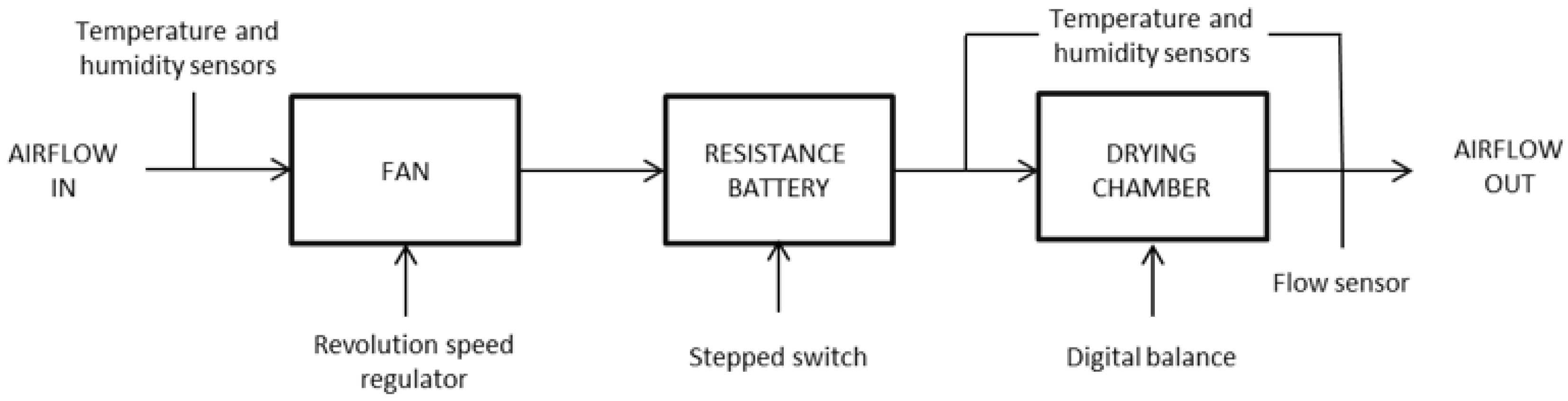
Furthermore, the experiment is done with two tomato derivatives: peels and seeds and sludge. They showed an initial moisture content of 66% by weight (wet basis). In this case, drying experiments were conducted respectively at 25 C, 35 C and 45 C drying air temperatures and at 1.0 m/s and 1.3 m/s air velocities according to the methodology indicated.
Moreover, the samples of fresh sludge were obtained from the wastewater treatment plant of a local tomato industry located in the province of Badajoz (in the Southwest area of Spain). These samples showed an initial moisture content of 63% by weight (wet basis). This value was calculated as indicated by the Norm UNE 32001 [
43]. Drying experiments were conducted at 30
C, 40
C and 50
C drying air temperatures and at 0.9 m/s and 1.3 m/s air velocities according to the explained methodology.
