1. Introduction
In the non-fossil policy of modern society, wind energy has become one of the most promising renewable energy sources due to low CO
2 emissions during its entire lifespan, which makes a wind farm a very reliable and efficient choice in windy sites [
1,
2,
3]. Besides the visual aspects, it is noted that the noise impact may represent a major hindrance to new wind farms [
4,
5]. Considering the noise pollution and the wind energy utilization, wind turbines are usually installed in complex territory like hills or mountains under very harsh environmental conditions [
6], and they suffer from changing weather, temperature, random wind speed, wind shear effect, tower shadow effect and severe loads. Moreover, the wind shear and tower shadow effect play a key role in reducing the accuracy of predicting wind speed, which makes wind turbines operate under fluctuating conditions [
7]. All these adverse factors cause wind turbines to encounter failure. To face the challenges associated with wind turbine failure, condition monitoring has developed rapidly to increase the availability and reduce the operations and maintenance costs of wind turbines [
8]. Condition monitoring involves sensors and signal processing equipment to identify the changes in the wind turbine components, predict early faults and schedule the condition-based maintenance in time. The common approaches for the condition monitoring of wind turbines include vibration analysis, acoustics, oil analysis, strain measurement, and thermography [
9].
There are many studies focused on condition monitoring and relevant technological innovations. As vibration analysis is still the most popular approach, many studies have contributed to signal-processing methods for condition monitoring, such as the short-time Fourier transform (STFT), Wigner–Ville distribution (WVD) [
10,
11] and wavelet transform (WT) [
12,
13]. Alternatively, the S-transform is superior in the time-frequency analyses of non-stationary signals, which eliminates the limitations of STFT and WT [
14]. Moreover, the empirical mode decomposition (EMD) method shows excellent performance in non-stationary signal processing due to its local adaptive feature [
15,
16]. Nevertheless, the EMD also has some limits in application due to its recursive calculation and mode-mixing problems [
17,
18]. To overcome the drawbacks of the EMD method, variational mode decomposition (VMD) has been proposed by decomposing a multicomponent signal into a set of intrinsic mode functions (IMFs) [
19], which has been proven beneficial in signal reconstruction and noise reduction [
20]. Among the prior literature, the analysis techniques based on vibration data [
21,
22] have been widely used for condition monitoring. In Ref. [
23], the data analyses for condition monitoring include conventional statistical analyses, trend estimation, physical modeling analyses and machine learning. However, the Supervisory Control and Data Acquisition (SCADA) data analysis yields false alarms [
24,
25] frequently due to the low sampling rate and noisy training data. Additionally, the monitoring data vary over a wide range with the random operational conditions and the weather environment, challenging the model accuracy of condition monitoring systems [
22].
Alternatively, some effort has been invested in data preprocessing to normalize the operational variability. Refs. [
26,
27] incorporate the temperature of the gearbox as a reference parameter to evaluate the health status of wind turbines. By building the energy balance model, the efficiency loss of the turbine output power could be calculated to deliver the fault information. However, the environmental temperature varied with the changes in season and affected the accuracy of the proposed method. To normalize the variable monitoring data, many studies have proposed using a statistical parameter as the indicator feature, such as the average root mean square (RMS) amplitude, extreme value, average deviation, skewness, kurtosis, shape factor, and cross zero rate [
28].
Along with what was discussed above, the selection of the statistical parameter also needs to be taken seriously because the features that carry useful information are beneficial for increasing the computational efficiency and the fault detection accuracy. Many feature selection criteria have been proposed to improve the performance of identification systems. The Wilcoxon rank sum and information gain were adopted and compared in the classification of muscle fatigue using surface electromyography signals [
29]. In Ref. [
30], the Laplacian score (LS) is adopted to refine the fault features that were extracted from the planetary gearboxes under non-stationary working conditions. The selected features were trained in a least square support vector machine. In Ref. [
31], considering the high dimensionality of the extracted original feature, the ReliefF algorithm is used to select optimal features to optimize the support vector machine (SVM) performance. Additionally, genetic algorithms (GAs) have been used to select the input features and the characteristic parameters of the classifiers for bearing fault detection. In general, feature ranking is widely utilized in condition monitoring and fault diagnosis to enhance the accuracy of the classification result and ease the computational burden.
