
HF-SCA: Hands-Free Strong Customer Authentication Based on a Memory-Guided Attention Mechanisms

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Literature Review
- A licensing regime for payment institutions;
- The transparency of conditions and information requirements for payment services, including charges;
- The rights and obligations of users and providers of payment services;
- Strict security requirements for electronic payments and the protection of consumers’ financial data, in order to guarantee safe authentication and reduce the risk of fraud.
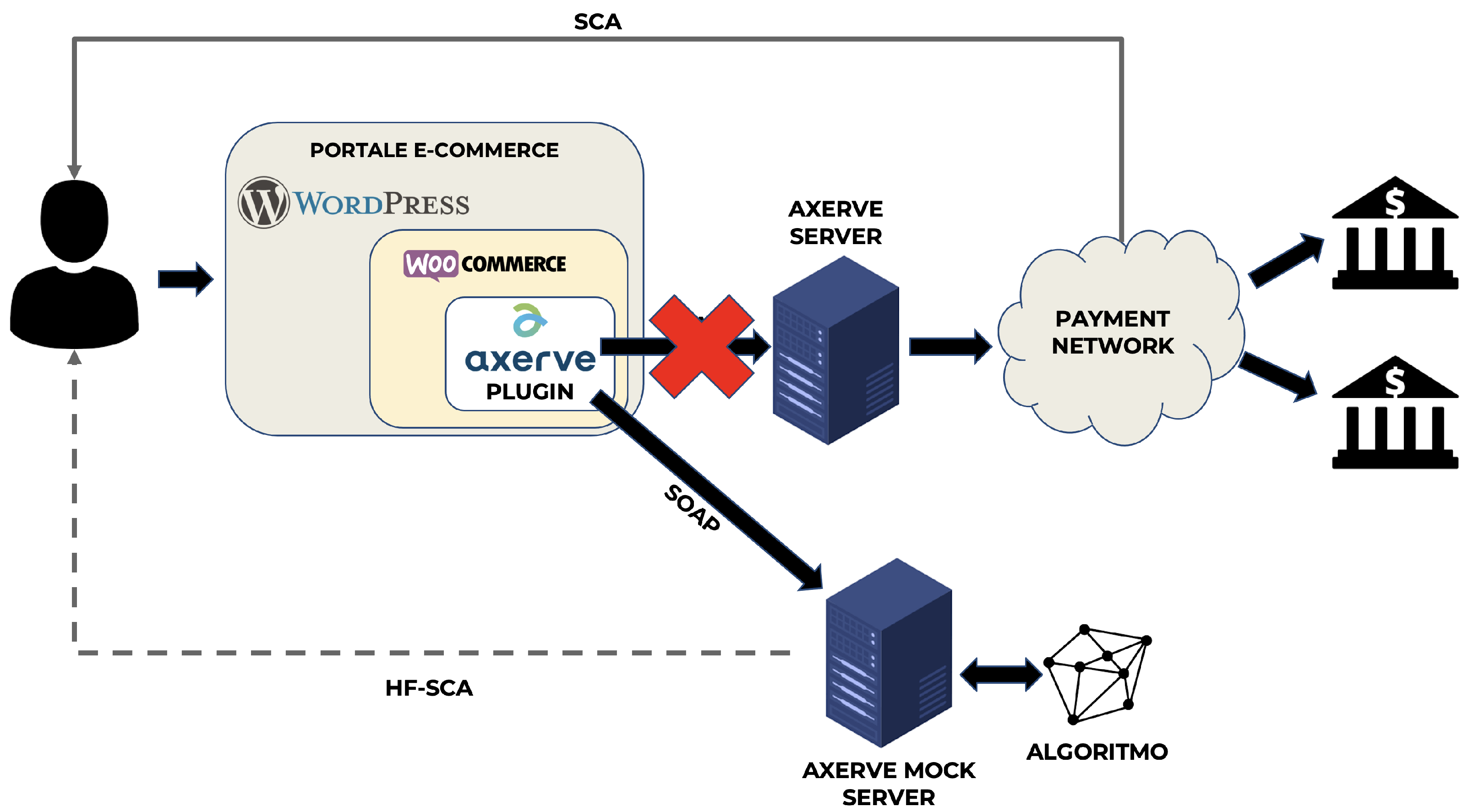
3. Materials and Methods
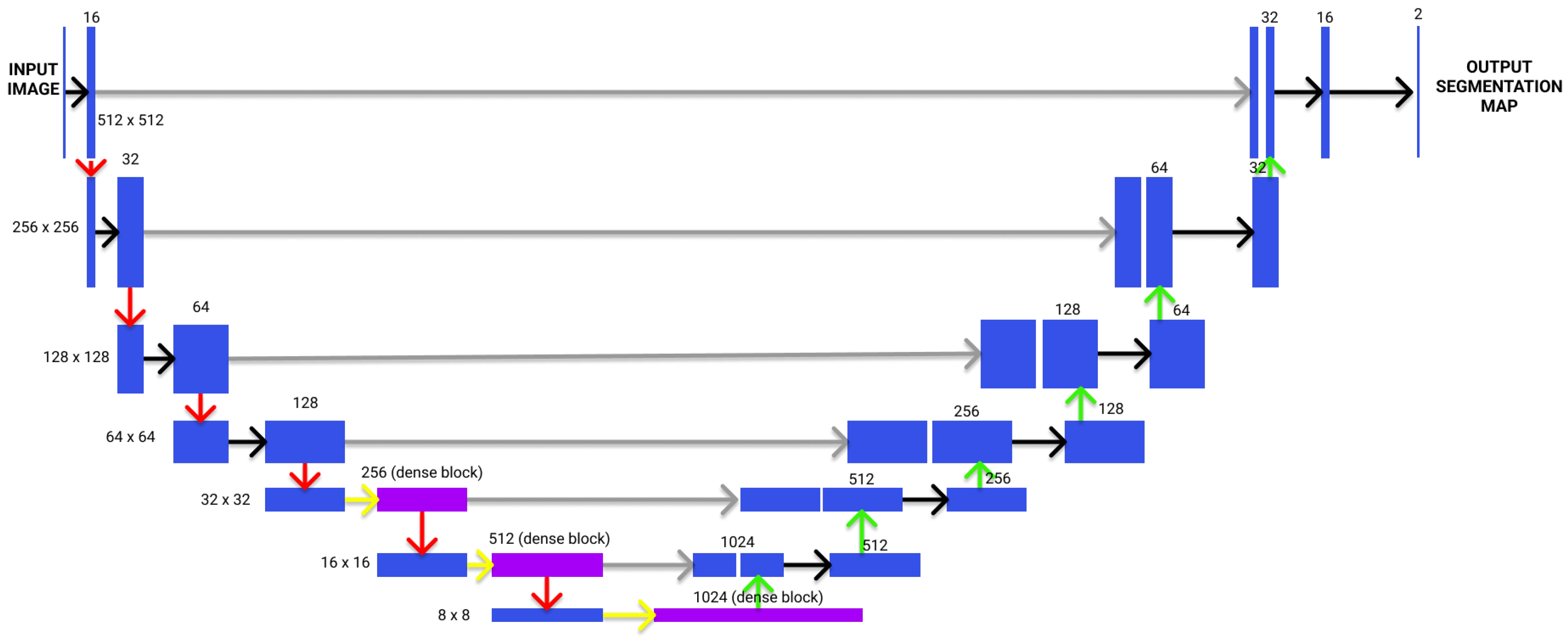
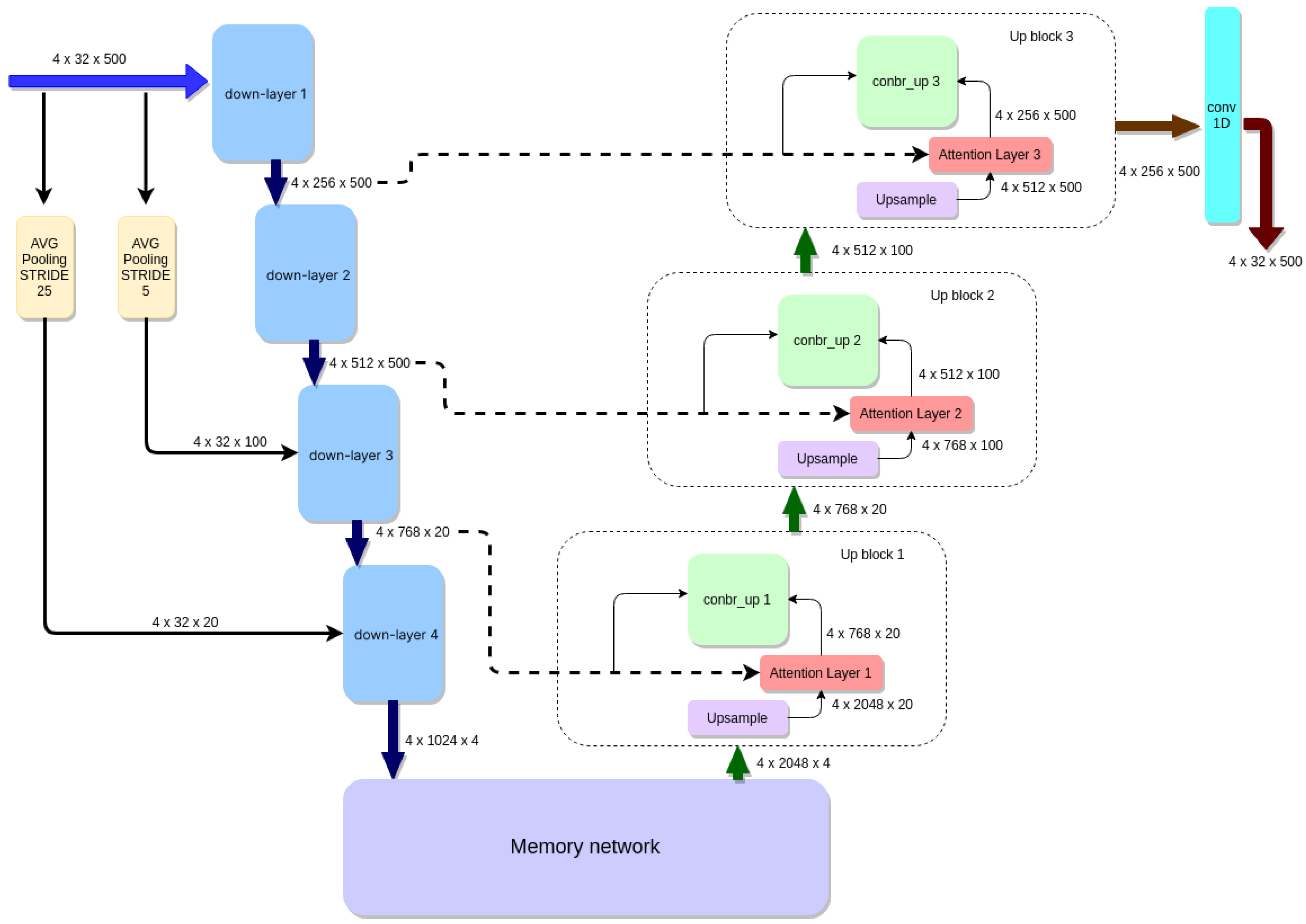
3.1. Encoding Side
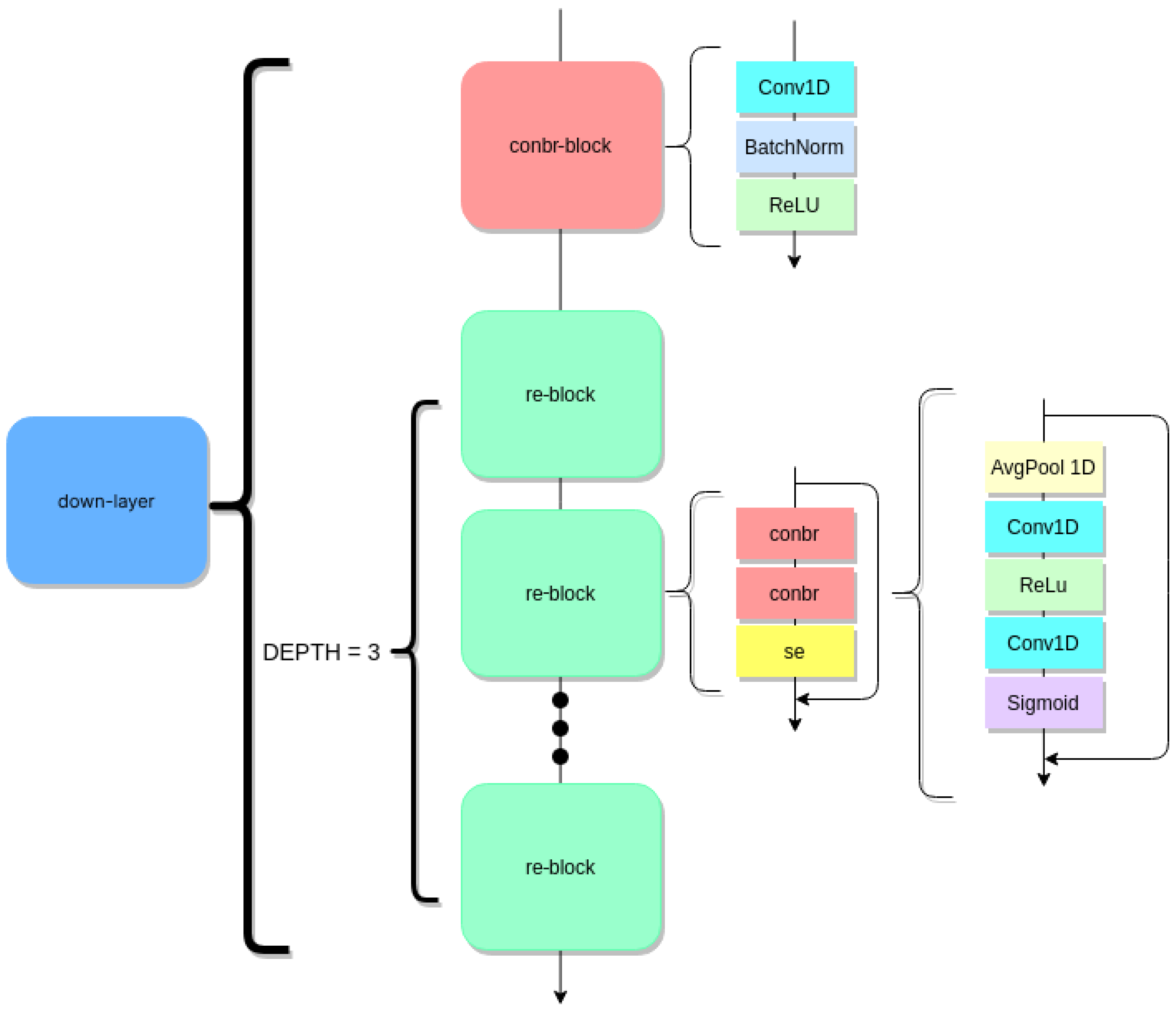
3.2. Down-Layer and Average Pooling
