State Rules Mining and Probabilistic Fault Analysis for 5 MW Offshore Wind Turbines


Abstract
1. Introduction
2. Rule Mining of Operating States for Offshore WTs using MPQEA
2.1. Fuzzy Rule-Based Classification Systems
- Knowledge base: Including the fuzzy rule base and data base.
- Reasoning strategy: The classification mechanism of samples using the fuzzy rules in the knowledge base.
2.1.1. Match Degree
2.1.2. Rule Weight
2.1.3. Classification Process
2.2. Fuzzy Classification Rule Mining based on MPQEA
2.2.1. Fuzzy Partition of State Variables
- Small (S2), Large (L2)
- Small (S3), Middle (M3), Large (L3)
- Small (S4), Middle Small (MS4), Middle Large (ML4), Large (L4)
- Small (S5), Middle Small (MS5), Middle (M5), Middle Large (ML5), Large (L5)
2.2.2. Generation of Initial State Rules
2.2.3. Multi-Population Quantum Coding
2.2.4. Hybrid Updating Strategy
3. NREL-5MW Offshore WT Fault Identification and Probability Analysis
3.1. Fault Descriptions
3.2. Fault Identification and Probability Analysis Scheme
3.2.1. Feature Selection using the ReliefF Algorithm
- Algorithm 1: ReliefF
- Input: Training data set: D, Iteration: m, Number of nearest neighbor samples: k.
- Output: Prediction vector of feature weight: W.
- (1)
- Initialize the feature vector: W(A) = 0, A = 1, 2, …, p;
- (2)
- for i = 1:m
- (3)
- Randomly select a sample di from D;
- (4)
- For the class corresponding to di, find k nearest neighbors Hj;
- (5)
- For each class C≠class(di), find k nearest neighbors Mj(C);
- (6)
- for A = 1:p
- (7)
- end / skip to step (6)
- (8)
- end // skip to step (2)
3.2.2. Fault Identification and Probability Analysis for Offshore WTs
- Step 1:
- For the online state xp, its match degrees μAq(xp) to each rule are calculated by Equation (2);
- Step 2:
- For each rule, calculate the product of its rule weight RWq and μAq(xp), named as Yq;
