1. Introduction
For the last decade, energy efficiency (EE) of wireless communication systems, which measures the effectiveness of the power consumption utilized for the data transmission, has been emerging as an important performance metric for the next-generation networking scenarios including wireless sensor networks, device-to-device communications, and internet-of-things (IoT) systems [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. The EE metric was introduced in [
1], and it is defined as the ratio of achievable data rate to total power consumption. The fractional programming framework was employed in [
1,
2] to address the EE maximization problems in various configurations. Extending these works, the EE maximizing cooperative communication strategies were investigated in the multi-cell multi-user networks [
3,
4,
5,
6,
7,
8,
9,
10]. Weighted sum EE metrics was intensively studied in [
4,
5,
6,
7]. Zero forcing (ZF)-based coordinated beamforming schemes were proposed in [
4], which maximize the sum EE of the multiple heterogeneous networks. To further increase the EE performance, the works in [
5,
6,
7] relaxed the ZF assumption and presented optimization algorithms for identifying efficient precoding solution without the ZF condition. Due to the multi-cell and multi-user interference terms, the weighted sum EE maximization problems are no longer convex and cannot be tackled by the off-the-shelf convex optimization software. Hence, handling the non-convexity of the EE maximization tasks has been an important issue in the multi-cell environment. The authors of [
5,
6] employed the fractional programming framework for the weighted EE maximization problem in the multi-cell systems and provided alternating optimization algorithms where blocks of the optimization variables are determined in an iterative manner. However, such an alternating calculation loses the globally optimality of the weighted EE maximization problems. This issue was addressed in [
7] by applying the branch-and-bound (BnB) method, which iteratively searches lower and upper bounds of the original problem and converges the globally optimal point. However, the iterative bound searches and solution calculations of the BnB algorithm would result in high computational complexity for the fast fading environment where the beamforming solution may not be timely obtained for the real-time communication services.
The sum EE maximization would not be an appropriate design approach since it cannot guarantee the quality of the EE for heterogeneous wireless devices. In particular, in the multi-cell systems, the EE of each cell was defined as the sum EE of all intra-cell users [
4,
5,
6,
7]. Obviously, such a design leads to highly unbalanced EE performance among multiple cells and mobile users, and cannot guarantee the EE performance of each wireless devices. To overcome this issue, the EE fairness has been suggested as an alternative performance measure of the sum EE metric [
3,
8,
9,
10]. The fairness of the EE can be examined by the minimum EE performance among multiple wireless devices. Thus, the EE fairness optimization has been typically expressed as the maximization task of the minimum EE performance, resulting in the max-min formulations. The max-min nature of the EE fairness formulation ensures that all the wireless devices achieve the same level of EE performance. However, the maximization of the EE fairness would be more difficult than that of the sum EE performance due to the non-smooth and non-convex objective functions. The Dinkelhach method was adopted in [
8] along with the alternating optimization process for solving the EE fairness maximization problem in the multi-cell networks. To reduce the computational complexity of the alternating optimization, the successive convex approximation (SCA) framework was applied to maximize the minimum EE performance [
3,
9,
10]. Among those, the conic approximation strategy provided in [
3] has been revealed as the most effective solution in terms of both the performance and the computational complexity.
The previous works have mostly focused on the traditional optimization techniques, and thus they relied on the convex optimization software such as the CVX. The optimization approaches are powerful for identifying model-based calculation algorithms with guaranteed convergence. However, the convex optimization software generally requires iterative computations for each channel realization, implying that the algorithms in [
3,
8,
9,
10] would not be practical for the fast fading environment in which the channel statistics would change before computing the solution. Hence, the conventional optimization approaches might not be a good solution for handling the EE fairness maximization problems in real-time communication scenarios. In addition, due to the non-convexity of the EE formulation, the optimization algorithms in [
3,
8,
9,
10] cannot guarantee the globally optimality for their convergence point. It is thus not easy to identify the globally optimal performance based on the traditional optimization techniques.
To tackle these difficulties, deep learning (DL) techniques [
11,
12] have recently applied in the design of wireless communication systems [
13,
14,
15,
16,
17] and resource management algorithms [
18,
19,
20,
21,
22,
23]. The data-driven optimization capability of the DL has been shown to be efficient for addressing model-free and non-convex formulations in the wireless communication networks. The possibility of the DL was investigated in [
13,
14,
15,
16,
17] for a design of end-to-end physical layer communication modules. Meanwhile, there have been intensive studies on using deep neural networks (DNNs) to solve wireless resource allocation problems [
18,
19,
20,
21,
22,
23]. The authors of [
18] proposed a supervised learning method which learns the input–output behavior of an existing power control scheme, the weighted minimum mean square error (WMMSE) algorithm, to maximize the sum rate performance in an interference channel (IFC) setup. The method in [
18] achieves a similar performance of the WMMSE algorithm with much reduced time complexity. However, the supervised learning nature in [
18] can only produce the DNN simply memorizing the locally optimal solution of the WMMSE algorithm. Hence, it is not easy to handle the non-convexity of the resource allocation problems and the supervised learning approach generally yields the degraded sum rate performance.