3.3. Decoding Side
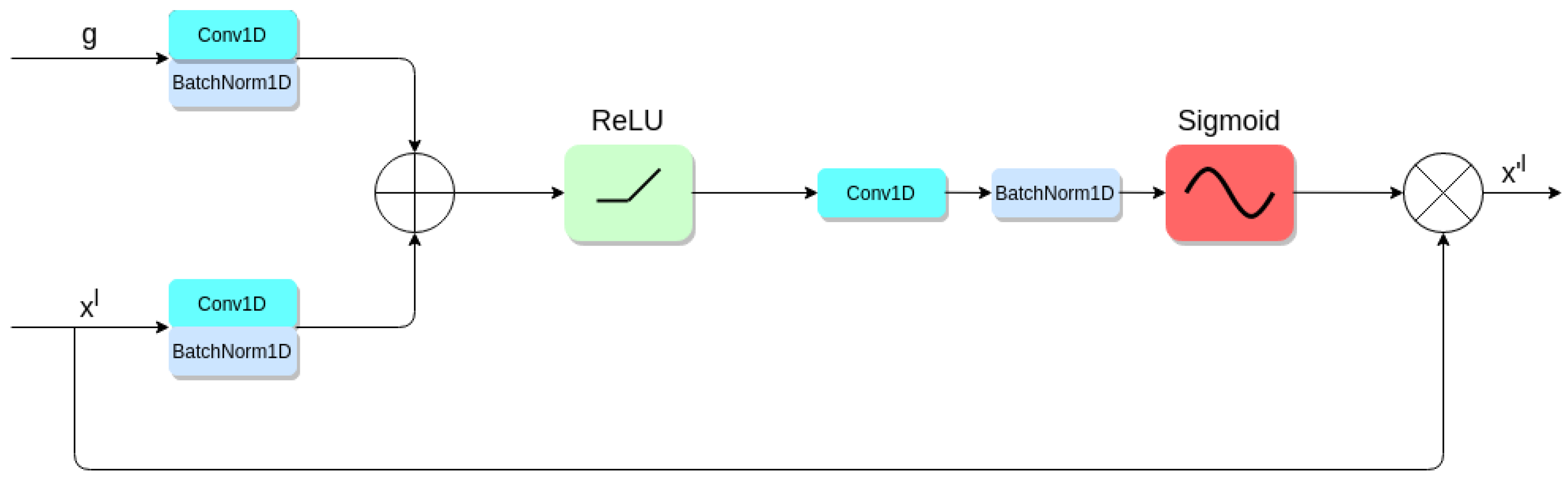
3.4. Attention Mechanisms in the Proposed Solution
3.5. Memory Network Block
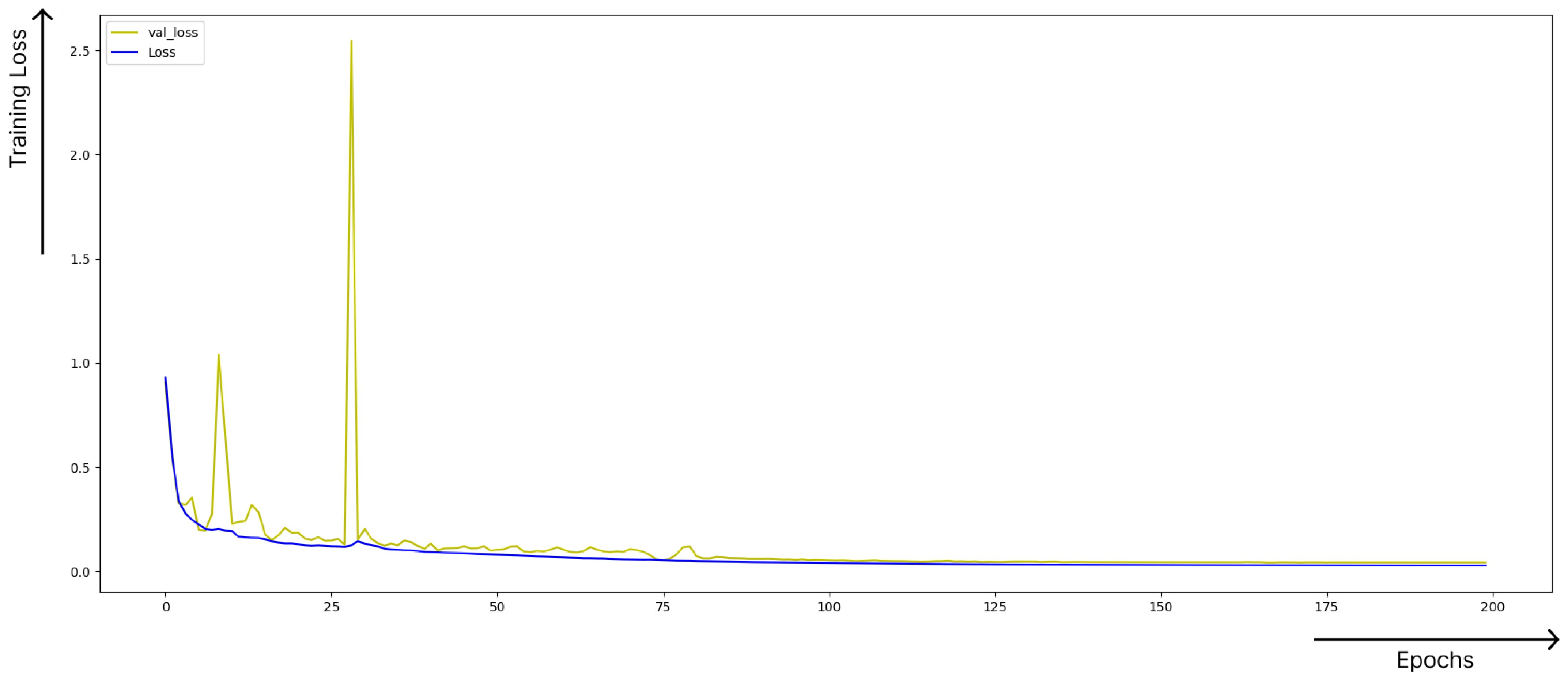
3.6. Training Data and Tools
4. Results and Discussion
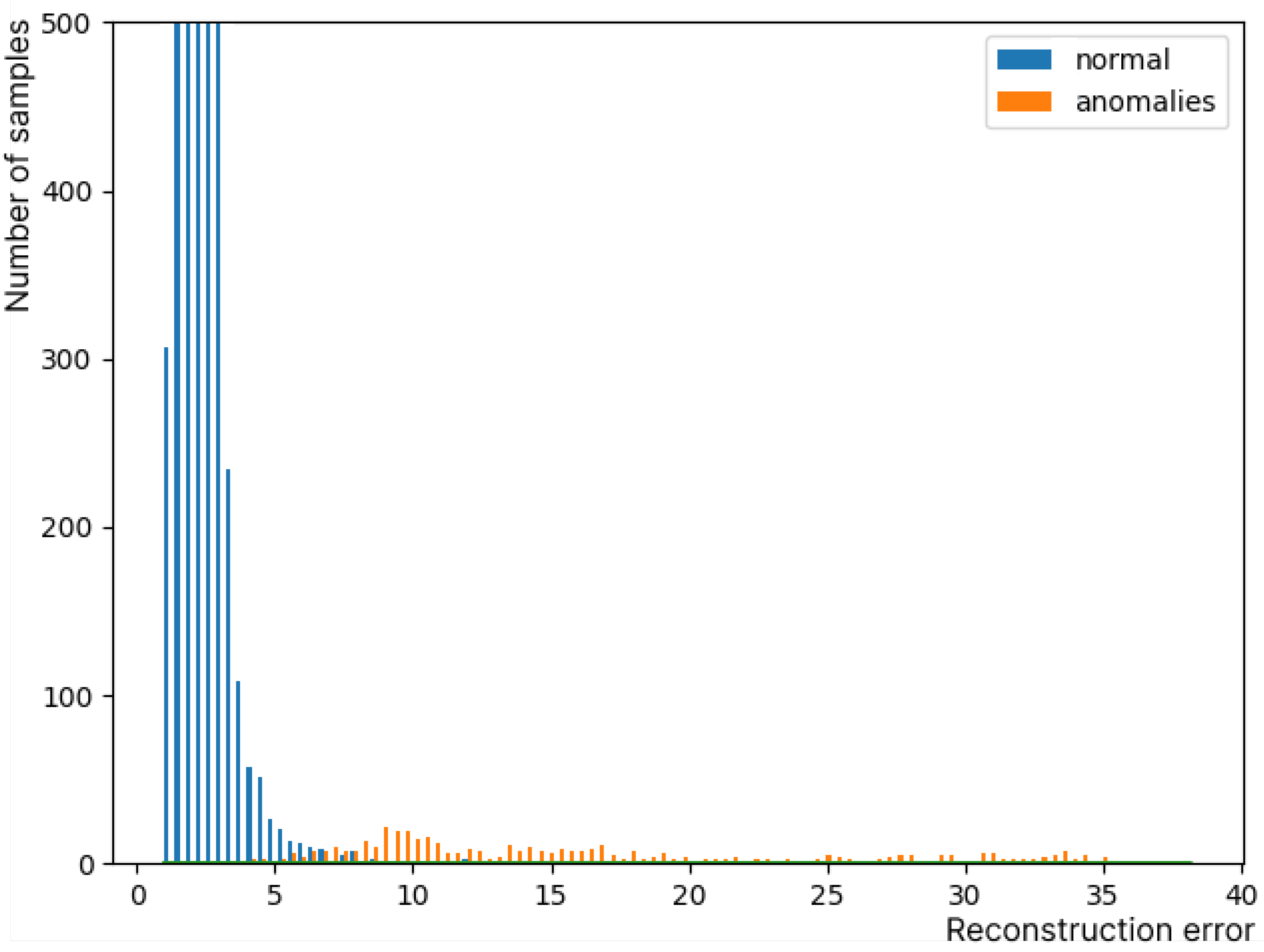
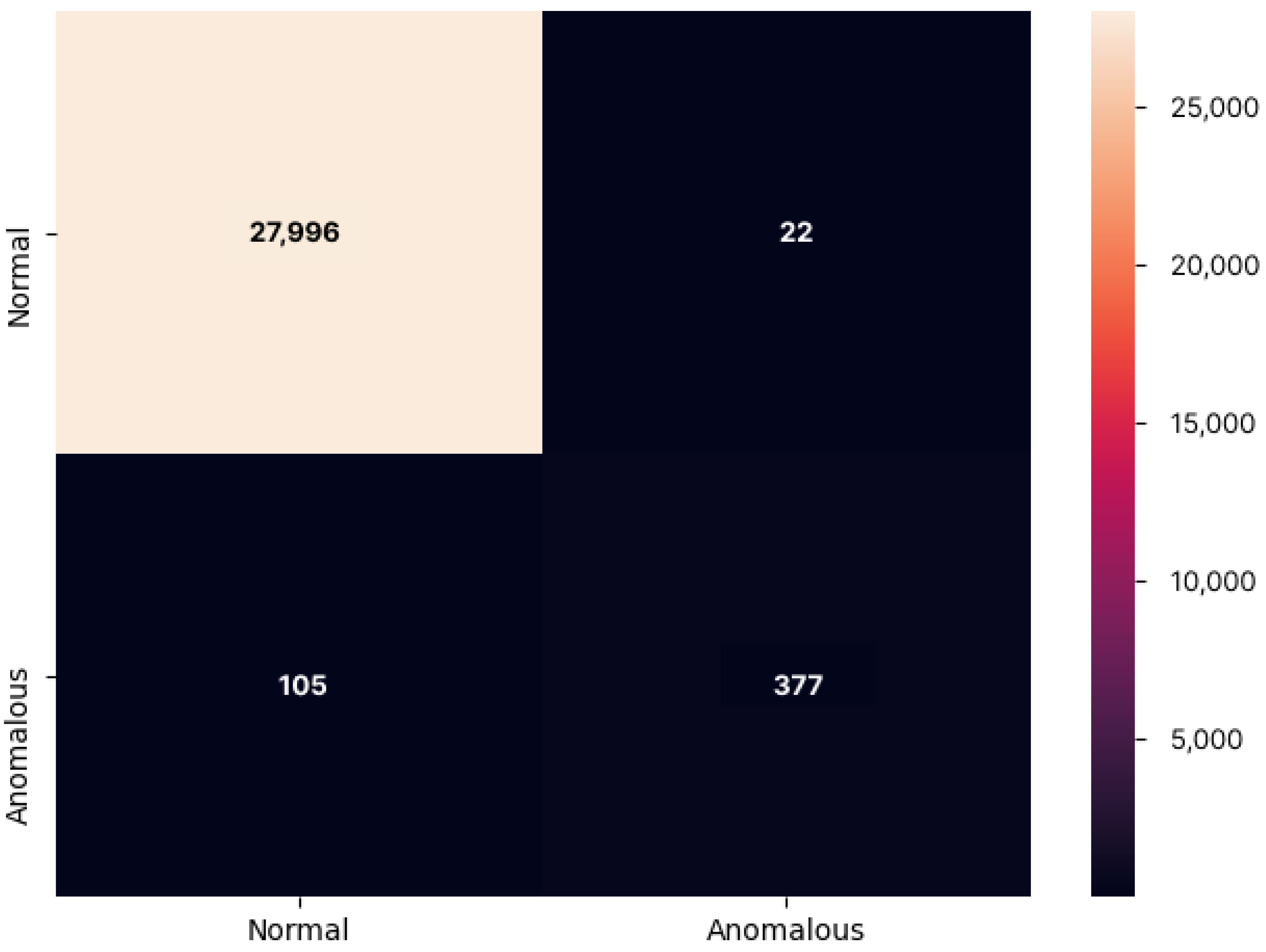
4.1. Performance Validation
4.1.1. Hyperparameter Optimisation