- Step 3:
- Find the biggest three Yq with different fault labels, Ymax (fault i), i = 1, 2, 3. And the corresponding fault labels are specified as the possible faults;
- Step 4:
- The probability of each possible fault is calculated as follows:
- Step 5:
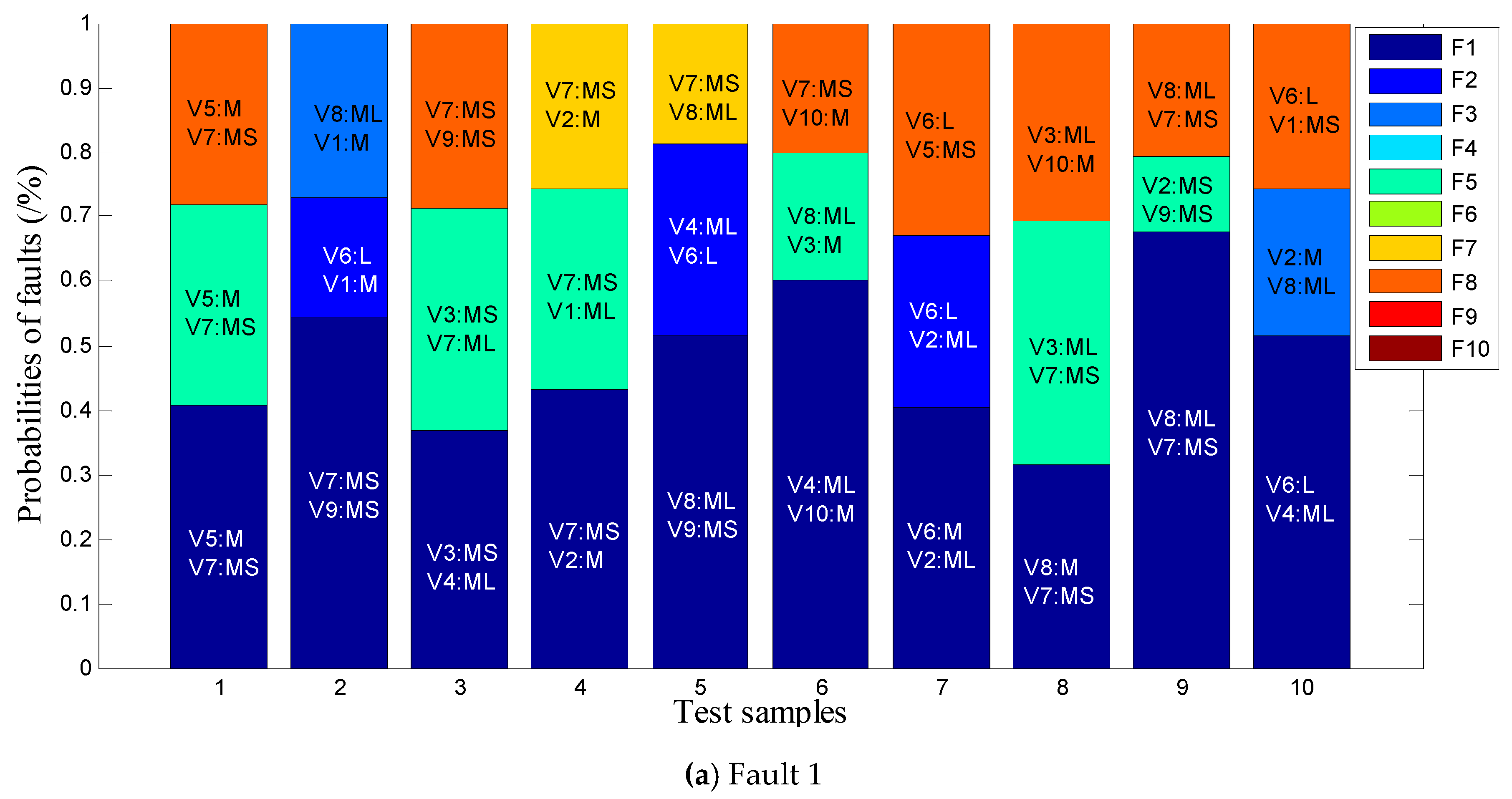
- For all possible faults, find k critical state variables with the maximal memberships in step 1, and provide their corresponding language labels in the respective “winner rule”, where k is 2 in this work.
4. Experiments and Results Analysis
4.1. Numerical Experiments
- (1)
- FH-GBML-IVFS-Amp [32]: For the well-known Fuzzy Hybrid Genetics-Based Machine Learning algorithm, this method replaced the fuzzy set to Interval-Valued Fuzzy Sets and proposed the amplitude optimization strategy by GA.
- (2)
- GAGRAD [33]: The rule set in GAGRAD is represented by a constrained network, and a two phase method is used to optimize the rule set. In the first phase, the rule set is optimized by GA, and the fuzzy sets are adjusted in the second phase by gradient-based optimization.
4.2. Fault Identification and Probability Analysis for Offshore WTs
4.2.1. Feature Selection
4.2.2. Fault Identification
4.2.3. Fault Probability Analysis
5. Conclusions
- (1)
- The proposed MPQEA-FRBCS can improve the classification performance of FRBCS in initial rule generation and rule set optimization. Hence, for the 18 well-known UCI data sets, MPQEA-FRBCS improves the average classification accuracy by 3.11% and 4.42% relative to FH-GBML-IVFS-Amp and GAGRAD, respectively.
- (2)
- The application of MPQEA-FRBCS to the operating state identification of offshore WTs improves the identification accuracy. From the comparison of the results with those of four other fault identification methods, MPQEA-FRBCS obviously improves identification accuracy by 6.73%, 8.83%, 12.46%, and 11.26%.
