand cars [
78] and is therefore unlike Kenya where 99% of vehicles are second-hand [
47]. Their vehicles perform better than Kenya’s, though reliable minibus taxi data (equivalent to
matatu) is often not available. Kenyan
matatu 14 seaters are old (16.9 ± 0.2 years) and are originally 9 seater vans converted into 14 seater; overloading and old age is a large component of the fleet; this likely accounts for the poorer fuel economy compared to South Africa. The bigger
matatus, equivalent to urban buses, are relatively new and have a better fuel economy comparable to the Chinese fleet. However with expected vehicle technology deterioration [
79] further aggravated by poor road conditions, low fuel quality and lack of inspection and maintenance (I/M) programmes this advantage in fuel economy may not be maintained.
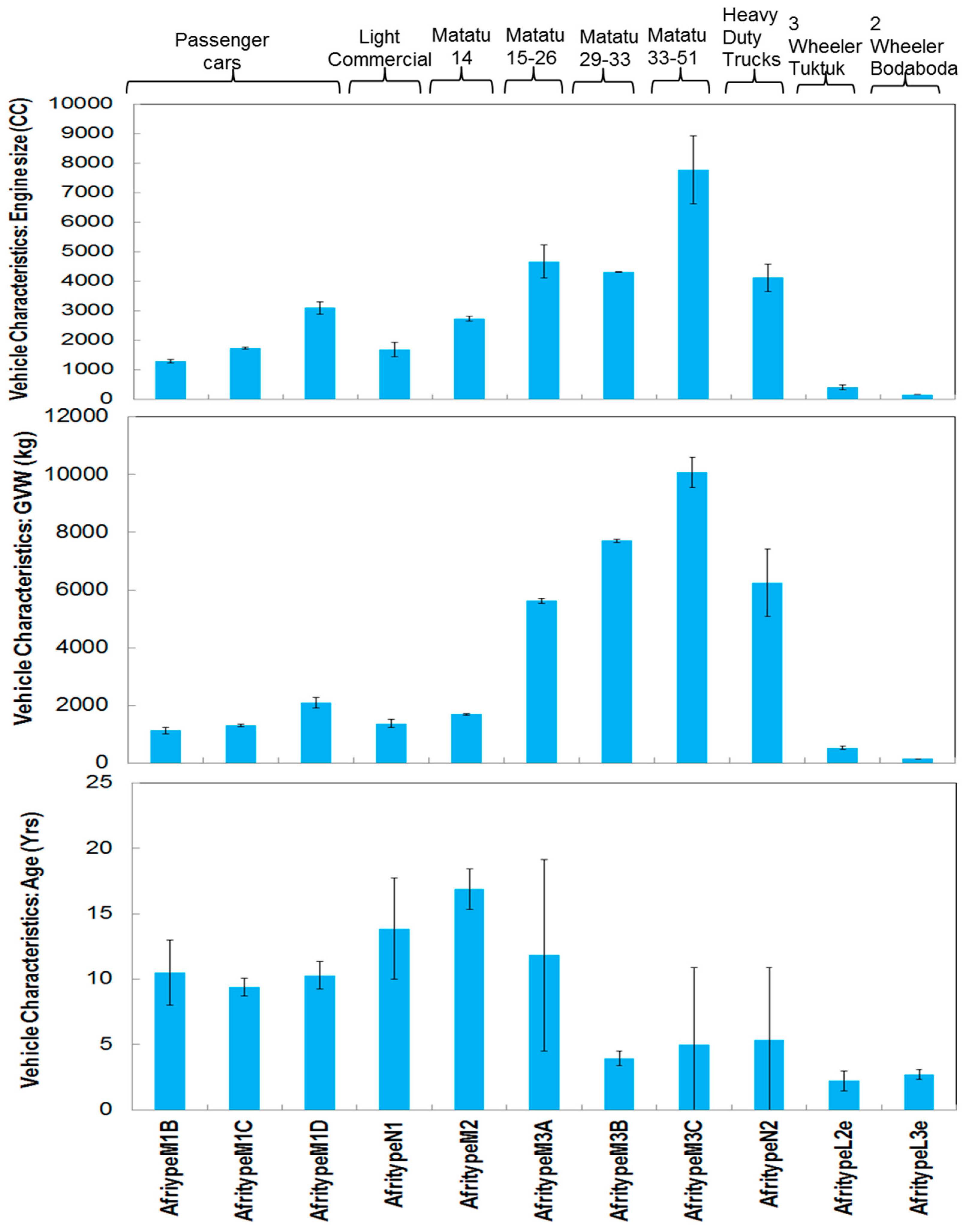
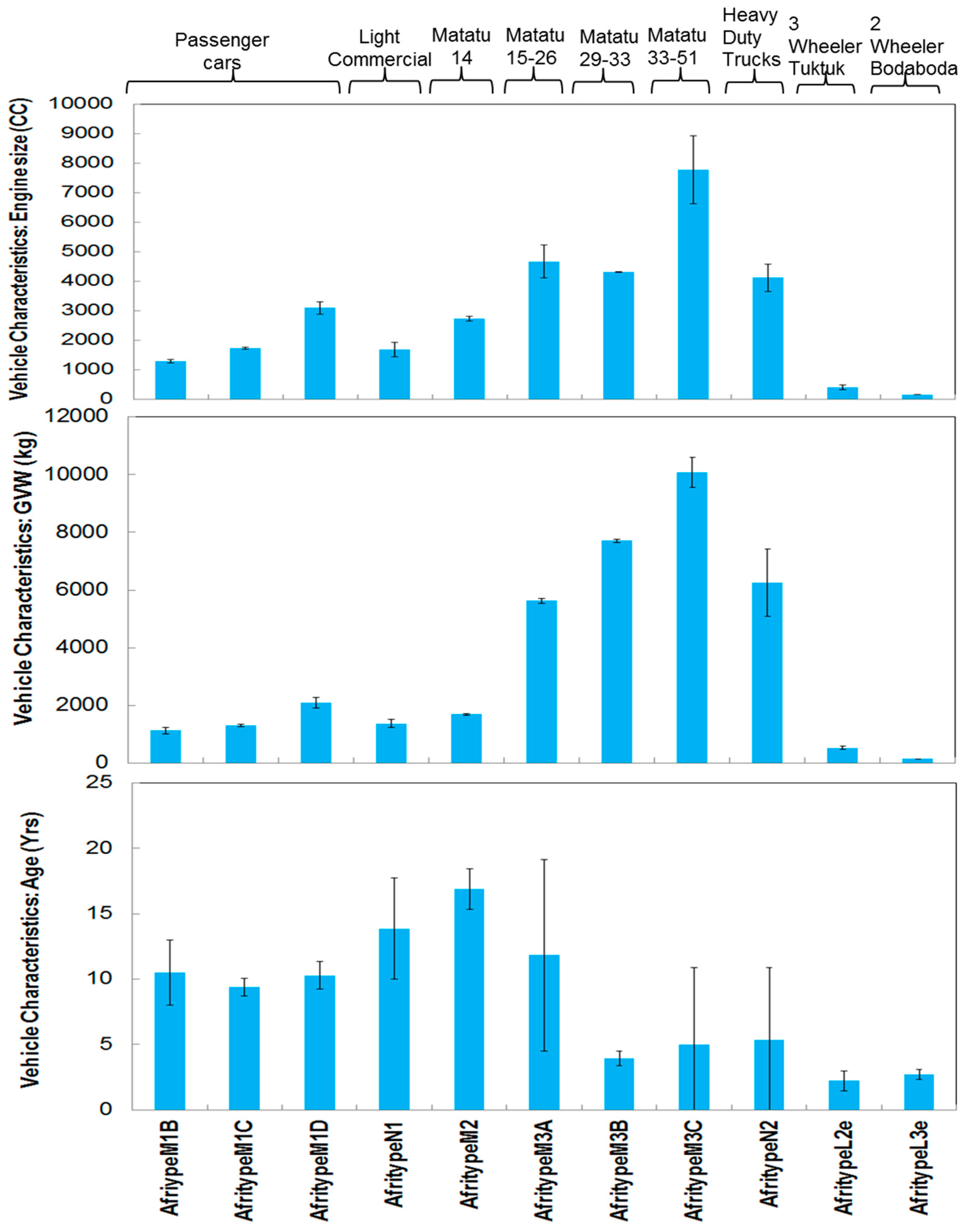
The age of the vehicle is normally an indicator of the emission control technology and hence emissions from the vehicle [
24,
80]. This may hold true for countries that enforce emission compliance checks when importing vehicles and have regular I/M programs [
19]. Imported vehicles with emissions control technology often have these removed or they malfunction without an enforceable I/M program [
19]. The vehicle fleet average age for four wheelers is often high in Kenya: passenger cars 11.1 ± 0.57 years,
matatu 8.80 ± 1.24 years. However, age may not to be a good indicator for emission technology on light duty vehicles in Kenya as a previous study [
37] has shown. This is because in Lents et al. [
37] the vehicles had the required technology but the fuel quality (unleaded petrol) required may not meet standards for emission reduction devices (catalytic converters) to function. Age is also not a good indicator for the technology of emission reduction on HDVs as the original equipment manufacturers (OEMs) are not responsible for the final vehicle configuration other than the powertrain, chassis and cab [
81]. This is supported by the findings of this study of a significant variance in the age of HDV (75%), shown in
Figure 3: AfritypeM3C and AfritypeN2 differ by 118% and 105% respectively. In Kenya most HDV, such as trucks, are imported as engine chassis and cab and built in the country for various uses:
matatus, buses and heavy commercial trucks. However, the sample size for the HDVs for this study was limited, this is because HDVs (trucks and lorries) have limited geographical areas of circulation in Nairobi. Thus, the HDV variance should be viewed cautiously until further studies are conducted with a bigger sample size.
