Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses



Abstract
1. Introduction
1.1. Condition-Based Maintenance
1.2. Reliability Studies
1.3. Research Overview
- Review the issues and highlight the bottlenecks that have arisen in recently-published works as a result of wind turbine data availability and quality in the context of reliability studies
- To do the same from the context of attempting condition monitoring with SCADA data
- Summarise these issues and place them in the context of present initiatives to address them
2. Turbine Data Sources
2.1. SCADA Data
2.1.1. Operational Data
2.1.2. Availability Data
2.1.3. Alarm System Data
- Information messages: These are generated to communicate any change in the operation mode of the turbine, not related to faults; for example, when wind speed is below cut-in speed, a change in grid conditions or when a maintenance switch has been engaged.
- Warning alarms are generated when certain control variables or operating conditions move close to the limits of acceptable bounds.
- Fault alarms are generated when these limits are exceeded.
2.2. Maintenance Logs and Work Orders
3. Issues Encountered in Wind Turbine Reliability Studies
3.1. WMEP
3.2. WindStats
3.2.1. LWK
3.2.2. Ribrant et al.
3.3. ReliaWind
3.4. CREW
3.5. Kaidis et al.
3.6. AWESOME Project
3.7. Carroll et al.: Onshore
3.8. Carroll et al.: Offshore
3.9. Reliability Studies’ Conclusions
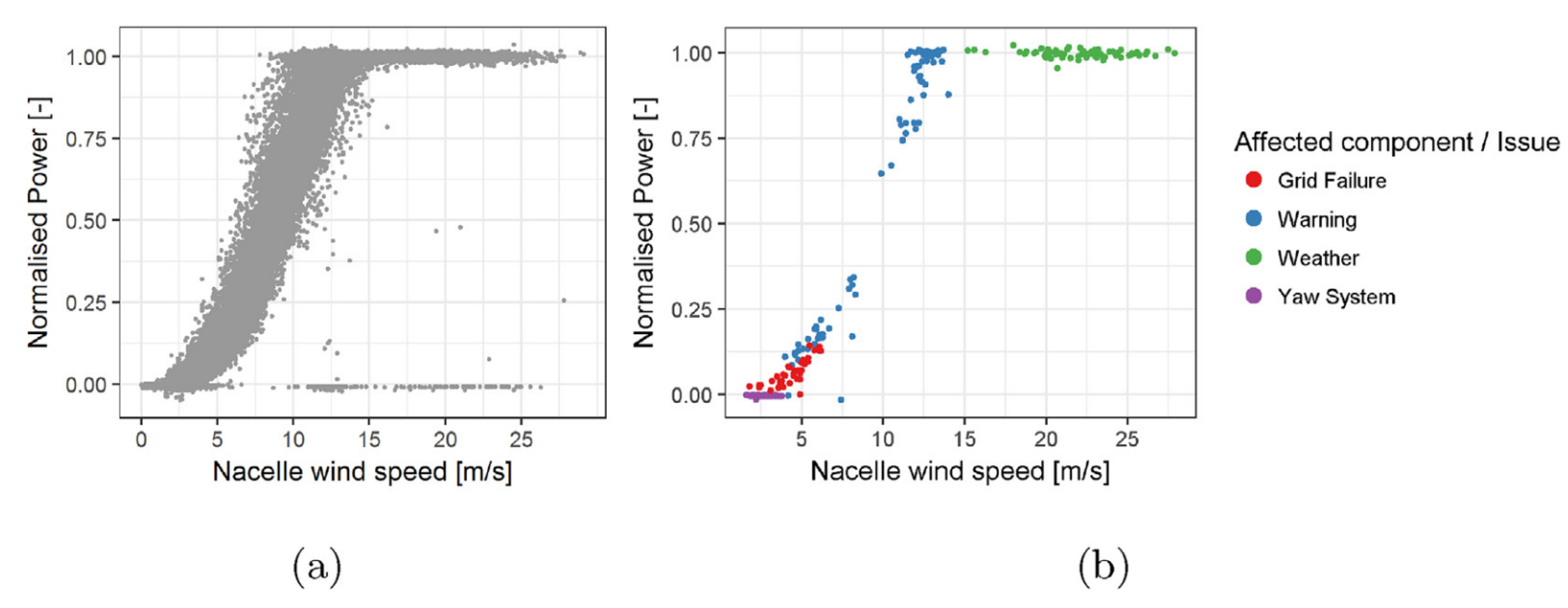
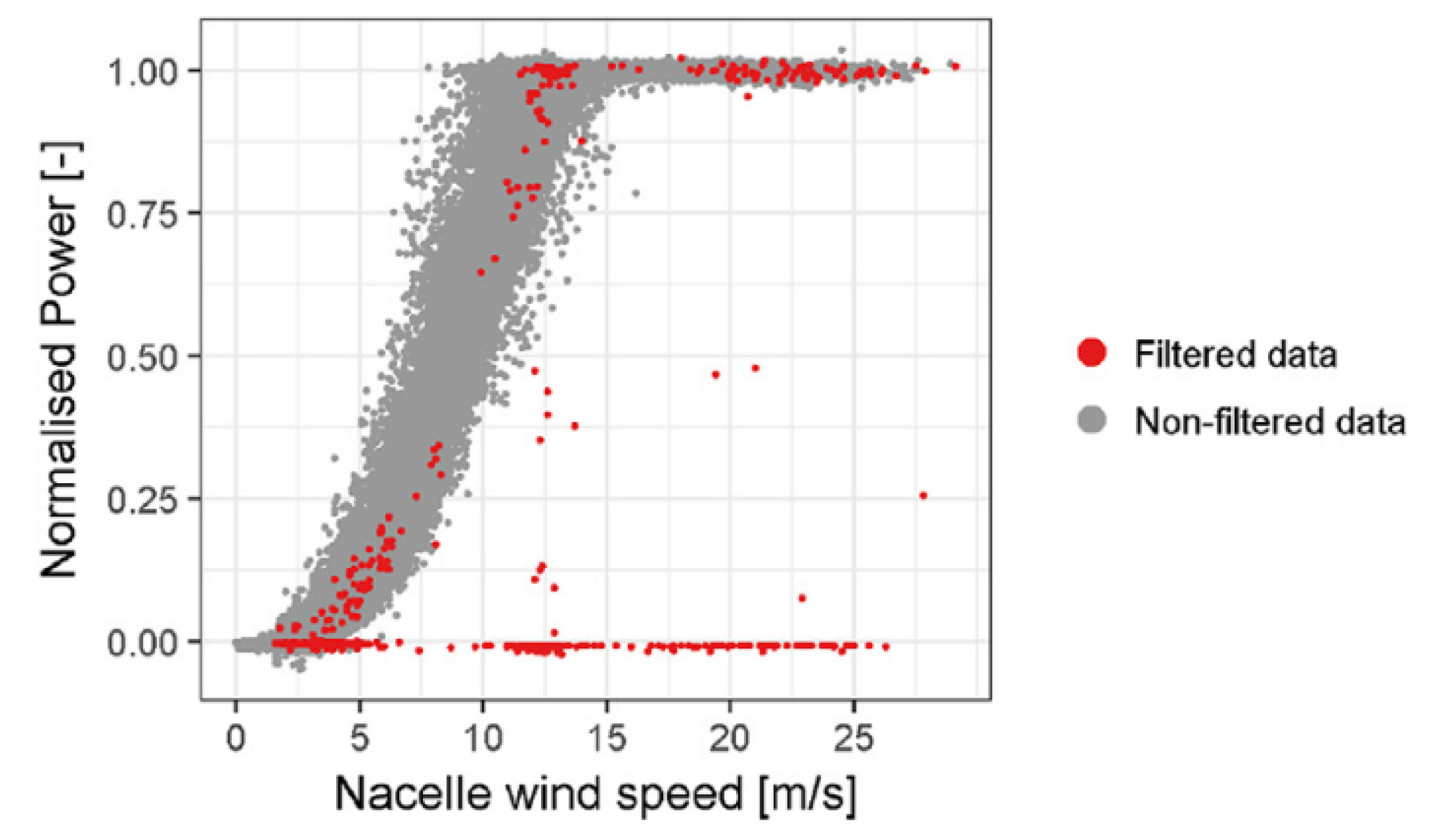
4. Issues Encountered in Condition Monitoring Using SCADA Data
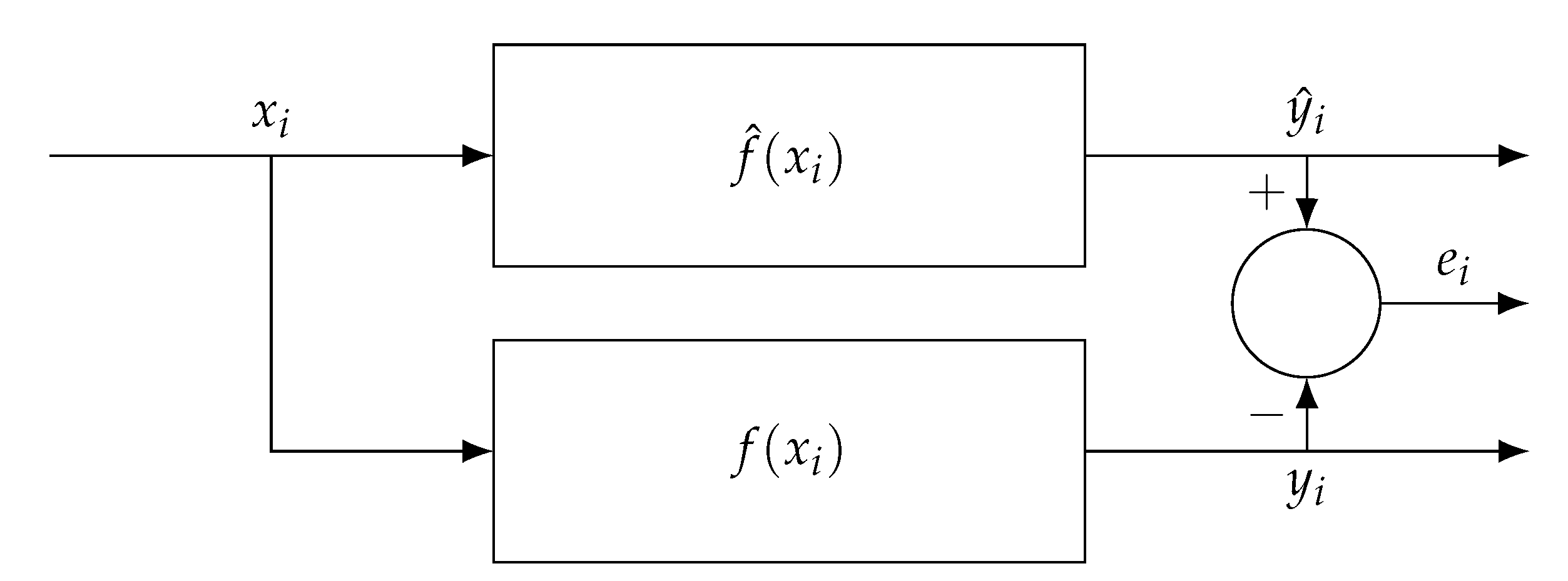
4.1. NBM: Performance Monitoring
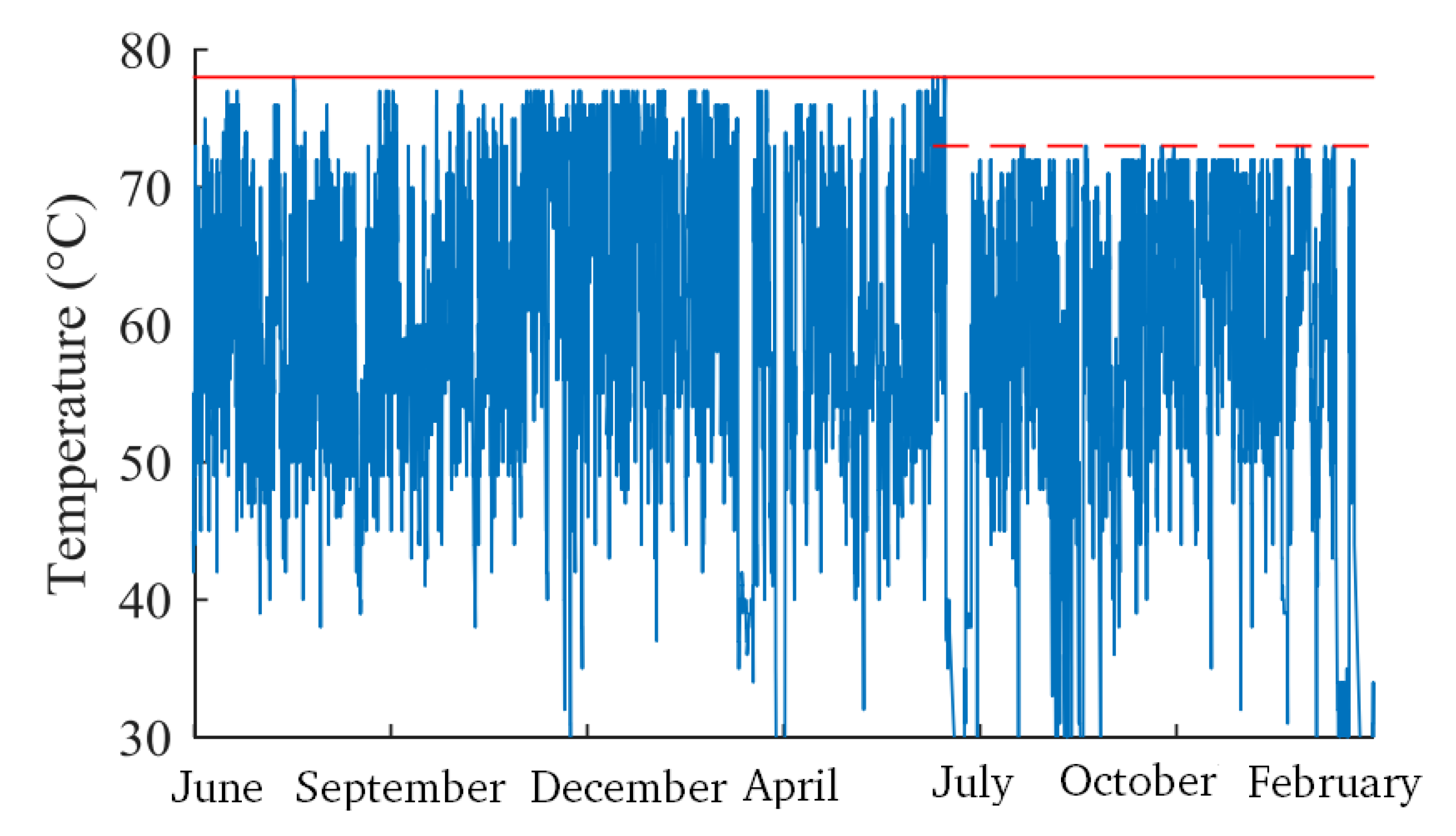
4.2. NBM: Temperature Modelling
4.3. NBM: Other Approaches
4.4. Classification-Based Approaches
4.5. Enhancing Turbine Alarms
4.6. CBM Conclusions
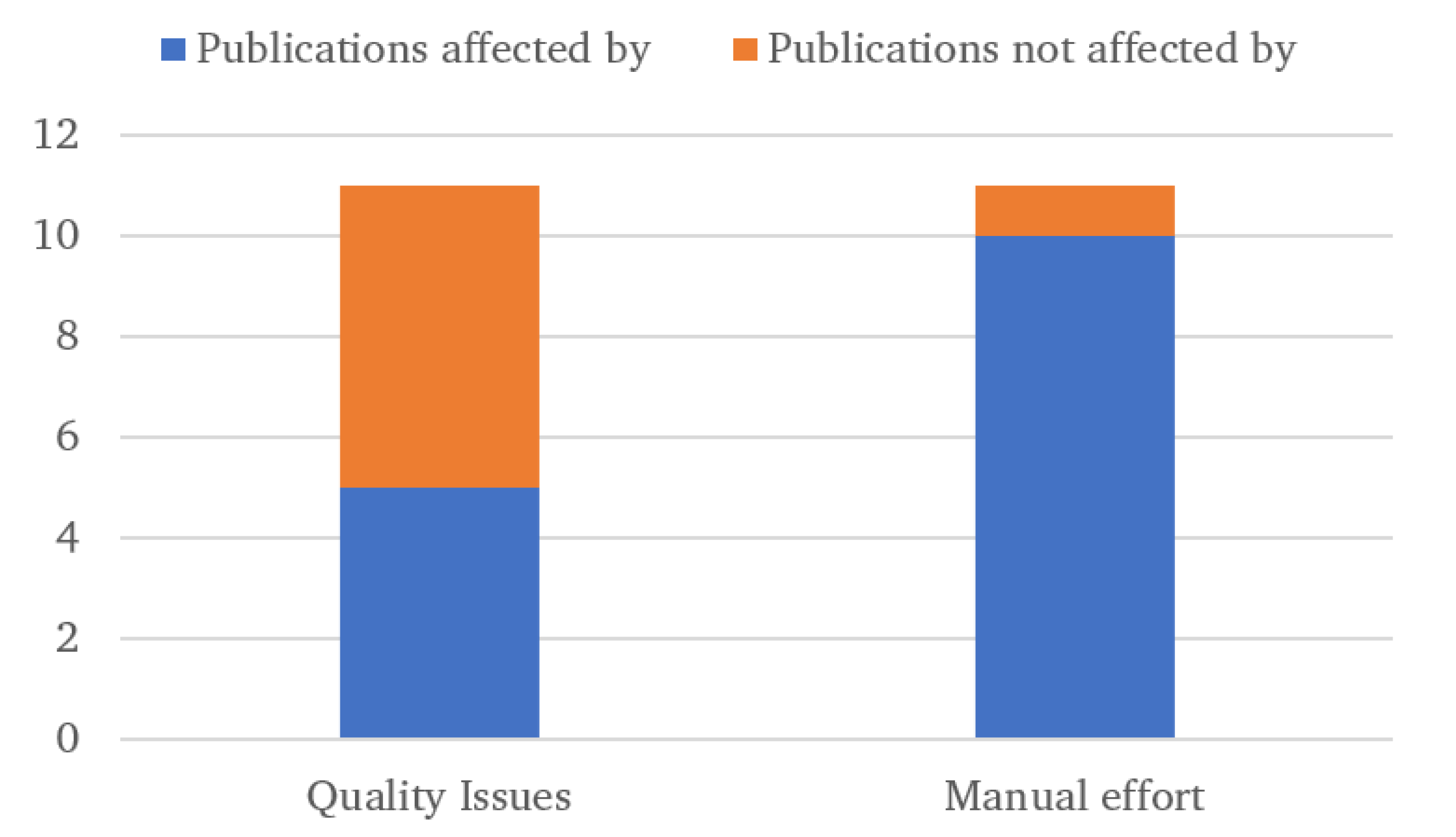
5. Summary of Issues and Proposed Solutions
5.1. Summary of Issues
- Lack of standardisation in SCADA data and maintenance records
- -
- Standard alarm codes
- -
- Standard column names for 10-min data
- -
- Standard, universal taxonomy
- -
- Standard structured database format for maintenance records
- Issues with openness and access to data for researchers, including access to higher resolution (≥10 min) data
- Better context or reduced volume for alarms data
5.2. Industry Experiences
5.3. Existing Standards
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- International Renewable Energy Agency. Renewable Power Generation Costs in 2017; Technical Report; International Renewable Energy Agency: Abu Dhabi, UAE, 2018. [Google Scholar]