4.1.2. Experimental Results
4.1.3. Final Results
4.1.4. Comparing Results with State of the Art
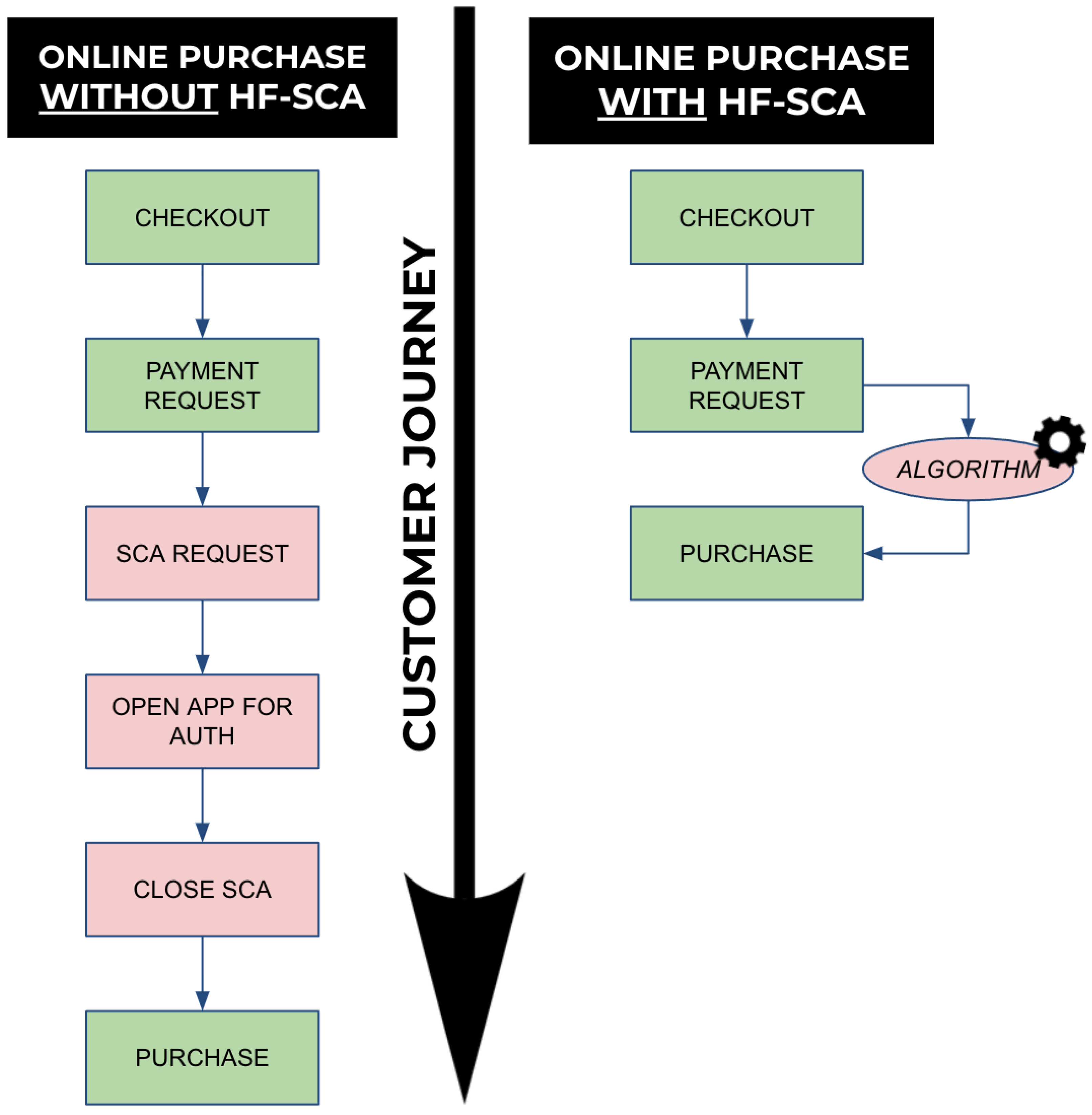
4.2. Functional Validation
- HF-SCA can deliver a much shorter customer journey, hence bypassing (when the risk is low) the need for SCA;
- HF-SCA enables innovative use cases, because customers have their hands free to perform other activities while making online purchases.
