Research and Application of a Novel Combined Model Based on Multiobjective Optimization for Multistep-Ahead Electric Load Forecasting


Abstract
:1. Introduction
2. Literature Review
- (1)
- Applying the decomposition and reconstruction strategy, data preprocessing methods are adopted to extract main features of the original data by eliminating high-frequency signals, making predictions more accurate. Decomposing the original power data and reconstructing it into a filtering sequence can eliminate the irregularity and uncertainty of the data and achieve better power load forecasting performance.
- (2)
- Applying the multiobjective optimization algorithm, the optimal weight coefficient of each single model can be optimized. Our proposed combined model is not only robust, but also economical in power load forecasting. Moreover, it has higher precision and greater stability.
- (3)
- With the combination of the linear model (ARIMA) and nonlinear models (WNN, ELM, and BPNN), the developed model can reflect both the linearity and nonlinearity of electrical load data. Our proposed model can use each individual model thoroughly and it spontaneously overcomes limitations such as low precision and instability to ensure the effectiveness of power load forecasting.
- (4)
- The new combined model beats other single models and will provide effective technical support for power system management. The developed model was simulated and examined based on the electric load data of three different sites, which indicates its strong robustness and adaptability regardless of location and forecasting steps.
3. Methods
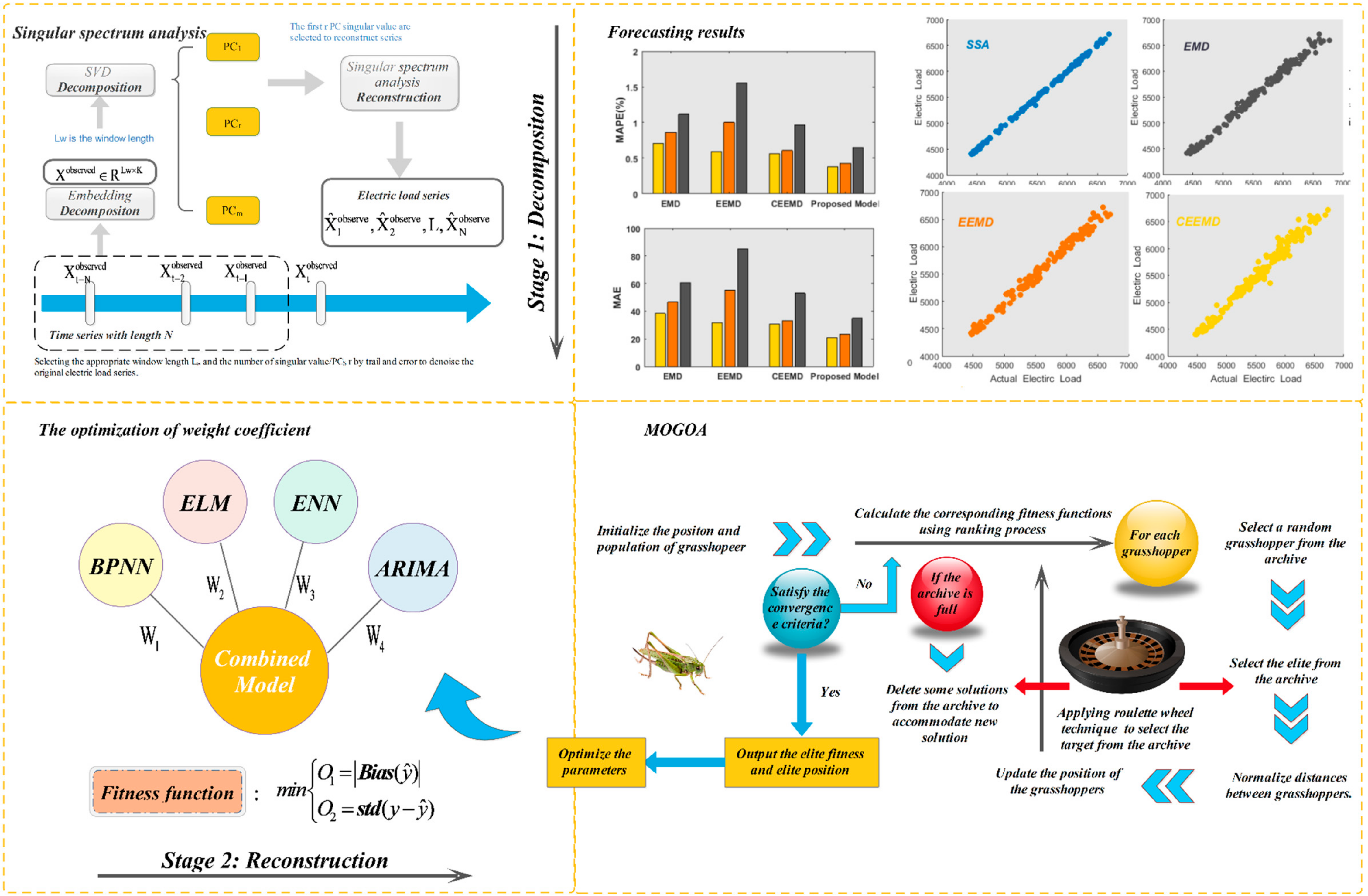
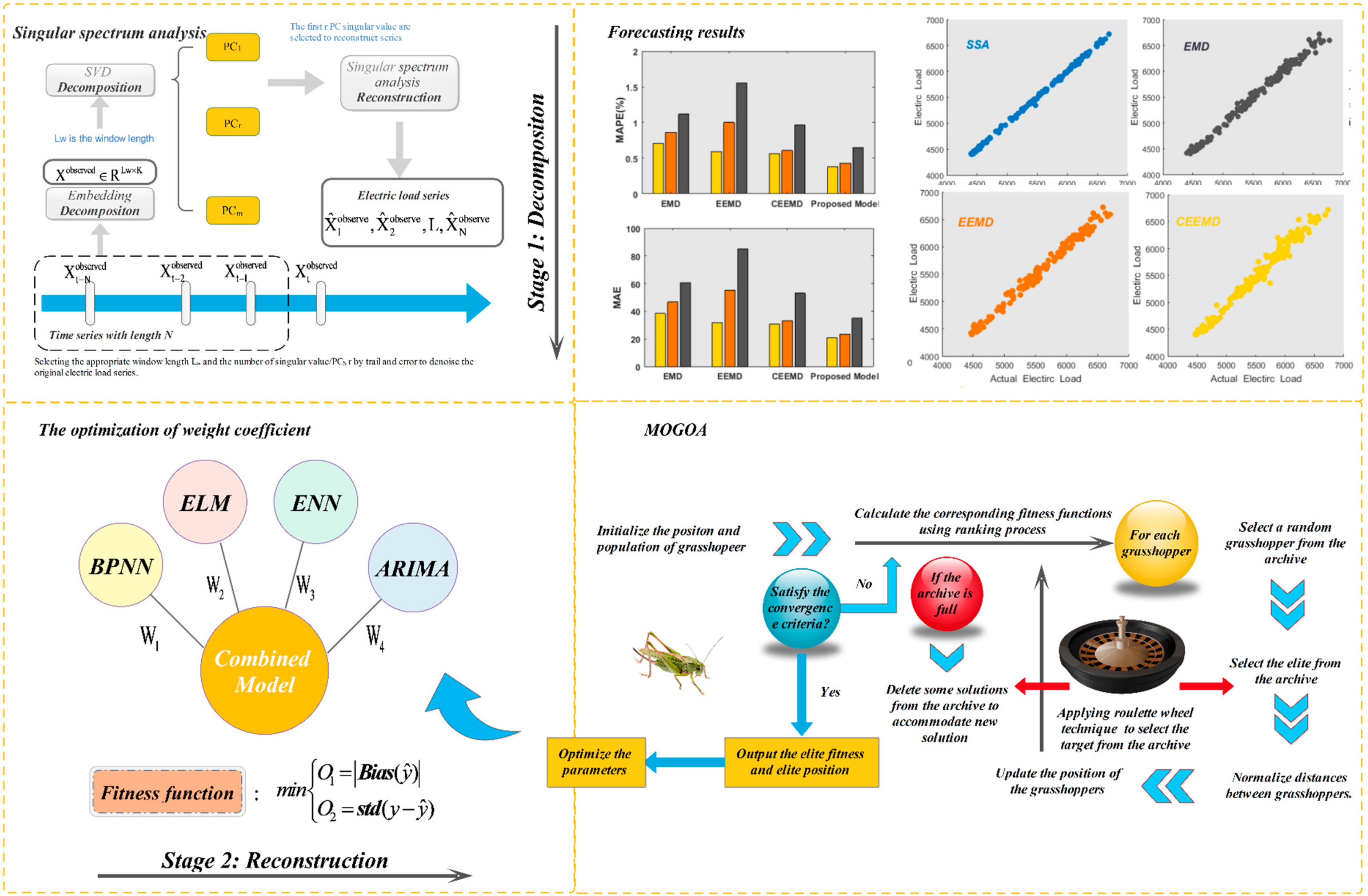
3.1. SSA Technique
3.2. Wavelet Neural Network
3.3. Extreme Learning Machine
3.4. Back Propagation Neural Network
3.5. Autoregressive Integrated Moving Average Model
3.6. Basic concepts of Multiobjective Optimization Problems
3.7. Multiobjective Grasshopper Optimization Algorithm
| Algorithm 1:MOGOA | |
| Objective functions: Input:
Output:
| |
Parameters:
| |
  | |
3.8. SSA-MOGOA Combined Model
3.8.1. Stage 1: Data Preprocessing
3.8.2. Stage 2: Individual Models used for Forecasting
3.8.3. Stage 3: Optimization of Weight Parameters of Combined Model
4. Experiments and Analysis
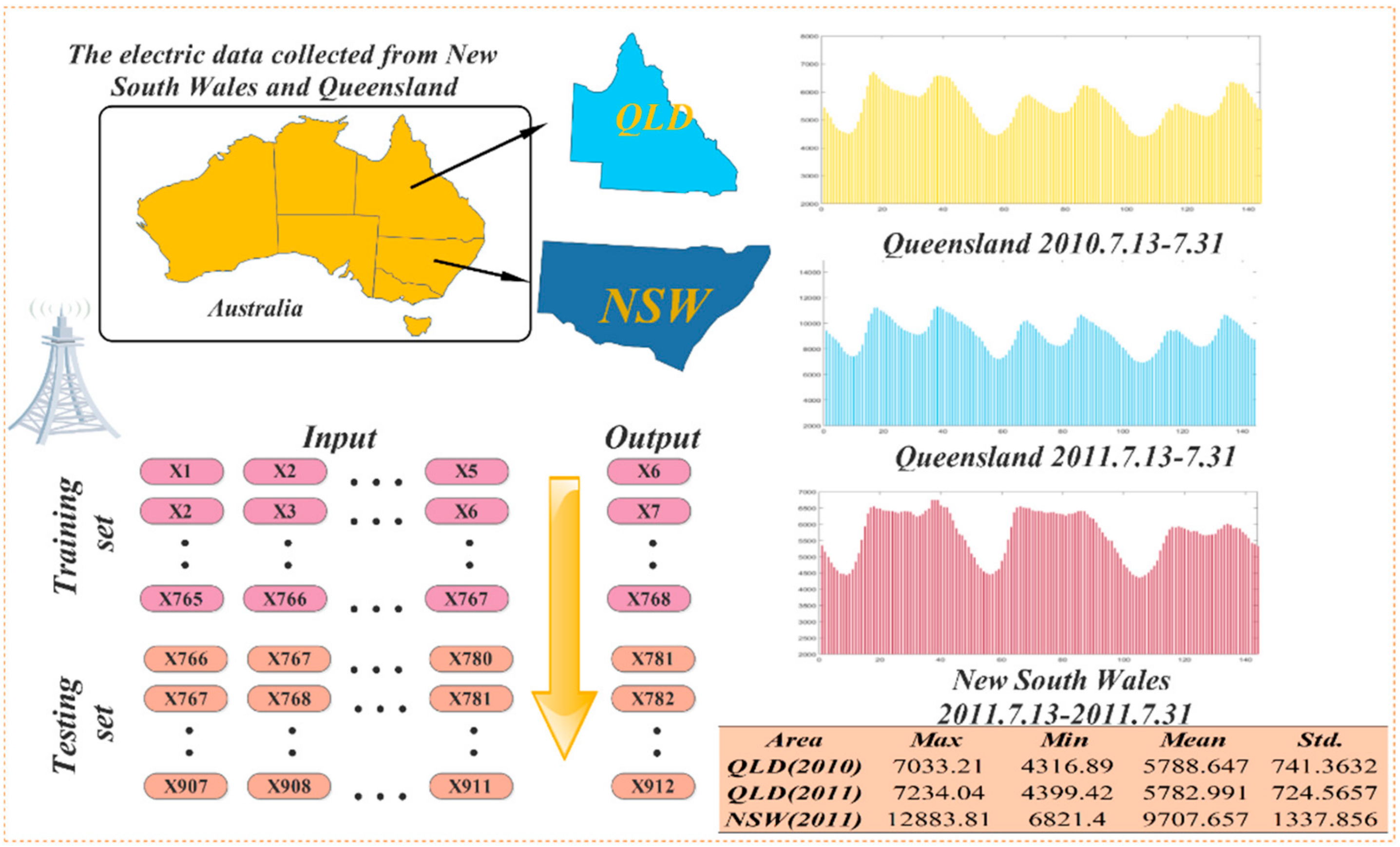
4.1. Datasets
4.2. Performance Metrics
4.3. Testing Method
4.3.1. Diebold–Mariano Test
4.3.2. Forecasting Effectiveness
4.4. Experiments and Analysis
4.4.1. Experiment I: Compare with Other Models Based on SSA
- By observing the experimental results using the 2010 Queensland power data, the following results were found: First of all, the most obvious was that our proposed combined model had the best prediction performance whether the statistical indicator was MAE, RMSE, or MAPE; in other words, the smallest error metrics values. Second, if we look closely at the forecasting steps, we can find that the forecasting accuracy gets worse. In one-step forecasting, our proposed model’s MAPE value is 0.37%, and it increases to 0.68% in three-step forecasting.