- VGB PowerTech. Levelised Cost of Electricity LCOE 2015; Technical Report; VGB PowerTech: Berlin, Germany, 2015. [Google Scholar]
- Yang, W.; Tavner, P.J.; Crabtree, C.J.; Feng, Y.; Qiu, Y. Wind turbine condition monitoring: Technical and commercial challenges. Wind Energy 2014, 17, 673–693. [Google Scholar] [CrossRef]
- Yürüşen, N.Y.; Tautz-Weinert, J.; Watson, S.J.; Melero, J.J. The Financial Benefits of Various Catastrophic Failure Prevention Strategies in a Wind Farm: Two market studies (UK-Spain). J. Phys. 2017, 926, 012014. [Google Scholar] [CrossRef]
- Kothamasu, R.; Huang, S.H.; VerDuin, W.H. System health monitoring and prognostics—A review of current paradigms and practices. Int. J. Adv. Manuf. Technol. 2006, 28, 1012–1024. [Google Scholar] [CrossRef]
- Ben-Daya, M.; Duffuaa, S.O.; Raouf, A.; Knezevic, J.; Ait-Kadi, D. Handbook of Maintenance Management and Engineering; Springer: London, UK, 2009; pp. 223–235. [Google Scholar]
- Yang, W.; Court, R.; Jiang, J. Wind turbine condition monitoring by the approach of SCADA data analysis. Renew. Energy 2013, 53, 365–376. [Google Scholar] [CrossRef]
- Tautz-Weinert, J.; Watson, S.J. Using SCADA data for wind turbine condition monitoring—A review. IET Renew. Power Gener. 2017, 11, 382–394. [Google Scholar] [CrossRef]
- Artigao, E.; Martín-Martínez, S.; Honrubia-Escribano, A.; Gómez-Lázaro, E. Wind turbine reliability: A comprehensive review towards effective condition monitoring development. Appl. Energy 2018, 228, 1569–1583. [Google Scholar] [CrossRef]
- ISO. ISO 14224: 2016 Petroleum, Petrochemical and Natural Gas Industries—Collection and Exchange of Reliability and Maintenance Data for Equipment; ISO: Geneva, Switzerland, 2016. [Google Scholar]
- Spinato, F. The Reliability Wind of Turbines. Ph.D. Thesis, Durham University, Durham, UK, 2008. [Google Scholar]
- Pfaffel, S.; Faulstich, S.; Rohrig, K. Performance and reliability of wind turbines: A review. Energies 2017, 10, 1904. [Google Scholar] [CrossRef]
- Leahy, K.; Hu, R.L.; Konstantakopoulos, I.C.; Spanos, C.J.; Agogino, A.M.; O’Sullivan, D.T. Diagnosing and Predicting Wind Turbine Faults from SCADA Data Using Support Vector Machines. Int. J. Progn. Health Manag. 2018, 9, 1–11. [Google Scholar]
- Faulstich, S.; Durstewitz, M.; Hahn, B.; Knorr, K.; Rohrig, K. Windenergy Report Germany 2008; Technical Report; ISET: Kassel, Germany, 2008. [Google Scholar]
