
An Artificial Neural Network for Analyzing Overall Uniformity in Outdoor Lighting Systems


 ,
,  ,
,
Abstract
:1. Introduction
2. Street Lighting/Experimental Context
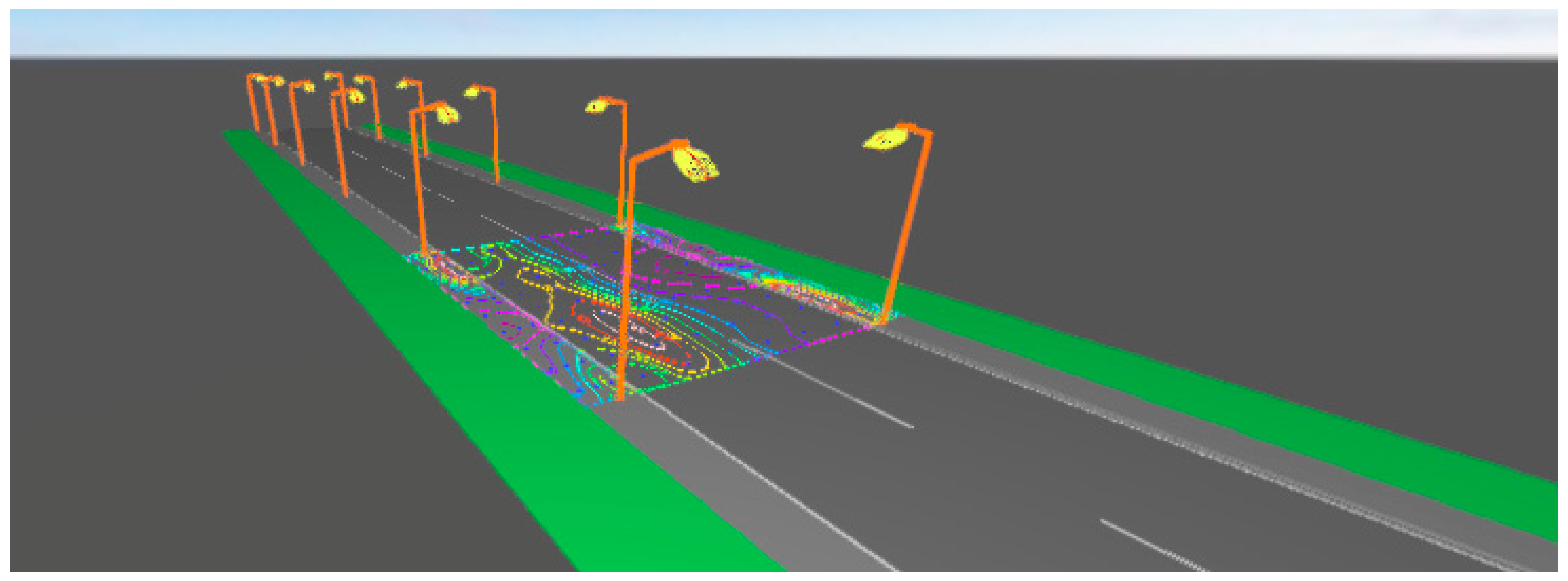
The Simulation Software
3. Artificial Neural Networks
3.1. ANN Application in Lighting Systems
- (1)
- Adaptive learning: An ability to learn how to do tasks based on the data given for training or initial experience.
- (2)
- Self-Organization: An ANN can create its own organization or representation of the information it receives during learning time.
- (3)
- Real Time Operation: ANN computations may be carried out in parallel, and special hardware devices are being designed and manufactured which take advantage of this capability.
- (4)
- Fault Tolerance via Redundant Information Coding: Partial destruction of a network leads to the corresponding degradation of performance. However, some network capabilities may be retained even with major network damage.
- (a)
- Determination of the effective reflectance of ceiling, room and floor cavities: This is a preliminary requirement for the determination of coefficient of utilization in the zonal cavity method.
- (b)
- Determination of the coefficient of utilization (CU): The CU table is provided for the discrete values of room cavity ratio (RCR), effective reflectance of ceiling cavity (ERCC) and room cavity wall reflectance (RWR) are calculated.
- (c)
- Other areas of application of ANN: In a similar way, the ANN may be used for the determination of correction factors for the coefficient of utilization, utilization factor in the room index method, glare index, correction factor for glare index, direct ratios, light output ratios from polar curves, selection of lighting fixtures. illuminance at any point using photometric data and upward and downward light output ratios.
3.2. ANN Development
- Feed-forward networks: Feed-forward ANNs allow signals to travel one-way only; from input to output. There is no feedback (loops), i.e., the output of any layer does not affect that same layer. Feed-forward ANNs tend to be straightforward networks that associate inputs with outputs. They are extensively used in pattern recognition. This type of organization is also referred to as bottom-up or top-down.
- Feedback networks: Feedback networks can have signals traveling in both directions by introducing loops in the network. Feedback networks are very powerful and can get extremely complicated. Feedback networks are dynamic; their ‘state’ is changing continuously until they reach an equilibrium point. They remain at the equilibrium point until the input changes and a new equilibrium needs to be found. Feedback architectures are also referred to as interactive or recurrent, although the latter term is often used to denote feedback connections in single-layer organizations.
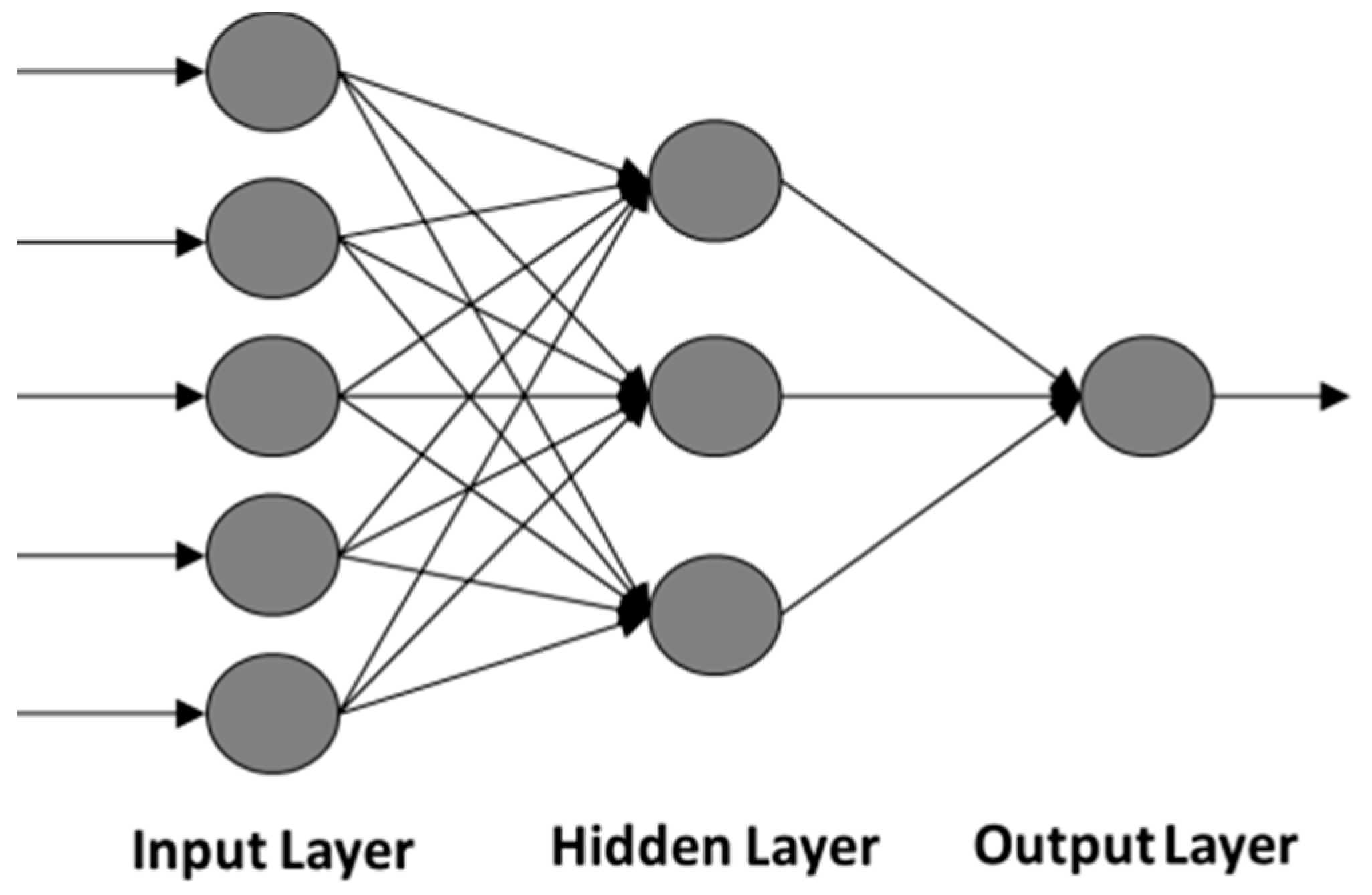
- Network layers: The commonest type of artificial neural network consists of three groups, or layers, of units. A layer of “input” units is connected to a layer of “hidden” units, which is connected to a layer of “output” units. The activity of the input units represents the raw information that is fed into the network. The activity of each hidden unit is determined by the activities of the input units and the weights on the connections between the input and the hidden units. The behavior of the output units depends on the activity of the hidden units and the weights between the hidden and output units. This simple type of network is interesting because the hidden units are free to construct their own representations of the input. The weights between the input and hidden units determine when each hidden unit is active, and so by modifying these weights, a hidden unit can choose what it represents. We also distinguish single-layer and multi-layer architectures. The single-layer organization, in which all units are connected to one another, constitutes the most general case and is of more potential computational power than hierarchically structured multi-layer organizations. In multi-layer networks, units are often numbered by layer, instead of following a global numbering.
- Perceptrons: The perceptron turns out to be a neuron with weighted inputs with some additional, fixed, pre-processing. Units are called association units and their task is to extract specific, localized featured from the input data. They were mainly used in pattern recognition even though their capabilities extended a lot more.
