A Regional Photovoltaic Output Prediction Method Based on Hierarchical Clustering and the mRMR Criterion


Abstract
1. Introduction
2. Theoretical Background
2.1. Empirical Orthogonal Function
- (1)
- The original data matrix is normalized for anomaly processing to obtain a data matrix Xm × n, where m is the number of plants and n is the time series.
- (2)
- Calculate the covariance matrix of the anomaly matrix X via Equation (2):
- (3)
- The corresponding eigenvalues λ1, λ2…, λm and the feature vectors Vm × n are calculated by utilizing the Equations (3) and (4):where V1, V2, … Vm are the spatial feature vectors of the original farm and E is an diagonal matrix with m × n dimension.
- (4)
- The variance of the matrix Xm × n is represented by the eigenvalues λ—the larger λ is, the greater its contribution to the total variance. The variance contribution rate of the k th feature vector Vk is defined as below in Equation (5):
2.2. Condensed Hierarchical Clustering Algorithm
- (1)
- Calculate the cosine distance between each pair of the n-column vectors, and construct the distance matrix d;
- (2)
- Use the unweighted averaging method to calculate the similarity between clusters. Two clusters calculated with the smallest distance are merged into a new cluster.
- (3)
- Check if the number of clusters is 1. If not, go to step (2);
- (4)
- Draw a cluster diagram to determine the number of sub-regions. Classify similar power plants into the same sub-region.
2.3. Mutual Information and the mRMR Criterion
2.4. Elman Neural Network
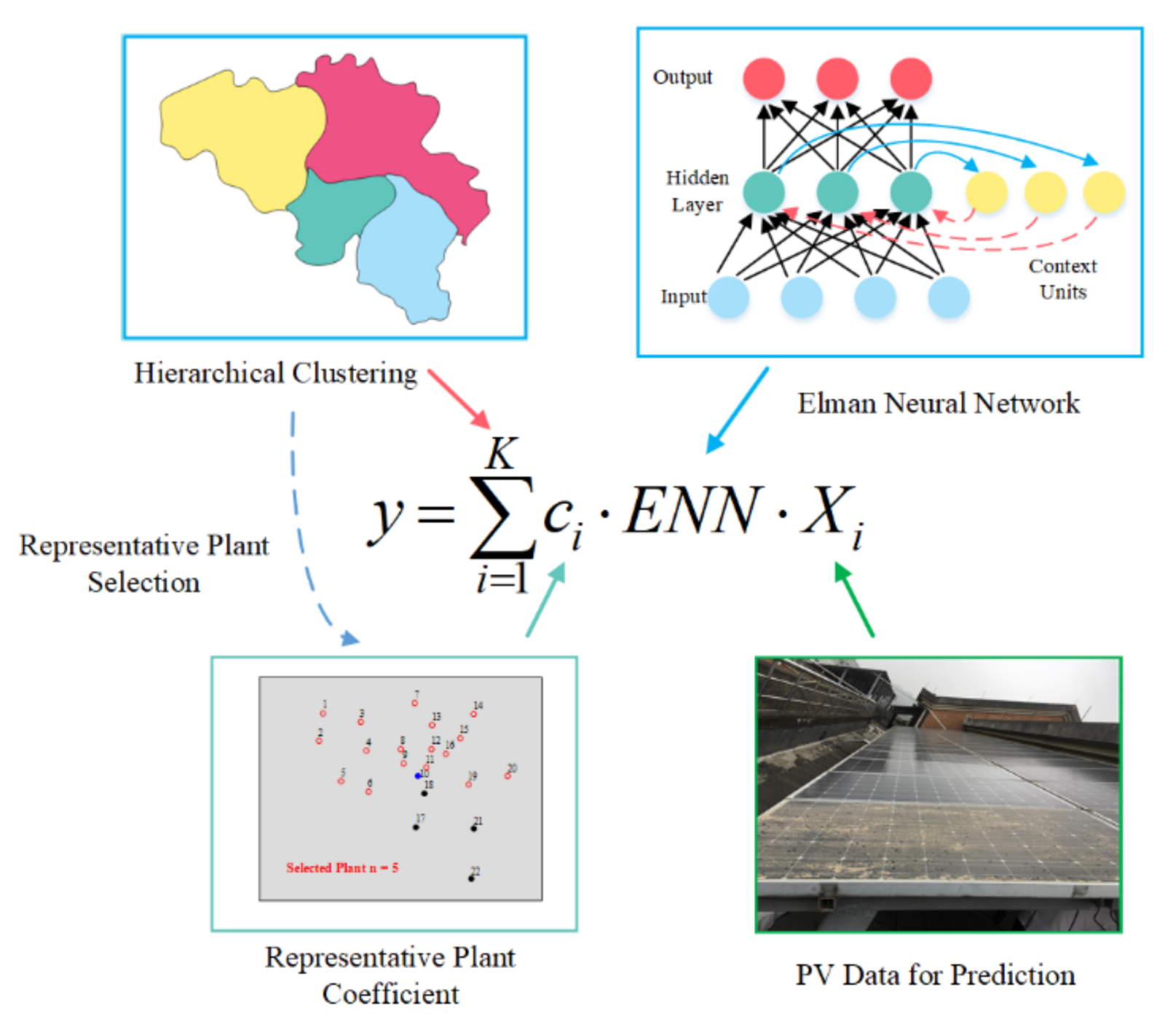
3. Proposed Method
3.1. Representative Power Plant Selection Model
- (1)
- Calculate the mutual information I(v, V) between the power output of each single power plant and the power output value of the sub-region, and calculate the mutual information I(vi, vj) between the single power plants in the sub-region;
- (2)
- When I(v, V) reaches the maximum, mark the data set S = {v}, F = F − {v};
- (3)
- Calculate the feature set F based on the incremental search algorithm, where the feature v satisfies Equation (14) and S = S ∪{v}, F = F − {v};
- (4)
- Determine whether the number of features in the subset reaches n. If so, output the subset S. Otherwise, repeat step (3) and continue the search until the number of features is n.
