A Novel Deep Feature Learning Method Based on the Fused-Stacked AEs for Planetary Gear Fault Diagnosis

Abstract
:1. Introduction
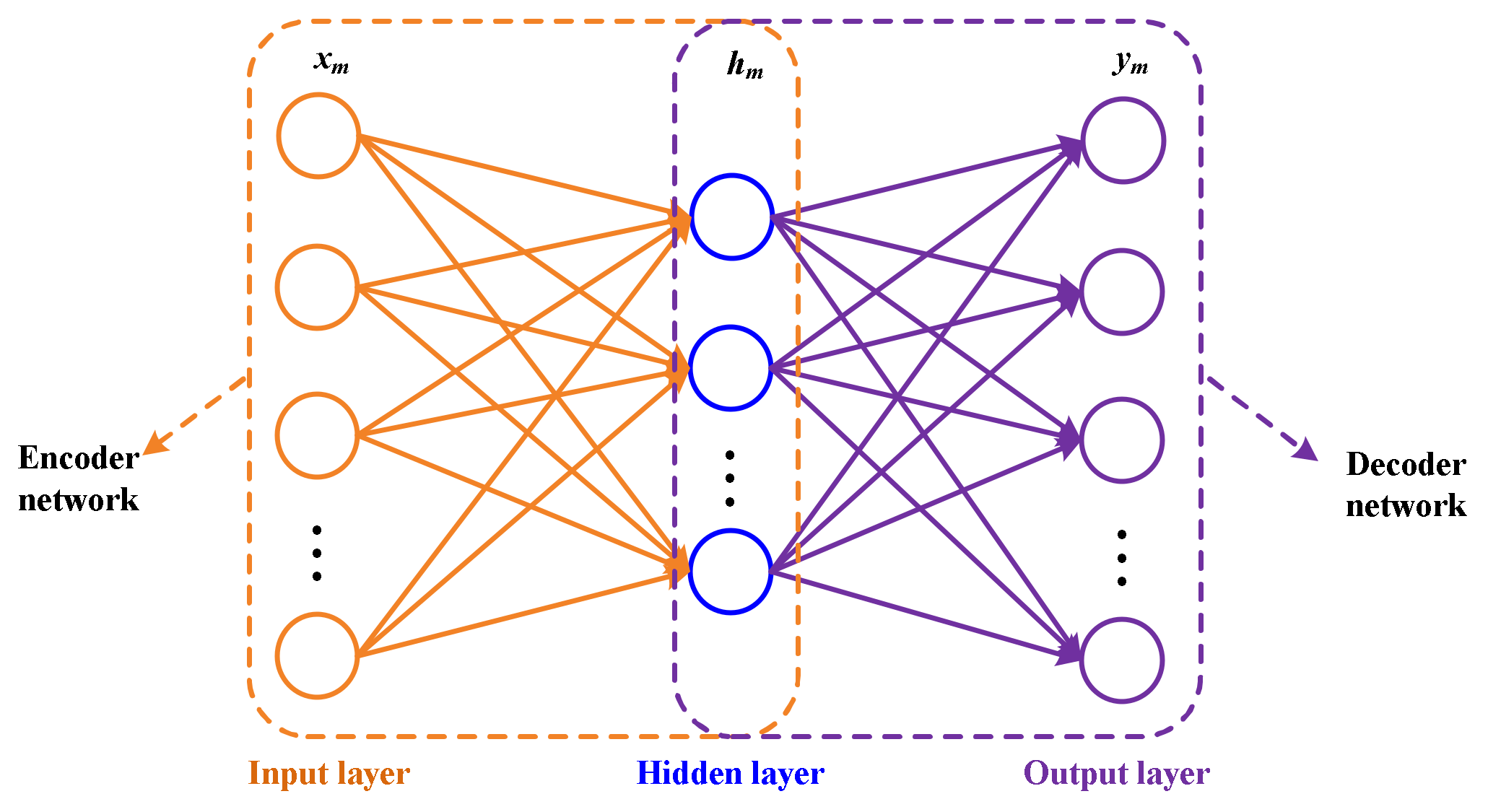
2. Basic Autoencoder (AE)
3. The Proposed Method
3.1. Sparse Autoencoder (SAE)
3.2. Contractive Autoencoder (CAE)
3.3. Quantum Ant Colony Algorithm (QACA)
3.3.1. Quantum Coding and Quantum Rotation Gate
3.3.2. Ant Transfer Rules and Transfer Probability
3.3.3. Pheromone Updating
3.4. The Proposed Method
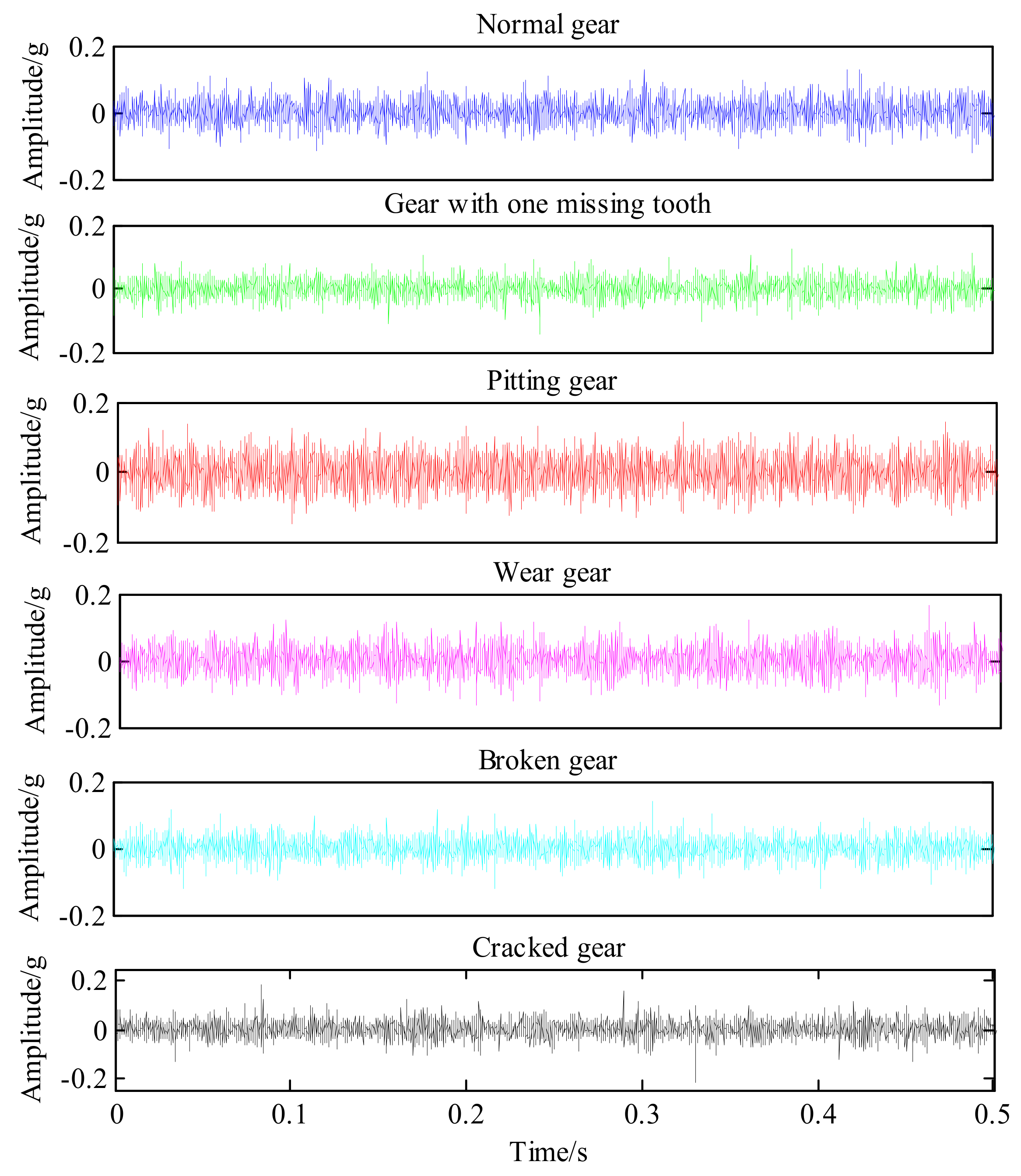
4. Experiment Introduction
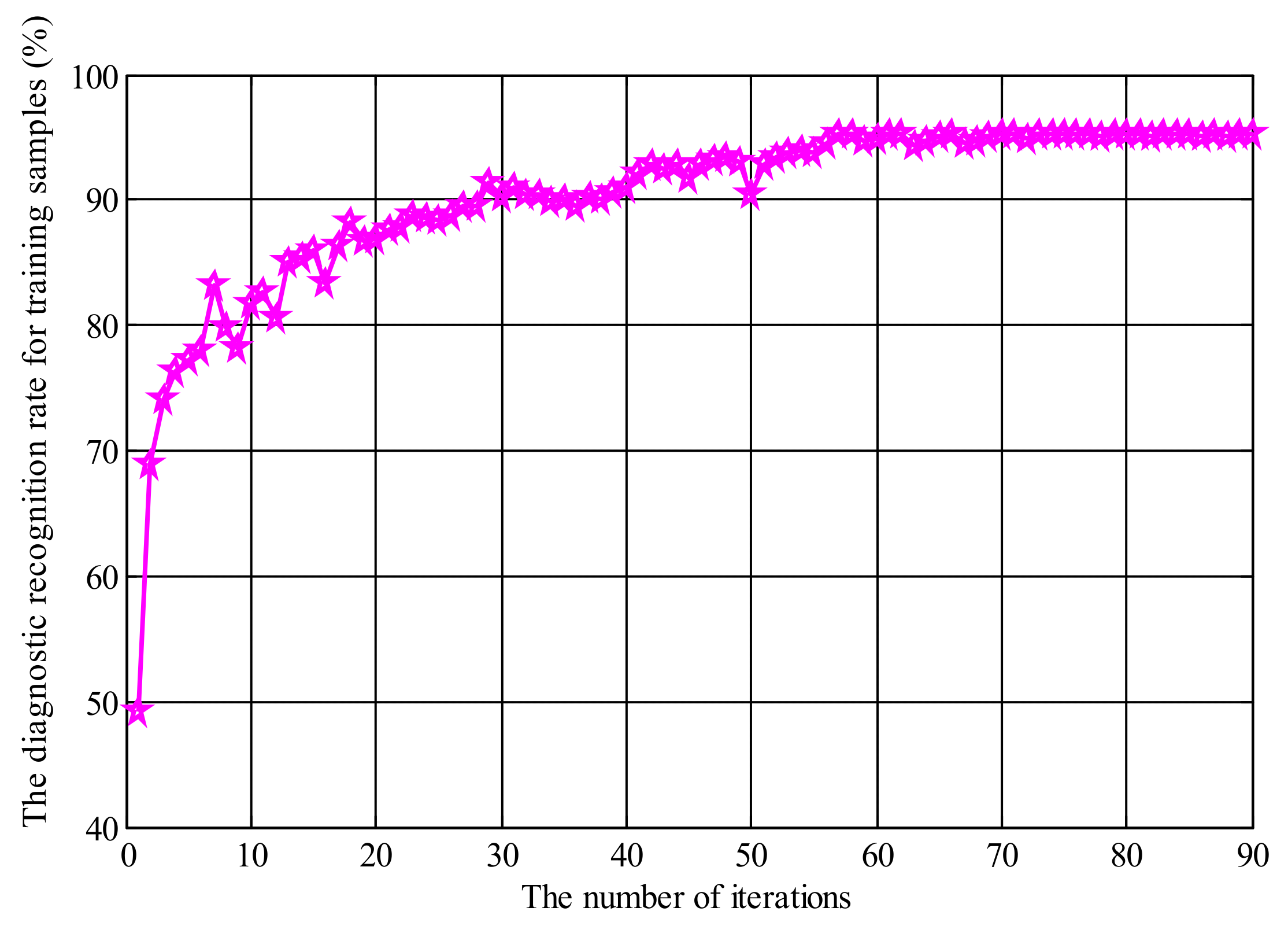
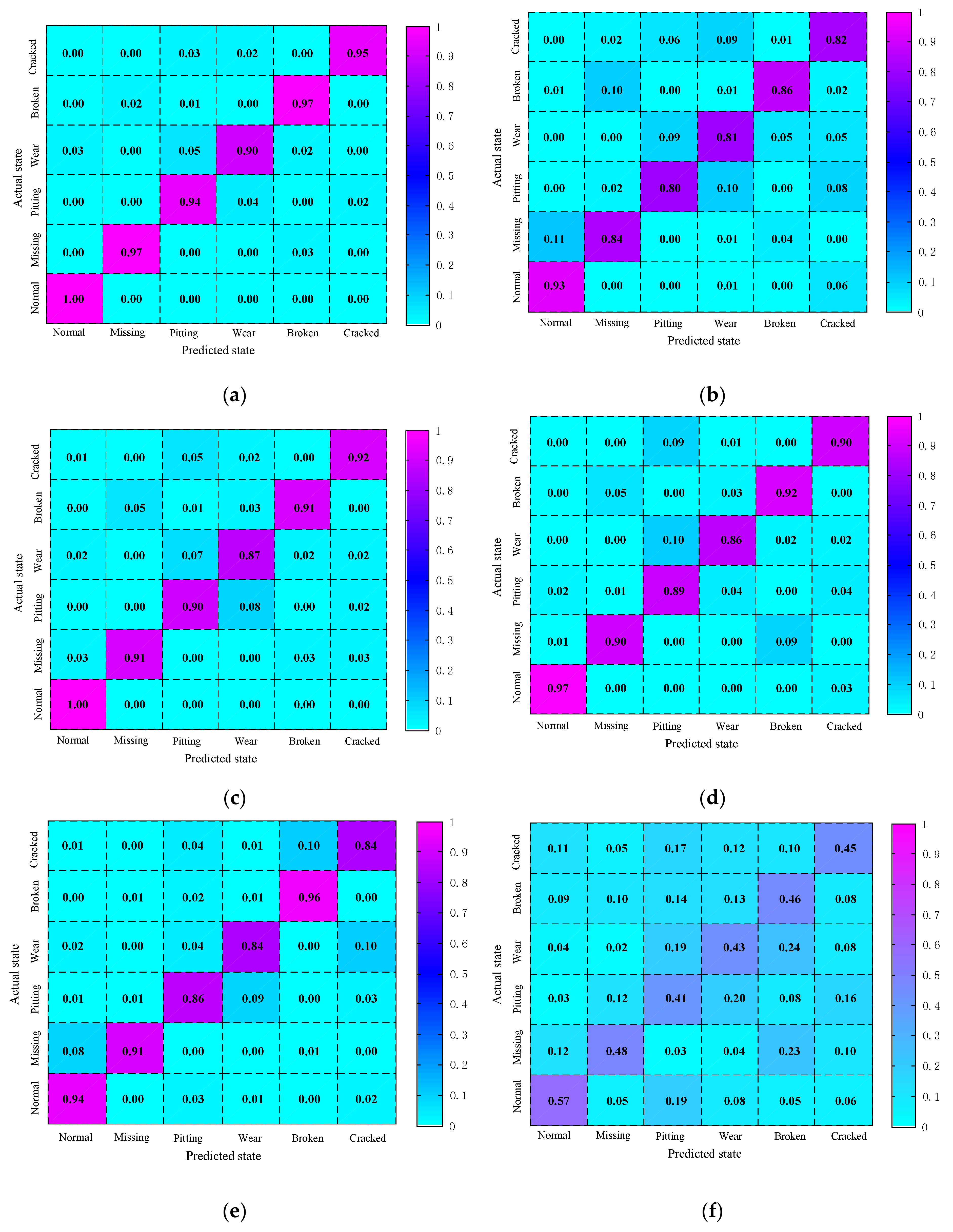
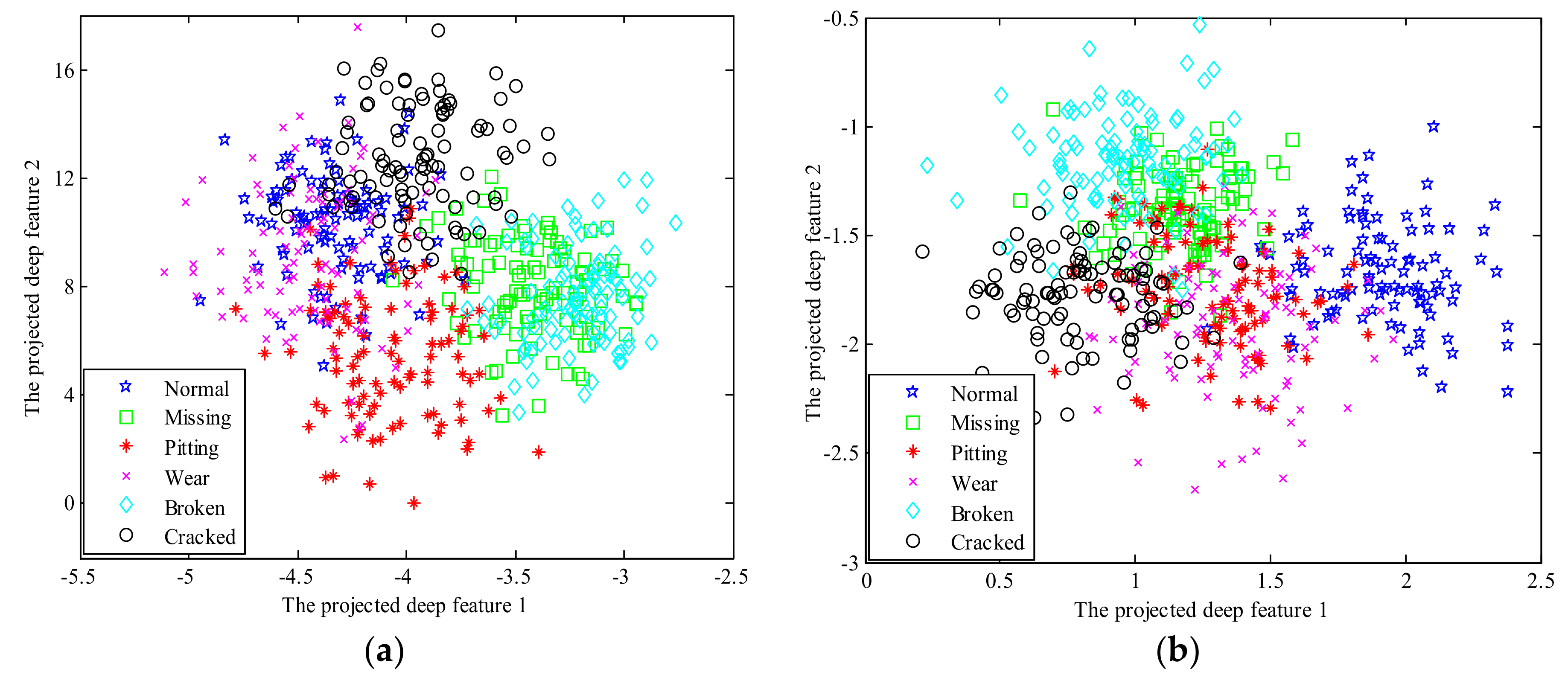
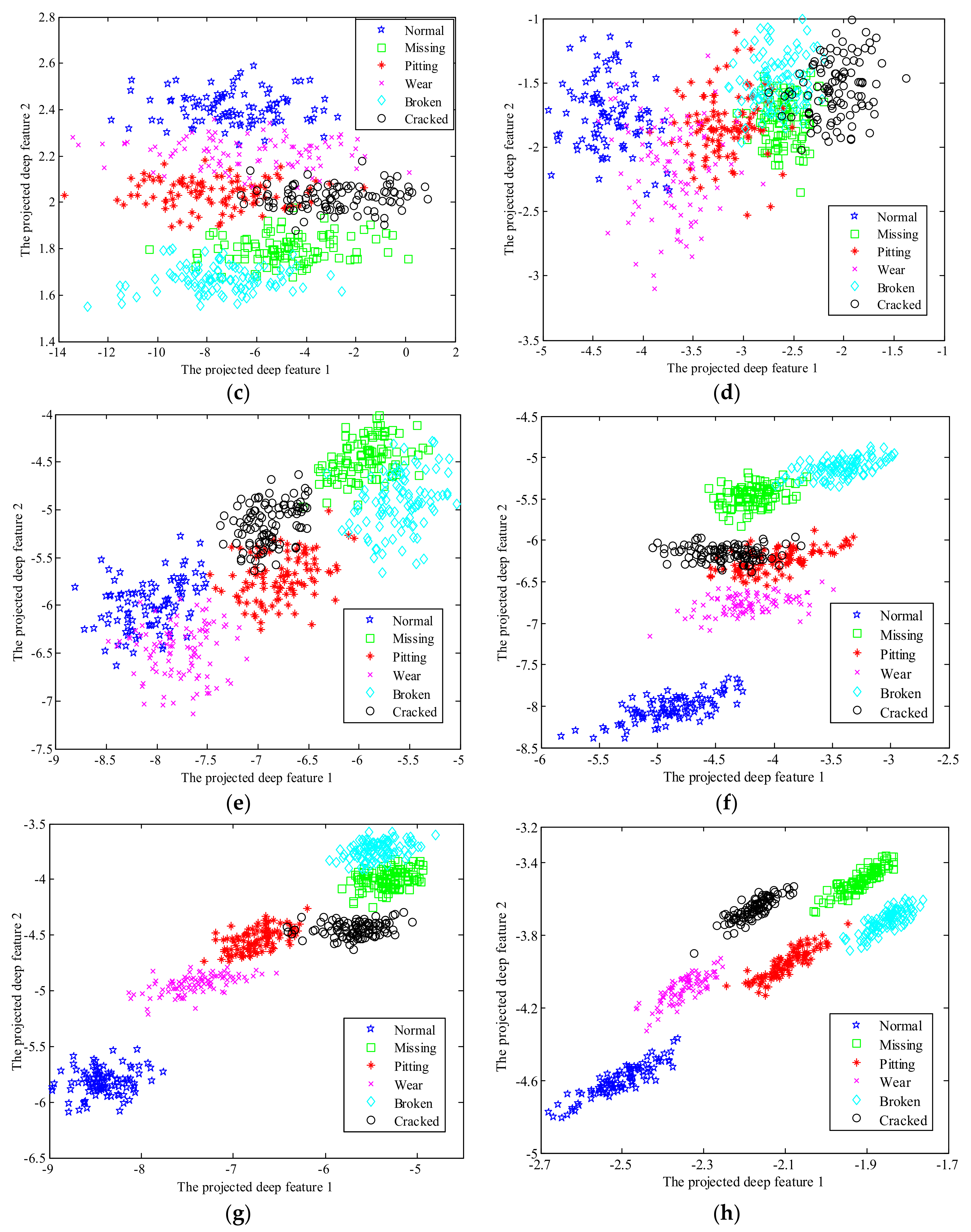
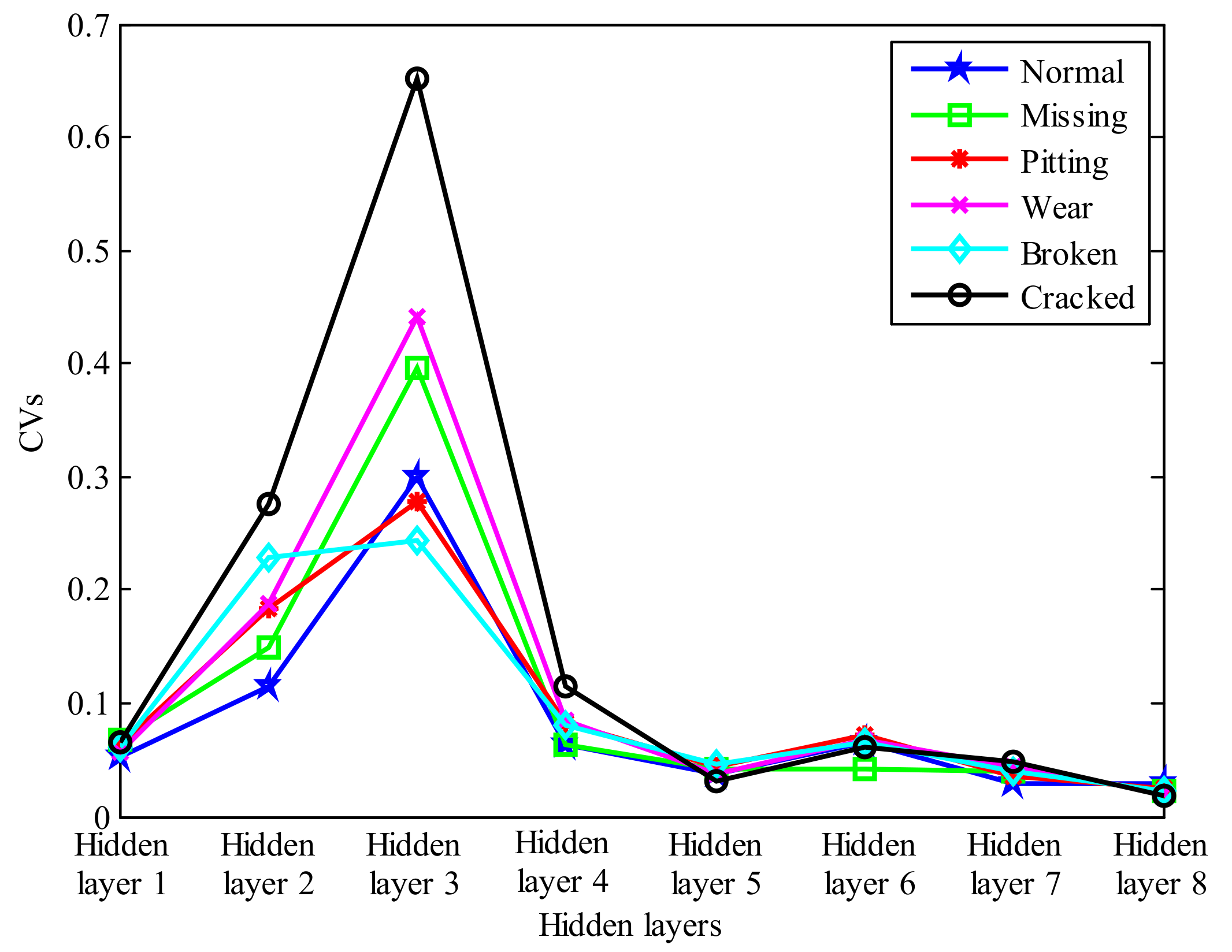
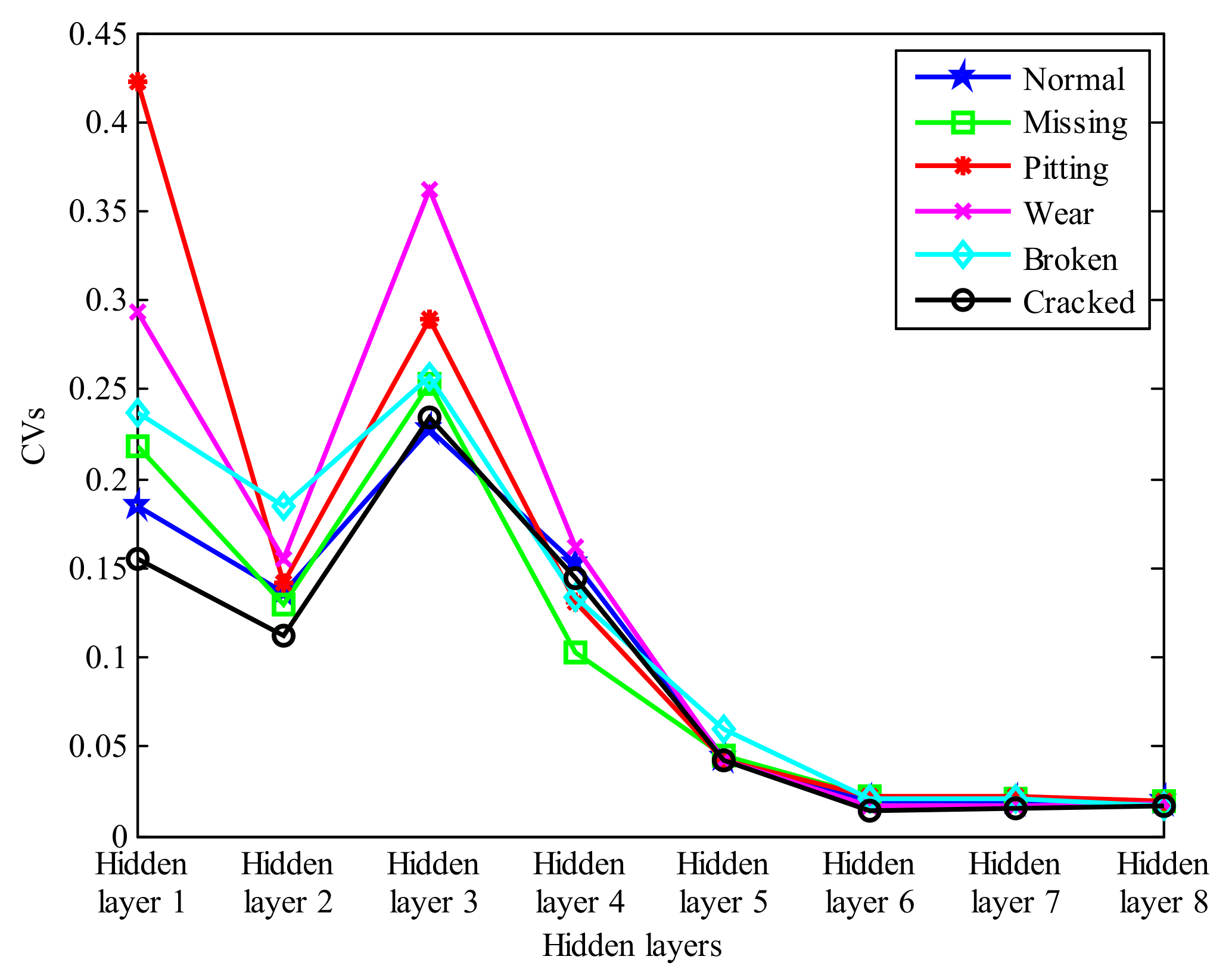
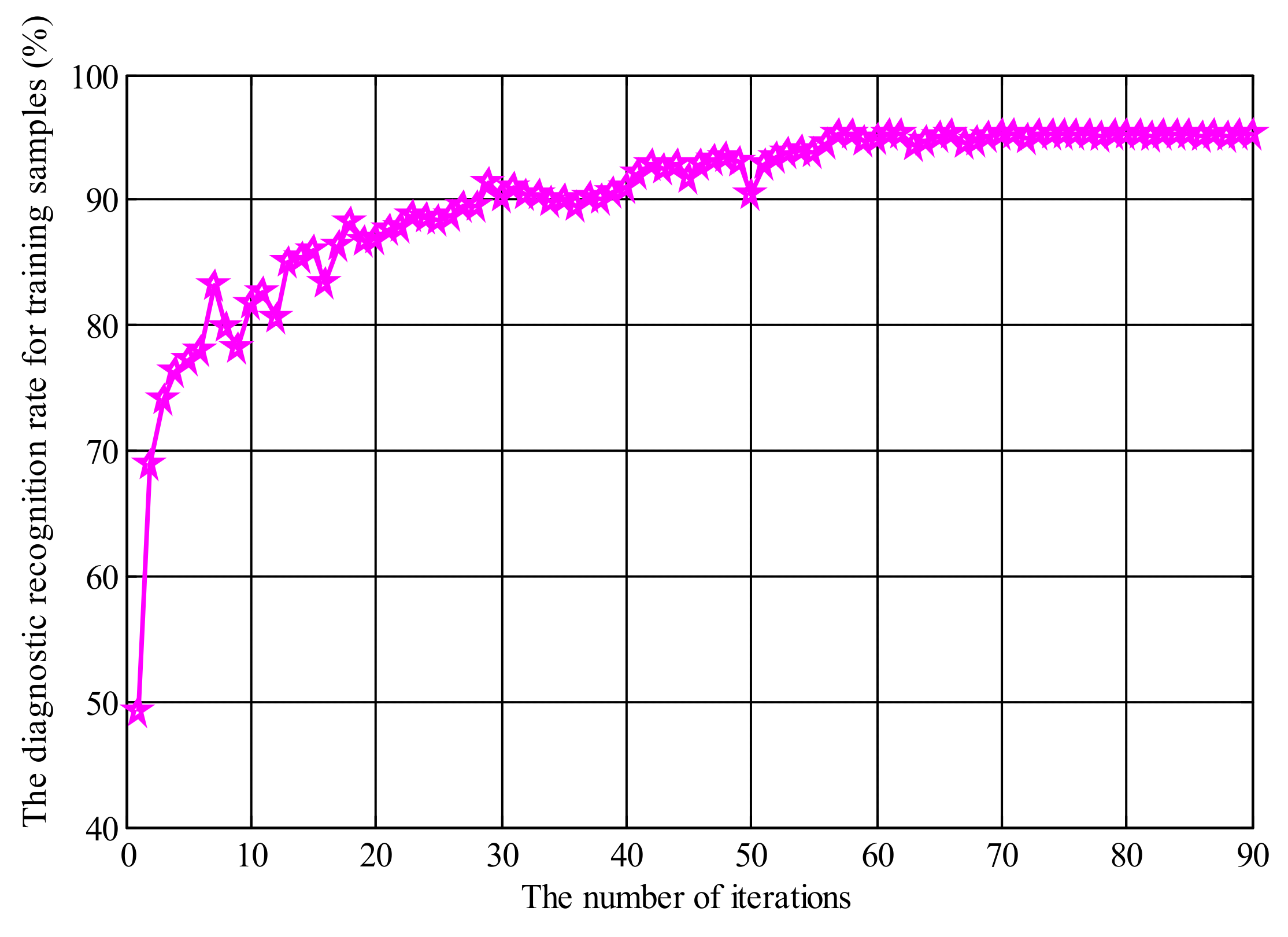
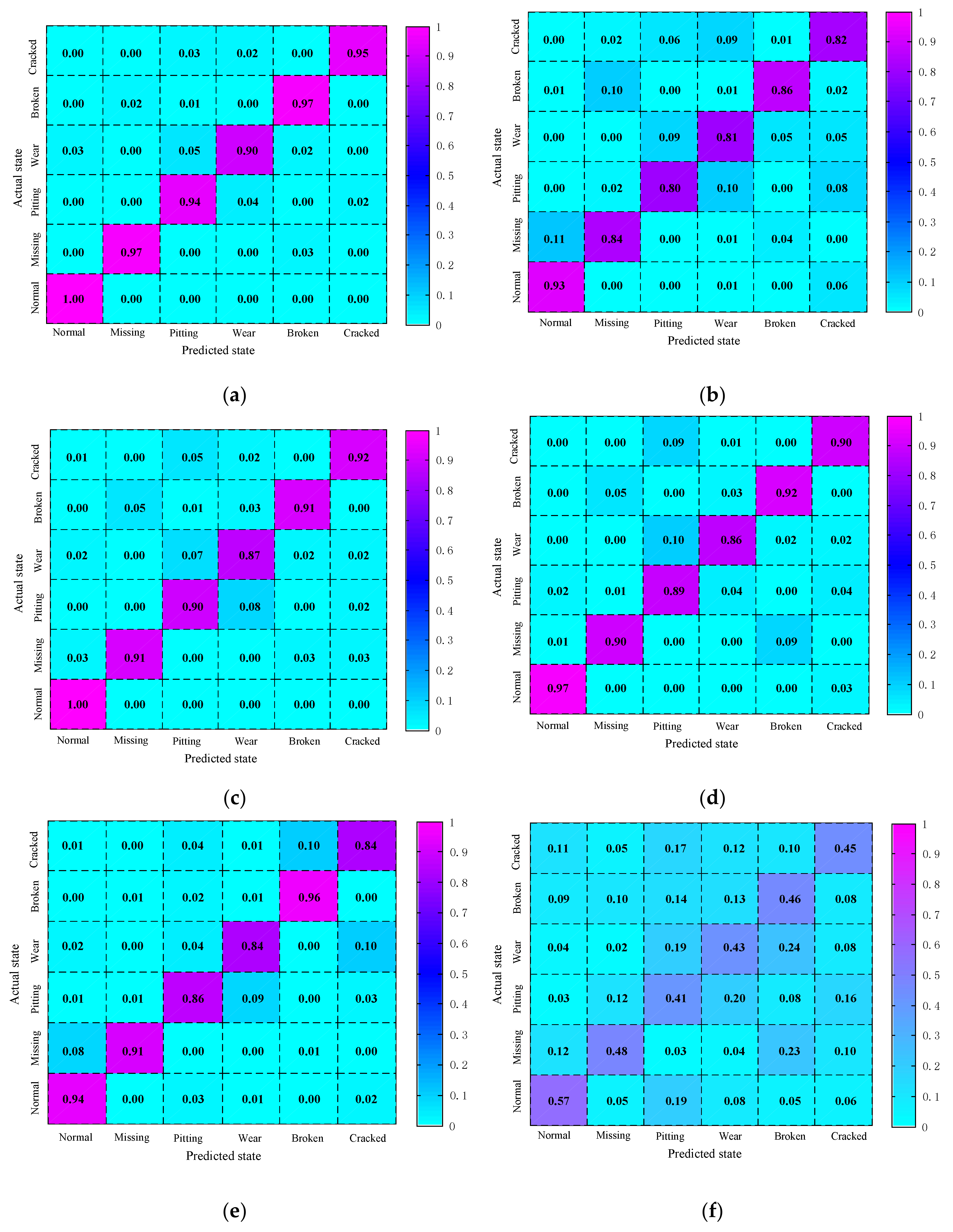
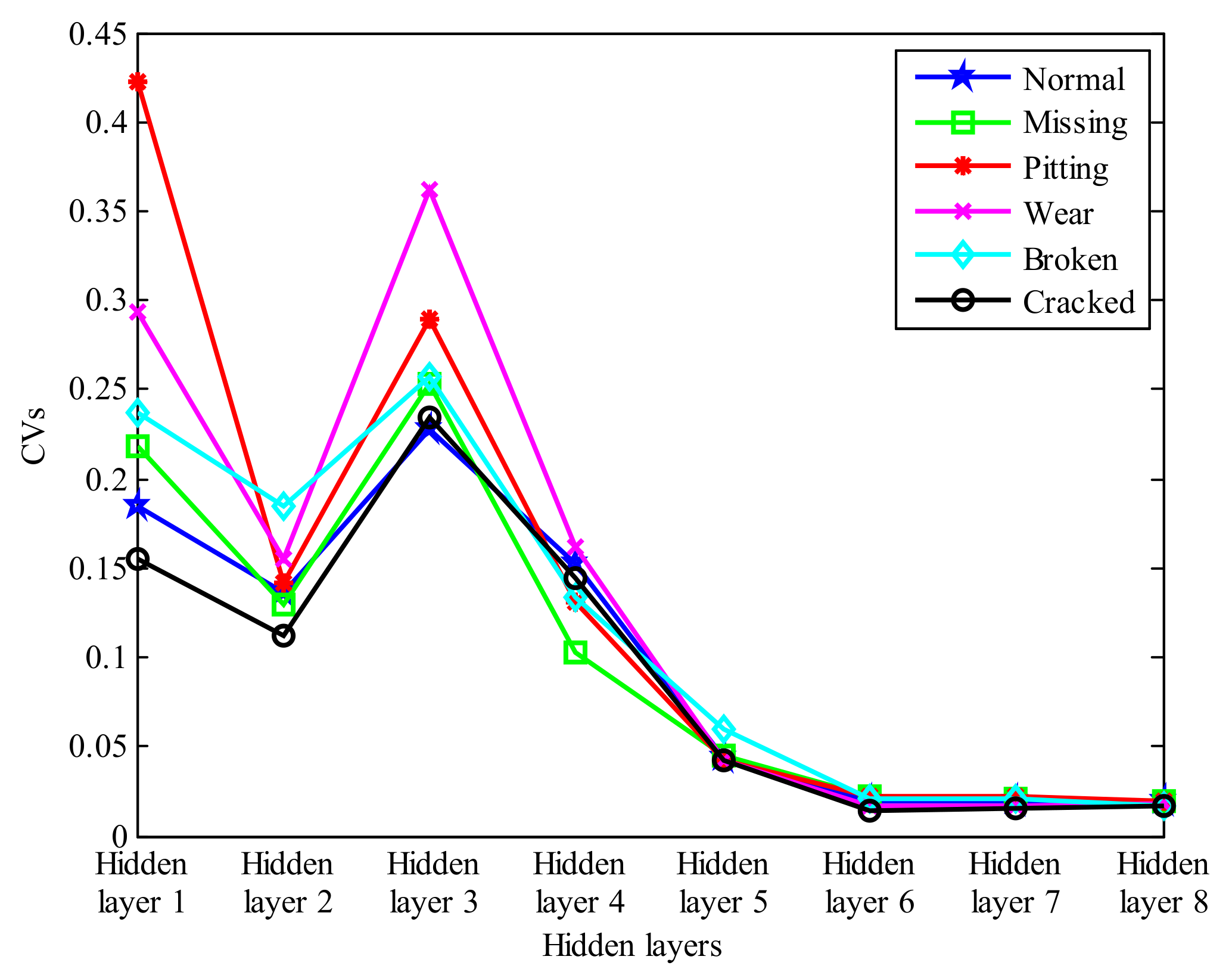
5. Experimental Results and Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, F.T.; Liu, C.X.; Su, W.S.; Xue, Z.G.; Han, Q.K. Combined failure diagnosis of slewing bearings based on MCKD-CEEMD-ApEn. Shock Vib. 2018, 2018, 6321785. [Google Scholar] [CrossRef]