In this article, an alternative methodology for the condition monitoring of roller bearings is proposed to investigate the effectiveness of multifeature fusion under the varying operating conditions of wind turbines. In particular, the vibration signal was decomposed to a set of intrinsic mode functions by VMD. The statistical features of each IMF, which cover the multiscale moments and other commonly used statistical properties of the distribution, are extracted by using the LibXtract library. The Fisher score is adopted to select the effective features. Finally, the selected features are imported into the multi-class classifier. To be specific, the multi-class classifier focuses mainly on multi-class SVM. Meanwhile, an artificial neural network (ANN) is imported as reference for verification. Both the accuracy of the evaluation results and the computational efficiency will be presented. The main contributions of the proposed approach include the following: (1) the bearing detection of CM was performed on a range of fluctuating operating conditions rather than on a certain fixed condition; (2) based on the permutation entropy and Fisher score, the proposed method mitigates the adverse impact of the fluctuating conditions; and (3) experimental investigations were performed to verify the efficiency of the proposed method by presenting the experimental results and the performance analysis.
The remainder of this paper is organized as follows:
Section 2 gives a brief review of the theoretical background.
Section 3 presents the experimental setup and the proposed method of condition monitoring based on feature extraction, selection and classification.
Section 4 presents the experimental description and the analysis, together with the discussion. Finally, the conclusions are presented.
4. Results and Discussion
4.1. Experimental Description
To verify the performance of the proposed method, a scaled-down test-rig was designed and built in a laboratory environment in
Figure 3, which was simulated as an integral system of the wind turbine. Two three-phase asynchronous induction motors were fixed on both ends of the bed. One motor was operated as the mechanical power source under the torque-control mode, while the other was simulated under the speed-control mode as the generator. Both motors were driven by a high-performance motion control system. The controlling torque and speed curves were obtained from the kinetics model of the original wind turbine. In this study, the roller bearing fixed in the gearbox was operated under simulated conditions, such as in wind turbines. Moreover, a data acquisition chassis, a National Instruments cDAQ-9132 (2016, National Instruments, Austin, TX, USA), combined with a NI-9401 digital input/output module and an analog NI-9234 voltage input module, was adopted to collect the operational data. An integral piezoelectric accelerometer was adopted to gather the vibration signal by the NI 9234. The rotational speed and torque signal were acquired by the torque-tachometer connected with the NI-9401. The interface software LabVIEW 2017 was programmed to control the motion and collect the data series. The parameters of the piezoelectric accelerometer were 50 g for the range and 96.7 mV/g for the sensitivity. The frequency response range is from 0.5 Hz to 5 kHz and the excitation current is 2 mA. The corresponding sampling frequency was 2 kHz, and the sampling time was 1 s.
An experimental study was performed to evaluate the effectiveness of the proposed method. Four rolling bearings were set with different fault conditions. The defects in the outer races were introduced as small rectangular slits cut using electro-discharge machining. The rectangular slit is 3 mm wide with 0.1 mm deep, 3 mm wide with 0.2 mm deep and 3 mm wide with 0.4 mm deep. The four different bearings, marked as NM, LF, MF and HF, represented the normal-, low-, medium- and high-fault bearings, respectively. The detail for the experimental bearings is shown in