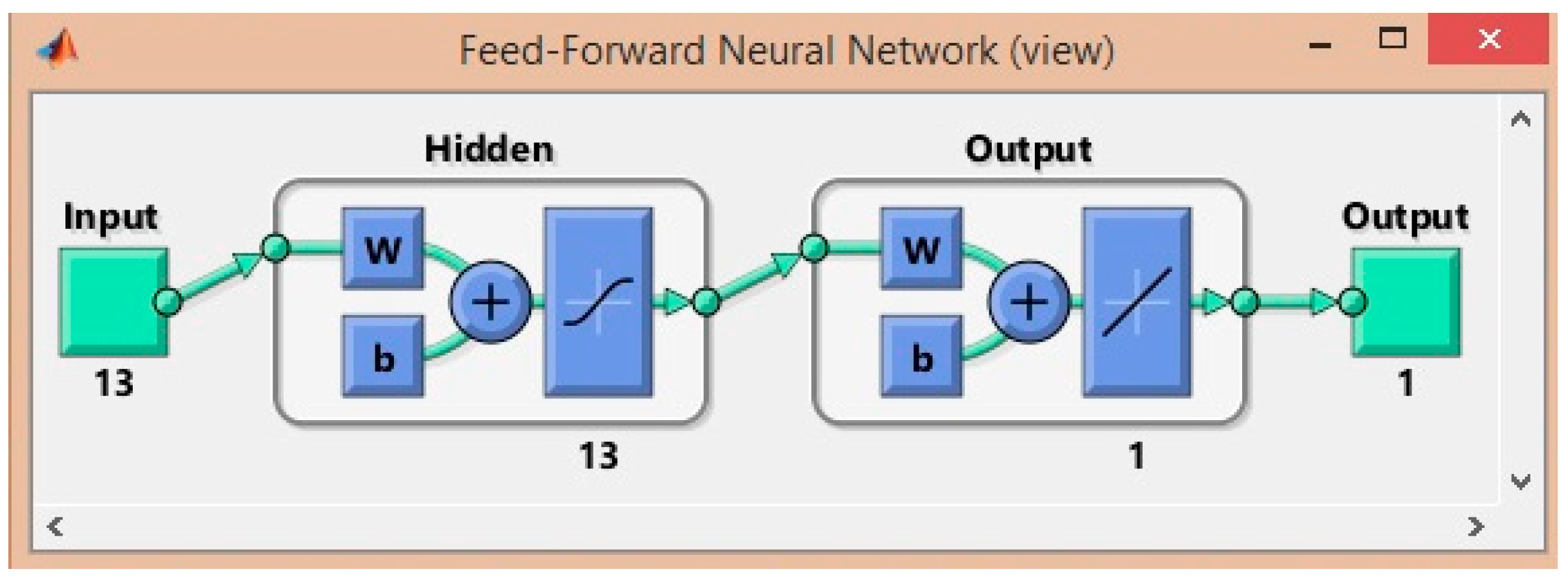
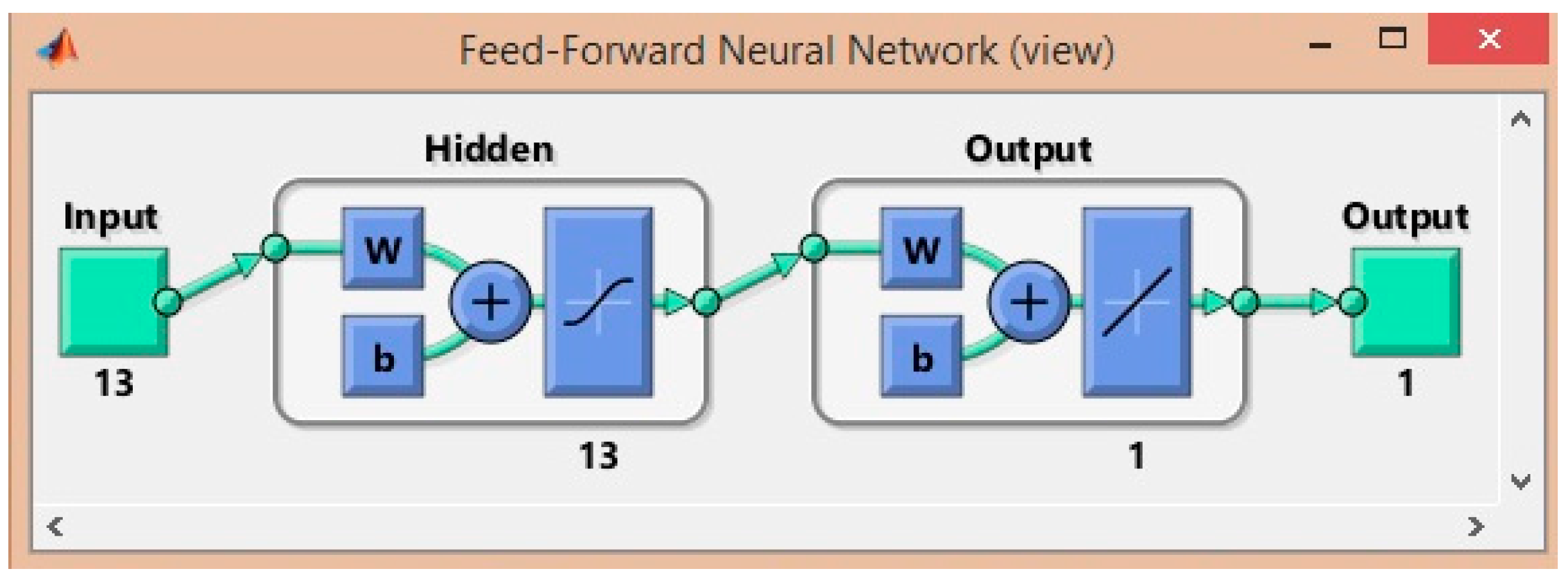
3.3. Feedforward Neural Network (FNN)
- The number of layers
- The number of neurons in each layer
- The activation function
- The training algorithm (because this determines the final value of the weights and biases).
3.4. Number of Layers
3.5. Number of Neurons in Each Layer
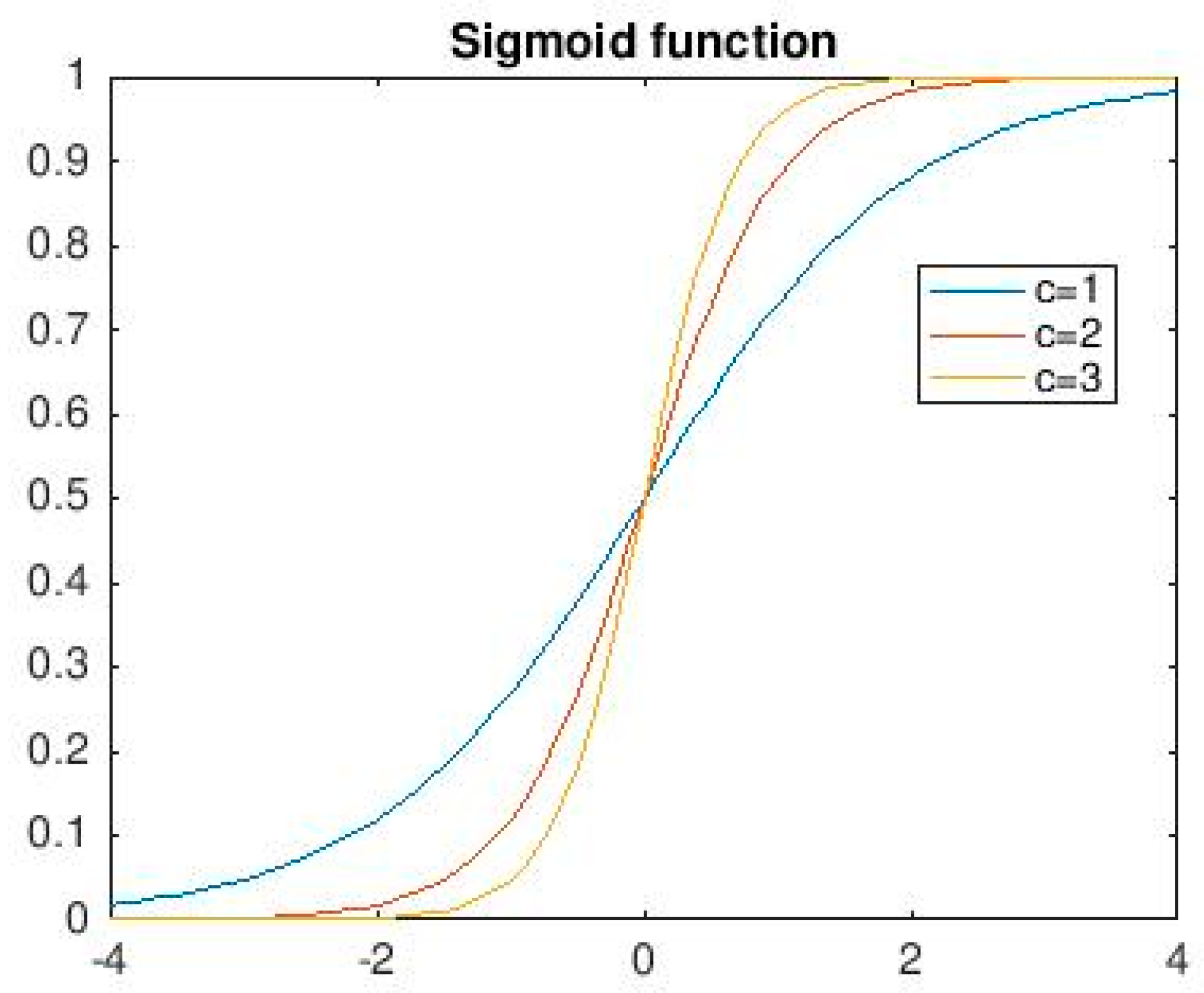
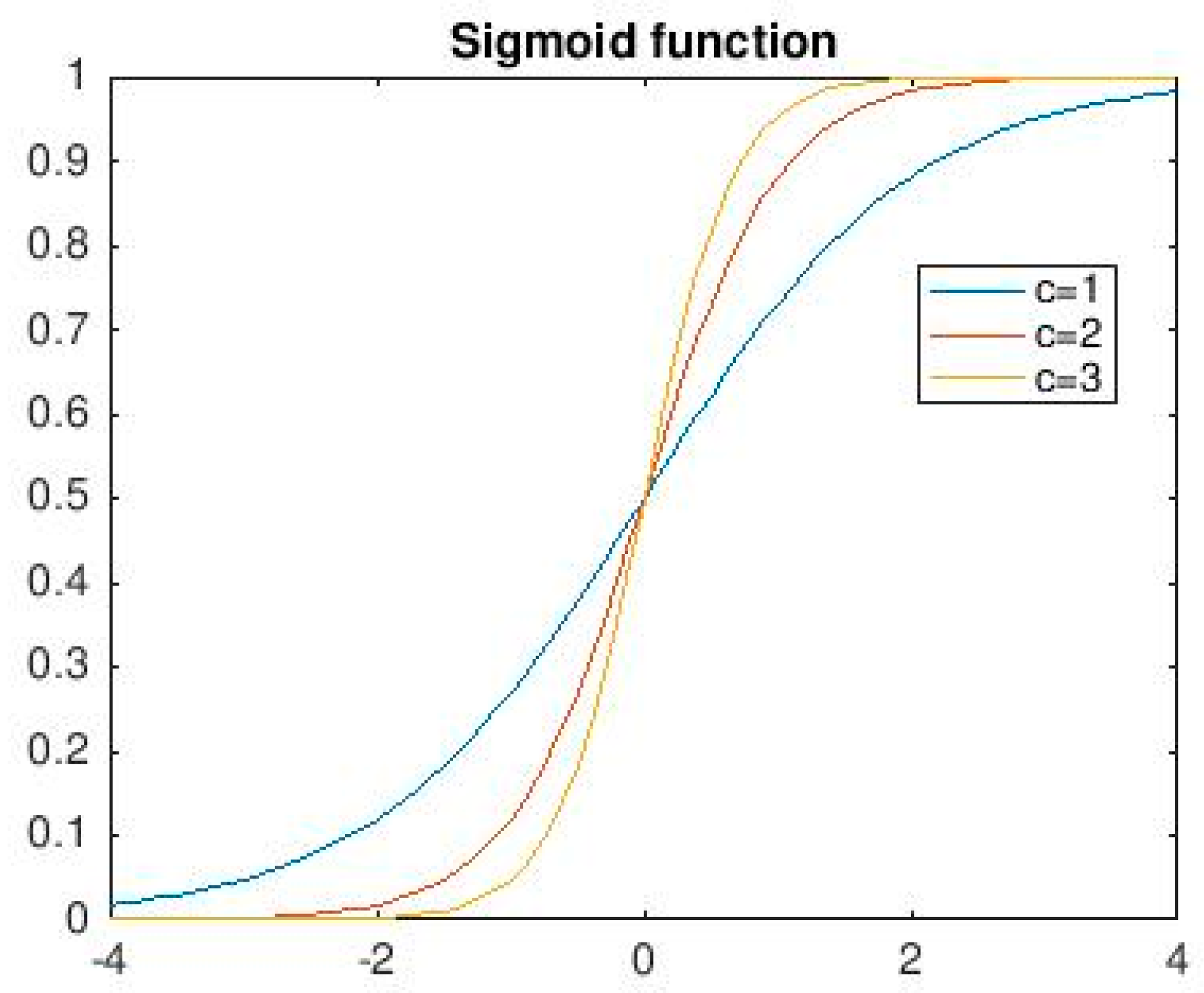
3.6. Activation Function of Each Layer
