Application of Spectral Clustering Algorithm to ES-MDA with DCT for History Matching of Gas Channel Reservoirs


Abstract
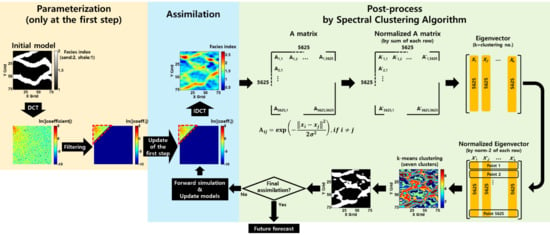
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Share and Cite
Kim, S.; Lee, K. Application of Spectral Clustering Algorithm to ES-MDA with DCT for History Matching of Gas Channel Reservoirs. Energies 2019, 12, 4394. https://doi.org/10.3390/en12224394
Kim S, Lee K. Application of Spectral Clustering Algorithm to ES-MDA with DCT for History Matching of Gas Channel Reservoirs. Energies. 2019; 12(22):4394. https://doi.org/10.3390/en12224394
Chicago/Turabian StyleKim, Sungil, and Kyungbook Lee. 2019. "Application of Spectral Clustering Algorithm to ES-MDA with DCT for History Matching of Gas Channel Reservoirs" Energies 12, no. 22: 4394. https://doi.org/10.3390/en12224394
APA StyleKim, S., & Lee, K. (2019). Application of Spectral Clustering Algorithm to ES-MDA with DCT for History Matching of Gas Channel Reservoirs. Energies, 12(22), 4394. https://doi.org/10.3390/en12224394