1. Introduction
Reducing the Levelized Cost of Energy (LCoE) remains the overall driver for the development of the wind energy sector [
1,
2]. Typically, the Operation and Maintenance (O&M) costs account for 20–25% of the total LCoE for both onshore and offshore wind in comparison to 15% for coal, 10% for gas, and 5% for nuclear [
3]. Over the years, great efforts have been made to reduce the O&M cost of wind energy using emerging technologies, such as automation [
4], data analytics [
5,
6], smart sensors [
7], and Artificial Intelligence (AI) [
8]. The aim of these technologies is to achieve more efficient operation, inspection, and maintenance with minimal human interference. However, having a technology that can be deployed for on-site blade inspection for both onshore and offshore wind turbines under unpredictable weather conditions and that can acquire high-quality data efficiently is still a challenging task. One possible solution is to use the drone-based inspection of the wind turbine blades.
The drone-based approach enables low-cost and frequent inspections, high-resolution optical image acquisition, and minimal human intervention, thereby allowing predictive maintenance at lower costs [
9]. Wind turbine surface damages exhibit recognizable visual traits that can be imaged by drones with optical cameras. These damages include for example leading edge erosion, surface cracks, damaged lightning receptors, damaged vortex generators, and so forth. They are externally visible even in their early stages of development. Moreover, some of these damages, such as surface cracks, even indicate severe internal structural damages [
10]. Nevertheless, internal damages such as delamination, debonding, or internal cracks are not detectable using the drone-based inspection with optical cameras. This study is limited to surface damages of the wind turbine blades.
Extracting damage information from a large number of high-resolution inspection images requires significant manual effort, which is one of the reasons for the overall inspection cost still remaining at a high level. In addition, manual image inspection is tedious and therefore error-prone. By automatically providing suggestions to experts on highly probable damage locations, we can significantly reduce the required man-hours and simultaneously enhance manual detection performance, as a result minimizing the labor cost involved with the analysis of inspection data. With regular cost-efficient and accurate drone inspection, the scheduled maintenance of wind turbines can be performed less frequently, potentially bringing down the overall maintenance cost, contributing to the reduction of LCoE.
Only very few research works have addressed the machine learning-based approaches for surface damage detection of wind turbine blades from drone images. One example, however, is Wang et al. [
11], who used drone inspection images for crack detection. To automatically extract damage information, they used Haar-like features [
12,
13] and ensemble classifiers selected from a set of base models including logitBoost [
14], decision trees [
15], and support vector machines [
16]. Their work was limited to detecting the crack and relied on classical machine learning methods.
Recently, deep learning technology has become efficient and popular, providing groundbreaking performances in detection systems for the last four years [
17]. In this work, we addressed the problem of damage detection by deploying a deep learning object detection framework to aid human annotation. The main advantages of deep learning over other classical object detection methods are: it automatically finds the most discriminate features for the identification of objects, and it is achieved through an optimization process by minimizing the identification and localization errors.
Large size variations of different surface damages of wind turbine blades, in general, are a challenge for machine learning algorithms. In this study, we overcame this challenge with the help of advanced image augmentation methods. Image augmentation is the process of creating extra training images by altering images in the training sets. With the help of augmentation, different versions of the same image are created encapsulating different possible variations during drone acquisition [
18].
The main contributions of this work are three-fold:
Automated suggestion system for damage detection in drone inspection images: implementation of a deep learning framework for automated suggestions of surface damages on wind turbine blades captured by drone inspection images. We show that deep learning technology is capable of giving reliable suggestions with almost human-level accuracy to aid manual annotation of damages.
Higher precision in the suggestion model achieved through advanced data augmentation: The advanced augmentation step called the “Multi-scale pyramid and patching scheme” enables the network to achieve better learning. This scheme significantly improves the precision of suggestions, especially for high-resolution images and for object classes that are very rare and difficult to learn.
Publication of the wind turbine inspection dataset: This work produced a publicly-available drone inspection image of the “Nordtank” turbine over the years of 2017 and 2018. The dataset is hosted within the Mendeley public dataset repository [
19].