5. Discussion
- Autoencoder. Despite the main backbone not being a proper autoencoder, U-net is based on the same idea. It adds skip connections which provide an alternative path to gradient (with backpropagation) avoiding the gradient-vanishing phenomenon. In addition, a substitution of standard convolution blocks was made, replacing them with squeeze-and-excitation blocks. They enhance the representation ability of the network and perform dynamic channel-wise features recalibration.
- Attention mechanisms. They facilitate fraudulent patterns recognition by the network. The whole architecture tries to focus its attention on some features. The attention logic is led by these mechanisms.
- Memory network. It lies on the latent space, replacing the bottleneck layer introduced by the original U-net architecture. The memory layer boosts the AD ability, plunging the architecture in a multimodal environment.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | https://ecomms2s.sella.it/gestpay/GestPayWS/WsCryptDecrypt.asmx?wsdl, accessed on 24 July 2022. |
References
- Ahmed, Mohiuddin. 2017. Thwarting dos attacks: A framework for detection based on collective anomalies and clustering. Computer 50: 76–82. [Google Scholar] [CrossRef]
- Al-Qatf, Majjed, Yu Lasheng, Mohammed Al-Habib, and Kamal Al-Sabahi. 2018. Deep learning approach combining sparse autoencoder with svm for network intrusion detection. IEEE Access 6: 52843–56. [Google Scholar] [CrossRef]
- Ali, Haseeb, Mohd Salleh, Kashif Hussain, Ayaz Ullah, Arshad Ahmad, and Rashid Naseem. 2019. A review on data preprocessing methods for class imbalance problem. International Journal of Engineering & Technology 8: 390–97. [Google Scholar] [CrossRef]
- Alrawashdeh, Khaled, and Carla Purdy. 2016. Toward an online anomaly intrusion detection system based on deep learning. Paper presented at the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, December 18–20; pp. 195–200. [Google Scholar] [CrossRef]
- Althubiti, Sara, William Nick, Janelle Mason, Xiaohong Yuan, and Albert Esterline. 2018. Applying long short-term memory recurrent neural network for intrusion detection. South African Computer Journal 56: 1–5. [Google Scholar] [CrossRef]
- Arun, Gurumurthy Krishnamurthy, and Kaliyappan Venkatachalapathy. 2020. Intelligent feature selection with social spider optimization based artificial neural network model for credit card fraud detection. IIOABJ 11: 85–91. [Google Scholar]
- Asha, R. B., and Suresh Kumar. 2021. Credit card fraud detection using artificial neural network. Global Transitions Proceedings 2: 35–41. [Google Scholar] [CrossRef]
- Aygun, R. Can, and A. Gokhan Yavuz. 2017. Network anomaly detection with stochastically improved autoencoder based models. Paper presented at the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, June 26–28; pp. 193–98. [Google Scholar] [CrossRef]
- Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2016. Neural machine translation by jointly learning to align and translate. arXiv arXiv:1409.0473. [Google Scholar]
- Bank of Italy. n.d. Bank of Italy Regulatory Sandbox. Available online: https://www.bancaditalia.it/focus/sandbox/progetti-ammessi/index.html?com.dotmarketing.htmlpage.language=102&dotcache=refresh#faq8761-7 (accessed on 24 July 2022).
- Caione, Adriana, Alessandro Fiore, Luca Mainetti, Luigi Manco, and Roberto Vergallo. 2017. Wox: Model-driven development of web of things applications. In Managing the Web of Things. Amsterdam: Elsevier, pp. 357–87. [Google Scholar]
- Cao, Van Loi, Miguel Nicolau, and James Mcdermott. 2016. A hybrid autoencoder and density estimation model for anomaly detection. In International Conference on Parallel Problem Solving from Nature. Cham: Springer, pp. 717–26. [Google Scholar] [CrossRef]
- Chalapathy, Raghavendra, and Sanjay Chawla. 2019. Deep learning for anomaly detection: A survey. arXiv arXiv:1901.03407. [Google Scholar]
- Chen, Zhiyuan, Waleed Mahmoud Soliman, Amril Nazir, and Mohammad Shorfuzzaman. 2021. Variational autoencoders and wasserstein generative adversarial networks for improving the anti-money laundering process. IEEE Access 9: 83762–85. [Google Scholar] [CrossRef]
- Cheng, Dawei, Sheng Xiang, Chencheng Shang, Yiyi Zhang, Fangzhou Yang, and Liqing Zhang. 2020. Spatio-temporal attention-based neural network for credit card fraud detection. Proceedings of the AAAI Conference on Artificial Intelligence 34: 362–69. [Google Scholar] [CrossRef]
- Cheng, Dawei, Xiaoyang Wang, Ying Zhang, and Liqing Zhang. 2020. Graph neural network for fraud detection via spatial-temporal attention. IEEE Transactions on Knowledge and Data Engineering 34: 3800–13. [Google Scholar] [CrossRef]
- Ebong, Jimmy, and Babu George. 2021. Financial inclusion through digital financial services (dfs): A study in uganda. Journal of Risk and Financial Management 14: 393. [Google Scholar] [CrossRef]
- EU. 2016. Directive (eu) 2015/2366 of the European Parliament and of the Council of 25 November 2015 on Payment Services in the Internal Market. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A32015L2366 (accessed on 24 July 2022).
- Fu, Kang, Dawei Cheng, Yi Tu, and Liqing Zhang. 2016. Credit Card Fraud Detection Using Convolutional Neural Networks. Cham: Springer. [Google Scholar]
- Gao, Rongfang, Tiantian Zhang, Shaohua Sun, and Zhanyu Liu. 2019. Research and improvement of isolation forest in detection of local anomaly points. Journal of Physics: Conference Series 1237: 052023. [Google Scholar] [CrossRef] [Green Version]
- Garcia Cordero, Carlos, Sascha Hauke, Max Mühlhäuser, and Mathias Fischer. 2016. Analyzing flow-based anomaly intrusion detection using replicator neural networks. Paper presented at the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, December 12–14; pp. 317–24. [Google Scholar] [CrossRef]
- González, Gastón García, Pedro Casas, Alicia Fernández, and Gabriel Gómez. 2020. On the usage of generative models for network anomaly detection in multivariate time-series. CoRR 4: 49–52. [Google Scholar] [CrossRef]
- Higa, Kyota, Hideaki Sato, Soma Shiraishi, Katsumi Kikuchi, and Kota Iwamoto. 2019. Anomaly detection combining discriminative and generative models. Paper presented at the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, December 9–10. [Google Scholar]
- Hu, Jie, Li Shen, Samuel Albanie, Gang Sun, and Enhua Wu. 2019. Squeeze-and-excitation networks. Paper presented at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, June 18–23. [Google Scholar]
- Huang, Gao, Zhuang Liu, and Kilian Q. Weinberger. 2016. Densely connected convolutional networks. CoRR arXiv:abs/1608.06993. [Google Scholar]
- Imam, Tasadduq, Angelique McInnes, Sisira Colombage, and Robert Grose. 2022. Opportunities and barriers for fintech in saarc and asean countries. Journal of Risk and Financial Management 15: 77. [Google Scholar] [CrossRef]
- Intrator, Yotam, Gilad Katz, and Asaf Shabtai. 2018. Mdgan: Boosting anomaly detection using multi-discriminator generative adversarial networks. arXiv arXiv:1810.05221. [Google Scholar]
- Jurgovsky, Johannes, Michael Granitzer, Konstantin Ziegler, Sylvie Calabretto, Pierre-Edouard Portier, Liyun He, and Olivier Caelen. 2018. Sequence classification for credit-card fraud detection. Expert Systems with Applications 100: 234–45. [Google Scholar] [CrossRef]
- Kadłubek, Marta, Eleftherios Thalassinos, Joanna Domagała, Sandra Grabowska, and Sebastian Saniuk. 2022. Intelligent transportation system applications and logistics resources for logistics customer service in road freight transport enterprises. Energies 15: 4668. [Google Scholar] [CrossRef]
- Kaggle. n.d.a Credit Card Fraud Detection. Available online: https://www.kaggle.com/mlg-ulb/creditcardfraud (accessed on 24 July 2022).