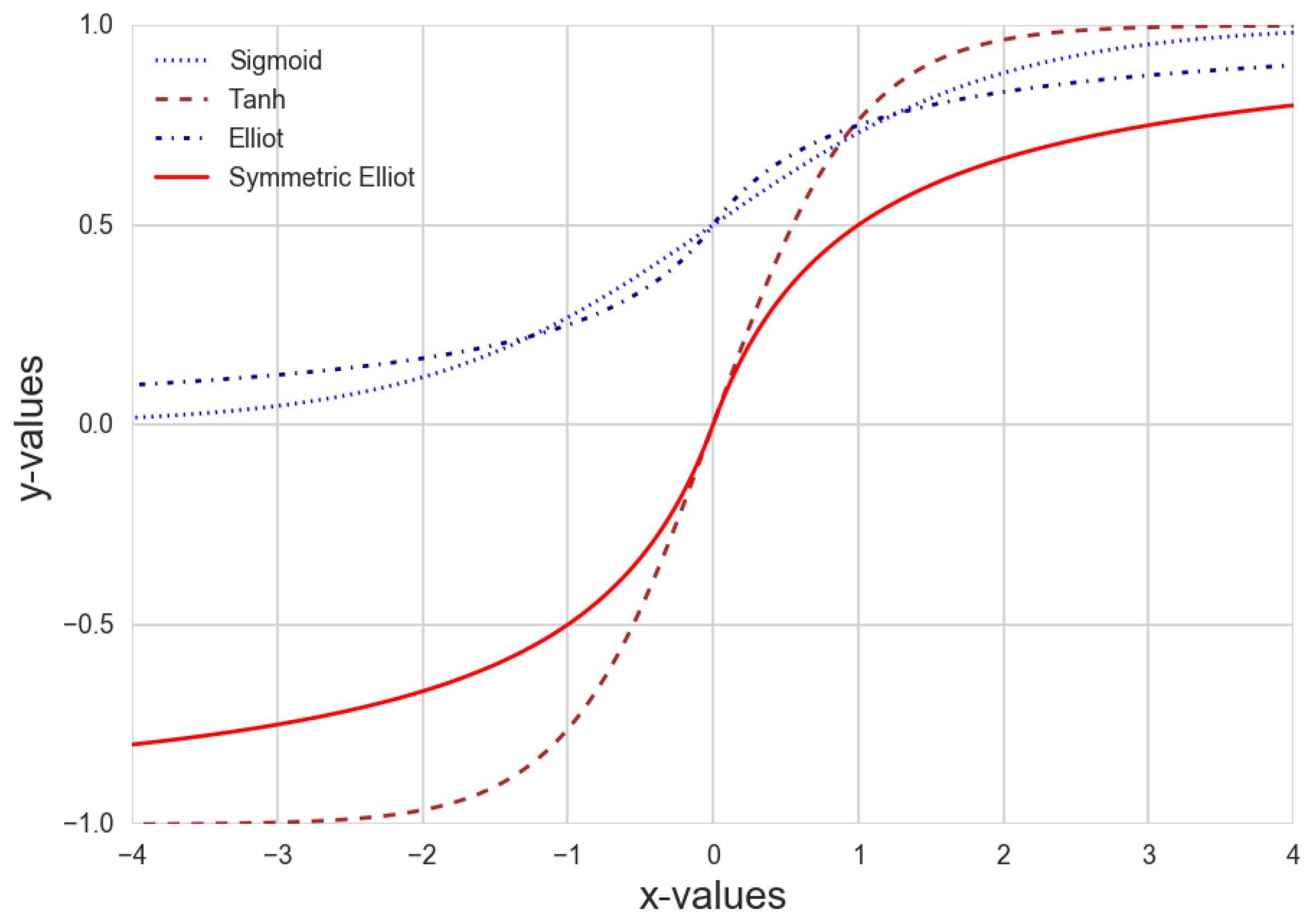
6.1. No Noise
The results of the peels and seeds experiment without noise are detailed in
Table 1. ELMs achieved better results than the state-of-the-art techniques. Elliot–ELM got the lowest error measurement for MAE, Elliot Symmetric–ELM the lowest MSE and the highest one for
score. Tanh–ELM got the lowest MEDAE. According to all the error measurements, ELM outperforms the tested forecasting techniques. The second-best technique for MAE and MSE is Random Forest, for MEDAE is
k-NN and for
is Regression Trees. Within the ELMs, Elliot–ELM got the lowest MAE, Elliot Symmetric–ELM the lowest MSE and the highest
, but the lowest MEDAE is achieved by the Tanh–ELM.
The results of the sludge experiment without noise are detailed in
Table 2. ELMs achieved better results than the state-of-the-art techniques. Sigmoid-ELM got the lowest for all the error measurements, just for
the other ELMs (Tanh, Elliot and Symmetric Elliot) got the same score than the winner. According to all the error measurements, ELM outperforms again the tested forecasting techniques. The second-best technique for MAE is Linear Regression, for MSE and
is
k-NN, for MEDAE is Random Forest.
