
AI and Financial Fraud Prevention: Mapping the Trends and Challenges Through a Bibliometric Lens




Abstract
1. Introduction
2. Materials and Methods
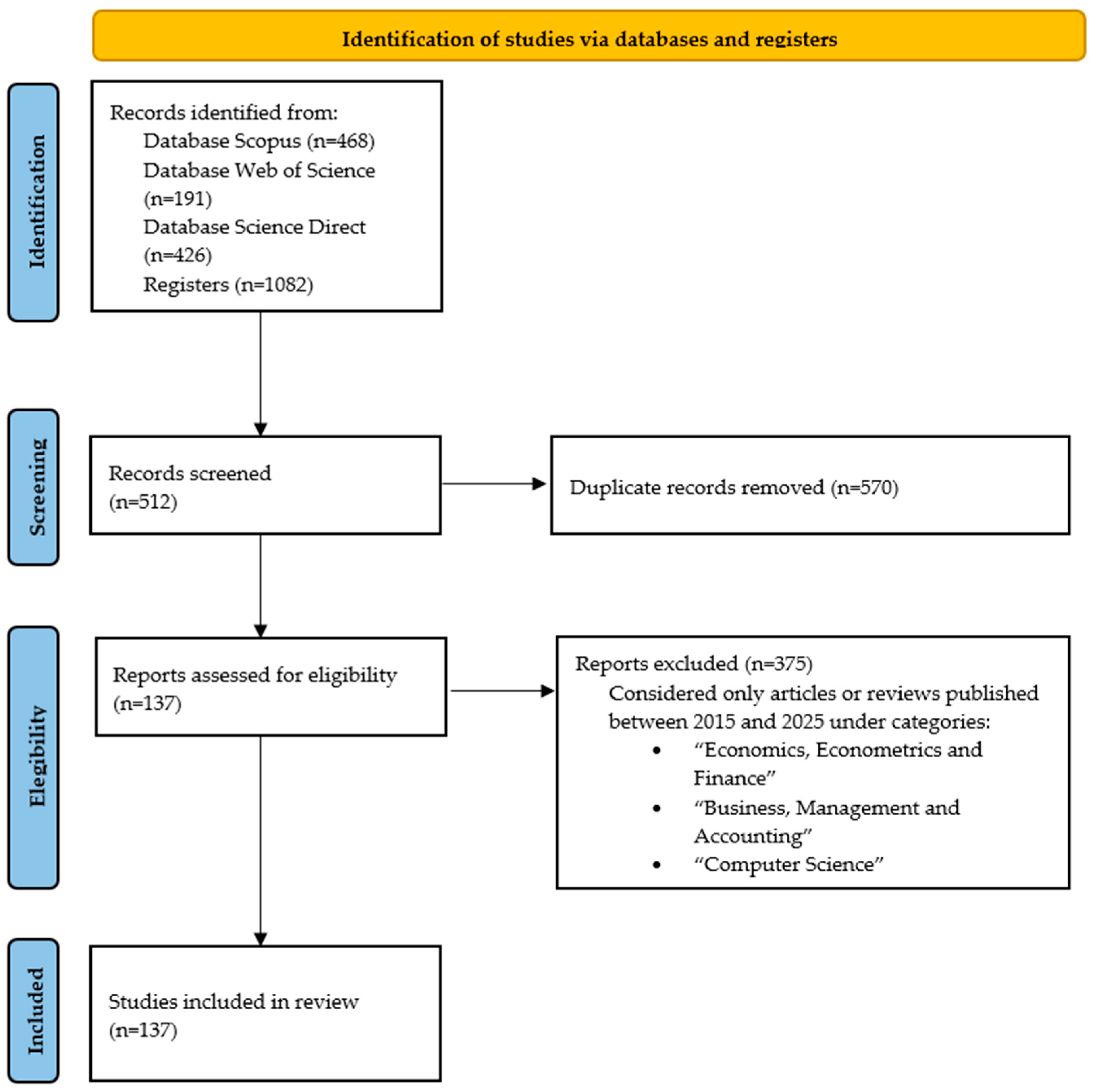
2.1. Methodology
2.2. Data Collection
2.3. Analysis Framework
3. Results
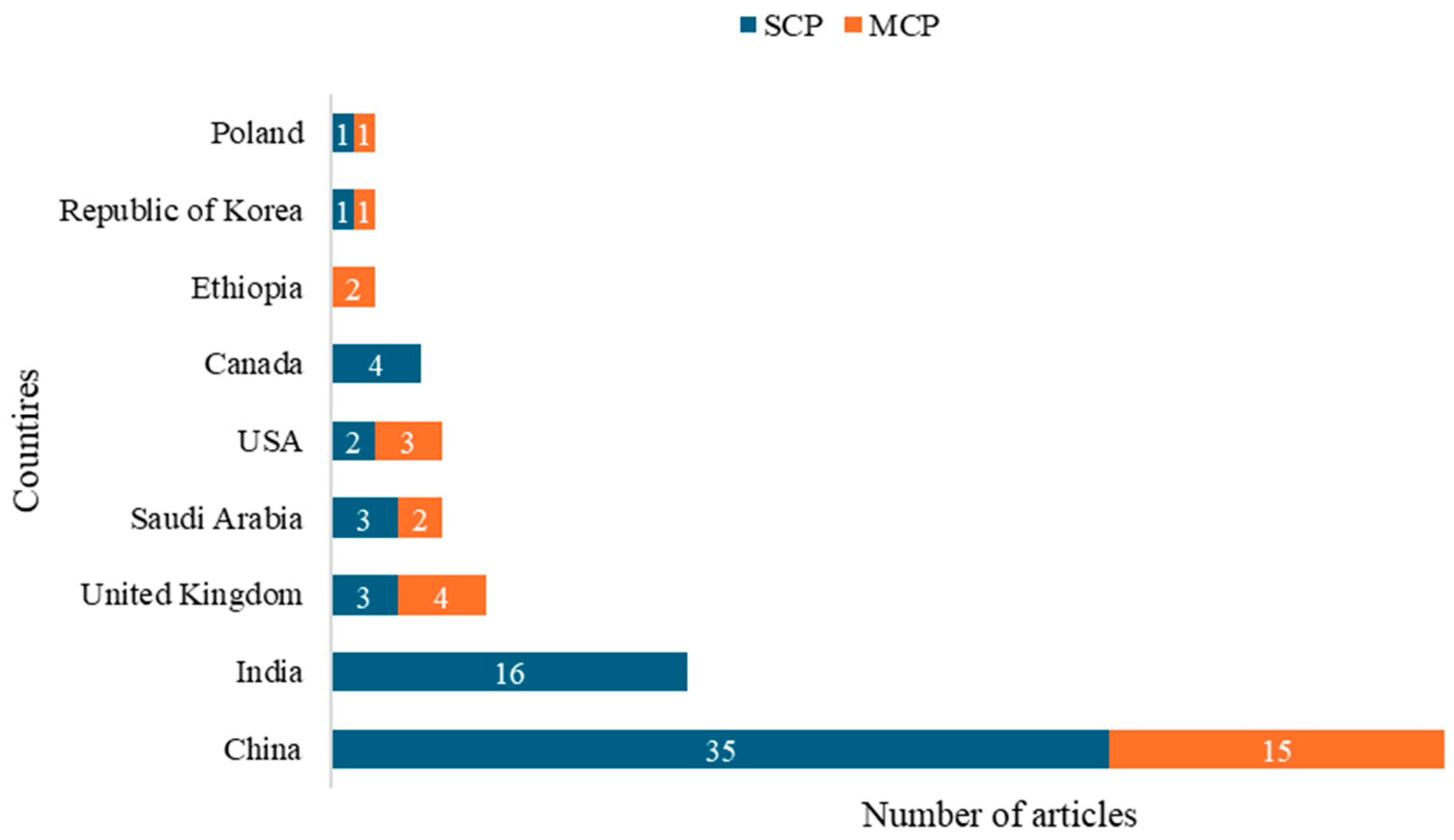
3.1. General Information
3.2. Most Relevant Sources
3.3. Main Authors, Articles, and Affiliations
- The lilac cluster predominantly addresses financial fraud detection through advanced big data and artificial intelligence techniques, such as deep neural networks, graph algorithms, and privacy-preserving federated learning (L. Wang et al., 2021);
- The red cluster explores cutting-edge quantum machine learning methods, including quantum graph neural networks and quantum classifiers, to improve the accuracy and efficiency of detecting fraudulent activities in financial data (Y. Wang & Zhu, 2024);
- The blue cluster investigates diverse approaches to financial fraud detection, such as the analysis of abnormal managerial tone in Chinese listed firms (X. Wang, 2024), the development of intelligent support systems based on a three-level relationship penetration model (R. Li et al., 2023), and the integration of generative AI in economic and financial research (Zhang et al., 2022);
- The brown cluster emphasizes enhancing fraud prediction models through innovative key indicator selection using hybrid machine learning approaches (L. Wang et al., 2021) and applying fusion models for more effective predictive systems (J. Li et al., 2024).
