Forecasting of Coal Demand in China Based on Support Vector Machine Optimized by the Improved Gravitational Search Algorithm

Abstract
:1. Introduction
- (1)
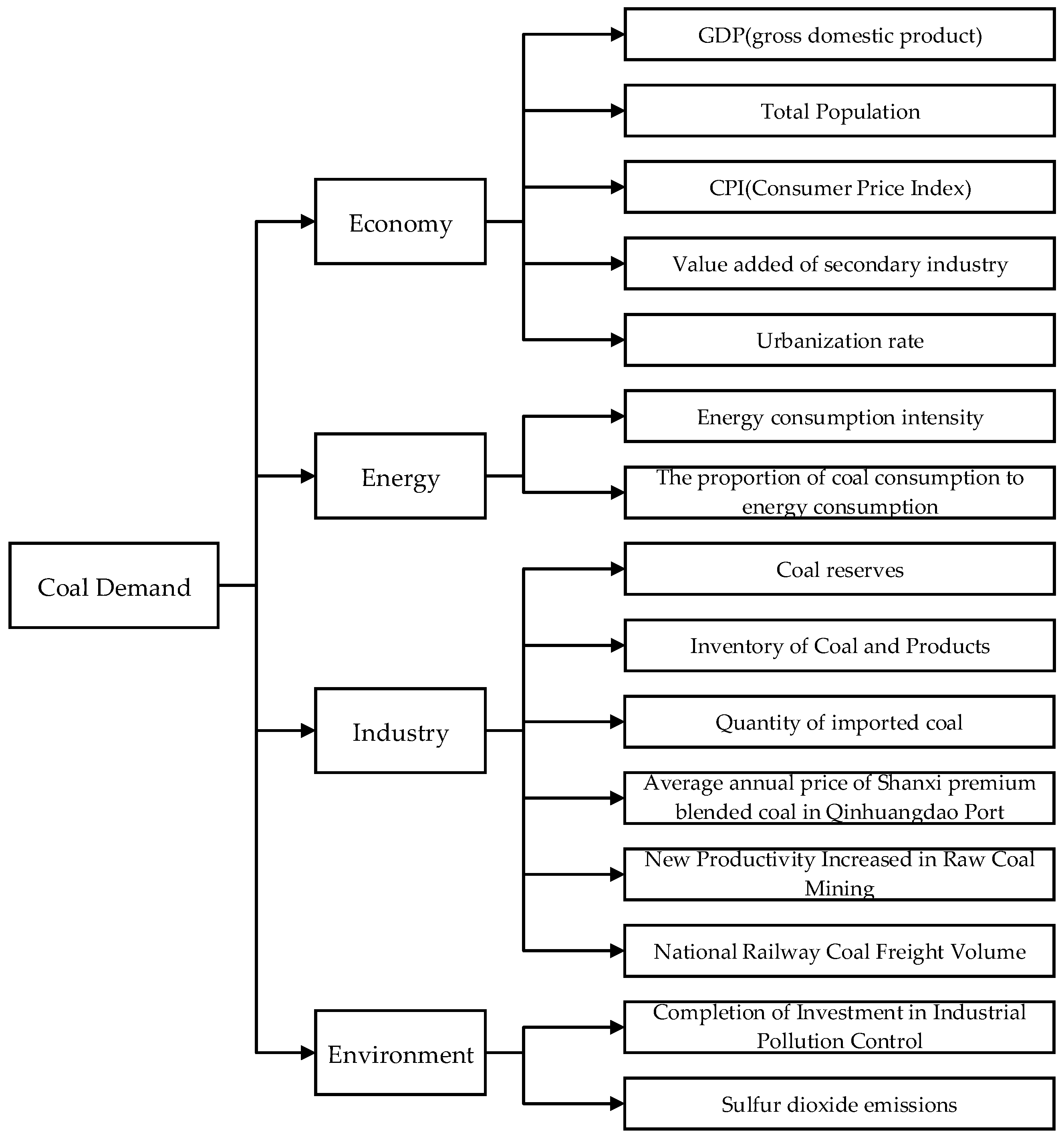
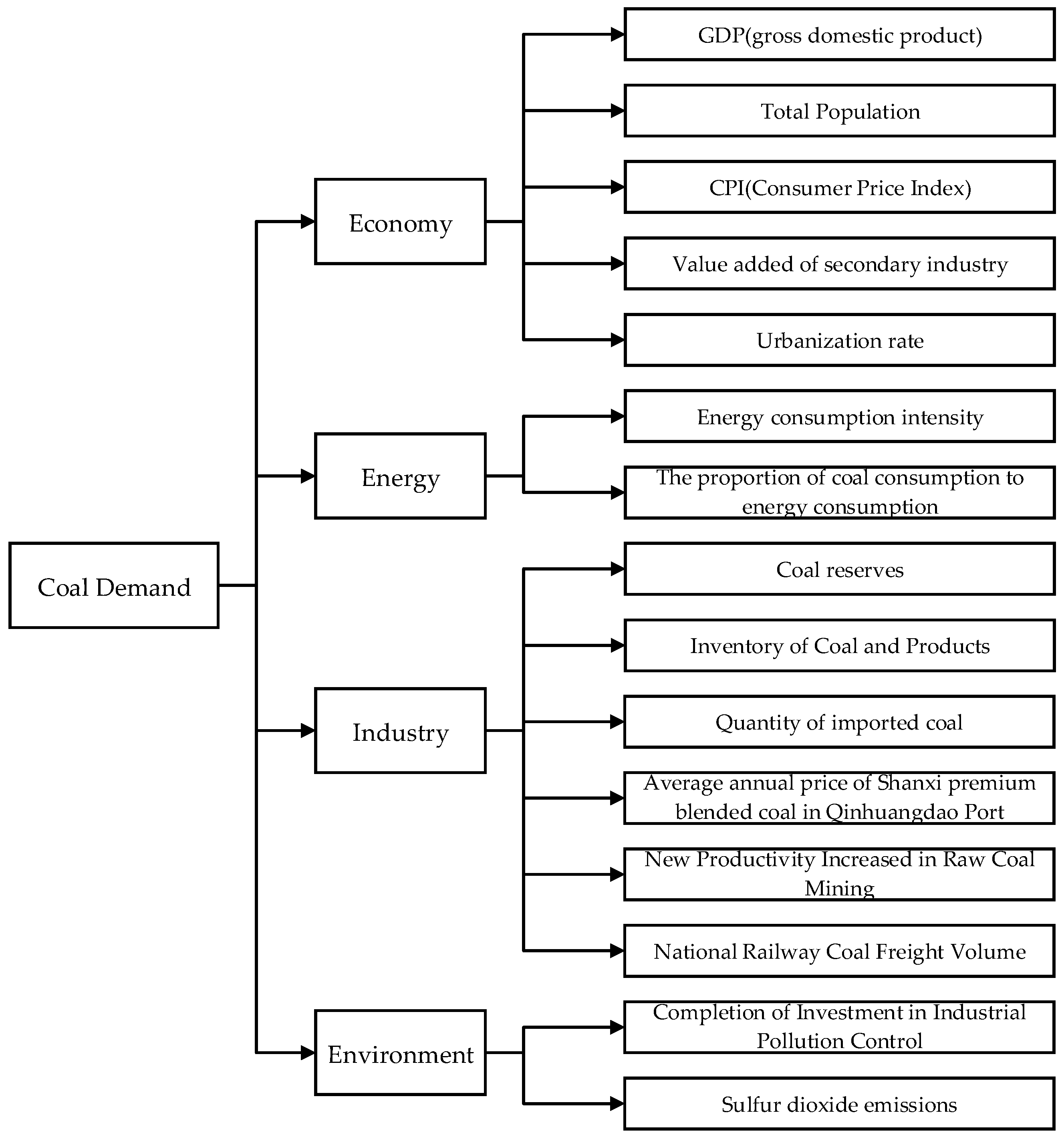
- In the analysis of the influencing factors of coal demand, combined with the actual situation of coal production and consumption, economic, social, and environmental constraints, this paper systematically selected 15 impact indicators from the four dimensions of economy, energy, industry, and environment. The grey correlation method was used to select the key indicators as the input variables of the forecasting model.
- (2)
- Forecasting of coal demand based on the improved gravitational search algorithm–support vector machine (IGSA–SVM). Compared to the traditional optimization algorithm, GSA has the characteristics of fast convergence and strong pioneering performance when optimizing SVM. By introducing the memory function and boundary mutation strategy of particle swarm optimization, it avoids falling into the local optimum when GSA optimizes the parameters of SVM.
