A Hybrid Recommender System to Improve Circular Economy in Industrial Symbiotic Networks




Abstract
:1. Introduction
2. Background
2.1. Industrial Symbiosis and Sustainability
2.2. Recommender Systems
- Background data: information/data required by the system before the instantiation of the recommendation process (may be related to users, items context as well as to the recommendation process itself).
- Input data that is the information provided by the user to the system to receive recommendations.
- The core recommendation component, the algorithm used that combines and processes the background and input data to produce meaningful recommendations aligned with the active user’s request. The functionality of this component heavily depends on the type and scope of the RSs, as well as the data that this system is asked to process.
2.3. Case-Based Reasoning
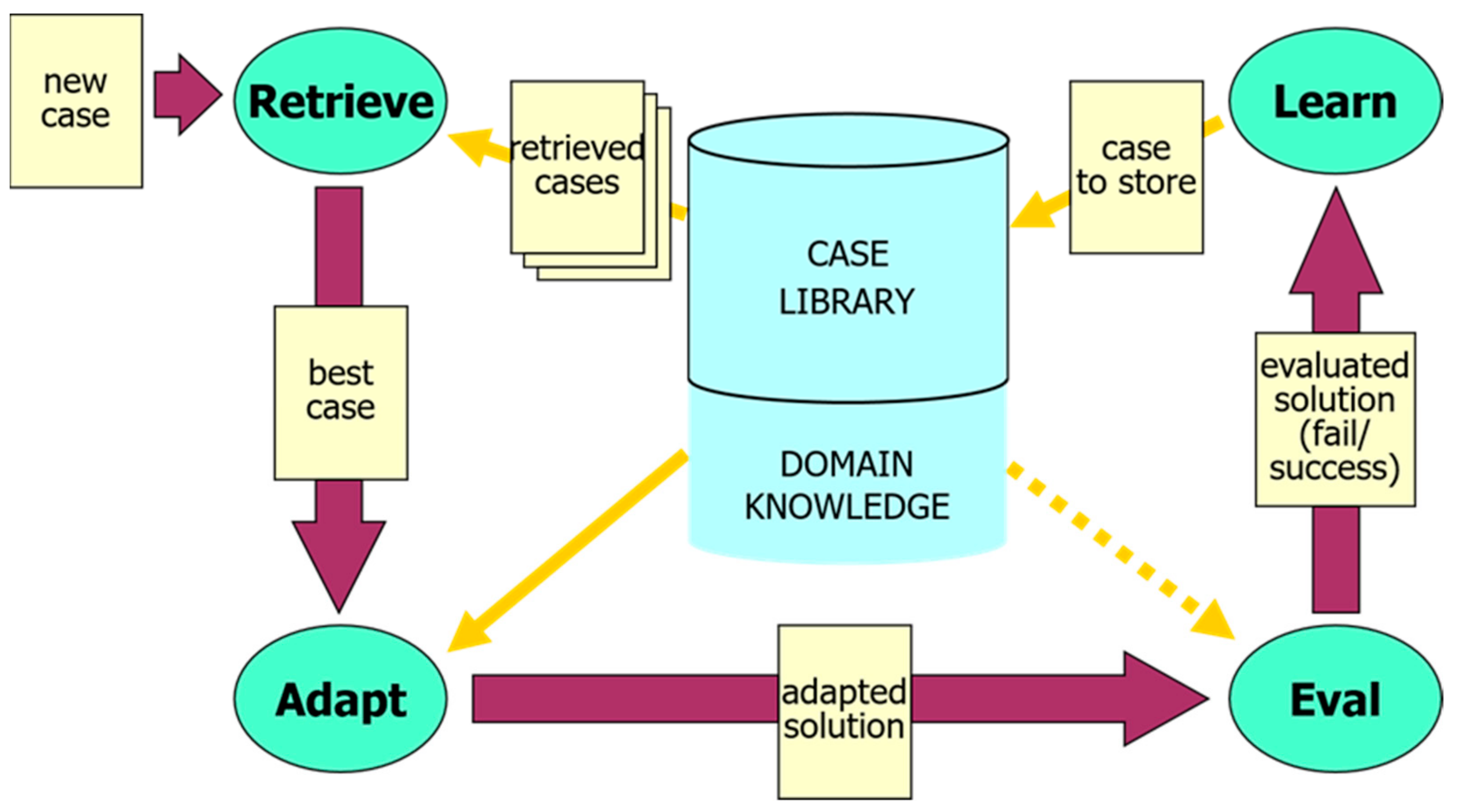
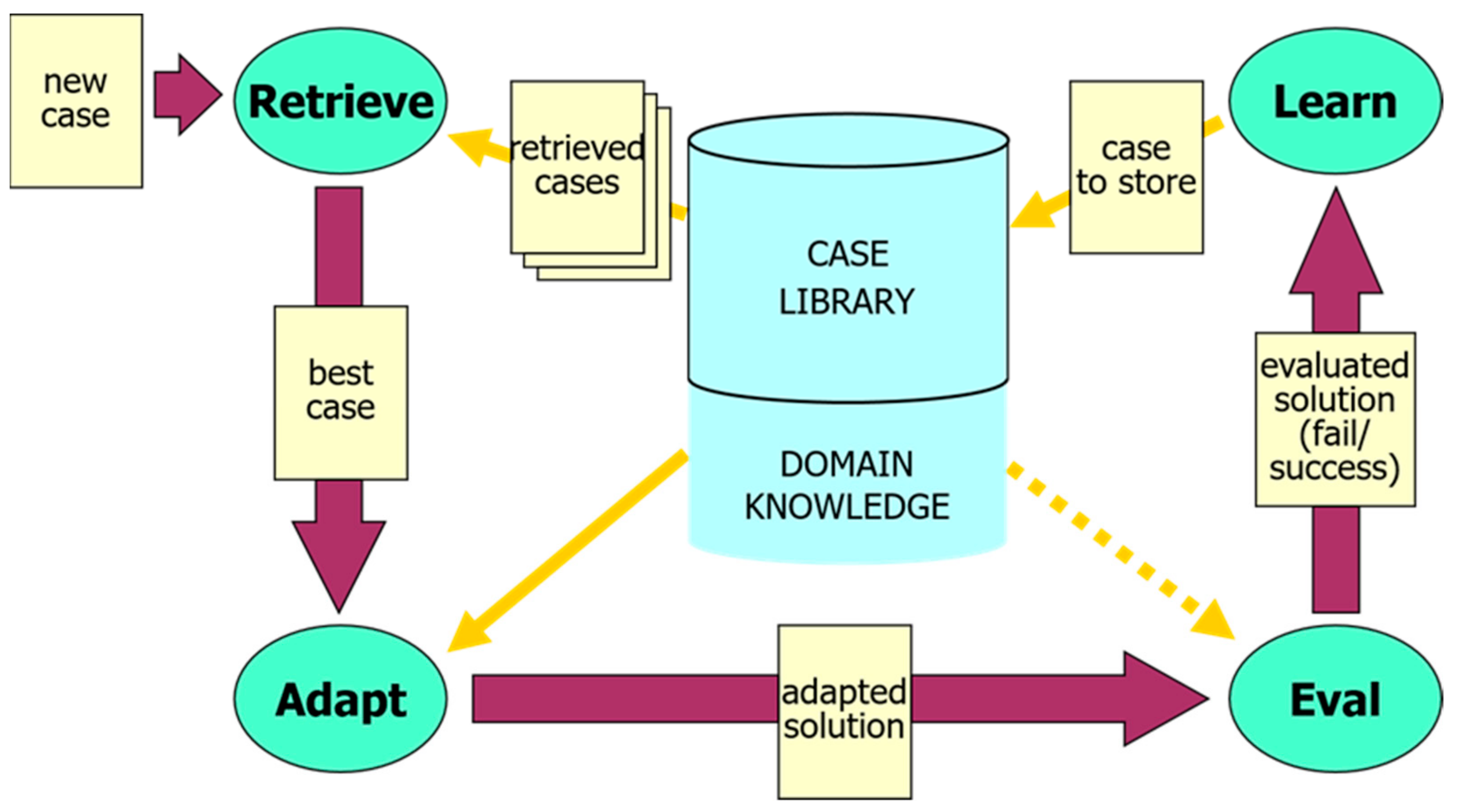
2.3.1. CBR Cycle
- Retrieve: the most relevant cases among those previously experienced from the case memory.