- Kaggle. n.d.b Fifth Kaggle Solution. Available online: https://www.kaggle.com/jinkaido/credit-card-fraud-recall-96-simple (accessed on 24 July 2022).
- Kaggle. n.d.c First Kaggle Solution. Available online: https://www.kaggle.com/ilijagracanin/credit-fraud-optuna-xgb-96-aoc-94-recall (accessed on 24 July 2022).
- Kaggle. n.d.d Fourth Kaggle Solution. Available online: https://www.kaggle.com/omkarsabnis/credit-card-fraud-detection-using-neural-networks (accessed on 24 July 2022).
- Kaggle. n.d.e Second Kaggle Solution. Available online: https://www.kaggle.com/rheemaagangwani/95-accuracy-with-roc-curve (accessed on 24 July 2022).
- Kaggle. n.d.f Third Kaggle Solution. Available online: https://www.kaggle.com/deepaksurana/fraud-detection-using-autoencoders-in-keras (accessed on 24 July 2022).
- Latah, Majd. 2018. When deep learning meets security. arXiv arXiv:1807.04739. [Google Scholar]
- Lin, Zilong, Yong Shi, and Zhi Xue. 2021. Idsgan: Generative adversarial networks for attack generation against intrusion detection. In Pacific-Asia Conference on Knowledge Discovery and Data Mining. Cham: Springer. [Google Scholar]
- Lopez-Martin, Manuel, Belén Carro, Antonio Sanchez-Esguevillas, and Jaime Lloret. 2017. Conditional variational autoencoder for prediction and feature recovery applied to intrusion detection in iot. Sensors 17: 1967. [Google Scholar] [CrossRef] [Green Version]
- Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. 2015. Effective approaches to attention-based neural machine translation. arXiv arXiv:1508.04025. [Google Scholar]
- Malaiya, Ritesh K., Donghwoon Kwon, Jinoh Kim, Sang C. Suh, Hyunjoo Kim, and Ikkyun Kim. 2018. An empirical evaluation of deep learning for network anomaly detection. Paper presented at the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, March 5–8; pp. 893–98. [Google Scholar] [CrossRef]
- Matsubara, Takashi, Ryosuke Tachibana, and Kuniaki Uehara. 2018. Anomaly machine component detection by deep generative model with unregularized score. Paper presented at the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, July 8–13; pp. 1–8. [Google Scholar] [CrossRef]
- Mirsky, Yisroel, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai. 2018. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv arXiv:1802.09089. [Google Scholar]
- Naseer, Sheraz, Yasir Saleem, Shehzad Khalid, Muhammad Khawar Bashir, Jihun Han, Muhammad Munwar Iqbal, and Kijun Han. 2018. Enhanced network anomaly detection based on deep neural networks. IEEE Access 6: 48231–46. [Google Scholar] [CrossRef]
- Oktay, Ozan, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, and et al. 2018. Attention u-net: Learning where to look for the pancreas. arXiv arXiv:1804.03999. [Google Scholar]
- Park, Hyunjong, Jongyoun Noh, and Bumsub Ham. 2020. Learning memory-guided normality for anomaly detection. Paper presented at the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, June 13–19. [Google Scholar]
- Paul, Pongku Kumar, Seppo Virtanen, and Antti Hakkala. 2020. Strong Customer Authentication: Security Issues and Solution Evaluation. Master’s thesis, University of Turku, Turku, Finland. [Google Scholar]
- Porwal, Utkarsh, and Smruthi Mukund. 2019. Credit card fraud detection in e-commerce. Paper presented at the 2019 18th IEEE International Conference on Trust, Security Furthermore, Privacy in Computing Furthermore, Communications/13th IEEE International Conference on Big Data Science Furthermore, Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, August 5–8; pp. 280–87. [Google Scholar] [CrossRef]
- Randhawa, Kuldeep, Chu Kiong Loo, Manjeevan Seera, Chee Peng Lim, and Asoke K. Nandi. 2018. Credit card fraud detection using adaboost and majority voting. IEEE Access 6: 14277–84. [Google Scholar] [CrossRef]
- Rawat, Waseem, and Zenghui Wang. 2017. Deep convolutional neural networks for image classification: A comprehensive review. Neural Computation 29: 1–98. [Google Scholar] [CrossRef] [PubMed]
- Reshetnikova, Liudmila, Natalia Boldyreva, Maria Perevalova, Svetlana Kalayda, and Zhanna Pisarenko. 2021. Conditions for the growth of the “silver economy” in the context of sustainable development goals: Peculiarities of russia. Journal of Risk and Financial Management 14: 401. [Google Scholar] [CrossRef]
- Rigaki, Maria, and Ahmed Elragal. 2017. Adversarial Deep Learning against Intrusion Detection Classifiers. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2:1116037 (accessed on 24 July 2022).
- Ring, Markus, Daniel Schlör, Dieter Landes, and Andreas Hotho. 2019. Flow-based network traffic generation using generative adversarial networks. Computers & Security 82: 156–72. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer. [Google Scholar]
- Saarnilehto, Ilkka. 2018. Problems and possibilities of the payment services directive (psd2). In ProCIEdings of the Seminar in ComputerScience: Internet, Data and Things (CS-E4000). Espoo: AALTO University, pp. 71–82. [Google Scholar]
- Sella. n.d. Sella Data Challenge. Available online: https://www.sella.it/banca-online/landing/data-challenge/index.jsp (accessed on 24 July 2022).