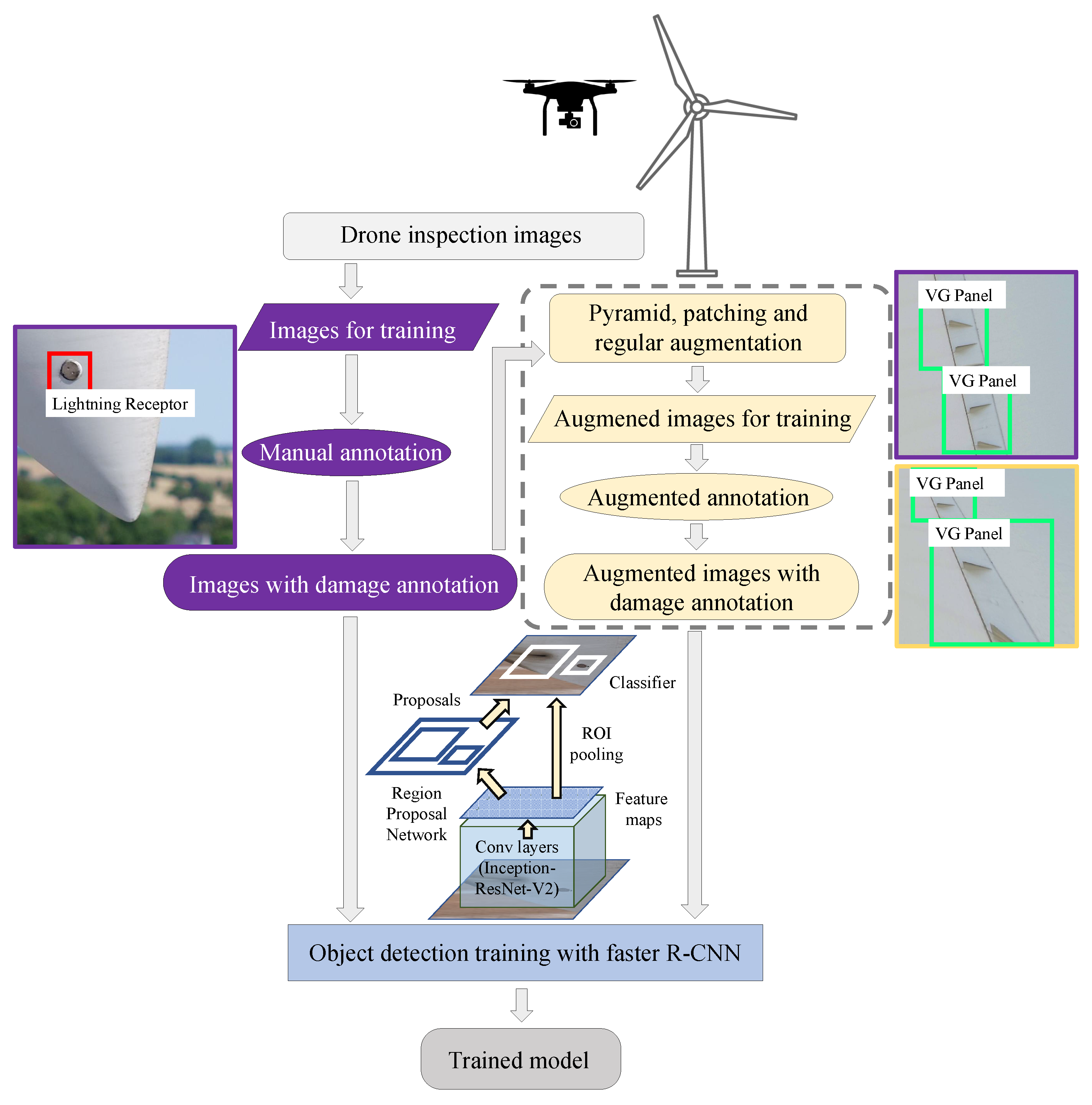
The surface damage suggestion system is trained using faster R-CNN [
20], which is a state-of-the-art deep learning object detection framework. Faster R-CNN works efficiently and with high accuracy compared to other frameworks, while identifying objects in terms of the bounding box from large images. The Convolutional Neural Network (CNN) is used as the backbone architecture in that framework for extracting feature descriptors with high discriminative power. The suggestion model is trained on drone inspection images of different wind turbines. We also employed advanced augmentation methods (as described in details in the Materials and Methods Section) to generalize the learned model. The more generalized model helps the system perform better on challenging test images during inference. Inference is the process of applying the trained model to an input image to receive the detected or, in our case, the suggested object in return.
Figure 1 illustrates the flowchart of the proposed method. To begin with, damages on wind turbine blades that are imaged using drone inspections are annotated in terms of bounding boxes by field experts. Annotated images are also augmented with the proposed advanced augmentation schemes (such as the pyramid, patching, and regular augmentations, as described in details in the Materials and Methods Section) to increase the number of training samples. The faster R-CNN deep learning object detection framework is applied to train from these annotated and augmented annotated images. Within the faster R-CNN framework, the backbone CNN in this case is the deep one, called the Inception-ResNet-V2 architecture. CNN converts images into high-level spatial features called the feature map. The region proposal network tries to estimate where the objects could be located, and ROI pooling is used to extract relevant features from the feature map for that particular region and based on that classifier, making the decision of whether an object of that particular class is present or not. After the training, the deep learning framework produces a detection model that can be applied for new inspection image analysis.
2. Materials and Methods
2.1. Manual Annotation
For this work, four classes were defined: Leading Edge erosion (LE erosion), Vortex Generator panel (VG panel), VG panel with missing teeth, and lightning receptor. Examples of each of these classes are illustrated in
Figure 2.
Figure 2a,g,h illustrates the examples of leading edge erosion annotated by experts using bounding boxes.