- Reuse (or adapt): the information and knowledge provided by the by the retrieved case(s) in order to solve the new problem.
- Revise (or evaluate): the solution obtained
- Retain (or learn): the parts of the solution/experience that are likely to be used (reused or avoided) for future purposes and incorporate this new knowledge into the case base.
2.3.2. The Similarity Concept in CBR
2.4. Case-Based Recommenders
3. System Description
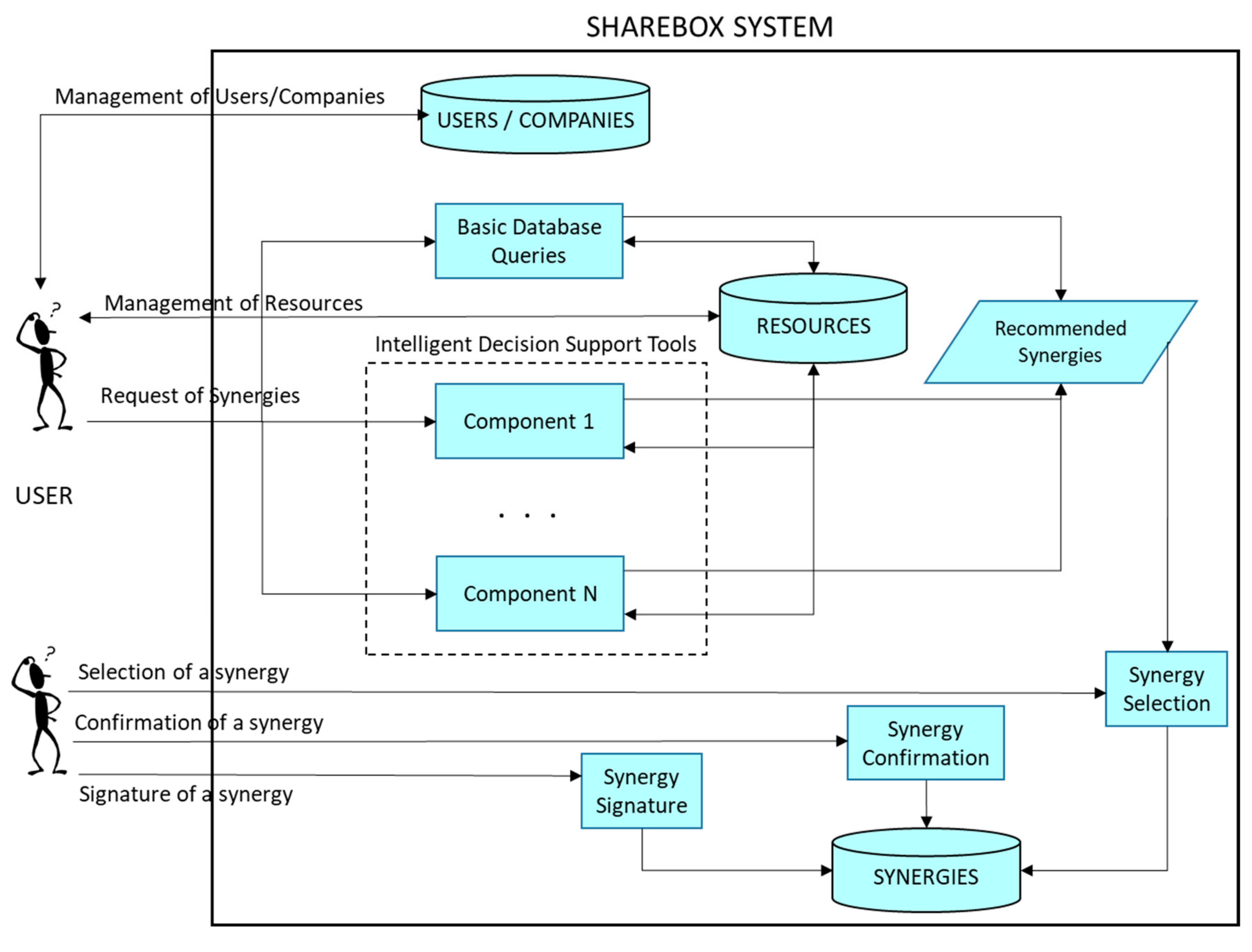
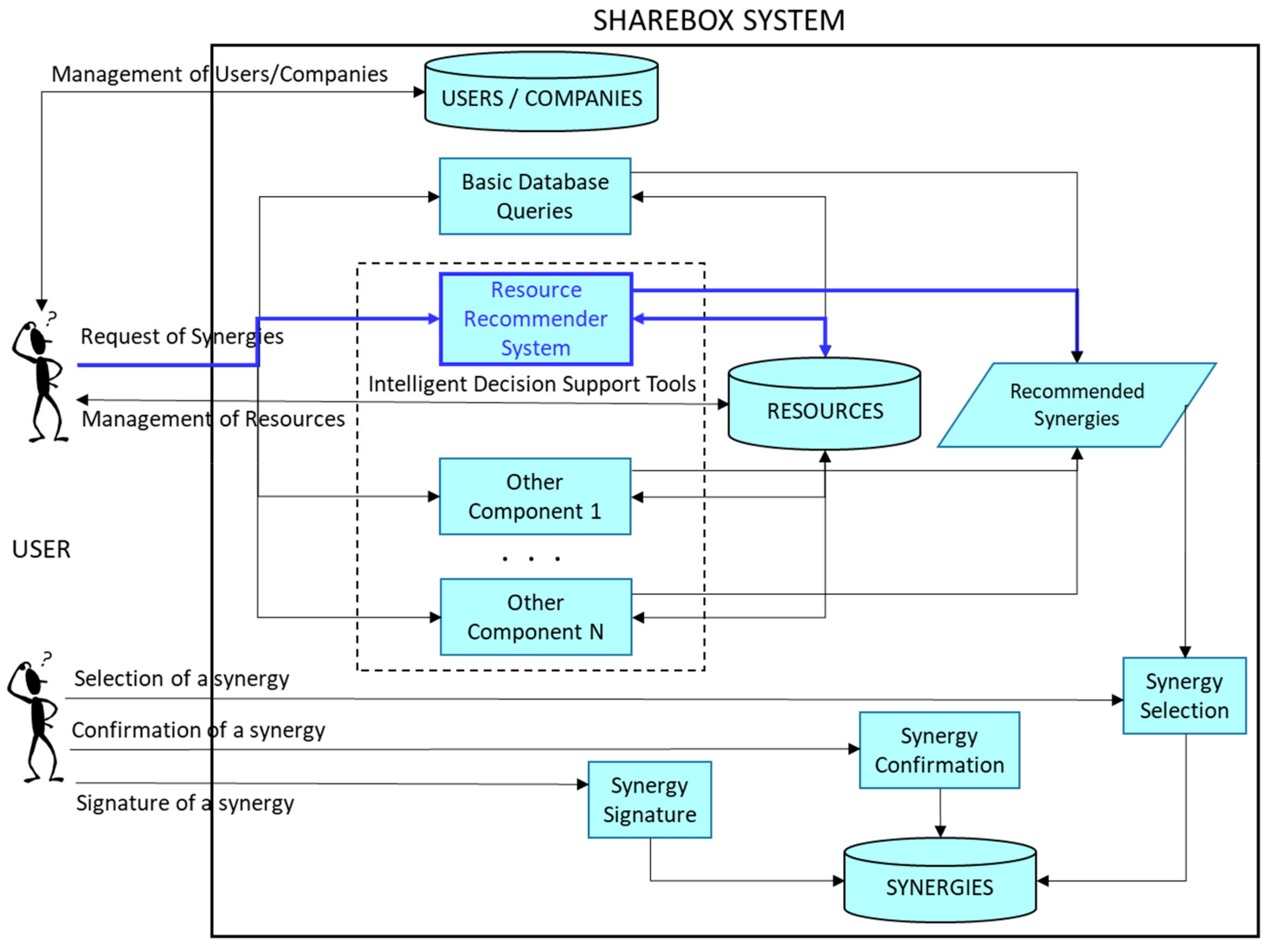
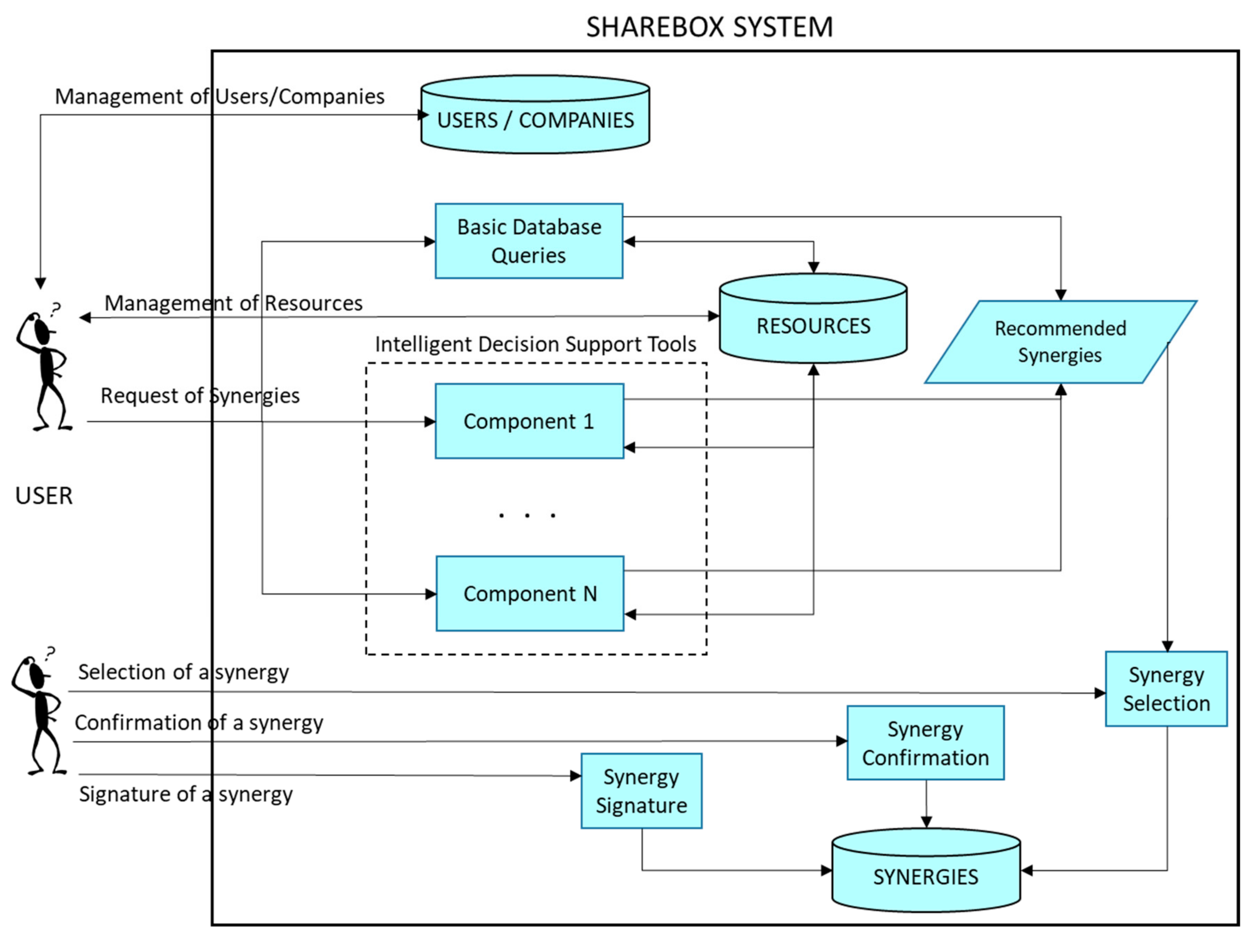
3.1. The SHAREBOX Platform
3.2. Hybrid Recommender System Overview
3.3. Scope
- Given:
- ○
- A list of company sites, with their industry codes, geographical locations, resource needs, and offers
- ○
- A query that consists of, at least, the site location, the resource type, in terms of European Waste Code (EWC), category and the definition of whether it is a needed or offered waste
- Generate the list of the N most adequate resource synergy candidates, those from the available matching in a locally optimal way the given query.