- (3)
- The proposed probabilistic fault identification scheme with interpretable critical variables can provide abundant and reliable reference information for maintenance personnel. The probability results of two and three sequences show 14% and 23% improvement in identification accuracy relative to the original accuracy of MPQEA-FRBCS, respectively. Meanwhile, the proposed fault identification scheme identifies the critical state variable of a fault to ensure interpretability.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaouihasnaoui, F.; Tameghe, T.A.; Ekemb, G. Wind turbine condition monitoring: state-of-the-art review, new trends, and future challenges. Energies 2014, 7, 2595–2630. [Google Scholar] [CrossRef]
- Tautz-Weinert, J.; Watson, S.J. Using scada data for wind turbine condition monitoring—A review. IET Renew. Power Gener. 2017, 11, 382–394. [Google Scholar] [CrossRef]
- Chen, B.; Matthews, P.C.; Tavner, P.J. Automated on-line fault prognosis for wind turbine pitch systems using supervisory control and data acquisition. IET Renew. Power Gener. 2015, 9, 503–513. [Google Scholar] [CrossRef]
- Deng, X.; Pan, Q.; Gao, Q. Research on the modeling and simulation of permanent magnet direct-driven wind turbine rotor imbalance fault. Power Syst. Prot. Control 2018, 46, 35–40. [Google Scholar]
- Asian, S.; Ertek, G.; Haksoz, C.; Pakter, S.; Ulun, S. Wind turbine accidents: a data mining study. IEEE Syst. J. 2017, 11, 1567–1578. [Google Scholar] [CrossRef]
- Quan, Z.; Xiong, T.; Wang, M.; Xiang, C.; Xu, Q. Diagnosis and early warning of wind turbine faults based on cluster analysis theory and modified ANFIS. Energies 2017, 10, 898. [Google Scholar]
- Mojallal, A.; Lotfifard, S. Multi-physics graphical model-based fault detection and isolation in wind turbines. IEEE Trans. Smart Grid 2017, 99, 1–10. [Google Scholar] [CrossRef]
- Laouti, N.; Othman, S.; Alamir, M. Combination of model-based observer and support vector machines for fault detection of wind turbines. Int. J. Autom. Comput. 2014, 11, 274–287. [Google Scholar] [CrossRef]
- Cho, S.; Gao, Z.; Moan, T. Model-based fault detection, fault isolation and fault-tolerant control of a blade pitch system in floating wind turbines. Renew. Energy 2018, 120, 1–10. [Google Scholar] [CrossRef]
- Bi, R.; Zhou, C.; Hepburn, D.M. Detection and classification of faults in pitch-regulated wind turbine generators using normal behavior models based on performance curves. Renew. Energy 2017, 105, 674–688. [Google Scholar] [CrossRef]
- Zhang, D.; Qian, L.; Mao, B.; Huang, C.; Si, Y. A data-driven design for fault detection of wind turbines using random forests and XGboost. IEEE Access 2018, 6, 21020–21031. [Google Scholar] [CrossRef]
- Colone, L.; Reder, M.; Tautz-Weinert, J.; Melero, J.J.; Natarajan, A.; Watson, S.J. Optimization of data acquisition in wind turbines with data-driven conversion functions for sensor measurements. Energy Procedia 2017, 137, 571–578. [Google Scholar] [CrossRef]
- Chen, B.; Matthews, P.C.; Tavner, P.J. Wind turbine pitch faults prognosis using a-priori knowledge-based anfis. Expert Syst. Appl. 2014, 40, 6863–6876. [Google Scholar] [CrossRef]
- Hu, R.L.; Leahy, K.; Konstantakopoulos, I.C.; Auslander, D.M.; Spanos, C.J.; Agogino, A.M. Using domain knowledge features for wind turbine diagnostics. In Proceedings of the 15th IEEE International Conference on Machine Learning and Applications, Anaheim, CA, USA, 18–20 December 2016. [Google Scholar]