Figure 2b,d,e illustrates the lightning receptors.
Figure 2c shows the example of a VG panel with missing teeth.
Figure 2c,f show the examples of well-functioning VG panels. These classes served as the passive indicators of the health condition of the wind turbine blades. The reason behind choosing these classes for experimentation was that all these types of damages produce specific visual traits recognizable by humans and would be valuable if a machine could learn to do the same.
A VG panel and a lightning receptor are not specific damage types, but rather external components on the wind turbine blade that often have to be visually checked during inspections. For inspection purpose, it is of value to detect the location of the lighting receptors and then identify if they are damaged/burned or not. In such cases, the machine learning task could be designed to identify damaged and non-damaged lightning receptors automatically. In this work, we simplified the task into first detecting the lightning receptor and, afterward, if needed, classifying them into damaged or non-damaged ones.
Table 1 summarizes the number of annotations for each class, which are annotated by experts and considered as ground truths. These annotated images were taken from the dataset titled “EasyInspect dataset” owned by EasyInspect ApS company, comprising drone inspection of different types of wind turbine blades located in Denmark. From the pool of available images, 60% were used for training and 40% for testing. As there was a limited number of examples of some damage types such as damaged lightning receptors, 40% of the samples were kept for reliable testing. To evaluate the performance of the developed system it is important to have a substantial number of unseen samples to examine. Annotations in the training set comprised of the annotations from full resolution images that were randomly selected. Annotations in the testing set comprised of the annotations from full-resolution images and also from cropped images containing objects of interest. This was done to make the testing part challenging by varying the scale of an object compared to the size of the image.
2.2. Image Augmentations
Some types of damages on wind turbine blades are rare, and it is hard to collect representative samples during inspections. For deep learning, it is necessary to have thousands of training samples that are representative of the depicted patterns in order to obtain a good detection model [
21]. The general approach is to use example images from the training set and then augment them in ways that represent probable variations in appearances, maintaining the core properties of object classes.
2.2.1. Regular Augmentations
