1. Introduction
Nowadays, artificial intelligence (AI) has successfully been used for understanding human speech [
1,
2], competing at a high level in strategic game systems (such as Chess [
3] and Go [
4,
5]), self-driving vehicles [
6,
7], and interpreting complex data [
8,
9]. Reinforcement learning (RL) [
10,
11], which is a vital branch of AI, has potential in the area of intelligent transportation. There are two advantages of RL: First, due to its generality, agents can effectively study many disciplines in a complex environment such as the metro network [
12,
13,
14]; second, an agent with full exploration of the environment can give proper decisions in real-time, which means that RL can be used in optimization problems with real-time requirements. Until now, the train timetable rescheduling (TTR) problem [
15,
16,
17,
18] has been repeatedly discussed, however, there is only a small amount of literature using RL as a possible solution. Šemrov et al. [
19] used a rescheduling method based on RL in a railway network in Slovenia. They illustrated that the rescheduling effect of the proposed method were at least equivalent and often superior to the simple first-in-first-out (FIFO) method and the random walk method. Yin et al. [
20] developed an intelligent train operation (ITO) algorithm based on RL to calculate optimal decisions, which minimize the reward for both total time-delay and energy-consumption. Both literatures are based on the Q-learning algorithm [
21,
22] belonging to RL. However, Q-learning is limited by the dimensionality of action: The number of action increases exponentially with the number of degrees of freedom [
23].
The energy-aimed train timetable rescheduling (ETTR) problem is rarely mentioned in previous literatures. It is different from traditional TTR problems, which focus on minimizing the total delay time of passengers [
18] or minimizing the overall delays of all trains [
24,
25], the ETTR problem focuses on the energy optimization after disturbances break the pre-scheduled timetable. Gong et al. [
26] proposed an integrated energy-efficient operation methodology (EOM) to solve the ETTR problem. The objectives are compensating dwell time disturbances in real-time and reducing the total energy in a whole travel. EOM saves the overall energy consumption by reducing the travel time in the next sections immediately after a delay and pulling the delayed train back to the original optimal timetable, although temporarily more energy is consumed in the transition process.
In this paper, DDPG is applied to solve the ETTR problem. This algorithm is a model-free, off-policy actor-critic algorithm using deep function approximators that can learn policies in high-dimensional, continuous action spaces [
23]. It is successfully applied in fields such as robotic control [
27] and traffic light timing optimization [
28]. Superior to Q-learning, both state spaces and action spaces are continuous [
29], which means that the observation values such as the speed and position of trains are continuous, and the target values such as the rescheduled travel time and dwelling time are also continuous. EOM only reschedules the delayed train, however, DDPG reschedules all trains in the network immediately after a disturbance happens.
The remainder of the paper is organized as follows.
Section 2 introduces the principles of DDPG for a regular system.
Section 3 presents three models for the metro network: Train traffic model, train movement model, and energy consumption model. In
Section 4, four experiments based on a real-world network of the Shanghai Metro Line 1 (SML1) is presented to validate the DDPG algorithm. The final section concludes the paper.
2. Principles of Deep Deterministic Policy Gradient
DDPG, a recently developed algorithm in reinforcement learning, is used to solve complex tasks from an unprocessed, high-dimensional, sensory input [
23]. This algorithm is comparable to the human level in many Atari video games. However, it has not been used in the area of intelligent transportation. This algorithm inherits its own advantage from earlier algorithms such as Q-learning and the deep Q-network [
30]. What is more, compared with Q-learning, it has continuous action space. Compared with the deep Q-network, it has a policy network to provide deterministic action. In the following, the principle of DDPG is introduced.
Obeying a standard reinforcement learning setup, an agent interacts with an environment in discrete timesteps based on a Markov decision process (MDP). At each timestep
, the agent receives state
, takes action
, and receives reward
. At the next timestep, the environment receives the action
and generates new state
with transition dynamics
. The state space is
and the action space is
. Previous RL algorithms such as the deep Q-network define the target policy
, which maps the state to a probability distribution over the action. The action–value function describes an expected return after taking action
in state
and thereafter following policy
, which is formulated according to the Bellman equation:
where the discounting factor meets
.
Both DDPG and Q-learning have a deterministic policy gradient. The deterministic policy gradient is the expected gradient of the action–value function gradient, which can be estimated much more efficiently than the usual stochastic policy gradient [
29]. Considering the target policy
directly maps state to deterministic action, the action–value function is formulated as:
where
can be learned off-policy.
Q-learning [
21] uses the greedy policy
to update the action–value function, then the training iteration of
is formulated as:
where
is the learning rate.
in Q-learning is a table, which provides a limit space for possible values of action and state, so Q-learning cannot be straightforwardly used in a continuous space.
DDPG is a member of the actor-critic algorithm, which contains four neural networks: Current critic network
, current actor network
, target critic network
and target actor network
, where
,
,
and
are the weights of each network.
and
are a copy of
and
respectively in the structures. Both
and
are partially updated from the current networks at each timestep. The current critic network is updated by minimizing the loss function:
where
The current actor network is updated by the gradient function:
The gradient function is continuous, which ensures that the action of the agent is updated within a continuous space. The specific Algorithm 1 process is described as follows:
| Algorithm 1. DDPG algorithm |
| Randomly initialize critic network , actor network with weights and . |
| Initialize target network and with weights |
| Initialize replay buffer |
| for to do |
| Initialize a random process |
| Receive initial state from environment |
| for to do |
| Select action according to the current actor network |
| Execute action in the environment , and receive reward and new state |
| Store transition in buffer |
| Sample a random minibatch of transitions from |
| Set |
| Update the critic by minimizing the loss: |
| Update the actor policy using the sampled gradient: |
|
| Update the target networks: |
|
| end for |
| end for |
4. Apply DDPG to ETTR
The ETTR problem is regarded as a complex problem for the reason of three points. First, it is a typical non-convex optimization problem. There are many local minimum points leading to difficultly searching the optimal schedule. Second, this problem has a high-quality real-time requirement. Disturbances in a metro network will bring a series of chain reactions that make an offline schedule not optimal anymore. Third, disturbances occur randomly at different stations on different trains, and the length of the disturbances is stochastic.
In this section, DDPG, a model-free, off-policy actor-critic algorithm, is proposed to solve the ETTR problem. The algorithm is able to solve the three points above properly. First, the proposed method has an advantage in solving complex non-convex optimization problems. Second, it reschedules the timetable in real-time, which effectively avoids chain reactions and saves more energy. Third, it has self-adaptability to make appropriate choices according to disturbances. According to the introduction of the DDPG algorithm in
Section 2, neural networks take an important role, which correct themselves during each training episode, and provide good advices for an agent during each testing episode. The well-trained neural networks can deduce the result in real-time during each policy decision process.
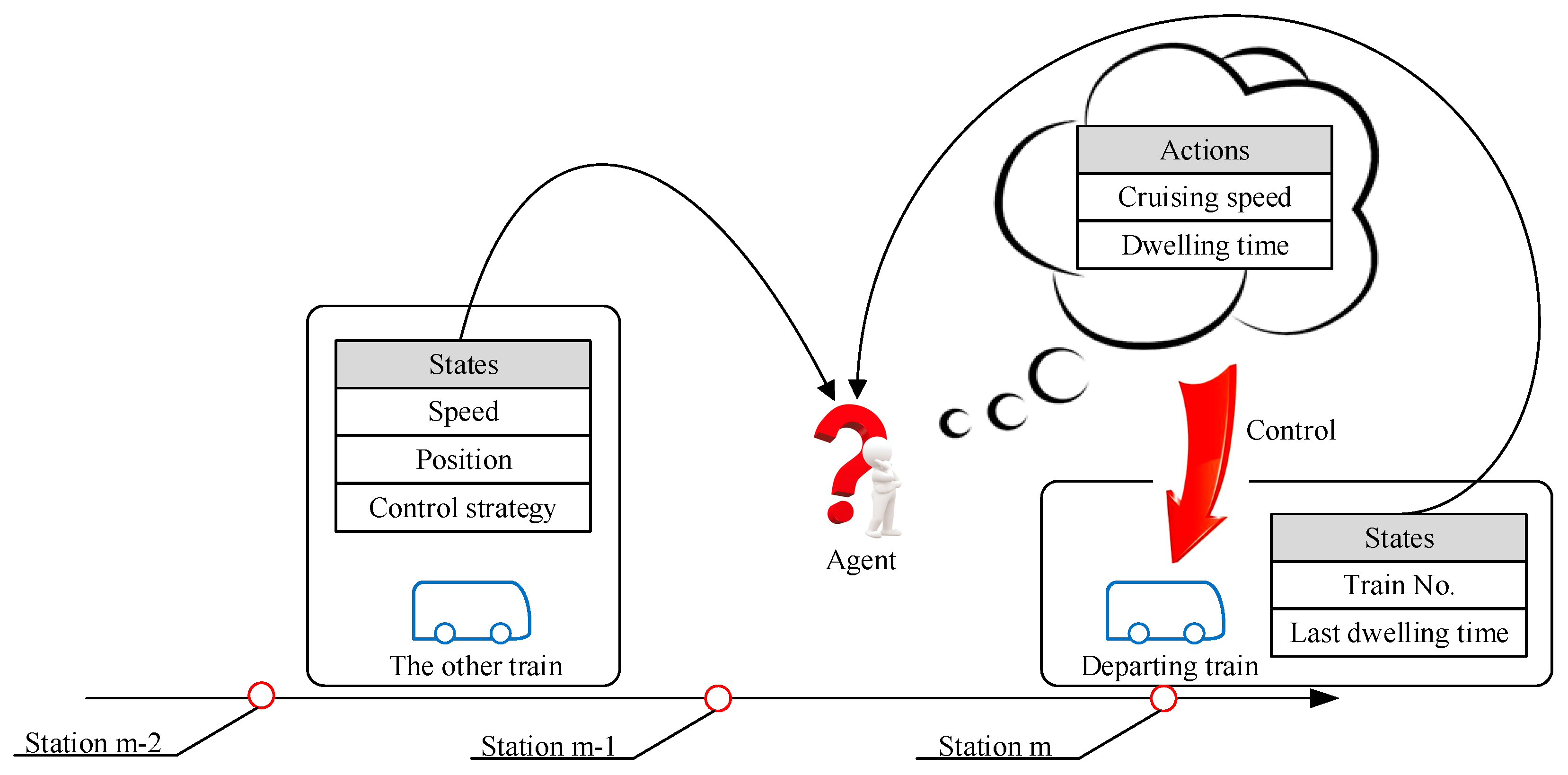
The environment and its state, agent and its action, and the reward feedback are the five fundamental components of DDPG. In the following, the definition details are provided to solve the specific ETTR problem.