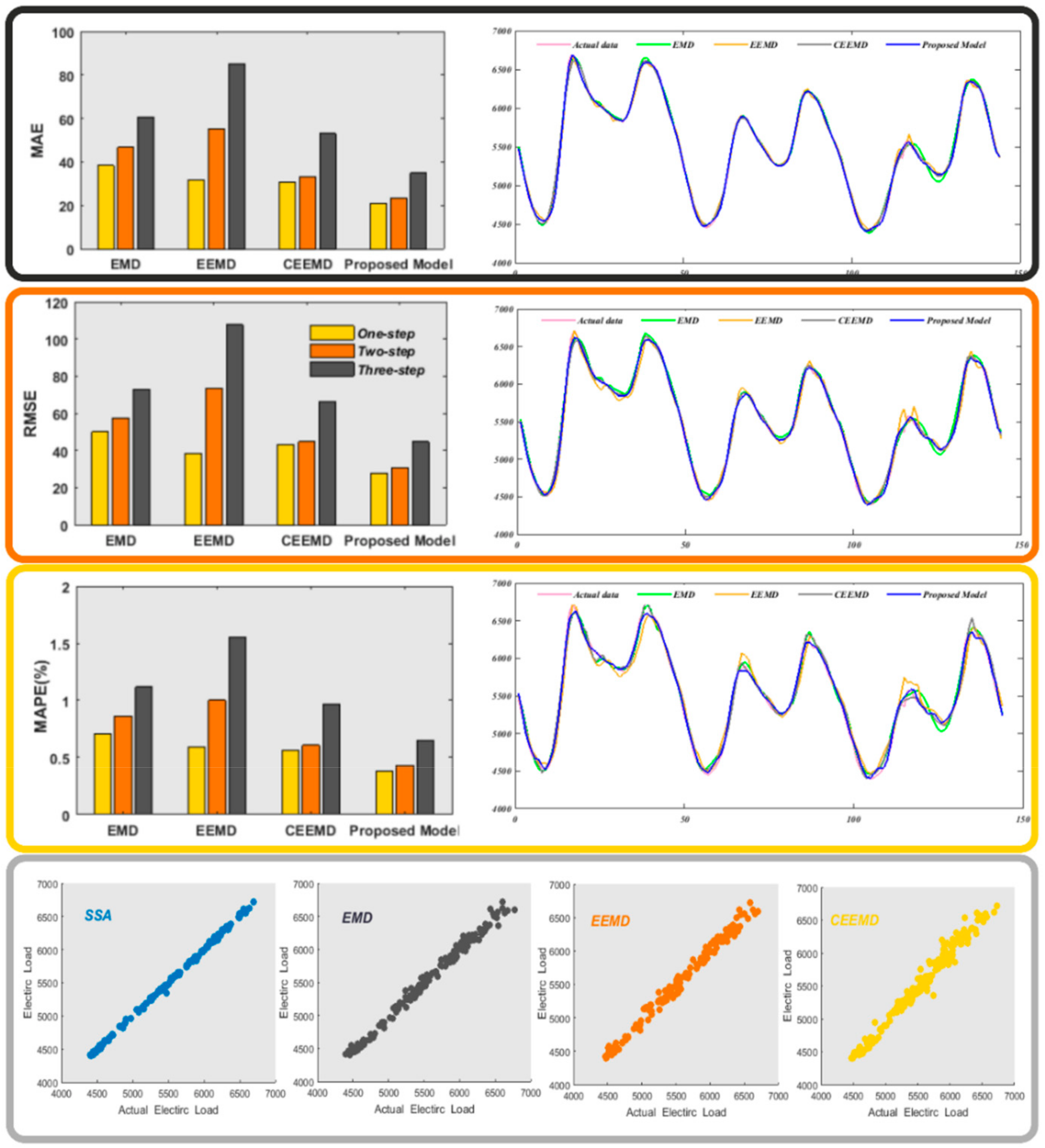
- For the 2011 Queensland power data, we found the following: First, our proposed model was still the most accurate one. It is worth mentioning that in one-step forecasting, the forecasting gap between our model and the SSA-ELM model was big. Specifically, the MAE values of our model and SSA-ELM were 20.79 and 23.90, respectively, while they were 21.26 and 22.35 with the 2011 Queensland power station data. The superiority of the proposed model can be more intuitively reflected in the Figure 3.
- Regarding the results using the 2011 New South Wales power data, compared to the first two experiments, which used electric load data from Queensland, the error metric values were significantly larger in the third experiment. This reflects the differences among different power plants. The great thing was that our proposed combined model still outperformed other SSA-based models in one-step to three-step forecasting. This is powerful proof that our model is indeed superior. At the same time, we can also determine the necessity of combining models through this experiment by the fact that it really can improve forecast accuracy.
4.4.2. Experiment II: Comparing Models using Other Data Preprocessing Methods
- Observing the experimental results using the 2010 Queensland power data, the proposed combined model achieved the highest forecasting accuracy. In contrast, the CEEMD preprocessed model was the most effective among the other three data processing methods, with MAPE values of 0.54%, 0.64%, and 0.90% from one-step to three-step forecasting, respectively. For the proposed model, MAPE values were 0.37%, 0.45%, and 0.68% from one to three steps, respectively.
- For the experiment using the 2011 Queensland power data, according to the evaluation criteria, the proposed model outperformed the other models. The MAPE values of the models using EMD, EEMD, and CEEMD were, respectively, 0.33%, 0.21%, and 0.18% higher than those of the proposed model in one-step forecasting. Figure 4 shows a comparison of the one- to three-step forecasting performance of Experiment II. It can be concluded that the proposed combined model achieved the highest accuracy compared to the models using other data preprocessing methods in three-step forecasting.
- When using the 2011 New South Wales power data, similar to Experiment I, compared to the first two experiments using data from Queensland, the error metric values of the third experiment were significantly larger. This reflects the difference between different power plants. In addition, there were also some interesting conclusions. For example, in the first two sets of power plant data, the CEEMD model performed better than the EMD model, but in the third group, the EMD and CEEMD models performed almost the same. However, our model still the performed the best. We can also determine the necessity of applying singular spectrum analysis (SSA) in our model so that it performs better than the other three classic data processing methods.
4.4.3. Experiment III: Comparing with Classic Models
- With the experiments using the 2010 Queensland power data, we found that, first, our proposed combined model had the best prediction performance whether the statistical indicator was MAE, RMSE, or MAPE. For instance, taking the one-step forecasting MAE values for comparison, the values were 46.12, 47.54, 51.24, 45.76, 46.24, 64.08, 38.971, and 21.26. The proposed model’s MAE value was only about half of other methods’ values. Second, in two- and three-step forecasting, the combined model was more effective than the other methods. The prediction performance of all other models was significantly worse than that of our model and there was still a big gap, which was sufficient to reflect the excellence of our model.