3.2. Proposed Algorithm
4. Results and Discussion
4.1. Experimental Data Description
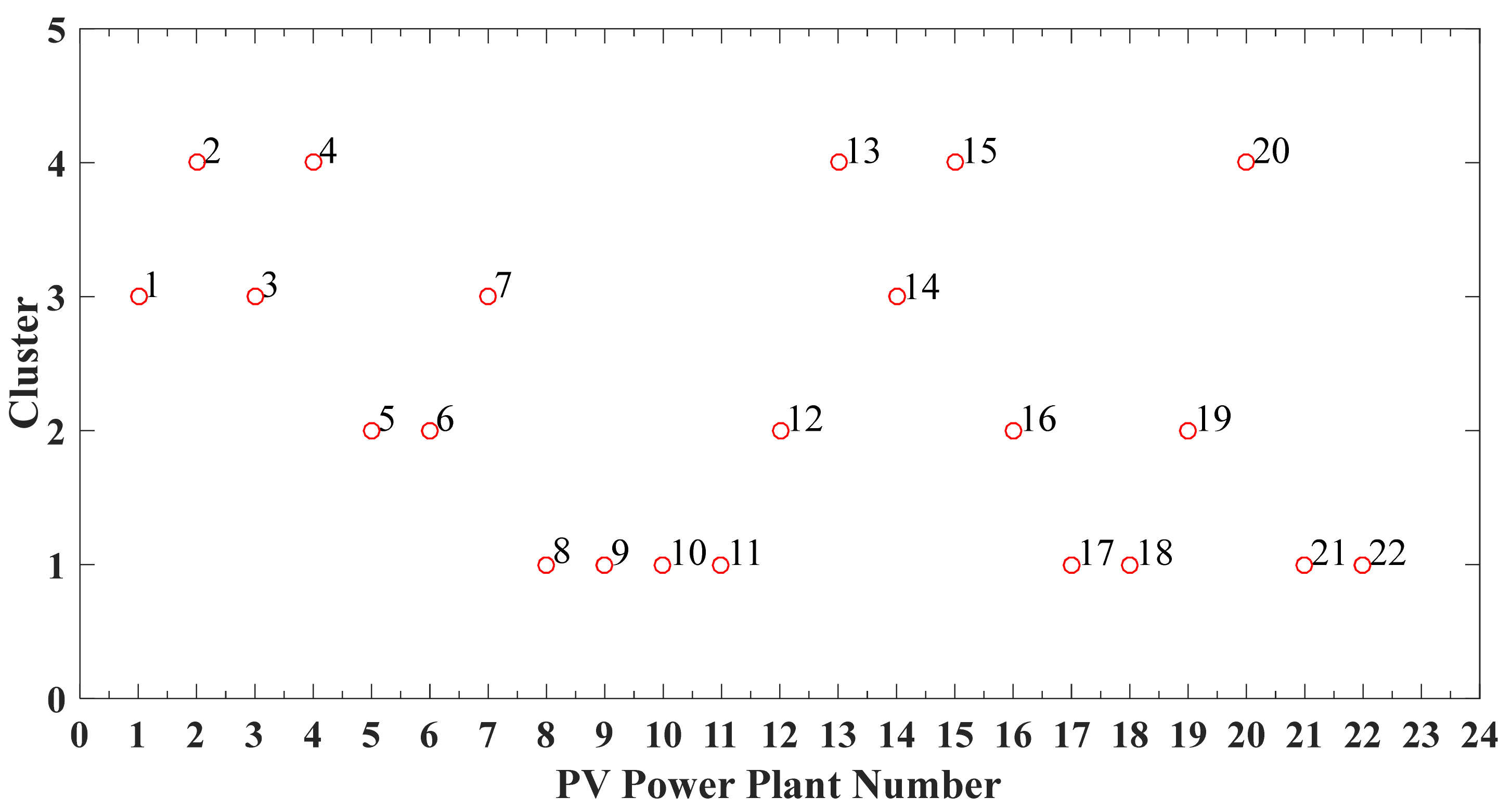
4.2. Sub-Region Division Analysis