- Hahn, B.; Durstewitz, M.; Rohrig, K. Reliability of Wind Turbines: Experiences of 15 years with 1500 WTs. In Wind Energy: Proceedings of the Euromech Colloquium; Springer: Berlin, Germany, 2007; pp. 329–332. [Google Scholar] [CrossRef]
- Faulstich, S.; Hahn, B.; Tavner, P.J. Wind turbine downtime and its importance for offshore deployment. Wind Energy 2011, 14, 327–337. [Google Scholar] [CrossRef]
- Tavner, P.J.; Xiang, J.; Spinato, F. Reliability analysis for wind turbines. Wind Energy 2006, 10, 1–18. [Google Scholar] [CrossRef]
- Spinato, F.; Tavner, P.; van Bussel, G.; Koutoulakos, E. Reliability of wind turbine subassemblies. IET Renew. Power Gener. 2009, 3, 387. [Google Scholar] [CrossRef]
- Ribrant, J.; Bertling, L.M. Survey of failures in wind power systems with focus on Swedish wind power plants during 1997–2005. IEEE Trans. Energy Convers. 2007, 22, 167–173. [Google Scholar] [CrossRef]
- Wilkinson, M.; Hendriks, B.; Spinato, F.; Delft, T.V. Measuring Wind Turbine Reliability—Results of the Reliawind Project. In Proceedings of the European Wind Energy Association Conference, Brussels, Belgium, 14–17 March 2011; pp. 1–8. [Google Scholar]
- Peters, V.A.; Ogilvie, A.B.; Bond, C.R. Continuous Reliability Enhancement for Wind (CREW) Database: Wind Plant Reliability Benchmark; Technical Report; Sandia National Laboratories: Albuquerque, NM, USA, 2012.
- Leahy, K.; Gallagher, C.; O’Donovan, P.; Bruton, K.; O’Sullivan, D. A Robust Prescriptive Framework and Performance Metric for Diagnosing and Predicting Wind Turbine Faults Based on SCADA and Alarms Data with Case Study. Energies 2018, 11, 1738. [Google Scholar] [CrossRef]
- Kaidis, C.; Uzunoglu, B.; Amoiralis, F. Wind turbine reliability estimation for different assemblies and failure severity categories. IET Renew. Power Gener. 2015, 9, 892–899. [Google Scholar] [CrossRef]
- Reder, M.D.; Gonzalez, E.; Melero, J.J. Wind Turbine Failures—Tackling current Problems in Failure Data Analysis. J. Phys. 2016, 753, 072027. [Google Scholar] [CrossRef]
- Gonzalez, E.; Reder, M.; Melero, J.J. SCADA alarms processing for wind turbine component failure detection. J. Phys. 2016, 753, 072019. [Google Scholar] [CrossRef]
- Carroll, J.; McDonald, A.; McMillan, D. Reliability Comparison of Wind Turbines With DFIG and PMG Drive Trains. IEEE Trans. Energy Convers. 2015, 30, 663–670. [Google Scholar] [CrossRef]