4.1. Environment and Agent
To solve the ETTR problem, an environment is established in
Section 3. A single agent is introduced, which makes proper decisions when disturbances happen. Different from playing video games, the agent does not need to take action at each timestep, but rather, make decisions in the departure instant of each train. Disturbances always happen in the dwelling time, caused by a sudden peak point of passenger flow. Hence, the agent needs to adjust the travel time and dwelling time after the disturbances, and take advantage of the recover energy as much as possible.
4.2. State
The state selection is an important step of the DDPG algorithm, which directly affects the accuracy of decisions made by the agent. Increasing the dimension of state spaces will increase the complexity of the actor network, leading to a more training period. However, the more complex network structure helps the agent to have a deeper understanding to the environment. In the ETTR problem based on the two-train network, five quantities are chosen for the observation of the agent: The number of the departing train and its last dwelling time, the control strategy, and the current speed/position of the other running trains. In the three-train network, the dimension of the state space will be eight. Normalization is needed in the state inputs.
4.3. Action
The objective of the agent is to find a proper travel time and dwelling time for the departing train. In
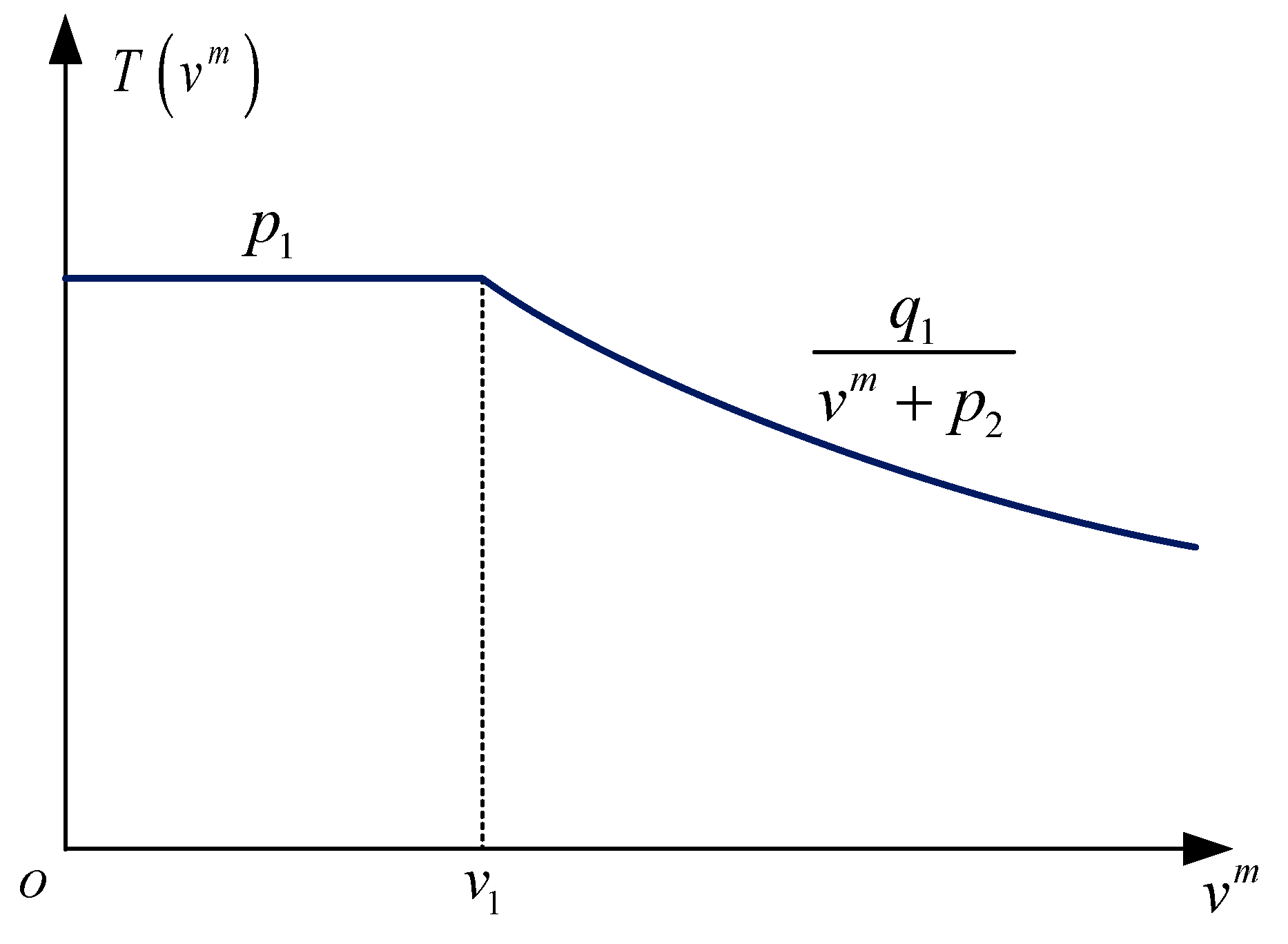
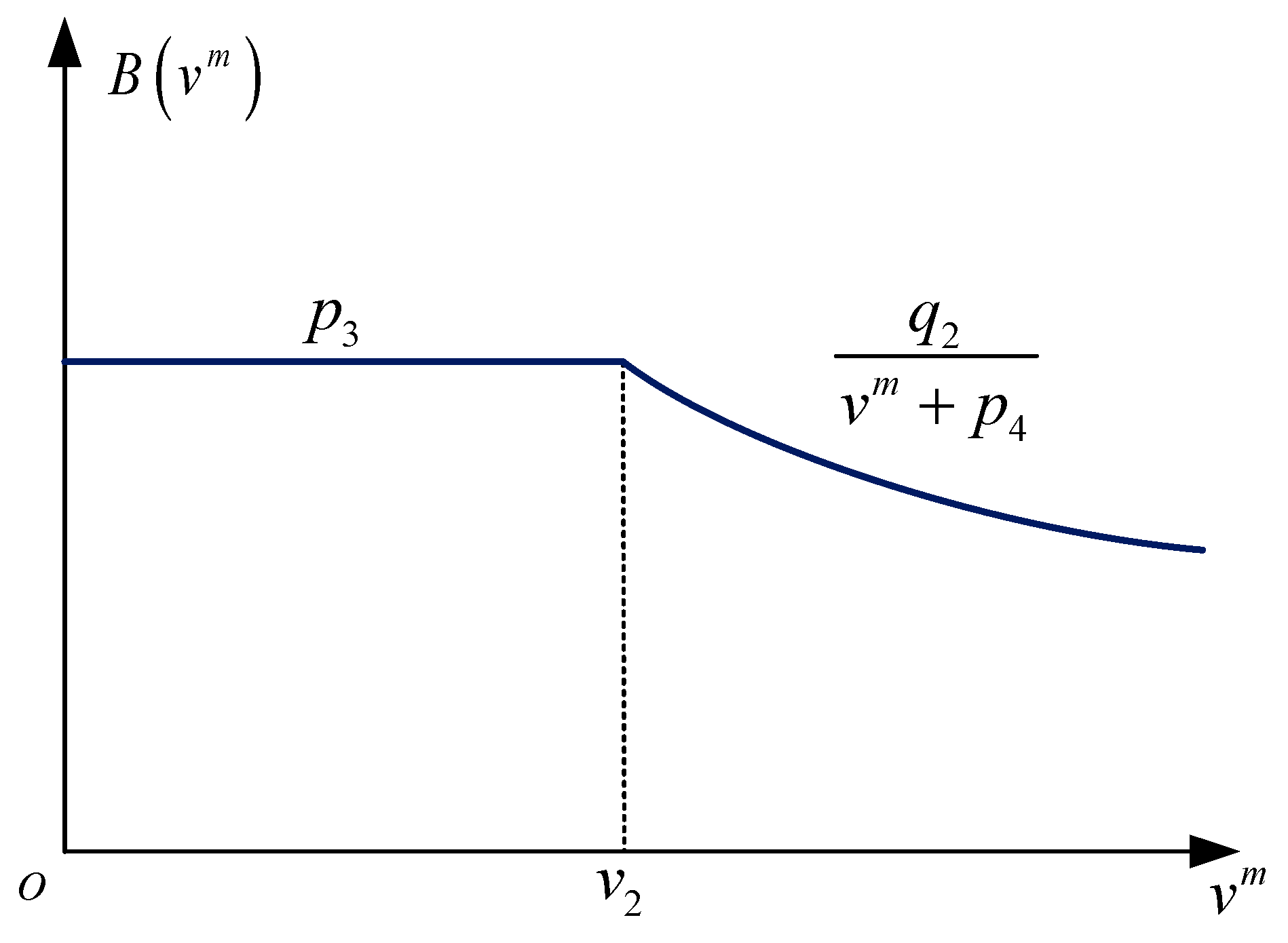
Section 3.4, the relation between the travel time and the cruising speed is formulated. Hence, it is reasonable to define the action as the cruising speed and the dwelling time of the departing train. Both actions have upper bounds and lower bounds.
4.4. Rewards
Disturbances happen randomly at different stations on different trains. The duration of each disturbance has random values. Rewards of the agent are set to maximize the recover energy and minimize the traction energy of the DDPG. Weight coefficients are essential, which make sure that the recover energy and the traction energy are in the same order of magnitude. The reward function is formulated as follows.
where
is a parameter.