Comparing FE values from different parts of the world is rather uncertain. The studies from which data were compared in
Figure 9, had both diesel and petrol vehicles of similar capacity, mass and power specifications. However, identical average properties were not possible for some countries (for example the USA) due to different categories for vehicle weight and engine size. Even when vehicles had identical properties to fleets in other parts of the world, their utility, especially those of the informal sector, were different. To overcome this challenge, developing country fleets (India, South Africa and Thailand) were sought for comparison as their fleets included an informal sector and had similarity in utility. But the informal transport sector in SSA is usually poorly organized and the industry is often deregulated unlike Asia [
24,
30,
33]. The methods to measure FE also differed; real-world exhaust measurement were sought as these were deemed to be most accurate [
74,
76,
82,
83] but few such studies are undertaken, thus other in-use vehicle studies were also included [
24,
29,
75]. The year the study was undertaken may also have contributed to the uncertainty as that may change the technology the vehicles may have and the fuel quality. To reduce this effect, the comparator studies were limited to years between 2010–2015. Furthermore, fuel consumption becomes extremely high under traffic congestion [
17,
84] which is a severe and worsening reality in Nairobi, as in most developing cities [
50,
85,
86,
87,
88]. Therefore, traffic congestion ought to be factored into FE studies although often, this is not the case [
16]. However even with these limitations, we can conclude vehicle activity and thus fuel economy developed for formal transport sectors does not map the complexity of the informal sector due to different vehicle types and utility of the vehicles
4.2. Imputation
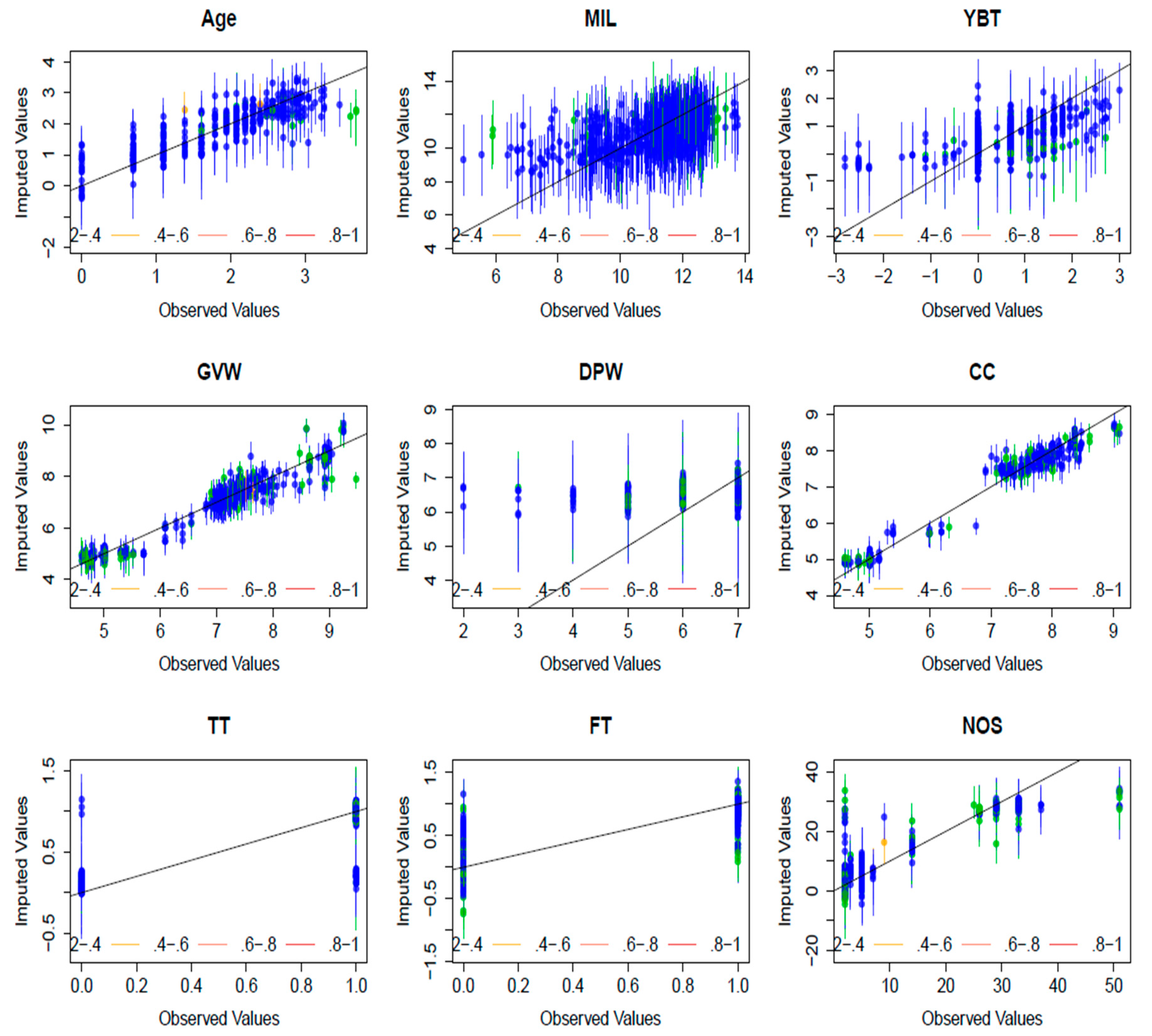
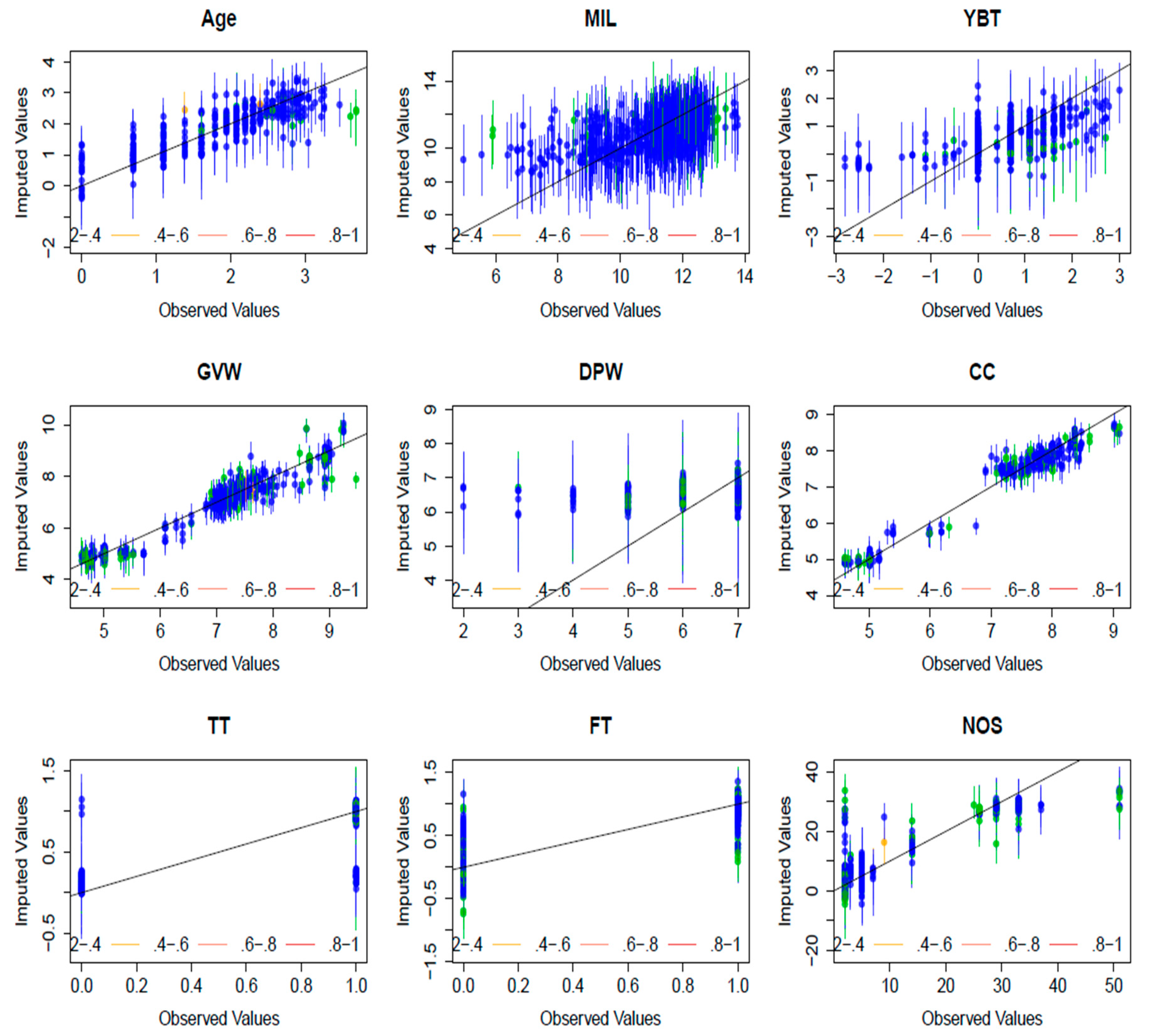
Multiple imputation of incomplete multivariate data was successfully applied to the vehicle fleet data. The diagnostics of the imputation in
Figure 6 shows around 90% of the confidence intervals for the variables CC, GVW, Age, MIL, DPW, YBT, TT, FT and NOS contain the
y =
x line, which means that the true observed value falls within this range, and therefore the imputation was effective in predicting the missing values. The result of the imputation is a bigger data complement than if only those observations for which every variable measured were to be included. The imputation for Engine Size (CC) was a better imputation than Days per Week (DPW). Engine size of the vehicle was verifiable through second-hand vehicle websites and linked to other variables such as GVW, transmission, type of fuel and number of seats. Also, the number of times a vehicle is driven per week (DPW) may be strongly linked to variables not sought after in the questionnaire such as type of job, distance from home or work, fuel price change.
