Hydro Power Reservoir Aggregation via Genetic Algorithms


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Implications of Reservoir Capacities
3. Deterministic Hydropower Scheduling Equivalent
4. Scaleable Deterministic Model
5. Parameter Fitting
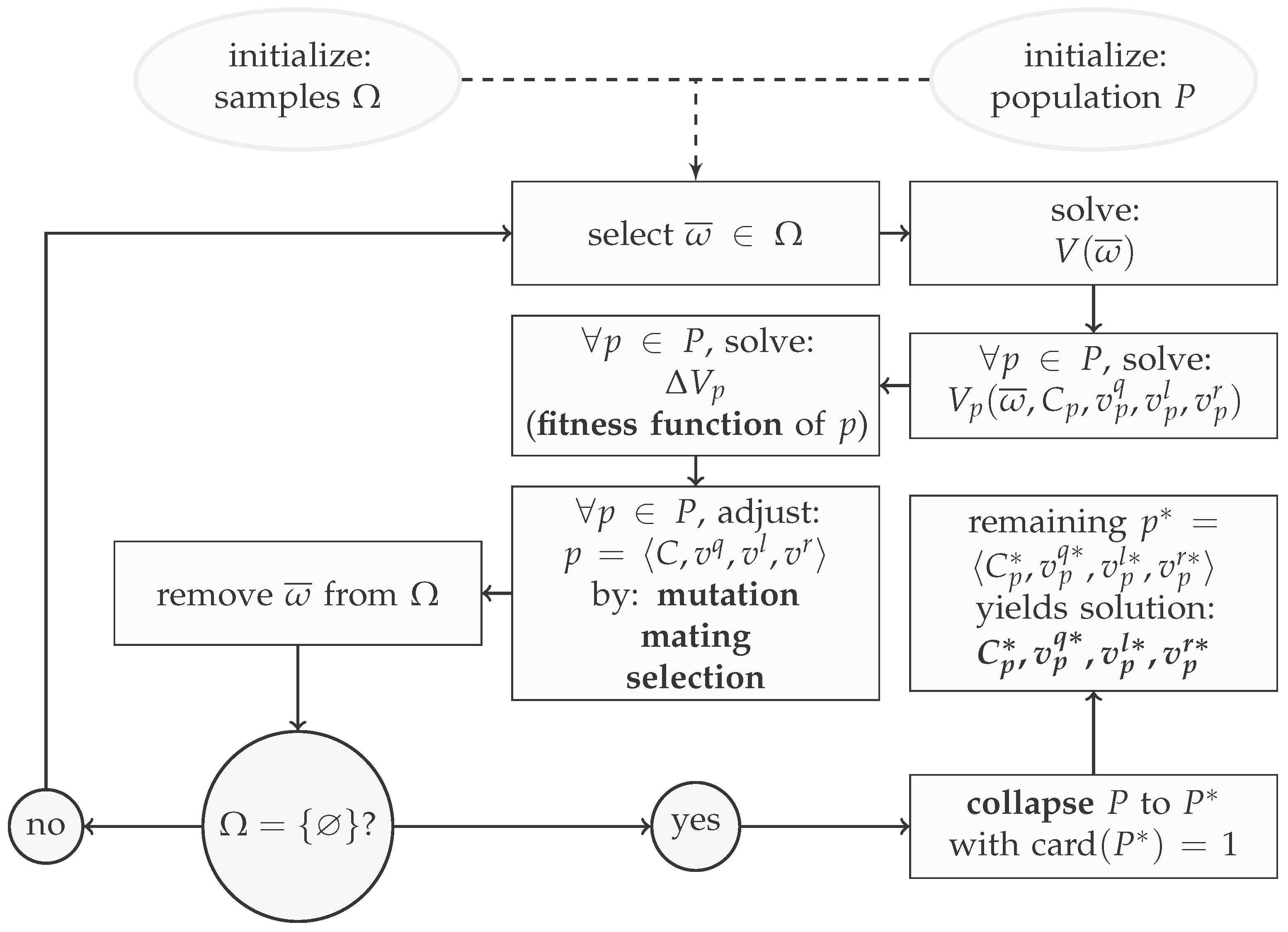
6. Genetic Algorithm
- mutation: changes in decision variables based on random variables drawn from predetermined possibility distributions,
- crossover (”mating”): merger of decision variables of “parents” to establish new “children” that are added to the population,
- selection: removal of members of P by comparing their fitness values.
