1. Introduction
Recent developments of complex systems, such as aircraft engines, engineering machines, high-speed vehicles and computer numerical control (CNC) systems have been emphasized by the increasing requirements of on-line health monitoring for the purpose of maximizing its operational reliability and safety [
1,
2,
3]. As the core part and power source of aircrafts, the reliable operation of an aero engine is critical for ensuring the reliability and safety of the aircraft, and to maintain its availability, and reduce its maintenance costs [
4,
5,
6]. Among them, prognostics and health management (PHM) is an effective approach and one of the most commonly-used [
7,
8]. In particular, residual useful life (RUL) estimation is a key technology for PHM. In general, RUL estimation is to indicate the system/component lifetime before it can no longer perform its function, which is also an important way to reduce production loss, save maintenance costs and avoid fatal machine breakdowns of the equipment before its failure [
9,
10,
11,
12].
Since the aircraft engine is a complex system, there are various monitored performance data from different positions during its operation. How to estimate RUL of an aircraft engine by utilizing these data has become the focus of most engine industries. Until now, approaches to predict system lifetime can be broadly categorized into three types: physics-based models, data-driven approaches and hybrid approaches [
12,
13,
14]. Generally, a physics-based model utilizes the failure physical model of the system/component to estimate its RUL, which is usually based on the system/component’s physics of failure or physics of dynamics deeply [
15,
16,
17,
18,
19]. It can usually obtain reasonable and accurate predictions of RUL based on physical models with limited historical data [
20]. However, it is usually different or too expensive to apply a physics-based model to a complex system. Besides, this approach has shown significant limitations due to the assumptions and simplifications of the adopted models [
21]. The data-driven approach utilizes the monitored operational data relating to system health for RUL estimation [
22,
23], which is preferred when the system’s failure physics is complicated or unavailable but systems’ degradation procedure and degradation data are available. Note from [
3] that the data-driven approach provides accurate RUL predictions for a complex system, which can be applied quickly and cheaply compared to the physics-based model. Furthermore, recent development of sensor technology and simulation capabilities enables us to continuously monitor the healthy situation of a complex system and obtain the related large amount of performance index data. In addition, data-driven approaches can be divided into three categories: statistical techniques and artificial intelligence (AI) techniques. The former includes regression methods such as the auto-regressive and moving average (ARMA) models, and the later includes neural networks and supporting vector machine (SVM), fuzzy logic, etc. The third approach, the so-called hybrid approach proposed by Hansen et al. [
24], is the combination of physics-based and data-driven models, in which prognostics results are claimed to be more reliable and accurate, but few studies have been reported [
20].
Data-driven RUL prediction models, which are most widely applied in the field of prognostics or PHM, mainly include extrapolation models and statistical models. The extrapolation model is usually used to fit a curve of a system degradation evolution by regression, extrapolate the curve to the failure threshold and obtain the RUL between the current moment and the predicted failure time [
25]. The statistical model establishes the relationship between a system’s failure likelihood and its degradation indicator from collected CM (condition maintenance) and failure data [
26]. The statistical model approach is classified into the models based on the direct CM data and indirect CM data. The models based on the direct CM data include the proportional hazards model [
27,
28], proportional covariate model (PCM) [
29], Wiener processes, Gamma processes and Markovian-based models. The models based on the indirect CM data include stochastic filtering-based models, covariate-based hazard models and hidden Markov model (HMM) [
30], hidden semi-Markov models (HSMM), etc. Statistical models are the most effective ones for RUL estimation when system failure procedure is invisible. Most research has been conducted in RUL estimation based on data-driven models. Stetter and Witczak [
31] explored various degradation modeling techniques and how to select the degradation indicator to estimate the RUL. Lee et al. [
32] reviewed various methodologies and techniques in PHM research and proposed the systematic PHM design methodology, namely 5S methodology. Moreover, current methodologies of RUL estimation can be summarized as three classes as shown in
Figure 1.