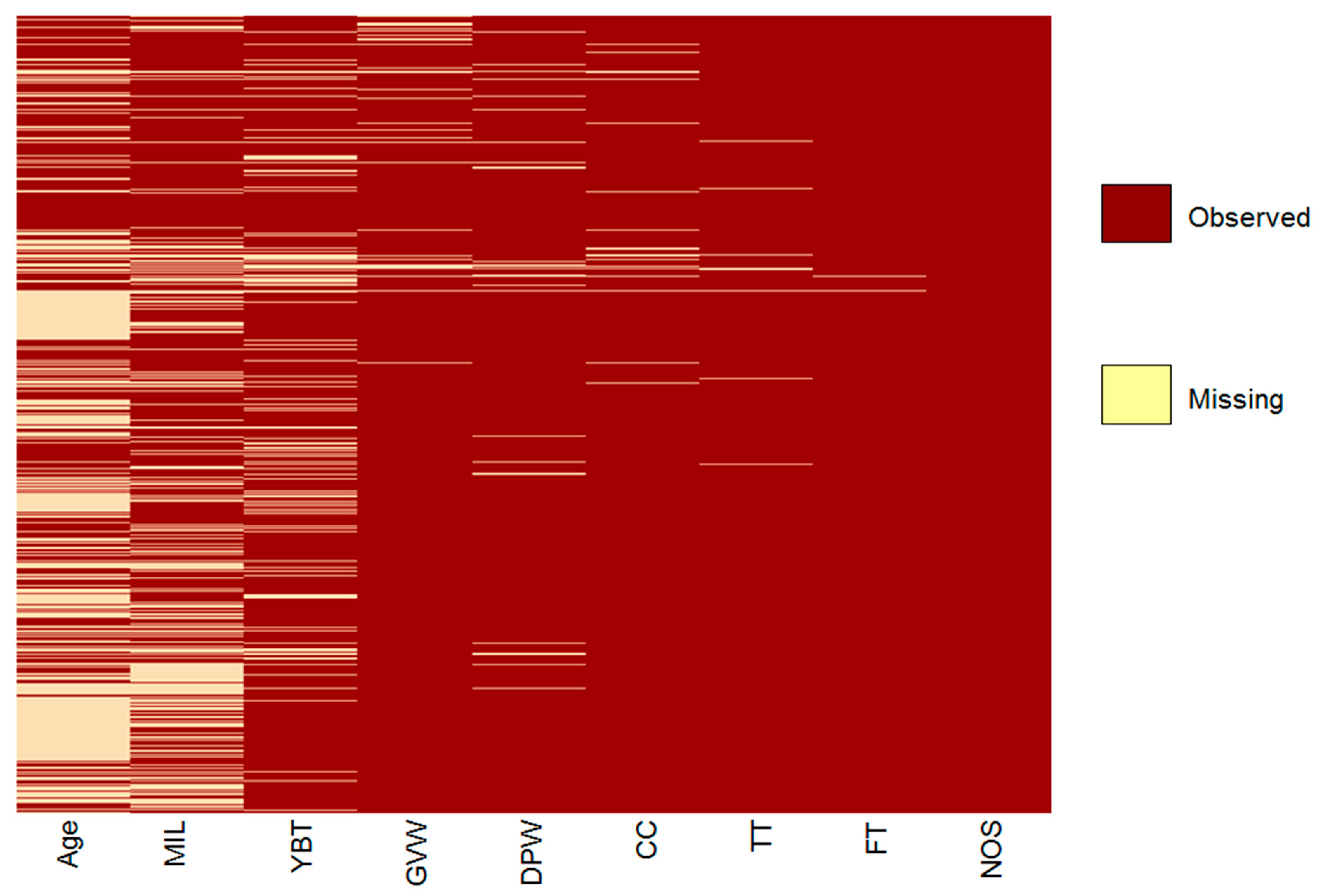
The map of the missing values in
Figure 5 shows the variable Age has the most missing values, 46%. This is because during the interviews, if the driver of the vehicle was not the owner, they often did not have the vehicle logbook, thus the age of vehicle, when the vehicle was bought, engine size and weight was not verifiable on site. Secondary data from vehicle sales websites were used to verify and supplement this information where possible. A previous traffic survey in Nairobi was not able to directly ascertain the age of the vehicle and relied on odometer readings as a proxy for the age of vehicles the [
36]. This is because at the time vehicle imports were restricted to new vehicles so this proxy worked, in 2015, 99% of vehicles imported are second-hand [
47]. MIL, which is the odometer reading, had the second highest missing values, 29%. Drivers of
bodabodas,
tuktuks,
matatus and taxis openly admitted to tampering with the odometers. This finding was supported by a previous study which had very low mileage from a multiple regression methodology to determine average mileage, and concluded that tampering had occurred [