3.4. Problem Data Entities
3.4.1. Current System Status
- Name: identifier of the resource
- Description: basic information describing the resource
- Keywords: automatically and user assigned
- Waste code(s): EWC(s) of the registered resource
- Direction (Have/Want): defines whether the resource is offered or needed by the company site
- Quantity: maybe a specific number or in some cases it is possible to have no limitations in the resource production, in terms of theoretically unlimited availability
- ○
- The quantity may also be defined after two parties have expressed mutual interest in forming a synergy and negotiations have been initialized
- Measure unit: depending on the type of resource
- Availability: refers to the frequency by each it is generated or requested. Mainly, there are resources of continuous availability, therefore from the moment these are registered they are always generated/needed, thus in any time moment may be provided or are always needed
- Site: each resource, rather than to a company, is associated with the site where it can be found
- Industrial code: defining the industrial category of the site
- Resources: that has previously registered on the platform as needed or offered
- Address: the geographical location of the site
- ○
- Presented by the geographical coordinates, longitude and latitude
- Company: that this site belongs to
3.4.2. User Query
- Keyword(s): One or more keywords describing the resource requested
- Direction: Refers to the type of need, whether it is about a needed (want) or an offered (have) resource
- EWC: The waste code of the requested resource
- ○
- Given in the three hierarchical levels, the chapter, the subchapter and the code.
- ○
- Search method (Filter or Rank): Refers to the extraction of resource candidates, whether only those with EWC exactly matching the one in the query can be used (filter), or whether the similarity of the EWCs of the existing and the requested resources will be evaluated (rank). In the second case, the resources are ranked based on advanced similarity functions applied to the EWCs of the resources available and the requested one.
- Category: The resource category of the requested resource
- ○
- Presented in three hierarchical levels
- ○
- Search method (Filter or Rank): Same as for EWC, but evaluating the exact match or similarity of the resources’ category with the one in the query.
- Site: the geolocation of the site where the resource is located or needed. The site does not refer to the company, but to the exact resource, as companies might be registered by their head offices, while they may have various sites where their resources are stored or various processes where the resources are needed.
- ○
- Presented by the geographic coordinates, longitude and latitude.
3.5. Query Resolution
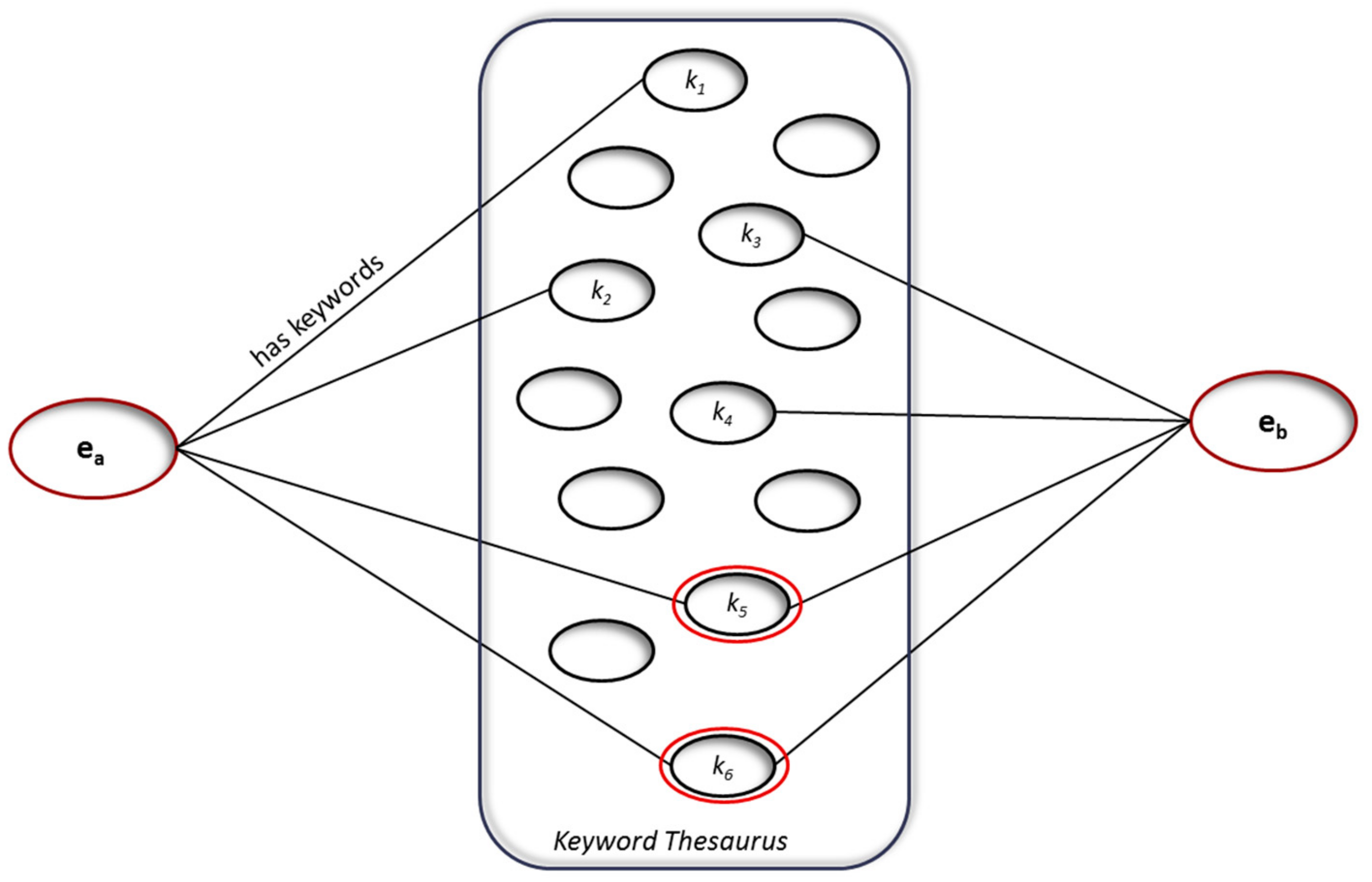
- EWCs are associated with keywords that describe them.