6.1. Individual
6.2. Feedback Function
6.3. Algorithm Parameters
- -
- Due to crossover, the increase is exponential (with every generation, the size of the population increases by 100%) and the model requires large quantities of scaling; the population was collapsed to 67% of its size after each generation (via tournament selection as denoted above).
- -
- To eventually collapse the population to a single individual, a second set is required. On those scenarios , no mutations and crossovers are applied. The rate of collapse per generation can be calculated as .
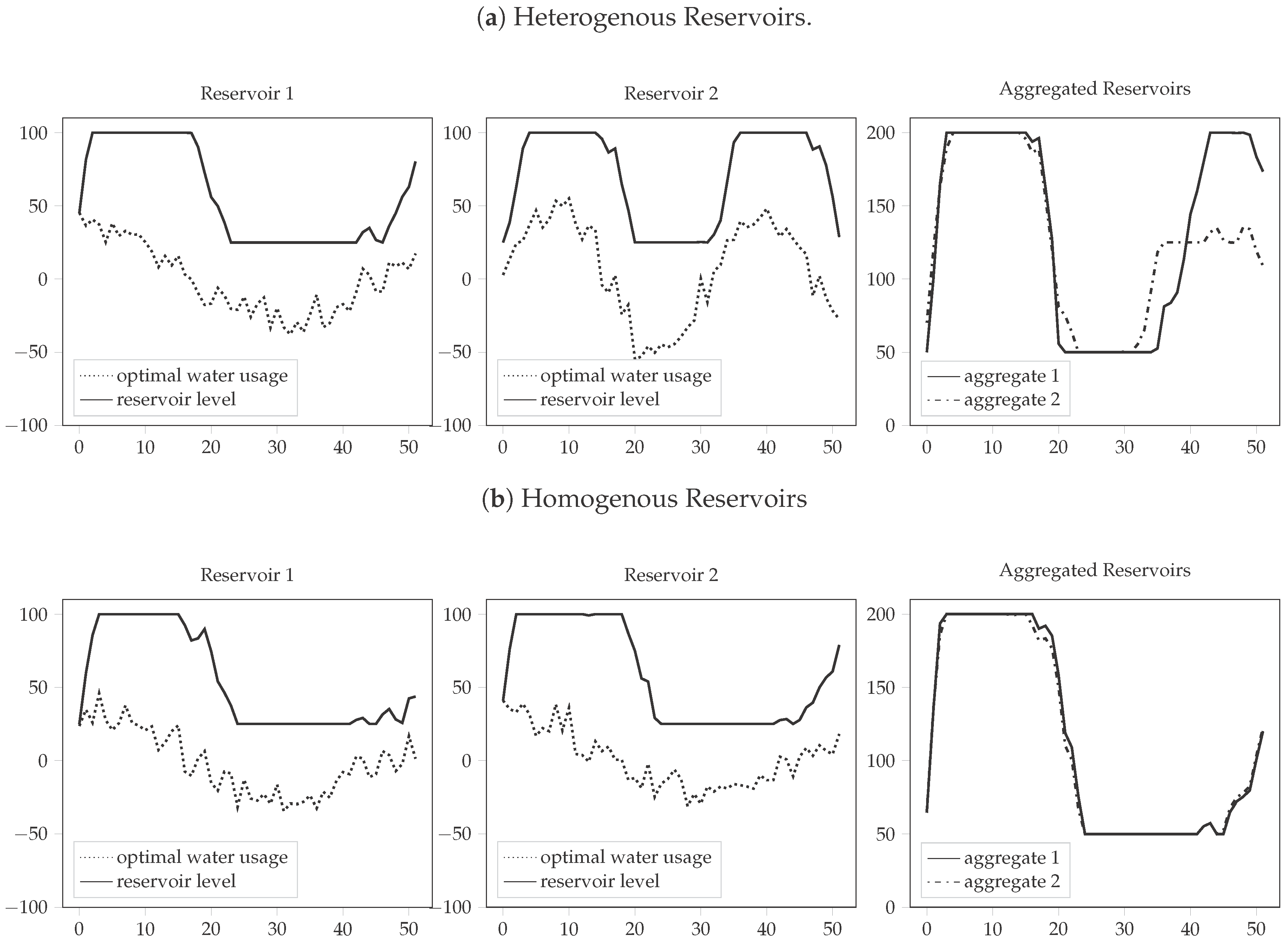
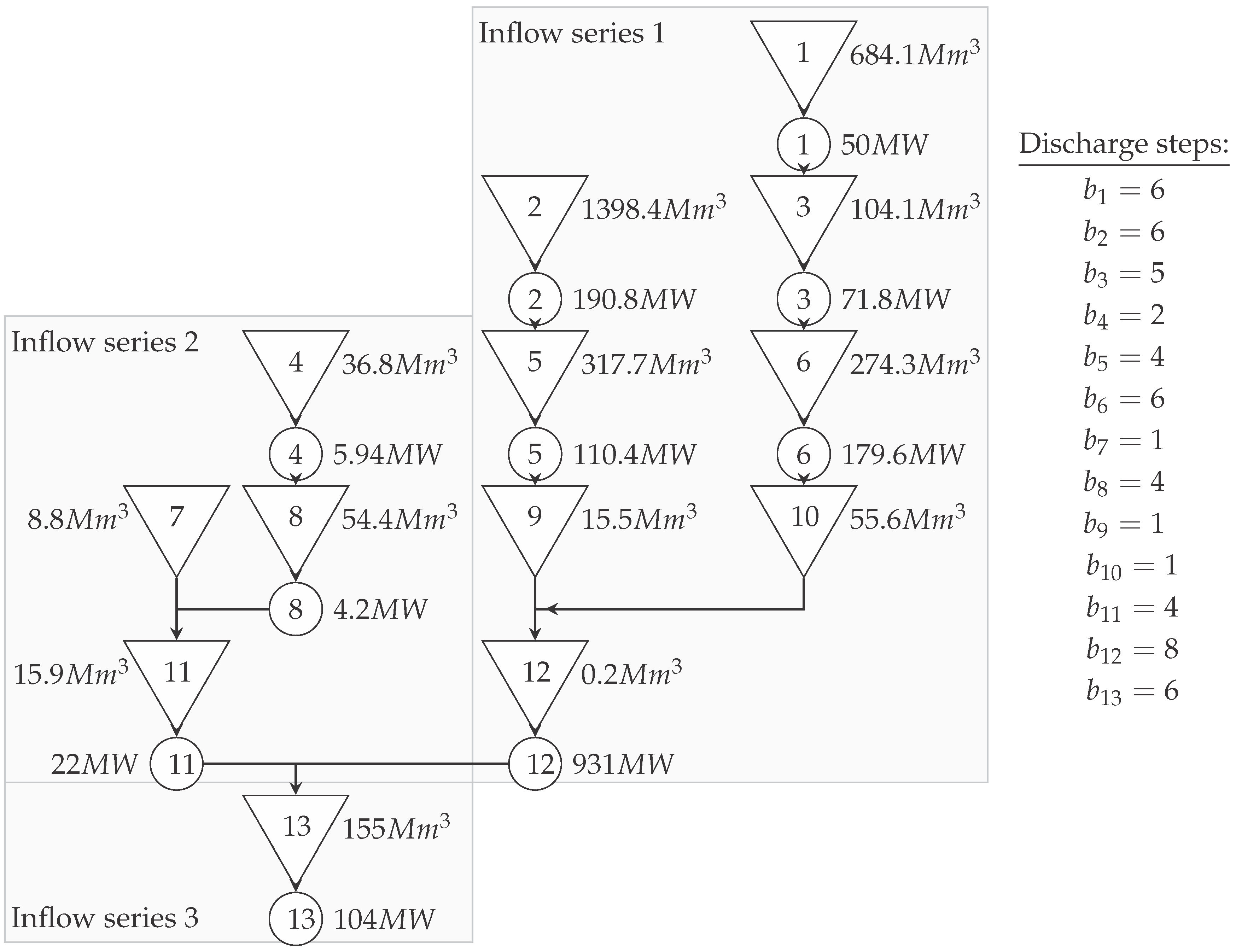
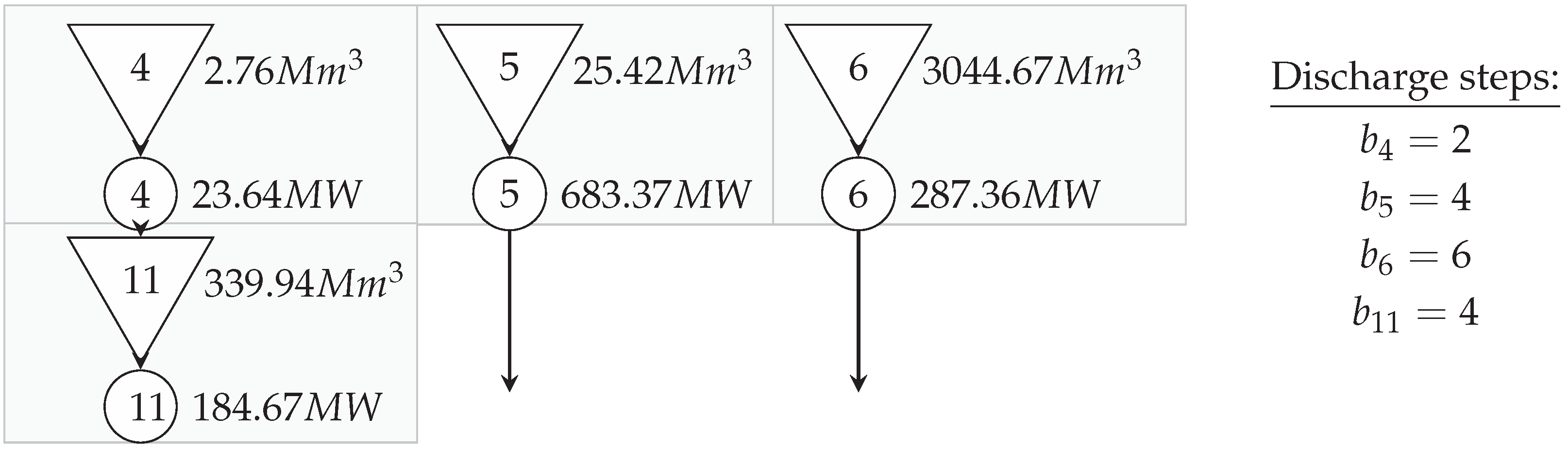
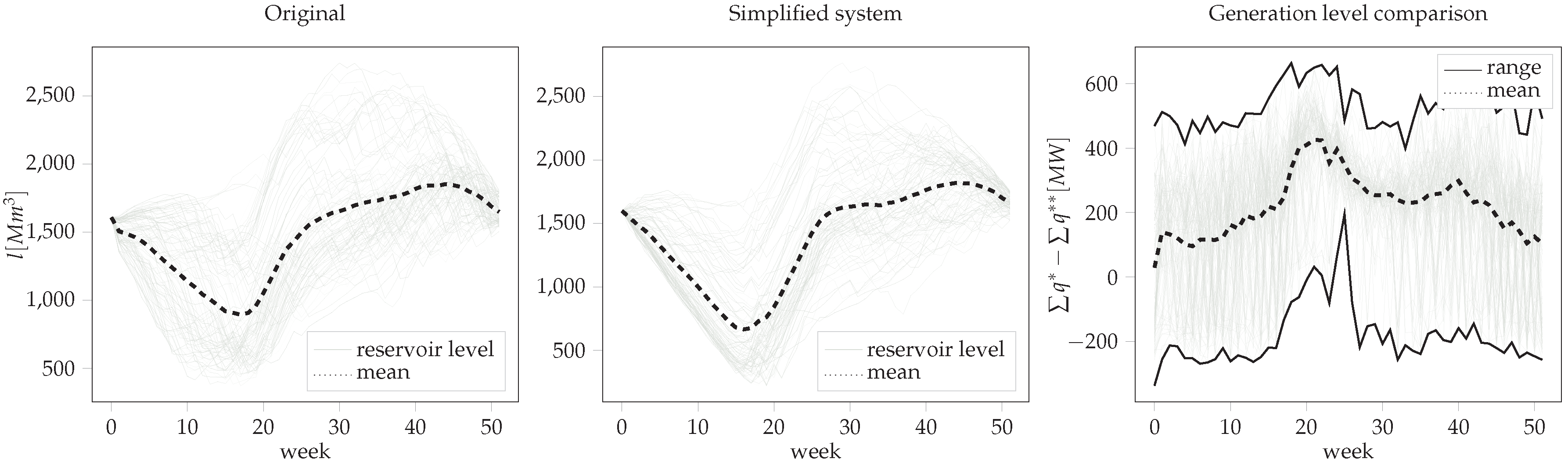
7. Case Study
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Nomenclature
| Indexes: | |
| scenario | |
| generation unit/reservoir | |
| discharge steps of generation unit i | |
| t | time period |
| alternative time period | |
| Variables: | |
| generation | |
| spillage | |
| station cut | |
| generation leverage variable | |
| inventory leverage variable | |
| inflow leverage variable | |
| Parameters: | |
| market price | |
| maximum generation capacity of generator i | |
| maximum generation capacity of discarche step b | |
| hydrological inflow | |
| conversion rate | |
| maximum reservoir capacity | |
| water value | |
| water course matrix | |
| start period hydrological inventory | |
| end period hydrological inventory | |
| maximum spillage | |
| w | weight factor |