Regular augmentations are defined as conventional ways of augmenting images for increasing the number of training samples. There are many different types of commonly-used augmentation methods that could be selected based on the knowledge about object classes and the possible occurrences of variances during acquisition. Taking drone inspection and wind turbine properties into consideration, four types of regular augmentation were chosen to be used in this work, which are listed below. These four types of regular augmentations were selected to represent real-life possibilities that could occur during drone inspection of wind turbine blades and have been proven to provide positive impacts on deep learning-based image classification tasks [
22,
23,
24].
Perspective transformation for the camera angle variation simulation.
Left-to-right flip or top-to-bottom flip to simulate blade orientation: e.g., pointing up or down.
Contrast normalization for variations in lighting conditions.
Gaussian blur simulating out of focus images.
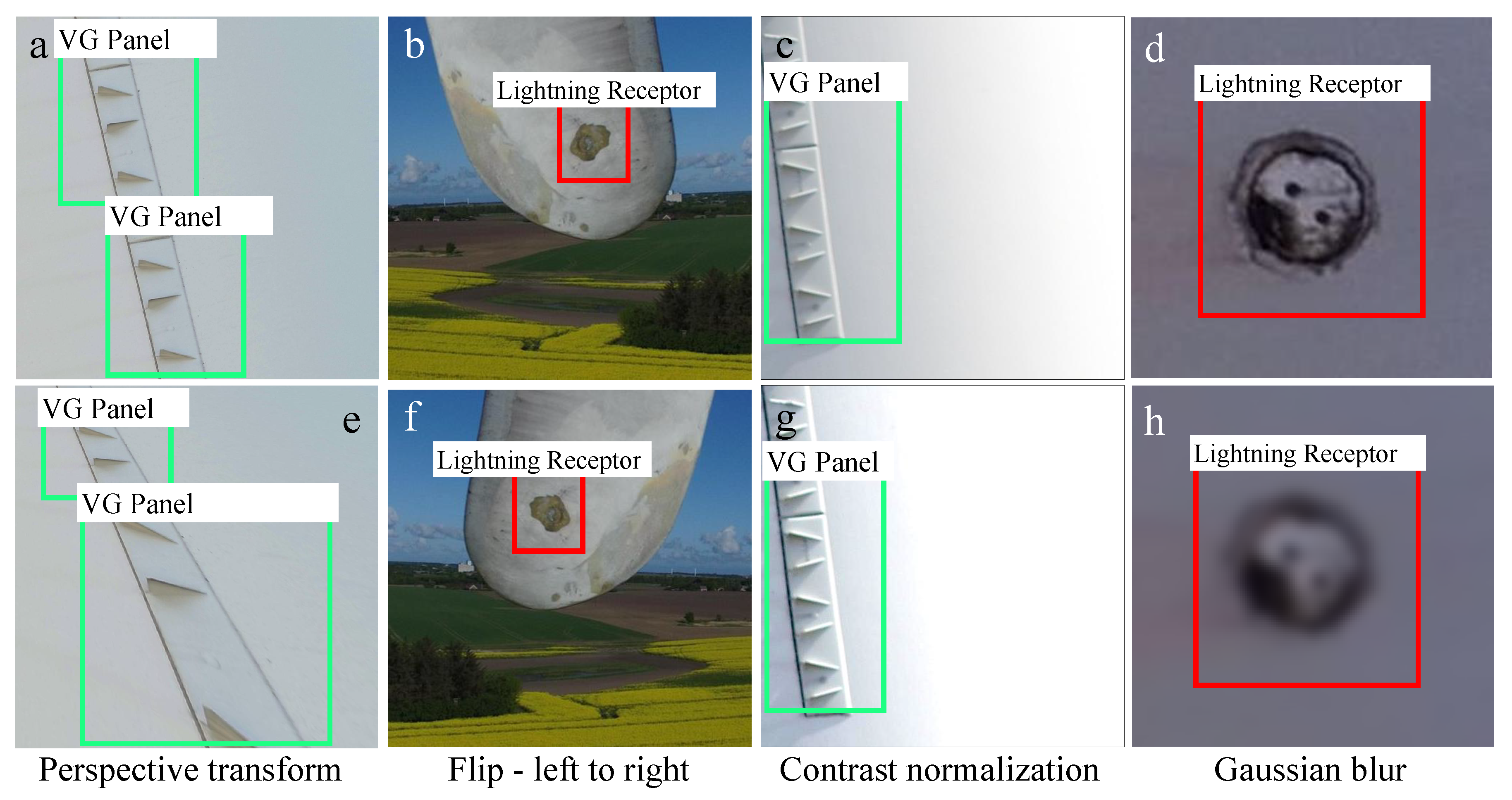
Figure 3 illustrates the examples of regular augmentations of the wind turbine inspection images containing damage examples.
Figure 3e is the perspective transform of
Figure 3a, where both images illustrate the same VG panels;
Figure 3f is left-to-right flipping of the image patch of
Figure 3b containing a lightning receptor.
Figure 3g is the contrast normalized version of
Figure 3c.
Figure 3h is the augmented image of the lightning receptor in
Figure 3d simulating de-focusing of the camera using approximate Gaussian blur.
2.2.2. Pyramid and Patching Augmentation
Drones deployed to acquire the dataset typically were equipped with very high-resolution cameras. High-resolution cameras allowed the drones to capture essential details, being at a further and safer distance from the turbines. These high-resolution images allowed the flexibility of training from rare types of damages and a wide variety of backgrounds at a different resolution using the same image.
The deep learning object detection frameworks such as the faster R-CNN framework have predefined input image dimensions that typically allow for a maximum input image dimension (either height or width) of 1000 pixels [
20,
25]. This is maintained through re-sizing higher resolution images while keeping the ratio between width and height in situ. For high-resolution images, this limitation creates new challenges due to damages being minimal in pixel sizes compared to full image size.
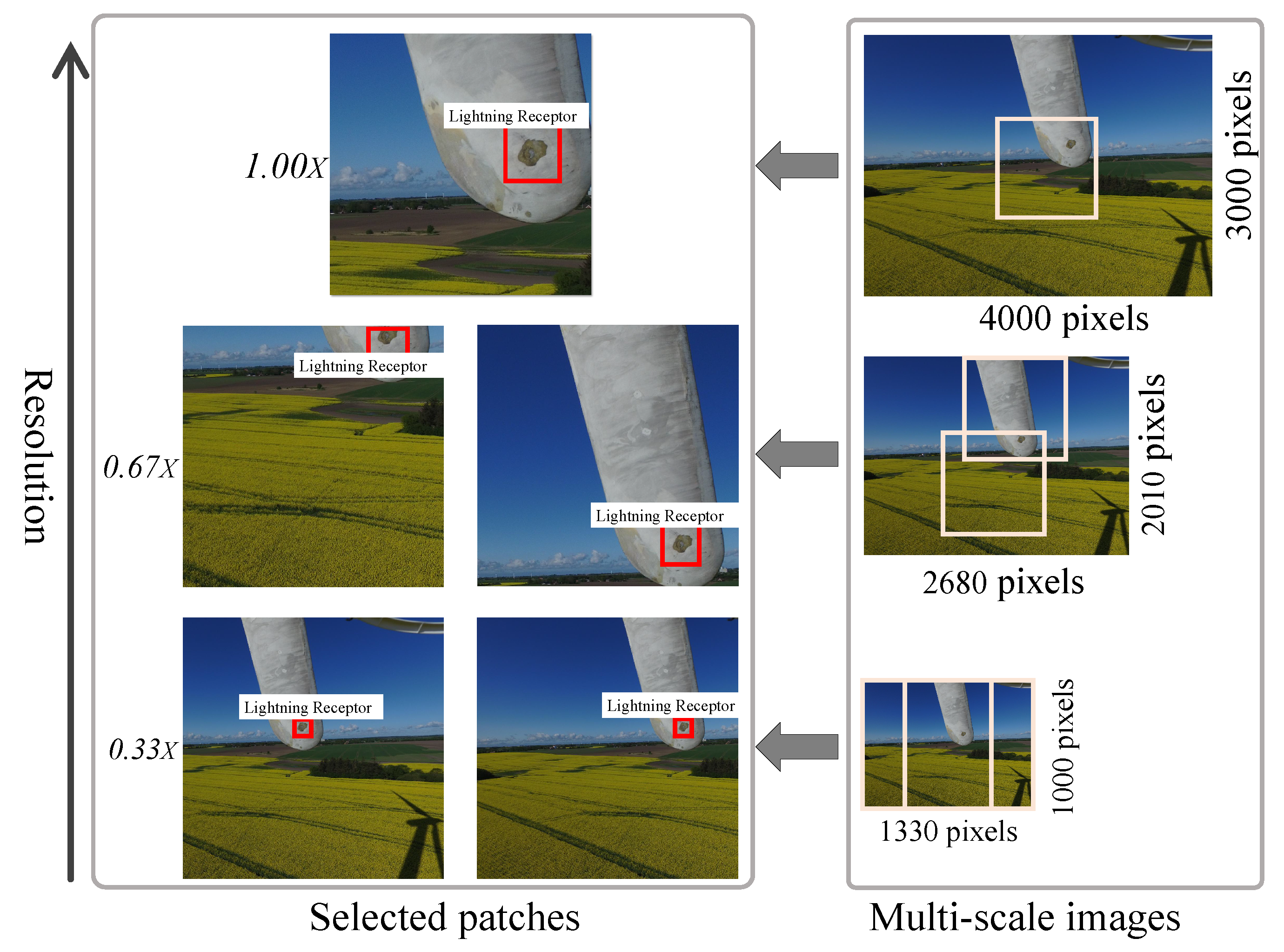
In
Figure 4, on the right is the pyramid scheme, and on the left is the patching scheme. The bottom level of the pyramid scheme is defined as the image size where either the height or width is 1000 pixels. In the pyramid, from top to bottom, images are scaled from
to
, simulating from the highest to the lowest resolutions. Sliding windows with
overlap were scanned over the images at each resolution to extract patches containing at least one object. Resolution conversions were performed through the linear interpolation method [
26]. For example, in
Figure 4, top right, the acquired full resolution image is