- Fu, L.; Zhu, T.T.; Zhu, K.; Yang, Y.L. Condition monitoring for the roller bearings of wind turbines under variable working conditions based on the fisher score and permutation entropy. Energies 2019, 12, 3085. [Google Scholar] [CrossRef]
- Lu, S.L.; He, Q.B.; Wang, J. A review of stochastic resonance in rotating machine fault detection. Mech. Syst. Signal Process. 2019, 116, 230–260. [Google Scholar] [CrossRef]
- Zhao, C.; Feng, Z.P.; Wei, X.K.; Qin, Y. Sparse classification based on dictionary learning for planet bearing fault identification. Expert Syst. Appl. 2018, 108, 233–245. [Google Scholar] [CrossRef]
- Chen, X.H.; Li, H.Y.; Cheng, G.; Peng, L.P. Study on planetary gear degradation state recognition method based on the features with multiple perspectives and LLTSA. IEEE Access 2019, 7, 7565–7576. [Google Scholar] [CrossRef]
- Kandukuri, S.T.; Klausen, A.; Karimi, H.R.; Robbersmyr, K.G. A review of diagnostics and prognostics of low-speed machinery towards wind turbine farm-level health management. Renew. Sust. Energy. Rev. 2016, 53, 697–708. [Google Scholar] [CrossRef]
