A Hybrid Short-Term Load Forecasting Framework with an Attention-Based Encoder–Decoder Network Based on Seasonal and Trend Adjustment


Abstract

1. Introduction
- We developed a novel hybrid prediction framework: A hybrid STA–AED framework was developed to predict electric load. Instead of processing the original electric load series directly, the proposed approach splits data into three components by the seasonal and trend decomposing technique first.
- Based on the multi-head attention mechanism, we developed an attention-based encoder–decoder architecture for power load forecasting.
- The model was implemented in univariate load series data only. For other forecasting approaches, a variety variables were considered as predictive model inputs to improve the accuracy of prediction, such as holiday arrangement, weather, and economic environment. However, our proposed model was implemented without utilizing other input features and gained better prediction results still.
- Our approach was evaluated on a real-world dataset. Compared with other counterpart models, our approach achieved the best prediction accuracy in 14 out of 15 experiments.
2. The Proposed Method
2.1. The Overview of the Proposed Framework
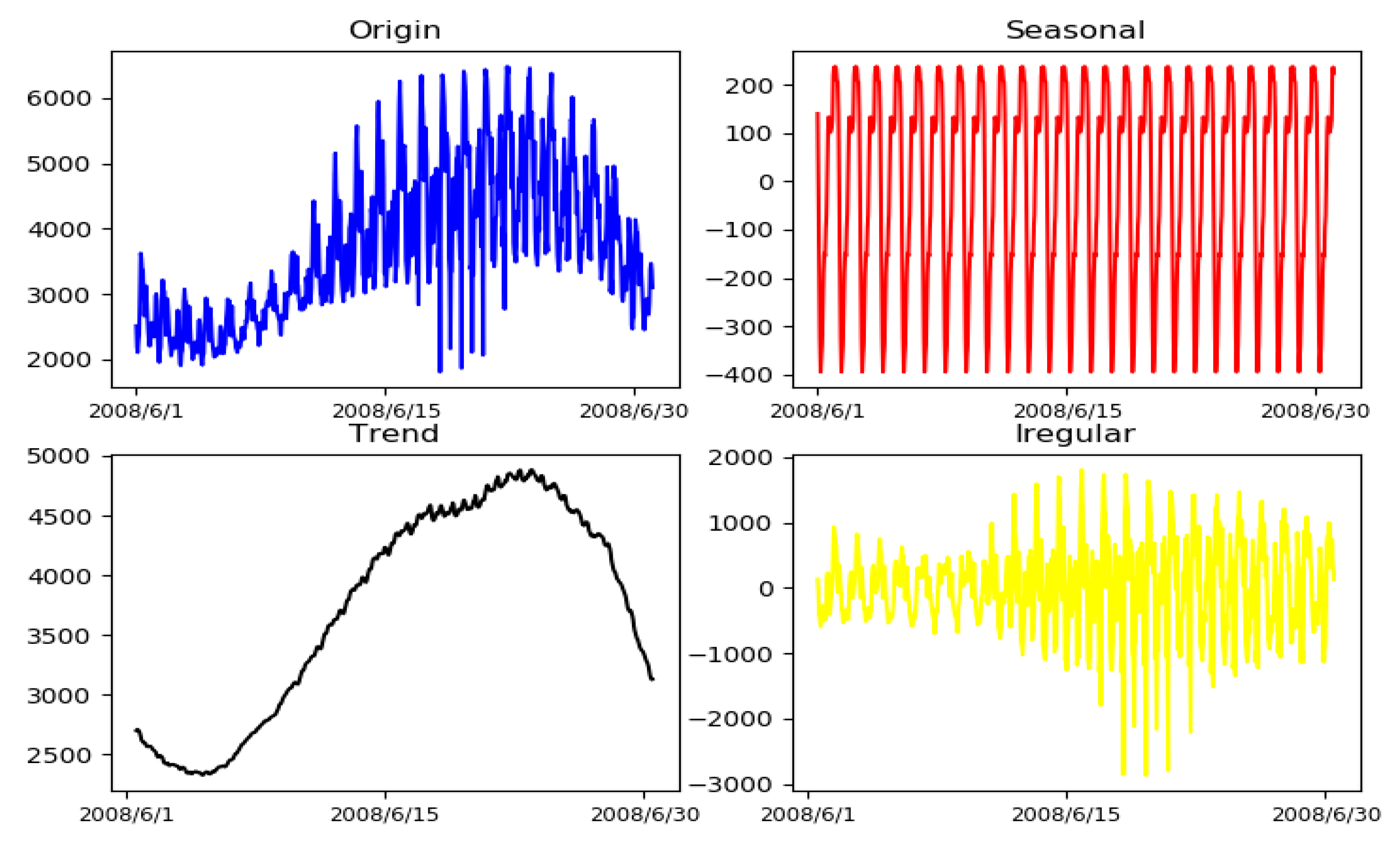
2.2. Seasonal and Trend Adjustment
2.3. Attention-Based Models
2.4. Encoder with Multi-Head Attention
2.5. Decoder
3. Experiments and Results
3.1. Dataset Description
3.2. Model Evaluation Indexes
3.3. Method Comparison
- (1)
- Random forest regressor: Random forest regressor is one of the most widely used traditional machine learning methods.