- With the 2011 Queensland power data, the results were as follows: First, our proposed model was still the most accurate. Second, although the data were from a different year, it is clear that forecasting results of the first two experiments are fairly similar, which reflects the stability of our method. The RMSE values of the proposed model were 27.75, 30.73, and 44.80 for one to three steps, respectively.
- For the 2011 New South Wales power data, the RMSE values of the proposed model were 57.63, 73.87, and 97.92 for one to three steps, respectively. The great thing is that our proposed combined model still outperformed the other data processing methods in one- to three-step forecasting. This is powerful proof that our model is indeed the best of all eight models. Although not as accurate as the predictions in the first two experiments, the degree of improvement in the prediction results did not change much at around 50%. This will be discussed in the next section.
5. Discussion
5.1. Multiobjective Grasshopper Algorithm Experiments
- (a)
- MOGOA gets the best IGD values among the optimization algorithms in all four test functions, which proves that its optimizing ability is superior to that of MODA and MOALO.
- (b)
- By observing the contrast of the number of the Pareto optimal solutions calculated by MOGOA, MODA, and MOALO shown in Figure 6, we find that MOGOA had the most Pareto optimal solutions among all three algorithms.
5.2. Proposed Model’s Effectiveness
5.3. Proposed Combined Model’s Improvements
- Comparing the proposed model with other SSA-based models, it is obvious that the novel proposed model has lower MAPE values. For example, the average improvement of the proposed model’s MAPE is 7.71%, 29.18%, and 51.88% compared with the SSA-ELM model, which is the least improved of the four models.
- Comparing the proposed model with the other three data preprocessing methods, its superiority is obvious. The lowest MAPE improvement is 22.09%, while the largest comes to 56.84%, which fully reflects the excellent prediction accuracy of our proposed model.
- Comparing the proposed model with the classic models, forecasting accuracy is greatly improved in every experiment. Compared with the ARIMA model, the proposed model improves by 45.75%, 62.68%, and 56.47% while the ARIMA model was the single model with the best prediction accuracy in the experiment.
5.4. Combined Strategy
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Song, J.; Wang, J.; Lu, H. A novel combined model based on advanced optimization algorithm for short-term wind speed forecasting. Appl. Energy 2018, 215, 643–658. [Google Scholar] [CrossRef]
- Koprinska, I.; Rana, M.; Agelidis, V.G. Correlation and instance based feature selection for electricity load forecasting. Knowl.-Based Syst. 2015, 82, 29–40. [Google Scholar] [CrossRef]
- Kaytez, F.; Taplamacioglu, M.C.; Cam, E.; Hardalac, F. Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines. Int. J. Electr. Power 2015, 67, 431–438. [Google Scholar] [CrossRef]
- Ou, T.C.; Hong, C.M. Dynamic operation and control of microgrid hybrid power systems. Energy 2014, 66, 314–323. [Google Scholar] [CrossRef]
- Raviv, E.; Bouwman, K.E.; Dijk, D.V. Forecasting day-ahead electricity prices: Utilizing hourly prices. Energy Econ. 2015, 50, 227–239. [Google Scholar] [CrossRef]
- Wang, J.; Du, P.; Niu, T.; Yang, W. A novel hybrid system based on a new proposed algorithm—Multi-Objective Whale Optimization Algorithm for wind speed forecasting. Appl. Energy 2017. [Google Scholar] [CrossRef]
- Takeda, H.; Tamura, Y.; Sato, S. Using the ensemble Kalman filter for electricity load forecasting and analysis. Energy 2016, 104, 184–198. [Google Scholar] [CrossRef]
- Lei, M.; Shiyan, L.; Chuanwen, J.; Hongling, L.; Yan, Z. A review on the forecasting of wind speed and generated power. Renew. Sustain. Energy Rev. 2009, 13, 915–920. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, Z.H.; Su, Z.Y.; Zhao, Z.Y.; Xiao, X.; Liu, F. An improved multi-step forecasting model based on WRF ensembles and creative fuzzy systems for wind speed. Appl. Energy 2016, 162, 808–826. [Google Scholar] [CrossRef]
- Cheng, W.Y.Y.; Liu, Y.; Bourgeois, A.J.; Wu, Y.; Haupt, S.E. Short-term wind forecast of a data assimilation/weather forecasting system with wind turbine anemometer measurement assimilation. Renew. Energy 2017, 107, 340–351. [Google Scholar] [CrossRef]
- Landberg, L. Short-term prediction of local wind conditions. J. Wind Eng. Ind. Aerodyn. 2001, 89, 235–245. [Google Scholar] [CrossRef]
- Negnevitsky, M.; Johnson, P.; Santoso, S. Short term wind power forecasting using hybrid intelligent systems. In Proceedings of the 2007 IEEE Power Engineering Society General Meeting, Tampa, FL, USA, 24–28 June 2007; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Li, C.; Fu, W.; Peng, T. A compound structure of ELM based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 143, 360–376. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M.; Poolla, K.; Varaiya, P. Exploiting sparsity of interconnections in spatio-temporal wind speed forecasting using Wavelet Transform. Appl. Energy 2016, 165, 735–747. [Google Scholar] [CrossRef]
- Jung, J.; Broadwater, R.P. Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 2014, 31, 762–777. [Google Scholar] [CrossRef]