Unsupervised learning-based power control schemes have recently been investigated [
19,
20,
21,
22,
23] to overcome the limitations of the supervised training strategy. The unsupervised learning does not need the training label data, i.e., the solution obtained by the WMMSE as in [
18], and finds an effective resource management solution by itself. The DNNs are employed to approximate the unknown optimal solution directly, whose approximation accuracy is guaranteed by the universal approximation theorem. As a result, it is possible to identify the globally optimal resource allocation solution by utilizing well-designed DNNs. In [
19], the sum rate and the sum EE maximization problems were tackled via the DNNs trained in an unsupervised manner. It was shown that the unsupervised learning techniques perform better than the WMMSE algorithm which achieves a locally optimal solution for the sum rate maximization problem. In addition, the computational complexity of the DNN-based power control scheme is much lower than that of the WMMSE method requiring the iterative calculations. Similar results have been observed in [
20,
21,
22,
23], where the possibilities of the DNN for solving the non-convex sum rate maximization problem in cognitive radio and device-to-device communication setups. However, since these methods are restricted to the sum performance optimization, it is still not clear whether the DL-based approach is valid for the EE fairness maximization task with the fractional and non-smooth objective function.
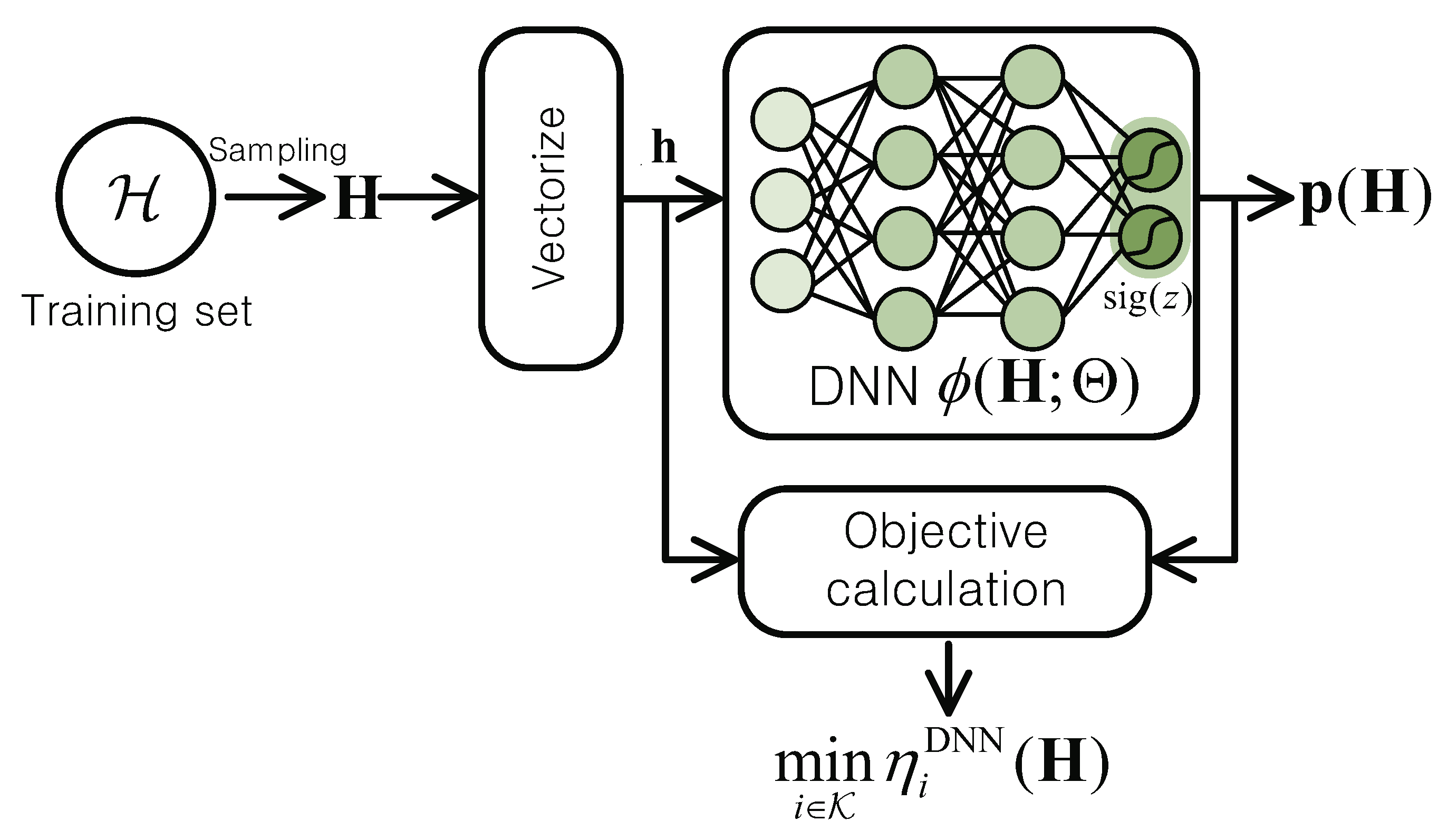
In this paper, we revisit the EE fairness maximization problem for the IFC, where the globally optimal solution is generally not available due to the non-convexity [
3]. Our target is to apply the DL technique for improving the EE fairness performance of existing optimization approaches as well as reducing the computational complexity. We introduce a fully-connected DNN structure for approximating a mapping from the channel vector to the optimal power control solution. The original EE fairness maximization problem determining unknown solution computation strategy is reformulated into the training task of the DNN such that it can produce an effective power allocation solution. However, the state-of-the-art DL libraries, which are based on the gradient descent (GD) method, would not be feasible in our formulation due to the non-smooth max-min EE objective function. We thus derive a modification of the GD update rule for the EE fairness maximization problem. An unsupervised training algorithm is proposed which does not require any information regarding the optimal power control policy. The test performance of the trained DNN was examined through intensive numerical simulations. It was verified that the proposed DNN-based power control scheme performs better than the best known performance achieved by the SCA framework [
3]. In addition, the numerical results prove that the DNN can significantly reduce the execution time of the conventional SCA method.