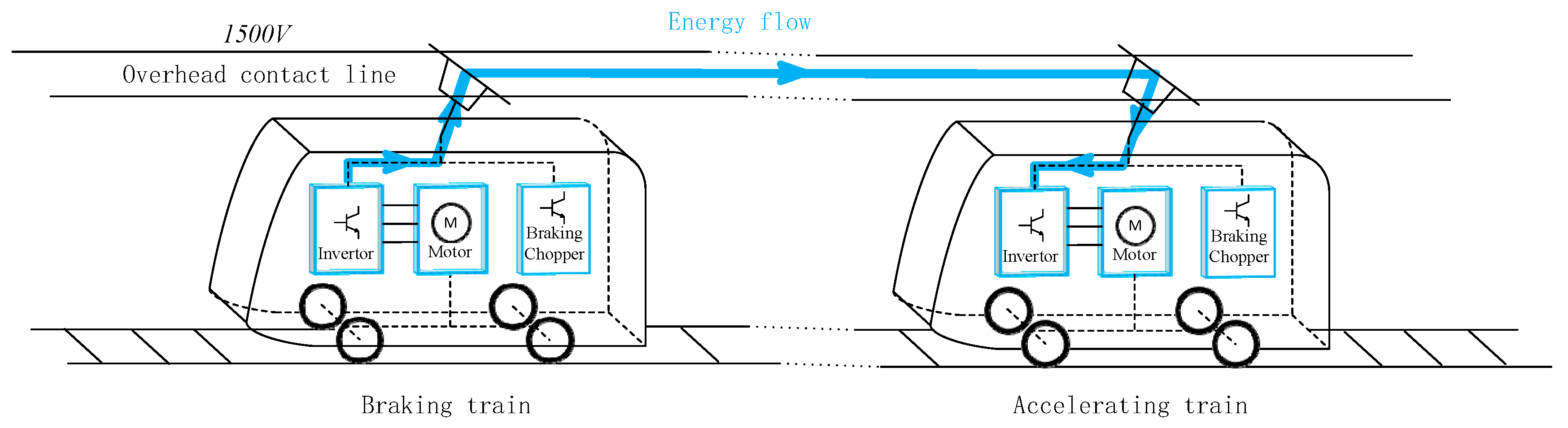
Figure 5 shows the sketch map of the DDPG in a two-train network, where the agent is observing the state of trains in the metro network from the environment and thinking which action should be taken for the departing train. The action works on the environment, then the trains get into the next state. During each step, the environment provides a reward to the agent.
5. Experimental Validation
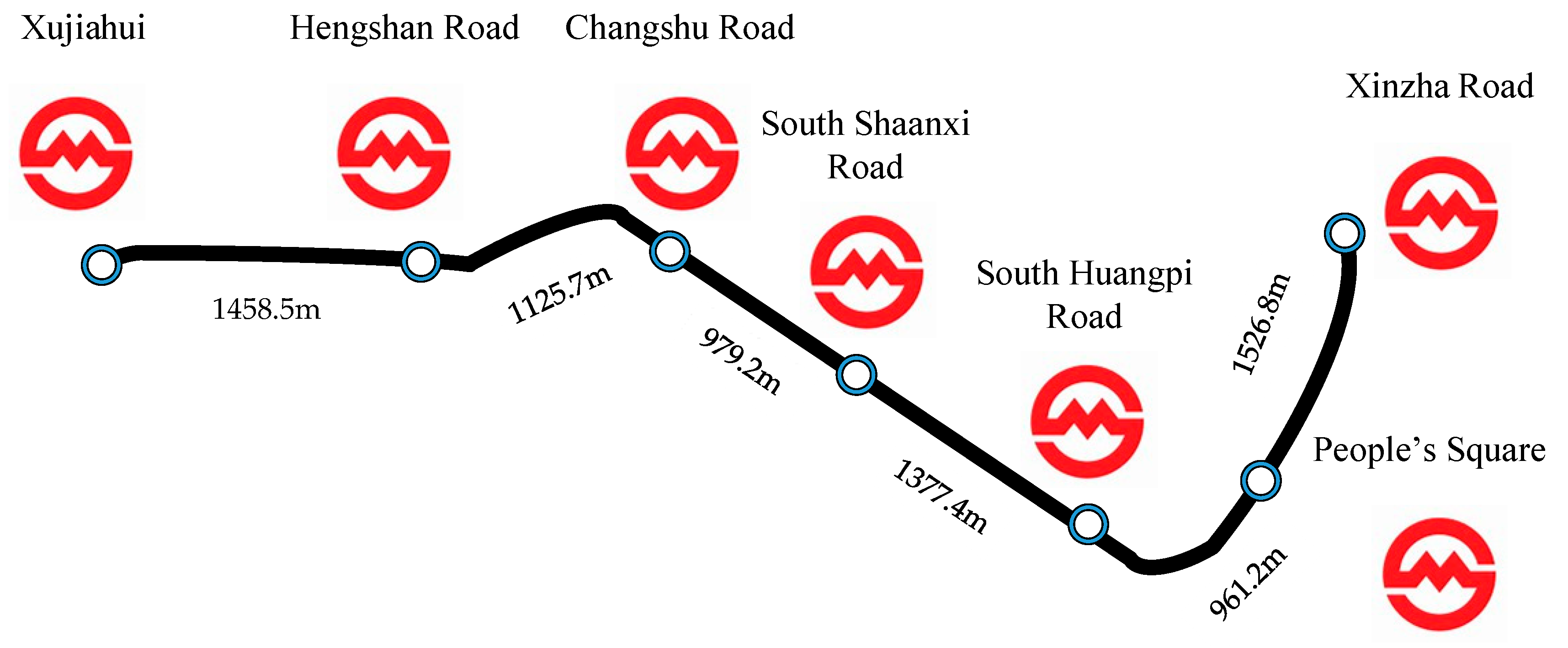
In order to validate DDPG in the ETTR problem, numerical experiments are conducted in the Shanghai Metro Line 1 (SML1), which is one of the oldest metro lines in China. There are a total of 28 stations with a daily ridership of over 1,000,000 passengers [
36]. According to the statistical data in daily peak hours, the metro network implements a tight schedule, of which the average traveling time during a section is only 2 min, and the uniform interval time between two trains is 164 s The first three experiments are based on a situation that two trains run on a segment of SML1 from Xujiahui to the Xinzha Road. The last experiment focuses on a three-train network in the same segment. Information of stations and segments are shown in
Figure 6.
Experiment 1: The objective of the first experiment is to schedule an offline optimal timetable without any disturbance. The foundation settings are listed as follows. The headway is set as 120 s. The dwelling time consists of a fixed dwelling time and a flexible dwelling time [
26]. The fixed dwelling time is set as 20 s while the flexible dwelling time ranges from 10–15 s. The cruising speed is
m/s. In this setup, the traffic block conflicts [
24] will not happen. The genetic algorithm (GA) is used to obtain the optimal cruising speed and the flexible dwelling time at each station for each train. The final optimal result is shown in
Table 1.
It takes 4325 s to obtain an offline timetable using a PC with Intel i7-4720HQ CPU. This reflects that GA is not suitable for adjusting the timetable in real-time when disturbances happen.
Experiment 2: DDPG is used to adjust the cruising speed and flexible dwelling time, when a disturbance happens at train No.1 on the Changshu Road Station. In this experiment, disturbances are discretely sampled, uniformly selected from a discrete point set
. The neuronal structure of the actor network is set as
, and the neuronal structure of the critic network is set as
. In essence, DDPG samples history data from a process that the agent interacts with the environment, and this data is used to update both the actor network and the critic network. The training process is offline, so the total training episode will not affect the real-time performance. The total training episode cannot be too small to search stable rewards, and it cannot be too large that the actor network and the critic network are overfitted. According to the training performance, the total episode is set as 3000.
Table 2 lists the set of the other parameters in DDPG.
Here,
Memory_capacity represents the size of the buffer
,
Batch_size represents the size of the minibatch
,
represents the update rates from the current network to the target network,
represents the discount factor, and
is the reward parameter.
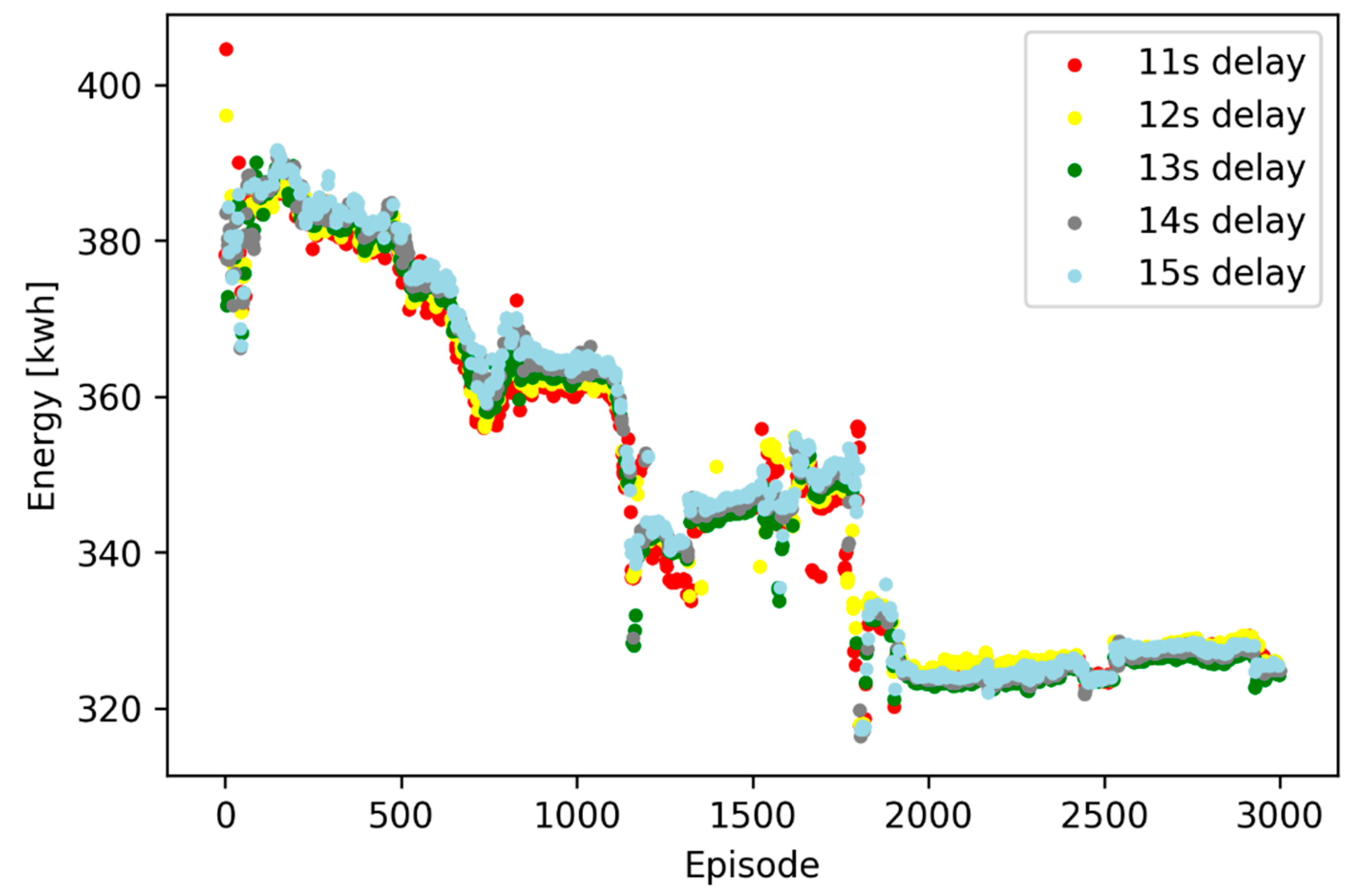
Figure 7 shows the total energy consumption for each episode, more specifically, the training episodes of DDPG under discretely sampling random disturbances.