Referring to the previous literature and existing methods, a structured form of methodology for RUL prediction is expressed as shown in
Figure 1.
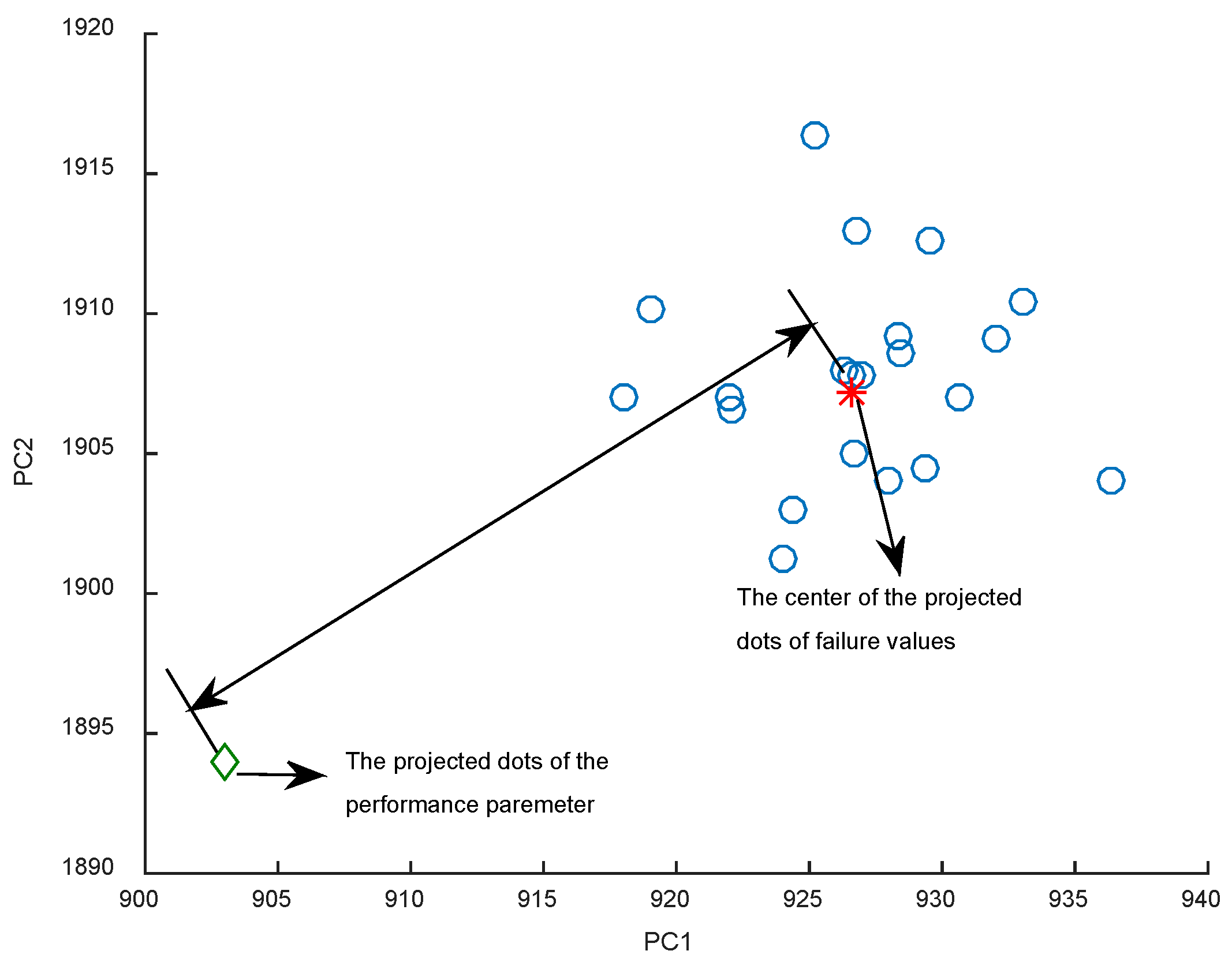
When utilizing the data-driven approach for RUL estimation, the whole run-to-failure data of systems are normally needed, but it is difficult to obtain enough run-to-failure data for the long-life systems with high reliability. Thus, it might lead to a large error if the available system history data are lacking. The same problem will arise when the ARMA model is employed. However, if there are some similar systems to the researched system, the failure and performance-deteriorated information of these similar systems are useful for RUL estimation of the researched system. In general, the principle of similarity-based RUL prediction approach is given as follows: if an operating system has similar performance to the reference system during a time range, then assume that they have a similar RUL. Because this reference system is an identical system with the operating system physically, moreover, they operate under the same working conditions