| maximum number of power stations/reservoirs in the system | |
| Functions: | |
| defines a function | |
| operation function of a system | |
| reservoir level | |
| profit function | |
| generation cost function | |
| periodic inflow | |
| periodic loss | |
| water course matrix with cuts C applied | |
| optimal operation | |
| Sets: | |
| scenario set | |
| P | population |
| Tuples: | |
| p | individual |
Appendix A. Maximum Spillage Constraint
Appendix B. Scenario Generation

Appendix C. Network Matrix Rerouting
References
- Pereira, M.; Pinto, L. Multi-stage stochastic optimization applied to energy planning. Math. Program. 1991, 52, 359–375. [Google Scholar] [CrossRef]
- Gjelsvik, A.; Belsnes, M.M.; Haugstad, A. An algorithm for stochastic medium-term hydrothermal scheduling under spot price uncertainty. In Proceedings of the 13th Power Systems Computation Conference (PSCC), Trondheim, Norway, 28 June–2 July 1999; pp. 1079–1085. [Google Scholar]
- Wolfgang, O.; Haugstad, A.; Mo, B.; Gjelsvik, A.; Wangensteen, I.; Doorman, G. Hydro reservoir handling in Norway before and after deregulation. Energy 2009, 34, 1642–1651. [Google Scholar] [CrossRef]
- Steeger, G.; Barroso, L.A.; Rebennack, S. Optimal Bidding Strategies for Hydro-Electric Producers: A Literature Survey. IEEE Trans. Power Syst. 2014, 29, 1758–1766. [Google Scholar] [CrossRef]
- Pereira-Cardenal, S.J.; Mo, B.; Gjelsvik, A.; Riegels, N.D.; Arnbjerg-Nielsen, K.; Bauer-Gottwein, P. Joint optimization of regional water-power systems. Adv. Water Resour. 2016, 92, 200–207. [Google Scholar] [CrossRef]