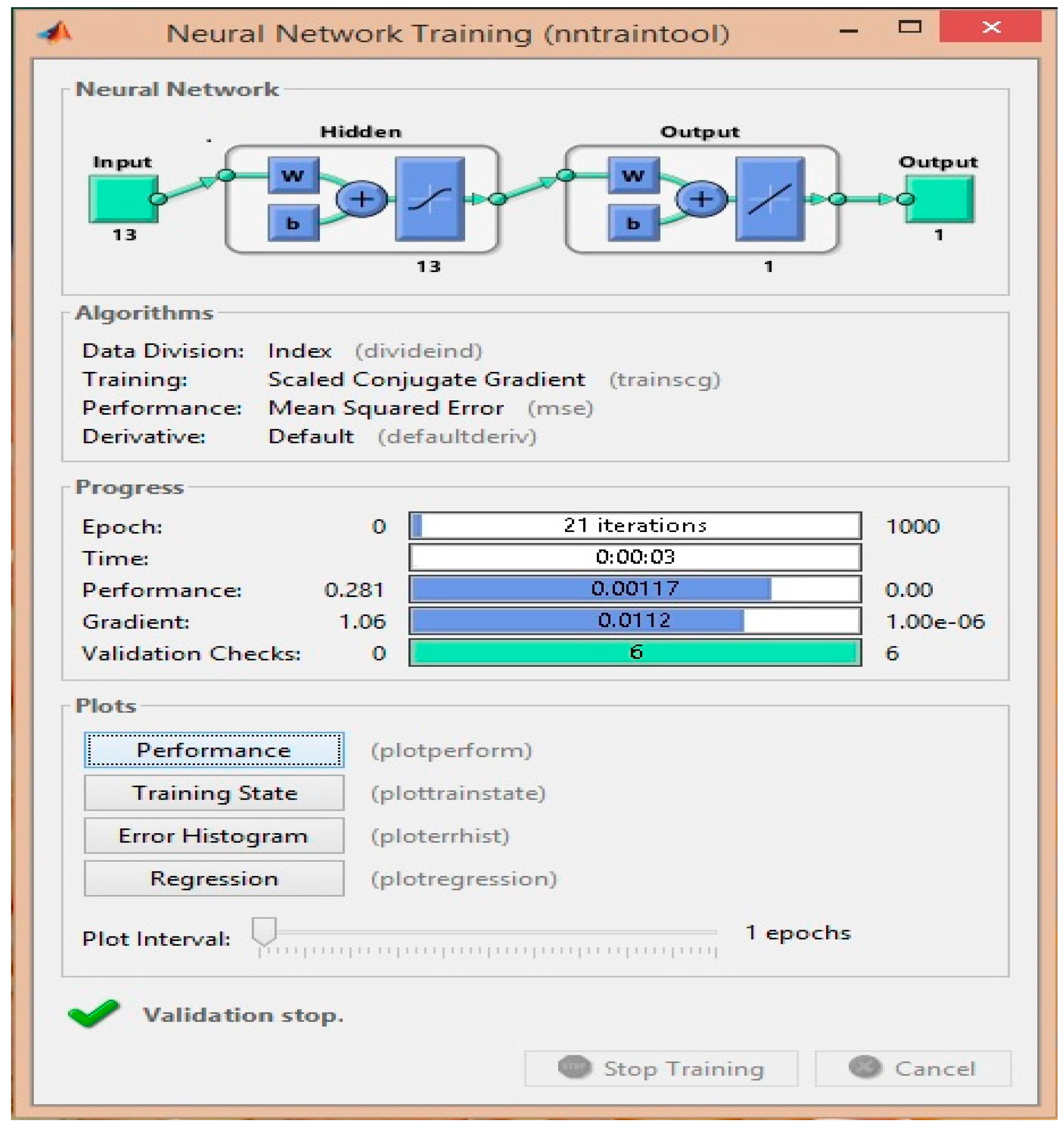
3.7. Training Algorithm
3.7.1. Levenberg-Marquadt Back-Propagation
3.7.2. Scaled Conjugated Gradient Back-Propagation
3.7.3. Gradient Descent with Momentum
3.7.4. Gradient Descent with Adaptive Learning Rate Back-Propagation
3.7.5. Gradient Descent with Momentum and Adaptive Learning Rate Back-Propagation
3.7.6. Gradient Descent Back-Propagation
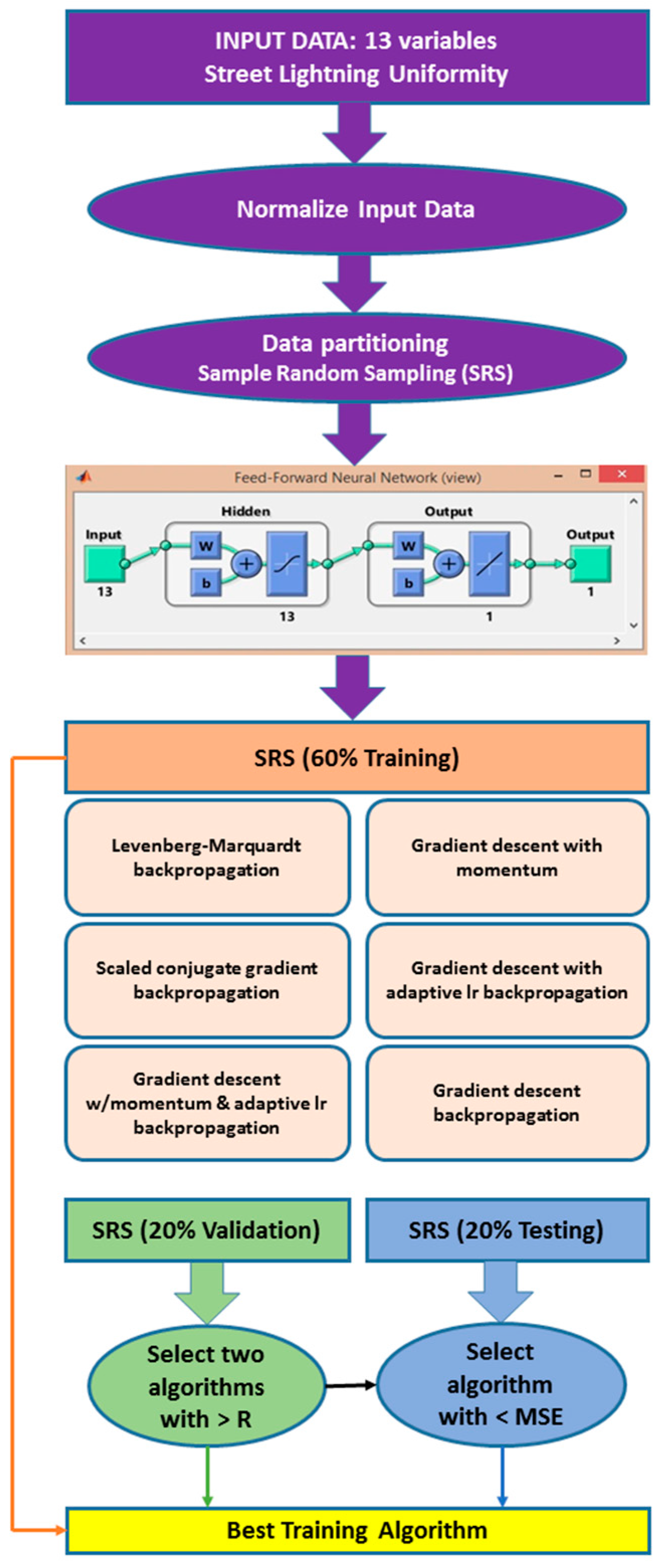
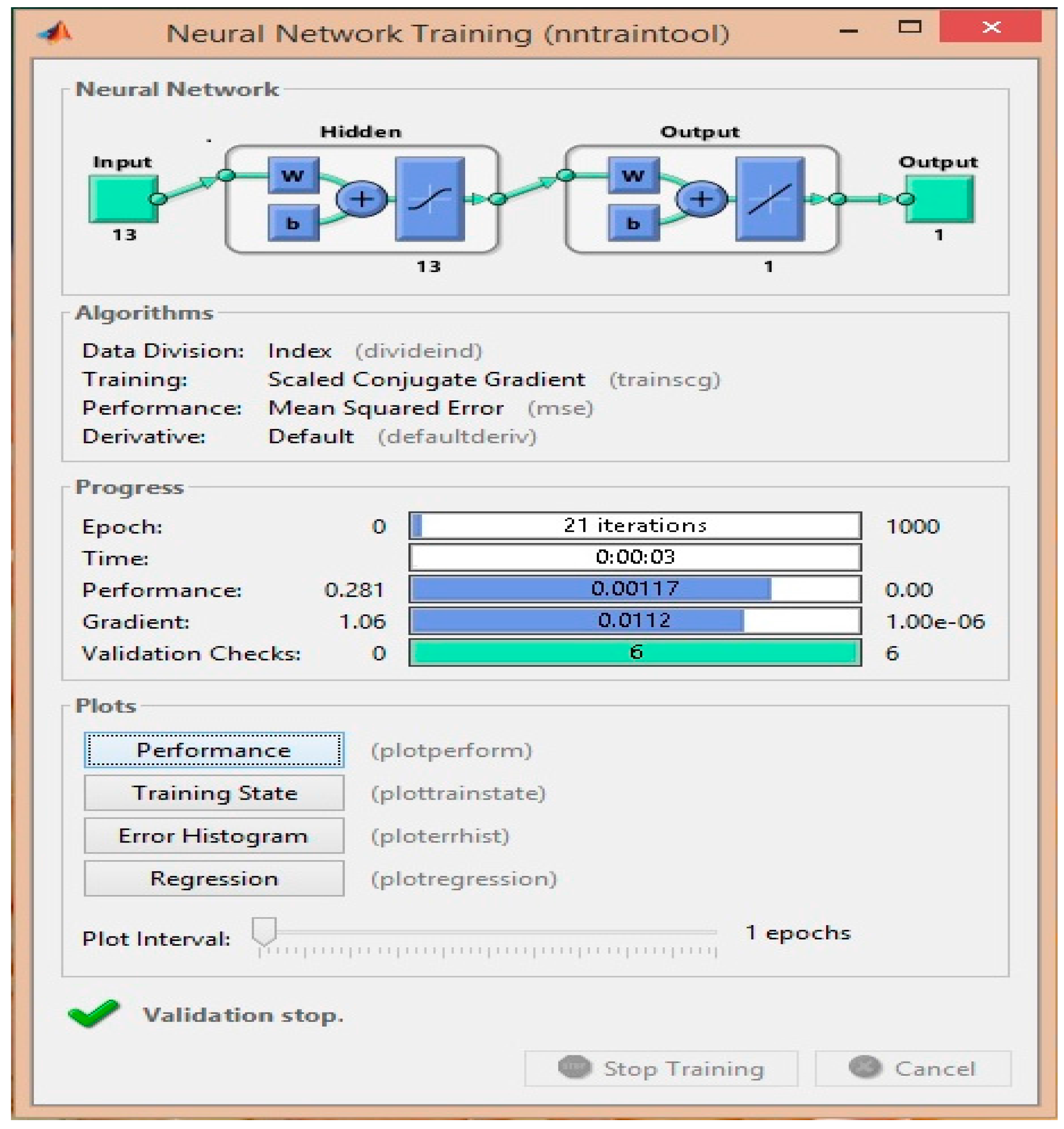