As shown in
Figure 7, the beginning episodes (between zero and 50) are the exploration process, where the agent has a rapid progress but has not found a proper solution. A similar process happens on the episode 1200 and 1800. During 1200 to 1300 and 1550 to 1750, the agent sinks into the local extremum and energy consumption stays stable. In these situations, the agent can escape from local extremum and search new solutions. After the 2000-episode training, the agent stays stable under different disturbances.
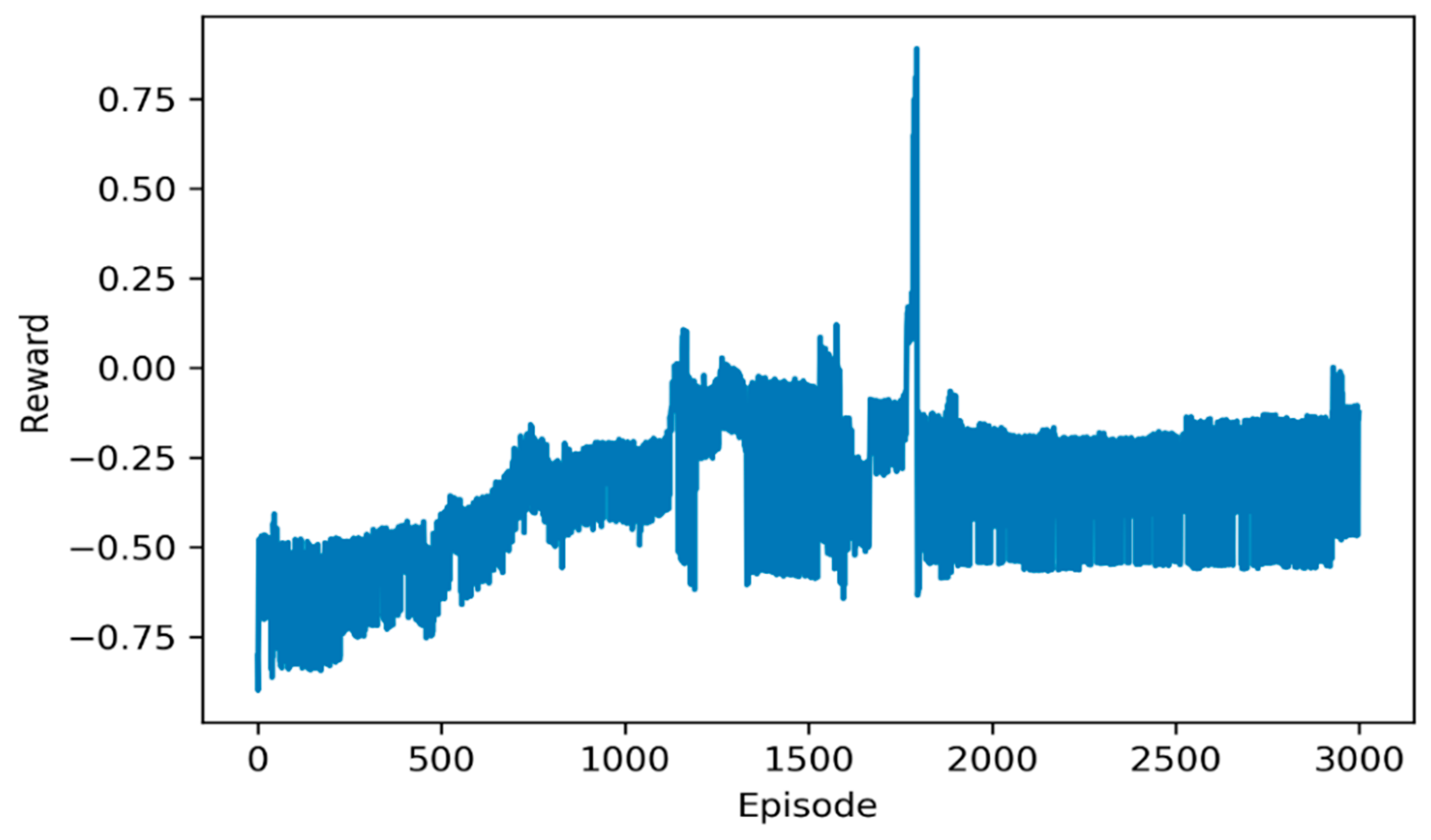
Figure 8 shows the rewards during optimization.
In
Figure 8, the reward curve presents an uptrend with the episode increasing, but it is not beyond zero in the final episode. According to the reward function, the reason is obvious that the relative traction energy and the relative feedback energy are cancelled out. In another word, the final reward is not beyond zero, because DDPG saves the traction energy, while wastes the feedback energy.
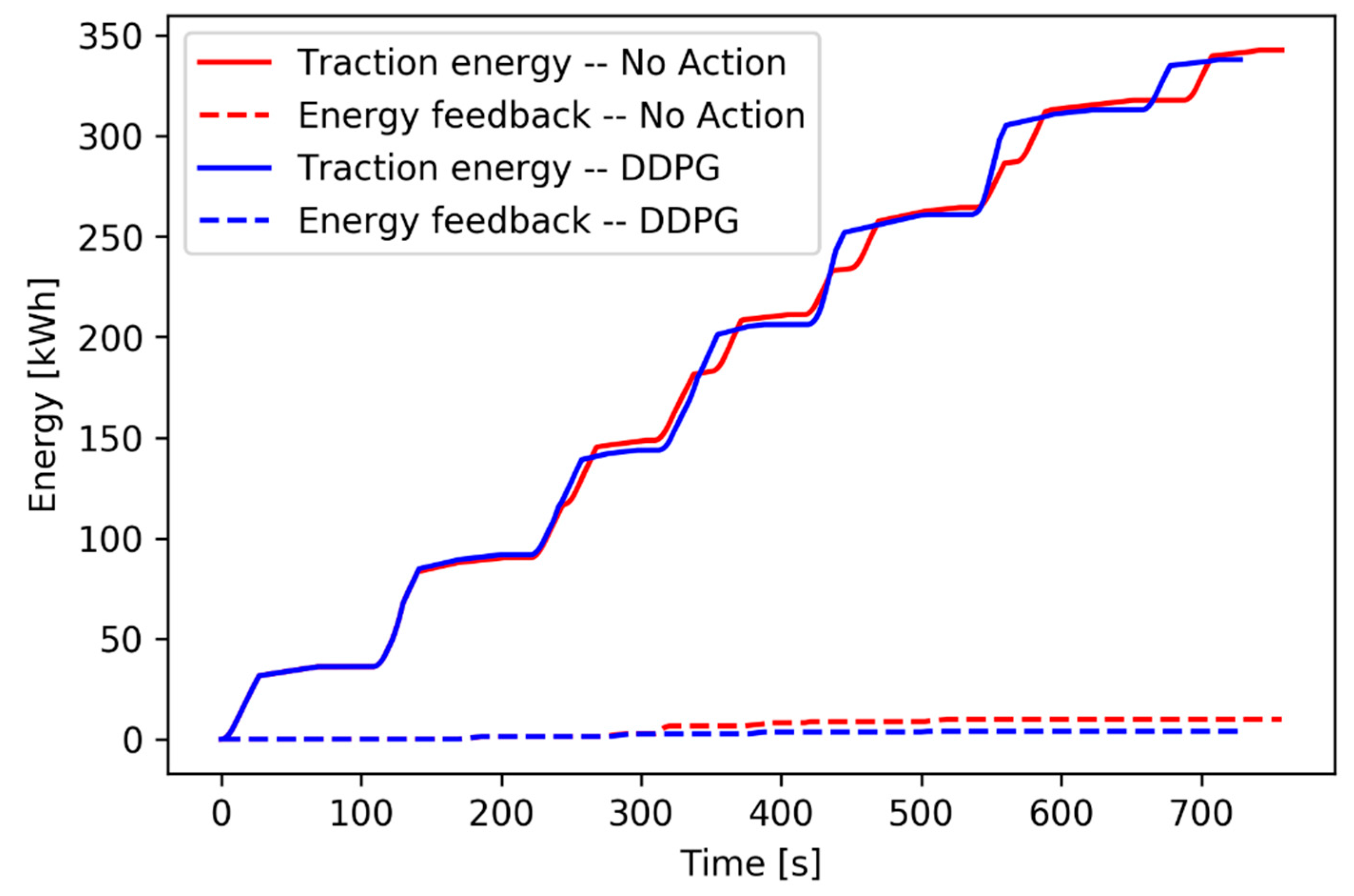
Figure 9 shows the energy accumulation for one episode under an 11 s delay.
Comparison on the traction energy consumption and the energy feedback shows that the agent of DDPG adopts a series of action, which reduces the traction energy but ignore gains in the energy feedback.
The training episodes above only show the trend of the agent searching solutions, but do not validate that it saves energy. Hence, test episodes are implemented.