- (2)
- Gradient boosting decision tree (GBDT): GBDT is one of the commonly used machine learning algorithms. It is very popular in load forecasting because of its excellent automatic feature combination ability and efficient operation.
- (3)
- Gated recurrent units (GRUs): GRUs are a widely used variant of the recurrent neural network (RNN). GRUs are similar to long short-term memory (LSTM) but with fewer parameters than LSTM.
- (4)
- Encoder–decoder: This approach is based on encoder–decoder architecture without applying the attention mechanism.
- (5)
- Encoder–decoder with multi-head attention: The only difference with the method proposed in this paper is that the input data are not processed by the seasonal and trend decomposing technique.
3.4. The Detailed Exprimental Setting
3.5. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yukseltan, E.; Yucekaya, A.; Bilge, A.H. Forecasting electricity demand for Turkey: Modeling periodic variations and demand segregation. Appl. Energy 2017, 193, 287–296. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Yang, H.; Huang, C.M. A new short-term load forecasting approach using self-organizing fuzzy ARMAX models. IEEE Trans. Power Syst. 1998, 13, 217–225. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Vu, D.H.; Muttaqi, K.M.; Agalgaonkar, A.P.; Bouzerdoum, A. Short-term electricity demand forecasting using autoregressive based time varying model incorporating representative data adjustment. Appl. Energy 2017, 195, 790–801. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, P.; Chu, Y.; Li, W.; Wu, Y.; Ni, L.; Bao, Y.; Wang, K. Short-term electrical load forecasting using the Support Vector Regression (SVR) model to calculate the demand response baseline for office buildings. Appl. Energy 2017, 195, 659–670. [Google Scholar] [CrossRef]
- Avami, A.; Boroushaki, M. Energy Consumption Forecasting of Iran Using Recurrent Neural Networks. Energy Sour. Part B Econ. Plan. Policy 2011, 6, 339–347. [Google Scholar] [CrossRef]
- Lloyd, J.R. GEFCom2012 hierarchical load forecasting: Gradient boosting machines and Gaussian processes. Int. J. Forecast. 2014, 30, 369–374. [Google Scholar] [CrossRef]
- Liu, N.; Tang, Q.; Zhang, J.; Fan, W.; Liu, J. A hybrid forecasting model with parameter optimization for short-term load forecasting of micro-grids. Appl. Energy 2014, 129, 336–345. [Google Scholar] [CrossRef]
- Tripathi, M.M.; Upadhyay, K.G.; Singh, S.N. Short-Term Load Forecasting Using Generalized Regression and Probabilistic Neural Networks in the Electricity Market. Electr. J. 2008, 21, 24–34. [Google Scholar] [CrossRef]
- Guan, C.; Luh, P.B.; Michel, L.D.; Wang, Y.; Friedland, P.B. Very Short-Term Load Forecasting: Wavelet Neural Networks with Data Pre-Filtering. IEEE Trans. Power Syst. 2013, 28, 30–41. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M.; Li, R. Deep Learning for Household Load Forecasting—A Novel Pooling Deep RNN. IEEE Trans. Smart Grid 2017, 9, 5271–5280. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gensler, A.; Henze, J.; Sick, B.; Raabe, N. Deep Learning for solar power forecasting—An approach using AutoEncoder and LSTM Neural Networks. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 002858–002865. [Google Scholar]
- Chen, Z.; Sun, L. Short-Term Electrical Load Forecasting Based on Deep Learning LSTM Networks. Electr. Technol. 2018, 158, 2922–2927. [Google Scholar]
- Lu, K.; Zhao, Y.; Wang, X.; Cheng, Y.; Pang, X.; Sun, W.; Jiang, Z.; Zhang, Y.; Xu, N.; Zhao, X. Short-term electricity load forecasting method based on multilayered self-normalizing GRU network. In Proceedings of the IEEE Conference on Energy Internet and Energy System Integration, Beijing, China, 26–28 November 2017; pp. 1–5. [Google Scholar]
- Zheng, J.; Xu, C.; Zhang, Z.; Li, X. Electric load forecasting in smart grids using Long-Short-Term-Memory based Recurrent Neural Network. In Proceedings of the 2017 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2017. [Google Scholar]
- Wang, Y.; Liu, M.; Bao, Z.; Zhang, S. Short-Term Load Forecasting with Multi-Source Data Using Gated Recurrent Unit Neural Networks. Energies 2018, 11, 1138. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Jiang, X.; Xiao, Z.; Zhang, B.; Zhen, X.; Cao, X.; Doermann, D.; Shao, L. Crowd Counting and Density Estimation by Trellis Encoder-Decoder Network. Available online: https://arxiv.org/abs/1903.00853 (accessed on 15 September 2019).