3.4. Most-Cited Articles
3.5. Institutional Contributions
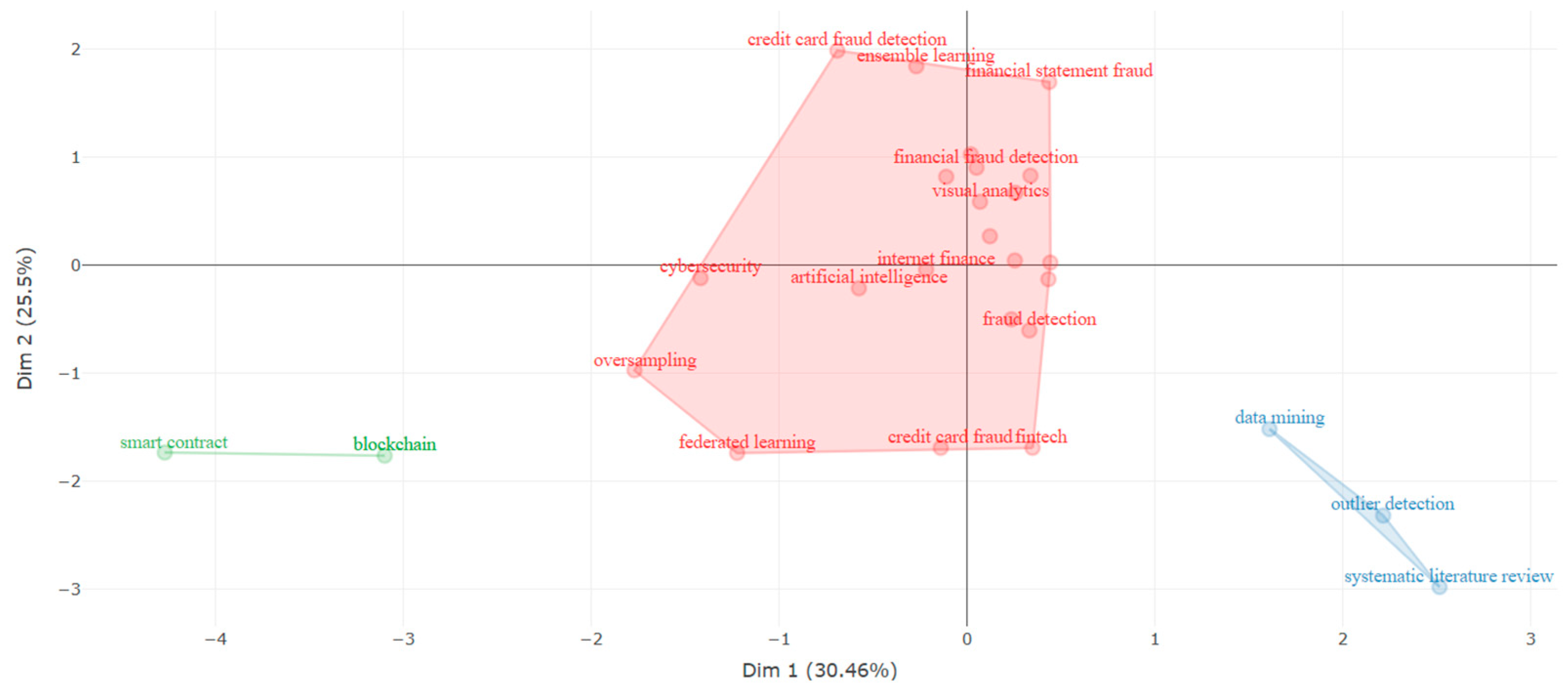
3.6. Research Clusters, Trends, and Gaps
3.7. Further Analysis
4. Conclusions
Limitations
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ahmed, S., Alshater, M. M., El Ammari, A., & Hammami, H. (2022). Artificial intelligence and machine learning in finance: A bibliometric review. Research in International Business and Finance, 61, 101646. [Google Scholar] [CrossRef]
- Almazroi, A. A., & Ayub, N. (2023). Online payment fraud detection model using machine learning techniques. IEEE Access, 11, 137188–137203. [Google Scholar] [CrossRef]
- Araújo, C. A. (2006). Bibliometria: Evolução histórica e questões atuais. Em Questão, 12(1), 11–32. [Google Scholar]
- Aria, M., & Cuccurullo, C. (2017). Bibliometrix: An R-tool for comprehensive science mapping analysis. Journal of Infometrics, 11(4), 959–975. [Google Scholar] [CrossRef]
- Awosika, T., Shukla, R. M., & Pranggono, B. (2024). Transparency and privacy: The role of explainable AI and federated learning in financial fraud detection. IEEE Access, 12, 64551–64560. [Google Scholar] [CrossRef]
- Baabdullah, T., Alzahrani, A., Rawat, D. B., & Liu, C. (2024). Efficiency of Federated learning and blockchain in preserving privacy and enhancing the performance of Credit Card Fraud Detection (CCFD) systems. Future Internet, 16, 196. [Google Scholar] [CrossRef]
- Baghdadi, P., Korukoglu, S., Bilici, M. A., & Onan, A. (2025). The potential of energy-based RBM and xLSTM for real-time predictive analytics in credit card fraud detection. Journal of Data Analysis and Information Processing, 13(1), 79–100. [Google Scholar] [CrossRef]
- Belanche, D., Belk, R. W., Casaló, L. V., & Flavián, C. (2024). The dark side of artificial intelligence in services. The Service Industries Journal, 44(3–4), 149–172. [Google Scholar] [CrossRef]
- Biswas, B., Mukhopadhyay, A., Kumar, A., & Delen, D. (2024). A hybrid framework using explainable AI (XAI) in cyber-risk management for defence and recovery against phishing attacks. Decision Support Systems, 177, 114102. [Google Scholar] [CrossRef]
- Błaszczyński, J., De Almeida Filho, A. T., Matuszyk, A., Szeląg, M., & Słowiński, R. (2021). Auto loan fraud detection using dominance-based rough set approach versus machine learning methods. Expert Systems with Applications, 163, 113740. [Google Scholar] [CrossRef]
- Bou Reslan, F., & Jabbour Al Maalouf, N. (2024). Assessing the transformative impact of AI adoption on efficiency, fraud detection, and skill dynamics in accounting practices. Journal of Risk and Financial Management, 17(12), 577. [Google Scholar] [CrossRef]
- Bradford, S. (1985). Specific subjects. Journal of Information Science, 10(4), 173–180. [Google Scholar]
- Chadegani, A. A., Salehi, H., Yunus, M. M., Farhadi, H., Fooladi, M., Farhadi, M., & Ebrahim, N. A. (2013). A comparison between two main academic literature collections: Web of Science and Scopus databases. Asian Social Science, 9(5), 18–26. [Google Scholar] [CrossRef]
- Chen, Y., Zhao, C., Xu, Y., & Nie, C. (2025). Year-over-year developments in financial fraud detection via deep learning: A systematic literature review. arXiv, arXiv:2502.00201. [Google Scholar]
- Chhatwani, M. (2022). Does robo-advisory increase retirement worry? A causal explanation. Managerial Finance, 48, 611–628. [Google Scholar] [CrossRef]
- Choi, D., & Lee, K. (2018). An artificial intelligence approach to financial fraud detection under IoT environment: A survey and implementation. Security and Communication Networks, 2018(1), 5483472. [Google Scholar] [CrossRef]
- Chueke, G. V., & Amatucci, M. (2015). O que é bibliometria? Uma introdução ao fórum. Internext, 10(2), 1–5. [Google Scholar] [CrossRef]