- Chen, X.H.; Cheng, G.; Li, Y.; Peng, L.P. Fault diagnosis of planetary gear based on entropy feature fusion of DTCWT and OKFDA. J. Vib. Control 2018, 24, 5044–5061. [Google Scholar] [CrossRef]
- Feng, Z.P.; Zhang, D.; Zuo, M.J. Planetary gearbox fault diagnosis via joint amplitude and frequency demodulation analysis based on variational mode decomposition. Appl. Sci. 2017, 7, 775. [Google Scholar] [CrossRef]
- Liang, X.H.; Zuo, M.J.; Liu, L.B. A windowing and mapping strategy for gear tooth fault detection of a planetary gearbox. Mech. Syst. Signal Process. 2016, 80, 445–459. [Google Scholar] [CrossRef]
- Cerrada, M.; Sanchez, R.V.; Pacheco, F. Hierarchical feature selection based on relative dependency for gear fault diagnosis. Appl. Intell. 2016, 44, 687–703. [Google Scholar] [CrossRef]
- Wang, F.T.; Deng, G.; Ma, L.J. Convolutional neural network based on spiral arrangement of features and its application in bearing fault diagnosis. IEEE Access 2019, 7, 64092–64100. [Google Scholar] [CrossRef]
- Lei, Y.G.; Jia, F.; Zhou, X.; Lin, J. Deep learning-based method for machinery health monitoring with big data. J. Mech. Eng. 2015, 51, 49–56. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern.: Syst. 2018, 48, 11–20. [Google Scholar] [CrossRef]
- Oh, H.; Jung, J.H.; Jeon, B.C.; Youn, B.D. Scalable and unsupervised feature engineering using vibration-imaging and deep learning for rotor system diagnosis. IEEE Trans. Ind. Electron. 2018, 65, 3539–3549. [Google Scholar] [CrossRef]
- Gao, Z.H.; Ma, C.B.; Song, D.; Liu, Y. Deep quantum inspired neural network with application to aircraft fuel system fault diagnosis. Neurocomputing 2017, 238, 13–23. [Google Scholar] [CrossRef]
- Liu, G.F.; Bao, H.Q.; Han, B.K. A stacked autoencoder-based deep learning neural network for achieving gearbox fault diagnosis. Math. Probl. Eng. 2018, 2018, 5105709. [Google Scholar]
- Feng, J.; Lei, Y.; Guo, L.; Lin, J.; Xing, S. A neural network constructed by deep learning technique and its application to intelligent fault diagnosis of machines. Neurocomputing 2018, 272, 619–628. [Google Scholar]