Table 3 shows the testing results under different disturbances, with the trained neural networks in
Figure 7.
Table 3 shows that, under the larger delay, about 2% energy can be saved, but under the smaller delay, the agent can hardly save energy. On the basis of discretely sampling random disturbances, there are not enough samples supporting the learning of the agent, leading to an unremarkable percentage of energy saving. The experiment reflects that discretely sampling random disturbances cannot train out optimal DDPG networks. Experiment 3 gives a proper solution to promote the learning efficiency of the agent.
Experiment 3: DDPG is used to adjust the cruising speed and flexible dwelling time, when a disturbance happens at Train No.1 on the Changshu Road Station. The disturbance is in the continuous section
. The maximum training episode is set as 3800. The structure of the actor network and the critic network are set the same as they are in Experiment 2. Other parameters in DDPG are set as
Table 4.
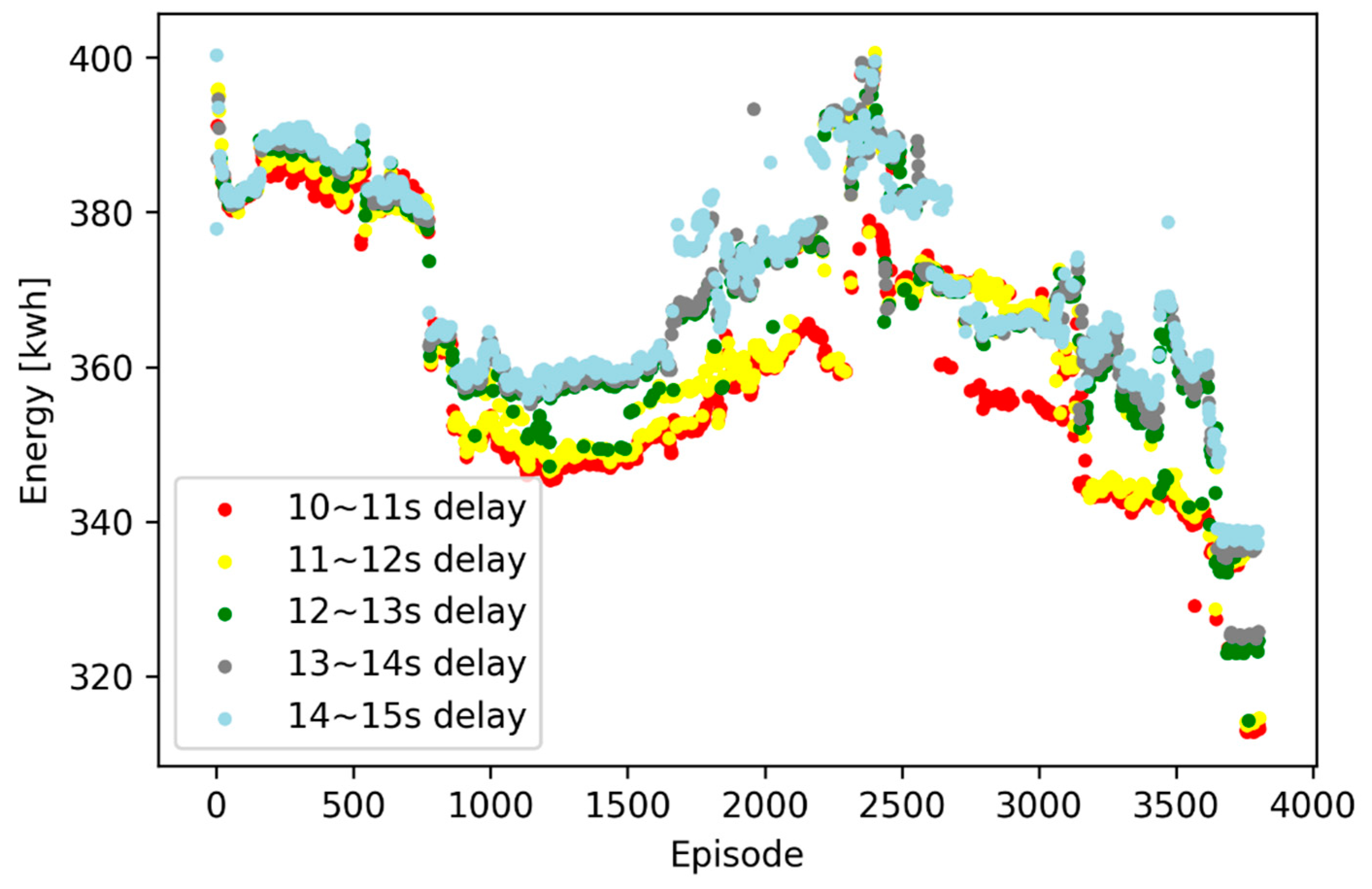
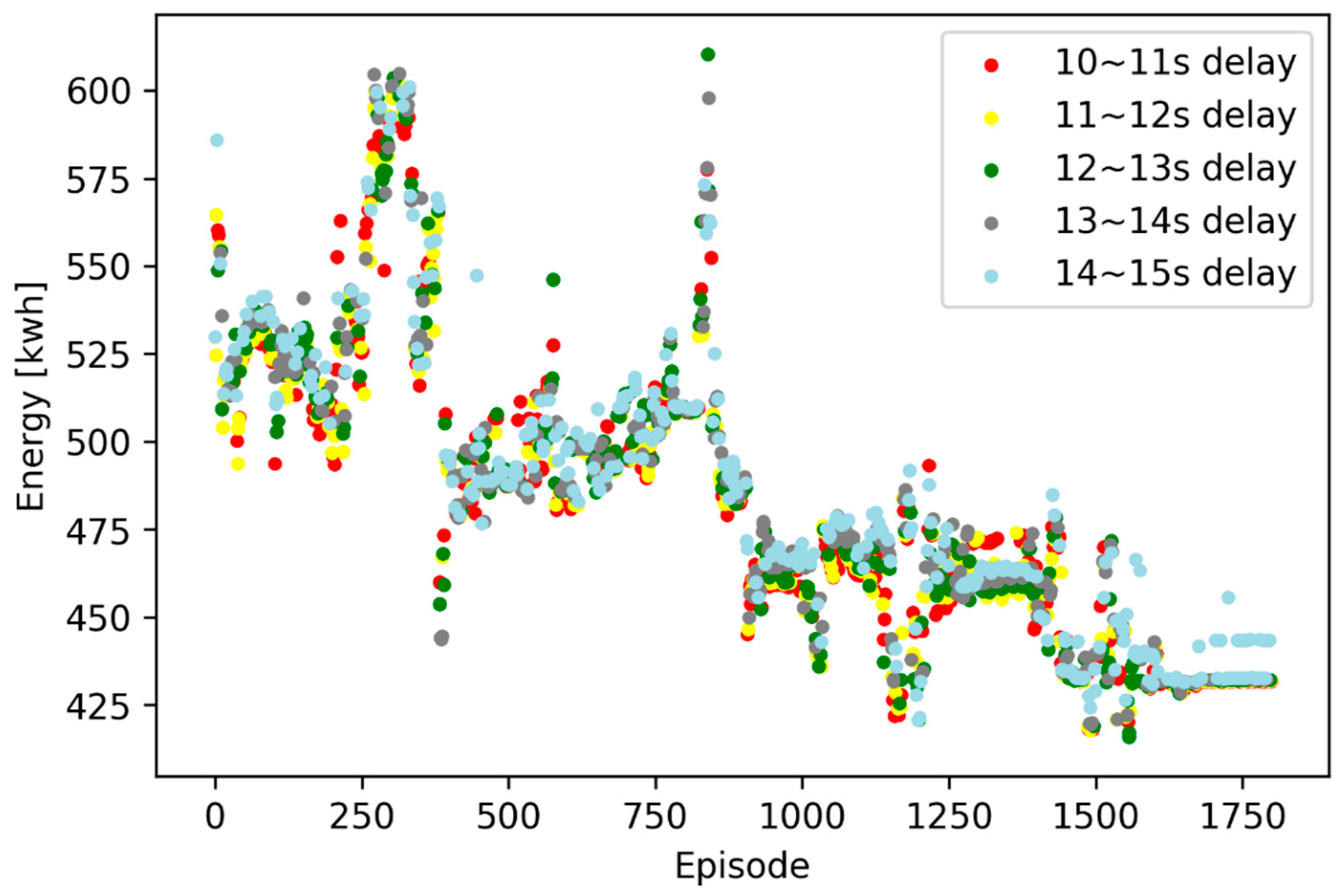
Figure 10 shows the total energy consumption in each training episode under continuously sampling random disturbances by DDPG.
Compared with
Figure 7, the convergence speed of the scatters in
Figure 10 is slower, and the final performance of energy saving is better. Both the actor network and the critic networks are well trained and the agent is not hovering around the local extremum.