6.2. Noise
Real-world data are affected by several issues where noise is a critical factor [
44]. In real-world applications, it is not possible to avoid the presence of noise in data. The source of noise relevant for this paper is the attribute noise [
45]. The goal of this experimental approach is to test the accuracy of the proposed methodology in the presence of real-world noise.
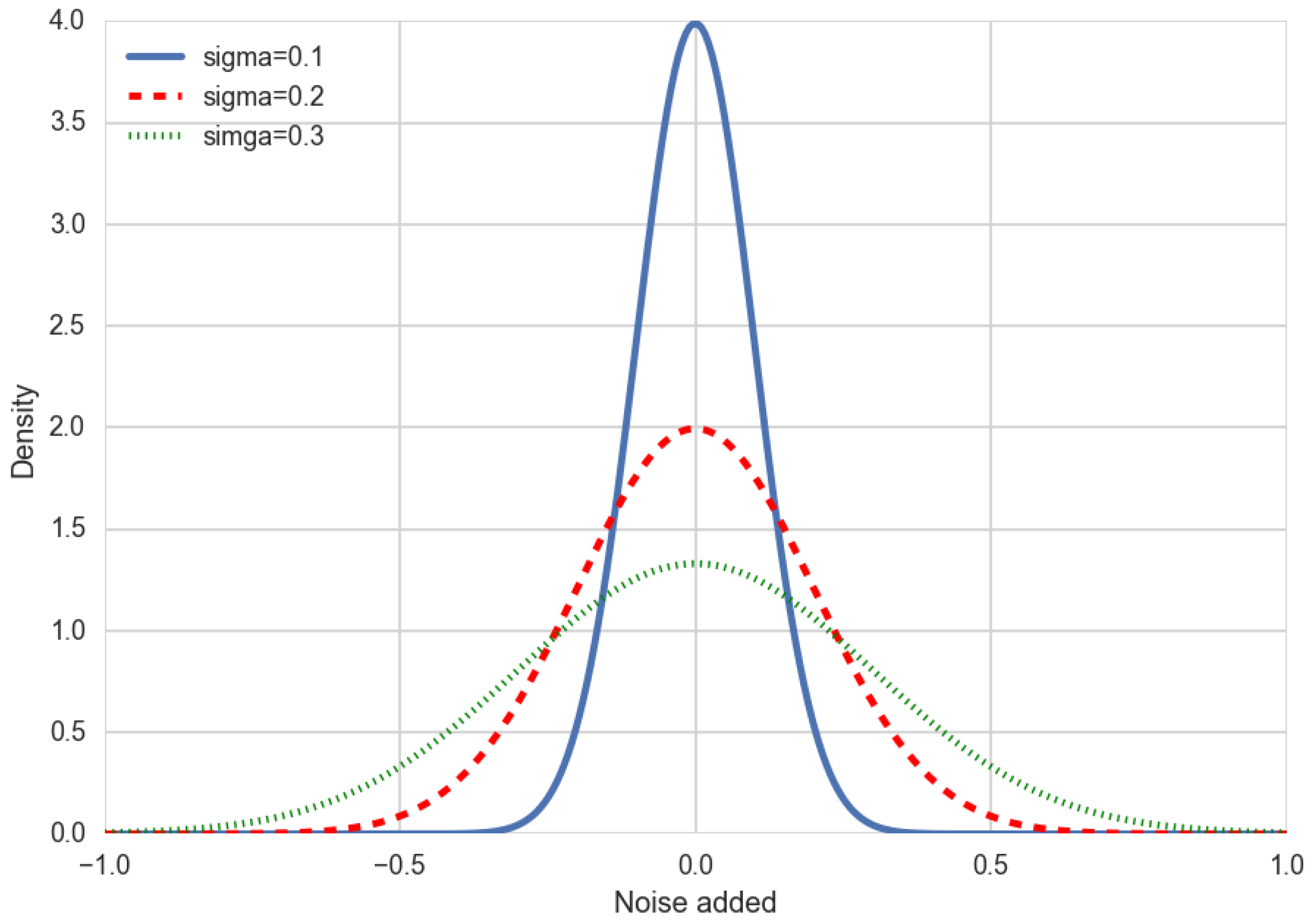
In this work, Gauss distribution is used to include noise in the data. The Gaussian noise is statistical noise with a probability density function equal to that of the Gaussian distribution. Gaussian noise is therefore noise whose frequency spectrum (after a Fourier transform) has a bell-shaped curve.