- Feng, J.; Lei, Y.G.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72–73, 303–315. [Google Scholar]
- Thirukovalluru, R.; Dixit, S.; Sevakula, R.K.; Verma, N.K. A salour generating feature sets for fault diagnosis using denoising stacked auto-encoder. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management (ICPHM), Ottawa, ON, Canada, 20–22 June 2016; pp. 1–7. [Google Scholar]
- Martin, G.S.; Droguett, E.L.; Meruane, V. Deep variational auto-encoders: A promising tool for dimensionality reduction and ball bearing elements fault diagnosis. Struct. Health Monit. 2019, 18, 1092–1128. [Google Scholar] [CrossRef]
- Udmale, S.S.; Singh, S.K.; Bhirud, S.G. A bearing data analysis based on kurtogram and deep learning sequence models. Measurement 2019, 145, 665–677. [Google Scholar] [CrossRef]
- Shao, H.D.; Jiang, H.K.; Zhao, H.W.; Wang, F. A novel deep autoencoder feature learning method for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2017, 95, 187–204. [Google Scholar] [CrossRef]
- Wu, E.Q.; Zhou, G.R.; Zhu, L.M.; Wei, C.F.; Ren, H.; Sheng, R.S.F. Rotated Sphere Haar Wavelet and Deep Contractive Auto-Encoder Network With Fuzzy Gaussian SVM for Pilot’s Pupil Center Detection. IEEE Trans. Cybern. 2019. [Google Scholar] [CrossRef]
- Shao, H.D.; Jiang, H.K.; Wang, F.; Zhao, H.W. An enhancement deep feature fusion method for rotating machinery fault diagnosis. Knowl.-Based Syst. 2017, 199, 200–220. [Google Scholar] [CrossRef]
- Xia, G.Q.; Han, Z.W.; Zhao, B.; Liu, C.Y.; Wang, X.W. Global Path Planning for Unmanned Surface Vehicle Based on Improved Quantum Ant Colony Algorithm. Math. Probl. Eng. 2019, 2019, 2902170. [Google Scholar] [CrossRef]
- Mahdi, F.P.; Vasant, P.; Abdullah-Ai-Wadud, M.; Watada, J.; Kallimani, V. A quantum-inspired particle swarm optimization approach for environmental/economic power dispatch problem using cubic criterion function. Int. Trans. Electr. Energy Syst. 2018, 28, e2497. [Google Scholar] [CrossRef]
- Li, J.J.; Xu, B.W.; Yang, Y.S.; Wu, H.F. Three-phase qubits-based quantum ant colony optimization algorithm for path planning of automated guided vehicles. Int. J. Robot. Autom. 2019, 34, 156–163. [Google Scholar] [CrossRef]