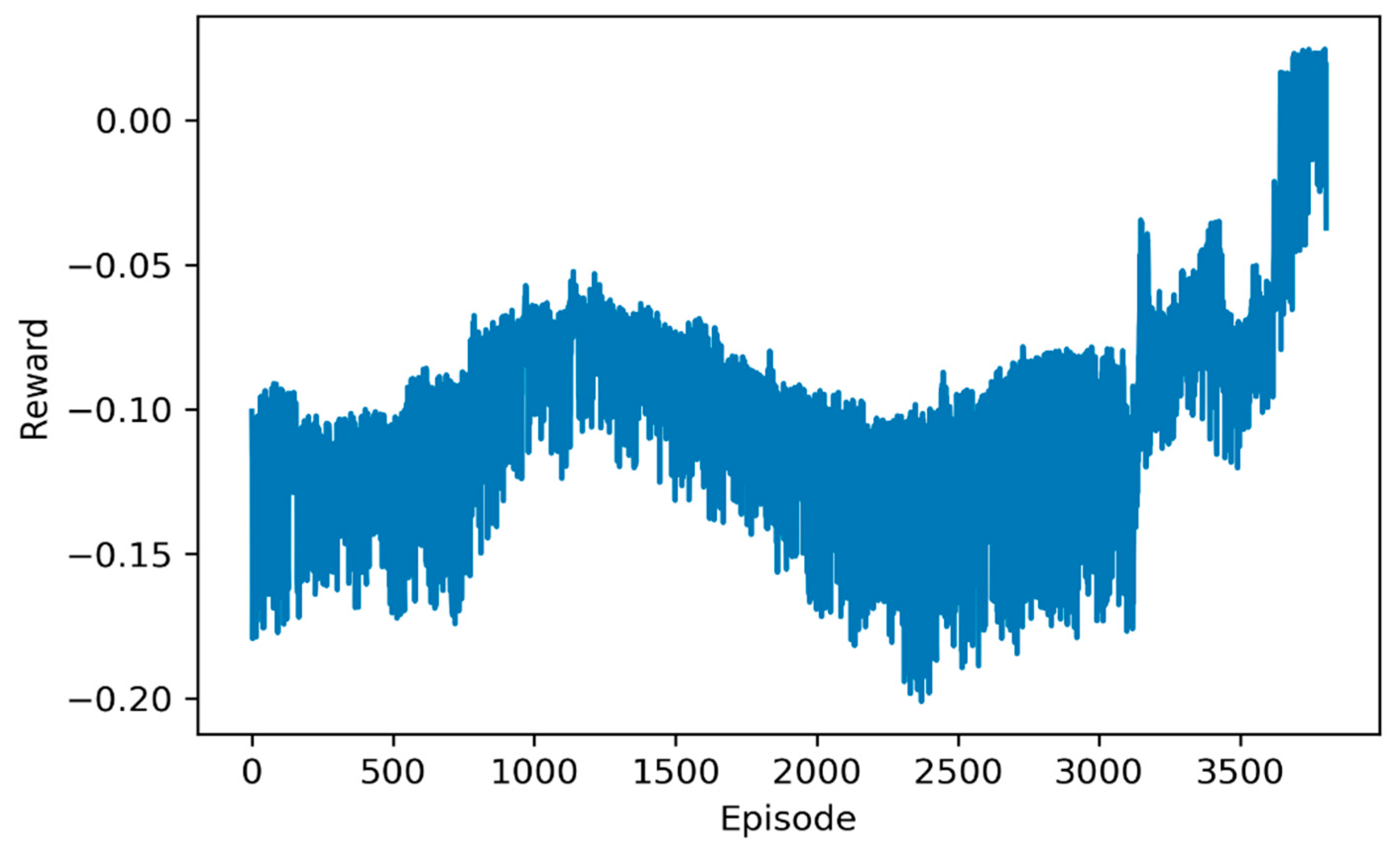
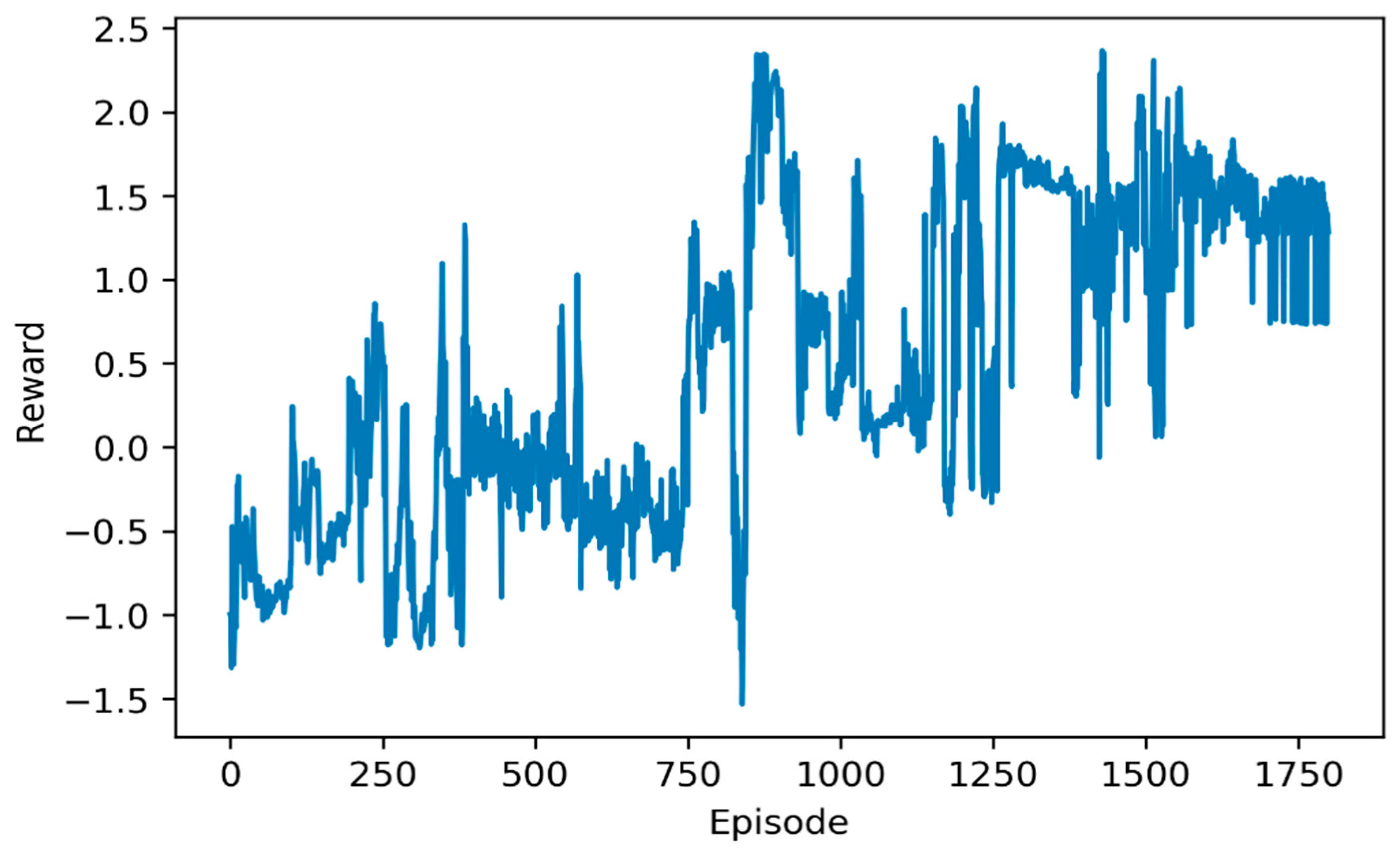
Figure 11 shows the rewards in the training episodes by DDPG. During the 3000 to 3800 episodes, the reward significantly increases, and finally beyond zero.
In the following, testing episodes are implemented, which try to validate that the performance of the agent is as well as it is in the final training episodes, and to validate the real-time characteristic of the well-learned agent.
The testing episodes is set as 10, and the disturbance is also random selected in the uniform distribution that
.
Table 5 shows the total energy consumption for each testing episode and the average time spent for each policy decision.
Compared with
Table 3, the DDPG training under random continuous disturbances can save more energy, because the random continuous disturbances provide enough different samples, which promotes the agent to understand the environment. The energy saving percent in the testing episode, which keeps stable in different cases of delay, has a similar distribution with that in the training episode. It indicates that the agent is well learned in the training episodes, and overfitting is not happening in the actor network and the critic network. Compared to GA, DDPG has a natural advantage in terms of the average time spent in each policy decision process.
Figure 12 shows the energy accumulation for one testing episode under a 10.76 s delay.
As shown in
Figure 12, the DDPG agent also chooses to reduce the average speed to save the traction energy. Different from experiment 2, the energy feedback increases from 305 s. This makes the DDPG in this experiment save more energy than before. Although the reward function increases the weight of the energy feedback, reducing the traction energy seems to be bring a higher return for the agent in the two-train network.
For the reason of unremarkable energy feedback in the two-train network, it is essential to take a three-train network for validation.
Experiment 4: DDPG is used to adjust the cruising speed and flexible dwelling time, when a disturbance happens at Train No.1 on the Changshu Road Station. The disturbance is in the continuous section
. The maximum training episode is set as 1800. The structure of the actor network and the critic network are set the same as they are in experiment 3.
Memory_capacity is set as 500 and
is set as 20, and other parameters in DDPG are set the same as in
Table 4. The only difference between experiment 4 and 3 is the number of the running trains. The headway of each train is set as 120 s.
First, an offline optimal timetable is built by GA under no disturbance situation.
Table 6 shows the selected cruising speed and dwelling time.
Figure 13 shows the total energy consumption in each training episode under continuously sampling random disturbances by DDPG.
According to
Figure 13 and
Figure 14, during training, energy consumption is fluctuated in a downward trend and rewards climb up and beyond zero. The final episode is not the minimum point, but it is a stable point under different disturbances.
Table 7 shows the performance of the agent in the testing episodes. As shown in
Table 7, the agent saves energy ranging from 5.87% to 7.37% under different disturbances. Moreover, the time to obtain an action is only 2.23 ms on average, which indicates that DDPG still has a real-time feature in the three-train network. Compared with the two-train network, DDPG saves more energy in the three-train network.