- Carroll, J.; McDonald, A.; McMillan, D. Failure rate, repair time and unscheduled O&M cost analysis of offshore wind turbines. Wind Energy 2016, 19, 1107–1119. [Google Scholar] [CrossRef]
- Butler, S.; Ringwood, J.; O’Connor, F. Exploiting SCADA system data for wind turbine performance monitoring. In Proceedings of the 2013 IEEE Conference on Control and Fault-Tolerant Systems (SysTol), Nice, France, 9–11 October 2013; pp. 389–394. [Google Scholar] [CrossRef]
- Park, J.Y.; Lee, J.K.; Oh, K.Y.; Lee, J.S. Development of a Novel Power Curve Monitoring Method for Wind Turbines and Its Field Tests. IEEE Trans. Energy Convers. 2014, 29, 119–128. [Google Scholar] [CrossRef]
- Marvuglia, A.; Messineo, A. Monitoring of wind farms’ power curves using machine learning techniques. Appl. Energy 2012, 98, 574–583. [Google Scholar] [CrossRef]
- Gonzalez, E.; Stephen, B.; Infield, D.; Melero, J.J. Using high-frequency SCADA data for wind turbine performance monitoring: A sensitivity study. Renew. Energy 2019, 131, 841–853. [Google Scholar] [CrossRef]
- Cambron, P.; Lepvrier, R.; Masson, C.; Tahan, A.; Pelletier, F. Power curve monitoring using weighted moving average control charts. Renew. Energy 2016, 94, 126–135. [Google Scholar] [CrossRef]
- Kusiak, A.; Zheng, H.; Song, Z. Models for monitoring wind farm power. Renew. Energy 2009, 34, 583–590. [Google Scholar] [CrossRef]
- Leahy, K.; Hu, R.L.; Konstantakopoulos, I.C.; Spanos, C.J.; Agogino, A.M. Diagnosing wind turbine faults using machine learning techniques applied to operational data. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management (ICPHM), Ottawa, ON, Canada, 20–22 June 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Garlick, W.G.; Dixon, R.; Watson, S.J. A Model-based Approach to Wind Turbine Condition Monitoring using SCADA Data. In Proceedings of the 20th International Conference on Systems Engineering, Coventry, UK, 8–10 September 2009. [Google Scholar]
- Butler, S. Prognostic Algorithms for Condition Monitoring and Remaining Useful Life Estimation. Ph.D. Thesis, NUI Maynooth, Maynooth, Ireland, 2012. [Google Scholar]
- Bangalore, P.; Letzgus, S.; Karlsson, D.; Patriksson, M. An artificial neural network-based condition monitoring method for wind turbines, with application to the monitoring of the gearbox. Wind Energy 2017, 20, 1421–1438. [Google Scholar] [CrossRef]
- Kusiak, A.; Verma, A. Monitoring wind farms with performance curves. IEEE Trans. Sustain. Energy 2013, 4, 192–199. [Google Scholar] [CrossRef]