- Shayesteh, E.; Amelin, M.; Soder, L. Multi-Station equivalents for Short-term hydropower scheduling. IEEE Trans. Power Syst. 2016, 31, 4616–4625. [Google Scholar] [CrossRef]
- Valdes, B.J.B.; Filippo, J.M.D.; Strzepek, K.M.; Restrepo, P.J. Aggregation-Disaggregation Approach to Multireservoir Operation. J. Water Resour. Plan. Manag. 1992, 118, 423–444. [Google Scholar] [CrossRef]
- Archibald, T.; McKinnon, K.; Thomas, L. An aggregate stochastic dynamic programming model of multi-reservoir systems. Water Resour. Res. 1997, 33, 333–340. [Google Scholar] [CrossRef]
- Turgeon, A.; Charbonneau, R. An aggregation-disaggregation approach to long-term reservoir management. Water Resour. Res. 1998, 34, 3585–3594. [Google Scholar] [CrossRef]
- Turgeon, A. Solving reservoir management problems with serially correlated inflows. River Basin Manag. III 2005, 83, 247–255. [Google Scholar]
- Turgeon, A. Optimal rule curves for interconnected reservoirs. River Basin Manag. IV 2007, I, 87–96. [Google Scholar]
- Liu, P.; Guo, S.; Xu, X.; Chen, J. Derivation of Aggregation-Based Joint Operating Rule Curves for Cascade Hydropower Reservoirs. Water Resour. Manag. 2011, 25, 3177–3200. [Google Scholar] [CrossRef]
- Söder, L.; Rendelius, J. Two-Station Equivalent of Hydro Power Systems. In Proceedings of the 15th Power Systems Computation Conference (PSCC), Liège, Belgium, 22–26 August 2005; pp. 22–26. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer Science & Business Media: Berlin, Germany, 1995. [Google Scholar]