We compute the Gaussian noise with the following probability density
where
is the mean and
the standard deviation. We are going to use three amplitudes of noise in the training data. They are computed with the same mean
and different standard deviations’ values (low:
, middle:
and high:
).
Figure 6 shows the Gaussian probability densities applied for generating Gaussian noise.
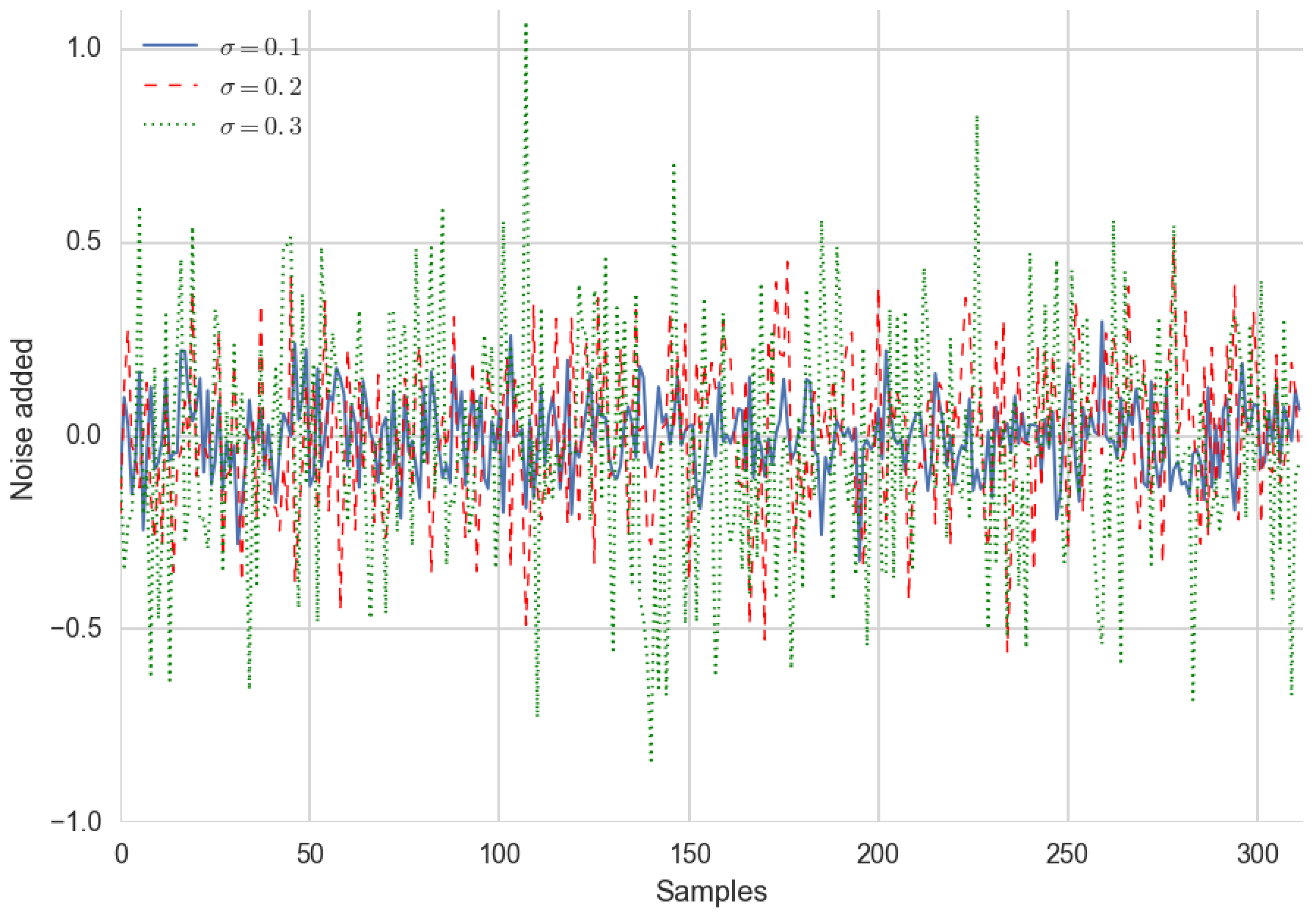
Figure 7 shows the three Gaussian noises added to training data for each sample.