2. Relevant Literature Review
2.1. Relevant Research on Coal Demand Forecasting
2.2. Relevant Methods for Energy Demand Forecasting
3. Methods and Models
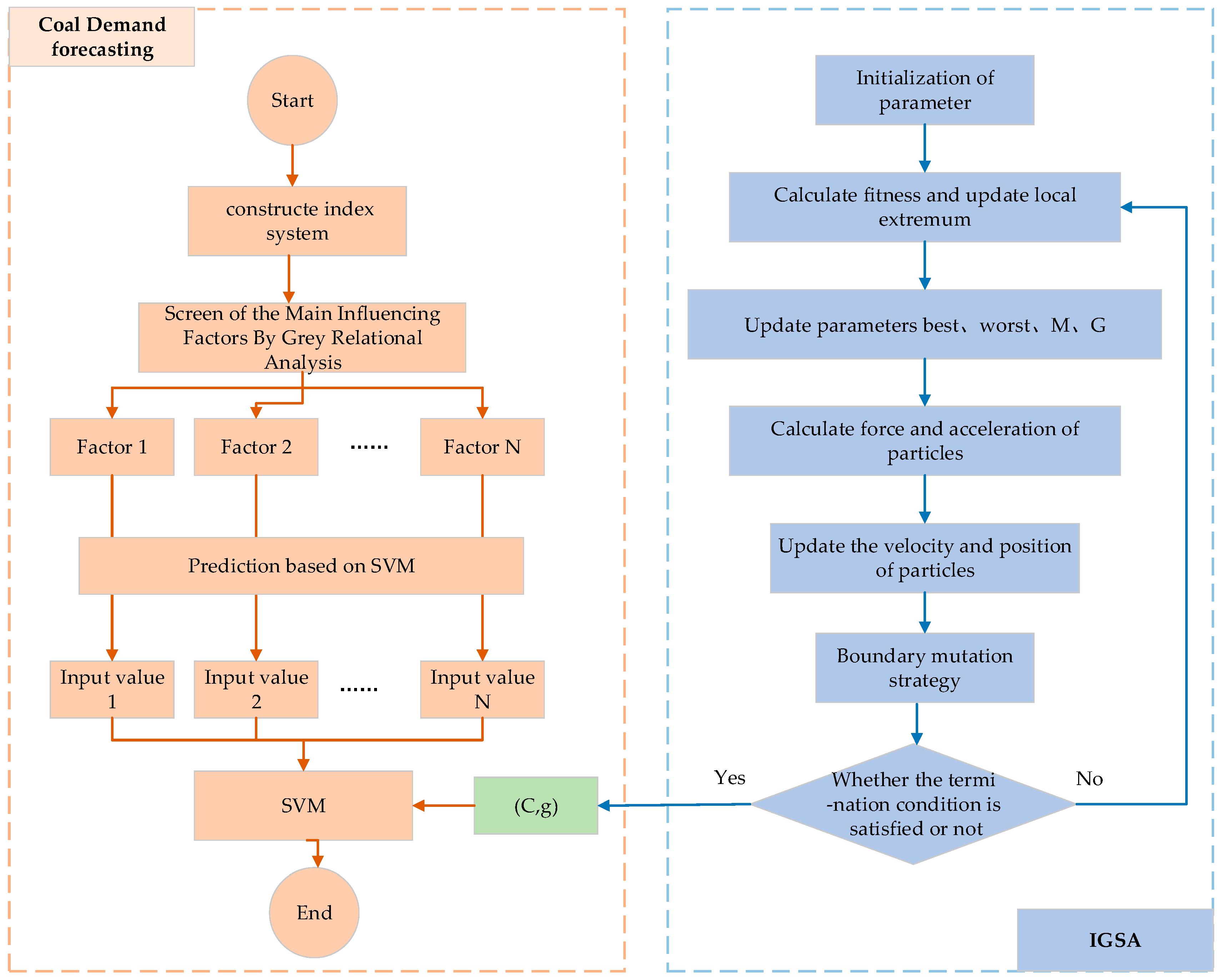
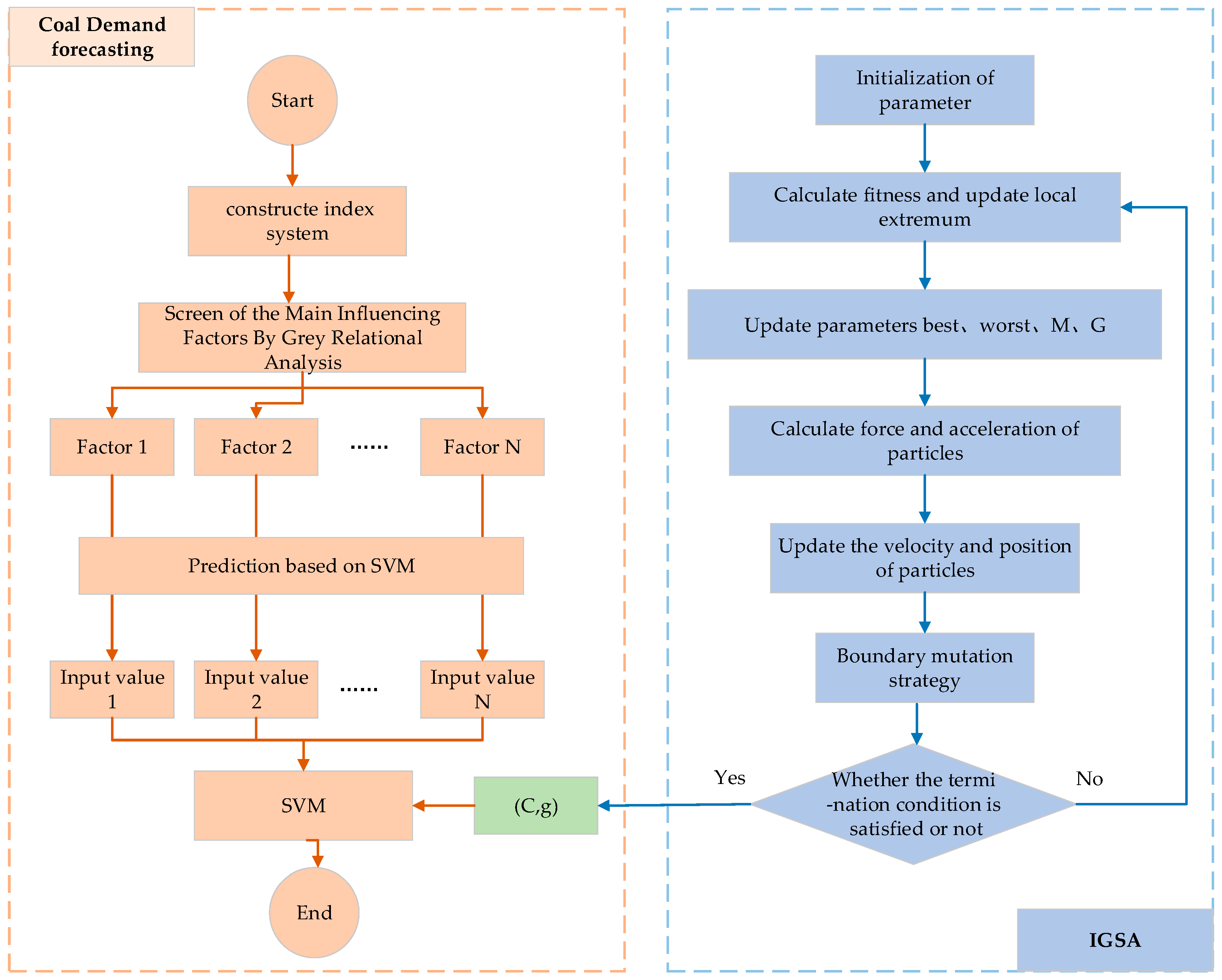
3.1. Screening of the Main Influencing Factors Based on Grey Relational Analysis
3.2. Construction of IGSA–SVM Forecasting Model
3.2.1. Support Vector Machine
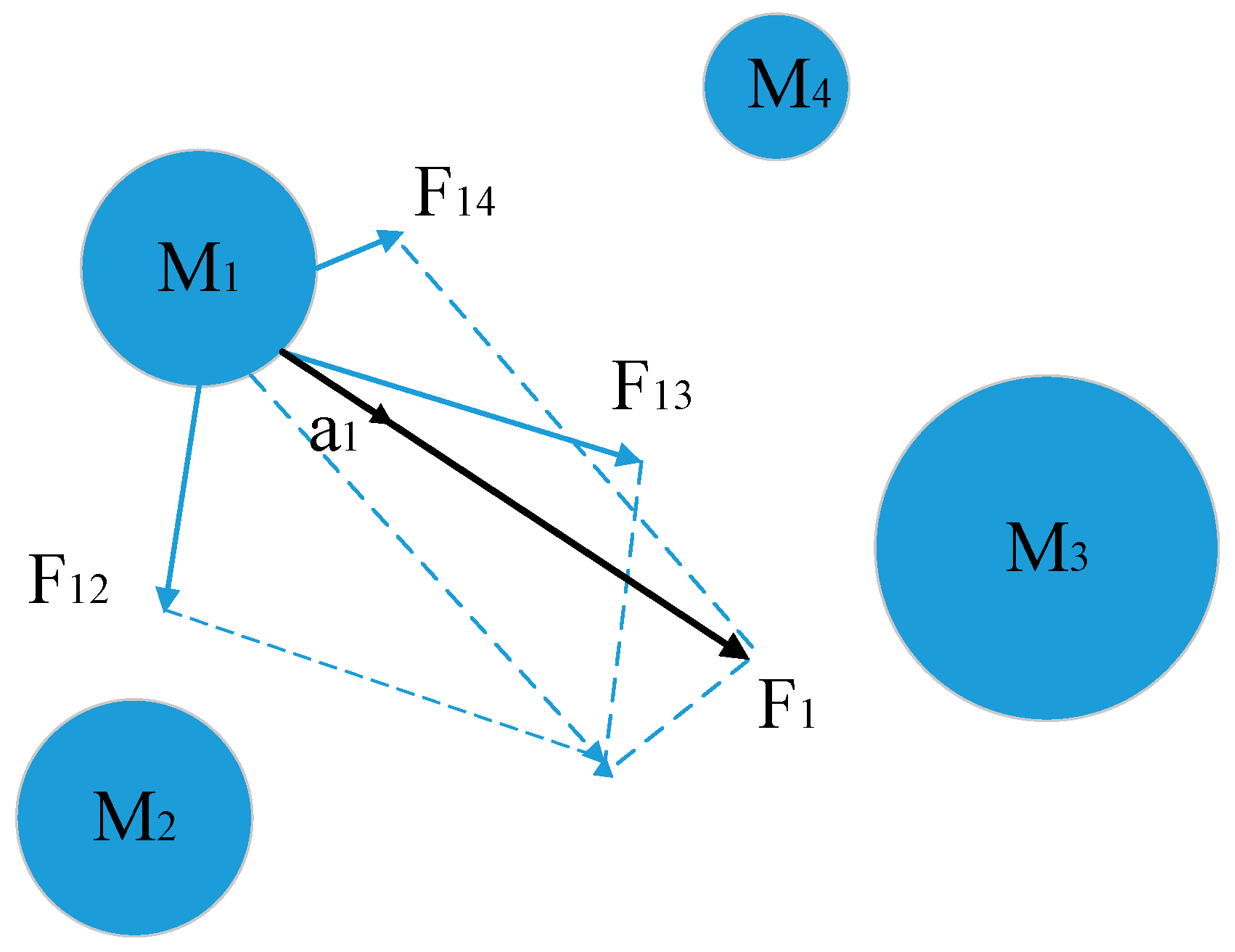
3.2.2. Gravitational Search Algorithm
3.2.3. Improved Gravitational Search Algorithm
3.2.4. IGSA–SVM Forecasting Model
3.3. Forecasting Process
4. Empirical and Comparative Analysis
4.1. Influencing Factor Screening for Model Input
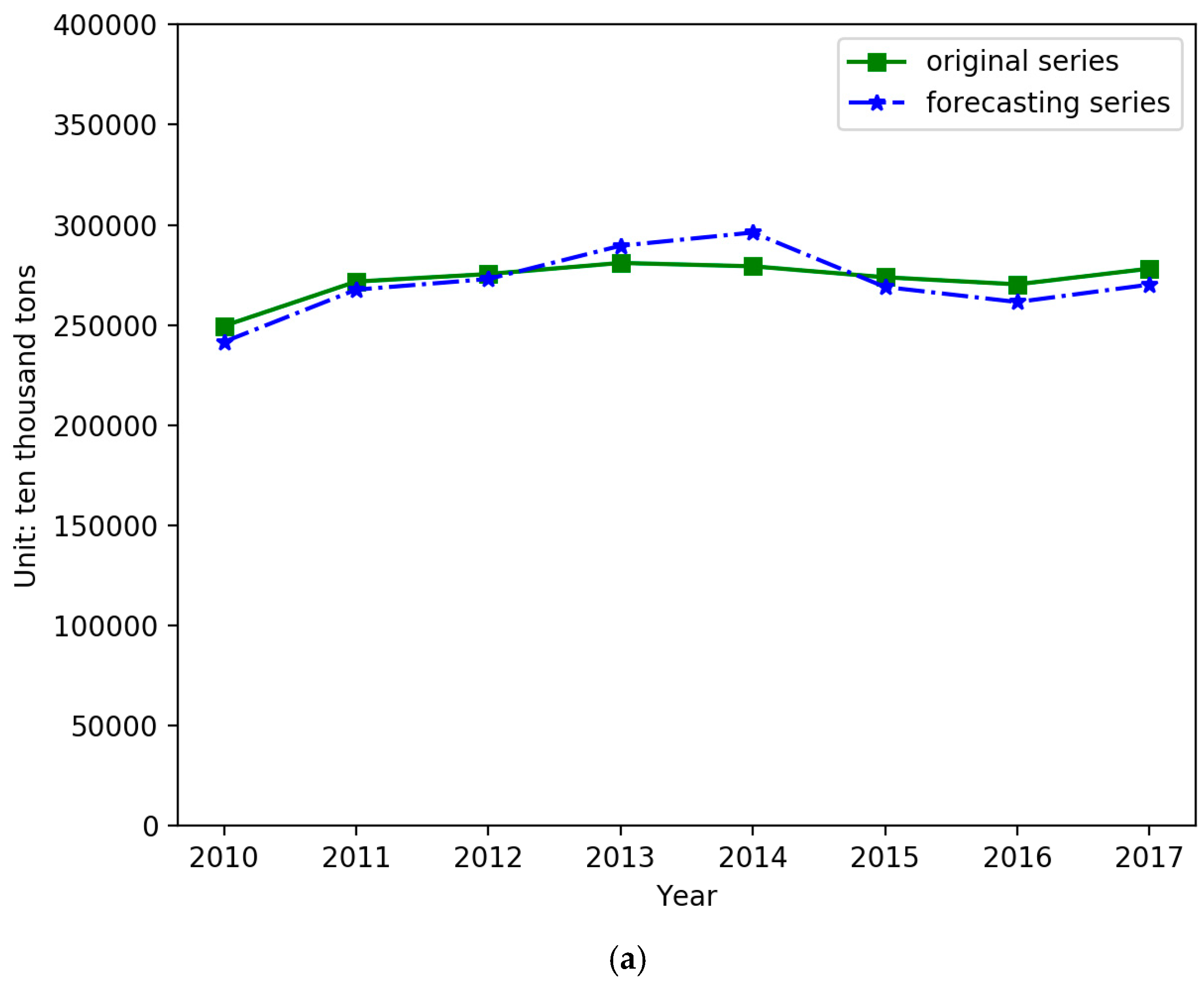
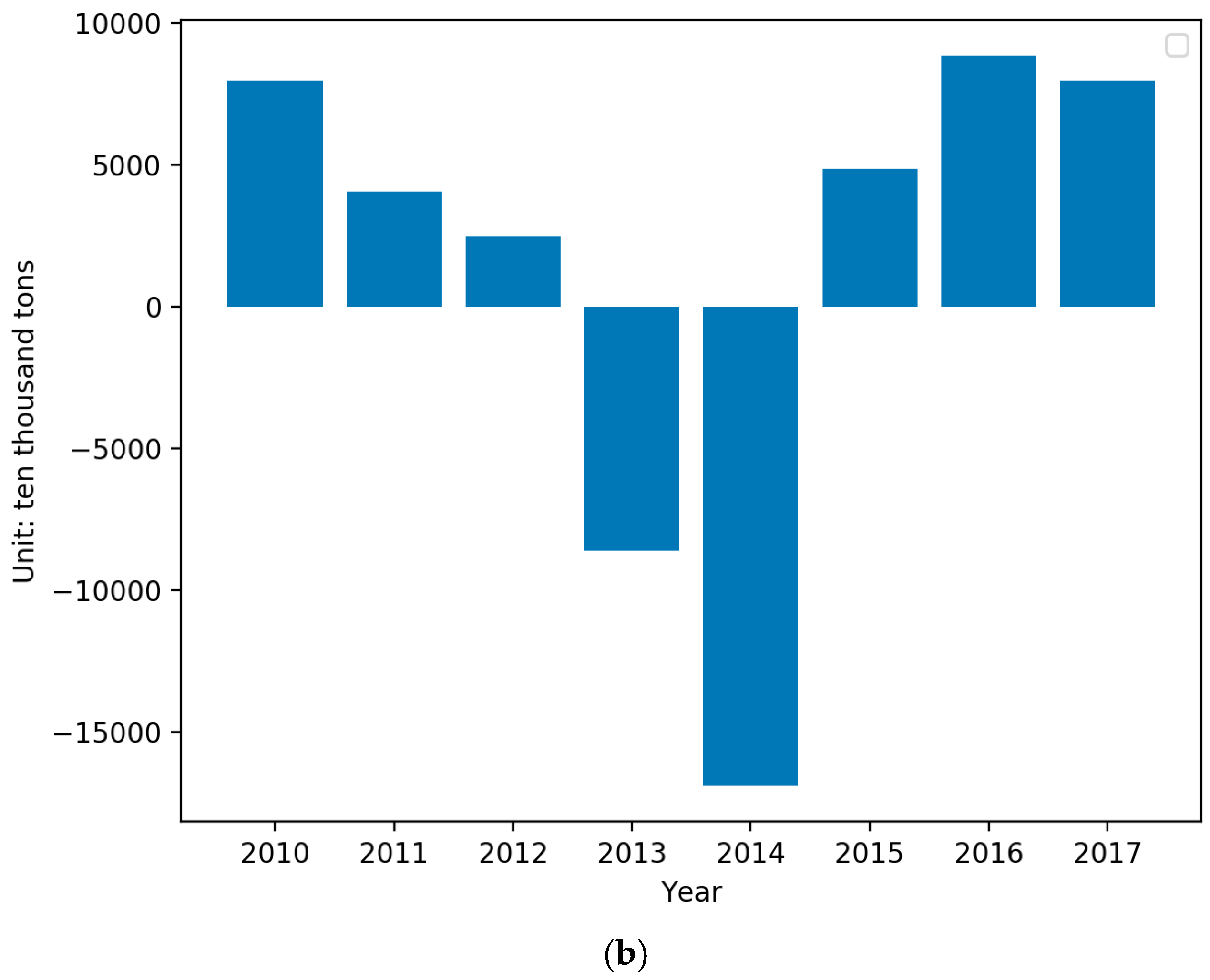
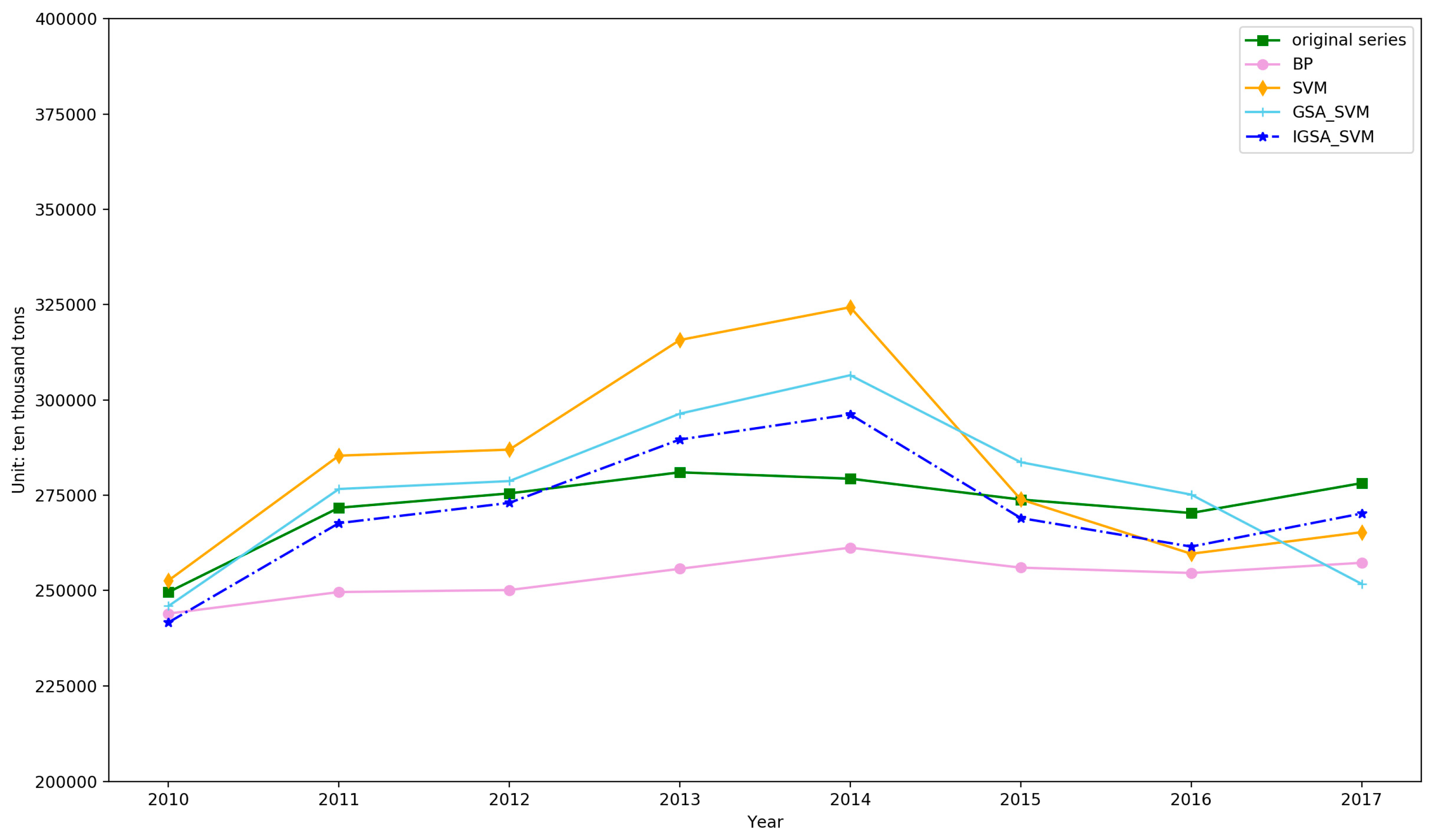
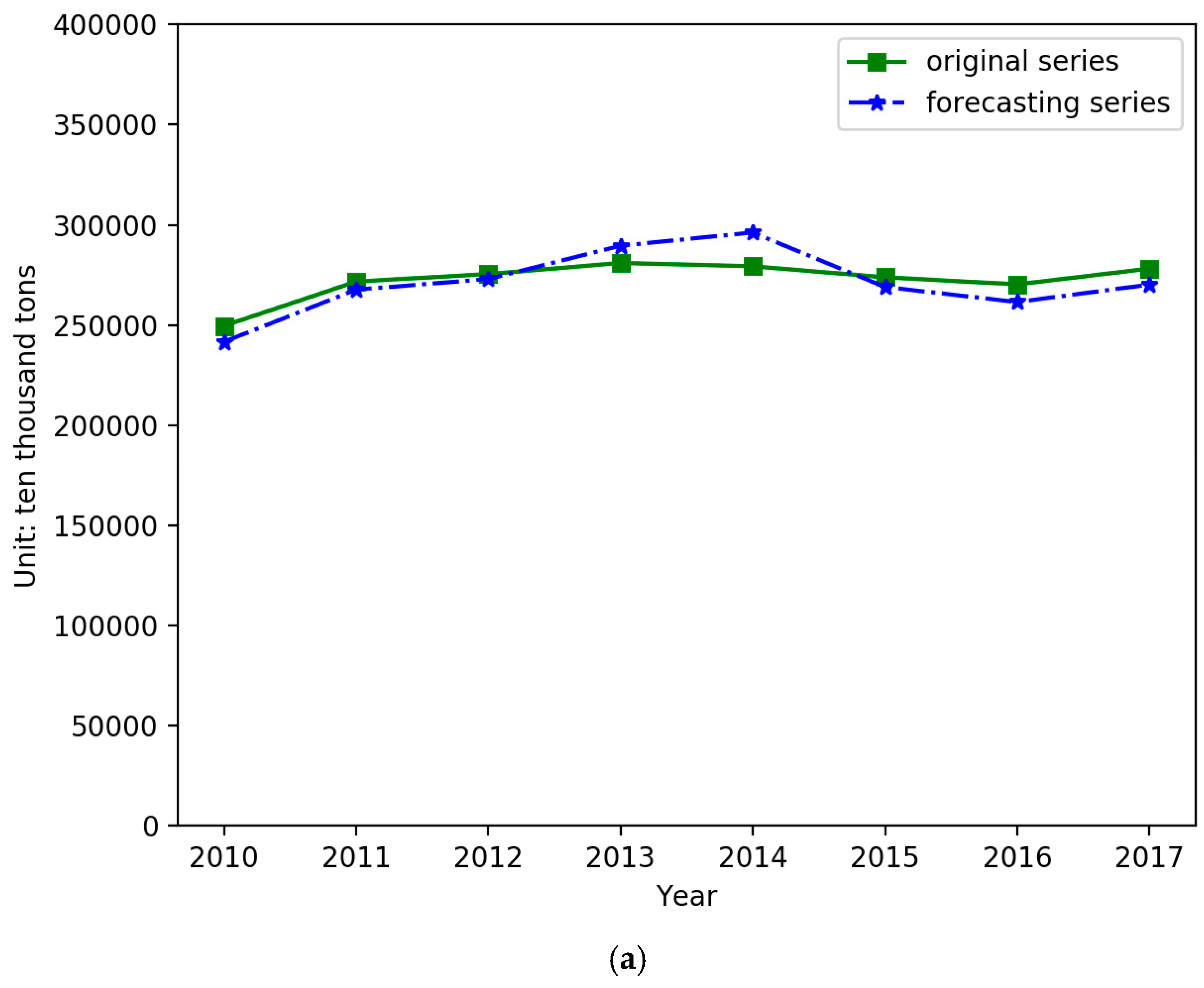
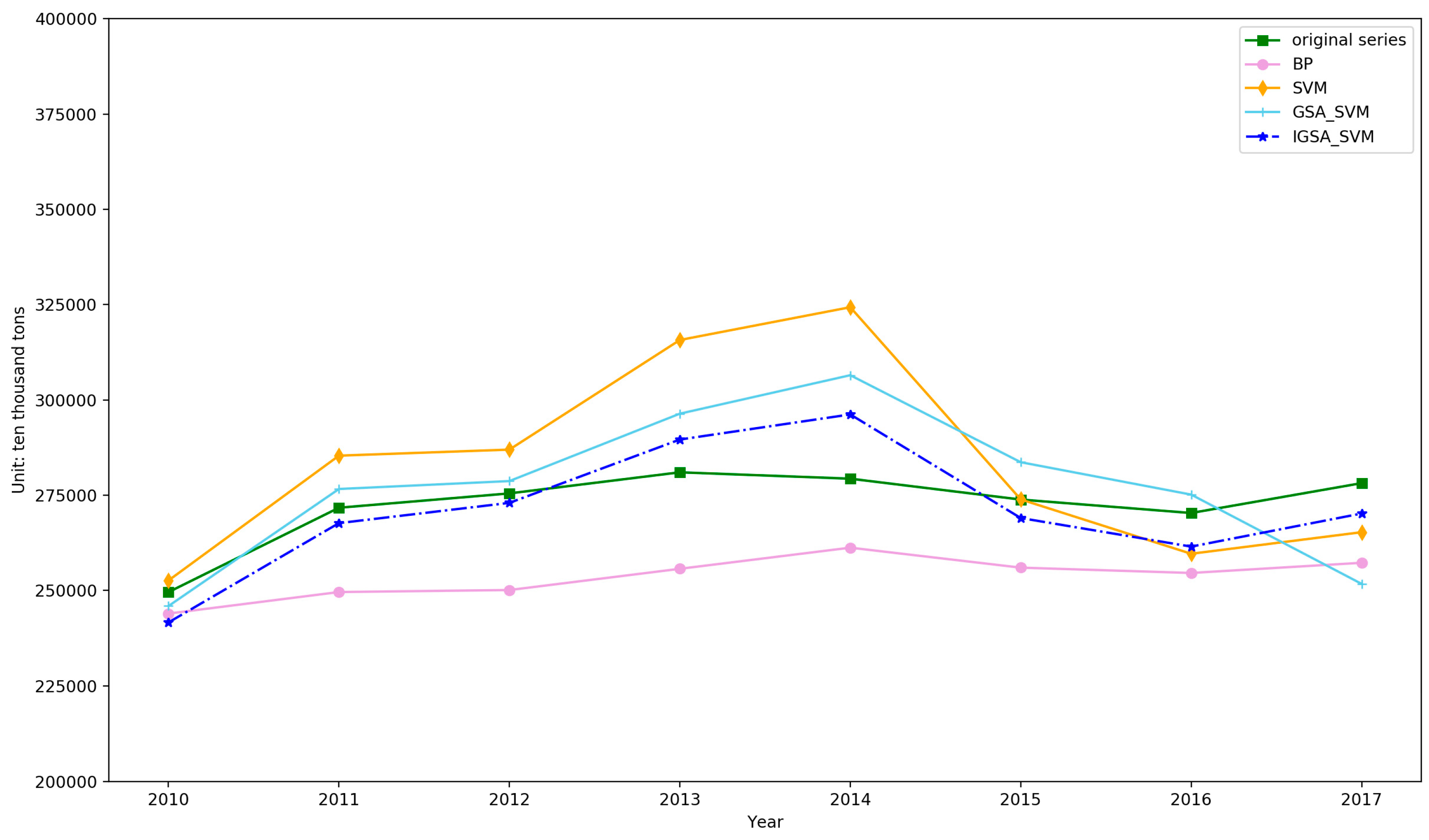
4.2. Forecasting and Comparative Analysis
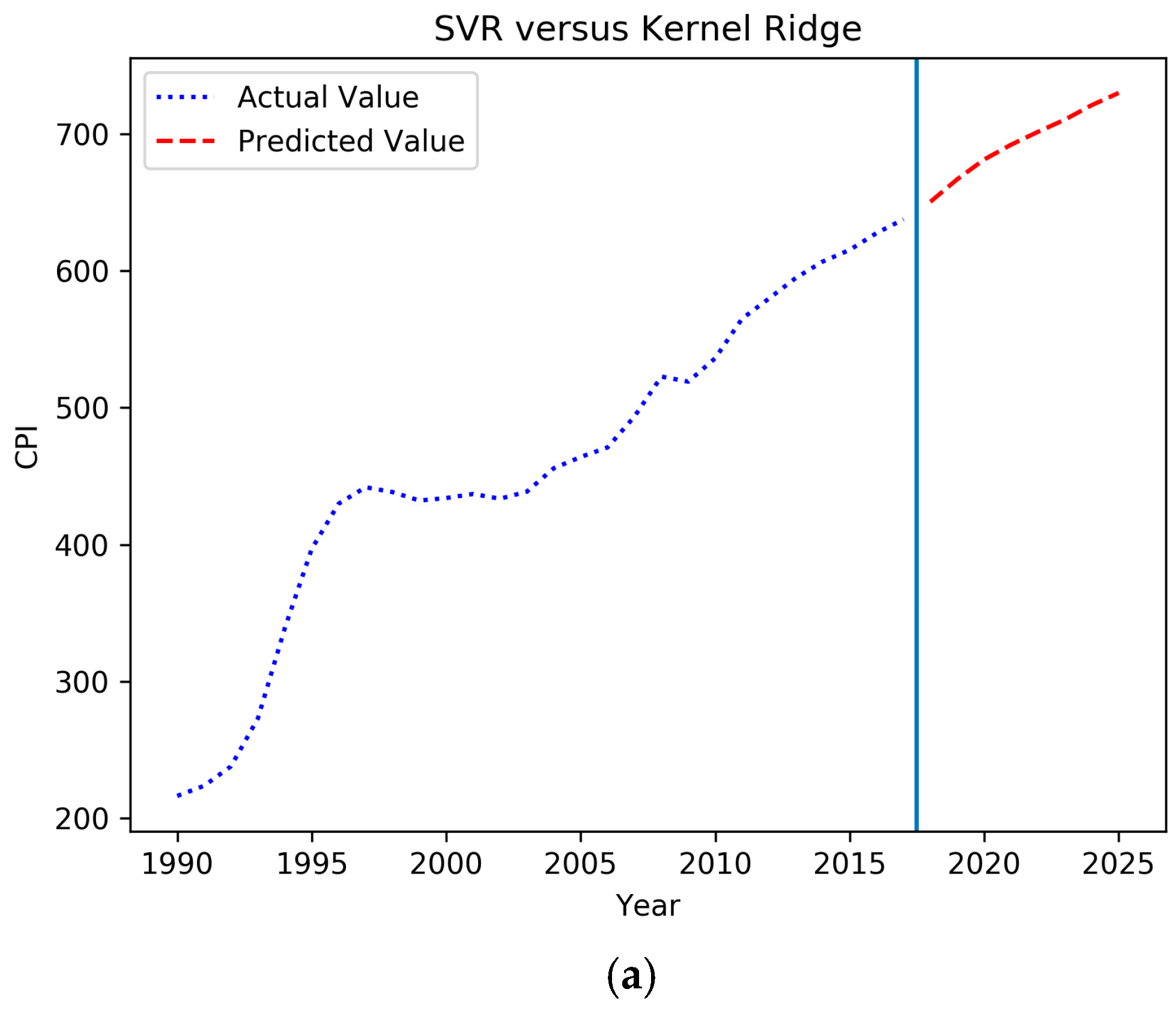
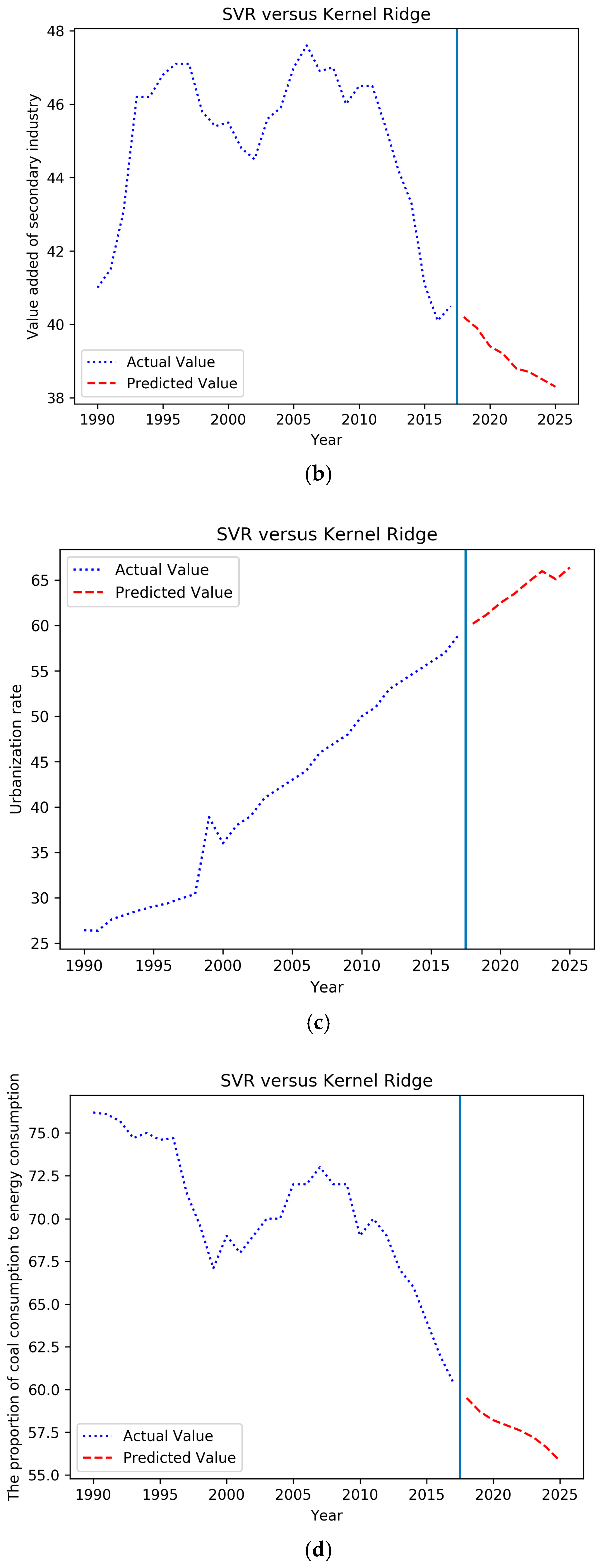
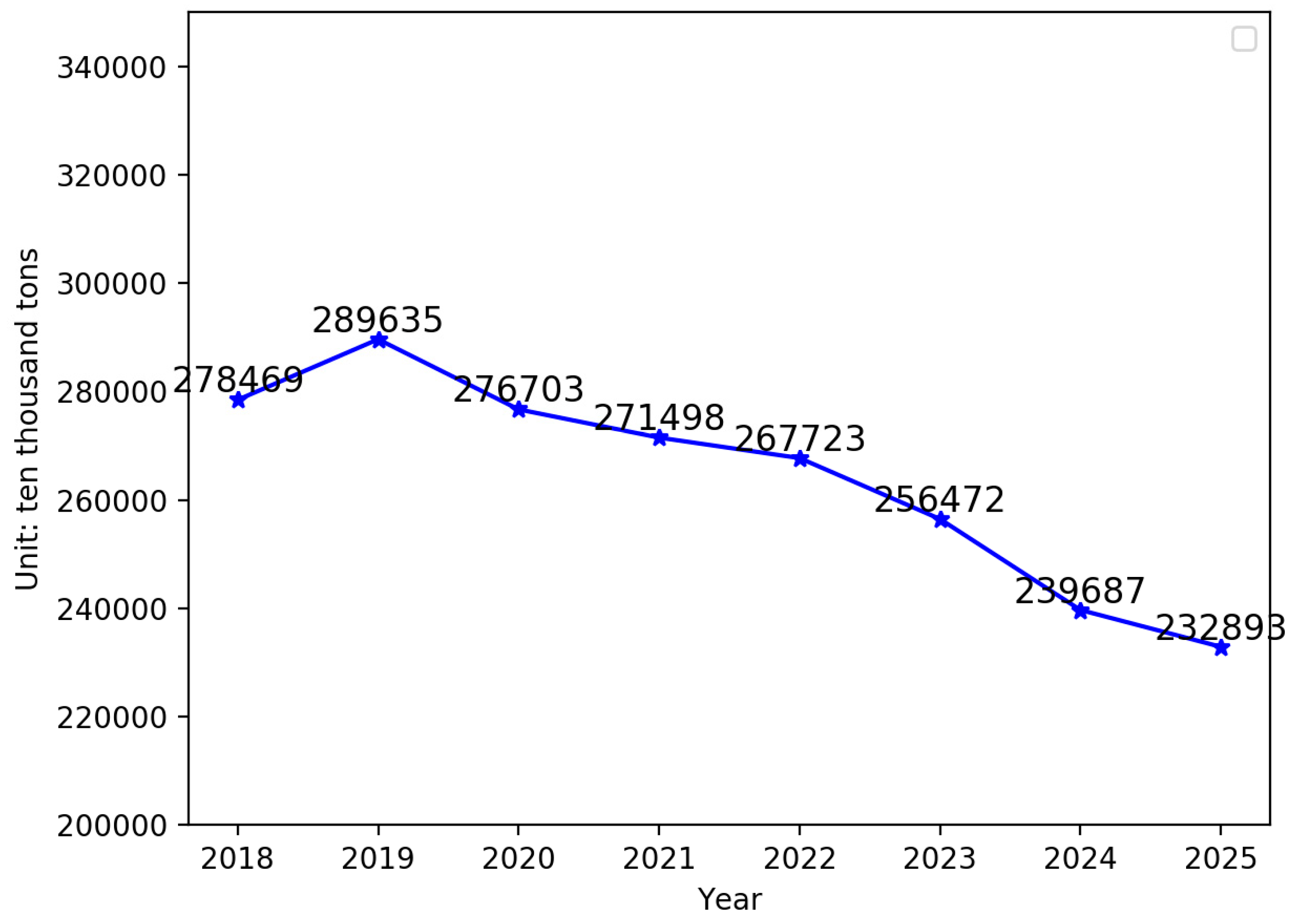
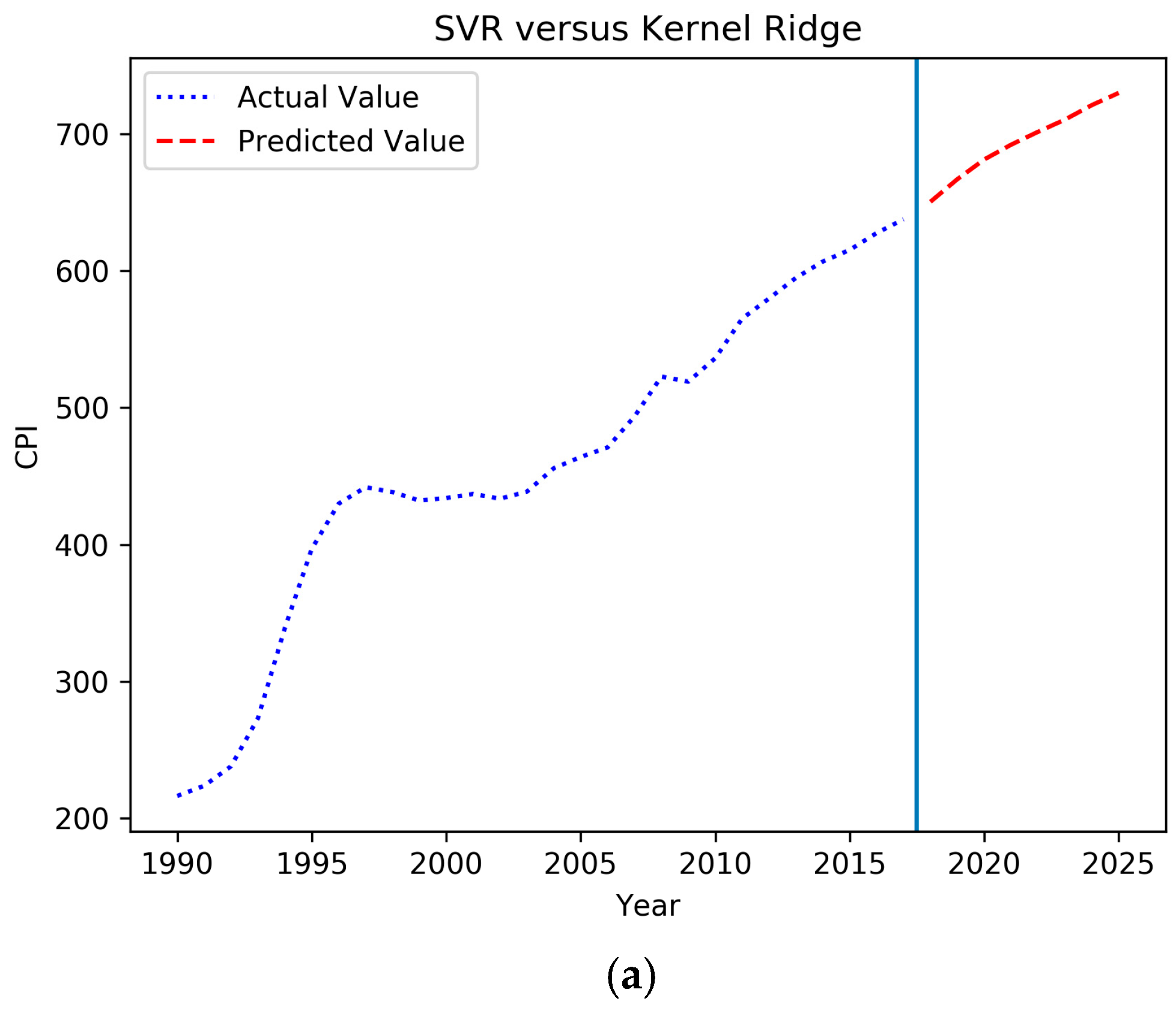
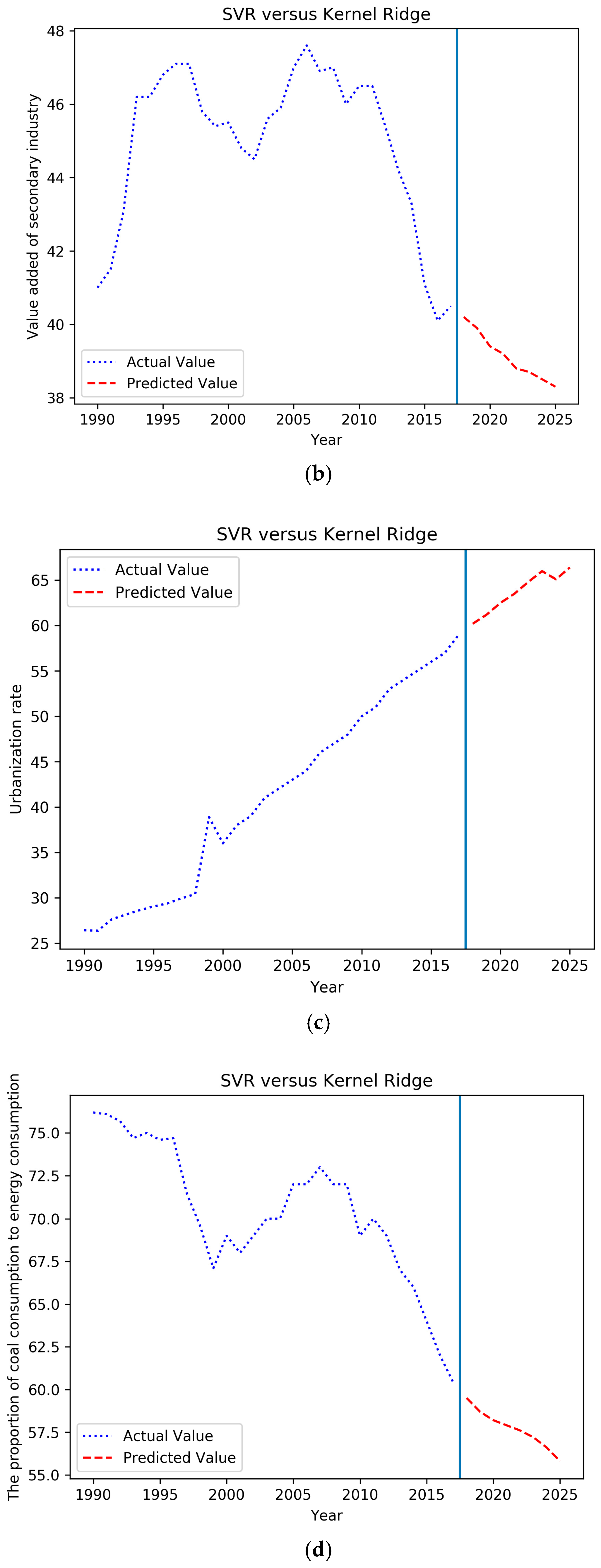
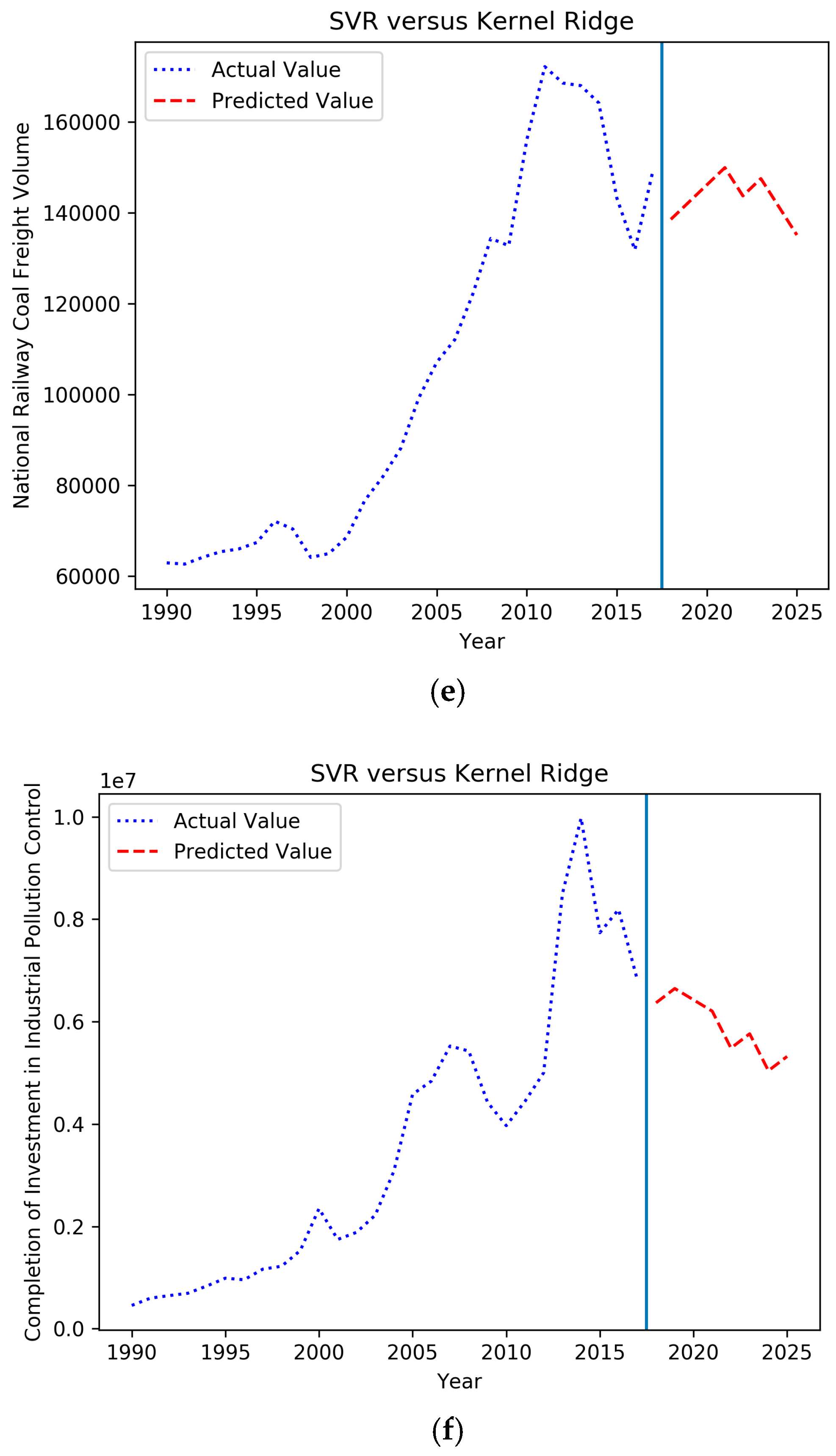
4.3. Forecasting Based on the IGSA–SVM
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shi, D. Current situation and development Suggestions of coal chemical industry. Guangzhou Chem. Ind. 2018, 24, 14–16. [Google Scholar]
- Michieka, N.M.; Fletcher, J. An investigation of the role of China’s urban population on coal consumption. Enery Policy 2012, 48, 668–676. [Google Scholar] [CrossRef]
- Chong, C.; Ma, L.; Li, Z.; Ni, W.; Song, S. Logarithmic mean Divisia index (LMDI) decomposition of coal consumption in China based on the energy allocation diagram of coal flows. Energy 2015, 85, 366–378. [Google Scholar] [CrossRef]
- Kulshreshtha, M.; Parikh, J.K. Modeling demand for coal in India: Vector autoregressive models with ciontegrated variables. Energy 2000, 25, 149–168. [Google Scholar] [CrossRef]
- Lin, B.; Wu, W. Coal demand in China’s current economic development. China Soc. Sci. 2018, 2, 141–161. [Google Scholar]