and reference systems that have already failed. In addition, if there are more reference systems similar to the researched one, the similarity-based approach can be introduced through a weighted average of the reference systems’ RUL as the researched one’s RUL [
33], while the weight is proportional to the similarity between the researched and reference systems. According to this, the similarity-based RUL prediction model gives more reasonable results without modeling the deteriorated process of the researched system. Besides, with the development of PHM, there are abundant historical deteriorated data before failure that could be utilized to perform PHM.
Zio et al. [
21] developed a similarity-based approach to predict the RUL by comparing its evolution data to the trajectory patterns of reference samples through fuzzy similarity analysis, and aggregating their time to failure in a weighted sum, which accounts for their similarity to the developing pattern [
21]. Gebraeel et al. [
22] presents a stochastic process by combining with a data analysis method and deterioration modeling of the components for RUL prediction.
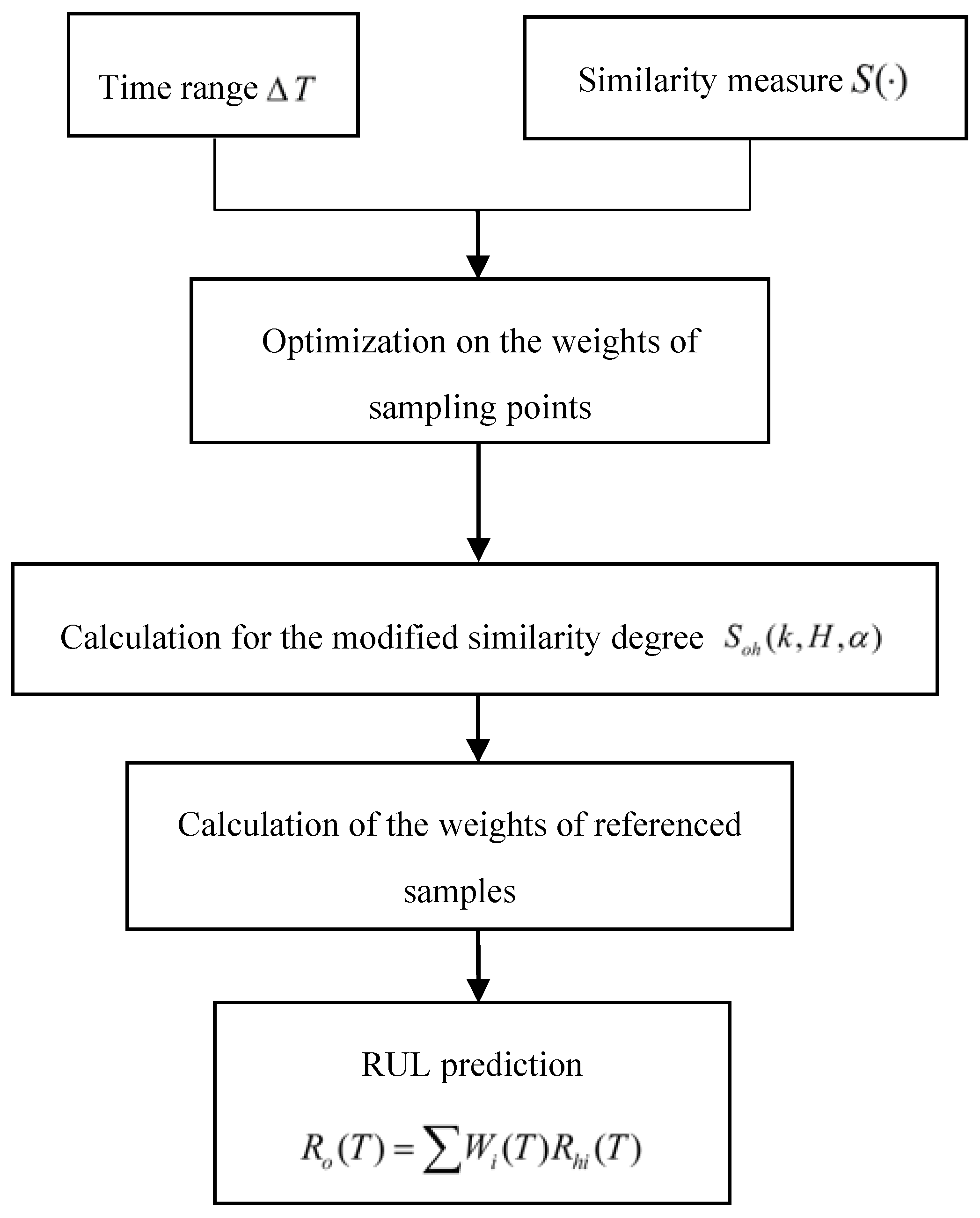
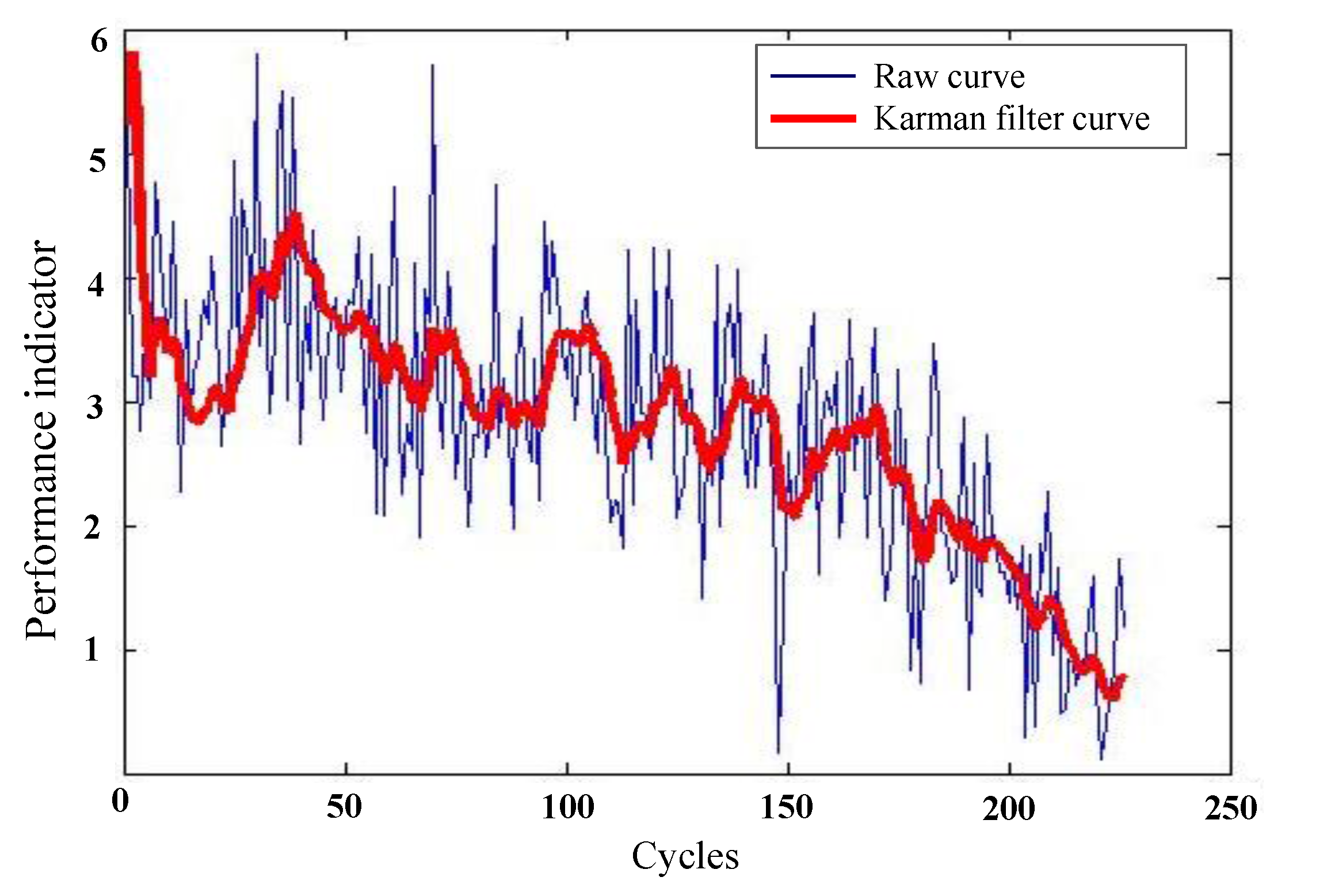
For the traditional similarity-based RUL prediction method, current and past degradation parameters of reference systems have an equal weight when calculating the similarity measure. However, as we all know, a system’s most recent performance to its current health/state is more relative than its earlier performance, and provides more information for its RUL than its earlier performance. Therefore, it is reasonable to assign more weight to a system’s most recent sampling point than its earlier sampling point of performance parameters when measuring its similarity with other systems. However, the traditional similarity-based method ignored this situation. Accordingly, this paper adopts a modified similar-based methodology which introduces a weight-adjusted coefficient to embody the different effect on the calculation of similarity degree from different time ranges while calculating the similarity measure. The more recent sampling point of performance, the bigger weight of the parameter is given. In addition, the earlier value of performance, the parameter is given smaller weight and this paper provides an approach to optimize the weight .
Until now, most research on the similarity-based model for RUL prediction are based on run-to-failure data, but sometimes there are only deteriorated performance data without run-to-failure data. How to utilize these deteriorated performance data, which do not work to failure, to estimate RUL of equipment by similarity-based method, is lacking and expected. Suspension history condition monitoring data usually contain useful information revealing the degradation situation of the system, including environmental factors and loading variations in actual situations, such as degradations and variations of stress amplitudes [
10,
11,
12,
34,
35]. If these data are properly used, it is helpful to estimate RUL more accurately, particularly when the failure data are insufficient and unavailable in some cases [
36,
37]. Li et al. [
38] used the suspension data to promote the prediction precision of a neural network. However, how to utilize these suspension data to predict RUL of the equipment has not been deeply studied.