- Wang, Y.; Ma, X.; Qian, P. Wind turbine fault detection and identification through pca-based optimal variable selection. IEEE Trans. Sustain. Energy 2018, 99, 1–9. [Google Scholar] [CrossRef]
- Ruiz, M.; Mujica, L.E.; Alférez, S. Wind turbine fault detection and classification by means of image texture analysis. Mech. Syst. Signal Process. 2018, 107, 149–167. [Google Scholar] [CrossRef]
- Pashazadeh, V.; Salmasi, F.R.; Araabi, B.N. Data driven sensor and actuator fault detection and isolation in wind turbine using classifier fusion. Renew. Energy 2017, 80, 151–158. [Google Scholar] [CrossRef]
- Paternain, D.; Bustince, H.; Pagola, M. Capacities and overlap indexes with an application in fuzzy rule-based classification systems. Fuzzy Sets Syst. 2016, 305, 70–94. [Google Scholar] [CrossRef]
- Derhami, S.; Smith, A.E. A technical note on the paper “hga: hybrid genetic algorithm in fuzzy rule-based classification systems for high-dimensional problems”. Appl. Soft Comput. 2016, 41, 91–93. [Google Scholar] [CrossRef]
- Prusty, M.R.; Jayanthi, T.; Chakraborty, J.; Seetha, H.; Velusamy, K. Performance analysis of fuzzy rule based classification system for transient identification in nuclear power plant. Ann. Nucl. Energy 2015, 76, 63–74. [Google Scholar] [CrossRef]
- Chen, S.M.; Hsin, W.C. Weighted fuzzy interpolative reasoning based on the slopes of fuzzy sets and particle swarm optimization techniques. IEEE Trans. Cybern. 2017, 45, 1250–1261. [Google Scholar] [CrossRef] [PubMed]
- Zare, M.; Koch, M. Groundwater level fluctuations simulation and prediction by ANFIS-and hybrid wavelet-ANFIS/ fuzzy c-means (FCM) clustering models: application to the Miandarband plain. J. Hydro-Environ. Res. 2017, 18, 63–76. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Qian, X.Y.; Peng, H.D.; Wang, J.H. An allele real-coded quantum evolutionary algorithm based on hybrid updating strategy. Comput. Intell. Neurosci. 2016, 9, 50–58. [Google Scholar] [CrossRef] [PubMed]
- Layeb, A. A hybrid quantum inspired harmony search algorithm for 0-1 optimization problems. J. Comput. Appl. Math. 2013, 253, 14–25. [Google Scholar] [CrossRef]
- Kuhne, P.; Poschke, F.; Schulte, H. Fault estimation and fault-tolerant control of the fast NREL 5-MW reference wind turbine using a proportional multi-integral observer. Int. J. Adapt. Control Signal Process. 2017, 32, 568–585. [Google Scholar] [CrossRef]
- Zanon, A.; De Gennaro, M.; Kühnelt, H. Wind energy harnessing of the NREL 5 MW reference wind turbine in icing conditions under different operational strategies. Renew. Energy 2018, 115, 760–772. [Google Scholar] [CrossRef]
- Odgaard, P.F.; Stoustrup, J.; Kinnaert, M. Fault-tolerant control of wind turbines: A benchmark model. IEEE Trans. Control Syst. Technol. 2012, 45, 313–318. [Google Scholar]
- Abdelghaffar, H.M.; Woolsey, C.A.; Rakha, H.A. Comparison of three approaches to atmospheric source localization. J. Aerosp. Inf. Syst. 2017, 14, 40–52. [Google Scholar] [CrossRef]
- Palma-Mendoza, R.J.; Rodriguez, D.; De-Marcos, L. Distributed relieff-based feature selection in spark. Knowl. Inf. Syst. 2018, 19, 1–20. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: introduction and review. J. Biomed. Inf. 2018, 85, 189–203. [Google Scholar] [CrossRef]
- Bache, K.; Lichman, M. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/datasets.html (accessed on 4 March 2019).