- Tang, Tuan A, Lotfi Mhamdi, Des McLernon, Syed Ali Raza Zaidi, and Mounir Ghogho. 2016. Deep learning approach for network intrusion detection in software defined networking. Paper presented at the 2016 International Conference on Wireless Networks and Mobile Communications (WINCOM), Fez, Morocco, October 26–29; pp. 258–63. [Google Scholar] [CrossRef]
- Tapia Hermida, Alberto Javier. 2018. The second payment services directive. Financial Stability Review, 57–78. [Google Scholar]
- Varmedja, Dejan, Mirjana Karanovic, Srdjan Sladojevic, Marko Arsenovic, and Andras Anderla. 2019. Credit card fraud detection—Machine learning methods. Paper presented at the 2019 18th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, March 20–22; pp. 1–5. [Google Scholar] [CrossRef]
- Yin, Chuanlong, Yuefei Zhu, Shengli Liu, Jinlong Fei, and Hetong Zhang. 2018. An enhancing framework for botnet detection using generative adversarial networks. Paper presented at the 2018 International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, May 26–28; pp. 228–34. [Google Scholar] [CrossRef]
- Yu, Yang, Jun Long, and Zhiping Cai. 2017. Network intrusion detection through stacking dilated convolutional autoencoders. Security and Communication Networks 2017: 4184196. [Google Scholar] [CrossRef]
- Zolotukhin, Mikhail, Timo Hamalainen, Tero Kokkonen, and Jarmo Siltanen. 2016. Increasing web service availability by detecting application-layer ddos attacks in encrypted traffic. Paper presented at the 2016 23rd International Conference on Telecommunications (ICT), Thessaloniki, Greece, May 16–18; pp. 1–6. [Google Scholar] [CrossRef]
- Zoppi, Tommaso, Andrea Ceccarelli, and Andrea Bondavalli. 2020. Into the unknown: Unsupervised machine learning algorithms for anomaly-based intrusion detection. Paper presented at the 2020 50th Annual IEEE-IFIP International Conference on Dependable Systems and Networks-Supplemental Volume (DSN-S), Valencia, Spain, June 29–July 2; p. 81. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | Model Architecture | References |
|---|---|---|
| Generative | DCA , SAE , RBM , DBN , CVAE | Yu et al. (2017); Zolotukhin et al. (2016); Garcia Cordero et al. (2016); Alrawashdeh and Purdy (2016); Tang et al. (2016); Lopez-Martin et al. (2017); Al-Qatf et al. (2018); Mirsky et al. (2018); Aygun and Yavuz (2017) |
| Hybrid | GAN | Lin et al. (2021); Yin et al. (2018); Ring et al. (2019); Latah (2018); Intrator et al. (2018); Matsubara et al. (2018); Cao et al. (2016); Rigaki and Elragal (2017) |
| Discriminative | RNN , LSTM , CNN | Malaiya et al. (2018); Althubiti et al. (2018); Naseer et al. (2018) |
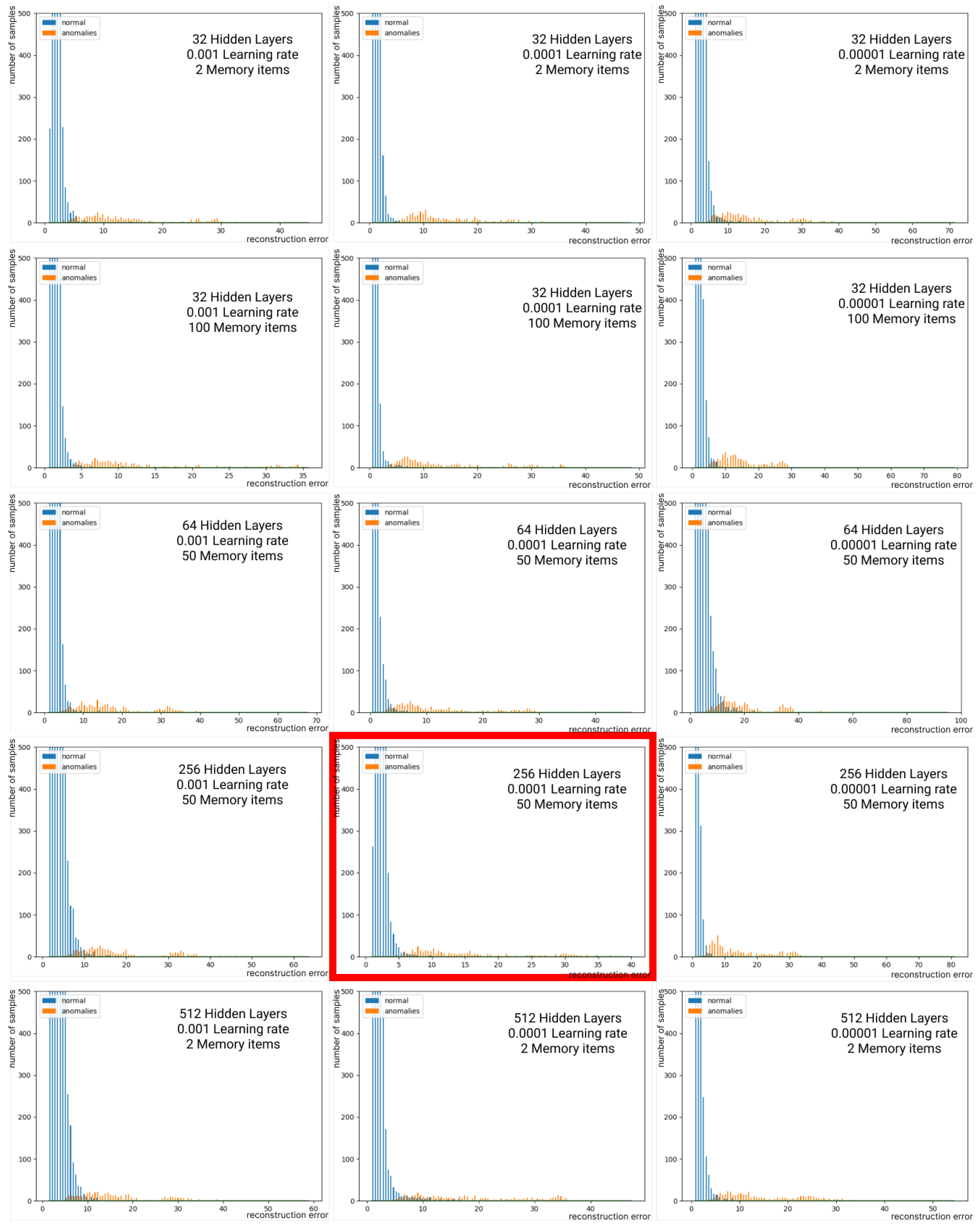
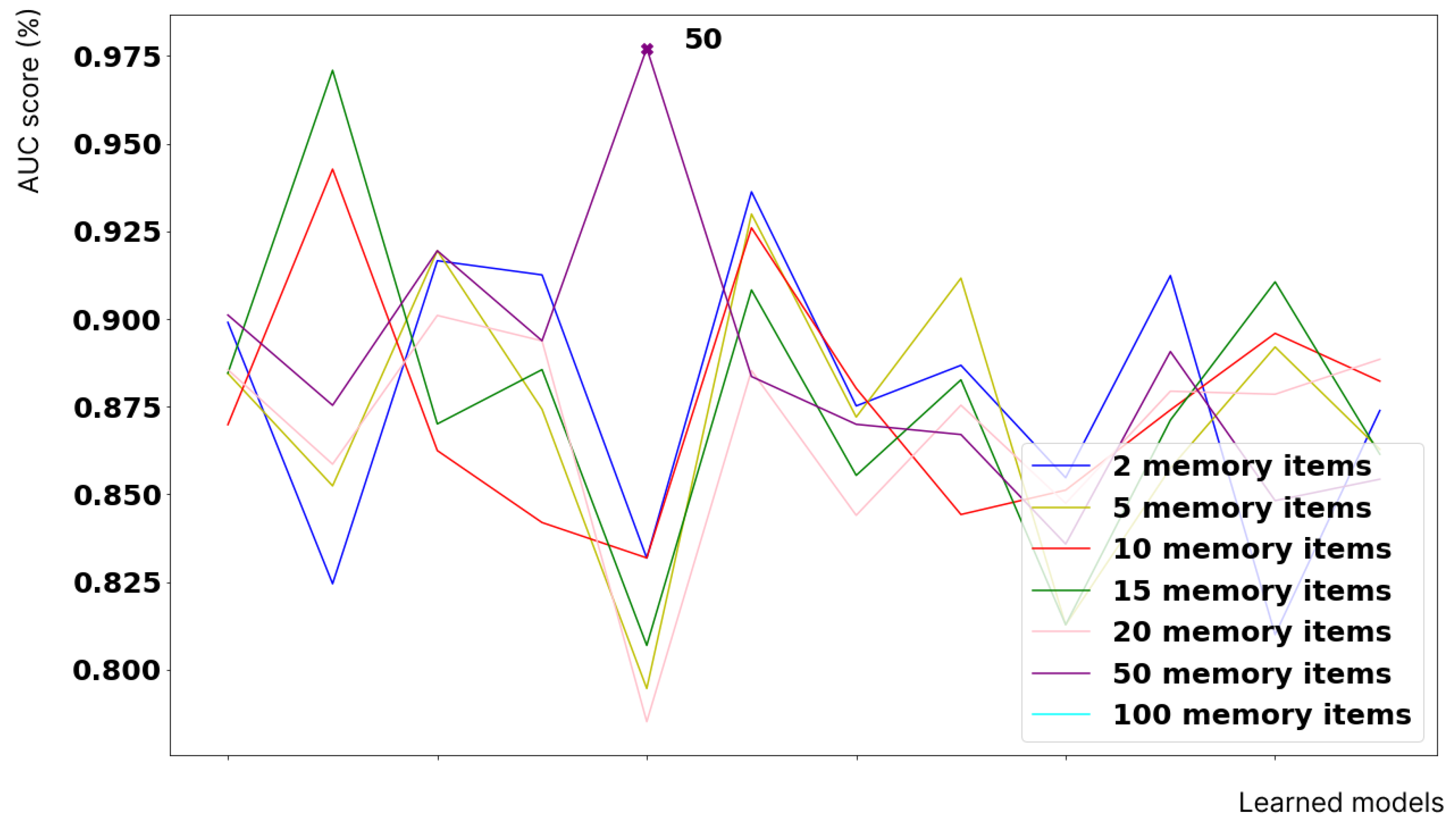
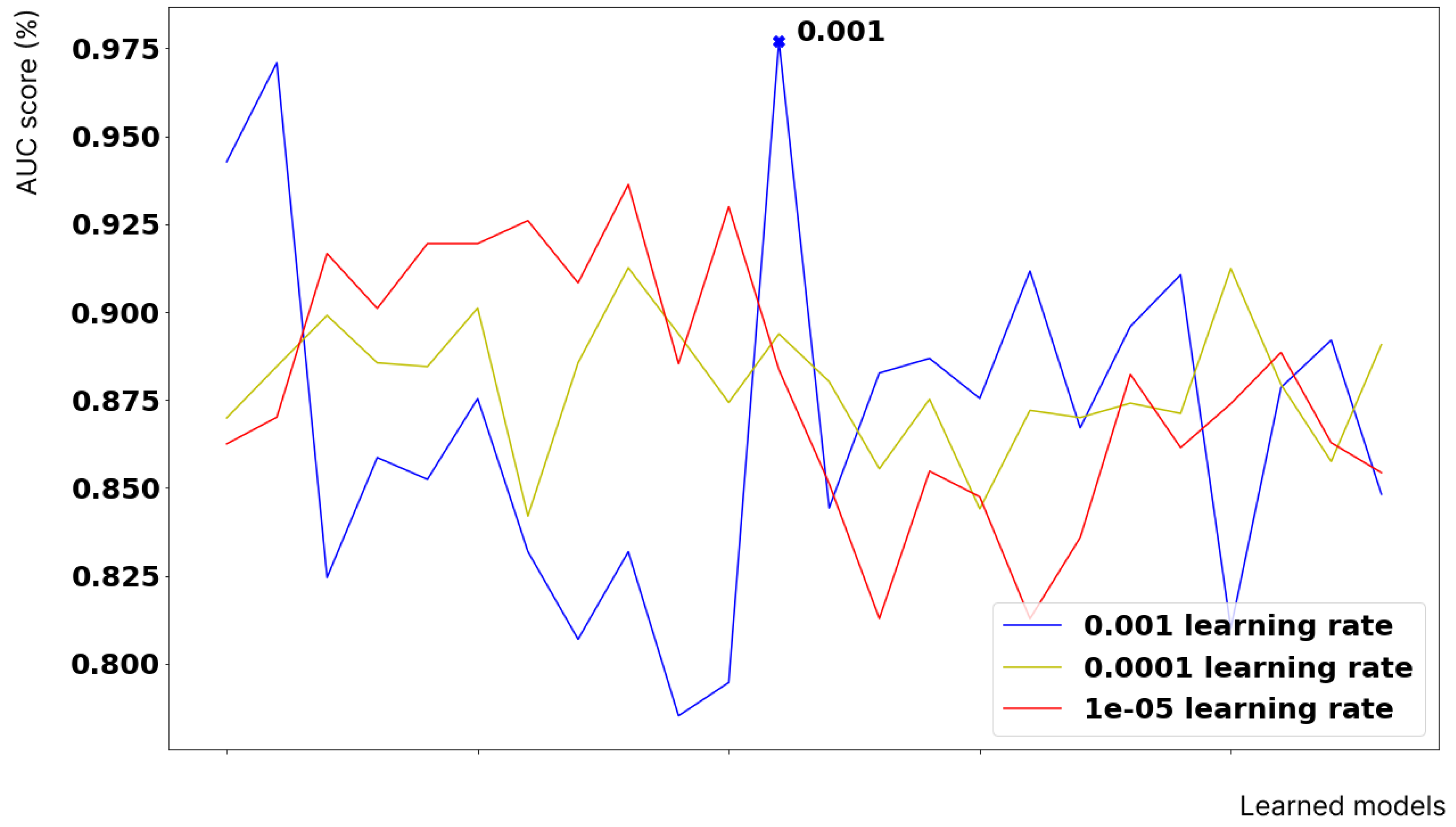
| M | 2 | 5 | 10 | 15 | 20 | 50 | 100 | |
|---|---|---|---|---|---|---|---|---|