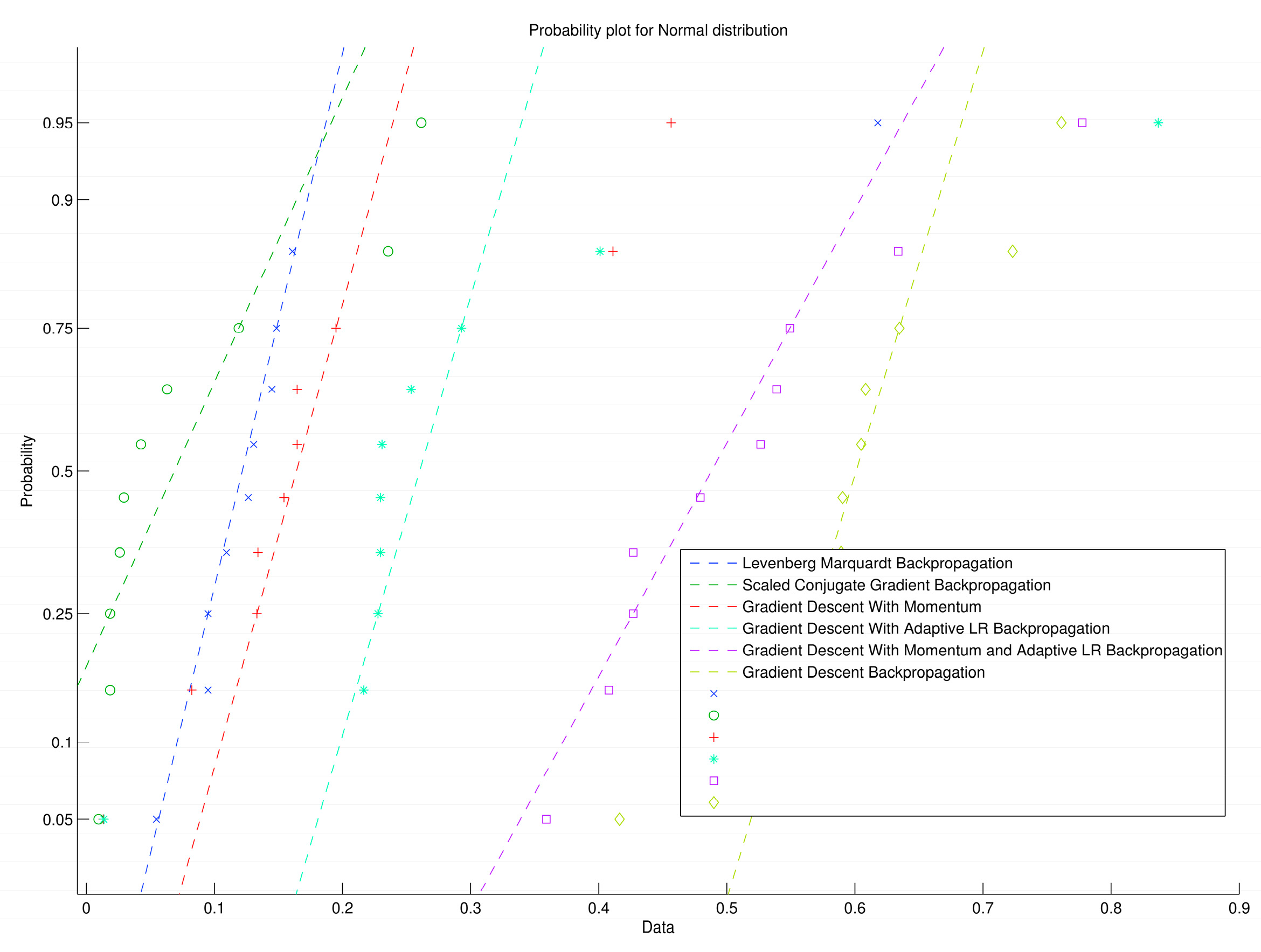
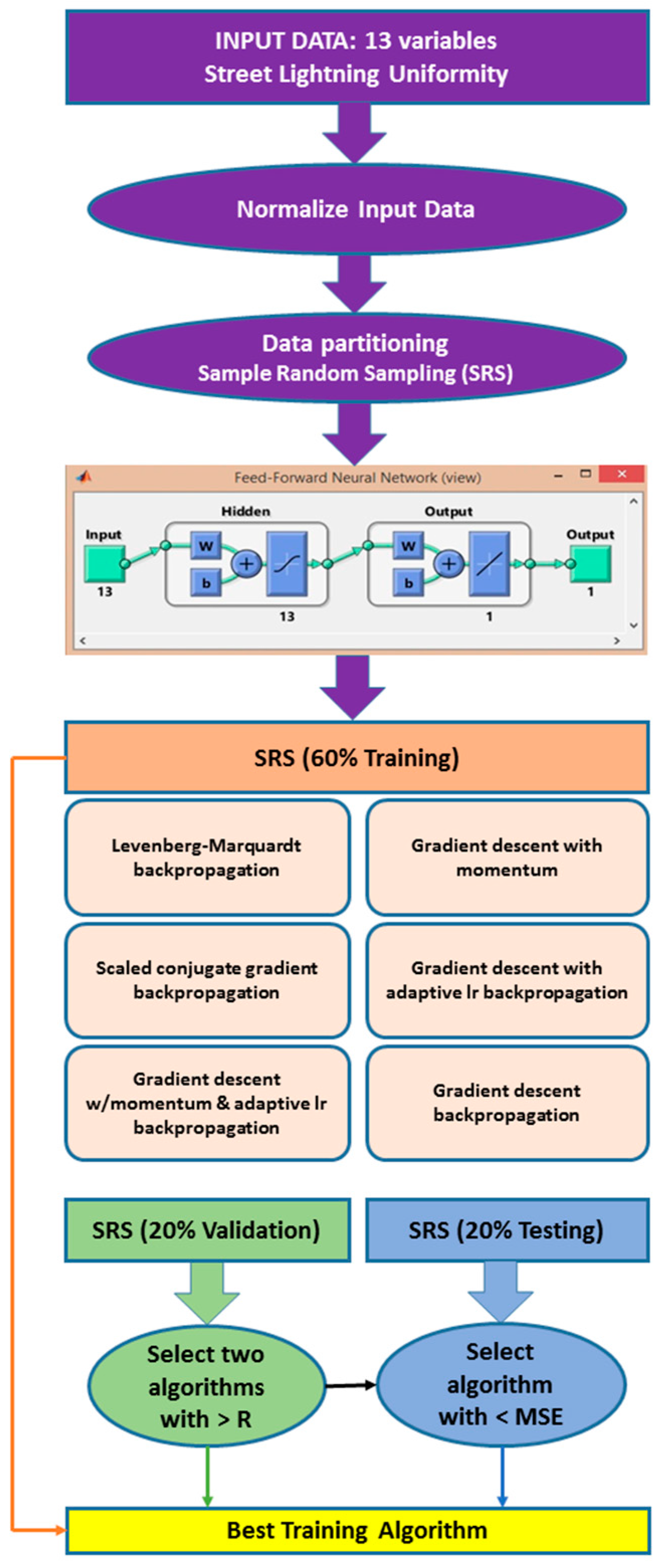
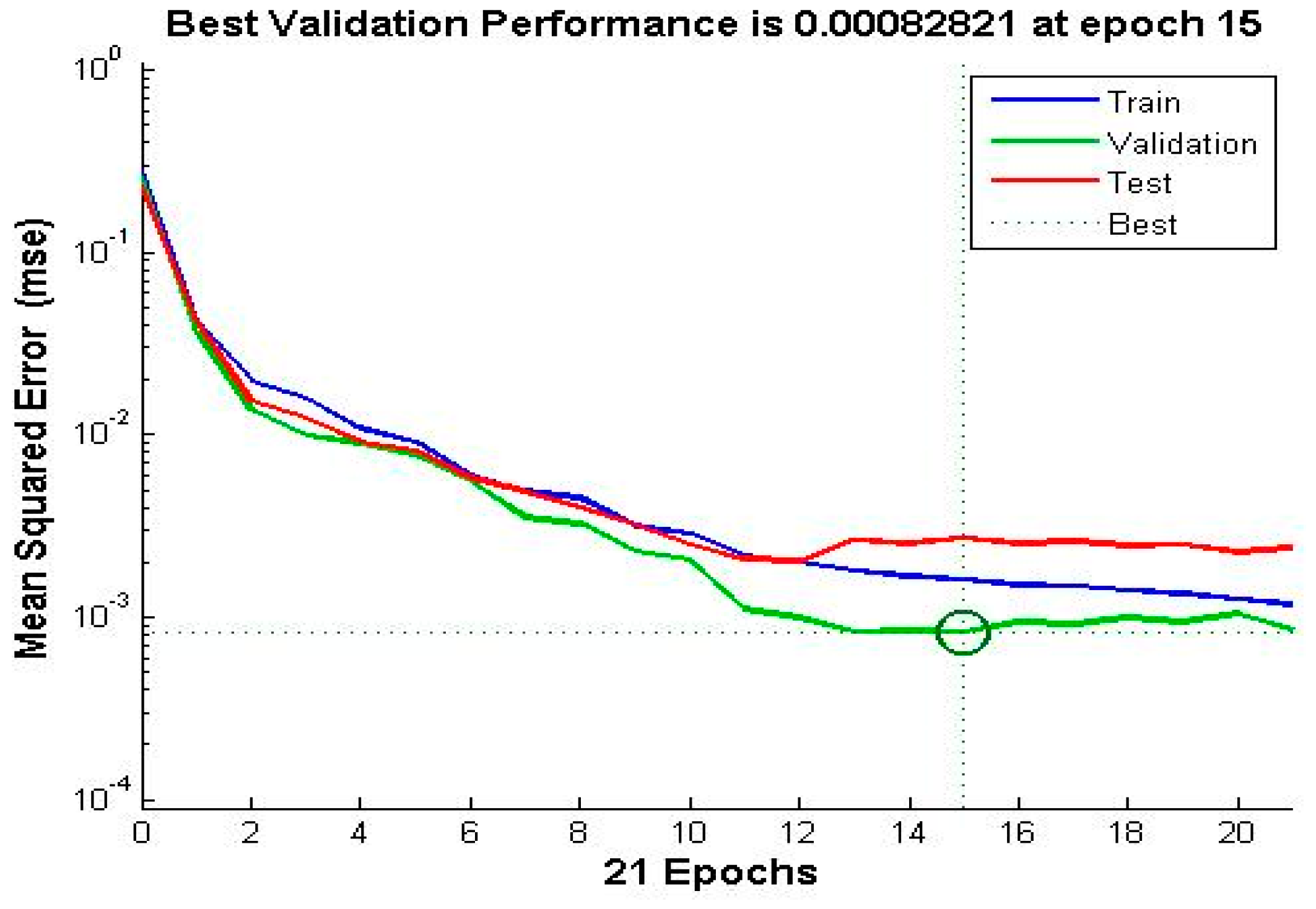
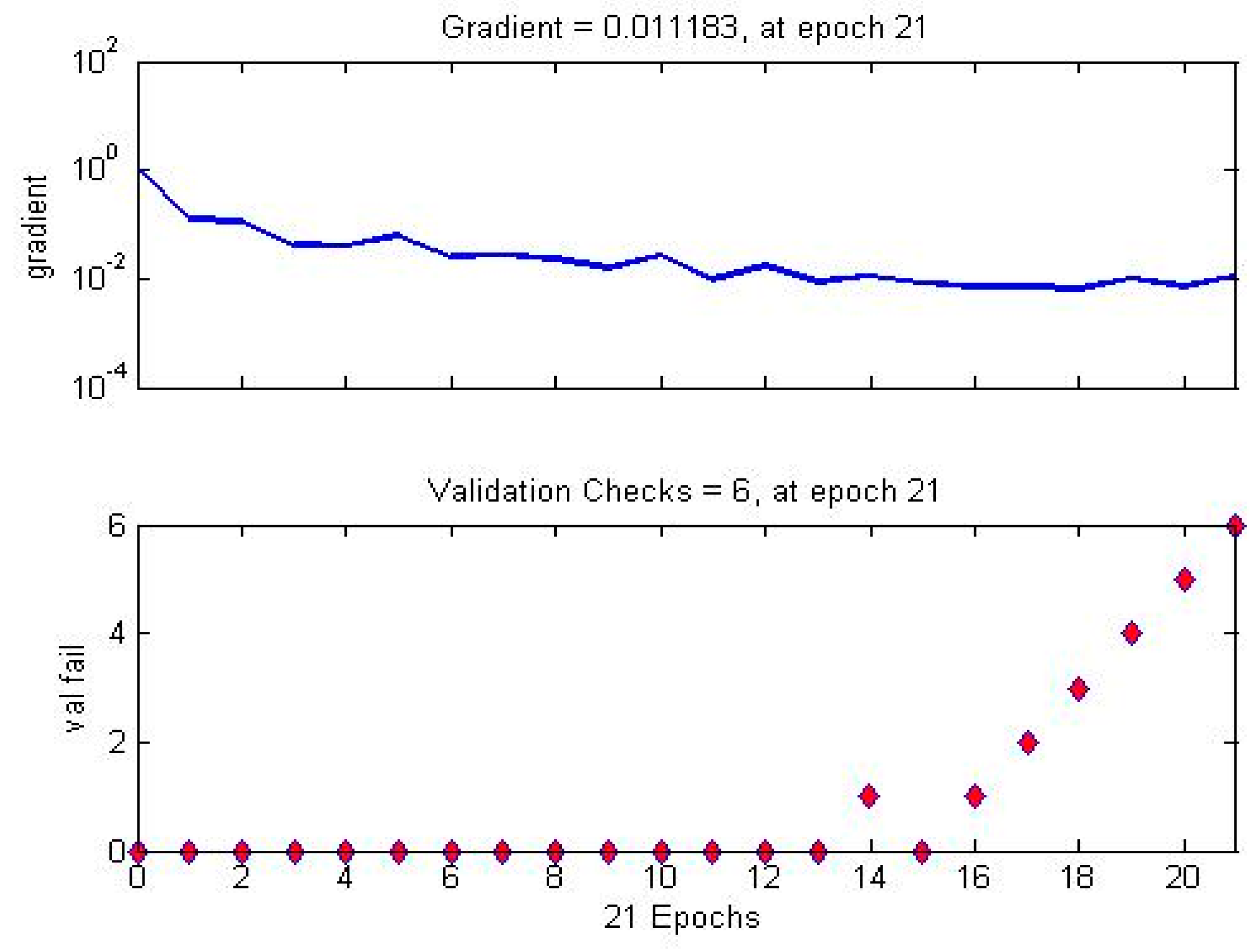
3.8. Validation Process
- (1)
- Select the two algorithms with the highest regression parameters (R) for the training step
- (2)
- Select the two algorithms with the highest regression parameters (R) for the validation step
- (3)
- Select the algorithm with the lowest values (MSE) in all the processes.