pixels, where the lightning receptor only occupies around
pixels. When fed to CNN during training in full resolution, it would be resized to the pre-defined network input size, where the lightning receptor would be occupying a tiny portion of
pixels. Hence, it is rather complicated to acquire enough recognizable visual traits of the lightning receptor.
Using the multi-scale pyramid and patching scheme on the acquired high-resolution training images, scale-varied views of the same object were generated and fed to the neural network. In this scheme, the main full-resolution image was scaled to multiple resolution images (, , ), and on each of these images, patches containing objects were selected with the help of a sliding window with overlap. The selected patches were always pixels.
The flowchart of this multi-scale pyramid and patching scheme is shown in
Figure 4. This scheme helps to represent object capture at different camera distances, allowing the detection model to be efficiently trained on both low- and high-resolution images.
2.3. Damage Detection Framework
With recent advances in deep learning for object detection, new architectures are frequently proposed, establishing groundbreaking performances. Currently, different stable meta architectures are publicly-available and have already been successfully deployed for many challenging applications. Among deep learning object detection frameworks, one of the best-performing methods is the faster R-CNN [
20,
27]. We also experimented with other object detection frameworks such as R-CNN [
25], fast R-CNN [
28], SSD [
29], and R-FCN [
30]. It was found that indeed, the faster R-CNN outperformed others in terms of accuracy when real-time processing was not needed, and deep CNN architectures like ResNet [
31] were used for feature extraction. In our work, the surface damage detection and classification using drone inspection images were performed using faster R-CNN [
20].
Faster R-CNN [
20] uses a Region Proposal Network (RPN) [
32] trained on feature descriptors extracted by CNN to predict bounding boxes for objects of interest. The CNN architecture automatically learns features such as texture, spatial arrangement, class size, shape, and so forth, from training examples. These automatically-learned features are more appropriate than hand-crafted features.
Convolutional layers in CNN summarize information based on the previous layer’s content. The first layer usually learns edges; the second finds patterns in edges encoding shapes of higher complexity, and so forth. The last layer contains a feature map of much smaller spatial dimensions than the original image. The last layer feature map summarizes information about the original image. We experimented with both lighter CNN architectures such as InceptionV2 [
33] and ResNet50 [
31] and heavier CNN architectures such as ResNet101 [
31] and Inception-ResNet-V2 [
34].