This paper is organized as follows.
Section 2 describes the system model for the IFC and formulates the EE fairness maximization problem. The proposed DNN approach and the unsupervised training strategy are presented in
Section 3. We provide numerical results of the trained DNNs in
Section 4 and compare its performance with traditional optimization approaches. Finally, the paper is terminated with conclusions in
Section 5.
Throughout this paper, we employ uppercase boldface letters, lowercase boldface letters, and normal letters for matrices, vectors, and scalar quantities, respectively. Sets of m-by-n complex-valued and real-valued matrices are denoted by and , respectively. The expectation operation over random variable X is represented as .
2. System Model
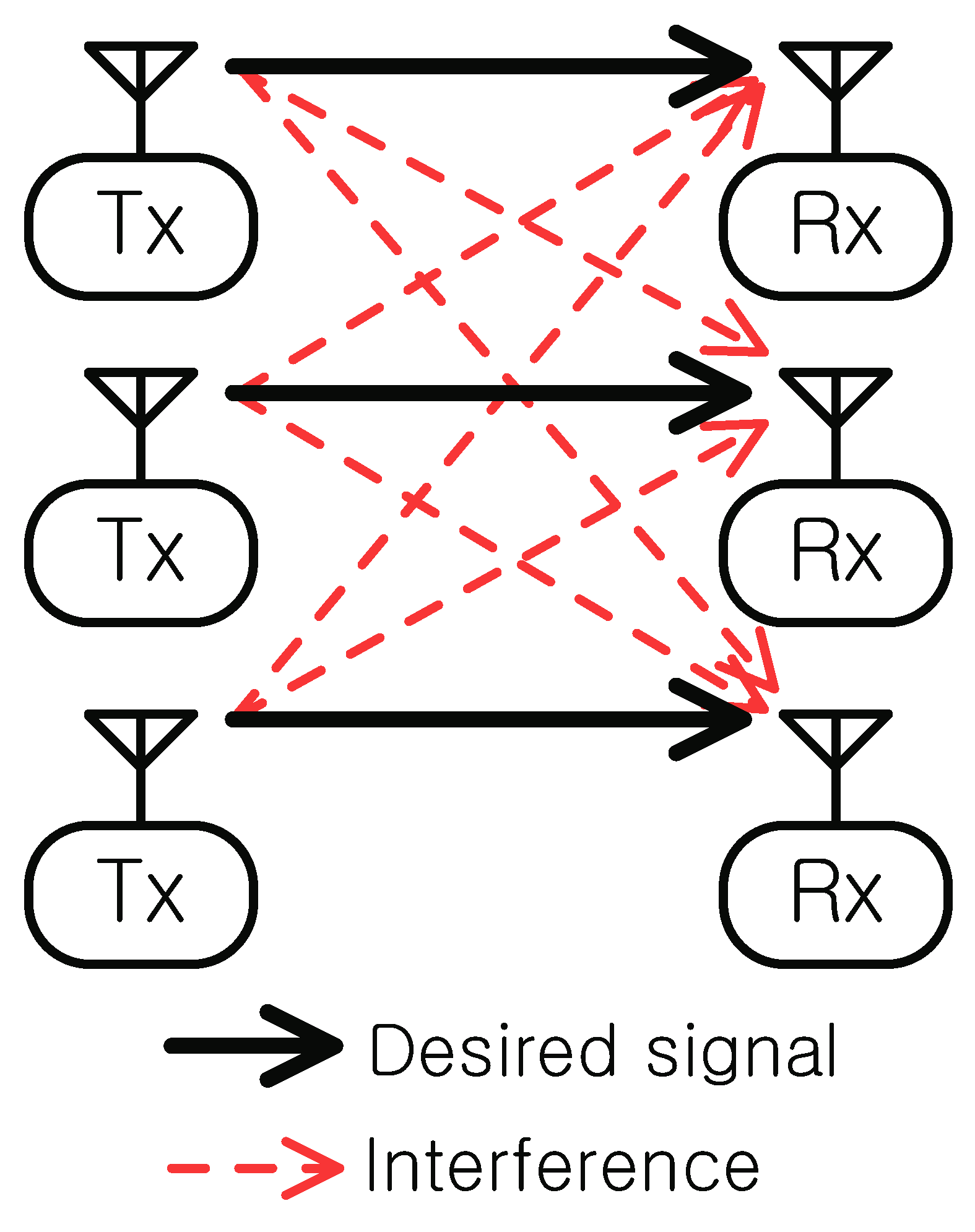
We consider an IFC in
Figure 1 in which multiple transmitters convey information to multiple receivers at the same time over the same frequency band. Without loss of the generality, it is assumed that there exist total
K transmitter–receiver pairs. Let
be the set of indices of the transmitters and receivers, i.e., index
k can refer to transmitter
k or receiver
k. Each receiver is supported by its corresponding transmitter, and the signals leaked from each transmitter to other receivers act as interference degrading the communication performance. Such a scenario prevails in practical wireless networks including multi-cell communication systems, IoT, and device-to-device networks.