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Soft + Hardwired Attention: An LSTM Framework for Human Trajectory Prediction and Abnormal Event Detection. Neural Netw. 2017, 108, 466–478. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cheng, W.; Shen, Y.; Zhu, Y.; Huang, L. A Neural Attention Model for Urban Air Quality Inference: Learning the Weights of Monitoring Stations. In Proceedings of the National Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2151–2158. [Google Scholar]
- Ma, F.; Chitta, R.; Zhou, J.; You, Q.; Sun, T.; Gao, J. Dipole: Diagnosis Prediction in Healthcare via Attention-based Bidirectional Recurrent Neural Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1903–1911. [Google Scholar]
- Paparoditis, E.; Sapatinas, T. Short-Term Load Forecasting: The Similar Shape Functional Time Series Predictor. IEEE Trans. Power Syst. 2012, 28, 3818–3825. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Lu, H.; Dong, Y.; Lu, X. Short term load forecasting technique based on the seasonal exponential adjustment method and the regression model. Energy Convers. Manag. 2013, 70, 1–9. [Google Scholar] [CrossRef]
- Wang, J.; Li, L.; Niu, D.; Tan, Z. An annual load forecasting model based on support vector regression with differential evolution algorithm. Appl. Energy 2012, 94, 65–70. [Google Scholar] [CrossRef]
- Ribeiro, M.; Grolinger, K.; ElYamany, H.F.; Higashino, W.A.; Capretz, M.A. Transfer Learning with Seasonal and Trend Adjustment for Cross-Building Energy Forecasting. Energy Build. 2018, 165, 352–363. [Google Scholar] [CrossRef]
- Taieb, S.B.; Hyndman, R.J. A gradient boosting approach to the Kaggle load forecasting competition. Int. J. Forecast. 2014, 30, 382–394. [Google Scholar] [CrossRef]
- Ji, Z.; Xiong, K.; Pang, Y.; Li, X. Video Summarization with Attention-Based Encoder-Decoder Networks. CoRR 2017, abs/1708.09545. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zone Number | Random Forest Regressor | STA–Random Forest Regressor | GBDT | STA–GBDT | GRU | STA–GRU | Encoder–Decoder | STA–Encoder–Decoder | Encoder–Decoder Attention | STA–AED |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 13.77% | 16.24% | 13.16% | 15.71% | 13.09% | 6.12% | 8.59% | 6.54% | 3.80% | 2.70% |
| 5 | 18.70% | 21.21% | 18.19% | 16.62% | 10.87% | 8.99% | 10.25% | 7.65% | 5.07% | 4.16% |
| 6 | 10.39% | 12.16% | 9.87% | 10.10% | 9.55% | 4.05% | 7.59% | 4.25% | 3.26% | 2.18% |
| 7 | 10.09% | 11.95% | 9.58% | 10.02% | 8.78% | 4.12% | 6.50% | 3.80% | 2.31% | 2.26% |
| 9 | 10.39% | 13.68% | 15.63% | 18.45% | 10.15% | 8.52% | 9.58% | 5.66% | 9.97% | 2.02% |
| 11 | 13.16% | 17.36% | 12.37% | 14.31% | 11.13% | 5.77% | 8.65% | 5.08% | 2.79% | 2.91% |
| 12 | 13.94% | 17.19% | 13.83% | 17.93% | 11.06% | 6.79% | 9.32% | 6.37% | 4.58% | 2.25% |
| 13 | 12.84% | 14.06% | 11.77% | 12.53% | 10.41% | 7.25% | 8.59% | 6.12% | 5.87% | 5.26% |
| 14 | 15.74% | 21.56% | 15.85% | 19.82% | 13.24% | 7.86% | 10.57% | 7.67% | 7.33% | 6.11% |
| 15 | 10.87% | 17.58% | 9.99% | 17.11% | 9.05% | 6.53% | 7.56% | 6.30% | 6.34% | 4.73% |
| 16 | 14.75% | 19.66% | 14.03% | 17.89% | 11.79% | 7.13% | 8.23% | 6.42% | 5.23% | 4.95% |