- Tautz-Weinert, J.; Watson, S.J. Challenges in Using Operational Data for Reliable Wind Turbine Condition Monitoring. In Proceedings of the The 27th International Ocean and Polar Engineering Conference (ISOPE), San Francisco, CA, USA, 25–30 June 2017; pp. 613–620. [Google Scholar]
- Wang, L.; Zhang, Z.; Xu, J.; Liu, R. Wind Turbine Blade Breakage Monitoring with Deep Autoencoders. IEEE Trans. Smart Grid 2016, 3053, 1–10. [Google Scholar] [CrossRef]
- Lind, P.G.; Vera-Tudela, L.; Wächter, M.; Kühn, M.; Peinke, J. Normal behaviour models for wind turbine vibrations: Comparison of neural networks and a stochastic approach. Energies 2017, 10, 1944. [Google Scholar] [CrossRef]
- Lind, P.G.; Herráez, I.; Wächter, M.; Peinke, J. Fatigue load estimation through a simple stochastic model. Energies 2014, 7, 8279–8293. [Google Scholar] [CrossRef]
- Kusiak, A.; Li, W. The prediction and diagnosis of wind turbine faults. Renew. Energy 2011, 36, 16–23. [Google Scholar] [CrossRef]
- Kusiak, A.; Verma, A. A data-driven approach for monitoring blade pitch faults in wind turbines. IEEE Trans. Sustain. Energy 2011, 2, 87–96. [Google Scholar] [CrossRef]
- Leahy, K.; Gallagher, C.; O’Donovan, P.; O’Sulllivan, D.; O’Sullivan, D.T. Cluster analysis of wind turbine alarms for characterising and classifying stoppages. IET Renew. Power Gener. 2018, 12, 1146–1154. [Google Scholar] [CrossRef]
- Godwin, J.L.; Matthews, P. Classification and Detection of Wind Turbine Pitch Faults Through SCADA Data Analysis. Int. J. Prog. Health Manag. 2013, 4, 11. [Google Scholar]
- Chen, B.; Matthews, P.C.; Tavner, P.J. Wind turbine pitch faults prognosis using a-priori knowledge-based ANFIS. Expert Syst. Appl. 2013, 40, 6863–6876. [Google Scholar] [CrossRef]
- Qiu, Y.; Feng, Y.; Tavner, P.; Richardson, P.; Erdos, G.; Chen, B. Wind turbine SCADA alarm analysis for improving reliability. Wind Energy 2012, 15, 951–966. [Google Scholar] [CrossRef]
- Chen, B.; Qiu, Y.; Feng, Y.; Tavner, P.; Song, W. Wind turbine SCADA alarm pattern recognition. In Proceedings of the IET Conference on Renewable Power Generation (RPG 2011), Edinburgh, UK, 6–8 September 2011; p. 163. [Google Scholar] [CrossRef]
- Kusiak, A. Renewables: Share data on wind energy. Nature 2016, 529, 19–21. [Google Scholar] [CrossRef]
- Gayo, J.B. ReliaWind Project Final Report; Technical Report; Gamesa Innovation and Technology: Madrid, Spain, 2011. [Google Scholar]
- Tavner, P. Offshore Wind Turbines: Reliability, availability and maintenance; Institution of Engineering and Technology: Stevenage, UK, 2012. [Google Scholar] [CrossRef]