- Siarry, P. Evolutionary Algorithms. In Metaheuristics; Springer International: Cham, Switzerland, 2016; pp. 115–175. [Google Scholar]
- Cai, X.; McKinney, D.C.; Lasdon, L.S. Solving nonlinear water management models using a combined genetic algorithm and linear programming approach. Adv. Water Res. 2001, 24, 667–676. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, X.; Qin, H. Optimal operation of multi-reservoir hydropower systems using enhanced comprehensive learning particle swarm optimization. J. Hydro-Environ. Res. 2016, 10, 50–63. [Google Scholar] [CrossRef]
- Saad, M.; Bigras, P.; Turgeon, A.; Duquette, R. Fuzzy learning decomposition for the scheduling of hydroelectric power systems. Water Resour. Res. 1996, 32, 179–186. [Google Scholar] [CrossRef]
- Lee, J.H.; Labadie, J.W. Stochastic optimization of multireservoir systems via reinforcement learning. Water Resour. Res. 2007, 43, 1–16. [Google Scholar] [CrossRef]
- Hveding, V. Digital simulation techniques in power system planning. Econ. Plan. 1968, 8, 118–139. [Google Scholar] [CrossRef]
- Førsund, F.R. Hveding’s Conjecture: On the Aggregation of a Hydroelectric Multiplant—Multireservoir System. In CREE Working Paper; Oslo Centre for Research on Environmentally friendly Energy: Oslo, Norway, 2014; pp. 1–30. [Google Scholar]
- Sintef Energy Research. EMPS—Multi Area Power Market Simulator. Available online: https://www.sintef.no/en/software/emps-multi-area-power-market-simulator/ (accessed on 10 December 2017).