- Cummings, M. (2021). Rethinking the maturity of artificial intelligence in safety-critical settings. AI Magazine, 42(1), 6–15. [Google Scholar] [CrossRef]
- Dasari, S., & Kaluri, R. (2024). An effective classification of DDoS attacks in a distributed network by adopting hierarchical machine learning and hyperparameters optimization techniques. IEEE Access, 12, 10834–10845. [Google Scholar] [CrossRef]
- Deng, T., Bi, S., & Xiao, J. (2025). Transformer-based financial fraud detection with cloud-optimized real-time streaming. arXiv, arXiv:2501.19267. [Google Scholar]
- Duan, W., Hu, N., & Xue, F. (2024). The information content of financial statement fraud risk: An ensemble learning approach. Decision Support Systems, 182, 114231. [Google Scholar] [CrossRef]
- Gerhardt, T. E., & Silveira, D. T. (2009). Métodos de pesquisa. Plageder. [Google Scholar]
- Goodell, J. W., Kumar, S., Lim, W. M., & Pattnaik, D. (2021). Artificial intelligence and machine learning in finance: Identifying foundations, themes, and research clusters from bibliometric analysis. Journal of Behavioral and Experimental Finance, 32, 100577. [Google Scholar] [CrossRef]
- Gupta, S., & Mehta, S. K. (2024). Feature selection for dimension reduction of financial data for detection of financial statement frauds in context to indian companies. Global Business Review, 25, 323–348. [Google Scholar] [CrossRef]
- Hajek, P., & Henriques, R. (2017). Mining corporate annual reports for intelligent detection of financial statement fraud—A comparative study of machine learning methods. Knowledge-Based Systems, 128, 139–152. [Google Scholar] [CrossRef]
- Hamadou, I., Yumna, A., Hamadou, H., & Jallow, M. S. (2024). Unleashing the power of artificial intelligence in Islamic banking: A case study of Bank Syariah Indonesia (BSI). Modern Finance, 2(1), 131–144. [Google Scholar] [CrossRef]
- Hilal, W., Gadsden, S. A., & Yawney, J. (2022). Financial fraud: A review of anomaly detection techniques and recent advances. Expert Systems with Applications, 193, 116429. [Google Scholar] [CrossRef]
- Hsin, Y. Y., Dai, T. S., Ti, Y. W., Huang, M. C., Chiang, T. H., & Liu, L. C. (2022). Feature engineering and resampling strategies for fund transfer fraud with limited transaction data and a time-inhomogeneous modi operandi. IEEE Access, 10, 86101–86116. [Google Scholar] [CrossRef]
- Huang, L., Abrahams, A., & Ractham, P. (2022). Enhanced financial fraud detection using cost-sensitive cascade forest with missing value imputation. Intelligent Systems in Accounting, Finance and Management, 29(3), 133–155. [Google Scholar] [CrossRef]
- Ileberi, E., Sun, Y., & Wang, Z. (2022). A machine learning based credit card fraud detection using the GA algorithm for feature selection. Journal of Big Data, 9(1), 24. [Google Scholar] [CrossRef]
- Innan, N., Marchisio, A., Bennai, M., & Shafique, M. (2024). QFNN-FFD: Quantum federated neural network for financial fraud detection. arXiv, arXiv:2404.02595. [Google Scholar]
- Ismail, M. M., & Haq, M. A. (2024). Enhancing enterprise financial fraud detection using machine learning. Engineering, Technology & Applied Science Research, 14(4), 14854–14861. [Google Scholar] [CrossRef]
- Itoo, F., Mittal, M., & Singh, S. (2021). Comparison and analysis of logistic regression, Naïve Bayes and KNN machine learning algorithms for credit card fraud detection. International Journal of Information Technology, 13(4), 1503–1511. [Google Scholar] [CrossRef]
- Jagtiani, J., & John, K. (2018). Fintech: The impact on consumers and regulatory responses. Journal of Economics and Business, 100, 1–6. [Google Scholar] [CrossRef]
- Jeong, D. H., Jeong, B. K., & Ji, S. Y. (2024). Leveraging machine learning to analyze semantic user interactions in visual analytics. Information, 15, 351. [Google Scholar] [CrossRef]