- Wennerhag, L.B.; Tjernberg, P. Wind Turbine Operation and Maintenance: Survey of the Development and Research Needs; Technical Report; Elforsk: Stockholm, Sweden, 2012. [Google Scholar]
- Van Kuik, G.A.M.; Peinke, J.; Nijssen, R.; Lekou, D.; Mann, J.; Sørensen, J.N.; Ferreira, C.; van Wingerden, J.W.; Schlipf, D.; Gebraad, P.; et al. Long-term research challenges in wind energy—A research agenda by the European Academy of Wind Energy. Wind Energy Sci. 2016, 1, 1–39. [Google Scholar] [CrossRef]
- Hahn, B.; Welte, T.; Faulstich, S.; Bangalore, P.; Boussion, C.; Harrison, K.; Miguelanez-Martin, E.; O’Connor, F.; Pettersson, L.; Soraghan, C.; et al. Recommended Practice 17: Wind Farm Data Collection and Reliability Assessment for O&M Optimization. Energy Procedia 2017, 137, 358–365. [Google Scholar] [CrossRef]
- Sempreviva, A.M.; Vesth, A.; Bak, C.; Verelst, D.R.; Giebel, G.; Danielsen, H.K.; Mikkelsen, L.P.; Andersson, M.; Vasiljevic, N.; Barth, S.; et al. Integrated Research Programme on Wind Energy: Taxonomy and Meta Data for Wind Energy R & D; DTU Wind Energy: Roskilde, Denmark, 2017. [Google Scholar] [CrossRef]
- VGB PowerTech. RDS-PP—Application Guideline; Part 32: Wind Power Plants; Technical Report; VGB PowerTech: Berlin, Germany, 2014. [Google Scholar]
- NERC. GADS Wind Turbine Generation: Data Reporting Instructions; Technical Report; NERC: Atlanta, GA, USA, 2018. [Google Scholar]
- International Electrotechnical Commission (IEC). IEC 61400-26-1: Time Based Availability for Wind Turbines; International Electrotechnical Commission: Geneva, Switzerland, 2010. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Timestamp | Wind Speed (avg.) m/s | Wind Speed (max.) m/s | Wind Speed (min.) m/s | Power (avg.) kW | Ambient Temp (avg.) °C | Bearing Temp (avg.) °C |
|---|---|---|---|---|---|---|
| 09 June 2014 14:10:00 | 5.8 | 7.4 | 4.1 | 367 | 17.9 | 25.0 |
| 09 June 2014 14:20:00 | 5.7 | 7.1 | 4.1 | 378 | 17.5 | 24.6 |
| 09 June 2014 14:30:00 | 5.6 | 6.5 | 4.5 | 384 | 17.6 | 25.1 |
| 09 June 2014 14:40:00 | 5.8 | 7.5 | 3.9 | 426 | 18.1 | 23.7 |
| Code | Description | Category | Severity | ||
|---|---|---|---|---|---|
| 02:13:38 | 07:56:14 | Normal operation | No fault | Information | |
| 07:56:14 | 08:37:32 | Low wind cut out | Weather | Information | |
| 08:37:32 | 23:44:02 | Normal operation | No fault | Information |
| O&M Data Type | Information Derived | Disadvantages |
|---|---|---|