Table 3. In particular, the rotation speed was set at 700 and 1100 rpm. Meanwhile, the torque of the load motor was set at 0.5 and 2 N·m.
4.2. Permutation Entropy Analysis
As mentioned above, the permutation energy is selected as one of the statistical input features for the classification. However, the permutation energy varied with the different levels of the VMD method. Hence, the determination of the decomposition level is important for feature extraction.
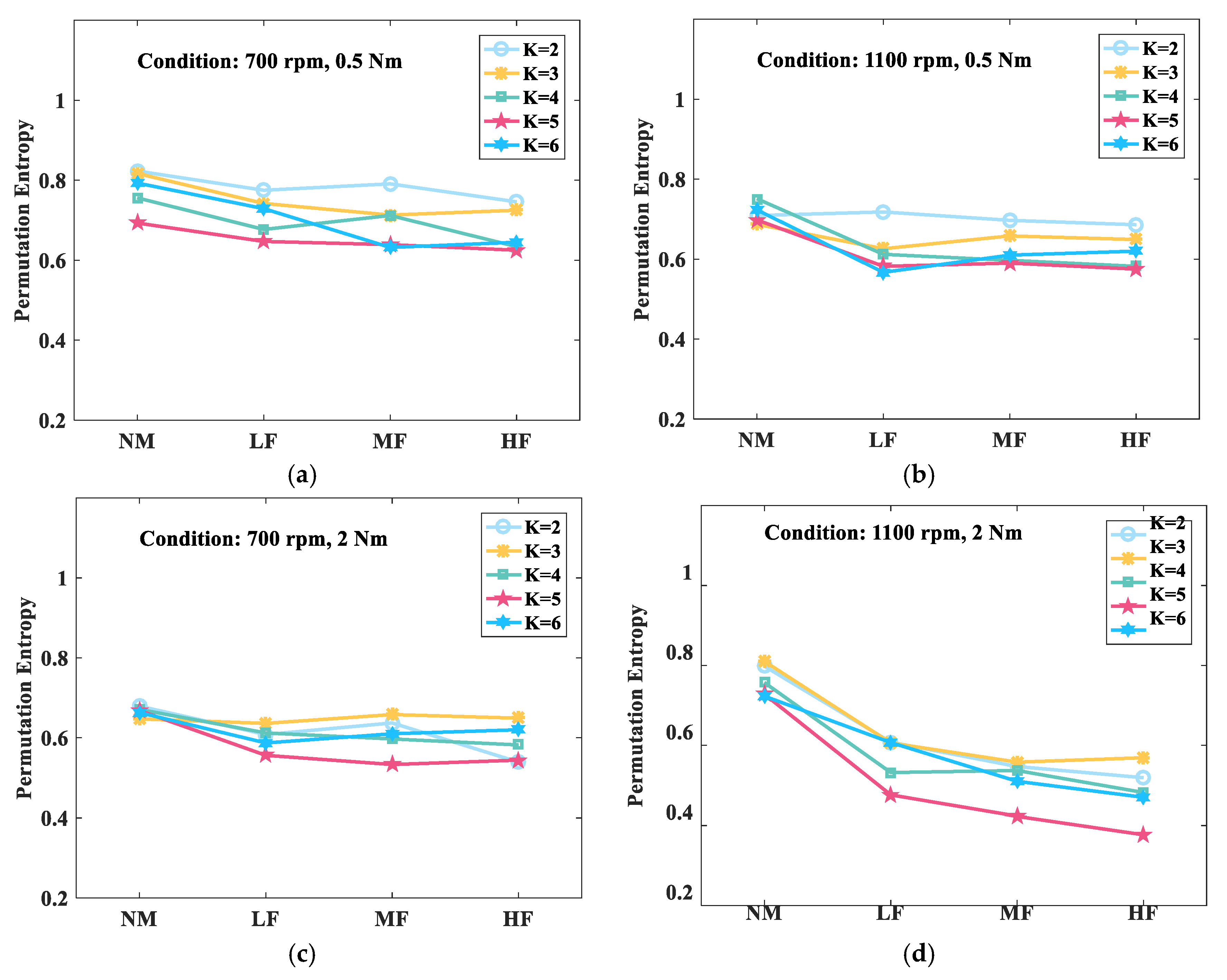
Figure 4 shows the variation result of the permutation entropy with different decomposed levels for the different defective bearings. This figure showed that the fluctuating operating conditions affected the permutation entropy of the worn bearings in the same decomposed levels. To be specific,
Figure 4a–d represents permutation entropy results in four different condition of 700 rpm/0.5 N·m, 1100 rpm/0.5 nm, 700 rpm/2 N·m, and 1100 rpm/2 N·m, correspondingly. For instance, when the decomposed level K was 5, the permutation entropy of the low fault bearing was 0.64 in the operating conditions of 700 rpm and 0.5 N·m. Meanwhile, the entropy value dropped to 0.49 in the operating conditions of 1100 rpm and 2 N·m. In addition, by analyzing the overall trend, the permutation entropy value decreased with the wear status of the bearings. For another instance, when the decomposed level K was 5, the permutation entropy of the bearings in different wear conditions decreased from 0.74 to 0.39, under the operating conditions of 1100 rpm and 2 N·m.
Based on the observation, the following can be concluded: (1) for a specific operating condition, the permutation entropy value exhibited a decreasing trend in the wear status of the bearings; (2) for a specific bearing, the permutation entropy value decreased slowly with an increasing rotation speed and load torque; and (3) the selection of the decomposed level K had an influence on the permutation entropy of the defective bearings.
From the experimental result, it was determined that the permutation entropy had the ability to recognize the wear status of the bearings under fluctuating conditions. Nevertheless, it is noticeable that the permutation entropy did not behave monotonically when the decomposed level K was 2, 3 and 6. As a result, the determination of the decomposed level K was vital during the VMD process. The small number of IMFs resulted in a lack of decomposition while the large number of IMFs led to excessive decomposition. Therefore, the analysis of the permutation entropy not only depends on the wear status of the bearings but also relies on the determination of the VMD level K. Particularly, it should be noted that the condition monitoring based on the entropy analysis alone may lead to inaccurate or even incorrect results. Consequently, the multi-feature fusion will be discussed in detail as follows.
4.3. Multifeature Fusion
Considering the weakness of the single-feature analysis, multi-feature fusion is adopted to evaluate the health condition of the bearings. In the extraction process from the fault information, the feature vectors of the sample sets need to be normalized. Since the elements of feature sets have different units, the numerical value must be normalized. In this paper, the min–max normalization method is imported in Equation (13) as follows, where the
Zi is the normalized result,
Fmax is the maximum data of the vector,
Fmin is the minimum data, respectively.