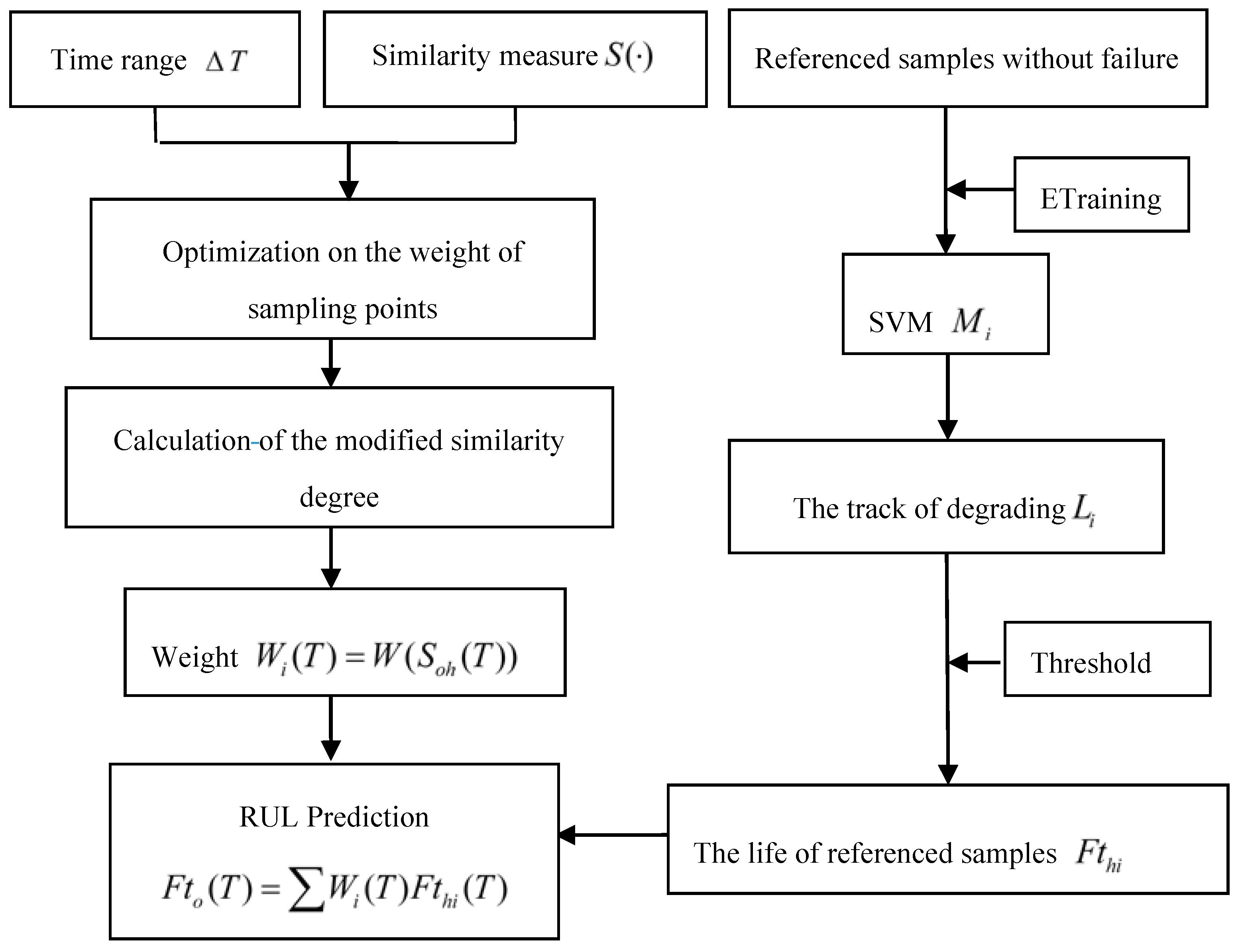
This paper attempts to develop a modified similarity and SVM-based method to predict the RUL of an aircraft engine, including two schemes with different reference samples. The first scheme adopts a modified similarity-based method for estimating the RUL of the engine with abundant run-to-failure data of referenced samples, which is named as the modified similarity methodology based on run-to-failure data. The second scheme utilizes deteriorated data of samples without running to failure to estimate the RUL of the operating sample based on SVM and similarity methodology, named as the modified similarity and SVM methodology based on deteriorated data. The structure of this paper is as follows.
Section 2 provides a detailed description of two approaches aimed for RUL estimation under two situations.
Section 3 introduces how to utilize the proposed approaches to estimate the RUL of an aircraft engine.