| 17 | 10.24% | 14.08% | 9.77% | 12.51% | 9.02% | 5.22% | 6.34% | 4.89% | 3.64% | 2.73% |
| 18 | 13.53% | 16.87% | 12.79% | 14.75% | 10.15% | 6.53% | 7.21% | 5.87% | 4.30% | 3.90% |
| 19 | 15.01% | 18.22% | 15.14% | 17.21% | 12.37% | 7.46% | 8.34% | 7.12% | 6.91% | 4.98% |
| 20 | 10.35% | 13.01% | 9.67% | 11.41% | 9.02% | 5.33% | 7.25% | 5.10% | 4.27% | 3.78% |
| Zone Number | Random Forest Regressor | STA–Random Forest Regressor | GBDT | STA–GBDT | GRU | STA–GRU | Encoder–Decoder | STA–Encoder–Decoder | Encoder–Decoder Attention | STA–AED |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2663.64 | 4721.40 | 2550.32 | 4473.39 | 1912.17 | 1312.31 | 1355.67 | 925.86 | 881.57 | 731.64 |
| 5 | 1327.91 | 2121.71 | 1306.42 | 1870.86 | 1182.13 | 792.49 | 756.32 | 535.86 | 489.90 | 382.97 |
| 6 | 19317.86 | 30628.96 | 18760.28 | 26958.93 | 13131.39 | 9216.30 | 12115.67 | 8642.18 | 6868.42 | 4854.46 |
| 7 | 19411.65 | 31197.98 | 18858.14 | 27094.56 | 12446.93 | 9704.31 | 8752.35 | 7105.42 | 6170.82 | 5419.37 |
| 9 | 7289.98 | 9179.87 | 9907.69 | 18006.75 | 8518.75 | 7026.93 | 7568.50 | 6859.89 | 7175.57 | 5476.51 |
| 11 | 14860.07 | 31699.12 | 14007.46 | 27006.26 | 12828.20 | 8415.57 | 8531.56 | 6523.21 | 3749.97 | 4625.02 |
| 12 | 19785.30 | 47365.13 | 19417.93 | 41700.66 | 17923.31 | 12499.21 | 14321.34 | 8953.23 | 6868.09 | 5466.82 |
| 13 | 2589.48 | 3498.78 | 2409.35 | 3121.04 | 1894.69 | 1680.42 | 1859.23 | 1675.42 | 1451.41 | 1412.30 |
| 14 | 3409.58 | 7096.82 | 3508.16 | 6586.08 | 3367.25 | 2333.92 | 2532.56 | 2035.43 | 1896.70 | 1817.25 |
| 15 | 7191.28 | 15457.41 | 6735.61 | 14092.31 | 5316.52 | 5253.35 | 6231.34 | 5071.21 | 4466.80 | 4462.52 |
| 16 | 4564.60 | 8572.97 | 4292.14 | 7498.77 | 3942.94 | 2656.92 | 3587.23 | 2875.32 | 2023.26 | 1813.00 |
| 17 | 3753.61 | 7179.55 | 3628.80 | 6493.66 | 3035.14 | 2318.65 | 2653.54 | 2012.67 | 1546.58 | 1366.90 |
| 18 | 30252.61 | 53231.76 | 28873.02 | 46827.62 | 21374.29 | 17821.83 | 19876.34 | 15321.43 | 12758.16 | 12275.82 |
| 19 | 12488.28 | 22224.10 | 12547.69 | 20381.70 | 8957.18 | 7885.67 | 8531.47 | 7031.15 | 6533.16 | 6056.17 |
| 20 | 9845.51 | 16640.13 | 9173.17 | 15172.12 | 5937.26 | 5925.59 | 8765.21 | 5768.77 | 5407.09 | 4651.63 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, Z.; Xu, X. A Hybrid Short-Term Load Forecasting Framework with an Attention-Based Encoder–Decoder Network Based on Seasonal and Trend Adjustment. Energies 2019, 12, 4612. https://doi.org/10.3390/en12244612
Meng Z, Xu X. A Hybrid Short-Term Load Forecasting Framework with an Attention-Based Encoder–Decoder Network Based on Seasonal and Trend Adjustment. Energies. 2019; 12(24):4612. https://doi.org/10.3390/en12244612
Chicago/Turabian StyleMeng, Zhaorui, and Xianze Xu. 2019. "A Hybrid Short-Term Load Forecasting Framework with an Attention-Based Encoder–Decoder Network Based on Seasonal and Trend Adjustment" Energies 12, no. 24: 4612. https://doi.org/10.3390/en12244612
APA StyleMeng, Z., & Xu, X. (2019). A Hybrid Short-Term Load Forecasting Framework with an Attention-Based Encoder–Decoder Network Based on Seasonal and Trend Adjustment. Energies, 12(24), 4612. https://doi.org/10.3390/en12244612