- Jebaraj, S.; Iniyan, S.; Goic, R. Forecasting of Coal Consumption Using an Artificial Neural Network and Comparison with Various Forecasting Techniques. Energy Sources Part. A Recovery Utilization Environ. Eff. 2011, 33, 1305–1316. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Z.; Chai, J.; Wang, S. Coal demand forecasting model based on consumption structure division. Syst. Eng. 2014, 32, 112–123. (In Chinese) [Google Scholar]
- Hao, Y.; Zhang, Z.Y.; Liao, H.; Wei, Y.M. China’s farewell to coal: A forecast of coal consumption through 2020. Energy Policy 2015, 86, 444–455. [Google Scholar] [CrossRef]
- Yawei, O.; Li, O. A forecast of coal demand based on the simultaneous equations model. In Proceedings of the 2011 IEEE International Symposium on IT in Medicine and Education, Cuangzhou, China, 9–11 December 2012. [Google Scholar]
- Wang, Y.; Li, X. The influence of renewable energy power generation development on coal demand. J. North. China Electr. Power Univ. (Soc. Sci. Ed.) 2014, 5, 13–16. [Google Scholar]
- Wang, Y.; Chen, X.; Han, Y. Forecast of Passenger and Freight Traffic Volume based on Elasticity Coefficient Method and Grey Model. Proced. Soc. Behav. Sci. 2013, 96, 136–147. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Y.; Zou, J.; Liu, L. Energy profile model based on multiple linear regression analysis. China High.-tech Zone 2018, 13, 52. [Google Scholar]
- Tsekouras, G.J.; Dialynas, E.N.; Hatziargyriou, N.D. A non-linear multivariable regression model for midterm energy forecasting of power systems. Electr. Power Syst. Res. 2007, 77, 1560–1568. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, G.; Wang, Y. Research on China’s energy consumption combination forecasting model based on Shapley value. Energy Eng. 2012, 6, 5–9. [Google Scholar]
- Chi, K.C.; Nuttall, W.J.; Reiner, D.M. Dynamics of the UK natural gas industry: System dynamics modelling and long-term energy policy analysis. Technol. Forecast. Soc. Chang. 2009, 76, 339–357. [Google Scholar] [Green Version]
- Kou, A.; Zhou, W.; Hu, Q. GM (1,1) Model for Forecasting and Analysis of China’s Energy Consumption. China Market. 2018, 16, 15–16. [Google Scholar]