- Sanz, J.A.; Galar, M.; Jurio, A.; Brugos, A.; Pagola, M.; Bustince, H. Medical diagnosis of cardiovascular diseases using an interval-valued fuzzy rule-based classification system. Appl. Soft Comput. 2014, 20, 103–111. [Google Scholar] [CrossRef]
- Dombi, J.; Gera, Z. Rule based fuzzy classification using squashing functions. J. Intell. Fuzzy Syst. 2008, 19, 3–8. [Google Scholar]
- Maesono, Y.; Moriyama, T.; Lu, M. Smoothed nonparametric tests and approximations of p-values. Ann. Inst. Stat. Math. 2017, 70, 969–982. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Rated power (Pn) | 5 MW |
| Blade number | 3 |
| Tower height | 87.6 m |
| Diameter of rotor | 126 m |
| Cut in wind speed, rated wind speed, cut-out wind speed | 3 m/s, 11.4 m/s, 25 m/s |
| Ratio of gearbox | 98 |
| Nominal generator speed (wg,n) | 1173.7 rpm |
| Sensor Type | Symbol | Unit | Noise Level |
|---|---|---|---|
| Wind speed at hub height | vw, | m/s | 0.0071 |
| Rotor speed | ωr, | rad/s | 10−4 |
| Generator speed | ωg | rad/s | 2·10−4 |
| Generator torque | τg | NM | 0.9 |
| Generated electrical power | Pe | W | 10 |
| Pitch angle of i-th blade | βi | deg | 1.5·10−3 |
| Azimuth angle at low speed side | ϕ | rad | 10-4 |
| Blade root moment of i-th blade | Mβi | NM | 103 |
| Tower top acceleration in x direction | Xacc | m/s2 | 5·10−4 |
| Tower top acceleration in y direction | Yacc | m/s2 | 5·10−4 |
| Yaw error | Ξe | deg | 5·10−2 |
| No. | Fault Location | Fault Representation | Parameter Settings | Duration |
|---|---|---|---|---|
| 1 | Blade root bending moment sensor | Scaling | M scaled by 0.95 | 20–45 s |
| 2 | Accelerometer | Offset | −0.5 m/s2 offset on Xacc and Yacc | 75–100 s |
| 3 | Generator speed sensor | Scaling | ωg scaled by 0.95 | 130–155 s |
| 4 | Pitch angle sensor | Stuck | βi hold to 1 deg | 185–210 s |
| 5 | Generator power sensor | Scaling | Pe scaled by 1.1 | 240–265 s |
| 6 | Low speed shaft position encoder | Bit error | random offset on ϕ | 295–320 s |
| 7 | Pitch actuator | Abrupt change in dynamics | ω1 = 5.73, ζ1 = 0.45 | 350–410 s |
| 8 | Pitch actuator | Slow change in dynamics | ω2 = 3.42, ζ2 = 0.9 | 440–465 s |
| 9 | Torque offset | Offset | 1000NM offset on τg | 495–520 s |
| 10 | Yaw drive | Stuck drive | Yaw angular velocity set to 0 rad/s | 550–575 s |
| Data-Set | #S | #F | #C | Data-Set | #S | #F | #C |
|---|---|---|---|---|---|---|---|
| Balance | 625 | 4 | 3 | Iris | 150 | 4 | 3 |
| Bupa | 345 | 6 | 2 | New-Thyroid | 215 | 5 | 3 |
| Car | 1728 | 6 | 4 | Page blocks | 548 | 10 | 5 |
| Cleveland | 297 | 13 | 5 | Penbased | 1099 | 16 | 10 |
| Contraceptive | 1473 | 9 | 3 | Pima | 768 | 8 | 2 |
| Ecoli | 336 | 7 | 8 | Tae | 151 | 5 | 3 |
| Glass | 214 | 9 | 6 | Vehicle | 846 | 18 | 4 |
| Haberman | 306 | 3 | 2 | Wine | 178 | 13 | 3 |
| Hepatitis | 155 | 19 | 2 | Wisconsin | 683 | 9 | 2 |
| Algorithms | Parameter Settings |
|---|---|
| FH-GBML-IVFS-Amp | Number of rules: 5 × d; number of rule sets: 200; mutation probability: 1/d; crossover probability: 0.9; don’t care probability: 0.5; iterations: 1000. |
| GAGRAD | Population size: 100; mutation probability: 0.02; crossover probability: 0.6; iteration: 100; number of hidden neurons: 4 × d. |
| MPQEA-FRBCS | Iterations: 100; population size: 20; mutation probability: 0.1; K (evolutionary amplitude in hybrid update strategy): 0.5; number of rules: 5 × d; don’t care probability: 0.1. |