- Resources are associated with their attributes where the EWCs are one of these attributes.
- Company sites are associated with the resources they have and could offer or would need, with a given frequency or at a specific time moment.
3.5.1. Search Method: Filtering or Ranking
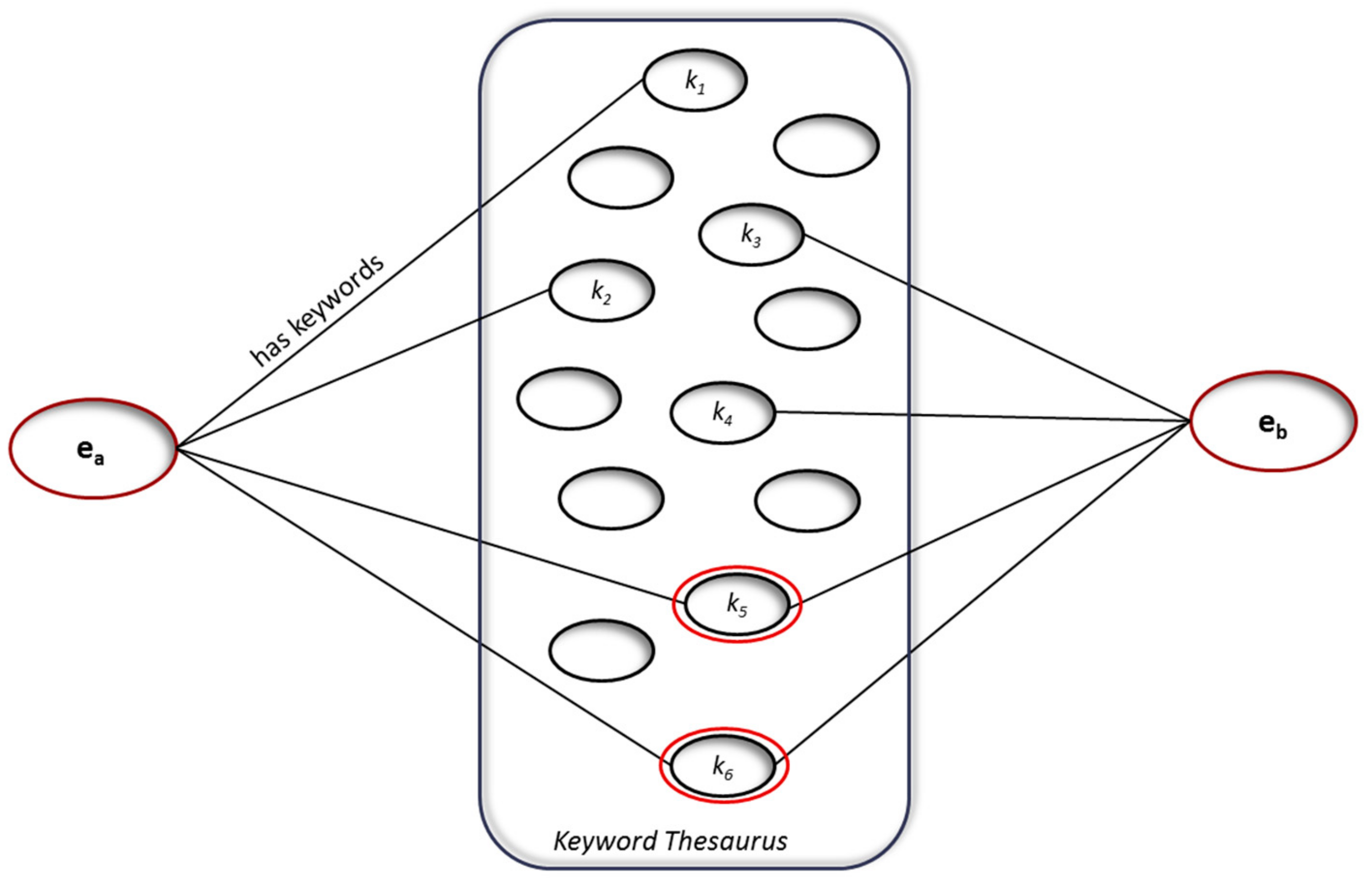
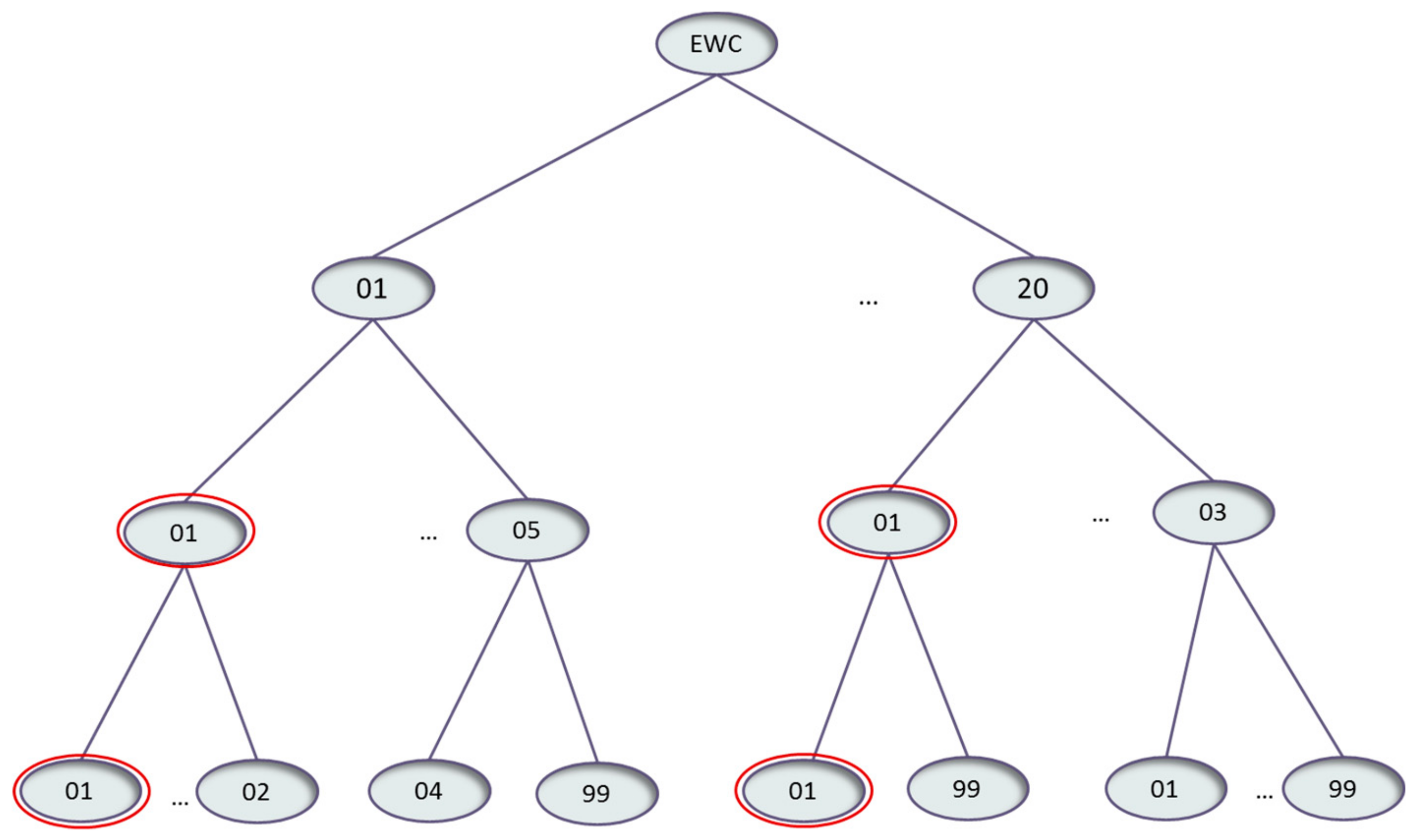
3.5.2. EWC Analysis and Similarities—EWC Representation and Similarity Functions
- 20 Chapters—Business sectors
- Subchapters—Processes
- Codes—Waste descriptions
3.5.3. Category Similarity
3.5.4. Keyword Similarity
3.5.5. Advanced Ordering
3.6. Recommendations’ Generation
3.6.1. Process Overview
| Algorithm 1. Recommendations’ generation algorithm. | |
| Input: | Current resources’ status , new query |
| Output: | TopN resource recommendations |
| 1: | Initialize recommender: Load parameters |
| 2: | Analyze |
| 3: | Retrieve : filtered resources |
| 4: | if () |
| 5: | for () |
| 6: | if () |
| 7: | |
| 8: | |
| 9: | Rank candidates in |
| 10: | if () |
| 11: | |
| 12: | else |
| 13: | |
| 14: | return |
3.6.2. Resolution Workflow
- A user inserts a resource request, containing the specifications of the desired resource, in terms of key words, EWC codes and resource categories, the resource direction specifying whether it is a desired or an offered resource, and finally the search method mode, defining it apart from the exact matching descriptions other similar resources can be considered as candidates. In addition, the site geolocation is retrieved from the stored records.
- A first filtering of the resources is performed, based on the request direction parameter that has been specified in the user query. If the performed query is about a want waste only the records related to have waste(s) will be evaluated. On the other hand, in the case of a have request only the want records will be taken into account. If the user is simply browsing to see what resources are available in the system and no direction is stated, all of the resources are retrieved at this stage.
- The recommender will then identify the candidates that could address the user request, in terms of resource properties. By candidates, we refer to the various alternative resources with characteristics that could serve a user request. First, if a user has specified a filtering mode at EWC or category level, first the available resources are filtered based on this parameter. Subsequently, this new set of resources is used for further evaluation.