| H | ||||||||
| 32 | 88.68% | 90.16% | 84.42% | 88.26% | 87.54% | 89.70% | 88.12% | |
| 64 | 81.00% | 89.29% | 89.58% | 90.06% | 87.85% | 84.82% | 85.14% | |
| 128 | 82.45% | 85.24% | 94.27% | 96.08% | 85.86% | 87.54% | 84.13% | |
| 256 | 83.18% | 79.46% | 83.18% | 80.69% | 78.51% | 97.71% | 91.87% | |
| 512 | 82.10% | 78.46% | 81.11% | 78.12% | 76.24% | 94.98% | 89.98% | |
| Method | Score | Author |
|---|---|---|
| XGBoost | 96% | Kaggle (n.d.c) |
| Random forest | 94.4% | Kaggle (n.d.e) |
| Autoencoder | 94% | Kaggle (n.d.f) |
| Neural network | 92.2% | Kaggle (n.d.d) |
| Decision tree | 87% | Kaggle (n.d.d) |
| Naive Bayes | 90.7% | Kaggle (n.d.d) |
| Nearest neighbours | 96% | Kaggle (n.d.b) |
| Proposed solution | 97.7% |
| Hidden Layers | Complete Model (AUC%) | U-Net (AUC%) |
|---|---|---|
| 32 | 89.70% | 86.88% |
| 64 | 84.82% | 88.64% |
| 128 | 87.54% | 77.46% |
| 256 | 97.71% | 76.21% |
| Method | Precision | Accuracy | F1-Score | AUC | Reference |
|---|---|---|---|---|---|
| Logistic regression | 58.82% | 97.46% | 91.84% | N.D. | Varmedja et al. (2019) |
| Naive Bayes | 16.17% | 82.65% | 99.23% | N.D. | Varmedja et al. (2019) |
| Random forest | 96.38% | 81.63% | 99.96% | N.D. | Varmedja et al. (2019) |
| Multilayer perceptron | 79.21% | 81.63% | 99.93% | N.D. | Varmedja et al. (2019) |
| SSO-ANN | N.D. | 93.20% | 95.21% | N.D. | Arun and Venkatachalapathy (2020) |
| Decision tree | N.D. | 71.20% | 80.41% | N.D. | Arun and Venkatachalapathy (2020) |
| Isolation Forest | N.D. | N.D. | N.D. | 95.24% | Porwal and Mukund (2019) |
| Ensemble | N.D. | N.D. | N.D. | 93.11% | Porwal and Mukund (2019) |
| Proposed solution | 99.92% | 99.55% | 99.77% | 97.70% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Distante, C.; Fineo, L.; Mainetti, L.; Manco, L.; Taccardi, B.; Vergallo, R. HF-SCA: Hands-Free Strong Customer Authentication Based on a Memory-Guided Attention Mechanisms. J. Risk Financial Manag. 2022, 15, 342. https://doi.org/10.3390/jrfm15080342
Distante C, Fineo L, Mainetti L, Manco L, Taccardi B, Vergallo R. HF-SCA: Hands-Free Strong Customer Authentication Based on a Memory-Guided Attention Mechanisms. Journal of Risk and Financial Management. 2022; 15(8):342. https://doi.org/10.3390/jrfm15080342
Chicago/Turabian StyleDistante, Cosimo, Laura Fineo, Luca Mainetti, Luigi Manco, Benito Taccardi, and Roberto Vergallo. 2022. "HF-SCA: Hands-Free Strong Customer Authentication Based on a Memory-Guided Attention Mechanisms" Journal of Risk and Financial Management 15, no. 8: 342. https://doi.org/10.3390/jrfm15080342
APA StyleDistante, C., Fineo, L., Mainetti, L., Manco, L., Taccardi, B., & Vergallo, R. (2022). HF-SCA: Hands-Free Strong Customer Authentication Based on a Memory-Guided Attention Mechanisms. Journal of Risk and Financial Management, 15(8), 342. https://doi.org/10.3390/jrfm15080342