Regarding this experiment, data gathering in laboratory environments does not include noise, since it is normally clean, the sensors and their connections are very accessible and there is specialised staff in charge of their care. However, in industrial working conditions, the situation changes. In the environment of the sensors, there may be dust, grease and other fouling agents; these sensors are not usually located in points where they can be easily checked and it is not usual to have staff in charge of its continuous review.
In the industrial drying processes in which we are interested, it is usual for distorted data records to invalidate the measurements and therefore the process control should be less accurate. For these reasons, it is worth testing the proposal with noisy data, both Gaussian and uncorrelated uniform.
The results of the peels and seeds experiment with Gaussian noise (
) are detailed in
Table 3. ELMs achieved better results than the state-of-the-art techniques. Tanh–ELM got the lowest error measurement for MAE, Elliot Symmetric–ELM the lowest scores for MSE and MEDAE and the highest one for
score. According to all the error measurements, ELM outperforms the tested forecasting techniques and Elliot–ELM is the best within the ELM flavours. The second-best technique for MAE and MEDAE is
k-NN, for MSE and
is Random Forest.
The results of the sludge experiment with noise (
) are detailed in
Table 4. ELMs achieved better results than the state-of-the-art techniques. Elliot–ELM got the lowest error measurement for MAE, MEDAE and the highest one for
. Elliot Symmetric–ELM got the lowest scores for MSE. According to all the error measurements, ELM outperforms the tested forecasting techniques and Elliot–ELM is the best within the ELM flavours. The second-best technique for MAE, MSE and MEDAE is
k-NN, for
is Random Forest.
The results of the peels and seeds experiment with noise (
) are detailed in
Table 5. ELMs achieved better results than the state-of-the-art techniques. Elliot–ELM got the lowest error measurement for all the error measurements. According to all the error measurements, ELM outperforms the tested forecasting techniques and Elliot–ELM is the best within the ELM flavours. The second-best technique for MAE, MSE and
is Random Forest and for MEDAE is
k-NN.
The results of the sludge experiment with noise (
) are detailed in
Table 6. ELMs achieved better results than the state-of-the-art techniques. Elliot–ELM got the lowest error measurement for all the error measurements. According to all the error measurements, ELM outperforms the tested forecasting techniques and Elliot–ELM is the best within the ELM flavours. The second-best technique for all the error measurements is Random Forest.
The results of the peels and seeds experiment with noise (
) are detailed in
Table 7. ELMs achieved better results than the state-of-the-art techniques. Symmetric Elliot–ELM got the lowest error measurement for MAE, MEDAE and the highest one for
. Elliot–ELM got the lowest scores for MEDAE. According to all the error measurements, ELM outperforms the tested forecasting techniques and Elliot–ELM is the best within the ELM flavours. The second-best technique for MAE, MSE and MEDAE is
k-NN, for
is Random Forest.
The results of the sludge experiment with noise (
) are detailed in
Table 8. ELMs achieved better results than the state-of-the-art techniques. Elliot–ELM got the lowest error measurement for MSE and the highest one for
. Tanh–ELM got the lowest scores for MAE and MEDAE. According to all the error measurements, ELM outperforms the tested forecasting techniques and the second-best technique for MAE, MSE and MEDAE and
is Random Forest.