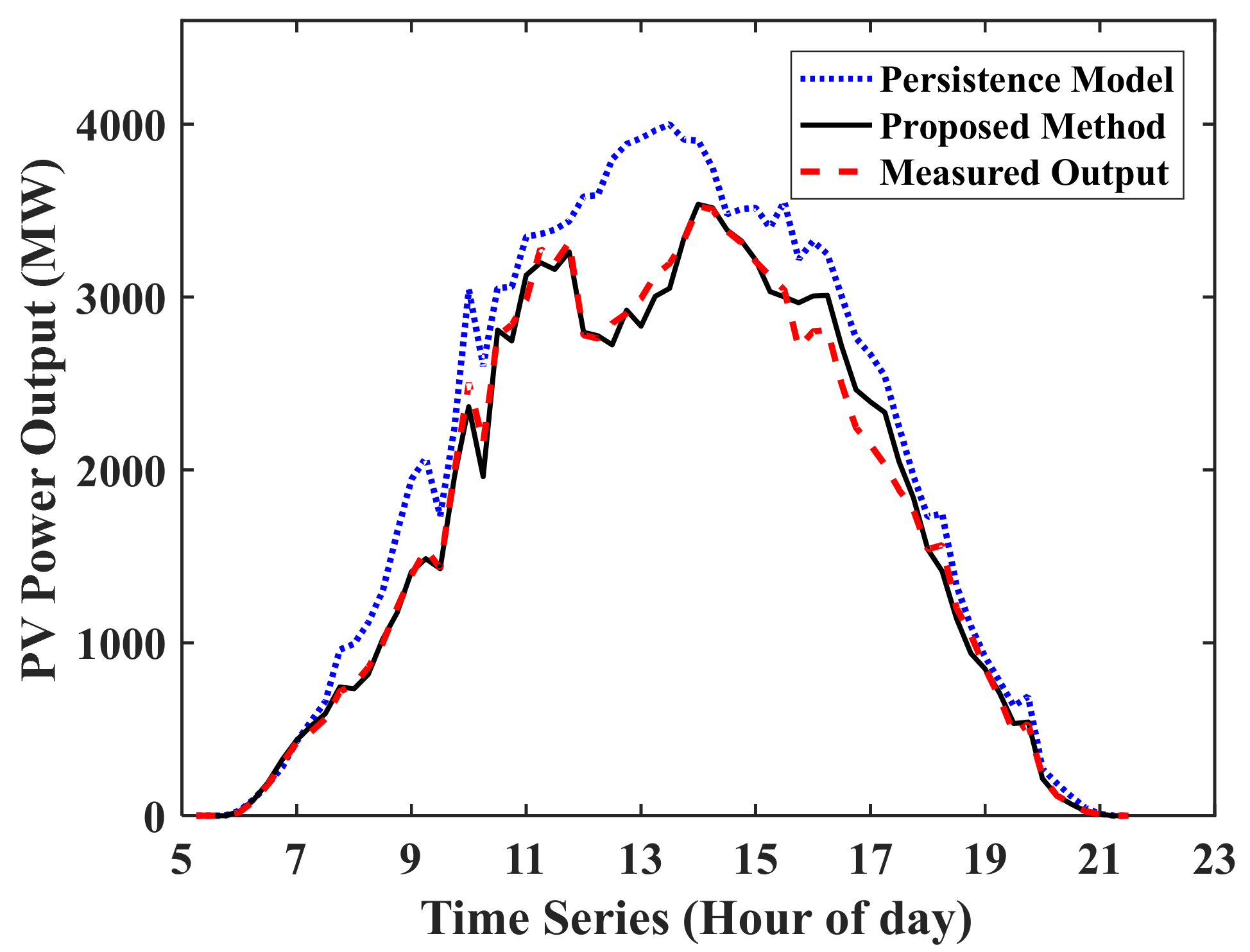
4.3. Regional PV Output Prediction
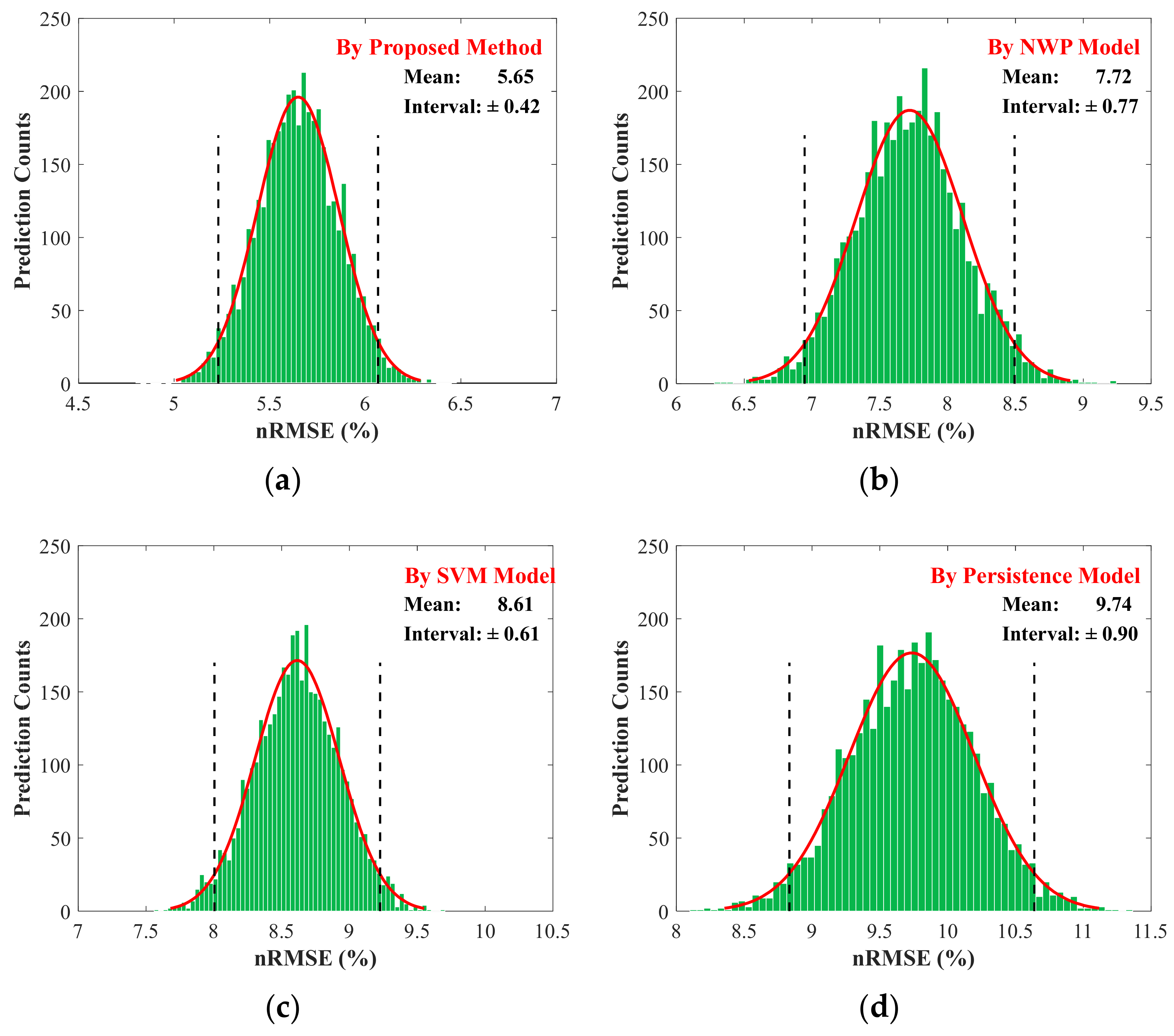
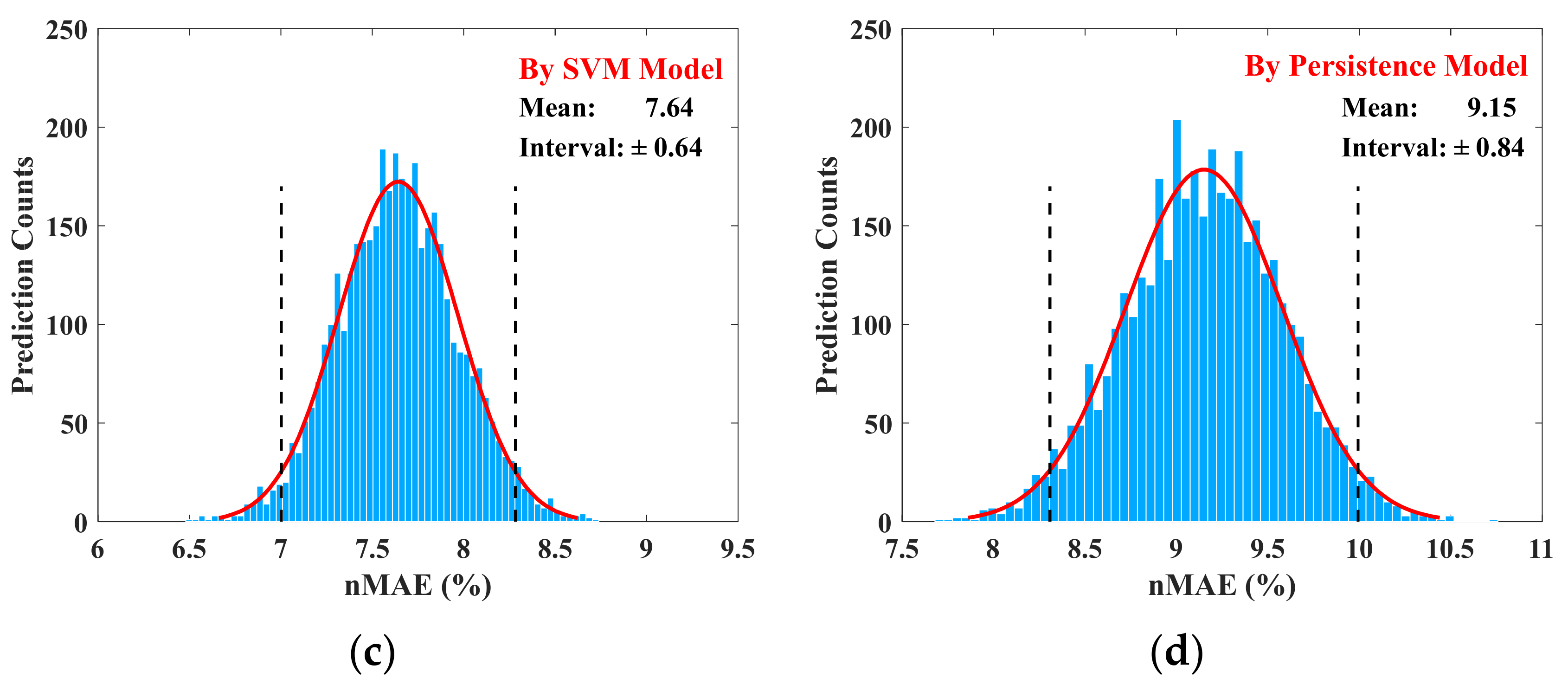