- Jullum, M., Løland, A., Huseby, R. B., Ånonsen, G., & Lorentzen, J. (2020). Detecting money laundering transactions with machine learning. Journal of Money Laundering Control, 23(1), 173–186. [Google Scholar] [CrossRef]
- Khetani, V., Gandhi, Y., Bhattacharya, S., Ajani, S. N., & Limkar, S. (2023). Cross-domain analysis of ML and DL: Evaluating their impact in diverse domains. International Journal of Intelligent Systems and Applications in Engineering, 11(7s), 253–262. [Google Scholar]
- Kirkos, E., Spathis, C., & Manolopoulos, Y. (2007). Data mining techniques for the detection of fraudulent financial statements. Expert Systems with Applications, 32(4), 995–1003. [Google Scholar] [CrossRef]
- Krishna, V. R., & Boddu, S. (2023). Financial Fraud detection using improved artificial humming bird algorithm with modified extreme learning machine. International Journal on Recent and Innovation Trends in Computing and Communication, 11, 5–14. [Google Scholar] [CrossRef]
- Kumar, B. S., & Ravi, V. (2016). A survey of the applications of text mining in financial domain. Knowledge-Based Systems, 114, 128–147. [Google Scholar] [CrossRef]
- Kumar, N., Srivastava, J. D., & Bisht, H. (2019). Artificial intelligence in insurance sector. Journal of the Gujarat Research Society, 21(7), 79–91. [Google Scholar]
- Li, J., Guo, C., Lv, S., Xie, Q., & Zheng, X. (2024). Financial fraud detection for Chinese listed firms: Does managers’ abnormal tone matter? Emerging Markets Review, 62, 101170. [Google Scholar] [CrossRef]
- Li, R., Liu, Z., Ma, Y., Yang, D., & Sun, S. (2023). Internet financial fraud detection based on graph learning. IEEE Transactions on Computational Social Systems, 10(3), 1394–1401. [Google Scholar] [CrossRef]
- Lin, H., Gao, S., Gotz, D., Du, F., He, J., & Cao, N. (2018). RCLens: Interactive rare category exploration and identification. IEEE Transactions on Visualization and Computer Graphics, 24, 2223–2237. [Google Scholar] [CrossRef]
- Liu, L., Tsai, W. T., Bhuiyan, M. Z. A., Peng, H., & Liu, M. (2022). Blockchain-enabled fraud discovery through abnormal smart contract detection on Ethereum. Future Generation Computer Systems, 128, 158–166. [Google Scholar] [CrossRef]
- Liu, W., Wang, Z., & Zhang, X. (2025). Research on financial fraud detection by integrating latent semantic features of annual report text with accounting indicators. Journal of Accounting & Organizational Change. [Google Scholar] [CrossRef]
- Lotka, A. J. (1926). The frequency distribution of scientific productivity. Journal of the Washington Academy of Sciences, 16(12), 317–323. [Google Scholar]
- Lu, X., Wijayaratna, K., Huang, Y., & Qiu, A. (2022). AI-enabled opportunities and transformation challenges for SMEs in the post-pandemic era: A review and research agenda. Frontiers in Public Health, 10, 885067. [Google Scholar] [CrossRef] [PubMed]
- Masood, M., Nawaz, M., Malik, K. M., Javed, A., Irtaza, A., & Malik, H. (2023). Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Applied Intelligence, 53(4), 3974–4026. [Google Scholar] [CrossRef]
- Merigó, J. M., Pedrycz, W., Weber, R., & de la Sotta, C. (2018). Fifty years of Information Sciences: A bibliometric overview. Information Sciences, 432, 245–268. [Google Scholar] [CrossRef]
- Moher, D., Shamseer, L., Clarke, M., Ghersi, D., Liberati, A., Petticrew, M., Shekelle, P., & Stewart, L. A. (2015). Preferred reporting items for Systematic Review and Meta-Analysis Protocols (PRISMA-P) 2015: Elaboration and explanation. Research Methods & Reporting, 349, g7647. [Google Scholar]
- Mongeon, P., & Paul-Hus, A. (2016). The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics, 106, 213–228. [Google Scholar] [CrossRef]