- Finally, the core recommendation mechanism, with scope to return the ordered list containing the closest matchings of the requested waste, is based on a similarity/distance function comparing the user’s request(s) and the existing cases’ parameters. Let q be the user request and r one of the existing resources after the filtering processes. The locations of the companies as these have been entered to the platform, the available and requested quantities along with their degree of similarity are among the parameters that are used in the distance function. More specifically, the total semantic distance among q and r will be a function of the following general form:
- is the similarity function that is used to calculate the semantic distance of the requested and the candidate resources, given that not only exact matches (the same resource) are considered as acceptable solutions, but also closely similar resources may be used. This function is a combination of the similarity functions (5) described previously and the terms described in Section 3.5.3 and Section 3.5.4.
- is a function that evaluates the geographical distance between the requesting and the candidate sites’ locations.
4. Case Study
- Industrial Cluster (La Mina Industrial Zone and Castelló Harbour) in Nules, Castelló de la Plana, Spain
- Industrie Center Obernburg, in nearby Frankfurt, Germany
- Uslan Eco-Industrial Park (EIP), South Korea
- TaigaNova Eco-Industrial Park in Fort McMurray, AB, Canada
- CleanTech Park, Singapore
4.1. Industrial Ecosystem
- CeramProd, which is an industry producing ceramic manufacturing products, like Floor-Tile-Ceramics, Wall-Tile-Ceramics, and Roof-Tile-Ceramics, and it needs Frites, Recycled-Water, and Pigments.
- NewFarm, which is a modern industry producing several outputs of a farm like Feathers, Leather-cuttings, Milk, and needs Wooden-Packaging and Glass-Bottles.
- StoneRock, which is an industry producing several materials, like Chrome, Paint-Powders, Frites, and needs Mechanical-Equipment and Sand.
- SweetHome, which is a modern industry producing several home items like Pillows, Bed-Sheets, Table-Clothes, and needs Feathers, Silk-Waste, and Wooden-Packaging.
- HotelNew, which a hotel inside the industrial park which has Wooden-Packaging, produces Domestic-Wastewater and needs Pillows, Bed-Sheets, and Drinking-Water.
- ConsMat, which is a modern industry producing materials for the construction, and mainly produces Bricks, and needs Sludge, Pigments, Paint-Powders, and Recycled-Water.
- DrinkWater is a modern WasteWater Treament Plant including a tertiary treatment devoted to the production of DrinkingWater and also generates Sludge as a subproduct, and it needs Industrial-Wastewater, Domestic-Wastewater, and punctually it needs Steel-Pipes for some maintenance operations.
- ChefRest, is a restaurant within the industrial park which produces Domestic-Wastewater, and needs Milk, Drinking-Water, Table-Clothes, and Textile-Packaging.