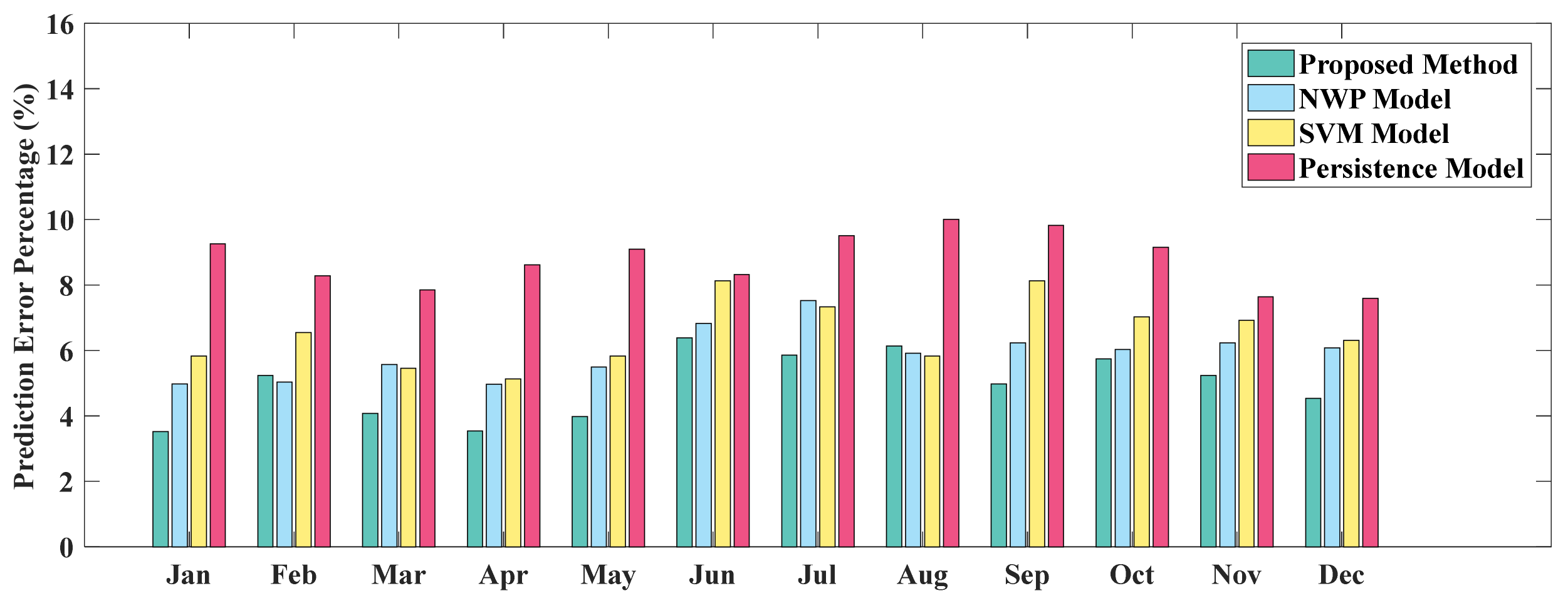
4.4. Performance Analysis
5. Conclusions
- The sub-region division model based on the EOF decomposition and hierarchical clustering has the ability to describe the time–space characteristics of the PV power plants, which is more reasonable compared with the sub-region division method only by geographical locations.