Throughout the paper, quasi-static frequency-flat fading is assumed, but the channel coefficient would vary at each transmission time block. Denoting
as the complex channel coefficient between transmitter
i and receiver
j (
), the received signal
at receiver
i is written by
where
stands for the transmitted symbol at transmitter
i,
equals the Gaussian noise, and
is the transmit power of transmitter
i. From Equation (
1), the data rate achieved at receiver
i is written by
where
is the channel gain between transmitter
i and receiver
j,
indicates the channel matrix collecting all the channel gains. Here, the transmit power
,
, is now represented as a function of the channel gain matrix
to be optimized for each channel realization
.
The EE of transmitter
i is defined as the ratio of the achievable rate
to its total power consumption
which includes the overall power related to the signal transmission and circuit operations. The total power consumption
at transmitter
i can be characterized as [
3,
10]
where
accounts for the efficiency of the power amplifier and
denotes the static operation power of circuitry such as the mixer, the cooling systems, the power supply, the frequency synthesizer, the digital-to-analog converter, etc. [
1]. Then, the EE
of transmitter
i is expressed as
In a practical IFC setup, due to the heterogeneous nature of wireless propagation, the EE performance of multiple transmitter–receiver pairs is highly asymmetric. Hence, we desire to balance the EE performance by maximizing the minimum EE averaged over an arbitrary given fading distribution
. The instantaneous minimum EE
for a given channel realization
can be represented as
Then, the problem for maximizing the average minimum EE
is formulated as
where
is the concatenation of the transmit power of all the transmitters and the constraint in Equation (7) indicates the transmit power constraint with
being the maximum allowable transmit power budget at transmitter
i.
In general, Equation (
6) is a non-convex problem [
24], and it is highly difficult to identify the globally optimal solution
. To address the non-convexity of Equation (
6), theoretical optimization techniques have been applied in recent literature [
3,
10]. In particular, the SCA framework [
25] is adapted in [
3,
10], which tackle a series of convex approximations of Equation (
6) in an iterative manner. The monotonic convergence and the complexity analysis of these SCA-based algorithms have been intensively studied. However, the conventional methods [
3,
10] suffer from several implementation challenges. First, due to the coupled variables in the objective function of Equation (
6), the SCA framework cannot guarantee the quality of the convergence points of the SCA algorithms. To be specific, the conventional methods can only satisfy the necessary optimality condition, and, obviously, this limits the performance of the solution since they generally converges to poor local optimum and saddle points. Next, the iterative nature of the SCA framework incurs expensive and repetitive calculations for the algorithms in [
3,
10], resulting in the expensive computation cost for the transmitters. This becomes severe in the fast fading scenario where the channel coefficients
changes before computing the solution of Equation (
6) through the iterations.
To overcome such limitations of traditional optimization approaches, we propose a DL-based power control scheme for the minimum EE maximization problem in Equation (
6). The DL-based resource management techniques have been recently investigated [
18,
19,
20,
21,
22,
23]. Existing studies have mostly focused on the sum rate maximization problem [
18,
20,
21,
22,
23], which has been known to be simpler than our formulation in Equation (
6). Although the sum EE maximization was considered in [
19], it is not clear whether the max-min EE formulation can be indeed addressed by the DL algorithms. Therefore, the expression power of the DNNs for solving the EE fairness problem in Equation (
6) has not been adequately examined in the literature. It is worth noting that, since the training of DNNs are typically based on the gradient descent method [
12,
26], it would not be straightforward to verify the feasibility of the state-of-the-art DL libraries for addressing the non-smooth optimization problem in Equation (
6). Therefore, maximizing the EE fairness performance is a nontrivial task through the exiting sum metric training rules [
18,
19,
20,
21,
22,
23].
4. Numerical Results
In this section, we present numerical results evaluating the maximized minimum (max-min) EE performance of the proposed DNN scheme. Unless otherwise stated, a DNN with
hidden layers was considered. The dimension of the hidden layer was set to
, whereas the output layer dimension was fixed to
K to produce
K-dimensional transmit power solution
. The ReLU function
, which is a popular choice for hidden activation functions [
11,
12,
13,
20], was adopted for all hidden layers. We applied the batch normalization technique [
31] after each hidden and output layer to accelerate the training process. Unless otherwise stated, the learning rate
and the mini-batch size
S were set to
and
, respectively. The early stopping [
11] was employed with
training iterations and
validation samples.
We utilized the Adam method [
26] for the SGD algorithm. At each iteration
t, the update rules of the moving average of the gradient
, the second moment
, and the DNN parameter
are given, respectively, by [
26]
where
is defined as the instantaneous gradient of the cost function, ⊘ denotes the element-wise division, and
indicates the element-wise square root of the vector
. Two hyper parameters
and
adjust the decaying rates of the moving average of the first and the second momentums of the gradient, respectively. Following [
26], we fixed
and
. A positive parameter
was introduced to avoid numerical errors. For the initialization,
and
were set to the zero vectors.