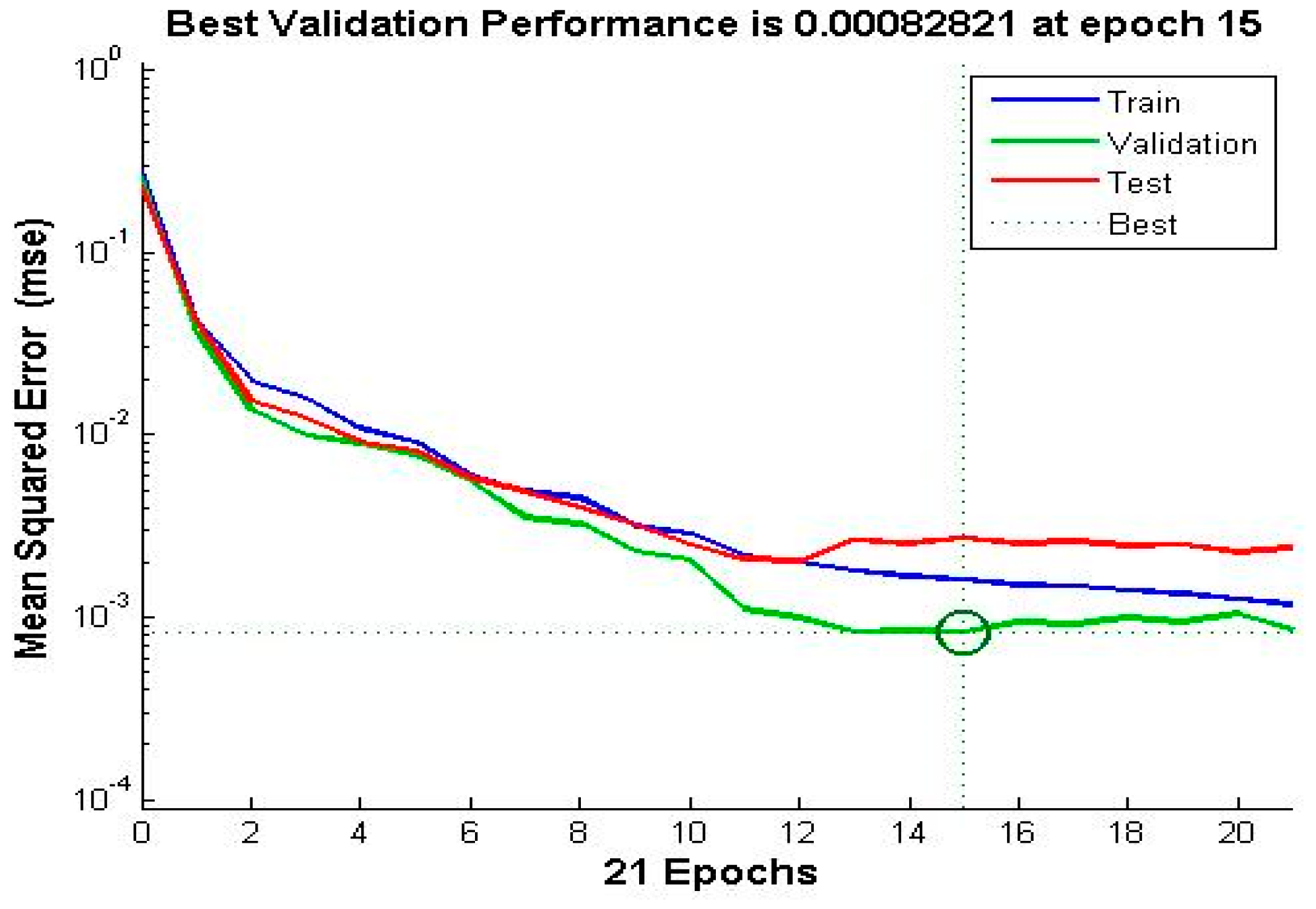
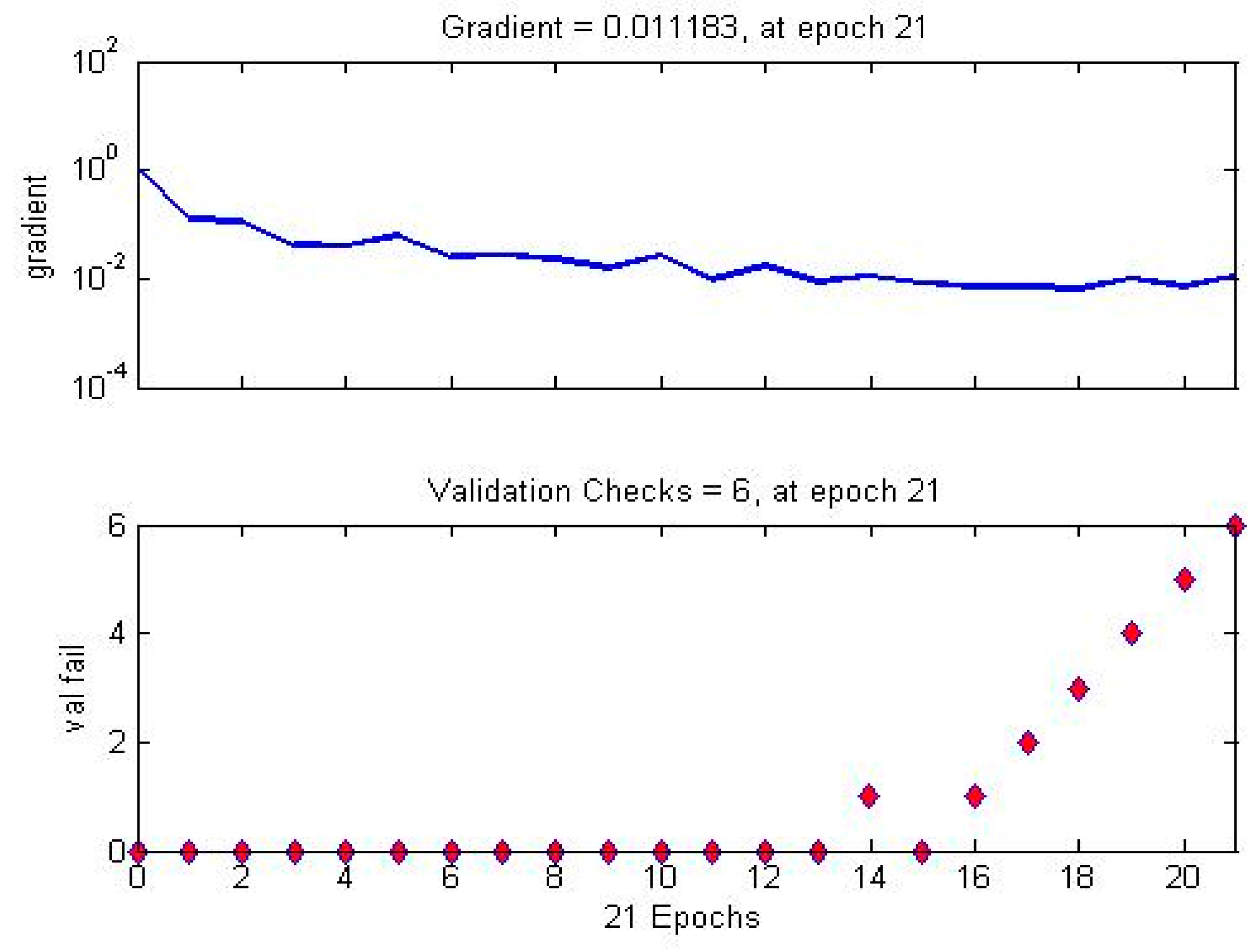
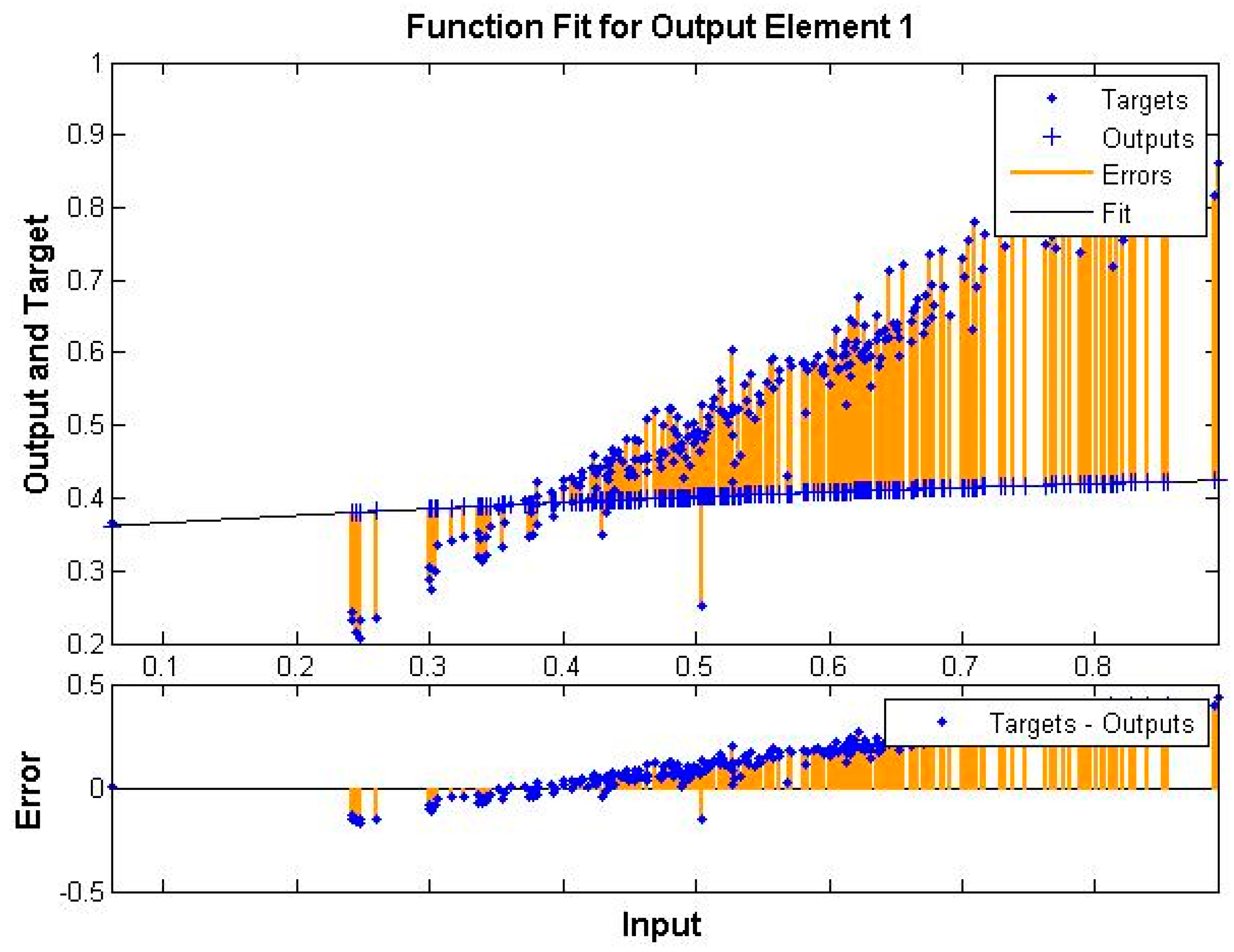
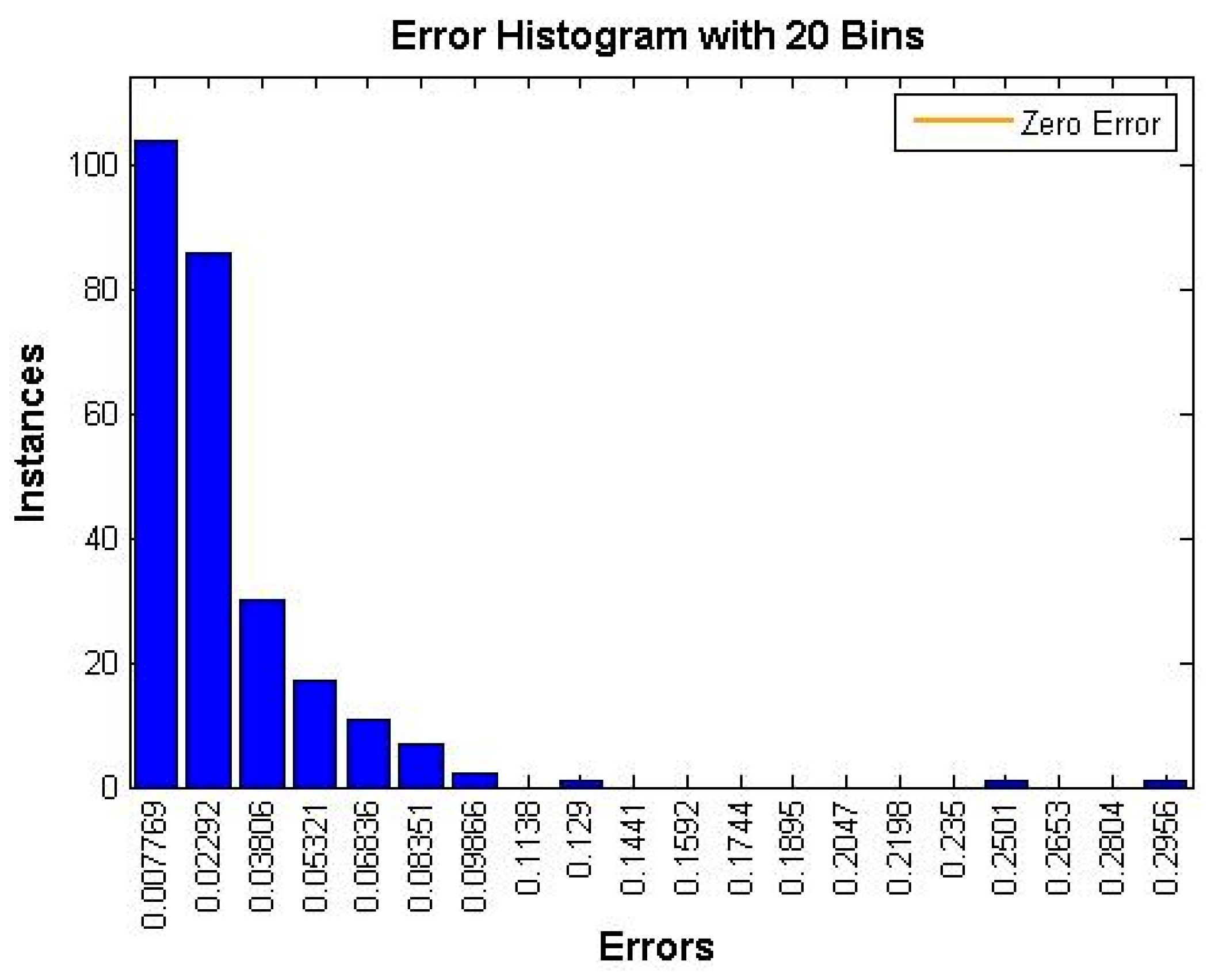
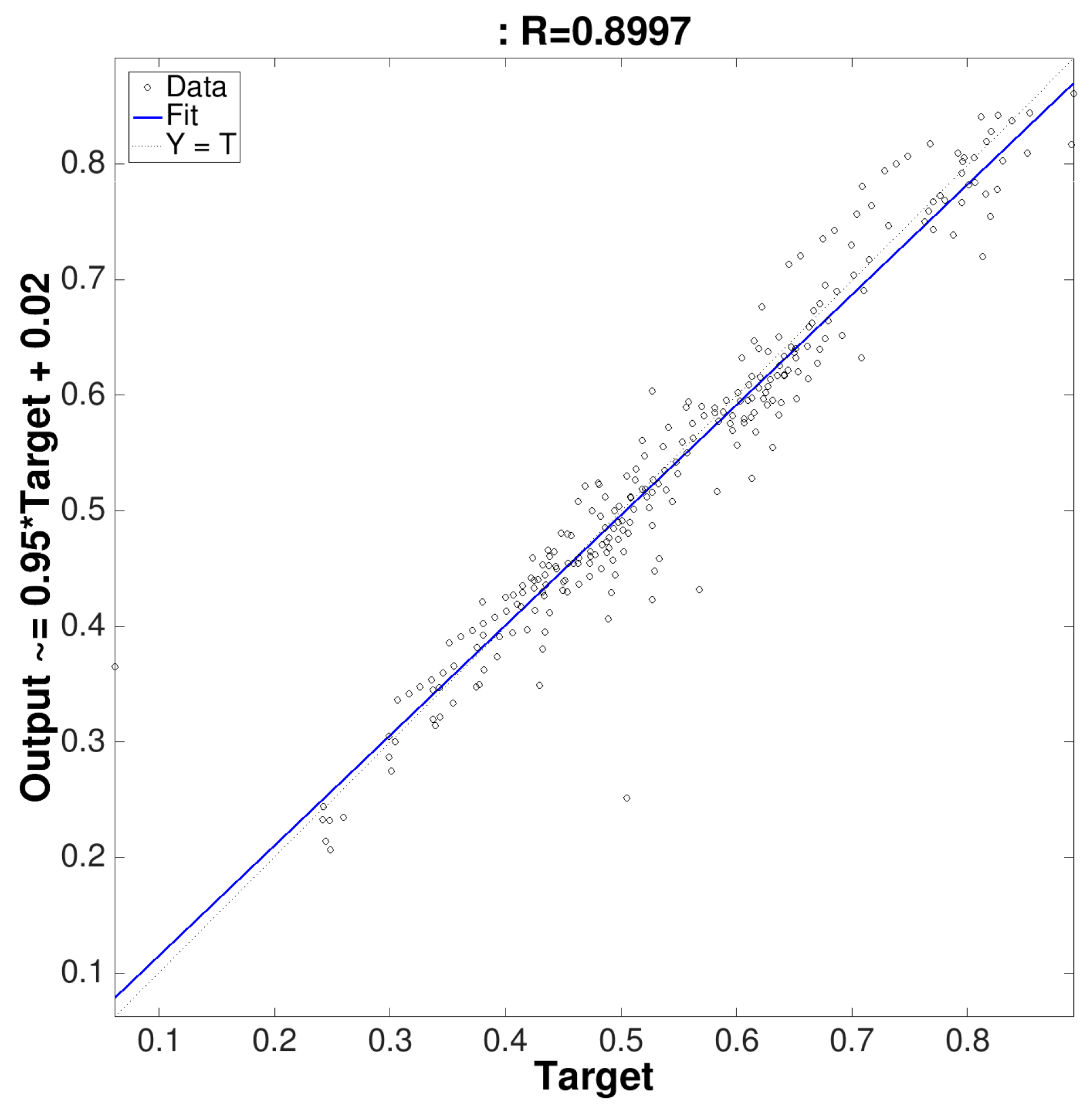
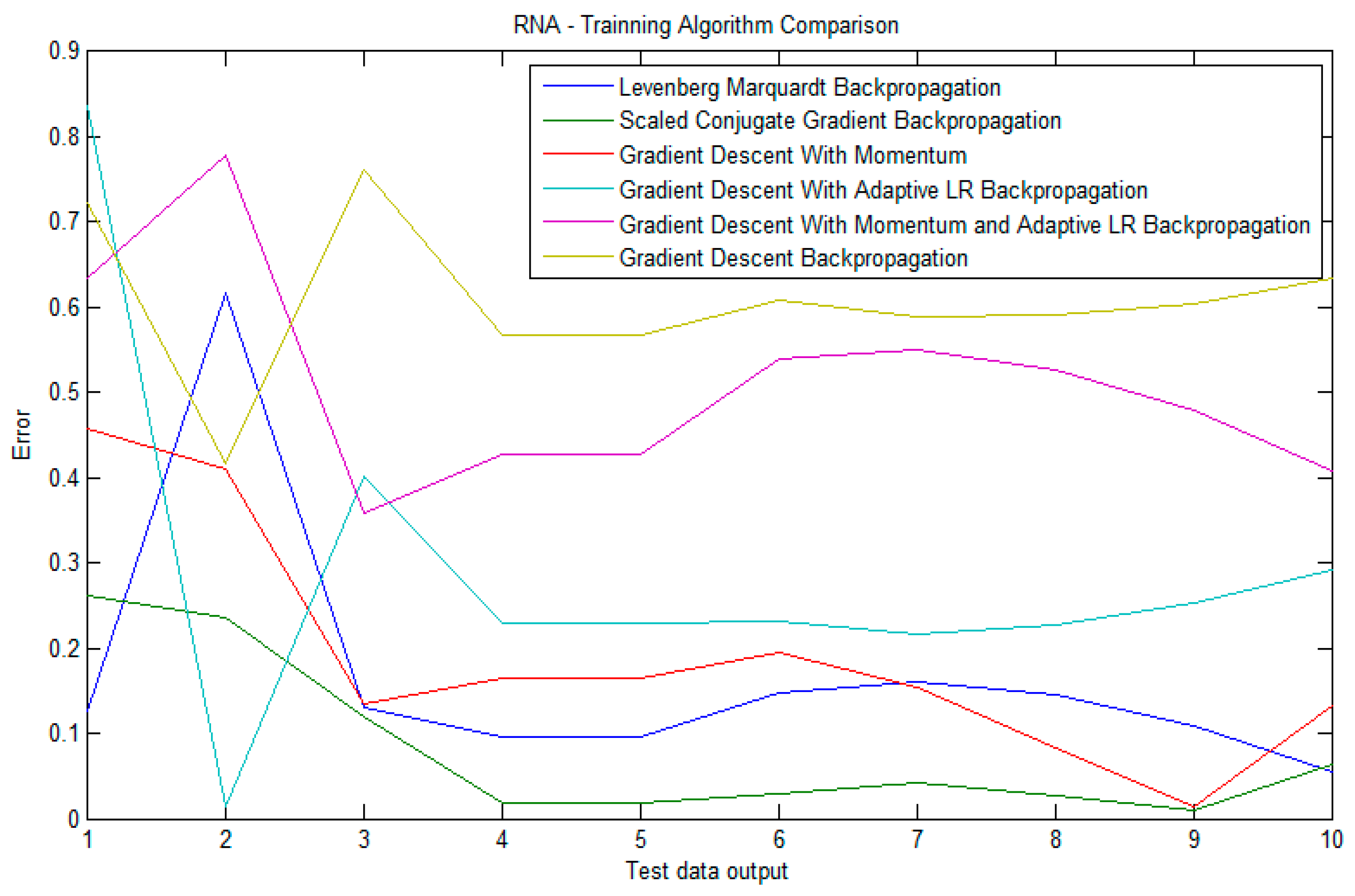
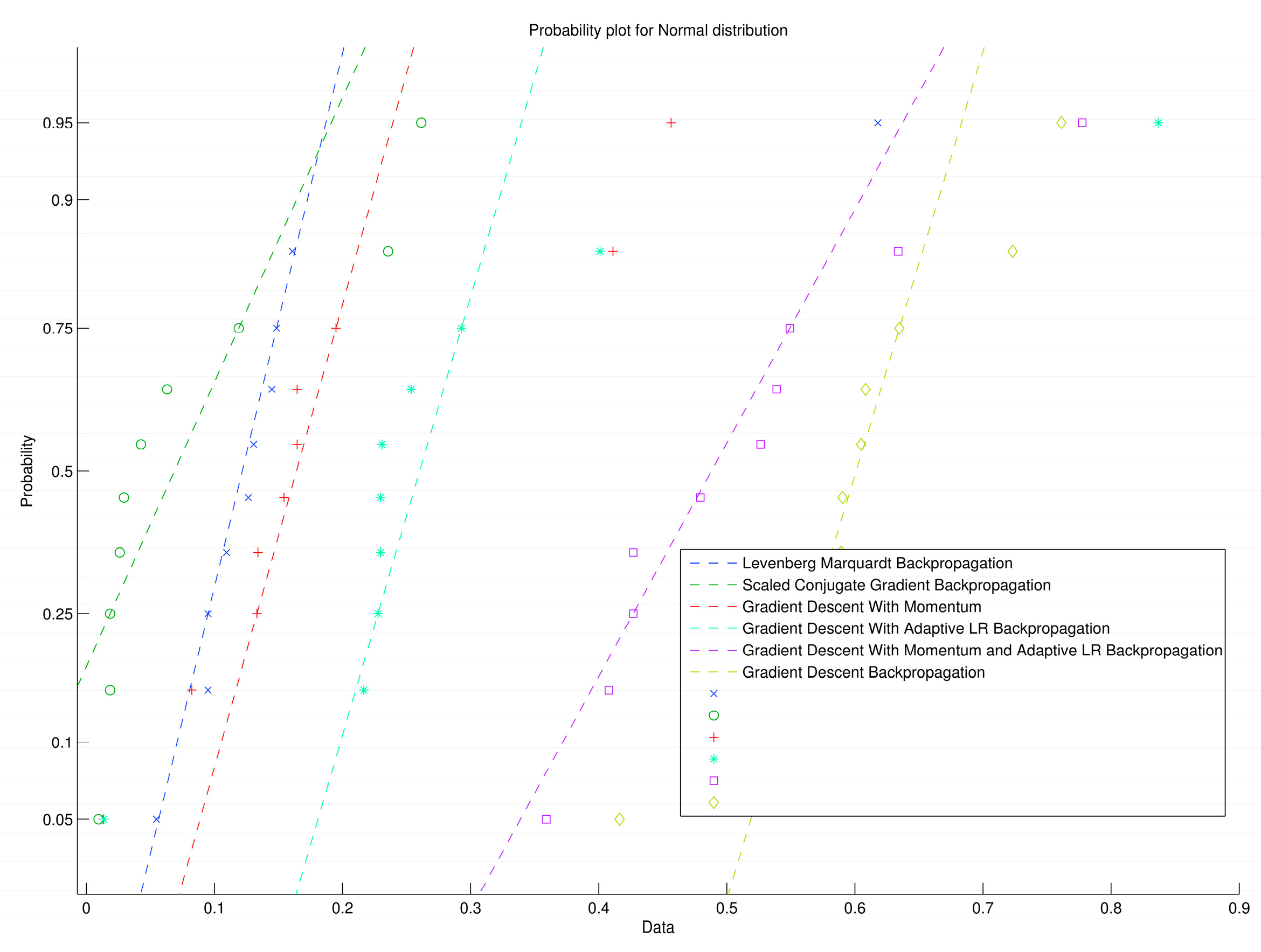
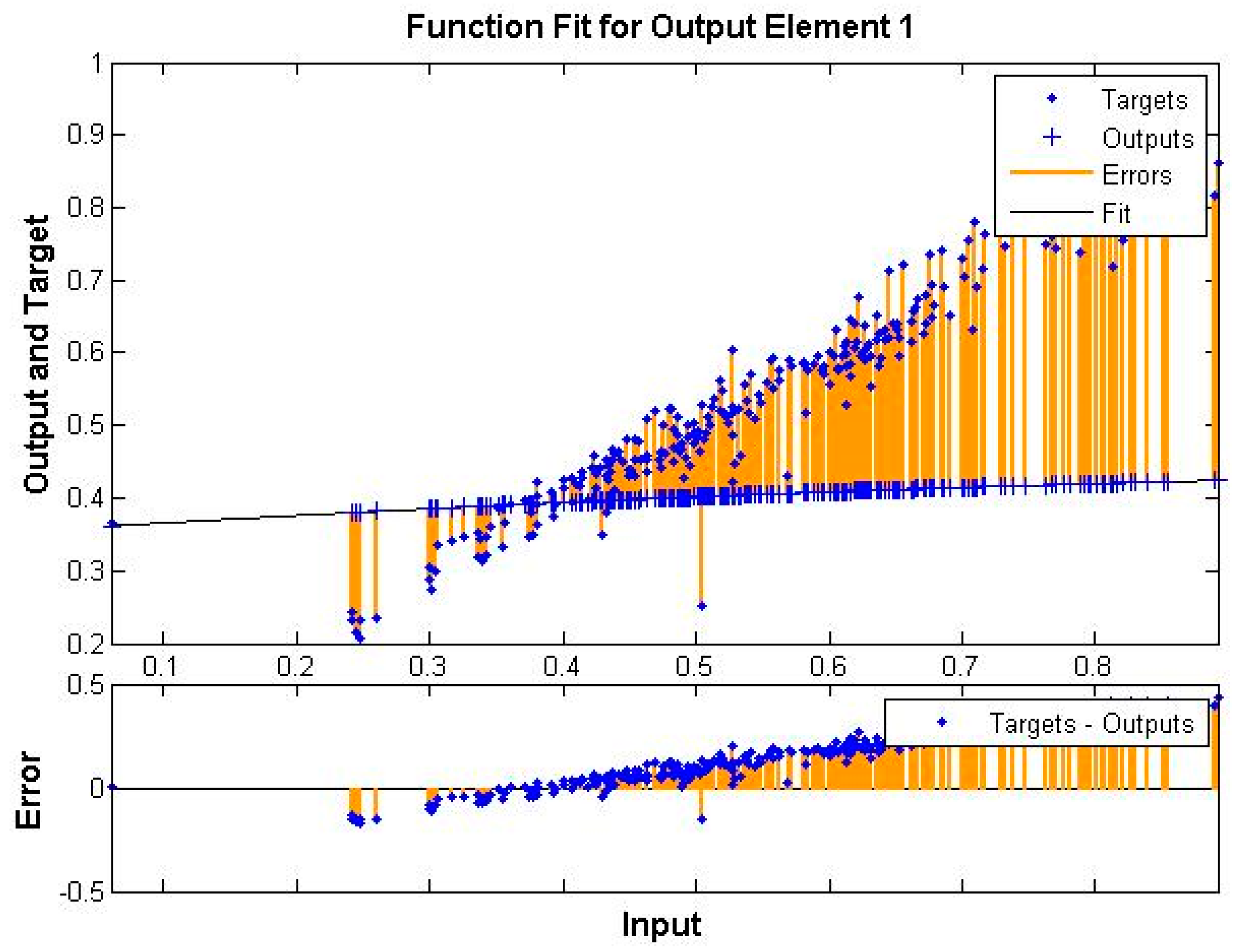
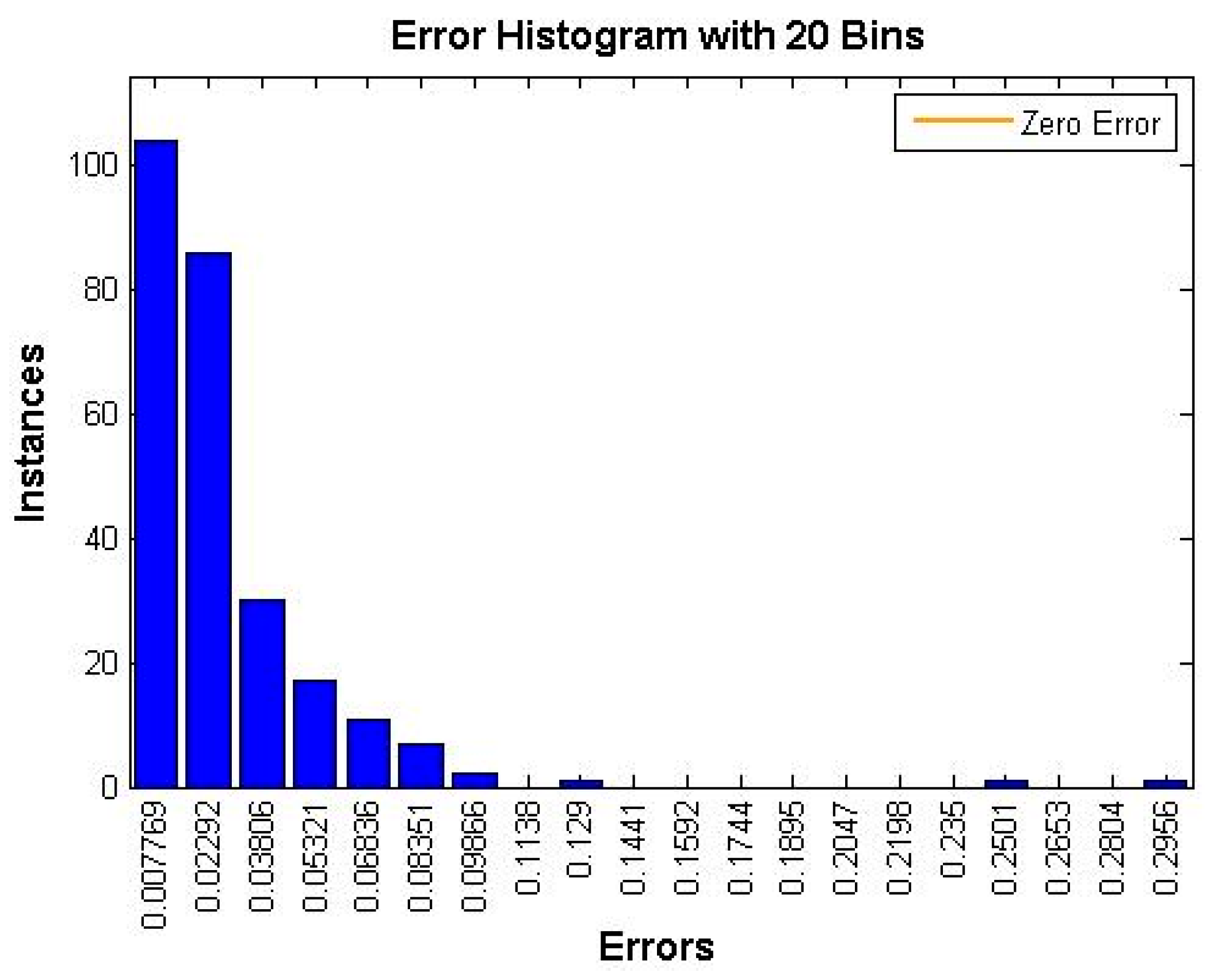
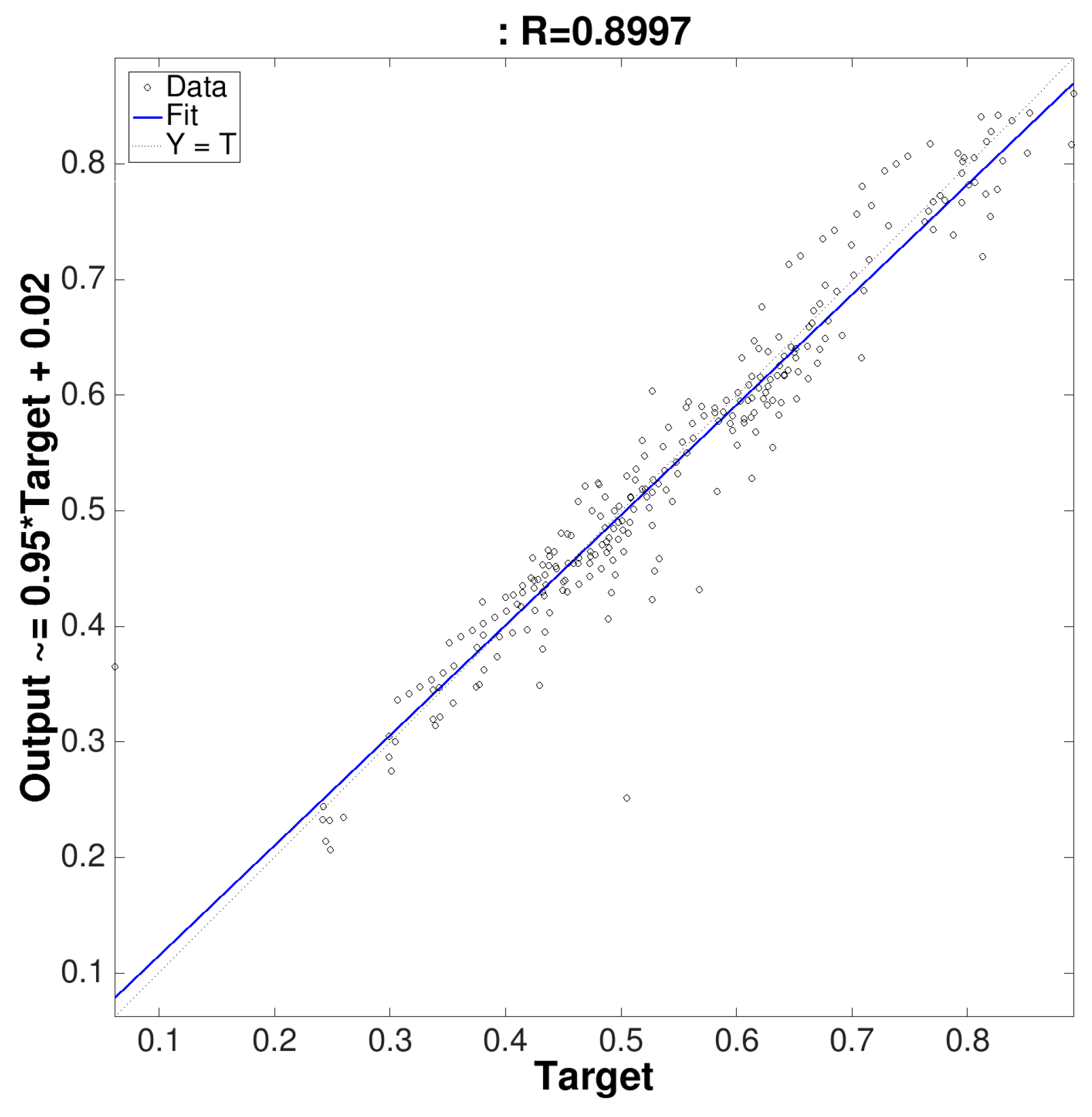
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Lorenc, T.; Petticrew, M.; Whitehead, M.; Neary, D.; Clayton, S.; Wright, K.; Thomson, H.; Cummins, S.; Sowden, A.; Renton, A. Environmental interventions to reduce fear of crime: Systematic review of effectiveness. J. Syst. Rev. 2013, 2. [Google Scholar] [CrossRef] [PubMed]
- Space, D. Crime Prevention through Environmental Design; Mac: New York, NY, USA, 1972. [Google Scholar]
- Reusel, K.V. A look ahead at energy-efficient electricity applications in a modern world. In Proceedings of the European Conference on Thermoelectrics, Bergen, Norway, 16–20 June 2008.
- Equipment Energy Efficiency (E3) Program. Street Lighting Strategy. Available online: http://www.energyrating.gov.au/wp-content/uploads/Energy_Rating_Documents/Library/Lighting/Street_Lighting/Draft-streetlight-Strategy.pdf (accessed on 18 October 2016).