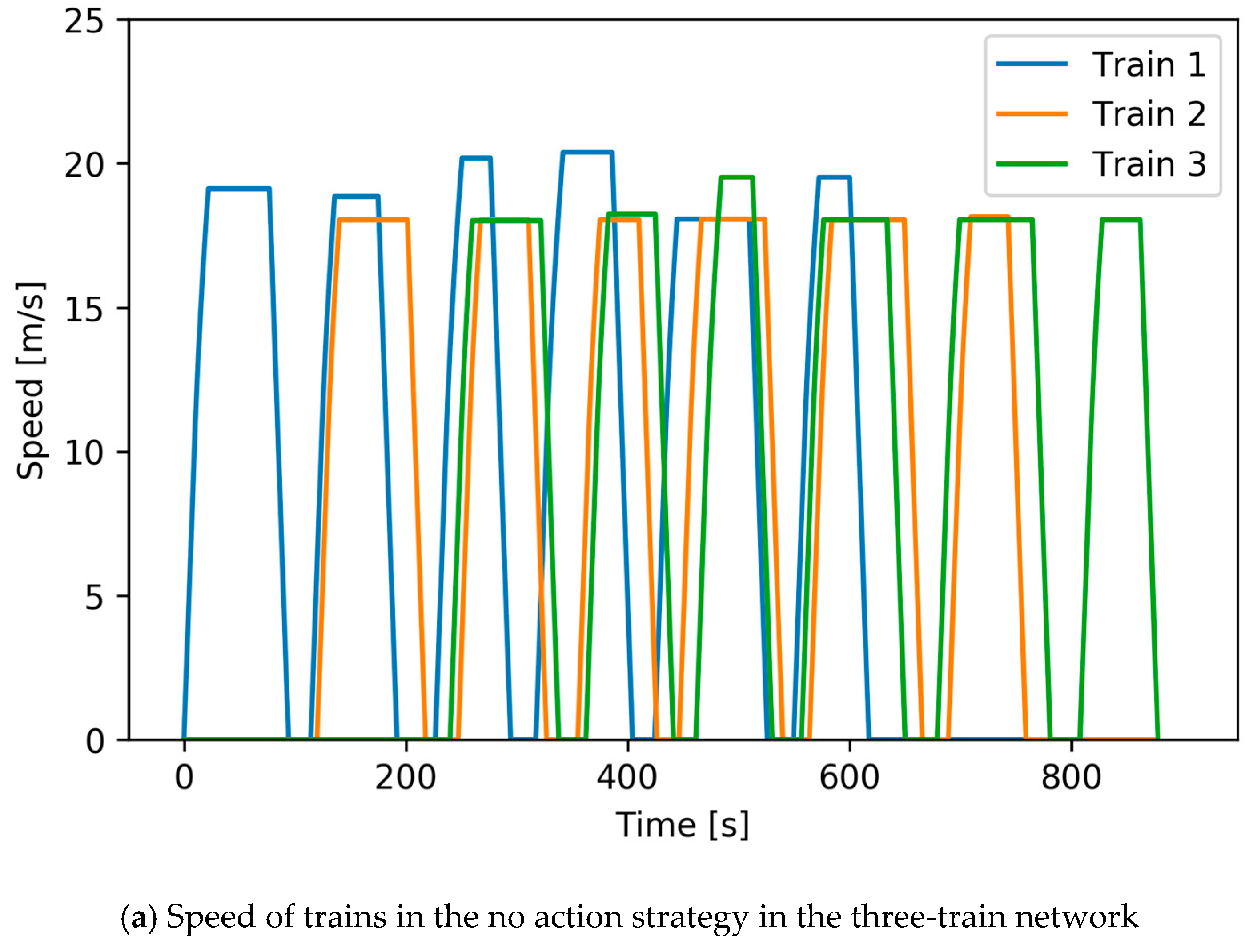
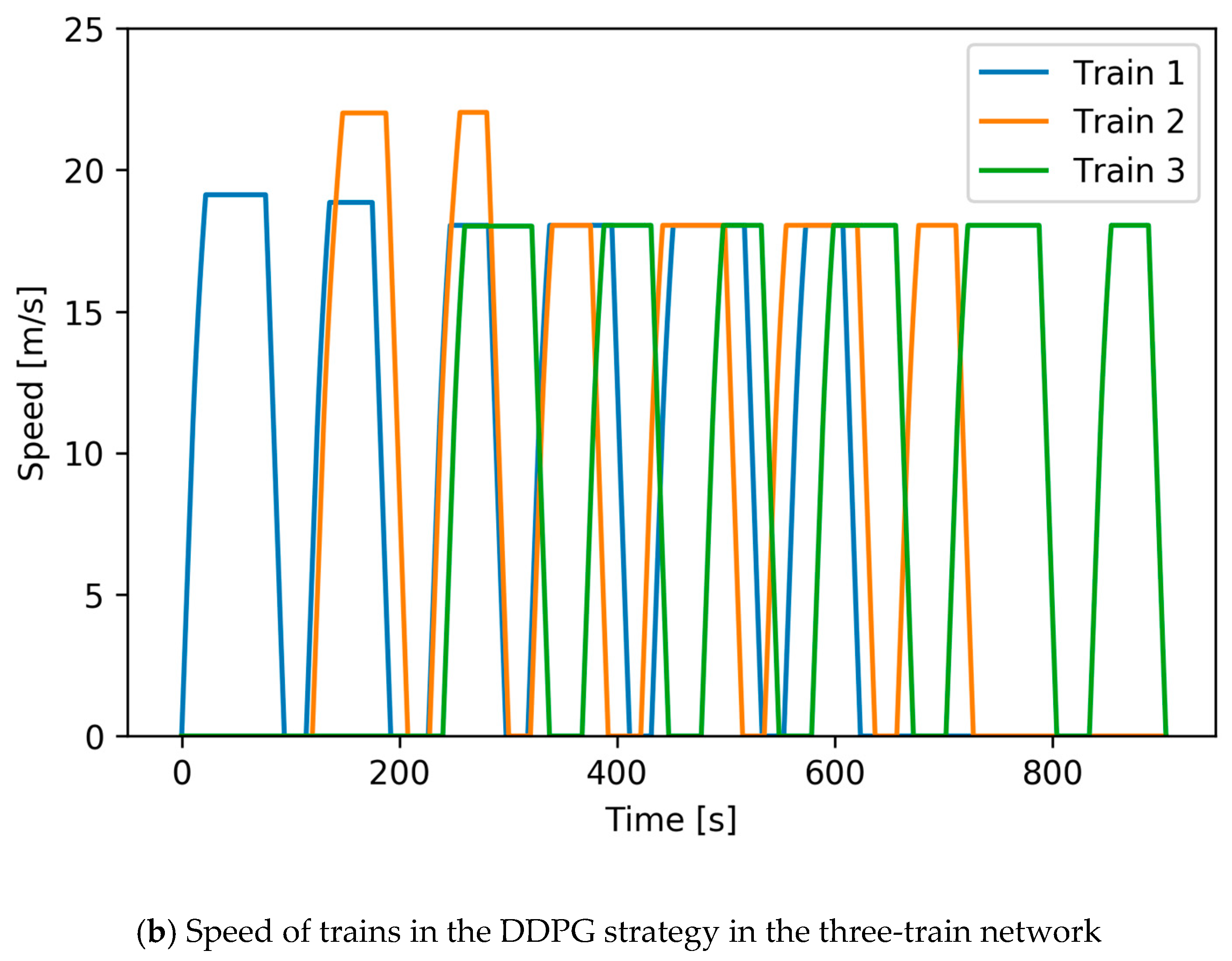
Figure 15 shows the speed curves under a 13.60 s delay in the three-train network, in which
Figure 15a shows the speed of trains in the no action strategy and
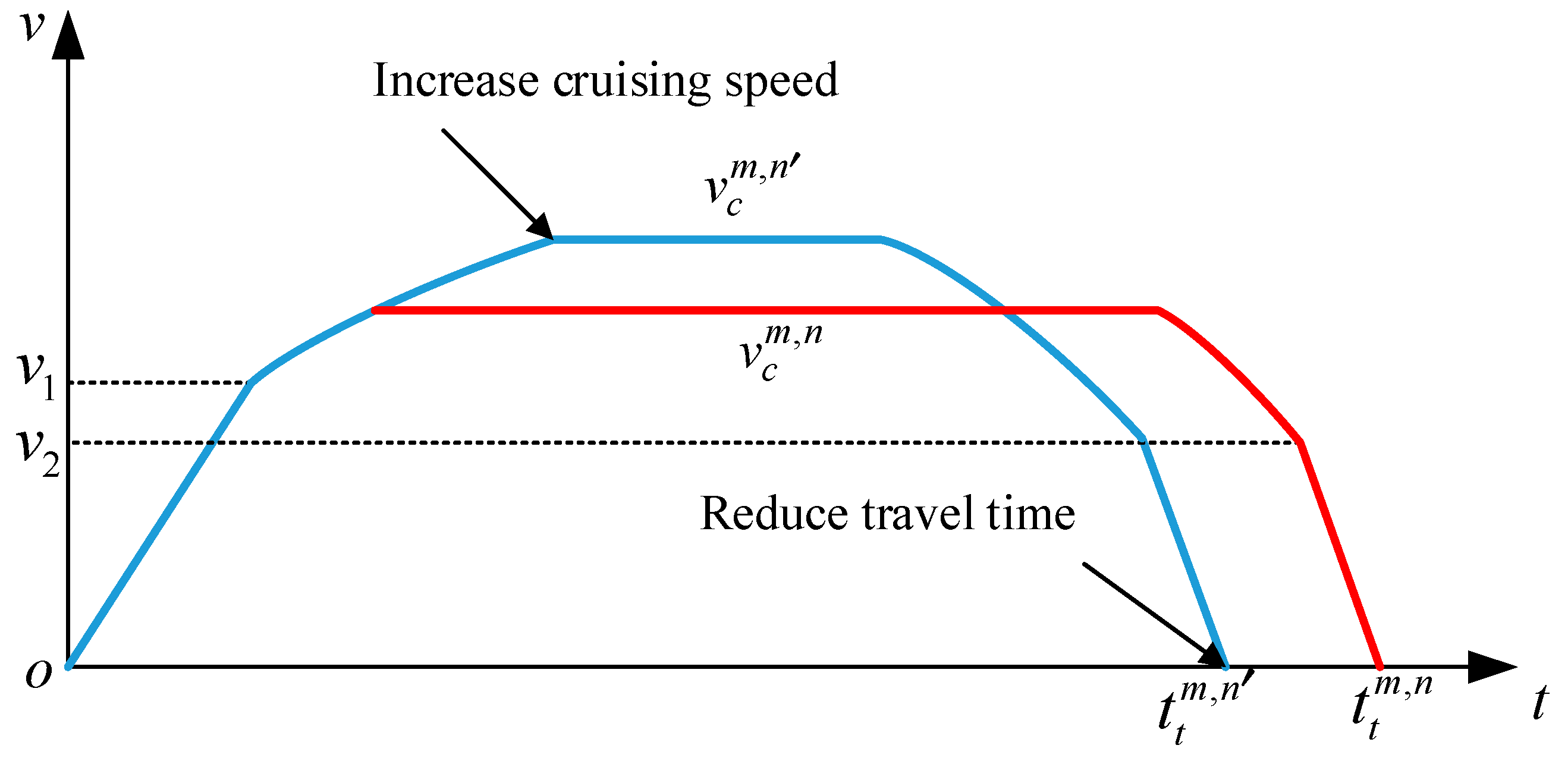
Figure 15b shows the speed of trains in the DDPG strategy. DDPG raises the cruising speed of train No.2 in the first two interstation, and adjusts the dwelling time to synchronize acceleration and braking, which maximizes the feedback energy. DDPG also reduces the cruising speed in other interstations of train No.2 and the cruising speed of other trains to reduce the traction energy.