Then, the feature selection method is applied to filter the redundant features. According to the calculated values of the Fisher score, the highly distinguishable features were sorted from the original vectors, which were then fed into the SVM model for the wearing-status classification. As referred to in Subsection 2.4, the stratified sampling method was employed for the multiclass SVM in this study case, which treated one class at a time as well as other classes combined. By utilizing this method, the negative sample sets were more representative in the training set, guaranteeing that the SVM model is more robust than the traditional random sampling.
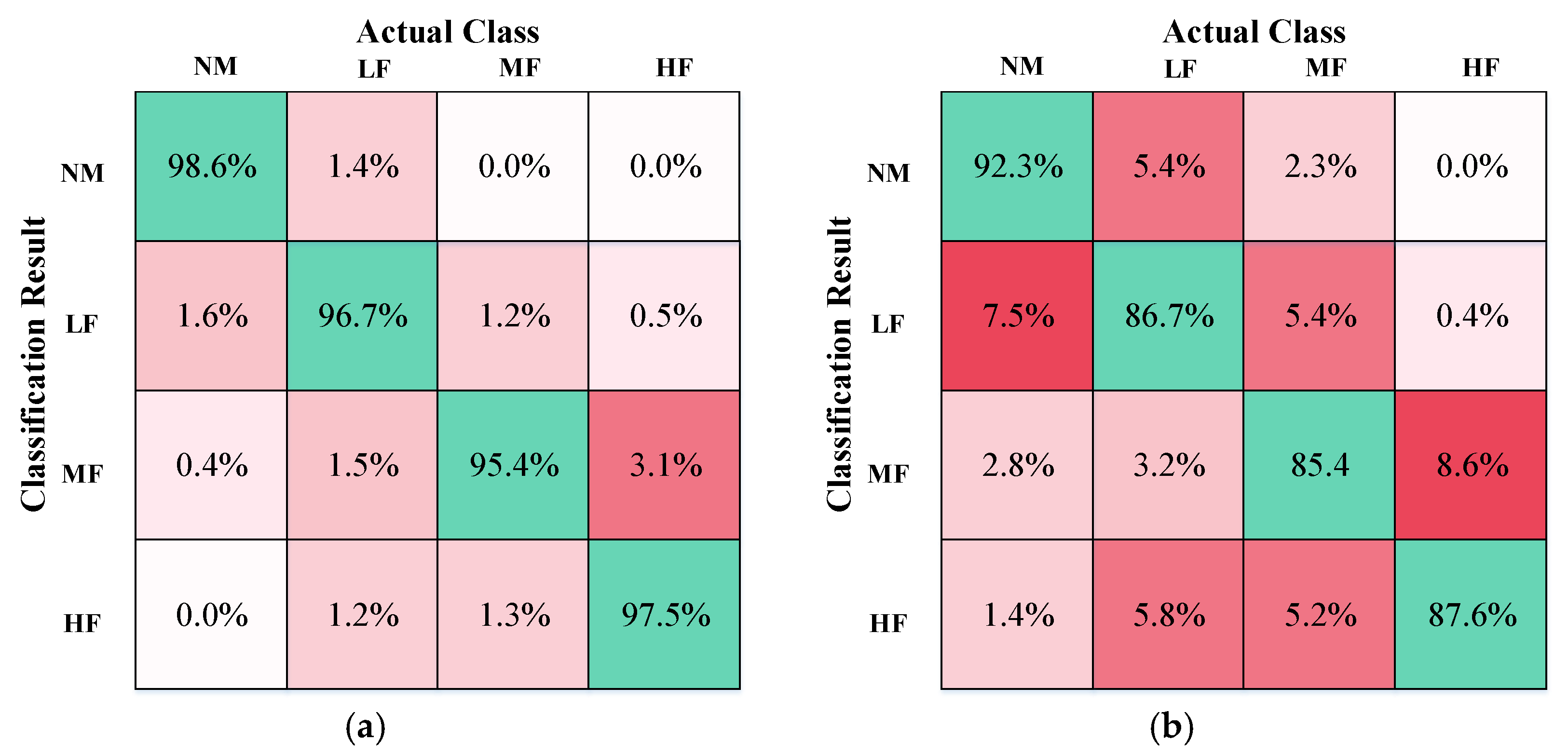
Figure 5a shows the classification results obtained by utilizing the Fisher score method for feature selection.
Figure 5b shows the classification results by adopting all 20 features without optimized selection. As observed from the table of results, the classification accuracy was better by distinguishing the relevant features. Certainly, the computational burden would also be relieved, since the dimensions of the feature vector were reduced. For comparison, the ratio of the samples for the training set to the test set is 1:4. Twenty percent of the sample sets were selected for training, and the other 80% of the sample sets were generated for testing. The final statistical results were calculated for 200 trials.