- Zhang, J.; Yao, Z.; Xu, X.; Nan, Y. Coal demand forecasting based on Grey GM (1,1) model. J. North. China Inst. Sci. Technol. 2016, 13, 106–108. (In Chinese) [Google Scholar]
- Khotanzad, A.; Afkhami-Rohani, R.; Maratukulam, D. ANNSTLF-artificial neural network short-term load forecaster-generation three. IEEE Trans. Power Syst. 1998, 13, 1413–1422. [Google Scholar] [CrossRef]
- De, G.; Gao, W. Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method. Energies 2018, 11, 2938. [Google Scholar] [CrossRef]
- Xie, M.; Deng, J.; Liang, J. Cooling load forecasting method based on support vector machine optimized with entropy and variable accuracy roughness set. Power Syst. Technol. 2017, 41, 210–214. [Google Scholar]
- Dai, S.; Niu, D.; Han, Y. Forecasting of Energy-Related CO2 Emissions in China Based on GM (1,1) and Least Squares Support Vector Machine Optimized by Modified Shuffled Frog Leaping Algorithm for Sustainability. Sustainability 2018, 10, 958. [Google Scholar] [CrossRef]
- Damrongkulkamjorn, P.; Churueang, P. Monthly energy forecasting using decomposition method with application of seasonal ARIMA. In Proceedings of the 2005 International Power Engineering Conference, Singapore, 29 November–2 December 2005. [Google Scholar]
- Li, T.; Hu, Z.; Jia, Y.; Wu, J.; Zhou, Y. Forecasting Crude Oil Prices Using Ensemble Empirical Mode Decomposition and Sparse Bayesian Learning. Energies 2018, 11, 1882. [Google Scholar] [CrossRef]
- Liu, X.; Mao, G.; Ren, J.; Li, R.Y.M.; Guo, J.; Zhang, L. How might China achieve its 2020 emissions target? A scenario analysis of energy consumption and CO2 emissions using the system dynamics model. J. Clean. Prod. 2015, 103, 401–410. [Google Scholar] [CrossRef]
- Mollaiy-Berneti, S. Developing energy forecasting model using hybrid artificial intelligence method. J. Cent. South. Univ. Engl. Ed. 2015, 22, 3026–3032. [Google Scholar] [CrossRef]
- Cao, G.; Wu, L. Support vector regression with fruit fly optimization algorithm for seasonal electricity consumption forecasting. Energy 2016, 115, 734–745. [Google Scholar] [CrossRef]
- Kuo, P.-H.; Huang, C.-J. A High Precision Artificial Neural Networks Model for Short-Term Energy Load Forecasting. Energies 2018, 11, 213. [Google Scholar] [CrossRef]