- Babu, C.N.; Reddy, B.E. A moving-average filter based hybrid ARIMA-ANN model for forecasting time series data. Appl. Soft Comput. 2014, 23, 27–38. [Google Scholar] [CrossRef]
- Niu, X.; Wang, J. A combined model based on data preprocessing strategy and multi-objective optimization algorithm for short-term wind speed forecasting. Appl. Energy 2019, 241, 519–539. [Google Scholar] [CrossRef]
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A review of wind power and wind speed forecasting methods with different time horizons. N. Am. Power Symp. 2010, 1–8. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Wang, J.Z.; Zhao, G.; Dong, Y. Application of residual modification approach in seasonal ARIMA for electricity demand forecasting: A case study of China. Energy Policy 2012, 48, 284–294. [Google Scholar] [CrossRef]
- Brożyna, J.; Mentel, G.; Szetela, B.; Strielkowski, W. Multi-Seasonality in the TBATS Model Using Demand for Electric Energy as a Case Study. Econ. Comput. Econ. Cybern. Stud. Res. 2018, 52, 229–246. [Google Scholar] [CrossRef]
- Ahmad, A.S.; Hassan, M.Y.; Abdullah, M.P.; Rahman, H.A.; Hussion, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sust. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, C.; Su, J.; Wang, J. Research and application based on the swarm intelligence algorithm and artificial intelligence for wind farm decision system. Renew. Energy 2019, 134, 681–697. [Google Scholar] [CrossRef]
- Sadaei, H.J.; de Lima e Silva, P.C.; Guimarães, F.G.; Lee, M.H. Short-term load forecasting by using a combined method of convolutional neural networks and fuzzy time series. Energy 2019. [Google Scholar] [CrossRef]
- Park, D.C.; Sharkawi, M.A.; Marks, R.J. Electric load forecasting using a neural network. IEEE Trans. Power Syst. 1991, 6, 442–449. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Du, P.; Li, Y. Research and application of a hybrid forecasting framework based on multi-objective optimization for electrical power system. Energy 2018, 148, 59–78. [Google Scholar] [CrossRef]
- Lou, C.W.; Dong, M.C. A novel random fuzzy neural networks for tackling uncertainties of electric load forecasting. Int. J. Electr. Power Energy Syst. 2015, 73, 34–44. [Google Scholar] [CrossRef]
- Okumus, I.; Dinler, A. Current status of wind energy forecasting and a hybrid method for hourly predictions. Energy Convers. Manag. 2016, 123, 362–371. [Google Scholar] [CrossRef]
- Hong, C.M.; Ou, T.C.; Lu, K.H. Development of intelligent MPPT (maximum power point tracking) control for a grid-connected hybrid power generation system. Energy 2013, 50, 270–279. [Google Scholar] [CrossRef]
- Che, J.; Wang, J. Short-term electricity prices forecasting based on support vector regression and Auto-regressive integrated moving average modeling. Energy Convers. Manag. 2010, 51, 1911–1917. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Liang, X.F.; Li, Y.F. New wind speed forecasting approaches using fast ensemble empirical model decomposition, genetic algorithm, mind evolutionary algorithm and artificial neural networks. Renew. Energy 2015, 83, 1066–1075. [Google Scholar] [CrossRef]
- Wu, C.; Wang, J.; Chen, X.; Du, P.; Yang, W. A Novel Hybrid System Based on Multi-objective Optimization for Wind Speed Forecasting. Renew. Energy 2019. [Google Scholar] [CrossRef]
- Bates, J.M.; Granger, C.W.J. The combination of forecasts. Oper. Res. Q 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Diebold, F.X. Element of Forecasting, 4th ed.; Thomson South-Western: Cincinnati, OH, USA, 2007; pp. 257–287. [Google Scholar]
- Pesaran, M.H.; Pick, A.; Timmermann, A. Variable selection, estimation and inference for multi-period forecasting problems. J. Econom. 2011, 164, 173–187. [Google Scholar] [CrossRef]
- Zhang, W.; Qu, Z.; Zhang, K.; Mao, W.; Ma, Y.; Fan, X. A combined model based on CEEMDAN and modified flower pollination algorithm for wind speed forecasting. Energy Convers Manag. 2017, 136, 439–451. [Google Scholar] [CrossRef]
- Yang, Y.; Che, J.; Li, Y.; Zhao, Y.; Zhu, S. An incremental electric load forecasting model based on support vector regression. Energy 2016, 113, 796–808. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Li, Y.F. Comparison of two new ARIMA-ANN and ARIMA-Kalman hybrid methods for wind speed prediction. Appl. Energy 2012, 98, 415–424. [Google Scholar] [CrossRef]
- Cardenas-Barrera, J.L.; Meng, J.; Castillo-Guerra, E.; Chang, L. A neural network approach to multi-step-ahead, short-term wind speed forecasting. In Proceedings of the IEEE 2013 12th International Conference on Machine Learning and Applications, Miami, FL, USA, 4–7 December 2013; Volume 2, pp. 243–248. [Google Scholar]
- Wang, J.; Gao, Y.; Chen, X. A novel hybrid interval prediction approach based on modified lower upper bound estimation in combination with multi-objective salp swarm algorithm for short-term load forecasting. Energies 2018, 11, 1561. [Google Scholar] [CrossRef]
- Barbounis, T.G.; Theocharis, J.B. A locally recurrent fuzzy neural network with application to the wind speed prediction using spatial correlation. Neurocomputing 2007, 70, 1525–1542. [Google Scholar] [CrossRef]
- Yang, D.; Sharma, V.; Ye, Z.; Lim, L.I.; Zhao, L.; Aryaputera, A.W. Forecasting of global horizontal irradiance by exponential smoothing, using decompositions. Energy 2015, 81, 111–119. [Google Scholar] [CrossRef]