4.2. Resource Recommendations’ Examples
4.2.1. “Wanting Wooden Packaging” Resolution Workflow
- Keyword(s): packaging
- Direction: Want
- EWC: 15 01 03
- ○
- Search method: Filter
- Category: null
- Site: SweetHome geolocation
4.2.2. “Wanting Plastic Packaging” Resolution Workflow
- Keyword(s): packaging
- Direction: Want
- EWC: 15 01 02
- ○
- Search method: Rank
- Category: null
- Site: ChefRest geolocation
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P.B., Eds.; Springer: Boston, MA, USA, 2011; pp. 1–35. [Google Scholar]
- Chertow, M.R. Uncovering Industrial Symbiosis. J. Ind. Ecol. 2007, 11, 11–30. [Google Scholar] [CrossRef]
- Gatzioura, A.; Sànchez-Marrè, M.; Gibert, K. A Hybrid recommender system for industrial symbiotic networks. In Proceedings of the 9th International Congress on Environmental Modelling & Software (iEMSs 2018), Fort Collins, CO, USA, 24–28 June 2018. [Google Scholar]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model. User Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Bistline, J.E.; Rai, V. The role of carbon capture technologies in greenhouse gas emissions-reduction models: A parametric study for the US power sector. Energy Policy 2010, 38, 1177–1191. [Google Scholar] [CrossRef]
- European Communities. Waste Management Options and Climate Change; European Communities: Brussels, Belgium, 2001. [Google Scholar]
- Climate Change. United Nations Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2001; 3 Volumes. Available online: www.ipcc.ch (accessed on 13 September 2019).
- European Environmental Agency. More from Less Material Resource Efficiency in Europe; Technical Report, EEA Report No. 10/2016; European Environmental Agency: Copenhagen, Denmark, 2016; Volume 10. [Google Scholar]
- Walmsley, T.G.; Ong, B.H.; Klemeš, J.J.; Tan, R.R.; Varbanov, P.S. Circular Integration of processes, industries, and economies. Renew. Sustain. Energy Rev. 2019, 107, 507–515. [Google Scholar] [CrossRef]
- Klemeš, J.J.; Kravanja, Z. Forty years of Heat Integration: Pinch Analysis (PA) and mathematical programming (MP). Curr. Opin. Chem. Eng. 2013, 2, 461–474. [Google Scholar] [CrossRef]
- El-Halwagi, M.M. Sustainable Design through Process Integration; Butterworth-Heinemann/Elsevier: London, UK, 2012. [Google Scholar]
- Porzio, G.F.; Colla, V.; Matarese, N.; Nastasi, G.; Branca, T.A.; Amato, A.; Bergamasco, M. Process integration in energy and carbon intensive industries: an example of exploitation of optimization techniques and decision support. Appl. Therm. Eng. 2014, 70, 1148–1155. [Google Scholar] [CrossRef]
- Kermani, M.; Kantor, I.D.; Wallerand, A.S.; Granacher, J.; Ensinas, A.V.; Maréchal, F. A Holistic Methodology for Optimizing Industrial Resource Efficiency. Energies 2019, 12, 1315. [Google Scholar] [CrossRef]
- The Biofuels Directive (2015/1513). European Parliament, 2015. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32015L1513&from=EN (accessed on 13 September 2019).
- European Commission. Renewable Energy Directive 2009/28/EC; European Commission: Brussels, Belgium, 2009. [Google Scholar]
- Eurostat. Energy Balance Sheets 2011–2012; Technical Report 9; Eurostats (European Union): Brussels, Belgium, 2014. [Google Scholar] [CrossRef]
- EC Directive 1999/31/EC. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX%3A31999L0031&from=EN (accessed on 13 September 2019).
- EC Directive 2000/53/EC on End-of-Life Vehicles. Available online: https://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=CONSLEG:2000L0053:20050701:EN:PDF (accessed on 13 September 2019).
- EC Directive 2002/96/EC on Waste Electrical Equipment. Available online: https://ec.europa.eu/environment/waste/weee/index_en.htm (accessed on 13 September 2019).
- EC Directive 2006/66/EC on Batteries. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:32006L0066&from=EN (accessed on 13 September 2019).
- Pearce, D.W.; Turner, R.K. Economics of Natural Resources and the Environment; JHU Press: Baltimore, MD, USA, 1990. [Google Scholar]
- Frosch, R.A.; Gallopoulos, N.E. Strategies for Manufacturing. Sci. Am. 1989, 261, 144–152. [Google Scholar] [CrossRef]
- McKinsey & Company. Towards the Circular Economy: Economic and Business Rationality for an Accelerated Transition; Ellen McArthur Foundation: Cowes, UK, 2012. [Google Scholar]
- EUR-Lex. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52019DC0190&from=EN (accessed on 13 September 2019).