The Inception [
33] architecture by Google contains an inception module as one of the building blocks, and the computational cost is about
-times higher than that of GoogLeNet [
35]. The ResNet architecture [
31] is known for its residual blocks, which help to reduce the impact of vanishing gradients from the top layers to the bottom layers during training. Inception-ResNet-V2 [
34] is one of the extensions of the inception architectures that incorporates both the inception blocks and residual ones. This particular CNN network was used as the backbone architecture in our final model within a faster R-CNN framework for extracting highly discriminating feature descriptors. This network is computationally heavy and was found to provide state-of-the-art performances for object detection tasks [
27].
2.4. Performance Measure: Mean Average Precision
All the reported performances in terms of Mean Average Precision (MAP) were measured during inference on the test images, where the inference is the process of applying the trained model to an input image to receive the detected and classified object in return. In this work, we called it suggestions if the trained model from deep learning was being used.
MAP is commonly used in computer vision to evaluate object detection performance during inference. An object proposal is considered accurate only if it overlaps with the ground truth with more than a certain threshold. Intersection over Union (IoU) is used to measure the overlap of a prediction and the ground truth where ground truth refers to the original damages identified and annotated by experts in the field.
The IoU value corresponds to the ratio of the common area over the sum of the proposed detection and ground truth areas (as shown in Equation (
1), where
P and
are the predicted and ground truth bounding boxes, respectively). If the value is more than
, the prediction or, in this case, the suggestion is considered as a true positive. This
value is relatively conservative, as it makes sure that the ground truth and the detected object have a very similar bounding box location, size, and shape. For addressing human perception diversities, we used a
IoU threshold for considering a detection as a true positive.
Per class precision for each image,
, was calculated using Equation (
2). For each class, average precision,
was measured over all the images in the dataset using Equation (
3). Finally, MAP was measured as the mean of average precision for each class over all the classes in the dataset (see Equation (
4)). Throughout this work, the MAP is reported in percentage.
2.5. Software and Codes
We used the Tensorflow [
36] deep learning API for experimenting with the faster R-CNN object detection method with different CNN architectures. These architectures were compared with each other under the proposed augmentation schemes. For implementing the regular augmentations, the imgaug (
https://github.com/aleju/imgaug) package was used, and for the pyramid and patching augmentation, an in-house python library was developed. Inception-ResNet-V2 and other CNN weights were initialized from the pre-trained weight on the Common Objects in COntext (COCO) dataset [
37]. The COCO dataset consists of 80 categories of regular objects and is commonly used for bench-marking deep learning object detection performance.
2.6. Hardware
All the experiments reported in this work were performed on a GPU cluster machine with 11-GB GeForce GTX 1080 Graphics Cards within a Linux operating system. The initial time required for training 275 epochs (where one epoch is defined as when all the images in the training set had been used at least once for optimization of the detection model) using Inception-V2, ResNet-50, ResNet-101, and Inception-ResNet-V2 networks was on average 6.3 h, 10.5 h, 16.1 h, and 27.9 h, respectively.
2.7. Dataset
2.7.1. EasyInspect Dataset
The EasyInspect dataset is a non-public inspection dataset provided by EasyInspect ApS, which contains images ( pixels in size) of different types of damages on wind turbines from different manufacturers. The four classes are LE erosion, VG panel, VG panel with missing teeth, and lightning receptor.
2.7.2. DTU Drone Inspection Dataset
In this work, we produced a new public dataset entitled DTU—Drone inspection images of the wind turbine. It is the only public wind turbine drone inspection image dataset containing a total of 701 high-resolution images. This dataset contains temporal inspection images of 2017 and 2018 covering the “Nordtank” wind turbine located at DTU Wind Energy’s test site at Roskilde, Denmark. The dataset comes with the examples of damages or mounted objects such as VG panel, VG panel with missing teeth, LE erosion, cracks, lightning receptor, damaged lightning receptor, missing surface material, and others. It is hosted at [
19].
3. Results
3.1. Augmentation of Training Images Provides a Significant Gain in Performance
Comparing different augmentation types showed that a combination of the regular, pyramid, and patching augmentations produced a more accurate suggestion model, especially for the deeper CNN architectures as the backbone for the faster R-CNN framework. Using CNN architecture ResNet-101 for example (as shown in
Table 2 in column “all”), without any augmentation, the MAP (detailed in the Materials and Methods Section) of damage suggestion was very low with a value of
. With the help of the patching augmentation, the precision improved significantly (as for this case, the MAP increased to
). In
Table 2, all the experimental results are reported in terms of MAP. VG and VGMT represent the VG panel and the VG with Missing Teeth, respectively. “All” is the overall MAP comprising all four classes.
Together with the patching and the regular augmentations, the MAP increased slightly to . However, the pyramid scheme dramatically improved the performance of the trained model up to . The best performing configuration was the last one with the combination of the pyramid, patching, and regular augmentation schemes, generating an MAP of .
As shown in
Figure 5a–d, the proposed combination of all the proposed augmentation methods significantly and consistently improved the performance of the model and lifts it to above
for all four CNN architecture.