- Li, R.; Jin, Y. A wind speed interval prediction system based on multi-objective optimization for machine learning method. Appl. Energy 2018, 228, 2207–2220. [Google Scholar] [CrossRef]
- Patterson, D.W. Artificial Neural Networks: Theory and Applications; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Vel_azquez, S.; Carta, J.A.; Matías, J.M. Influence of the input layer signals of ANNs on wind power estimation for a target site: A case study. Renew. Sustain. Energy Rev. 2011, 15, 1556–1566. [Google Scholar] [CrossRef]
- Koo, J.; Han, G.D.; Choi, H.J.; Shim, J.H.; Lund, H.; Kaiser, M.J. Wind-speed prediction and analysis based on geological and distance variables using an artificial neural network: A case study in South Korea. Energy 2015, 93, 1296–1302. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J. A robust combination approach for short-term wind speed forecasting and analysisecombination of the ARIMA (autoregressive integrated moving average), ELM (extreme learning machine), SVM (support vector machine) and LSSVM (least square SVM) forecasts using a GPR (gaussian process regression) model. Energy 2015, 93, 41–56. [Google Scholar]
- Xiao, L.; Wang, J.; Hou, R.; Wu, J. A combined model based on data pre-analysis and weight coefficients optimization for electrical load forecasting. Energy 2015, 82, 524–549. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, J.; Guo, Z. Research on combined model based on multi-objective optimization and application in time series forecast. Soft Comput. 2018. [Google Scholar] [CrossRef]
- Wang, J.-J.; Zhang, W.-Y.; Liu, X.; Wang, C.-Y. Modifying Wind Speed Data Observed from Manual Observation System to Automatic Observation System Using Wavelet Neural Network. Phys. Procedia 2012, 25, 1980–1987. [Google Scholar] [CrossRef]
- Li, S.; Goel, L.; Wang, P. An ensemble approach for short-term load forecasting by extreme learning machine. Appl. Energy 2016, 170, 22–29. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Meng, A.; Ge, J.; Yin, H.; Chen, S. Wind speed forecasting based on wavelet packet decomposition and artificial neural networks trained by crisscross optimization algorithm. Energy Convers. Manag. 2016, 114, 75–88. [Google Scholar] [CrossRef]
- Heng, J.; Wang, C.; Zhao, X.; Xiao, L. Research and Application Based on Adaptive Boosting Strategy and Modified CGFPA Algorithm: A Case Study for Wind Speed Forecasting. Sustainability 2016, 8, 235. [Google Scholar] [CrossRef]
- McClelland, J.L.; Rumelhart, D.E. An Interactive Activation Model of Context Effects in Letter Perception: Part I. An Account of Basic Findings. Read. Cogn. Sci. 1988, 580–596. [Google Scholar] [CrossRef]
- Mirjalili, S.Z.; Mirjalili, S.; Saremi, S.; Faris, H.; Aljarah, I. Grasshopper optimization algorithm for multi-objective optimization problems. Appl. Intell. 2017, 48, 805–820. [Google Scholar] [CrossRef]
- Niu, M.; Sun, S.; Wu, J.; Yu, L.; Wang, J. An innovative integrated model using the singular spectrum analysis and nonlinear multi-layer perceptron network optimized by hybrid intelligent algorithm for short-term load forecasting. Appl. Math. Model. 2016, 40, 4079–4093. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, W.; Wang, J. Air quality early-warning system for cities in China. Atmos. Environ. 2017, 148, 239–257. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R. Comparing predictive accuracy. J. Bus. Econ. Stat. 1995, 13, 253–265. [Google Scholar]
- Yang, Z.; Wang, J. A combination forecasting approach applied in multistep wind speed forecasting based on a data processing strategy and an optimized artificial intelligence algorithm. Appl. Energy 2018, 230, 1108–1125. [Google Scholar] [CrossRef]
- Yang, X.S. A New Metaheuristic Bat-Inspired Algorithm. Nature Inspired Cooperative Strategies for Optimization (NICSO); Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; Volume 284, pp. 65–74. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset. | Samples | Numbers | Statistical Indicator(kw) | |||
|---|---|---|---|---|---|---|
| Max | Min | Mean | Std. | |||
| QLD(2010) | All samples | 912 | 7033.21 | 4316.89 | 5788.65 | 741.36 |
| Training | 768 | 7033.21 | 4316.89 | 5803.04 | 746.40 | |
| Testing | 144 | 6476.49 | 4361.6 | 5711.87 | 708.99 | |
| QLD(2011) | All samples | 912 | 7234.04 | 4399.42 | 5782.99 | 724.57 |
| Training | 768 | 7234.04 | 4412.33 | 5834.35 | 729.96 | |
| Testing | 144 | 6718.05 | 4399.42 | 5509.06 | 627.75 | |
| NSW(2011) | All samples | 912 | 12883.81 | 6821.4 | 9707.66 | 1337.86 |
| Training | 768 | 12883.81 | 6821.4 | 9819.03 | 1346.71 | |
| Testing | 144 | 11314.46 | 6939.18 | 9113.68 | 1115.41 | |
| Metric | Definition | Equation |
|---|---|---|
| MAE | The mean absolute error of N forecasting results | |
| RMSE | The square root of the average of error squares | |
| MAPE | The average of N absolute percentage error |
| Dataset | Model | MAE | RMSE | MAPE (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | ||
| QLD(2010) | SSA-BP | 24.78 | 32.79 | 62.15 | 30.87 | 39.70 | 80.51 | 0.44 | 0.58 | 1.10 |
| SSA-ELM | 22.35 | 36.58 | 68.08 | 28.35 | 44.18 | 86.52 | 0.40 | 0.66 | 1.20 | |
| SSA-WNN | 26.23 | 52.69 | 95.45 | 36.09 | 68.78 | 126.16 | 0.47 | 0.93 | 1.71 | |
| SSA-ARIMA | 39.18 | 40.71 | 43.54 | 52.83 | 54.84 | 57.59 | 0.70 | 0.72 | 0.78 | |
| Proposed Model | 21.26 | 25.94 | 37.97 | 26.98 | 32.83 | 46.51 | 0.37 | 0.45 | 0.68 | |
| QLD(2011) | SSA-BP | 26.21 | 35.21 | 71.09 | 34.48 | 45.07 | 86.81 | 0.50 | 0.65 | 1.31 |