All the channel gains for the training, validation, and testing steps were generated with the Rayleigh fading. The transmit power constraint
for each transmitter
i was fixed as
and the power amplifier efficiency
was given as
[
3]. The training was implemented in Python with Tensorflow on a PC with Intel Core i7 CPU
GHz, 32 GB of RAM, and GeForce RTX 2080 GPU.
4.1. DNN Validation
In this subsection, we validate our hyper-parameter setting for the DNN training such as the number of hidden layers and the mini-batch size. In
Figure 4, we first present the convergence of the training and the validation performance of the proposed DNN with
and
dBm for
and 30 dBm. As reference, we consider the following three baselines.
SCA [3]: The SCA-based iterative optimization algorithm in [
3] was implemented with the CVX and MOSEK solver.
Maximum power: The transmit power was set to it maximum value as , .
Random power: A random transmission policy was employed where is uniformly distributed over .
It is shown that the performance of the DNN evaluated over the training and the validation sets converges well, implying that the proposed SGD update (Equation (
24)) is effective for the max-min formulation in Equation (
6). It is interesting to see that the proposed DNN method performs better than other baselines, especially the conventional SCA-based optimization approach [
3]. Due to the non-convex nature of Equation (
6), the SCA algorithm developed in [
3] cannot guarantee the global optimality and converges to the KKT stationary point of Equation (
6). On the contrary, the proposed DL approach is able to identify the global optimum for Equation (
6) as discussed in the universal approximation theorem [
27,
28]. This infers that the DNN could handle the non-convexity of the EE fairness maximization problem with the data-driven SGD update rule in Equation (
24).
Figure 5 illustrates the convergence behavior of the validation performance with
,
dBm, and
dBm for various number of hidden layers
L. The convergence performance of a DNN with a single hidden layer, i.e.,
, is worse than other configurations, whereas the performance of DNNs with
, 5, and 7 hidden layers show similar performance. However, it is observed that the convergence speed of the case with
is slower than that of
and 5. This is because the DNN with such a large number of hidden layers overfits to its training data [
11]. Hence, the validation performance of the DNN with
would not that be good compared to other cases. We thus fixed
for the rest of the simulation.
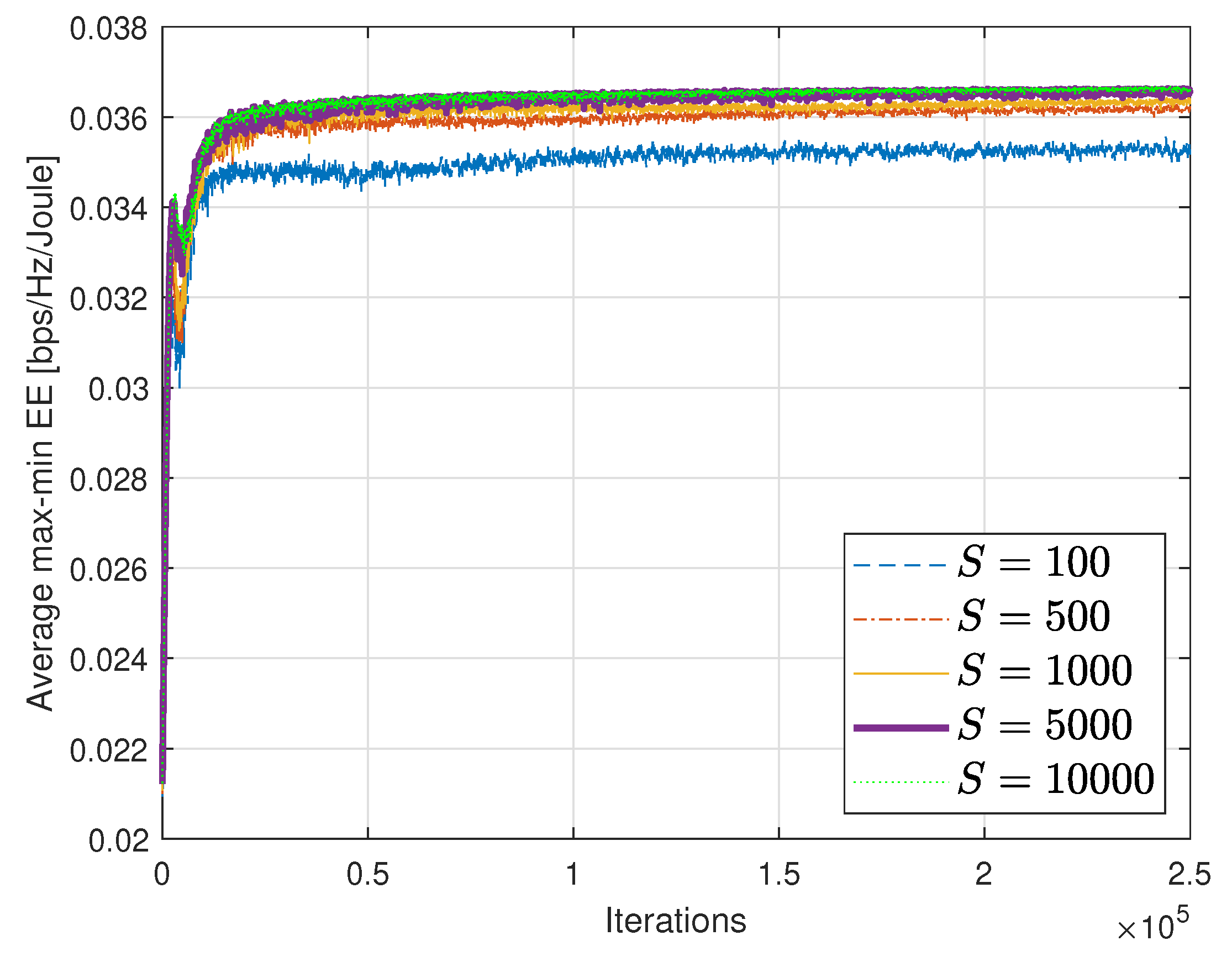
In
Figure 6, we plot the convergence performance with different mini-batch size
S. The DNN trained with a small mini-batch set (
and 500) converges to a poor performance. We can see that increasing the mini-batch size is beneficial to improve the validation performance of the DNN since the empirical expectation of the sub-gradient in Equation (
24) becomes more accurate as
S grows. However, a large mini-batch size needs intensive SGD computation in the training step. Thus, we need to choose an appropriate
S for achieving a good trade-off between the performance and the training complexity. In
Figure 6, we can see that
is an efficient choice for our scenario.