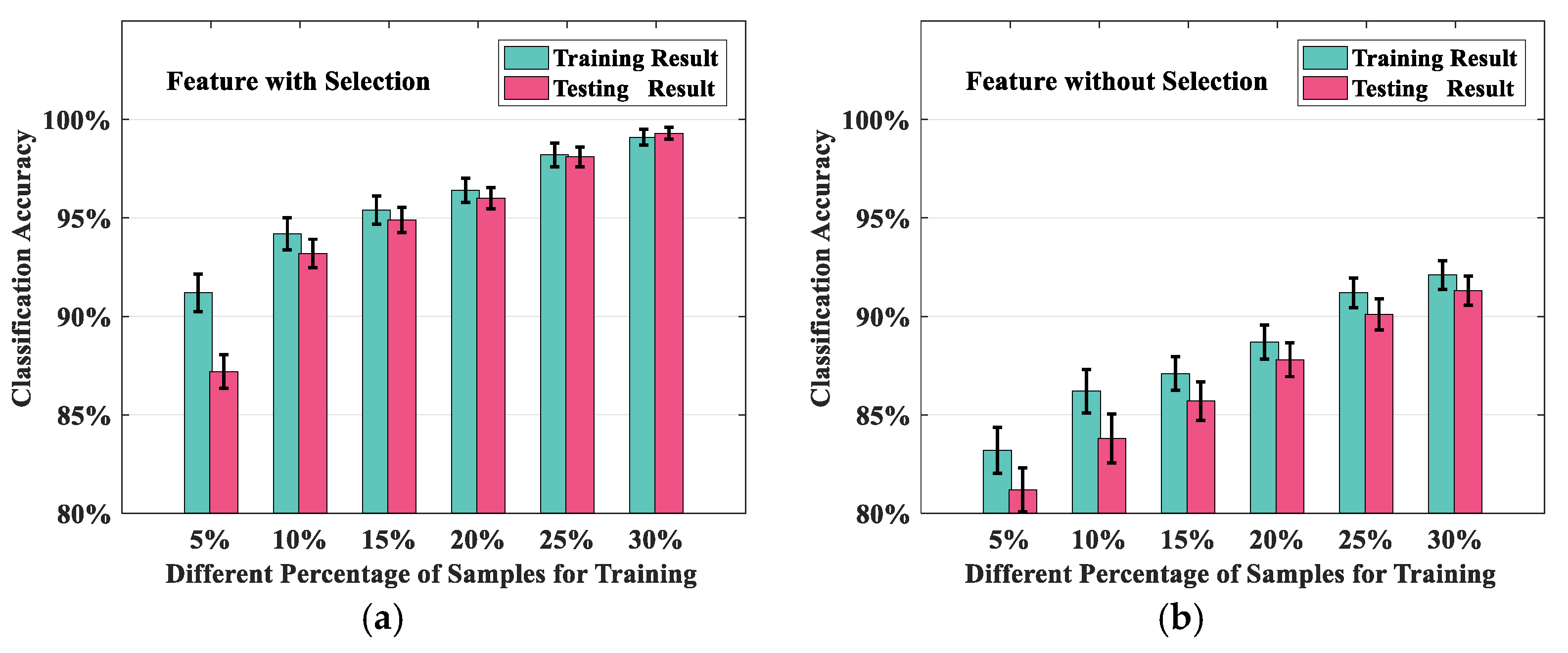
To further investigate the effectiveness of the feature selection, we performed the proposed method by using different ratios of training and testing sets. The percentages for training were increased by 5%, 10%, 15%, 20%, 25% and 30%. To reduce the random effects, 1000 trials were performed for each training set percentage. The samples were obtained and chosen under different operational conditions.
Figure 6a,b shows the error bar graphs from averaging the accuracy values for the training and testing results. The error standard deviations are also marked. In particular, the top 10 features were selected for the classification training. The details of the number of features selected are discussed later in the next paragraph. Comparing
Figure 6a,b, it was observed that the training and test accuracy values with the feature selection was better than the accuracy values without the feature selection. When the training percentage was selected as 5%, the difference between the training and test accuracy values was larger than 5%, which demonstrated that the SVM training model was underfitting. Obviously, for each subfigure, the testing accuracy was enhanced with the increased percentage of the training sets, while the classification error decreased. When the training percentage increased to 30%, the training and test accuracy values were close to those of the feature selection method. However, without feature selection, the training and test results did not achieve consistency regardless of the training set percentages from 5% to 30%. The comparison results verified the necessity of the feature selection process.