| SSA-ELM | 23.90 | 34.98 | 90.62 | 30.43 | 45.20 | 118.89 | 0.44 | 0.65 | 1.69 | |
| SSA-WNN | 35.30 | 80.94 | 169.98 | 45.58 | 100.84 | 216.67 | 0.68 | 1.53 | 3.16 | |
| SSA-ARIMA | 42.82 | 44.60 | 48.70 | 58.27 | 58.10 | 61.19 | 0.77 | 0.81 | 0.90 | |
| Proposed Model | 20.79 | 23.43 | 34.84 | 27.75 | 30.73 | 44.80 | 0.38 | 0.43 | 0.65 | |
| NSW(2011) | SSA-BP | 47.49 | 77.03 | 130.75 | 62.67 | 97.79 | 159.54 | 0.53 | 0.86 | 1.49 |
| SSA-ELM | 46.43 | 73.69 | 153.61 | 59.45 | 90.02 | 197.51 | 0.51 | 0.82 | 1.74 | |
| SSA-WNN | 58.74 | 125.89 | 258.21 | 75.26 | 163.72 | 324.61 | 0.66 | 1.43 | 2.94 | |
| SSA-ARIMA | 90.62 | 95.95 | 105.31 | 127.67 | 128.47 | 130.37 | 0.99 | 1.04 | 1.16 | |
| Proposed Model | 44.29 | 57.83 | 77.74 | 57.63 | 73.87 | 97.92 | 0.48 | 0.64 | 0.86 | |
| Dataset | Model | MAE | RMSE | MAPE (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | ||
| QLD(2010) | EMD | 39.86 | 47.91 | 56.38 | 45.93 | 56.44 | 67.71 | 0.72 | 0.88 | 1.05 |
| EEMD | 33.72 | 42.97 | 55.97 | 50.84 | 56.95 | 70.47 | 0.60 | 0.78 | 0.99 | |
| CEEMD | 30.04 | 35.90 | 51.47 | 36.74 | 44.14 | 64.19 | 0.54 | 0.64 | 0.90 | |
| Proposed Model | 21.26 | 25.94 | 37.97 | 26.98 | 32.83 | 46.51 | 0.37 | 0.45 | 0.68 | |
| QLD(2011) | EMD | 38.37 | 46.63 | 60.59 | 50.13 | 57.51 | 72.93 | 0.71 | 0.86 | 1.12 |
| EEMD | 31.56 | 55.11 | 84.83 | 38.57 | 73.23 | 107.65 | 0.59 | 1.00 | 1.56 | |
| CEEMD | 30.48 | 32.89 | 53.04 | 43.11 | 44.62 | 66.12 | 0.56 | 0.61 | 0.97 | |
| Proposed Model | 20.79 | 23.43 | 34.84 | 27.75 | 30.73 | 44.80 | 0.38 | 0.43 | 0.65 | |
| NSW(2011) | EMD | 60.95 | 74.46 | 110.60 | 83.78 | 95.41 | 135.10 | 0.66 | 0.82 | 1.24 |
| EEMD | 65.29 | 112.21 | 166.16 | 80.19 | 140.71 | 213.64 | 0.73 | 1.25 | 1.81 | |
| CEEMD | 62.29 | 82.48 | 100.39 | 82.51 | 100.77 | 125.26 | 0.67 | 0.92 | 1.12 | |
| Proposed Model | 44.29 | 57.83 | 77.74 | 57.63 | 73.87 | 97.92 | 0.48 | 0.64 | 0.86 | |
| Dataset | Model | MAE | RMSE | MAPE (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | ||
| QLD(2010) | BP | 46.12 | 80.44 | 119.79 | 59.34 | 102.45 | 150.21 | 0.81 | 1.40 | 2.10 |
| BP-MODA | 47.54 | 86.23 | 121.67 | 59.98 | 108.89 | 162.77 | 0.84 | 1.52 | 2.13 | |
| WNN | 51.24 | 99.72 | 145.12 | 64.72 | 136.56 | 189.77 | 0.90 | 1.75 | 2.58 | |
| ENN | 45.76 | 82.88 | 126.34 | 60.95 | 104.71 | 168.20 | 0.80 | 1.46 | 2.24 | |
| ELM | 46.24 | 85.19 | 130.82 | 59.28 | 110.41 | 171.58 | 0.81 | 1.50 | 2.34 | |
| RBF | 64.08 | 134.02 | 185.37 | 86.13 | 185.85 | 275.07 | 1.12 | 2.33 | 3.22 | |
| ARIMA | 38.97 | 73.96 | 88.00 | 49.44 | 91.95 | 105.91 | 0.70 | 1.32 | 1.58 | |
| Proposed Model | 21.26 | 25.94 | 37.97 | 26.98 | 32.83 | 46.51 | 0.37 | 0.45 | 0.68 | |
| QLD(2011) | BP | 45.61 | 93.75 | 147.05 | 64.12 | 127.47 | 217.66 | 0.82 | 1.71 | 2.66 |
| BP-MODA | 44.23 | 85.21 | 124.31 | 61.31 | 116.22 | 163.60 | 0.79 | 1.56 | 2.28 | |
| WNN | 62.72 | 138.62 | 200.49 | 80.68 | 181.26 | 268.88 | 1.16 | 2.55 | 3.75 | |
| ENN | 50.62 | 98.11 | 152.69 | 70.11 | 135.34 | 207.65 | 0.92 | 1.80 | 2.79 | |
| ELM | 48.77 | 96.45 | 158.82 | 66.91 | 133.68 | 216.32 | 0.89 | 1.76 | 2.91 | |
| RBF | 85.22 | 170.73 | 308.71 | 198.05 | 524.76 | 971.50 | 1.53 | 3.10 | 5.64 | |
| ARIMA | 37.50 | 68.01 | 87.55 | 46.94 | 87.81 | 107.32 | 0.71 | 1.28 | 1.64 | |
| Proposed Model | 20.79 | 23.43 | 34.84 | 27.75 | 30.73 | 44.80 | 0.38 | 0.43 | 0.65 | |
| NSW(2011) | BP | 89.72 | 163.56 | 276.83 | 124.34 | 215.84 | 349.76 | 0.96 | 1.79 | 3.05 |
| BP-MODA | 85.23 | 180.48 | 268.43 | 110.79 | 251.79 | 360.47 | 0.92 | 1.98 | 2.94 | |
| WNN | 92.97 | 243.25 | 400.39 | 118.54 | 323.58 | 538.95 | 1.02 | 2.71 | 4.52 | |
| ENN | 101.07 | 191.08 | 282.89 | 133.22 | 265.73 | 362.33 | 1.09 | 2.08 | 3.13 | |
| ELM | 98.76 | 205.09 | 317.34 | 130.92 | 274.27 | 410.74 | 1.06 | 2.24 | 3.53 | |
| RBF | 149.92 | 216.50 | 351.10 | 280.01 | 318.79 | 449.90 | 1.60 | 2.36 | 3.84 | |
| ARIMA | 78.00 | 130.15 | 159.76 | 95.68 | 161.82 | 203.99 | 0.88 | 1.46 | 1.80 | |
| Proposed Model | 44.29 | 57.83 | 77.74 | 57.63 | 73.87 | 97.92 | 0.48 | 0.64 | 0.86 | |
| ZDT1 | ZDT2 |
| Minimize: Minimize: Where: | Minimize: Minimize: Where: |
| ZDT3 | ZDT1 with linear front |
| Minimize: Minimize: Where: | Minimize: Minimize: Where: |
| Algorithm | Ave. | Std. | Median | Min | Max |
|---|---|---|---|---|---|
| ZDT1 | |||||
| MOALO | 0.006213 | 0.007038 | 0.005901 | 0.004272 | 0.024323 |
| MODA | 0.005826 | 0.005798 | 0.005082 | 0.002613 | 0.025404 |
| MOGOA | 0.004275 | 0.003089 | 0.004669 | 0.002573 | 0.024234 |
| ZDT2 | |||||
| MOALO | 0.009454 | 0.007343 | 0.008998 | 0.004738 | 0.022138 |
| MODA | 0.008173 | 0.005193 | 0.008532 | 0.003643 | 0.023234 |
| MOGOA | 0.008015 | 0.003140 | 0.005395 | 0.002157 | 0.023118 |
| ZDT3 | |||||
| MOALO | 0.027063 | 0.000867 | 0.026627 | 0.028135 | 0.026727 |
| MODA | 0.025089 | 0.000521 | 0.024982 | 0.028182 | 0.027322 |
| MOGOA | 0.024270 | 0.000469 | 0.024246 | 0.024186 | 0.023801 |
| ZDT1 with linear front | |||||
| MOALO | 0.006821 | 0.005623 | 0.006532 | 0.005431 | 0.026626 |
| MODA | 0.006101 | 0.005541 | 0.005926 | 0.003863 | 0.024777 |
| MOGOA | 0.005569 | 0.004986 | 0.003985 | 0.002211 | 0.024461 |
| Model | 1-step | 2-step | 3-step |
|---|---|---|---|
| SSA-BP | 2.7503 * | 3.8971 * | 6.1244 * |
| SSA-ELM | 1.6379 ** | 3.9104 * | 6.3244 * |
| SSA-WNN | 4.0126 * | 6.8486 * | 7.3544 * |