Section 4 concludes the current research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
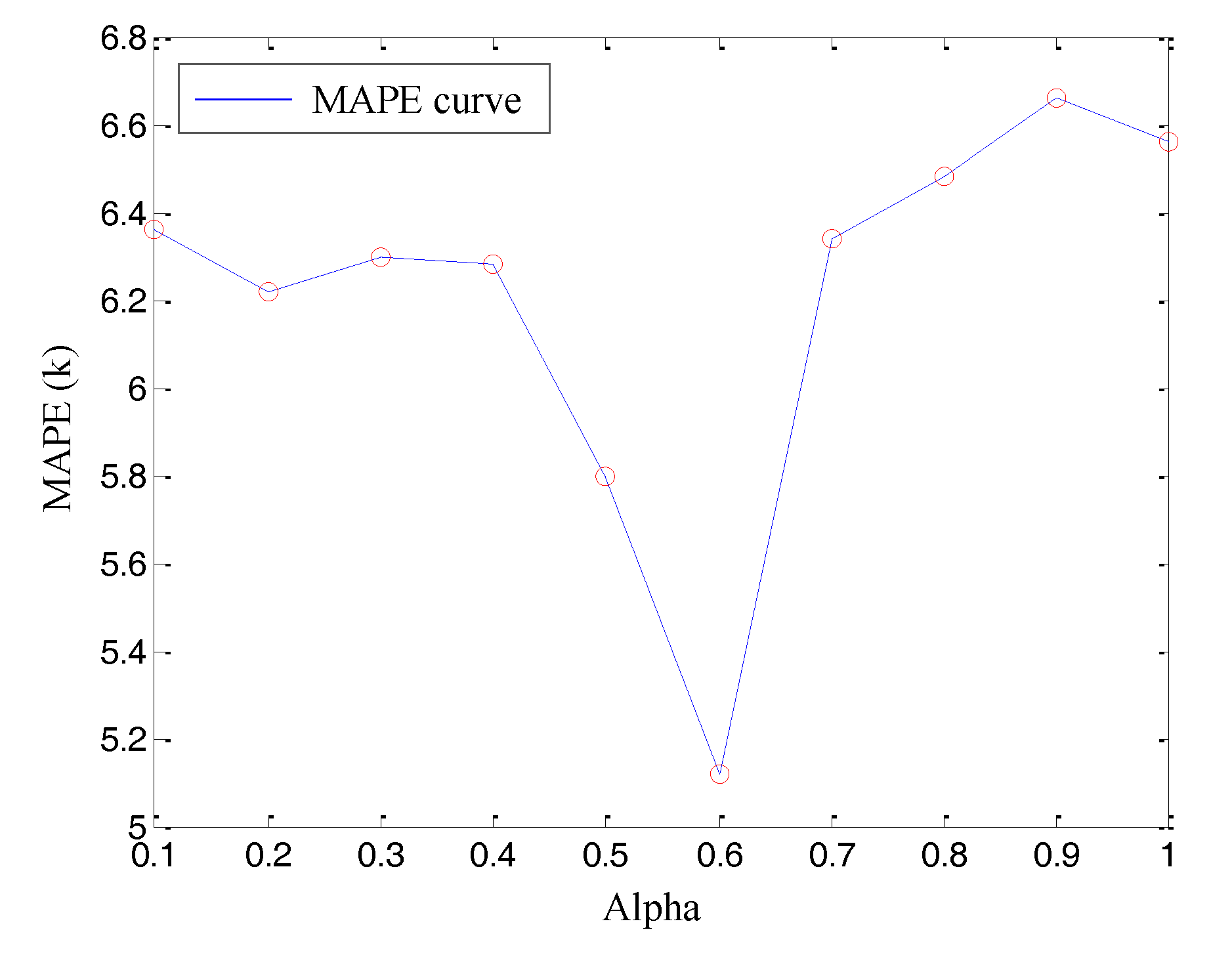{kind=link}
{kind=link}