- Motie, S., & Raahemi, B. (2024). Financial fraud detection using graph neural networks: A systematic review. Expert Systems with Applications, 240, 122156. [Google Scholar] [CrossRef]
- Navarrete, C. B., Malverde, M. G. M., Lagos, P. S., & Mujica, A. D. B. (2018). A web-based systematic literature review management software. SoftwareX, 7, 360–372. [Google Scholar] [CrossRef]
- Newman, M. E., & Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review E, 69(2), 026113. [Google Scholar] [CrossRef] [PubMed]
- Ngai, E. W., Hu, Y., Wong, Y. H., Chen, Y., & Sun, X. (2011). The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decision Support Systems, 50(3), 559–569. [Google Scholar] [CrossRef]
- Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff, J. M., Akl, E., Brennan, S. E., Chou, R., Glanville, J., Grimshaw, J., Hróbjartsson, A., Lalu, M. M., Li, T., Loder, E. W., Mayo-Wilson, E., Mcdonald, S., … Moher, D. (2021). The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. The British Medical Journal, 372(71), n71. [Google Scholar] [CrossRef] [PubMed]
- Payer, R. C., Quelhas, O. L. G., & Bergiante, N. C. R. (2024). Framework to supporting monitoring the circular economy in the context of industry 5.0: A proposal considering circularity indicators, digital transformation, and Sustainability. Journal of Cleaner Production, 466, 142850. [Google Scholar] [CrossRef]
- Pranto, T. H., Hasib, K. T. A. M., Rahman, T., Haque, A. B., Islam, A. K. M. N., & Rahman, R. M. (2022). Blockchain and machine learning for fraud detection: A privacy-preserving and adaptive incentive based approach. IEEE Access, 10, 87115–87134. [Google Scholar] [CrossRef]
- Quevedo-Silva, F., Santos, E. B. A., Brandão, M. M., & Vils, L. (2016). Estudo bibliométrico: Orientações sobre sua aplicação. Revista Brasileira de Marketing, 15(2), 246–262. [Google Scholar] [CrossRef]
- Ranganatha, H. R., & Syed Mustafa, A. (2025). Enhancing fraud detection efficiency in mobile transactions through the integration of bidirectional 3d quasi-recurrent neural network and blockchain technologies. Expert Systems with Applications, 260, 125179. [Google Scholar] [CrossRef]
- Secinaro, S., Brescia, V., Calandra, D., & Biancone, P. (2020). Employing bibliometric analysis to identify suitable business models for electric cars. Journal of Cleaner Production, 264, 121503. [Google Scholar] [CrossRef]
- Sengupta, K., & Das, P. K. (2023). Detection of financial fraud: Comparisons of some tree-based machine learning approaches. Journal of Data, Information and Management, 5(1), 23–37. [Google Scholar] [CrossRef]
- Shi, F., & Zhao, C. (2023). Enhancing financial fraud detection with hierarchical graph attention networks: A study on integrating local and extensive structural information. Finance Research Letters, 58, 104458. [Google Scholar] [CrossRef]
- Tayeb, M., & El Kafhali, S. (2025). Combining autoencoders and deep learning for effective fraud detection in credit card transactions. Operations Research Forum, 6, 8. [Google Scholar] [CrossRef]
- Tudisco, A., Volpe, D., Ranieri, G., Curato, G., Ricossa, D., Graziano, M., & Corbelletto, D. (2024). Evaluating the computational advantages of the variational quantum circuit model in financial fraud detection. IEEE Access, 12, 102918–102940. [Google Scholar] [CrossRef]
- Usman, A. U., Abdullahi, S. B., Liping, Y., Alghofaily, B., Almasoud, A. S., & Rehman, A. (2024). Financial fraud detection using value-at-risk with machine learning in skewed data. IEEE Access, 12, 64285–64299. [Google Scholar] [CrossRef]
- Wang, L., Cheng, H., Zheng, Z., Yang, A., & Zhu, X. (2021). Ponzi scheme detection via oversampling-based long short-term memory for smart contracts. Knowledge-Based Systems, 228, 107312. [Google Scholar] [CrossRef]