| SSA-ARIMA | 4.9261 * | 5.0164 * | 4.0033 * |
| EMD | 5.4365 * | 5.5545 * | 5.7057 * |
| EEMD | 4.3034 * | 5.0669 * | 5.21 * |
| CEEMD | 3.7225 * | 3.8063 * | 4.3806 * |
| BP | 4.7348 * | 5.9805 * | 6.3855 * |
| BP-MODA | 5.2960 * | 5.8782 * | 6.2118 * |
| WNN | 6.3481 * | 6.2092 * | 7.1581 * |
| ENN | 5.3966 * | 6.1685 * | 6.3538 * |
| ELM | 5.4820 * | 5.7369 * | 6.3290 * |
| RBF | 3.3792 * | 3.7372 * | 3.5957 * |
| ARIMA | 5.6641 * | 7.0336 * | 7.5187 * |
| Model | 1-step | 2-step | 3-step | |||
|---|---|---|---|---|---|---|
| 1-order | 2-order | 1-order | 2-order | 1-order | 2-order | |
| Proposed Model | 0.9959 | 0.9962 | 0.9949 | 0.9957 | 0.9927 | 0.9935 |
| SSA-BP | 0.9951 | 0.9950 | 0.9931 | 0.9935 | 0.9870 | 0.9869 |
| SSA-ELM | 0.9955 | 0.9956 | 0.9929 | 0.9935 | 0.9846 | 0.9831 |
| SSA-WNN | 0.9940 | 0.9932 | 0.9870 | 0.9847 | 0.9740 | 0.9684 |
| SSA-ARIMA | 0.9918 | 0.9923 | 0.9914 | 0.9919 | 0.9905 | 0.9910 |
| EMD | 0.9930 | 0.9929 | 0.9915 | 0.9914 | 0.9887 | 0.9888 |
| EEMD | 0.9936 | 0.9941 | 0.9899 | 0.9900 | 0.9855 | 0.9844 |
| CEEMD | 0.9941 | 0.9944 | 0.9928 | 0.9939 | 0.9900 | 0.9903 |
| BP | 0.9914 | 0.9918 | 0.9837 | 0.9829 | 0.9740 | 0.9734 |
| BP-MODA | 0.9915 | 0.9921 | 0.9831 | 0.9844 | 0.9755 | 0.9772 |
| WNN | 0.9897 | 0.9884 | 0.9766 | 0.9745 | 0.9638 | 0.9625 |
| ENN | 0.9906 | 0.9908 | 0.9822 | 0.9820 | 0.9728 | 0.9721 |
| ELM | 0.9908 | 0.9911 | 0.9817 | 0.9824 | 0.9707 | 0.9709 |
| RBF | 0.9858 | 0.9847 | 0.9740 | 0.9690 | 0.9589 | 0.9473 |
| ARIMA | 0.9924 | 0.9929 | 0.9865 | 0.9872 | 0.9833 | 0.9836 |
| Model | Site 1 | Site 2 | Site 3 | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | 1-step | 2-step | 3-step | |
| SSA-BP | 22.64% | 33.80% | 50.34% | 8.66% | 25.58% | 42.01% | 14.66% | 21.23% | 38.48% | 15.32% | 26.87% | 43.61% |
| SSA-ELM | 12.61% | 33.77% | 61.43% | 4.96% | 22.46% | 50.35% | 5.55% | 31.32% | 43.85% | 7.71% | 29.18% | 51.88% |
| SSA-WNN | 43.95% | 71.78% | 79.41% | 27.19% | 55.24% | 70.63% | 19.65% | 51.45% | 60.49% | 30.26% | 59.49% | 70.18% |
| SSA-ARIMA | 50.37% | 46.41% | 27.33% | 51.26% | 38.70% | 25.26% | 46.33% | 37.50% | 13.76% | 49.32% | 40.87% | 22.12% |
| EMD | 45.58% | 49.99% | 41.74% | 27.16% | 22.09% | 30.29% | 48.34% | 48.42% | 35.46% | 40.36% | 40.17% | 35.83% |
| EEMD | 35.39% | 56.84% | 58.19% | 34.38% | 48.75% | 52.29% | 37.92% | 41.76% | 32.02% | 35.90% | 49.12% | 47.50% |
| CEEMD | 31.79% | 28.77% | 32.63% | 28.47% | 30.30% | 23.02% | 30.47% | 29.66% | 25.22% | 30.24% | 29.58% | 26.96% |
| BP | 53.29% | 74.77% | 75.57% | 49.74% | 64.28% | 71.63% | 53.78% | 67.55% | 67.77% | 52.27% | 68.87% | 71.66% |
| BP-MODA | 51.66% | 72.40% | 71.48% | 47.87% | 67.72% | 70.57% | 55.26% | 70.17% | 68.35% | 51.60% | 70.10% | 70.13% |
| WNN | 66.78% | 83.08% | 82.65% | 52.83% | 76.47% | 80.86% | 58.62% | 74.15% | 73.79% | 59.41% | 77.90% | 79.10% |
| ENN | 58.38% | 76.02% | 76.67% | 55.70% | 69.29% | 72.41% | 53.43% | 68.92% | 69.90% | 55.84% | 71.41% | 72.99% |
| ELM | 56.65% | 75.48% | 77.67% | 54.65% | 71.56% | 75.49% | 53.92% | 69.74% | 71.14% | 55.07% | 72.26% | 74.77% |
| RBF | 74.90% | 86.07% | 88.46% | 69.96% | 72.97% | 77.51% | 66.48% | 80.54% | 79.01% | 70.45% | 79.86% | 81.66% |
| ARIMA | 45.65% | 66.20% | 60.38% | 45.25% | 56.24% | 51.93% | 46.34% | 65.59% | 57.11% | 45.75% | 62.68% | 56.47% |
| Dateset | Multi-Step | Model | MAE | RMSE | MAPE (%) |
|---|---|---|---|---|---|
| QLD(2010) | 1-step | Simple average strategy | 28.13 | 37.04 | 0.50 |
| Proposed model | 21.26 | 26.98 | 0.37 | ||
| 2-step | Simple average strategy | 40.69 | 51.88 | 0.72 | |
| Proposed model | 25.94 | 32.83 | 0.45 | ||
| 3-step | Simple average strategy | 67.30 | 87.69 | 1.20 | |
| Proposed model | 37.97 | 46.51 | 0.68 | ||
| QLD(2011) | 1-step | Simple average strategy | 32.06 | 42.19 | 0.60 |
| Proposed model | 20.79 | 27.75 | 0.38 | ||
| 2-step | Simple average strategy | 48.93 | 62.31 | 0.91 | |
| Proposed model | 23.43 | 30.73 | 0.43 | ||
| 3-step | Simple average strategy | 95.10 | 120.89 | 1.76 | |
| Proposed model | 34.84 | 44.80 | 0.65 | ||
| NSW(2011) | 1-step | Simple average strategy | 60.82 | 81.26 | 0.67 |
| Proposed model | 44.29 | 57.63 | 0.48 | ||
| 2-step | Simple average strategy | 93.14 | 120.00 | 1.04 | |
| Proposed model | 57.83 | 73.87 | 0.64 | ||
| 3-step | Simple average strategy | 161.97 | 203.01 | 1.83 | |
| Proposed model | 77.74 | 97.92 | 0.86 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wang, J.; Lu, H. Research and Application of a Novel Combined Model Based on Multiobjective Optimization for Multistep-Ahead Electric Load Forecasting. Energies 2019, 12, 1931. https://doi.org/10.3390/en12101931
Zhang Y, Wang J, Lu H. Research and Application of a Novel Combined Model Based on Multiobjective Optimization for Multistep-Ahead Electric Load Forecasting. Energies. 2019; 12(10):1931. https://doi.org/10.3390/en12101931
Chicago/Turabian StyleZhang, Yechi, Jianzhou Wang, and Haiyan Lu. 2019. "Research and Application of a Novel Combined Model Based on Multiobjective Optimization for Multistep-Ahead Electric Load Forecasting" Energies 12, no. 10: 1931. https://doi.org/10.3390/en12101931
APA StyleZhang, Y., Wang, J., & Lu, H. (2019). Research and Application of a Novel Combined Model Based on Multiobjective Optimization for Multistep-Ahead Electric Load Forecasting. Energies, 12(10), 1931. https://doi.org/10.3390/en12101931