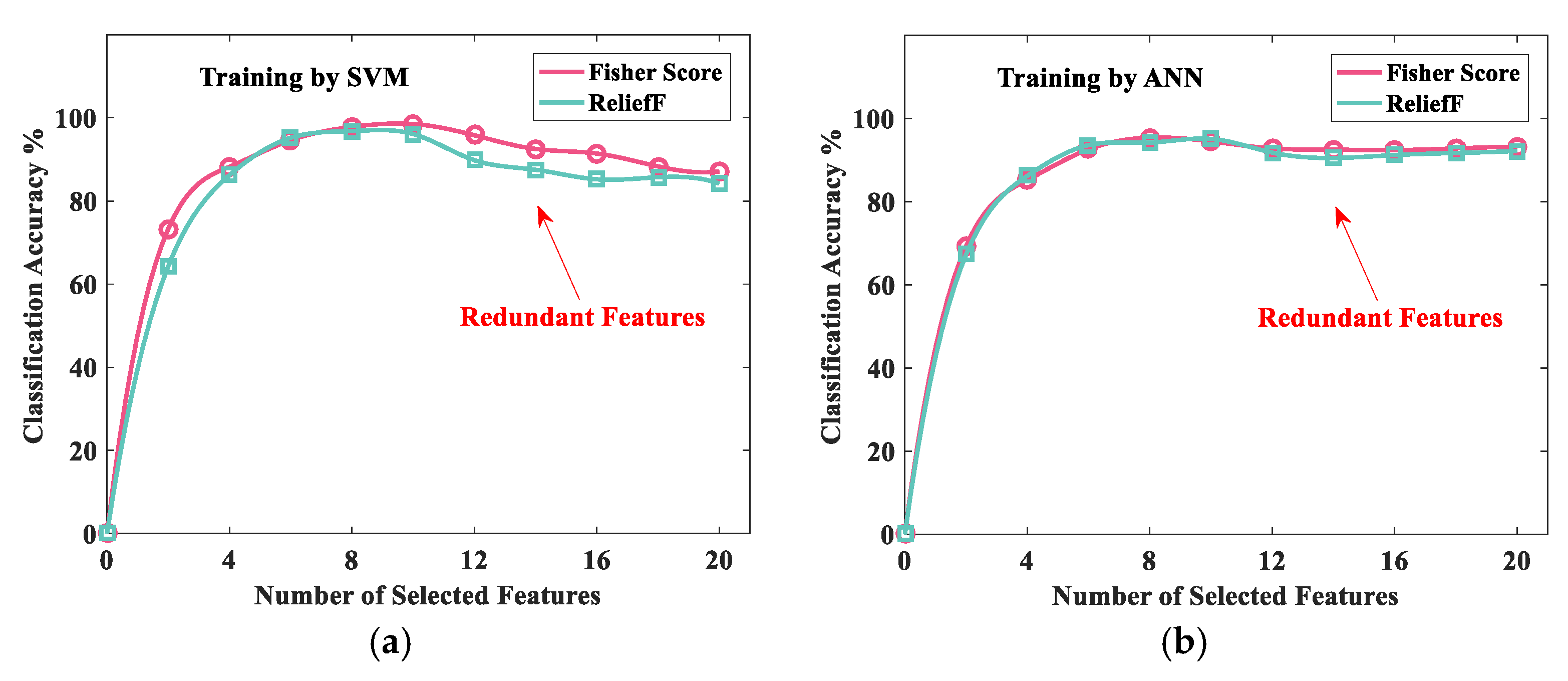
In this case, the SVM and artificial neural network (ANN) classifiers were applied to demonstrate the effect of the number of selected features. The sample sets were partitioned into 10 equal folds, and the tests were performed for 10 iterations. The number of test instances was 1000. The embedded dimension parameter of the permutation entropy was set to 6. The time delay parameter of the permutation entropy was set as 1. For the SVM classifier, the penalty parameter was set to 20, and the radial basis kernel was selected as the kernel function. For the ANN classifier, a topology with 1 hidden layer was constructed. The sensory units of the input layer are fed into the mentioned features including the statistical information in time domain, energy and entropy. In particular, the number of the sensory units is equal with the selected feature. Four neurons are set in the output layer because of the binary coding. Moreover, in our experiment, the best number of neurons is 16. The learning rate was set to 0.3, and the momentum was set to 0.2 for the multilayer perceptron. Two feature-ranking methods, the Fisher score and ReliefF algorithm, were used for the feature selection.
Figure 7 shows the accuracy results by extracting different features through these two methods, where
Figure 7a,b presents training results by SVM model and ANN model, correspondingly. It was observed that the prediction accuracy of the SVM classifier achieved 98.6% when the top 10 ranked features were selected by the Fisher score method. Similarly, the accuracy of the SVM classifier with the ReliefF algorithm reached 97.6% when the classifiers were fed the 10 top-ranked features. The ANN classifier also gave a similar prediction accuracy with the 8 top-ranked features. However, the SVM classifier with the Fisher scoring method showed better performance in identifying defective bearings, particularly in varying operational conditions.