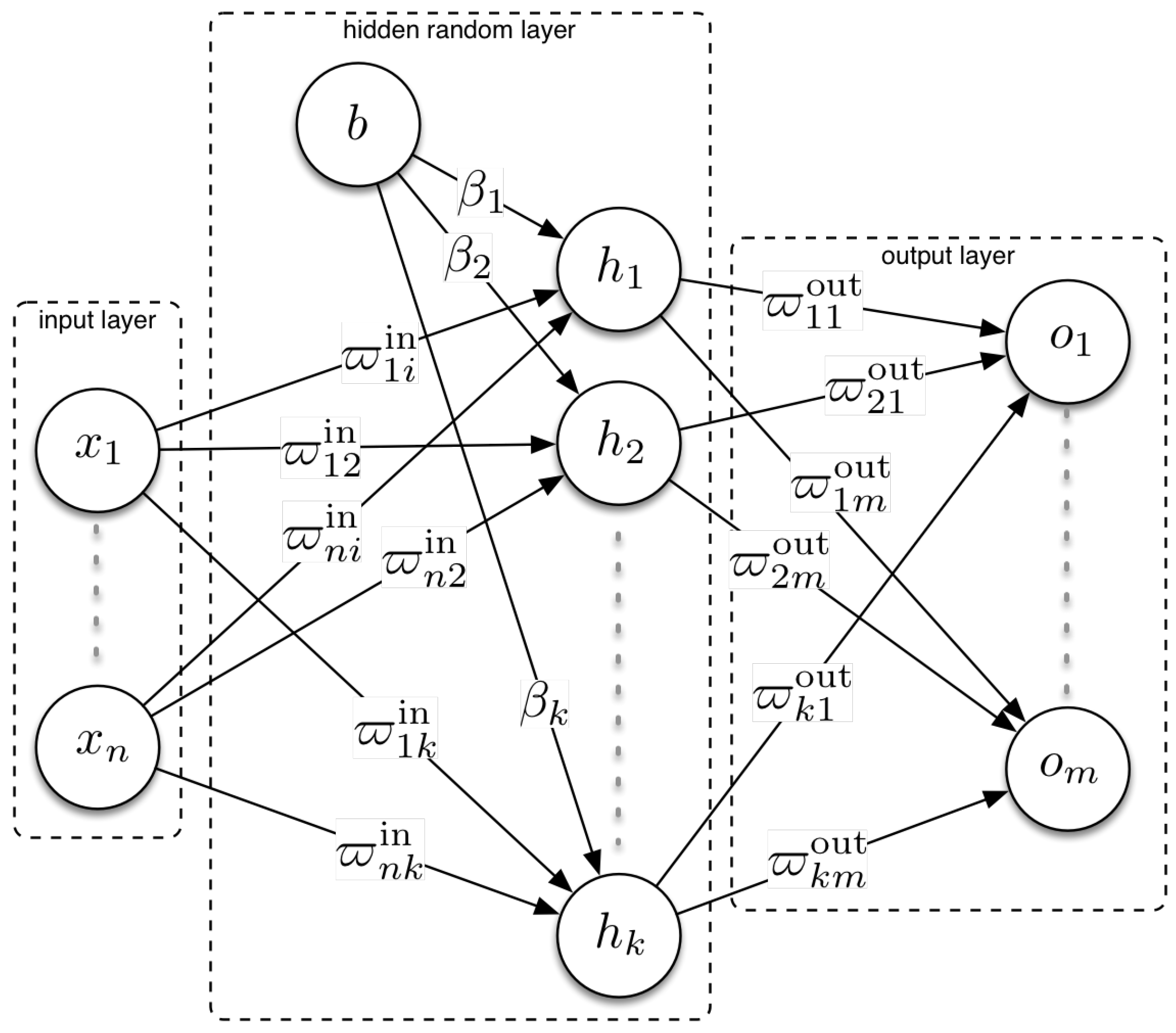{kind=link}