| A. Maintenance logs | • Accurate failure info • Information for downtimes • Cost of repair | • Sometimes available only in hard copies • Can be difficult to read or incomplete |
| B. Operation and alarm logs | • Failures and duration | • Unknown alarm codes • Numerous stops for the same failure • No environmental conditions info |
| C. 10-min SCADA and alarms | • Failure data • Information for further analysis (e.g., root cause analysis) • Environmental parameters • Comparison/verification of logs (if both available) | • Large amount of data, require time-consuming processing • Not all alarms indicate failures • No maintenance activity described |
| D. Service provider bills | • Maintenance cost • Indications for the kind of failures | • Less detailed info about failures |
| E. Component purchase bills | • Information for component replacements | • No downtime information • No failure information |
| Study Name | Published | Reporting Period | Number of Turbines | Turbine Capacity (MW) | Data Collection | Failure Defined As | Taxonomy | Quality Issues? | Manual Effort Issues? |
|---|---|---|---|---|---|---|---|---|---|
| WMEP [15,16] | 2007, 2011 | 1989–2006 | 1500 | <1 | Manual report | - | 11 assemblies/parts | No | Yes |
| WindStats-WSD [17,18] | 2006, 2009 | 1994–2003 | 2345–851 | 0.1–2.5 | Manual report-quarterly | Manual on site restart | 12 assemblies/parts | No | Yes |
| WindStats-WSDK [17,18] | 2006, 2009 | 1995–2004 | 1295–4285 | 0.1–2.5 | Manual report-monthly | Manual on site restart | same as above | Yes | Yes |
| LWK [18] | 2009 | 1993–2006 | 158–643 | 0.2–2 | Manual report-annually | Manual on site restart | same as above | No | Yes |
| Ribrant et al. [19] | 2007 | 2000–2004 | 527–723 | 0.5–1.5 | Manual report | On-site restart and repair | 13 assemblies/parts | No | Yes |
| ReliaWind [20] | 2011 | 2008–2011 | max. 350 | >0.8 | SCADA, work orders, contractor reports | 1 hour downtime and manual restart | ReliaWind | Yes | Yes |
| CREW [21] | 2012 | - | 800–900 | 1.3–1.4 | SCADA | Any fault event | SPS proprietary | Yes | No |
| Kaidis et al. [23] | 2015 | (avg 705 days) | max. 63 | 0.85–3 | SCADA | Manual on site restart | ReliaWind | Yes | Yes |
| AWESOME [24] | 2016 | 2013–2015 | - | 1–3 | OEM work order database | On-site restart and repair | ReliaWind-Extended | Yes | Yes |
| Carroll-onshore [26] | 2015 | <5 years | max. 2222 | 1.5–2.5 | OEM work order and materials databases | On-site repair where material is consumed | Drivetrain only (gen/converter) | No | Yes |