4.2. Performance Comparison
In this subsection, we focus on evaluating the test performance of the trained DNN and comparison with the baseline methods.
Figure 7 depicts the average max-min EE performance with respect to the transmit power budget
P with
dBm for
and 4. It is clear that the proposed DNN-based power control scheme is superior to other baselines. In particular, the proposed DNN method performs better than the conventional optimization approach [
3] regardless of
K and
P.
Table 1 shows the average CPU running time of the SCA method [
3] and the proposed DNN scheme. Notice that the computations of the SCA method are online tasks which should be performed for each channel realization, whereas the training of the DNN can be performed offline with the aid of the training data collected in advance. Since the proposed DL approach does not require any retraining processes, the offline training complexity does not affect the online execution time of the trained DNN. Therefore, for fair comparison, the complexity of the DNN was evaluated only for the online testing step for producing the power control solution via successive linear operations in Equation (
9). We implemented the test calculation of the trained DNN using Matlab and CPU and Matlab with CVX carried out the SCA algorithm. The CPU simulation was performed on a PC with Intel Core i5 CPU and 8 GB of RAM. We can see that the proposed DNN remarkably reduces the CPU running time compared to that of the SCA algorithm [
3], which iteratively calculates the solution for each channel realization. This is because the real-time computation of the trained DNN is simply realized by the cascaded matrix multiplications and additions in Equation (
9). Therefore, the power control solution of the proposed DNN method can be easily obtained compared to the iterative SCA algorithm [
3]. It is also worth noting that the complexity of the proposed DL method only depends on the number of receivers
K but not the transmit power constraint
P since the proposed DNN structure relies only on
K. The results in
Table 1 infer that the proposed DNN not only improves the EE fairness performance but also reduces the energy required for the optimization tasks at the transmitters. Therefore, the proposed DL-based power control strategy could provide high EE performance in terms of both the communication and the computations.
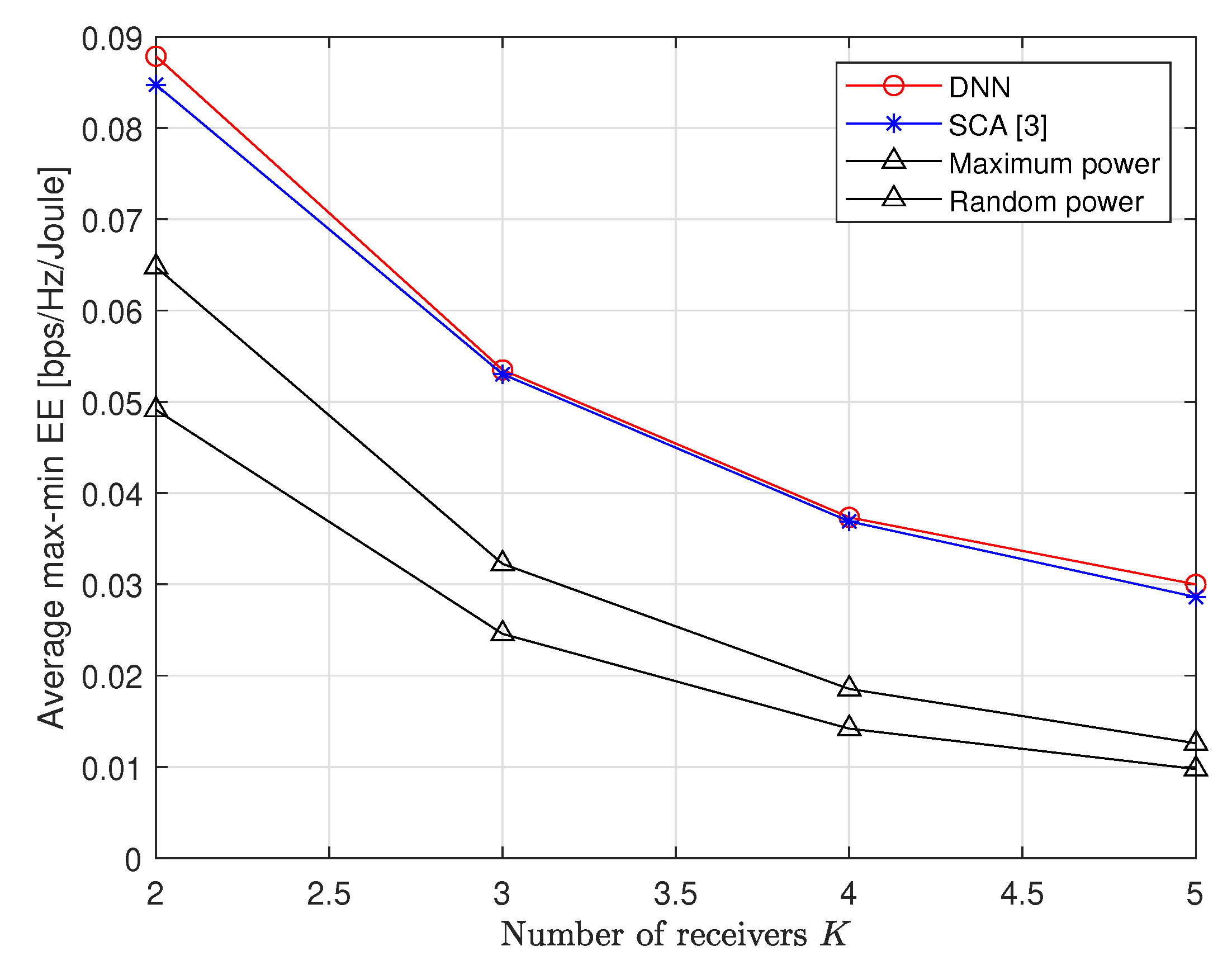
Figure 8 presents the average max-min EE performance with respect to the number of receivers
K. Both the proposed DNN scheme and the conventional SCA algorithm show a similar performance for a large
K. However, as observed in
Table 1, the computational complexity of the DNN is much lower than that of the conventional SCA approach. We thus conclude that the proposed DNN scheme still has advantages over the method in [
3] even with a small performance gain.
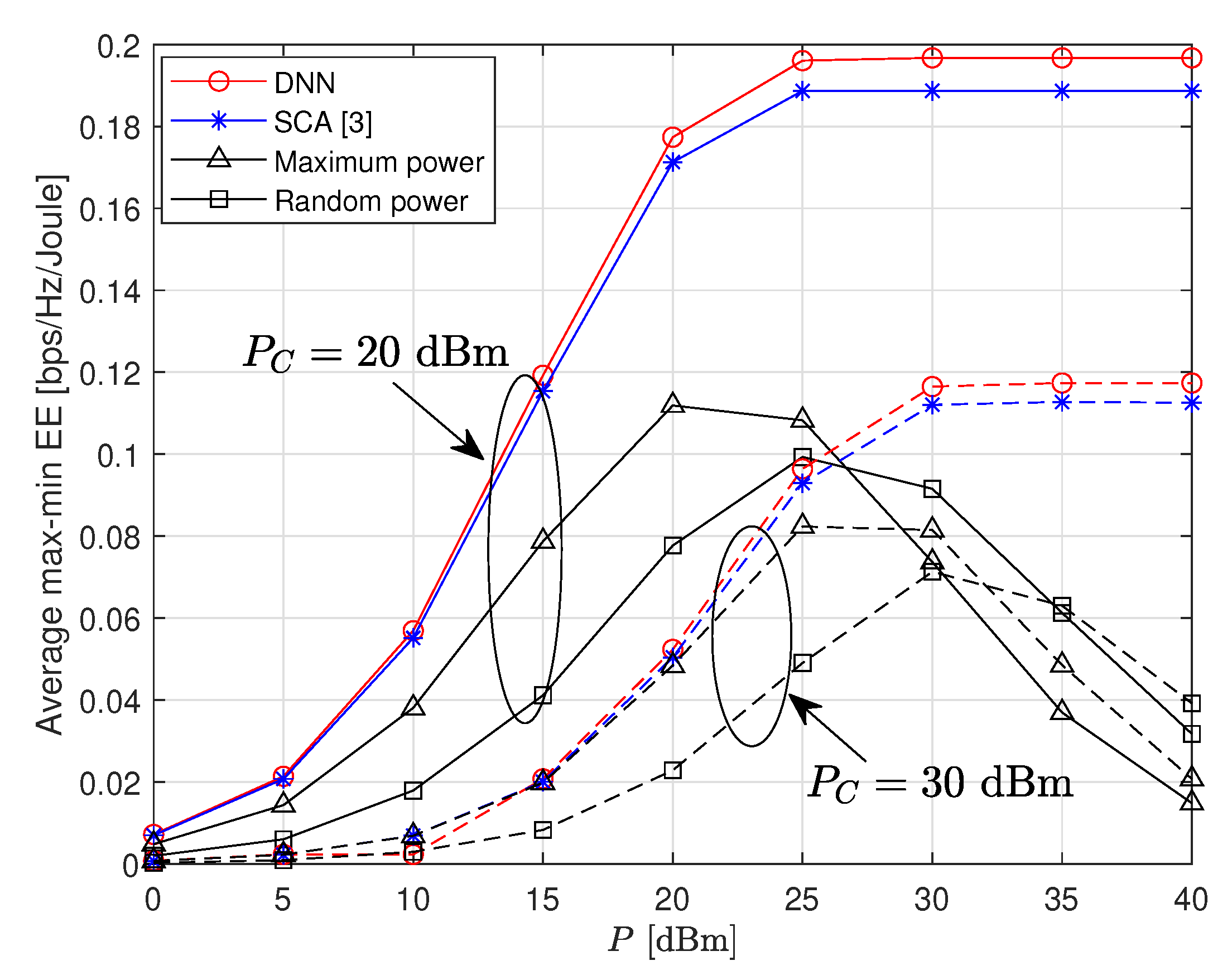
Figure 9 provides the average max-min EE performance by changing
P with various circuit power
. It is revealed that the performance gain achieved by the proposed DNN scheme gets larger as
P increases. We can also see that the DNN is still powerful for a large circuit power with
dBm.