Interestingly, from the accuracy trend obtained, it was noted that the diagnostic accuracy was enhanced at first with the increased number of ranked features. However, once the dimensionality of the feature vectors was larger than the optimized selected number, the identification performance decreased.
4.4. Performance Analysis
In this article, the performance of the proposed method was depicted with the following values: precision for the correctly identified defective bearings,
Pdefect; recall for the correctly identified defective bearings,
Rdefect; precision for the incorrectly identified defective bearings,
Pother; and recall for the incorrectly identified defective bearings,
Rother.
TP represents the number of true positive instances, which means that the defected bearing is identified correctly. FP represents the number of false positive instances, which means that another bearing is identified as the monitored defective bearing incorrectly. FN represents the number of false negative instances, which means that the defected bearing is incorrectly identified as another bearing. TN represents the number of true negative instances, which means that another bearing was correctly identified as the monitored defective bearing. The SVM classifier with the Fisher score method was trained with the training dataset The classification threshold was set to 0.5. The cost values C and
γ of the SVM model were set to 100 and 0.02, respectively. Considering the robustness of the identification of the defective bearings under fluctuating conditions, four datasets were selected to evaluate the performance of the proposed method. Each dataset was obtained in different operational conditions, which are presented in
Table 4 in detail.
The performance of the proposed method on different datasets is summarized in
Table 4. The average results of
Pdefect,
Rdefect,
Pother and
Rother were 96.7%, 93.7%, 92.4% and 98.6% for Dataset I, respectively, under conditions of 700 rpm and 0.5 N·m. For Dataset II, the values were 97.5%, 94.6%, 97.2% and 96.8%, respectively, under conditions of 1100 rpm and 0.5 N·m. For Dataset III, under conditions of 1100 rpm and 0.5 N·m, the results were 96.4%, 94.3%, 95.7% and 98.5%, respectively, and for Dataset IV, the results were 95.2%, 92.9%, 94.5% and 98.9%. From
Table 4, the statistical results show that the proposed method causes low false positives. However, the false negative cases were relatively higher than the false positive cases. This result reflects the fact that the proposed classifier was able to identify the fault level of the defect bearing accurately, avoiding the increase in the false alarm rate.
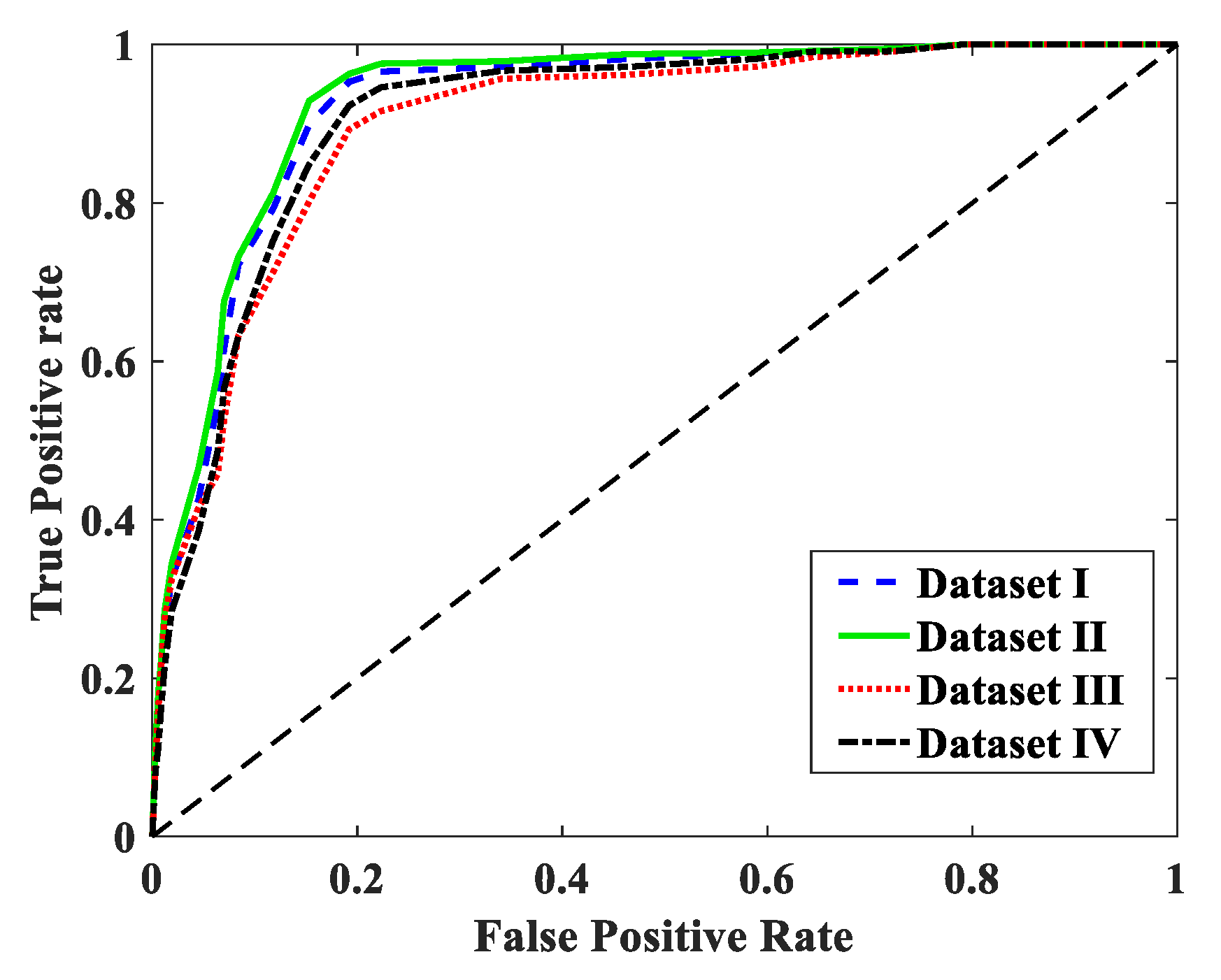
As an evaluation method for the classifier, the receiver operating characteristic (ROC) value has been widely used to depict the tradeoff relationship between the true positive rate and the false positive rate.
Figure 8 shows the four ROC curves to represent the true positive rate versus the false positive rate, which were calculated by a varying the threshold value
θ. The threshold value was varied from 0 to 1 with a step of 0.02. The areas of the four ROC curves were 0.923, 0.931, 0.901 and 0.912, as shown in
Figure 9. To be specific,
Figure 9a showed the ROC value in SVM training model, which is aimed to analyze the classifier performance with different selected features. Meanwhile