36]. Engine size (CC) and GVW were still verifiable via websites thus the missing values were less in the original dataset before the imputation.
4.3. Fuel Economy Model
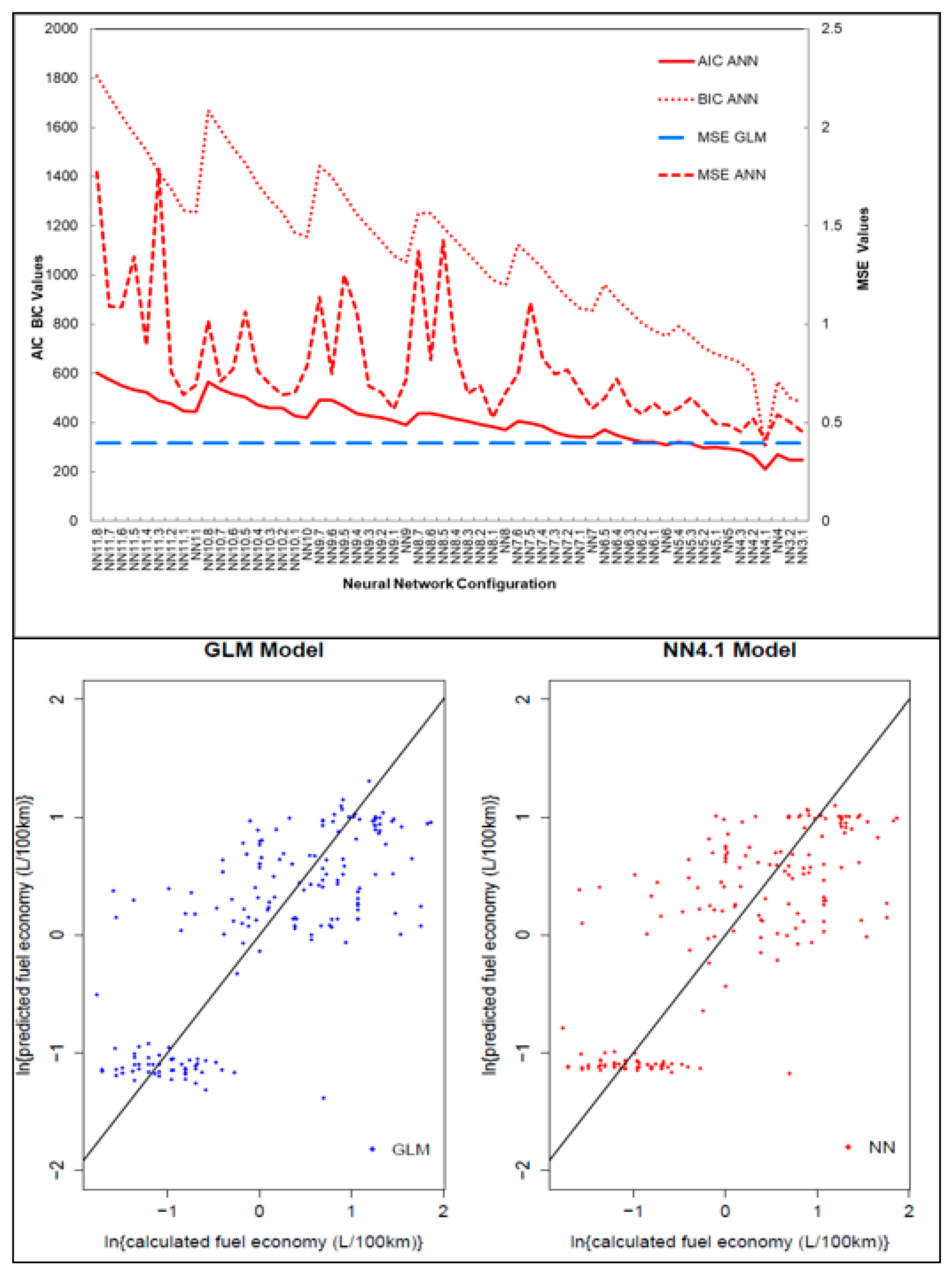
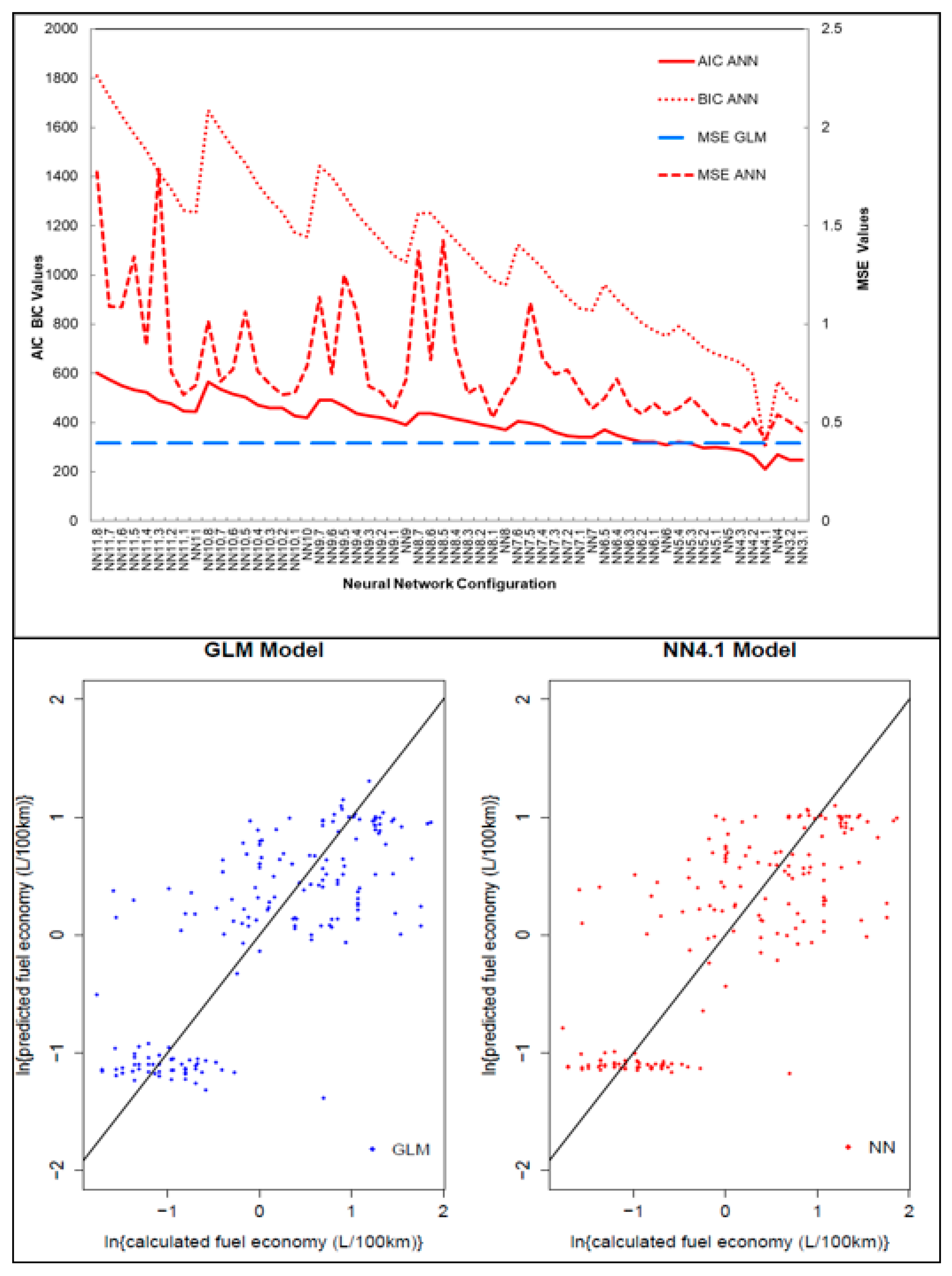
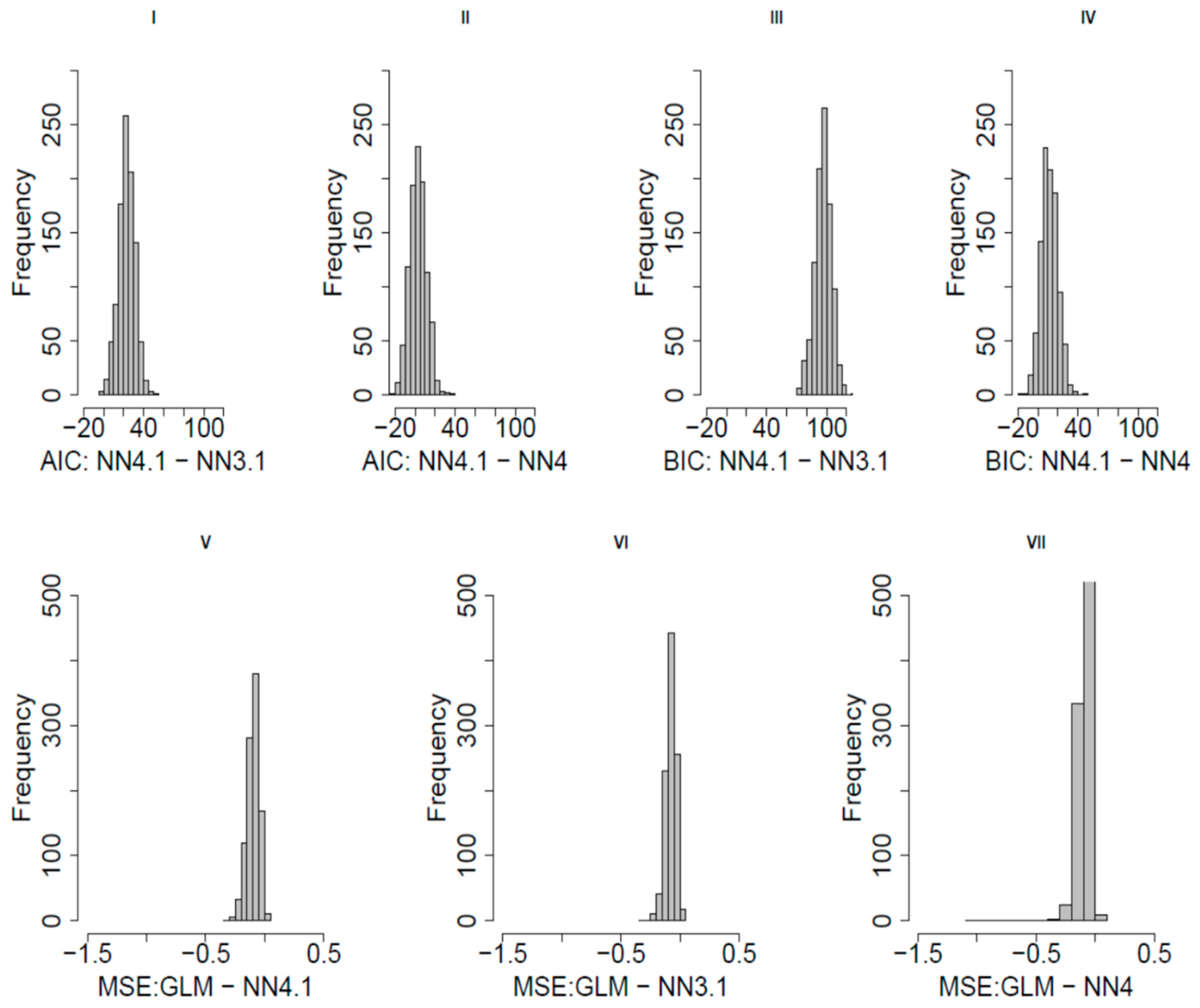
In assessing the comparative statistics in
Figure 8, the GLM model consistently performed better than ANN model, engine size was deemed to be most significant in predicting FE. We chose a cross-validation approach to guard our predictor selection approach against over-fitting [
39,
49,
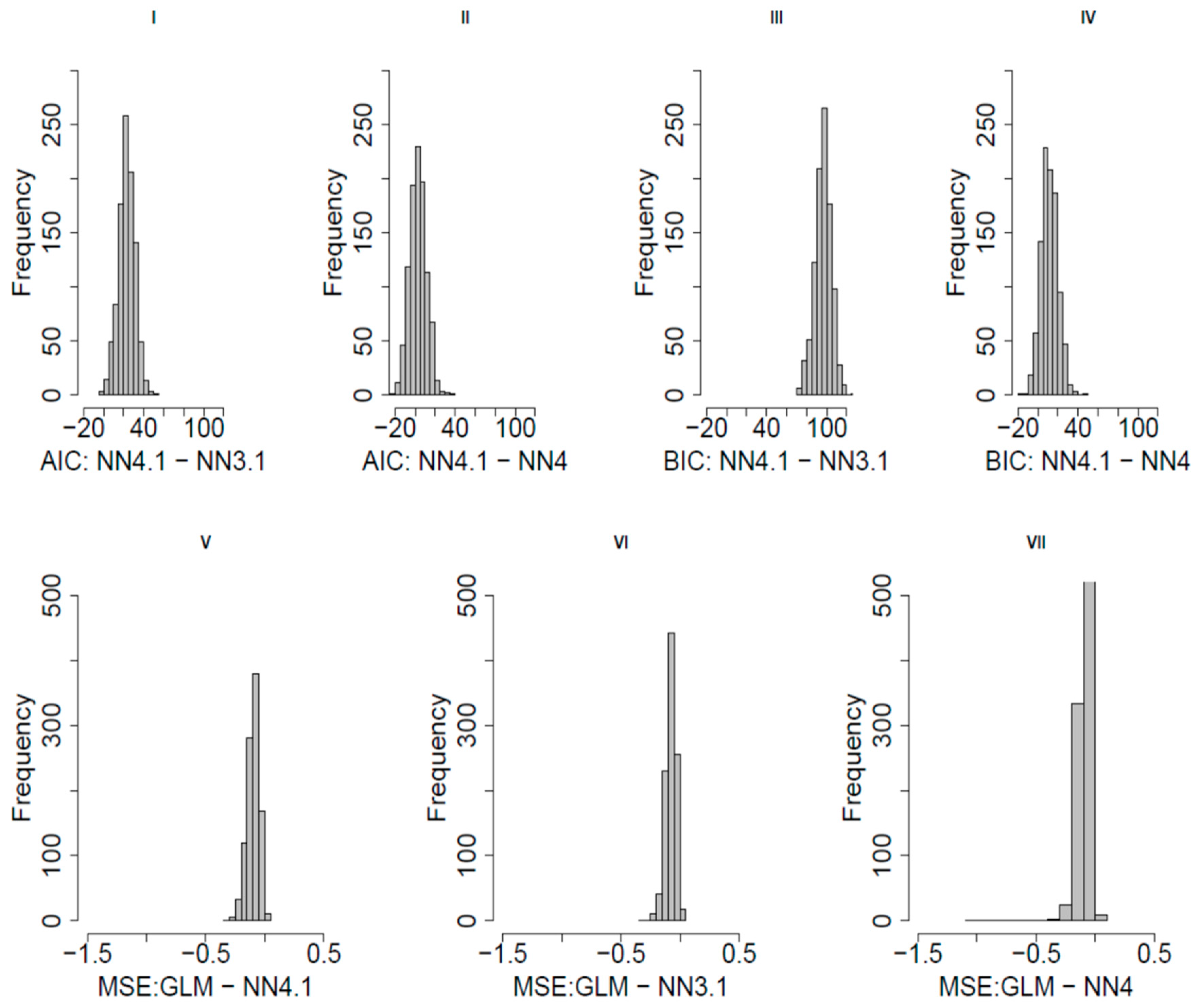
89]. The cross-validation procedure supports our analysis with regards to this goal in three ways. First, the use of information criteria (AIC, BIC) uses indices that provide a numerical summary that takes into account both the fit to the observed data as well as the number of parameters (here layers of the ANN). Unduly complex models were therefore penalised and less likely to end up in our final set of potential