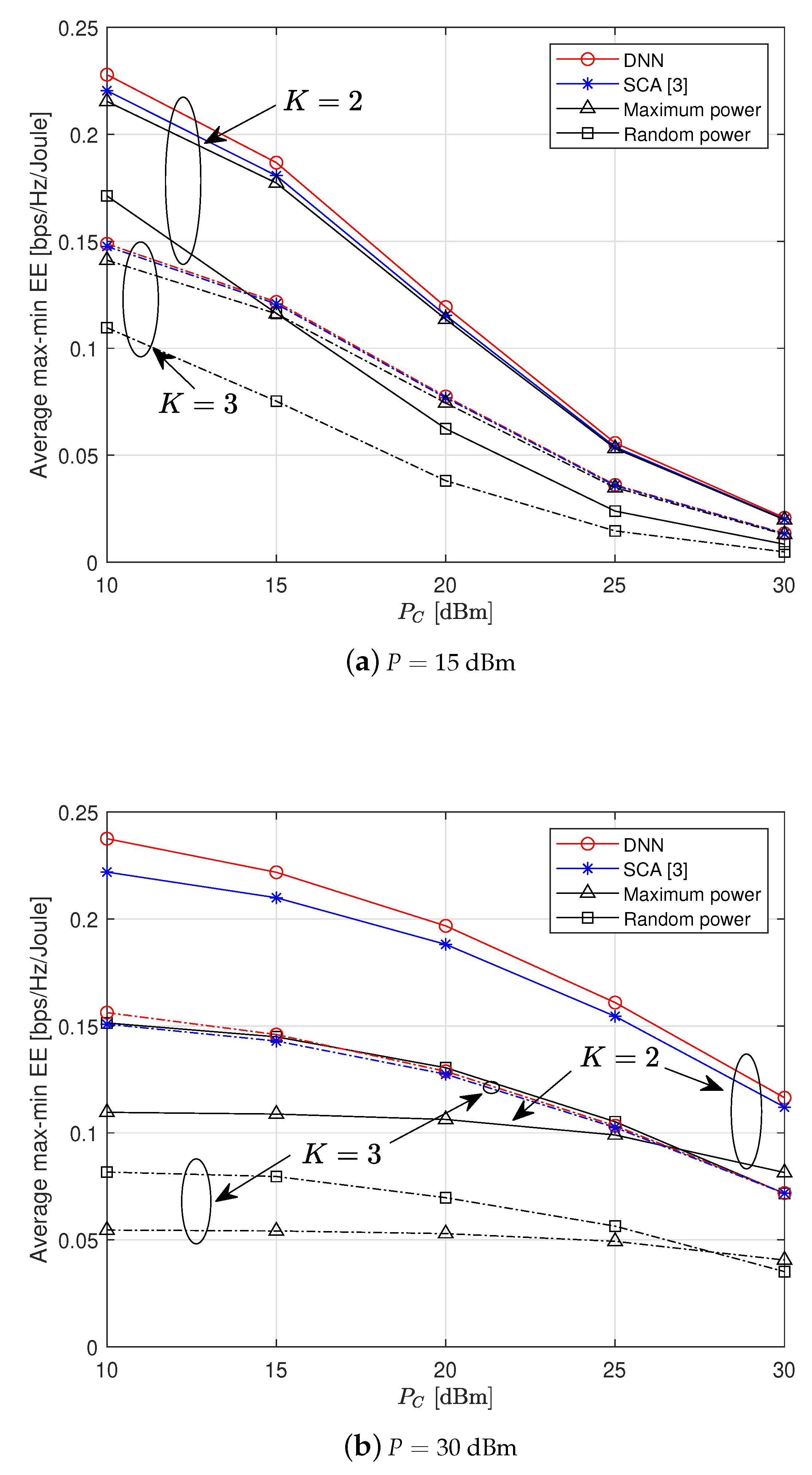
To further examine the impact of the circuit power, we present the average max-min EE performance in
Figure 10 for
and 3. It is shown that the proposed DL method performs well regardless of the circuit power
. We observe that the gain achieved by the proposed DL scheme over the conventional SCA algorithm gets larger as
decreases. The DNN scheme becomes more powerful in the high regime of
dBm (
Figure 10b). Such a performance gain obtained by the DL approach is significantly meaningful with much reduced computational complexity.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}