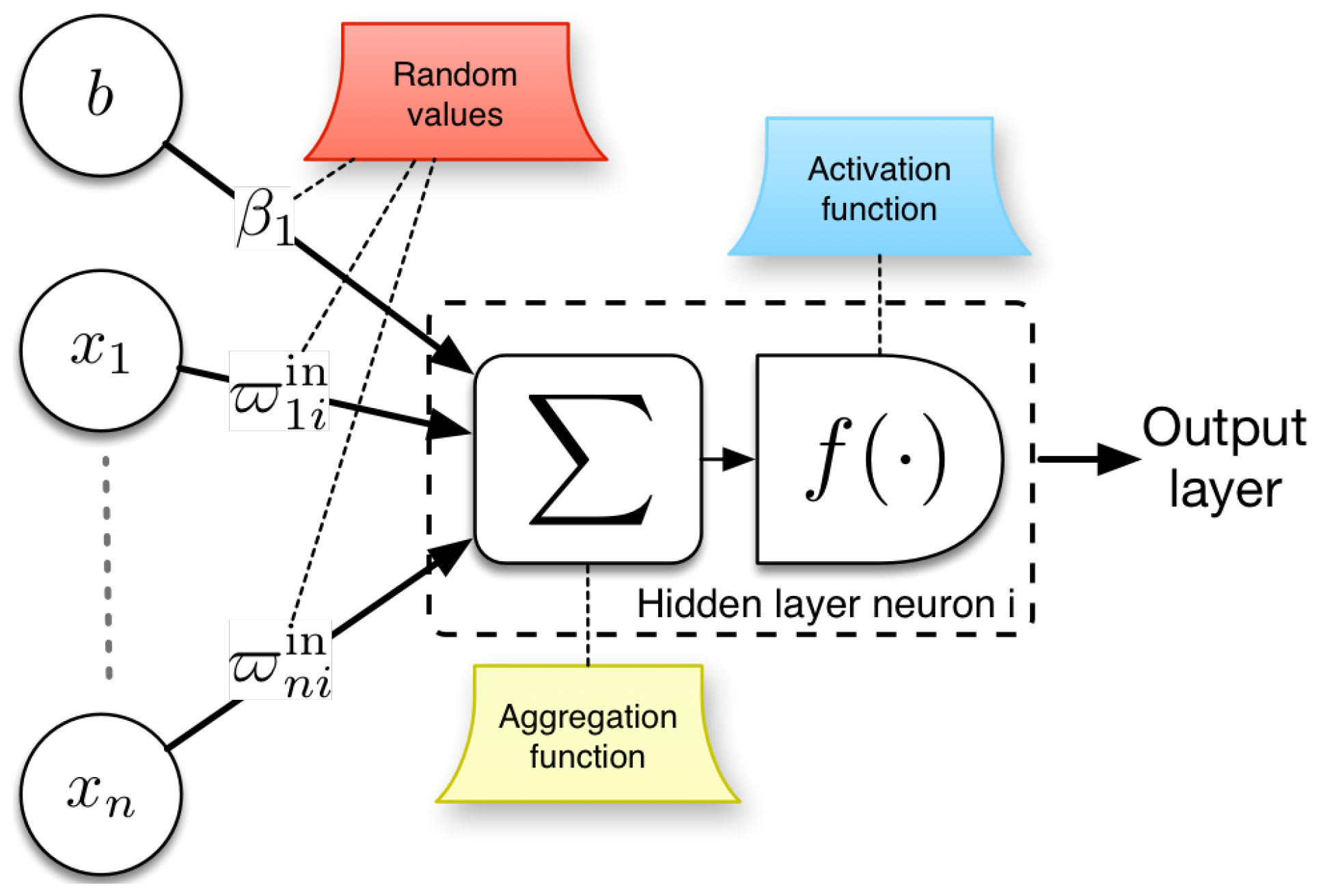{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}