| Carroll-offshore [27] | 2016 | 5 years | max. 350 | 2–4 | OEM work order and materials databases | On-site repair where material is consumed | 19 assemblies/parts | No | Yes |
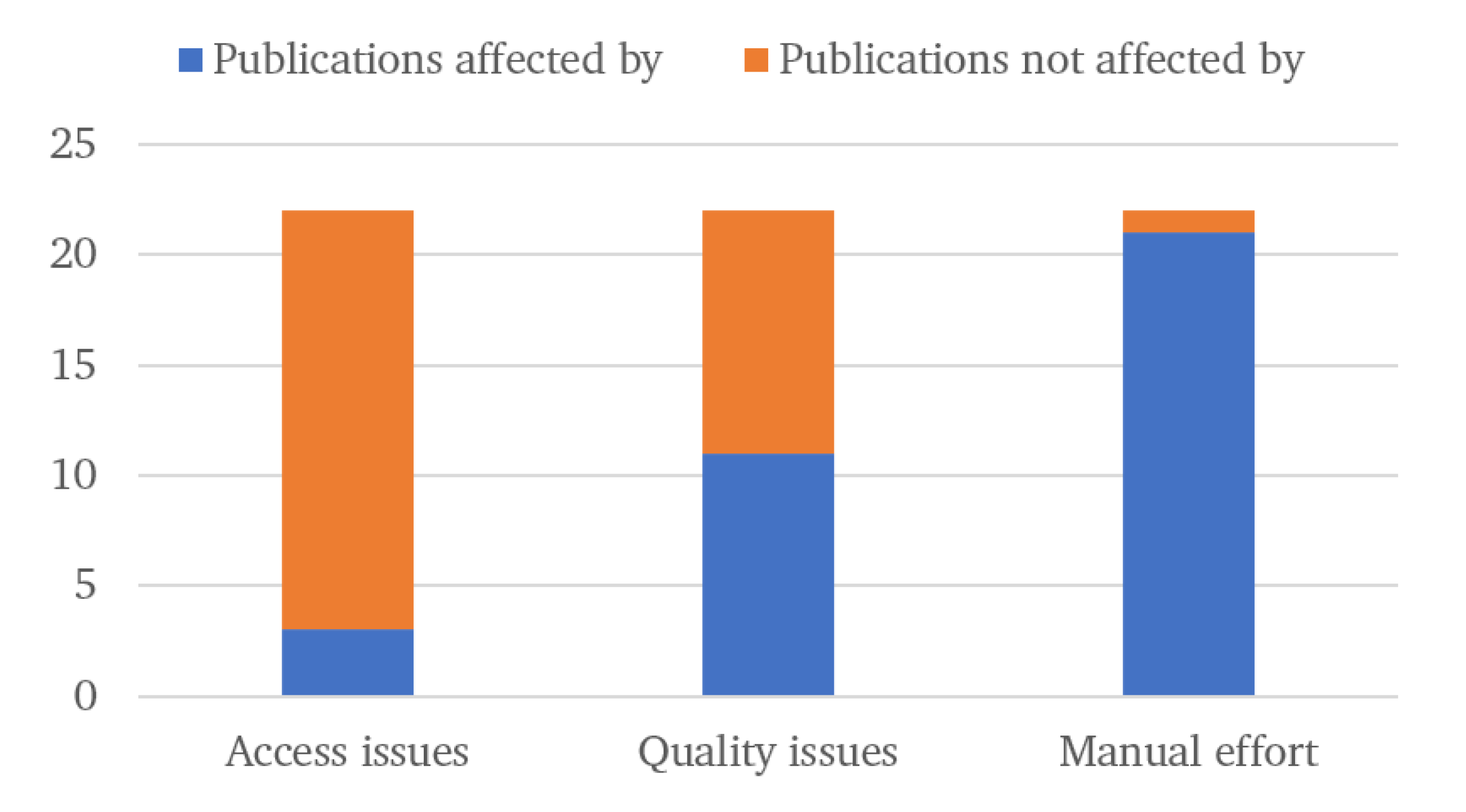
| Publication | Published | Technique | Filtering | Access Issues? | Quality Issues? | Manual Effort Issues? |
|---|---|---|---|---|---|---|
| [31] | 2019 | NBM-PM | Alarms and work orders | No | No | Yes |
| [28] | 2013 | NBM-PM | Statistical and domain knowledge | No | Yes | Yes |
| [29] | 2014 | NBM-PM | Statistical | No | Yes | Yes |
| [30] | 2012 | NBM-PM | Statistical | No | No | Yes |
| [32] | 2016 | NBM-PM | Statistical | No | Yes | Yes |
| [33] | 2009 | NBM-PM | Statistical and domain knowledge | No | Yes | Yes |
| [35] | 2009 | NBM-T | Work orders | No | No | Yes |
| [36] | 2012 | NBM-T | Work orders | No | No | Yes |
| [40] | 2016 | NBM-O | Work orders | No | No | Yes |
| [41] | 2017 | NBM-O | Statistical | No | No | No |
| [37] | 2017 | NBM-T | Statistical and domain knowledge | No | No | Yes |
| [39] | 2017 | NBM-T | Alarms and work orders | Yes | Yes | Yes |
| [43] | 2011 | Class. | Alarms | No | Yes | Yes |
| [44] | 2011 | Class. | Alarms (processed) | No | No | Yes |
| [13] | 2018 | Class. | Alarms | No | Yes | Yes |
| [22] | 2018 | Class. | Alarms (processed) | Yes | No | Yes |
| [46] | 2013 | Class. | Work orders | No | No | Yes |
| [47] | 2013 | Class. | Work orders | No | No | Yes |
| [48] | 2012 | alarms | Alarms (processed) | No | Yes | Yes |
| [25] | 2016 | alarms | Alarms (processed) | No | Yes | Yes |
| [45] | 2018 | alarms | Alarms (processed) | Yes | Yes | Yes |
| [49] | 2011 | alarms | Alarms (processed) | No | Yes | Yes |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leahy, K.; Gallagher, C.; O’Donovan, P.; O’Sullivan, D.T.J. Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses. Energies 2019, 12, 201. https://doi.org/10.3390/en12020201
Leahy K, Gallagher C, O’Donovan P, O’Sullivan DTJ. Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses. Energies. 2019; 12(2):201. https://doi.org/10.3390/en12020201
Chicago/Turabian StyleLeahy, Kevin, Colm Gallagher, Peter O’Donovan, and Dominic T. J. O’Sullivan. 2019. "Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses" Energies 12, no. 2: 201. https://doi.org/10.3390/en12020201
APA StyleLeahy, K., Gallagher, C., O’Donovan, P., & O’Sullivan, D. T. J. (2019). Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses. Energies, 12(2), 201. https://doi.org/10.3390/en12020201