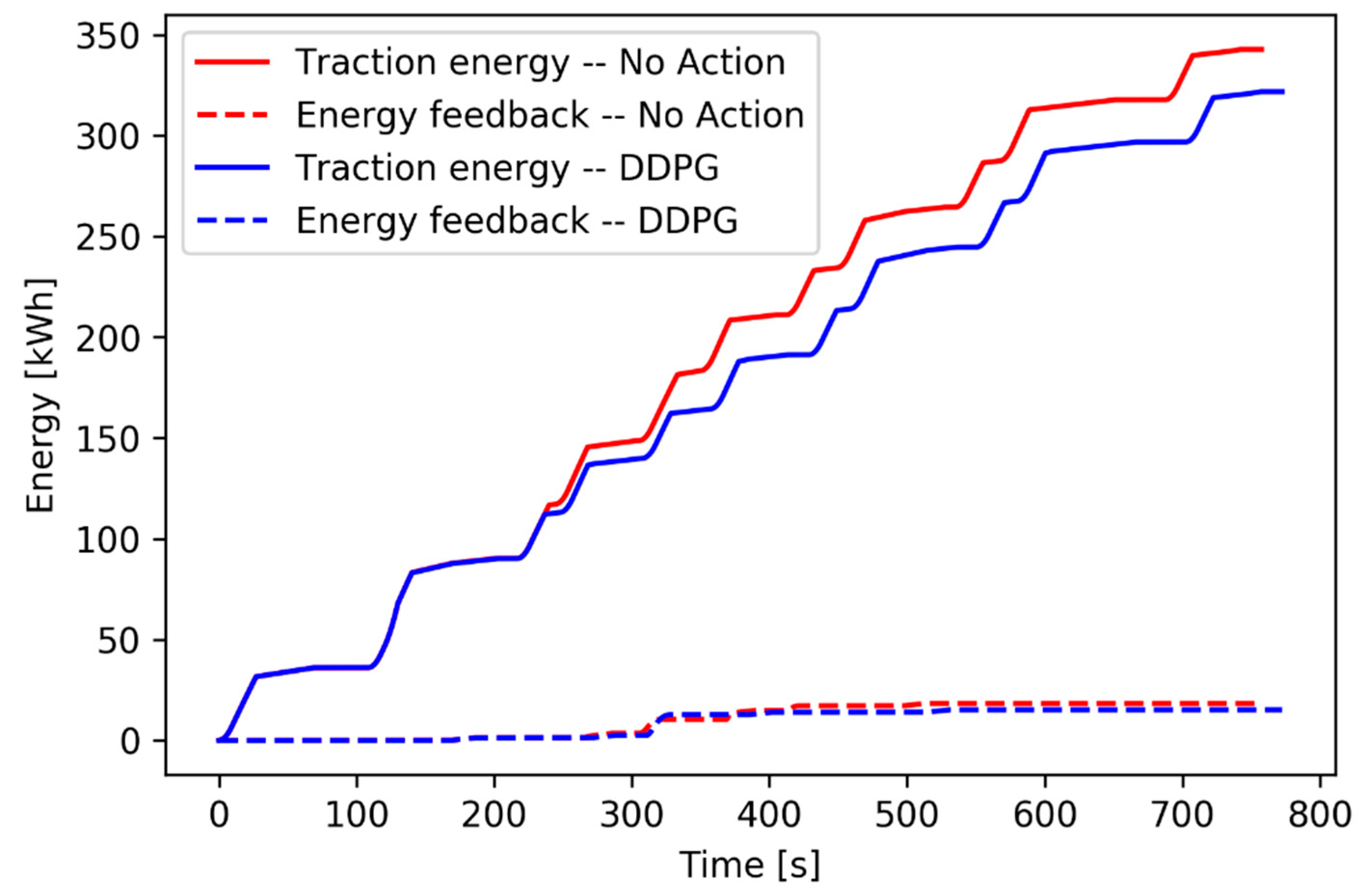
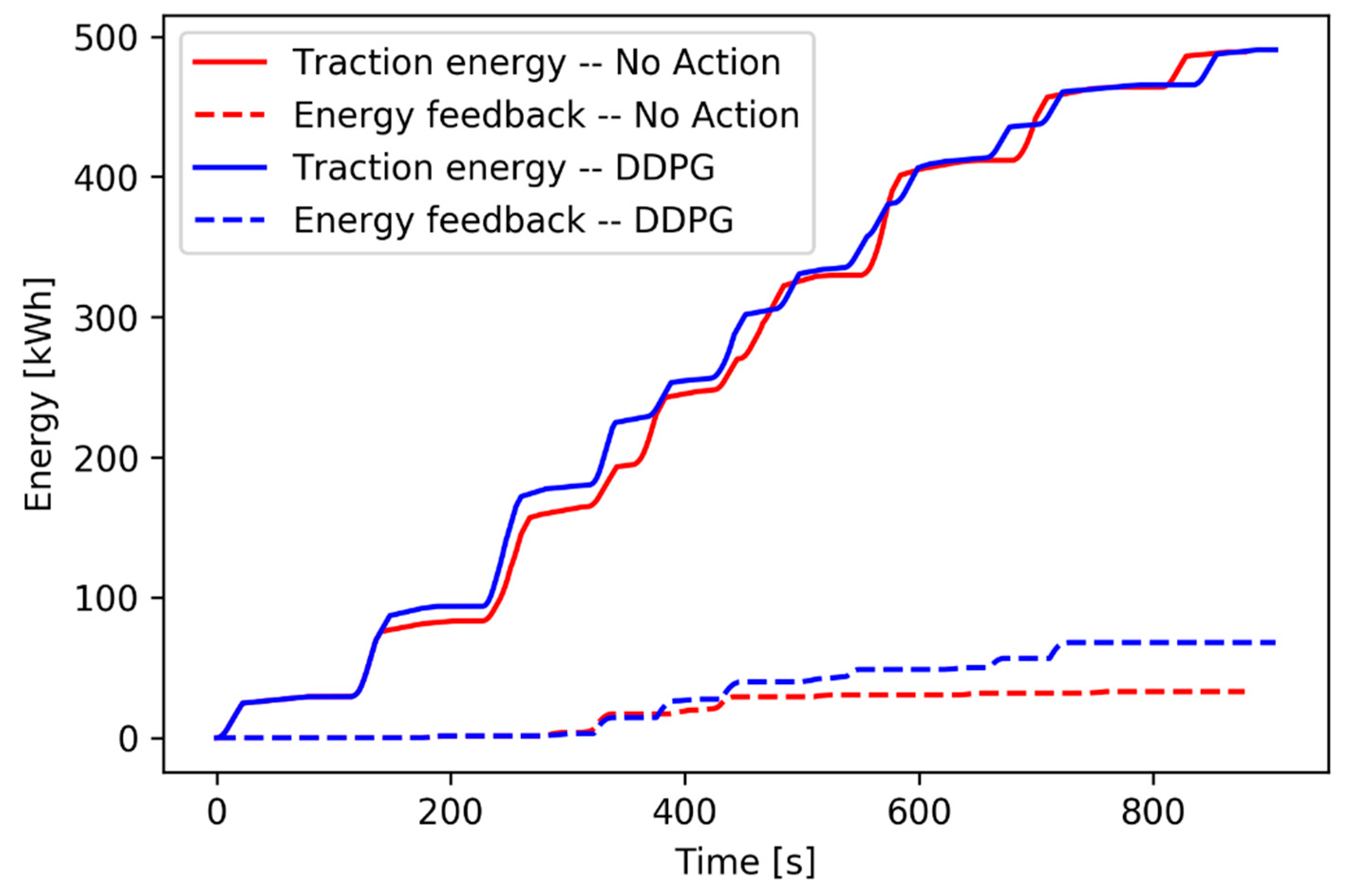
Figure 16 shows the traction energy and the energy feedback under a 13.60 s delay, which indirectly reflects the effects of the reward function in the three-train network.
As shown in
Figure 16, the reward function weights the energy feedback and the traction energy, which forces the agent tending to promote the energy feedback in priority. The blue solid curve shows that DDPG cannot save more traction energy in the three-train network. However, as shown by the dotted lines, this algorithm saves considerable energy on the energy feedback. In terms of total effects, the provided strategy effectively saves more energy in the three-train network.
6. Conclusions
In this paper, a deep deterministic policy gradient algorithm is applied in the energy-aimed timetable rescheduling problem by rescheduling the timetable after disturbances happen and maximizing the regenerative energy from the braking trains. As required by the ETTR problems, DDPG reschedules the timetable in real-time to avoid the chain reactions and saves more energy, and provides a proper cruising speed and dwelling time adaptively under random disturbances.
Superior to the Q-learning algorithm, the observations of DDPG such as the speed and the position of trains are continuous, and the targets such as the cruising speed and the dwelling time are continuous as well. This algorithm can deal with random continuous disturbances, and take continuous action, which is unable to be achieved by the Q-learning algorithm.
GA is suitable for building an offline timetable without disturbances. However, it is not suitable for the ETTR problem for taking too much computation time (4325 s in the above experiment) to obtain an offline timetable for the two-train network. By comparison, DDPG has real-time features for the neural network structure. During the testing episode under the random continuous disturbances, it takes a very short time, ranging from 1.27 ms to 1.99 ms, to choose a pair of proper action.
The proper training mode will improve the performance of DDPG. According to the experimental studies on the Shanghai Metro Line 1, the agent trains under discretely sampling random disturbances, and saves energy from 0.11% to 2.21%. By comparison, the agent performs better after the training under continuously sampling random disturbances, which saves energy from 0.31% to 5.41% in the testing episodes. DDPG can also be used in the three-train network. It takes 2.23 ms on average to obtain a pair of proper action, and the rate of the saving energy ranges from 5.87% to 7.37%.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}