- Zhang, M.; Mu, H.; Li, G.; Ning, Y. Forecasting the transport energy demand based on PLSR method in China. Energy 2009, 34, 1396–1400. [Google Scholar] [CrossRef]
- Hsu, J.F.; Chang, J.M.; Cho, M.Y.; Wu, Y.H. Development of Regression Models for Prediction of Electricity by Considering Prosperity and Climate. In Proceedings of the 2016 3rd International Conference on Green Technology and Sustainable Development (GTSD), Kaohsiung, Taiwan, 24–25 November 2016. [Google Scholar]
- Hu, Y.C. A genetic-algorithm-based remnant grey prediction model for energy demand forecasting. PLoS ONE 2017, 12, e0185478. [Google Scholar] [CrossRef]
- Zou, S.; Ding, Z. China’s coal demand forecasting model based on ABA-ESA. China Coal 2018, 44, 9–14. [Google Scholar]
- Kefayat, M.; Ara, A.L.; Niaki, S.A.N. A hybrid of ant colony optimization and artificial bee colony algorithm for probabilistic optimal placement and sizing of distributed energy resources. Energy Convers. Manag. 2015, 92, 149–161. [Google Scholar] [CrossRef]
- Rahman, M.N.; Esmailipour, A.; Zhao, J. Machine Learning with Big Data An Efficient Electricity Generation Forecasting System. Big Data Res. 2016, 5, 9–15. [Google Scholar] [CrossRef]
- Wang, R.; Li, J.; Wang, J.; Gao, C. Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine. Energies 2018, 11, 1712. [Google Scholar] [CrossRef]
- Dai, S.; Niu, D.; Li, Y. Forecasting of Energy Consumption in China Based on Ensemble Empirical Mode Decomposition and Least Squares Support Vector Machine Optimized by Improved Shuffled Frog Leaping Algorithm. Appl. Sci. 2018, 8, 678. [Google Scholar] [CrossRef]
- Zhang, L.; Ge, R.; Chai, J. Prediction of China’s Energy Consumption Based on Robust Principal Component Analysis and PSO-LSSVM Optimized by the Tabu Search Algorithm. Energies 2019, 12, 196. [Google Scholar] [CrossRef]
- Han, Z.; Wan, J.; Liu, K. Prediction and model optimization of gasoline octane number based on near-infrared spectroscopy. Anal. Lab. 2015, 34, 1268–1271. [Google Scholar]
- Liu, A.; Xue, Y.; Hu, J.; Liu, L. Super-short-term prediction of wind power based on GA optimization SVM. Power Syst. Prot. Control. 2015, 2, 90–95. (In Chinese) [Google Scholar]