- Hinton, G.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure of Planetary Gearbox | The First Stage Planetary Gear | The Second Stage Planetary Gear | ||||
|---|---|---|---|---|---|---|
| Sun Gear | Planet Gear | Ring Gear | Sun Gear | Planet Gear | Ring Gear | |
| Teeth | 20 | 40 | 100 | 28 | 36 | 100 |
| Motor Speed | Sampling Frequency | Load | Sample Length |
|---|---|---|---|
| 3000 r/min | 6400 Hz | 13.5 Nm | 3200 |
| Hidden Layers of Deep Learning Architecture | Hidden Layer 1 | Hidden Layer 2 | Hidden Layer 3 | Hidden Layer 4 | Hidden Layer 5 | Hidden Layer 6 | Hidden Layer 7 | Hidden Layer 8 |
|---|---|---|---|---|---|---|---|---|
| The specific location of SAEs and CAEs | SAE1 | SAE2 | SAE3 | CAE1 | SAE4 | SAE5 | CAE2 | CAE3 |
| The weight of sparsity penalty itemfor SAE | × | × | × | |||||
| The weight of contractive penalty itemfor CAE | × | × | × | × | × |
| The Testing Samples for Different Planetary Gear States | Diagnostic Recognition Rate |
|---|---|
| Normal gear | 100% |
| Gear with one missing tooth | 97% |
| Pitting gear | 94% |
| Wear gear | 90% |
| Broken gear | 97% |
| Cracked gear | 95% |
| Average diagnostic recognition rate | 95.5% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Ji, A.; Cheng, G. A Novel Deep Feature Learning Method Based on the Fused-Stacked AEs for Planetary Gear Fault Diagnosis. Energies 2019, 12, 4522. https://doi.org/10.3390/en12234522
Chen X, Ji A, Cheng G. A Novel Deep Feature Learning Method Based on the Fused-Stacked AEs for Planetary Gear Fault Diagnosis. Energies. 2019; 12(23):4522. https://doi.org/10.3390/en12234522
Chicago/Turabian StyleChen, Xihui, Aimin Ji, and Gang Cheng. 2019. "A Novel Deep Feature Learning Method Based on the Fused-Stacked AEs for Planetary Gear Fault Diagnosis" Energies 12, no. 23: 4522. https://doi.org/10.3390/en12234522
APA StyleChen, X., Ji, A., & Cheng, G. (2019). A Novel Deep Feature Learning Method Based on the Fused-Stacked AEs for Planetary Gear Fault Diagnosis. Energies, 12(23), 4522. https://doi.org/10.3390/en12234522