- The representative power plant selection is beneficial and vital for the power output prediction of the regional PV plants. By utilizing the mRMR criterion, both accuracy and the computational efficiency will be improved. Additionally, faced with the lack of power data for some PV plants, the advantage of the representative selection model will surpass other PV prediction methods.
- The proposed prediction algorithm can mitigate the adverse impact of fluctuating PV power output. Particularly, the prediction errors are small regardless of whether the regional PV output ranges are flat or greatly fluctuating. The results from an annual case study show that, compared with the NWP model, the SVM model and the persistence model, the proposed prediction method reduces the nMAE by 4.62%, thereby effectively improving the prediction accuracy.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Marinelli, M.; Maule, P.; Hahmann, A.N.; Gehrke, O.; Norgard, P.B.; Cutululis, N.A. Wind and photovoltaic large-scale regional models for hourly production evaluation. IEEE Trans. Sustain. Energy 2015, 6, 916–923. [Google Scholar] [CrossRef]
- Beranek, V.; Olsan, T.; Libra, M.; Poulek, V.; Sedlacek, J.; Dang, M.Q.; Tyukhov, I.I. New monitoring system for photovoltaic power plants’ management. Energies 2018, 1, 2495. [Google Scholar] [CrossRef]
- Libra, M.; Beranek, V.; Sedlacek, J.; Poulek, V.; Tyukhov, I.I. Roof photovoltaic power plant operation during the solar eclipse. Sol. Energy 2016, 140, 109–112. [Google Scholar] [CrossRef]
- Fu, L.; Wei, Y.D.; Fang, S.; Zhou, X.J.; Lou, J.Q. Condition monitoring for roller bearings of wind turbines based on health evaluation under variable operating states. Energies 2017, 10, 1564. [Google Scholar] [CrossRef]
- Fu, L.; Wei, Y.D.; Fang, S.; Tian, G.; Zhou, X.J. A wind energy generation replication method with wind shear and tower shadow effects. Adv. Mech. Eng. 2018, 10, 3. [Google Scholar] [CrossRef]
- Meral, M.E.; Dincer, F. A review of the factors affecting operation and efficiency of photovoltaic based electricity generation systems. Renew. Sust. Energ. Rev. 2011, 5, 2176–2184. [Google Scholar] [CrossRef]
- Reikard, G. Predicting solar radiation at high resolutions: A comparison of time series forecasts. Sol. Energy. 2009, 83, 342–349. [Google Scholar] [CrossRef]
- Bae, K.Y.; Jang, H.S.; Sung, D.K. Hourly solar irradiance prediction based on support vector machine and its error analysis. IEEE Trans. Power Syst. 2019, 32, 935–945. [Google Scholar] [CrossRef]
- Rodriguez, F.; Fleetwood, A.; Galarza, A.; Fontan, L. Predicting solar energy generation through artificial neural networks using weather forecasts for microgrid control. Renew. Energy 2018, 126, 855–864. [Google Scholar] [CrossRef]
- Lin, P.J.; Peng, Z.N.; Lai, Y.F.; Cheng, S.Y.; Chen, Z.C.; Wu, L.J. Short-term power prediction for photovoltaic power plants using a hybrid improved Kmeans-GRA-Elman model based on multivariate meteorological factors and historical power datasets. Energy Conv. Manag. 2018, 177, 704–717. [Google Scholar] [CrossRef]
- Lamsal, D.; Sreeram, V.; Mishra, Y.; Kumar, D. Achieving a minimum power fluctuation rate in wind and photovoltaic output power using discrete Kalman filter based on weighted average approach. IET Renew. Power Gener. 2018, 12, 633–638. [Google Scholar] [CrossRef]
- Chow, C.W.; Urquhart, B.; Lave, M.; Dominguez, A.; Kleissl, J.; Shields, J.; Washom, B. Intra-hour forecasting with a total sky imager at the UC San Diego solar energy testbed. Sol. Energy 2011, 85, 2881–2893. [Google Scholar] [CrossRef]
- Zeng, J.W.; Qiao, W. Short-term solar power prediction using a support vector machine. Renew. Energy. 2013, 52, 118–127. [Google Scholar] [CrossRef]
- Cao, J.C.; Lin, X.C. Study of hourly and daily solar irradiation forecast using diagonal recurrent wavelet neural networks. Energy Conv. Manag. 2008, 49, 1396–1406. [Google Scholar] [CrossRef]
- Demirhan, H.; Renwick, Z. Missing value imputation for short to mid-term horizontal solar irradiance data. Appl. Energy. 2018, 225, 998–1012. [Google Scholar] [CrossRef]