- European Commission. EC Report from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions. Implementation of the Circular Economy Action Plan; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- Lombardi, D.R.; Laybourn, P. Redefining Industrial Symbiosis. J. Ind. Ecol. 2012, 16, 28–37. [Google Scholar] [CrossRef]
- Chertow, M.R. Industrial Symbiosis: Literature and Taxonomy. Ann. Rev. Energy Environ. 2000, 25, 313–337. [Google Scholar] [CrossRef]
- Costa, I.; Massard, G.; Agarwal, A. Waste management policies for industrial symbiosis development: case studies in European countries. J. Clean. Prod. 2010, 18, 815–822. [Google Scholar] [CrossRef]
- Van Capelleveen, G.; Amrit, C.; Yazan, D.M. A literature survey of information systems facilitating the identification of industrial symbiosis. In From Science to Society; Springer: Cham, Switzerland, 2018; pp. 155–169. [Google Scholar]
- Van Capelleveen, G.; Amrit, C.; Yazan, D.M.; Zijm, H. The influence of knowledge in the design of a recommender system to facilitate industrial symbiosis markets. Environ. Model. Softw. 2018, 110, 139–152. [Google Scholar] [CrossRef]
- Yazdanpanah, V.; Yazan, D.M.; Zijm, W.H.M. FISOF: A formal industrial symbiosis opportunity filtering method. Eng. Appl. Artif. Intell. 2019, 81, 247–259. [Google Scholar] [CrossRef]
- Deshpande, M.; Karypis, G. Item-based top-n recommendation algorithms. ACM Trans. Inf. Syst. 2004, 22, 143–177. [Google Scholar] [CrossRef]
- Melville, P.; Sindhwani, V. Recommender Systems. In Encyclopedia of Machine Learning; Springer: Berlin/Heidelberg, Germany, 2010; chapter: 00338; pp. 829–838. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 1–19. [Google Scholar] [CrossRef]
- Lopez de Mantaras, R. Case-Based Reasoning. In Machine Learning and Its Application; LNAI; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2049, pp. 127–145. [Google Scholar]
- Kolodner, J.L. An introduction to case-based reasoning. Artif. Intell. Rev. 1992, 6, 3–34. [Google Scholar] [CrossRef]
- Bridge, D.; Göker, M.H.; McGinty, L.; Smyth, B. Case-based recommender systems. Knowl. Eng. Rev. 2006, 20, 315. [Google Scholar] [CrossRef]
- Leake, D.B. CBR in Context: The Present and Future. Case-Based Reasoning: Experiences, Lessons, and Future Directions; MIT Press: Cambridge, MA, USA, 1996; pp. 3–30. [Google Scholar]
- Núñez, H.; Sànchez-Marrè, M.; Cortés, U.; Comas, J.; Martínez, M.; Rodríguez-Roda, I.; Poch, M. A comparative study on the use of similarity measures in case-based reasoning to improve the classification of environmental system situations. Environ. Model. Softw. 2004, 19, 809–819. [Google Scholar] [CrossRef]
- Finnie, G.; Sun, Z. Similarity and metrics in case-based reasoning. Int. J. Intell. Syst. 2002, 17, 273–287. [Google Scholar] [CrossRef]
- Gibert, K.; Nonell, R.; Velarde, J.M.; Colillas, M.M. Knowledge Discovery with clustering: impact of metrics and reporting phase by using KLASS. Neural Netw. World 2005, 4, 319–326. [Google Scholar]
- Gibert, K.; Valls, A.; Batet, M. Introducing semantic variables in mixed distance measures. Impact on hierarchical clustering. Knowl. Inf. Syst. 2014, 40, 559–593. [Google Scholar] [CrossRef]
- Lorenzi, F.; Ricci, F. Case-based recommender systems: A unifying view. In Intelligent Techniques for Web Personalization; Springer: Berlin/Heidelberg, Germany, 2005; pp. 89–113. [Google Scholar]
- Gatzioura, A. A Hybrid Approach for Item collection Recommendations: An Application to Automatic Playlist Continuation. Ph.D. Dissertation, Universitat Politècnica de Catalunya, Barcelona, Spain, 2018. [Google Scholar]
- Gatzioura, A.; Sànchez-Marrè, M. A case-based reasoning framework for music playlist recommendations. In Proceedings of the 4th IEEE International Conference on Control, Decision and Information Technologies (CoDIT’17), Barcelona, Spain, 5–7 April 2017. [Google Scholar]
- Scottish Environment Protection Agency. Available online: https://www.sepa.org.uk/media/139146/sepa-waste-thesaurus-2014.pdf (accessed on 1 August 2019).
- National Waste Collection Permit Office. Available online: http://www.nwcpo.ie/forms/EWC_code_book.pdf (accessed on 1 August 2019).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Company | Product | H/W | Quant |
|---|---|---|---|
| CeramProd | Floor-Tile-Ceramics | Have | 2000 |
| CeramProd | Wall-Tile-Ceramics | Have | 8000 |
| CeramProd | Roof-Tile-Ceramics | Have | 1000 |
| CeramProd | Frites | Want | 5700 |
| CeramProd | Recycled-Water | Want | 15,000 |
| CeramProd | Pigments | Want | 3750 |
| NewFarm | Feathers | Have | 2 |
| NewFarm | Leather-cuttings | Have | 50 |
| NewFarm | Milk | Have | 3000 |
| NewFarm | Wooden-Packaging | Want | 1500 |
| NewFarm | Glass-Bottles | Want | 2500 |
| StoneRock | Chrome | Have | 4150 |
| StoneRock | Pigments | Have | 6000 |
| StoneRock | Paint-Powders | Have | 1000 |
| StoneRock | Mechanical-Equipment | Want | 4000 |
| StoneRock | Sand | Want | 8000 |
| StoneRock | Frites | Have | 6100 |
| SweetHome | Feathers | Want | 5 |
| SweetHome | Silk-Waste | Want | 2500 |
| SweetHome | Wooden-Packaging | Want | 1000 |
| SweetHome | Pillows | Have | 200 |
| SweetHome | Bed-Sheets | Have | 400 |
| SweetHome | Table-Clothes | Have | 300 |
| HotelNew | Pillows | Want | 100 |
| HotelNew | Bed-Sheets | Want | 50 |
| HotelNew | Wooden-Packaging | Have | 1000 |
| HotelNew | Cardboard-Packaging | Have | 1000 |
| HotelNew | Drinking-Water | Want | 20,000 |
| HotelNew | Domestic-Wastewater | Have | 6000 |
| ConsMat | Sludge | Want | 20,000 |
| ConsMat | Bricks | Have | 250 |
| ConsMat | Pigments | Want | 3000 |
| ConsMat | Paint-Powders | Want | 250 |
| ConsMat | Recycled-Water | Want | 5000 |
| DrinkWater | Drinking-Water | Have | 25,000 |
| DrinkWater | Industrial-Wastewater | Want | 35,000 |
| DrinkWater | Domestic-Wastewater | Want | 4000 |
| DrinkWater | Sludge | Have | 8000 |
| DrinkWater | Steel-Pipes | Want | 6000 |
| ChefRest | Milk | Want | 1000 |
| ChefRest | Drinking-Water | Want | 5000 |
| ChefRest | Domestic-Wastewater | Have | 2500 |
| ChefRest | Table-Clothes | Want | 30 |
| ChefRest | Plastic-Packaging | Want | 2000 |
| ChefRest | Wooden Pallets | Have | 2000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gatzioura, A.; Sànchez-Marrè, M.; Gibert, K. A Hybrid Recommender System to Improve Circular Economy in Industrial Symbiotic Networks. Energies 2019, 12, 3546. https://doi.org/10.3390/en12183546
Gatzioura A, Sànchez-Marrè M, Gibert K. A Hybrid Recommender System to Improve Circular Economy in Industrial Symbiotic Networks. Energies. 2019; 12(18):3546. https://doi.org/10.3390/en12183546
Chicago/Turabian StyleGatzioura, Anna, Miquel Sànchez-Marrè, and Karina Gibert. 2019. "A Hybrid Recommender System to Improve Circular Economy in Industrial Symbiotic Networks" Energies 12, no. 18: 3546. https://doi.org/10.3390/en12183546
APA StyleGatzioura, A., Sànchez-Marrè, M., & Gibert, K. (2019). A Hybrid Recommender System to Improve Circular Economy in Industrial Symbiotic Networks. Energies, 12(18), 3546. https://doi.org/10.3390/en12183546