- Saini, L.M.; Aggarwal, S.K.; Kumar, A. Parameter optimisation using genetic algorithm for support vector machine-based price-forecasting model in National electricity market. IET Gener. Trans. Distrib. 2010, 4, 36–49. [Google Scholar] [CrossRef]
- Zhu, C.; Chen, X.; Wang, Z.; Zhang, X. Defect prediction model for object oriented software based on particle swarm optimized SVM. Comput. Appl. 2017, 37, 60–64. [Google Scholar]
- Bao, L.; Chen, H.; Guo, J.; Yuan, Y. Application of SVM based on improved PSO algorithm in methane measurement. Chin. J. Sens. Actuators. 2017, 9, 1454–1458. (In Chinese) [Google Scholar] [CrossRef]
- Rubio, G.; Pomares, H.; Rojas, I.; Herrera, L.J. A heuristic method for parameter selection in LS-SVM: Application to time series prediction. Int. J. Forecast. 2010, 3, 725–739. [Google Scholar] [CrossRef]
- Xu, D.; Ding, S. Research on improved GWO-optimized SVM-based short-term load prediction for cloud computing. Computer Engineering and Applications. Comput. Eng. Appl. 2017, 7, 68–73. (In Chinese) [Google Scholar]
- Feng, T.; Zhong, Y.; Liu, X.; Yu, L. Application of least square support vector machine based on adaptive artificial swarm optimization algorithm in deformation prediction. J. Jiangxi Univ. Sci. Technol. 2008, 39, 35–39. [Google Scholar]
- Rashedi, E.; Nezamabadi-pour, H.; Saryazdi, S. GSA: A Gravitational Search Algorithm. Inf. Sci. 2009, 179, 2232–2248. [Google Scholar] [CrossRef]
- Wang, H.; Han, Z.; Xu, X.; Li, X. Prediction model of steam turbine exhaust enthalpy based on gray correlation analysis and gsa-lssvm. Electr. Power Constr. 2016, 37, 115–122. (In Chinese) [Google Scholar]
- Chen, Y.; Yin, X.; Tan, R. A network security situation prediction model based on gsa-svm. J. Air Force Eng. Univ. (Nat. Sci. Ed.) 2018, 19, 82–87. [Google Scholar]
- Cui, D.; Huang, E. Application of improved gravity search algorithm and support vector machine in monthly runoff prediction in dry season. People’s Pearl River 2016, 37, 48–52. [Google Scholar]
- Deng, J. Grey Theory Foundation; Huazhong University of Science and Technology Press: Wuhan, China, 2002. [Google Scholar]