- Lorenz, E.; Hurka, J.; Heinemann, D.; Beyer, H.G. Irradiance forecasting for the power prediction of grid-connected photovoltaic systems. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2009, 2, 2–10. [Google Scholar] [CrossRef]
- Lipperheide, M.; Bosch, J.L.; Kleissl, J. Embedded nowcasting method using cloud speed persistence for a photovoltaic power plant. Sol. Energy 2015, 112, 232–238. [Google Scholar] [CrossRef]
- Lonij, V.P.A.; Brooks, A.E.; Cronin, A.D.; Leuthold, M.; Koch, K. Intra-hour forecasts of solar power production using measurements from a network of irradiance sensors. Sol. Energy 2013, 97, 58–66. [Google Scholar] [CrossRef]
- Pierro, M.; De Felice, M.; Maggioni, E.; Moser, D.; Perotto, A.; Spade, F.; Cornaro, C. Data-driven upscaling methods for regional photovoltaic power estimation and forecast using satellite and numerical weather prediction data. Sol. Energy 2017, 158, 1026–1038. [Google Scholar] [CrossRef]
- Fonseca, J.G.D.; Oozeki, T.; Ohtake, H.; Takashima, T.; Ogimoto, K. Regional forecasts of photovoltaic power generation according to different data availability scenarios: A study of four methods. Prog. Photovoltaics 2015, 23, 1203–1218. [Google Scholar] [CrossRef]
- Saint-Drenan, Y.M.; Good, G.H.; Braun, M.; Freisinger, T. Analysis of the uncertainty in the estimates of regional PV power generation evaluated with the upscaling method. Sol. Energy 2016, 135, 536–550. [Google Scholar] [CrossRef]
- Malvoni, M.; De Giorgi, M.G.; Congedo, P.M. Photovoltaic forecast based on hybrid PCA-LSSVM using dimensionality reducted data. Neurocomputing 2016, 211, 72–83. [Google Scholar] [CrossRef]
- Fonseca, J.G.D.; Oozeki, T.; Takashima, T.; Koshimizu, G.; Uchida, Y.; Ogimoto, K. Use of support vector regression and numerically predicted cloudiness to forecast power output of a photovoltaic power plant in Kitakyushu, Japan. Prog. Photovoltaics 2012, 20, 874–882. [Google Scholar] [CrossRef]
- Saint-Drenan, Y.M.; Good, G.H.; Braun, M. A probabilistic approach to the estimation of regional photovoltaic power production. Sol. Energy 2017, 147, 257–276. [Google Scholar] [CrossRef]
- Shaker, H.; Zareipour, H.; Wood, D. Impacts of large-scale wind and solar power integration on California’s net electrical load. Renew. Sust. Energ. Rev. 2016, 58, 761–774. [Google Scholar] [CrossRef]
- Shivashankar, S.; Mekhilef, S.; Mokhlis, H.; Karimi, M. Mitigating methods of power fluctuation of photovoltaic (PV) sources—A review. Renew. Sust. Energ. Rev. 2016, 59, 1170–1184. [Google Scholar] [CrossRef]
- Zhang, J.; Hodge, B.M.; Lu, S.Y.; Hamann, H.F.; Lehman, B.; Simmons, J.; Campos, E.; Banunarayanan, V.; Black, J.; Tedesco, J. Baseline and target values for regional and point PV power forecasts: Toward improved solar forecasting. Sol. Energy 2015, 122, 804–819. [Google Scholar] [CrossRef]
- Zhu, T.; Qu, Z.; Xu, H.; Zhang, J.; Shao, Z.; Chen, Y.; Prabhakar, S.; Yang, J. RiskCog: Unobtrusive real-time user authentication on mobile devices in the wild. IEEE Trans. Mob. Comput. 2019. [Google Scholar] [CrossRef]
- Fu, L.; Zhu, T.; Zhu, K.; Yang, Y.Y. Condition monitoring for the roller bearings of wind turbines under variable working conditions based on the fisher score and permutation entropy. Energies 2019, 12, 804–819. [Google Scholar] [CrossRef]
- Farzaneh, S.; Forootan, E. Reconstructing regional ionospheric electron density: A combined spherical slepian function and empirical orthogonal function approach. Surv. Geophys. 2018, 39, 289–309. [Google Scholar] [CrossRef]
- Aliahmadipour, L.; Eslami, E. GHFHC: Generalized hesitant fuzzy hierarchical clustering algorithm. Int. J. Intell. Syst. 2016, 31, 855–871. [Google Scholar] [CrossRef]
- Tellaroli, P.; Bazzi, M.; Donato, M.; Brazzale, A.R.; Draghici, S. Cross-Clustering: A partial clustering algorithm with automatic estimation of the number of clusters. PLoS ONE 2016, 11, 3. [Google Scholar] [CrossRef] [PubMed]