Figure 5a–d represents sequentially lighter to deeper CNN backbone architectures used for deep learning feature extraction. The CNN networks explored in this work were: Inception-V2, ResNet-50, ResNet-101, and Inception-ResNet-V2. In each individual figure (a–d): the y-axis represents the MAP of the suggestion on the test set, which are reported in percentage.
For any specific type of augmentation, MAPs, in general, were higher for the deeper networks (which were ResNet-101 and Inception-ResNet-V2) than for the lighter ones. For these two deeper networks, note that regular augmentation on top of the multi-scale pyramid and patching scheme added on average gain in MAP. For lighter networks (Inception-V2 and ResNet-50), due to the limited search space, the network tended to learn and map better without the addition of regular augmentation. The results also demonstrated that for the small dataset (where some types of damages were extremely rare), it was beneficial to generate augmented images following class variation probabilities in terms of scale, light conditions, focuses, and acquisition angles.
3.2. The CNN Architecture Performs Better as It Goes Deeper
When comparing the four selected CNN backbone architectures for the faster R-CNN framework, the Inception-ResNet-V2, which was the deepest, performed the best among all. If we fixed the augmentation to the combination of pyramid, patching, and regular, the MAP of the Inception-V2, ResNet-50, ResNet-101, and Inception-ResNet-V2 would be
,
,
, and
, respectively (as shown in
Figure 5 and in
Table 2). The number of layers in each of these networks representing the depth of the network could be arranged in the same order, as well (where Inception-V2 was the lightest and Inception-ResNet-V2 the deepest). This demonstrates that the performance regarding MAP increased as the network went deeper. The gain in performance of deeper networks comes with the cost of a longer training time and higher requirements on the hardware.
3.3. Faster Damage Detection with the Suggestive System in Inspection Analysis
The time required for automatically suggesting damage locations for new images using the trained model depends on the size of the input image and the depth of the CNN architecture used. In the presented case, the average time required for inferring a high-resolution image using Inception-V2, ResNet-50, ResNet-101, and Inception-ResNet-V2 networks (after leading the model) was respectively 1.36 s, 1.69 s, 1.87 s, and 2.11 s; whereas, for human-based analysis without suggestions, it can take around 20 s–3 min per image depending on the difficulty level for identification. With the deep learning-aided suggestion system for humans, the analysis time went significantly down (almost to two-thirds) compared to human speed without suggestions and also produced better accuracy (see
Table 3).
Damages on unseen inspection images were annotated by experts having deep learning-aided suggestions as bounding boxes and without. In the case of suggestive bounding boxes, experts only needed to correct, whereas in the case of “without suggestion”, they needed to draw the bounding box from scratch. While annotating 100 randomly-selected images, with suggestion, it took on average 131 s per image, whereas without suggestion, it was around 200 s per image. Human results (in terms of precision) with and without suggestions are called “Human” and “Suggestions aiding human”. The precision of the deep learning trained model’s suggestion is called “Suggestions”. To access the precision of “Suggestions”, the best-performing model Inception-ResNet-V2 within the faster R-CNN framework equipped with pyramid, patching, and regular augmentation was used.
4. Discussion
With the deep learning-based automated damage suggestion system, the best performing model in the proposed method produced precision, which is within the range of the average human precision of . In the case of deep learning-aided suggestion for humans, the MAP improved significantly to , and the required processing time became two-thirds that on average for each image. This result suggests that humans can benefit from suggestions by knowing where to look for damages in images, especially for difficult cases like VG panels with missing teeth.
The experimental results show that for a smaller image dataset of wind turbine inspection, the performance was more sensitive to the quality of image augmentation than the selection of CNN architecture. One of the main reasons is that most damage types can have a considerably large variance in appearance, which makes the deployed network dependent on a larger number of examples from which to learn.
The combination of ResNet and inception modules in Inception-ResNet-V2 learned difficult damage types such as missing teeth in a vortex generator with more reliability than by the other CNN architectures.