models (NN4, NN4.1, NN3.1). Secondly, the use of the MSE in a test sample ensures that if a model is prone to over-fitting the training dataset it will produce worse MSEs in this sample and would again be less likely to be selected. Thirdly, running this analysis as a bootstrap (incl. repeated multiple imputation of missing data adding further robustness) allows us to compare the potential for over/fitting as well as adequate fit in one go.
Figure 7 shows that the overwhelming majority of the bootstrap runs actually support the fit of simpler neural networks than NN4.1 (NN3.1: AIC in 99.7% and BIC in 100% of runs; NN4: AIC 62.7% BIC 92.2%, respectively) and the MSE supported the GLM consistently (NN4.1 worse than MSE in 99.0%; NN4 in 99.1%; NN3.1 in 98.3% of cross validation runs). The model performance and prediction of the GLM achieved higher accuracy, this finding is contrary to a fuel economy study that compared regression models to ANN, ANN model achieved higher accuracy [
39]. This may be because the success of the ANN relies on reliable input and output data to train the algorithm and bigger datasets are better for ANN model precision in prediction for instance Slavin et al. [
39] and Alice et al. [
49]. Limited and incomplete vehicle fleet data is often a challenge in SSA, so while ANN is a powerful tool in modelling complex relations and systems [
39,
90,
91], due to the smaller dataset it was not the better predictive model when compared to GLM model.
Engine size was deemed to be most significant although three other variables also showed significant relationships with fuel economy: weight of the vehicle (GVW), whether the vehicle was bought in Kenya (UK) and whether it was used overseas (UO), the latter two indicating that these cars consumed more fuel than the newly bought cars. Thus, the study was able to identify aspects of the vehicle fleet character (especially engine size and weight of the vehicle) are key to predicting fuel economy changes, thus providing a focus on those parameters that are vital to obtain while conducting questionnaire surveys in order to derive an accurate estimate of fleet fuel economy.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}