- Ge, Y.; Avitabile, V.; Heuvelink, G.B.M.; Wang, J.H.; Herold, M. Fusion of pan-tropical biomass maps using weighted averaging and regional calibration data. Int. J. Appl. Earth Obs. Geoinf. 2014, 31, 13–24. [Google Scholar] [CrossRef]
- Herman, G.; Zhang, B.; Wang, Y.; Ye, G.; Chen, F. Mutual information-based method for selecting informative feature sets. Pattern Recognit. 2014, 46, 3315–3327. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 3315–3327. [Google Scholar] [CrossRef]
- Peng, H.C.; Long, F.H.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.M.; Hong, C.M.; Chen, C.H. Neural-network-based mppt control of a stand-alone hybrid power generation system. IEEE Trans. Power Electron. 2011, 26, 3571–3581. [Google Scholar] [CrossRef]
- Dong, Q.C.; Feng, J.Q. Outlier detection and disparity refinement in stereo matching. J. Vis. Commun. Image Represent. 2019, 60, 380–390. [Google Scholar] [CrossRef]
- Dong, Q.C.; Feng, J.Q. Adaptive disparity computation using local and non-local cost aggregations. Multimed. Tools Appl. 2018, 77, 31647–31663. [Google Scholar] [CrossRef]
- Yang, L.; Wang, F.; Zhang, J.J.; Ren, W.H. Remaining useful life prediction of ultrasonic motor based on Elman neural network with improved particle swarm optimization. Measurement 2019, 143, 27–38. [Google Scholar] [CrossRef]
- Lan, H.; Zhang, C.; Hong, Y.Y.; He, Y.; Wen, S.L. Day-ahead spatiotemporal solar irradiation forecasting using frequency based hybrid principal component analysis and neural network. Appl. Energy. 2019, 247, 389–402. [Google Scholar] [CrossRef]
- De Schepper, E.; Van Passel, S.; Lizin, S.; Achten, W.M.J. Cost-efficient emission abatement of energy and transportation technologies: Mitigation costs and policy impacts for Belgium. Clean Technol. Environ. Policy 2014, 16, 1107–1118. [Google Scholar] [CrossRef]
- Pierro, M.; Bucci, F.; De Felice, M.; Maggioni, E.; Moser, D.; Perotto, A.; Spada, F.; Cornaro, C. Multi-Model ensemble for day ahead prediction of photovoltaic power generation. Sol. Energy 2016, 134, 132–146. [Google Scholar] [CrossRef]
- Mittermaier, M.P.; Bullock, R. Using MODE to explore the spatial and temporal characteristics of cloud cover forecasts from high-resolution NWP models. Meteorol. Appl. 2013, 20, 187–196. [Google Scholar] [CrossRef]
- Bacher, P.; Madsen, H.; Nielsen, H.A. Online short-term solar power forecasting. Sol. Energy 2009, 83, 772–1783. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Value | Sub-Region 1 | Sub-Region 2 | Sub-Region 3 | Sub-Region 4 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Plant No. | 20 | 4 | 7 | 3 | 16 | 6 | 17 | 18 | 22 | 21 |
| Transform coefficient | 6.697 | 4.469 | 3.903 | 3.995 | 5.035 | 4.236 | 5.997 | 5.147 | 8.154 | 6.803 |
| Weighting factor | 0.501 | 0.498 | 0.500 | 0.499 | 0.507 | 0.493 | 0.251 | 0.250 | 0.249 | 0.248 |
| Error Analysis | Sub-Region 1 | Sub-Region 2 | Sub-Region 3 | Sub-Region 4 | Entire Region |
|---|---|---|---|---|---|
| Mean absolute error (MAE) | 5.13% | 6.83% | 6.62% | 5.73% | 4.69% |
| Root mean square error (RMSE) | 6.10% | 7.58% | 7.19% | 6.50% | 5.67% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, L.; Yang, Y.; Yao, X.; Jiao, X.; Zhu, T. A Regional Photovoltaic Output Prediction Method Based on Hierarchical Clustering and the mRMR Criterion. Energies 2019, 12, 3817. https://doi.org/10.3390/en12203817
Fu L, Yang Y, Yao X, Jiao X, Zhu T. A Regional Photovoltaic Output Prediction Method Based on Hierarchical Clustering and the mRMR Criterion. Energies. 2019; 12(20):3817. https://doi.org/10.3390/en12203817
Chicago/Turabian StyleFu, Lei, Yiling Yang, Xiaolong Yao, Xufen Jiao, and Tiantian Zhu. 2019. "A Regional Photovoltaic Output Prediction Method Based on Hierarchical Clustering and the mRMR Criterion" Energies 12, no. 20: 3817. https://doi.org/10.3390/en12203817
APA StyleFu, L., Yang, Y., Yao, X., Jiao, X., & Zhu, T. (2019). A Regional Photovoltaic Output Prediction Method Based on Hierarchical Clustering and the mRMR Criterion. Energies, 12(20), 3817. https://doi.org/10.3390/en12203817