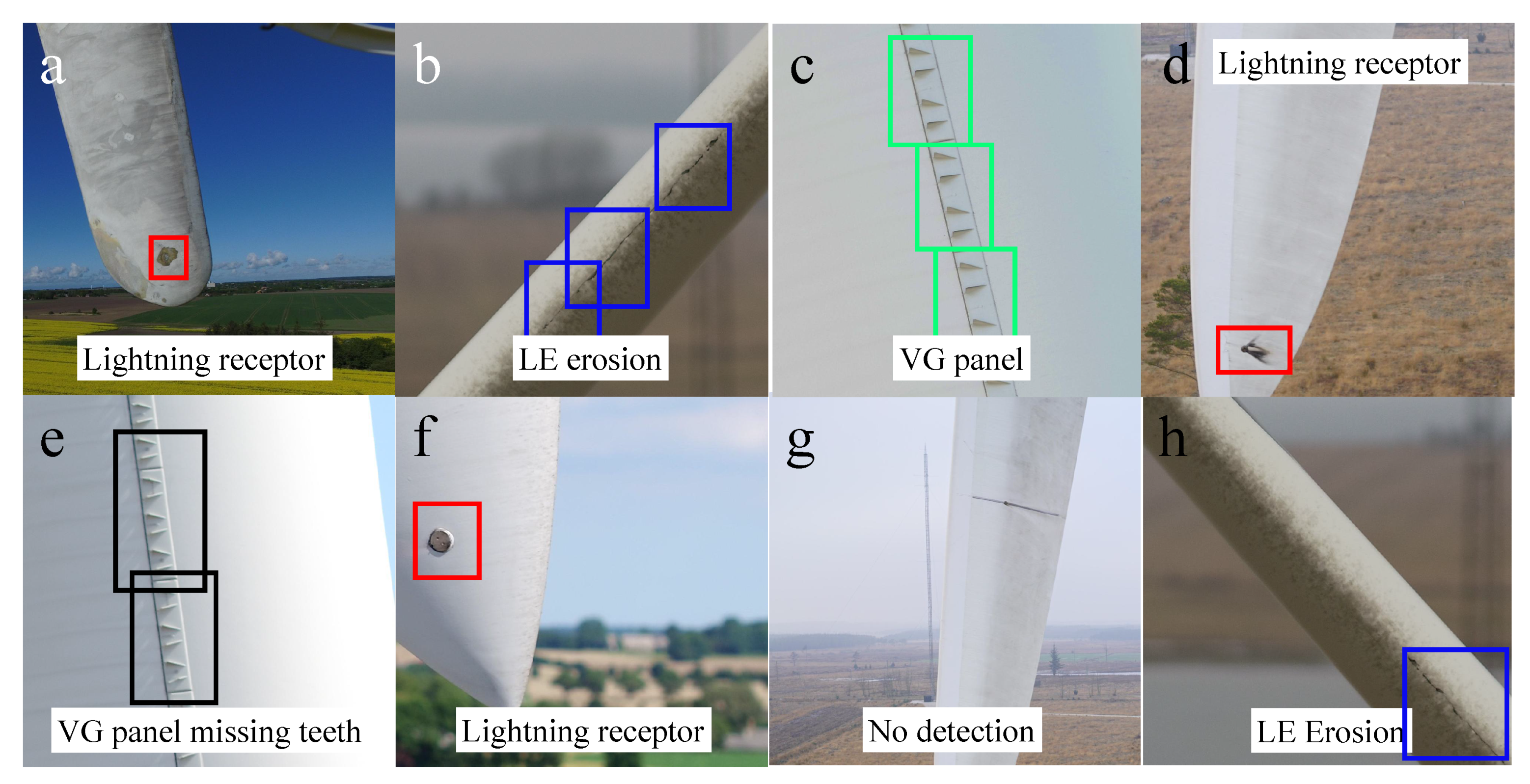
Figure 6 illustrates some of the suggestion results on inspection images for testing.
Figure 6a,d,f illustrates suggested lighting receptors;
Figure 6b,h shows LE erosion suggestion;
Figure 6c,e illustrates the suggestion of VG panels with intact teeth and those with missing teeth, respectively. The latter exemplifies one of the very challenging tasks for automated damage suggestion method.
Figure 6g shows the example of when no damage is detected. The suggestion model developed in this study performed well for challenging images, providing almost human-level precision. When there was no valid class present in the image, the trained model found only the background class and presented “No detection” as the label for that image (an example is shown in
Figure 3g).
This automated damage suggestion system has a potential cost advantage over the current manual one. Currently, drone inspections typically can cover up to 10 or 12 wind turbines per day. Damage detection, however, is much less efficient, as it involves considerable data interpretation for damage identification, annotation, classification, etc., which has to be conducted by skilled personnel. This process would incur significant labor cost considering the huge amount of images taken by the drones from the field. Using the deep learning framework for the suggestion to aid manual damage detection, the entire inspection and analysis process can be partially automated to minimize human intervention.
With suggested damages and subsequent corrections by human experts, over time, the number of annotated training examples would be increased and fed to the developed system for updating the trained suggestion model. This continuous way of learning through the help of human experts can increase the accuracy of the deep learning model (expected to provide 2–5% gain in MAP) and also reduce the required time for human corrections.
Relevant information about the damages, i.e., their size and location on the blade, can be used for further analysis in estimating wind turbine structural and aerodynamic conditions. The highest standalone MAP achieved with the proposed method was , which is almost within human-level precision given the complexity of the problem and the conservative nature of the performance indicator. The developed automated detection system at its current state can safely work as a suggestion system for experts to finalize the damage locations from inspection data.
The required computational power and deep learning training can incur higher initial cost mainly due to the fact that acquiring training images comprising damage examples is expensive. However in the long run, a well-trained model on damage types of interest can produce a less expensive and more reliable solution to the drone inspection analysis task. With this proposed method, the majority of surface damages on the wind turbine blade can be semi-automatically recognized and reported for future actions in terms of maintenance.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}