- Mei, H.; Liu, D.; He, Y. Fault Diagnosis of SVM Analog Circuits Optimized by Improved Gravity Search Algorithms. Microelectr. Comput. 2018, 408, 115–121. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Influencing Factor | Grey Relational Degree |
|---|---|
| GDP | 0.8602 |
| Total Population | 0.943 |
| CPI | 0.9754 |
| Value added of secondary industry | 0.9517 |
| Urbanization rate | 0.9733 |
| Energy consumption intensity | 0.8982 |
| The proportion of coal consumption to energy consumption | 0.9573 |
| Coal reserves | 0.9241 |
| Inventory of Coal and Products | 0.65 |
| Quantity of imported coal | 0.6263 |
| Average annual price of Shanxi premium blended coal in Qinhuangdao Port | 0.9426 |
| New Productivity Increased in Raw Coal Mining | 0.9364 |
| National Railway Coal Freight Volume | 0.9861 |
| Completion of Investment in Industrial Pollution Control | 0.9544 |
| Sulfur dioxide emissions | 0.9285 |
| Year | Total Coal Consumption (Ten Thousand Tons of Standard Coal) | CPI (1978 = 100) | Value Added of Secondary Industry (%) | Urbanization Rate (%) | The Proportion of Coal Consumption to Energy Consumption (%) | National Railway Coal Freight Volume (Ten Thousand Yuan) | Completion of Investment in Industrial Pollution Control (Ten Thousand Yuan) |
|---|---|---|---|---|---|---|---|
| 1990 | 75211.686 | 216.4 | 41 | 26.41 | 76.2 | 62870 | 454465 |
| 1991 | 78978.863 | 223.8 | 41.5 | 26.37 | 76.1 | 62603 | 597306 |
| 1992 | 82641.69 | 238.1 | 43.1 | 27.63 | 75.7 | 64108 | 646661 |
| 1993 | 86646.771 | 273.1 | 46.2 | 28.14 | 74.7 | 65336 | 693270 |
| 1994 | 92052.75 | 339 | 46.2 | 28.62 | 75 | 65943 | 833313 |
| 1995 | 97857.296 | 396.9 | 46.8 | 29.04 | 74.6 | 67357 | 987376 |
| 1996 | 103794.16 | 429.9 | 47.1 | 29.37 | 74.7 | 72058 | 956135 |
| 1997 | 98793.695 | 441.9 | 47.1 | 29.92 | 71.5 | 70345 | 1164386 |
| 1998 | 92020.944 | 438.4 | 45.8 | 30.4 | 69.6 | 64081 | 1220461 |
| 1999 | 81862 | 432.2 | 45.4 | 38.89 | 67.1 | 64917 | 1527307 |
| 2000 | 100670.34 | 434 | 45.50 | 36.00 | 69.00 | 68545 | 2347895 |
| 2001 | 105771.96 | 437 | 44.80 | 38.00 | 68.00 | 76625 | 1745280 |
| 2002 | 116160.25 | 433.5 | 44.50 | 39.00 | 69.00 | 81852 | 1883663 |