- Zadeh, L. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Fortin, F.A.; De Rainville, F.M.; Gardner, M.A.; Parizeau, M.; Gagné, C. DEAP: Evolutionary Algorithms Made Easy. J. Mach. Learn. Res. 2012, 13, 2171–2175. [Google Scholar]
- Turgeon, A. A decomposition method for the long–term scheduling of reservoirs in series. Water Resour. Res. 1981, 17, 1565–1570. [Google Scholar] [CrossRef]
- Löhndorf, N. An empirical analysis of scenario generation methods for stochastic optimization. Eur. J. Oper. Res. 2016, 255, 121–132. [Google Scholar] [CrossRef]
- Glassermann, P. Monte Carlo Methods in Financial Engineering; Springer Science & Business Media: Berlin, Germany, 2003. [Google Scholar]
- Birge, J.R.; Louveaux, F. Introduction to Stochastic Programming, 2nd ed.; Springer: Berlin, Germany, 2011; pp. 135–149, 289–338. [Google Scholar]





© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Löschenbrand, M.; Korpås, M. Hydro Power Reservoir Aggregation via Genetic Algorithms. Energies 2017, 10, 2165. https://doi.org/10.3390/en10122165
Löschenbrand M, Korpås M. Hydro Power Reservoir Aggregation via Genetic Algorithms. Energies. 2017; 10(12):2165. https://doi.org/10.3390/en10122165
Chicago/Turabian StyleLöschenbrand, Markus, and Magnus Korpås. 2017. "Hydro Power Reservoir Aggregation via Genetic Algorithms" Energies 10, no. 12: 2165. https://doi.org/10.3390/en10122165
APA StyleLöschenbrand, M., & Korpås, M. (2017). Hydro Power Reservoir Aggregation via Genetic Algorithms. Energies, 10(12), 2165. https://doi.org/10.3390/en10122165