- Herranz, C. Interview with Alfonso Beltrán García-Echaniz, managing director of the Institute for Diversification and Energy Saving (IDAE). J. Phys. Soc. 2011, 21, 26–29. [Google Scholar]
- Dully, M. Traffic Safety Evaluation of Future Road Lighting Systems. Master’s Thesis, Linköping University, Linköping, Sweden, 2013. [Google Scholar]
- Coetzer, R.C.; Hancke, G.P. Eye detection for a real-time vehicle driver fatigue monitoring system. In Proceedings of the Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011.
- Güler, Ö.; Onaygil, S. A new criterion for road lighting: Average visibility level uniformity. J. Light Vis. Environ. 2003, 27, 39–46. [Google Scholar] [CrossRef]
- Matout, N. Estimation of the Influence of Artificial Roadway Lighting on Road Collision Frequency. Ph.D. Thesis, Concordia University, Montreal, QC, Canada, 2013. [Google Scholar]
- Halonen, L.G. Intelligent Road Lighting Control Systems; Report 50; Helsinki University of Technology: Espoo, Finland, 2008. [Google Scholar]
- Royal Decree 1890/2008 (2008), 14th November, by Approving Energetic Efficiency. Regulation in Outdoor Lighting Installations and Their Complementary Instructions EA-01 and EA-07. Available online: https://www.boe. es/boe/dias/2008/11/19/pdfs/A45988-46057. pdf (accessed on 5 January 2015).
- Fournier, F.; Cassarly, W.J.; Rolland, J.P. Method to improve spatial uniformity with lightpipes. Opt. Lett. 2008, 33, 1165–1167. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Bergmans, J.W.; Schenk, T.C.; Linnartz, J.P.; Rietman, R. Uniform illumination rendering using an array of LEDs: A signal processing perspective. IEEE Trans. Signal Process. 2009, 57, 1044–1057. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater level forecasting using artificial neural networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Sędziwy, A.; Kozień-Woźniak, M. Computational support for optimizing street lighting design. J. Complex Syst. Dependabil. 2012, 170, 241–255. [Google Scholar]
- Jackett, M.; Frith, W. Quantifying the impact of road lighting on road safety—A New Zealand study. IATSS Res. 2013, 36, 139–145. [Google Scholar] [CrossRef]
- Lighting against Crime. A Guide for Crime Reduction Professionals. Available online: http://www.securedbydesign.com/ pdfs/110107_LightingAgainstCrime.pdf (accessed on 18 October 2016).
- Mara, K.; Underwood, P.; Pasierb, B.P.; McColgan, M.; Morante, P. Street Lighting Best Practices; Hiline Enegineering: Richland, WA, USA, 2005. [Google Scholar]
- Fisher, A. A Review of Street Lighting in Relation to Road Safety; Australian Government Publishing Service: Canberra, Australia, 1971. [Google Scholar]
- Anderson, N.H. Empirical Directions in Design and Analysis; Erlbaum: Mahwah, NJ, USA, 2001. [Google Scholar]
- McLeod, I. Simple random sampling. In Encyclopedia of Statistical Sciences; Kotz, S., Johnson, N.L., Eds.; Wiley: New York, NY, USA, 1988; Volume 8, pp. 478–479. [Google Scholar]
- Schaeffer, R.L.; Ott, R.L.; Mendenhall, W. Elementary Survey Sampling, 6th ed.; Thompson Learning: Belmont, CA, USA, 2006. [Google Scholar]
- Pizzuti, S.; Annunziato, M.; Moretti, F. Smart street lighting management. Energy Effic. 2013, 6, 607–616. [Google Scholar] [CrossRef]
- Benardos, P.G.; Vosniakos, G.C. Optimizing feedforward artificial neural network architecture. Eng. Appl. Artif. Intell. 2007, 20, 365–382. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Barron, A.R. A comment on “Neural networks: A review from a statistical perspective”. Stat. Sci. 1994, 9, 33–35. [Google Scholar] [CrossRef]
- Lippmann, R.P. An introduction to computing with neural nets. IEEE ASSP Mag. 1987, 4, 4–22. [Google Scholar] [CrossRef]
- Cybenko, G. Continuous Valued Neural Networks with Two Hidden Layers are Sufficient; Technical Report; Tuft University: Medford, MA, USA, 1988. [Google Scholar]
- Lapedes, A.; Farber, R. How neural nets work. In Neural Information Processing Systems; Anderson, D.Z., Ed.; American Institute of Physics: New York, NY, USA, 1988; pp. 442–456. [Google Scholar]
- Wong, F.S. Time series forecasting using back-propagation neural networks. Neurocomputing 1991, 2, 147–159. [Google Scholar] [CrossRef]
- Tang, Z.; Fishwick, P.A. Feedforward neural nets as models for time series forecasting. ORSA J. Comput. 1993, 5, 374–385. [Google Scholar] [CrossRef]
- Kang, S. An Investigation of the Use of Feedforward Neural Networks for Forecasting. Ph.D. Thesis, Kent State University, Kent, OH, USA, 1991. [Google Scholar]
- De Groot, C.; Wurtz, D. Analysis of univariate time series with connectionist nets: A case study of two classical examples. Neurocomputing 1991, 3, 177–192. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain non-linear problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef]
- Marquardt, D.W. An algorithm for the least-squares estimation of nonlinear parameters. SIAM J. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Kaj Madsen, Hans Bruun Nielsen, Ole Tingleff Methods for Non-Linear Least Squares Problems (2nd ed.). Informatics and Mathematical Modelling, Technical University of Denmark, DTU. Available online: http://www2.imm.dtu.dk/pubdb/views/edoc_download.php/3215/pdf/imm3215.pdf (accessed on 25 January 2017).
- Lourakis, M.L.; Argyros, A.A. Is levenberg-marquardt the most efficient optimization algorithm for implementing bundle adjustment? In Proceedings of the Tenth IEEE International Conference on Computer Vision, Marseille, France, 12–18 October 2005.
- Wilamowski, B.M.; Iplikci, S.; Kaynak, O.; Efe, M.O. An algorithm for fast convergence in training neural networks. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 15–19 July2001.
- Møller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Gopalakrishnan, K. Effect of training algorithms on neural networks aided pavement diagnosis. Int. J. Eng. Sci. Technol. 2010, 2, 83–92. [Google Scholar] [CrossRef]
- Beale, M.; Hagan, M.; Demut, H. Neural Network Toolbox User’s Guide; Mathworks: Natick, MA, USA, 2010. [Google Scholar]
- Pramanik, N.; Panda, R.K. Application of neural network and adaptive neurofuzzy inference systems for river flow prediction. Hydrol. Sci. J. 2009, 54, 247–260. [Google Scholar] [CrossRef]
- Makarynskyy, O. Improving wave predictions with artificial neural networks. Ocean Eng. 2004, 31, 709–724. [Google Scholar] [CrossRef]
- Mba, L.; Meukam, P.; Kemajou, A. Application of artificial neural network for predicting hourly indoor air temperature and relative humidity in modern building in humid region. Energy Build. 2016, 121, 32–42. [Google Scholar] [CrossRef]
- Chae, Y.T.; Horesh, R.; Hwang, Y.; Lee, Y.M. Artificial neural network model for forecasting sub-hourly electricity usage in commercial buildings. Energy Build. 2016, 111, 184–194. [Google Scholar] [CrossRef]
- Ji, Y.; Xu, P.; Duan, P.; Lu, X. Estimating hourly cooling load in commercial buildings using a thermal network model and electricity submetering data. Appl. Energy 2016, 169, 309–323. [Google Scholar] [CrossRef]
- Moon, J.W.; Chung, S.K. Development of a thermal control algorithm using artificial neural network models for improved thermal comfort and energy efficiency in accommodation buildings. Appl. Therm. Eng. 2016, 103, 1135–1144. [Google Scholar] [CrossRef]
- Kariminia, S.; Motamedi, S.; Shamshirband, S.; Piri, J.; Mohammadi, K.; Hashim, R.; Roy, C.; Petković, D.; Bonakdari, H. Modelling thermal comfort of visitors at urban squares in hot and arid climate using NN-ARX soft computing method. Theor. Appl. Climatol. 2016, 124, 991–1004. [Google Scholar] [CrossRef]
- Papantoniou, S.; Kolokotsa, D. Prediction of outdoor air temperature using neural networks: Application in 4 European cities. Energy Build. 2016, 114, 72–79. [Google Scholar] [CrossRef]
- Şahin, M.; Oğuz, Y.; Büyüktümtürk, F. ANN-based estimation of time-dependent energy loss in lighting systems. Energy Build. 2016, 116, 455–467. [Google Scholar] [CrossRef]
- Kim, W.; Jeon, Y.; Kim, Y. Simulation-based optimization of an integrated daylighting and HVAC system using the design of experiments method. Appl. Energy 2016, 162, 666–674. [Google Scholar] [CrossRef]
- Romero, V.P.; Maffei, L.; Brambilla, G.; Ciaburro, G. Modelling the soundscape quality of urban waterfronts by artificial neural networks. Appl. Acoust. 2016, 111, 121–128. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Variable Description |
|---|---|
| Type of lamp | Mercury Vapor |
| High Pressure Sodium Vapor | |
| Low Pressure Sodium Vapor | |
| Metal Halide | |
| LED | |
| Luminaire arrangement | Unilateral |
| Paired | |
| Quincunx | |
| Power of the lamp | Power consumed divided by the time it takes to consume [w] |
| Width of the lamp | Physical dimension of the lamp [cm] |
| Interdistance | Distance between two luminaires [m] |
| Spacing between luminaire and road | Distance between the lights and the road [m] |
| Mounting height | Data Lamp height [m] |
| Arm length | Length of the arm supporting the lamp [m] |
| Tilt arm | Tilt arm supporting the lamp [degrees] |
| System flux | Measure of perceived light output [lumen] |
| Lamp flux | Power emitted by a light source as visible radiation [lumen] |
| Colour temperature | Temperature of an ideal black-body radiator that radiates light of comparable hue to the light source [°K] |
| Luminaire power | Power of the complete lighting unit [w] |
| Training Methods | Step | MSE | R |
|---|---|---|---|
| Levenberg-Marquardt back-propagation | Training | 0.0123 | 0.6644 |
| Validation | 0.0095 | 0.8997 | |
| Testing | 0.0516 | −0.0531 | |
| Scaled conjugate gradient back-propagation | Training | 1.6627 | 0.1063 |
| Validation | 0.3712 | 0.8983 | |
| Testing | 0.0146 | 0.6128 | |
| Gradient descent with momentum | Training | 0.5760 | −0.3032 |
| Validation | 0.0503 | −0.8773 | |
| Testing | 0.0535 | −0.0212 | |
| Gradient descent with adaptive lr back-propagation | Training | 4.3641 | 0.3517 |
| Validation | 4.0630 | 0.1115 | |
| Testing | 0.1268 | 0.3491 | |
| Gradient descent w/momentum & adaptive lr back-propagation | Training | 6.0454 | −0.0046 |
| Validation | 0.0305 | 0.3640 | |
| Testing | 0.2339 | −0.3598 | |
| Gradient descent back-propagation | Training | 0.0155 | 0.6747 |
| Validation | 0.0054 | 0.8820 | |
| Testing | 0.3753 | 0.8123 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Corte-Valiente, A.D.; Castillo-Sequera, J.L.; Castillo-Martinez, A.; Gómez-Pulido, J.M.; Gutierrez-Martinez, J.-M. An Artificial Neural Network for Analyzing Overall Uniformity in Outdoor Lighting Systems. Energies 2017, 10, 175. https://doi.org/10.3390/en10020175
Corte-Valiente AD, Castillo-Sequera JL, Castillo-Martinez A, Gómez-Pulido JM, Gutierrez-Martinez J-M. An Artificial Neural Network for Analyzing Overall Uniformity in Outdoor Lighting Systems. Energies. 2017; 10(2):175. https://doi.org/10.3390/en10020175
Chicago/Turabian StyleCorte-Valiente, Antonio Del, José Luis Castillo-Sequera, Ana Castillo-Martinez, José Manuel Gómez-Pulido, and Jose-Maria Gutierrez-Martinez. 2017. "An Artificial Neural Network for Analyzing Overall Uniformity in Outdoor Lighting Systems" Energies 10, no. 2: 175. https://doi.org/10.3390/en10020175
APA StyleCorte-Valiente, A. D., Castillo-Sequera, J. L., Castillo-Martinez, A., Gómez-Pulido, J. M., & Gutierrez-Martinez, J.-M. (2017). An Artificial Neural Network for Analyzing Overall Uniformity in Outdoor Lighting Systems. Energies, 10(2), 175. https://doi.org/10.3390/en10020175