| Data Sets | MPQEA-FRBCS | FH-GBML-IVFS-Amp | GAGRAD | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Balance | 80.28 | 81.36 | 80.84 | 80.48 | 82.28 | 78.72 |
| Bupa | 75.33 | 64.56 | 74.33 | 62.61 | 60.65 | 61.16 |
| Car | 76.74 | 73.51 | 75.33 | 73.26 | 61.77 | 60.83 |
| Cleveland | 63.77 | 55.29 | 65.26 | 56.91 | 59.26 | 53.89 |
| Contraceptive | 54.32 | 50.31 | 51.32 | 48.27 | 50.36 | 50.57 |
| Ecoli | 88.90 | 86.92 | 81.26 | 72.91 | 87.80 | 86.32 |
| Glass | 75.29 | 66.73 | 74.27 | 57.94 | 53.50 | 52.86 |
| Haberman | 81.56 | 74.47 | 78.75 | 72.22 | 74.43 | 73.53 |
| Hepatitis | 94.07 | 87.96 | 92.06 | 83.75 | 83.75 | 82.50 |
| Iris | 98.83 | 97.00 | 98.82 | 96.00 | 94.83 | 95.33 |
| New-Thyroid | 95.51 | 94.27 | 97.66 | 93.49 | 89.19 | 87.91 |
| Page blocks | 95.21 | 93.94 | 96.07 | 94.16 | 90.19 | 89.60 |
| Penbased | 94.78 | 89.03 | 83.85 | 78.27 | 78.93 | 77.73 |
| Pima | 80.91 | 74.26 | 78.71 | 75.00 | 75.78 | 75.00 |
| Tae | 79.65 | 58.77 | 66.11 | 52.32 | 56.63 | 49.03 |
| Vehicle | 70.28 | 67.26 | 69.46 | 62.30 | 60.55 | 59.70 |
| Wine | 96.60 | 90.72 | 98.87 | 90.97 | 98.31 | 95.44 |
| Wisconsin | 98.74 | 96.22 | 97.65 | 95.75 | 93.45 | 92.97 |
| Avg. | 83.38 | 77.92 | 81.15 | 74.81 | 75.09 | 73.50 |
| Method | R+ | R− | p-Value | Hypothesis |
|---|---|---|---|---|
| Vs FH-GBML-IVFS-Amp | 153 | 18 | 0.0031 | Rejected |
| Vs GAGRAD | 156 | 15 | 0.0021 | Rejected |
| Comparing Algorithms | Identification Accuracy [%] | Parameter Settings |
|---|---|---|
| GAGRAD (FRBCS-1) | 61.55 | Population size: 100; iterations: 100; crossover probability: 0.6; mutation probability: 0.02. |
| FH-GBML-IVFS-Amp (FRBCS-2) | 65.18 | Population size: 20; iterations: 1000; crossover probability: 0.9; mutation probability: 0.1. |
| C4.5 | 62.75 | Confidence level: 0.25; minimum leaf distance: 5. |
| Classifier fusion | 67.18 | KNN: K = 1. C4.5: confidence level: 0.02. RBF: the variance of the Gaussian: 1.4. Hidden nodes: 100. |
| MPQEA-FRBCS | 74.01 | Iterations: 50; population size: 10; mutation probability: 0.1; rule size: 120. |
| Faults | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | All Faults |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc-original | 0.80 | 0.65 | 0.58 | 0.94 | 0.58 | 0.77 | 0.71 | 0.62 | 0.71 | 0.85 | 0.72 |
| Acc-p2 | 0.87 | 0.78 | 0.76 | 1.00 | 0.84 | 0.89 | 0.86 | 0.79 | 0.86 | 0.95 | 0.86 |
| Acc-p3 | 0.92 | 0.94 | 0.88 | 1.00 | 0.96 | 1.00 | 0.94 | 0.90 | 1.00 | 1.00 | 0.95 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, X.; Zhang, Y.; Gendeel, M. State Rules Mining and Probabilistic Fault Analysis for 5 MW Offshore Wind Turbines. Energies 2019, 12, 2046. https://doi.org/10.3390/en12112046
Qian X, Zhang Y, Gendeel M. State Rules Mining and Probabilistic Fault Analysis for 5 MW Offshore Wind Turbines. Energies. 2019; 12(11):2046. https://doi.org/10.3390/en12112046
Chicago/Turabian StyleQian, Xiaoyi, Yuxian Zhang, and Mohammed Gendeel. 2019. "State Rules Mining and Probabilistic Fault Analysis for 5 MW Offshore Wind Turbines" Energies 12, no. 11: 2046. https://doi.org/10.3390/en12112046
APA StyleQian, X., Zhang, Y., & Gendeel, M. (2019). State Rules Mining and Probabilistic Fault Analysis for 5 MW Offshore Wind Turbines. Energies, 12(11), 2046. https://doi.org/10.3390/en12112046