Figure 9b shows the ROC value by ANN training model, correspondingly. For the condition monitoring prediction, a large false positive rate would incur a higher cost, due to the unnecessary maintenance for the wind turbine, than would a small true positive rate. Inversely, a small true positive rate would also degrade the usefulness of the condition monitoring system. Observed from the ROC curves, the proposed method has sufficient flexibility to satisfy various requirements, either for the fault-detection sensitivity or specificity.
In addition, as mentioned in
Section 3.1, the selected feature threshold value is very important. In
Figure 7, it can be observed that the top 10 ranked features are proper in Fisher score. Meanwhile the ROC values verify that the top 12 ranked features are proper in Fisher score for SVM model as well as the ANN model. Combined with the selection results in
Figure 1, we choose the Fisher score threshold as 0.3, and the ReliefF threshold as 0.2.
5. Conclusions
This paper presents a new evaluation method for rolling bearings in a fluctuating operational environment. By utilizing the variational mode decomposition, the vibration signal was decomposed to obtain a set of intrinsic mode functions. The statistical approach and the permutation entropy were adopted to extract the corresponding features, which helped to improve the feature extraction capability. Subsequently, feature selection methods, the Fisher score and ReliefF algorithm, were introduced to rank the relevant features based on the scores from high to low. The reconstructed feature vectors were fed into the SVM classifier for training to identify the health condition of the bearings. Several experiments were performed and analyzed to investigate the validity of the proposed method. The conclusions of this research are summarized as follows. The permutation entropy analysis had the ability to recognize the wear status of the bearings under fluctuating conditions. Nevertheless, the determination of the decomposed level K was vital during the VMD process. In particular, it should be noted that condition monitoring based on an entropy analysis alone may lead to inaccurate or even incorrect results. Moreover, the feature selection process is beneficial and vital for the health evaluation of the bearings. By distinguishing the relevant and irrelevant features, both the accuracy of the identification results and the computational efficiency will be improved. In particular, the Fisher score method showed better performance in ranking the relevant features under varying operational conditions. The proposed method can mitigate the adverse impact of fluctuating the wind turbine conditions and permit the identification of the real bearing state more effectively. From the performance analysis, the proposed method showed sufficient flexibility to satisfy various requirements, either for fault-detection sensitivity or specificity.
In future studies, the selection of the VMD parameters will be optimized using information entropy theory rather than in an experiential determination. Additionally, the semisupervised on-line learning method will be utilized to handle the unlabeled data at the training stage in the proposed work.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}