- Wang, X. (2024). A study on financial early warning for technology companies incorporating big data and random forest algorithms. International Journal of Grid and Utility Computing, 15(3–4), 343–351. [Google Scholar] [CrossRef]
- Wang, Y., & Zhu, G. (2024). Construction of accounting fraud and its audit countermeasure model based on computer technology. Journal of Information & Knowledge Management, 23(4), 2450042. [Google Scholar] [CrossRef]
- West, J., & Bhattacharya, M. (2016). Intelligent financial fraud detection: A comprehensive review. Computers & Security, 57, 47–66. [Google Scholar] [CrossRef]
- Xia, P., Zhu, X., Charles, V., Zhao, X., & Peng, M. (2024). A novel heuristic-based selective ensemble prediction method for digital financial fraud risk. IEEE Transactions on Engineering Management, 71, 8002–8018. [Google Scholar] [CrossRef]
- Zhang, Z., Ma, Y., & Hua, Y. (2022). Financial fraud identification based on stacking ensemble learning algorithm: Introducing MD&A text information. Computational Intelligence and Neuroscience, 2022, 1–14. [Google Scholar] [CrossRef]
- Zhang, Z., Wang, Z., & Cai, L. (2025). Predicting financial fraud in Chinese listed companies: An enterprise portrait and machine learning approach. Pacific-Basin Finance Journal, 90, 102665. [Google Scholar] [CrossRef]
- Zhao, D., Wang, Z., Schweizer-Gamborino, F., & Sornette, D. (2025). Polytope fraud theory. International Review of Financial Analysis, 97, 103734. [Google Scholar] [CrossRef]
- Zhao, X., Wu, Y., Lee, D. L., & Cui, W. (2019). iForest: Interpreting random forests via visual analytics. IEEE Transactions on Visualization and Computer Graphics, 25, 407–416. [Google Scholar] [CrossRef]
- Zheng, X., Li, J., Lu, M., & Wang, F.-Y. (2024). New paradigm for economic and financial research with generative AI: Impact and perspective. IEEE Transactions on Computational Social System, 11, 3457–3467. [Google Scholar] [CrossRef]
- Zhou, H., Sun, G., Fu, S., Fan, X., Jiang, W., Hu, S., & Li, L. (2020). A Distributed approach of big data mining for financial fraud detection in a supply chain. Computers, Materials & Continua, 64, 1091–1105. [Google Scholar] [CrossRef]
- Zhu, S., Wu, H., Ngai, E. W. T., Ren, J., He, D., Ma, T., & Li, Y. (2024). A financial fraud prediction framework based on stacking ensemble learning. Systems, 12, 588. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Articles | Affiliation |
|---|---|---|
| Zhao Wang | 4 | Accounting School, Capital University of Economics and Business, China |
| Jingyu Li | 3 | School of Economics and Management, Beijing University of Technology, China |
| Yubin Li | 3 | School of Economics and Management, Harbin Institute of Technology, China |
| Shi Qiu | 3 | School of Economics and Management, Changsha University, China |
| Lei Wang | 3 | Chinese Academy of Sciences, China |
| Reference | Citations | Major Contributions and Objectives | Top Criticisms or Issues Reviewed | Main Methodological Aspects |
|---|---|---|---|---|
| West and Bhattacharya (2016) | 714 | Addresses the association between fraud types, CI-based detection algorithms, and their performance | The growing reliance on new technologies can exacerbate the problem of financial fraud | Uses data mining to review the literature |
| Goodell et al. (2021) | 687 | It highlights aspects of fraud prevention with concern for 3 main aspects: portfolio construction, valuation, and investor behavior; financial fraud and distress; and sentiment inference, forecasting, and planning | Problems and vulnerabilities in fraud detection systems | It uses analyses of co-citation, co-occurrence, confluence, and bibliometric coupling |