| 2003 | 138352.27 | 438.7 | 45.60 | 41.00 | 70.00 | 88132 | 2218281 |
| 2004 | 161657.26 | 455.8 | 45.90 | 42.00 | 70.00 | 99210 | 3081060 |
| 2005 | 189231.16 | 464 | 47.00 | 43.00 | 72.00 | 107082 | 4581909 |
| 2006 | 207402.11 | 471 | 47.60 | 44.00 | 72.00 | 112034 | 4839485 |
| 2007 | 225795.45 | 493.6 | 46.90 | 46.00 | 73.00 | 122080.63 | 5523909 |
| 2008 | 229236.87 | 522.7 | 47.00 | 47.00 | 72.00 | 134325 | 5426404 |
| 2009 | 240666.22 | 519 | 46.00 | 48.00 | 72.00 | 132720.15 | 4426207 |
| 2010 | 249568.42 | 536.1 | 46.50 | 50.00 | 69.00 | 156020 | 3969768 |
| 2011 | 271704.19 | 565 | 46.50 | 51.00 | 70.00 | 172125.74 | 4443610 |
| 2012 | 275464.53 | 579.7 | 45.40 | 53.00 | 69.00 | 168515.29 | 5004573 |
| 2013 | 280999.36 | 594.8 | 44.20 | 54.00 | 67.00 | 167945.66 | 8496647 |
| 2014 | 279328.74 | 606.7 | 43.30 | 55.00 | 66.00 | 164130.57 | 9976511 |
| 2015 | 273849.49 | 615.2 | 41.10 | 56.00 | 64.00 | 143221.23 | 7736822 |
| 2016 | 270320 | 627.5 | 40.10 | 57.00 | 62.00 | 131790.73 | 8190041 |
| 2017 | 278159 | 637.5 | 40.50 | 59.00 | 60.40 | 149129.86 | 6815345 |
| Error Types | BP | SVM | GSA–SVM | IGSA–SVM |
|---|---|---|---|---|
| RMSE | 19798.56 | 21902.20 | 15164.49 | 8721.86 |
| MAE | 18877.36 | 16439.78 | 11925.47 | 7694.94 |
| MAPE | 6.87 | 5.94 | 4.31 | 2.82 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, Z. Forecasting of Coal Demand in China Based on Support Vector Machine Optimized by the Improved Gravitational Search Algorithm. Energies 2019, 12, 2249. https://doi.org/10.3390/en12122249
Li Y, Li Z. Forecasting of Coal Demand in China Based on Support Vector Machine Optimized by the Improved Gravitational Search Algorithm. Energies. 2019; 12(12):2249. https://doi.org/10.3390/en12122249
Chicago/Turabian StyleLi, Yanbin, and Zhen Li. 2019. "Forecasting of Coal Demand in China Based on Support Vector Machine Optimized by the Improved Gravitational Search Algorithm" Energies 12, no. 12: 2249. https://doi.org/10.3390/en12122249
APA StyleLi, Y., & Li, Z. (2019). Forecasting of Coal Demand in China Based on Support Vector Machine Optimized by the Improved Gravitational Search Algorithm. Energies, 12(12), 2249. https://doi.org/10.3390/en12122249