| Hilal et al. (2022) | 534 | Focuses on highlighting recent advances in the areas of semi-supervised and unsupervised learning in financial fraud prevention | Increasing vulnerabilities in financial data security systems | Review and multi-methods |
| Masood et al. (2023) | 511 | Detailed analysis of existing tools and machine learning (ML)-based approaches to deepfake generation | Improve the domains of deepfake generation and detection | Review and multi-methods |
| Hajek and Henriques (2017) | 397 | Combines financial information and management commentary in corporate annual reports in structuring fraud prevention methods | Document-based fraud detection | Use of wide range of machine learning methods |
| Ileberi et al. (2022) | 303 | Proposes a credit card fraud detection mechanism based on machine learning (ML) using the genetic algorithm (AG) for trait selection | Specific assessment of credit card fraud | Use of multiple algorithms for testing |
| Itoo et al. (2021) | 298 | Uses a logistic-regression-based model for fraud prediction that has been found to be better compared to other prediction models developed from naïve Bayes and K-nearest neighbors for credit card fraud prevention | Credit card data is highly skewed, which leads to inefficient prediction of fraudulent transactions | Resampling (oversampling or subsampling) for best results |
| X. Zhao et al. (2019) | 226 | A visual analytical system is proposed with the objective of interpreting models and predictions of random forests | Low interpretability of the decision tree model | Two use scenarios and a qualitative user study were conducted |
| Choi and Lee (2018) | 186 | Fraud detection by resource selection, sampling, and application of supervised and unsupervised algorithms | Accurate detection based on multiple technologies | Use of multiple algorithms for testing |
| Khetani et al. (2023) | 121 | It covers the effects of DL and ML algorithms in different industries, such as healthcare, NLP, financial services, and network security | Lack of a study that holistically encompasses different sectors | Multi-domain analysis of DL and ML algorithms in various domains |
| Affiliation | Articles |
|---|---|
| Hunan University of Finance and Economics (China) | 13 |
| Shandong University (China) | 7 |
| Luoyang Normal University (China) | 6 |
| Beijing University of Technology (China) | 5 |
| Chongqing University (China) | 5 |
| Guizhou Normal University (China) | 5 |
| Shandong University of Finance and Economics (China) | 5 |
| Sun Yat-sen University (China) | 5 |
| Tongji University (China) | 5 |
| Universidad Cooperativa de Colombia (Colombia) | 5 |
| Universiti Teknologi Malaysia (Malaysia) | 5 |
| University of Chinese Academy of Sciences (China) | 5 |
| Yantai University (China) | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moura, L.; Barcaui, A.; Payer, R. AI and Financial Fraud Prevention: Mapping the Trends and Challenges Through a Bibliometric Lens. J. Risk Financial Manag. 2025, 18, 323. https://doi.org/10.3390/jrfm18060323
Moura L, Barcaui A, Payer R. AI and Financial Fraud Prevention: Mapping the Trends and Challenges Through a Bibliometric Lens. Journal of Risk and Financial Management. 2025; 18(6):323. https://doi.org/10.3390/jrfm18060323
Chicago/Turabian StyleMoura, Luiz, Andre Barcaui, and Renan Payer. 2025. "AI and Financial Fraud Prevention: Mapping the Trends and Challenges Through a Bibliometric Lens" Journal of Risk and Financial Management 18, no. 6: 323. https://doi.org/10.3390/jrfm18060323
APA StyleMoura, L., Barcaui, A., & Payer, R. (2025). AI and Financial Fraud Prevention: Mapping the Trends and Challenges Through a Bibliometric Lens. Journal of Risk and Financial Management, 18(6), 323. https://doi.org/10.3390/jrfm18060323